
Reimaginando las estrategias clásicas en MQL5 (Parte XI): Cruce de medias móviles (II)

Anteriormente hemos tratado el tema de la previsión de cruces de medias móviles. El artículo se encuentra disponible en este enlace. Observamos que los cruces de medias móviles son más fáciles de pronosticar que los cambios de precios directamente. Hoy volveremos a tratar este problema tan conocido pero con un enfoque totalmente diferente.
Ahora queremos investigar en profundidad qué diferencia supone esto para nuestras aplicaciones comerciales y cómo este hecho puede mejorar sus estrategias comerciales. Los cruces de medias móviles son una de las estrategias comerciales más antiguas que existen. Es un desafío construir una estrategia rentable utilizando una técnica tan ampliamente conocida. Sin embargo, espero mostrarles en este artículo que los perros viejos sí pueden aprender trucos nuevos.
Para ser empíricos en nuestras comparaciones, primero construiremos una estrategia comercial en MQL5 para el par EURGBP utilizando solo los siguientes indicadores:
- 2 medias móviles exponenciales aplicadas al precio de cierre. Uno con un período de 20 y el otro establecido en 60.
- El oscilador estocástico con los ajustes predeterminados de 5,3,3 aplicados, configurado en el modo de media móvil exponencial y configurado para realizar sus cálculos en el modo CLOSE_CLOSE.
- El indicador Average True Range (ATR) con un período de 14 para establecer nuestros niveles de take-profit y stop-loss.
Más adelante en este artículo analizaremos en profundidad los parámetros con los que se realizó la prueba retrospectiva. Sin embargo, tomaremos nota de los indicadores clave de rendimiento durante la prueba retrospectiva, como el ratio de Sharpe, la proporción de operaciones rentables, el beneficio máximo y otros indicadores de rendimiento importantes.
Una vez completado, sustituiremos cuidadosamente todas las reglas de negociación heredadas por reglas de negociación algorítmicas aprendidas a partir de nuestros datos de mercado. Entrenaremos tres modelos de IA para que aprendan a realizar previsiones:
- Volatilidad futura: Esto se logrará mediante el entrenamiento de un modelo de IA para pronosticar la lectura del ATR.
- Relación entre la variación del precio y los cruces de las medias móviles: Crearemos dos estados discretos en los que pueden encontrarse las medias móviles. Las medias móviles solo pueden estar en un estado a la vez. Esto ayudará a nuestro modelo de IA a centrarse en los cambios críticos del indicador y en el efecto medio de estos cambios en los niveles de precios futuros.
- Relación entre la variación del precio y el oscilador estocástico: En esta ocasión crearemos tres estados discretos, de los cuales el oscilador estocástico solo puede ocupar uno a la vez. Nuestro modelo aprenderá entonces el efecto medio de los cambios críticos en el oscilador estocástico.
Estos tres modelos de IA no se entrenarán en ninguno de los periodos de tiempo que utilizaremos para nuestra prueba retrospectiva. Nuestra prueba retrospectiva se llevará a cabo desde 2022 hasta junio de 2024, y nuestros modelos de IA se entrenarán desde 2011 hasta 2021. Nos aseguramos de no solapar el entrenamiento y las pruebas retrospectivas, para poder intentar acercarnos lo máximo posible al rendimiento real del modelo con datos que no ha visto antes.
Aunque parezca increíble, hemos mejorado con éxito todos los indicadores de rendimiento en todos los ámbitos. Nuestra nueva estrategia de trading fue más rentable, tuvo un índice de Sharpe más alto y ganó más de la mitad, el 55%, de todas las operaciones que realizó durante el periodo de backtesting.
Si una estrategia tan antigua y ampliamente utilizada puede hacerse más rentable, creo que esto debería animar a cualquier lector a pensar que sus estrategias también pueden hacerse más rentables, siempre y cuando se planteen de la forma adecuada.
La mayoría de los operadores trabajan duro durante largos periodos de tiempo para crear sus estrategias de trading y casi nunca hablan en profundidad sobre sus preciadas estrategias personales. Por lo tanto, el cruce de la media móvil sirve como punto neutro de debate que todos los miembros de nuestra comunidad pueden utilizar como referencia. Espero poder ofrecerte un marco generalizado que puedas complementar con tus propias estrategias de trading y, si sigues este marco adecuadamente, deberías notar algunas mejoras en tus propias estrategias.
Primeros pasos
Para empezar, iniciaremos nuestro IDE MetaEditor y comenzaremos creando una aplicación de trading que nos servirá como referencia.
Queremos implementar una estrategia sencilla de cruce de medias móviles, así que empecemos. Primero importaremos la biblioteca comercial.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Defina las variables globales.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask;
Creación de manejadores para nuestros indicadores técnicos.
//+------------------------------------------------------------------+ //| Technical indicator handlers | //+------------------------------------------------------------------+ int slow_ma_handler,fast_ma_handler,stochastic_handler,atr_handler; double slow_ma[],fast_ma[],stochastic[],atr[];
También fijaremos algunas de nuestras variables como constantes.
//+------------------------------------------------------------------+ //| Constants | //+------------------------------------------------------------------+ const int slow_period = 60; const int fast_period = 20; const int atr_period = 14;
Algunas de nuestras entradas deben controlarse manualmente. Por ejemplo, el tamaño del lote y el ancho del stop-loss.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Money Management" input int lot_multiple = 5; //Lot size input group "Risk Management" input int atr_multiple = 5; //Stop Loss Width
Cuando nuestro sistema se esté cargando, llamaremos a una función especial para configurar nuestros indicadores técnicos y guardar los datos del mercado.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our technical indicators and fetch market data setup(); //--- return(INIT_SUCCEEDED); }
De lo contrario, si ya no utilizamos la aplicación comercial, liberemos los recursos que ya no necesitamos.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); }
Si no tenemos posiciones abiertas en el mercado, buscaremos una oportunidad de trading.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } }
Esta función inicializará nuestros indicadores técnicos y guardará el tamaño de lote especificado por el usuario final.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); }
Ahora crearemos una función para guardar ofertas de precios actualizadas cuando las recibamos.
//+------------------------------------------------------------------+ //| Fetch updated market data | //+------------------------------------------------------------------+ void update(void) { //--- Update our market prices bid = SymbolInfoDouble("EURGBP",SYMBOL_BID); ask = SymbolInfoDouble("EURGBP",SYMBOL_ASK); //--- Copy indicator buffers CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(slow_ma_handler,0,0,1,slow_ma); CopyBuffer(fast_ma_handler,0,0,1,fast_ma); CopyBuffer(stochastic_handler,0,0,1,stochastic); }
Esta función finalmente verificará nuestra señal comercial. Si se encuentra la señal, entraremos en nuestras posiciones con stop-loss y take-profit establecidos por el ATR.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Can we buy? if((fast_ma[0] > slow_ma[0]) && (stochastic[0] > 80)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((fast_ma[0] < slow_ma[0]) && (stochastic[0] < 20)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Ahora estamos listos para realizar pruebas retrospectivas de nuestro sistema comercial. Entrenaremos el algoritmo de cruce de medias móviles simples que acabamos de definir anteriormente con los datos diarios del mercado EURGBP. Nuestro periodo de backtest será desde principios de enero de 2022 hasta finales de junio de 2024. Estableceremos el parámetro «Forward» en falso (false). Los datos del mercado se modelarán utilizando ticks reales que nuestra terminal tendrá que solicitar a nuestro bróker. Esto garantizará que los resultados de nuestras pruebas emulen fielmente las condiciones del mercado que se dieron ese día.
Fig. 1: Algunos de los ajustes para nuestra prueba retrospectiva.
Fig. 2: Los parámetros restantes de nuestra prueba retrospectiva.
Los resultados de nuestra prueba retrospectiva inicial no son alentadores. Nuestra estrategia de trading perdió dinero durante toda la prueba. Sin embargo, esto tampoco es sorprendente, ya que sabemos que los cruces de medias móviles son señales de trading retardadas. La figura 3 a continuación resume el saldo de nuestra cuenta de operaciones durante la prueba.
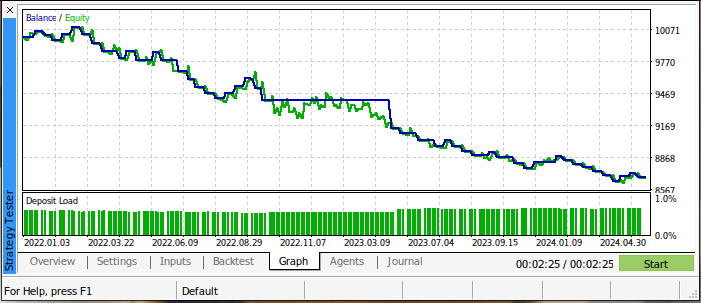
Fig. 3: El saldo de nuestra cuenta de trading al realizar la prueba retrospectiva.
Nuestro índice de Sharpe fue de -5,0 y perdimos el 69,57% de todas las operaciones que realizamos. Nuestra pérdida media fue mayor que nuestra ganancia media. Estos son indicadores de mal rendimiento. Si utilizáramos este sistema de trading en su estado actual, sin duda perderíamos nuestro dinero rápidamente.
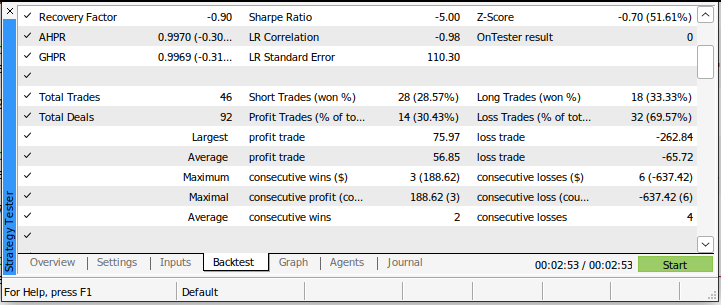
Fig. 4: Detalles de nuestra prueba retrospectiva utilizando un enfoque tradicional para operar en los mercados.
Las estrategias basadas en cruces de medias móviles y el oscilador estocástico se han explotado ampliamente y es poco probable que ofrezcan alguna ventaja significativa que podamos aprovechar como operadores humanos. Sin embargo, esto no implica que no haya ninguna ventaja material que nuestros modelos de IA puedan aprender. Vamos a emplear una transformación especial conocida como «codificación ficticia» para representar el estado actual de los mercados en nuestro modelo de IA.
La codificación ficticia se utiliza cuando se tiene una variable categórica no ordenada y se asigna una columna para cada valor que puede tomar. Por ejemplo, imagina que el equipo de MQL5 te permitiera decidir qué tema de color quieres que tenga tu instalación de MetaTrader 5. Las opciones disponibles son rojo, rosa o azul. Podemos recopilar esta información mediante una base de datos con tres columnas tituladas «Rojo», «Rosa» y «Azul», respectivamente. La columna que seleccionó durante la instalación se establecerá en uno, las demás columnas permanecerán en 0. Esta es la idea detrás de la codificación ficticia.
La codificación ficticia es muy eficaz porque, si hubiéramos seleccionado una representación diferente de la información, como 1-Rojo, 2-Rosa y 3-Azul, nuestros modelos de IA podrían aprender interacciones falsas en los datos que no existen en la vida real. Por ejemplo, el modelo puede aprender que 2 y medio puede ser el color óptimo. Por lo tanto, la codificación ficticia nos ayuda a presentar nuestros modelos con información categórica de una manera que garantiza que el modelo no asuma implícitamente que existe una escala en los datos que se le proporcionan.
Nuestras medias móviles tendrán dos estados: el primer estado se activará cuando la media móvil rápida esté por encima de la lenta. De lo contrario, se activará el segundo estado. Solo un estado puede estar activo en un momento dado. Es imposible que el precio se encuentre en ambos estados al mismo tiempo. Del mismo modo, nuestro oscilador estocástico tendrá 3 estados. Uno se activará si el precio está por encima del valor 80 en el indicador, el segundo se activará cuando el precio esté por debajo de la zona 20. De lo contrario, se activará el tercer estado.
El estado activo se establecerá en 1 y todos los demás estados se establecerán en 0. Esta transformación obligará a nuestro modelo a aprender el cambio medio en el objetivo a medida que el precio se mueve a través de los diferentes estados de nuestro indicador. Esto se parece mucho a lo que hacen los operadores humanos profesionales. El trading no es como la ingeniería, no podemos esperar una precisión milimétrica. Más bien, los mejores operadores humanos, con el tiempo, aprenden qué es lo más probable que suceda a continuación. Entrenar nuestro modelo utilizando codificación ficticia nos llevará al mismo resultado. Nuestro modelo optimizará sus parámetros para aprender el cambio medio en el precio, dado el estado actual de los indicadores técnicos.
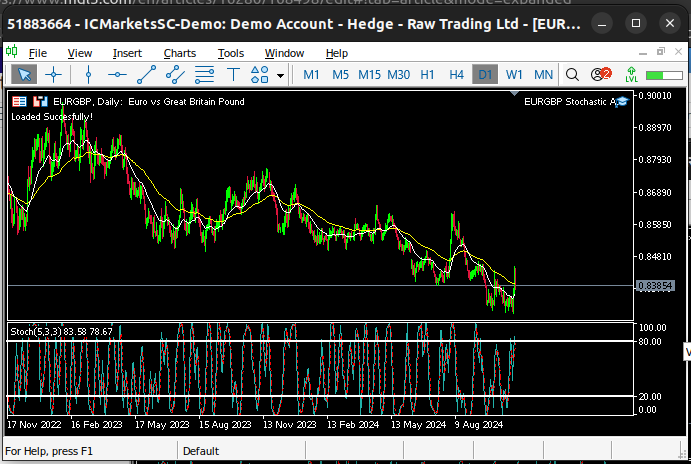
Fig. 5: Visualización del mercado diario EURGBP.
El primer paso que daremos para crear nuestros modelos de IA es recopilar los datos que necesitamos. Siempre es recomendable recuperar los mismos datos que se utilizarán en producción. Esa es la razón por la que utilizaremos este script MQL5 para obtener todos nuestros datos de mercado desde el terminal MetaTrader 5. Las diferencias inesperadas entre cómo se calculan los valores de los indicadores en diferentes bibliotecas pueden dejarnos con resultados insatisfactorios al final del día.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_fast_handler,ma_slow_handler,stoch_handler,atr_handler; double ma_fast[],ma_slow[],stoch[],atr[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator ma_fast_handler = iMA(Symbol(),PERIOD_CURRENT,20,0,MODE_EMA,PRICE_CLOSE); ma_slow_handler = iMA(Symbol(),PERIOD_CURRENT,60,0,MODE_EMA,PRICE_CLOSE); stoch_handler = iStochastic(Symbol(),PERIOD_CURRENT,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR(Symbol(),PERIOD_D1,14); //--- Load the indicator values CopyBuffer(ma_fast_handler,0,0,size,ma_fast); CopyBuffer(ma_slow_handler,0,0,size,ma_slow); CopyBuffer(stoch_handler,0,0,size,stoch); CopyBuffer(atr_handler,0,0,size,atr); ArraySetAsSeries(ma_fast,true); ArraySetAsSeries(ma_slow,true); ArraySetAsSeries(stoch,true); ArraySetAsSeries(atr,true); //--- File name string file_name = "Market Data " + Symbol() +" MA Stoch ATR " + " As Series.csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MA Fast","MA Slow","Stoch Main","ATR"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), ma_fast[i], ma_slow[i], stoch[i], atr[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Análisis exploratorio de datos
Ahora que hemos obtenido los datos del mercado desde la terminal, comencemos a analizarlos.
#Import the libraries import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Leer los datos.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv")
Añadamos un objetivo binario para ayudarnos a visualizar los datos.
#Let's visualize the data data["Binary Target"] = 0 data.loc[data["Close"].shift(-look_ahead) > data["Close"],"Binary Target"] = 1 data = data.iloc[:-look_ahead,:]
Escalar los datos.
#Scale the data before we start visualizing it from sklearn.preprocessing import RobustScaler scaler = RobustScaler() data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Usaremos la biblioteca 'plotly' para visualizar los datos.
import plotly.express as px
Veamos cómo nos ayudan las medias móviles lenta y rápida a diferenciar los movimientos alcistas y bajistas del mercado.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average fig = px.scatter_3d( data, x=data.index, y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of Time, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'Time', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
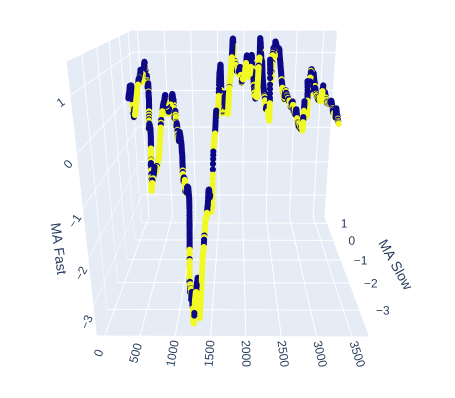
Fig. 6: Visualización de la relación entre las medias móviles y el objetivo.
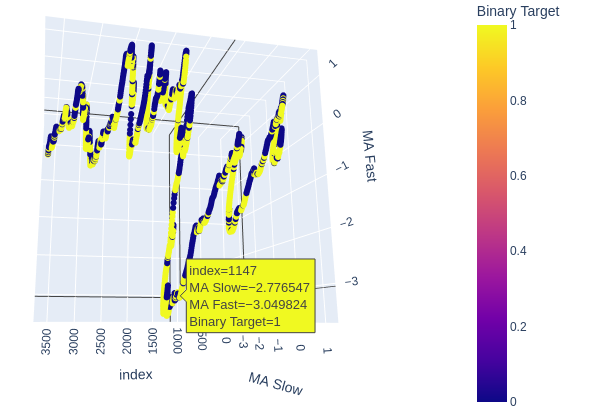
Fig. 7: Nuestras medias móviles parecen agrupar la acción alcista y bajista de los precios en una medida razonable.
Veamos si tal vez la volatilidad del mercado tiene algún efecto sobre el objetivo. Reemplazaremos el tiempo del eje X y, en su lugar, colocaremos el valor ATR, y las medias móviles lentas y rápidas mantendrán sus posiciones.
# Create a 3D scatter plot showing the ineteraction between the slow and fast moving average and the ATR fig = px.scatter_3d( data, x='ATR', y='MA Slow', z='MA Fast', color='Binary Target', title="3D Scatter Plot of ATR, The Slow Moving Average, and The Fast Moving Average", labels={'x': 'ATR', 'y': 'MA Fast', 'z':'MA Slow'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
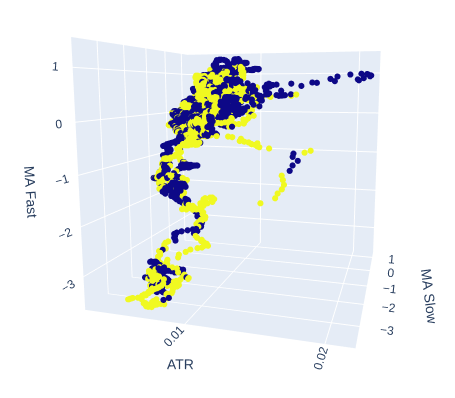
Fig. 8: El ATR parece aportar poca claridad a nuestra visión del mercado. Es posible que tengamos que modificar ligeramente la lectura de la volatilidad para que resulte informativa.
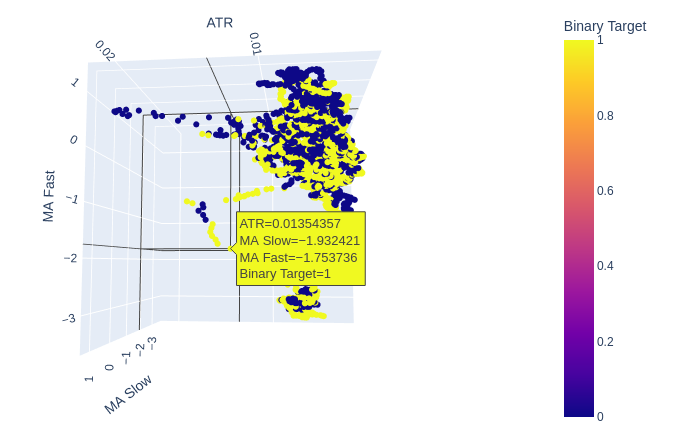
Fig. 9: El ATR parece exponer grupos de movimientos alcistas y bajistas en los precios. Sin embargo, los grupos son pequeños y es posible que no se produzcan con la frecuencia suficiente como para formar parte de una estrategia comercial fiable.
Las dos medias móviles y el oscilador estocástico juntos dan a nuestros datos de mercado una estructura completamente nueva.
# Creating a 3D scatter plot of the slow and fast moving average and the stochastic oscillator fig = px.scatter_3d( data, x='MA Fast', y='MA Slow', z='Stoch Main', color='Binary Target', title="3D Scatter Plot of Time, Close Price, and The Stochastic Oscilator", labels={'x': 'Time', 'y': 'Close Price', 'z': 'Stochastic Oscilator'} ) # Update layout for custom size fig.update_layout( width=800, # Width of the figure in pixels height=600 # Height of the figure in pixels ) # Adjust marker size for visibility fig.update_traces(marker=dict(size=2)) # Set marker size to a smaller value fig.show()
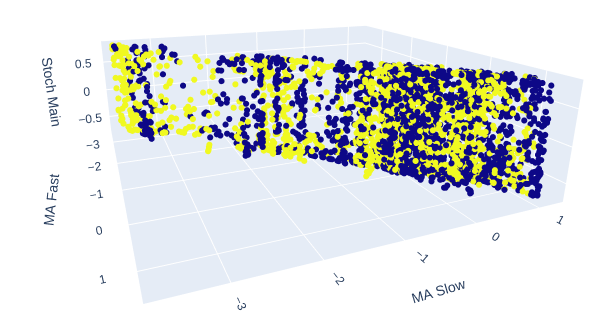
Fig. 10: La lectura principal estocástica y las dos medias móviles proporcionan unas zonas alcistas y bajistas bien definidas.
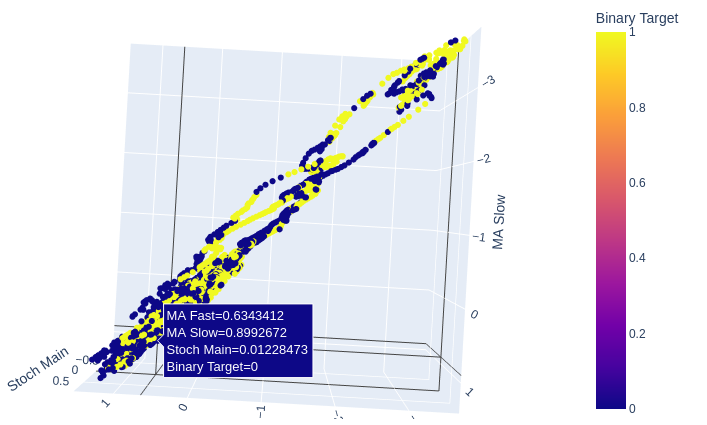
Fig. 11: La relación entre las dos medias móviles y el estocástico puede ser más adecuada para revelar una acción alcista del precio que una acción bajista.
Dado que estamos utilizando 3 indicadores técnicos y 4 cotizaciones de precios diferentes, nuestros datos tienen 7 dimensiones, pero solo podemos visualizar 3 como máximo. Podemos transformar nuestros datos en solo dos columnas utilizando técnicas de reducción de dimensionalidad. El análisis de componentes principales es una opción muy utilizada para resolver este tipo de problemas. Podemos utilizar el algoritmo para resumir todas las columnas de nuestro conjunto de datos original en solo 2 columnas.
A continuación, crearemos un diagrama de dispersión de los dos componentes principales y determinaremos en qué medida nos permiten identificar el objetivo.
# Selecting features to include in PCA features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow']] pca = PCA(n_components=2) pca_components = pca.fit_transform(features.dropna()) # Plotting PCA results # Create a new DataFrame with PCA results and target variable for plotting pca_df = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2']) pca_df['target'] = data['Binary Target'].iloc[:len(pca_components)] # Add target column # Plot PCA results with binary target as hue fig = px.scatter( pca_df, x='PC1', y='PC2', color='target', title="2D PCA Plot of OHLC Data with Target Hue", labels={'PC1': 'Principal Component 1', 'PC2': 'Principal Component 2', 'color': 'Target'} ) # Update layout for custom size fig.update_layout( width=600, # Width of the figure in pixels height=600 # Height of the figure in pixels ) fig.show()
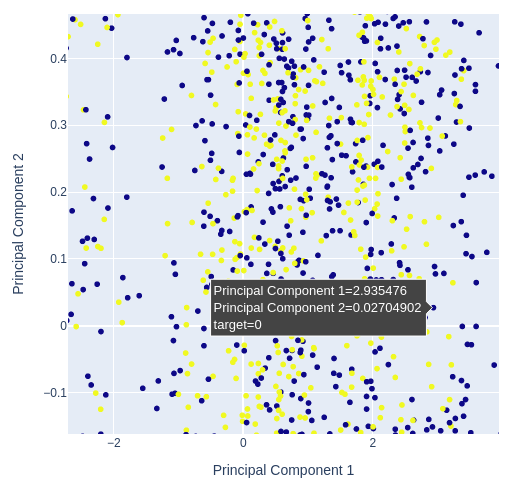
Fig. 12: Ampliación de una parte aleatoria de nuestro diagrama de dispersión de los dos primeros componentes principales para ver cómo se separan las fluctuaciones de precios.
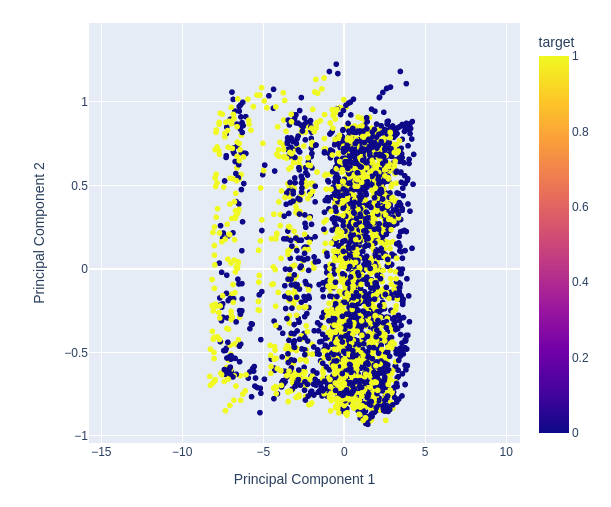
Fig. 13: La visualización de nuestros datos nos muestra que el PCA no añade una mejor separación al conjunto de datos.
Los algoritmos de aprendizaje no supervisado, como KMeansClustering, pueden ser capaces de aprender patrones en los datos que no son evidentes para nosotros. El algoritmo creará etiquetas para los datos que se le proporcionen, sin ninguna información sobre el objetivo.
La idea es que nuestro algoritmo de agrupamiento KMeans pueda aprender dos clases a partir de nuestro conjunto de datos que separen bien nuestras dos clases. Lamentablemente, el algoritmo KMeans no cumplió realmente con nuestras expectativas. Observamos movimientos alcistas y bajistas en los precios de ambas clases, según el algoritmo generado a partir de los datos.
from sklearn.cluster import KMeans # Select relevant features for clustering features = data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main','ATR']] target = data['Binary Target'].iloc[:len(features)] # Ensure target matches length of features # Apply K-means clustering with 2 clusters kmeans = KMeans(n_clusters=2) clusters = kmeans.fit_predict(features) # Create a DataFrame for plotting with target and cluster labels plot_data = pd.DataFrame({ 'target': target, 'cluster': clusters }) # Plot with seaborn's catplot to compare the binary target and cluster assignments sns.catplot(x='cluster', hue='target',kind='count', data=plot_data) plt.title("Comparison of K-means Clusters with Binary Target") plt.show()
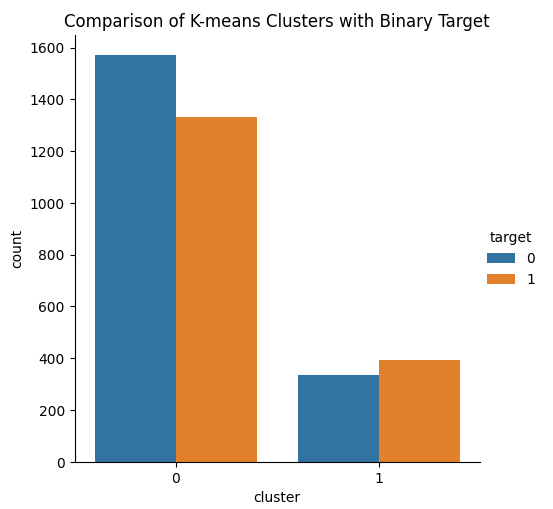
Fig. 14: Visualizando los dos clústeres, nuestro algoritmo KMeans aprendió a partir de los datos del mercado.
También podemos comprobar las relaciones entre las variables midiendo la correlación de cada entrada con nuestro objetivo. Ninguna de nuestras variables tiene coeficientes de correlación fuertes con nuestro objetivo. Tenga en cuenta que esto no refuta la existencia de una relación que podamos modelar.
#Read in the data data = pd.read_csv("Market Data EURGBP MA Stoch ATR As Series.csv") #Add targets data["ATR Target"] = data["ATR"].shift(-look_ahead) data["Target"] = data["Close"].shift(-look_ahead) - data["Close"]
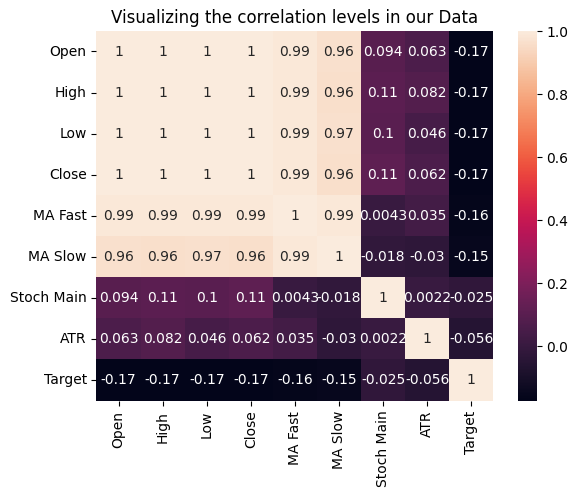
Fig. 15: Visualización de los niveles de correlación en nuestro conjunto de datos.
Ahora transformemos nuestros datos de entrada. Tenemos tres formas en las que podemos utilizar nuestros indicadores:
- La lectura actual.
- Estados de Markov.
- Diferencia con respecto a su valor anterior.
Diferencia con respecto a su valor anterior. La forma óptima de presentar los datos variará en función de factores como el indicador que se esté modelando y el mercado al que se aplique dicho indicador. Dado que no hay otra forma de determinar la opción ideal, realizaremos una búsqueda exhaustiva de todas las opciones posibles para cada indicador.
Presta atención a la columna «Hora» (Time) de nuestro conjunto de datos. Tenga en cuenta que nuestros datos abarcan desde el año 2010 hasta 2021. ¿Esto no se superpone con el período que utilizaremos para nuestra prueba retrospectiva?
#Let's think of the different ways we can show the indicators to our AI Model #We can describe the indicator by its current reading #We can describe the indicator using markov states #We can describe the change in the indicator's value #Let's see which form helps our AI Model predict the future ATR value data["ATR 1"] = 0 data["ATR 2"] = 0 #Set the states data.loc[data["ATR"] > data["ATR"].shift(look_ahead),"ATR 1"] = 1 data.loc[data["ATR"] < data["ATR"].shift(look_ahead),"ATR 2"] = 1 #Set the change in the ATR data["Change in ATR"] = data["ATR"] - data["ATR"].shift(look_ahead) #We'll do the same for the stochastic data["STO 1"] = 0 data["STO 2"] = 0 data["STO 3"] = 0 #Set the states data.loc[data["Stoch Main"] > 80,"STO 1"] = 1 data.loc[data["Stoch Main"] < 20,"STO 2"] = 1 data.loc[(data["Stoch Main"] >= 20) & (data["Stoch Main"] <= 80) ,"STO 3"] = 1 #Set the change in the stochastic data["Change in STO"] = data["Stoch Main"] - data["Stoch Main"].shift(look_ahead) #Finally the moving averages data["MA 1"] = 0 data["MA 2"] = 0 #Set the states data.loc[data["MA Fast"] > data["MA Slow"],"MA 1"] = 1 data.loc[data["MA Fast"] < data["MA Slow"],"MA 2"] = 1 #Difference in the MA Height data["Change in MA"] = (data["MA Fast"] - data["MA Slow"]) - (data["MA Fast"].shift(look_ahead) - data["MA Slow"].shift(look_ahead)) #Difference in price data["Change in Close"] = data["Close"] - data["Close"].shift(look_ahead) #Clean the data data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) #Drop the last 2 years of test data data = data.iloc[:((-365*2) - 18),:] data.dropna(inplace=True) data.reset_index(inplace=True,drop=True) data
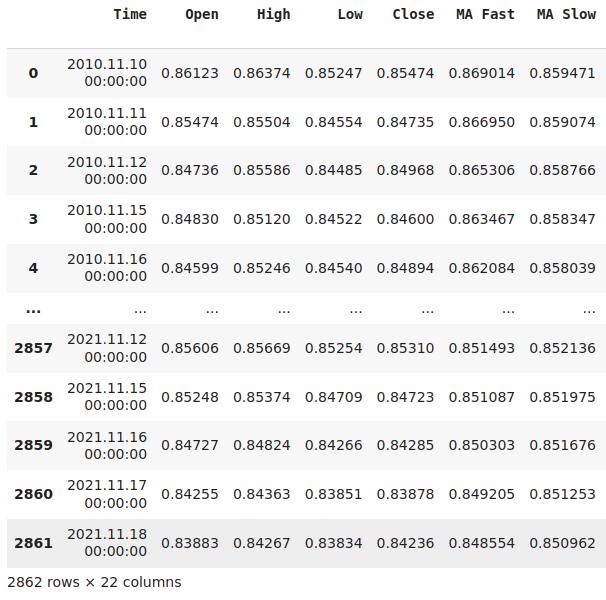
Fig. 16: Visualización de nuestros datos de mercado tras transformarlos adecuadamente.
Veamos qué forma de presentación es más eficaz para que nuestro modelo aprenda el cambio en el precio dado el cambio en nuestros indicadores. Utilizaremos un árbol regresor de refuerzo de gradiente como nuestro modelo de elección.
#Let's see which method of presentation is most effective from sklearn.ensemble import GradientBoostingRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Defina los parámetros de nuestra validación cruzada de series temporales.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)Ahora establezcamos un umbral. Cualquier modelo que pueda ser superado simplemente utilizando el precio de cierre para predecir la variación del precio no es un buen modelo.
#Our baseline accuracy forecasting the change in price using current price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Close"]],data.loc[:,"Target"],cv=tscv))
-0.14861941262441164
En la mayoría de los problemas, siempre podemos obtener mejores resultados utilizando la variación del precio, en lugar de solo el precio actual.
#Our accuracy forecasting the change in price using current change in price np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in Close"]],data.loc[:,"Target"],cv=tscv))
-0.1033528767401429
Nuestro modelo puede funcionar aún mejor si le proporcionamos el oscilador estocástico.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Stoch Main"]],data.loc[:,"Target"],cv=tscv))
-0.09152071417994265
Sin embargo, ¿es esto lo mejor que podemos hacer? ¿Qué pasaría si, en su lugar, le diéramos a nuestro modelo el cambio en el oscilador estocástico? ¡Nuestra capacidad para pronosticar los cambios en los precios mejora!
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in STO"]],data.loc[:,"Target"],cv=tscv))
-0.07090156075020868
¿Qué crees que pasará si ahora aplicamos nuestro enfoque de codificación ficticia? Hemos creado tres columnas para indicar de forma sencilla en qué estado se encuentra el indicador. Nuestras tasas de error se reducen. Este resultado es muy interesante, ya que estamos obteniendo mejores resultados que un operador que intenta predecir los cambios en el precio a partir del precio actual o la lectura actual del oscilador estocástico. Pero hay que tener en cuenta que no sabemos si esto es cierto en todos los mercados posibles. Solo estamos seguros de que esto es cierto en el mercado EURGBP en el marco temporal diario.
#Our accuracy forecasting the change in price using the stochastic np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"],cv=tscv))
Ahora evaluemos nuestra precisión a la hora de predecir los cambios en el precio utilizando la lectura actual de las dos medias móviles. Los resultados no parecen buenos, nuestras tasas de error son más altas que nuestra precisión utilizando solo el precio de cierre para predecir el cambio futuro en el precio. Este modelo debe abandonarse y no es apto para su uso en producción.
#Our accuracy forecasting the change in price using the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA Slow","MA Fast"]],data.loc[:,"Target"],cv=tscv))
Si transformamos nuestros datos para poder ver el cambio en los valores de la media móvil, nuestros resultados mejoran. Sin embargo, seguirá siendo mejor utilizar un modelo más sencillo que solo tenga en cuenta el precio de cierre actual.
#Our accuracy forecasting the change in price using the change in the moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in MA"]],data.loc[:,"Target"],cv=tscv))
Sin embargo, si aplicamos nuestra técnica de codificación ficticia a los datos del mercado, comenzamos a superar a cualquier operador del mismo mercado que utilice cotizaciones de precios ordinarias en el marco temporal diario. Nuestras tasas de error se reducen a mínimos históricos nunca antes vistos. Esta transformación es poderosa. Recuerde que esto ayuda al modelo a centrarse más en los cambios críticos en el valor del indicador, en lugar de aprender la correspondencia exacta de cada valor posible que puede tomar nuestro indicador.
#Our accuracy forecasting the change in price using the state of moving averages np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"],cv=tscv))
Para los lectores que están aprendiendo este tema por primera vez, esta sección es especialmente importante. Como seres humanos, tendemos a ver patrones, incluso cuando no existen. Lo que has leído hasta ahora puede darte la impresión de que la codificación ficticia es siempre tu mejor aliada. Sin embargo, este no es el caso. Observe lo que sucede cuando intentamos optimizar nuestro modelo final de IA que va a predecir la lectura futura del ATR.
No compares los resultados que verás ahora con los resultados que acabamos de comentar. Las unidades del objetivo han cambiado. Por lo tanto, una comparación directa entre nuestra precisión a la hora de predecir los cambios en el precio y nuestra precisión a la hora de predecir el valor futuro del ATR no tiene sentido en la práctica.
Básicamente, estamos creando un nuevo umbral. Nuestra precisión a la hora de predecir el ATR utilizando valores anteriores del ATR es nuestra nueva referencia. Cualquier técnica que dé lugar a un mayor error no es óptima y debe abandonarse.
#Our accuracy forecasting the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR"]],data.loc[:,"ATR Target"],cv=tscv))
Hasta ahora, hoy hemos observado que nuestras tasas de error disminuyen cada vez que pasamos a nuestro modelo la diferencia en los datos en lugar de los datos en su forma actual. Sin embargo, esta vez nuestro error fue aún peor.
#Our accuracy forecasting the ATR using the change in the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["Change in ATR"]],data.loc[:,"ATR Target"],cv=tscv))
-0.5916640039518372
Además, codificamos ficticiamente el indicador ATR para indicar si había estado subiendo o bajando. Nuestras tasas de error seguían siendo inaceptables. Por lo tanto, utilizaremos nuestro indicador ATR tal cual y el oscilador estocástico y nuestras medias móviles se codificarán de forma ficticia.
#Our accuracy forecasting the ATR using the current state of the ATR np.mean(cross_val_score(GradientBoostingRegressor(),data.loc[:,["ATR 1","ATR 2"]],data.loc[:,"ATR Target"],cv=tscv))
Exportación a ONNX
Open Neural Network Exchange (ONNX) es un protocolo de código abierto que define una representación universal para todos los modelos de aprendizaje automático. Esto nos permite desarrollar y compartir modelos en cualquier lenguaje, siempre y cuando ese lenguaje sea totalmente compatible con la API ONNX. ONNX nos permite exportar los modelos de IA que acabamos de desarrollar y utilizarlos directamente en nuestros modelos de IA para tomar nuestras decisiones comerciales, en lugar de utilizar reglas comerciales fijas.
#Load the libraries we need import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Defina la forma de entrada de cada modelo.
#Define the input shapes #ATR AI initial_types_atr = [('float_input', FloatTensorType([1, 1]))] #MA AI initial_types_ma = [('float_input', FloatTensorType([1, 2]))] #STO AI initial_types_sto = [('float_input', FloatTensorType([1, 3]))]
Ajustar cada modelo a todos los datos que tenemos.
#ATR AI Model atr_ai = GradientBoostingRegressor().fit(data.loc[:,["ATR"]],data.loc[:,"ATR Target"]) #MA AI Model ma_ai = GradientBoostingRegressor().fit(data.loc[:,["MA 1","MA 2"]],data.loc[:,"Target"]) #Stochastic AI Model sto_ai = GradientBoostingRegressor().fit(data.loc[:,["STO 1","STO 2","STO 3"]],data.loc[:,"Target"])
Guarde los modelos ONNX.
#Save the ONNX models onnx.save(convert_sklearn(atr_ai, initial_types=initial_types_atr),"EURGBP ATR.onnx") onnx.save(convert_sklearn(ma_ai, initial_types=initial_types_ma),"EURGBP MA.onnx") onnx.save(convert_sklearn(sto_ai, initial_types=initial_types_sto),"EURGBP Stoch.onnx")
Implementación en MQL5
Utilizaremos el mismo algoritmo de negociación que hemos desarrollado hasta ahora. Solo cambiaremos las reglas fijas que establecimos inicialmente y, en su lugar, permitiremos que nuestra aplicación de trading realice sus operaciones siempre que nuestros modelos nos den una señal clara. Además, comenzaremos importando los modelos ONNX que hemos desarrollado.
//+------------------------------------------------------------------+ //| EURGBP Stochastic AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the AI Modules | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP MA.onnx" as const uchar ma_onnx_buffer[]; #resource "\\Files\\EURGBP ATR.onnx" as const uchar atr_onnx_buffer[]; #resource "\\Files\\EURGBP Stoch.onnx" as const uchar stoch_onnx_buffer[];
Además, comenzaremos importando los modelos ONNX que hemos desarrollado.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double vol,bid,ask; long atr_model,ma_model,stoch_model; vectorf atr_forecast = vectorf::Zeros(1),ma_forecast = vectorf::Zeros(1),stoch_forecast = vectorf::Zeros(1);
También debemos actualizar nuestro procedimiento de desinicialización. Nuestro modelo también debería liberar los recursos que estaban siendo utilizados por nuestros modelos ONNX.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(fast_ma_handler); IndicatorRelease(slow_ma_handler); IndicatorRelease(atr_handler); IndicatorRelease(stochastic_handler); OnnxRelease(atr_model); OnnxRelease(ma_model); OnnxRelease(stoch_model); }
Obtener predicciones de nuestros modelos ONNX no es tan costoso como entrenar los modelos. Sin embargo, para realizar rápidamente pruebas retrospectivas de nuestros algoritmos de negociación, obtener una predicción de IA en cada tick resulta caro. Nuestras pruebas retrospectivas serán mucho más rápidas si obtenemos predicciones de nuestros modelos de IA cada 5 minutos.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated quotes update(); //--- Only on new candles static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_M5,0); if(time_stamp != current_time) { time_stamp = current_time; //--- If we have no open positions, check for a setup if(PositionsTotal() == 0) { find_setup(); } } }
También necesitamos actualizar la función responsable de configurar nuestros indicadores técnicos. La función configurará nuestros modelos de IA y validará que los modelos se hayan cargado correctamente.
//+------------------------------------------------------------------+ //| Setup technical market data | //+------------------------------------------------------------------+ void setup(void) { //--- Setup our indicators slow_ma_handler = iMA("EURGBP",PERIOD_D1,slow_period,0,MODE_EMA,PRICE_CLOSE); fast_ma_handler = iMA("EURGBP",PERIOD_D1,fast_period,0,MODE_EMA,PRICE_CLOSE); stochastic_handler = iStochastic("EURGBP",PERIOD_D1,5,3,3,MODE_EMA,STO_CLOSECLOSE); atr_handler = iATR("EURGBP",PERIOD_D1,atr_period); //--- Fetch market data vol = lot_multiple * SymbolInfoDouble("EURGBP",SYMBOL_VOLUME_MIN); //--- Create our onnx models atr_model = OnnxCreateFromBuffer(atr_onnx_buffer,ONNX_DEFAULT); ma_model = OnnxCreateFromBuffer(ma_onnx_buffer,ONNX_DEFAULT); stoch_model = OnnxCreateFromBuffer(stoch_onnx_buffer,ONNX_DEFAULT); //--- Validate our models if(atr_model == INVALID_HANDLE || ma_model == INVALID_HANDLE || stoch_model == INVALID_HANDLE) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } //--- Set the sizes of our ONNX models ulong atr_input_shape[] = {1,1}; ulong ma_input_shape[] = {1,2}; ulong sto_input_shape[] = {1,3}; if(!(OnnxSetInputShape(atr_model,0,atr_input_shape)) || !(OnnxSetInputShape(ma_model,0,ma_input_shape)) || !(OnnxSetInputShape(stoch_model,0,sto_input_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } ulong output_shape[] = {1,1}; if(!(OnnxSetOutputShape(atr_model,0,output_shape)) || !(OnnxSetOutputShape(ma_model,0,output_shape)) || !(OnnxSetOutputShape(stoch_model,0,output_shape))) { Comment("[ERROR] Failed to load AI modules: ",GetLastError()); } }
En nuestro anterior algoritmo de trading, simplemente abríamos nuestras posiciones siempre que los indicadores se alineaban a nuestro favor. Ahora, en cambio, abriremos nuestras posiciones si nuestros modelos de IA nos dan una señal clara de negociación. Además, nuestros niveles de take-profit y stop-loss se establecerán dinámicamente en función de los niveles de volatilidad previstos. Esperamos haber creado un filtro utilizando IA que nos proporcione señales de trading más rentables.
//+------------------------------------------------------------------+ //| Check if we have an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Predict future ATR values vectorf atr_model_input = vectorf::Zeros(1); atr_model_input[0] = (float) atr[0]; //--- Predicting future price using the stochastic oscilator vectorf sto_model_input = vectorf::Zeros(3); if(stochastic[0] > 80) { sto_model_input[0] = 1; sto_model_input[1] = 0; sto_model_input[2] = 0; } else if(stochastic[0] < 20) { sto_model_input[0] = 0; sto_model_input[1] = 1; sto_model_input[2] = 0; } else { sto_model_input[0] = 0; sto_model_input[1] = 0; sto_model_input[2] = 1; } //--- Finally prepare the moving average forecast vectorf ma_inputs = vectorf::Zeros(2); if(fast_ma[0] > slow_ma[0]) { ma_inputs[0] = 1; ma_inputs[1] = 0; } else { ma_inputs[0] = 0; ma_inputs[1] = 1; } OnnxRun(stoch_model,ONNX_DEFAULT,sto_model_input,stoch_forecast); OnnxRun(atr_model,ONNX_DEFAULT,atr_model_input,atr_forecast); OnnxRun(ma_model,ONNX_DEFAULT,ma_inputs,ma_forecast); Comment("ATR Forecast: ",atr_forecast[0],"\nStochastic Forecast: ",stoch_forecast[0],"\nMA Forecast: ",ma_forecast[0]); //--- Can we buy? if((ma_forecast[0] > 0) && (stoch_forecast[0] > 0)) { Trade.Buy(vol,"EURGBP",ask,(ask - (atr[0] * atr_multiple)),(ask + (atr_forecast[0] * atr_multiple)),"EURGBP"); } //--- Can we sell? if((ma_forecast[0] < 0) && (stoch_forecast[0] < 0)) { Trade.Sell(vol,"EURGBP",bid,(bid + (atr[0] * atr_multiple)),(bid - (atr_forecast[0] * atr_multiple)),"EURGBP"); } } //+------------------------------------------------------------------+
Realizaremos nuestra prueba retrospectiva durante el mismo periodo que utilizamos anteriormente, desde principios de enero de 2022 hasta junio de 2024. Recordemos que cuando entrenamos nuestro modelo de IA, no disponíamos de datos en el rango de la prueba retrospectiva. Realizaremos la prueba utilizando el mismo símbolo, el par EURGBP, en el mismo marco temporal, el marco temporal diario.
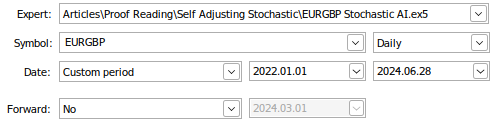
Fig. 17: Prueba retrospectiva de nuestro modelo de IA.
Fig. 17: Prueba retrospectiva de nuestro modelo de IA. Básicamente, estamos tratando de aislar la diferencia que supone que nuestras decisiones sean tomadas por nuestros modelos de IA.
Fig. 18: Los parámetros restantes de nuestra prueba retrospectiva.
¡Nuestra estrategia comercial fue más rentable durante el período de prueba! Esta es una gran noticia, ya que a los modelos no se les mostraron los datos que estamos utilizando en la prueba retrospectiva. Por lo tanto, podemos tener expectativas positivas al utilizar este modelo para operar con una cuenta real.
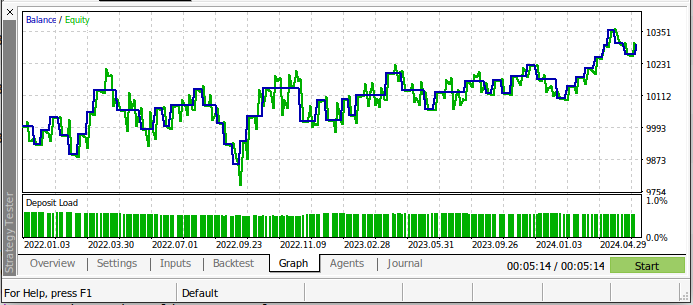
Fig. 19: Resultados de la comprobación retrospectiva de nuestro modelo de IA en las fechas de prueba.
Fig. 19: Resultados de la comprobación retrospectiva de nuestro modelo de IA en las fechas de prueba. Además, nuestro índice de Sharpe ahora es positivo y solo el 44% de nuestras operaciones fueron operaciones con pérdidas.
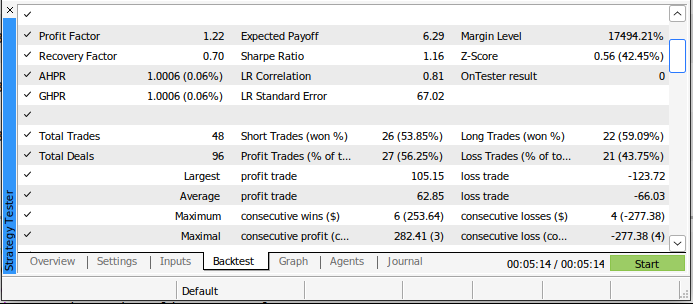
Fig. 20: Resultados detallados de las pruebas retrospectivas de nuestra estrategia de negociación basada en inteligencia artificial.
Conclusión
Espero que, después de leer este artículo, estés de acuerdo conmigo en que la IA puede utilizarse realmente para mejorar nuestras estrategias de trading. Incluso la estrategia de trading clásica más antigua puede reinventarse utilizando la IA y renovarse para alcanzar nuevos niveles de rendimiento. Parece que el truco consiste en transformar de forma inteligente los datos de los indicadores para ayudar a los modelos a aprender de manera eficaz. La técnica de codificación ficticia que hemos mostrado hoy nos ha ayudado mucho. Pero no podemos concluir que sea la mejor opción para todos los mercados posibles. Es posible que la técnica de codificación ficticia sea la mejor opción que tenemos para un determinado grupo de mercados. Sin embargo, podemos concluir con seguridad que el cruce de medias móviles puede renovarse eficazmente utilizando la IA.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16280
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Gracias Gamu . Me gustan tus publicaciones y trato de aprender reproduciendo tus pasos.
Estoy teniendo algunos problemas espero que esto puede ayudar a otros.
1) mis pruebas con usted EURGBP_Stochastic diario utilizando el script suministrado sólo produce 2 órdenes y, posteriormente, la relación de Sharpe de 0,02 . Creo que tengo la misma configuración que usted, pero en 2 corredores que produce sólo 2 órdenes.
2) como un aviso para los demás puede que tenga que modificar la configuración del símbolo para que coincida con su corredor (por ejemplo, EURGBP a EURGBP.i) si es necesario
3) Cuando intento exportar los datos obtengo un array fuera de rango para el ATR, creo que esto se debe a que no consigo 100000 registros en mi Array (si lo cambio a 677) puedo obtener un archivo con 677 filas. Para mi el valor por defecto para max barras en un gráfico es 50000, si lo cambio a 100000 el tamaño de mi array es solo 677, pero posiblemente tengo una mala configuración. Tal vez usted también podría incluir la secuencia de comandos de extracción de datos en su descarga .
4)He copiado el código de su artículo para probarlo en Python. Obtengo un error look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: el nombre 'look_ahead' no está definido
5) cuando cargué su cuaderno de Juypiter lo encuentro necesitado tener mirada adelante fijada #Preveamos 20 pasos en el futuro
look_ahead = 20 , Después de esto he utilizado su archivo incluido sólo pero estoy atascado en el siguiente error , posiblemente relacionados con sólo tener 677 filas .
Ejecuto #Escala los datos antes de empezar a visualizarlos
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
que me da un error que no entiendo cómo resolver
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Se está intentando establecer un valor en una copia de un slice de un DataFrame. Intente utilizar .loc[row_indexer,col_indexer] = value en su lugar Consulte las advertencias en la documentación: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Gracias Gamu . Disfruto con tus publicaciones e intento aprender reproduciendo tus pasos.
Estoy teniendo algunos problemas espero que esto puede ayudar a otros.
1) mis pruebas con usted EURGBP_Stochastic diario utilizando el script suministrado sólo produce 2 órdenes y, posteriormente, la relación de Sharpe de 0,02 . Creo que tengo la misma configuración que usted, pero en 2 corredores que produce sólo 2 órdenes.
2) como un aviso para los demás puede que tenga que modificar la configuración del símbolo para que coincida con su corredor (por ejemplo, EURGBP a EURGBP.i) si es necesario
3) Cuando intento exportar los datos obtengo un array fuera de rango para el ATR, creo que esto se debe a que no consigo 100000 registros en mi Array (si lo cambio a 677) puedo obtener un archivo con 677 filas. Para mi el valor por defecto para max barras en un grafico es 50000, si lo cambio a 100000 el tamaño de mi array es solo 677, pero posiblemente tengo una mala configuracion. Tal vez usted también podría incluir la secuencia de comandos de extracción de datos en su descarga .
4)He copiado el código de su artículo para probarlo en Python. Obtengo un error look_ahead not defined ----> 3 data.loc[data["Close"].shift(-look_ahead) > data["Close"], "Binary Target"] = 1
4 data = data.iloc[:-look_ahead,:]
NameError: el nombre 'look_ahead' no está definido
5) cuando cargué su cuaderno de Juypiter encuentro que necesitó tener mirada adelante fijada #Preveamos 20 pasos en el futuro
look_ahead = 20 , Después de esto he utilizado su archivo incluido sólo pero estoy atascado en el siguiente error , posiblemente relacionados con sólo tener 677 filas .
Ejecuto #Escala los datos antes de empezar a visualizarlos
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
data[['Abierto', 'Alto', 'Bajo', 'Cierre', 'MA Rápido', 'MA Lento','Estoc Principal']] = scaler.fit_transform(data[['Abierto', 'Alto', 'Bajo', 'Cierre', 'MA Rápido', 'MA Lento','Estoc Principal']])
lo que me da un error que no entiendo como resolver
ipython-input-6-b2a044d397d0>:4: SettingWithCopyWarning: Se está intentando establecer un valor en una copia de un slice de un DataFrame. Intente utilizar .loc[row_indexer,col_indexer] = value en su lugar Consulte las advertencias en la documentación: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']] = scaler.fit_transform(data[['Open', 'High', 'Low', 'Close', 'MA Fast', 'MA Slow','Stoch Main']])
Qué pasa Neil, confío en que estés bien.
Gracias Gamu Aprecio que , Sí, sé que hay muchas partes móviles , Voy a ver si esto va a resolver mis problemas
Gracias Gamu Aprecio que, Sí, sé que hay muchas partes móviles, voy a ver si esto va a resolver mis problemas