Artículos sobre aprendizaje automático en el trading
Creación de robots comerciales basados en inteligencia artificial: integración nativa con Python, operaciones con matrices y vectores, bibliotecas de matemáticas y estadística y mucho más.
Aprenda a usar el aprendizaje automático en el trading. Neuronas, perceptrones, redes convolucionales y recurrentes, modelos predictivos: parta de lo básico y avance hasta construir su propia IA. Aprenderá a entrenar y aplicar redes neuronales para el comercio algorítmico en los mercados financieros.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Predicción de tipos de cambio mediante métodos clásicos de aprendizaje automático: Modelos Logit y Probit
Hoy hemos intentado construir un experto comercial para predecir las cotizaciones de los tipos de cambio. El algoritmo se basa en modelos de clasificación clásicos: la regresión logística y probit. Como filtro para las señales comerciales, hemos utilizado el criterio de la razón de verosimilitud.

Redes neuronales en el trading: Uso de modelos de lenguaje para la predicción de series temporales
Continuamos nuestro análisis de los modelos de pronóstico de series temporales. En este artículo le propongo familiarizarnos con un algoritmo complejo construido sobre el uso de un modelo de lenguaje previamente entrenado.

Redes neuronales en el trading: Transformador jerárquico de doble torre (Final)
Seguimos construyendo el modelo del transformador jerárquico Hidformer de dos torres, diseñado para analizar y predecir series temporales multivariantes complejas. En este artículo llevaremos el trabajo iniciado anteriormente a su conclusión lógica probando el modelo con datos históricos reales.

Cuantificación en el aprendizaje automático (Parte 2): Preprocesamiento de datos, selección de tablas, entrenamiento del modelo CatBoost
En este artículo, hablaremos de la aplicación práctica de la cuantificación en la construcción de modelos arbóreos. Asimismo, analizaremos los métodos de selección de tablas cuantificadas y el preprocesamiento de datos. El material se presentará sin fórmulas matemáticas complejas, en un lenguaje accesible.

Redes neuronales: así de sencillo (Parte 74): Predicción de trayectorias con adaptación
Este artículo presenta un método bastante eficaz de previsión de trayectorias de múltiples agentes, capaz de adaptarse a diversas condiciones ambientales.

Redes neuronales en el trading: Framework comercial híbrido con codificación predictiva (StockFormer)
Hoy le presentamos el StockFormer, un sistema comercial híbrido que combina algoritmos de codificación predictiva y de aprendizaje por refuerzo (RL). El framework utiliza 3 ramas del Transformer con un mecanismo Diversified Multi-Head Attention (DMH-Attn) integrado que mejora el módulo de atención vainilla gracias a un bloque Feed-Forward multicabeza que permite captar diversos patrones de series temporales en diferentes subespacios.

Computación cuántica y trading: Una nueva mirada a las previsiones de precios
En el artículo analizaremos un enfoque innovador para predecir los movimientos de precios en los mercados financieros utilizando la computación cuántica. La atención se centrará en la aplicación del algoritmo Quantum Phase Estimation (QPE) para encontrar precursores de patrones de precios, lo que permitirá acelerar considerablemente el proceso de análisis de los datos de mercado.

Visión por computadora para el trading (Parte 1): Creamos una funcionalidad básica sencilla
Sistema de previsión de EURUSD mediante visión por computadora y aprendizaje profundo. Descubra cómo las redes neuronales convolucionales pueden reconocer patrones de precios complejos en el mercado de divisas y predecir la evolución de los tipos con una precisión de hasta el 54%. El artículo revela la metodología de creación de un algoritmo que usa tecnologías de inteligencia artificial para analizar visualmente los gráficos en lugar de los indicadores técnicos tradicionales. El autor muestra el proceso de transformación de los datos de precios en "imágenes", su procesamiento por una red neuronal y una visión única de la "conciencia" de la IA a través de mapas de activación y mapas de calor de la atención. El práctico código Python que utiliza la biblioteca MetaTrader 5 permite a los lectores reproducir el sistema y aplicarlo a sus propias transacciones.

Teoría de categorías en MQL5 (Parte 20): Autoatención y transformador
Hoy nos apartaremos un poco de nuestros temas habituales y veremos parte del algoritmo de ChatGPT. ¿Tiene alguna similitud o concepto tomado de las transformaciones naturales? Intentaremos responder estas y otras preguntas usando nuestro código en formato de clase de señal.

Perspectivas bursátiles a través del volumen: más allá de los gráficos OHLC
Sistema de negociación algorítmica que combina el análisis de volumen con técnicas de aprendizaje automático, concretamente redes neuronales LSTM. A diferencia de los enfoques tradicionales de negociación, que se centran principalmente en los movimientos de los precios, este sistema hace hincapié en los patrones de volumen y sus derivados para predecir los movimientos del mercado. La metodología incorpora tres componentes principales: análisis de derivadas de volumen (derivadas primera y segunda), predicciones LSTM para patrones de volumen e indicadores técnicos tradicionales.

Análisis cuantitativo de tendencias: Recopilamos estadísticas en Python
¿Qué es el análisis cuantitativo de tendencias en el mercado Forex? Recopilamos estadísticas sobre las tendencias, su magnitud y distribución en el par de divisas EURUSD. Cómo el análisis cuantitativo de tendencias puede ayudarle a crear un asesor comercial rentable.

Teoría de categorías en MQL5 (Parte 2)
La teoría de categorías es una rama diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.

Aprendizaje automático y Data Science (Parte 20): Elección entre LDA y PCA en tareas de trading algorítmico en MQL5
En este artículo analizaremos los métodos de reducción de la dimensionalidad y su aplicación en el entorno comercial MQL5. En concreto, exploraremos los matices del análisis discriminante lineal (LDA) y el análisis de componentes principales (PCA) y analizaremos su impacto en el desarrollo de estrategias y el análisis de mercados.

Análisis angular de los movimientos de precios: un modelo híbrido para predecir los mercados financieros
¿Qué es el análisis angular de los mercados financieros? ¿Cómo usar los ángulos de precios y el aprendizaje automático para predecir con una exactitud de 67? ¿Cómo combinar un modelo de regresión y clasificación con características angulares y obtener un algoritmo que funcione? ¿Qué tiene que ver Gann con esto? ¿Por qué los ángulos de movimiento de los precios son una buena señal para el aprendizaje automático?

Redes neuronales en el trading: Detección adaptativa de anomalías del mercado (DADA)
Hoy vamos a familiarizarnos con el framework DADA, un método innovador para detectar anomalías en las series temporales. Este ayuda a distinguir las fluctuaciones aleatorias de las presuntas anomalías. A diferencia de los métodos tradicionales, el DADA puede adaptarse de forma flexible a distintos datos. En lugar de un nivel de compresión fijo, usa múltiples opciones y elige la más adecuada para cada caso.

Algoritmo de optimización de reacciones químicas (CRO) (Parte II): Ensamblaje y resultados
En la segunda parte, reuniremos los operadores químicos en un único algoritmo y presentaremos un análisis detallado de sus resultados. Descubramos cómo el método de optimización de reacciones químicas (CRO) aborda la solución de problemas complejos en funciones de prueba.

Redes neuronales: así de sencillo (Parte 70): Mejoramos las políticas usando operadores de forma cerrada (CFPI)
En este trabajo, proponemos introducir un algoritmo que use operadores de mejora de políticas de forma cerrada para optimizar las acciones offline del Agente.

Redes neuronales: así de sencillo (Parte 78): Detector de objetos basado en el Transformer (DFFT)
En este artículo, le propongo abordar la creación de una estrategia comercial desde una perspectiva diferente. Hoy no pronosticaremos los movimientos futuros de los precios, sino que trataremos de construir un sistema comercial basado en el análisis de datos históricos.

Optimización del búfalo africano - African Buffalo Optimization (ABO)
El artículo se centra en el algoritmo de optimización del búfalo africano (ABO), un enfoque metaheurístico desarrollado en 2015 y basado en el comportamiento único de estos animales. El artículo detalla los pasos de implementación del algoritmo y su eficacia a la hora de encontrar soluciones a problemas complejos, lo cual lo convierte en una valiosa herramienta en el campo de la optimización.

Redes neuronales en el trading: Agente multimodal con herramientas complementarias (Final)
Seguimos trabajando en la implementación de los algoritmos para el agente multimodal de comercio financiero (FinAgent), diseñado para analizar los datos multimodales de la dinámica de mercado y los patrones comerciales históricos.

Redes neuronales en el trading: Modelos bidimensionales del espacio de enlaces (Quimera)
Descubra el innovador framework Chimera, un modelo bidimensional de espacio de estados que utiliza redes neuronales para analizar series temporales multivariantes. Este método ofrece una gran precisión con un bajo coste computacional, superando a los enfoques tradicionales y a las arquitecturas de Transformer.

Redes neuronales en el trading: Pipeline inteligente de predicciones (Final)
Este artículo ofrecerá una visión fascinante de cómo la incorporación de SwiGLU revela patrones de mercado ocultos y cómo la escasa combinación de expertos dentro de Decoder-Only Transformer hace que las predicciones sean más precisas a un coste computacional razonable. En este trabajo, analizaremos con detalle la integración de Time-MoE en MQL5 y OpenCL, describiendo la configuración y el entrenamiento del modelo paso a paso.

Cómo desarrollar un agente de aprendizaje por refuerzo en MQL5 con Integración RestAPI (Parte 3): Creación de jugadas automáticas y scripts de prueba en MQL5
Este artículo explora la implementación de jugadas automáticas en el juego del tres en raya de Python, integrado con funciones de MQL5 y pruebas unitarias. El objetivo es mejorar la interactividad del juego y asegurar la robustez del sistema a través de pruebas en MQL5. La exposición cubre el desarrollo de la lógica del juego, la integración y las pruebas prácticas, y finaliza con la creación de un entorno de juego dinámico y un sistema integrado confiable.

Algoritmo de optimización Brain Storm - Brain Storm Optimization (Parte II): Multimodalidad
En la segunda parte del artículo pasaremos a la aplicación práctica del algoritmo BSO, realizaremos tests con funciones de prueba y compararemos la eficacia de BSO con otros métodos de optimización.

Reimaginando las estrategias clásicas (Parte IV): SP500 y bonos del Tesoro de EE.UU.
En esta serie de artículos, analizamos estrategias de trading clásicas utilizando algoritmos modernos para determinar si podemos mejorar la estrategia utilizando IA. En el artículo de hoy, retomamos un enfoque clásico para operar con el SP500 utilizando la relación que guarda con los bonos del Tesoro estadounidense.

Redes neuronales en el trading: Modelo hiperbólico de difusión latente (Final)
El uso de procesos de difusión anisotrópica para codificar los datos de origen en un espacio latente hiperbólico, como se propone en el framework HypDIff, ayuda a preservar las características topológicas de la situación actual del mercado y mejora la calidad de su análisis. En el artículo anterior, empezamos a aplicar los enfoques propuestos usando herramientas MQL5. Hoy continuaremos el trabajo iniciado, llevándolo a su conclusión lógica.

Redes neuronales: así de sencillo (Parte 63): Entrenamiento previo del Transformador de decisiones no supervisado (PDT)
Continuamos nuestra análisis de la familia de métodos del Transformador de decisiones. En artículos anteriores ya hemos observado que entrenar el transformador subyacente en la arquitectura de estos métodos supone todo un reto y requiere una gran cantidad de datos de entrenamiento marcados. En este artículo, analizaremos un algoritmo para utilizar trayectorias no marcadas para el entrenamiento previo de modelos.

Hibridación de algoritmos basados en poblaciones. Esquema secuencial y paralelo
En este artículo, nos sumergiremos en el mundo de la hibridación de algoritmos de optimización analizando tres tipos clave: la mezcla de estrategias y la hibridación secuencial y paralela. Asimismo, realizaremos una serie de experimentos combinando y probando los algoritmos de optimización correspondientes.

Optimización con el juego del caos — Game Optimization (CGO)
Hoy presentamos el nuevo algoritmo metaheurístico de Chaos Game Optimisation (CGO), que demuestra una capacidad única para mantener una alta eficiencia al trabajar con problemas de alta dimensionalidad. A diferencia de la mayoría de los algoritmos de optimización, el CGO no solo no pierde rendimiento, sino que a veces incluso lo aumenta cuando se escala el problema, lo cual supone su característica clave.
Características del Wizard MQL5 que debe conocer (Parte 30): Normalización por lotes en el aprendizaje automático
La normalización por lotes es el preprocesamiento de datos antes de introducirlos en un algoritmo de aprendizaje automático, como una red neuronal. Esto siempre se hace teniendo en cuenta el tipo de activación que utilizará el algoritmo. Por lo tanto, exploramos los diferentes enfoques que se pueden adoptar para aprovechar los beneficios de esto, con la ayuda de un Asesor Experto ensamblado por un asistente.

Pronosticamos barras Renko con ayuda de IA CatBoost
¿Cómo utilizar las barras Renko junto con la IA? Hoy analizaremos el trading Renko en Fórex con una precisión de previsión del 59,27%. Asimismo, exploraremos las ventajas de las barras Renko para filtrar el ruido del mercado, aprenderemos por qué los indicadores de volumen son más importantes que los patrones de precios y cómo establecer el tamaño óptimo del bloque Renko para el EURUSD. s decir, veremos una guía paso a paso para integrar CatBoost, Python y MetaTrader 5 para crear nuestro propio sistema de previsión Forex Renko. Resulta ideal para tráders que buscan ir más allá del análisis técnico tradicional.

Aplicación de la selección de características localizadas en Python y MQL5
Este artículo explora un algoritmo de selección de características introducido en el artículo 'Local Feature Selection for Data Classification' de Narges Armanfard et al. El algoritmo se implementa en Python para construir modelos clasificadores binarios que pueden integrarse con aplicaciones de MetaTrader 5 para la inferencia.

Red neuronal en la práctica: Función de recta
En este artículo, pasaremos rápidamente por algunos métodos para obtener la función que podría representar nuestros datos en la base. No me adentraré en detalles sobre cómo usar estadísticas y estudios de probabilidad para interpretar los resultados. Dejo esto como tarea para aquellos que realmente deseen profundizar en la parte matemática del asunto. De todas formas, estudiar estos temas será crucial para que puedas comprender todo lo que involucra los estudios de redes neuronales. Aquí seré bastante suave con el tema.

Teoría de categorías en MQL5 (Parte 3)
La teoría de categorías es una rama diversa y en expansión de las matemáticas, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo destacar algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.
Red neuronal en la práctica: Mínimos cuadrados
Aquí en este artículo, veremos algunas cosas, entre ellas: Cómo muchas veces las fórmulas matemáticas parecen más complicadas cuando las miramos, que cuando las implementamos en código. Además de este hecho, también se mostrará cómo puedes ajustar el cuadrante del gráfico, así como un problema curioso que puede suceder en tu código MQL5. Algo que sinceramente no sé cómo explicar, ya que no lo entendí. A pesar de eso, mostraré cómo corregirlo en el código.

De Python a MQL5: Un viaje hacia los sistemas de trading inspirados en la cuántica
El artículo analiza el desarrollo de un sistema de negociación inspirado en la cuántica, pasando de un prototipo en Python a una implementación en MQL5 para la negociación en el mundo real. El sistema utiliza principios de computación cuántica, como la superposición y el entrelazamiento, para analizar los estados del mercado, aunque funciona en ordenadores clásicos utilizando simuladores cuánticos. Las características principales incluyen un sistema de tres qubits para analizar ocho estados del mercado simultáneamente, períodos de revisión de 24 horas y siete indicadores técnicos para el análisis del mercado. Aunque los índices de precisión puedan parecer modestos, proporcionan una ventaja significativa cuando se combinan con estrategias adecuadas de gestión de riesgos.

Inferencia causal en problemas de clasificación de series temporales
En este artículo, examinaremos la teoría de la inferencia causal utilizando el aprendizaje automático, así como la implementación del enfoque personalizado en Python. La inferencia causal y el pensamiento causal tienen sus raíces en la filosofía y la psicología y desempeñan un papel importante en nuestra comprensión de la realidad.
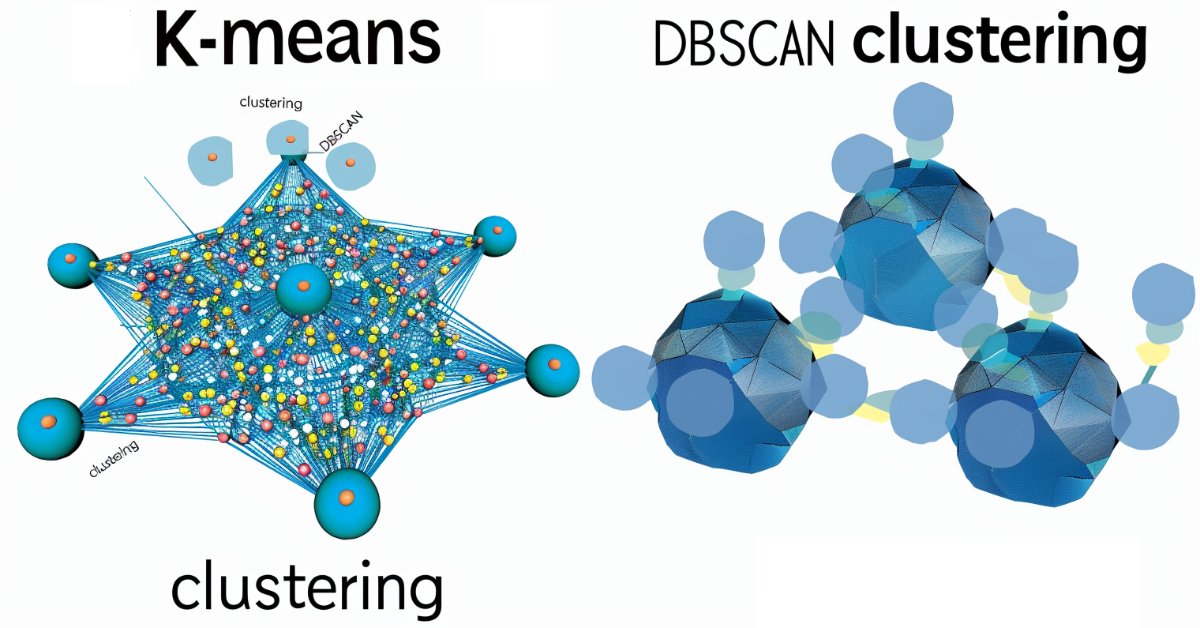
Características del Wizard MQL5 que debe conocer (Parte 13): DBSCAN para la clase experta de señales
El agrupamiento basado en densidad para aplicaciones con ruido (DBSCAN) es una forma no supervisada de agrupar datos que apenas requiere parámetros de entrada, salvo solo 2, lo cual, en comparación con otros enfoques como k-means, es una ventaja. Profundizamos en cómo esto podría ser constructivo para probar y eventualmente operar con Asesores Expertos montados por Wizard MQL5.

Puntuación de propensión (Propensity score) en la inferencia causal
Este artículo trata el tema del emparejamiento en la inferencia causal. El emparejamiento se usa para emparejar observaciones similares en un conjunto de datos. Esto es necesario para identificar correctamente los efectos causales, eliminando el sesgo. Hoy explicaremos cómo esto ayuda a crear sistemas comerciales basados en el aprendizaje automático que se vuelven más robustos con nuevos datos en los que no se ha entrenado. El papel principal lo asignaremos a la puntuación de propensión, ampliamente utilizada en la inferencia causal.

Algoritmo de optimización basado en la migración animal (Animal Migration Optimization, AMO)
El artículo está dedicado al algoritmo AMO, que modela la migración estacional de los animales en busca de condiciones óptimas para la vida y la reproducción. Las principales características de AMO incluyen el uso de vecindad topológica y un mecanismo de actualización probabilística, lo que lo hace fácil de implementar y flexible para diversas tareas de optimización.