Artículos sobre aprendizaje automático en el trading
Creación de robots comerciales basados en inteligencia artificial: integración nativa con Python, operaciones con matrices y vectores, bibliotecas de matemáticas y estadística y mucho más.
Aprenda a usar el aprendizaje automático en el trading. Neuronas, perceptrones, redes convolucionales y recurrentes, modelos predictivos: parta de lo básico y avance hasta construir su propia IA. Aprenderá a entrenar y aplicar redes neuronales para el comercio algorítmico en los mercados financieros.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Algoritmo de optimización aritmética (AOA): De AOA a SOA (Simple Optimization Algorithm)
En este artículo, presentamos el algoritmo de optimización aritmética (AOA) basado en operaciones aritméticas simples: suma, resta, multiplicación y división. Estas operaciones matemáticas básicas sirven como base para encontrar soluciones óptimas a diversos problemas.
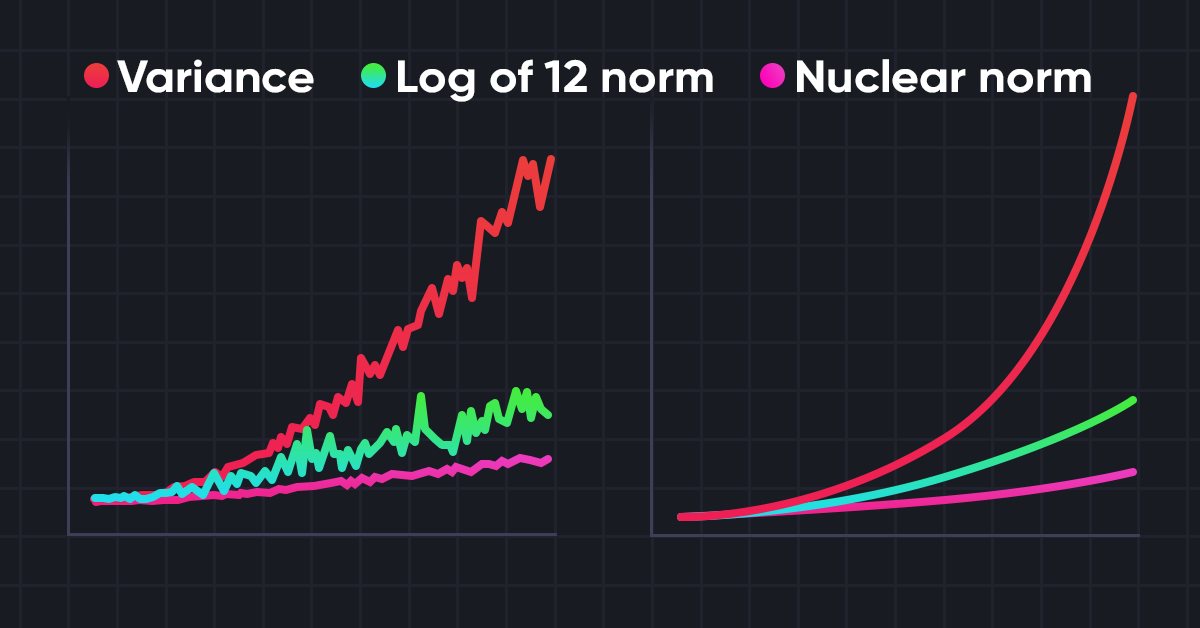
Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración
La exploración del entorno en tareas de aprendizaje por refuerzo es un problema relevante. Con anterioridad, ya hemos analizado algunos de estos enfoques. Hoy le propongo introducir otro método basado en la maximización de la norma nuclear, que permite a los agentes identificar estados del entorno con un alto grado de novedad y diversidad.

Medimos la informatividad de los indicadores
El aprendizaje automático se ha convertido en una técnica popular de desarrollo de estrategias. Por lo general, en el trading se presta más atención a la maximización de la rentabilidad y la precisión de los pronósticos. Al mismo tiempo, el procesamiento de los datos utilizados para la construcción de los modelos predictivos permanece en la periferia. En este artículo, analizaremos el uso del concepto de entropía para evaluar la idoneidad de los indicadores en la construcción de modelos predictivos, como se describe en el libro «Testing and Tuning Market Trading Systems» de Timothy Masters.

Obtenga una ventaja sobre cualquier mercado (Parte V): Datos alternativos de FRED (Federal Reserve Economic Data) sobre el EURUSD
En el debate de hoy, utilizamos datos diarios alternativos de la Reserva Federal de St. Louis sobre el índice amplio del dólar estadounidense y una colección de otros indicadores macroeconómicos para predecir el tipo de cambio futuro del EURUSD. Lamentablemente, aunque los datos parecen tener una correlación casi perfecta, no logramos obtener ninguna mejora material en la precisión de nuestro modelo, lo que posiblemente nos sugiere que los inversores podrían estar mejor si utilizan cotizaciones de mercado ordinarias.

Predicción de tendencias con LSTM para estrategias de seguimiento de tendencias
La memoria a corto y largo plazo (Long Short-Term Memory, LSTM) es un tipo de red neuronal recurrente (Recurrent Neural Network, RNN) diseñada para modelar datos secuenciales capturando de manera efectiva las dependencias a largo plazo y abordando el problema del gradiente que se desvanece. En este artículo, exploraremos cómo utilizar LSTM para predecir tendencias futuras, mejorando el rendimiento de las estrategias de seguimiento de tendencias. El artículo tratará sobre la introducción de conceptos clave y la motivación detrás del desarrollo, la obtención de datos de MetaTrader 5, el uso de esos datos para entrenar el modelo en Python, la integración del modelo de aprendizaje automático en MQL5 y la reflexión sobre los resultados y las aspiraciones futuras basadas en pruebas estadísticas retrospectivas.

Algoritmos de optimización de la población: microsistema inmune artificial (Micro Artificial immune system, Micro-AIS)
El artículo habla de un método de optimización basado en los principios del sistema inmune del organismo -Micro Artificial immune system, (Micro-AIS)-, una modificación del AIS. El Micro-AIS usa un modelo más simple del sistema inmunitario y operaciones sencillas de procesamiento de la información inmunitaria. El artículo también analizará las ventajas e inconvenientes del Micro-AIS en comparación con el AIS convencional.

Aprendizaje automático y Data Science (Parte 31): Uso de los modelos de inteligencia artificial CatBoost
Los modelos de IA CatBoost han ganado popularidad masiva recientemente entre las comunidades de aprendizaje automático debido a su precisión predictiva, eficiencia y robustez ante conjuntos de datos dispersos y difíciles. En este artículo, vamos a discutir en detalle cómo implementar este tipo de modelos en un intento de vencer al mercado de divisas.

Marcado de datos en el análisis de series temporales (Parte 2): Creando conjuntos de datos con marcadores de tendencias utilizando Python
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.

Modelos ocultos de Markov para la predicción de la volatilidad siguiendo tendencias
Los modelos ocultos de Markov (Hidden Markov Models, HMM) son potentes herramientas estadísticas que identifican los estados subyacentes del mercado mediante el análisis de los movimientos observables de los precios. En el ámbito bursátil, los HMM mejoran la predicción de la volatilidad y proporcionan información para las estrategias de seguimiento de tendencias mediante la modelización y la anticipación de los cambios en los regímenes de mercado. En este artículo, presentaremos el procedimiento completo para desarrollar una estrategia de seguimiento de tendencias que utiliza HMM para predecir la volatilidad como filtro.

Algoritmo de cerradura de código (Сode Lock Algorithm, CLA)
En este artículo repensaremos las cerraduras de código, transformándolas de mecanismos de protección en herramientas para resolver problemas complejos de optimización. Descubra el mundo de las cerraduras de código, no como simples dispositivos de seguridad, sino como inspiración para un nuevo enfoque de la optimización. Hoy crearemos toda una población de "cerraduras" en la que cada cerradura representará una solución única a un problema. A continuación, desarrollaremos un algoritmo que "forzará" estas cerraduras y hallará soluciones óptimas en ámbitos que van desde el aprendizaje automático hasta el desarrollo de sistemas comerciales.

Redes neuronales: así de sencillo (Parte 39): Go-Explore: un enfoque diferente sobre la exploración
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.
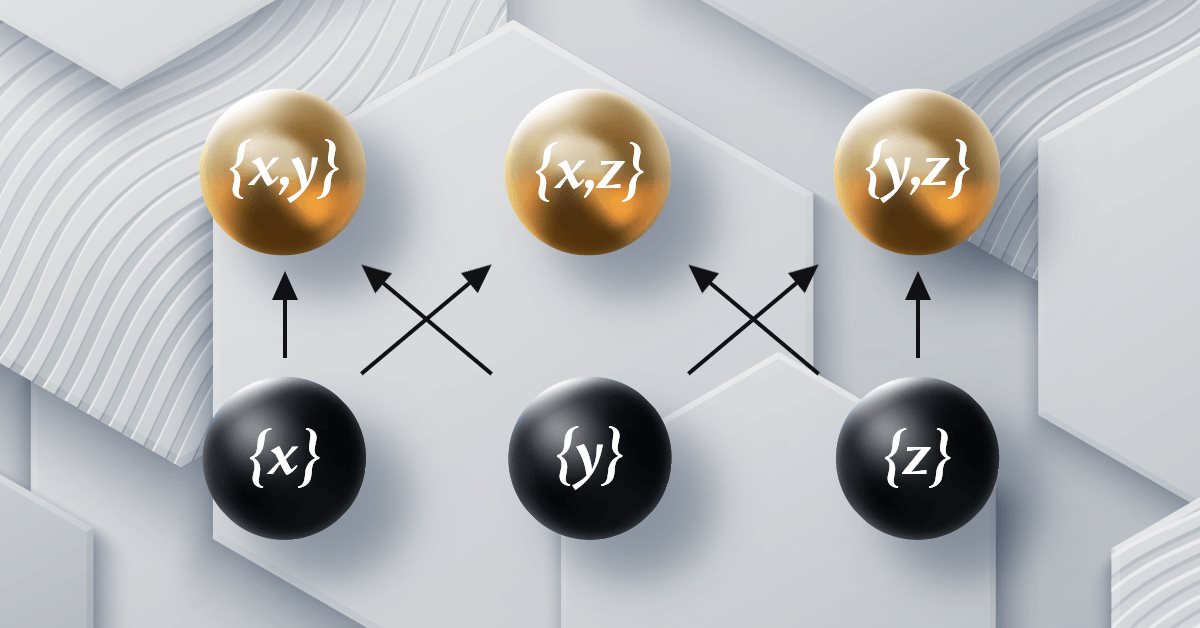
Teoría de categorías en MQL5 (Parte 12): Orden
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.

Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa
Ya hemos hablado más de una vez de la importancia de seleccionar correctamente la función de recompensa que utilizamos para estimular el comportamiento deseado del Agente añadiendo recompensas o penalizaciones por acciones individuales. Pero la cuestión que sigue abierta es el descifrado de nuestras señales por parte del Agente. En este artículo hablaremos sobre la descomposición de la recompensa en lo que respecta a la transmisión de señales individuales al Agente entrenado.

Redes neuronales: así de sencillo (Parte 61): El problema del optimismo en el aprendizaje por refuerzo offline
Durante el aprendizaje offline, optimizamos la política del Agente usando los datos de la muestra de entrenamiento. La estrategia resultante proporciona al Agente confianza en sus acciones. No obstante, dicho optimismo no siempre está justificado y puede acarrear mayores riesgos durante el funcionamiento del modelo. Hoy veremos un método para reducir estos riesgos.

Redes neuronales en el trading: Modelos de difusión direccional (DDM)
Hoy proponemos al lector familiarizarse con los modelos de difusión direccional que explotan el ruido anisotrópico y direccional dependiente de los datos durante la difusión directa para capturar representaciones gráficas significativas.

Redes neuronales en el trading: Inyección de información global en canales independientes (InjectTST)
La mayoría de los métodos modernos de pronóstico de series temporales multimodales utilizan el enfoque de canales independientes. Esto ignora la dependencia natural de los diferentes canales de la misma serie temporal. Un uso coherente de ambos enfoques (canales independientes y mixtos) es la clave para mejorar el rendimiento de los modelos.

Redes neuronales en el trading: Modelos "ligeros" de pronóstico de series temporales
Los modelos ligeros de pronóstico de series temporales logran un alto rendimiento utilizando un número mínimo de parámetros, lo que, a su vez, reduce el consumo de recursos computacionales y agiliza la toma de decisiones. De este modo consiguen una calidad de previsión comparable a la de modelos más complejos.

Algoritmos de optimización de la población: Evolución de grupos sociales (Evolution of Social Groups, ESG)
En este artículo analizaremos el principio de construcción de algoritmos multipoblacionales y como ejemplo de este tipo de algoritmos consideraremos la evolución de grupos sociales (ESG), un nuevo algoritmo de autor. Así, analizaremos los conceptos básicos, los mecanismos de interacción con la población y las ventajas de este algoritmo, y revisaremos su rendimiento en problemas de optimización.

Modelo matricial de pronóstico basado en cadenas de Márkov
Hoy vamos a crear un modelo matricial de pronóstico basado en las cadenas de Márkov. ¿Qué son las cadenas de Márkov y cómo se puede usar una cadena de Márkov para negociar en Forex?

Redes neuronales: así de sencillo (Parte 38): Exploración auto-supervisada por desacuerdo (Self-Supervised Exploration via Disagreement)
Uno de los principales retos del aprendizaje por refuerzo es la exploración del entorno. Con anterioridad, hemos aprendido un método de exploración basado en la curiosidad interior. Hoy queremos examinar otro algoritmo: la exploración mediante el desacuerdo.

Redes neuronales: así de sencillo (Parte 41): Modelos jerárquicos
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.

Creación de una estrategia de retorno a la media basada en el aprendizaje automático
Este artículo propone otro enfoque original para crear sistemas comerciales basados en el aprendizaje automático, usando la clusterización y el etiquetado de transacciones para estrategias de retorno a la media.

Redes neuronales: así de sencillo (Parte 75): Mejora del rendimiento de los modelos de predicción de trayectorias
Los modelos que creamos son cada vez más grandes y complejos. Esto aumenta los costes no sólo de su formación, sino también de su funcionamiento. Sin embargo, el tiempo necesario para tomar una decisión suele ser crítico. A este respecto, consideremos los métodos para optimizar el rendimiento del modelo sin pérdida de calidad.
Redes neuronales en el trading: Transformador vectorial jerárquico (Final)
Continuamos nuestro análisis del método del Transformador Vectorial Jerárquico. En este artículo finalizaremos la construcción del modelo. También lo entrenaremos y probaremos con datos históricos reales.

Redes neuronales: así de sencillo (Parte 51): Actor-crítico conductual (BAC)
Los dos últimos artículos han considerado el algoritmo SAC (Soft Actor-Critic), que incorpora la regularización de la entropía en la función de la recompensa. Este enfoque equilibra la exploración del entorno y la explotación del modelo, pero solo es aplicable a modelos estocásticos. El presente material analizará un enfoque alternativo aplicable tanto a modelos estocásticos como deterministas.
Cuantificación en el aprendizaje automático (Parte 1): Teoría, ejemplo de código, análisis sintáctico de la aplicación CatBoost
En este artículo, hablaremos de la aplicación teórica de la cuantificación en la construcción de modelos arbóreos. Asimismo, analizaremos los métodos de cuantificación implementados en CatBoost. El material se presentará sin fórmulas matemáticas complejas, en un lenguaje accesible.
Redes neuronales: así de sencillo (Parte 86): Transformador en U
Continuamos nuestro repaso a los algoritmos de previsión de series temporales. En este artículo nos familiarizaremos con los métodos del Transformador en U.

Aprendizaje automático y Data Science (Parte 17): ¿Crece el dinero en los árboles? Bosques aleatorios en el mercado Fórex
Este artículo le presentará los secretos de la alquimia algorítmica, introduciéndole con precisión las particularidades de los paisajes financieros. Asimismo, aprenderá cómo los bosques aleatorios transforman los datos en predicciones y le servirán de ayuda al navegar por las complejidades de los mercados financieros. Intentaremos identificar el papel de los bosques aleatorios en los datos financieros y comprobaremos si pueden ayudar a aumentar los beneficios.
Algoritmo de optimización de reacciones químicas (CRO) (Parte I): Química de procesos en la optimización
En la primera parte de este artículo, nos sumergiremos en el mundo de las reacciones químicas y descubriremos un nuevo enfoque de la optimización. La optimización de reacciones químicas (Chemical Reaction Optimization, CRO) utiliza principios derivados de las leyes de la termodinámica para lograr resultados eficientes. Desvelaremos los secretos de la descomposición, la síntesis y otros procesos químicos que se convirtieron en la base de este innovador método.

Aprendizaje automático y Data Science (Parte 32): Mantener actualizados los modelos de IA, aprendizaje en línea
En el cambiante mundo del comercio, adaptarse a los cambios del mercado no es solo una opción, es una necesidad. Cada día surgen nuevos patrones y tendencias, lo que dificulta que incluso los modelos de aprendizaje automático más avanzados sigan siendo eficaces ante condiciones en constante evolución. En este artículo, exploraremos cómo mantener tus modelos relevantes y receptivos a los nuevos datos del mercado mediante el reentrenamiento automático.

Aprendizaje automático y Data Science (Parte 37): Uso de patrones de velas japonesas e inteligencia artificial para superar al mercado
Los patrones de velas japonesas ayudan a los operadores a comprender la psicología del mercado e identificar tendencias en los mercados financieros, lo que permite tomar decisiones de inversión más informadas que pueden conducir a mejores resultados. En este artículo, exploraremos cómo utilizar los patrones de velas japonesas con modelos de IA para lograr un rendimiento óptimo en las operaciones comerciales.

Algoritmo de evolución del caparazón de tortuga (Turtle Shell Evolution Algorithm, TSEA)
Hoy hablaremos sobre un algoritmo de optimización único inspirado en la evolución del caparazón de las tortugas. El algoritmo TSEA emula la formación gradual de los sectores de piel queratinizada que representan soluciones óptimas a un problema. Las mejores soluciones se vuelven más "duras" y se encuentran más cerca de la superficie exterior, mientras que las menos exitosas permanecen "blandas" y se hallan en el interior. El algoritmo utiliza la clusterización de soluciones según su calidad y distancia, lo cual permite conservar las opciones menos acertadas y aporta flexibilidad y adaptabilidad.

Uso del algoritmo de aprendizaje automático PatchTST para predecir la acción del precio durante las próximas 24 horas
En este artículo, aplicamos un algoritmo de red neuronal relativamente complejo lanzado en 2023 llamado PatchTST para predecir la acción del precio durante las próximas 24 horas. Utilizaremos el repositorio oficial, haremos ligeras modificaciones, entrenaremos un modelo para EURUSD y lo aplicaremos para realizar predicciones futuras tanto en Python como en MQL5.
Teoría de categorías en MQL5 (Parte 16): Funtores con perceptrones multicapa
Seguimos analizando los funtores y cómo se pueden implementar utilizando redes neuronales artificiales. Dejaremos temporalmente el enfoque que implica el pronóstico de la volatilidad e intentaremos implementar nuestra propia clase de señales para establecer señales de entrada y salida para una posición.

Red neuronal en la práctica: La primera neurona
En este artículo, comenzaremos a crear algo que muchos se sorprenden al ver funcionando: una simple y modesta neurona que lograremos programar con muy poco código en MQL5. La neurona funcionó perfectamente en las pruebas que realicé. Bueno, retrocedamos un poco en esta misma serie sobre redes neuronales, para que puedas entender de qué estoy hablando.

Redes neuronales: así de sencillo (Parte 37): Atención dispersa (Sparse Attention)
En el artículo anterior, analizamos los modelos relacionales que utilizan mecanismos de atención en su arquitectura. Una de las características de dichos modelos es su mayor uso de recursos informáticos. Este artículo propondrá uno de los posibles mecanismos para reducir el número de operaciones computacionales dentro del bloque Self-Attention o de auto-atención, lo cual aumentará el rendimiento del modelo en su conjunto.

Redes neuronales: así de sencillo (Parte 60): Online Decision Transformer (ODT)
En los 2 últimos artículos nos hemos centrado en el método Decision Transformer, que modela las secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. En el artículo de hoy, analizaremos otro algoritmo para optimizar este método.

Redes neuronales: así de sencillo (Parte 64): Método de clonación conductual ponderada conservadora (CWBC)
Como resultado de las pruebas realizadas en artículos anteriores, hemos concluido que la optimalidad de la estrategia entrenada depende en gran medida de la muestra de entrenamiento utilizada. En este artículo, nos familiarizaremos con un método bastante sencillo y eficaz para seleccionar trayectorias para el entrenamiento de modelos.

Asesor de autoaprendizaje con red neuronal basada en matriz de estados
Asesor de autoaprendizaje con red neuronal basada en matriz de estados. Hoy combinaremos cadenas de Márkov con una red neuronal multicapa MLP, escrita en la biblioteca ALGLIB MQL5. ¿Cómo podemos combinar las cadenas de Márkov y las redes neuronales para realizar previsiones en Forex?

Marcado de datos en el análisis de series temporales (Parte 4): Descomposición de la interpretabilidad usando el marcado de datos
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.