Artículos sobre aprendizaje automático en el trading
Creación de robots comerciales basados en inteligencia artificial: integración nativa con Python, operaciones con matrices y vectores, bibliotecas de matemáticas y estadística y mucho más.
Aprenda a usar el aprendizaje automático en el trading. Neuronas, perceptrones, redes convolucionales y recurrentes, modelos predictivos: parta de lo básico y avance hasta construir su propia IA. Aprenderá a entrenar y aplicar redes neuronales para el comercio algorítmico en los mercados financieros.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Aprendizaje automático y Data Science (Parte 26): La batalla definitiva en la previsión de series temporales: redes neuronales LSTM frente a GRU
En el artículo anterior, hablamos de una RNN sencilla que, a pesar de su incapacidad para comprender las dependencias a largo plazo en los datos, fue capaz de realizar una estrategia rentable. En este artículo hablaremos tanto de la memoria a largo plazo (LSTM) como de la unidad recurrente controlada (GRU). Estas dos se introdujeron para superar las deficiencias de una RNN simple y ser más astuta que ella.

Regresiones espurias en Python
Las regresiones espurias ocurren cuando dos series de tiempo exhiben un alto grado de correlación puramente por casualidad, lo que conduce a resultados engañosos en el análisis de regresión. En tales casos, aunque las variables parezcan estar relacionadas, la correlación es casual y el modelo puede no ser confiable.

Algoritmos de optimización de la población: Algoritmo de enjambre de aves (Bird Swarm Algorithm, BSA)
El artículo analiza un algoritmo BSA basado en el comportamiento de las aves, que se inspira en las interacciones colectivas de bandadas de aves en la naturaleza. Las diferentes estrategias de búsqueda de individuos en el BSA, que incluyen el cambio entre el comportamiento de vuelo, la vigilancia y la búsqueda de alimento, hacen que este algoritmo sea multidimensional. El algoritmo usa los principios del comportamiento de las bandadas, la comunicación, la adaptabilidad, el liderazgo y el seguimiento de las aves para encontrar con eficacia soluciones óptimas.

Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
Seguimos explorando el aprendizaje por refuerzo. En este artículo, hablaremos del método de aprendizaje Q profundo o deep Q-learning. El uso de este método permitió al equipo de DeepMind crear un modelo capaz de superar a los humanos jugando a los videojuegos de ordenador de Atari. Nos parece útil evaluar el potencial de esta tecnología para las tareas comerciales.

Modelos de clasificación de la biblioteca Scikit-learn y su exportación a ONNX
En este artículo, analizaremos el uso de todos los modelos de clasificación del paquete Scikit-learn para resolver el problema de la clasificación de los iris de Fisher; asimismo, intentaremos convertir estos al formato ONNX y usar los modelos resultantes en programas MQL5. También compararemos la precisión de los modelos originales y sus versiones ONNX en el conjunto de datos completo Iris dataset.

Experimentos con redes neuronales (Parte 2): Optimización inteligente de una red neuronal
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.

Redes neuronales: así de sencillo (Parte 49): Soft Actor-Critic
Continuamos nuestro análisis de los algoritmos de aprendizaje por refuerzo en problemas de espacio continuo de acciones. En este artículo, le propongo introducir el algoritmo Soft Astog-Critic (SAC). La principal ventaja del SAC es su capacidad para encontrar políticas óptimas que no solo maximicen la recompensa esperada, sino que también tengan la máxima entropía (diversidad) de acciones.

Algoritmos de optimización de la población: Algoritmos de estrategias evolutivas (Evolution Strategies, (μ,λ)-ES y (μ+λ)-ES)
En este artículo, analizaremos un grupo de algoritmos de optimización conocidos como "estrategias evolutivas" (Evolution Strategies o ES). Se encuentran entre los primeros algoritmos basados en poblaciones que usan principios evolutivos para encontrar soluciones óptimas. Hoy le presentaremos los cambios introducidos en las variantes clásicas de ES y revisaremos la función de prueba y la metodología del banco de pruebas para los algoritmos.
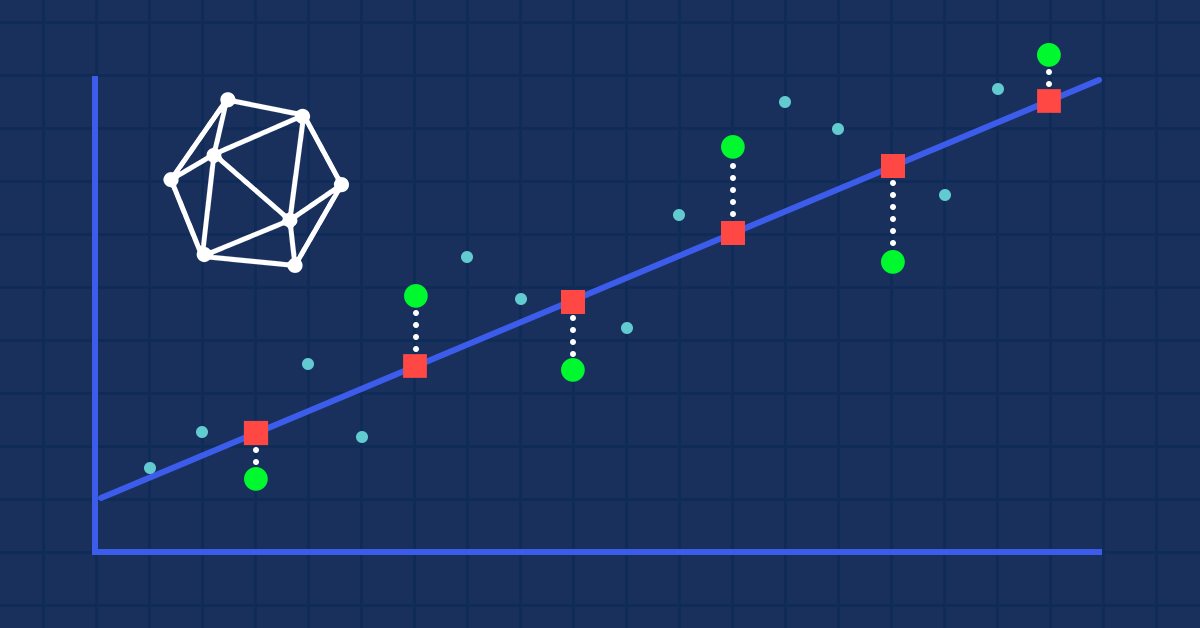
Evaluación de modelos ONNX usando métricas de regresión
La regresión es una tarea que consiste en predecir un valor real a partir de un ejemplo sin etiquetar. Para evaluar la precisión de las predicciones de los modelos de regresión, se usan las llamadas métricas de regresión.

Algoritmos de optimización de la población: Algoritmo de búsqueda gravitacional (GSA)
El GSA es un algoritmo de optimización basado en la población e inspirado en la naturaleza no viviente. La simulación de alta fidelidad de la interacción entre los cuerpos físicos, gracias a la ley de la gravedad de Newton presente en el algoritmo, permite observar la mágica danza de los sistemas planetarios y los cúmulos galácticos, capaz de hipnotizar en la animación. Hoy vamos a analizar uno de los algoritmos de optimización más interesantes y originales. Adjuntamos un simulador de movimiento de objetos espaciales.

Redes neuronales: así de sencillo (Parte 82): Modelos de ecuaciones diferenciales ordinarias (NeuralODE)
En este artículo, hablaremos de otro tipo de modelos que están destinados a estudiar la dinámica del estado ambiental.

Redes neuronales: así de sencillo (Parte 14): Clusterización de datos
Lo confieso: ha pasado más de un año desde que publiqué el último artículo. En tanto tiempo, me ha sido posible repensar mucho, desarrollar nuevos enfoques. Y en este nuevo artículo, me gustaría alejarme un poco del método anteriormente usado de aprendizaje supervisado, y sugerir una pequeña inmersión en los algoritmos de aprendizaje no supervisado. En particular, vamos a analizar uno de los algoritmos de clusterización, las k-medias.

Introducción a MQL5 (Parte 2): Variables predefinidas, funciones comunes y operadores de flujo de control
En este artículo, seguiremos familiarizándonos con el lenguaje de programación MQL5. Esta serie de artículos no es solo un tutorial, sino también una puerta de entrada al mundo de la programación. ¿Qué hace especiales a estos artículos? Hemos procurado que las explicaciones sean sencillas para que los conceptos complejos resulten accesibles a todos. Aunque el material es accesible, para obtener los mejores resultados será necesario reproducir activamente todo lo que vamos a tratar. Solo así obtendremos el máximo beneficio de estos artículos.

Aprendizaje automático y Data Science (Parte 21): Desbloqueando las redes neuronales: desmitificando los algoritmos de optimización
Sumérjase en el corazón de las redes neuronales mientras desmitificamos los algoritmos de optimización utilizados dentro de la red neuronal. En este artículo, descubra las técnicas clave que liberan todo el potencial de las redes neuronales, impulsando sus modelos a nuevas cotas de precisión y eficacia.

Dominando ONNX: Un punto de inflexión para los tráders de MQL5
Sumérjase en el mundo de ONNX, un potente formato abierto para compartir modelos de aprendizaje automático. Descubra cómo el uso de ONNX puede revolucionar el trading algorítmico en MQL5, permitiendo a los tráders integrar sin problemas modelos avanzados de IA y llevar sus estrategias al siguiente nivel. Descubra los secretos de la compatibilidad multiplataforma y aprenda a liberar todo el potencial de ONNX en sus operaciones MQL5. Mejore sus operaciones con esta guía detallada de ONNX.

Experimentos con redes neuronales (Parte 1): Recordando la geometría
Las redes neuronales lo son todo. En este artículo, usaremos la experimentación y enfoques no estándar para desarrollar un sistema comercial rentable y comprobaremos si las redes neuronales pueden ser de alguna ayuda para los comerciantes.

Algoritmos de optimización de la población: Enjambre de partículas (PSO)
En este artículo, analizaremos el popular algoritmo de optimización de la población «Enjambre de partículas» (PSO — particle swarm optimisation). Con anterioridad, ya discutimos características tan importantes de los algoritmos de optimización como la convergencia, la tasa de convergencia, la estabilidad, la escalabilidad, y también desarrollamos un banco de pruebas y analizamos el algoritmo RNG más simple.

Redes neuronales: así de sencillo (Parte 31): Algoritmos evolutivos
En el artículo anterior, comenzamos a analizar los métodos de optimización sin gradiente, y también nos familiarizamos con el algoritmo genético. Hoy continuaremos con el tema iniciado, y estudiaremos otra clase de algoritmos evolutivos.

Aprendizaje automático y Data Science (Parte 28): Predicción de múltiples futuros para el EURUSD mediante IA
Es una práctica común que muchos modelos de Inteligencia Artificial predigan un único valor futuro. Sin embargo, en este artículo profundizaremos en la poderosa técnica de utilizar modelos de aprendizaje automático para predecir múltiples valores futuros. Este enfoque, conocido como pronóstico de múltiples pasos, nos permite predecir no sólo el precio de cierre de mañana, sino también el de pasado mañana y más allá. Al dominar la previsión en varios pasos, los operadores y los científicos de datos pueden obtener conocimientos más profundos y tomar decisiones más informadas, mejorando significativamente sus capacidades de predicción y planificación estratégica.

El problema del desacuerdo: profundizando en la explicabilidad de la complejidad en la IA
En este artículo hablaremos de los problemas relacionados con los explicadores y la explicabilidad en la IA. Los modelos de IA suelen tomar decisiones difíciles de explicar. Además, el uso de múltiples explicadores suele provocar el llamado "problema del desacuerdo". Al fin y al cabo, la comprensión clara del funcionamiento de los modelos resulta fundamental para aumentar la confianza en la IA.

Redes neuronales: así de sencillo (Parte 20): Autocodificadores
Continuamos analizando los algoritmos de aprendizaje no supervisado. El lector podría preguntarse sobre la relevancia de las publicaciones recientes en el tema de las redes neuronales. En este nuevo artículo, retomaremos el uso de las redes neuronales.

Arbitraje estadístico con predicciones
Daremos un paseo por el arbitraje estadístico, buscaremos con Python símbolos de correlación y cointegración, haremos un indicador para el coeficiente de Pearson y haremos un EA para operar arbitraje estadístico con predicciones hechas con Python y modelos ONNX.

Algoritmos de optimización de la población: Algoritmo de siembra y crecimiento de árboles (Saplings Sowing and Growing up — SSG)
El algoritmo de siembra y crecimiento de árboles (SSG) está inspirado en uno de los organismos más resistentes del planeta, que es un ejemplo notable de supervivencia en una amplia variedad de condiciones.

Algoritmos de optimización de la población: Búsqueda de bancos de peces (Fish School Search — FSS)
La búsqueda de bancos de peces (FSS) es un nuevo algoritmo de optimización moderno inspirado en el comportamiento de los peces en un banco, la mayoría de los cuales, hasta el 80%, nadan en una comunidad organizada de parientes. Se ha demostrado que las asociaciones de peces juegan un papel importante a la hora de buscar alimento y protegerse contra los depredadores de forma eficiente.

Algoritmos de optimización de la población: Algoritmo de forrajeo bacteriano (Bacterial Foraging Optimisation — BFO)
La estrategia de búsqueda de alimento de la bacteria E.coli inspiró a los científicos para crear el algoritmo de optimización BFO. El algoritmo contiene ideas originales y enfoques prometedores para la optimización y merece ser investigado en profundidad.

Redes neuronales: así de sencillo (Parte 65): Aprendizaje supervisado ponderado por distancia (DWSL)
En este artículo, le presentaremos un interesante algoritmo que se basa en la intersección de los métodos de aprendizaje supervisado y por refuerzo.

Creación de un modelo de restricción de tendencia de velas (Parte 9): Asesor Experto de múltiples estrategias (I)
Hoy, exploraremos las posibilidades de incorporar múltiples estrategias en un Asesor Experto (Expert Advisor, EA) utilizando MQL5. Los asesores expertos ofrecen capacidades más amplias que solo indicadores y scripts, lo que permite enfoques comerciales más sofisticados que pueden adaptarse a las condiciones cambiantes del mercado. Encuentre más información en este artículo de discusión.
Algoritmos de optimización de la población: Algoritmo de optimización de la dinámica espiral (Spiral Dynamics Optimization, SDO)
Este artículo presenta un algoritmo de optimización basado en los patrones de las trayectorias en espiral en la naturaleza, como las conchas de los moluscos: el algoritmo de optimización de la dinámica espiral o SDO. El algoritmo propuesto ha sido repensado y modificado a fondo por el autor: en el artículo analizaremos por qué estos cambios han sido necesarios.

Redes neuronales: así de sencillo (Parte 80): Modelo generativo y adversarial del Transformador de grafos (GTGAN)
En este artículo, le presentamos el algoritmo GTGAN, introducido en enero de 2024 para resolver problemas complejos de disposición arquitectónica con restricciones gráficas.

Redes neuronales: así de sencillo (Parte 21): Autocodificadores variacionales (VAE)
En el anterior artículo, vimos el algoritmo del autocodificador. Como cualquier otro algoritmo, tiene ventajas y desventajas. En la implementación original, el autocodificador se encarga de dividir los objetos de la muestra de entrenamiento tanto como sea posible. Y en este artículo, en cambio, hablaremos de cómo solucionar algunas de sus deficiencias.

Algoritmos de optimización de la población: Algoritmo de optimización de ballenas (Whale Optimization Algorithm, WOA)
El algoritmo de optimización de ballenas (WOA) es un algoritmo metaheurístico inspirado en el comportamiento y las estrategias de caza de las ballenas jorobadas. La idea básica del WOA es imitar el método de alimentación denominado "red de burbujas", en el que las ballenas crean burbujas alrededor de la presa para atacarla después en espiral.

Redes neuronales: así de sencillo (Parte 32): Aprendizaje Q distribuido
En uno de los artículos de esta serie, nos familiarizamos con el método de aprendizaje Q. Este método promedia las recompensas de cada acción. En 2017 se presentaron dos trabajos que muestran un mayor éxito al estudiar la función de distribución de recompensas. Vamos a analizar la posibilidad de utilizar esta tecnología para resolver nuestros problemas.

Redes neuronales: así de sencillo (Parte 19): Reglas asociativas usando MQL5
Continuamos con el tema de la búsqueda de reglas asociativas. En el artículo anterior, vimos los aspectos teóricos de este tipo de problemas. En el presente artículo, mostraremos la implementación del método FP-Growth usando MQL5. Y también pondremos a prueba nuestra aplicación con datos reales.

Representaciones en el dominio de la frecuencia de series temporales: El espectro de potencia
En este artículo, veremos métodos asociados con el análisis de series temporales en el dominio de la frecuencia. También prestaremos atención a los beneficios del estudio de las funciones espectrales de series temporales al construir modelos predictivos. Además, analizaremos algunas perspectivas prometedoras para el análisis de series temporales en el dominio de la frecuencia utilizando la transformada discreta de Fourier (DFT).
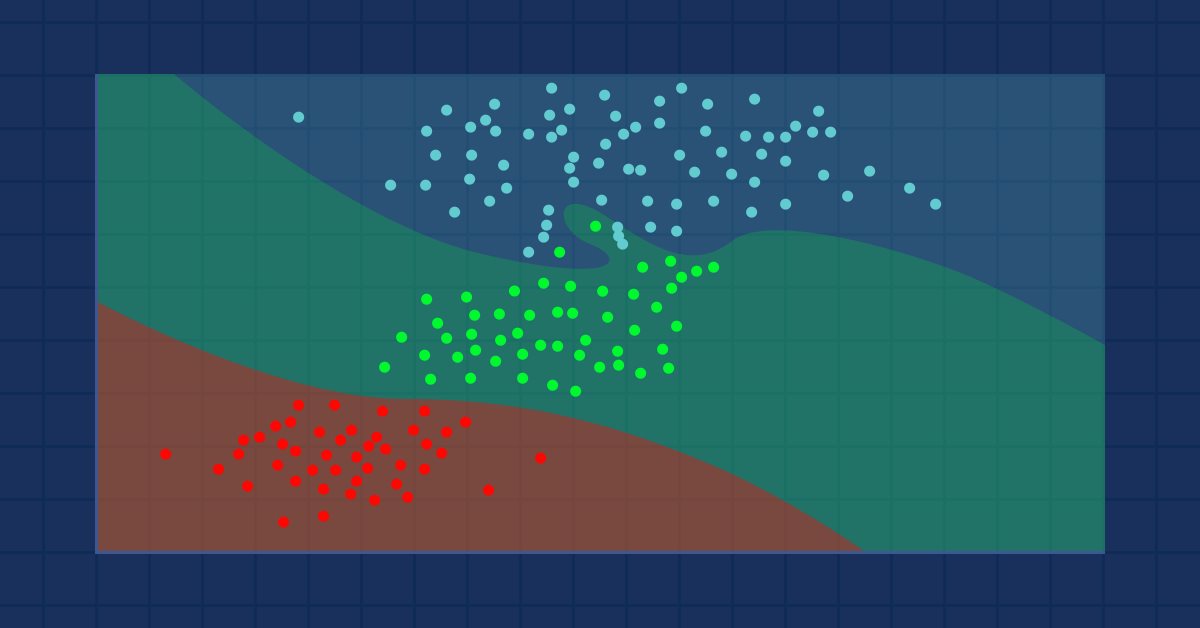
Aprendizaje automático y Data Science (Parte 9): Algoritmo de k vecinos más próximos (KNN)
Se trata de un algoritmo perezoso que no aprende a partir de una muestra de entrenamiento, sino que almacena todas las observaciones disponibles y clasifica los datos en cuanto recibe una nueva muestra. A pesar de su sencillez, este método se usa en muchas aplicaciones del mundo real.

Introducción a MQL5 (Parte 4): Estructuras, clases y funciones de tiempo
En esta serie, seguiremos desvelando los secretos de la programación. En nuestro nuevo artículo, aprenderemos los fundamentos de las estructuras, las clases y las funciones de tiempo y adquiriremos nuevas habilidades para lograr una programación eficiente. Esta guía será probablemente útil no solo para los principiantes, sino también para los desarrolladores experimentados, ya que simplifica conceptos complejos, ofreciendo información valiosa para dominar MQL5. Así que hoy podrá seguir aprendiendo cosas nuevas, mejorando sus conocimientos de programación y dominando el mundo del trading algorítmico.

Aprendizaje automático y data science (Parte 04): Predicción de una caída bursátil
En este artículo, intentaremos usar nuestro modelo logístico para predecir una caída del mercado de valores según las principales acciones de la economía estadounidense: NETFLIX y APPLE. Analizaremos estas acciones, y también usaremos la información sobre las anteriores caídas del mercado en 2019 y 2020. Veamos cómo funcionará nuestro modelo en las poco favorables condiciones actuales.
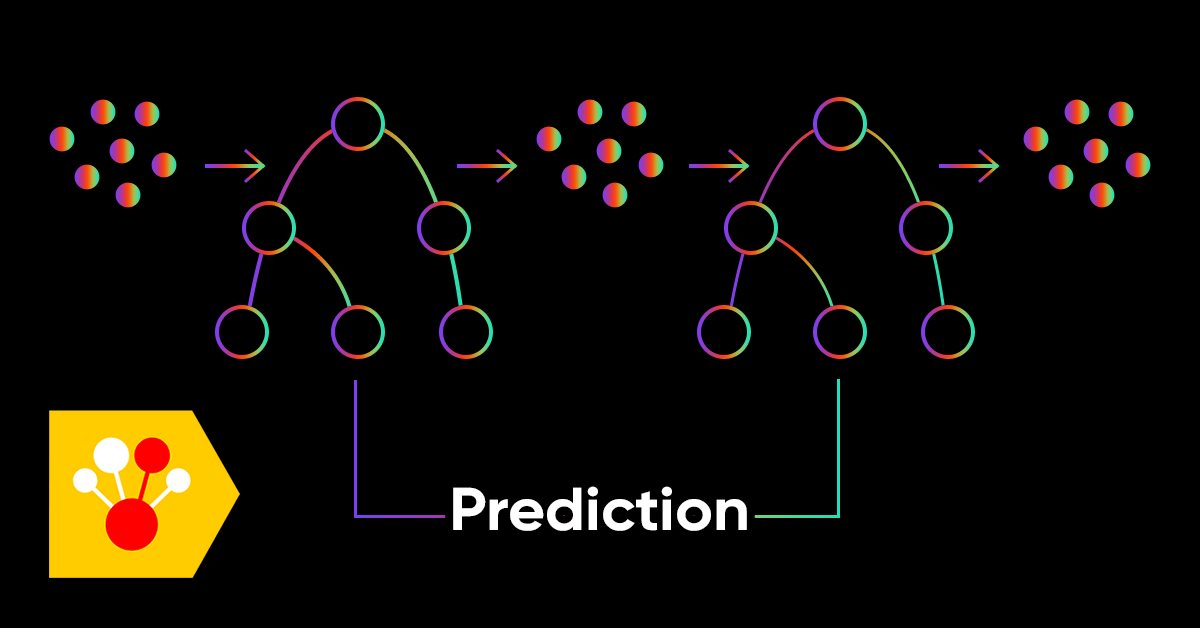
Gradient boosting en el aprendizaje de máquinas transductivo y activo
En este artículo, el lector podrá familiarizarse con los métodos de aprendizaje automático activo basados en datos reales, descubriendo además cuáles son sus ventajas y desventajas. Puede que estos métodos terminen por ocupar un lugar en su arsenal de modelos de aprendizaje automático. El término transducción fue introducido por Vladímir Naúmovich Vápnik, el inventor de la máquina de vectores de soporte (SVM).

Sistema de arbitraje de alta frecuencia en Python con MetaTrader 5
Hoy vamos a crear un sistema de arbitraje legal a los ojos de los brókeres, que creará miles de precios sintéticos en el mercado Fórex, los analizará y negociará con éxito para obtener beneficios.
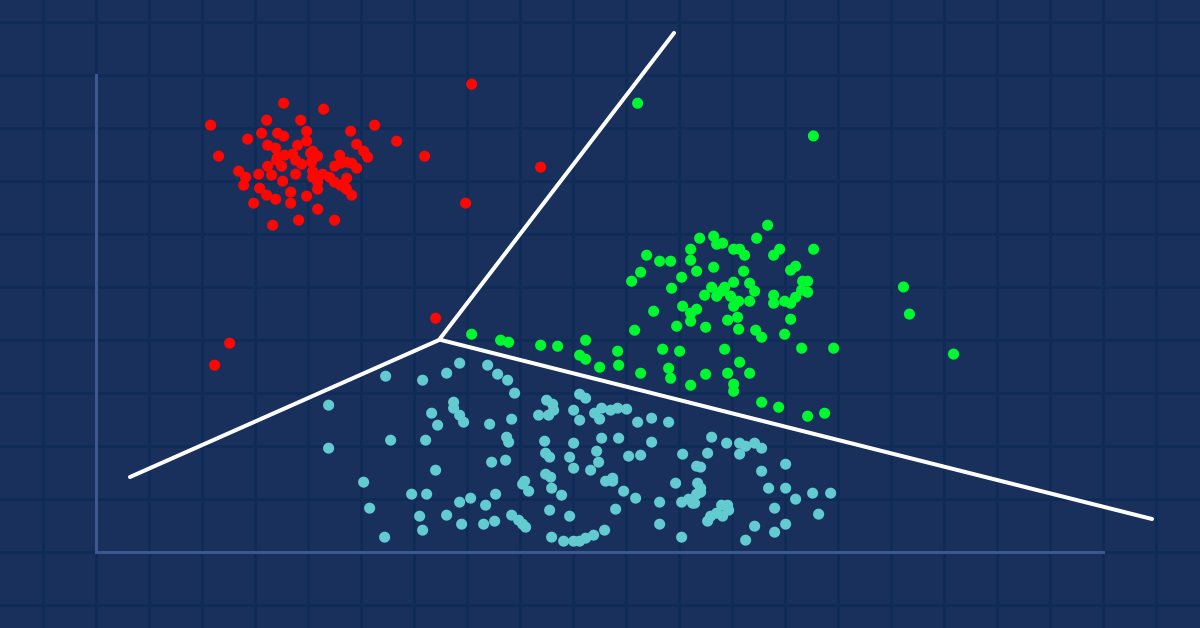
Aprendizaje automático y Data Science (Parte 8): Clusterización con el método de k-medias en MQL5
Para todos los que trabajan con datos, incluidos los tráders, la minería de datos puede descubrir posibilidades completamente nuevas, porque a menudo los datos no son tan simples como parecen. Resulta difícil para el ojo humano ver patrones y relaciones profundas en un conjunto de datos. Una solución sería el algoritmo de k-medias o k-means. Veamos si resulta útil.