
Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa

Introducción
Continuamos nuestro análisis de los métodos de aprendizaje por refuerzo. Como ya sabrá, todos los algoritmos para entrenar modelos en esta área del aprendizaje automático se basan en el paradigma de maximización de las recompensas del entorno. Y la función de recompensa juega un papel clave en el proceso de entrenamiento del modelo. Sus señales rara vez resultan erróneas.
En un intento de incentivar al Agente para que se ciña al comportamiento deseado, hemos introducido recompensas y penalizaciones adicionales en la función de recompensa. Por ejemplo, con frecuencia hemos hecho que la función de recompensa resulte más compleja en un simple intento de estimular al Agente a explorar el entorno, y hemos introducido penalizaciones por no actuar. Al mismo tiempo, la arquitectura del modelo y la función de recompensa siguen siendo fruto de las consideraciones subjetivas del arquitecto del modelo.
Durante el proceso de entrenamiento, el modelo puede encontrar diversas dificultades y obstáculos, incluso con un enfoque de diseño cuidadoso. Es posible que el agente no logre los resultados deseados por muchos motivos diferentes, cuya búsqueda se convierte en una “adivinanza en posos de café”. Pero ¿cómo podemos entender que el Agente interpreta correctamente nuestras señales en la función de recompensa? En un intento por comprender esta cuestión, surge el deseo de dividir la recompensa en componentes aparte. El uso de recompensas descompuestas y el análisis de la influencia de componentes individuales puede resultar muy útil a la hora de hallar formas de optimizar el proceso de entrenamiento del modelo. Esto nos permitirá comprender mejor cómo los diferentes aspectos influyen en el comportamiento del Agente, identificar las causas de los problemas y ajustar eficazmente la arquitectura del modelo, el proceso de entrenamiento o la función de recompensa.
1. La necesidad de la descomposición de la recompensa.
La descomposición del valor de la función de recompensa es un método simple y de gran aplicación que puede gestionar una amplia variedad de desafíos. En el aprendizaje por refuerzo, el agente obtiene una recompensa, que suele ser la suma de muchos componentes. Cada uno de ellos pretende codificar algún aspecto del comportamiento deseado del Agente. Partiendo de esta recompensa compuesta, el Agente aprende una función de valor única y compleja. Usando la descomposición de valores, el Agente aprende una función de valor para cada componente de la recompensa. Y cualquier función tomada de ellos probablemente tendrá una forma más simple.
Para optimizar la estrategia, la función de valor compuesto se reconstruye tomando una suma ponderada de las funciones de valor de los componentes.
La descomposición de recompensas se puede incluir en una amplia gama de métodos distintos, incluida la familia de métodos Actor-Crítico que estamos analizando.
No obstante, las capacidades adicionales de diagnóstico y entrenamiento de la descomposición de la función de recompensa tienen el coste de una tarea de predicción más compleja: en lugar de entrenar una función de valor único, se deben entrenar múltiples funciones. Un análisis de la influencia de este factor en el rendimiento del Agente se realiza en el artículo "Value Function Decomposition for Iterative Design of Reinforcement Learning Agents". Los autores descubrieron que al añadir la descomposición de la función de recompensa al algoritmo Soft Actor-Critic, los resultados del entrenamiento del modelo resultan inferiores a los del algoritmo original. No obstante, los autores sugirieron opciones para mejorar el algoritmo. Esto ha permitido no solo igualar el algoritmo Soft Actor-Critic original, sino incluso a veces superar su rendimiento. Dichas mejoras se pueden aplicar a la descomposición de funciones de recompensa y a otros algoritmos de la familia Actor-Crítico.
Podemos adaptar una amplia gama de algoritmos de aprendizaje por refuerzo para utilizar la descomposición de la función de recompensa según el siguiente patrón:
- Cambiamos el modelo de función Q para obtener en la salida del modelo un elemento para cada componente de la función de recompensa.
- Utilizamos un algoritmo básico de aprendizaje de funciones Q para actualizar cada componente.
Este patrón funcionará para algoritmos de aprendizaje de modelos de espacio de acciones tanto discretos como continuos.
La idea es muy simple, pero como hemos mencionado antes, los autores del artículo descubrieron la ineficacia de la "solución frontal" al utilizarse la descomposición de recompensas en el marco del algoritmo SAC. Permítanme recordarles las fórmulas de optimización de la función Q en este algoritmo.

Aquí vemos el uso de la estimación mínima del estado futuro de los modelos objetivo de dos críticos. Como se indica en el punto 2 de la plantilla, para actualizar los parámetros de cada componente de la función Q utilizamos un algoritmo básico. Sin embargo, como ha demostrado la práctica, el uso de un valor mínimo por componentes provoca un desequilibrio del modelo. Seleccionar un modelo con la puntuación general mínima funciona de manera más eficiente, y se hace usando las estimaciones de sus componentes para entrenar modelos.
En general, se supone que la función de recompensa del modelo supone una función lineal de sus componentes.
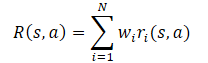
Al aplicar la linealidad del valor esperado, nos encontramos con que la función Q hereda la estructura lineal de la función de recompensa.
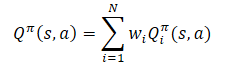
A menos que se indique lo contrario, supondremos que Wi=1 para todo i. Y como los pesos de los componentes son eliminados de la función Q, se pueden cambiar sin modificar el pronóstico objetivo del componente. Esto nos permite evaluar la política para cualquier combinación de pesos.
Hay otro punto al que vale la merece prestar atención: la optimización de la función de recompensa descompuesta supone la optimización del modelo según muchos criterios, y esta, además, tiene problemas característicos de la optimización multicriterio: gradientes conflictivos, alta curvatura y grandes diferencias en las magnitudes de gradiente. Para minimizar el impacto negativo de este factor, los autores del método proponen usar el algoritmo Conflict-Averse Gradient Descent (CAGrad), desarrollado para un entorno de aprendizaje por refuerzo multitarea. Este método tiene como objetivo suavizar los problemas anteriores de optimización multicriterio. La idea básica consiste en reemplazar el gradiente de una función objetivo multitarea con una suma ponderada de los gradientes para cada tarea individual. Para ello resolveremos el siguiente problema de optimización:
![]()
donde d es el vector de actualización,
g₀ es el gradiente promedio,
c es el coeficiente de velocidad de convergencia en el rango [0, 1).
Resolviendo este problema de optimización, podremos considerar la influencia de cada componente en la optimización y centrarnos en mejorar la peor estimación en cada paso.
2. Implementación con MQL5
2.1 Creamos una nueva clase de modelo
Vamos a implementar nuestra propia versión de la descomposición de la función de recompensa basada en el algoritmo SAC+DICE. Diremos de inmediato que, debido a las peculiaridades de la implementación de los algoritmos, no heredaremos de la clase CNet_SAC_DICE creada en el artículo anterior, pero aún así utilizaremos los desarrollos realizados anteriormente. Crearemos una nueva clase CNet_SAC_D_DICE a su imagen y semejanza, cuya estructura detallaremos a continuación.
class CNet_SAC_D_DICE : protected CNet { protected: CNet cActorExploer; CNet cCritic1; CNet cCritic2; CNet cTargetCritic1; CNet cTargetCritic2; CNet cZeta; CNet cNu; CNet cTargetNu; vector<float> fLambda; vector<float> fLambda_m; vector<float> fLambda_v; int iLatentLayer; float fCAGrad_C; int iCAGrad_Iters; int iUpdateDelay; int iUpdateDelayCount; //--- float fLoss1; float fLoss2; vector<float> fZeta; vector<float> fQWeights; //--- vector<float> GetLogProbability(CBufferFloat *Actions); vector<float> CAGrad(vector<float> &grad); public: //--- CNet_SAC_D_DICE(void); ~CNet_SAC_D_DICE(void) {} //--- bool Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1); //--- virtual bool Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &Rewards, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float discount, float tau); virtual void GetLoss(float &loss1, float &loss2) { loss1 = fLoss1; loss2 = fLoss2; } virtual bool TargetsUpdate(float tau); //--- virtual void SetQWeights(vector<float> &weights) { fQWeights=weights; } virtual void SetCAGradC(float c) { fCAGrad_C=c; } virtual void SetLambda(vector<float> &lambda) { fLambda=lambda; fLambda_m=vector<float>::Zeros(lambda.Size()); fLambda_v=fLambda_m; } virtual void TargetsUpdateDelay(int delay) { iUpdateDelay=delay; iUpdateDelayCount=delay; } //--- virtual bool Save(string file_name, bool common = true); bool Load(string file_name, bool common = true); };
En la estructura de clases dada vemos los objetos modelo prestados. Pero en lugar de variables para guardar el coeficiente de Lagrange y sus promedios, usaremos vectores cuyo tamaño será igual al número de componentes de la función de recompensa. Aquí añadiremos el vector fQWeights para almacenar los coeficientes de peso de cada componente. La variable fCAGrad_C la seleccionaremos para registrar el coeficiente de velocidad de convergencia del método CAGrad.
Y resulta bastante natural que estos cambios se reflejen en el constructor de clases. En esta primera etapa, inicializaremos todos los vectores de longitud unitaria.
CNet_SAC_D_DICE::CNet_SAC_D_DICE(void) : fLoss1(0), fLoss2(0), fCAGrad_C(0.5f), iCAGrad_Iters(15), iUpdateDelay(100), iUpdateDelayCount(100) { fLambda = vector<float>::Full(1, 1.0e-5f); fLambda_m = vector<float>::Zeros(1); fLambda_v = vector<float>::Zeros(1); fZeta = vector<float>::Zeros(1); fQWeights = vector<float>::Ones(1); }
El método para inicializar una clase y crear modelos anidados se ha migrado casi por completo del artículo anterior. Solo hemos realizado cambios en el tamaño de los vectores.
bool CNet_SAC_D_DICE::Create(CArrayObj *actor, CArrayObj *critic, CArrayObj *zeta, CArrayObj *nu, int latent_layer = -1) { ResetLastError(); //--- if(!cActorExploer.Create(actor) || !CNet::Create(actor)) { PrintFormat("Error of create Actor: %d", GetLastError()); return false; } //--- if(!opencl) { Print("Don't opened OpenCL context"); return false; } //--- if(!cCritic1.Create(critic) || !cCritic2.Create(critic)) { PrintFormat("Error of create Critic: %d", GetLastError()); return false; } //--- if(!cZeta.Create(zeta) || !cNu.Create(nu)) { PrintFormat("Error of create function nets: %d", GetLastError()); return false; } //--- if(!cTargetCritic1.Create(critic) || !cTargetCritic2.Create(critic) || !cTargetNu.Create(nu)) { PrintFormat("Error of create target models: %d", GetLastError()); return false; } //--- cActorExploer.SetOpenCL(opencl); cCritic1.SetOpenCL(opencl); cCritic2.SetOpenCL(opencl); cZeta.SetOpenCL(opencl); cNu.SetOpenCL(opencl); cTargetCritic1.SetOpenCL(opencl); cTargetCritic2.SetOpenCL(opencl); cTargetNu.SetOpenCL(opencl); //--- if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), 1.0) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), 1.0) || !cTargetNu.WeightsUpdate(GetPointer(cNu), 1.0)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- cZeta.getResults(fZeta); ulong size = fZeta.Size(); fLambda = vector<float>::Full(size,1.0e-5f); fLambda_m = vector<float>::Zeros(size); fLambda_v = vector<float>::Zeros(size); fQWeights = vector<float>::Ones(size); iLatentLayer = latent_layer; //--- return true; }
Tenga en cuenta que aquí estamos inicializando el vector de pesos fQWeights con valores unitarios. Si su función de recompensa ofrece otros coeficientes, deberá utilizar el método SetQWeights. No obstante, deberá llamarlo tras inicializar la clase usando el método Create; de lo contrario, sus coeficientes se sobrescribirán con valores unitarios.
El algoritmo Conflict-Averse Gradient Descent lo trasladaremos a un método CAGrad aparte. En los parámetros, este método obtendrá un vector de gradientes y retornará el vector ajustado.
En el cuerpo del método, primero haremos un pequeño trabajo preparatorio, en el que:
- determinaremos el valor promedio del gradiente;
- escalaremos los gradientes para mejorar la estabilidad computacional;
- prepararemos las variables y vectores locales.
vector<float> CNet_SAC_D_DICE::CAGrad(vector<float> &grad) { matrix<float> GG = grad.Outer(grad); GG.ReplaceNan(0); if(MathAbs(GG).Sum() == 0) return grad; float scale = MathSqrt(GG.Diag() + 1.0e-4f).Mean(); GG = GG / MathPow(scale,2); vector<float> Gg = GG.Mean(1); float gg = Gg.Mean(); vector<float> w = vector<float>::Zeros(grad.Size()); float c = MathSqrt(gg + 1.0e-4f) * fCAGrad_C; vector<float> w_best = w; float obj_best = FLT_MAX; vector<float> moment = vector<float>::Zeros(w.Size());
Tras completar el trabajo preparatorio, organizaremos un ciclo para resolver el problema de optimización. En el cuerpo del ciclo, resolveremos iterativamente la tarea de localizar el vector de actualización óptimo utilizando el método de descenso de gradiente.
for(int i = 0; i < iCAGrad_Iters; i++) { vector<float> ww; w.Activation(ww,AF_SOFTMAX); float obj = ww.Dot(Gg) + c * MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f); if(MathAbs(obj) < obj_best) { obj_best = MathAbs(obj); w_best = w; } if(i < (iCAGrad_Iters - 1)) { float loss = -obj; vector<float> derev = Gg + GG.MatMul(ww) * c / (MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f) * 2) + ww.MatMul(GG) * c / (MathSqrt(ww.MatMul(GG).Dot(ww) + 1.0e-4f) * 2); vector<float> delta = derev * loss; ulong size = delta.Size(); matrix<float> ident = matrix<float>::Identity(size, size); vector<float> ones = vector<float>::Ones(size); matrix<float> sm_der = ones.Outer(ww); sm_der = sm_der.Transpose() * (ident - sm_der); delta = sm_der.MatMul(delta); if(delta.Ptp() != 0) delta = delta / delta.Ptp(); moment = delta * 0.8f + moment * 0.5f; w += moment; if(w.Ptp() != 0) w = w / w.Ptp(); } }
Después de completar las iteraciones del ciclo, ajustaremos los gradientes de error utilizando los pesos óptimos. El resultado se retornará al programa que realiza la llamada.
w_best.Activation(w,AF_SOFTMAX); float gw_norm = MathSqrt(w.MatMul(GG).Dot(w) + 1.0e-4f); float lmbda = c / (gw_norm + 1.0e-4f); vector<float> result = ((w * lmbda + 1.0f / (float)grad.Size()) * grad) / (1 + MathPow(fCAGrad_C,2)); //--- return result; }
Hemos organizado todo el proceso de aprendizaje, como en la clase CNet_SAC_DICE, en el método CNet_SAC_D_DICE::Study. No obstante, a pesar de la unidad de enfoques y la similitud externa, existen muchas diferencias en el algoritmo y la estructura del método. Los primeros cambios los hemos introducido en los parámetros del método. Aquí hemos reemplazado la variable de recompensa reward por el vector de recompensas descompuestas Rewards.
Además, hemos excluido el vector de logaritmos de probabilidades de acción ActionsLogProbab. Como ya sabe, el algoritmo Soft Actor-Critic incluye un componente de entropía en la función de recompensa para estimular al Agente a repetir acciones con baja probabilidad, mientras que la descomposición de la función de recompensa asigna un elemento separado para cada componente. Por lo tanto, los logaritmos de probabilidad ya están presentes en el vector Rewards descompuesto, así que no necesitaremos duplicarlos en un vector aparte.
bool CNet_SAC_D_DICE::Study(CArrayFloat *State, CArrayFloat *SecondInput, CBufferFloat *Actions, vector<float> &Rewards, CBufferFloat *NextState, CBufferFloat *NextSecondInput, float discount, float tau) { //--- if(!Actions) return false;
En el cuerpo del método, verificaremos la relevancia del puntero al búfer resultante de acciones completadas. Y con esto completaremos el bloque de control de nuestro método.
Pasando a la siguiente etapa, debemos decir que durante el entrenamiento del modelo, hemos notado un aumento significativo e irracional en las estimaciones de los estados posteriores por parte de los modelos objetivo. Dichas estimaciones han excedido con creces las recompensas reales, lo que ha provocado la adaptación mutua del modelo entrenado y su copia objetivo sin tener en cuenta las recompensas reales del entorno.
Para minimizar este efecto, en la etapa inicial hemos decidido entrenar el modelo utilizando la recompensa acumulativa real. Un rechazo total del uso de modelos objetivo también tiene un efecto negativo. De hecho, en el búfer de reproducción de experiencias, la evaluación acumulativa se limita a los periodos de entrenamiento. Puede resultar muy diferente para estados y acciones similares dependiendo de la distancia hasta el final del conjunto de entrenamiento. Esto lo suavizará el modelo objetivo. Además, el modelo objetivo ayuda a estimar los estados según las acciones de la política actual. Conforme aumenta el número de iteraciones de actualización de los parámetros del Agente, la política actual diferirá cada vez más de la política en el búfer de reproducción de experiencias, cosa que no podemos ignorar. Pero necesitamos un modelo objetivo con estimaciones adecuadas. Por ello, necesitaremos dos modos de funcionamiento del método: con el uso de modelos objetivo y sin él.
En el proceso de organización del algoritmo del método, nos hemos guiado por las siguientes consideraciones:
- Si hay que utilizar modelos objetivo, el usuario transmitirá en los parámetros los punteros a los estados futuros. El vector Rewards contendrá una recompensa descompuesta solo por la acción realizada en el estado actual.
- Si se renuncia al uso de modelos objetivo, el usuario no transmitirá los punteros a los estados futuros (las variables de parámetro contendrán NULL). El vector Rewards contendrá la recompensa acumulada descompuesta.
Por lo tanto, verificaremos a continuación el puntero al estado futuro y, de ser necesario, determinaremos una acción en el estado futuro según la política actual, evaluando luego el par estado-acción.
if(!!NextState) if(!CNet::feedForward(NextState, 1, false, NextSecondInput)) return false; if(!cTargetCritic1.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1) || !cTargetCritic2.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false; //--- if(!cTargetNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this), layers.Total() - 1)) return false;
Acto seguido, realizaremos una pasada directa de la política conservadora tal como está. Luego reemplazaremos las acciones y realizaremos una pasada directa por los modelos del bloque DICE,
if(!CNet::feedForward(State, 1, false, SecondInput)) return false; CBufferFloat *output = ((CNeuronBaseOCL*)((CLayer*)layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite(); if(!cNu.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false; if(!cZeta.feedForward(GetPointer(this), iLatentLayer, GetPointer(this))) return false;
y determinaremos los valores de las funciones de pérdida de los modelos del bloque Distribution Correction Estimation. Este paso lo describimos con detalle en el artículo anterior. Solo enfatizaremos que, si nos negamos a utilizar el modelo objetivo, el vector para evaluar el estado futuro next_nu se rellenará con valores cero.
vector<float> nu, next_nu, zeta, ones; cNu.getResults(nu); cZeta.getResults(zeta); if(!!NextState) cTargetNu.getResults(next_nu); else next_nu = vector<float>::Zeros(nu.Size()); ones = vector<float>::Ones(zeta.Size()); vector<float> log_prob = GetLogProbability(output); int shift = (int)(Rewards.Size() - log_prob.Size()); if(shift < 0) return false; float policy_ratio = 0; for(ulong i = 0; i < log_prob.Size(); i++) policy_ratio += log_prob[i] - Rewards[shift + i] / LogProbMultiplier; policy_ratio = MathExp(policy_ratio / log_prob.Size()); vector<float> bellman_residuals = (next_nu * discount + Rewards) * policy_ratio - nu; vector<float> zeta_loss = MathPow(zeta, 2.0f) / 2.0f - zeta * (MathAbs(bellman_residuals) - fLambda) ; vector<float> nu_loss = zeta * MathAbs(bellman_residuals) + MathPow(nu, 2.0f) / 2.0f; vector<float> lambda_los = fLambda * (ones - zeta);
A continuación, actualizaremos el vector de coeficientes de Lagrange utilizando el método de optimización Adam.
Tenga en cuenta que corregiremos el vector de gradientes de error utilizando el método CAGrad discutido anteriormente, mientras que el uso de operaciones vectoriales nos permitirá trabajar con vectores con la misma sencillez que trabajamos con variables simples.
Los valores ajustados los guardaremos en el vector correspondiente.
vector<float> grad_lambda = CAGrad((ones - zeta) * (lambda_los * (-1.0f))); fLambda_m = fLambda_m * b1 + grad_lambda * (1 - b1); fLambda_v = fLambda_v * b2 + MathPow(grad_lambda, 2) * (1.0f - b2); fLambda += fLambda_m * lr / MathSqrt(fLambda_v + lr / 100.0f);
El siguiente paso consistirá en actualizar los parámetros del modelo v, ζ. El algoritmo para estas operaciones seguirá siendo el mismo. Simplemente reemplazaremos las variables por vectores y usaremos operaciones vectoriales.
CBufferFloat temp; temp.BufferInit(MathMax(Actions.Total(), SecondInput.Total()), 0); temp.BufferCreate(opencl); //--- update nu int last_layer = cNu.layers.Total() - 1; CLayer *layer = cNu.layers.At(last_layer); if(!layer) return false; CNeuronBaseOCL *neuron = layer.At(0); if(!neuron) return false; CBufferFloat *buffer = neuron.getGradient(); if(!buffer) return false; vector<float> nu_grad = CAGrad(nu_loss * (zeta * bellman_residuals / MathAbs(bellman_residuals) - nu)); if(!buffer.AssignArray(nu_grad) || !buffer.BufferWrite()) return false; if(!cNu.backPropGradient(output, GetPointer(temp))) return false;
Los vectores de gradiente de error los corregiremos necesariamente utilizando el algoritmo Conflict-Averse Gradient Descent en el método CNet_SAC_D_DICE::CAGrad.
//--- update zeta last_layer = cZeta.layers.Total() - 1; layer = cZeta.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; vector<float> zeta_grad = CAGrad(zeta_loss * (zeta - MathAbs(bellman_residuals) + fLambda) * (-1.0f)); if(!buffer.AssignArray(zeta_grad) || !buffer.BufferWrite()) return false; if(!cZeta.backPropGradient(output, GetPointer(temp))) return false;
En esta etapa terminaremos de trabajar con los objetos del bloque Distribution Correction Estimation y pasaremos al procedimiento de entrenamiento de nuestros modelos de los Críticos. Primero realizaremos una pasada directa de estos. Ya hemos realizado anteriormente el pasada directa del Actor.
//--- feed forward critics if(!cCritic1.feedForward(GetPointer(this), iLatentLayer, output) || !cCritic2.feedForward(GetPointer(this), iLatentLayer, output)) return false;
El siguiente paso será determinar el vector de valores de referencia para actualizar los parámetros de los Críticos. Aquí tenemos dos puntos a considerar, y ambos se refieren a los modelos objetivo. Primero comprobaremos si su uso es necesario para evaluar el estado y la acción posteriores. Para ello, comprobaremos el puntero al estado posterior del sistema.
Si utilizamos modelos objetivo para evaluar el par estado-acción posterior, entonces deberemos seleccionar el Crítico objetivo con la puntuación añadida mínima. La estimación añadida se obtendrá fácilmente multiplicando el vector de coeficientes de peso de los componentes de la función de recompensa por el vector de recompensa predictiva descompuesta obtenida de la pasada directa de los modelos objetivo. A continuación, lo único que deberemos hacer es seleccionar la estimación mínima y guardar el vector de valores predichos del modelo seleccionado.
Si renunciamos a evaluar los estados posteriores, el vector de valores predichos se rellenará con valores cero.
vector<float> result; if(fZeta.CompareByDigits(vector<float>::Zeros(fZeta.Size()),8) == 0) fZeta = MathAbs(zeta); else fZeta = fZeta * 0.9f + MathAbs(zeta) * 0.1f; zeta = MathPow(MathAbs(zeta), 1.0f / 3.0f) / (MathPow(fZeta, 1.0f / 3.0f) * 10.0f); vector<float> target = vector<float>::Zeros(Rewards.Size()); if(!!NextState) { cTargetCritic1.getResults(target); cTargetCritic2.getResults(result); if(fQWeights.Dot(result) < fQWeights.Dot(target)) target = result; }
Luego ajustaremos las estimaciones del pronóstico por el factor de descuento y las sumaremos con la recompensa del estado actual.
target = (target * discount + Rewards); ulong total = log_prob.Size(); for(ulong i = 0; i < total; i++) target[shift + i] = log_prob[i] * LogProbMultiplier;
En el vector resultante ajustaremos el logaritmo de la probabilidad de acciones en la política actual. Aquí vale la pena señalar que los logaritmos de las probabilidades de acción almacenados en el búfer de reproducción de experiencias ya están contenidos en el vector de recompensa. Reemplazaremos sus valores de los logaritmos de la política actual para entrenar al crítico a evaluar considerando la política actual.
Tras determinar los valores objetivo, calcularemos el error de predicción del primer Crítico y el gradiente del error para cada componente de la función Q. Los gradientes resultantes se ajustarán utilizando el algoritmo Conflict-Averse Gradient Descent.
//--- update critic1 cCritic1.getResults(result); vector<float> loss = zeta * MathPow(result - target, 2.0f); if(fLoss1 == 0) fLoss1 = MathSqrt(fQWeights.Dot(loss) / fQWeights.Sum()); else fLoss1 = MathSqrt(0.999f * MathPow(fLoss1, 2.0f) + 0.001f * fQWeights.Dot(loss) / fQWeights.Sum()); vector<float> grad = CAGrad(loss * zeta * (target - result) * 2.0f);
Luego transferiremos los gradientes de error corregidos al búfer del Crítico 1 correspondiente y realizaremos una pasada inversa a través del modelo.
last_layer = cCritic1.layers.Total() - 1; layer = cCritic1.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.AssignArray(grad) || !buffer.BufferWrite()) return false; if(!cCritic1.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
Aquí efectuaremos una pasada inversa parcial del Actor para ajustar el bloque de preprocesamiento de los datos de origen.
Después repetiremos las operaciones para el segundo Crítico.
//--- update critic2 cCritic2.getResults(result); loss = zeta * MathPow(result - target, 2.0f); if(fLoss2 == 0) fLoss2 = MathSqrt(fQWeights.Dot(loss) / fQWeights.Sum()); else fLoss2 = MathSqrt(0.999f * MathPow(fLoss2, 2.0f) + 0.001f * fQWeights.Dot(loss) / fQWeights.Sum()); grad = CAGrad(loss * zeta * (target - result) * 2.0f); last_layer = cCritic2.layers.Total() - 1; layer = cCritic2.layers.At(last_layer); if(!layer) return false; neuron = layer.At(0); if(!neuron) return false; buffer = neuron.getGradient(); if(!buffer) return false; if(!buffer.AssignArray(grad) || !buffer.BufferWrite()) return false; if(!cCritic2.backPropGradient(output, GetPointer(temp)) || !backPropGradient(SecondInput, GetPointer(temp), iLatentLayer)) return false;
En el siguiente bloque de nuestro método actualizaremos las políticas. No olvide que el algoritmo SAC+DICE prevé el entrenamiento de dos políticas de actores: conservadoras y optimistas. Primero implementaremos la actualización de las políticas conservadoras. Ya hemos realizado antes una pasada directa para este modelo.
Para entrenar a los Actores, usaremos el Crítico con error promedio mínimo. Definiremos dicho modelo y almacenaremos el puntero al mismo en una variable local.
vector<float> mean; CNet *critic = NULL; if(fLoss1 <= fLoss2) { cCritic1.getResults(result); cCritic2.getResults(mean); critic = GetPointer(cCritic1); } else { cCritic1.getResults(mean); cCritic2.getResults(result); critic = GetPointer(cCritic2); }
Aquí cargaremos las estimaciones pronosticadas de cada uno de los Críticos. Luego determinaremos los valores de referencia para la pasada inversa de los modelos utilizando la fórmula.
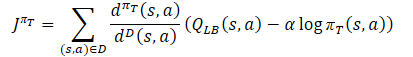
Al mismo tiempo, nos aseguraremos de corregir el vector de gradientes de error utilizando el método Conflict-Averse Gradient Descent.
vector<float> var = MathAbs(mean - result) / 2.0f; mean += result; mean /= 2.0f; target = mean; for(ulong i = 0; i < log_prob.Size(); i++) target[shift + i] = discount * log_prob[i] * LogProbMultiplier; target = CAGrad(zeta * (target - var * 2.5f) - result) + result;
A continuación, solo necesitaremos trasladar los datos obtenidos al búfer y realizar una pasada inversa del Crítico y el Actor. Para evitar el ajuste mutuo de los modelos, antes de iniciar las operaciones desactivaremos el modo de entrenamiento del Crítico. En este caso, solo lo usaremos para transmitir el gradiente de error al Actor.
CBufferFloat bTarget; bTarget.AssignArray(target); critic.TrainMode(false); if(!critic.backProp(GetPointer(bTarget), GetPointer(this)) || !backPropGradient(SecondInput, GetPointer(temp))) { critic.TrainMode(true); return false; }
Todavía no hemos utilizado el modelo de Actor optimista, en contraposición al conservador. Por lo tanto, antes de iniciar el proceso de actualización de sus parámetros, deberemos realizar una pasada directa con el estado actual del entorno.
//--- update exploration policy if(!cActorExploer.feedForward(State, 1, false, SecondInput)) { critic.TrainMode(true); return false; } output = ((CNeuronBaseOCL*)((CLayer*)cActorExploer.layers.At(layers.Total() - 1)).At(0)).getOutput(); output.AssignArray(Actions); output.BufferWrite();
Como en el caso del Actor conservador, reemplazaremos el vector de acciones y obtendremos los logaritmos de probabilidades, pero considerando la política optimista.
cActorExploer.GetLogProbs(log_prob);
Y determinaremos el vector de valores de referencia para la pasada inversa de los modelos, pero según la fórmula de política optimista.
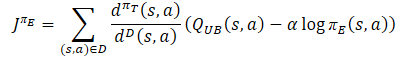
El vector de gradientes de error se corregirá utilizando el método Conflict-Averse Gradient Descent.
target = mean; for(ulong i = 0; i < log_prob.Size(); i++) target[shift + i] = discount * log_prob[i] * LogProbMultiplier; target = CAGrad(zeta * (target + var * 2.0f) - result) + result;
Luego realizaremos una pasada inversa a través de los modelos y retornaremos el Crítico al modo de entrenamiento del modelo.
bTarget.AssignArray(target); if(!critic.backProp(GetPointer(bTarget), GetPointer(cActorExploer)) || !cActorExploer.backPropGradient(SecondInput, GetPointer(temp))) { critic.TrainMode(true); return false; } critic.TrainMode(true);
A continuación deberemos actualizar los modelos objetivo. Y aquí hemos hechos más adiciones para evitar la distorsión de las estimaciones de los estados futuros y la adaptación de los modelos de los Críticos a los valores de sus copias objetivo.
Los parámetros de los modelos objetivo se actualizarán en cada iteración solo si ya no se utilizan para evaluar el estado posterior. Si los modelos objetivo se utilizan durante el entrenamiento, su actualización se realizará con retraso.
Por lo tanto, primero verificaremos si es necesario actualizar los modelos y solo luego realizaremos las operaciones.
if(!!NextState) { if(iUpdateDelayCount > 0) { iUpdateDelayCount--; return true; } iUpdateDelayCount = iUpdateDelay; } if(!cTargetCritic1.WeightsUpdate(GetPointer(cCritic1), tau) || !cTargetCritic2.WeightsUpdate(GetPointer(cCritic2), tau) || !cTargetNu.WeightsUpdate(GetPointer(cNu), tau)) { PrintFormat("Error of update target models: %d", GetLastError()); return false; } //--- return true; }
Después de completar con éxito todas las iteraciones del método, finalizaremos su funcionamiento con el resultado true.
La descomposición de recompensas y el uso de vectores han provocado cambios en otros métodos, incluyendo los métodos para trabajar con archivos, pero no nos detendremos en ellos ahora. Podrá familiarizarse con ellos, así como con el código completo de todos los métodos de la nueva clase, en el archivo adjunto "MQL5\Experts\SAC-D&DICE\Net_SAC_D_DICE.mqh".
2.2 Ajustamos las estructuras de almacenamiento de datos
Ahora pasaremos a trabajar en el archivo “MQL5\Experts\SAC-D&DICE\Trajectory.mqh”. Pero si antes aquí cambiábamos la arquitectura de los modelos, ahora la hemos dejado prácticamente sin cambios. Solo necesitaremos cambiar el número de neuronas en la salida del Crítico. Deberían ser suficientes para descomponer la función de recompensa, pero antes de especificar su número, definiremos la estructura de la recompensa descompuesta.
En el primer elemento con índice "0" indicaremos el cambio relativo del balance. Como ya sabrá, nuestro principal objetivo es maximizar los beneficios en el mercado.
En el parámetro con índice "1", indicaremos el valor relativo del cambio en la Equidad. Un valor negativo indicará una reducción no deseada, mientras que uno positivo indicará un beneficio no realizado.
Destacaremos otro elemento de penalización adicional por la falta de posiciones abiertas.
A continuación sumaremos los logaritmos de probabilidades de acciones. Como ya sabe, la longitud del vector de logaritmos de probabilidades es igual al vector de acciones.
//+------------------------------------------------------------------+ //| Rewards structure | //| 0 - Delta Balance | //| 1 - Delta Equity ( "-" Drawdown / "+" Profit) | //| 2 - Penalty for no open positions | //| 3... - LogProbs vector | //+------------------------------------------------------------------+
Así, el tamaño de la capa neuronal de los resultados del Crítico será 3 elementos mayor que el número de acciones.
#define NActions 6 //Number of possible Actions #define NRewards 3+NActions //Number of rewards
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- Actor ........ ........ //--- Critic critic.Clear(); //--- Input layer ........ ........ //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
A continuación, debemos decir que la descomposición de la recompensa también ha cambiado la estructura de almacenamiento de los datos en el búfer de reproducción de experiencias. Ahora una variable no será suficiente para registrar la recompensa, necesitaremos una serie de datos. Al mismo tiempo, hemos introducido el componente de entropía en el array de recompensas y no necesitaremos un array aparte para volver a registrar estos valores. Por lo tanto, en la estructura de descripción del estado, reemplazaremos el array log_prob por rewards, y ajustaremos los métodos para copiar la estructura y trabajar con archivos.
struct SState { float state[HistoryBars * BarDescr]; float account[AccountDescr - 4]; float action[NActions]; float rewards[NRewards]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(rewards, obj.rewards); } };
En la estructura de trayectoria STrjectory, eliminaremos el array de recompensas Rewards, ya que la recompensa ahora se describirá en la estructura de estado SState, y realizaremos cambios específicos en los métodos estructurales,
struct STrajectory { SState States[Buffer_Size]; int Total; float DiscountFactor; bool CumCounted; //--- STrajectory(void); //--- bool Add(SState &state); void CumRevards(void); //--- bool Save(int file_handle); bool Load(int file_handle); };
Podrá encontrar el código completo de las estructuras mencionadas y sus métodos en el archivo adjunto.
2.3 Creamos un modelo de entrenamiento de asesores
Seguimos adelante: ahora comenzaremos a trabajar en los asesores de entrenamiento del modelo. Durante el entrenamiento, como antes, utilizamos tres asesores:
- Research: recopilación de una base de datos de ejemplos
- Study: entrenamiento de modelos
- Test: comprobación de los resultados obtenidos.
En los asesores Research y Test, los cambios han afectado únicamente a la preparación de la estructura de la descripción del estado del entorno y la recompensa recibida al final del método OnTick. Si antes sumábamos las recompensas y las penalizaciones, ahora añadiremos cada componente a su propio elemento del array. En este caso, deberemos cumplir con la estructura de datos anterior. Cada elemento del array deberá rellenarse obligatoriamente. Si falta el valor del componente, escribiremos "0" en el elemento del array correspondiente. Este enfoque nos dará confianza en la exactitud de los datos usados.
void OnTick() { //--- ........ ........ //--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f-bAccount[1]; vector<float> log_prob; Actor.GetLogProbs(log_prob); if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) { sState.action[i] = ActorResult[i]; sState.rewards[i + 3] = log_prob[i] * LogProbMultiplier; } if(!Base.Add(sState)) ExpertRemove(); }
Podrá encontrar el código completo de los asesores en el archivo adjunto.
Los modelos se entrenarán, como es habitual, con el asesorStudy. Como hemos mencionado antes, hemos dividido el proceso de entrenamiento de modelos en dos etapas:
- Entrenamiento con recompensa acumulativa real (sin modelos objetivo).
- Entrenamiento con modelos objetivo.
La duración de la primera etapa estará determinada por una constante.
#define StartTargetIteration 20000
Debemos señalar que el entrenamiento sin modelos objetivo se realiza solo al iniciar por primera vez el asesor Study, cuando no hay modelos previamente entrenados.
Si, al inicio, el asesor de entrenamiento ha logrado cargar modelos previamente entrenados, entonces los modelos objetivo se utilizarán desde la primera iteración de entrenamiento.
Este control se implementa en el método OnInit del asesor.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models if(!Net.Load(FileName, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Net.Create(actor, critic, critic, critic, LatentLayer)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; StartTargetIter = StartTargetIteration; } else StartTargetIter = 0; //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Como podemos ver, al crear nuevos modelos, escribimos el valor de la constante StartTargetIteration en la variable StartTargetIter . Si cargamos modelos previamente entrenados, almacenaremos "0" en la variable de retraso.
Las iteraciones de entrenamiento están organizadas en el método Train. Al inicio del método, como de costumbre, determinaremos el número de trayectorias guardadas en el búfer de reproducción de experiencias. Y organizaremos un ciclo de entrenamiento con el número de iteraciones especificadas en el parámetro externo del asesor.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
En el cuerpo del ciclo, tomaremos muestras aleatorias del estado en una de las trayectorias guardadas, después de lo cual transferiremos la información sobre el estado seleccionado a los búferes de datos y un vector.
//--- bState.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- bActions.AssignArray(Buffer[tr].States[i].action); vector<float> rewards; rewards.Assign(Buffer[tr].States[i].rewards);
Tenga en cuenta que en esta etapa solo preparamos información sobre el estado seleccionado. Para no realizar trabajos innecesarios, generaremos la información sobre el estado posterior solo si es necesario.
Luego comprobaremos si es necesario utilizar modelos objetivo para estimar el estado posterior comparando la iteración de entrenamiento actual y el valor de la variableStartTargetIter. Si el número de iteraciones no ha alcanzado el valor umbral, realizaremos el entrenamiento con valores acumulativos. Pero hay un momento a considerar. Al guardar datos en el búfer de reproducción de experiencias, calcularemos el total acumulado de los valores de todos los componentes de la recompensa. Solo que necesitaremos el componente de entropía sin el total acumulado. Por lo tanto, organizaremos un ciclo y eliminaremos los valores acumulados solo del componente de entropía de la función de recompensa.
//--- if(iter < StartTargetIter) { ulong start = rewards.Size() - bActions.Total(); for(ulong r = start; r < rewards.Size(); r++) rewards[r] -= Buffer[tr].States[i + 1].rewards[r] * DiscFactor; if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), rewards, NULL, NULL, DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Y luego llamaremos al método de entrenamiento de nuestra nueva clase. Aquí indicaremos "NULL" en los parámetros de estado posteriores.
Tras alcanzar el umbral de uso de las funciones objetivo, primero prepararemos la información sobre el estado posterior del sistema.
else { //--- Target bNextState.AssignArray(Buffer[tr].States[i + 1].state); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1]; if(PrevBalance == 0) { iter--; continue; } bNextAccount.Clear(); bNextAccount.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); bNextAccount.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); bNextAccount.Add(Buffer[tr].States[i + 1].account[2]); bNextAccount.Add(Buffer[tr].States[i + 1].account[3]); bNextAccount.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); bNextAccount.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); bNextAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); bNextAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Luego eliminaremos los valores acumulados de todos los componentes de la función de recompensa, dejando solo las recompensas del estado actual,
for(ulong r = 0; r < rewards.Size(); r++) rewards[r] -= Buffer[tr].States[i + 1].rewards[r] * DiscFactor; if(!Net.Study(GetPointer(bState), GetPointer(bAccount), GetPointer(bActions), rewards, GetPointer(bNextState), GetPointer(bNextAccount), DiscFactor, Tau)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
y llamaremos al método de entrenamiento para el modelo de nuestra clase. Esta vez especificaremos los objetos con los datos de estado posteriores.
Tras la iteración del ciclo, imprimiremos un mensaje para informar al usuario y pasar a la siguiente iteración.
//--- if(GetTickCount() - ticks > 500) { float loss1, loss2; Net.GetLoss(loss1, loss2); string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), loss1); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), loss2); Comment(str); ticks = GetTickCount(); } }
Después de completar con éxito todas las iteraciones del ciclo, limpiaremos el campo de comentarios en el gráfico, y forzaremos la actualización de los modelos objetivo. Enviaremos el resultado del entrenamiento al registro de MetaTrader 5 e iniciaremos el proceso de cierre del asesor.
Comment(""); //--- float loss1, loss2; Net.GetLoss(loss1, loss2); Net.TargetsUpdate(Tau); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", loss1); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", loss2); ExpertRemove(); //--- }
Con esto podemos dar por concluido nuestro trabajo con los asesores de entrenamiento del modelo. En los archivos adjuntos encontrará el código completo de todos los programas utilizados.
3. Simulación
Más arriba hemos propuesto una opción de implementación para un enfoque de descomposición de la función de recompensa basado en el algoritmo SAC+DICE, y ahora podemos evaluar los resultados del trabajo realizado en la práctica. Al igual que antes, el entrenamiento de los modelos se ha realizado con datos históricos de EURUSD, marco temporal H1, en un intervalo temporal que abarca los primeros 5 meses de 2023. Todos los parámetros de los indicadores se usan por defecto. El balance inicial es de 10000 USD.
El proceso de entrenamiento del modelo es iterativo y se alternará con las etapas de recopilación de ejemplos en un búfer de acumulación de experiencias y la actualización de los parámetros del modelo.
En la primera etapa, crearemos una base primaria de datos de ejemplos utilizando modelos de actor llenos de parámetros aleatorios. Como resultado, obtendremos una serie de pasadas aleatorias que generan conjuntos de datos “Estado → Acción → Nuevo Estado → Recompensa” independientes de la política.
A diferencia de todos los algoritmos anteriormente considerados, en este caso recopilaremos los datos descompuestos sobre las recompensas del entorno por las acciones del Agente.
Tras recopilar los ejemplos, realizaremos el entrenamiento inicial de nuestro modelo. Para ello iniciaremos el asesor "..\SAC-D&DICE\Study.mq5".
Debo decir que con el entrenamiento primario sin utilizar modelos objetivo, observamos una tendencia constante hacia la disminución en los errores de ambos críticos. No obstante, al utilizar modelos objetivo para estimar el estado posterior, se observan picos caóticos (poco frecuentes) en el error de predicción. Después de lo cual podremos observar un retorno suave al nivel de error anterior.
En la segunda etapa, reiniciaremos el asesor de recopilación de datos de entrenamiento en el modo de optimización del simulador de estrategias con una búsqueda completa de parámetros. Esta vez, para todas las pasadas, utilizaremos el Actor optimista entrenado en la primera etapa. La dispersión de los resultados de las pasadas individuales es inferior a la recopilación de datos inicial y se debe a la estocasticidad de la política del Actor.
El proceso de recopilación de ejemplos y el entrenamiento del modelo se repetirá varias veces hasta obtener el resultado deseado o alcanzar un mínimo local, cuando la siguiente iteración de la recopilación de ejemplos y el entrenamiento del modelo no produzca avances.
En el proceso de entrenamiento del modelo hemos obtenido una política del Actor capaz de generar un pequeño beneficio durante el periodo de entrenamiento.


A pesar del beneficio obtenido, la política aprendida está lejos de nuestras metas. En el gráfico de balance vemos un movimiento ondulatorio con una amplitud bastante grande. De las 28 transacciones, solo el 32% se ha cerrado con beneficios. El beneficio total se ha logrado gracias a que el volumen de la transacción con beneficio supera al volumen de la perdedora. Entonces, el beneficio promedio de una transacción será 2 veces superior a la pérdida promedio, mientras que el beneficio máximo por transacción será casi 3,5 veces la pérdida máxima. Como resultado, el factor de beneficio es ligeramente superior a 1.
En defensa del modelo, podemos decir que el asesor también ha mostrado ganancias con los nuevos datos. Un mes después del periodo de entrenamiento, el modelo ha logrado obtener casi el 20% de los ingresos, lo cual supera el resultado del conjunto de entrenamiento. Sin embargo, las estadísticas de los resultados son comparables a los datos del conjunto de entrenamiento. Durante el proceso de prueba, solo se han realizado 4 transacciones y solo una de ellas se ha cerrado con ganancias. Pero el beneficio de esta operación es 12,8 veces superior al máximo de las operaciones perdedoras.


Comparando los resultados de la muestra de entrenamiento y del periodo posterior, podemos suponer que con los nuevos datos estamos observando el comienzo de una ola de rentabilidad tras la cual es posible una disminución en el futuro previsible.
En general, el modelo es capaz de generar beneficios, pero se requiere una optimización adicional.
Conclusión
En el presente artículo, presentamos un enfoque de la descomposición de la función de recompensa que nos permite entrenar a los Agentes de forma más eficiente. La descomposición de la recompensa permite analizar la influencia de varios componentes en las decisiones tomadas por el Agente.
Hemos implementado el algoritmo usando MQL5 e integrado la descomposición de la función de recompensa en el método SAC+DICE.
Durante la prueba práctica del algoritmo implementado, hemos logrado obtener un modelo capaz de generar ganancias tanto en el conjunto de entrenamiento como fuera de él. Esto indica la capacidad de generalización del algoritmo.
No obstante, los resultados obtenidos distan mucho de nuestros deseos. Al mismo tiempo, la descomposición de la función de recompensa permite analizar la influencia de los componentes individuales de la función de recompensa en el resultado del entrenamiento. Le animo a que experimente incluyendo y excluyendo componentes individuales, así como a evaluar su impacto en el resultado del entrenamiento.
Enlaces
- Conflict-Averse Gradient Descent for Multi-task Learning
- Value Function Decomposition for Iterative Design of Reinforcement Learning Agents
- Redes neuronales: así de sencillo (Parte 52): Exploración con optimismo y corrección de la distribución
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | Net_SAC_D_DICE.mqh | Biblioteca de clases | Clase de modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13098
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Gracias Dmitry, Hice clic en su perfil de vendedor con la esperanza de encontrar algunos EAs nn que podía probar.
He tomado un curso MQL5 udemy en nn, ahora tratando de profundizar. Estoy empezando con su serie de artículos.