
Redes neuronales en el trading: Transformador jerárquico de doble torre (Final)

Introducción
En el artículo anterior, presentamos los aspectos teóricos del framework Hidformer, diseñado específicamente para analizar y predecir series temporales multivariantes complejas. El modelo demuestra una gran eficacia en el procesamiento de datos dinámicos y volátiles, gracias a su arquitectura única.
Un elemento clave del Hidformer es el uso de mecanismos de atención avanzados no solo para identificar dependencias obvias en los datos, sino también para descubrir relaciones profundas y ocultas. Para ello, el modelo usa un codificador de doble torre o dos torres, en el que cada torre analiza de forma independiente los datos de origen. Una de las torres se especializa en el análisis de estructuras temporales, identificando tendencias y patrones, mientras que la segunda se encarga de la exploración de los datos en el dominio de la frecuencia. Este enfoque ofrece una visión global de la dinámica del mercado, permitiendo considerar las variaciones tanto a corto plazo como a largo plazo de las series de precios.
Un aspecto innovador del modelo es el uso de un mecanismo de atención recursiva para analizar las dependencias temporales, lo cual nos permite acumular de forma consistente información sobre patrones complejos de dinámica del instrumento financiero analizado. Junto con el mecanismo de atención lineal utilizado para analizar el espectro de frecuencias de los datos de origen, este enfoque optimiza el coste computacional y garantiza la estabilidad del proceso de aprendizaje. Esto permite que el framework Hidformer se adapte eficazmente a la multidimensionalidad y no linealidad de los datos analizados, proporcionando previsiones más fiables en mercados de alta volatilidad.
El decodificador del modelo, basado en un perceptrón multicapa, nos permite pronosticar la secuencia completa de precios en un solo paso, minimizando el riesgo de acumulación de errores típico de la previsión paso a paso. Esto mejora significativamente la calidad de las previsiones a largo plazo, lo cual hace que el modelo sea especialmente valioso para aplicaciones prácticas en el análisis financiero.
A continuación le mostramos la visualización del framework Hidformer realizada por el autor.
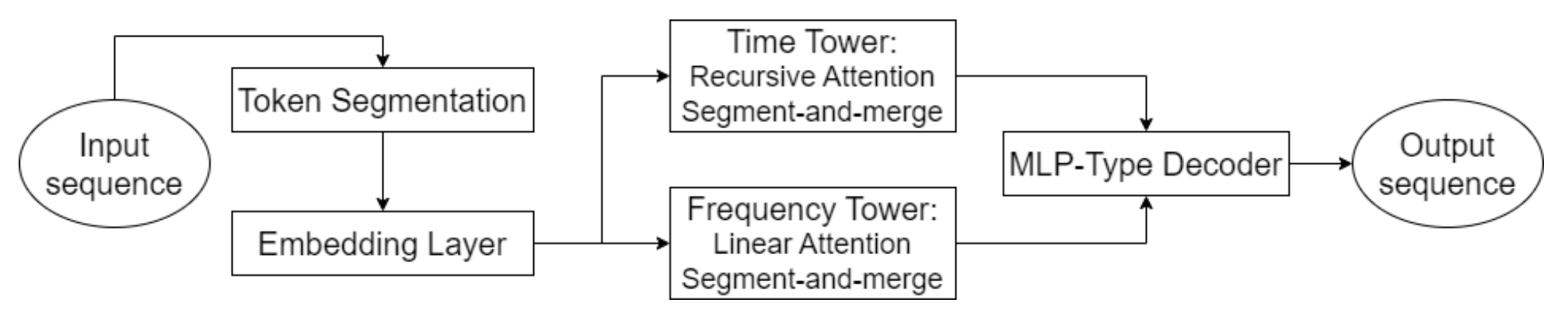
En la parte práctica del artículo anterior, realizamos algunos trabajos preparatorios y pusimos en práctica nuestra visión de los algoritmos de atención recursiva y lineal. Hoy continuaremos el trabajo iniciado para basarnos en los planteamientos propuestos por los autores del framework Hidformer.
Análisis de secuencias temporales
Los autores del framework Hidformer propusieron una arquitectura de codificador de doble torre, que hemos tomado como base. En nuestra implementación, cada torre codificadora se representa como un objeto independiente, lo cual permitirá adaptar el modelo con flexibilidad a diferentes tareas. Sin embargo, a diferencia del framework original, hemos introducido una serie de modificaciones dictadas por el cambio en el problema resuelto por el modelo. Inicialmente, el framework se desarrolló para predecir la continuación de las series temporales analizadas, pero nosotros hemos ido un poco más allá.
Basándonos en la experiencia adquirida en la aplicación de los frameworks MacroHFT y FinCon, hemos usado torres codificadoras como agentes independientes que generan opciones para las próximas transacciones comerciales. Este planteamiento ha permitido ampliar considerablemente la funcionalidad del sistema.
De forma similar a la arquitectura original del Hidformer, nuestros agentes analizan los datos del mercado en forma de secuencias temporales multidimensionales y sus características de frecuencia. El uso del mecanismo de atención recursiva permite detectar dependencias en series temporales multivariantes, mientras que el análisis del espectro de frecuencias se realiza usando objetos de atención lineal. Este enfoque ofrece una comprensión más profunda de los patrones estructurales de los datos y permite que el modelo se adapte a los cambios en las condiciones del mercado en tiempo real, lo cual resulta especialmente importante en el trading de alta frecuencia y el trading algorítmico.
Además, cada agente está equipado con un módulo de análisis recurrente de la secuencia de decisiones tomadas que permite evaluarlas en el contexto de la dinámica del mercado. Este módulo ofrece la capacidad de analizar las decisiones pasadas, identificar las estrategias más acertadas y adaptar el modelo a las condiciones cambiantes del mercado.
El agente de análisis de secuencias temporales se construye como un objeto CNeuronHidformerTSAgent, cuya estructura le mostramos a continuación.
class CNeuronHidformerTSAgent : public CResidualConv { protected: CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveState; CResidualConv cResidualState; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerTSAgent(void) {}; ~CNeuronHidformerTSAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerTSAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Como clase padre, en este caso, usamos un bloque convolucional con retroalimentación, que actuará como bloque FeedForward de uno de los bloques de atención internos.
Cabe señalar que la estructura presentada incluye una amplia gama de componentes diversos, cada uno de los cuales desempeña su función única en la organización de algoritmos de una nueva clase. Estos elementos aportan versatilidad al planteamiento, permitiendo que el modelo se adapte a distintos escenarios de procesamiento de la información y análisis de patrones complejos. Conoceremos cada uno de estos componentes con más detalle a medida que construyamos los métodos de la clase.
Todos los objetos internos se han declarado estáticamente, lo cual nos permite dejar vacíos el constructor y el destructor de la clase, mientras que la inicialización de todos los objetos internos heredados y declarados se realiza en el método Init. En los parámetros de este método, obtendremos una serie de constantes que nos darán una idea inequívoca de la arquitectura del objeto creado.
bool CNeuronHidformerTSAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
Las operaciones de inicialización de objetos comienzan con la llamada al método correspondiente de la clase padre, en el que ya están dispuestos los puntos necesarios de control e inicialización de los objetos heredados. Tenga en cuenta que las interfaces del objeto padre deben formar los resultados esperados del agente. En este caso, a la salida del agente esperamos recibir un tensor de operaciones comerciales, donde cada operación está representada por tres parámetros principales: el volumen de la operación y los niveles de stop-loss y take-profit. En ese caso, las operaciones de compra y venta se representan en filas separadas de esta matriz. Así, al llamar al método de inicialización de la clase padre, fijamos el tamaño de las ventanas iniciales de datos y resultados en 3, y la longitud de la secuencia como tres veces menor que el vector de acciones del agente.
Una vez ejecutadas con éxito las operaciones de la clase padre, se inicializan los objetos internos recién declarados. Primero se inicializan las estructuras responsables de formar el tensor de rol del agente. Hemos tomado prestado el concepto de estas estructuras de la arquitectura del framework FinCon y lo hemos adaptado a la tarea actual. La principal ventaja de este concepto consiste en dividir las funciones de análisis de los datos de origen entre varios agentes que trabajan en paralelo, lo cual les permite centrar su atención en aspectos concretos de la secuencia analizada.
//--- Role int index = 0; if(!caRole[0].Init(10 * window_key, index, OpenCL, 1, optimization, iBatch)) return false; caRole[0].getOutput().Fill(1); index++; if(!caRole[1].Init(0, index, OpenCL, 10 * window_key, optimization, iBatch)) return false;
A continuación, se inicializa el módulo de atención cruzada relativa para resaltar las características clave de los datos de origen, según el contexto de la función del agente.
//--- State to Role index++; if(!cStateToRole.Init(0, index, OpenCL, window, window_key, units_count, heads, window_key, 10, optimization, iBatch)) return false;
Tras la etapa inicial de procesamiento de los datos de origen, volvemos a la arquitectura de autoría del framework Hidformer, que proporciona un mecanismo para segmentar los datos de origen antes de pasarlos al codificador. Debemos señalar que la segmentación se realiza de forma independiente en cada torre, lo cual evita correlaciones no deseadas entre distintos flujos de datos y aumenta la adaptabilidad del modelo a secuencias fuente heterogéneas.
En nuestra versión modificada, hemos complementado la funcionalidad del agente sustituyendo la segmentación clásica por un módulo especializado S3. Este módulo no solo realiza la segmentación de datos, sino que también implementa un mecanismo para la mezcla de segmentos entrenada. Este enfoque permite identificar mejor las dependencias ocultas entre las distintas partes de la secuencia. Como resultado, el agente es capaz de formar representaciones más estables y generalizadas.
//--- State index++; if(!cShuffle.Init(0, index, OpenCL, window, window * units_count, optimization, iBatch)) return false;
Los datos preparados en los pasos anteriores se introducen en un codificador compuesto por un módulo de atención recursiva y un bloque convolucional con retroalimentación.
index++; if(!cRecursiveState.Init(0, index, OpenCL, window, window_key, units_count, heads, stack_size, optimization, iBatch)) return false; index++; if(!cResidualState.Init(0, index, OpenCL, window, window, units_count, optimization, iBatch)) return false;
Un codificador de este tipo nos permite analizar la secuencia original en el contexto del último precio, identificando probables niveles de apoyo y resistencia, u objetos de formación de patrones estable
Y en el siguiente paso, volvemos a desviarnos de la versión del autor del framework Hidformer y añadimos un módulo para analizar las acciones realizadas previamente por el agente. Aquí, primero analizamos recursivamente las acciones recientes del agente en el contexto de su secuencia histórica.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Luego utilizamos el módulo de atención cruzada multiescala para analizar la política del agente usada en el contexto de la dinámica del mercado.
index++; if(!cActionToState.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
E implementaremos la funcionalidad del bloque FeedForward con ayuda de la clase padre.
Una vez inicializados correctamente todos los objetos internos, retornamos el resultado lógico de las operaciones al programa que realiza la llamada y finalizamos el método.
A continuación pasamos a la construcción de algoritmos de pasada directa, que organizamos como parte del método feedForward. En los parámetros de este método obtenemos el puntero al objeto que contiene los datos de origen.
bool CNeuronHidformerTSAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
En el cuerpo del método, primero generamos el tensor de descripción de rol del agente actual. Sin embargo, solo realizamos esta operación durante el entrenamiento del modelo. No resulta difícil adivinar que, durante el funcionamiento del modelo, se generará un tensor de rol fijo en cada iteración de pase directa, lo que hace innecesaria esta operación. Por consiguiente, primero comprobamos el modo del modelo y solo después llamamos al método de pasada directa de la capa interna completamente conectada de la generación del tensor de rol. Este planteamiento nos permitirá eliminar operaciones innecesarias en el modo de explotación del modelo y reducir el tiempo dedicado al proceso de toma de decisiones.
A continuación, se procede al procesamiento de los datos de origen obtenidos. Aquí destacamos primero los puntos relevantes para el papel de nuestro agente. Esta operación se realiza usando el objeto de atención cruzada.
//--- State to Role if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false;
Luego segmentamos y mezclamos el estado analizado del entorno con colocación de acentos.
//--- State if(!cShuffle.FeedForward(cStateToRole.AsObject())) return false;
Después, procesamos en el módulo de atención recursiva, donde la descripción del estado del entorno analizado se enriquece con los datos de la dinámica del movimiento de precios anterior.
if(!cRecursiveState.FeedForward(cShuffle.AsObject())) return false; if(!cResidualState.FeedForward(cRecursiveState.AsObject())) return false;
A continuación, se analiza en profundidad la política de comportamiento del agente. En primer lugar, se analiza la última decisión tomada en el contexto de las acciones anteriores almacenadas en la memoria del módulo de atención recursiva.
//--- Action if(!cRecursiveAction.FeedForward(AsObject())) return false;
A continuación, se analiza la política de acción del agente en el contexto de la dinámica del cambio del entorno mediante el módulo de atención cruzada multiescala.
if(!cActionToState.FeedForward(cRecursiveAction.AsObject(), cResidualState.getOutput())) return false;
Resulta fácil ver que la arquitectura del módulo de análisis de la acción del agente está tomada del descodificador clásico del Transformer. El descodificador clásico utiliza secuencialmente los módulos Sefl-Attention → Cross-Attention → FeedForward. En nuestro caso, el módulo Self-Attention se ha sustituido por un objeto de atención recursiva de acuerdo con los planteamientos del framework del Hidformer. Guiándonos por los mismos planteamientos, sustituimos la multiplicidad de cabezas de Cross-Attention por la multiescalabilidad. Ya solo queda añadir el bloque FeedForward. Su función es desempeñada por los recursos de la clase padre. Pero antes de utilizarlos, debemos considerar que a la entrada de este singular descodificador se suministran los resultados de la pasada directa anterior de nuestro método. Y para la correcta ejecución de las operaciones de pasada inversa, conviene guardarlos. Para ello, sustituimos los punteros a los búferes de datos heredados, y solo entonces llamamos al método de pasada directa de la clase padre.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CResidualConv::feedForward(cActionToState.AsObject()); }
Después retornamos el resultado lógico de las operaciones al programa que realiza la llamada y finalizamos el método.
El siguiente paso de nuestro trabajo es la construcción de algoritmos de pasada inversa. Como ya sabe, el proceso de pasada inversa en nuestros objetos está representado por dos métodos: calcInputGradients y updateInputWeights. El primero es responsable de corregir la distribución del gradiente de error entre todos los objetos que intervienen en el proceso de toma de decisiones según su influencia en el resultado final. Y en la segunda, se optimizan los parámetros entrenados del modelo para minimizar el error global. El algoritmo del segundo método no suele ser complicado. Al fin y al cabo, en él solo solemos llamar a los métodos homónimos de los objetos internos que contienen los parámetros a entrenar, transmitiendo los datos de origen utilizados en la pasada directa. El algoritmo del método de distribución del gradiente de error, por otra parte, está estrechamente relacionado con los flujos de información directa y requiere una descripción más detallada.
En los parámetros del método de distribución de gradientes de error calcInputGradients, obtenemos el puntero al objeto de datos de origen. Se trata del mismo objeto que se transmitió en la pasada directa. solo que esta vez tenemos que pasarle el gradiente de error correspondiente a la influencia de los datos de entrada en el resultado del modelo. Obviamente, necesitamos el puntero correcto al objeto para pasar los datos. Por lo tanto, en el cuerpo del método comprobamos inmediatamente la relevancia del puntero recibido.
bool CNeuronHidformerTSAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Y después de pasar con éxito un pequeño bloque de control, construimos el algoritmo de distribución del gradiente de error.
Hemos dicho muchas veces que los flujos de información de la distribución de gradiente son completamente iguales a los flujos análogos de pasada directa, solo que dirigidos en sentido contrario. Las operaciones del método de pasada directa terminaban llamando al método de la clase padre. Por lo tanto, la distribución del gradiente de error comienza con el uso de medias heredadas. Aquí, llamamos al método homónimo de la clase padre para transmitir el error al nivel de objeto multiescala de atención cruzada de la política de comportamiento del agente y la dinámica del mercado.
if(!CResidualConv::calcInputGradients(cActionToState.AsObject())) return false;
A continuación, debemos dividir el gradiente de error resultante entre dos flujos de información de análisis de políticas del comportamiento del agente y el estado del entorno, representado por una serie temporal multivariante.
if(!cRecursiveAction.calcHiddenGradients(cActionToState.AsObject(), cResidualState.getOutput(), cResidualState.getGradient(), (ENUM_ACTIVATION)cResidualState.Activation())) return false;
Primero distribuimos el gradiente de error a lo largo de la línea troncal de análisis de la política de comportamiento del agente. Para ello, debemos pasarlo por el módulo de atención recursiva de las acciones del agente. Pero aquí tenemos que prestar atención a que los datos de origen de este bloque eran los resultados de la pasada directa anterior de nuestro objeto. Los hemos guardado cuidadosamente en un búfer de datos especial. Y ahora, para distribuir correctamente los errores, necesitamos devolverlos temporalmente al búfer de resultados con los resultados existentes intactos. Para ello, volvemos a realizar la sustitución de los punteros del búfer de datos.
Además, al realizar la asignación del gradiente de error, sobrescribiremos los datos existentes en el búfer de interfaz correspondiente de nuestro objeto. Esto resulta altamente indeseable, porque todavía los necesitaremos para ajustar los parámetros entrenados. Por ello, realizamos la sustitución de punteros y búferes de gradiente de error.
Solo después de tener la seguridad de que se han almacenado todos los datos necesarios, realizamos las operaciones de distribución del gradiente de error a través del módulo de atención recursiva. Y tras ejecutar las operaciones con éxito, retornamos los punteros a los búferes de datos al estado inicial.
//--- Action CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cRecursiveAction.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cRecursiveAction.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
A continuación, procedemos a la distribución del gradiente de error a lo largo de la línea troncal del análisis de series temporales multivariantes de la descripción del estado del entorno. Aquí, primero reducimos los errores al nivel del módulo de atención recursiva del estado del entorno analizado.
//--- State if(!cRecursiveState.calcHiddenGradients(cResidualState.AsObject())) return false;
Y luego, lo pasamos al nivel del bloque de segmentación y mezcla.
if(!cShuffle.calcHiddenGradients(cRecursiveState.AsObject())) return false;
A partir de ahí, pasamos la información a la capa de objetos de atención cruzada, que analiza los datos de origen en el contexto de la función del agente.
if(!cStateToRole.calcHiddenGradients(cShuffle.AsObject())) return false;
Partiendo de él, el gradiente de error se divide de nuevo en dos flujos de información: hacia el objeto de datos de origen y hacia la línea troncal de formación del rol del agente.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
Aquí cabe señalar que, a lo largo de la cadena de formación del rol del agente, no distribuimos más el gradiente de error. Al fin y al cabo, la primera capa de este MLP tiene un valor fijo, y los parámetros entrenados solo contienen la segunda capa neuronal, cuyo error ya hemos transmitido.
Ahora solo tenemos que retornar el resultado lógico de las operaciones al programa que realiza la llamada y finalizar el método.
Con esto concluye nuestra revisión de los algoritmos usados para construir los métodos para que el agente analice la secuencia temporal del estado del entorno. Puede leer el código completo del objeto presentado y todos sus métodos por sí mismo en el archivo adjunto.
Trabajando con el dominio de la frecuencia
La siguiente etapa de nuestro trabajo es la construcción de un agente que analice las características frecuenciales de la señal analizada. Diremos de entrada que la estructura de la construcción del agente es bastante similar a la del agente de análisis de secuencias temporales anteriormente mencionado. Pero al mismo tiempo no está exento de algunas peculiaridades relacionadas con la transformación de la señal original en el espectro de frecuencias. En nuestra aplicación, para extraer componentes de alta y baja frecuencia de la señal analizada que describen el estado del entorno, usamos una transformada wavelet discreta tomada del framework Multitask-Stockformer.
Asimismo, implementamos los algoritmos del agente del dominio de la frecuencia como un objeto CNeuronHidformerFreqAgent, cuya estructura se muestra a continuación.
class CNeuronHidformerFreqAgent : public CResidualConv { protected: CNeuronTransposeOCL cTranspose; CNeuronLegendreWaveletsHL cLegendre; CNeuronTransposeRCDOCL cHLState; CNeuronLinerAttention cAttentionState; CResidualConv cResidualState; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerFreqAgent(void) {}; ~CNeuronHidformerFreqAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerFreqAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
En la estructura presentada resulta fácil notar nombres similares de los objetos internos, que nos hablan de la estructura relacionada de los agentes del dominio del tiempo y de la frecuencia. Pero hay algunas diferencias que consideraremos con más detalle durante la construcción de los algoritmos para los métodos de la nueva clase.
Todos los objetos internos se declaran estáticamente, lo cual nos permite dejar vacíos el constructor y el destructor de nuestro objeto, mientras que la inicialización de todos los objetos recién declarados y heredados se realizará en el método Init.
bool CNeuronHidformerFreqAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
En los parámetros de este método obtenemos una serie de constantes que nos permiten interpretar sin ambigüedades la arquitectura del objeto creado. Y en el cuerpo del método llamamos directamente al método homónimo de la clase padre, en el que ya están implementados los puntos de control necesarios y la inicialización de los objetos e interfaces heredados. Y aquí debemos señalar que, a pesar de la diferencia en los dominios de los datos analizados, esperamos obtener el mismo tensor comercial en la salida del agente. Por lo tanto, los enfoques descritos anteriormente para llamar al método de inicialización de la clase padre en el agente de análisis de series temporales resultan relevantes aquí también.
A continuación, inicializamos los objetos recién declarados. Y aquí vemos inmediatamente la diferencia en la construcción de los agentes de distinto dominio. El agente de análisis de características de frecuencia carece de módulo de generación de rol. En nuestra aplicación, no tenemos previsto usar un gran número de agentes del dominio de la frecuencia.
Además, el bloque de segmentación se ha sustituido por un módulo de transformada wavelet discreta. En este caso, la transformación de la serie temporal en el dominio de la frecuencia se realiza en la sección de secuencias unitarias. Y por comodidad al trabajar con secuencias unitarias necesitamos transponer previamente la matriz de datos de origen.
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Luego dividimos la serie temporal unitaria en segmentos iguales. Para cada segmento, se realiza una transformada wavelet discreta, lo cual permite identificar componentes estructurales significativos de las dependencias temporales. El tamaño mínimo del segmento se limita a cinco elementos, lo cual supone un equilibrio entre la precisión del análisis y el coste computacional.
index++; uint wind = (units_count>=20 ? (units_count + 3) / 4 : units_count); uint units = (units_count + wind - 1) / wind; if(!cLegendre.Init(0, index, OpenCL, wind, wind, units, filters, window, optimization, batch)) return false;
Aquí debemos señalar que a la salida del módulo de transformada wavelet discreta obtenemos un tensor que contiene componentes de alta y baja frecuencia de la señal analizada. En este caso, el componente de alta frecuencia sigue directamente al componente de baja frecuencia de cada segmento individual y los datos pueden representarse como un tensor tridimensional [Segment, [Low, High], Filters].
Para el análisis posterior, resulta importante separar los datos en sus respectivos componentes. Sin embargo, como se supone que se realizan operaciones idénticas en ambos tipos de señales, es más racional organizar su procesamiento en paralelo. En este sentido, no dividimos explícitamente la señal en objetos separados, sino que realizamos una transposición tensorial, lo cual permite una gestión más eficiente de los recursos informáticos y un procesamiento más rápido de los datos.
index++; if(!cHLState.Init(0, index, OpenCL, units * window, 2, filters, optimization, iBatch)) return false;
Ahora, como prevén los autores del framework Hidformer, usamos el algoritmo de atención lineal. En nuestro caso, realizamos análisis separados de los componentes de alta y baja frecuencia, lo cual nos permite identificar los patrones más significativos y cambiar de forma adaptativa la estrategia de procesamiento de la señal según sus características frecuenciales.
index++; if(!cAttentionState.Init(0, index, OpenCL, filters, filters, units* window, 2, optimization, iBatch)) return false;
Luego pasamos los resultados obtenidos a través de un bloque convolucional de realimentación, que actúa como el módulo FeedForward de nuestro codificador en el dominio de la frecuencia.
index++; if(!cResidualState.Init(0, index, OpenCL, filters, filters, 2 * units * window, optimization, iBatch)) return false;
A continuación, inicializamos el bloque de análisis de la política usada por el agente, similar al que se ha comentado anteriormente al construir el agente de análisis de la secuencia temporal. No obstante, deberemos considerar un pequeño detalle: Mientras que para el módulo de atención lineal la secuencia de segmentos no resulta importante, ya que toda la secuencia se analiza a la vez, en el caso del módulo de atención cruzada multiescala nos enfrentamos al problema de la priorización de segmentos. Al fin y al cabo, nuestro módulo de atención cruzada multiescala está diseñado para trabajar con secuencias temporales y ofrece prioridad a los elementos más recientes.
Para resolver este problema, usaremos el objeto de segmentación y mezcla. En este caso, nuestros datos ya están segmentados y nos preocupa más el proceso de permutación entrenada de los segmentos. Este enfoque permite al modelo aprender por sí mismo la priorización de segmentos partiendo de los datos ofrecidos en la muestra de entrenamiento.
index++; if(!cShuffle.Init(0, index, OpenCL, filters, cResidualState.Neurons(), optimization, iBatch)) return false;
No vamos a detenernos a describir la funcionalidad de los objetos utilizados por el módulo de análisis de la política del agente, ya que aquí se mantienen los planteamientos descritos en la construcción del agente de análisis de secuencias temporales.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false; index++; if(!cActionToState.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, filters, 2 * units * window, optimization, iBatch)) return false; //--- return true; }
Después de inicializar con éxito todos los objetos internos, finalizamos el método devolviendo primero el resultado lógico del método al programa que realiza la llamada.
Para ahorrar extensión al artículo, le propongo estudiar los métodos de pasada directa e inversa por su cuenta. Sus algoritmos se basan en los mismos principios descritos anteriormente para la construcción de los métodos similares de los agentes de análisis de secuencias temporales. Encontrará el código completo de los objetos presentados de ambos agentes y sus métodos en el archivo adjunto.
Objeto de nivel superior
Tras construir los objetos de las torres de análisis de las series temporales multivariantes y sus características de frecuencia, para construir un framework Hidformer coherente, solo nos queda combinarlos en una única estructura y añadir un descodificador. Los autores del framework Hidformer utilizaron un MLP como decodificador para predecir la continuación esperada de las series temporales analizadas. A pesar de haber introducido cambios en el problema resuelto por el modelo, para su implementación, también podemos utilizar el perceptrón para generar la solución final. Sin embargo, hemos ido un poco más allá y tomado prestada la idea del hiperagente en el framework MacroHFT. Inspirándonos en esta idea, hemos creado un nuevo objeto CNeuronHidformer, cuya estructura se muestra a continuación.
class CNeuronHidformer : public CNeuronBaseOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronHidformerTSAgent caTSAgents[4]; CNeuronHidformerFreqAgent caFreqAgents[2]; CNeuronMacroHFTHyperAgent cHyperAgent; CNeuronBaseOCL cConcatenated; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformer(void) {}; ~CNeuronHidformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint stack_size, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
En la arquitectura presentada del nuevo objeto, podemos identificar fácilmente similitudes estructurales con la clase CNeuronMacroHFTque forma parte del framework MacroHFT. De hecho, la nueva estructura es una versión modificada de esta, en la que hemos mantenido los principios básicos de construcción, pero hemos introducido cambios puntuales para mejorar la eficacia del procesamiento de datos.
La diferencia clave son los ajustes reconfigurados de los agentes de análisis del entorno. Esta versión usa seis agentes especializados: cuatro de ellos realizan el análisis de las secuencias temporales multivariantes, mientras que dos están diseñados para procesar los datos de origen en el dominio de la frecuencia. Para garantizar un análisis equilibrado, todos los agentes se distribuyen equitativamente entre el procesamiento de las representaciones directas y las transpuestas de los datos de origen. Esta arquitectura permite una exploración más detallada de distintos aspectos de los datos de origen, destacando patrones ocultos y ajustando de forma adaptativa la estrategia de procesamiento.
En general, el cambio en la estructura de los agentes solo ha supuesto cambios menores en los algoritmos de los métodos del nuevo objeto. La lógica básica de funcionamiento permanece inalterada y se conservan todos los principios clave del modelo. Aprovechando esta circunstancia, le sugiero que se familiarice con los algoritmos de construcción de los métodos. En el archivo adjunto se incluye el código completo de este objeto y todos sus métodos.
Arquitectura del modelo
Digamos ahora unas palabras sobre la arquitectura del modelo entrenado. Creo que se habrá dado cuenta de que la arquitectura que hemos construido es una especie de sinergia entre los frameworks Hidformer y MacroHFT. La arquitectura del modelo entrenado y sus métodos de entrenamiento no son una excepción. Como parte de nuestro trabajo, hemos copiado la arquitectura del modelo construido al implementar el framework MacroHFT y sustituido solo una capa.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHidformer; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Scales descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Por lo demás, la arquitectura del funcionamiento permanece inalterada, incluido el uso del agente de gestión de riesgos. En el archivo adjunto figura una descripción completa de la arquitectura del modelo. También le presentamos el código completo de los programas de entrenamiento y prueba del modelo, que hemos trasladado íntegramente del artículo anterior sin modificaciones.
Simulación
Ya hemos trabajado bastante para hacer realidad nuestra propia visión de los planteamientos propuestos por los autores del framework Hidformer. Y ahora nos acercamos al momento de mayor responsabilidad: probar la eficacia de las soluciones aplicadas con datos históricos reales. En nuestra implementación, hemos tomado prestado mucho del framework MacroHFT. Y resulta bastante lógico comparar los resultados del nuevo modelo con este framework concreto. Para ello, vamos a entrenar el nuevo modelo con la muestra de entrenamiento del modelo recopilado previamente para entrenar nuestra implementación del framework MacroHFT.
Permítame recordarle que la muestra de entrenamiento se recopiló sobre datos históricos para todo el año 2024 del framework temporal M1 y el par de divisas EURUSD. Los parámetros de todos los indicadores analizados se han usado por defecto.
Asimismo, hemos usado los mismos asesores expertos para entrenar y probar el modelo. El modelo lo hemos probado con los datos históricos de enero de 2025, manteniendo intactos todos los demás parámetros. Ahora le presentamos los resultados de las pruebas.
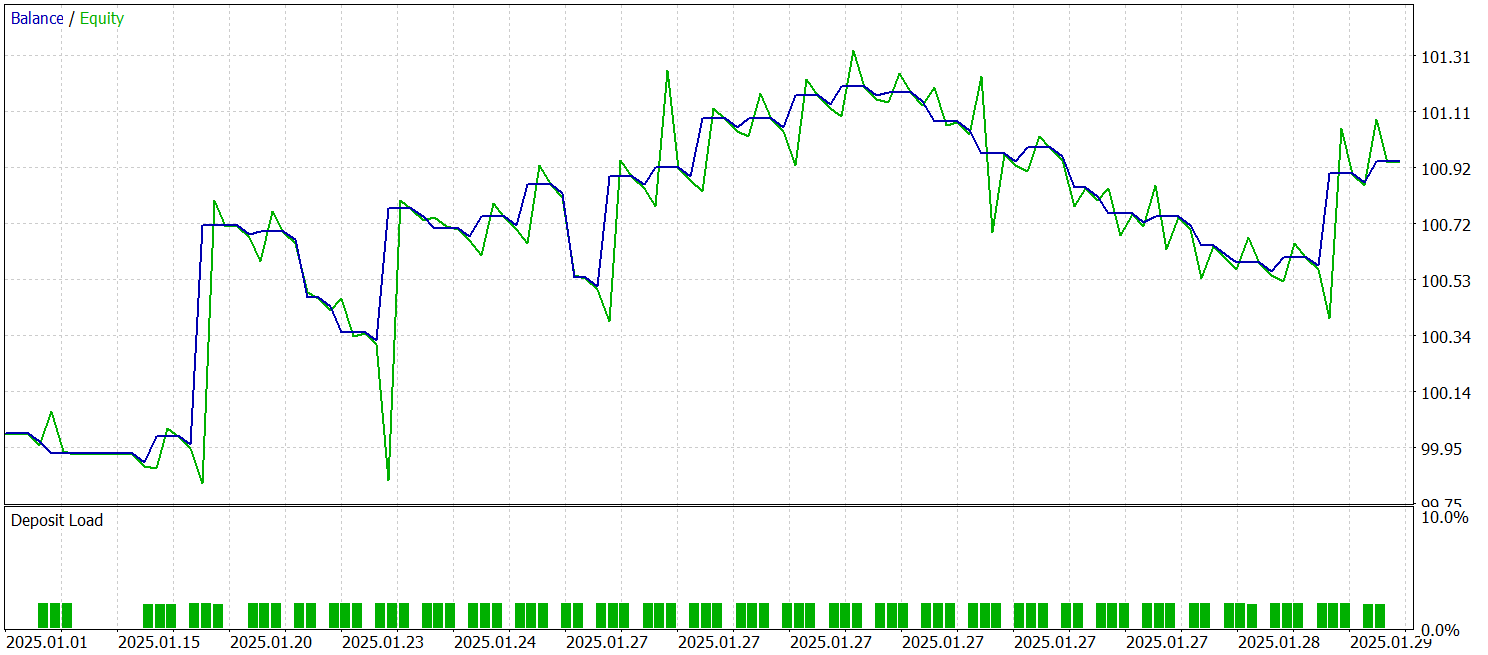
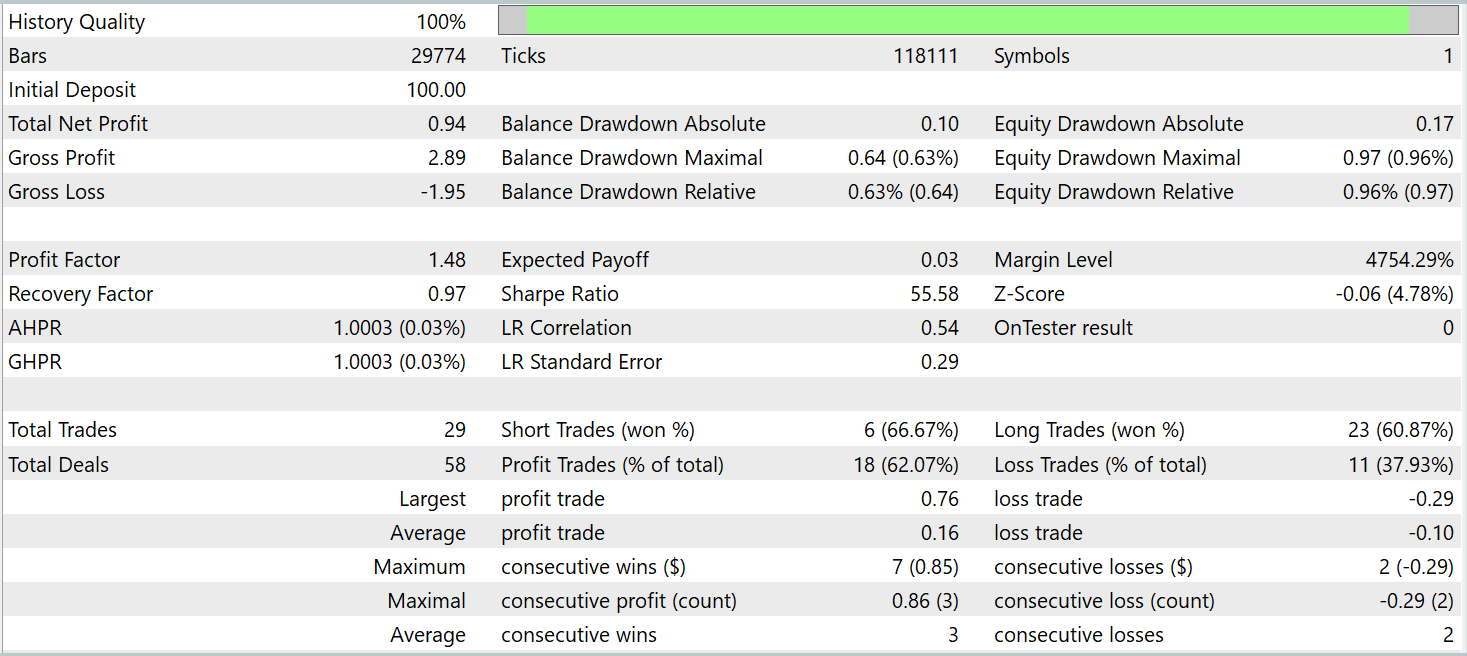
Según los resultados de las pruebas, el modelo ha sido capaz de obtener beneficios con datos históricos ajenos a la muestra de entrenamiento. En total, el modelo ha realizado 29 transacciones durante el mes natural. Esto supone una media de poco más de una transacción por día comercial, lo cual sin duda no es suficiente para el trading de alta frecuencia. En este caso, hemos obtenido más del 60% de transacciones rentables, y la media de transacciones rentables es un 60% superior a la media de transacciones perdedoras.
Conclusión
Hoy nos hemos familiarizado con el framework Hidformer, diseñado para analizar y predecir series temporales multivariantes complejas. El modelo muestra una gran eficacia gracias a su exclusiva arquitectura de codificador de doble torre. Una torre se especializa en analizar la estructura temporal de los datos de origen, mientras que la segunda trabaja con su representación frecuencial. El uso de un mecanismo de atención recursivo nos permite identificar patrones complejos de cambios de precio, mientras que el mecanismo de atención lineal reduce la complejidad computacional del análisis de secuencias largas.
La parte práctica de nuestro trabajo presenta la implementación de nuestra propia visión de los enfoques propuestos mediante MQL5. Así hemos entrenado el modelo con datos históricos reales y lo hemos probado con datos ajenos a la muestra de entrenamiento. Los resultados de las pruebas demuestran el potencial del modelo. Sin embargo, debemos entrenar el modelo con datos más representativos, realizando pruebas exhaustivas antes de utilizarlo para negociar en mercados reales.
Enlaces
- Hidformer: Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer: Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17104
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso