
Teoría de categorías en MQL5 (Parte 18): Cuadrado de la naturalidad
Introducción
La teoría de categorías puede parecer demasiado subjetiva para los tráders de MQL5. Hasta ahora, en esta serie de artículos, hemos adoptado un enfoque que abarca todo el sistema, favoreciendo los morfismos para pronosticar y clasificar datos financieros.
Las transformaciones naturales, un concepto clave en la teoría de categorías, a menudo se consideran simplemente como asignaciones de funtores. Esta visión, aunque no sea incorrecta, puede llevar a cierta confusión al considerar que un funtor relaciona dos objetos, ya que surge la pregunta ¿con qué objetos relaciona la transformación natural? La respuesta corta es: dos objetos del codominio de funtores. En este artículo intentaremos mostrar qué hay detrás de esta definición y también incluiremos un ejemplar de una clase de asesor final que utilizará este morfismo para predecir cambios en la volatilidad.
Al ilustrar las transformaciones naturales, usaremos dos categorías como ejemplos. Este es el número mínimo para un par de funtores usados al definir la transformación natural. El primero constará de dos objetos que contendrán valores de indicadores normalizados. Analizaremos los indicadores ATR y Bollinger Bands. La segunda categoría, que servirá como categoría de codominio ya que habrá dos funtores que conduzcan a ella, incluirá cuatro objetos que captarán los rangos de las barras de precios de los valores que queremos predecir.
Categorías
La categoría de valores del indicador se menciona en nuestro artículo solo para ayudar a comprender los conceptos aquí presentados, y desempeñará un papel mínimo en la predicción de la volatilidad que nos interesa porque dependeremos principalmente del cuadrado de la naturalidad para lograr este objetivo. Sin embargo, no se puede subestimar su importancia. No existe mucha información en Internet sobre el cuadrado de la naturalidad. Le recomiendo revisar este post (en inglés) para obtener más información.
Volvamos ahora a nuestra categoría de dominio. Como ya hemos mencionado, tenemos dos objetos: uno con valores ATR y otro con valores de las Bandas de Bollinger. Estos valores estarán normalizados para que los objetos tengan una cardinalidad (tamaño) fija. Los valores representados en cada objeto representarán los cambios correspondientes en los valores del indicador. Estos cambios se registrarán en incrementos del 10%, desde menos 100% hasta más 100%, lo cual significa que cada objeto tendrá una cardinalidad de 21, por lo que incluirá los siguientes valores:
{
-100, -90, -80, -70, -60, -50, -40, -30, -20, -10,
0,
10, 20, 30, 40, 50, 60, 70, 80, 90, 100
}
Un morfismo que vincule estos objetos idénticos a elementos combinará valores dependiendo de si se han registrado al mismo tiempo, actualizando así los datos sobre los cambios en dos valores del indicador.
Estos valores de cambio de indicador podrían haberse tomado de cualquier otro indicador relacionado con la volatilidad. Los principios siguen siendo los mismos. El cambio en el valor del indicador se dividirá por la suma de los valores absolutos de las lecturas del indicador anterior y actual para obtener una fracción decimal. Luego multiplicaremos esta fracción por 10 y redondearemos a cero. Después multiplicaremos nuevamente por 10 y le asignaremos un índice en nuestros objetos descritos anteriormente dependiendo del valor al que sea equivalente.
La categoría de rango de la barra de precios constará de cuatro objetos que serán el foco de atención del cuadrado de la naturalidad utilizado para realizar los pronósticos. Como nuestra categoría de dominio (con los cambios del indicador) constará de dos objetos, y tendremos dos funtores que van desde ella hacia este codominio, de ello se puede deducir que cada uno de estos funtores se asignará a un objeto. Los objetos mapeados no siempre tienen que ser diferentes; sin embargo, en nuestro caso, para ayudar a aclarar nuestros conceptos, permitiremos que cada objeto mostrado en la categoría de dominio tenga su propio objeto de codominio en la categoría de rangos de precios. Entonces, 2 objetos multiplicados por 2 funtores nos darán 4 objetos de punto final, miembros de nuestra categoría de codominio.
Como tenemos cuatro objetos y no queremos que se den duplicaciones, cada objeto registrará un conjunto distinto de cambios en el rango de la barra de precios. Para ayudarnos con esto, los dos funtores representarán diferentes deltas de pronóstico. Un funtor mostrará el rango de precios de la barra después de una barra, mientras que el otro funtor mostrará los cambios en el rango de precios después de dos barras. Además, los mapeos de entidades ATR se referirán a rangos de precios en una barra, mientras que los mapeos de entidades de Bandas de Bollinger se referirán a rangos de precios en dos barras. A continuación le mostraremos un listado que implementa todo lo anterior:
CElement<string> _e; for(int i=0;i<m_extra_training+1;i++) { double _a=((m_high.GetData(i+_x)-m_low.GetData(i+_x))-(m_high.GetData(i+_x+1)-m_low.GetData(i+_x+1)))/((m_high.GetData(i+_x)-m_low.GetData(i+_x))+(m_high.GetData(i+_x+1)-m_low.GetData(i+_x+1))); double _c=((m_high.GetData(i+_x)-m_low.GetData(i+_x))-(m_high.GetData(i+_x+2)-m_low.GetData(i+_x+2)))/((m_high.GetData(i+_x)-m_low.GetData(i+_x))+(m_high.GetData(i+_x+2)-m_low.GetData(i+_x+2))); double _b=((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) -(fmax(m_high.GetData(i+_x+2),m_high.GetData(i+_x+3))-fmin(m_low.GetData(i+_x+2),m_low.GetData(i+_x+3)))) /((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) +(fmax(m_high.GetData(i+_x+2),m_high.GetData(i+_x+3))-fmin(m_low.GetData(i+_x+2),m_low.GetData(i+_x+3)))); double _d=((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) -(fmax(m_high.GetData(i+_x+3),m_high.GetData(i+_x+4))-fmin(m_low.GetData(i+_x+3),m_low.GetData(i+_x+4)))) /((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) +(fmax(m_high.GetData(i+_x+3),m_high.GetData(i+_x+4))-fmin(m_low.GetData(i+_x+3),m_low.GetData(i+_x+4)))); ... }
Estos objetos tendrán el mismo tamaño porque solo registrarán los cambios actuales. Los morfismos entre ellos se desplazarán usando el método del cuadrado de conmutación de la proyección del rango de precios de una barra a una proyección de rango de precios de dos barras, dos barras de precios por delante. Aprenderemos más sobre esto al definir formalmente las transformaciones naturales a continuación.
La relación entre los rangos de las barras de precio y los datos de mercado resultantes también se han mostrado en nuestra fuente anterior. Los cambios registrados en cada objeto no se normalizarán, como es el caso de los valores del indicador, sino que los cambios en el rango se dividirán por la suma de los rangos de las barras actuales y anteriores para producir un valor decimal no redondeado.
Funtores: Vinculación de los valores del indicador con los rangos de barras de precio
Los funtores se introdujeron en nuestra serie hace cuatro artículos, pero aquí se tratan como un par de dos categorías. Los funtores de completitud mapean no solo objetos, sino también morfismos, por lo que, como nuestra categoría de dominio de valor del indicador tiene dos objetos y un morfismo, esto significará que nuestra categoría de codominio tendrá tres puntos de salida: dos del objeto y uno del morfismo para cada funtor. Con dos funtores, esto nos dará seis puntos finales en nuestro codominio.
La correspondencia entre los valores enteros normalizados de los indicadores y los cambios decimales del rango de la barra de precios (cambios que se registran como fracciones en lugar de valores brutos) puede realizarse usando los perceptrones multicapa comentados en los dos últimos artículos. Hay muchos otros métodos para crear dicho mapeo que aún no hemos explorado en esta serie, por ejemplo, el método de bosques aleatorios.
Esta ilustración pretende únicamente completar el cuadro y ayudarnos comprender qué supone la transformación natural y cuáles son todos sus requisitos previos. Cuando los tráders encuentran nuevos conceptos, la pregunta más importante para ellos es ¿cuál es su aplicación y qué ventajas ofrece? Por eso mismo hemos dicho al principio que para nuestros propósitos de predicción nos centraremos en el cuadrado de la naturalidad, que se define únicamente por los cuatro objetos en la categoría de codominio. Por lo tanto, mencionar aquí la categoría de dominio y sus objetos simplemente nos ayudará a definir las transformaciones naturales, mientras que no nos ayudará en nuestra aplicación específica en este artículo.
Transformaciones naturales: cerrando la brecha
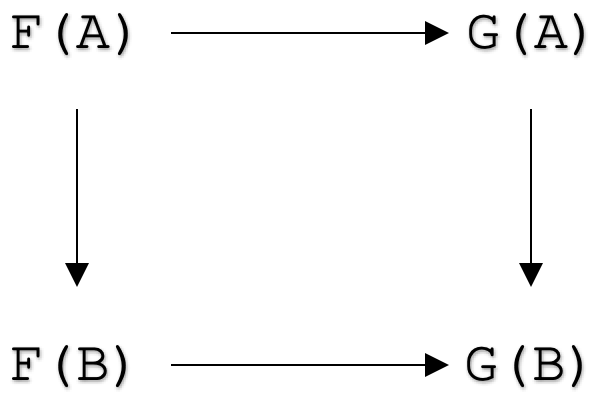
Ahora podemos examinar los axiomas de las transformaciones naturales para pasar a su aplicación. Formalmente, una transformación natural entre funtores
F: C --> D
y
G: C --> D
es una familia de morfismos
ηA: F(A) --> G(A)
para todos los objetos A en la categoría C es tal que para todos los morfismos
f: A --> B
El siguiente esquema desplazará en la categoría C :
Hay mucho material en Internet sobre transformaciones naturales, pero aún así podría resultar útil mirar una definición más visual que conduzca al cuadrado de la naturalidad. Para hacer esto, digamos que tenemos dos categorías C y D, y la categoría C tiene dos objetos X e Y definidos así:
X = {5, 6, 7}
y
Y = {Q, R, S}
Supongamos también que tenemos un morfismo entre estos objetos, f definido como:
f: X à Y
tal que f(5) = S, f(6) = R y f(7) = R.
En este ejemplo, dos funtores F y G entre las categorías C y D ejecutarán dos cosas simples. Ahora prepararemos una lista y una lista de listas respectivamente. Entonces el funtor F aplicado a X dará como resultado:
[5, 6, 5, 7, 5, 6, 7, 7]
y de forma similar el funtor G (una lista de listas) dará:
[[5, 6], [5, 7, 5, 6, 7], [7]]
Si aplicamos estos funtores de manera similar al objeto Y, obtendremos 4 objetos en la categoría de codominio D. Se representarán como mostramos a continuación:

Tenga en cuenta que por ahora solo nos estamos enfocando en cuatro objetos en la categoría D. Como tenemos dos objetos en nuestro dominio categoría C, también tendremos dos transformaciones naturales, cada una con respecto a un objeto en la categoría C. Estas se presentarán a continuación:
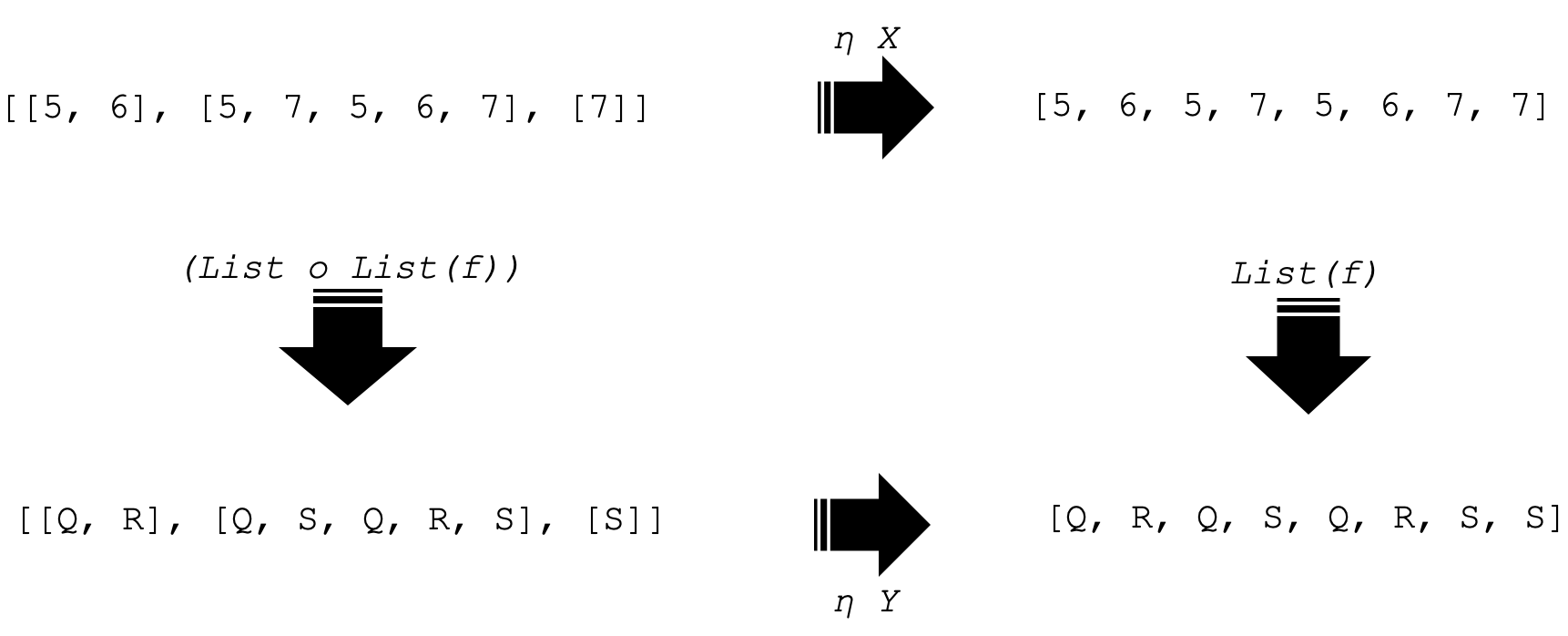
La imagen de arriba muestra el cuadrado de la naturalidad. Las flechas indican conmutaciones. Las dos flechas horizontales son nuestras transformaciones naturales (NT) con respecto a cada objeto en C, mientras que las flechas verticales representan la salida del funtor cuando se aplica a un morfismo f en la categoría C para los funtores F y G.
La importancia de mantener la estructura y las relaciones es un aspecto clave de las NT que puede pasarse por alto, pero a pesar de su simplicidad, resulta fundamental. Para aclarar nuestro punto de vista, veremos un ejemplo tomado de la cocina. Digamos que tenemos dos chefs famosos, llamémoslos A y B. Cada uno de ellos tiene una forma única de preparar el mismo plato a partir de un conjunto estándar de ingredientes. Trataríamos los ingredientes como un objeto dentro de una categoría más amplia de tipos de ingredientes, mientras que los dos platos que prepara cada chef también pertenecerían a otra categoría más amplia de tipos de platos. Una transformación natural entre los dos platos preparados por nuestros Chefs A y B registrará los ingredientes y preparaciones adicionales necesarias para cambiar el plato preparado por el Chef A al plato preparado por el Chef B. Con este enfoque, registraremos más información y podremos verificar y ver si, digamos, el plato del Chef C necesitaría una NT similar para coincidir con el plato del Chef B, y si no, ¿en qué medida? Sin embargo, comparaciones aparte, usar una NT para obtener el plato del Chef B requerirá la receta, el estilo de cocina y los métodos del Chef A. Y esto significará que dicha información deberá guardarse. Esta información almacenada también será importante como medio para desarrollar nuevas recetas o incluso probar las existentes para adaptarse a las restricciones dietéticas de alguien.
Solicitud: Pronóstico de volatilidad
Ahora podremos examinar las posibles aplicaciones en el pronóstico. Hemos analizado bastante el tema en esta serie cómo predecir cambios en el rango de la barra de precios. Utilizaremos este pronóstico para determinar, en primer lugar, si necesitamos ajustar el trailing stop en las posiciones abiertas y, en segundo lugar, cuánto debemos ajustarlo.
La implementación del cuadrado de la naturalidad como herramienta clave en esta tarea se realizará mediante perceptrones multicapa (MLP), como fue el caso en nuestros dos últimos artículos, con la diferencia de que aquí estos MLP se compondrán alrededor de la conmutación cuadrática (square commutation). Esto nos permitirá probar nuestros pronósticos, ya que dos etapas cualesquiera pueden producir una predicción. Las cuatro esquinas del cuadrado reflejarán diferentes pronósticos en algún momento del futuro sobre los cambios en el rango de nuestras barras de precios. A medida que avancemos hacia la esquina D, veremos más hacia el futuro, además, la esquina A solo pronosticará el cambio de rango para la siguiente barra, y esto significa que si podemos entrenar MLP que conecten las cuatro esquinas utilizando el cambio de rango para la barra de precios más reciente, podremos hacer predicciones mucho más allá de una sola barra.
En la siguiente lista se muestran los pasos necesarios para aplicar nuestras NT y obtener un pronóstico:
//+------------------------------------------------------------------+ //| NATURAL TRANSFORMATION CLASS | //+------------------------------------------------------------------+ class CTransformation { protected: public: CDomain<string> domain; //codomain object of first functor CDomain<string> codomain;//codomain object of second functor uint hidden_size; CMultilayerPerceptron transformer; CMLPBase init; void Transform(CDomain<string> &D,CDomain<string> &C) { domain=D; codomain=C; int _inputs=D.Cardinality(),_outputs=C.Cardinality(); if(_inputs>0 && _outputs>0) { init.MLPCreate1(_inputs,hidden_size+fmax(_inputs,_outputs),_outputs,transformer); } } // void Let() { this.codomain.Let(); this.domain.Let(); }; CTransformation(void){ hidden_size=1; }; ~CTransformation(void){}; };
Primero, tenemos la clase NT mencionada anteriormente. En cuanto a la definición aleatoria, podríamos esperar que incluya un ejemplar de los dos funtores que relaciona. Esto es aplicable, pero la cantidad de código aumentará significativamente. El punto clave en las NT son las dos regiones representadas por funtores. Precisamente estas hemos destacado.
//+------------------------------------------------------------------+ //| NATURALITY CLASS | //+------------------------------------------------------------------+ class CNaturalitySquare { protected: public: CDomain<string> A,B,C,D; CTransformation AB; uint hidden_size_bd; CMultilayerPerceptron BD; uint hidden_size_ac; CMultilayerPerceptron AC; CTransformation CD; CMLPBase init; CNaturalitySquare(void){}; ~CNaturalitySquare(void){}; };
El cuadrado de la naturalidad, cuyo esquema hemos mostrado arriba, también tendrá su propia clase, representada por ejemplares de la clase NT. Sus cuatro esquinas, expresadas como A, B, C y D, son objetos capturados por la clase de dominio, y solo dos de sus morfismos serán MLP directos, mientras que los otros dos se reconocerán como NT.
Implementación práctica en MQL5
Una implementación práctica en MQL5, dado nuestro uso de MLP, inevitablemente encontrará problemas, principalmente con la forma en que entrenamos y almacenamos lo que hemos aprendido (pesos de la red). En este artículo, a diferencia de los dos últimos, los pesos de entrenamiento no se almacenarán en absoluto, lo cual significa que en cada nueva columna se generará y entrenará un nuevo ejemplar de cada uno de los cuatro MLP. Esto se implementará utilizando la función de actualización como se muestra a continuación:
//+------------------------------------------------------------------+ //| Refresh function for naturality square. | //+------------------------------------------------------------------+ double CTrailingCT::Refresh() { double _refresh=0.0; m_high.Refresh(-1); m_low.Refresh(-1); int _x=StartIndex(); // atr domains capture 1 bar ranges // bands' domains capture 2 bar ranges // 1 functors capture ranges after 1 bar // 2 functors capture ranges after 2 bars int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CMLPReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(m_extra_training+1,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(m_extra_training+1,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(m_extra_training+1,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(m_extra_training+1,1+1); CElement<string> _e; for(int i=0;i<m_extra_training+1;i++) { ... if(i<m_extra_training+1) { _xy_ab[i].Set(0,_a);//in _xy_ab[i].Set(1,_b);//out _xy_bd[i].Set(0,_b);//in _xy_bd[i].Set(1,_d);//out _xy_ac[i].Set(0,_a);//in _xy_ac[i].Set(1,_c);//out _xy_cd[i].Set(0,_c);//in _xy_cd[i].Set(1,_d);//out } } m_train.MLPTrainLM(m_naturality_square.AB.transformer,_xy_ab,m_extra_training+1,m_decay,m_restarts,_info_ab,_report_ab); ... // if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { ... } return(_refresh); }
La función de actualización anterior entrenará MLP inicializados con pesos aleatorios solo en la última barra de precios. Claramente, esto no resultará suficiente para otros sistemas comerciales o implementaciones de código general; sin embargo, el parámetro de entrada m_extra_training, que se mantiene en un valor predeterminado de cero para nuestros propósitos de prueba, se podrá ajustar (aumentándolo) para permitir pruebas más exhaustivas antes de realizar pronósticos.
El uso del parámetro para entrenamiento adicional sobrecargará inevitablemente el rendimiento del experto y, de hecho, muestra por qué en este artículo se ha evitado por completo leer y escribir pesos durante el entrenamiento.
Ventajas y limitaciones
Si realizamos pruebas en EURUSD en el periodo diario del 01.08.2022 al 01.08.2023, una de nuestras mejores ejecuciones producirá el siguiente resultado:


Si ejecutamos las pruebas con la misma configuración en un periodo no optimizado (en nuestro caso, un año antes de nuestro rango de prueba), obtendremos resultados negativos que no reflejarán el rendimiento obtenido en el informe anterior. Como podemos ver, todos los beneficios se han obtenido al activarse los stop loss.
En comparación con los enfoques anteriormente usados en esta serie para pronosticar la volatilidad, este enfoque ciertamente requiere muchos recursos y claramente necesita cambios en la forma en que definimos nuestros cuatro objetos en el cuadrado de la naturalidad para posibilitar el movimiento hacia adelante durante periodos no optimizados.
Conclusión
En resumen, el concepto clave descrito aquí es el de transformación natural. Esta es importante para vincular categorías al captar la diferencia entre un par paralelo de funtores que conectan categorías. Los casos de uso aquí analizados han involucrado la predicción de la volatilidad usando el cuadrado de la naturalidad, pero otras posibles aplicaciones incluyen la generación de señales de entrada y salida, así como la determinación de la dimensión de las posiciones. Además, puede resultar de utilidad mencionar que en este artículo y a lo largo de esta serie, no hemos realizado ninguna pasada preliminar con la configuración optimizada resultante. Por lo tanto, probablemente no podremos trabajar de inmediato (es decir, tal como se proporciona el código), pero podremos hacerlo con ciertas modificaciones, combinando las ideas presentadas con otras estrategias que el lector podría aplicar. Es por eso que resulta útil usar las clases magistrales de MQL5, ya que permiten hacerlo fácilmente.
Enlaces
Enlaces a artículos en Wikipedia y stackexchange.com.
Notas a las aplicaciones
Coloque el archivo SignalCT_16_.mqh en la carpeta MQL5\include\Expert\Signal\ y el archivo ct_16.mqh en la carpeta MQL5\include\.
También podrá encontrar útiles las recomendaciones de aquí sobre cómo crear un asesor utilizando el wizard. Como se indica en el artículo, no hemos utilizado trailing stops dinámicos ni márgenes fijos para gestionar el capital. Ambos componentes forman parte de la biblioteca MQL5. Como siempre, este artículo no pretende presentarle el Grial, sino una idea que pueda adaptar a su propia estrategia.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13200
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Está bien traducido terminológicamente el artículo, ¿existe realmente 😁?
¿La teoría de categorías o su aplicabilidad al comercio? La primera está definitivamente ahí, pero sobre la segunda - la respuesta no es tan categórica).