Teoría de categorías en MQL5 (Parte 16): Funtores con perceptrones multicapa
Introducción
Nuestra serie de artículos muestra cómo algunos de los conceptos fundamentales de la teoría de categorías se pueden representar y usar en el código MQL5 para ayudar a los tráders a desarrollar sistemas comerciales más sólidos. Existen muchos aspectos a considerar en la teoría de categorías, pero los funtores y las transformaciones naturales son quizás los más importantes entre ellos. Centrándonos nuevamente en los funtores (como en los dos artículos anteriores), destacaremos una de las ideas fundamentales de la teoría.
Sin embargo, en este artículo, aunque todavía hablamos de funtores, exploraremos su aplicación para generar señales de entrada y salida, a diferencia del artículo anterior, en el que solo abarcamos la configuración de un Trailing Stop. Nuevamente, esto no significa que el código incluido contenga el Santo Grial, más bien, es una idea que el lector debe mejorar y modificar dependiendo de cómo vea los mercados.
Una panorámica rápida del artículo anterior: Funtores y gráficos en MQL5
Los funtores suponen un mapeo de categorías que capturan las relaciones no solo entre objetos en dos categorías, sino también entre morfismos de estas categorías. Esto significa que implementaremos una de dos comparaciones en el código al hacer predicciones.
Los grafos, que pueden considerarse como representaciones de sistemas interconectados con flechas y vértices, se introdujeron en la serie en la parte 11. En el artículo anterior los ilustramos con los datos del calendario económico disponibles en el terminal MetaTrader 5 y usamos una hipótesis simple que relaciona 4 puntos de datos diferentes que forman parte de la serie temporal. Como se muestra en el artículo, este grafo es en realidad una categoría separada.
Sin embargo, los funtores discutidos en nuestro último artículo asignan las dos categorías usando una ecuación lineal simple. En el código publicado había opciones para escalar a una ecuación cuadrática, pero no se implementaron en las pruebas realizadas para el artículo. Entonces, el mapeo de funtores, en esencia, tomaba el valor del objeto en la categoría de dominio, lo multiplicaba por un factor y añadía una constante para obtener el valor del objeto en el codominio. Era lineal porque el coeficiente y la constante eran en realidad la inclinación y la intersección con el eje «y» de una ecuación lineal simple.
Funtores de la teoría de categorías basados en datos del calendario económico
El reformateo de los datos del calendario económico como categoría, logrado mediante gráficos, resultó apropiado dada la compleja interconexión de los datos del calendario. Como podemos ver en la pestaña de calendario del terminal MetaTrader 5, existen muchos tipos diferentes de datos económicos. Este problema se destacó en el artículo anterior, donde la necesidad de recopilar estos datos al tomar decisiones comerciales para un par de divisas puede resultar difícil debido a la dependencia de la divisa. Para garantizar la seguridad, no es necesario fusionar datos. Sin embargo, debemos tener en cuenta el hecho de que algunos de estos datos dependen de otros datos económicos, especialmente porque trabajamos con el S&P 500. Para solucionar este problema, en el último artículo planteamos una hipótesis simple: el índice de precios al consumo (IPC) dependerá del índice PMI, que a su vez depende de la subasta de rendimientos a 10 años (10-year yield auction), cuyos resultados dependen de las ventas minoristas. Entonces, en lugar de una serie temporal de solo uno de estos datos económicos, tendremos una serie de varios puntos que conforman la volatilidad subyacente del S&P 500.
No obstante, en este artículo nos interesa el índice S&P 500 no solo por su volatilidad, como ya ocurría en artículos anteriores, sino también por sus tendencias. Queremos realizar pronósticos sobre sus tendencias a corto plazo (mensuales) y utilizar estos pronósticos para abrir posiciones en nuestro asesor. Esto significa que trataremos con la clase de señal de asesor y no con la clase final como lo hemos estado haciendo hasta ahora en esta serie. Por lo tanto, implementar transformaciones basadas en funtores en un gráfico de datos del calendario económico ofrecerá como resultado un cambio previsto en el índice S&P 500. Esta implementación se logrará usando un perceptrón multicapa.
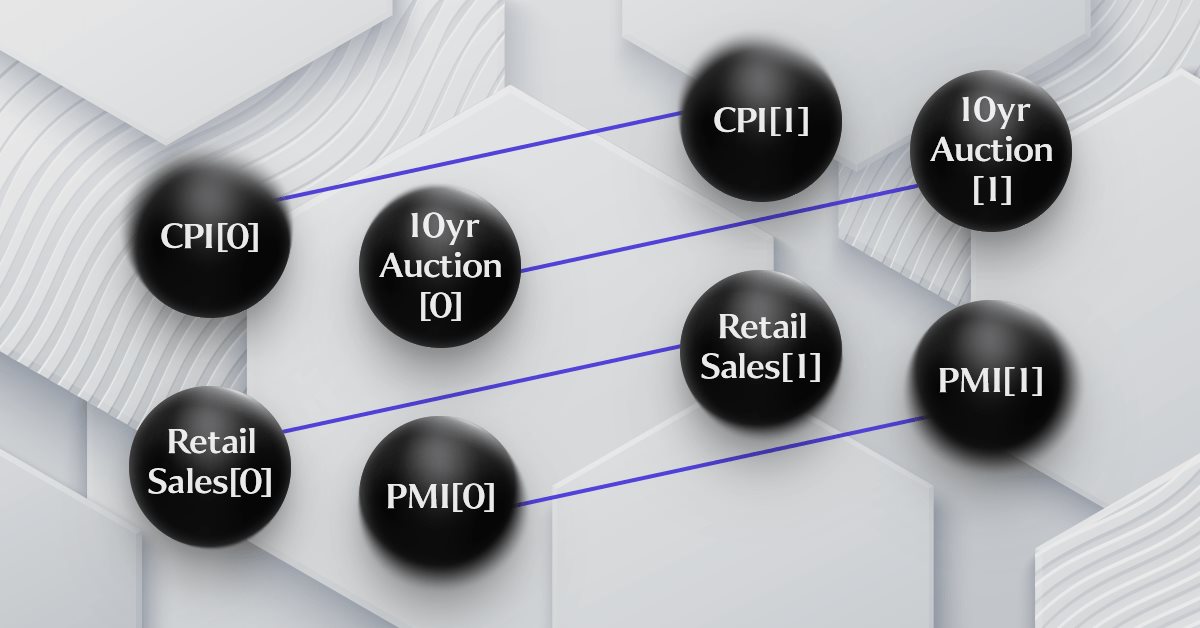
En el último artículo, proporcionamos una representación esquemática de nuestra hipótesis simple que relaciona los cuatro puntos de datos económicos bajo consideración, pero estaba demasiado simplificada y no se mostraba como un gráfico de serie temporal. Intentaremos lograr esto en el siguiente esquema:

Como podemos ver en el esquema, la adición de objetos de series temporales agrega cierta complejidad, lo que claramente refuerza el hecho de que se trata de un grafo. La hipótesis en la que se basa el plan es controvertida. Algunos dirán, por ejemplo, que el índice de precios al consumo es resultado de las ventas minoristas, que a su vez se ven influenciadas por el PMI, que depende de la oferta monetaria medida por los resultados de las subastas a 10 años. Incluso hay otras opciones con datos económicos diferentes o de mayor importancia que pueden ser más importantes a la hora de influir en el delta de las perspectivas del S&P 500. La buena noticia es que, a pesar de todas estas posibles permutaciones e hipótesis, el simulador de estrategias en el terminal puede refutar todos estos argumentos, por lo que resulta útil comunicar claramente nuestras ideas en un formato que pueda probarse de manera efectiva.
Para ayudar con esto, el wizard MQL5 facilita el montaje de un asesor en unos pocos clics, incluso si todo lo que hemos escrito es un archivo de señal.
Funtores de teoría de categorías para los valores del índice S&P 500
En un archivo de señal, la representación de los valores del índice S&P 500 supone una categoría porque, como describimos en el último artículo, cada vértice del grafo (punto de datos) es equivalente a un objeto y, por lo tanto, las flechas entre los vértices pueden considerarse como morfismos. Un objeto puede tener un solo elemento, pero en este caso el dato incluirá más que solo el valor de interés, ya que los datos adicionales no considerados para nuestra categoría incluyen: la fecha de publicación de los datos económicos, los pronósticos de consenso para estos datos que conducen a su publicación y otra información. Todos ellos se enumeran en la pestaña del calendario del terminal MetaTrader. Este enlace lo llevará a una página con los tipos de eventos de calendario y cada atributo enumerado será aplicable a nuestro objeto. Todos estos datos forman entonces un objeto, o lo que llamamos un conjunto, en la categoría del calendario económico.
Desafortunadamente, el uso de funtores para el análisis y preprocesamiento de datos históricos del calendario económico solo se puede efectuar en el simulador de estrategias y no directamente desde los servidores MetaQuotes. Esto supone definitivamente un cuello de botella que superaremos exportando los datos a un archivo CSV usando un script y luego leyendo ese archivo CSV en el simulador de estrategias, como en el artículo anterior. La diferencia aquí es que hacemos esto para un ejemplar de la clase de señal del asesor y no para la clase final. Como estamos tratando con dos funtores, el script utilizado ha creado dos archivos: con el prefijo true, lo cual significa que el funtor se aplica a objetos, y con el prefijo false, lo que significa que se aplica a morfismos. Los archivos se adjuntan al artículo.
En el esquema anterior se muestra una representación gráfica de los valores convertidos del índice S&P 500.
Arquitectura de una red neuronal basada en funtores
Los funtores en calidad de perceptrones multicapa (redes neuronales) en este artículo suponen un paso adelante con respecto a las relaciones lineales o cuadráticas anteriores, que usamos al hacer coincidir categorías, e incluso objetos dentro de una categoría (ya que las relaciones de morfismo entre dos elementos se pueden definir de la misma manera). Como ya enfatizamos anteriormente, el uso de funtores implica mapear no solo los objetos de dos categorías, sino también sus correspondientes morfismos. Entonces uno puede verificar el otro, es decir, si se conocen los objetos en la categoría de un codominio, entonces estarán implícitos los morfismos y viceversa. Esto significará que estaremos tratando con dos perceptrones entre nuestras categorías.
Este artículo no explicará los conceptos básicos de los perceptrones, dado que existen numerosos artículos sobre este tema no solo en este sitio web sino en Internet en general, por eso animamos al lector a realizar su propia investigación de los antecedentes si le sirve de aclaración respecto al presente material. La arquitectura de red presentada aquí se implementó en gran medida gracias a Alglib, disponible en el IDE de MetaTrader en la carpeta Include\Math. Y así es como inicializamos el perceptrón usando la biblioteca:
//+------------------------------------------------------------------+ //| Function to train Perceptron. | //+------------------------------------------------------------------+ bool CSignalCT::Train(CMultilayerPerceptron &MLP) { CMLPBase _base; CMLPTrain _train; if(!ReadPerceptron(m_training_profit)) { _base.MLPCreate1(__INPUTS,m_hidden,__OUTPUTS,MLP); m_training_profit=0.0; } else { printf(__FUNCSIG__+" read perceptron, with profit: "+DoubleToString(m_training_profit)); } ... return(false); }
Los perceptrones usados en esta biblioteca son muy simples y constan de tres capas: una capa de entrada, una capa oculta y una capa de salida. Nuestra categoría de datos económicos contiene cuatro puntos de datos a la vez (según nuestra hipótesis), por lo que el número de entradas en la capa oculta será de cuatro. El número de puntos en la capa oculta será uno de los pocos parámetros a optimizar, pero nuestro valor predeterminado será siete. Luego, finalmente, la capa de salida mostrará un resultado: el cambio previsto en el índice S&P 500. El conocimiento de los pesos, las desviaciones y las funciones de activación resulta clave para comprender el funcionamiento de los perceptrones con conexión directa. Animamos al lector a realizar investigaciones sobre estos temas según corresponda.
Entrenando una red neuronal basada en un functor
El proceso de aprendizaje utilizando los datos históricos del calendario económico se realizará mediante el algoritmo Levenberg-Marquardt. Al igual que sucede con la propagación directa e inversa, el código es procesado por funciones AlgLib. Implementaríamos el entrenamiento usando la biblioteca de la siguiente manera:
int _info=0; CMatrixDouble _xy; CMLPReport _report; TrainingLoad(m_training_stop,_xy,m_training_points,m_testing_points); // if(m_training_points>0) { _train.MLPTrainLM(MLP,_xy,m_training_points,m_decay,m_restarts,_info,_report); if(_info>0){ return(true); } }
La parte clave aquí es rellenar la matriz XY con los datos de entrada del archivo csv en el directorio compartido. La matriz extraerá los cuatro puntos de datos definidos en cada fila de datos como datos históricos cada vez que se genere una nueva columna (o en un temporizador) y los usará para entrenar la red y generar sus pesos y desplazamientos. El rellenado de la matriz XY de entrada lo gestionará la función TrainingLoad como se muestra a continuación:
//+------------------------------------------------------------------+ //| Function Get Training Points and Initialize Training Matrix. | //+------------------------------------------------------------------+ void CSignalCT::TrainingLoad(datetime Date,CMatrixDouble &XY,int &TrainingPoints,int &TestingPoints) { TrainingPoints=0; TestingPoints=0; ResetLastError(); string _file="_s_"+m_currency+"_"+m_symbol.Name()+"_"+EnumToString(m_period)+"_"+string(m_objects)+".csv"; int _handle=FileOpen(_file,FILE_SHARE_READ|FILE_ANSI|FILE_COMMON,"\n",CP_ACP); if(_handle!=INVALID_HANDLE) { string _line=""; int _line_length=0; while(!FileIsLineEnding(_handle)) { //--- find out how many characters are used for writing the line _line_length=FileReadInteger(_handle,INT_VALUE); //--- read the line _line=FileReadString(_handle,_line_length); string _values[]; ushort _separator=StringGetCharacter(",",0); if(StringSplit(_line,_separator,_values)==6) { datetime _date=StringToTime(_values[0]); _d_economic.Let(); _d_economic.Cardinality(4); //printf(__FUNCSIG__+" initializing for: "+TimeToString(Date)+" at: "+TimeToString(_date)); if(_date<Date) { TrainingPoints++; // XY.Resize(TrainingPoints,__INPUTS+__OUTPUTS); for(int i=0;i<__INPUTS;i++) { XY[TrainingPoints-1].Set(i,StringToDouble(_values[i+1])); } // XY[TrainingPoints-1].Set(__INPUTS,StringToDouble(_values[__INPUTS+1])); } else { TestingPoints++; } } } FileClose(_handle); } else { printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError())); } }
Merece la pena señalar que una vez entrenadas, la razón por la que las redes neuronales funcionan y son populares es por su capacidad para desarrollar y reutilizar pesos y desplazamientos. En este artículo, estos pesos y desplazamientos se almacenarán con una función especial que el autor aún no está listo para compartir: en el listado encontrará un enlace a la misma en forma de biblioteca ex5, pero no el código de esta.
Normalmente, al entrenar una red, utilizamos el preprocesamiento de datos, cuyo objetivo consiste en normalizar los datos a valores comparables y dividirlos en conjuntos de entrenamiento y prueba. Sin embargo, para nuestros objetivos, entrenaremos un conjunto de datos históricos cargados al inicializar el asesor y luego lo probaremos usando una porción separada de los datos CSV, la división de los datos de entrenamiento determinada por la fecha de entrada. Como nuestro único parámetro a optimizar será el número de pesos en la capa oculta (de 5 a 12), escribiremos los pesos de la red entrenada en un archivo en el directorio compartido y al final de cada pasada de optimización, solo si los criterios de optimización de esa pasada superan los criterios de optimización del archivo ya escrito en el anterior. Si se realiza la grabación, cuando la red se inicialice en la siguiente pasada, los pesos iniciales se escribirán desde este archivo.
La propagación inversa del error (retropropagación) y el descenso de gradiente son procesados por la función MLPTrainLM, que se encuentra en la clase CMLPTrain de la biblioteca AlgLib .
Generación de señales comerciales usando funtores y redes neuronales.
La categoría S&P 500, que supone el orden lineal de los cambios de índice forma un codominio para nuestros "dos" funtores del calendario de categorías de datos económicos. Permítanme recordarles que existen “dos”, porque los objetos y los morfismos están relacionados. Así, nuestra señal sobre el periodo de prueba definido por la fecha de entrada leída del archivo CSV será generada por los pesos obtenidos al final de cada entrenamiento. El código adjunto a este artículo se entrenará cada vez que se inicialice el asesor. El artículo va acompañado de un archivo de señales que, al igual que los archivos adjuntos en artículos anteriores, se puede usar después del montaje en el wizard MQL5 a través de MetaEditor IDE. Podríamos haber practicado más con el temporizador, ya que cada nueva columna ofrece una nueva fila de datos para nuestro archivo CSV, sin embargo, este enfoque no se trata en el artículo; recomendamos al lector que lo explore por su cuenta, ya que podrá detectar rápidamente más señales emergentes.
Nuestra función GetOutput, como en artículos anteriores, será responsable de recuperar el valor en función del cual procesamos nuestra decisión comercial. Como puede ver en la lista a continuación, además de actualizar las categorías con los valores actuales, las entradas de red se preparan según las lecturas del calendario actual del archivo csv en el directorio compartido. Estas se rellenarán en el array "_x_inputs", desde el cual el array se envía a la red mediante la función MLPProcess, que forma parte de la clase CMLPBase. Esto se muestra a continuación:
//+------------------------------------------------------------------+ //| Get Output value, forecast for next change in price bar range. | //+------------------------------------------------------------------+ double CSignalCT::GetOutput(datetime Date) { if(Date>=D'2023.07.01') { printf(__FUNCSIG__+" log profit: "+DoubleToString(m_training_profit)+", account profit: "+DoubleToString(m_account.Profit())+", equity: "+DoubleToString(m_account.Equity())+", deposit: "+DoubleToString(m_training_deposit)); if(m_training_profit<m_account.Equity()-m_training_deposit) { printf(__FUNCSIG__+" perceptron write... "); m_training_profit=m_account.Equity()-m_training_deposit; WritePerceptron(m_training_profit,_MLP); } } ... _value="";_e.Let();_e.Cardinality(1); _d_economic.Get(3,_e);_e.Get(0,_value); _x_inputs[3]=StringToDouble(_value);//printf(__FUNCSIG__+" val 4: "+_value); //forward feed?... CMLPBase _base; _base.MLPProcess(_MLP,_x_inputs,_y_inputs); _output=_y_inputs[0]; //printf(__FUNCSIG__+" output is: "+DoubleToString(_output)); return(_output); }
También es posible incorporar la gestión de riesgos y el tamaño de las posiciones en un sistema comercial utilizando estas técnicas, que pueden incluir el tamaño basado en la intensidad de la señal. Por supuesto, esto requerirá la normalización del valor de la señal y, como siempre, se deberá tener mucho cuidado al cambiar los tamaños de posición. Sin embargo, estos cambios se pueden lograr creando un ejemplar especial de la clase ExpertMoney de la misma manera que usamos nuestro propio ejemplar de la clase ExpertSignal al definir los puntos de entrada y salida.
Backtesting y evaluación del desempeño
Nuestro backtest optimizará el número ideal de pesos en la capa oculta. Como van del 5 al 12, solo hay ocho opciones y, sin embargo, queremos hacer varias pruebas con cada número de pesos antes de elegir el número perfecto. Entonces, para tener múltiples ejecuciones, añadiremos un parámetro que no afectará al rendimiento del asesor pero que deberá optimizarse y, por lo tanto, añadirá ejecuciones adicionales al proceso de optimización para permitir que cada opción de número de pesos realice múltiples ejecuciones de prueba. Como hemos mencionado antes, si al final de cada ejecución el resultado de la prueba es mejor que el último archivo escrito en la carpeta compartida, entonces estos pesos reemplazarán a los escritos anteriormente. El criterio de optimización será el máximo beneficio. Realizaremos nuestras ejecuciones en un periodo de tiempo mensual porque los datos económicos del calendario se actualizarán con esa frecuencia de promedio. Hemos realizado pruebas del índice S&P 500 en un periodo mensual del 1 de julio al 1 de agosto de 2022, y nuestra mejor ejecución para el functor objeto-objeto ha producido los siguientes resultados:

De forma similar, nuestro funtor morfismo-morfismo ha producido los siguientes resultados:

El análisis de los indicadores clave de los informes sobre la reducción y el índice de ganancias muestra la mayor eficiencia del funtor morfismo-morfismo. ¿Quizá esto sea algo a lo que valga la pena prestar atención en trabajos futuros? La respuesta a esta pregunta dependerá no solo de las pruebas con valores alternativos, sino también del uso de diferentes enfoques de entrenamiento al realizar las pruebas, como aquellos que consideran si el entrenamiento debe realizarse en cada nueva barra o trimestralmente.
Conclusión
Los resultados clave de las pruebas de perceptrones son que se puede diseñar un sistema comercial usando una señal similar a la presentada en el archivo de señales. En la fase de desarrollo, debe disponerse de una categoría de dominio adecuada con datos en un formato fácilmente accesible para el simulador de la estrategias, y como las pruebas fiables suelen abarcar varios años, estos datos deberán ser amplios.
El valor del uso de perceptrones multicapa como funtores no supone un simple paso adelante. Dados los numerosos tipos y formatos que pueden utilizar las redes neuronales, esta aplicación tiene un gran potencial. El artículo ofrece enlaces a estudios adicionales sobre los perceptrones. Es un tema bien conocido y ampliamente documentado. Muchos de los conceptos ya discutidos, incluidos los límites, los colímites y las propiedades universales, se pueden formular utilizando redes neuronales.
Enlaces
En el artículo se proporcionan enlaces a artículos de la Wikipedia.
Notas a las aplicaciones
Coloque el archivo SignalCT_16_.mqh en la carpeta MQL5\include\Expert\Signal\ y el archivo ct_16.mqh en la carpeta MQL5\include\.
También podrá encontrar útiles las recomendaciones de aquí sobre cómo crear un asesor utilizando el wizard. Como se indica en el artículo, no hemos utilizado trailing stops dinámicos ni márgenes fijos para gestionar el capital. Ambos componentes forman parte de la biblioteca MQL5. Como siempre, en este artículo no pretendemos presentarle el Grial, sino ofrecerle una idea que pueda adaptar a su propia estrategia.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13116
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso