Redes neuronales: así de sencillo (Parte 86): Transformador en U

Introducción
La previsión de series temporales a largo plazo resulta importante para el trading. La arquitectura del Transformer presentada en 2017 ha demostrado un rendimiento impresionante en las áreas de procesamiento del lenguaje natural (PLN) y de visión por ordenador (CV). El uso de mecanismos de autoatención nos permiten captar eficazmente las dependencias a lo largo de intervalos temporales prolongados, extrayendo información clave del contexto. Y resulta bastante natural que rápidamente se haya propuesto un gran número de algoritmos diferentes para resolver problemas de series temporales utilizando este mecanismo.
Sin embargo, estudios recientes han demostrado que las redes simples de perceptrón multicapa (MLP) pueden superar la precisión de los modelos basados en el Transformer en varios conjuntos de datos de series temporales. No obstante, la arquitectura del Transformer ha demostrado su eficacia en varios ámbitos e incluso ha encontrado aplicaciones prácticas. Por lo tanto, su poder de representación debería ser relativamente potente, y debería haber mecanismos para utilizarlo. Una de las opciones de perfeccionamiento del algoritmo vainilla Transformer es el artículo "U-shaped Transformer: Retain High Frequency Context in Time Series Analysis", que presenta el algoritmo del transformador en U.
1. Algoritmo
Probablemente habría que decir de entrada que los autores del método de Transformador en U han realizado un trabajo exhaustivo y han propuesto no solo formas de optimizar la arquitectura clásica del Transformer, sino también un enfoque para la formación de modelos.
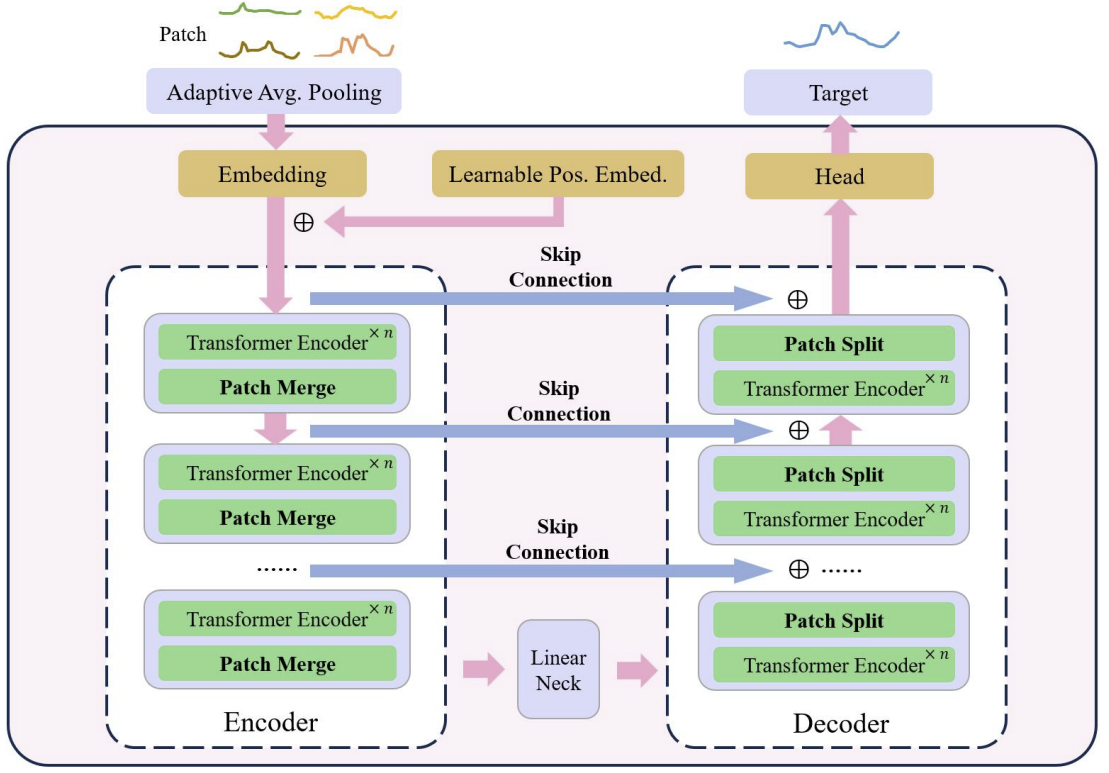
Es bien sabido que el entrenamiento de modelos basados en la arquitectura del Transformer requiere importantes recursos computacionales y una amplia muestra de entrenamiento. Por ello, se usan ampliamente varios modelos preentrenados en tareas de PNL y CV. Desgraciadamente, nos vemos privados de tal oportunidad al resolver problemas de series temporales. Esto se debe a que la naturaleza y la estructura de las series temporales son muy diversas. Conscientes de ello, los autores del método de transformador en U proponen dividir el proceso de entrenamiento del modelo en 2 etapas.
En primer lugar, se propone entrenar un modelo de transformador en U con un conjunto de datos relativamente grande para recuperar datos de origen enmascarados aleatoriamente. Esto permitirá al modelo explorar la estructura de los datos de origen, las dependencias y el contexto de las secuencias, aparte de filtrar eficazmente diversos ruidos. Además, en su artículo, los autores del método incluyen en su muestra de entrenamiento datos de diferentes series temporales, recopilados no solo en diferentes intervalos de tiempo, sino de diferentes fuentes. De este modo querían entrenar al Transformador en U para tareas completamente distintas.
En el segundo paso, se congelan los pesos del transformador en U. A ello se añade la "cabeza" de la toma de decisiones, mientras que el ajuste fino se realiza para resolver problemas específicos en una muestra de entrenamiento relativamente pequeña.
Esto resuelve el problema de utilizar un transformador en U preentrenado para múltiples tareas.
Resulta fácil ver que el ajuste fino es mucho más rápido y requiere menos recursos en comparación con el proceso completo de entrenamiento del transformador en U.
El proceso global se muestra a continuación en la representación del autor.
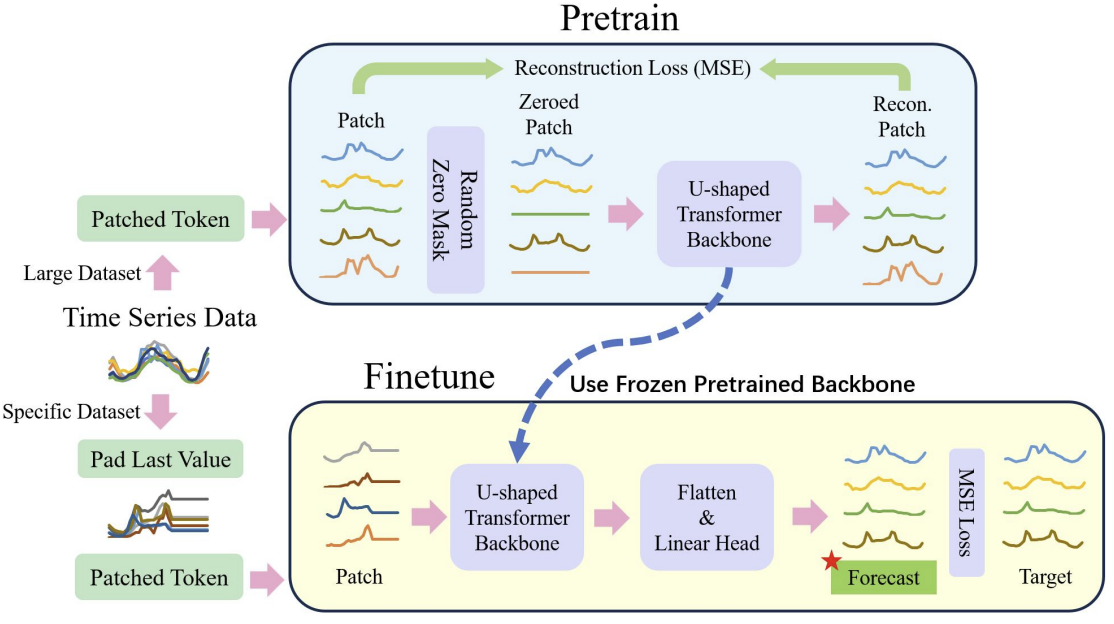
El núcleo del transformador en U es el apilamiento de capas del Transformer. Varias capas del Transformer forman un grupo. Y tras procesar el grupo, se realizan operaciones de fusión o división de parches para integrar características de diferentes escalas.
Se utilizan varias skip-connections para transferir rápidamente datos del codificador al descodificador. Esto permite que los datos de alta frecuencia se desplacen rápidamente a la salida de la red neuronal sin un procesamiento excesivo. Los datos de origen del grupo del Transformer se suministran a la salida del decodificador con la misma forma. Durante el proceso de codificación de los datos de origen, a medida que descendemos en el modelo, se filtran continuamente las características de alta frecuencia mientras se extraen las características comunes. Durante el proceso de descodificación, los rasgos comunes se reconstruyen continuamente con información detallada procedente de la skip-connection, lo que finalmente da lugar a una representación temporal de una serie que combina características de alta y baja frecuencia.
Las operaciones con parches son componentes críticos para el modelo de transformador en U. Son las que permiten obtener señales a diferentes escalas. Las características seleccionadas modifican directamente qué información se incluirá en el contexto principal del cálculo de la atención. Los enfoques tradicionales suelen dividir las series temporales en matrices dobles y tratarlas como canales independientes. Los autores del método del transformador en U consideran que este enfoque es demasiado tosco, ya que la información de parches de diferentes canales en el mismo paso temporal no procede de regiones vecinas. Por ello, proponen usar una convolución con un tamaño de ventana y un tamaño de paso igual a 2 como combinación de parches, lo cual duplica el número de canales. Así se garantiza que el parche anterior no se fragmente, logrando una mejor fusión de escalas. Durante el proceso de descodificación, los autores del método utilizan convoluciones transpuestas como operación de división de parches.
El método del transformador en U utiliza la convolución con un núcleo de puntos como método de incorporación para asignar cada parche a un espacio de mayor dimensionalidad. A continuación, los autores del método preparan un codificador posicional relativo entrenable para cada parche, que se añade directamente a los parches incorporados para mejorar la acumulación de conocimientos previos entre parches.
Como ya hemos mencionado, los autores del método U-shaped Transformer utilizan un enfoque de incorporación basado en parches para dividir los datos de series temporales en bloques más pequeños. Utilizan la tarea previa de recuperación de parches como nuestra tarea previa. Los autores del método creen que la recuperación de parches no enmascarados puede mejorar la solidez del modelo frente a datos ruidosos con valor cero.
Tras el preentrenamiento, el ajuste se realiza en la parte concreta de la cabeza encargada de generar las tareas objetivo. En este caso, además, congelamos todos los componentes salvo las redes de cabezas.
Para mejorar la generalizabilidad del modelo y explotar el potencial del Transformer con grandes conjuntos de datos, se utiliza un conjunto de datos más amplio.
Con el objetivo de mitigar aún más el desequilibrio de los datos, se utiliza el muestreo aleatorio ponderado, en el que se equilibra el número de muestras de diferentes conjuntos de datos durante el entrenamiento.
Y para paliar el problema de la inestabilidad del aprendizaje en los modelos basados en el Transformer, los autores del método sugieren normalizar cada minilote para ajustar los datos de origen a una distribución normal estándar.
Como resultado, el método de preprocesamiento de datos propuesto ofrece una extracción eficiente de características de diferentes partes del conjunto de datos y elimina eficazmente el problema del desequilibrio de datos durante el entrenamiento conjunto en múltiples conjuntos de datos.
2. Implementación con MQL5
Tras repasar los aspectos teóricos del método, vamos a pasar a la parte práctica de nuestro artículo, donde implementaremos una de las variantes de los enfoques propuestos utilizando herramientas MQL5.
Como ya hemos mencionado, el transformador en U utiliza varias soluciones arquitectónicas que tendremos que aplicar. Y empezaremos con el bloque de codificación posicional entrenado.
2.1 Codificación posicional
El bloque de codificación posicional está diseñado para introducir información en la serie temporal sobre la posición de los elementos en la secuencia. Como sabrá, el algoritmo de Self-Attention analiza las dependencias entre elementos independientemente de su lugar en la secuencia. Pero la información sobre el lugar que ocupa un elemento en la secuencia y sobre la distancia entre los elementos analizados de la misma desempeña a veces un papel importante. Esto resulta especialmente cierto en el caso de las secuencias temporales. Para añadir esta información, el Transformer clásico usa la adición de una secuencia sinusoidal a los datos originales. La periodicidad de las secuencias sinusoidales es fija y puede variar en distintas implementaciones según el tamaño de la secuencia analizada.
Las series temporales se caracterizan por una cierta periodicidad, y a veces tienen múltiples características de frecuencia. En tales casos, resulta necesario un trabajo adicional para seleccionar las características de frecuencia del tensor de codificación posicional de tal forma que no distorsione los datos originales y no introduzca información adicional en ellos.
En el artículo del autor, no existe una descripción detallada del método utilizado de codificación posicional entrenado. Tengo la impresión de que los autores del método seleccionaron el coeficiente de codificación posicional para cada elemento de la secuencia durante el entrenamiento del modelo. Y que se fijará durante su explotación.
En nuestra aplicación, iremos un poco más allá y haremos que los coeficientes de codificación posicional dependan de los datos de origen. Utilizaremos una capa simple completamente conectada para generar el tensor de codificación posicional. Naturalmente, entrenaremos esta capa a medida que avancemos.
Para implementar el mecanismo propuesto, crearemos la nueva clase CNeuronLearnabledPE. Y como en la mayoría de los casos, heredaremos la funcionalidad principal de la clase básica de la capa neuronal CNeuronBaseOCL.
class CNeuronLearnabledPE : public CNeuronBaseOCL { protected: CNeuronBaseOCL cPositionEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronLearnabledPE(void) {}; ~CNeuronLearnabledPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronLearnabledPE; } virtual void SetOpenCL(COpenCLMy *obj); };
En la estructura de clases, podemos ver 1 objeto de capa básica de red neuronal anidada cPositionEncoder, que contiene los parámetros entrenados de nuestro tensor de codificación posicional. Este objeto se ha indicado como estático, lo cual nos permitirá dejar vacíos el constructor y el destructor de la clase.
La inicialización de la instancia de la clase se realiza en el método Init, en cuyos parámetros transmitiremos toda la información necesaria para inicializar correctamente los objetos anidados.
bool CNeuronLearnabledPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cPositionEncoder.Init(0, 1, OpenCL, numNeurons, optimization, iBatch)) return false; cPositionEncoder.SetActivationFunction(TANH); SetActivationFunction(None); //--- return true; }
El algoritmo del método es bastante simple: En el cuerpo del método, primero llamaremos al método homónimo de la clase padre, que comprueba los parámetros externos recibidos e inicializa los objetos heredados. Luego determinaremos el resultado de las operaciones según el valor lógico retornado tras la ejecución del método llamado.
El siguiente paso será la inicialización del objeto anidado cPositionEncoder. Para el objeto anidado, estableceremos la tangente hiperbólica como función de activación. Como es sabido, el rango de valores de esta función va de "-1" a "1", lo cual se corresponde con el rango de valores de las secuencias de ondas sinusoidales.
Para nuestra clase de codificación de posición dinámica, en cambio, no habrá función de activación.
Una vez que todas las iteraciones se hayan completado con éxito, finalizaremos el método con un resultado de true.
Describiremos el algoritmo de pasada directa de nuestro método en el método CNeuronLearnabledPE::feedForward. Similar al método homónimo de la clase padre, el método recibirá en sus parámetros un puntero al objeto de la capa neuronal precedente que contiene los datos originales.
bool CNeuronLearnabledPE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPositionEncoder.FeedForward(NeuronOCL)) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cPositionEncoder.getOutput(), Output, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
A partir de los datos de origen obtenidos, generaremos primero el tensor de codificación posicional. Y luego añadirá los valores obtenidos al tensor de datos de origen.
La ejecución de todas las operaciones estará controlada por los valores retornados por los métodos llamados.
El algoritmo para el método de distribución del gradiente de error CNeuronLearnabledPE::calcInputGradients es un poco más complicado. En los parámetros, también obtendremos el puntero al objeto de la capa neuronal precedente a la que vamos a transmitir el gradiente de error.
bool CNeuronLearnabledPE::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeActivation(cPositionEncoder.getOutput(), cPositionEncoder.getGradient(), Gradient, cPositionEncoder.Activation())) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), Gradient, NeuronOCL.Activation())) return false; //--- return true; }
En el cuerpo del método, primero comprobaremos la relevancia del puntero obtenido en los parámetros.
A continuación, corregiremos el gradiente de error obtenido de la capa posterior a la función de activación del objeto interior. Recordemos que durante el proceso de inicialización especificamos la función de activación para el objeto interno, pero dejamos el objeto CNeuronLearnabledPE sin función de activación. Como consecuencia, el gradiente de error en el búfer de nuestra capa no se ha corregido para la función de activación.
A continuación, repetiremos la operación de corrección del gradiente de error, pero esta vez sobre la función de activación de la capa anterior.
Nótese que no haremos la llamada al método de distribución del gradiente de error a través del objeto interno de generación del tensor de codificación posicional. La cuestión es que para realizar la operación de actualización de los parámetros de esta capa solo necesitaremos la presencia de un gradiente de error en su salida. Y no necesitaremos transmitir el gradiente de error a través del objeto a la capa precedente, ya que el bloque de generación del tensor de codificación posicional no debe afectar a los datos originales ni a su incorporación.
Para completar la implementación del algoritmo de pasada inversa de la clase CNeuronLearnabledPE, crearemos el método para actualizar los parámetros entrenados updateInputWeights. Este método está simplificado al máximo y consistirá en llamar al método homónimo del objeto anidado.
bool CNeuronLearnabledPE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return cPositionEncoder.UpdateInputWeights(NeuronOCL); }
Podrá leer el código completo de esta clase y todos sus métodos por sí mismo en el archivo adjunto.
2.2 Clase de transformador en U
Vamos a seguir con nuestra versión de la aplicación de los planteamientos propuestos por los autores del método del U-shaped Transformer. Debemos decir que la solución a la arquitectura de la implementación de la scip-connection entre el codificador y el decodificador, a pesar de su aparente simplicidad, ha resultado no ser tan inequívoca. Por un lado, podríamos usar la referencia al ID de la capa interna y transmitir los datos del codificador al decodificador. Y no hay ninguna dificultad en hacerlo. Pero hay una pregunta sobre el paso del gradiente de error a través de la scip-connection. Al fin y al cabo, toda la arquitectura de pasada inversa de nuestras clases se basa en sobrescribir el gradiente de error en la pasada inversa posterior. Por lo tanto, cualquier gradiente de error que transmitamos a través de la scip-connection se eliminará durante las operaciones de transferencia del gradiente a través de las capas neuronales entre objetos de scip-connection.
Aquí es donde surge la idea de crear toda la arquitectura del Transformador en U dentro de una única clase. Pero necesitaremos un mecanismo para construir un número diferente de bloques Codificador-Decodificador con un número diferente de capas del Transformer en cada bloque. Hemos encontrado la salida en la creación recurrente de objetos. Aprenderemos más sobre el mecanismo elegido durante la propia aplicación.
Para implementar nuestro bloque de transformador en U, crearemos la clase CNeuronUShapeAttention, que, al igual que la anterior, heredará la funcionalidad principal de la clase básica de la capa neuronal CNeuronBaseOCL.
class CNeuronUShapeAttention : public CNeuronBaseOCL { protected: CNeuronMLMHAttentionOCL cAttention[2]; CNeuronConvOCL cMergeSplit[2]; CNeuronBaseOCL *cNeck; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); //--- public: CNeuronUShapeAttention(void) {}; ~CNeuronUShapeAttention(void) { delete cNeck; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUShapeAttention; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *net, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
En el cuerpo de la clase, crearemos un array de 2 elementos de la clase de atención multicabeza CNeuronMLMHAttentionOCL. Estos serán el codificador y decodificador del bloque actual.
Aquí crearemos un array de 2 elementos de capa convolucional que utilizaremos para trabajar con los parches.
Y colocaremos todos los elementos entre el codificador y el decodificador del bloque actual en el objeto de la clase básica de la capa neuronal cNeck, que en este caso será dinámico. Resulta un poco cuestionable cómo se "hacinan" un número indeterminado de bloques en un solo bloque... Para responder a esta cuestión, le propongo acudir al método de inicialización del objeto Init.
Como siempre, obtendremos las constantes básicas de la arquitectura del objeto en los parámetros del método:
- window - tamaño de la ventana de datos de origen (vector de descripción de 1 elemento de la secuencia);
- window_key - tamaño del vector interno de descripción de 1 elemento de la secuencia en las entidades Self-Attention Query, Key, Value;
- heads — número de cabezas de atención;
- units_count — número de elementos de la secuencia;
- layers — número de capas de atención en un bloque;
- inside_bloks — número de bloques anidados del U-shaped Transformer.
Los parámetros window, window_key, heads y layers se utilizarán sin cambios para los bloques actual y anidado del U-shaped Transformer.
bool CNeuronUShapeAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
En el cuerpo del método, primero llamaremos al método homónimo de la clase padre, que controlará los parámetros recibidos e inicializará los objetos heredados.
A continuación, inicializaremos los objetos del codificador y la separación de parches.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2 * window, 4 * window, (units_count + 1) / 2, optimization, iBatch)) return false;
Y luego vendrá el bloque más interesante del método de inicialización. Primero comprobaremos el número de bloques anidados especificados. Y si es mayor que "0", crearemos e inicializaremos un bloque anidado del Transformador en U similar a la clase actual. Solo aumentaremos el número de elementos de la secuencia en un factor de 2, que se corresponderá con el resultado de la división de los parches. Y el número de bloques anidados se reducirá en "1".
if(inside_bloks > 0) { CNeuronUShapeAttention *temp = new CNeuronUShapeAttention(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, 2 * units_count, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Luego almacenaremos el puntero al objeto creado en la variable cNeck. Para ello hemos declarado un objeto dinámico. Así, llamando de forma recurrente a la función de inicialización, crearemos el número necesario de grupos de Transformadores en U anidados.
En el último bloque, crearemos una capa convolucional de dependencia lineal entre el codificador y el decodificador.
{
CNeuronConvOCL *temp = new CNeuronConvOCL();
if(!temp)
return false;
if(!temp.Init(0, 2, OpenCL, window, window, window, 2 * units_count, optimization, iBatch))
{
delete temp;
return false;
}
cNeck = temp;
}
A continuación, inicializaremos los objetos del Decodificador y la fusión de parches.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, 2 * units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, 2 * window, 2 * window, window, units_count, optimization, iBatch)) return false;
Y para eliminar las operaciones de copiado redundantes, implementaremos la sustitución del búfer de gradiente de error.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
Luego finalizaremos el método.
Con este telón de fondo, la pasada directa parece sencillo. En él, nos limitaremos a llamar uno por uno a los métodos homónimos de la capa interna según el algoritmo de Transformador en U. En primer lugar, los datos sin procesar pasarán por el bloque del Codificador,
bool CNeuronUShapeAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
después de lo cual realizaremos la separación de parches,
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
y llamaremos al método de pasada directa para bloques anidados.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject())) return false;
Los datos procesados de este modo se introducirán en el Decodificador
if(!cAttention[1].FeedForward(cNeck)) return false;
y en la capa de fusión de parches.
if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
Por último, sumaremos los resultados del bloque del transformador en U actual con los datos de origen resultantes (scip-connection) para conservar la señal de alta frecuencia.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), Output, 1, false)) return false; //--- return true; }
Luego finalizaremos el método.
Tras organizar la pasada directa, procederemos a crear los métodos de pasada inversa. En primer lugar, crearemos el método CNeuronUShapeAttention::calcInputGradients de distribución del gradiente de error, en cuyos parámetros obtendremos el puntero al objeto de la capa anterior al que tenemos que transmitir el gradiente de error.
bool CNeuronUShapeAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
En el cuerpo del método comprobaremos directamente la relevancia del puntero recibido.
Gracias a la sustitución de los búferes de datos, el gradiente de error ya estará almacenado en el búfer de la capa de fusión de parches anidada. E inmediatamente llamaremos al método correspondiente de distribución del gradiente de error.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
A continuación, transmitiremos el gradiente de error a través del Decodificador.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
Y después pasaremos secuencialmente el gradiente de error a través de los bloques internos del transformador en U, la capa de separación de parches y el Codificador.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject())) return false; if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Luego sumaremos los gradientes de error en la entrada y la salida del bloque (scip-connection) actual.
if(!SumAndNormilize(prevLayer.getGradient(), Gradient, prevLayer.getGradient(), 1, false)) return false; if(!DeActivation(prevLayer.getOutput(), prevLayer.getGradient(), prevLayer.getGradient(), prevLayer.Activation())) return false; //--- return true; }
Acto seguido, corregiremos el gradiente de error por la función de activación de la capa anterior y finalizaremos el método.
La distribución del gradiente de error irá seguida del ajuste de los parámetros del modelo entrenado. Esta funcionalidad se ejecutará en el método CNeuronUShapeAttention::updateInputWeights. El algoritmo del método es bastante simple: Bastará con llamar uno a uno a los métodos correspondientes de los objetos anidados.
bool CNeuronUShapeAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].UpdateInputWeights(NeuronOCL)) return false; if(!cMergeSplit[0].UpdateInputWeights(cAttention[0].AsObject())) return false; if(!cNeck.UpdateInputWeights(cMergeSplit[0].AsObject())) return false; if(!cAttention[1].UpdateInputWeights(cNeck)) return false; if(!cMergeSplit[1].UpdateInputWeights(cAttention[1].AsObject())) return false; //--- return true; }
Y, por supuesto, no nos olvidaremos de supervisar el progreso de las operaciones en cada paso.
También deberíamos detenernos un poco en los métodos de trabajo con archivos. Si el método CNeuronUShapeAttention::Save guarda los datos, será bastante sencillo. Simplemente llamaremos a los métodos correspondientes de la clase padre y de todos los objetos anidados a su vez.
bool CNeuronUShapeAttention::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; for(int i = 0; i < 2; i++) { if(!cAttention[i].Save(file_handle)) return false; if(!cMergeSplit[i].Save(file_handle)) return false; } if(!cNeck.Save(file_handle)) return false; //--- return true; }
El método CNeuronUShapeAttention::Load tiene sus propios matices, y estos se relacionan con la organización de la carga de los bloques del Transformador en U anidados. Primero llamaremos al método de la clase padre como de costumbre para cargar los objetos heredados.
bool CNeuronUShapeAttention::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
A continuación, en un ciclo cargaremos los datos del Codificador, el Decodificador y las capas de parches.
for(int i = 0; i < 2; i++) { if(!LoadInsideLayer(file_handle, cAttention[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cMergeSplit[i].AsObject())) return false; }
Después vendrá la fase de carga de bloques anidados. Pero aquí, como recordará, utilizaremos un puntero dinámico al objeto. Por tanto, son posibles varias opciones. En una variable, un puntero puede ser irrelevante o apuntar a un objeto de una clase distinta.
Luego leeremos desde el fichero el tipo del objeto deseado. Y comprobaremos el tipo del objeto apuntado por la variable cNeck. Cuando los tipos sean distintos, eliminaremos el objeto existente.
int type = FileReadInteger(file_handle); if(!!cNeck) { if(cNeck.Type() != type) delete cNeck; }
A continuación, comprobaremos si el puntero de la variable está actualizado y, de ser necesario, crearemos un nuevo objeto del tipo correspondiente.
if(!cNeck) { switch(type) { case defNeuronUShapeAttention: cNeck = new CNeuronUShapeAttention(); if(!cNeck) return false; break; case defNeuronConvOCL: cNeck = new CNeuronConvOCL(); if(!cNeck) return false; break; default: return false; } }
Una vez finalizados los trabajos preparatorios, cargaremos los datos del objeto desde el archivo.
cNeck.SetOpenCL(OpenCL); if(!cNeck.Load(file_handle)) return false;
Al final del método, intercambiaremos los búferes de gradiente de error.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
Luego finalizaremos el método.
El código completo de todos los métodos de esta clase y de todos los demás programas usados en la preparación del artículo se encuentra en el anexo.
2.3 Arquitectura del modelo
Tras crear las nuevas clases para construir nuestros modelos, pasaremos a describir la arquitectura de los modelos entrenados, que escribiremos, como siempre, en el archivo "...\Experts\UShapeTransformer\Trajectory.mqh".
Ya hemos indicado antes que los autores del método del Transformador en U proponen entrenar los modelos en 2 etapas. En el primer paso, entrenaremos al Codificador para que recupere los datos enmascarados. Como consecuencia, la descripción de la arquitectura del modelo del Codificador se colocará en el método aparte CreateEncoderDescriptions. En los parámetros del método, se transmitirá un puntero a un objeto de array dinámico para registrar la descripción de la arquitectura del modelo.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
En el cuerpo del método comprobaremos la relevancia del puntero obtenido y, si es necesario, crearemos una nueva instancia del array dinámico.
A continuación, crearemos una capa de datos de origen de tamaño suficiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos de entrada se introducirán en el modelo en forma "bruta". Y realizaremos su preprocesamiento previo en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Luego recordaremos el número de capa de la capa de normalización por lotes para especificarlo en la capa de normalización inversa.
Después utilizaremos el enmascaramiento de datos para entrenar el Codificador. Y para realizar el enmascaramiento, crearemos la capa Dropout.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, fijaremos la probabilidad de enmascaramiento en 0,4, que se corresponde con el 40% de los datos originales.
Tenga en cuenta que lo que enmascaramos son los datos de origen, no sus incorporaciones.
En el siguiente paso, utilizaremos 2 capas de convolución para generar incorporaciones de los datos de origen enmascarados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = descr.window; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Luego añadiremos la codificación posicional a los datos originales. En este caso, utilizaremos la codificación posicional entrenable.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count*prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Y ahora vamos a añadir el bloque del Transformador en U. Vamos ahora a prestar un poco de atención a la descripción de la capa y a fijarnos en las variables utilizadas:
- descr.count — tamaño de la secuencia;
- descr.window — tamaño del vector de descripción de 1 elemento de la secuencia;
- descr.step — número de cabezas de atención;
- descr.window_out — tamaño del elemento de las entidades internas de atención;
- descr.layers — número de capas en cada bloque del Transformer;
- descr.batch — número de bloques anidados del Transformador en U.
Como podemos ver, la mayoría de los parámetros se toman de los bloques de atención.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUShapeAttention; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 3; descr.batch = 2; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación viene un bloque de decisión de 3 capas totalmente conectadas.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Tenga en cuenta que, a la salida del codificador, queremos obtener los datos de origen reconstruidos más algunos valores predichos. De este modo, vamos a entrenar el Transformador en U para captar las dependencias no solo en los datos de origen, sino también para encontrar puntos de referencia para construir valores predictivos.
Al final del Codificador, añadiremos una capa de normalización inversa para que los valores recuperados y predichos sean comparables a los datos de origen.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Cambiar la arquitectura del Codificador requiere cambiar la constante de la capa oculta para recuperar los datos del modelo.
#define LatentLayer 9
Además, cambiar el tamaño de la capa de resultados del Codificador también requiere ajustes en la arquitectura de los modelos del Actor y el Crítico que utilizan estos datos. La arquitectura de los modelos especificados se presenta en el método CreateDescriptions. En los parámetros, el método obtendrá los punteros a 2 arrays dinámicos para registrar las arquitecturas de los modelos correspondientes.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método comprobaremos los punteros obtenidos y, si es necesario, crearemos nuevos arrays dinámicos.
En primer lugar, describiremos la arquitectura del Actor. Luego suministraremos un vector de descripción del estado de la cuenta a la entrada del modelo.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos resultantes serán procesados por la capa de enlace completo.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, añadiremos 5 capas de atención cruzada que compararán la información sobre el estado de la cuenta y las posiciones abiertas con los valores reconstruidos y previstos generados por el Codificador.
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, HistoryBars+NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Cabe señalar aquí que en las fases de entrenamiento de la política del Actor y de la explotación, no enmascararemos los datos de origen. Sin embargo, se espera que el Codificador entrenado no solo prediga las condiciones del entorno posteriores, sino que también actúe como una especie de filtro de valores históricos, eliminando diversos ruidos en ellos.
Al final del modelo tendremos una unidad de toma de decisiones con una "cabeza" estocástica.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
La arquitectura del Crítico ha recibido ajustes similares, por lo que no nos detendremos ahora en su descripción. Le recomiendo que la revise por usted mismo en el archivo adjunto.
2.4 Asesor de entrenamiento del Codificador
Tras describir la arquitectura de los modelos, nos centraremos en el asesor de entrenamiento del modelo de Codificador. Debemos decir que en este artículo hemos utilizado la muestra de entrenamiento recopilada para el artículo anterior. Como recordarán, en él utilizamos toda una serie de datos históricos para describir el estado del entorno. Este enfoque tiene ventajas y desventajas. Las ventajas incluyen evitar una pila dentro del modelo para acumular datos históricos, y la capacidad de utilizar los estados muestreados para entrenar modelos. En el lado negativo, hay un crecimiento significativo del archivo de muestras de entrenamiento, que almacena múltiples veces datos repetidos. Sí, y en el proceso de funcionamiento el modelo en cada paso repite el recálculo de los datos históricos para toda la profundidad de la historia analizada. Pero en esta fase, lo que nos importa es la comparación clara entre los datos suministrados a la entrada del modelo y los datos recuperados por este tras el enmascaramiento. Por ello, para probar los enfoques propuestos, hemos decidido optar por esta solución.
En general, el EA "...\Experts\UShapeTransformer\StudyEncoder.mq5" ha sido construido sobre la base del asesor experto similar del artículo anterior, así que no nos detendremos a analizar todos sus métodos. Veremos solo el método de entrenamiento del modelo Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Al principio del método, haremos un pequeño trabajo preparatorio. Definiremos las probabilidades de muestreo de las trayectorias según sus rendimientos y declararemos las variables locales.
A continuación, organizaremos el ciclo de entrenamiento del modelo con el número de iteraciones especificado por el usuario en los parámetros externos.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
En el cuerpo del ciclo, muestrearemos la trayectoria y 1 estado en ella para entrenar el modelo. Cargaremos la información sobre el estado seleccionado en el buffer de datos.
bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y llamaremos al método de pasada directa de nuestro modelo, transmitiéndole los datos cargados.
Una vez completada con éxito la pasada directa, en el búfer de resultados del modelo se almacenará alguna representación de los indicadores del entorno históricos y sus valores previstos. En este momento no nos interesa el resultado concreto.
Ahora tenemos que producir datos reales sobre los estados del entorno próximos y analizados. Como en el último artículo, primero cargaremos los estados del entorno posteriores desde el búfer de repetición de experiencias.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
Y los complementaremos con los datos introducidos en la entrada del modelo en la pasada directa. Recordemos que tenemos datos desenmascarados en el búfer.
if(!Result.AddArray(GetPointer(bState))) continue;
Ahora que hemos preparado el búfer de valores objetivo, podemos realizar una pasada inversa del modelo y ajustar los pesos para minimizar el error.
if(!Encoder.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tras actualizar los parámetros del modelo, informaremos al usuario sobre el progreso del entrenamiento y pasaremos a la siguiente iteración.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Deberemos necesariamente comprobar los resultados de todas las operaciones.
Si todas las iteraciones del ciclo de entrenamiento del modelo tienen éxito, borraremos el campo de comentarios en el gráfico del instrumento.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Asimismo, enviaremos la información sobre los resultados del entrenamiento al registro de MetaTrader 5 e iniciaremos el proceso de finalización del asesor experto.
Podrá ver el código completo del asesor en el archivo adjunto.
El asesor de entrenamiento de la política del Actor y el Crítico "...\Experts\RevIN\Study.mq5" se ha trasladado del artículo anterior casi sin cambios. Lo mismo puede decirse de los asesores de interacción con el entorno. Por lo tanto, no entraremos en detalles sobre sus algoritmos en el ámbito de este artículo. En el archivo adjunto, podrá ver por sí mismo el código completo de todos los programas utilizados en la preparación de este artículo.
Sin embargo, me gustaría destacar una vez más que en todos los asesores expertos, excepto en el asesor experto de entrenamiento del Codificador, el modo de entrenamiento deberá estar desactivado para el modelo del Codificador.
Encoder.TrainMode(false);
Esto nos ayudará a desactivar el enmascaramiento de los datos de origen.
3. Simulación
Más arriba, hemos aprendido los aspectos teóricos del método del transformador en U y hemos realizado bastante trabajo para implementar los enfoques propuestos utilizando herramientas MQL5. Ahora es el momento de probar los resultados de nuestro trabajo con datos históricos reales.
Como ya hemos mencionado, entrenaremos los modelos con la muestra de entrenamiento recogida para el artículo anterior. Ahora no vamos a detenernos en la descripción detallada de los métodos de recopilación de la muestra de entrenamiento, que ya hemos descrito con detalle anteriormente.
El modelo se entrenará con datos históricos de 2023 del instrumento EURUSD y el marco temporal H1. La prueba de la política del Actor entrenado se realizará en el simulador de estrategias de MetaTrader 5 con los datos históricos de enero de 2024 manteniendo el instrumento y el marco temporal de entrenamiento del modelo.
Según el enfoque propuesto por los autores del método del transformador en U, entrenaremos los modelos en 2 etapas. Primero entrenaremos el Codificador con los datos de entrenamiento previamente recogidos.
Hay que decir aquí que el modelo del Codificador solo analizará los datos históricos del instrumento. Por lo tanto, no necesitaremos recoger pasadas adicionales en el proceso de entrenamiento del Codificador, y podremos establecer directamente un número lo suficientemente grande de iteraciones de entrenamiento del modelo y esperar a que se complete el proceso del mismo.
En este punto, hemos notado un cambio positivo en la calidad de la predicción de los estados del entorno.
La segunda etapa del entrenamiento de la política del Actor será iterativa. En esta fase, alternaremos entre el entrenamiento de la política del Actor y la recopilación de información adicional sobre el entorno añadiendo nuevas pasadas a la muestra de entrenamiento utilizando el asesor experto "...\Experts\UShapeTransformer\Research.mq5" y la política actual del Actor.
Mediante un proceso de aprendizaje iterativo, podremos obtener un modelo capaz de generar beneficios tanto en la muestra de entrenamiento como en la de prueba.
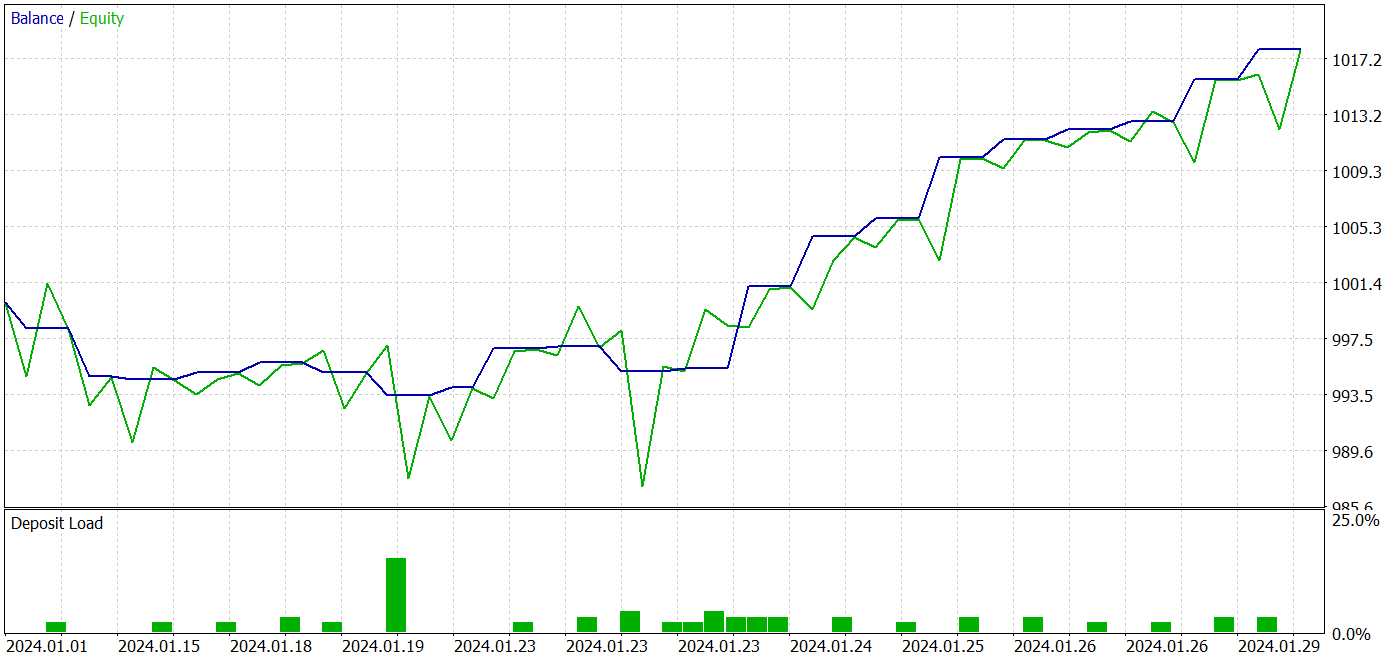
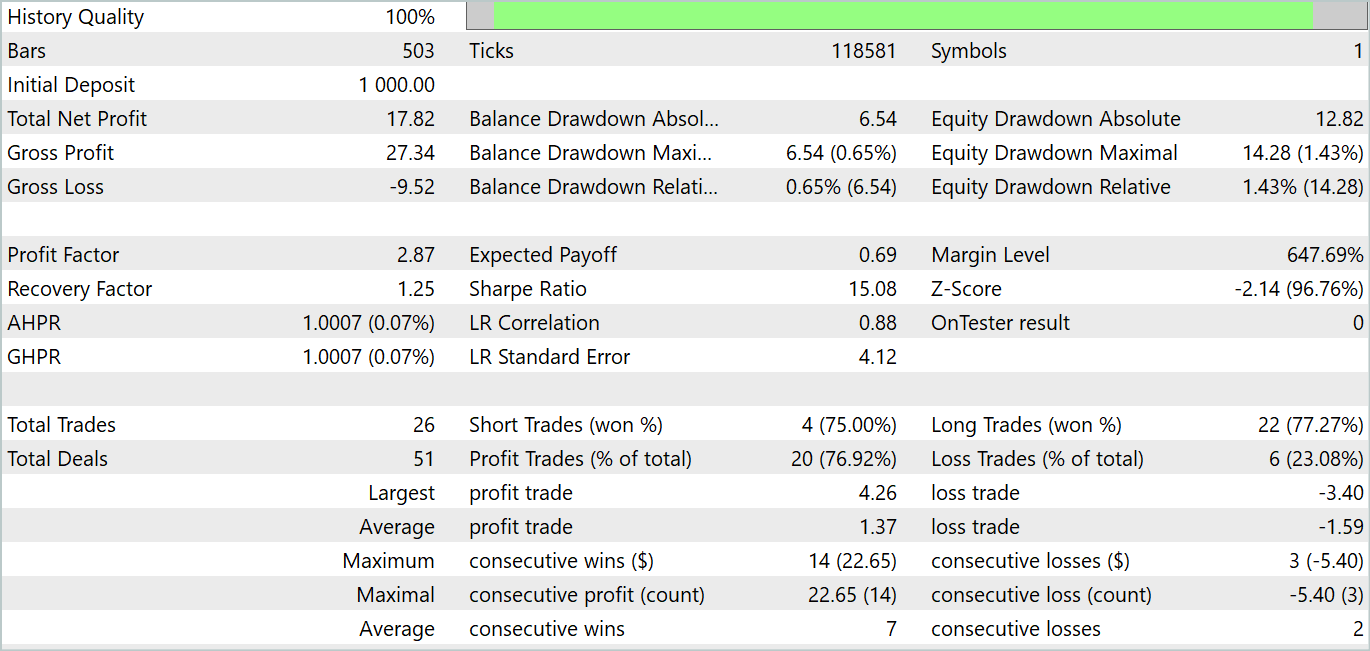
El modelo ha realizado 26 transacciones durante el periodo de prueba: 20 de ellas se han cerrado con beneficio, lo cual ha supuesto un 76,92%. Al mismo tiempo, el factor de beneficio ha sido de 2,87.
Los resultados obtenidos son prometedores, pero un periodo de prueba de 1 mes resulta bastante corto para evaluar la estabilidad del modelo.
Conclusión
En este artículo, nos hemos familiarizado con la arquitectura del transformador en U, que se ha diseñado específicamente para la previsión de series temporales. El enfoque propuesto combina las ventajas de los transformadores y los perceptrones totalmente conectados para captar eficazmente las dependencias a largo plazo en los datos temporales y manejar el contexto de alta frecuencia.
Uno de los principales logros del transformador en U es el uso de scip-connection y las operaciones entrenables de combinación y separación de parches. Esto permite al modelo extraer eficazmente características de diferentes escalas y captar mejor la información.
En la parte práctica del artículo, hemos implementado los enfoques propuestos usando herramientas MQL5. Así, hemos entrenado y probado el modelo resultante con datos históricos reales. Los resultados de las pruebas han sido bastante buenos.
No obstante, queremos insistir nuevamente en que todos los programas utilizados en la preparación de este artículo están destinados únicamente a la demostración de los enfoques propuestos y no están listos para su uso en mercados reales. Los resultados de las pruebas en un intervalo de 1 mes solo pueden demostrar las capacidades del modelo, pero no confirman su rendimiento estable en un intervalo temporal amplio.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de cobros de ejemplo Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14766
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso