
Основы программирования на MQL5: Файлы

Содержание
- Введение
- Чтение текстового файла
- Создание текстового файла
- Запись в конец текстового файла
- Изменение заданной строки текстового файла
- Чтение текстового файла в массив
- Создание текстового файла с разделителями
- Чтение текстового файла с разделителями
- Чтение файла с разделителями в массив
- Запись массива в текстовый файл с разделителями
- Файлы UNICODE
- Дополнительные функции для работы с текстовыми файлами с разделителями
- Бинарные файлы
- Бинарные файлы, переменные
- Бинарные файлы, структуры
- Чтение структур по переменным
- Определение файла UNICODE, функция FileReadInteger
- Бинарные файлы, массивы, массивы структур
- Бинарные файлы, строки, массивы строк
- Общая папка для файлов
- Файлы в тестере
- Общий доступ к файлам
- Использование файлов для обмена данными между терминалами
- Еще несколько функций
- Работа с папками
- Получение списка файлов
- Кодовая страница
- Работа с файлами без ограничений
- Несколько полезных скриптов
- Дополнительные материалы по теме
- Заключение
- Файлы приложения
Введение
Функции для работы с файлами есть почти во всех языках программирования, и MQL5 в этом смысле — не исключение. Хотя при программировании советников и индикаторов на MQL5 работать с использованием файлов приходится не всегда, (а скорее даже — очень редко), но тем не менее, каждый экспертописатель рано или поздно с этим сталкивается. Диапазон задач, для которых может потребоваться работа с файлами, достаточно широк. Это может быть генерация собственного отчета о торговле, создание специальных файлов с какими-либо сложными параметрами для советника или индикатора, чтение рыночных данных (например, календаря новостей) и т.п. В данной статье будут рассмотрены все функции по работе с файлами в MQL5. Для каждой из них будут предложены несложные практические задания, выполняя которые, вы приобретете полезные навыки по работе с файлами. Кроме учебных примеров, в ходе статьи будут созданы несколько полезных функций, которые смогут пригодиться в практической деятельности.
В документации по MQL5 описание файловых функций расположено по следующей ссылке.
Чтение текстового файла
Самое простая и наиболее часто используемая функция — чтение текстовых файлов. Не будем сильно затягивать с теорией, постараемся поскорее приступить к практике. Поскольку данная статья посвящена программированию, у вас уже должен быть открыт редактор MetaEditor. Если вы этого еще не сделали — откройте его. В редакторе выполните команду: Главное меню — Открыть каталог данных. В открывшейся папке вы увидите папку MQL5. Откройте ее, затем — расположенную в ней папку Files. Именно в ней и должны располагаться файлы, которые можно обрабатывать файловыми функциями MQL5. Это ограничение предназначено для обеспечения информационной безопасности. Пользователи терминала MetaTrader активно обмениваются между собой программами, написанными на MQL5. Если бы этого ограничения не было, то недоброжелателям было бы очень легко нанести вред вашему компьютеру: удалить или испортить важные файлы или похитить персональные данные.
В только что открытой папке MQL5/Files создадим текстовый файл. Для этого щелкните мышкой где-нибудь в свободном месте папки, и в открывшемся контекстном меню выберите команду: Создать — Текстовый документ. При создании файла дайте ему имя "test", полное имя файла должно быть "test.txt". Будет значительно удобнее, если вы включите на вашем компьютере режим отображения расширения файлов.
После переименовывания файла щелкните на нем, чтобы открыть его: он откроется в редакторе "Блокнот". Запишите в файл 2 — 3 строки текста и сохраните его. При сохранении файла убедитесь, что выбрана кодировка ANSI (выпадающий список в нижней части окна сохранения файла, рис. 1).
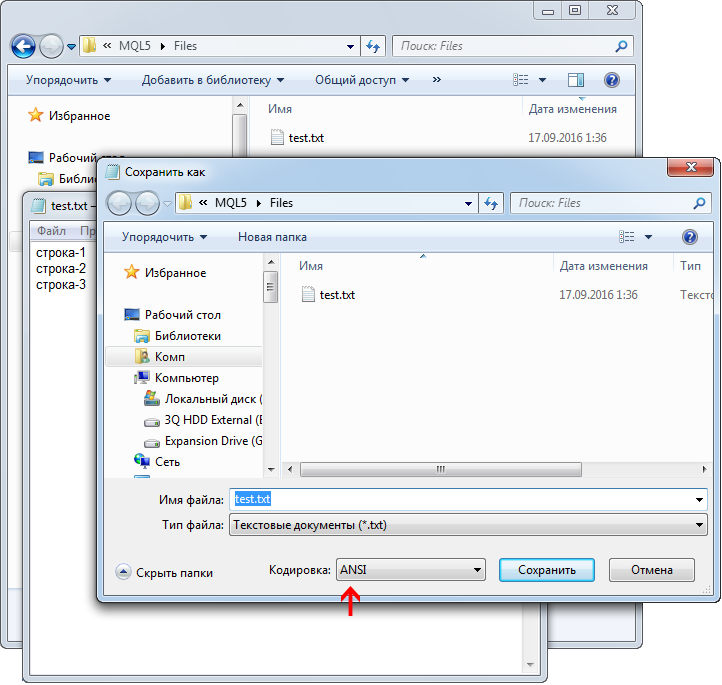
Рис. 1. Сохранение текстового файла из "Блокнота" Windows. Красной стрелкой показан выбор кодировки файла
Теперь мы будем читать этот файл средствами MQL5. В редакторе MetaEditor создадим скрипт, назовем его "sTestFileRead".
Прежде чем читать файл или писать в него, его необходимо открыть, а по завершению работы — закрыть. Открытие файла выполняется функцией FileOpen(), у которой есть два обязательных параметра. Первым параметром указывается имя файла. Укажем имя ранее созданного файла "test.txt". Заметьте: указывается не полный путь к файлу, а только путь от папки MQL5/Files. Вторым параметром указывается комбинация флагов, определяющая режим работы с файлами. Мы собираемся читать файл, значит укажем флаг FILE_READ. Файл "test.txt" является текстовым в кодировке ANSI, значит, укажем еще два флага: FILE_TXT и FILE_ANSI. Флаги комбинируются через выполнение логической операции "или", обозначаемой знаком "|".
Функция FileOpen() возвращает хэндл файла. Не будем вдаваться в подробности, что такое хэндл. Скажем просто, что это некоторое числовое значение (тип int), которое в дальнейшем используется вместо строкового имени файла. Строковое имя файла указывается только при открытии файла, а затем, при выполнении каких-либо действий с этим файлом, используется его хэндл.
Значит, открываем файл (пишем код в функции OnStart() скрипта "sTestFileRead"):
int h=FileOpen("test.txt",FILE_READ|FILE_ANSI|FILE_TXT);
После открытия файла обязательно необходимо выполнить проверку, действительно ли файл открылся. Это выполняется с помощью проверки значения полученного хэндла:
if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; }
Ошибка при открытии файла — это частое и обычное явление. Если файл уже открыт, то открыть его второй раз нельзя. Файл может быть открыт и в какой-либо сторонней программе. Например, при открытии файла в "Блокноте" Windows этот же файл можно открыть из MQL5. Но если же открыть его в Microsoft Excel, то одновременно открыть его не удастся больше ниоткуда.
Чтение данных из текстового файла (открытого с флагом FILE_TXT) выполняется функцией FileReadString(). Чтение выполняется построчно, один вызов функции читает одну строку файла. Прочитаем одну строку и выведем ее в окно сообщений:
string str=FileReadString(h); Alert(str);
Закроем файл:
FileClose(h); Обратите внимание, вызов функций FileReadString() и FileClose() выполняется с указанием хэндла (переменная h), полученного при открытии файла функцией FileOpen().
Теперь можно выполнить скрипт "sTestFileRead". Если что-то не будет получаться, сравните свой код с файлом "sTestFileRead" из приложения к статье. В результате работы скрипта должно открыться окно с первой строкой из файла "test.txt" (рис. 2).
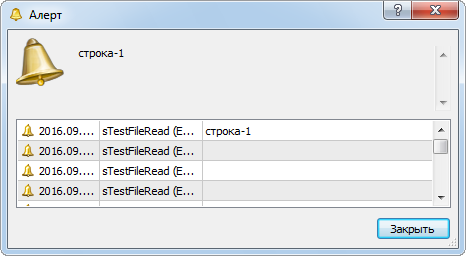
Рис. 2. Результат работы скрипта "sTestFileRead"
Итак, пока мы прочитали только одну строку файла "test.txt". Чтобы прочесть остальные две, можно вызвать функцию FileReadString() еще два раза, но на практике количество строк файла может быть неизвестно заранее. Для решения этой задачи пригодится функция FileIsEnding() и оператор цикла while. Если по мере чтения файла мы доходим до его конца, функция FileIsEnding() возвращает true. С использованием этой функции напишем свою функцию для чтения всех строк файла и вывода их в окно сообщений. Она может пригодится для различных учебных экспериментов по работе с файлами. Получаем следующую функцию:
void ReadFileToAlert(string FileName){ int h=FileOpen(FileName,FILE_READ|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } Alert("=== Начало ==="); while(!FileIsEnding(h)){ string str=FileReadString(h); Alert(str); } FileClose(h);
Создадим скрипт "sTestFileReadToAlert", скопируем в него эту функцию и вызовем ее из функции OnStart() скрипта:
void OnStart(){ ReadFileToAlert("test.txt"); }
В результате работы скрипта откроется окно сообщений со строкой "=== Начало ===" и всеми тремя строками файла "test.txt". Теперь файл прочитан полностью (рис. 3).
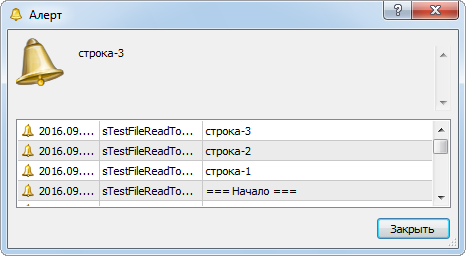
Рис. 3. Благодаря функции FileIsEnding() и цикла do while файл прочитан полностью
Создание текстового файла
Для создания файла его необходимо открыть функцией FileOpen(). Откроем файл с именем "test.txt", но вместо флага FILE_READ нужно указать флаг FILE_WRITE:
int h=FileOpen("test.txt",FILE_WRITE|FILE_ANSI|FILE_TXT);
После открытия не забудьте проверить хэндл, как мы уже делали при чтении файла. Если функция выполнена успешно, будет создан новый файл "test.txt". Если же файл уже существовал, он будет полностью очищен. Будьте внимательны и аккуратны при открытии файлов для записи, не потеряйте ценные данные.
Запись в текстовый файл выполняется функцией FileWrite(), первым параметром функции указывается хэндл файла, а вторым — записываемая в файл строка. При каждом вызове функции FileWrite() выполняется запись новой строки.
Запишем в файл в цикле десять строк. Окончательно получим следующий код скрипта (в приложении скрипт "sTestFileCreate"):
void OnStart(){ int h=FileOpen("test.txt",FILE_WRITE|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } for(int i=1;i<=10;i++){ FileWrite(h,"Строка-"+IntegerToString(i)); } FileClose(h); Alert("Файл создан"); }
После выполнения этого кода в файле "test.txt" будет находиться десять строк. Для проверки содержимого файла его можно открыть в "Блокноте" или выполнить скрипт "sTestFileReadToAlert".
Обратите внимание на функцию FileWrite(). У нее может быть не только два аргумента, но и значительно больше. В функцию можно передать несколько строковых переменных, и при записи они будут объединены в одну строку. В только что приведенном коде вызов функции FileWrite() можно записать следующим образом:
FileWrite(h,"Строка-",IntegerToString(i));
Функция сама объединит строки при записи.
Запись в конец текстового файла
Иногда бывает необходимо сохранить содержимое существующего файла и дописать в его конец еще одну или несколько строк текста. Для выполнения таких действий файл нужно открыть одновременно для записи и для чтения. То есть, при вызове функции FileOpen() необходимо указать оба флага: FILE_READ И FILE_WRITE.
int h=FileOpen("test.txt",FILE_READ|FILE_WRITE|FILE_ANSI|FILE_TXT);
Если файл с указанным именем не существует, он будет создан. Если же он уже есть, то будет открыт, и при этом все его содержимое сохранится. Однако если при этом сразу начать писать в файл, его старое содержимое будет стерто, поскольку запись будет выполняться с начала файла.
При работе с файлами существует такое понятие, как "указатель" — это числовое значение, определяющее в файле позицию, с которой будут выполняться следующая запись или чтение из файла. При открытии файла указатель автоматически устанавливается в начало файла, а по мере чтения или записи данных он автоматически перемещается на величину считанных или записанных данных. При необходимости можно произвольно перемещать указатель. Для этого применяется функция FileSeek().
Чтобы сохранить старое содержимое и добавить новое в конец файла, прежде чем выполнять запись, необходимо переместить указатель в конец файла:
FileSeek(h,0,SEEK_END);
В функцию FileSeek() передаются три параметра: хэндл, величина смещения указателя и позиция, от которой выполняется отсчет смещения. В данном примере константа SEEK_END означает конец файла. Таким образом выполняется смещение указателя на величину 0 байт от конца файла, то есть, в самый его конец.
Окончательно получаем следующий код скрипта для дополнения файла:
void OnStart(){ int h=FileOpen("test.txt",FILE_READ|FILE_WRITE|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } FileSeek(h,0,SEEK_END); FileWrite(h,"Дополнительная строка"); FileClose(h); Alert("Файл дополнен"); }
Этот скрипт также есть в приложении к статье, его имя — "sTestFileAddToFile". Попробуйте запустить скрипт, затем проверьте содержимое файла "test.txt". Каждый вызов скрипта "sTestFileAddToFile" будет добавлять по строке к файлу "test.txt".
Изменение заданной строки текстового файла
Несмотря на возможность свободного перемещения указателя по файлу, с текстовыми файлами это может быть использовано только для дополнения файла и совершенно неприменимо для внесения изменений. Невозможно внести изменения в какую-то определенную строку файла. Дело в том, что строки файла — это условное понятие, ведь на самом деле в файле нет никаких строк, а есть один непрерывный ряд данных. В этом ряду иногда встречаются специальные символы, невидимые в текстовом редакторе. Они указывают, что следующие данные надо отображать с новой строки. Если и установить указатель в начало строки и начать выполнять запись, то в случае, когда размер записываемых данных меньше заменяемой строки, в строке останутся старые данные. Если же размер новой строки больше размера старой строки, будут затерты символы перехода на новую строку и часть данных следующей строки.
Поэкспериментируем: попробуем заменить в файле "test.txt" вторую строку. Для этого откроем файл для чтения и записи, считаем одну строку, чтобы переместить указатель на начало второй строки, и попробуем записать новую строку из двух букв "AB" (скрипт "sTestFileChangeLine2-1" в приложении):
void OnStart(){ int h=FileOpen("test.txt",FILE_READ|FILE_WRITE|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } string str=FileReadString(h); FileWrite(h,"AB"); FileClose(h); Alert("Выполнено"); }
В результате работы этого скрипта файл "test.txt" будет выглядеть в "Блокноте" следующим образом (рис. 4):
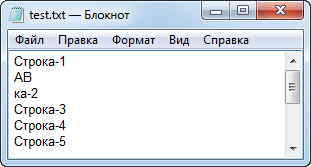
Рис. 4. Результат попытки изменения одной строки текстового файла
Вместо второй строки появились две новых: "AB" и "ка-2". Можно догадаться, что "ка-2" — это остатки от второй строки, в которой оказались стертыми четыре знака. Дело в том, что при записи строки функцией FileWrite() она добавляет в конец записываемого текста символы перехода на новую строку, а в операционной системе Windows их два. Два знака от строки "AB" и два знака перехода на новую строку в сумме и дают стертые 4 символа.
Восстановим файл "test.txt" выполнив скрипт "sTestFileCreate", и теперь попробуем заменить вторую строку более длинной строкой. Запишем строку "Строка-12345" (скрипт "sTestFileChangeLine2-2" в приложении):
void OnStart(){ int h=FileOpen("test.txt",FILE_READ|FILE_WRITE|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } string str=FileReadString(h); FileWrite(h,"Строка-12345"); FileClose(h); Alert("Выполнено"); }
Посмотрим файл (рис. 5):
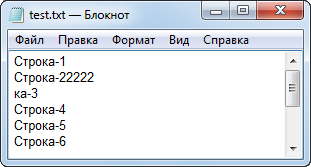
Рис. 5. Результат второй попытки изменения одной строки текстового файла
Как видим, поскольку новая строка была длиннее старой, то задета и третья строка.
Единственный вариант внесения изменений в текстовые файлы — это их полное считывание и запись заново. Нужно прочитать файл в массив, внести изменения в нужные элементы массива и сохранить его построчно в другой файл, затем удалить старый файл, а новый переименовать. В некоторых случаях можно обойтись и без массива: по мере чтения строк из одного файла записывать их в другой, в определенный момент внести изменения в нужную строку и записать ее, а потом, как и в первом случае, удалить старый файл и переименовать новый.
Попробуем вариант без массива. Для этого сначала потребуется создать временный файл. Напишем функцию получения уникального имени временного файла. В функцию будет передаваться имя файла и его расширение, а в самой функции будет выполняться проверка, существует ли такой файл (стандартной функцией FileIsExists()). Если он существует, то к имени будет добавляться число, пока не окажется, что такого файла нет. Получается следующая функция:
string TmpFileName(string Name,string Ext){ string fn=Name+"."+Ext; // сформировали имя int n=0; while(FileIsExist(fn)){ // если файл существует n++; fn=Name+IntegerToString(n)+"."+Ext; // добавляем к имени число } return(fn); }
Создадим скрипт "sTestFileChangeLine2-3", скопируем в него эту функцию, а в функции OnStart() будем располагать следующий код.
Откроем файл "test.txt" для чтения:
int h=FileOpen("test.txt",FILE_READ|FILE_ANSI|FILE_TXT);
Получим имя временного файла и откроем его:
string tmpName=TmpFileName("test","txt"); int tmph=FileOpen(tmpName,FILE_WRITE|FILE_ANSI|FILE_TXT);
Читаем файл построчно и считаем строки. Все прочитанные строки сразу записываются во временный файл, а вторая строка заменяется:
int cnt=0; while(!FileIsEnding(h)){ cnt++; string str=FileReadString(h); if(cnt==2){ // заменяем строку FileWrite(tmph,"Новая строка-2"); } else{ // переписываем строку без изменений FileWrite(tmph,str); } }
Закрываем оба файла:
FileClose(tmph); FileClose(h);
Осталось удалить исходный файл и переименовать временный. Для удаления используется стандартная функция FileDelete().
FileDelete("test.txt");
Для переименовывания используем стандартную функцию FileMove(), которая предназначена для перемещения или переименовывания файлов. В функцию передаются четыре обязательных параметра: имя перемещаемого файла (файл-источник), флаг расположения файла, имя нового файла (файл назначения), флаг перезаписи. С именами файлов должно быть все понятно, поэтому подробнее остановимся на втором и четвертом параметрах — флагах. Второй параметр определяет расположение исходного файла. Дело в том, что файлы, с которыми можно работать в MQL5, могут располагаться не только в папке MQL5/Files терминала, но и в общей папке всех терминалов. Позже рассмотрим этот момент подробней, а пока просто ставим 0. Последний параметр определяет расположение файла назначения, и еще может иметь дополнительный флаг, определяющий действия в случае, если файл назначения существует. Поскольку мы удалили исходный файл самостоятельно (файл назначения), четвертым параметром указываем 0:
FileMove(tmpName,0,"test.txt",0);
Прежде чем выполнять скрипт "sTestFileChangeLine2-3", восстановите файл "test.txt" скриптом "sTestFileCreate". После работы скрипта "sTestFileChangeLine2-3" файл "text.txt" должен иметь следующее содержимое (рис. 6):
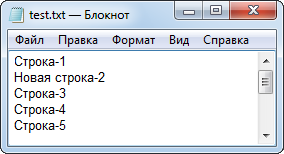
Рис. 6. Содержимое файла после замены строки
Вернемся к функции FileMove(). Если четвертым параметром указать флаг FILE_REWRITE, позволяющий перезаписывать файл назначения:
FileMove(tmpName,0,"test.txt",FILE_REWRITE);
то в этом случае из скрипта можно не удалять исходный файл. Этот вариант используется в скрипте "sTestFileChangeLine2-3" из приложения к статье.
Вместо функции FileMove() можно использовать другую стандартную функцию FileCopy(), но тогда придется удалять временный файл:
FileCopy(tmpName,0,"test.txt",FILE_REWRITE); FileDelete(tmpName);
Чтение текстового файла в массив
Одна полезная функция уже была написана в этой статье (получение свободного имени файла). Теперь напишем еще одну функцию, очень часто используемую при работе с файлами — чтение файла в массив. В функцию передается имя файла и строковый массив, массив передается по ссылке, а в функции заполняется содержимым файла. Функция возвращает true/false в зависимости от успешности ее работы.
bool ReadFileToArray(string FileName,string & Lines[]){ ResetLastError(); int h=FileOpen(FileName,FILE_READ|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ int ErrNum=GetLastError(); printf("Ошибка открытия файла %s # %i",FileName,ErrNum); return(false); } int cnt=0; // при помощи этой переменной будем считать количество строк файла while(!FileIsEnding(h)){ string str=FileReadString(h); // читаем очередную строку из файла // обрезаем пробелы слева и справа, чтобы выявить и не использовать пустые строки StringTrimLeft(str); StringTrimRight(str); if(str!=""){ if(cnt>=ArraySize(Lines)){ // массив полностью заполнен ArrayResize(Lines,ArraySize(Lines)+1024); // увеличиваем размер массива на 1024 элемента } Lines[cnt]=str; // отправляем прочитанную строку в массив cnt++; // увеличиваем счетчик прочитанных строк } } ArrayResize(Lines,cnt); FileClose(h); return(true); }
Подробно эту функцию рассматривать мы не будем: на данный момент, после уже изученного в этой статье материала, она должна быть понятна. К тому же она подробно прокомментирована, остановимся только на некоторых деталях. После чтения строки из файла в переменную str выполняется обрезание пробелов по краям строки функциями StringTrimLeft() и StringTrimRight(). Затем выполняется проверка, не пустая ли строка str. Это сделано для того, чтобы пропустить ненужные пустые строки. По мере заполнения массива он увеличивается не по одному элементу, а блоками по 1024, так функция будет работать значительно быстрее. В конце выполняется масштабирование массива в соответствии с фактически считанным количеством строк.
В приложении эта функция находится в скрипте "sTestFileReadFileToArray".
Создание текстового файла с разделителями
До сих пор в этой статье нам приходилось иметь дело только с простыми текстовыми файлами. Существует еще одна разновидность текстовых файлов: текстовые файлы с разделителями. Обычно они имеют расширение csv (сокращение от анг. "comma ceparated values", переводимое как "значения, разделенные запятой"). По сути, это обычные текстовые файлы, которые можно открывать в текстовых редакторах, читать и редактировать вручную. Один из знаков (не обязательно это будет запятая) является разделителем полей в строках. В связи с этим, с такими файлами можно выполнять несколько иные действия, нежели с простыми текстовыми файлами. Основное отличие заключается в том, что если в простом текстовом файле при вызове функции FileRedaString() происходит считывание целой строки, в файлах с разделителем происходит считывание до разделителя или до конца строки. Есть также отличие и в работе функции FileWrite(): все перечисляемые в функции записываемые переменные не просто соединяются в одну строку, а между ними добавляется разделитель.
Поэкспериментируем с созданием csv-файла. Для создания открываем файл так же, как уже открывали текстовый файл на запись, но только вместо флага FILE_TXT указываем флаг FILE_CSV. Третьим параметром указывается символ, используемый в качестве разделителя:
int h=FileOpen("test.csv",FILE_WRITE|FILE_ANSI|FILE_CSV,";");
Запишем в файл десять строк по три поля:
for(int i=1;i<=10;i++){ string str="Строка-"+IntegerToString(i)+"-"; FileWrite(h,str+"1",str+"2",str+"3"); }
В конце не забываем закрывать файл. В приложении код этого примера находится в скрипте "sTestFileCreateCSV". В результате работы этого примера создается файл "test.csv". Содержимое файла показано на рис. 7. Как видим, параметры функции FileWrite() не просто соединились в одну строку, а между ними добавлен разделитель.
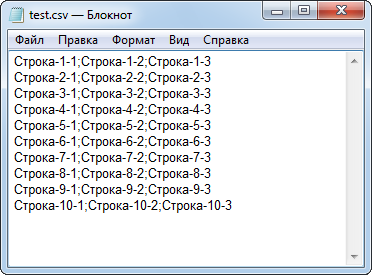
Рис. 7. Содержимое файла с разделителями
Чтение текстового файла с разделителями
Попробуем прочитать файл csv точно так же, как читали текстовый файл в самом начале этой статьи. Сделаем копию скрипта "sTestFileReadToAlert" с именем "sTestFileReadToAlertCSV". В функции ReadFileToAlert() изменим первую строку:
int h=FileOpen(FileName,FILE_READ|FILE_ANSI|FILE_CSV,";");
Функцию ReadFileToAlert() переименуем в ReadFileToAlertCSV() и изменим имя файла, передаваемого в функцию:
void OnStart(){ ReadFileToAlertCSV("test.csv"); }
По результату работы скрипта будет видно, что файл прочитан по одному полю. Хотелось бы определить, когда прочитаны поля одной строки и начинается новая строка. Для этого будет полезна функция FileIsLineEnding().
Сделаем копию скрипта "sTestFileReadToAlertCSV" с именем "sTestFileReadToAlertCSV2", переименуем функцию "ReadFileToAlertCSV" в "ReadFileToAlertCSV2" и внесем в нее изменения. Добавим функцию FileIsLineEnding(): если она возвращает true, будем выводить разделительную строку "---".
void ReadFileToAlertCSV2(string FileName){ int h=FileOpen(FileName,FILE_READ|FILE_ANSI|FILE_CSV,";"); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } Alert("=== Начало ==="); while(!FileIsEnding(h)){ string str=FileReadString(h); Alert(str); if(FileIsLineEnding(h)){ Alert("---"); } } FileClose(h); }
Теперь поля, выводимые скриптом в окно сообщений, будут разделяться на группы (рис. 8).
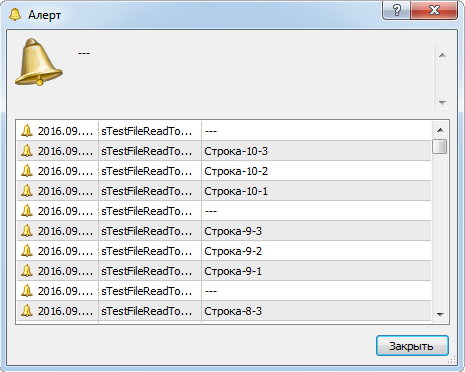
Рис. 8. Разделители "---" между группами полей одной строки файла
Чтение файла с разделителями в массив
Разобравшись в особенностях работы с csv-файлами, напишем еще одну практически полезную функцию для чтения csv-файла в массив. Чтение будет выполняться в массив структур, где каждый элемент будет соответствовать одной строке файла. В структуре будет находиться строковый массив, каждый элемент которого будет соответствовать одному полю строки.
Описание структуры:
struct SLine{ string field[]; };
Функция:
bool ReadFileToArrayCSV(string FileName,SLine & Lines[]){ ResetLastError(); int h=FileOpen(FileName,FILE_READ|FILE_ANSI|FILE_CSV,";"); if(h==INVALID_HANDLE){ int ErrNum=GetLastError(); printf("Ошибка открытия файла %s # %i",FileName,ErrNum); return(false); } int lcnt=0; // переменная для подсчета строк int fcnt=0; // переменная для подсчета полей строки while(!FileIsEnding(h)){ string str=FileReadString(h); // новая строка (новый элемент массива структур) if(lcnt>=ArraySize(Lines)){ // массив структур полностью заполнен ArrayResize(Lines,ArraySize(Lines)+1024); // увеличиваем размер массива на 1024 элемента } ArrayResize(Lines[lcnt].field,64);// изменяем размер массива в структуре Lines[lcnt].field[0]=str; // присваиваем значение первого поля // начинаем читать остальные поля в строке fcnt=1; // пока занят один элемент в массиве полей while(!FileIsLineEnding(h)){ // читаем остальные поля в строке str=FileReadString(h); if(fcnt>=ArraySize(Lines[lcnt].field)){ // массив полей полностью заполнен ArrayResize(Lines[lcnt].field,ArraySize(Lines[lcnt].field)+64); // увеличиваем размер массива на 64 элемента } Lines[lcnt].field[fcnt]=str; // присваиваем значение очередного поля fcnt++; // увеличиваем счетчик полей } ArrayResize(Lines[lcnt].field,fcnt); // изменяем размер массива полей в соответствии с фактическим количеством полей lcnt++; // увеличиваем счетчик строк } ArrayResize(Lines,lcnt); // изменяем массив структур (строк) в соответствии с фактическим количеством строк FileClose(h); return(true); }
Подробно разбирать эту функцию не будем, остановимся только на основных принципиальных моментах. В начале цикла while(!FileIsEnding(h)) выполняется чтение одного поля. Здесь становится известно, что в массив структур добавляется элемент. Проверяем размер массива, и, если надо, увеличиваем его размер на 1024 элемента. Сразу же изменяем размер массива для полей. Ему сразу задается размер в 64 элемента, и элементу с индексом 0 присваивается значение прочитанного из файла первого поля строки. После этого в цикле while(!FileIsLineEnding(h)) прочитываем все остальные поля. Прочитав очередное поле, проверяем размер массива, и если надо, то увеличиваем его, затем отправляем прочитанное из файла строку в массив. Дочитав строку до конца (выйдя из цикла while(!FileIsLineEnding(h)) ), изменяем размер массива полей в соответствии с фактическим количеством полей. В самом конце изменяем размер массива строк в соответствии с фактическим количеством прочитанных строк.
В приложении данная функция находится в скрипте "sTestFileReadFileToArrayCSV". Скрипт читает файл "test.csv" в массив и выводит этот массив в окно сообщений. Результат точно такой же, как на рис. 8.
Запись массива в текстовый файл с разделителями
Если количество полей в строке известно заранее, это несложно. Такая задача уже решалась в этой статье в разделе "Создание текстового файла с разделителями". Для случая, когда количество полей неизвестно, можно самостоятельно в цикле собрать все поля в одну строку через разделитель и записать ее в файл, открытый с флагом FILE_TXT.
Открываем файл:
int h=FileOpen("test.csv",FILE_WRITE|FILE_ANSI|FILE_TXT);
Собираем все поля (элементы массива) в одну строку через разделитель. В конце строки разделителя не должно быть, иначе в строке будет лишнее пустое поле:
string str=""; int size=ArraySize(a); if(size>0){ str=a[0]; for(int i=1;i<size;i++){ str=str+";"+a[i]; // соединяем поля через разделитель } }
Записываем строку в файл и закрываем его:
FileWriteString(h,str); FileClose(h);
Это пример находится в приложении в скрипте "sTestFileWriteArrayToFileCSV".
Файлы UNICODE
До сих пор при открытии файлов во всех случаях указывался флаг FILE_ANSI, определяющий их кодировку. В этой кодировке одному символу соответствует один байт, а следовательно, весь набор ограничен количеством 256 символов. В настоящее время широко используется кодировка UNICODE, в которой один символ определяется несколькими байтами и текстовый файл может содержать очень большое количество символов: от алфавитов разных языков до иероглифов и прочих графических символов.
Немного поэкспериментируем. Откройте в редакторе скрипт "sTestFileReadToAlert", сохраните его с именем "sTestFileReadToAlertUTF" и измените флаг FILE_ANSI на FILE_UNICODE:
int h=FileOpen(FileName,FILE_READ|FILE_UNICODE|FILE_TXT);
Поскольку файл "test.txt" сохранен в кодировке ANSI, в результате работы скрипта откроется окно со странным набором символов (рис. 9).

Рис. 9. Странный текст при несовпадении кодировки файла и кодировки указанной при открытии файла
Очевидно, это происходит от несовпадения кодировки файла и кодировки, указанной при открытии файла.
Откройте в редакторе скрипт "sTestFileCreate" сохраните его с именем "sTestFileCreateUTF" и измените флаг FILE_ANSI на FILE_UNICODE:
int h=FileOpen("test.txt",FILE_WRITE|FILE_UNICODE|FILE_TXT);
Запустите скрипт "sTestFileCreateUTF", чтобы создать новый файл "test.txt". Теперь скрипт "sTestFileReadToAlertUTF" выведет читаемый текст (рис. 10).
Рис. 10. Чтение скриптом "sTestFileReadToAlertUTF" файла, созданного скриптом "sTestFileCreateUTF"
Откройте файл "test.txt" в редакторе "Блокнот" и выполните команду главного меню "Сохранить как". В нижней части окна сохранения файла можно увидеть, что в списке "Кодировка" выбрано "Unicode". "Блокнот" каким-то образом определил кодировку файла. Файлы в кодировке Unicode начинаются со стандартного набора символов, так называемого BOM (byte order mark, отметка о последовательности байтов). Чуть позже, при изучении бинарных файлов, мы еще вернемся к этому вопросу и напишем функцию для определения типа текстового файла (ANSI или UNCODE).
Дополнительные функции для работы с текстовыми файлами с разделителями
Из всего обилия файловых функций для работы с содержимым текстовых файлов (как простых, так и с разделителями) практически можно ограничиться только двумя функциями: FileWrite() и FileReadString(). Функция FileReadString(), кроме того, используется и при работе с бинарными файлами (о бинарных файлах поговорим чуть ниже). Кроме функции FileWrite(), можно использовать функцию FileWriteString(), но это не принципиальный вопрос.
При работе с текстовыми файлами с разделителем могут использоваться еще несколько функций, которые могут сделать работу более удобной: FileReadBool(), FileReadNumber() и FileReadDatetime(). Функция FileReadNumber() предназначена для чтения чисел. Если заранее известно, что читаемое из файла поле включает в себя только число, можно применить эту функцию. Ее действие идентично чтению строки функцией FileReadString() и преобразованию ее в число функцией StringToDouble(). Аналогично, функция FileReadBool() предназначена для чтения значений типа bool, в строке может быть записан текст "true" или "false" или числа "0" или "1". Функция FileReadDatetime() предназначена для чтения даты в строковом формате и преобразования ее в числовое значение типа datetime. Ее действие аналогично чтению строки и преобразованию ее функцией StringToTime().
Бинарные файлы
Рассмотренные ранее текстовые файлы очень удобны тем, что их содержимое, читаемое программными методами, соответствует тому, что вы видите в файле, открыв его в текстовом редакторе. Можно легко проконтролировать результаты работы программы, посмотрев файл в редакторе, а при необходимости файл можно изменить вручную. Недостаток текстовых файлов — ограниченные возможности при работе с ними (вспомните, с какими сложностями пришлось столкнуться при замене одной строки файла).
Если текстовые файлы имеют незначительный размер, использовать их очень удобно, но при больших размерах работа с ними становится очень медленной. Если необходимо работать с большими объемами данных и делать это максимально быстро, необходимо использовать бинарные файлы.
При открытии файла в бинарном режиме вместо флага FILE_TXT или FILE_CSV указывается флаг FILE_BIN. Указывать флаги кодировки FILE_ANSI или FILE_UNCODE нет смысла, ведь бинарный файл — это файл с цифрами.
Конечно, из любопытства можно взглянуть на содержимое бинарного файла в текстовом редакторе типа "Блокнота": можно увидеть буквы и даже читаемый текст, если он имеется в файле, но это больше связано с особенностями работы "Блокнота", нежели с содержимым файла.
Посмотреть на бинарный файл в текстовом редакторе еще можно, но редактировать его там определенно не следует, потому что в итоге файл окажется поврежденным. Не будем вдаваться в подробности, почему так происходит, просто примем это как факт. Конечно, существуют и специальные редакторы для бинарных файлов, позволяющие выполнять их редактирование, но все равно процесс этот не будет наглядным и интуитивно понятным.
Бинарные файлы, переменные
Наибольшее количество функций для работы с файлами в MQL5 предназначены для применения в бинарном режиме. Есть функции для записи/чтения переменных различных типов:
Все функции записи/чтения переменных рассматривать мы не будем: достаточно одной, ведь использование остальных функций абсолютно идентично. Поэкспериментируем с функциями FileWriteDouble() и FileReadDouble().
Сначала создадим файл и запишем в него три переменных, затем будем читать их в произвольном порядке.
Открываем файл:
int h=FileOpen("test.bin",FILE_WRITE|FILE_BIN);
Пишем в файл три переменные double со значениями 1.2, 3.45, 6.789:
FileWriteDouble(h,1.2); FileWriteDouble(h,3.45); FileWriteDouble(h,6.789);
Не забудьте закрыть файл.
В приложении скрипт с этим кодом имеет имя "sTestFileCreateBin". В результате работы скрипта в папке MQL5/Files появится файл "test.bin". Все-таки взглянем на содержимое файла в "Блокноте" (рис. 11). Для этого откройте "Блокнот" и перетащите на него файл:

Рис. 11. Бинарный файл в "Блокноте"
Как видим, нет смысла смотреть такие файлы в блокноте.
Теперь прочитаем файл. Очевидно, для чтения должна использоваться функция FileReadDouble(). Откроем файл:
int h=FileOpen("test.bin",FILE_READ|FILE_BIN);
Объявим три переменные, прочитаем в них значения из файла и выведем их в окно сообщений:
double v1,v2,v3; v1=FileReadDouble(h); v2=FileReadDouble(h); v3=FileReadDouble(h); Alert(DoubleToString(v1)," ",DoubleToString(v2)," ",DoubleToString(v3));
Не забывайте закрыть файл. В приложении скрипт с этим кодом имеет имя "sTestFileReadBin". В результате работы скрипта получим сообщение: 1.20000000 3.45000000 6.78900000.
В бинарные файлы, зная их структуру, можно вносить ограниченные изменения. Попробуем изменить значение второй переменной, не перезаписывая весь файл.
Откроем файл:
int h=FileOpen("test.bin",FILE_READ|FILE_WRITE|FILE_BIN);
После открытия нужно переместить указатель на нужную позицию. Для вычисления позиции удобно пользоваться функцией sizeof(). Она возвращает размер указанного типа данных. Полезно также будет ознакомиться с типами данных и их размерами. Перемещаем указатель на начало второй переменной:
FileSeek(h,sizeof(double)*1,0);
Для наглядности записано умножение sizeof(double)*1, чтобы было понятно, что подразумевается окончание первой переменной. Если бы надо было изменить третью переменную, то нужно было бы выполнить умножение на 2.
Записываем новое значение:
FileWriteDouble(h,12345.6789);
В приложении этот код находится в скрипте с именем "sTestFileChangeBin". После выполнения этого скрипта выполняем скрипт "sTestFileReadBin" и получаем: 1.20000000 12345.67890000 6.78900000.
Таким же образом можно читать и не весь файл, а только заданную переменную. Напишем код для чтения третей переменной double из файла "test.bin".
Откроем файл:
int h=FileOpen("test.bin",FILE_READ|FILE_BIN);
Переместим указатель, прочитаем значение и выведем его в окно:
FileSeek(h,sizeof(double)*2,SEEK_SET); double v=FileReadDouble(h); Alert(DoubleToString(v));
Скрипт с этим примером находится в приложении, имя файла — "sTestFileReadBin2". В результате работы скрипта получим: 6.78900000 — значение третьей переменной. Самостоятельно измените этот код так, чтобы прочитать вторую переменную.
Точно таким же образом можно сохранить и читать переменные других типов, их комбинации. Важно знать структуру файла, чтобы правильно вычислять позицию для установки указателя.
Бинарные файлы, структуры
Если в файл нужно писать несколько переменных разного типа, будет намного удобней писать/читать переменные не по одной, а описать структуру и читать/писать целую структуру. Обычно так и делается: файл начинается со структуры, описывающей расположение данных в файле (формат файла), а затем располагаются данные. Однако имеется ограничение: в структуре не должно быть динамических массивов и строк, потому что их размер неизвестен.
Поэкспериментируем с записью и чтением структуры в файл. Опишем структуру с несколькими переменными разного типа:
struct STest{ long ValLong; double VarDouble; int ArrInt[3]; bool VarBool; };
В приложении этот код располагается в скрипте с именем "sTestFileWriteStructBin". В функции OnStart() объявим две переменные и заполним их разными значениями:
STest s1; STest s2; s1.ArrInt[0]=1; s1.ArrInt[1]=2; s1.ArrInt[2]=3; s1.ValLong=12345; s1.VarDouble=12.34; s1.VarBool=true; s2.ArrInt[0]=11; s2.ArrInt[1]=22; s2.ArrInt[2]=33; s2.ValLong=6789; s2.VarDouble=56.78; s2.VarBool=false;
Теперь, как обычно, откроем файл:
int h=FileOpen("test.bin",FILE_WRITE|FILE_BIN);
Запишем в него обе структуры:
FileWriteStruct(h,s1); FileWriteStruct(h,s2);
Не забудьте закрыть файл. Исполните этот скрипт, чтобы создался файл.
Теперь будем читать файл. Прочитаем вторую структуру.
Откроем файл:
int h=FileOpen("test.bin",FILE_READ|FILE_BIN);
Переместим указатель на начало второй структуры:
FileSeek(h,sizeof(STest)*1,SEEK_SET);
Объявим переменную (добавьте в начало файла описание структуры STest), прочитаем в нее данные из файла:
STest s;
FileReadStruct(h,s); Выведем значения полей структуры в окно:
Alert(s.ArrInt[0]," ",s.ArrInt[1]," ",s.ArrInt[2]," ",s.ValLong," ",s.VarBool," ",s.VarDouble);
В результате работы в окне сообщений увидим строку: 11 22 33 6789 false 56.78. Строка соответствует данным второй структуры.
Код этого примера расположен в приложении в скрипте с именем "sTestFileReadStructBin".
Чтение структур по переменным
В MQL5 поля структур следуют одно за другим, без смещения (выравнивания), поэтому можно без каких-либо сложностей читать отдельные поля структур.
Прочитаем значение переменной double из второй структуры в файле "test.bin". Важно правильно рассчитать позицию для установки указателя:
FileSeek(h,sizeof(STest)+sizeof(long),SEEK_SET);
Все остальное аналогично тому, что мы уже много раз делали в этой статье: открыть файл, прочитать, закрыть. Код этого примера находится в приложении в скрипте с именем "sTestFileReadStructBin2".
Определение файла UNICODE, функция FileReadInteger
Немного разобравшись с бинарными файлами, можно создать полезную функцию для определения файла UNICODE. Эти файлы можно отличить по значению начального байта, равному 255. Коду 255 соответствует непечатный символ, поэтому в нормальном ANSI файле его не может быть.
Значит, необходимо прочитать из файла один байт и проверить его значение. Для чтения различных целочисленных переменных, кроме long, используется функция FileReadInteger(). В нее передается параметр, указывающий размер читаемой переменной. Читаем из файла один байт в переменную v:
uchar v=FileReadInteger(h,CHAR_VALUE);
Остается только проверить значение переменой. Ниже приведен полный код функции:
bool CheckUnicode(string FileName,bool & Unicode){ ResetLastError(); int h=FileOpen(FileName,FILE_READ|FILE_BIN); if(h==INVALID_HANDLE){ int ErrNum=GetLastError(); printf("Ошибка открытия файла %s # %i",FileName,ErrNum); return(false); } uchar v=FileReadInteger(h,CHAR_VALUE); Unicode=(v==255); FileClose(h); return(true); }
Функция возвращает true/false, в зависимости от того, удалось ли выполнить проверку. Первым параметром в функцию передается имя файла, а вторым по ссылке переменная, в которой после выполнения функции будет значение true для файлов UNICODE и false для файлов ANSI.
Код этой функции с примером ее вызова находится в приложении в скрипте "sTestFileCheckUnicode". Запустите скрипт "sTestFileCreate" и проверьте его тип скриптом "sTestFileCheckUnicode", затем запустите скрипт "sTestFileCreateUTF" и еще раз запустите скрипт "sTestFileCheckUnicode". Вы получите другой результат.
Бинарные файлы, массивы, массивы структур
Основное преимущество бинарных файлов становится заметным при работе со значительными размерами данных. Данные при этом обычно располагаются в массивах (отдельными переменными сложно получить значительный размер) и в строках. Массивы могут быть не только из переменных стандартного типа, но и из структур, которые должны соответствовать уже описанным ранее требованиям. В них не должно быть динамических массивов и строк.
Массивы записываются в файл функцией FileWriteArray(). Первым параметром в функцию, как обычно, передается хэндл файла, затем имя массива. Два последующих параметра необязательны. Если нужно сохранить не весь массив, можно указать индекс начального элемента массива и количество сохраняемых элементов.
Чтение массивов выполняется функцией FileReadArray(), параметры функции идентичны параметрам функции FileWriteArray().
Поэкспериментируем, запишем в файл массив int из трех элементов:
void OnStart(){ int h=FileOpen("test.bin",FILE_WRITE|FILE_BIN); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } int a[]={1,2,3}; FileWriteArray(h,a); FileClose(h); Alert("Файл записан"); }
В приложении этот код расположен в файле "sTestFileWriteArray".
Теперь прочитаем его (в приложении скрипт "sTestFileReadArray") и выведем в окно:
void OnStart(){ int h=FileOpen("test.bin",FILE_READ|FILE_BIN); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } int a[]; FileReadArray(h,a); FileClose(h); Alert(a[0]," ",a[1]," ",a[2]); }
В результате работы скрипта получим строку "1 2 3", что соответствует записанному ранее массиву. Обратите внимание: размер массива не был определен, и при вызове функции FileReadArray() он тоже не указывался, произошло считывание всего файла. Однако в файле может находиться не один массив, а любое их количество, и они могут иметь различные типы. Поэтому было бы неплохо сохранять в файл и сведения о размере файла. Запишем в файл два массива: один типа int, второй типа double. Но перед ними запишем по переменной int с их размерами:
void OnStart(){ int h=FileOpen("test.bin",FILE_WRITE|FILE_BIN); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } // два массива int a1[]={1,2,3}; double a2[]={1.2,3.4}; // определяем размеры массивов int s1=ArraySize(a1); int s2=ArraySize(a2); // записываем массив 1 FileWriteInteger(h,s1,INT_VALUE); // запись размера массива FileWriteArray(h,a1); // собственно запись массива // записываем массив 2 FileWriteInteger(h,s2,INT_VALUE); // запись размера массива FileWriteArray(h,a2); // собственно запись массива FileClose(h); Alert("Файл записан"); }
Этот код находится в приложении в скрипте "sTestFileWriteArray2".
Теперь, при чтении файла, сначала прочитываем размер массива, затем будем считывать в массив указанное количество элементов:
void OnStart(){ int h=FileOpen("test.bin",FILE_READ|FILE_BIN); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } int a1[]; double a2[]; int s1,s2; s1=FileReadInteger(h,INT_VALUE); // считываем размер массива 1 FileReadArray(h,a1,0,s1); // считаем в массив заданное в s1 количество элементов s2=FileReadInteger(h,INT_VALUE); // считываем размер массива 1 FileReadArray(h,a2,0,s2); // считаем в массив заданное в s2 количество элементов FileClose(h); Alert(ArraySize(a1),": ",a1[0]," ",a1[1]," ",a1[2]," :: ",ArraySize(a2),": ",a2[0]," ",a2[1]); }
Этот код находится в приложении в скрипте "sTestFileReadArray2".
В результате работы скрипт выведет сообщение: 3 : 1 2 3 - 2 : 1.2 3.4, что соответствует размерам и содержимому ранее записанных в файл массивов.
При чтении массивов функцией FileReadArray() автоматически выполняется масштабирование массива, но имейте в виду: масштабирование выполняется, только если текущий размер меньше, чем количество считываемых элементов. Если же размер массива больше, размер не меняется, только выполняется заполнение части массива.
Работа с массивами структур совершенно идентична работе с массивами стандартных типов, поскольку размер структуры определен конкретно (отсутствуют динамические массивы и строки). Пример с массивами структур не будет приводиться, поэкспериментируйте самостоятельно.
Хотелось бы еще напомнить: поскольку мы можем свободно перемещать указатель по файлу, можно считывать не весь массив, а только какой-то один из его элементов или часть массива. Важно правильно вычислить позицию, в которую нужно переместить указатель. Пример чтения отдельных элементов тоже не будет приводиться в целях экономии объема статьи. Поэкспериментируйте с этим самостоятельно.
Бинарные файлы, строки, массивы строк
Для записи строки в бинарный файл используется функция FileWriteString(), в которую передаются два обязательных параметра: хэндл файла и записываемая в файл строка. Третий параметр необязательный: можно указать количество записываемых символов, если нужно записать не всю строку целиком.
Чтение строки выполняется функцией FileReadString(). В ней первым параметром указывается хэндл, а второй— необязательный — используется для указания количества считываемых символов.
В общем принцип записи/считывания строк очень похож на принцип работы с массивом: строка аналогична всему массиву, а один символ строки аналогичен одному элементу массива, поэтому не будем рассматривать пример записи/считывания одной строки. Рассмотрим более сложный пример: запись и чтение строкового массива. Сначала в файл запишем переменную int с размером массива, потом в цикле будем записывать отдельные элементы, перед каждым записывая переменную int с его размером:
void OnStart(){ int h=FileOpen("test.bin",FILE_WRITE|FILE_BIN); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } string a[]={"Строка-1","Строка-2","Строка-3"}; // записываемый массив FileWriteInteger(h,ArraySize(a),INT_VALUE); // запись размера массива for(int i=0;i<ArraySize(a);i++){ FileWriteInteger(h,StringLen(a[i]),INT_VALUE); // запись размера строки (одного элемента массива) FileWriteString(h,a[i]); } FileClose(h); Alert("Файл записан"); }
В приложении этот код находится в скрипте "sTestFileWriteStringArray".
При чтении сначала прочитаем размер массива, затем изменим его размер и будем считывать отдельные элементы, предварительно считывая их размеры:
void OnStart(){ int h=FileOpen("test.bin",FILE_READ|FILE_BIN); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } string a[]; // в этот массив будем читать файл int s=FileReadInteger(h,INT_VALUE); // считываем размер массива ArrayResize(a,s); // изменение размера массива for(int i=0;i<s;i++){ // по всем элементам массива int ss=FileReadInteger(h,INT_VALUE); // чтение размера строки a[i]=FileReadString(h,ss); // чтение строки } FileClose(h); // вывод прочитанного массива Alert("=== Начало ==="); for(int i=0;i<ArraySize(a);i++){ Alert(a[i]); } }
В приложении этот код находится в скрипте "sTestFileReadStringArray".
Общая папка для файлов
До сих пор мы имели дело с файлами, располагающимися в папке MQL5/Files. Но это не единственное место, где могут располагаться файлы. В редакторе MetaEditor в главном меню выполните команду: Файл - Открыть общую папку данных. Откроется папка, в которой вы увидите папку Files. В этой папке тоже могут располагаться файлы, доступные из программ, написанных на MQL5. Обратите внимание на путь к ней (рис. 12):

Рис. 12. Путь к общей папке данных
Путь к общей папке данных никак не связан с путем к терминалу и путем к папке Files, с которой мы имели дело в течение всей статьи. Сколько бы терминалов у вас не работало (в том числе запущенных с ключом "/portable"), для всех них будет открываться одна и та же общая папка.
Пути к папкам можно определить программно. Путь к папке данных (в которой располагается папка MQL5/Files с которой мы имели дело в течение всей статьи):
TerminalInfoString(TERMINAL_DATA_PATH);
Путь к общей папке данных (в которой располагается папка Files):
TerminalInfoString(TERMINAL_COMMONDATA_PATH);
Точно так же можно определить и путь к терминалу (корневую папку, в которой установлен терминал):
TerminalInfoString(TERMINAL_PATH);
Так же, как и с папкой MQL5/Files, при работе с файлами из общей папки нет необходимости указывать полный путь, достаточно в комбинацию флагов, передаваемых функции FileOpen(), добавить флаг FILE_COMMON. Некоторые файловые функции имеют непосредственно параметр для указания флага общей папки. К таким функциям относятся, в частности, FileDelete(), FileMove(), FileCopy().
Скопируем файл "test.txt" из папки MQL5/Files в общую папку данных:
if(FileCopy("test.txt",0,"test.txt",FILE_COMMON)){ Alert("Файл скопирован"); } else{ Alert("Ошибка копирования файла"); }
В приложении этот код находится в скрипте "sTestFileCopy". После исполнения скрипта в общей папке Files появится файл "test.txt". Если запустить скрипт второй раз, получим сообщение об ошибке. Чтобы сообщения об ошибке не было, необходимо разрешить перезапись файла, добавить флаг FILE_REWRITE:
FileCopy("test.txt",0,"test.txt",FILE_COMMON|FILE_REWRITE)
Теперь скопируем файл из общей папки в эту же папку с другим именем (в приложении скрипт "sTestFileCopy2"):
FileCopy("test.txt",FILE_COMMON,"test_copy.txt",FILE_COMMON)
А теперь — из общей папки в папку MQL5/Files (в приложении скрипт "sTestFileCopy3"):
FileCopy("test.txt",FILE_COMMON,"test_copy.txt",0)
Функция FileMove() вызывается идентично, только копия не создается, а файл перемещается (или переименовывается).
Файлы в тестере
Вся работа с файлами, рассмотренная до этого момента, касалась работы программ MQL5 (скриптов, экспертов, индикаторов) работающих на счете (запущенных на графике). При работе эксперта в тестере все обстоит совсем иначе. Тестер в MetaTrader5 имеет возможность выполнения распределенного (облачного) тестирования с использованием удаленных агентов. Грубо говоря, прогоны оптимизации 1-10 (цифры, разумеется условные) выполняются на одном компьютере, одновременно выполняются прогоны 11-20 на другом компьютере и т.д. От этого возникают некоторые сложности и, соответственно, особенности при работе с файлами. Рассмотрим эти особенности и выведем принципы, которых надо придерживаться при работе с файлами в тестере.
Если при обычной работе с файлами функция FileOpen() обращается к файлам, расположенным в папке MQL5/Files, которая находится в папке данных терминала, то при тестировании выполняется обращение к файлам в папке MQL5/Files, которая находится в папке агента тестирования. Если файлы нужны только в процессе одного прохода оптимизации (или одиночного тестирования), например, для хранения данных о позиции или отложенных ордерах, то все нормально, только нужно очистить файлы перед очередным проходом (при инициализации эксперта). Если же файл будет использоваться для определения каких-либо параметров работы эксперта и скорее всего, создается вручную, то он будет располагаться в папке MQL5/Files папки данных терминала. Это означает, тестируемый эксперт его не увидит. Для того, чтобы эксперт имел доступ к этому файлу, его нужно передать агенту. Это делается в эксперте через указание свойства "#property tester_file". Таким образом можно передать любое количество файлов:
#property tester_file "file1.txt" #property tester_file "file2.txt" #property tester_file "file3.txt"
Однако, если даже файл указан через " "#property tester_file", то если выполнить в него запись, эксперт выполнит запись в копию файла, расположенную в папке агента тестирования. Файл в папке данных терминала останется без изменений. Дальнейшее чтение файла экспертом будет выполняться из папки агента, то есть, будет читаться измененный файл. Значит, если в процессе тестирования и оптимизации эксперту нужно сохранять какие-то данные для дальнейшего анализа, сохранение данных в файл неприменимо, для этих целей нужно пользоваться фреймами.
Если не использовать удаленные агенты, можно работать с файлами из общей папки (при открытии файла указывать флаг FILE_COMMON). В этом случае нет необходимости указывать имя файла в свойствах эксперта, и эксперт сможет выполнять в файл запись. Короче говоря, при использовании общей папки данных нет никаких особенностей в работе с файлами из тестера, кроме того, что вы не должны пользоваться удаленными агентами. Также при этом нужно следить внимательно за именами файлов, чтобы тестируемый эксперт не испортил файл, используемый реально работающим экспертом. Определить работу в тестере можно программно:
MQLInfoInteger(MQL5_TESTER)
В случае тестирования нужно использовать другие имена файлов.
Общий доступ к файлам
Как уже упоминалось в этой статье, если файл открыт, то открыть его второй раз не получится: будет выдана ошибка. Если с файлом уже работает одна программа, то работать с ним в другой программе будет невозможно, пока он не будет закрыт. Однако MQL5 предоставляет возможность общего использования файлов. Для этого при открытии файла необходимо указать дополнительный флаг FILE_SHARE_READ (общий доступ для чтения) или FILE_SHARE_WRITE (общий доступ для записи). Несмотря на наличие таких возможностей, пользоваться ими нужно очень аккуратно и с пониманием дела. Операционные системы на сегодняшний день многозадачны, поэтому никто не гарантирует последовательности в выполнении действий запись — чтение. Если разрешить общий доступ на запись и чтение, может получиться так, что одна программа пишет, а другая тут же читает записанное не до конца. Таким образом, требуется принятие мер по синхронизации обращений к файлу разных программ. Эта задача довольно сложная и значительно выходящая за пределы данной статьи. К тому же, скорее всего, можно обойтись без синхронизации и без совместного доступа к файлам (что и будет показано чуть ниже на примере использования файлов для обмена данными между терминалами).
Единственный случай, когда можно смело открывать файл с общими правами на чтение (FILE_SHARE_READ) и когда разрешение такого доступа оправдано, — это случай, если файл используется для определения каких-то параметров работы эксперта или индикатора, типа файла конфигурации. Файл создается вручную или дополнительным скриптом, затем считывается несколькими экземплярами эксперта или индикатора при инициализации. При инициализации несколько экспертов могут попытаться открыть файл почти одновременно, поэтому следует предоставить им такую возможность. При этом есть гарантия, что при чтении файла в него не идет запись.
Использование файлов для обмена данными между терминалами
Сохраняя файлы в общую папку, можно обеспечить обмен данными между терминалами. Конечно, использование файлов для таких целей не является лучшим решением, но в некоторых случаях может пригодиться. Задача решается просто: никакой общий доступ к файлу не используется, файл открывается обычным образом. Пока выполняется запись, больше никто не может открыть файл. По окончанию записи файл закрывается, и другие экземпляры программ могут его прочитать. Ниже приведен код функции передачи (записи) данных скрипта "sTestFileTransmitter":
bool WriteData(string str){ for(int i=0;i<30 && !IsStopped();i++){ // несколько попыток int h=FileOpen("data.txt",FILE_WRITE|FILE_ANSI|FILE_TXT); if(h!=INVALID_HANDLE){ // удалось открыть файл FileWriteString(h,str); // записываем данные FileClose(h); // закрываем файл Sleep(100); // делаем паузу побольше, чтобы другие программы // имели гарантированную возможность считать данные return(true); // в случае успеха возвращаем true } Sleep(1); // делаем минимальную паузу, чтобы дать другим программам // завершить чтение файла и сразу поймать // момент, когда файл будет свободен } return(false); // если не удалось записать данные }
Делается несколько попыток открытия файла. Если файл открылся, выполняется запись, закрытие файла и относительно длинная пауза (функция Sleep(100)), чтобы другие программы успели открыть файл. В случае ошибки открытия выполняется короткая пауза (функция Sleep(1)), чтобы как можно быстрее "поймать" момент, когда файл будет свободен.
Функция приема (чтения) работает по такому же принципу. В приложении скрипт с функцией приема имеет имя "sTestFileReceiver", полученные данные скрипт выводит функцией Comment(). Запустите скрипт-передатчик на одном графике, скрипт-приемник на другом графике (или в другом экземпляре терминала).
Еще несколько функций
Уже рассмотрены почти все функции по работе с файлами, осталось несколько очень редко используемых: FileSize(), FileTell(), FileFlush(). Функция FileSize() возвращает размер открытого файла в байтах:
void OnStart(){ int h=FileOpen("test.txt",FILE_READ|FILE_ANSI|FILE_TXT); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } ulong size=FileSize(h); FileClose(h); Alert("Размер файла "+IntegerToString(size)+" (байт)"); }
В приложении этот код находится в скрипте "sTestFileSize". При выполнении этого скрипта откроется окно с сообщением о размере файла.
Функция FileTell() возвращает положение файлового указателя открытого файла. Функция используется настолько редко, что мне даже сложно придумать с ней пример. Просто отметим ее существование и вспомним о ней в случае необходимости.
Функция FileFlush() более полезна практически. Как написано в документации, функция выполняет "сброс на диск всех данных, оставшихся в файловом буфере ввода-вывода". Эффект от вызова функции такой же, как от закрытия файла и его нового открытия (только экономней, и файловый указатель остается там, где был). Как известно, файлы хранятся в виде записей на жестком диске. Однако, пока файл открыт, запись выполняется в буфер, а не на диск. Запись на диск произойдет при закрытии файла. Поэтому, в случае аварийного завершения работы программы, поскольку файл не будет закрыт, данные не сохранятся. Если после каждой записи данных в файл вызывать FileFlush(), данные будут сохранены на диск, и аварийное завершение работы программы не доставит проблем.
Работа с папками
Кроме работы с файлами, в MQL5 есть несколько функций по работе с папками: FolderCreate(), FolderDelete(), FolderClean(). Функция FolderCreate используется для создания папки. У всех функций по два параметра. Первый параметр обязательный для имени папки. Второй дополнительный — для флага FILE_COMMON (для работы с папками в общей папке данных).
FolderDelete() используется для удаления указанной папки. Удалить можно только пустую папку. Но очистка содержимого папки не является проблемой, для этого существует функция FolderClean(), функция полностью очищает указанную папку, в том числе удаляет и вложенные папки и файлы.
Получение списка файлов
Иногда при работе с файлами бывает нужно найти файл, имя которого точно неизвестно. Имя файла может состоять из известного начала и иметь неизвестное числовое окончание, например "file1.txt", "file2.txt" и т.д. В этом случае можно получить имена файлов по маске с использованием функций FileFindFirst(), FileFindNext(), FileFindClose(). Данные функции находят не только файлы, но и папки. Имя папки можно отличить от имени файла по обратному слэшу в конце.
Напишем полезную функцию для получения списка файлов и папок. В один массив соберем имена файлов, в другой— имена папок:
void GetFiles(string folder, string & files[],string & folders[],int common_flag=0){ int files_cnt=0; // счетчик файлов int folders_cnt=0; // счетчик папок string name; // переменная для получения имени файла или папки long h=FileFindFirst(folder,name,common_flag); // получаем хэндл поиска и имя // первого файла/папки (если он/она есть) if(h!=INVALID_HANDLE){ // есть хотя бы один файл или папка do{ if(StringSubstr(name,StringLen(name)-1,1)=="\\"){ // папка if(folders_cnt>=ArraySize(folders)){ // проверяем размер массива, // увеличиваем его, если надо ArrayResize(folders,ArraySize(folders)+64); } folders[folders_cnt]=name; // отправляем имя папки в массив folders_cnt++; // считаем папки } else{ // файл if(files_cnt>=ArraySize(files)){ // проверяем размер массива, // увеличиваем его, если надо ArrayResize(files,ArraySize(files)+64); } files[files_cnt]=name; // отправляем имя файла в массив files_cnt++; // считаем файлы } } while(FileFindNext(h,name)); // получение имени следующего файла или папки FileFindClose(h); // завершение поиска } ArrayResize(files,files_cnt); // изменение размера массива в соответствии с // фактическим количеством файлов ArrayResize(folders,folders_cnt); // изменение размера массива в соответствии // с фактическим количеством папок }
Поэкспериментируем с этой функцией, будем вызывать ее из скрипта следующим образом:
void OnStart(){ string files[],folders[]; GetFiles("*",files,folders); Alert("=== Начало ==="); for(int i=0;i<ArraySize(folders);i++){ Alert("Папка: "+folders[i]); } for(int i=0;i<ArraySize(files);i++){ Alert("Файл: "+files[i]); } }
В приложении скрипт имеет имя "sTestFileGetFiles". Обратите внимание на маску поиска "*":
GetFiles("*",files,folders); С такой маской будут найдены все файлы и папки, расположенные в папке MQL5/Files.
Чтобы найти все файлы и папки, начинающиеся со слова "test", подойдет маска "test*". Если нужны только файлы с расширением "txt", потребуется маска "*.txt", и т.п. Попробуйте создать папку и в ней несколько файлов, например, папку "folder1". Для получения списка файлов, расположенных в ней, подойдет маска "folder1\\*".
Кодовая страница
В этой статье в примерах кода часто использовалась функция FileOpen(). Поговорим об одном из ее параметров, который до сих пор оставался без внимания. Это параметр codepage — кодовая страница. Кодовая страница — это таблица соответствия текстового символа и его числового значения. Более понятно будет на примере с кодировкой ANSI. В этой кодировке в таблице символов всего 256 символов, то есть, для разных языков используется своя кодовая страница, определяемая в настройках операционной системы. Этой кодовой странице соответствует константа CP_ACP, с которой по умолчанию вызывается функция FileOpen(). Очень маловероятно, что кому-то когда-нибудь потребуется использовать другую кодовую страницу, поэтому нет смысла вдаваться в подробности по данной теме, достаточно общего знакомства.
Работа с файлами без ограничений
Иногда бывает нужна возможность работать с файлами за пределами файловой "песочницы" терминала (за пределами папки MQL5/Files и общей папки). Это может значительно расширить функциональность программ на MQL5: можно будет обрабатывать файлы с исходным кодом, автоматически вносить в них изменения, на лету генерировать файлы изображений для графического интерфейса, генерировать код и т.п. Если вы будете делать это для себя либо пользоваться услугами программиста, которому вы доверяете, это допустимо. В статьях уже имеется материал на эту тему: статья Файловые операции через WinAPI. Есть и более простой способ. MQL5 располагает всеми средствами работы с файлами, поэтому достаточно переместить требуемый файл в "песочницу" терминала, выполнить с ним необходимые действия и переместить назад. Для этого достаточно всего лишь одной функции WinAPI - CopyFile.
Чтобы программа MQL5 могла использовать функции WinAPI, необходимо разрешение на их использование. Разрешение включается в настройках терминала (Главное меню - Сервис - Настройки - Советники - Разрешить импорт DLL), в этом случае включается общее разрешение на терминал для всех вновь запускаемых программ. Общее разрешение можно не включать, а включать его только для запускаемой программы. Если программа выполняет обращение к функциям WinAPI или прочим DLL, у нее в окне свойств появится вкладка "Зависимости" и в ней опция "Разрешить импорт DLL".
Существует два варианта функции CopyFile: CopyFileA() и более современная CopyFileW(). Обе функции можно использовать, но для функции CopyFileA() необходимо предварительно преобразовывать строковые аргументы. Как это делается, можно посмотреть в статье Основы программирования на MQL5 - Строки в разделе "Вызов функций API". Лучше использовать более современную функцию CopyFileW(), для нее строковые аргументы указываются как есть, без лишних преобразований.
Для использования функции CopyFileW() cначала надо выполнить ее импорт. Она располагается в библиотеке "kernel32.dll":
#import "kernel32.dll" int CopyFileW(string,string,int); #import
В приложении этот код располагается в скрипте с именем "sTestFileWinAPICopyFileW".
Скрипт будет копировать файл со своим собственным исходным кодом в папку MQL5/Files:
void OnStart(){ string src=TerminalInfoString(TERMINAL_DATA_PATH)+"\\MQL5\\Scripts\\"+MQLInfoString(MQL_PROGRAM_NAME)+".mq5"; string dst=TerminalInfoString(TERMINAL_DATA_PATH)+"\\MQL5\\Files\\"+MQLInfoString(MQL_PROGRAM_NAME)+".mq5"; if(CopyFileW(src,dst,0)==1){ Alert("Файл скопирован"); } else{ Alert("Не удалоcь скопировать файл"); } }
При успешной работе функция CopyFileW() возвращает 1, иначе 0. Третий параметр функции указывает, можно ли перезаписывать файл при существовании файла назначения: 0 — можно, 1 — нельзя. Запустите скрипт. Если он отработает успешно, проверьте папку MQL5/Files.
Имейте в виду, что операционная система накладывает свои ограничения на возможности копирования файлов. Есть так называемые "параметры контроля учетных записей". Если они включены, то в некоторые места (или из некоторых) файлы не получится копировать. Например, невозможно скопировать файл в корень системного диска.
Несколько полезных скриптов
Кроме создания полезных функций по работе с файлами, создадим еще пару полезных скриптов, для закрепления изученного в статье материала. Создадим скрипт экспорта котировок в файл csv и скрипт для экспорта результатов торговли, тоже в файл csv.
Скрипт экспорта котировок будет иметь параметры для определения даты начала и даты окончания данных и параметры, определяющие, использовать ли эти даты, или же экспортировать все данные полностью. Чтобы у скрипта открывалось окно свойств, необходимо указать соответствующее свойство:
#property script_show_inputs
Далее объявляются внешние параметры:
input bool UseDateFrom = false; // Указывать дату начала input datetime DateFrom=0; // Дата начала input bool UseDateTo=false; // Указывать дату окончания input datetime DateTo=0; // Дата окончания
Пишем код в функции OnStrat() скрипта. В соответствии с параметрами скрипта определяем даты:
datetime from,to; if(UseDateFrom){ from=DateFrom; } else{ int bars=Bars(Symbol(),Period()); if(bars>0){ datetime tm[]; if(CopyTime(Symbol(),Period(),bars-1,1,tm)==-1){ Alert("Ошибка определения начала данных, повторите попытку чуть позже"); return; } else{ from=tm[0]; } } else{ Alert("Выполняется построение таймфрема, повторите попытку чуть позже"); return; } } if(UseDateTo){ to=DateTo; } else{ to=TimeCurrent(); }
Если используются переменные для определения даты, то берутся их значения, иначе используется TimeCurrent() для времени окончания, а время начала определяется по времени первого бара.
Располагая датами, копируем котировки в массив типа MqlRates:
MqlRates rates[]; if(CopyRates(Symbol(),Period(),from,to,rates)==-1){ Alert("Ошибка копирования котировок, повторите попытку чуть позже"); }
Сохраняем данные из этого массива в файл:
string FileName=Symbol()+" "+IntegerToString(PeriodSeconds()/60)+".csv"; int h=FileOpen(FileName,FILE_WRITE|FILE_ANSI|FILE_CSV,";"); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; } // записываем данные в файл в формате: Time, Open, High, Low, Close, Volume, Ticks // первая строка, что бы знать, где что находится FileWrite(h,"Time","Open","High","Low","Close","Volume","Ticks"); for(int i=0;i<ArraySize(rates);i++){ FileWrite(h,rates[i].time,rates[i].open,rates[i].high,rates[i].low,rates[i].close,rates[i].real_volume,rates[i].tick_volume); } FileClose(h); Alert("Сохранение выполнено, см. файл "+FileName);
При успешном выполнении скрипт откроет окно с сообщением об успешном сохранении файла или же выдаст сообщение об ошибке. В приложении готовый скрипт имеет имя "sQuotesExport".
Теперь перейдем к скрипту сохранения истории торговли. Начало примерно такое же: сначала внешние переменные, только с определением времени начала все проще — при запросе истории достаточно указать время начала 0:
datetime from,to; if(UseDateFrom){ from=DateFrom; } else{ from=0; } if(UseDateTo){ to=DateTo; } else{ to=TimeCurrent(); }
Выделяем историю:
if(!HistorySelect(from,to)){ Alert("Ошибка выделение истории"); return; }
Открываем файл:
string FileName="history.csv"; int h=FileOpen(FileName,FILE_WRITE|FILE_ANSI|FILE_CSV,";"); if(h==INVALID_HANDLE){ Alert("Ошибка открытия файла"); return; }
Записываем первую строку с наименованием полей:
FileWrite(h,"Time","Deal","Order","Symbol","Type","Direction","Volume","Price","Comission","Swap","Profit","Comment");
Проходя в цикле по всем сделкам, записываем в файл сделки buy и sell:
for(int i=0;i<HistoryDealsTotal();i++){ ulong ticket=HistoryDealGetTicket(i); if(ticket!=0){ long type=HistoryDealGetInteger(ticket,DEAL_TYPE); if(type==DEAL_TYPE_BUY || type==DEAL_TYPE_SELL){ long entry=HistoryDealGetInteger(ticket,DEAL_ENTRY); FileWrite(h,(datetime)HistoryDealGetInteger(ticket,DEAL_TIME), ticket, HistoryDealGetInteger(ticket,DEAL_ORDER), HistoryDealGetString(ticket,DEAL_SYMBOL), (type==DEAL_TYPE_BUY?"buy":"sell"), (entry==DEAL_ENTRY_IN?"in":(entry==DEAL_ENTRY_OUT?"out":"in/out")), DoubleToString(HistoryDealGetDouble(ticket,DEAL_VOLUME),2), HistoryDealGetDouble(ticket,DEAL_PRICE), DoubleToString(HistoryDealGetDouble(ticket,DEAL_COMMISSION),2), DoubleToString(HistoryDealGetDouble(ticket,DEAL_SWAP),2), DoubleToString(HistoryDealGetDouble(ticket,DEAL_PROFIT),2), HistoryDealGetString(ticket,DEAL_COMMENT) ); } } else{ Alert("Ошибка выделения сделки, повторите попытку"); FileClose(h); return; } }
Обратите внимание: для типа сделки (buy/sell) и направления (in/out) выполняется преобразование значений в строки, а некоторые значения типа double преобразуются в строки с двумя знаками после запятой.
В конце закрываем файл и выводим сообщение:
FileClose(h); Alert("Сохранение выполнено, см. файл "+FileName);
В приложении этот скрипт имеет имя "sHistoryExport".
Дополнительные материалы по теме
В разделе статей имеется большое количество материалов, в той или иной мере, касающихся работы с файлами и заслуживающих внимания:
- Альтернативный лог-файл c использованием HTML и CSS
- Взаимодействие между MetaTrader 4 и Matlab посредством CSV-файлов
- Графики и диаграммы в формате HTML
- Групповые файловые операции
- Текстовые файлы для хранения входных параметров советников, индикаторов и скриптов
- Как подготовить котировки MetaTrader 5 для других программ
- Обработка ошибок и логирование в MQL5
- Поиск ошибок и ведение лога
- Работаем с ZIP-архивами средствами MQL5 без использования сторонних библиотек
- Работа с файлами. Пример визуализация важных рыночных событий
- Рецепты MQL5 - Записываем историю сделок в файл и строим графики балансов для каждого символа в Excel
- Рецепты MQL5 - Сохраняем результаты оптимизации торгового эксперта по указанным критериям
- Файловые операции через WinAPI
Заключение
Вот и рассмотрены все функции по работе с файлами в MQL5. Казалось бы, это довольно узкая тема, однако статья получилось довольно объемная. При этом некоторые вопросы, касающиеся работы с файлами, рассмотрены лишь поверхностно, без достаточного количества практических примеров. Но наиболее часто встречающиеся задачи по работе с файлами рассмотрены очень подробно, в том числе и особенности работы с файлами в тестере. Кроме того, создано несколько полезных функций, да и все учебные примеры были практически ориентированными и логически завершенными. Весь приведенный код прилагается к статье в виде скриптов.
Файлы приложения
- sTestFileRead — чтение одной строки из текстового файла ANSI и вывод ее в окно сообщений.
- sTestFileReadToAlert — чтение всех строк из текстового файла ANSI и вывод их в окно сообщений.
- sTestFileCreate — создание текстового файла ANSI.
- sTestFileAddToFile — добавление строки к текстовому файлу ANSI.
- sTestFileChangeLine2-1 — неправильная попытка изменения отдельной строки в текстовом файле ANSI.
- sTestFileChangeLine2-2 — еще одна неправильная попытка изменения отдельной строки в текстовом файле ANSI.
- sTestFileChangeLine2-3 — замена одной строки в текстовом файле ANSI через перезапись всего файла.
- sTestFileReadFileToArray — полезная функция чтения текстового файла ANSI в массив.
- sTestFileCreateCSV — создание файла CSV ANSI.
- sTestFileReadToAlertCSV — чтение файла CSV ANSI в окно сообщений по полям.
- sTestFileReadToAlertCSV2 — чтение файла CSV ANSI в окно сообщений по полям с разделением строк.
- sTestFileReadFileToArrayCSV — чтение файла CSV ANSI в массив структур.
- sTestFileWriteArrayToFileCSV — запись массива одной строкой в файл CSV ANSI.
- sTestFileReadToAlertUTF — чтение текстового файла UNICODE и вывод его в окно сообщений.
- sTestFileCreateUTF — создание текстового файла UNICODE.
- sTestFileCreateBin — создание бинарного файла и запись в него трех переменных double.
- sTestFileReadBin — чтение трех переменных double из бинарного файла.
- sTestFileChangeBin — перезапись второй переменной double в бинарном файле.
- sTestFileReadBin2 — чтение третьей переменной double из бинарного файла.
- sTestFileWriteStructBin — запись структуры в бинарный файл.
- sTestFileReadStructBin — чтение структуры из бинарного файла.
- sTestFileReadStructBin2 — чтение одной переменной из бинарного файла со структурами.
- sTestFileCheckUnicode — проверка типа файла (ANSI или UNCODE).
- sTestFileWriteArray — запись массива в бинарный файл.
- sTestFileReadArray — чтение массива из бинарного файла
- sTestFileWriteArray2 — запись двух массивов в бинарный файл.
- sTestFileReadArray2 — чтение двух массивов из бинарного файла.
- sTestFileWriteStringArray — запись строкового массива в бинарный файл.
- sTestFileReadStringArray — чтение строкового массива из бинарного файла.
- sTestFileCopy — копирование файла из папки MQL5/Files в общую папку.
- sTestFileCopy2 — копирование файла в общей папке.
- sTestFileCopy3 — копирование файла из общей папки в папку MQL5/Files.
- sTestFileTransmitter — скрипт-передатчик данных через файл в общей папке.
- sTestFileReceiver — скрипт-приемник данных через файл в общей папке данных.
- sTestFileSize — определение размера файла.
- sTestFileGetFiles — получение списка файлов по маске.
- sTestFileWinAPICopyFileW — пример использования функции WinAPI CopyFileW().
- sQuotesExport — скрипт экспорта котировок.
- sHistoryExport — скрипт сохранения истории торговли.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Нейросеть: Самооптимизирующийся советник
Нейросеть: Самооптимизирующийся советник
 Кроссплатформенный торговый советник: Ордера
Кроссплатформенный торговый советник: Ордера
 Статистические распределения в MQL5 - берем лучшее из R и делаем быстрее
Статистические распределения в MQL5 - берем лучшее из R и делаем быстрее
 Быстрая оценка сигнала: торговая активность, графики просадки/загрузки и распределения MFE/MAE
Быстрая оценка сигнала: торговая активность, графики просадки/загрузки и распределения MFE/MAE
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
эта статья великолепна, большое спасибо за информацию.
В статье опечатка. В описании функции "Чтение файла с разделителями в массив" описание структуры:
а в должно быть (и в скрипте так):
А как можно уменшить размер файла? Примерно имею какой то файл BIN, в котором поддерживаю какие то данни, потом делаю дефрагмент файла и наконец хочу умешнит его длину, потому что сзади уже есть лишнее пространство. Как етого сделать? Нужна какая-нибудь функция типа FileResize(int newSize).
Большое спасибо, именно то, что я искал.
Есть только небольшая деталь в некоторых примерах кода.
На моем компьютере / моей версии mql5 пример для"открытия файла" не работает.
Я немного изменил его, чтобы он работал в моем случае.
См. здесь ниже.
Тем не менее, еще раз большое спасибо, это очень ценно!!!
int h = FileOpen("test1.txt", FILE_WRITE|FILE_ANSI|FILE_COMMON,"|",CP_ACP);