
Aprendizaje automático y Data Science (Parte 32): Mantener actualizados los modelos de IA, aprendizaje en línea

Contenido
- ¿Qué es el aprendizaje en línea?
- Ventajas del aprendizaje en línea
- Infraestructura de aprendizaje en línea para MetaTrader 5
- Automatización del proceso de formación y despliegue
- Aprendizaje en línea para modelos de IA de aprendizaje profundo
- Aprendizaje automático incremental
- Conclusión
¿Qué es el aprendizaje en línea?
El aprendizaje automático en línea es un método de aprendizaje automático en el que el modelo aprende de forma incremental a partir de un flujo de puntos de datos en tiempo real. Es un proceso dinámico que adapta su algoritmo predictivo a lo largo del tiempo, lo que permite que el modelo cambie a medida que llegan nuevos datos. Este método es increíblemente significativo en entornos ricos en datos que evolucionan rápidamente, como los datos comerciales, ya que puede proporcionar predicciones oportunas y precisas.
Al trabajar con datos comerciales, siempre es difícil determinar el momento adecuado para actualizar sus modelos y con qué frecuencia; por ejemplo, si tiene modelos de IA entrenados en Bitcoin durante el último año, la información reciente podría resultar ser valores atípicos para un modelo de aprendizaje automático considerando que esta criptomoneda alcanzó su nuevo precio más alto la semana pasada.
A diferencia de los instrumentos de divisas, que suelen subir y bajar dentro de rangos específicos históricamente, instrumentos como el NASDAQ 100, el S&P 500 y otros de su tipo, así como las acciones, suelen tender a aumentar y alcanzar nuevos valores máximos.
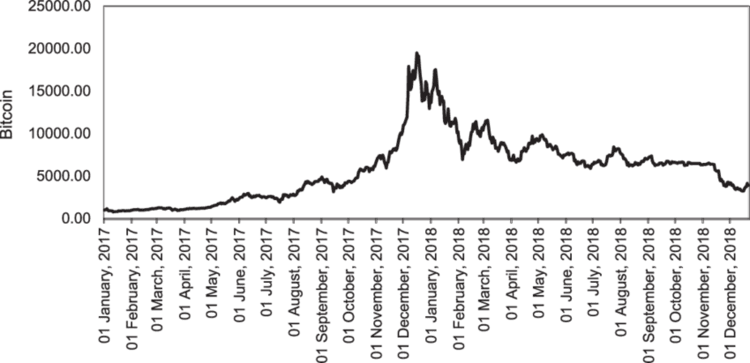
El aprendizaje en línea no solo se debe al temor de que la información de formación antigua quede obsoleta, sino también a la necesidad de mantener el modelo actualizado con información reciente que pueda tener algún impacto en lo que está sucediendo actualmente en el mercado.
Ventajas del aprendizaje en línea
- Adaptabilidad
Al igual que los ciclistas aprenden sobre la marcha, el aprendizaje automático en línea puede adaptarse a nuevos patrones en los datos, lo que puede mejorar su rendimiento con el tiempo. - Escalabilidad
Algunos métodos de aprendizaje en línea para algunos modelos procesan los datos de uno en uno. Esto hace que esta técnica sea más segura para los recursos computacionales limitados con los que contamos la mayoría de nosotros, lo que finalmente puede ayudar a escalar modelos que dependen de big data. - Predicciones en tiempo real
A diferencia del aprendizaje por lotes, que puede quedar obsoleto en el momento de su implementación, el aprendizaje en línea proporciona información en tiempo real que puede ser fundamental en muchas aplicaciones comerciales. - Eficiencia
El aprendizaje automático incremental permite el aprendizaje y la actualización continuos de los modelos, lo que puede dar lugar a un proceso de formación más rápido y rentable.
Ahora que comprendemos varias ventajas de esta técnica, veamos la infraestructura necesaria para que el aprendizaje en línea en MetaTrader 5 sea eficaz.
Infraestructura de aprendizaje en línea para MetaTrader 5
Infraestructura de aprendizaje en línea para MetaTrader 5

Paso 1: Cliente Python
Dentro de un cliente Python (script) es donde queremos crear modelos de IA basados en los datos de trading recibidos de MetaTrader 5.
Utilizando MetaTrader 5 (biblioteca Python), comenzamos inicializando la plataforma.
import pandas as pd import numpy as np import MetaTrader5 as mt5 from datetime import datetime if not mt5.initialize(): # Initialize the MetaTrader 5 platform print("initialize() failed") mt5.shutdown()
Tras la inicialización de la plataforma MetaTrader 5, podemos obtener información comercial de ella utilizando el método copy_rates_from_pos.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) if len(rates) < bars: # if the received information is less than specified print("Failed to copy rates from MetaTrader 5, error = ",mt5.last_error()) # create a pnadas DataFrame out of the obtained data df_rates = pd.DataFrame(rates) return df_rates
Podemos imprimir para ver la información obtenida.
print("Trading info:\n",getData(1, 100)) # get 100 bars starting at the recent closed bar
Salidas
time open high low close tick_volume spread real_volume 0 1731351600 1.06520 1.06564 1.06451 1.06491 1688 0 0 1 1731355200 1.06491 1.06519 1.06460 1.06505 1607 0 0 2 1731358800 1.06505 1.06573 1.06495 1.06512 1157 0 0 3 1731362400 1.06512 1.06564 1.06512 1.06557 1112 0 0 4 1731366000 1.06557 1.06579 1.06553 1.06557 776 0 0 .. ... ... ... ... ... ... ... ... 95 1731693600 1.05354 1.05516 1.05333 1.05513 5125 0 0 96 1731697200 1.05513 1.05600 1.05472 1.05486 3966 0 0 97 1731700800 1.05487 1.05547 1.05386 1.05515 2919 0 0 98 1731704400 1.05515 1.05522 1.05359 1.05372 2651 0 0 99 1731708000 1.05372 1.05379 1.05164 1.05279 2977 0 0 [100 rows x 8 columns]
Utilizamos el método copy_rates_from_pos, ya que nos permite acceder a la barra cerrada recientemente situada en el índice 1, lo cual resulta muy útil en comparación con el acceso mediante fechas fijas.
Siempre podemos estar seguros de que al copiar desde la barra situada en el índice 1, obtendremos la información que comienza en la barra recientemente cerrada hasta el número específico de barras que deseemos.
Después de recibir esta información, podemos realizar las tareas típicas de aprendizaje automático para estos datos.
Creamos un archivo independiente para nuestro modelo. Al colocar cada modelo en su propio archivo, facilitamos la llamada a estos modelos en el archivo «main.py», donde se implementan todos los procesos y funciones clave.
Archivo catboost_models.py
from catboost import CatBoostClassifier from sklearn.metrics import accuracy_score from onnx.helper import get_attribute_value from skl2onnx import convert_sklearn, update_registered_converter from sklearn.pipeline import Pipeline from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost.utils import convert_to_onnx_object # Example initial data (X_initial, y_initial are your initial feature matrix and target) class CatBoostClassifierModel(): def __init__(self, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None def train(self, iterations=100, depth=6, learning_rate=0.1, loss_function="CrossEntropy", use_best_model=True): # Initialize the CatBoost model params = { "iterations": iterations, "depth": depth, "learning_rate": learning_rate, "loss_function": loss_function, "use_best_model": use_best_model } self.model = Pipeline([ # wrap a catboost classifier in sklearn pipeline | good practice (not necessary tho :)) ("catboost", CatBoostClassifier(**params)) ]) # Testing the model self.model.fit(X=self.X_train, y=self.y_train, catboost__eval_set=(self.X_test, self.y_test)) y_pred = self.model.predict(self.X_test) print("Model's accuracy on out-of-sample data = ",accuracy_score(self.y_test, y_pred)) # a function for saving the trained CatBoost model to ONNX format def to_onnx(self, model_name): update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, self.skl2onnx_convert_catboost, parser=self.skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( self.model, "pipeline_catboost", [("input", FloatTensorType([None, self.X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(model_name, "wb") as f: f.write(model_onnx.SerializeToString())
Para obtener más información sobre este modelo CatBoost implementado, consulte este artículo. He utilizado el modelo CatBoost como ejemplo, pero puede utilizar cualquiera de sus modelos preferidos.
Ahora que tenemos esta clase para ayudarnos con la inicialización, el entrenamiento y el almacenamiento del modelo CatBoost. Implementemos este modelo en el archivo «main.py».
Archivo main.py
Una vez más, comenzamos recibiendo los datos de la aplicación de escritorio MetaTrader 5.
data = getData(start=1, bars=1000)
Si observas detenidamente el modelo CatBoost, verás que se trata de un modelo clasificador. Aún no tenemos la variable objetivo para este clasificador, creemos una.
# Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows
Podemos eliminar todas las variables futuras y otras características con muchos valores cero de la matriz X 2D, y asignar la variable «target» a la matriz y 1D.
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"]
A continuación, dividimos la información en muestras de entrenamiento y validación, inicializamos el modelo CatBoost con los datos del mercado y lo entrenamos.
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train()
Por último, guardamos este modelo en formato ONNX en un directorio común de MetaTrader 5.
Paso 2: Carpeta común (Common)
Utilizando MetaTrader 5 Python, podemos obtener la información en la ruta común.
terminal_info_dict = mt5.terminal_info()._asdict()
common_path = terminal_info_dict["commondata_path"] Aquí es donde queremos guardar todos los modelos de IA entrenados de este cliente Python que tenemos.
Al acceder a la carpeta común mediante MQL5, normalmente se hace referencia a una subcarpeta «Files» que se encuentra dentro de la carpeta común (Common). Para facilitar el acceso a estos archivos desde MQL5, debemos guardar los modelos en esa subcarpeta.
# Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Por último, tenemos que agrupar todas estas líneas de código en una sola función para que sea más fácil llevar a cabo todos estos procesos diferentes cuando queramos.
def trainAndSaveCatBoost(): data = getData(start=1, bars=1000) # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() # Preparing the target variable data["future_open"] = data["open"].shift(-1) # shift one bar into the future data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: # bullish signal target.append(1) else: # bearish signal target.append(0) data["target"] = target # add the target variable to the dataframe data = data.dropna() # drop empty rows X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) catboost_model = catboost_models.CatBoostClassifierModel(X_train, X_test, y_train, y_test) catboost_model.train() # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist catboost_model.to_onnx(model_name=os.path.join(models_path, "catboost.H1.onnx"))
Llamemos a esta función y veamos qué hace.
trainAndSaveCatBoost()
exit() # stop the script Resultado:
0: learn: 0.6916088 test: 0.6934968 best: 0.6934968 (0) total: 163ms remaining: 16.1s 1: learn: 0.6901684 test: 0.6936087 best: 0.6934968 (0) total: 168ms remaining: 8.22s 2: learn: 0.6888965 test: 0.6931576 best: 0.6931576 (2) total: 175ms remaining: 5.65s 3: learn: 0.6856524 test: 0.6927187 best: 0.6927187 (3) total: 184ms remaining: 4.41s 4: learn: 0.6843646 test: 0.6927737 best: 0.6927187 (3) total: 196ms remaining: 3.72s ... ... ... 96: learn: 0.5992419 test: 0.6995323 best: 0.6927187 (3) total: 915ms remaining: 28.3ms 97: learn: 0.5985751 test: 0.7002011 best: 0.6927187 (3) total: 924ms remaining: 18.9ms 98: learn: 0.5978617 test: 0.7003299 best: 0.6927187 (3) total: 928ms remaining: 9.37ms 99: learn: 0.5968786 test: 0.7010596 best: 0.6927187 (3) total: 932ms remaining: 0us bestTest = 0.6927187021 bestIteration = 3 Shrink model to first 4 iterations. Model's accuracy on out-of-sample data = 0.5
El archivo .onnx se puede ver en Common\Files.
Paso 3: MetaTrader 5
Ahora, en MetaTrader 5, tenemos que cargar este modelo guardado en formato ONNX.
Comenzamos importando la librería que nos ayudará con esta tarea.
Dentro de "Online Learning Catboost.mq5":
#include <CatBoost.mqh> CCatBoost *catboost; input string model_name = "catboost.H1.onnx"; input string symbol = "EURUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; string common_path;
Lo primero que queremos hacer dentro de la función Oninit es comprobar si el archivo existe en la carpeta común. Si no existe, esto podría indicar que el modelo no se ha entrenado.
A continuación, inicializamos el modelo ONNX pasando el indicador ONNX_COMMON_FOLDER para cargar explícitamente el modelo desde la carpeta común «Common».
int OnInit() { //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize a catboost model catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- }
Para utilizar este modelo cargado para realizar predicciones, podemos volver al script de Python y comprobar qué características se utilizaron para el entrenamiento después de que se eliminaran algunas.
Las mismas características y en el mismo orden deben recopilarse en MQL5.
Archivo de código Python «main.py».
X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] print(X.head())
Resultado:
time open high low close tick_volume 0 1726772400 1.11469 1.11584 1.11453 1.11556 3315 1 1726776000 1.11556 1.11615 1.11525 1.11606 2812 2 1726779600 1.11606 1.11680 1.11606 1.11656 2309 3 1726783200 1.11656 1.11668 1.11590 1.11622 2667 4 1726786800 1.11622 1.11644 1.11605 1.11615 1166
Ahora, obtengamos esta información dentro de la función OnTick y llamemos a la función predict_bin, que predice clases.
Esta función predecirá dos clases que se observaron en la variable objetivo que preparamos en el cliente Python. 0 (alcista), 1 (bajista).
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, 1, rates); //copy the recent closed bar information vector x = { (double)rates[0].time, rates[0].open, rates[0].high, rates[0].low, rates[0].close, (double)rates[0].tick_volume}; Comment(TimeCurrent(),"\nPredicted signal: ",catboost.predict_bin(x)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Resultado:
Automatización del proceso de formación y despliegue
Hemos podido entrenar e implementar el modelo en MetaTrader 5, pero esto no es lo que queremos, nuestro objetivo principal es automatizar todo el proceso.
Dentro del entorno virtual Python, tenemos que instalar la biblioteca schedule.
$ pip install schedule
Este pequeño módulo puede ayudar a programar cuándo queremos que se ejecute una función específica. Como ya hemos agrupado el código para recopilar datos, entrenar y guardar el modelo en una sola función, programemos esta función para que se ejecute cada minuto.
schedule.every(1).minute.do(trainAndSaveCatBoost) #schedule catboost training # Keep the script running to execute the scheduled tasks while True: schedule.run_pending() time.sleep(60) # Wait for 1 minute before checking again
Esta función de programación funciona de maravilla. :-)
En nuestro asesor experto principal, también programamos cuándo y con qué frecuencia nuestro EA debe cargar el modelo desde el directorio común, con lo que actualizamos eficazmente el modelo para nuestro robot de trading.
Podemos usar la función OnTimer, que también funciona a las mil maravillas.
int OnInit() { //--- Check if the model file exists .... //--- Initialize a catboost model .... //--- if (!EventSetTimer(60)) //Execute the OnTimer function after every 60 seconds { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- .... } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnTimer(void) { if (CheckPointer(catboost) != POINTER_INVALID) delete catboost; //--- Load the new model after deleting the prior one from memory catboost = new CCatBoost(); if (!catboost.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the catboost model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Resultado:
HO 0 13:14:00.648 Online Learning Catboost (EURUSD,D1) 2024.11.18 12:14 New model loaded FK 0 13:15:55.388 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:15 New model loaded JG 0 13:16:55.380 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:16 New model loaded MP 0 13:17:55.376 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:17 New model loaded JM 0 13:18:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:18 New model loaded PF 0 13:19:55.368 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:19 New model loaded CR 0 13:20:55.387 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:20 New model loaded NO 0 13:21:55.377 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:21 New model loaded LH 0 13:22:55.379 Online Learning Catboost (GBPUSD,H1) 2024.11.18 12:22 New model loaded
Ahora que hemos visto cómo se puede programar el proceso de entrenamiento y mantener los nuevos modelos sincronizados con el Asesor Experto en MetaTrader 5. Aunque el proceso es fácil de implementar para la mayoría de las técnicas de aprendizaje automático, puede resultar complicado cuando se trabaja con modelos de aprendizaje profundo, como las redes neuronales recurrentes (RNN), que no pueden incluirse en el proceso pipeline de Sklearn, lo que nos facilita el trabajo cuando utilizamos diversos modelos de aprendizaje automático.
Veamos cómo se puede aplicar esta técnica al trabajar con Gated Recurrent Unit (GRU), que es una forma especial de red neuronal recurrente.
Aprendizaje en línea para modelos de IA de aprendizaje profundo
En el cliente Python
Aplicamos los conceptos típicos del aprendizaje automático dentro de la clase GRUClassifier. Para obtener más información sobre GRU, consulte este artículo.
Después de entrenar el modelo, lo guardamos en ONNX, esta vez también guardamos la información del escalador estándar en archivos binarios, lo que nos ayudará más adelante a normalizar de forma similar los nuevos datos en MQL5 tal y como están actualmente en Python.
Archivo gru_models.py
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx class GRUClassifier(): def __init__(self, time_step, X_train, X_test, y_train, y_test): self.X_train = X_train self.X_test = X_test self.y_train = y_train self.y_test = y_test self.model = None self.time_step = time_step self.classes_in_y = np.unique(self.y_train) def train(self, learning_rate=0.001, layers=2, neurons = 50, activation="relu", batch_size=32, epochs=100, loss="binary_crossentropy", verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.X_train.shape[2]))) self.model.add(GRU(units=neurons, activation=activation)) # input layer for layer in range(layers): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=neurons, activation=activation)) self.model.add(Dropout(0.5)) self.model.add(Dense(units=len(self.classes_in_y), activation='softmax', name='output_layer')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=learning_rate) self.model.compile(optimizer=adam_optimizer, loss=loss, metrics=['accuracy']) early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.X_train, self.y_train, epochs=epochs, batch_size=batch_size, validation_data=(self.X_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.X_test, self.y_test, verbose=verbose) print("Gru accuracy on validation sample = ",val_accuracy) def to_onnx(self, model_name, standard_scaler): # Convert the Keras model to ONNX spec = (tf.TensorSpec((None, self.time_step, self.X_train.shape[2]), tf.float16, name="input"),) self.model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(model_name, "wb") as f: f.write(onnx_model.SerializeToString()) # Save the mean and scale parameters to binary files standard_scaler.mean_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_mean.bin") standard_scaler.scale_.tofile(f"{model_name.replace('.onnx','')}.standard_scaler_scale.bin")
Dentro del archivo «main.py», creamos una función responsable de todo lo que queremos que suceda con el modelo GRU.
def trainAndSaveGRU(): data = getData(start=1, bars=1000) # Preparing the target variable data["future_open"] = data["open"].shift(-1) data["future_close"] = data["close"].shift(-1) target = [] for row in range(data.shape[0]): if data["future_close"].iloc[row] > data["future_open"].iloc[row]: target.append(1) else: target.append(0) data["target"] = target data = data.dropna() # Check if we were able to receive some data if (len(data)<=0): print("Failed to obtain data from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = data.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = data["target"] X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, shuffle=False) ########### Preparing data for timeseries forecasting ############### time_step = 10 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) x_train_seq, y_train_seq = create_sequences(X_train, y_train, time_step) x_test_seq, y_test_seq = create_sequences(X_test, y_test, time_step) ###### One HOt encoding ####### y_train_encoded = to_categorical(y_train_seq) y_test_encoded = to_categorical(y_test_seq) gru = gru_models.GRUClassifier(time_step=time_step, X_train= x_train_seq, y_train= y_train_encoded, X_test= x_test_seq, y_test= y_test_encoded ) gru.train( batch_size=64, learning_rate=0.001, activation = "relu", epochs=1000, loss="binary_crossentropy", layers = 2, neurons = 50, verbose=1 ) # Save models in a specific location under the common parent folder models_path = os.path.join(common_path, "Files") if not os.path.exists(models_path): #if the folder exists os.makedirs(models_path) # Create the folder if it doesn't exist gru.to_onnx(model_name=os.path.join(models_path, "gru.H1.onnx"), standard_scaler=scaler)
Por último, podemos programar la frecuencia con la que se debe ejecutar la función trainAndSaveGRU, de forma similar a como lo hicimos con la función CatBoost.
schedule.every(1).minute.do(trainAndSaveGRU) #scheduled GRU training
Resultado:
Epoch 1/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 7s 87ms/step - accuracy: 0.4930 - loss: 0.6985 - val_accuracy: 0.5000 - val_loss: 0.6958 Epoch 2/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4847 - loss: 0.6957 - val_accuracy: 0.4931 - val_loss: 0.6936 Epoch 3/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5500 - loss: 0.6915 - val_accuracy: 0.4897 - val_loss: 0.6934 Epoch 4/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.4910 - loss: 0.6923 - val_accuracy: 0.4690 - val_loss: 0.6938 Epoch 5/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.5538 - loss: 0.6910 - val_accuracy: 0.4897 - val_loss: 0.6935 Epoch 6/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step - accuracy: 0.5037 - loss: 0.6953 - val_accuracy: 0.4931 - val_loss: 0.6937 Epoch 7/1000 ... ... ... 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step - accuracy: 0.4964 - loss: 0.6952 - val_accuracy: 0.4793 - val_loss: 0.6940 Epoch 20/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.5285 - loss: 0.6914 - val_accuracy: 0.4793 - val_loss: 0.6949 Epoch 21/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.5224 - loss: 0.6935 - val_accuracy: 0.4966 - val_loss: 0.6942 Epoch 22/1000 11/11 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step - accuracy: 0.5009 - loss: 0.6936 - val_accuracy: 0.5103 - val_loss: 0.6933 10/10 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step - accuracy: 0.4925 - loss: 0.6938 Gru accuracy on validation sample = 0.5103448033332825
En MetaTrader 5
Comenzamos cargando las bibliotecas que nos ayudarán con la tarea de cargar el modelo GRU y el escalador estándar.
#include <preprocessing.mqh> #include <GRU.mqh> CGRU *gru; StandardizationScaler *scaler; //--- Arrays for temporary storage of the scaler values double scaler_mean[], scaler_std[]; input string model_name = "gru.H1.onnx"; string mean_file; string std_file;
Lo primero que queremos hacer en la función OnInit es obtener los nombres de los archivos binarios del escalador, aplicamos este mismo principio al crear estos archivos.
string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin";
Por último, procedemos a cargar el modelo GRU en formato ONNX desde la carpeta común, también leemos los archivos escaladores en formato binario asignando sus valores en las matrices scaler_mean y scaler_std.
int OnInit() { string base_name__ = model_name; if (StringReplace(base_name__,".onnx","")<0) //we followed this same file patterns while saving the binary files in python client { printf("%s Failed to obtain the parent name for the scaler files, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } mean_file = base_name__ + ".standard_scaler_mean.bin"; std_file = base_name__ + ".standard_scaler_scale.bin"; //--- Check if the model file exists if (!FileIsExist(model_name, FILE_COMMON)) { printf("%s Onnx file doesn't exist",__FUNCTION__); return INIT_FAILED; } //--- Initialize the GRU model from the common folder gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Read the scaler files if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return INIT_FAILED; } scaler = new StandardizationScaler(scaler_mean, scaler_std); //Load the scaler class by populating it with values //--- Set the timer if (!EventSetTimer(60)) { printf("%s failed to set the event timer, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; }
Programamos el proceso de lectura de los archivos de escalador y modelo de la carpeta común en la función OnTimer.
void OnTimer(void) { //--- Delete the existing pointers in memory as the new ones are about to be created if (CheckPointer(gru) != POINTER_INVALID) delete gru; if (CheckPointer(scaler) != POINTER_INVALID) delete scaler; //--- if (!readArray(mean_file, scaler_mean) || !readArray(std_file, scaler_std)) { printf("%s failed to read scaler information",__FUNCTION__); return; } scaler = new StandardizationScaler(scaler_mean, scaler_std); gru = new CGRU(); if (!gru.Init(model_name, ONNX_COMMON_FOLDER)) { printf("%s failed to initialize the gru model, error = %d",__FUNCTION__,GetLastError()); return; } printf("%s New model loaded",TimeToString(TimeCurrent(), TIME_DATE|TIME_MINUTES)); }
Resultado:
II 0 14:49:35.920 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:49 New model loaded QP 0 14:50:35.886 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... MF 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) ONNX model Initialized IJ 0 14:50:35.919 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:50 New model loaded EN 0 14:51:35.894 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... JD 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) ONNX model Initialized EL 0 14:51:35.913 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:51 New model loaded NM 0 14:52:35.885 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... KK 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QQ 0 14:52:35.915 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:52 New model loaded DK 0 14:53:35.899 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... HI 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) ONNX model Initialized MS 0 14:53:35.935 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:53 New model loaded DI 0 14:54:35.885 Online Learning GRU (GBPUSD,H1) Initilaizing ONNX model... IL 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) ONNX model Initialized QE 0 14:54:35.908 Online Learning GRU (GBPUSD,H1) 2024.11.18 13:54 New model loaded
Para recibir las predicciones del modelo GRU, debemos tener en cuenta el valor del intervalo de tiempo, que ayuda a las redes neuronales recurrentes (RNN) a comprender las dependencias temporales en los datos.
Utilizamos un valor de intervalo de tiempo de diez (10) dentro de la función «trainAndSaveGRU».
def trainAndSaveGRU(): data = getData(start=1, bars=1000) .... .... time_step = 10
Recopilemos las últimas 10 barras (intervalos de tiempo) del historial a partir de la barra recientemente cerrada en MQL5. (así es como debe ser)
input int time_step = 10;
void OnTick() { //--- MqlRates rates[]; CopyRates(symbol, timeframe, 1, time_step, rates); //copy the recent closed bar information vector classes = {0,1}; //Beware of how classes are organized in the target variable. use numpy.unique(y) to determine this array matrix X = matrix::Zeros(time_step, 6); // 6 columns for (int i=0; i<time_step; i++) { vector row = { (double)rates[i].time, rates[i].open, rates[i].high, rates[i].low, rates[i].close, (double)rates[i].tick_volume}; X.Row(row, i); } X = scaler.transform(X); //it's important to normalize the data Comment(TimeCurrent(),"\nPredicted signal: ",gru.predict_bin(X, classes)==0?"Bearish":"Bullish");// if the predicted signal is 0 it means a bearish signal, otherwise it is a bullish signal }
Resultado:
Aprendizaje automático incremental
Algunos modelos son más eficaces y robustos que otros en lo que respecta a los métodos de entrenamiento. Cuando se busca «aprendizaje automático en línea» en Internet, la mayoría de la gente dice que es un proceso mediante el cual se vuelven a entrenar pequeños lotes de datos en el modelo con el fin de alcanzar un objetivo de entrenamiento mayor.
El problema es que muchos modelos no son compatibles o no funcionan bien cuando se les proporciona una muestra pequeña de datos.
Las técnicas modernas de aprendizaje automático, como CatBoost, se basan en el aprendizaje incremental. Este método de entrenamiento se puede utilizar para el aprendizaje en línea y puede ayudar a ahorrar mucha memoria cuando se trabaja con grandes volúmenes de datos, ya que estos se pueden dividir en pequeños fragmentos que se pueden volver a entrenar en el modelo inicial.
def getData(start = 1, bars = 1000): rates = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_H1, start, bars) df_rates = pd.DataFrame(rates) return df_rates def trainIncrementally(): # CatBoost model clf = CatBoostClassifier( task_type="CPU", iterations=2000, learning_rate=0.2, max_depth=1, verbose=0, ) # Get big data big_data = getData(1, 10000) # Split into chunks of 1000 samples chunk_size = 1000 chunks = [big_data[i:i + chunk_size].copy() for i in range(0, len(big_data), chunk_size)] # Use .copy() here for i, chunk in enumerate(chunks): # Preparing the target variable chunk["future_open"] = chunk["open"].shift(-1) chunk["future_close"] = chunk["close"].shift(-1) target = [] for row in range(chunk.shape[0]): if chunk["future_close"].iloc[row] > chunk["future_open"].iloc[row]: target.append(1) else: target.append(0) chunk["target"] = target chunk = chunk.dropna() # Check if we were able to receive some data if (len(chunk)<=0): print("Failed to obtain chunk from Metatrader5, error = ",mt5.last_error()) mt5.shutdown() X = chunk.drop(columns = ["spread","real_volume","future_close","future_open","target"]) y = chunk["target"] X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=0.8, random_state=42) if i == 0: # Initial training, training the model for the first time clf.fit(X_train, y_train, eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") else: # Incremental training by using the intial trained model clf.fit(X_train, y_train, init_model="model.cbm", eval_set=(X_val, y_val)) y_pred = clf.predict(X_val) print(f"---> Acc score: {accuracy_score(y_pred=y_pred, y_true=y_val)}") # Save the model clf.save_model("model.cbm") print(f"Chunk {i + 1}/{len(chunks)} processed and model saved.")
Resultado:
---> Acc score: 0.555 Chunk 1/10 processed and model saved. ---> Acc score: 0.505 Chunk 2/10 processed and model saved. ---> Acc score: 0.55 Chunk 3/10 processed and model saved. ---> Acc score: 0.565 Chunk 4/10 processed and model saved. ---> Acc score: 0.495 Chunk 5/10 processed and model saved. ---> Acc score: 0.55 Chunk 6/10 processed and model saved. ---> Acc score: 0.555 Chunk 7/10 processed and model saved. ---> Acc score: 0.52 Chunk 8/10 processed and model saved. ---> Acc score: 0.455 Chunk 9/10 processed and model saved. ---> Acc score: 0.535 Chunk 10/10 processed and model saved.
Puede seguir la misma arquitectura de aprendizaje en línea mientras construye el modelo de forma incremental y guardar el modelo final en formato ONNX en la carpeta «Common» (Común), para su uso en MetaTrader 5.
Reflexiones finales
El aprendizaje en línea es un enfoque excelente para mantener los modelos continuamente actualizados con una intervención manual mínima. Al implementar esta infraestructura, puede estar seguro de que sus modelos se mantendrán alineados con las últimas tendencias del mercado y se adaptarán rápidamente a la nueva información. Sin embargo, es importante señalar que el aprendizaje en línea a veces puede hacer que los modelos sean muy sensibles al orden en que se procesan los datos, por lo que a menudo puede ser necesaria la supervisión humana para verificar que el modelo y la información de entrenamiento tengan sentido lógico desde una perspectiva humana.Es necesario encontrar el equilibrio adecuado entre la automatización del proceso de aprendizaje y la evaluación periódica de los modelos para garantizar que todo funcione según lo previsto.
Tabla de archivos adjuntos
Infraestructura (Carpetas) | Archivos | Descripción y uso |
|---|---|---|
Cliente Python | - catboost_models.py - gru_models.py - main.py - incremental_learning.py | - En este archivo se puede encontrar un modelo CatBoost. - En este archivo se puede encontrar un modelo GRU. - El archivo Python principal para unir todo. - El aprendizaje incremental para el modelo CatBoost se implementa en este archivo. |
Carpeta común (Common) | - catboost.H1.onnx - gru.H1.onnx - gru.H1.standard_scaler_mean.bin - gru.H1.standard_scaler_scale.bin | Todos los modelos de IA en formato ONNX y los archivos escaladores en formatos binarios se pueden encontrar en esta carpeta. |
| MetaTrader 5 (MQL5) | - Experts\Online Learning Catboost.mq5 - Experts\Online Learning GRU.mq5 - Include\CatBoost.mqh - Include\GRU.mqh - Include\preprocessing.mqh | - Implementa un modelo CatBoost en MQL5. - Implementa un modelo GRU en MQL5. - Un archivo de biblioteca para inicializar e implementar un modelo CatBoost en formato ONNX. - Un archivo de biblioteca para inicializar e implementar un modelo GRU en formato ONNX. - Un archivo de biblioteca que contiene el escalador estándar para normalizar los datos para el uso del modelo ML. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16390
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola Omega J Msigwa
Te pregunte que versión de python estas usando para este articulo lo instale y hay un conflicto de librerías.
El conflicto es causado por:
El usuario pidió protobuf==3.20.3
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
Luego edité la versión como se sugiere y obtuve otro error de instalación.
Para solucionarlo podrías intentar
1. aflojar el rango de versiones de paquetes que ha especificado
2. eliminar versiones de paquetes para permitir que pip intente resolver el conflicto de dependencias
El conflicto es causado por:
El usuario solicitó protobuf==3.20.2
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
tensorboard 2.18.0 depende de protobuf!=4.24.0 y >=3.19.6
tensorflow-intel 2.18.0 depende de protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev y >=3.20.3
Para solucionar esto podrías intentar
1. aflojar el rango de versiones de paquetes que ha especificado
2. eliminar versiones de paquetes para permitir que pip intente resolver el conflicto de dependencias
Por favor, proporcione más instrucciones
Hola Omega J Msigwa
Te pregunte que versión de python estas usando para este articulo lo instale y hay un conflicto de librerías.
El conflicto es causado por:
El usuario solicitó protobuf==3.20.3
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
Luego edité la versión como se sugiere y obtuve otro error de instalación.
Para solucionar esto usted podría tratar de:
1. aflojar el rango de versiones de paquetes que has especificado
2. eliminar versiones de paquetes para permitir que pip intente
resolver el conflicto de dependencias
El conflicto está causado por:
El usuario solicitó protobuf==3.20.2
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
tensorboard 2.18.0 depende de protobuf!=4.24.0 y >=3.19.6
tensorflow-intel 2.18.0 depende de protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev y >=3.20.3
Para solucionarlo puedes intentar
1. aflojar el rango de versiones de paquetes que has especificado
2. eliminar versiones de paquetes para permitir que pip intente resolver el conflicto de dependencias
Por favor, proporcione más instrucciones
Hola Omega J Msigwa
Te pregunte que versión de python estas usando para este articulo lo instale y hay un conflicto de librerías.
El conflicto es causado por:
El usuario solicitó protobuf==3.20.3
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
Luego edité la versión como se sugiere y obtuve otro error de instalación.
Para solucionar esto usted podría tratar de:
1. aflojar el rango de versiones de paquetes que has especificado
2. eliminar versiones de paquetes para permitir que pip intente resolver el conflicto de dependencias
El conflicto es causado por:
El usuario solicitó protobuf==3.20.2
onnx 1.17.0 depende de protobuf>=3.20.2
onnxconverter-common 1.14.0 depende de protobuf==3.20.2
tensorboard 2.18.0 depende de protobuf!=4.24.0 y >=3.19.6
tensorflow-intel 2.18.0 depende de protobuf!=4.21.0, !=4.21.1, !=4.21.2, !=4.21.3, !=4.21.4, !=4.21.5, <6.0.0dev y >=3.20.3
Para solucionarlo puedes intentar
1. aflojar el rango de versiones de paquetes que has especificado
2. eliminar versiones de paquetes para permitir que pip intente resolver el conflicto de dependencias
Por favor, proporcione más instrucciones
numpy==1.23.5