Redes neuronales: así de sencillo (Parte 55): Control interno contrastado (CIC)

Introducción
En artículos anteriores, ya hemos hablado de las ventajas de uso de los modelos jerárquicos. También analizamos métodos de aprendizaje de modelos capaces de extraer y destacar habilidades individuales del Agente. Las habilidades aprendidas pueden resultar útiles para alcanzar el objetivo final de la tarea en cuestión. Ejemplos de estos algoritmos son DIAYN, DADS y EDL. Los algoritmos anteriores abordan el proceso de aprendizaje de habilidades de formas distintas, pero todos ellos se han utilizado para problemas de espacios discretos de acciones. Hoy hablaremos de otro enfoque en el aprendizaje de habilidades del Agente y veremos su aplicación a la resolución de problemas en el espacio continuo de acciones.
1. Principales componentes del CIC
En las prácticas de aprendizaje por refuerzo, los algoritmos de preentrenamiento se utilizan ampliamente para preentrenar Agentes con recompensas internas autocontroladas. A grandes rasgos, estos algoritmos pueden dividirse en 3 categorías: los basados en competencias, los basados en conocimientos y los basados en datos. Las pruebas realizadas en Unsupervised Reinforcement Learning Benchmark demuestran que los algoritmos basados en competencias resultan inferiores a los de otras categorías.
Los algoritmos basados en competencias tratan de maximizar la información mutua entre los estados observados y el vector latente de habilidades. Esta información mutua se valorará mediante el modelo del Discriminador. Normalmente, como Discriminador se utiliza un modelo de clasificador o regresor. No obstante, para lograr precisión en las tareas de clasificación y regresión, necesitaremos una enorme cantidad de diversos datos de entrenamiento. En entornos sencillos en los que el número de comportamientos potenciales resulta limitado, los métodos basados en las competencias demuestran su eficacia. Pero en entornos con muchas opciones potenciales de comportamiento, su eficacia se reduce sustancialmente.
Los entornos complejos requieren una gran variedad de habilidades, y para procesarlos, necesitaremos un Discriminador con mucha potencia. La contradicción entre este requisito y las limitadas capacidades de los Discriminadores existentes impulsó la creación del método Contrastive Intrinsic Control (CIC).
El método Contrastive Intrinsic Control es un nuevo enfoque de valoración contrastiva de la densidad para aproximar la entropía condicional del Discriminador. El método funciona con transiciones entre estados y vectores de habilidades, lo cual permite aplicar potentes métodos de aprendizaje de representaciones, desde el procesamiento visual de datos hasta el descubrimiento de habilidades. El método propuesto puede aumentar la estabilidad y la eficacia del aprendizaje del Agente en diversos entornos.
El algoritmo Contrastive Intrinsic Control comienza entrenando al Agente en el entorno mediante retroalimentación y obteniendo las trayectorias de los estados y acciones. A continuación, las representaciones se entrenan utilizando Predictive Coding (CPC), lo cual motiva al Agente a extraer características clave de estados y acciones. Luego se formarán representaciones que tienen en cuenta las dependencias entre estados sucesivos.
La recompensa interna desempeñará un papel esencial a la hora de determinar qué estrategias de comportamiento hay que maximizar. En el CIC, la entropía de las transiciones entre estados se maximiza, lo cual favorece la diversidad del comportamiento del Agente. Esto permitirá al Agente explorar y crear una amplia variedad de estrategias de comportamiento.
Tras generar la variedad de habilidades y estrategias, el algoritmo CIC utilizará el Discriminador para concretar las representaciones de las habilidades. El Discriminador pretende que los estados resulten predecibles y estables. De este modo, el Agente aprenderá a "utilizar" las habilidades en situaciones predecibles.
La combinación de la exploración motivada por recompensas internas y el uso de habilidades para la acción predecible creará un enfoque equilibrado para crear estrategias diversas y eficaces.
Como resultado, el algoritmo Contrastive Predictive Coding estimula al Agente a detectar y aprender una amplia gama de estrategias de comportamiento, a la vez que posibilita un aprendizaje estable. A continuación le mostramos la visualización del algoritmo del autor.

Conoceremos el algoritmo con más detalle durante su aplicación.
2. Implementación usando MQL5
Al comenzar nuestra implementación del algoritmo Contrastive Intrinsic Control usando las herramientas MQL5, deberemos definir algunos puntos clave. En primer lugar, el algoritmo de entrenamiento del modelo se dividirá en 2 grandes etapas:
- el entrenamiento de habilidades sin recompensas externas del entorno;
- el entrenamiento de la política de resolución de tareas basada en recompensas externas.
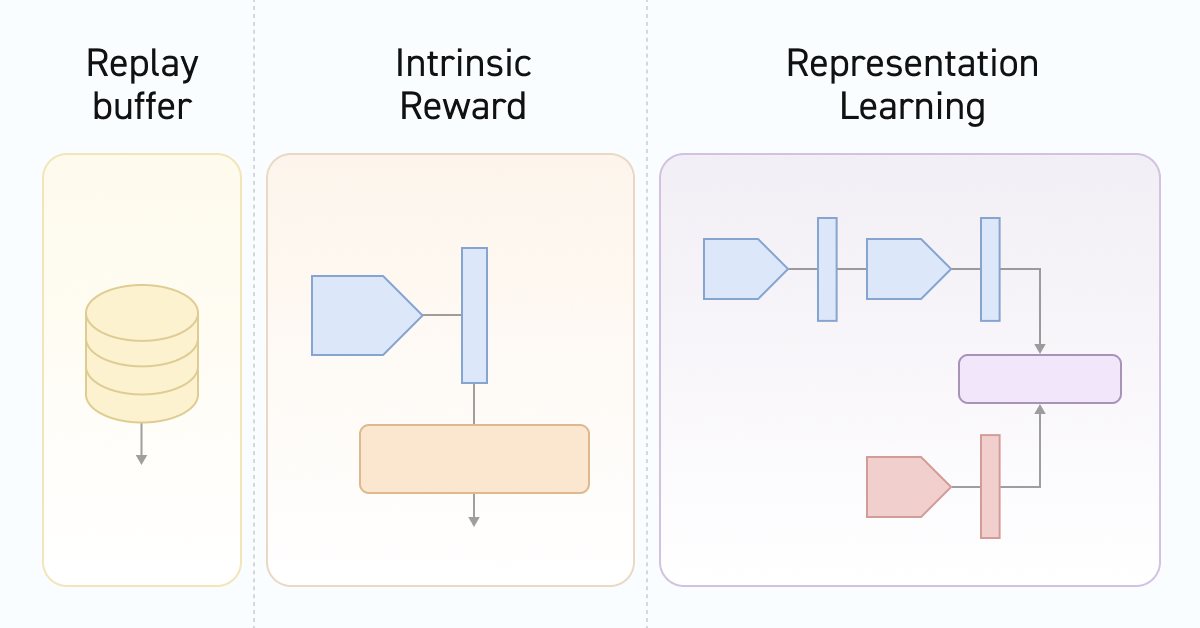
En segundo lugar, el entrenamiento del Discriminador explora la correspondencia entre las transiciones de estado y las habilidades. Y aquí deberemos prestar atención al hecho de que precisamente estamos trabajando con el cambio de estado, no mediante recompensas externas por pasar a un nuevo estado, ni tampoco con la acción que ha dado lugar a ese estado. Si trazamos analogías con los algoritmos comentados anteriormente que operaban con los mismos datos, DIAYN basado en el modelo de estado original y nuevo determinaba la habilidad. En DADS, por el contrario, basándose en el estado inicial y la habilidad, el Discriminador predecía el siguiente estado. En este método, sin embargo, determinaremos el error de contraste entre la transición (estados inicial y posterior) y la habilidad utilizada por el Agente. Al hacerlo, se formarán representaciones latentes de los estados y habilidades. Será precisamente el Discriminador el que influya en el entrenamiento del codificador de estados, que posteriormente será utilizado por el Agente y el planificador. Y esto se reflejará en la arquitectura de los modelos que utilizamos. Precisamente esto nos ha llevado a incluir el codificador del entorno en un modelo aparte.
2.1 Descripción de la arquitectura de los modelos
Y así nos acercamos sin problemas al método CreateDescriptions para describir las arquitecturas de los modelos usados. En los parámetros de este método veremos los punteros a los arrays de descripción de las arquitecturas de los 6 modelos, de cuya finalidad hablaremos en su proceso de descripción.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; }
En primer lugar tendremos el modelo de codificador de estado del entorno. Más arriba ya empezamos a hablar de la funcionalidad de este modelo. Como ya sabrá, nuestro estado del entorno consta de 2 bloques: el de datos históricos y el de estado de la cuenta. Estos tensores los suministraremos a la entrada de nuestro codificador. La arquitectura de este modelo nos recordará al bloque de preprocesamiento de datos de origen anteriormente usado en los modelos de Actor.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; } //--- State Encoder state_encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = NSkills; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!state_encoder.Add(descr)) { delete descr; return false; }
A continuación, veremos la arquitectura del Actor. Sigue siendo el mismo modelo, solo que excluiremos el bloque de preprocesamiento de los datos de origen, ubicado en un Codificador independiente. Pero hay un detalle a considerar. Asimismo, añadiremos otro tensor de datos de origen que describirá la habilidad que se está utilizando.
Y para garantizar que las políticas de comportamiento del Actor al utilizar diferentes habilidades sean claramente separables, abandonaremos el uso de políticas estocásticas.
//--- Actor actor.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Como de costumbre, tras el Actor, describiremos la arquitectura del Crítico. Y aquí es donde deberemos pensar en su funcionalidad. A primera vista, la pregunta resulta bastante prosaica. El crítico calculará la recompensa esperada por pasar a un nuevo estado. Y la recompensa de una transición concreta dependerá de la acción realizada, no de la habilidad utilizada. Obviamente, la acción será seleccionada por el Actor según la habilidad especificada, pero al entorno no le importarán los motivos que han impulsado al Agente: estará reaccionando a sus efectos.
Por otro lado, el Crítico evaluará la política del Actor y pronosticará la recompensa esperada del uso posterior de la política, mientras que las políticas del Actor estarán directamente relacionadas con la habilidad utilizada. Por lo tanto, en los datos de origen del Crítico deberán transmitirse el estado actual del entorno, la habilidad utilizada y la acción elegida por el Actor. Y aquí utilizaremos una técnica que ya ha sido elaborada antes. Tomaremos el estado latente del Actor, que ya considera la descripción del estado del entorno y la habilidad utilizada, y añadiremos la acción seleccionada por el Actor. De este modo, la arquitectura del Crítico ha permanecido inalterada, pero el identificador del estado latente del Actor ha cambiado.
Asimismo, hemos renunciado a la descomposición de la función de recompensa. Es una medida forzada. Como ya hemos mencionado, entrenaremos el modelo en 2 etapas. Y en cada etapa, utilizaremos una función de recompensa diferente. Así que nos enfrentaremos a una elección: utilizar la descomposición de recompensas y entrenar a 2 Críticos diferentes en cada etapa, o suprimir la descomposición de la recompensa, pero utilizar el mismo Crítico para las dos etapas. hemos decidido seguir el segundo camino.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
A continuación, aportaremos nuestra visión para optimizar el algoritmo. La cuestión es que, como recompensa interna, los autores del método proponen usar la entropía de las transiciones mediante el método de partículas a partir de k vecinos más próximos, como hicimos en el artículo anterior. Solo que los autores utilizaron el espacio entre transiciones del minipaquete en la representación del codificador entrenado. Y para ello, necesitaremos codificar algún paquete de transición en cada iteración de la actualización de parámetros. No podemos codificar un minipaquete una vez y utilizar esa representación en el proceso de entrenamiento. Después de todo, después de cada actualización de los parámetros del codificador, cambiará el espacio de resultados del mismo.
Pero sabemos que incluso un modelo de convolución aleatoria puede darnos información suficiente para comparar dos estados. Por ello, a efectos de la recompensa interna, crearemos un modelo convolucional no entrenable. Y antes del proceso de entrenamiento, crearemos primero una representación concisa de todas las transiciones a partir del búfer de repetición de experiencias. Y durante el entrenamiento, solo codificaremos la transición analizada.
Cuando hablamos de transición, en este caso, nos referimos a los 2 estados posteriores del entorno.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 512 / 8; descr.window = 8; descr.step = 8; int prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Y luego pasaremos al Discriminador. Debemos decir que en este caso el Discriminador constará de 2 modelos. El modelo al que hemos dejado el nombre de Discriminador, tomará como entrada 2 estados de entorno consecutivos y retornará alguna representación de transición latente. Obsérvese que, al igual que en el caso anterior, el modelo solo codificará la transición en el entorno, sin considerar la habilidad utilizada ni la acción realizada. Aquí, utilizaremos los resultados del codificador para los 2 estados siguientes como datos de entrada.
A la salida del modelo, utilizaremos SoftMax para normalizar los resultados obtenidos.
//--- Descriminator descriminator.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
El segundo componente del Discriminador será un modelo para representar la representación latente de la habilidad utilizada. De la funcionalidad del modelo se deduce que solo recibirá en la entrada la habilidad que se está utilizando, mientras que retornará su representación comprimida como un tensor similar a la representación de la transición latente (el resultado del modelo del Discriminador).
Precisamente los resultados de estos dos modelos serán los datos para los controles internos contrastados. Como consecuencia, también utilizaremos SoftMax en la salida del modelo.
//--- Skills project skill_project.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- return true; }
Aunque estos dos últimos modelos utilizarán datos de entrada diferentes, tendrán una funcionalidad bastante similar. Por eso utilizaremos para ellos soluciones arquitectónicas parcialmente similares.
Como podemos ver, hemos completado el método de descripción de las decisiones arquitectónicas de los modelos utilizados. Pero en dicho método no se describe la arquitectura del planificador. La cuestión es que no utilizaremos un planificador en la fase de habilidades. Adelantándome un poco, diremos que en la primera fase del entrenamiento, generaremos aleatoriamente representaciones de habilidades. Esto permitirá a nuestro Actor aprender mejor las distintas políticas de comportamiento. Pero utilizaremos el planificador para entrenar la política de uso de las habilidades para lograr el objetivo deseado. Por eso hemos sacado el modelo de planificador al método aparte SchedulerDescriptions.
bool SchedulerDescriptions(CArrayObj *scheduler) { //--- Scheduller if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } scheduler.Clear(); //--- CLayerDescription *descr = NULL; //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.window = prev_count; descr.optimization = ADAM; descr.activation = SIGMOID; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Aquí concluiremos nuestro trabajo de descripción de las soluciones arquitectónicas de los modelos utilizados y procederemos a construir el algoritmo de funcionamiento de estos.
2.2 Asesor de recopilación de muestras de entrenamiento
Al igual que antes, utilizaremos varios programas para entrenar el modelo. El primer asesor "...\CIC\Research.mq5" se utilizará para recopilar una muestra de entrenamiento. El proceso de recogida de datos en sí no ha cambiado, salvo que necesitaremos usar varios modelos de manera secuencial para formar la acción del Actor. Pero primero tendremos que crearlos en el método de inicialización OnInit del asesor.
En el cuerpo de este método inicializaremos todos los indicadores necesarios como de costumbre.
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Y luego cargaremos los modelos de Codificador y Actor. Si no hay modelos preentrenados disponibles, generaremos modelos aleatorios.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); CArrayObj *descr = new CArrayObj(); if(!CreateDescriptions(encoder,actor, descr,descr,descr,descr)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } delete encoder; delete actor; delete descr; //--- }
No obstante, la situación será un poco diferente con el Planificador. De hecho, necesitaremos recopilar los datos de la muestra de entrenamiento para ambas fases de entrenamiento. Y utilizar el modelo del Planificador en la primera etapa puede limitar en cierta medida el espacio de acción del Actor. Por otro lado, usar un tensor de habilidades generado aleatoriamente será prácticamente lo mismo que utilizar un Planificador con parámetros aleatorios. En este caso, además, resultará mucho más rápido que una pasada directa del modelo.
Al mismo tiempo, en la segunda etapa de entrenamiento, por el contrario, será deseable utilizar un Planificador preentrenado. Al fin y al cabo, no solo recogerá datos en el ámbito de las acciones de su política, sino que también evaluará los resultados de su entrenamiento.
Por lo tanto, intentaremos cargar el modelo del Planificador preentrenado, y escribiremos el resultado de la operación en la bandera utilizando un vector de habilidad aleatorio.
bRandomSkills = (!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true));
A continuación, trasladaremos todos los modelos que utilizamos a un único contexto OpenCL.
COpenCLMy *opcl = Encoder.GetOpenCL();
Actor.SetOpenCL(opcl);
if(!bRandomSkills)
Scheduler.SetOpenCL(opcl);
Después comprobaremos que los modelos se correspondan
Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- if(!bRandomSkills) { Scheduler.GetLayerOutput(0,Result); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Scheduler doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } }
e inicializaremos las variables.
//--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
A continuación, recogeremos los datos en el método OnTick. Al igual que antes, todas las operaciones se realizarán solo al abrir una nueva barra.
void OnTick() { //--- if(!IsNewBar()) return;
Aquí recogeremos primero los datos históricos y la información sobre el estado de la cuenta. Este proceso se mantendrá sin cambios desde los algoritmos discutidos anteriormente y no nos detendremos en él ahora. Así que pasaremos directamente a la organización de la pasada directa de modelos. Y la primera que implementaremos es la llamada al codificador.
//--- Encoder if(!Encoder.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
A continuación, comprobaremos la bandera de uso un vector de habilidades aleatorio. Si conseguimos cargar antes el modelo del Planificador, llamaremos al Planificador y al Actor secuencialmente.
//--- Scheduler & Actor if(!bRandomSkills) { if(!Scheduler.feedForward((CNet *)GetPointer(Encoder),-1,NULL,-1) || !Actor.feedForward(GetPointer(Encoder),-1,GetPointer(Scheduler),-1)) return; }
En caso contrario, primero generaremos un tensor de habilidad aleatorio. No deberemos olvidarnos de normalizarlo con la función SoftMax, ya que hablamos de vectores de probabilidad de uso de habilidades individuales. Y solo entonces llamaremos al Actor.
else { vector<float> skills = vector<float>::Zeros(NSkills); for(int i = 0; i < NSkills; i++) skills[i] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); bSkills.AssignArray(skills); if(bSkills.GetIndex() >= 0 && !bSkills.BufferWrite()) return; if(!Actor.feedForward(GetPointer(Encoder),-1,(CBufferFloat *)GetPointer(bSkills))) return; }
Como resultado de la pasada directa del modelo, obtendremos un cierto tensor de acción en la salida Actor. Pero debemos decir aquí que la renuncia a las políticas estocásticas provocará asociaciones rígidas del Actor entre los datos de entrada y la acción elegida. Y para realizar la exploración del entorno, añadiremos un poco de ruido al vector de acción resultante.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- for(ulong i = 0; i < temp.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.1f; temp[i] += rnd; } temp.Clip(0.0f,1.0f); ActorResult = temp;
Solo después de estas operaciones realizaremos las acciones del Actor y guardaremos el resultado en el búfer de repetición de experiencias.
Obsérvese aquí que mantendremos el mismo conjunto de datos sin el identificador de habilidad. Al fin y al cabo, para aprender los modelos del entorno, necesitaremos transiciones y recompensas, mientras que generaremos los diferentes vectores de identificación de habilidades durante el proceso de entrenamiento, lo cual nos permitirá ampliar varias veces la muestra de entrenamiento sin interacción adicional con el entorno.
El resto del código del método, así como el asesor en su conjunto, no se han modificado y lo hemos tomado de asesores similares analizados anteriormente, así que no entraremos en detalles ahora. Podrá familiarizarse por sí mismo con el código en el archivo adjunto.
2.3 Entrenamiento de habilidades
La primera etapa del entrenamiento de modelos, el entrenamiento de las habilidades, lo hemos organizado en el asesor "...\CIC\Pretrain.mq5". En muchos aspectos, está construido por analogía con los asesores "Study.mq5" revisados anteriormente, pero teniendo en cuenta las especificidades del algoritmo Contrastive Intrinsic Control que estamos analizando.
El algoritmo del método de inicialización OnInit del asesor no se distinguirá de los métodos homónimos de los asesores similares considerados anteriormente. Nos centraremos solo en la lista de modelos usados. Aquí veremos los modelos del Codificador, del Actor, de los 2 Críticos, del Codificador de convolución aleatoria y del Discriminador. Pero el modelo objetivo solo será el modelo del Codificador.
Necesitaremos dos modelos de Codificador para codificar los estados del entorno analizados y posteriores utilizados por el Discriminador.
Sin embargo, no utilizaremos los modelos objetivo del Actor y el Crítico, ya que en esta fase estaremos entrenando al Actor para que realice acciones separables bajo la acción de una habilidad concreta en unas condiciones de entorno determinadas. No buscaremos acumular recompensas internas para las distintas habilidades: las maximizamos en cada momento.
int OnInit() { //--- ....... ....... //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Descriminator.Load(FileName + "Des.nnw", temp, temp, temp, dtStudied, true) || !SkillProject.Load(FileName + "Skp.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *encoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *descrim = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); CArrayObj *skill_poject = new CArrayObj(); if(!CreateDescriptions(encoder,actor, critic, convolution,descrim,skill_poject)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Descriminator.Create(descrim) || !SkillProject.Create(skill_poject) || !Convolution.Create(convolution)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!TargetEncoder.Create(encoder)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), 1.0f); } //--- OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); Descriminator.SetOpenCL(OpenCL); SkillProject.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
El proceso de entrenamiento del modelo se organizará directamente en el método Train.
Al igual que en el artículo anterior, al inicio del método codificaremos todas las transiciones disponibles entre estados en el búfer de repetición de experiencias. El algoritmo para construir el proceso resultará idéntico, salvo por algunos detalles. Codificaremos las transiciones. Por lo tanto, ofreceremos al codificador aleatorio un tensor de entrada de 2 estados consecutivos sin considerar las acciones realizadas.
Y el segundo punto a destacar: en esta fase solo estaremos utilizando recompensas internas, lo cual significa que excluiremos el procesamiento de recompensas de entorno externas.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
A continuación, declararemos las variables locales.
vector<float> reward = vector<float>::Zeros(NRewards); vector<float> rewards1 = reward, rewards2 = reward; int bar = (HistoryBars - 1) * BarDescr;
Y organizaremos un ciclo de entrenamiento de modelos. En el cuerpo del ciclo, al igual que antes, seleccionaremos aleatoriamente una trayectoria y un estado analizado del búfer de repetición de experiencias.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Sobre los datos de estado muestreados, formaremos los tensores de datos iniciales de nuestros modelos.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Aquí también formaremos un tensor aleatorio de la habilidad utilizada.
//--- Skills vector<float> skills = vector<float>::Zeros(NSkills); for(int sk = 0; sk < NSkills; sk++) skills[sk] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); Skills.AssignArray(skills); if(Skills.GetIndex() >= 0 && !Skills.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Primero introduciremos los datos de origen generados en la entrada de nuestro Codificador.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Y luego realizaremos una pasada directa del Actor.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Skills))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A partir del tensor de acción resultante, formaremos el estado posterior previsto. No tenemos ningún problema con los datos históricos de movimientos de precios, simplemente los tomaremos del búfer de reproducción de experiencias. Pero para calcular el estado de previsión de la cuenta, crearemos el método ForecastAccount, cuyo algoritmo conoceremos un poco más tarde.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Y luego realizaremos una pasada directa del Codificador objetivo para obtener una representación latente del estado posterior.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
En esta etapa, tendremos una representación latente de los 2 estados del entorno posteriores y podremos obtener un vector de representación de la transición. Y entonces obtendremos el vector de representación de habilidades.
//--- Descriminator if(!Descriminator.feedForward(GetPointer(Encoder),-1,GetPointer(TargetEncoder),-1) || !SkillProject.feedForward(GetPointer(Skills),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
El resultado de contrastar los dos vectores resultantes servirá como primera parte de nuestra recompensa interna. La maximización de esta recompensa estimulará al Actor a aprender habilidades fácilmente separables y predecibles que se asignarán fácilmente a transiciones de estado individuales en el entorno.
Descriminator.getResults(rewards1); SkillProject.getResults(rewards2); float norm1 = rewards1.Norm(VECTOR_NORM_P,2); float norm2 = rewards2.Norm(VECTOR_NORM_P,2); reward[0] = (rewards1 / norm1).Dot(rewards2 / norm2);
E inmediatamente actualizaremos los parámetros de los modelos del Discriminador. Sin complicar innecesariamente el algoritmo, simplemente entrenaremos el modelo del Discriminador en una aproximación de la representación comprimida de la habilidad, y el modelo de proyección de habilidades para aproximarnos a una representación concisa de una transición.
Al mismo tiempo, entrenaremos el Codificador con una representación del estado del entorno que podría identificarse con algún tipo de habilidad. Luego entrenaremos el Codificador basándonos en los gradientes de error obtenidos del Discriminador, del mismo modo que el Actor y el Crítico en un espacio continuo de acciones.
Result.AssignArray(rewards2); if(!Descriminator.backProp(Result,GetPointer(TargetEncoder)) || !Encoder.backPropGradient(GetPointer(Account),GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.AssignArray(rewards1); if(!SkillProject.backProp(Result,(CNet *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
El segundo componente de nuestra función de recompensa interna será la penalización por no tener posiciones abiertas en el momento actual. Tomaremos la información sobre la disponibilidad de las transacciones del estado de cuentas previsto,
if(forecast[3] == 0.0f && forecast[4] == 0.f) reward[0] -= Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance;
y el tercer componente de nuestra recompensa interna será la entropía de transición, que estimulará al Actor a aprender una variedad de comportamientos y a dominar un gran número de habilidades. Para obtener la entropía de transición, primero obtendremos una representación comprimida de la transición en el espacio del codificador aleatorio y determinaremos los k vecinos más próximos en el método KNNReward.
State.AddArray(GetPointer(Account)); State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding);
Después añadiremos la entropía de transición resultante a nuestra recompensa interna.
Ahora que hemos entrenado el significado completo de nuestra recompensa interior integrada podemos comenzar a entrenar el Crítico y el Actor. Ya hemos realizado anteriormente el pasada directa del Actor. Ahora llamaremos a la pasada directa de ambos Críticos,
Result.AssignArray(reward); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
y entrenaremos al actor utilizando el crítico con un error mínimo. Después comprobaremos el error de la media móvil de los Críticos, y primero realizaremos la pasada inversa del Crítico con el error mínimo. Le seguirá la pasada inversa del Actor. Y completaremos la pasada inversa del Crítico con el mayor error medio de predicción de la acción del Actor.
if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) { if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
A continuación, actualizaremos los parámetros del Codificador objetivo y notificaremos al usuario sobre el estado del proceso de entrenamiento del modelo.
//--- Update Target Nets TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completadas todas las iteraciones del ciclo de entrenamiento, borraremos el campo de comentarios del gráfico e iniciaremos el proceso de cierre del programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Para tener una idea general del proceso de aprendizaje, analizaremos otro método para formar el estado de pronóstico de la cuenta ForecastAccount. En los parámetros, el método obtendrá el puntero al anterior estado de la cuenta, el tensor de acción, el valor de beneficio de una posición larga de 1 lote para la siguiente barra y una marca temporal para la siguiente barra. El tamaño del beneficio para 1 lote se determinará antes de llamar al método basado en la información y la siguiente vela. Esta operación solo será posible con un entrenamiento offline basado en datos los históricos de los movimientos de precio.
En el cuerpo del método, haremos primero un pequeño trabajo preparatorio. Aquí declararemos las variables locales y cargaremos alguna información sobre el instrumento. Tenga en cuenta que como no especificaremos un instrumento en ninguna parte de los datos de entrenamiento, utilizaremos los datos del instrumento gráfico. Por lo tanto, para procesar el entrenamiento correctamente, deberemos ejecutar el asesor en el gráfico del instrumento que nos interese.
vector<float> ForecastAccount(float &prev_account[], CBufferFloat *actions,double prof_1l,float time_label) { vector<float> account; vector<float> act; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
Por comodidad, transferiremos los datos obtenidos en los parámetros a vectores.
actions.GetData(act); account.Assign(prev_account);
Después ajustaremos las acciones del agente para abrir una posición solo en una dirección en la diferencia de los volúmenes declarados. Y luego comprobaremos que los recursos sean suficientes para realizar las operaciones. Si no hay recursos suficientes en la cuenta, pondremos a cero el volumen de transacciones.
if(act[0] >= act[3]) { act[0] -= act[3]; act[3] = 0; if(act[0]*margin_buy >= MathMin(account[0],account[1])) act[0] = 0; } else { act[3] -= act[0]; act[0] = 0; if(act[3]*margin_sell >= MathMin(account[0],account[1])) act[3] = 0; }
A continuación vendrán las operaciones de descifrado de las acciones obtenidas. El proceso se construirá por analogía con el algoritmo de las acciones en el asesor de recogida de datos de entrenamiento, solo que en lugar de realizar acciones, cambiaremos los elementos relevantes de la descripción del estado de la cuenta. Veamos primero los elementos de una posición larga. Si el volumen de la operación es igual a "0" o los niveles de stop son inferiores a la separación mínima del instrumento, este conjunto de parámetros indicará el cierre de la transacción. Por supuesto, si estaba abierta. Luego pondremos a cero el tamaño de la posición actual en esta dirección, y añadiremos los beneficios/pérdidas acumulados al balance actual.
//--- buy control if(act[0] < min_lot || (act[1] * MaxTP * Point()) <= stops || (act[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; }
En caso de abrirse o mantenerse una posición, normalizaremos el volumen de operaciones, y compararemos el volumen resultante con el volumen abierto anteriormente. Si la posición era mayor a la ofrecida por el Actor, el beneficio/pérdidas acumulados se dividirá proporcionalmente a los volúmenes propuesto y cerrado. Las pérdidas y ganancias del volumen que se va a cerrar se añadirán al balance. Dejaremos la diferencia en el campo de beneficios acumulados, y cambiaremos el volumen de la posición al volumen sugerido por el Actor. Asimismo, añadiremos al volumen acumulado el beneficio/pérdida de la transición al siguiente estado del entorno.
else { double buy_lot = min_lot + MathRound((double)(act[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
Las operaciones se repetirán para las posiciones cortas.
//--- sell control if(act[3] < min_lot || (act[4] * MaxTP * Point()) <= stops || (act[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(act[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
El beneficio acumulado de las posiciones largas y cortas constituirá el beneficio acumulado de la cuenta, mientras que la suma de los beneficios acumulados y el balance darán la medida de la Equidad.
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
A partir de los valores obtenidos, formaremos un vector de descripción del estado de la cuenta y lo retornaremos al programa que realiza la llamada.
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
Una vez finalizado el proceso de entrenamiento, todos los modelos se guardarán en el método de desinicialización del asesor OnDeinit.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetEncoder.Save(FileName + "Enc.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Convolution.Save(FileName + "CNN.nnw", 0, 0, 0, TimeCurrent(), true); Descriminator.Save(FileName + "Des.nnw", 0, 0, 0, TimeCurrent(), true); SkillProject.Save(FileName + "Skp.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Con esto damos por concluido nuestro trabajo sobre el asesor de entrenamiento previo de habilidades del Actor sin recompensa externa. El código completo de dicho asesor se puede encontrar en el archivo adjunto. Allí hallará también el código completo de todos los programas utilizados en el artículo.
2.4 Asesor de ajuste fino
El proceso de entrenamiento del modelo se completará con el entrenamiento del Planificador, que generará el vector de habilidades a utilizar y controlará así las acciones del Actor.
La política del Planificador se entrenará para maximizar la recompensa externa. Su proceso de entrenamiento lo organizaremos en el asesor "...\CIC\Finetune.mq5". El asesor se construirá de forma similar al anterior, pero existen ciertos matices. Para que el asesor funcione se necesitarán modelos preentrenados del Codificador, el Actor y el Crítico. También utilizaremos copias objetivo de los modelos anteriores.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !TargetActor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("No pretrained models found"); return INIT_FAILED; }
Además, cargaremos un modelo de Codificador convolucional aleatorio, pero no cargaremos los modelos del Discriminador. En esta fase, solo utilizaremos recompensas externas. Ya analizamos las políticas de comportamiento del Actor en el paso anterior. Ahora tendremos que aprender la política de alto nivel del Planificador.
Por lo tanto, precisamente tras cargar los modelos preentrenados trataremos de cargar el modelo del Planificador. Y si no encontramos ninguno, esta vez creamos un nuevo modelo y lo inicializaremos con parámetros aleatorios.
if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *descr = new CArrayObj(); if(!SchedulerDescriptions(descr) || !Scheduler.Create(descr)) { delete descr; return INIT_FAILED; } delete descr; }
A continuación, colocaremos todos los modelos en un único contexto OpenCL y desactivaremos el modo de entrenamiento del Actor y el Codificador.
OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); TargetActor.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Scheduler.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- Actor.TrainMode(false); Encoder.TrainMode(false);
Al final del método de inicialización, comprobaremos que la arquitectura de los modelos coincida y generaremos un evento de inicio para el proceso de entrenamiento.
vector<float> ActorResult; Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; } //--- Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del asesor, solo conservaremos los modelos del Crítico y el Planificador.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Scheduler.Save(FileName + "Sch.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
No creo que nadie cuestione la necesidad de entrenar al Planificador, pero el tema de la actualización de los parámetros del Crítico y la fijación de los parámetros del Actor probablemente merezca una aclaración. En el paso anterior, entrenamos las políticas del Actor según la habilidad utilizada, y en esta fase, aprenderemos a gestionar las habilidades. Por lo tanto, fijaremos los parámetros del Actor y entrenaremos al Planificador para que lo controle.
Otra cuestión a considerar sobre los críticos. El asunto es que en la fase de entrenamiento de habilidades, solo utilizaremos recompensas internas centradas en el entrenamiento de las diferentes habilidades del Actor. Y, por supuesto, los Críticos han creado dependencias entre las acciones del Actor y su efecto en la recompensa interna, pero en esta fase utilizaremos una recompensa externa, y es probable que se vea influida por las acciones del Actor de un modo completamente distinto. Así que nos tocará a nosotros reentrenar a los Críticos según las nuevas circunstancias.
También debemos aquí que, mientras que antes utilizábamos nuestras suposiciones sobre el impacto de la habilidad elegida en el resultado, ahora recorreremos el gradiente del error de recompensa desde el Crítico, pasando por el Actor, hasta el Planificador. Bueno, volvamos a nuestro asesor y veamos el algoritmo para organizar el proceso.
El proceso de entrenamiento del modelo se seguirá organizando con el método Train. Al igual que en el asesor de entrenamiento de habilidades comentado anteriormente, al principio del método realizaremos la codificación de las transiciones, solo que esta vez añadiremos la carga de recompensas externas del entorno, y tendremos en cuenta que solo tomaremos una recompensa por una transición individual. La recompensa acumulada la pronosticaremos utilizando los modelos objetivo.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float loss = 0; //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); for(ulong r = 0; r < temp.Size(); r++) temp[r] -= Buffer[tr].States[st + 1].rewards[r] * DiscFactor; rewards.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); rewards.Reshape(state,NRewards); total_states = state; }
A continuación, organizaremos un ciclo de entrenamiento del modelo. En el cuerpo del ciclo, muestreamos el estado del búfer de reproducción de experiencias,
vector<float> reward, rewards1, rewards2, target_reward; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } reward = vector<float>::Zeros(NRewards); rewards1 = reward; rewards2 = reward; target_reward = reward;
y prepararemos los búferes de datos de origen.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; if(PrevBalance == 0.0f || PrevEquity == 0.0f) continue; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Después de generar un conjunto completo de datos de entrada del estado seleccionado, realizaremos una pasada directa del Codificador.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Al codificador le seguirá una pasada directa del planificador, que evaluará la representación latente del estado del entorno y generará un vector de habilidades para el actor.
//--- Skills if(!Scheduler.feedForward(GetPointer(Encoder), -1, NULL,-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A su vez, el actor utilizará la habilidad especificada por el Planificador y analizará la representación latente del estado del entorno procedente del Codificador. Luego el Actor generará un vector de acción basado en el conjunto de datos de entrada.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nosotros, por nuestra parte, utilizaremos el vector de acciones resultante para predecir el siguiente estado del entorno,
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
y repetiremos las acciones, pero ya para el estado posterior mediante los modelos objetivo. El Planificador quedará excluido de esta cadena, ya que suponemos que se utilizará la misma habilidad.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Target if(!TargetActor.feedForward(GetPointer(TargetEncoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
No obstante, para evaluar la política del Actor, necesitaremos que el Crítico evalúe las acciones del Actor. Y aquí utilizaremos la estimación más baja para como predictor de la futura recompensa.
//--- if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; target_reward *= DiscFactor;
Estimaremos la acción actual basándonos en los k vecinos más próximos de la transición prevista. Para ello, utilizaremos un Codificador aleatorio.
State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding,rewards); reward += target_reward; Result.AssignArray(reward);
Después combinaremos la remuneración actual y la prevista. Ahora tendremos un valor objetivo para el entrenamiento del modelo. Nos queda por seleccionar el modelo del Crítico para actualizar los parámetros del Planificador. A continuación, realizaremos una pasada directa de ambos Críticos y elegiremos la puntuación mínima de la acción elegida por el Actor.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(rewards1); Critic2.getResults(rewards2);
Como en el asesor anterior, realizaremos una pasada inversa del Crítico, el Actor y el Planificador seleccionados. Y en el último realizaremos la pasada inversa del Crítico con la máxima valoración de las acciones del Actor.
if(rewards1.Sum() <= rewards2.Sum()) { loss = (loss * MathMin(iter,999) + (reward - rewards1).Sum()) / MathMin(iter + 1,1000); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { loss = (loss * MathMin(iter,999) + (reward - rewards2).Sum()) / MathMin(iter + 1,1000); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Al final de las iteraciones del ciclo de aprendizaje, nos quedará actualizar los modelos del Crítico objetivo e informar al usuario del progreso del proceso de aprendizaje del modelo.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), loss); Comment(str); ticks = GetTickCount(); } }
Una vez completadas todas las iteraciones del ciclo de entrenamiento del modelo, borraremos el campo de comentarios del gráfico e iniciaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", loss); ExpertRemove(); //--- }
Aquí concluimos el análisis de los programas de aplicación del algoritmo presentado. Aún no hemos visto al asesor de prueba de patrones entrenados. Lo hemos ajustado de forma similar al asesor de recopilación de muestras de entrenamiento, solo que no hemos añadido ruido aleatorio al vector de acciones para evaluar la calidad real del rendimiento de los modelos entrenados. En el archivo adjunto encontrará el código completo de todos los programas utilizados en el artículo.
3. Simulación
Hemos entrenado y probado los modelos con los datos históricos de los 5 primeros meses de 2023, el instrumento EURUSD y el marco temporal H1. Como siempre, los parámetros de todos los indicadores se han utilizado por defecto. Debemos decir de entrada que el proceso de entrenamiento de modelos es bastante largo. Los autores del método sugieren que en la primera etapa del entrenamiento de habilidades se realicen del orden de 2 millones de iteraciones. Obviamente, el número de iteraciones puede aumentarse para entornos más complejos. En el entrenamiento de nuestro modelo, hemos tomado este camino a lo largo de varios enfoques con recopilación de datos de entrenamiento adicionales.
Tras el entrenamiento de las habilidades viene la fase de perfeccionamiento y entrenamiento del Planificador. Esta etapa también tiene al menos 100 000 iteraciones. También les sugerimos que este paso se realice en varios enfoques. Primero inicializaremos un modelo aleatorio del Planificador y lo entrenaremos con un amplio conjunto de datos. Tras la primera pasada de entrenamiento del Planificador, recopilaremos conjuntos de entrenamiento adicionales que incluirán ejemplos sobre la interacción de la política del Planificador con el entorno. Esto ajustará sus políticas para mejor.
En el proceso, hemos podido entrenar un modelo capaz de generar beneficios. En el gráfico presentado con los resultados de las pruebas vemos una clara tendencia al alza de la línea de balance. Al mismo tiempo, resultan confusas algunas de las zonas de reducción de la Equidad, lo cual puede sugerir la necesidad de un entrenamiento adicional del modelo. Sabemos que los mercados financieros son entornos bastante estocásticos y complejos, y, como es de esperar, se necesitan periodos de entrenamiento más largos para obtener los resultados deseados.


Conclusión
En este artículo, hemos presentado un método prometedor en el campo del aprendizaje jerárquico por refuerzo, el "Control Interno Contrastivo" (CIC). Este método pertenece a la familia de algoritmos basados en recompensas internas autocontroladas. Basado en los principios del algoritmo DIAYN, pretende mejorar la extracción de las habilidades jerárquicas del Agente introduciendo el aprendizaje contrastivo.
Una de las características clave del CIC es su capacidad para entrenar diversas habilidades en entornos complejos en los que el número de comportamientos potenciales puede resultar bastante amplio. Esta propiedad resulta especialmente útil en el ámbito de la resolución de problemas con un espacio continuo de acciones. El uso del aprendizaje contrastivo permite guiar al Agente de forma que no solo pueda aprender eficazmente diversos escenarios, sino también extraer valiosos conocimientos de dichos escenarios.
En la parte práctica de nuestro artículo, hemos implementado el algoritmo usando herramientas MQL5. Asimismo, hemos entrenado y probado el modelo con datos históricos reales. Los resultados obtenidos sugieren la eficacia potencial del método. Pero el aprendizaje de un gran número de habilidades también exige unos costes proporcionales para el entrenamiento de los agentes.
Enlaces
- CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
- Representation Learning with Contrastive Predictive Coding
- Redes neuronales: así de sencillo (Parte 43): Dominando las habilidades sin función de recompensa
- Redes neuronales: así de sencillo (Parte 44): Estudiamos las habilidades de forma dinámica
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Pretrain.mq5 | Asesor | Asesor de entrenamiento de las habilidades del Actor |
| 3 | Finetune.mq5 | Asesor | Asesor de ajuste fino y entrenamiento del Planificador |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13212
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
La captura de pantalla en el artículo sólo muestra posiciones cortas (vender).
¿Cómo puedo hacer que funcione en ambos sentidos? El Asesor Experto ha dejado de aprender. Pretrain y Finetune vuelan fuera del gráfico después de la incrustación. Desgraciadamente. ¿Debo empezar de nuevo?
El Asesor Experto dejó de aprender. Pretrain y Finetune están volando fuera de la tabla después de Embedding.
¿Cuáles son los mensajes en el registro?
¿Qué son los mensajes de registro?
Smoke ha vuelto a la vida. Me di cuenta de una cosa extraña - después de pasar Investigación en el probador, el ordenador se cuelga durante un tiempo. Probablemente por eso se colgaba. Sigamos aprendiendo.
Smokehouse está vivo. Me di cuenta de una cosa extraña - después de pasar Investigación en el probador, el equipo se cuelga por un tiempo. Tal vez por eso salieron volando. Seguimos aprendiendo.
Después de pasar la investigación, la base de datos de ejemplos se guarda. Y si es lo suficientemente grande, puedes sentir que el ordenador se ralentiza mientras procesa la base de datos y la escribe en el disco. Naturalmente, si hay errores al guardar la base de datos, Pretrain y Finetune no podrán leerla y se bloquearán.