Интеграция MQL5 с пакетами обработки данных (Часть 4): Обработка больших данных

Введение
Финансовые рынки продолжают развиваться. Трейдеры больше не имеют дело только с ценовыми графиками и простыми индикаторами — им приходится иметь дело с потоком данных со всего мира. В эпоху больших данных успешная торговля зависит не только от стратегии, но и от того, насколько эффективно вы можете просеивать горы информации, чтобы найти полезные идеи. В этой статье, четвертой из нашей серии об интеграции MQL5 с инструментами обработки данных, основное внимание уделено навыкам бесперебойной работы с большими наборами данных. От тиковых данных в реальном времени до исторических архивов, охватывающих десятилетия, способность управлять большими данными быстро становится отличительной чертой сложной торговой системы.
Представьте себе, что вы анализируете миллионы точек данных, чтобы выявить едва заметные рыночные тренды или включаете внешние наборы данных, такие как социальные настроения или экономические индикаторы, в свою торговую среду MQL5. Возможности безграничны, но только если у вас есть правильные инструменты. В этой статье мы рассмотрим, как расширить возможности MQL5 за пределы его встроенных возможностей, интегрировав его с передовыми библиотеками обработки данных и решениями для работы с большими данными. Независимо от того, являетесь ли вы опытным трейдером, совершенствующим свое мастерство, или любознательным разработчиком, исследующим потенциал финансовых технологий, это руководство окажется полезным для вас. Оставайтесь с нами, чтобы узнать, как превратить огромные объемы данных в решающее преимущество.
Сбор исторических данных
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTC H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "BTC_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Для извлечения исторических данных сначала устанавливаем соединение с терминалом MetaTrader 5 с помощью функции mt5.initialize(). Это важно, поскольку пакет Python напрямую взаимодействует с работающей платформой MetaTrader 5. Мы настраиваем код, чтобы задать желаемый временной диапазон для извлечения данных, указав начальную и конечную даты. Объекты datetime создаются в часовом поясе UTC для обеспечения согласованности в разных часовых поясах. Затем скрипт использует функцию mt5.copy-rates-range() для запроса исторических почасовых данных для символа BTC/USD, начиная с 6 августа 2024 года по текущую дату и время.
Отключаемся от терминала MetaTrader 5 с помощью mt5.shutdown(), чтобы избежать дальнейших ненужных подключений. Извлеченные данные изначально отображаются в необработанном формате для подтверждения успешного извлечения данных. Преобразуем эти данные в pandas DataFrame для более легкой обработки и анализа. Кроме того, код преобразует временные метки Unix в читаемый формат даты и времени, гарантируя, что данные хорошо структурированы и готовы к дальнейшей обработке или анализу.
filename = "XAUUSD_H1_2nd.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Поскольку моя операционная система — Linux, мне приходится сохранять полученные данные в файл. Пользователи Windows могут получить данные с помощью следующего скрипта:
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTCUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10))
Если по какой-то причине получить исторические данные не удается, вы можете извлечь их вручную на платформе MetTrader 5, выполнив следующие действия. Запустите платформу MetaTrader и в верхней части панели выберите "Сервис" > "Настройки" > вкладка "Графики". Затем вам нужно будет выбрать количество баров на графике, которые вы хотите загрузить. Лучше всего выбрать вариант с неограниченным количеством баров, поскольку мы будем работать с датой и не будем знать, сколько баров в определенном периоде времени.
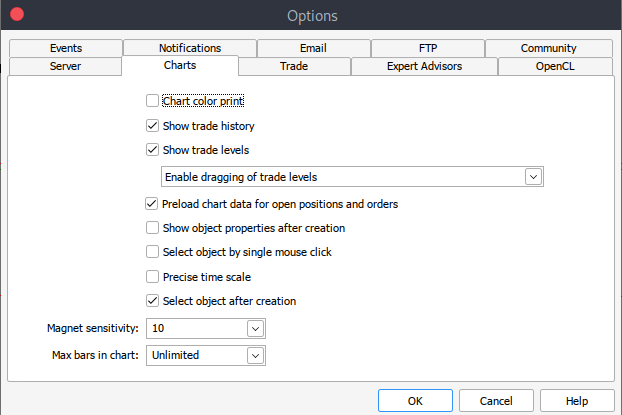
После этого загрузим реальные данные. Перейдите "Вид" > "Символы" > вкладка "Спецификация". Перейдите на вкладку "Бары" или "Тики" в зависимости от того, какие данные вы хотите загрузить. Введите начальную и конечную даты периода исторических данных, которые вы хотите загрузить, после чего нажмите "Запрос", чтобы загрузить данные и сохранить их в формате .csv.
Обработка больших данных MetaTrader 5 в Jupyter Lab
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_junkie/Documents/DataVisuals/BTCUSD_H1.csv' btc_data = pd.read_csv(file_path) # Display basic information about the dataset btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Результат:
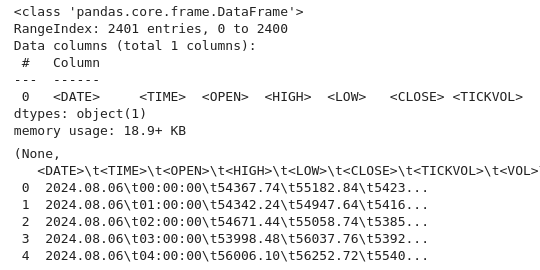
Как всегда, с помощью кода выше мы проверяем данные и изучаем структуру набора данных. Проверяем типы данных, форму и полноту (используя info()). Получаем содержимое и структуру набора данных (используя head()). Это стандартный первый шаг в исследовательском анализе данных, позволяющий убедиться в правильности загрузки данных и ознакомиться с их структурой.
# Reload the data with tab-separated values btc_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Результат:
Теперь используем этот код для перезагрузки набора данных из файла, в котором, как предполагается, используются значения, разделенные табуляцией (TSV), вместо формата по умолчанию с разделителями-запятыми. Благодаря указанию delimiter=`\t` в pd.read-csv(), данные корректно преобразуются в Pandas DataFrame для дальнейшего анализа. Затем мы используем btc-data-infor для отображения метаданных о наборе данных, таких как количество строк, столбцов, типов данных и любых пропущенных значений.
# Combine <DATE> and <TIME> into a single datetime column and set it as the index btc_data['DATETIME'] = pd.to_datetime(btc_data['<DATE>'] + ' ' + btc_data['<TIME>']) btc_data.set_index('DATETIME', inplace=True) # Drop the original <DATE> and <TIME> columns as they're no longer needed btc_data.drop(columns=['<DATE>', '<TIME>'], inplace=True) # Display the first few rows after modifications btc_data.head()
Результат:
# Check for missing values and duplicates missing_values = btc_data.isnull().sum() duplicate_rows = btc_data.duplicated().sum() # Clean data (if needed) btc_data_cleaned = btc_data.drop_duplicates() # Results missing_values, duplicate_rows, btc_data_cleaned.shape
Результат:
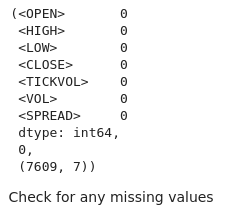
Из результатов видно, что в нашем наборе данных нет пропущенных значений.
# Check for missing values print("Missing values per column:\n", btc_data.isnull().sum()) # Check for duplicate rows print("Number of duplicate rows:", btc_data.duplicated().sum()) # Drop duplicate rows if any btc_data = btc_data.drop_duplicates()
Результат:
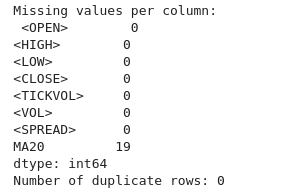
Как видим, у нас нет дублирующихся строк и столбцов.
# Calculate a 20-period moving average btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() import ta # Add RSI using the `ta` library btc_data['RSI'] = ta.momentum.RSIIndicator(btc_data['<CLOSE>'], window=14).rsi()
Здесь мы вычисляем 20-периодную скользящую среднюю и 14-периодный RSI на основе цен закрытия из btc-data Dataframe. Эти индикаторы, широко используемые в техническом анализе, добавляются в качестве новых столбцов (MA-20 и RSI) для дальнейшего анализа или визуализации. Эти шаги помогают трейдерам выявлять тренды и потенциальные состояния перекупленности или перепроданности на рынке.
import matplotlib.pyplot as plt # Plot closing price and MA20 plt.figure(figsize=(12, 6)) plt.plot(btc_data.index, btc_data['<CLOSE>'], label='Close Price') plt.plot(btc_data.index, btc_data['MA20'], label='20-period MA', color='orange') plt.legend() plt.title('BTC Closing Price and Moving Average') plt.show()
Результат:
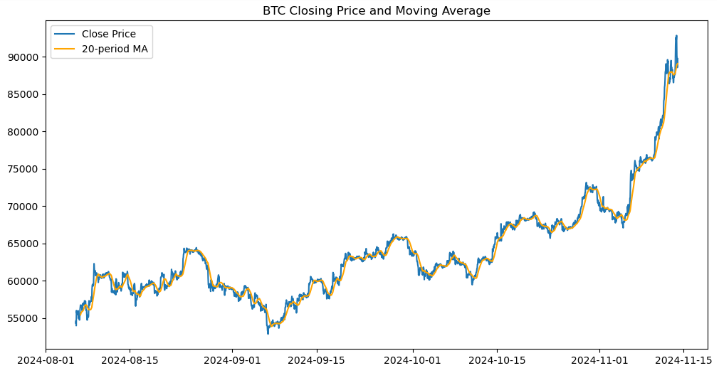
Мы создали визуальное представление цен закрытия биткоина и его 20-периодной скользящей средней (MA20) с помощью библиотеки Matplotlib. Она инициализирует фигуру размером 12x6 дюймов и отображает цены закрытия в зависимости от индекса DataFrame, обозначая ее Close Price (цена закрытия). На нее накладывается второй график 20-периодной скользящей средней оранжевого цвета, обозначенный как 20-period MA (20-периодная MA). Добавлена легенда для различения двух линий, а сам график называется BTC Closing Price and Moving Average (цена закрытия и скользящая средняя BTC). График наглядно отображает ценовые тренды и их соотношение со скользящей средней.
import numpy as np # Add log returns btc_data['Log_Returns'] = (btc_data['<CLOSE>'] / btc_data['<CLOSE>'].shift(1)).apply(lambda x: np.log(x)) # Save the cleaned data btc_data.to_csv('BTCUSD_H1_cleaned.csv')
Теперь мы рассчитываем логарифмическую доходность цен закрытия биткоина и сохраняем обновленный набор данных в новый CSV-файл. Логарифмическая доходность рассчитывается путем деления каждой цены закрытия на цену закрытия предыдущего периода и применения натурального логарифма к результату. Это достигается с помощью метода shift(1) для выравнивания каждой цены с предыдущей, после чего применяется лямбда-функция с np.log. Рассчитанные значения, хранящиеся в новом столбце Log-returns, обеспечивают более удобную для анализа меру изменения цен, особенно полезную для финансового моделирования и анализа рисков. Наконец, обновленный набор данных, включая недавно добавленный столбец Log-returns, мы сохраняем в файле с именем BTCUSD-H1-cleaned.csv для дальнейшего анализа.
import seaborn as sns import matplotlib.pyplot as plt # Correlation heatmap sns.heatmap(btc_data.corr(), annot=True, cmap='coolwarm') plt.title('Correlation Heatmap') plt.show()
Результат:
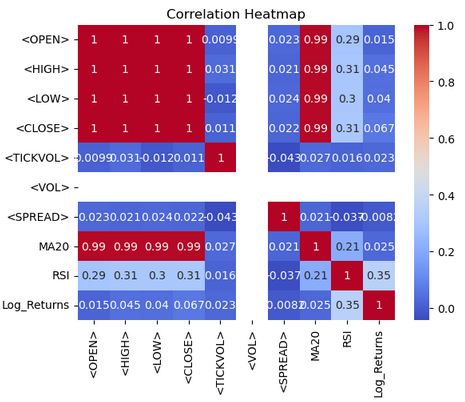
На основе тепловой карты мы визуализируем корреляции между числовыми столбцами в фрейме данных btc-data, используя Seaborn и Matplotlib. Функция btc-data.corr() вычисляет парные коэффициенты корреляции для всех числовых столбцов, количественно определяя линейные отношения между ними. Функция sns.heatmap() отображает эту корреляционную матрицу в виде тепловой карты, при этом annot=True используется для отображения значений корреляции в каждой ячейке, а cmap='coolwarm' — для использования разнообразной цветовой палитры для более легкой интерпретации. Более теплые тона (красные) отображают положительные корреляции, тогда как более холодные тона (синие) отображают отрицательные корреляции. Заголовок Correlation Heatmap (тепловая карта корреляций) добавляется с помощью Matplotlib, а график отображается с помощью plt.show(). Такая визуализация помогает с первого взгляда выявить закономерности и взаимосвязи в наборе данных.
from sklearn.model_selection import train_test_split # Define features and target variable X = btc_data.drop(columns=['<CLOSE>']) y = btc_data['<CLOSE>'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Мы подготавливаем фрейм данных btc-data для машинного обучения, разделяя его на обучающие и тестовые подмножества. Признаки (x) определяются путем удаления столбца <CLOSE> из набора данных, в то время как целевая переменная (y) установлена в столбце <CLOSE>, представляющем прогнозируемое значение. Затем функция train-test-split из Scikit-learn используется для разделения данных на обучающий и тестовый наборы, при этом 80% данных выделяется для обучения и 20% для тестирования, как указано в test-size=0.2. random-state=42 гарантирует воспроизводимость разделения, сохраняя согласованность между различными запусками.
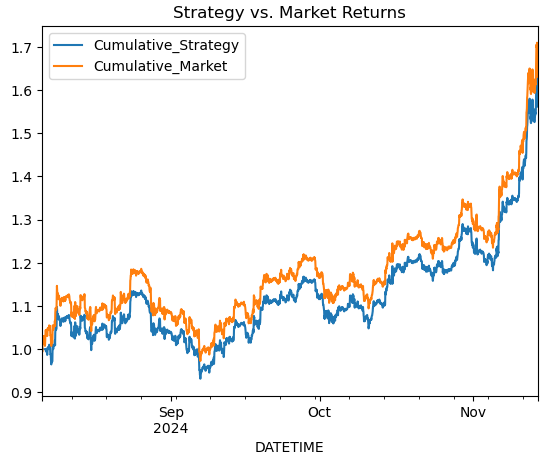
# Simple Moving Average Crossover Strategy btc_data['Signal'] = (btc_data['MA20'] > btc_data['RSI']).astype(int) btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'].shift(1) * btc_data['Returns'] # Plot cumulative returns btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data[['Cumulative_Strategy', 'Cumulative_Market']].plot(title='Strategy vs. Market Returns') plt.show()
Результат:
# Calculate short-term and long-term moving averages btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() btc_data['MA50'] = btc_data['<CLOSE>'].rolling(window=50).mean() # Generate signals: 1 for Buy, -1 for Sell btc_data['Signal'] = 0 btc_data.loc[btc_data['MA20'] > btc_data['MA50'], 'Signal'] = 1 btc_data.loc[btc_data['MA20'] < btc_data['MA50'], 'Signal'] = -1 # Shift signal to avoid look-ahead bias btc_data['Signal'] = btc_data['Signal'].shift(1)
# Calculate returns btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'] * btc_data['Returns'] # Calculate cumulative returns btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() # Plot performance import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(btc_data['Cumulative_Market'], label='Market Returns') plt.plot(btc_data['Cumulative_Strategy'], label='Strategy Returns') plt.title('Strategy vs. Market Performance') plt.legend() plt.show()
Результат:
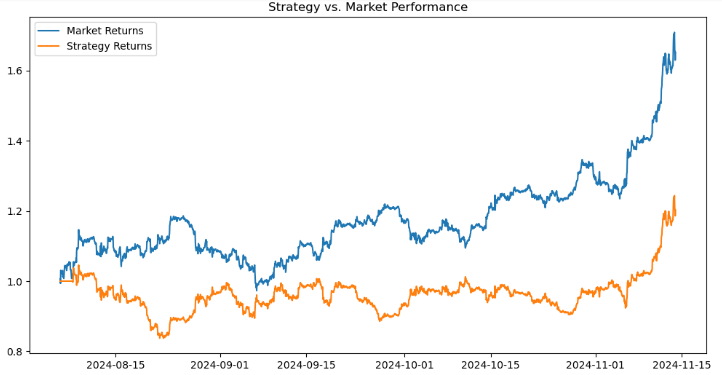
Оценим эффективность торговой стратегии по сравнению с рынком и визуализируем результаты. Сначала рассчитываем рыночную доходность как процентное изменение цены <CLOSE> с помощью pct-change() и сохраним их в столбце Returns. Доходность стратегии вычисляется путем умножения столбца signal (представляющего торговые сигналы, такие как 1 для покупки, -1 для продажи или 0 для удержания) на доходность рынка и сохранения результата в strategy-returns. Совокупная доходность как для рынка, так и для стратегии рассчитывается с использованием (1 + returns).comprod(), что имитирует совокупный рост 1 доллара, инвестированного в рынок (Cumulative-market) или следующего стратегии (Cumulative-strategy).
# Add RSI from ta.momentum import RSIIndicator btc_data['RSI'] = RSIIndicator(btc_data['<CLOSE>'], window=14).rsi() # Add MACD from ta.trend import MACD macd = MACD(btc_data['<CLOSE>']) btc_data['MACD'] = macd.macd() btc_data['MACD_Signal'] = macd.macd_signal() # Target variable: 1 if next period's close > current close btc_data['Target'] = (btc_data['<CLOSE>'].shift(-1) > btc_data['<CLOSE>']).astype(int)
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report # Define features and target features = ['MA20', 'MA50', 'RSI', 'MACD', 'MACD_Signal'] X = btc_data.dropna()[features] y = btc_data.dropna()['Target'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest Classifier model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train) # Evaluate the model y_pred = model.predict(X_test) print("Accuracy:", accuracy_score(y_test, y_pred)) print(classification_report(y_test, y_pred))
Результат:
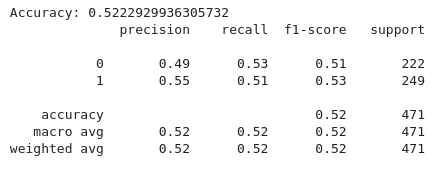
На основе приведенного выше кода мы реализуем конвейер машинного обучения для классификации торговых сигналов на основе технических индикаторов с использованием классификатора Random Forest. Сначала определяется набор признаков (x), включая такие индикаторы, как 20-периодные и 50-периодные скользящие средние (MA20, MA50), индекс относительной силы (RSI) и признаки, связанные с MACD (MACD, MACD-Signals). Целевая переменная (y) устанавливается в соответствии с целевым column, который обычно указывает сигналы на покупку, продажу или удержание. Затем данные (x) и (y) разделяются на обучающие и проверочные наборы, при этом 80% используется для обучения и 20% для тестирования, что обеспечивает согласованность посредством (random-state=42).
Классификатор случайного леса инициализируется 100 деревьями решений (n-estimators = 100) и обучается на обучающих данных (X-train и Y-train). Прогнозы модели на тестовом наборе (X-test) оцениваются с помощью показателя точности для определения ее корректности и отчета о классификации, предоставляющего подробные метрики, такие как точность, полнота и F1-оценка для каждого класса.
Затем мы развертываем модель, используя следующий код:
import joblib # Save the model joblib.dump(model, 'btc_trading_model.pkl')
Собираем всё вместе в MQL5
Мы собираемся подключить MQL5 к скрипту Python, который будет запускать нашу обученную модель. Для этого нам нужно будет настроить канал связи между MQL5 и Python. В этом случае мы будем использовать WebRequest.
//+------------------------------------------------------------------+ //| BTC-Big-DataH.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #include <Trade\Trade.mqh> CTrade trade;
В комплект входят все необходимые компоненты и торговая библиотека (trade.mqh) для управления торговлей.
// Function to get predictions from Python API double GetPrediction(double &features[]) { // Convert the features array to a JSON-like string string jsonRequest = "["; for (int i = 0; i < ArraySize(features); i++) { jsonRequest += DoubleToString(features[i], 6); if (i != ArraySize(features) - 1) jsonRequest += ","; } jsonRequest += "]"; // Define the WebRequest parameters string url = "http://127.0.0.1:5000/predict"; string hdrs = {"Content-Type: application/json"}; // Add headers if needed char data[]; StringToCharArray(jsonRequest, data); // Convert JSON request string to char array char response[]; ulong result_headers_size = 0; //-------------------------------------------------------------------------------------- string cookie=NULL; char post[], resultsss[]; // Send the WebRequest int result = WebRequest("POST", url, cookie, NULL, 500, post, 0, resultsss, hdrs); // Handle the response if (result == -1) { Print("Error sending WebRequest: ", GetLastError()); return -1; // Return an error signal } // Convert response char array back to a string string responseString; CharArrayToString(response, (int)responseString); // Parse the response (assuming the server returns a numeric value) double prediction = StringToDouble(responseString); return prediction; }
Функция GetPrediction() отправляет набор входных данных в API на основе Python и получает прогноз. Характеристики передаются в виде массива double-значений, которые преобразуются в строку в формате JSON для соответствия ожидаемому формату входных данных API. Это преобразование включает в себя итерацию массива признаков и добавление каждого значения в структуру массива, подобную JSON. Функция DoubleToString обеспечивает представление значений с шестью знаками после запятой. Затем сгенерированная строка JSON преобразуется в массив char.
TЗатем функция готовится выполнить запрос POST к конечной точке API (http://127.0.0.1:5000/predict) с помощью веб-запроса. Определяются необходимые параметры. После получения ответа API он преобразуется обратно в строку с помощью метода CharArrayToString. Если веб-запрос не выполнен, регистрируется ошибка, и функция возвращает -1.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick(){ // Calculate indicators double MA20 = iMA(_Symbol, PERIOD_CURRENT, 20, 0, MODE_SMA, PRICE_CLOSE); double MA50 = iMA(_Symbol, PERIOD_CURRENT, 50, 0, MODE_SMA, PRICE_CLOSE); double RSI = iRSI(_Symbol, PERIOD_CURRENT, 14, PRICE_CLOSE); // Declare arrays to hold MACD data double MACD_Buffer[1], SignalLine_Buffer[1], Hist_Buffer[1]; // Get MACD handle int macd_handle = iMACD(NULL, 0, 12, 26, 9, PRICE_CLOSE); if (macd_handle != INVALID_HANDLE) { // Copy the most recent MACD values into buffers if (CopyBuffer(macd_handle, 0, 0, 1, MACD_Buffer) <= 0) Print("Failed to copy MACD"); if (CopyBuffer(macd_handle, 1, 0, 1, SignalLine_Buffer) <= 0) Print("Failed to copy Signal Line"); if (CopyBuffer(macd_handle, 2, 0, 1, Hist_Buffer) <= 0) Print("Failed to copy Histogram"); } // Assign the values from the buffers double MACD = MACD_Buffer[0]; double SignalLine = SignalLine_Buffer[0]; // Assign features double features[5]; features[0] = MA20; features[1] = MA50; features[2] = RSI; features[3] = MACD; features[4] = SignalLine; // Get prediction double signal = GetPrediction(features); if (signal == 1){ MBuy(); // Adjust lot size } else if (signal == -1){ MSell(); } }
OnTick начинается с расчета ключевых технических индикаторов: 20-периодной и 50-периодной простых скользящих средних (MA20 и MA50) для отслеживания направления тренда и 14-периодного индекса относительной силы (RSI) для оценки динамики рынка. Кроме того, она извлекает значения для линии MACD, сигнальной линии и гистограммы с помощью функции iMACD, сохраняя эти значения в буферах после проверки хэндла MACD. Эти вычисляемые индикаторы собираются в массив features, который служит входными данными для модели машинного обучения, доступ к которой осуществляется через функцию GetPrediction. Эта модель прогнозирует торговое действие, возвращая 1 для сигнала на покупку или -1 для сигнала на продажу. На основе прогноза функция выполняет либо сделку на покупку с помощью MBuy, либо сделку на продажу с помощью MSell().
Python API
Ниже представлен веб-API, использующий Flask для предоставления прогнозов на основе предварительно обученной модели машинного обучения для принятия решений по торговле биткоином.
from flask import Flask, request, jsonify import joblib import pandas as pd # Load the model model = joblib.load('btc_trading_model.pkl') app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.json df = pd.DataFrame(data) prediction = model.predict(df) return jsonify(prediction.tolist()) app.run(port=5000)
Заключение
Мы разработали комплексное торговое решение, объединив обработку больших данных, машинное обучение и автоматизацию. Начав с исторических данных BTC/USD, мы обработали и очистили их, чтобы извлечь значимые характеристики, такие как скользящие средние, RSI и MACD. Мы использовали эти обработанные данные для обучения модели машинного обучения, способной прогнозировать торговые сигналы. Обученная модель была развернута как API на базе Flask, что позволило внешним системам запрашивать прогнозы. В MQL5 мы реализовали советник, который собирает значения индикаторов в реальном времени, отправляет их в API Flask для прогнозирования и совершает сделки на основе возвращенных сигналов.
Это интегрированное торговое решение расширяет возможности трейдеров, объединяя точность технических индикаторов с интеллектом машинного обучения. Используя модель машинного обучения, обученную на исторических данных, система адаптируется к динамике рынка, делая обоснованные прогнозы, которые могут улучшить результаты торговли. Развертывание модели через API обеспечивает гибкость, позволяя трейдерам интегрировать ее в различные платформы, такие как MQL5.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16446
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования