
Obtenga una ventaja sobre cualquier mercado (Parte III): Índice de gasto de Visa

Introducción
En la era de los macrodatos, el inversor moderno dispone de fuentes casi infinitas de datos alternativos. Cada conjunto de datos tiene el potencial de producir mayores niveles de precisión a la hora de pronosticar el rendimiento del mercado. Sin embargo, pocos conjuntos de datos cumplen esta promesa. En esta serie de artículos, lo ayudaremos a explorar el vasto panorama de datos alternativos, para ayudarlo a tomar una decisión informada sobre si debe incluir estos conjuntos de datos en su análisis o no, por otro lado, si estos conjuntos de datos arrojan resultados insatisfactorios, entonces podemos ayudarlo a ahorrar tiempo.
Nuestro razonamiento es que, al considerar conjuntos de datos alternativos no disponibles directamente en el terminal MetaTrader 5, podemos descubrir variables que predicen los niveles de precios con una precisión relativamente mayor en comparación con el participante ocasional del mercado que se basa únicamente en las cotizaciones del mercado.
Sinopsis de la estrategia comercial
VISA es una empresa multinacional estadounidense de servicios de pago. Fue fundada en 1958 y hoy la empresa opera una de las redes de procesamiento de transacciones más grandes del mundo. VISA está bien posicionada para ser una fuente de datos alternativos confiables porque ha penetrado en casi todos los mercados del mundo desarrollado. Además, el Banco de la Reserva Federal de St. Louis también recopila algunos de sus datos macroeconómicos de VISA.
En esta discusión, vamos a analizar el Índice de Impulso del Gasto de VISA (Spending Momentum Index, SMI). El índice es un indicador macroeconómico del comportamiento del gasto del consumidor. Los datos son agregados por VISA, utilizando sus redes propias y tarjetas de débito y crédito de marca VISA. Todos los datos están despersonalizados y se recogen en su mayoría en Estados Unidos. A medida que VISA continúa agregando datos de diferentes mercados, este índice podría eventualmente convertirse en un punto de referencia del comportamiento del consumidor global.
Utilizaremos un servicio API proporcionado por el Banco de la Reserva Federal de St. Louis para recuperar los conjuntos de datos SMI de VISA. La API de la Base de Datos Económica de la Reserva Federal (Federal Reserve Economic Database, FRED) nos permite acceder a cientos de miles de datos de series temporales económicas diferentes que se han recopilado de todo el mundo.
Sinopsis de la metodología
VISA publica mensualmente los datos del SMI y, al momento de redactar este artículo, contienen menos de 200 filas. Por lo tanto, necesitamos una técnica de modelado que sea simultáneamente resistente al sobreajuste y lo suficientemente flexible para capturar relaciones complejas. Este puede ser un trabajo ideal para una red neuronal.
Optimizamos 5 parámetros de una red neuronal profunda para clasificar los cambios en el EURUSD dado un conjunto de precios ordinarios de apertura, máximo, mínimo y cierre con 3 entradas adicionales, que son los conjuntos de datos VISA. Nuestro modelo optimizado fue capaz de alcanzar un 71% de precisión en la validación, superando así al modelo predeterminado. Sin embargo, el lector debe tener presente que esta precisión se refería a datos mensuales.
Utilizamos 1000 iteraciones de un algoritmo de búsqueda aleatoria para optimizar la red neuronal profunda y entrenamos exitosamente el modelo sin sobreajustarlo a los datos de entrenamiento. Por impresionantes que parezcan estos resultados, no podemos afirmar con seguridad que la relación observada sea confiable. Nuestros algoritmos de selección de características descartaron los tres conjuntos de datos VISA al seleccionar las características más importantes de manera no paramétrica. Además, los tres conjuntos de datos de VISA tienen puntuaciones de información mutua relativamente bajas, lo que puede indicarnos que los conjuntos de datos pueden ser independientes o que no hemos logrado exponer la relación de una manera significativa para nuestro modelo.
Extracción de datos
Para obtener los datos que necesitamos, primero debe crear una cuenta en el sitio web de FRED. Después de crear una cuenta, puede usar su clave API de FRED para acceder a los datos de series de tiempo económicas que posee la Reserva Federal de St. Louis y seguir nuestra discusión. Nuestros datos de mercado sobre las cotizaciones del EURUSD se obtendrán directamente de el terminal utilizando la API Python de MetaTrader 5.
Para comenzar, primero cargamos las bibliotecas que necesitamos.
#Import the libraries we need import pandas as pd import seaborn as sns import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Ahora configure su clave API FRED y obtenga los datos que necesitamos.
#Let's setup our FredAPI
fred = Fred(api_key="ENTER YOUR API KEY")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Definir el horizonte de pronóstico.
#Define how far ahead we want to forecast look_ahead = 10
Visualizar los datos
Visualicemos los tres conjuntos de datos.
visa_discretionary.plot(title="VISA Spending Momentum Index: Discretionary") 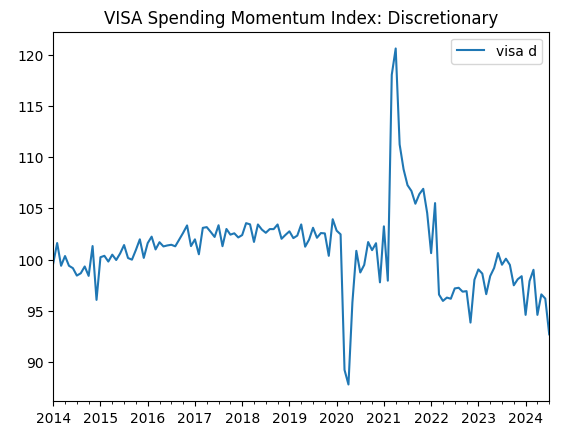
Figura 1: El primer conjunto de datos de VISA.
Ahora visualicemos el segundo conjunto de datos.
visa_headline.plot(title="VISA Spending Momentum Index: Headline") 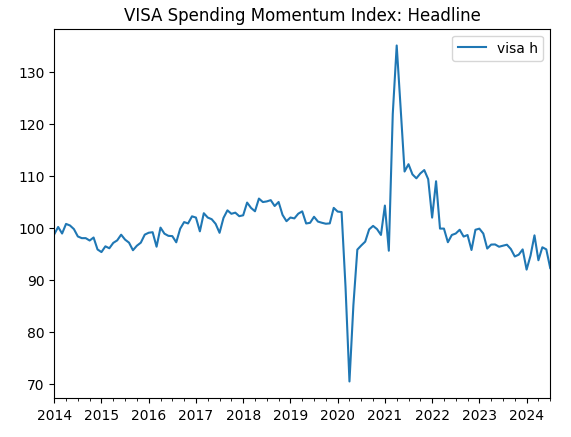
Figura 2: El segundo conjunto de datos de VISA.
Y finalmente, nuestro tercer conjunto de datos VISA.
visa_non_discretionary.plot(title="VISA Spending Momentum Index: Non-Discretionary") 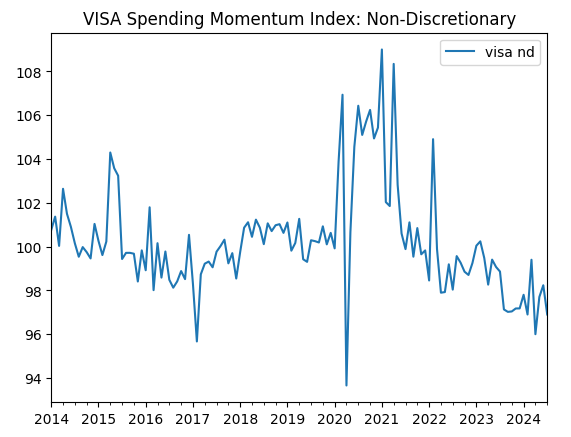
Figura 3: El tercer conjunto de datos de VISA.
Los dos primeros conjuntos de datos parecen casi idénticos; además, como veremos más adelante en nuestro análisis, tienen niveles de correlación de 0,89, lo que significa que pueden contener la misma información. Esto nos sugiere que podemos abandonar uno y conservar el otro. Sin embargo, permitiremos que nuestro algoritmo de selección de características decida si eso es necesario.
Obtención de datos desde nuestro terminal MetaTrader 5
Ahora inicializaremos nuestro terminal.
#Initialize the terminal
mt5.initialize()
Ahora especificaremos nuestra zona horaria.
#Set timezone to UTC timezone = pytz.timezone("Etc/UTC")
Crear un objeto de fecha y hora.
#Create a 'datetime' object in UTC utc_from = datetime(2024,7,1,tzinfo=timezone)
Obtener los datos de MetaTrader 5 y envolverlos en un marco de datos de pandas.
#Fetch the data eurusd = pd.DataFrame(mt5.copy_rates_from("EURUSD",mt5.TIMEFRAME_MN1,utc_from,visa_headline.shape[0]))
Etiquetemos los datos y usemos la marca de tiempo como nuestro índice.
#Label the data eurusd["target"] = np.nan eurusd.loc[eurusd["close"] > eurusd["close"].shift(-look_ahead),"target"] = 0 eurusd.loc[eurusd["close"] < eurusd["close"].shift(-look_ahead),"target"] = 1 eurusd.dropna(inplace=True) eurusd.set_index("time",inplace=True)
Ahora fusionaremos los conjuntos de datos utilizando las fechas que comparten.
#Let's merge the datasets merged_data = eurusd.merge(visa_headline,right_index=True,left_index=True) merged_data = merged_data.merge(visa_discretionary,right_index=True,left_index=True) merged_data = merged_data.merge(visa_non_discretionary,right_index=True,left_index=True)
Análisis exploratorio de datos
Estamos listos para explorar nuestros datos. Los gráficos de dispersión son útiles para visualizar la relación entre dos variables. Observemos los gráficos de dispersión creados por cada uno de los conjuntos de datos de VISA graficados frente al precio de cierre. Los puntos azules resumen los casos en los que el precio procedió a caer durante las siguientes 10 velas, mientras que los puntos naranjas resumen lo contrario.
Aunque la separación es ruidosa hacia el centro del gráfico, parece que en los niveles extremos los conjuntos de datos VISA separan razonablemente bien los movimientos ascendentes y descendentes.
#Let's create scatter plots sns.scatterplot(data=merged_data,y="close",x="visa h",hue="target").set(title="EURUSD Close Against VISA Momentum Index: Headline")
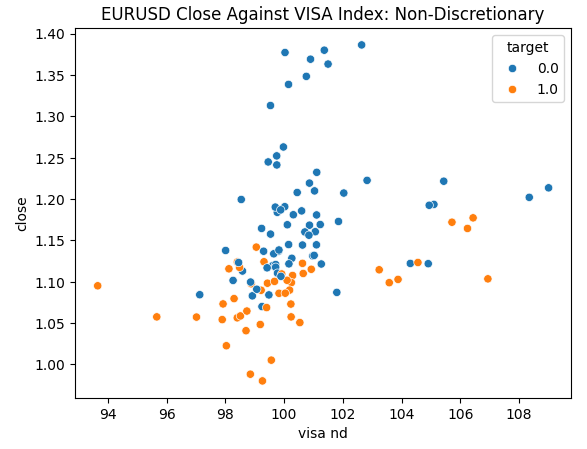
Figura 4: Gráfico de nuestro conjunto de datos de VISA no discrecional frente al cierre del EURUSD.
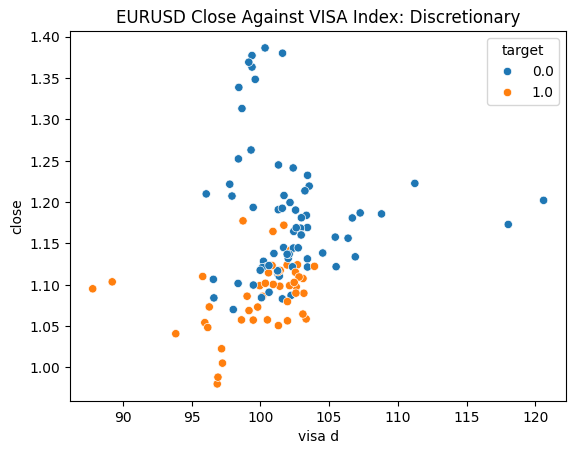
Figura 5: Representación gráfica de nuestro conjunto de datos de VISA discrecional frente al cierre del EURUSD.
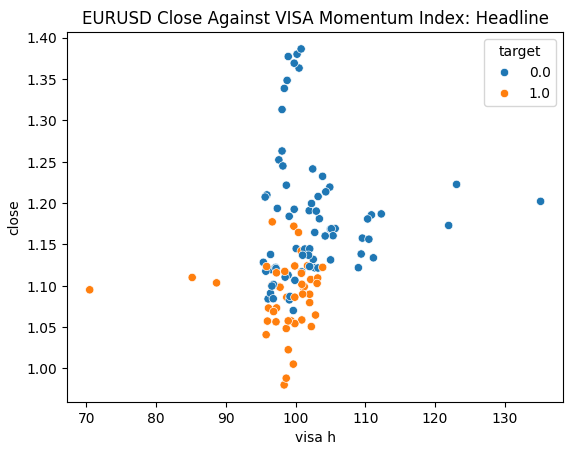
Figura 6: Representación gráfica de nuestro conjunto de datos VISA principal frente al cierre del EURUSD.
Los niveles de correlación entre los conjuntos de datos VISA y el mercado EURUSD son moderados y todos tienen valores positivos. Ninguno de los niveles de correlación es particularmente interesante para nosotros. Sin embargo, vale la pena señalar que el valor positivo indica que las dos variables tienden a subir y bajar juntas. Lo cual está en consonancia con nuestra comprensión de la macroeconomía: el gasto del consumidor en Estados Unidos tiene cierto nivel de influencia en los tipos de cambio. Si los consumidores deciden colectivamente no gastar, sus acciones reducirán la moneda total en circulación, lo que puede provocar una apreciación del dólar.
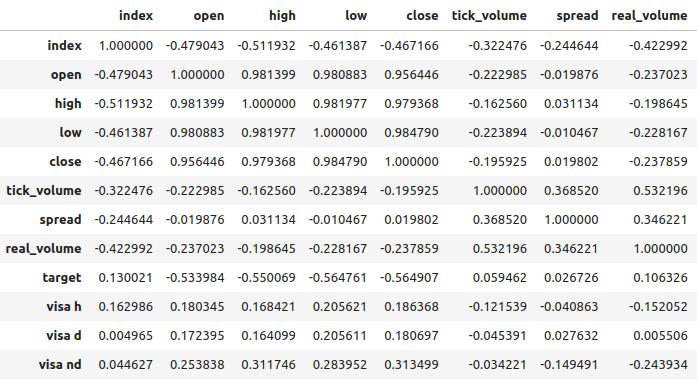
Figura 7: Análisis de correlación de nuestro conjunto de datos.
Selección de funciones
¿Qué importancia tiene la relación entre nuestro target y nuestras nuevas funcionalidades? Observemos si nuestro algoritmo de selección de características eliminará las nuevas características. Si nuestro algoritmo no selecciona ninguna de las nuevas variables, esto puede indicar que la relación no es confiable.
El algoritmo de selección avanzada comienza con un modelo nulo y agrega una característica a la vez, desde allí selecciona el mejor modelo de variable única y luego comienza a buscar una segunda variable y así sucesivamente. Nos devolverá el mejor modelo que construyó. En nuestro estudio, sólo el precio Open fue seleccionado por el algoritmo, lo que nos indica que la relación puede no ser estable.
Importamos las librerías que necesitamos.
#Let's see which features are the most important from mlxtend.feature_selection import SequentialFeatureSelector as SFS from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Crea el objeto de selección hacia adelante.
#Create the forward selection object sfs = SFS( MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"]), k_features=(1,train_X.shape[1]), forward=False, scoring="accuracy", cv=5 ).fit(train_X,train_y)
Grafiquemos los resultados.
fig1 = plot_sfs(sfs.get_metric_dict(),kind="std_dev") plt.title("Neural Network Backward Feature Selection") plt.grid()
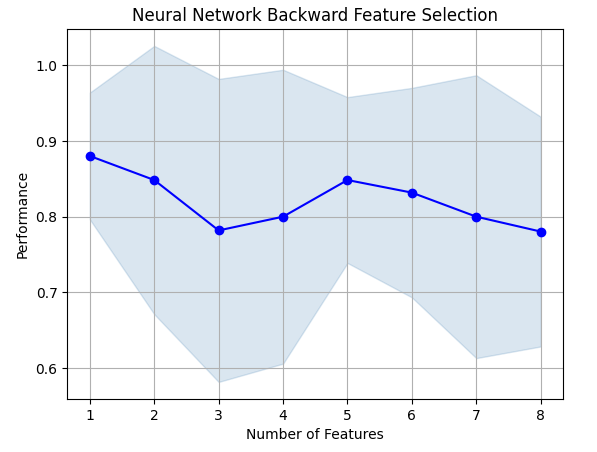
Figura 8: A medida que aumentamos el número de características en el modelo, nuestro rendimiento empeoró.
Lamentablemente, nuestra precisión siguió disminuyendo a medida que agregamos más funciones. Esto puede significar que la asociación simplemente no es tan fuerte o que no estamos exponiendo la asociación de una manera que nuestro modelo pueda interpretarla. Parece entonces que un modelo con una sola característica aún podría realizar el trabajo.
La mejor característica que identificamos.
sfs.k_feature_names_
Observemos ahora nuestras puntuaciones de información mutua (Mutual Information, MI). El MI nos informa de cuánto potencial tiene cada variable para predecir el objetivo, las puntuaciones del MI tienen un valor positivo y van desde 0 hasta el infinito en teoría, pero en la práctica rara vez observamos puntuaciones del MI superiores a 2 y una puntuación del MI superior a 1 es buena.
Importe el clasificador MI desde Scikit-learn.
#Mutual information
from sklearn.feature_selection import mutual_info_classif La puntuación MI para el conjunto de datos principal.
#Mutual information from the headline visa dataset, print(f"VISA Headline dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa h']],train_y)[0]}")
La puntuación MI para el conjunto de datos discrecional.
#Mutual information from the second visa dataset, print(f"VISA Discretionary dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa d']],train_y)[0]}")
Todos nuestros conjuntos de datos tuvieron puntuaciones MI bajas, lo que puede ser una razón convincente para intentar aplicar diferentes transformaciones al conjunto de datos VISA y, con suerte, podremos descubrir una asociación más fuerte.
Ajuste de parámetros
Intentemos ahora ajustar nuestra red neuronal profunda para pronosticar el EURUSD. Antes de eso, necesitamos escalar nuestros datos. Primero, restablezca el índice del conjunto de datos fusionado.
#Reset the index
merged_data.reset_index(inplace=True)
Definir el objetivo y los predictores.
#Define the target target = "target" ohlc_predictors = ["open","high","low","close","tick_volume"] visa_predictors = ["visa d","visa h","visa nd"] all_predictors = ohlc_predictors + visa_predictors
Ahora escalaremos y transformaremos nuestros datos. De cada valor de nuestro conjunto de datos, restaremos la media y la dividiremos por la desviación estándar de la columna respectiva. Vale la pena señalar que esta transformación es sensible a los valores atípicos.
#Let's scale the data scale_factors = pd.DataFrame(index=["mean","standard deviation"],columns=all_predictors) for i in np.arange(0,len(all_predictors)): #Store the mean and standard deviation for each column scale_factors.iloc[0,i] = merged_data.loc[:,all_predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,all_predictors[i]].std() merged_data.loc[:,all_predictors[i]] = ((merged_data.loc[:,all_predictors[i]] - scale_factors.iloc[0,i]) / scale_factors.iloc[1,i]) scale_factors
Echando un vistazo a los datos escalados.
#Let's see the normalized data merged_data
Importación de bibliotecas estándar.
#Lets try to train a deep neural network to uncover relationships in the data from sklearn.neural_network import MLPClassifier from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
Crea una división de entrenamiento y prueba.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"],test_size=0.5,shuffle=False)
Ajuste del modelo a las entradas disponibles. Recordemos que primero debemos pasar el modelo que queremos sintonizar, y luego especificar los parámetros del modelo que nos interesa. Después debemos indicar cuántos pliegues queremos utilizar para la validación cruzada.
tuner = RandomizedSearchCV(MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="accuracy", return_train_score=False )
Ajuste del afinador.
tuner.fit(train_X,train_y)
Veamos los resultados obtenidos sobre los datos de entrenamiento, ordenados de mejor a peor.
tuner_results = pd.DataFrame(tuner.cv_results_) params = ["param_activation","param_solver","param_alpha","param_learning_rate","param_learning_rate_init","mean_test_score"] tuner_results.loc[:,params].sort_values(by="mean_test_score",ascending=False)

Figura 9: Nuestros resultados de optimización.
Nuestra precisión más alta fue del 88% en los datos de entrenamiento. Tenga en cuenta que, debido a la naturaleza estocástica del algoritmo de optimización que hemos seleccionado, puede resultar difícil reproducir los resultados obtenidos en esta demostración.
Prueba de sobreajuste
Comparemos ahora nuestros modelos predeterminados y personalizados para ver si estamos sobreajustando los datos de entrenamiento. Si estamos sobreajustando, el modelo por defecto superará a nuestro modelo personalizado en el conjunto de validación; de lo contrario, nuestro modelo personalizado funcionará mejor.
Preparemos los 2 modelos.
#Let's compare the default model and our customized model on the hold out set default_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
Mida la precisión del modelo predeterminado.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
accuracy_score(test_y,default_model.predict(test_X))
La precisión de nuestro modelo personalizado.
#The accuracy of the defualt model
customized_model.fit(train_X,train_y)
accuracy_score(test_y,customized_model.predict(test_X))
Parece que hemos entrenado el modelo sin sobreajustarlo a los datos de entrenamiento. Tenga en cuenta también que nuestro error de entrenamiento suele ser siempre mayor que nuestro error de prueba, sin embargo la discrepancia entre ellos no debería ser demasiado grande. Nuestro error de entrenamiento fue del 88% y el error de prueba del 74%, esto es razonable. Una gran brecha entre el error de entrenamiento y el de prueba sería alarmante, ¡podría indicar que estábamos sobreajustando!
Implementando la estrategia
Primero, definimos las variables globales que utilizaremos.
#Let us now start building our trading strategy SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_MN1 DEVIATION = 1000 VOLUME = 0 LOT_MULTIPLE = 1
Ahora inicialicemos nuestro terminal MetaTrader 5.
#Get the system up
if not mt5.initialize():
print('Failed To Log in')
Ahora necesitamos saber más detalles sobre el mercado.
#Let's fetch the trading volume
for index,symbol in enumerate(mt5.symbols_get()):
if symbol.name == SYMBOL:
print(f"{symbol.name} has minimum volume: {symbol.volume_min}")
VOLUME = symbol.volume_min * LOT_MULTIPLE
Esta función obtendrá el precio de mercado actual para nosotros.
#A function to get current prices def get_prices(): start = datetime(2024,1,1) end = datetime.now() data = pd.DataFrame(mt5.copy_rates_range(SYMBOL,TIMEFRAME,start,end)) data['time'] = pd.to_datetime(data['time'],unit='s') data.set_index('time',inplace=True) return(data.iloc[-1,:])
Creemos también una función para obtener los datos alternativos más recientes de la API FRED.
#A function to get our alternative data def get_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] return(visa_d,visa_h,visa_n)
Necesitamos una función responsable de normalizar y escalar nuestras entradas.
#A function to prepare the inputs for our model def get_model_inputs(): LAST_OHLC = get_prices() visa_d , visa_h , visa_n = get_alternative_data() return( np.array([[ ((LAST_OHLC['open'] - scale_factors.iloc[0,0]) / scale_factors.iloc[1,0]), ((LAST_OHLC['high'] - scale_factors.iloc[0,1]) / scale_factors.iloc[1,1]), ((LAST_OHLC['low'] - scale_factors.iloc[0,2]) / scale_factors.iloc[1,2]), ((LAST_OHLC['close'] - scale_factors.iloc[0,3]) / scale_factors.iloc[1,3]), ((LAST_OHLC['tick_volume'] - scale_factors.iloc[0,4]) / scale_factors.iloc[1,4]), ((visa_d - scale_factors.iloc[0,5]) / scale_factors.iloc[1,5]), ((visa_h - scale_factors.iloc[0,6]) / scale_factors.iloc[1,6]), ((visa_n - scale_factors.iloc[0,7]) / scale_factors.iloc[1,7]) ]]) )
Entrenemos nuestro modelo con todos los datos que tenemos.
#Let's train our model on all the data we have model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation="logistic",solver="lbfgs",alpha=0.00001,learning_rate="constant",learning_rate_init=0.00001) model.fit(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"])
Esta función obtendrá una predicción de nuestro modelo.
#A function to get a prediction from our model def ai_forecast(): model_inputs = get_model_inputs() prediction = model.predict(model_inputs) return(prediction[0])
Ahora hemos llegado al corazón de nuestro algoritmo. Primero, comprobaremos cuántas posiciones tenemos abiertas. Luego obtendremos una predicción de nuestro modelo. Si no tenemos posiciones abiertas, utilizaremos el pronóstico de nuestro modelo para abrir una posición. De lo contrario, utilizaremos el pronóstico de nuestro modelo como señal de salida si tenemos posiciones abiertas.
while True: #Get data on the current state of our terminal and our portfolio positions = mt5.positions_total() forecast = ai_forecast() BUY_STATE , SELL_STATE = False , False #Interpret the model's forecast if(forecast == 0.0): SELL_STATE = True BUY_STATE = False elif(forecast == 1.0): SELL_STATE = False BUY_STATE = True print(f"Our forecast is {forecast}") #If we have no open positions let's open them if(positions == 0): print(f"We have {positions} open trade(s)") if(SELL_STATE): print("Opening a sell position") mt5.Sell(SYMBOL,VOLUME) elif(BUY_STATE): print("Opening a buy position") mt5.Buy(SYMBOL,VOLUME) #If we have open positions let's manage them if(positions > 0): print(f"We have {positions} open trade(s)") for pos in mt5.positions_get(): if(pos.type == 1): if(BUY_STATE): print("Closing all sell positions") mt5.Close(SYMBOL) if(pos.type == 0): if(SELL_STATE): print("Closing all buy positions") mt5.Close(SYMBOL) #If we have finished all checks then we can wait for one day before checking our positions again time.sleep(24 * 60 * 60)
We have 0 open trade(s)
Opening a sell position
Implementación en MQL5
Para implementar nuestra estrategia en MQL5, primero necesitamos exportar nuestros modelos al formato Open Neural Network Exchange (ONNX). ONNX es un protocolo para representar modelos de aprendizaje automático como una combinación de gráficos y aristas. Este protocolo estandarizado permite a los desarrolladores crear e implementar modelos de aprendizaje automático utilizando diferentes lenguajes de programación con facilidad. Lamentablemente, no todos los modelos y marcos de aprendizaje automático son totalmente compatibles con la API ONNX actual.
Para comenzar, importaremos algunas bibliotecas.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Luego debemos ingresar nuestra clave API FRED, para obtener acceso a los datos que necesitamos.
#Let's setup our FredAPI
fred = Fred(api_key="")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Tenga en cuenta que después de obtener los datos, los escalamos utilizando el mismo formato que se describió anteriormente. Hemos omitido esos pasos para evitar la repetición de la misma información. La única pequeña diferencia es que ahora estamos entrenando el modelo para predecir el precio de cierre real, no solo un objetivo binario.
Después de escalar los datos, intentemos ahora ajustar los parámetros de nuestro modelo.
#A few more libraries we need from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
Necesitamos particionar nuestros datos para tener un conjunto de entrenamiento para optimizar el modelo y un conjunto de validación que usaremos para probar el sobreajuste.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"close target"],test_size=0.5,shuffle=False)
Ahora realizaremos el ajuste de hiperparámetros; observe que configuramos la métrica de puntuación en “error cuadrático medio negativo”, esta métrica de puntuación identificará el modelo que produce el MSE (Mean Squared Error) más bajo como el modelo con mejor rendimiento.
tuner = RandomizedSearchCV(MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,early_stopping=True), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="neg_mean_squared_error", return_train_score=False, n_jobs=-1 )
Ajuste del objeto afinador.
tuner.fit(train_X,train_y)
Probemos ahora si hay sobreajuste.
#Let's compare the default model and our customized model on the hold out set default_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
La precisión de nuestro modelo predeterminado.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
Logramos superar nuestro modelo predeterminado en el conjunto de validación mantenido, lo que es una buena señal de que no estamos sobreajustando.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
0.006138795093781729
Ajustemos el modelo personalizado a todos los datos que tenemos, antes de exportarlo al formato ONNX.
#Fit the model on all the data we have
customized_model.fit(test_X,test_y)
Importación de bibliotecas de conversión ONNX.
#Convert to ONNX
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn
import netron
import onnx Define el tipo de entrada y la forma de nuestro modelo.
#Define the initial types initial_types = [("float_input",FloatTensorType([1,train_X.shape[1]]))]
Cree una representación ONNX del modelo en la memoria.
#Create the onnx representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
Almacene la representación ONNX en el disco duro.
#Save the ONNX model onnx_model_name = "EURUSD VISA MN1 FLOAT.onnx" onnx.save(onnx_model,onnx_model_name)
Ver el modelo ONNX en Netron.
#View the ONNX model
netron.start(onnx_model_name) 
Figura 10: Nuestra red neuronal profunda en formato ONNX.

Figura 11: Metadetalles de nuestro modelo ONNX.
Estamos casi listos para comenzar a construir nuestro Asesor Experto. Sin embargo, primero debemos crear un servicio Python en segundo plano que obtendrá los datos de FRED y los pasará a nuestro programa.
Primero, importamos las bibliotecas que necesitamos.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred from datetime import datetime
Luego iniciamos sesión usando nuestras credenciales FRED.
#Let's setup our FredAPI fred = Fred(api_key="")
Necesitamos definir una función que obtenga los datos por nosotros y los escriba en CSV.
#A function to write out our alternative data to CSV def write_out_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] data = pd.DataFrame(np.array([visa_d,visa_h,visa_n]),columns=["Data"],index=["Discretionary","Headline","Non-Discretionary"]) data.to_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_visa.csv")
Ahora necesitamos escribir un bucle que busque nuevos datos una vez al día y actualice nuestro archivo CSV.
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)Ahora que tenemos acceso a los últimos datos de FRED, podemos comenzar a construir nuestro Asesor Experto.
We will first load our ONNX model as a resource into our application. //+------------------------------------------------------------------+ //| VISA EA.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resorces | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD VISA MN1 FLOAT.onnx" as const uchar onnx_buffer[];
Luego cargaremos la biblioteca comercial para ayudarnos a abrir y administrar nuestras posiciones.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Hasta ahora nuestra aplicación va bien, creemos variables globales que usaremos en diferentes bloques de nuestra aplicación.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[8],std_values[8]; float visa_data[3]; vector model_forecast = vector::Zeros(1); double trading_volume = 0.3; int state = 0;
Antes de que podamos comenzar a utilizar nuestro modelo ONNX, primero debemos crear el modelo ONNX a partir del recurso que necesitamos al comienzo del programa. Después, necesitamos definir las formas de entrada y salida del modelo.
//+------------------------------------------------------------------+ //| Load the ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- Try create the ONNX model from the buffer we have onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model if(onnx_model == INVALID_HANDLE) { Comment("Failed to create the ONNX model. ",GetLastError()); return(false); } //--- Set the I/O shape ulong input_shape[] = {1,8}; ulong output_shape[] = {1,1}; //--- Validate the I/O shapes if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape. ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape. ",GetLastError()); return(false); } return(true); }
Recuerde que estandarizamos nuestros datos restando la media de la columna y dividiéndola por la desviación estándar de cada columna. Necesitamos almacenar estos valores en la memoria. Dado que estos valores nunca cambiarán, simplemente los he codificado en el programa.
//+------------------------------------------------------------------+ //| Mean & Standard deviation values | //+------------------------------------------------------------------+ void load_scaling_values(void) { //--- Mean & standard deviation values for the EURUSD OHLCV mean_values[0] = 1.146552; std_values[0] = 0.08293; mean_values[1] = 1.165568; std_values[1] = 0.079657; mean_values[2] = 1.125744; std_values[2] = 0.083896; mean_values[3] = 1.143834; std_values[3] = 0.080655; mean_values[4] = 1883520.051282; std_values[4] = 826680.767222; //--- Mean & standard deviation values for the VISA datasets mean_values[5] = 101.271017; std_values[5] = 3.981438; mean_values[6] = 100.848506; std_values[6] = 6.565229; mean_values[7] = 100.477269; std_values[7] = 2.367663; }
El servicio en segundo plano de Python que hemos creado siempre nos dará los últimos datos disponibles, vamos a crear una función para leer ese CSV y almacenar los valores en un array para nosotros.
//+-------------------------------------------------------------------+ //| Read in the VISA data | //+-------------------------------------------------------------------+ void read_visa_data(void) { //--- Read in the file string file_name = "fred_visa.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value); if(counter == 3) { Print("Discretionary data: ",value); visa_data[0] = (float) value; } if(counter == 5) { Print("Headline data: ",value); visa_data[1] = (float) value; } if(counter == 7) { Print("Non-Discretionary data: ",value); visa_data[2] = (float) value; } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the VISA data Print("VISA DATA: "); ArrayPrint(visa_data); //---Close the file FileClose(result); } }
Por último, debemos definir una función encargada de obtener predicciones de nuestro modelo. En primer lugar, almacenamos las entradas actuales en un vector float porque nuestro modelo tiene un tipo de entrada float como definimos cuando creamos los tipos iniciales de ONNX.
Recordemos que tenemos que escalar cada valor de entrada restando la media de la columna y dividiendo por la desviación estándar de la columna, antes de pasar las entradas a nuestro modelo.
//+--------------------------------------------------------------+ //| Get a prediction from our model | //+--------------------------------------------------------------+ void model_predict(void) { //--- Fetch input data read_visa_data(); vectorf input_data = {(float)iOpen("EURUSD",PERIOD_MN1,0), (float)iHigh("EURUSD",PERIOD_MN1,0), (float)iLow("EURUSD",PERIOD_MN1,0), (float)iClose("EURUSD",PERIOD_MN1,0), (float)iTickVolume("EURUSD",PERIOD_MN1,0), (float)visa_data[0], (float)visa_data[1], (float)visa_data[2] }; //--- Scale the data for(int i =0; i < 8;i++) { input_data[i] = (float)((input_data[i] - mean_values[i])/std_values[i]); } //--- Show the input data Print("Input data: ",input_data); //--- Obtain a forecast OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT|ONNX_DEFAULT,input_data,model_forecast); } //+------------------------------------------------------------------+
Definamos ahora el procedimiento de inicialización. Empezaremos cargando nuestro modelo ONNX, después leeremos el conjunto de datos VISA y, por último, cargaremos nuestros valores de escalado.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!load_onnx_model()) { //--- We failed to load the ONNX model return(INIT_FAILED); } //--- Read the VISA data read_visa_data(); //--- Load scaling values load_scaling_values(); //--- We were successful return(INIT_SUCCEEDED); }
Cuando nuestro programa deje de utilizarse, liberemos los recursos que ya no necesitamos.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we don't need OnnxRelease(onnx_model); ExpertRemove(); }
Siempre que dispongamos de nuevos datos de precios, primero obtendremos una predicción de nuestro modelo. Si no tenemos posiciones abiertas, seguiremos la entrada generada por nuestro modelo. Por último, si tenemos posiciones abiertas, utilizaremos nuestro modelo de IA para detectar con antelación posibles retrocesos en el precio.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Get a prediction from our model model_predict(); Comment("Model forecast: ",model_forecast[0]); //--- Check if we have any positions if(PositionsTotal() == 0) { //--- Note that we have no trades open state = 0; //--- Find an entry and take note if(model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Sell(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,"Gain an Edge VISA"); state = 1; } if(model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Buy(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,"Gain an Edge VISA"); state = 2; } } //--- If we have positions open, check for reversals if(PositionsTotal() > 0) { if(((state == 1) && (model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0))) || ((state == 2) && (model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)))) { Alert("Reversal detected, closing positions now"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

Figura 12: Nuestro Asesor Experto en VISA.

Figura 13: Ejemplo de salida de nuestro programa.

Figura 14: Nuestra aplicación en acción.
Conclusión
En este artículo le mostramos cómo seleccionar los datos que pueden ser útiles para su estrategia de negociación. Hemos hablado de cómo medir la fuerza potencial de sus datos alternativos y de cómo optimizar sus modelos para que pueda extraer el máximo rendimiento posible sin ajustar en exceso. Hay potencialmente cientos de miles de conjuntos de datos por explorar, y nos comprometemos a ayudarle a identificar los más informativos.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15575
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Gracias, Gamu
¡¡¡Gran artículo, gracias por compartirlo!!!
Gracias de nuevo Gamu. Bien escrito como siempre. Una gran plantilla comentada sobre cómo visualizar, escalar, probar, comprobar si hay sobreajuste, implementar un datafeed, predecir e implementar un sistema de comercio de un conjunto de datos . Fantástico muy apreciado