Artículos sobre aprendizaje automático en el trading
Creación de robots comerciales basados en inteligencia artificial: integración nativa con Python, operaciones con matrices y vectores, bibliotecas de matemáticas y estadística y mucho más.
Aprenda a usar el aprendizaje automático en el trading. Neuronas, perceptrones, redes convolucionales y recurrentes, modelos predictivos: parta de lo básico y avance hasta construir su propia IA. Aprenderá a entrenar y aplicar redes neuronales para el comercio algorítmico en los mercados financieros.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Redes neuronales: así de sencillo (Parte 77): Transformador de covarianza cruzada (XCiT)
En nuestros modelos, a menudo utilizamos varios algoritmos de atención. Y, probablemente, lo más frecuente es utilizar transformadores. Su principal desventaja es la necesidad de recursos. En este artículo, estudiaremos un nuevo algoritmo que puede ayudar a reducir los costes informáticos sin perder calidad.

Marcado de datos en el análisis de series temporales (Parte 1):Creamos un conjunto de datos con marcadores de tendencia utilizando el gráfico de un asesor
En esta serie de artículos, presentaremos varias técnicas de etiquetado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El etiquetado específico de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorar la precisión del modelo e incluso ayudarle a dar un salto cualitativo.

Introducción a MQL5 (Parte 6): Guía para principiantes sobre las funciones de matriz en MQL5 (II)
Embárquese en la siguiente fase de nuestro viaje MQL5. En este artículo para principiantes analizaremos el resto de funciones de la matriz y desmitificaremos conceptos complejos para que pueda elaborar estrategias de negociación eficaces. Hablaremos de ArrayPrint, ArrayInsert, ArraySize, ArrayRange, ArrarRemove, ArraySwap, ArrayReverse y ArraySort. Aumente su experiencia en negociación algorítmica con estas funciones de matriz esenciales. ¡Únase a nosotros en el camino hacia el dominio de MQL5!

Redes neuronales: así de sencillo (Parte 42): Procrastinación del modelo, causas y métodos de solución
La procrastinación del modelo en el contexto del aprendizaje por refuerzo puede deberse a varias razones, y para solucionar este problema deberemos tomar las medidas pertinentes. El artículo analiza algunas de las posibles causas de la procrastinación del modelo y los métodos para superarlas.

Métodos de optimización de la biblioteca ALGLIB (Parte I)
En este artículo nos familiarizaremos con los métodos de optimización de la biblioteca ALGLIB para MQL5. El artículo incluye ejemplos sencillos e ilustrativos de la aplicación de ALGLIB para resolver problemas de optimización, lo que hará que el proceso de dominio de los métodos resulte lo más accesible posible. Asimismo, analizaremos con detalle la conectividad de algoritmos como BLEIC, L-BFGS y NS y resolveremos un sencillo problema de prueba basado en ellos.

Indicador de fuerza y dirección de la tendencia en barras 3D
Hoy estudiaremos un nuevo enfoque del análisis de las tendencias del mercado basado en la visualización tridimensional y el análisis tensorial de la microestructura del mercado.

Teoría de categorías en MQL5 (Parte 15): Funtores con grafos
El artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5, analizando los funtores como un puente entre grafos y conjuntos. Volveremos nuevamente a los datos del calendario y, a pesar de sus limitaciones en el uso de un simulador de estrategias, justificaremos el uso de funtores para predecir la volatilidad mediante la correlación.

Teoría de categorías en MQL5 (Parte 19): Inducción cuadrática de la naturalidad
Continuamos analizando las transformaciones naturales considerando la inducción cuadrática de la naturalidad. Pequeñas restricciones en la implementación de las capacidades multidivisa para los asesores ensamblados usando el wizard MQL5 significan que estamos demostrando nuestras capacidades en la clasificación de datos usando un script. Las principales áreas de aplicación son la clasificación de las variaciones de precios y, como consecuencia, su previsión.

Aprendizaje automático y Data Science (Parte 18): La batalla por dominar la complejidad del mercado: SVD truncado frente a NMF
La descomposición del valor singular truncado (SVD, Singular Value Decomposition) y la factorización de matrices no negativas (NMF, Non-Negative Matrix Factorization) son técnicas de reducción de la dimensionalidad. Ambos desempeñan un papel importante en la elaboración de estrategias de negociación basadas en datos. Descubra el arte de reducir la dimensionalidad, desentrañar ideas y optimizar los análisis cuantitativos para obtener un enfoque informado que le permita navegar por las complejidades de los mercados financieros.

Redes neuronales en el trading: Sistema multiagente con validación conceptual (FinCon)
Hoy le proponemos familiarizarnos con el framework FinCon, un sistema multiagente basado en grandes modelos lingüísticos (LLM). El framework usa el refuerzo verbal conceptual para mejorar la toma de decisiones y la gestión del riesgo con el fin de realizar eficazmente diversas tareas financieras.
Teoría de Categorías en MQL5 (Parte 5): Ecualizadores
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.

Características del Wizard MQL5 que debe conocer (Parte 22): Redes generativas adversativas (RGAs) condicionales
Las redes generativas antagónicas son un emparejamiento de redes neuronales que se entrenan entre sí para obtener resultados más precisos. Adoptamos el tipo condicional de estas redes mientras buscamos una posible aplicación en la previsión de series de tiempo financieras dentro de una clase de señales expertas.
Teoría de categorías en MQL5 (Parte 22): Una mirada distinta a las medias móviles
En el presente artículo intentaremos simplificar los conceptos tratados en esta serie centrándonos en solo un indicador, el más común y probablemente el más fácil de entender: la media móvil. También veremos el significado y las posibles aplicaciones de las transformaciones naturales verticales.

Redes neuronales: así de sencillo (Parte 71): Previsión de estados futuros basada en objetivos (GCPC)
En trabajos anteriores, hemos introducido el método del Decision Transformer y varios algoritmos derivados de él. Asimismo, hemos experimentado con distintos métodos de fijación de objetivos. Durante los experimentos, hemos trabajado con distintas formas de fijar objetivos, pero el aprendizaje de la trayectoria ya recorrida por parte del modelo siempre quedaba fuera de nuestra atención. En este artículo, queremos presentar un método que llenará este vacío.

Redes neuronales en el trading: Resultados prácticos del método TEMPO
Continuamos familiarizándonos con el método TEMPO. En este artículo, analizaremos la efectividad de los enfoques propuestos con datos históricos reales.

Redes neuronales en el trading: Análisis de nubes de puntos (PointNet)
El análisis directo de nubes de puntos evita alcanza un tamaño de datos innecesario y mejora la eficacia de los modelos en tareas de clasificación y segmentación. Estos enfoques demuestran un alto rendimiento y solidez frente a las perturbaciones de los datos de origen.

Algoritmo de viaje evolutivo en el tiempo — Time Evolution Travel Algorithm (TETA)
Se trata de un algoritmo propio. En este artículo, le presentaremos el Algoritmo de viaje evolutivo en el tiempo (TETA), inspirado en el concepto de universos paralelos y flujos temporales. La idea básica del algoritmo es que, si bien no es posible viajar en el tiempo en el sentido habitual, podemos elegir una secuencia de acontecimientos que generen realidades distintas.

Codificación ordinal para variables nominales
En este artículo, analizamos y demostramos cómo convertir predictores nominales en formatos numéricos adecuados para algoritmos de aprendizaje automático, utilizando tanto Python como MQL5.

Algoritmos de optimización de la población: Algoritmo híbrido de optimización de forrajeo bacteriano con algoritmo genético (Bacterial Foraging Optimization - Genetic Algorithm, BFO-GA)
Este artículo presenta un nuevo enfoque para resolver problemas de optimización combinando las ideas de los algoritmos de optimización de forrajeo bacteriano (BFO) y las técnicas utilizadas en el algoritmo genético (GA) en un algoritmo híbrido BFO-GA. Dicha técnica utiliza enjambres bacterianos para buscar una solución óptima de manera global y operadores genéticos para refinar los óptimos locales. A diferencia del BFO original, ahora las bacterias pueden mutar y heredar genes.

Redes neuronales: así de sencillo (Parte 94): Optimización de la secuencia de entrada
Al trabajar con series temporales, siempre utilizamos los datos de origen en su secuencia histórica. Pero, ¿es ésta la mejor opción? Existe la opinión de que cambiar la secuencia de los datos de entrada mejorará la eficacia de los modelos entrenados. En este artículo te invito a conocer uno de los métodos para optimizar la secuencia de entrada.

Características del Wizard MQL5 que debe conocer (Parte 23): Redes neuronales convolucionales (CNNs, Convolutional Neural Networks)
Las redes neuronales convolucionales son otro algoritmo de aprendizaje automático que tiende a especializarse en descomponer conjuntos de datos multidimensionales en partes constituyentes clave. Examinamos cómo se consigue esto normalmente y exploramos una posible aplicación para los operadores en otra clase de señal del asistente MQL5.
Ingeniería de características con Python y MQL5 (Parte I): Predicción de medias móviles para modelos de IA de largo plazo
Las medias móviles son, con diferencia, los mejores indicadores para que nuestros modelos de IA realicen predicciones. Sin embargo, podemos mejorar aún más nuestra precisión transformando cuidadosamente nuestros datos. Este artículo le mostrará cómo puede crear modelos de IA capaces de realizar previsiones a más largo plazo que las que realiza actualmente sin que ello suponga una disminución significativa de su nivel de precisión. Es realmente sorprendente lo útiles que son las medias móviles.

Utilización del modelo de aprendizaje automático CatBoost como filtro para estrategias de seguimiento de tendencias
CatBoost es un potente modelo de aprendizaje automático basado en árboles que se especializa en la toma de decisiones basada en características estacionarias. Otros modelos basados en árboles, como XGBoost y Random Forest, comparten características similares en cuanto a su solidez, capacidad para manejar patrones complejos e interpretabilidad. Estos modelos tienen una amplia gama de usos, desde el análisis de características hasta la gestión de riesgos. En este artículo, vamos a explicar el procedimiento para utilizar un modelo CatBoost entrenado como filtro para una estrategia clásica de seguimiento de tendencias con cruce de medias móviles.

Asesores Expertos Auto-Optimizables con MQL5 y Python (Parte IV): Apilamiento de modelos
Hoy demostraremos cómo se pueden crear aplicaciones comerciales impulsadas por IA capaces de aprender de sus propios errores. Demostraremos una técnica conocida como apilamiento, mediante la cual usamos 2 modelos para hacer 1 predicción. El primer modelo suele ser un alumno más débil, y el segundo modelo suele ser un modelo más potente que aprende los residuos de nuestro alumno más débil. Nuestro objetivo es crear un conjunto de modelos, para lograr, con suerte, una mayor precisión.
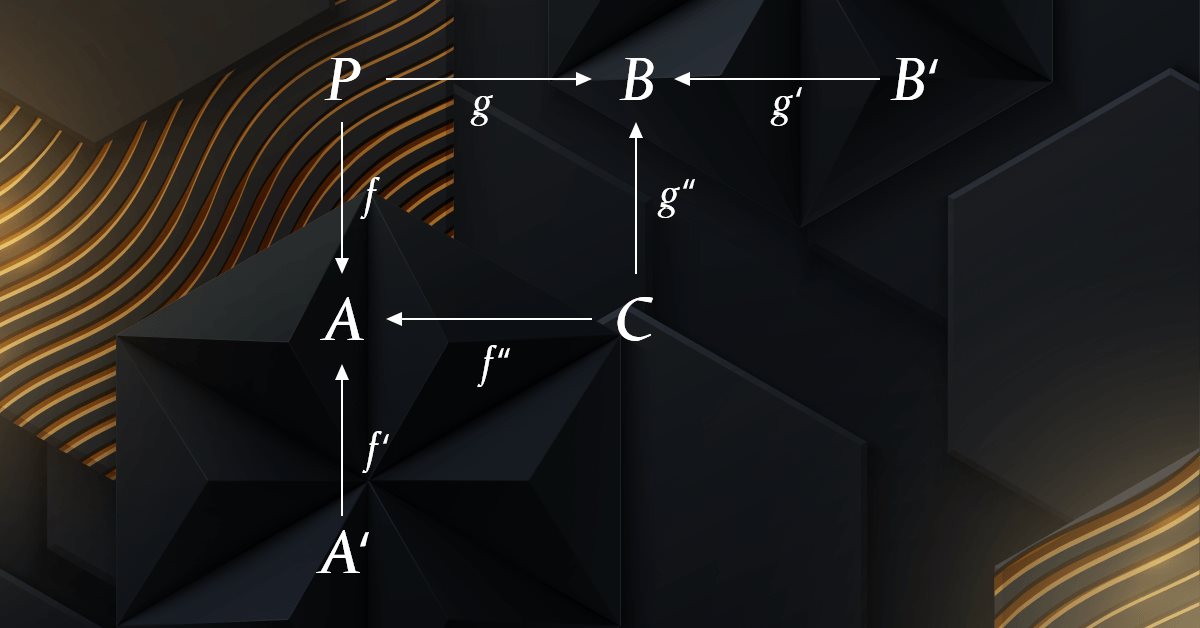
Teoría de categorías en MQL5 (Parte 4): Intervalos, experimentos y composiciones
La teoría de categorías es una rama de las matemáticas diversa y en expansión, relativamente inexplorada aún en la comunidad MQL5. Esta serie de artículos tiene como objetivo describir algunos de sus conceptos para crear una biblioteca abierta y seguir utilizando esta maravillosa sección para crear estrategias comerciales.

Clústeres de series temporales en inferencia causal
Los algoritmos de agrupamiento en el aprendizaje automático son importantes algoritmos de aprendizaje no supervisado que pueden dividir los datos originales en grupos con observaciones similares. Utilizando estos grupos, puede analizar el mercado de un grupo específico, buscar los grupos más estables utilizando nuevos datos y hacer inferencias causales. El artículo propone un método original de agrupación de series temporales en Python.

Teoría de Categorías en MQL5 (Parte 23): Otra mirada a la media móvil exponencial doble
En este artículo, seguiremos analizando desde un nuevo ángulo los indicadores comerciales más populares. Vamos a procesar una composición horizontal de transformaciones naturales. El mejor indicador para ello será la media móvil exponencial doble (Double Exponential Moving Average, DEMA).

El papel de la calidad del generador de números aleatorios en la eficiencia de los algoritmos de optimización
En este artículo, analizaremos el generador de números aleatorios Mersenne Twister y lo compararemos con el estándar en MQL5. También determinaremos la influencia de la calidad del generador de números aleatorios en los resultados de los algoritmos de optimización.

Características del Wizard MQL5 que debe conocer (Parte 07): Dendrogramas
La clasificación de datos para el análisis y la predicción es un área muy diversa del aprendizaje automático con un gran número de enfoques y métodos. En este artículo analizaremos uno de estos enfoques, a saber, la Clasificación Jerárquica Aglomerativa (Agglomerative Hierarchical Classification).

Introducción a la exploración de estructuras de mercado fractales con aprendizaje automático
Este artículo intentaremos examinar las series temporales financieras desde la perspectiva de las estructuras fractales autosimilares. Como contamos con demasiadas analogías que confirman la posibilidad de considerar las cotizaciones de mercado como fractales autosimilares, tenemos la oportunidad de formarnos una idea de los horizontes de previsión de dichas estructuras.
Algoritmo de optimización Brain Storm - Brain Storm Optimization (Parte I): Clusterización
En este artículo analizaremos un innovador método de optimización denominado BSO (Brain Storm Optimization), inspirado en el fenómeno natural de la tormenta de ideas. También discutiremos un nuevo enfoque de resolución de tareas de optimización multimodales que utiliza el método BSO y nos permite encontrar múltiples soluciones óptimas sin tener que determinar de antemano el número de subpoblaciones. En este artículo, también analizaremos los métodos de clusterización K-Means y K-Means++.

Redes neuronales: así de sencillo (Parte 90): Interpolación frecuencial de series temporales (FITS)
Al estudiar el método FEDformer, abrimos la puerta al dominio frecuencial de la representación de series temporales. En este nuevo artículo continuaremos con el tema iniciado, y analizaremos un método que permite no solo el análisis, sino también la predicción de estados posteriores en el ámbito privado.

Obtenga una ventaja sobre cualquier mercado (Parte IV): Índices CBOE de volatilidad del euro y el oro
Analizaremos datos alternativos curados por el 'Chicago Board Of Options Exchange' (CBOE) para mejorar la precisión de nuestras redes neuronales profundas al pronosticar el símbolo XAUEUR (oro).

Redes neuronales en el trading: Análisis de la situación del mercado usando el Transformador de patrones
A la hora de analizar la situación del mercado con nuestros modelos, el elemento clave es la vela. No obstante, sabemos desde hace tiempo que las velas pueden ayudar a predecir los movimientos futuros de los precios. Y en este artículo aprenderemos un método que nos permitirá integrar ambos enfoques.

Integración de un modelo de IA en una estrategia de trading MQL5 ya existente
Este tema se centra en la incorporación de un modelo de IA entrenado (como un modelo basado en redes LSTM o un modelo predictivo basado en aprendizaje automático) en una estrategia de trading MQL5 existente.

Integración de MQL5 con paquetes de procesamiento de datos (Parte 1): Análisis avanzado de datos y procesamiento estadístico
La integración permite un flujo de trabajo continuo en el que los datos financieros sin procesar de MQL5 se pueden importar a paquetes de procesamiento de datos como Jupyter Lab para realizar análisis avanzados que incluyen pruebas estadísticas.

Búsqueda con restricciones — Tabu Search (TS).
En este artículo se analiza el algoritmo de búsqueda tabú, uno de los primeros y más conocidos métodos de la metaheurística. Hoy mostraremos con detalle cómo funciona el algoritmo, empezando por la selección de una solución inicial y la exploración de las opciones vecinas, centrándonos en el uso de la lista tabú. El artículo abarcará los aspectos clave del algoritmo y sus características.
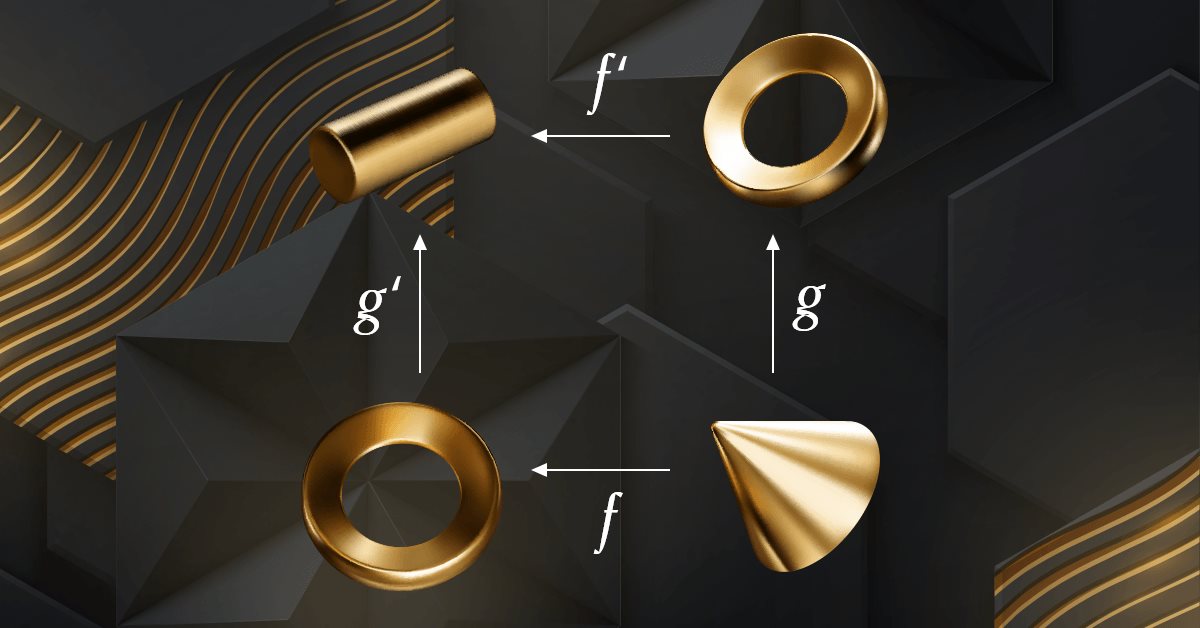
Teoría de Categorías en MQL5 (Parte 6): Productos fibrados monomórficos y coproductos fibrados epimórficos
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.

Redes neuronales: así de sencillo (Parte 40): Enfoques para utilizar Go-Explore con una gran cantidad de datos
Este artículo analizará el uso del algoritmo Go-Explore durante un largo periodo de aprendizaje, ya que la estrategia de elección aleatoria puede no conducir a una pasada rentable a medida que aumenta el tiempo de entrenamiento.

Teoría de Categorías en MQL5 (Parte 17): Funtores y monoides
Este es el último artículo de la serie sobre funtores. En él, revisaremos los monoides como categoría. Los monoides, que ya hemos introducido en esta serie, se utilizan aquí para ayudar a dimensionar la posición junto con los perceptrones multicapa.