Redes neuronales: así de sencillo (Parte 56): Utilizamos la norma nuclear para incentivar la exploración

Introducción
El aprendizaje por refuerzo se basa en el paradigma de la exploración independiente del entorno por parte del agente. A través de sus acciones, el Agente influye en el entorno, provocando su cambio. A cambio, el Agente recibe algún tipo de recompensa.
Y aquí destacan dos grandes problemas del aprendizaje por refuerzo: la exploración del entorno y la función de recompensa. Una función de recompensa correctamente diseñada animará al Agente a explorar el entorno y encontrar las estrategias de comportamiento óptimas.
No obstante, en la mayoría de los problemas prácticos, nos enfrentaremos a recompensas externas escasas. Para superar esta barrera, propusimos el uso de las llamadas recompensas internas, que permiten al Agente aprender nuevas habilidades que pueden serle útiles para obtener recompensas externas en el futuro. Sin embargo, debido a la estocasticidad del entorno, las recompensas internas pueden verse influidas por el ruido. La aplicación directa de valores predictivos ruidosos a las observaciones puede afectar negativamente al rendimiento del entrenamiento de la política del Agente. Además, muchos métodos usan la norma L2 o la varianza para medir la novedad de la exploración, lo cual aumenta el ruido debido a la operación de elevación al cuadrado.
Para resolver este problema, en el artículo "Nuclear Norm Maximization Based Curiosity-Driven Learning" se propuso un nuevo algoritmo para estimular la curiosidad de los agentes, basado en la maximización de la norma nuclear (Nuclear Norm Maximization - NNM). Esta recompensa interna puede evaluar con mayor precisión la novedad de la exploración del entorno. Al mismo tiempo, permite una gran resistencia al ruido y los valores atípicos.
1. La norma nuclear y su aplicación
Las normas matriciales, incluida la norma nuclear, se usan ampliamente en el análisis y los métodos computacionales del álgebra lineal. La norma nuclear desempeña un papel importante en el estudio de las propiedades de las matrices, los problemas de optimización, la evaluación de la condicionalidad y muchas otras áreas de las matemáticas y las ciencias aplicadas.
La norma nuclear de una matriz es una característica numérica que define el "tamaño" de la matriz. Representa un caso especial de la norma de Schatten y es igual a la suma de los valores singulares de la matriz.
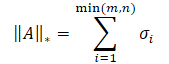
donde σi representa los elementos del vector de valores singulares de la matriz A.
En esencia, la norma nuclear es el casco convexo de la función de rango para un conjunto de matrices con la misma norma espectral. Esto nos permitirá usarlo para resolver diversos problemas de optimización.
La idea básica del método Nuclear Norm Maximization (NNM) consiste en estimar con precisión la novedad utilizando la norma nuclear de la matriz al visitar un estado, suavizando los efectos del ruido y de diversos valores atípicos. La matriz de tamaño n*m consta de n estados de entorno codificados. Cada estado tiene una dimensionalidad m. La matriz combina el estado actual s y sus (n - 1) estados vecinos más próximos. Aquí s representará un estado abstracto mapeando la observación multidimensional original en un espacio abstracto de baja dimensión. Como cada fila de la matriz S representa un estado codificado, podemos usar rank(S) para representar la diversidad dentro de la matriz. Un mayor rango de la matriz S implicará una mayor distancia lineal entre los estados codificados. Los autores del método son creativos y aplican la maximización del rango matricial para aumentar la diversidad del estudio. Esto estimulará al agente de nuestro modelo a visitar más estados diferentes con gran diversidad.
Existen dos enfoques para usar el rango máximo de una matriz: como la función de pérdida o como recompensa. Maximizar el rango de una matriz directamente es un problema bastante difícil con una función no convexa. Por lo tanto, no la usaremos como función de pérdida. No obstante, el valor del rango de la matriz es discreto y no puede reflejar con exactitud la novedad de los estados. Por ello, utilizar el valor bruto del rango de la matriz como recompensa para guiar el entrenamiento del modelo también resultará ineficaz.
Matemáticamente, el cálculo del rango de una matriz suele ser sustituido por su norma nuclear. Por consiguiente, la novedad puede mantenerse mediante la maximización aproximada de la norma nuclear. Comparada con el rango, la norma nuclear tiene varias propiedades positivas. En primer lugar, la convexidad de la norma nuclear permite desarrollar algoritmos de optimización rápidos y convergentes. En segundo lugar, la norma nuclear es una función continua, lo cual resulta importante para muchas tareas de aprendizaje.
Los autores del método NNM proponen determinar la recompensa interna mediante la siguiente fórmula
![]()
donde:
λ — peso para afinar el rango de valores de la norma nuclear;
‖S‖⋆ — norma nuclear de la matriz de estado;
‖S‖F — norma de Frobenius de la matriz de estado.
Ya nos hemos familiarizado con la normal nuclear de la matriz; la norma de Frobenius se calculará como la raíz cuadrada de la suma de los cuadrados de todos los elementos de la matriz.
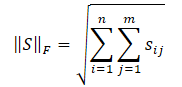
La desigualdad de Cauchy-Bunyakovsky nos permitirá realizar las siguientes transformaciones.
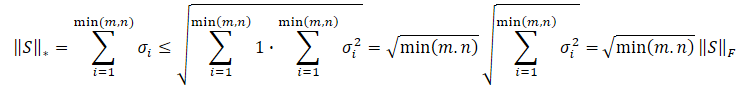
Obviamente, la raíz cuadrada de la suma de los cuadrados de los valores siempre será menor o igual que la suma de los propios valores, por ello, la norma nuclear de una matriz siempre será mayor o igual que la norma de Frobenius de la misma matriz. Así que podemos derivar las siguientes desigualdades.
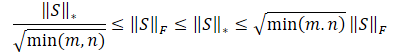
Esta desigualdad muestra que la norma nuclear y la norma de Frobenius se constriñen mutuamente. Si la norma nuclear aumenta, la norma de Frobenius también tenderá a aumentar.
Además, la norma de Frobenius tiene otra propiedad útil para nosotros: resulta estrictamente opuesta a la entropía en monotonicidad. Su aumento equivale a una disminución de la entropía. Como consecuencia, las repercusiones de la norma nuclear pueden dividirse en dos partes:
- Alta diversidad.
- Baja entropía.
Tenemos que estimular al Agente a visitar estados más nuevos, y nuestro objetivo es la diversidad. No obstante, una disminución de la entropía implicará un aumento de la agregación de estados, es decir, una gran similitud de estados. Por consiguiente, nuestro objetivo consistirá en fomentar el primer efecto y reducir el impacto del segundo. Para ello, dividiremos la norma nuclear de la matriz por su norma de Frobenius.
Dividiendo las desigualdades anteriores por la norma de Frobenius obtendremos:
![]()
Obviamente, el uso directo de una escala de recompensas de este tipo puede resultar perjudicial para el rendimiento del aprendizaje del modelo. Asimismo, la raíz de la dimensión mínima de la matriz de estado puede variar en diferentes entornos o con diferentes arquitecturas de modelos entrenados. Por lo tanto, resultará deseable renormalizar nuestra escala de recompensas. Y como min(m, n) ≤ max(m, n), obtendremos:
![]()
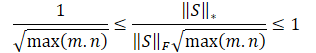
Los anteriores cálculos matemáticos nos permitirán determinar automáticamente el factor de ajuste del rango de valores de la norma nuclear de la matriz λ como
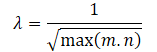
Así, la fórmula de la recompensa interna adoptará la forma que vemos:
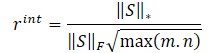
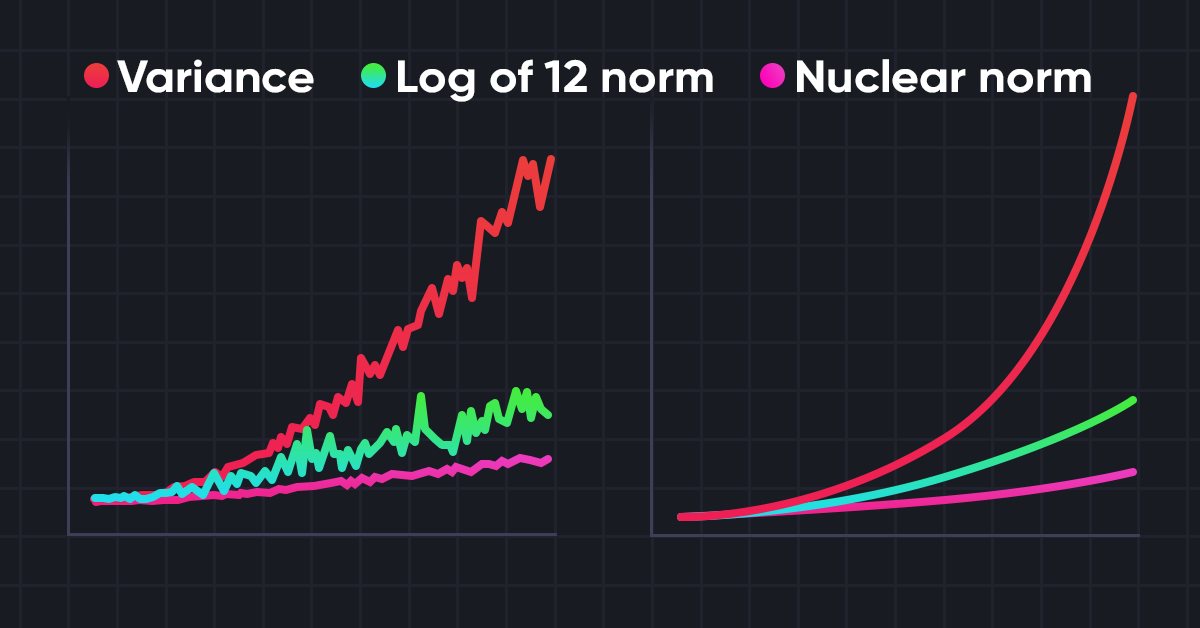
A continuación le mostraremos la visualización del autor del método Nuclear Norm Maximization.
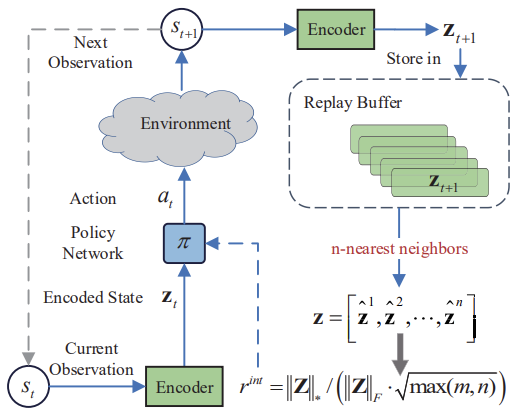
Los resultados de las pruebas presentados en el artículo del autor demuestran la superioridad del método propuesto sobre otros algoritmos de exploración del entorno. Esto incluye Intrinsic Curiosity Module y Self-Supervised Exploration via Disagreement, de los que ya hemos hablado anteriormente. Además, llama la atención sobre el hecho de que el método muestra mejores resultados cuando le añadimos ruido a los datos originales. Le propongo pasar a la parte práctica de nuestro artículo y evaluar las posibilidades del método para resolver nuestros problemas.
2. Implementación usando MQL5
Antes de empezar a aplicar el método Nuclear Norm Maximisation (NNM), destacaremos su principal innovación: la nueva fórmula de recompensa interna. En consecuencia, este enfoque podrá aplicarse como complemento de casi cualquier algoritmo de aprendizaje por refuerzo previamente analizado.
Nótese aquí que el algoritmo usa un codificador para traducir los estados del entorno a algún tipo de representación comprimida, y que también aplica el algoritmo de k vecinos más próximos para formar una matriz de representaciones comprimidas del estado del entorno.
A nuestro juicio, la solución más fácil parece ser implementar la recompensa interna propuesta en el algoritmo RE3. También se usa un codificador para traducir los estados del entorno a una representación comprimida. Para ello, utilizaremos un codificador convolucional aleatorio en RE3, lo cual reducirá el coste de entrenamiento del codificador.
Además, RE3 utiliza de forma similar los k estados más próximos para generar la recompensa interna. Solo que esta recompensa tiene una forma diferente.
Bueno, ya tenemos el rumbo claro, ahora podemos ponernos a trabajar. En primer lugar, copiaremos todos los archivos del directorio "...\Experts\NRE3\" a "...\Experts\NNNM\". No olvide que hay 4 archivos allí:
- Trajectory.mqh — biblioteca de constantes, estructuras y métodos comunes.
- Research.mq5 — asesor para interactuar con el entorno y recoger muestras de entrenamiento.
- Study.mq5 — asesor para el entrenamiento directo de modelos.
- Test.mq5 — asesor para probar los modelos entrenados.
También usaremos la recompensa descompuesta. La estructura del vector de recompensas será la siguiente.
//+------------------------------------------------------------------+ //| Rewards structure | //| 0 - Delta Balance | //| 1 - Delta Equity ( "-" Drawdown / "+" Profit) | //| 2 - Penalty for no open positions | //| 3 - NNM | //+------------------------------------------------------------------+
En el archivo "...\NNNM\Trajectory.mqh", aumentaremos el tamaño de la representación comprimida del estado del entorno y de la capa interna totalmente conectada de nuestros modelos.
#define EmbeddingSize 16 #define LatentCount 512
En el mismo archivo se encuentra el método CreateDescriptions para describir la arquitectura de los modelos usados. Hoy utilizaremos tres modelos de redes neuronales: Un Actor, un Crítico y un Codificador. Como este último, usaremos un codificador convolucional aleatorio.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
En el cuerpo del método, crearemos una variable local para almacenar el puntero al único objeto de descripción de la capa neuronal CLayerDescription y, de ser necesario, inicializaremos arrays dinámicos para describir las soluciones arquitectónicas de los modelos utilizados.
Primero crearemos una descripción de la arquitectura del Actor, que constará de 2 bloques: el preprocesamiento de datos iniciales y la toma de decisiones.
En la entrada del bloque de preprocesamiento de datos iniciales, introduciremos los datos históricos sobre los movimientos de precio del instrumento analizado y las métricas de los indicadores. Como podemos observar, los distintos indicadores tienen diferentes rangos de valores de sus métricas, lo cual repercute negativamente en la eficacia del entrenamiento de los modelos. Por lo tanto, normalizaremos los datos obtenidos utilizando la capa de normalización por lotes CNeuronBatchNormOCL.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego pasaremos los datos normalizados por 2 capas de convolución, para buscar patrones de indicadores individuales.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout=descr.window_out = HistoryBars/2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Los datos resultantes se procesarán usando capas neuronales totalmente conectadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
En esta fase del bloque inicial de preprocesamiento de datos, esperaremos obtener alguna representación latente de los datos históricos del instrumento analizado. Esto puede resultar suficiente para determinar la dirección de apertura o mantenimiento de una posición, pero no para realizar las funciones de gestión de dinero. Después complementaremos los datos con información sobre la cuenta.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Le seguirá un bloque de decisión formado de capas totalmente conectadas, que se completará con una capa estocástica de representación latente del autocodificador variacional. Al igual que antes, utilizaremos este tipo de capa en la salida del modelo para aplicar la política estocástica del Actor.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Ya hemos descrito al completo la arquitectura del Actor. En este caso, además, hemos construido un modelo para aplicar políticas estocásticas con el fin de subrayar la posibilidad de utilizar el método Nuclear Norm Maximization para este tipo de decisiones. Además, nuestro Actor trabajará en un espacio de acción continua. No obstante, esto no limitará el ámbito de aplicación del método NNM.
El siguiente paso será crear una descripción de la arquitectura del Crítico. Aquí utilizaremos la técnica ya elaborada y excluiremos el bloque de preprocesamiento de datos. Como datos de entrada, tomaremos la representación latente del estado de los datos históricos del instrumento y el estado de la cuenta de las capas neuronales internas del Actor. Para ello, combinaremos la representación interna del estado del entorno y el tensor de acciones generado por el Actor.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Los datos resultantes serán procesados por las capas totalmente conectadas de nuestro Crítico; luego se generará un vector de valores pronosticados en cuanto a la descomposición de nuestra función de recompensa.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Ya hemos descrito la arquitectura de los dos modelos. Ahora nos queda crear la arquitectura del codificador. Aquí regresamos a la parte teórica y observamos que el método NNM ofrece una comparación de los estados del entorno tras la transición St+1. Obviamente, el método se ha diseñado para el aprendizaje en línea. Pero hablaremos de eso un poco más tarde. En la fase de formación de la arquitectura del modelo, debemos entender que el codificador procesará los datos históricos del instrumento analizado y contabilizará los indicadores de estado. Luego crearemos una capa de datos de origen de tamaño suficiente.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Obsérvese que no hemos utilizado ni una capa de normalización de datos ni la combinación de los dos tensores de datos. Esto se debe a que no tenemos previsto entrenar este modelo, solo se utilizará para pasar una representación multidimensional del entorno a algún espacio comprimido aleatorio en el que mediremos la distancia entre estados. No obstante, utilizaremos una capa totalmente conectada que nos permitirá presentar los datos de forma comparable.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 1024; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; }
A continuación viene un bloque de capas de convolución para reducir la dimensionalidad de los datos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 1024 / 16; descr.window = 16; descr.step = 16; prev_wout = descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 8; descr.window = 8; descr.step = 8; prev_wout = descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Y, por último, reduciremos la dimensionalidad de los datos para la dimensión dada usando una capa totalmente conectada.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
El uso de capas totalmente conectadas en la entrada y la salida del codificador nos permitirá personalizar la arquitectura de la capa convolucional sin vinculación al tamaño de los datos de origen e incorporación de la representación comprimida.
Con esto concluiremos nuestro trabajo sobre la arquitectura de los modelos y podemos volver a la cuestión de la descripción del estado futuro. En el proceso de aprendizaje en línea, no tendríamos ninguna dificultad en este asunto, pero el aprendizaje en línea tiene sus desventajas, mientras que al utilizar el búfer de reproducción de experiencias, no tendremos dudas sobre los datos históricos de los movimientos de precio del instrumento analizado y los indicadores. El efecto sobre ellos de las acciones del Actor resultará tan leve que podemos despreciarlo. Otra cosa es el estado de la cuenta, este dependerá directamente de la dirección y el volumen de la posición abierta. Y tendremos que predecir el estado de la cuenta dependiendo del vector de acciones generado por el Actor basado en los resultados del análisis del estado actual. Implementaremos dicha funcionalidad en la función ForecastAccount.
En los parámetros del método, transmitiremos:
- prev_account — array de descripciones del estado actual de la cuenta (antes de las acciones del agente);
- actions — vector de acciones del Actor;
- prof_1l — beneficio por 1 lote de una posición larga;
- time_label — etiqueta temporal de la barra pronosticada.
Podemos observar una "dispersión" de los tipos de parámetros. Esto se relaciona con la fuente de obtención de datos. Obtendremos la descripción del estado actual de la cuenta y la marca temporal de la barra de pronóstico del búfer de reproducción de experiencias, donde los datos se almacenarán en arrays dinámicos de tipo float.
Obtendremos las acciones del Actor a partir de los resultados de una pasada directa del modelo como un vector.
vector<float> ForecastAccount(float &prev_account[], vector<float> &actions, double prof_1l, float time_label ) { vector<float> account; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
En el cuerpo de la función, haremos un poco de trabajo preparatorio. Luego determinaremos el lote mínimo del instrumento y el paso de cambio de volumen de la posición. A continuación, solicitaremos los niveles stop actuales. Y el tamaño del margen por transacción. Aquí cabe señalar que no hemos introducido un parámetro adicional para identificar el instrumento analizado. Utilizaremos el instrumento del gráfico en el que se ejecuta el programa. Por lo tanto, a la hora de entrenar los modelos, resulta muy importante respetar la herramienta de recopilación de datos de origen de la muestra de entrenamiento y el gráfico al que se adjunta el programa de entrenamiento de modelos.
A continuación, ajustaremos el vector de acciones del Actor para seleccionar una transacción en una sola dirección en la diferencia de volumen. Realizaremos operaciones similares en los asesores de interacción con el entorno. Respetar unas reglas únicas en todos los programas del proceso de entrenamiento de modelos resulta esencial para lograr el resultado deseado.
Aquí es donde comprobaremos que en la cuenta hay fondos suficientes para abrir una posición.
account.Assign(prev_account); //--- if(actions[0] >= actions[3]) { actions[0] -= actions[3]; actions[3] = 0; if(actions[0]*margin_buy >= MathMin(account[0],account[1])) actions[0] = 0; } else { actions[3] -= actions[0]; actions[0] = 0; if(actions[3]*margin_sell >= MathMin(account[0],account[1])) actions[3] = 0; }
Y ya sobre la base del vector de acciones ajustado pronosticaremos el estado de la cuenta. En primer lugar, comprobaremos las posiciones largas. Si fuera necesario cerrar una posición, transferiremos el beneficio acumulado al balance de la cuenta. A continuación, restableceremos el volumen de la posición abierta y el beneficio acumulado.
Al mantener una posición abierta, comprobaremos si es necesario cerrar parcialmente o recomprar en la posición. Si una posición se cierra parcialmente, dividiremos el beneficio acumulado de forma proporcional a la parte cerrada y a la parte restante, mientras que la parte de la posición que se va a cerrar se transferirá del beneficio acumulado al balance de la cuenta.
De ser necesario, ajustaremos el volumen de la posición abierta y modificaremos la magnitud de los beneficios/pérdidas acumulados en proporción al volumen de la posición mantenida.
//--- buy control if(actions[0] < min_lot || (actions[1] * MaxTP * Point()) <= stops || (actions[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; } else { double buy_lot = min_lot + MathRound((double)(actions[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
Repetiremos operaciones similares para las posiciones cortas.
//--- sell control if(actions[3] < min_lot || (actions[4] * MaxTP * Point()) <= stops || (actions[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(actions[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
A continuación, ajustaremos el total acumulado de beneficios/pérdidas en ambas direcciones y en la cuenta de Equidad.
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
A partir de los valores de predicción obtenidos, prepararemos un vector de descripción del estado de la cuenta en el formato de suministro de datos al modelo. Y retornaremos el resultado de las operaciones al programa que realiza la llamada.
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
Con esto concluiremos nuestro trabajo preparatorio y podremos pasar a la actualización de los programas de interacción del entorno y del entrenamiento de modelos. No olvidemos que el método NNM introduce cambios en la función de recompensa interna. Y esta funcionalidad no afectará al proceso de interacción con el entorno. Por lo tanto, los asesores "...\NNNM\Research.mq5" y "...\NNNM\Test.mq5" permanecerán sin cambios. Su código se encuentra en el archivo adjunto. La descripción de los algoritmos se ofrece en los artículos anteriores.
Nos centraremos en el asesor de entrenamiento de modelos "...\NNNM\Study.mq5". En primer lugar, debemos decir que el método NNM está diseñado principalmente para el aprendizaje en línea, como indica la yuxtaposición de los estados posteriores. Obviamente, podremos generar estados predictivos durante bastante tiempo, pero su ausencia en la base de comparaciones de estados puede repercutir negativamente en el proceso de entrenamiento en su conjunto. En efecto, en su ausencia, el modelo percibirá los estados como nuevos y estimulará su «revisitación» sin conocer sus visitas anteriores durante el entrenamiento.
En teoría, existen dos opciones para resolver este problema:
- Añadir estados predictivos a la base de datos de ejemplos.
- Reducir las iteraciones del ciclo de entrenamiento.
Ambos enfoques tienen sus desventajas. Al añadir estados predictivos a la base de datos de ejemplos, la rellenaremos de datos poco fiables e incompletos. Sí, hemos realizado un cálculo matemático basado en nuestros conocimientos a priori y en una serie de supuestos, y, sin embargo, hemos admitido cierto grado de error en ellos. Además, no disponemos de los valores reales de recompensa de estas acciones para entrenar el modelo. Por ello, hemos elegido el segundo método, a pesar de que implica más trabajo manual (más ejecuciones para la recopilación de datos de entrenamiento y el entrenamiento del modelo).
Reduciremos el número de iteraciones del ciclo de entrenamiento.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 10000; input float Tau = 0.001f;
En el proceso de entrenamiento, utilizaremos un Actor, dos Críticos y sus modelos objetivo, así como un codificador convolucional aleatorio. Todos los modelos de los Críticos tendrán la misma arquitectura pero parámetros diferentes, que se formarán durante el entrenamiento.
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetCritic1; CNet TargetCritic2; CNet Convolution;
Entrenaremos un Actor y dos Críticos. Actualizaremos suavemente los modelos de los Críticos objetivo a partir de los parámetros del Crítico correspondiente con el parámetro Tau. No entrenaremos un Codificador.
En el método de inicialización OnInit del asesor, cargaremos los datos de origen previamente recopilados. Y, si no podemos cargar los modelos preentrenados, inicializaremos otros nuevos según la arquitectura dada. Este proceso se ha mantenido sin cambios y podrá revisarlo usted mismo en el archivo adjunto. Bien, vamos a pasar directamente al método Train para el entrenamiento de modelos.
En este método, primero determinaremos el número de trayectorias almacenadas en el búfer de reproducción de experiencias y contaremos el número total de estados en ellas.
Luego prepararemos las matrices para registrar la incorporación de los estados y las recompensas externas correspondientes.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards);
A continuación, organizaremos un sistema de ciclos anidados, en cuyo cuerpo organizaremos la codificación de todos los estados del búfer de reproducción de experiencias. Después rellenaremos las matrices de incorporación de estados y recompensas correspondientes con los datos obtenidos. Nótese que guardaremos las recompensas de una sola transición a un nuevo estado sin considerar los valores acumulados hasta el final de la pasada. De este modo queremos reunir de una forma comparable estados cercanos en "espíritu" pero separados en el tiempo.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { rewards.Resize(state,NRewards); state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
Una vez preparado el estado de incorporación, pasaremos directamente a organizar el ciclo de entrenamiento del modelo. Como es habitual, el número de iteraciones del ciclo se establecerá usando un parámetro externo y añadiremos una comprobación del evento de finalización del programa por parte del usuario.
En el cuerpo del ciclo, seleccionaremos aleatoriamente una trayectoria y un estado individual de la memoria de reproducción de experiencias.
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } vector<float> reward, target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards);
Luego prepararemos los vectores para el registro de recompensas.
A continuación, prepararemos una descripción del siguiente estado. Tenga en cuenta que lo prepararemos independientemente de la necesidad de los modelos objetivo. Al fin y al cabo, la necesitaremos en cualquier caso para formar la recompensa interna según el método NNM,
//--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state);
mientras que la posterior descripción del vector del estado de la cuenta y la pasada directa de los modelos objetivo solo las realizaremos cuando sea necesario.
if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; }
A continuación realizaremos el entrenamiento de los críticos. En este bloque, primero prepararemos los datos del estado actual del entorno,
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
y luego realizaremos una pasada directa del Actor.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Aquí debemos señalar que para el entrenamiento del Crítico, utilizaremos las acciones reales del Actor al interactuar con el entorno y la recompensa real concedida, pero, en cualquier caso, se ha realizado una pasada directa del Actor para utilizar su bloque de preprocesamiento de datos de origen, que estaba excluido de la arquitectura del Crítico.
A continuación, prepararemos el búfer de acciones del Actor a partir del búfer de reproducción de experiencias y realizaremos una pasada directa de ambos Críticos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Tras la pasada directa, tendremos que realizar una pasada inversa y actualizar los parámetros de los modelos. Sin embargo, debemos recordar que estamos utilizando una función de recompensa descompuesta, y para optimizar los gradientes, se aplicará el método CAGrad. Obviamente, a pesar de tener un único objetivo, los gradientes de error de cada Crítico serán distintos. Y nosotros realizaremos actualizaciones de los modelos de forma sistemática. Primero corregiremos los gradientes de error y realizaremos una pasada inversa del Crítico 1.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Después repetiremos las operaciones para el Crítico 2. Y, por supuesto, controlaremos la ejecución de las operaciones en cada paso.
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Los modelos de los Críticos se entrenarán para evaluar correctamente las acciones del Actor en una determinada condición del entorno. Como resultado del modelo del Crítico, esperaremos obtener la recompensa predictiva correcta. Esta será la punta del iceberg, por así decirlo. Pero existe una parte que queda «por debajo del agua». Durante el proceso de entrenamiento, el Crítico aproximará la función Q y construirá ciertas dependencias entre las acciones del Actor y las recompensas.
Nuestro objetivo consistirá en maximizar la recompensa externa, pero esta no dependerá directamente de la calidad del entrenamiento del Crítico. Por el contrario, la recompensa se alcanzará con las acciones del Actor. Pero utilizaremos la función Q aproximada para corregir las acciones del Actor. El gradiente de error entre la evaluación por parte del Crítico de las acciones del Actor y la recompensa obtenida indicará la dirección de corrección de las acciones del Actor. La probabilidad de acciones sobreestimadas disminuirá, mientras que la probabilidad de acciones subestimadas aumentará.
Para entrenar al Actor, utilizaremos el Crítico con el error de predicción medio móvil mínimo, que potencialmente nos dará una estimación más precisa de las acciones del Actor.
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Ya hemos realizado una pasada directa del Actor y, para evaluar las acciones seleccionadas, necesitaremos realizar una pasada directa del Crítico seleccionado. Pero antes, prepararemos el vector de valores objetivo de recompensa, una tarea en absoluto trivial. Necesitaremos predecir de algún modo las recompensas externas del entorno y complementarlas con recompensas internas para estimular el potencial explorador del Actor.
Y por extraño que parezca, empezaremos por la recompensa interna, que determinaremos usando el método NNM. Antes ya describimos que para determinar la recompensa interna, necesitamos obtener una representación codificada del estado posterior. Los datos históricos del estado posterior ya han sido añadidos al búfer TargetState. Obtendremos el estado de pronóstico de la cuenta utilizando la función ForecastAccount descrita anteriormente.
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1, prof_1l,Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
Luego concatenaremos los dos tensores y realizaremos una pasada directa de dos modelos. Del Crítico para evaluar las acciones del Actor. Y del Codificador para obtener una representación concisa del estado predicho.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
A continuación, pasaremos a la formación del vector de recompensa. Recordemos que el vector target_reward contiene la desviación de la evaluación que realiza el Crítico objetivo respecto a las acciones del Actor de la recompensa acumulativa real obtenida al interactuar con el entorno. En esencia, este vector representará el impacto de un cambio de política en el resultado global.
Como recompensa externa objetivo de la acción actual del Actor, utilizaremos las recompensas reales de los k vecinos más próximos, ajustadas por la distancia entre vectores. Aquí estamos suponiendo que la recompensa por una acción será inversamente proporcional a la distancia hasta el vecino correspondiente.
La selección de los kvecinos más próximos y la formación de la recompensa interna se realizará directamente en la función KNNReward, cuyo algoritmo veremos un poco más adelante.
Pero aquí debemos considerar otra cosa. En la matriz de recompensas de los estados codificados, almacenaremos la recompensa externa solo para la última transición, sin total acumulativo. Por lo tanto, para obtener objetivos comparables necesitaremos añadir a target_reward las recompensas acumuladas obtenidas antes de completar la pasada actual desde el búfer de reproducción de experiencias.
next.Assign(Buffer[tr].States[i + 1].rewards); target_reward+=next; Convolution.getResults(rewards1); target_reward=KNNReward(7,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance) / DiscFactor; critic.getResults(reward); reward += CAGrad(target_reward - reward);
Ajustaremos la desviación de los valores de recompensa objetivo respecto a la estimación del Crítico utilizando el método Conflict-Averse Gradient Descent, y luego añadiremos los valores resultantes a los valores predichos por el Crítico. De este modo, obtendremos un vector de valores objetivo ajustados para la descomposición de la recompensa. Lo usaremos para ejecutar una pasada inversa y actualizar los parámetros del Actor. Luego desactivaremos previamente el modo de entrenamiento del Crítico, para no adaptar sus parámetros a los objetivos ajustados.
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Tras actualizar con éxito los parámetros del Actor, devolveremos el modelo del Crítico al modo de entrenamiento y actualizaremos los modelos objetivo de ambos Críticos.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
Así se completarán las iteraciones del ciclo de entrenamiento del modelo. Todo lo que tenemos que hacer es informar al usuario sobre el proceso de ejecución de las operaciones.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completadas con éxito todas las iteraciones del ciclo de entrenamiento, borraremos el área de comentarios del gráfico. luego registraremos los resultados del entrenamiento del modelo e inicializaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Y ahora, para entender bien cómo funciona el algoritmo de entrenamiento del modelo, veremos la función de formación KNNReward. Debemos decir que es precisamente esta función la que contendrá las principales características del método Nuclear Norm Maximization que nos ocupa.
En los parámetros, la función recuperará el número de vecinos más próximos analizados, la incorporación del estado analizado, las matrices de incorporación de los estados y las recompensas correspondientes del búfer de reproducción de experiencias.
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
En el cuerpo del método, comprobaremos la dimensionalidad de la incorporación en el estado actual y en los estados del búfer de reproducción de experiencias. En la aplicación actual, esta comprobación podría parecer redundante. Al fin y al cabo, obtenemos todas las incorporaciones utilizando un único codificador dentro de este asesor. Pero puede resultar incluso muy útil si decidimos generar estados de incorporación durante la interacción con el entorno y almacenarlos en un búfer de reproducción de experiencias, como se recomienda en el artículo sobre el método del autor
A continuación, haremos un pequeño trabajo preparatorio definiendo algunas constantes en variables locales. Y luego, de ser necesario, reduciremos el número de vecinos más próximos al número de estados del búfer de reproducción de experiencias. La probabilidad de que exista tal necesidad es bastante pequeña, pero este detalle hace que nuestro código resulte más versátil y esté protegido de errores en tiempo de ejecución.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); matrix<float> temp = matrix<float>::Zeros(states,size);
A continuación, definiremos la distancia entre el vector del estado analizado y los estados del búfer de reproducción de experiencias. Los valores obtenidos se almacenarán en el vector distance.
for(ulong i = 0; i < size; i++) temp.Col(MathPow(state_embedding.Col(i) - embedding[i],2.0f),i); vector<float> distance = MathSqrt(temp.Sum(1));
Ahora tendremos que determinar los k vecinos más próximos. Almacenaremos sus parámetros en las matrices k_embeding y k_rewards. Observe que estamos creando una fila más en la matriz k_embeding. En ella escribiremos la incorporación del estado analizado.
Luego transferiremos los datos a las matrices en un ciclo por el número de vectores a buscar. En el cuerpo del ciclo, utilizaremos la operación vectorial ArgMin para determinar la posición del valor mínimo en el vector de distancias. Sería nuestro vecino más cercano. Después transferiremos sus datos a las filas correspondientes de nuestras matrices, mientras que en el vector distancia, fijaremos la máxima constante posible en esta posición. Así, tras copiar los datos, cambiaremos la distancia mínima por el valor máximo. Y en la siguiente iteración del ciclo, la operación ArgMin nos dará la posición del siguiente vecino.
Nótese que cuando desplazamos un vector de recompensas, estamos ajustando sus valores por un factor inverso a la distancia entre vectores de estado.
matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; } k_embeding.Row(embedding,k);
Este algoritmo tiene varias ventajas:
- el número de iteraciones no depende del tamaño del búfer de reproducción de experiencias, lo cual resulta cómodo cuando se utilizan bases de datos voluminosas;
- no es necesario clasificar los datos, lo que suele consumir muchos recursos;
- copiamos los datos de cada vecino una sola vez, sin copiar ningún otro dato.
Después de transferir los datos de todos los vecinos necesarios con la última fila de la matriz k_embeding, añadiremos el estado actual.
A continuación, para determinar la norma nuclear de la matriz k_embeding e implementar el método NNM, necesitaremos encontrar los valores singulares de la matriz. Para ello, utilizaremos la operación matricial SVD.
matrix<float> U,V; vector<float> S; k_embeding.SVD(U,V,S);
Ahora los valores singulares de la matriz se almacenarán en el vector S y para determinar la norma nuclear solo tendremos que sumar sus valores. Pero antes, generaremos el vector de recompensas externas como un vector de valores medios por las columnas de la matriz de recompensas seleccionadas k_rewards.
Luego definiremos la recompensa interna utilizando el método NNM como la relación entre la norma nuclear de la matriz de incorporación de estados y su norma de Frobenius, y corregiremos el factor de escala de la norma nuclear. A continuación escribiremos el valor obtenido en el elemento correspondiente del vector de recompensas y retornaremos el vector de recompensas al programa que ha realizado la llamada.
vector<float> result = k_rewards.Mean(0); result[rew_size - 1] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); //--- return (result); }
Con esto podemos dar por completa la implementación del método Nuclear Norm Maximization utilizando las herramientas MQL5. En el archivo adjunto, encontrará el código completo de todos los programas usados en el artículo.
3. Simulación
Hoy hemos trabajado bastante para realizar la integración del método Nuclear Norm Maximization en el algoritmo RE3. Ahora es momento de pasar a la prueba del trabajo realizado. Como siempre, el entrenamiento y las pruebas de los modelos se realizarán usando los datos históricos de EURUSD, con el marco temporal H1 para los meses 1-5 de 2023. Los parámetros de todos los indicadores se utilizarán por defecto.
Al crear el asesor de entrenamiento "...\NNNNM\Study.mq5", ya hemos hablado de las peculiaridades de este método y del problema de la ausencia de estados generados en el búfer de reproducción de experiencias. Debido a ello, hemos decidido reducir el número de iteraciones en el ciclo de entrenamiento. Por supuesto, esto también repercutirá en todo el proceso de entrenamiento.
No hemos reducido el búfer de reproducción de experiencias en su conjunto, pero, al mismo tiempo, estará usted de acuerdo con que una base de 1,3 millones de estados no es necesaria para realizar 10 000 iteraciones de actualización de los parámetros del modelo. Sí, una base de datos más grande permite personalizar mejor el modelo, pero cuando hay más de 100 estados por cada iteración de actualización no somos capaces de trabajar a través de todos ellos. Por lo tanto, rellenaremos el búfer de reproducción de experiencias gradualmente. En la primera iteración, ejecutaremos el asesor de recopilación de datos de entrenamiento durante solo 50 ejecuciones. Con el intervalo histórico especificado, esto nos dará ya unos 120 000 estados para el entrenamiento del modelo.
Y tras la primera iteración de entrenamiento del modelo, aumentaremos la base de ejemplos con otras 50 pasadas. De este modo, rellenaremos gradualmente el búfer de reproducción de experiencias con nuevos estados que se corresponderán con las acciones del Actor dentro de la política entrenada.
Sí, este enfoque aumentará en gran medida el volumen de trabajo manual para ejecutar los asesores, pero nos permitirá mantener la base de datos de ejemplos relativamente actualizada. Y las recompensas internas que generaremos llevarán al Actor a explorar nuevos estados del entorno.
Durante el entrenamiento del modelo, hemos logrado obtener un modelo capaz de generar beneficios en la muestra de entrenamiento y generalizar el conocimiento aprendido a estados de entorno posteriores. Así, en el simulador de estrategias, el modelo entrenado ha sido capaz de generar un beneficio del 1% en el mes siguiente a la muestra de entrenamiento. Durante el periodo de prueba, el modelo ha realizado 133 operaciones, el 42% de las cuales se han cerrado con beneficios. El beneficio máximo por operación ha sido casi 2 veces superior a la operación máxima perdedora, mientras que el beneficio medio por operación ha sido un 40% superior a la pérdida media. Todo ello se ha combinado para producir un factor de beneficio de 1,02.


Conclusión
En este artículo, hemos introducido un enfoque novedoso para la exploración de estímulos en el aprendizaje por refuerzo basado en la maximización de la norma nuclear. Este método puede evaluar eficazmente la novedad de un estudio del entorno considerando la información histórica y ofreciendo una gran solidez frente al ruido y los valores atípicos.
En la parte práctica del trabajo, hemos integrado el método Nuclear Norm Maximization en el algoritmo RE3. También hemos entrenado el modelo y lo hemos probado en el simulador de estrategias de MetaTrader 5. Según los resultados de las pruebas, podemos afirmar que el método propuesto ha diversificado significativamente el comportamiento del Actor, en comparación con los resultados del entrenamiento del modelo con el método RE3 a secas. No obstante, ahora tendremos un comercio más caótico, lo cual puede sugerir la necesidad de encontrar el equilibrio entre exploración y explotación, introduciendo coeficientes de influencia adicionales en las funciones de recompensa.
Enlaces
- Nuclear Norm Maximization Based Curiosity-Driven Learning
- Redes neuronales: así de sencillo (Parte 53): Descomposición de la recompensa
- Redes neuronales: así de sencillo (Parte 54): Usamos un codificador aleatorio para una exploración eficiente (RE3)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13242
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso