Artículos sobre aprendizaje automático en el trading
Creación de robots comerciales basados en inteligencia artificial: integración nativa con Python, operaciones con matrices y vectores, bibliotecas de matemáticas y estadística y mucho más.
Aprenda a usar el aprendizaje automático en el trading. Neuronas, perceptrones, redes convolucionales y recurrentes, modelos predictivos: parta de lo básico y avance hasta construir su propia IA. Aprenderá a entrenar y aplicar redes neuronales para el comercio algorítmico en los mercados financieros.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Matrices y vectores en MQL5: funciones de activación
En este artículo, describiremos solo uno de los aspectos del aprendizaje automático: las funciones de activación. En las redes neuronales artificiales, las funciones de activación de neuronas calculan el valor de la señal de salida en función de los valores de una señal de entrada o un conjunto de señales de entrada. Hoy le mostraremos lo que hay "debajo del capó".

Algoritmos de optimización de la población: Algoritmo de murciélago (Bat algorithm - BA)
Hoy analizaremos el algoritmo de murciélago (Bat algorithm - BA), que posee una sorprendente convergencia en funciones suaves.
Aprendizaje automático y Data Science (Parte 01): Regresión lineal
Es hora de que los tráders entrenemos nuestros sistemas y aprendamos a tomar nuestras propias decisiones en función de lo que muestren los números. En este proceso, evitaremos los métodos visuales o intuitivos que usa todo el mundo. Marcharemos perpendicularmente a la dirección general.

Redes neuronales: así de sencillo (Parte 11): Variaciones de GTP
Hoy en día, quizás uno de los modelos de lenguaje de redes neuronales más avanzados sea GPT-3, que en su versión máxima contiene 175 mil millones de parámetros. Obviamente, no vamos a crear semejante monstruo en condiciones domésticas. Pero sí que podemos ver qué soluciones arquitectónicas se pueden usar en nuestro trabajo y qué ventajas nos ofrecerán.

Algoritmos de optimización de la población: Colonia artificial de abejas (Artificial Bee Colony - ABC)
Hoy estudiaremos el algoritmo de colonia artificial de abejas. Asimismo, complementaremos nuestros conocimientos con nuevos principios para el estudio de los espacios funcionales. En este artículo hablaremos sobre mi interpretación de la versión clásica del algoritmo.

Redes neuronales: así de sencillo (Parte 6): Experimentos con la tasa de aprendizaje de la red neuronal
Ya hemos hablado sobre algunos tipos de redes neuronales y su implementación. En todos los casos, hemos usado el método de descenso de gradiente para entrenar las redes neuronales, lo cual implica la elección de una tasa de aprendizaje. En este artículo, queremos mostrar con ejemplos lo importante que resulta elegir correctamente la tasa de aprendizaje, y también su impacto en el entrenamiento de una red neuronal.

Algoritmos de optimización de la población: Método de Nelder-Mead
En el artículo de hoy, le presentamos un estudio completo del método de Nelder-Mead, en el que se explica cómo el símplex (el espacio de parámetros de la función) se modifica y reordena en cada iteración para alcanzar la solución óptima; asimismo, describiremos una forma de mejorar este método.

Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R
En el artículo, descricribiremos las etapas del proceso de aprendizaje de máquinas usando un ejemplo concreto, y también adjuntaremos un código sobre el mismo. Para obtener los modelos, no necesitaremos conocer ningún lenguaje de programación como Python o R. Los conocimientos requeridos de MQL5 no serán profundos, iguales, por cierto, que los del autor del presente artículo; por eso, esperamos que este artículo sirva de guía para un amplio círculo de lectores que deseen valorar de forma experimental las posibilidades del aprendizaje de máquinas e implementar estas en sus desarrollos.

Desarrollo de un robot en Python y MQL5 (Parte 1): Preprocesamiento de datos
Desarrollar un robot de trading basado en aprendizaje automático: Una guía detallada. El primer artículo de la serie trata de la recogida y preparación de datos y características. El proyecto se ejecuta utilizando el lenguaje de programación y las librerías Python, así como la plataforma MetaTrader 5.


Neuroredes profundas (Parte VIII). Aumentando la calidad de la clasificación de los conjuntos bagging
En el artículo se analizan tres métodos con cuya ayuda podemos aumentar la calidad de clasificación de los conjuntos bagging y valorar su efectividad. Se ha evaluado cómo influye la optimización de los hiperparámetros de las redes neuronales ELM y los parámetros de post-procesado en la calidad de clasificación del conjunto.

Aprendizaje automático y data science (Parte 06): Descenso de gradiente
El descenso de gradiente juega un papel importante en el entrenamiento de redes neuronales y diversos algoritmos de aprendizaje automático: es un algoritmo rápido e inteligente. Sin embargo, a pesar de su impresionante funcionamiento, muchos científicos de datos todavía lo malinterpretan. Veamos sobre qué tratará este artículo.

Aprendizaje automático y Data Science (Parte 16): Una nueva mirada a los árboles de decisión
En la última parte de nuestra serie sobre aprendizaje automático y trabajo con big data, vamos a volver a los árboles de decisión. Este artículo va dirigido a los tráders que desean comprender el papel de los árboles de decisión en el análisis de las tendencias del mercado. Asimismo, contiene toda la información básica sobre la estructura, la finalidad y el uso de estos árboles. Hoy analizaremos las raíces y ramas de los árboles algorítmicos y veremos cuál es su potencial en relación con las decisiones comerciales. También echaremos juntos un nuevo vistazo a los árboles de decisión y veremos cómo pueden ayudarnos a superar los retos de los mercados financieros.

Modelo de aprendizaje profundo GRU en Python usando ONNX en asesores expertos, GRU vs LSTM
El artículo está dedicado al desarrollo de un modelo de aprendizaje profundo GRU ONNX en Python. En la parte práctica, implementaremos este modelo en un asesor comercial y, a continuación, compararemos el rendimiento del modelo GRU con LSTM (memoria a largo plazo).

Algoritmos de optimización de la población: Optimización de colonias de hormigas (ACO)
En esta ocasión, analizaremos el algoritmo de optimización de colonias de hormigas (ACO). El algoritmo es bastante interesante y ambiguo al mismo tiempo. Intentaremos crear un nuevo tipo de ACO.
Aprendizaje automático y data science (Parte 03): Regresión matricial
En esta ocasión, vamos a crear modelos usando matrices: estas ofrecen una gran flexibilidad y permiten crear modelos potentes que pueden manejar no solo cinco variables independientes, sino muchas otras, tantas como los límites computacionales de nuestro ordenador nos permitan. El presente artículo será muy interesante, eso seguro.

Redes neuronales: así de sencillo (Parte 29): Algoritmo actor-crítico con ventaja (Advantage actor-critic)
En los artículos anteriores de esta serie, nos familiarizamos con dos algoritmos de aprendizaje por refuerzo. Obviamente, cada uno de ellos tiene sus propias ventajas y desventajas. Como suele suceder en estos casos, se nos ocurre combinar ambos métodos en un algoritmo que incorporaría lo mejor de los dos, y así compensar las carencias de cada uno de ellos. En este artículo, hablaremos de dicho método.

Algoritmos de optimización de la población: Algoritmo de recocido simulado (Simulated Annealing, SA). Parte I
El algoritmo de recocido simulado es una metaheurística inspirada en el proceso de recocido de los metales. En nuestro artículo, realizaremos un análisis exhaustivo del algoritmo y mostraremos cómo muchas percepciones comunes y mitos que rodean a este método de optimización (el más popular y conocido) pueden ser incorrectos e incompletos. Anuncio de la segunda parte del artículo: "¡Conozca el algoritmo de recocido Isotrópico Simulado (Simulated Isotropic Annealing, SIA) del propio autor!"

Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas
Continuamos analizando los métodos de aprendizaje por refuerzo. En el artículo anterior, nos familiarizamos con el método de aprendizaje Q profundo, en el que entrenamos un modelo para predecir la próxima recompensa dependiendo de la acción realizada en una situación particular. Luego realizamos una acción según nuestra política y la recompensa esperada, pero no siempre es posible aproximar la función Q, o su aproximación no ofrece el resultado deseado. En estos casos, los métodos de aproximación no se utilizan para funciones de utilidad, sino para una política (estrategia) de acciones directa. Precisamente a tales métodos pertenece el gradiente de políticas o policy gradient.

Arbitraje triangular con predicciones
Este artículo simplifica el arbitraje triangular y le muestra cómo utilizar predicciones y software especializado para operar con divisas de forma más inteligente, incluso si es nuevo en el mercado. ¿Listo para operar con experiencia?

Algoritmos de optimización de la población: Algoritmo de luciérnagas (Firefly Algorithm - FA)
Hoy analizaremos el método de optimización «Búsqueda con ayuda del algoritmo de luciérnagas» 'Firefly Algorithm Search' (FA). Tras modificar el algoritmo, este ha pasado de ocupar un lugar marginal a convertirse en un verdadero líder en la tabla de calificación.

Creación de predicciones de series temporales mediante redes neuronales LSTM: Normalización del precio y tokenización del tiempo
Este artículo describe una estrategia simple para normalizar los datos del mercado utilizando el rango diario y entrenar una red neuronal para mejorar las predicciones del mercado. Los modelos desarrollados pueden utilizarse junto con un marco de análisis técnico existente o de forma independiente para ayudar a predecir la dirección general del mercado. Cualquier analista técnico puede perfeccionar aún más el marco descrito en este artículo para desarrollar modelos adecuados tanto para estrategias comerciales manuales como automatizadas.
Redes neuronales: así de sencillo (Parte 5): Cálculos multihilo en OpenCL
Ya hemos analizado algunos tipos de implementación de redes neuronales. Podemos ver con facilidad que se repiten las mismas operaciones para cada neurona de la red. Y aquí sentimos el legítimo deseo de aprovechar las posibilidades que ofrece la computación multihilo de la tecnología moderna para acelerar el proceso de aprendizaje de una red neuronal. En el presente artículo, analizaremos una de las opciones para tal implementación.

Introducción a MQL5 (Parte 5): Funciones de trabajo con arrays para principiantes
En el quinto artículo de nuestra serie, nos familiarizaremos con el mundo de los arrays en MQL5. Este artículo ha sido pensado para principiantes. En este artículo intentaremos repasar conceptos complejos de programación de manera simplificada para que el material resulte comprensible para todos. Asimismo, exploraremos conceptos básicos, discutiremos diferentes cuestiones y compartiremos conocimientos.

Aprendizaje automático y data science (Parte 05): Árboles de decisión usando como ejemplo las condiciones meteorológicas para jugar al tenis
Los árboles de decisión clasifican los datos imitando la forma de pensar de los seres humanos. En este artículo, veremos cómo construir árboles de decisión y usar estos para clasificar y predecir datos. El objetivo principal del algoritmo del árbol de decisión es dividir la muestra en datos con "impurezas" y en datos "limpios" o próximos a los nodos.
Aprendizaje automático y Data Science (Parte 11): Clasificador bayesiano ingenuo y teoría de la probabilidad en el trading
Comerciar con probabilidades es como caminar por la cuerda floja: requiere precisión, equilibrio y una clara comprensión del riesgo. En el mundo del trading, la probabilidad lo es todo: es lo que determina el resultado, el éxito o el fracaso, los beneficios o las pérdidas. Usando el poder de la probabilidad, los tráders pueden tomar decisiones mejor informadas, gestionar el riesgo con mayor eficacia y alcanzar sus objetivos financieros. Tanto si es usted un inversor experimentado como un tráder principiante, comprender las probabilidades puede ser la clave para liberar su potencial comercial. En este artículo, analizaremos el fascinante mundo del trading probabilístico y le mostraremos cómo llevar su modo de comerciar al siguiente nivel.
Aprendizaje automático y Data Science (Parte 07): Regresión polinomial
La regresión polinomial es un modelo flexible diseñado para resolver de forma eficiente problemas que un modelo de regresión lineal no puede gestionar. En este artículo, aprenderemos a crear modelos polinómicos en MQL5 y a sacar provecho de ellos.

Redes neuronales de propagación inversa del error en matrices MQL5
El artículo describe la teoría y la práctica de la aplicación del algoritmo de propagación inversa del error en MQL5 con la ayuda de matrices. Asimismo, incluye clases y ejemplos preparados del script, el indicador y el asesor.

Reimaginando estrategias clásicas en Python: Cruce de medias móviles (MAs, Moving Averages)
En este artículo, revisamos la estrategia clásica de cruce de medias móviles para evaluar su eficacia actual. Dado el tiempo transcurrido desde su creación, exploramos las posibles mejoras que la IA puede aportar a esta estrategia de negociación tradicional. Mediante la incorporación de técnicas de IA, pretendemos aprovechar las capacidades predictivas avanzadas para optimizar potencialmente los puntos de entrada y salida de las operaciones, adaptarnos a las condiciones variables del mercado y mejorar el rendimiento global en comparación con los enfoques convencionales.

Algoritmos de optimización de la población: Algoritmo genético binario (Binary Genetic Algorithm, BGA). Parte I
En este artículo, analizaremos varios métodos utilizados en algoritmos genéticos binarios y otros algoritmos poblacionales. Asimismo, repasaremos los principales componentes del algoritmo, como la selección, el cruce y la mutación, así como su impacto en el proceso de optimización. Además, estudiaremos las formas de presentar la información y su repercusión en los resultados de la optimización.
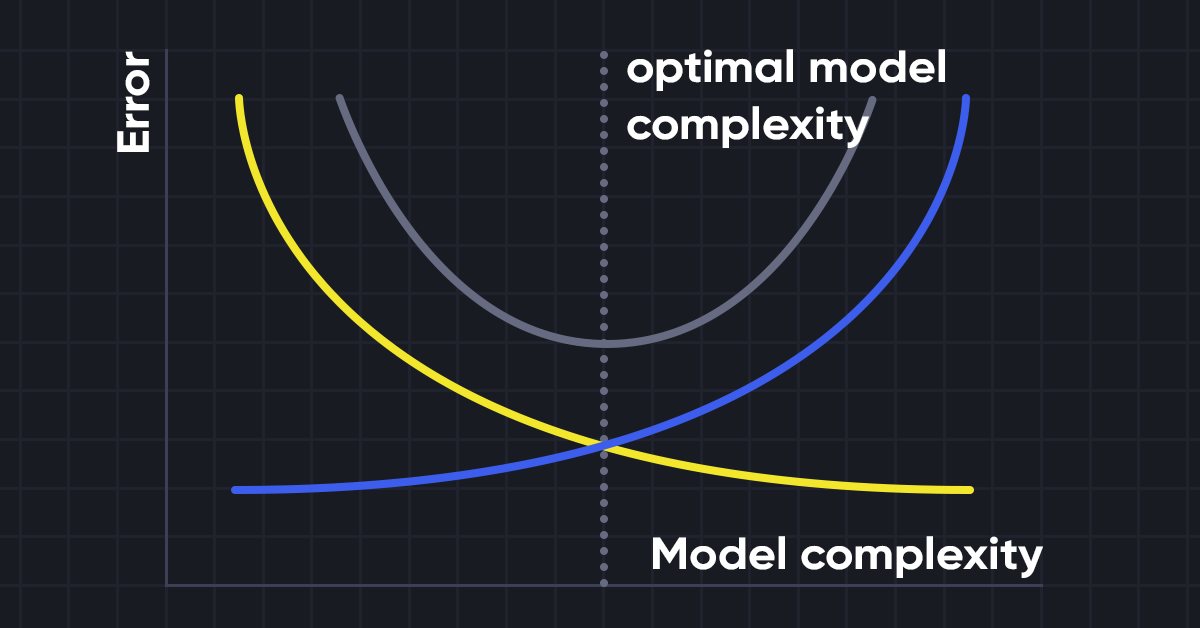
Aprendizaje automático y Data Science (Parte 10): Regresión de cresta
La regresión de cresta (Ridge Regression) es una técnica simple para reducir la complejidad del modelo y combatir el ajuste que puede derivar de una regresión lineal simple.
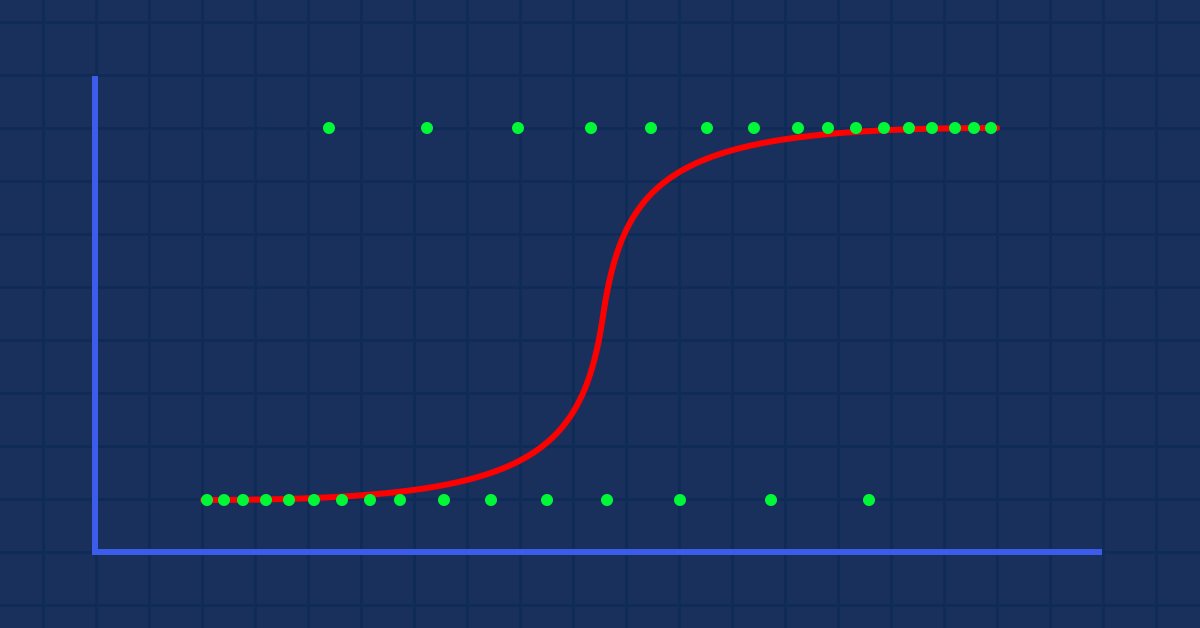
Aprendizaje automático y Data Science (Parte 02): Regresión logística
La clasificación de los datos es un punto crucial para los tráders algorítmicos y los programadores. En este artículo, nos centraremos en uno de los algoritmos logísticos de clasificación que podría ayudarnos a identificar los síes o los noes, las subidas y bajadas, las compras y las ventas.

Redes neuronales: así de sencillo (Parte 9): Documentamos el trabajo realizado
Ya hemos recorrido un largo camino y el código de nuestra biblioteca ha crecido de manera considerable. Resulta difícil monitorear todas las conexiones y dependencias. Y, obviamente, antes de proseguir con el desarrollo del proyecto, necesitaremos documentar el trabajo ya realizado y actualizar la documentación en cada paso posterior. Una documentación debidamente redactada nos ayudará a ver la integridad de nuestro trabajo.

Gradient boosting (CatBoost) en las tareas de construcción de sistemas comerciales. Un enfoque ingenuo
Entrenamiento del clasificador CatBoost en el lenguaje Python, exportación al formato mql5; análisis de los parámetros del modelo y simulador de estrategias personalizado. Para preparar los datos y entrenar el modelo, se usan el lenguaje de programación Python y la biblioteca MetaTrader5.

Algoritmos de optimización de la población: Búsqueda armónica (HS)
Hoy estudiaremos y pondremos a prueba un algoritmo de optimización muy potente, la búsqueda armónica (HS), que se inspira en el proceso de búsqueda de la armonía sonora perfecta. ¿Qué algoritmo lidera ahora mismo nuestra clasificación?

Modelos de regresión de la biblioteca Scikit-learn y su exportación a ONNX
En este artículo exploraremos la aplicación de modelos de regresión del paquete Scikit-learn e intentaremos convertirlos al formato ONNX y utilizaremos los modelos resultantes dentro de programas MQL5. Adicionalmente, compararemos la precisión de los modelos originales con sus versiones ONNX tanto para precisión flotante como doble. Además, examinaremos la representación ONNX de los modelos de regresión con el fin de comprender mejor su estructura interna y sus principios de funcionamiento.

Redes neuronales: así de sencillo (Parte 26): Aprendizaje por refuerzo
Continuamos estudiando los métodos de aprendizaje automático. En este artículo, iniciaremos otro gran tema llamado «Aprendizaje por refuerzo». Este enfoque permite a los modelos establecer ciertas estrategias para resolver las tareas. Esperamos que esta propiedad del aprendizaje por refuerzo abra nuevos horizontes para la construcción de estrategias comerciales.

Remuestreo avanzado y selección de modelos CatBoost con el método de fuerza bruta
Este artículo describe uno de los posibles enfoques respecto a la transformación de datos para mejorar las capacidades generalizadoras del modelo, y también analiza la iteración sobre los modelos CatBoost y la elección del mejor de ellos.

Aprendizaje de máquinas en sistemas comerciales con cuadrícula y martingale. ¿Apostaría por ello?
En este artículo, presentaremos al lector la técnica del aprendizaje automático para el comercio con martingale y cuadrícula. Para nuestra sorpresa, este enfoque, por algún motivo, no se ha tratado en absoluto en la red global. Después de leer el artículo, podremos crear nuestros propios bots.

Uso de modelos ONNX en MQL5
ONNX (Open Neural Network Exchange) es un estándar abierto para representar modelos de redes neuronales. En este artículo, analizaremos el proceso de creación de un modelo CNN-LSTM para pronosticar series temporales financieras, y también el uso del modelo ONNX creado en un asesor experto MQL5.

Algoritmos de optimización de la población: Optimización de malas hierbas invasoras (IWO)
La asombrosa capacidad de las malas hierbas para sobrevivir en una gran variedad de condiciones inspiró la idea de un potente algoritmo de optimización. El IWO es uno de los mejores entre los analizados anteriormente.