
Redes neuronales: así de sencillo (Parte 51): Actor-crítico conductual (BAC)

Introducción
Los 2 últimos artículos han tratado sobre el algoritmo Soft Actor-Critic (SAC). Recordemos que este algoritmo se usa para entrenar modelos estocásticos en un espacio continuo de acciones. La principal característica de este método es la introducción de un componente de entropía en la función de recompensa, lo cual permite ajustar el equilibrio entre la exploración del entorno y la explotación del modelo. Pero, al mismo tiempo, este enfoque también impone algunas limitaciones a los modelos entrenados. El uso de la entropía requiere una cierta noción de la probabilidad de que se produzcan acciones, lo cual resulta bastante difícil de calcular directamente para un espacio continuo de acciones.
Vamos a utilizar un enfoque de distribución cuantílica. Y aquí es donde añadiremos el ajuste de los hiperparámetros de la distribución cuantílica. El propio planteamiento del uso de una distribución cuantílica nos aleja ligeramente del espacio continuo de acciones, pues, al fin y al cabo, cada vez que elegimos una acción, estamos seleccionando un cuantil de la distribución de probabilidad aprendida y utilizando su media como acción. Sí, con un número suficientemente grande de cuantiles y un rango suficientemente pequeño de valores posibles, nos aproximaremos a un espacio continuo de acciones, pero esto conllevará un aumento de la complejidad del modelo y del coste del entrenamiento y la explotación. Y, por supuesto, esto impondrá una limitación a la arquitectura de los modelos entrenados.
En el presente artículo, hablaremos de un enfoque alternativo Behaviour-Guided Actor-Critic (BAC), introducido en abril de 2021.
1. Peculiaridades de construcción de los algoritmos
En primer lugar, reflexionaremos sobre la necesidad de la exploración del entorno en general. Creo que todo el mundo estará de acuerdo con la necesidad de este proceso, pero, ¿para qué en concreto y en qué fase?
Empezaremos con un ejemplo sencillo. Imaginemos que entramos por primera vez en una especie de habitación con 3 puertas idénticas y necesitamos hallar la salida a la calle. ¿Qué hacemos? Abriremos las puertas una a una hasta encontrar la correcta. Cuando volvamos a entrar en la misma habitación, para salir al exterior ya no abriremos todas las puertas, sino que iremos directamente a la salida, que ya conocemos. Si en esta situación tenemos una tarea diferente, entonces existirán varias opciones. Podemos volver a abrir todas las puertas, salvo la salida, que ya conocemos, y buscar la correcta. O bien podemos recordar qué puertas hemos abierto antes al buscar la salida y pensar si entre ellas estaba la correcta. Si recordamos la puerta correcta, nos dirigiremos a ella. En caso contrario, comprobaremos las puertas que no se hayan abierto antes.
Conclusión: la exploración del entorno es necesaria para, en un estado desconocido, seleccionar la acción correcta. Una vez hayamos encontrado la ruta necesaria, la exploración adicional del entorno solo podrá entorpecer el camino.
No obstante, puede que necesitemos investigar más el entorno cuando cambiemos la tarea en un estado conocido. Aquí se podría incluir la búsqueda de una ruta mejor: por ejemplo, en el caso de atravesar algunas habitaciones más para salir en la historia anterior, o si saliéramos por el lado equivocado del edificio.
De ahí que necesitemos un algoritmo que aumente la exploración del entorno en los estados inexplorados y la minimice en los estados previamente explorados.
La regularización entrópica usada en el SAC puede cumplir este requisito, pero solo con una serie de convenciones. La entropía de una acción es alta cuando su probabilidad es baja. Sí, el estado al que pasamos tras una acción con baja probabilidad es probablemente poco conocido, y la regularización entrópica nos empuja a cometerlo repetidamente para explorar mejor los estados posteriores, pero, ¿qué ocurre después de estudiar este vector de movimiento? Si hemos encontrado un camino mejor, el proceso de entrenamiento del modelo aumentará la probabilidad de acción y disminuirá la entropía. Esto se ajusta a nuestros requisitos. No obstante, la probabilidad de otras acciones disminuirá y su entropía aumentará, lo que nos empujará a seguir explorando otras vías, y solo un nivel significativo de recompensa positiva podrá mantener nuestro enfoque en este camino.
Por otra parte, si la nueva ruta no cumple nuestros requisitos, reduciremos la probabilidad de tal acción en el proceso de entrenamiento del modelo. Haciendo esto, su entropía aumentará todavía más, lo que nos impulsará a cometerla repetidamente. Y solo una recompensa negativa significativa (penalización) podrá disuadirnos de volver a cometer una imprudencia.
Por eso es muy importante una elección bien ponderada del coeficiente de temperatura, para garantizar el equilibrio adecuado entre la exploración y la explotación del modelo.
Es un poco raro. Comenzamos con una estrategia ε-greedy en la que el equilibrio entre exploración y explotación se regía por una constante de probabilidad. Luego complicamos el modelo y hablamos nuevamente de la importancia de la selección del coeficiente. Deja vu.
En busca de una solución diferente, nos hemos fijado en el algoritmo Behavior-Guided Actor-Critic (BAC), presentado en el artículo "Behavior-Guided Actor-Critic: Improving Exploration via Learning Policy Behavior Representation for Deep Reinforcement Learning". Los autores del método proponen al lector sustituir el componente de entropía en la función de recompensa por alguna medida del aprendizaje del modelo de la pareja "Estado-Acción".
La elección de la pareja "Estado-Acción" resulta bastante obvia: es aquello que conocemos en un momento determinado. Una vez en un determinado estado, elegiremos la acción. Esta determinará, hasta cierto punto, nuestra transición al siguiente estado y la recompensa por dicha transición. Al mismo tiempo, puede haber una transición a un nuevo estado esperado tras la misma acción, o puede darse un estado diferente (con cierta probabilidad). Por ejemplo, para abrir una puerta deberemos acercarnos a ella. Aquí es de esperar que nos encontremos más cerca de la puerta después de cada paso. Luego, girando el pomo de la puerta, la abriremos, aunque puede que esté cerrada con pestillo y no se abra (este es un factor que escapa a nuestro control). La recompensa o la penalización nos esperará al otro lado de la puerta, pero no lo sabremos hasta que lleguemos allí. Así, solo considerando todas las acciones posibles de un estado individual podremos hablar de una exploración completa del mismo.
Los autores del método proponen utilizar un autocodificador como medida de aprendizaje de la pareja "Estado-Acción". Debemos decir que ya nos hemos encontrado varias veces con el uso de autocodificadores en diferentes algoritmos, pero siempre se ha tratado de comprimir datos o construir algún tipo de modelo de interdependencia. La experiencia demuestra que la construcción de modelos de mercados financieros es una tarea bastante difícil debido al gran número de factores que influyen y que no siempre resultan evidentes. En este caso, sin embargo, se usa una propiedad diferente del autocodificador.
El autocodificador en su forma más pura es bastante bueno reproduciendo los datos de origen, pero un autocodificador es una red neuronal, y hemos dicho desde el principio que las redes neuronales solo funcionan bien con datos aprendidos. De lo contrario, su resultado podría ser imprevisible. Por eso siempre hacemos hincapié en la representatividad de la muestra de entrenamiento, y la invariabilidad de los hiperparámetros del modelo durante el entrenamiento y la explotación.
Los autores del método decidieron aprovechar esta propiedad de las redes neuronales. Tras entrenar con un conjunto de estados y las acciones correspondientes, obtendremos una buena copia de ellos a la salida del autocodificador, pero si solo introducimos una pareja "Estado-Acción" desconocida en la entrada del modelo, el error de copiado de datos aumentará drásticamente. Precisamente el error de copiado de datos es lo que utilizaremos como medida de la capacidad de aprendizaje de una pareja "Estado-Acción" individual.
Este enfoque presenta varias ventajas respecto a la regularización entrópica. En primer lugar, es aplicable tanto a modelos estocásticos como deterministas. El uso de un autocodificador no afectará a la elección de la arquitectura del Actor.
En segundo lugar, la recompensa incentivadora de la pareja "Estado-Acción" disminuirá a medida que avance el aprendizaje, independientemente de la recompensa obtenida y de la probabilidad de realizar una acción en el futuro. Y a medida que se entrena el autocodificador, tiende a "0", lo que llevará al pleno funcionamiento del modelo.
Sin embargo, cuando aparece un nuevo estado (y dada la capacidad de generalización de las redes neuronales, podemos decir que no será similar a otros aprendidos previamente), se activará inmediatamente el modo de exploración del entorno.
Y la recompensa incentivadora de una pareja "Estado-Acción" será completamente independiente del grado de aprendizaje, la probabilidad de realización u otros factores de otra acción en el mismo estado.
Obviamente, se trata de un espacio continuo de acciones, y el modelo será capaz de generalizar la experiencia. Y al aprender una pareja "Estado-Acción", el modelo podrá aplicar su experiencia anterior a estados similares y acciones próximas. Pero, en este caso, el error de transferencia de datos será igual de variable de forma continua y dependerá de la proximidad (similitud) de los estados y las acciones.
Matemáticamente, el aprendizaje de políticas puede representarse del siguiente modo:
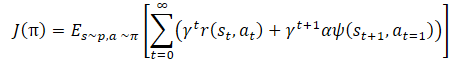
donde γ es el factor de descuento,
α es el coeficiente de temperatura,
ψ(St+1,At=1) - función de conducta del estado posterior (error de copiado del autocodificador).
Una vez más, vemos el coeficiente de temperatura para ajustar el equilibrio entre la exploración y la explotación del modelo. Lo que conduce de nuevo a las dificultades anteriormente mencionadas del ajuste de hiperparámetros y el entrenamiento de modelos. Los autores del método sugirieron una ligera modificación de la función de entrenamiento de la política.
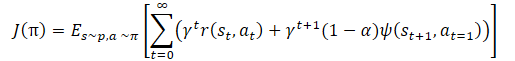
Y el propio coeficiente de temperatura α debe determinarse mediante la fórmula
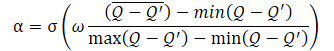
donde σ es la función sigmoidea,
ω es igual a 10,
Q es una red neuronal para evaluar la calidad de una acción.
La red neuronal Q utilizada aquí es un análogo del Crítico y evalúa la calidad de una acción en un determinado estado dada la política actual.
Como se desprende de la fórmula presentada, el coeficiente de temperatura (1-α) oscila entre 0 y 0,5. Aumenta cuando asciende la puntuación de calidad de la acción. Obviamente, en este punto, el error de copiado de datos del autocodificador tenderá a "0". Es muy probable que el modelo se encuentre actualmente en algún tipo de mínimo localizado, por lo que un estudio del entorno podría ayudar a salir de este estado.
Cuando la precisión del copiado de datos es baja, la calidad de la evaluación de las acciones en un estado determinado también se reduce al mismo tiempo, lo que hace crecer el denominador de la expresión dentro de la función sigmoidea, y, en consecuencia, el valor completo del argumento de la sigmoide disminuye y su resultado tiende a 0,5.
Aquí hay que señalar que siempre restamos el error menor al mayor. Por lo tanto, el argumento de la sigmoide será siempre mayor que "0", y casi nunca será igual a "0", ya que no podemos dividir por "0".
También debemos decir que el algoritmo presentado sigue siendo miembro de la gran familia de algoritmos Actor-Crítico y utiliza enfoques comunes con esta familia de algoritmos. Al igual que el SAC, el algoritmo se utiliza para entrenar políticas de Actor en un espacio continuo de acciones. Para estimar la calidad de una acción y la distribución del gradiente de error de la recompensa respecto a la acción, utilizaremos 2 modelos de Crítico. También usaremos la actualización suave de los modelos objetivo, un búfer de acumulación de experiencia y otros enfoques habituales para entrenar los modelos de Actor-Crítico.
2. Implementación usando MQL5
Tras considerar los aspectos teóricos del enfoque propuesto, pasaremos a su aplicación mediante MQL5. Empezaremos por la arquitectura de los modelos. Para poder comparar el rendimiento de los métodos, no hemos cambiado mucho la arquitectura de los modelos del artículo anterior. No obstante, hemos simplificado un poco la arquitectura del Actor y eliminado la última capa neuronal (muy compleja) que creamos para implementar el algoritmo estocástico del Actor del método SAC. Sin embargo, hemos dejado el uso de la política estocástica del Actor. Pero esta vez se conseguirá utilizando la capa de estado latente del autocodificador variacional. Como recordará, la entrada de esta capa neuronal es un tensor de datos que tiene exactamente 2 veces el tamaño de su búfer de resultados. El tensor de datos de origen especificado contiene la media y la varianza de la distribución de cada elemento de los resultados. De esta forma reduciremos la complejidad computacional pero dejaremos el modelo estocástico del Actor en un espacio continuo de acciones.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *autoencoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!autoencoder) { autoencoder = new CArrayObj(); if(!autoencoder) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2*NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El modelo del crítico se mantendrá inalterado y no nos detendremos en él.
Vamos a hablar un poco del modelo de autocodificador. Como ya hemos mencionado en el bloque teórico, el autocodificador se usa como elemento de memoria de las parejas "Estado-Acción" anteriormente comentadas. Podemos decir que es una especie de contador del número de visitas de estas parejas, pero no debemos olvidar que son las parejas "Estado-Acción" las que también evalúan nuestros Críticos. Más concretamente, el Crítico evalúa una acción individual en un estado concreto. Es una cuestión de terminología y conceptos, pero hablamos del mismo conjunto de datos.
Antes, para ahorrar recursos y tiempo de entrenamiento del modelo, eliminamos el bloque de preprocesamiento de datos de origen de la arquitectura del Crítico. En su lugar, utilizaremos los datos ya procesados del estado oculto del modelo del Actor. Y en la entrada del Crítico, concatenamos el estado oculto y el búfer de resultados del Actor, combinando así el estado y la acción en un único tensor.
Ahora vamos a ir un poco más lejos. Así, suministraremos el estado oculto de uno de los Críticos a la entrada de nuestro autocodificador. Sí, podríamos utilizar una capa de concatenación de 2 tensores de los datos originales por analogía con el Crítico, pero entonces tendríamos que resolver el problema de comparar el búfer de resultados del autocodificador con los dos búferes de datos de origen. Y el uso de un único búfer de datos de origen de la representación latente del Crítico nos permite utilizar un modelo de autocodificador más sencillo y comparar los datos de origen con sus resultados de su funcionamiento 1:1. Por lo tanto, en la arquitectura del autocodificador solo utilizaremos capas completamente conectadas.
//--- Autoencoder autoencoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 20; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(2)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(1)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(0)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- return true; }
Nótese que a partir de la capa 4 del autocodificador, no crearemos una descripción completa de las nuevas capas neuronales. En su lugar, simplemente copiaremos las descripciones creadas anteriormente en orden inverso, lo cual nos permite crear una copia especular del Codificador en el Decodificador, así, cualquier cambio en la arquitectura del Codificador (salvo la adición de nuevas capas) se reflejará inmediatamente en las capas del Decodificador correspondientes. Es una forma bastante cómoda de sincronizar la descripción de las arquitecturas de las capas neuronales, y puede aplicarse en varios casos.
Tras crear la descripción de la arquitectura del modelo, pasaremos a organizar el proceso de recopilación de la base de datos de ejemplos para el entrenamiento del modelo. Al igual que antes, este proceso se organizará en el asesor experto "...\BAC\Research.mq5". Debemos decir que el método BAC no introduce ningún cambio en el algoritmo de recogida de datos primarios. Por lo tanto, los cambios en este asesor han sido mínimos.
Más arriba, hemos modificado la función de descripción de la arquitectura del modelo para añadir la descripción del autocodificador. En consecuencia, al llamar a esta función en el método OnInit del asesor Research.mq5, necesitaremos transmitir los 3 punteros a los arrays dinámicos de descripción de la arquitectura del modelo. Pero como en este asesor usaremos solo un Actor y no necesitaremos la descripción de otros modelos, no crearemos un array adicional de objetos, sino que indicaremos dos veces el puntero del array de descripción de la arquitectura del Crítico. Esta llamada a la función creará primero una descripción de la arquitectura del Crítico, después esta se borrará y la arquitectura del autocodificador se escribirá en el array. Esto no resulta esencial para nosotros en este caso, ya que no se utiliza ni el modelo del Crítico ni el modelo de autocodificador.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Además, excluiremos el componente de entropía de la función de recompensa. En todo lo demás, el código del asesor permanecerá igual. El lector encontrará el código completo del asesor experto y todas sus funciones en el archivo adjunto.
En cambio, con el código del asesor de entrenamiento de modelos "..\BAC\Study.mq5", hemos tenido que trabajar un poco más. Aquí es donde utilizaremos e inicializaremos todos los modelos. Por consiguiente, antes de llamar al método de creación de la descripción de la arquitectura del modelo, crearemos un array dinámico adicional para el autocodificador.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Autoencoder.Load(FileName + "AEnc.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *autoencoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
Una vez obtenida la arquitectura del modelo, inicializaremos todos los modelos y controlaremos el proceso de las operaciones,
if(!Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Autoencoder.Create(autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
sin olvidarnos de los modelos objetivo de los críticos.
if(!TargetCritic1.Create(critic) || !TargetCritic2.Create(critic)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; } delete actor; delete critic; delete autoencoder; //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1.0f); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1.0f); }
Después, deberemos asegurarnos de trasladar todos los modelos a un contexto OpenCL. El autocodificador no será una excepción.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Autoencoder.SetOpenCL(OpenCL);
A continuación viene el bloque para comprobar la adecuación del modelo.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Y aquí añadiremos una comprobación de la coherencia entre las arquitecturas del autocodificador y el Crítico.
Critic1.GetLayerOutput(1, Result); latent_state = Result.Total(); Autoencoder.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Autoencoder doesn't match latent state Critic (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Al final del método, inicializaremos el búfer auxiliar como antes y llamaremos al evento de entrenamiento del modelo.
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Creo que se habrá dado cuenta de que no hemos creado un modelo adicional para evaluar la calidad de la acción para la función de cálculo dinámico del coeficiente de temperatura. Por algo hemos destacado que la funcionalidad de este modelo resulta similar a la del trabajo del Crítico. Y para simplificar el proceso global de entrenamiento, utilizaremos los modelos de nuestros críticos en la implementación del cálculo dinámico del coeficiente de temperatura.
Después de crear los modelos, no deberemos olvidarnos de guardar los modelos entrenados en el método de desinicialización del asesor OnDeinit. Aquí nos centraremos en el almacenamiento de todos los modelos, así como en los sufijos de los nombres de los archivos al realizar el guardado y los nombres especificados al cargar los modelos correspondientes.
void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Autoencoder.Save(FileName + "AEnc.nnw", Autoencoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
Con esto, podemos dar por concluido el trabajo preparatorio y podemos proceder a implementar el algoritmo de entrenamiento directo de modelos en el método Train de nuestro asesor.
Al principio del método, no nos llevaremos sorpresas. Como antes, organizaremos un ciclo de entrenamiento con el número de iteraciones especificado en los parámetros externos del asesor.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
En el cuerpo del ciclo, definiremos aleatoriamente la trayectoria de la base de datos de ejemplos y el paso de trayectoria específico. A continuación, cargaremos la información de estado posterior en los búferes de datos,
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
y realizaremos una pasada directa de los modelos del Actor y los 2 modelos objetivo del Crítico para determinar el valor del estado futuro dada la estrategia actualizada del Actor.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1]);
A primera vista, todo resulta igual que en el algoritmo SAC. También utilizaremos la puntuación mínima del estado entre las obtenidas de los 2 Críticos, pero tenga en cuenta que hemos excluido el componente entrópico, cosa que tiene sentido si consideramos el uso del método BAC. Sin embargo, no hemos añadido un componente de conducta. Se trata de una desviación deliberada respecto al algoritmo original. La cuestión es que estamos usando una base de datos de ejemplos obtenida de las pasadas de Actores con diferentes políticas, y la introducción de un componente de conducta ahora sesgará la evaluación del Crítico, pero no incentivará directamente al Actor. Sí, posteriormente obtendremos una estimulación indirecta del Actor al entrenarlo con las evaluaciones del Crítico, pero existe un reverso de la moneda, a saber: la correspondencia entre el número de veces que se utiliza la pareja "Estado-Acción" al entrenar al Crítico y una pareja "Estado-Acción" igual o similar (cercana) al entrenar el Actor. El desequilibrio puede darse en ambas direcciones. Por lo tanto, hemos decidido utilizar el Autocodificador para evaluar los estados y las acciones al entrenar al Actor. A nuestro juicio, esto permitirá una evaluación más precisa de la frecuencia de las visitas a los estados y de las acciones utilizadas por el Actor, considerando la actualización de su política de conducta.
El siguiente paso será el proceso de entrenamiento de los Críticos. Ahora cargaremos los datos del estado seleccionado de la base de datos de ejemplos en los búferes de datos,
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); Account.BufferWrite();
después de lo cual realizaremos una pasada directa del Actor. Recordemos que en este caso la utilizaremos para preprocesar los datos de origen del estado del entorno.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A continuación, deberemos realizar una pasada directa e inversa de los Críticos para ajustar sus parámetros. Al entrenar los modelos con el método SAC, utilizaremos la alternación de modelos. En este caso, entrenaremos ambos Críticos en paralelo usando los mismos ejemplos. Luego llamaremos los métodos de pasada directa de los Críticos para las acciones de la base de datos de ejemplos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Pero antes de realizar la pasada inversa, prepararemos los datos para calcular el coeficiente de temperatura del componente de conducta de nuestra función de recompensa. Primero compararemos los resultados de la primera evaluación del Crítico con la estimación del estado futuro calculada anteriormente y actualizaremos los valores de error mínimo, máximo y medio.
Observe que para la primera iteración, simplemente trasladaremos el error actual a las 3 variables, y luego actualizaremos el máximo y el mínimo según los resultados de la comparación. A continuación, consideraremos la media exponencial.
Critic1.getResults(Result); float error = reward - Result[0]; if(iter == 0) { MaxCriticError = error; MinCriticError = error; AvgCriticError = error; } else { MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error; }
Para el segundo Crítico, ya tenemos los valores iniciales de las variables, por lo que actualizaremos sus valores independientemente de la iteración de entrenamiento del modelo.
Critic2.getResults(Result); error = reward - Result[0]; MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error;
Al final del proceso de actualización de los parámetros del Crítico, nos quedará una pasada inversa de ambos modelos con la estimación mínima del estado futuro de los modelos objetivo como valor de referencia.
Result.Update(0, reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Con esto concluye el proceso de actualización de los parámetros de los críticos, y podemos pasar al entrenamiento de los Actores. A la hora de entrenar al Actor, los autores del método BAC recomiendan el uso de un Crítico con una evaluación mínima de la acción elegida. Para no realizar una pasada directa de los 2 Críticos y luego comparar sus resultados, haremos las cosas de forma un poco diferente. Tomaremos el Crítico con el mínimo error medio de predicción de la estimación del estado y la acción. Este valor se estimará nuevamente con cada pasada inversa del modelo del Crítico, y su recuperación requerirá un coste mínimo, insignificante en comparación con la realización de una pasada directa del modelo.
Y para no crear estructuras complejas de ramificación con repetición de las acciones para uno y otro modelo del Crítico, simplemente guardaremos el puntero al modelo necesario en una variable local, trabajando además con esta variable local.
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
A diferencia del TD3, los métodos Actor-Crítico actualizan la política del Actor en cada iteración, así que utilizaremos el mismo conjunto de entradas que elegimos para entrenar a los Críticos. Recordemos que en el entrenamiento del Crítico ya hemos realizado una pasada directa del Actor con el conjunto actual de datos de entrada. Por lo tanto, ahora nos bastará con realizar una pasada directa del Crítico seleccionado para evaluar las acciones del Actor en el estado actual dada su actualización de la política.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Autoencoder.feedForward(critic, 1, NULL, -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Tras realizar una pasada directa del Crítico, efectuaremos una pasada directa del Autocodificador. Y aquí hay un momento sutil: la cuestión es que antes, al vincular los 2 modelos en una única entidad, añadimos al método de pasada directa la sustitución de la capa de datos de origen del modelo posterior por un puntero de la capa latente del modelo que ofrece esos datos fuente. Y funciona muy bien cuando usamos un Actor como donante para los 2 Críticos. En la primera iteración, los Críticos eliminan la capa de datos de origen innecesaria y mantienen el puntero a la capa de estado latente del Actor, pero en el caso de Autocodificador se da la situación contraria: utilizaremos 2 modelos del Crítico como donante para el Autocodificador, y en la primera iteración, el Autocodificador eliminará la capa de datos de origen innecesaria y almacenará el puntero a la capa latente del Crítico utilizado. No obstante, al cambiarse el Crítico, se borrará la capa del mismo y se conservará el puntero a la capa del otro Crítico. Y un proceso así resulta totalmente indeseable. Además, perturba todo nuestro proceso de entrenamiento. Por consiguiente, tras eliminar por primera vez la capa de datos de origen, tendremos que desactivar la bandera de eliminación de objetos al actualizar el array de capa neuronal.
bool CNet::feedForward(CNet *inputNet, int inputLayer = -1, CNet *secondNet = NULL, int secondLayer = -1) { ........ ........ //--- if(layer.At(0) != neuron) if(!layer.Update(0, neuron)) { if(del_second) delete second; return false; } else layer.FreeMode(false); //--- ........ ........ //--- return true; }
Sí, se trata de una ligera desviación del proceso de aprendizaje y del algoritmo BAC, pero resulta fundamental para implementar la construcción del proceso.
Volvamos ahora al algoritmo de nuestro método de entrenamiento de modelos Train. Tras realizar una pasada directa del Autocodificador, deberemos estimar el error de copiado de datos. Para ello, cargaremos el resultado del Autocodificador y los datos de origen del estado latente del Crítico. Para aumentar la eficiencia de nuestro código, utilizaremos variables vectoriales, en las que cargaremos ambos búferes de datos,
Autoencoder.getResults(AutoencoderResult);
critic.GetLayerOutput(1, Result);
Result.GetData(CriticResult);
y luego cargaremos los resultados de la evaluación de las acciones por parte del Crítico.
critic.getResults(Result);
Necesitaremos ambos flujos de información para determinar el valor objetivo al entrenar la política del Actor. Por ello, combinaremos todo el cálculo en un solo bloque.
Antes hemos preparado los datos para calcular el coeficiente de temperatura, y ahora calcularemos primero el argumento de la sigmoide. A continuación, determinaremos el valor de la función y lo restaremos a "1".
float alpha = (MaxCriticError == MinCriticError ? 0 : 10.0f * (AvgCriticError - MinCriticError) / (MaxCriticError - MinCriticError)); alpha = 1.0f / (1.0f + MathExp(-alpha)); alpha = 1 - alpha; reward = Result[0]; reward = (reward > 0 ? reward + PoliticAdjust : PoliticAdjust); reward += AutoencoderResult.Loss(CriticResult, LOSS_MSE) * alpha;
Además, de forma similar a los planteamientos del DT3, desplazaremos los parámetros del Actor hacia el aumento de la rentabilidad de las operaciones. Por lo tanto, añadiremos una pequeña constante a la estimación actual de la acción para incentivar a los gradientes a desplazarse hacia un aumento de la rentabilidad.
Y al final de la formación del valor objetivo añadiremos el componente de conducta considerando la función de pérdida del Autocodificador. Observe que gracias a las operaciones vectoriales, el tamaño de la función de pérdida, independientemente del tamaño de los búferes de datos, se determinará literalmente en una línea.
Ahora, tras formar el valor objetivo, podremos realizar una pasada inversa del Crítico y el Actor para distribuir el gradiente de error hasta la acción y luego ajustar los parámetros del Actor.
Al igual que antes, para evitar el ajuste mutuo de los parámetros del Crítico y del Actor, desactivaremos el modo de entrenamiento del Crítico antes de realizar la pasada inversa, sin olvidarnos de volver a activarlo después de las operaciones.
Result.Update(0, reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Aquí deberemos tener en cuenta que estamos realizando 2 tipos de pasada inversa para el Actor. Primero distribuiremos el gradiente de error en el bloque de preprocesamiento de datos, lo cual nos permitirá afinar más los filtros de la capa de convolución para cumplir los requisitos de los Críticos. Y luego realizaremos una pasada inversa para ajustar el bloque de decisión para elegir una acción concreta. Resulta esencial realizar las operaciones en el orden de esta secuencia, puesto que, después de una pasada inversa completa con los ajustes en los parámetros del bloque de decisión, los gradientes de error para el bloque de preprocesamiento de datos también se reescribirán. Y en tal caso, la ejecución de una pasada directa adicional no solo no tendrá ningún efecto positivo, sino más bien lo contrario.
En este punto, hemos actualizado los parámetros del Crítico y el Actor. Ahora nos queda actualizar los parámetros del Autocodificador. Aquí todo resultará bastante sencillo. Así, transmitiremos los datos del estado latente del Crítico como valores de referencia y realizaremos una pasada inversa del modelo.
//--- Autoencoder study Result.AssignArray(CriticResult); if(!Autoencoder.backProp(Result, critic, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Al final de las iteraciones del ciclo de entrenamiento, actualizaremos los modelos objetivo de ambos Críticos e informamos al usuario del progreso del aprendizaje.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
El final del método de entrenamiento será el clásico:
- borramos el campo de comentarios,
- mostramos los resultados del entrenamiento,
- inicializamos la finalización del asesor experto.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
El código completo del asesor de entrenamiento y todos los programas utilizados figuran en los anexos. Allí también encontrará el código del asesor de prueba, que prácticamente no ha cambiado desde el último artículo. En el código del asesor, solo se ha eliminado el componente de entropía, mientras que se ha conservado la trayectoria recorrida.
Con esto, damos por finalizado el trabajo de construcción de los asesores expertos, y podemos pasar a probar el trabajo realizado y entrenar los modelos.
Debo decir que, a mi parecer, este trabajo ha resultado tener un número bastante grande de iteraciones de intercambio de datos entre la memoria principal y el contexto OpenCL. Esto resulta evidente en el bloque de definición del componente conductual de la función de recompensa: hay mucho en lo que pensar. Pero veamos antes cómo afecta esto al rendimiento general del proceso de entrenamiento del modelo.
3. Simulación
Hoy hemos trabajado bastante en la implementación del algoritmo BAC, y ahora es el momento de ver el resultado de nuestros esfuerzos. Al igual que antes, el entrenamiento de los modelos se ha realizado con datos históricos de EURUSD, marco temporal H1, en un intervalo temporal que abarca los primeros 5 meses de 2023. Todos los parámetros de los indicadores se usan por defecto. El balance inicial es de 10000 USD.
En la primera fase, hemos creado una muestra de entrenamiento de 300 pasadas aleatorias, lo que ha dado lugar a más de 750 000 conjuntos de datos individuales "Estado → Acción → Nuevo Estado → Recompensa". Hago hincapié en las palabras "pasadas aleatorias". En esta fase, no disponemos de un modelo pre-entrenado, y con cada pasada en el simulador de estrategias, el asesor experto "..\BAC\Research.mq5" generará un nuevo modelo y lo rellenará con parámetros aleatorios. Por consiguiente, el rendimiento de estos modelos será tan aleatorio como sus parámetros. En esta fase, no he restringido el nivel de rendimiento mínimo de la pasada para guardar en la base de datos de ejemplos.
Tras recopilar los ejemplos, realizamos el entrenamiento inicial de nuestro modelo. Para ello, ejecutamos el asesor experto "..\BAC\Study.mq5" durante 500000 iteraciones de entrenamiento para el modelo.
Tengo que decir que tras el entrenamiento inicial del modelo, la estocasticidad de la política del Actor ha resultado bastante fuerte. Esto se refleja en la gran variación de los resultados de algunas pasadas individuales.
En la segunda etapa, volvemos a ejecutar el asesor experto para recopilar los datos de entrenamiento en el modo de optimización del simulador de estrategias durante 300 iteraciones con búsqueda completa de parámetros. Esta vez limitaremos el nivel mínimo de rentabilidad al nivel de rentabilidad positiva (0 o ligeramente superior). Como resultado, se ha añadido un número relativamente pequeño de resultados. Literalmente 15-20 pasadas.
Tenga en cuenta al ejecutarse el asesor de recopilación de datos tras el entrenamiento inicial, se utiliza un único modelo pre-entrenado para todas las pasadas, y toda la variación de los resultados se debe a la estocasticidad de la política del Actor.
A continuación, volvemos a ejecutar el proceso de entrenamiento del modelo para las mismas 500000 iteraciones.
El proceso de recopilación de ejemplos y entrenamiento del modelo se repetirá varias veces hasta que se obtenga el resultado deseado o se alcance un mínimo local, cuando la siguiente iteración de recopilación de ejemplos y entrenamiento del modelo no producirá avances.
Cabe señalar que cuando se vuelve a ejecutar el asesor de recopilación de bases de ejemplos, no se borran las pasadas recogidas anteriormente, y las nuevas se añaden al final del archivo. Pero para evitar que se acumule una base de ejemplos demasiado grande, hemos añadido la constante MaxReplayBuffer en el archivo "..\BAC\Trajectory.mqh". Esta constante define el número máximo de pasadas (no el tamaño del archivo), y a medida que el búfer se rellene, se borrarán las pasadas más antiguas. Le recomiendo que use esta constante para ajustar el tamaño de la base de ejemplos según las capacidades técnicas de su equipo.
#define MaxReplayBuffer 500
Tras unas 7 iteraciones de actualización de la base de datos de ejemplos y entrenamiento del modelo, hemos logrado que el modelo sea capaz de generar beneficios en el horizonte temporal del entrenamiento. El gráfico muestra claramente una tendencia al alza en el crecimiento del capital. Sin embargo, existen algunas zonas poco rentables.


Durante los 5 meses del periodo de estudio, el asesor experto ha obtenido un 16% de beneficios con una reducción máxima del 8,41% sobre la equidad, mientras que en el balance, la reducción ha sido un poco inferior, del 6,68%. En total se han realizado 99 transacciones, de las cuales un 51,5% se ha cerrado con beneficios. El número de transacciones rentables es casi igual al número de transacciones perdedoras, pero la media de transacciones rentables es casi un 50% superior a la media de transacciones perdedoras. El factor de beneficio ha sido de 1,53 y el factor de recuperación se ha situado casi al mismo nivel,
pero estamos entrenando el modelo para poder utilizarlo en el futuro, no solo en el simulador de estrategias. Por lo tanto, resulta más importante que probemos el modelo con datos ajenos a la muestra de entrenamiento. Así, hemos realizado una prueba del mismo modelo con los datos históricos de junio de 2023. Todos los demás parámetros de la prueba han permanecido inalterados.


Debemos decir que los resultados de la prueba del modelo con los nuevos datos son comparables a los de la muestra de entrenamiento. En 1 mes el asesor ha obtenido algo más de un 3% de beneficios, lo cual resulta comparable al 16% en 5 meses de la muestra de entrenamiento. Se han realizado 11 transacciones, lo cual resulta inferior al indicador correspondiente en la muestra de entrenamiento. Lamentablemente, la proporción de transacciones rentables también es inferior a la proporción de la muestra de entrenamiento, constituyendo apenas un 36,4%. Sin embargo, la media de transacciones rentables es casi 6 veces superior a la media de transacciones perdedoras. Esto ha aumentado el factor de beneficio a 3,12.
Conclusión
En este artículo, hemos introducido otro algoritmo para entrenar modelos de Actor-Crítico guiados por la conducta. Al igual que el método SAC, pertenece a la gran familia de algoritmos Actor-Crítico y supone una alternativa al uso del método Soft Actor-Critic. Las ventajas del algoritmo analizado incluyen la capacidad de entrenar modelos tanto estocásticos como deterministas en un espacio continuo de acciones. El uso de este método no conlleva ninguna limitación en la construcción de los modelos entrenados.
En la parte práctica de este artículo, hemos implementado el algoritmo propuesto utilizando herramientas MQL5, y los resultados de las pruebas confirman la eficacia de nuestra aplicación.
Sin embargo, una vez más, todos los programas presentados solo demuestran la posibilidad de utilizar la tecnología, y no están preparados para utilizarse en mercados financieros reales. Antes de utilizarlos, deberemos perfeccionar los asesores expertos y realizar pruebas exhaustivas adicionales.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13024
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Gracias Señor @Dmitriy
//+------------------------------------------------------------------+
Hola a todos. Tengo esta versión después de unos 3-4 ciclos (colección de base de datos - formación - prueba) comenzó a dar sólo una línea recta en las pruebas. Las ofertas no se abren. Formación hizo todas las veces 500 000 iteraciones. Otro punto interesante - en un momento dado el error de uno de los críticos se hizo muy grande al principio, y luego poco a poco los errores de ambos críticos disminuyó a 0. Y durante 2-3 ciclos de los errores de ambos críticos están en 0. Y en las pruebas Test.mqh da una línea recta y no hay ofertas. En los pases de Research.mqh hay pases con ganancias y tratos negativos. También hay pases sin tratos y resultado cero. Sólo hubo 5 pases con resultado positivo en uno de los ciclos.
En general, es extraño. He estado entrenando estrictamente de acuerdo con las instrucciones de Dmitry en todos los artículos, y no he sido capaz de obtener un resultado de cualquier artículo. No entiendo lo que hago mal....
Nuevo artículo Neural networks made easy (Part 51): behavioural actor-criticism (BAC ) ha sido publicado:
Autor: Dmitriy Gizlyk
He descargado la carpeta comprimida, pero dentro había muchas otras carpetas.
Si es posible me gustaría que me explicaras como desplegar y entrenar.
Enhorabuena por el gran trabajo.
Muchas gracias