
От начального до среднего уровня: Шаблон и Typename (I)

Введение
В предыдущей статье "От начального до среднего уровня: Перегрузка", мы попытались объяснить один из самых сложных моментов в программировании, особенно на начальном этапе и когда сталкиваемся с чем-то, что на первый взгляд не имеет смысла. Несмотря на все сложности, возникающие при использовании перегрузки, очень важно понимать то, что происходит. Именно поэтому без этих знаний, вы, дорогой читатель, будете очень ограничены. Хуже того, вы не сможете понять и другие моменты, о которых мы расскажем в следующих статьях.
Хотя многие считают перегрузку ошибкой программирования, поскольку она делает код довольно сложным, без нее мы не могли бы создать или реализовать многие вещи. Поэтому для того, чтобы понять то, что будет рассказано в этой статье, мы должны хорошо понять всё изложенное в предыдущей статье. В противном случае, сегодняшняя тема станет для вас занозой и ее практически невозможно будет понять.
Однако без знаний, представленных в этой статье, почти нельзя двигаться вперед в поисках новых возможностей и механизмов программирования. Так что пора сосредоточиться на том, что мы увидим в этой статье, потому что здесь мы будем иметь дело с чем-то очень забавным, хотя и очень сложным, в зависимости от типа вещей, которые реализуются в каждый конкретный момент времени.
Шаблон и typename
Одна из самых сложных и трудных концепций, которая в конечном итоге может обескуражить начинающего программиста, - это перегрузка. Однако, как видно из предыдущей статьи, перегрузка - это лишь малая часть того, что мы можем реализовать, когда используемый нами язык позволяет нам определенные вещи или дает определенную степень свободы, как это бывает, когда мы начинаем работать с перегрузкой более глубоко.
Первое, что нужно понять, - это то, что перегрузка, когда выполняется так, как это было представлено в предыдущей статье, наглядно демонстрирует, какие типы мы можем использовать и когда мы их будем использовать, облегчая работу со значениями разной разрядности в различных сценариях. Но здесь мы увидим нечто гораздо более сложное, что превращает увиденное в предыдущей статье, в нечто исключительно дидактическое, поскольку всё рассказанное там, применимо и здесь, но в гораздо большем масштабе.
Некоторые из вас могут подумать: действительно ли мне нужно учиться пользоваться таким инструментом? Да, без таких инструментов многое из того, что можно сделать, окажется совершенно недоступным, если только вы не используете гораздо более сложные и трудные для освоения методы реализации. Так не лучше ли отложить эту часть и оставить ее для объяснения в другой раз? Например, после программирования индикаторов или советников. На самом деле, я думал об этом, поскольку всё, что было сделано и показали до настоящего момента, - это то, что должен знать любой новичок, прежде чем пытаться что-то программировать.
Однако я не вижу причин откладывать эту тему, хотя бы потому что я уже рассказывал о том, как реализовать советник полностью с нуля, как для автоматического программирования, так и для помощи в ручных операциях.
Об этом можно прочитать в статье "Как построить советник, работающий автоматически (Часть 15): Автоматизация (VII), где подробно рассказывалось, как это сделать в короткой серии из пятнадцати статей. Однако даже после публикации этих статей я заметил, что у многих есть элементарные сомнения по некоторым темам, а другие не хотят полагаться на готовые программы. Они хотят узнать, как всё это работает, чтобы создать собственные решения, отвечающие их потребностям.
Даже после завершения серии "Разработка системы репликации — моделирование рынка (Часть 01): Первые эксперименты (I)", я заметил, что многие даже не представляли, что такое возможно реализовать. Хотя данная серия статей еще не опубликована полностью, это произойдет в ближайшее время. И поскольку многие могут захотеть улучшить или понять часть этого кода, который, хотя и был подробно объяснен, но я не углублялся в отдельные моменты, именно эти моменты могут быть целью тех, кто хочет работать с чем бы то ни было.
Поскольку я не намерен обсуждать эти темы дальше (они уже очень хорошо изучены), по просьбе некоторых я начал показывать, как работать с нейронными сетями на MQL5. Я снова заметил, что некоторые не смогли выполнить многое из того, что было реализовано. Опять же, отсутствие достаточных знаний и базовых концепций программирования делает любое объяснение очень сложным и трудным для новичков. Многие не представляли, что можно реализовать нейронную сеть на чистом MQL5.
Для тех, кто не читал ни одной из моих статей на эту тему, первая из них "Нейронная сеть на практике: Секущая линия". Правда, многие статьи еще должны быть опубликованы. Но по мере публикации статей вы сможете заметить, что базовые знания программирования гораздо важнее, чем может показаться.
Хотя в этой серии статей я уже объяснял более сложные концепции, у меня всё еще было желание реализовать серию статей, ориентированных на основы программирования. Идея заключалась в том, чтобы начать объяснять всё с самых азов.
Теперь я уже объяснил, почему (хотя многие считают, что это не нужно начинающему программисту) наличие хорошо структурированного и прочного фундамента помогает понять многие другие коды, даже если ваша цель заключается в чем-то другом, например, в том, чтобы научиться применять базовый советник или индикатор, который поможет вам лучше торговать. Если это единственная цель, то лучше заплатить профессиональному программисту, чтобы он сделал это за вас, так вы сэкономите время и избежите головной боли.
Но, возвращаясь к нашему основному вопросу, повторим, что очень важно понять следующее: всё основано на том, что было показано в предыдущей статье. И, более того, без понимания всего предыдущего, ничего не будет иметь смысла.
Давайте начнем с чего-нибудь простого. И когда я говорю "простой", я имею в виду, что это должно быть довольно простым для понимания, ведь, несмотря на простоту понимания, у этой концепции есть несколько аспектов, которые трудно усвоить, учитывая объем необходимых для этого знаний. Взгляните на следующий код.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10, 25.)); 08. } 09. //+------------------------------------------------------------------+ 10. ulong Sum(ulong arg1, ulong arg2) 11. { 12. Print(__FUNCTION__, "::", __LINE__); 13. return arg1 + arg2; 14. } 15. //+------------------------------------------------------------------+ 16. double Sum(double arg1, double arg2) 17. { 18. Print(__FUNCTION__, "::", __LINE__); 19. return arg1 + arg2; 20. } 21. //+------------------------------------------------------------------+
Код 01
Данный код точно такой же, как и тот, с которого началась предыдущая статья. Но почему? Причина в том, что это идеальный вариант для ознакомления с шаблонами и чтобы узнать, что такое typename. В каком-то смысле правильнее было бы показать либо один, либо другой термин, чтобы было легче объяснить. Но в данный момент одно будет тесно связано с другим. И именно это может привести к тому, что те, кто только начинает работать, окажутся в полном замешательстве.
Однако, чтобы изначально упростить тему, мы не будем подробно останавливаться на практическом значении каждого термина. Я хочу, чтобы вы просто наблюдали и пытались разобраться в том, что происходит. Не старайтесь понять ни как оно работает, ни то, как это можно использовать в других случаях. Если вы попытаетесь сделать это самостоятельно, то окажетесь в тупике. Поэтому я прошу проявить терпение, поскольку со временем мы всё объясним, ведь то, что предстоит сделать, включает в себя гораздо больше, чем мы увидим в этой простой статье.
Теперь я хочу, чтобы вы обратили внимание на следующее: ЕДИНСТВЕННОЕ РАЗЛИЧИЕ между функцией в строке 10 и функцией в строке 16 - это ожидаемый и возвращаемый тип данных. В приведенном выше коде больше ничего не изменилось.
Заметить и понять это ОЧЕНЬ ВАЖНО, гораздо важнее, чем понимание всего остального. Если вы не видите этого, всё остальное будет бессмысленным. Код 01 работает, и компилятор понимает, что нужно создать. Думаю, всё стало ясно, ведь это уже объяснялось в предыдущей статье. Теперь возникает вопрос: нужно ли нам писать код 01 в том виде, в котором он есть? Или, скорее, нет ли лучшего и более простого способа написать этот же код?
Если вы поняли, о чем шла речь в предыдущей статье, то вы знаете, что если нам нужно использовать типы, отличающиеся от объявленных, нам придется создавать дополнительные функции или процедуры. И, делая это, мы дублируем код, рискуя значительно усложнить его доработку, поскольку перегруженные функции и процедуры рано или поздно приводят к определенным трудностям. Я говорю это на основании многолетнего опыта программирования. Перегрузка всегда приводит к долгосрочным проблемам.
Размышляя в этом направлении, можно сказать, что некоторые языки позволяют создавать нечто, напоминающее шаблон, т.е. нечто, что нужно изменить всего в нескольких местах, без необходимости дублировать его код. Это в теории, поскольку использование такого инструмента не так просто, как кажется. Но давайте начнем с азов. Если не считать что типы, используемые в функциях на строках 10 и 16, отличаются, всё остальное можно преобразовать в шаблон. Это первый момент, который мы должны понять.
Но, несмотря на всё это, у данного кода есть один фактор, делающий всё сложнее: строка 07. Чтобы не усложнять это начальное объяснение, давайте учтем, что в строке 06 используются целочисленные типы, а в строке 07 - данные с плавающей точкой. В данный момент я вам навязываю это условие, но позже мы увидим, что есть способы изменить его. Хорошо, договорились.
Мы увидим, как тот же самый код 01 можно написать в виде реализации, используя шаблон функции. Это можно увидеть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(10, 25)); 07. Print(Sum(-10.0, 25.0)); 08. } 09. //+------------------------------------------------------------------+ 10. template <typename T> 11. T Sum(T arg1, T arg2) 12. { 13. Print(__FUNCTION__, "::", __LINE__); 14. return arg1 + arg2; 15. } 16. //+------------------------------------------------------------------+
Код 02
Теперь мы приблизились к странной части. Выполнив код 01, вы получите результат, представленный на изображении ниже.
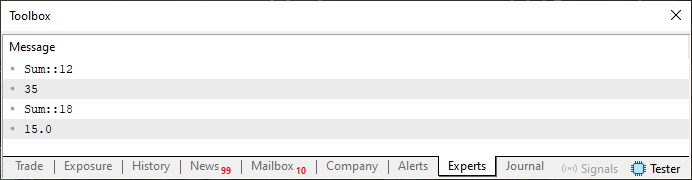
Рисунок 01
Однако, запустив код 02, мы увидим то, что показано на рисунке ниже.
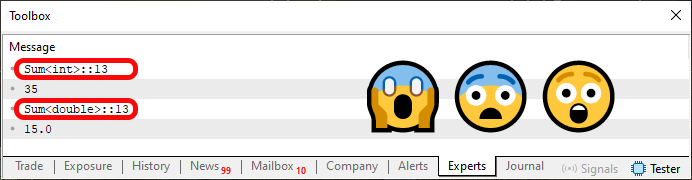
Рисунок 02
Вопрос: что здесь произошло? Ответ заключается в том, что мы преобразуем эти две функции из кода 01, в шаблон, который теперь показан в коде 02. Но вопрос, который действительно имеет значение, - это понять, что за информация выделена на рисунке 02. И вот здесь всё становится сложнее, если вы не поняли, что такое перегрузка функций или процедур. Это связано с тем, что в предыдущей статье мы объяснили, как компилятор может сделать так, чтобы функция или процедура была перегружена. Здесь мы неявно указываем компилятору, как он должен создать данную перегрузку.
Я использую слово "неявно", потому что МЫ НЕ ГОВОРИМ какой тип использовать. Это решение будет принимать компилятор. Поэтому в коде 01 мы использовали тип ulong в вызове строки 06, поскольку он будет использовать функцию строки 10, чей ожидаемый тип - значения типа ulong. Однако, когда мы позволили компилятору принять решение, он выбрал тип int, а не какой-либо другой, а это решение не всегда является лучшим. В некоторых случаях это может привести к тому, что результаты работы функций или процедур будут отличаться от ожидаемых.
Но не будем торопиться. Мы только начинаем работать в этой новой области. Нам еще многое предстоит увидеть, прежде чем мы вступим в эту область значений, отличных от ожидаемых.
Теперь я хочу, чтобы вы поняли следующее. Хотя на изображении 02 у нас есть четкое ощущение, что реализуется только одна процедура или, как в данном случае, функция; так происходит, потому что в обоих случаях мы обращаемся к одной и той же строке, то есть к строке 13, присутствующей в коде 02. Функция Sum, присутствующая в коде 02, НЕ ЯВЛЯЕТСЯ ФУНКЦИЕЙ, а шаблоном функции.
И что это означает на практике? Это значит, что как только компилятор обнаружит в нашем коде эту функцию, он посмотрит, нет ли уже такой, которая удовлетворяет нашим потребностям на данный момент. Если такой функции не существует, компилятор создаст ее, используя шаблон функции, объявленный между строками 10 и 15. Всё, что находится между этими строками, будет в некотором роде продублировано, но скорректировано так, чтобы оно использовалось правильно, как и предполагалось при создании кода.
Сейчас модно говорить, что искусственный интеллект может создавать код. То, что делается здесь, очень похоже, но без использования нейронных сетей или чего-то подобного.
Чтобы сделать это более понятным, мы внесем небольшое изменение в код 02, чтобы использовать функцию Sum с другими типами данных. Это можно увидеть чуть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print(Sum(130, 150)); 07. Print(Sum(130.0, 150.0)); 08. { 09. long v1 = 130, v2 = 150; 10. 11. Print(Sum(v1, v2)); 12. } 13. { 14. uchar v1 = 130, v2 = 150; 15. 16. Print(Sum(v1, v2)); 17. } 18. { 19. float v1 = 130, v2 = 150; 20. 21. Print(Sum(v1, v2)); 22. } 23. } 24. //+------------------------------------------------------------------+ 25. template <typename T> T Sum(T arg1, T arg2) 26. { 27. Print(__FUNCTION__, "::", __LINE__); 28. return arg1 + arg2; 29. } 30. //+------------------------------------------------------------------+
Код 03
Прошу заметить, что мы можем использовать как способ написания шаблона, показанный в коде 02, так и способ, показанный в коде 03. В данном случае в коде 03 мы делаем всё в одной строке, что не очень часто встречается в реальном коде, так как большинство программистов не используют эту форму, которая записана в строке 25 кода 03. Однако смысл тот же, что и в коде 02, только несколько менее распространенный.
Прекрасно, но дело не в этом, а в том, что при выполнении кода 03 получится то, что вы видите ниже.
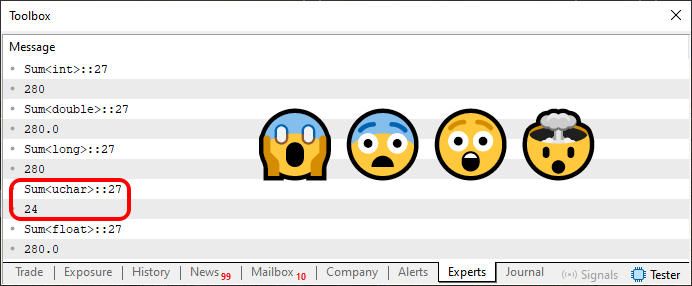
Рисунок 03
Теперь ситуация действительно осложнилась. «Я определенно больше ничего не понимаю - что за безумные, бессмысленные слова! Я это вижу своими глазами, но не могу поверить. Все значения равны, кроме одного. Это кажется мне абсурдным, и почему одна из сумм возвращает значение, настолько отличающееся от других?»
Да, разве я не говорил, что это будет весело? Хотя это очень сложно понять с первого взгляда. Давайте разберемся.
Помните, я говорил о том, что компилятор ищет лучший тип для каждого случая? Поэтому он создает перегруженные функции, чтобы код соответствовал тому, что нам нужно в данный момент. Прошу заметить следующее: когда выполняется строка шесть, лучшим типом является int. Поэтому создается перегруженная функция, которая использует именно этот тип. Сразу после этого у нас есть тип данных, который вводится как плавающая точка. В этом случае компилятор понимает, что лучший тип будет double. Именно поэтому используется этот тип. Во всех этих случаях компилятор использует неявную форму объявления, основанную на наилучшей реализованной модели данных, которая будет использоваться в качестве типа по умолчанию.
Теперь самое интересное: При вводе блоков между строками 08 и 12, 13 и 17, а также блока со строки 18 по 22 мы используем локальные переменные разных типов. Если вы не знаете, о чем я говорю, рекомендую вам прочитать первые статьи из серии. Там я объясняю, что такое локальные переменные и как долго каждая из них будет оставаться активной во время выполнения кода. Прошу заметить, что знания накапливаются. Поэтому не стоит позволять материалу накапливаться до начала его изучения и применения на практике.
Итак, в каждом из этих блоков у нас есть значения, которые меняются по ширине бита, в результате чего получается возможный диапазон. Таким образом, от типа используемой переменной зависит как результат операции, так и тип данных, которые функция использует.
Итак, каждую из строк, которую вы можете видеть на изображении 03, указывает, какой тип данных используется, и говорит нам о том, в каком диапазоне могут находиться значения. Я знаю, что сейчас это не имеет смысла. Однако мы уже обсуждали это, когда мы объясняли разницу между переменными и константами. Вернитесь назад и просмотрите данные статьи: эти знания теперь будут очень важны.
Тип uchar имеет диапазон от 0 до 255. Поскольку сумма значений равна 280, значение 24, выделенное на изображении 03, в точности соответствует произошедшему переполнению. Поскольку в типе uchar существует 256 возможных элементов, при превышении этого значения у нас 24 элемента переполнения. То есть счетчик был сброшен на ноль и перешел к элементу 24. Поэтому результатом суммы будет данное значение.
Обратите внимание, что это стало возможным только потому что мы явно указали компилятору, что используемый тип данных должен быть uchar. Если бы использовался другой, значение могло бы быть совершенно иным.
Поскольку данные коды будут находиться в приложении, попробуйте изменить тип данных с uchar на char и понаблюдайте за представленным результатом. Помните, что в этом случае компилятор выдаст предупреждение. Это связано с тем, что значения 130 и 150 выходят за пределы диапазона char. Однако можно уменьшить эти значения, чтобы они вписывались в диапазон. Как насчет того, чтобы добавить 90 к 80 и добавить тип данных char в строительные блоки? Уверяю вас, результат будет очень интересным.
Пытаемся понять, что здесь происходит
Как вы могли заметить, использование шаблона функции или процедуры избавляет нас от необходимости создавать несколько перегруженных функций или процедур, перекладывая на компилятор ответственность и работу по их созданию. Так мы сможем сосредоточиться на создании максимально читабельного кода. Однако, без понимания происходящего, трудно разобраться в том, как расширить этот ценный ресурс, которым является шаблон. Итак, давайте забудем обо всем остальном и постараемся сосредоточиться исключительно на понимании того, что происходит с этим шаблоном, который мы создаем в представленных здесь кодах. В основном мы сосредоточимся на коде 03, поскольку в нем используется больше типов данных, что облегчает понимание.
Для начала давайте еще раз взглянем на изображение 03. На этом изображении можно отчетливо заметить, что за именем функции следует символ «меньше чем», затем название типа и, наконец, символ «больше чем». Нас интересует именно идентификация типа, показанного на изображении 03.
Если посмотреть на код 03, то вы заметите, что в строке 25 НЕТ идентификации типа. Однако здесь есть кое-что интересное: зарезервированное слово "typename", за которым следует идентификатор. Идентификатор, который мы видим на изображении 03, очень похож на область, в которой typename появляется в коде 03. В этом, можно сказать, и кроется секрет.
Идентификатор, следующий за зарезервированным словом typename, позволяет компилятору определить тип данных, который шаблон будет использовать. Прошу заметить, что этот же идентификатор заменяет стандартное объявление, которое мы делаем при определении ожидаемого типа данных. Обычно программисты используют идентификатор T, но мы можем использовать любое название, лишь бы оно было правильно определено. Во время создания исполняемого файла данный идентификатор будет заменен компилятором на соответствующий тип.
Это дает нам большую свободу в использовании данного типа ресурсов, поскольку есть способы просто и недорого решить определенные типы сложных проблем. Об этом мы поговорим в следующей статье. Пока что я не хочу запутать вас переизбытком информации. Я просто хотел обратить ваше внимание на то, что утверждение, которое мы видим в строке 25 кода 03, можно изменить, чтобы сделать вещи более понятными для вас.
Например, мы можем изменить строку 25 кода 03 на строку, показанную ниже. Но даже в этом случае компилятор всё равно поймет, как работать с шаблоном.
template <typename Unknown> Unknown Sum(Unknown arg1, Unknown arg2)
Заключительные идеи
В этой статье мы начали рассматривать одну из концепций, которую избегают многие новички. Это связано с тем, что шаблоны - непростая тема, поскольку многие не понимают основного принципа, лежащего в основе шаблона: перегрузка функций и процедур. Хотя на данный момент была объяснена лишь первая часть огромного спектра возможностей, которые можно использовать с помощью шаблонов, понимание данной первой части очень важно. Многое из того, что будет показано и объяснено в следующих статьях, вытекает именно из этой базовой и начальной части.
Я считаю, что те, кто только начинает изучать программирование, могут запутаться в том, насколько полезны шаблоны и как правильно использовать этот вид ресурсов, присутствующих в MQL5. Но я хочу напомнить вам, что этот материал не требует быстрого усвоения. На самом деле, только время и практика помогут вам лучше понять подобную концепцию, которая будет применяться в дальнейшем.
Однако это не означает, что вы должны остановиться на достигнутом и перестать практиковать то, что здесь представлено. Изучение кодов, подобных тем, что представлены в приложениях, хотя и может показаться поначалу пустой тратой времени из-за их простоты, впоследствии может сэкономить много часов при разборке более сложных кодов, использующих все эти ресурсы. Запомните:
Знания накапливаются со временем. Они не возникают из ниоткуда и не передаются по наследству от одного человека к другому.
До встречи в следующей статье, где мы еще глубже погрузимся в вопрос использования шаблонов в их самом базовом и простом виде.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15658
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования