
Redes neuronales: así de sencillo (Parte 42): Procrastinación del modelo, causas y métodos de solución

Introducción
En el campo del aprendizaje por refuerzo, los modelos de redes neuronales se enfrentan con frecuencia al problema de la procrastinación, en el que el proceso de aprendizaje se ralentiza o se atasca. Los patrones de procrastinación pueden tener graves consecuencias a la hora de conseguir los objetivos establecidos y requieren de medidas adecuadas para superarlos. En este artículo analizaremos las principales causas de la procrastinación del modelo y sugeriremos métodos para resolverlas.
1. El problema de la procrastinación
Una de los principales motivos de la procrastinación del modelo es un entorno de aprendizaje inadecuado: el modelo puede encontrarse con un acceso limitado a los datos de entrenamiento o con recursos insuficientes. Las soluciones a este problema pasan por crear o actualizar el conjunto de datos, aumentar la diversidad de ejemplos de entrenamiento y añadir recursos adicionales para el mismo, como potencia de cálculo o modelos preentrenados para el aprendizaje por transferencia.
Otra razón para la procrastinación de un modelo puede ser la complejidad de la tarea que tiene que resolver, o el uso de un algoritmo de aprendizaje que requiera una gran cantidad de recursos informáticos. En este caso, la solución puede consistir en simplificar el problema o el algoritmo, optimizando los procesos computacionales y utilizando algoritmos más eficientes o el aprendizaje distribuido.
Un modelo puede procrastinar si carece de motivación para alcanzar sus objetivos. Establecer objetivos claros y pertinentes para el modelo, diseñar una función de recompensa que estimule la consecución de estos objetivos y utilizar técnicas de refuerzo como la introducción de recompensas y penalizaciones pueden ayudar a resolver este problema.
Si el modelo no recibe realimentación o no se actualiza según los nuevos datos, puede procrastinar su desarrollo. La solución consiste en establecer ciclos regulares de actualización del modelo basados en los nuevos datos y realimentaciones, y desarrollar mecanismos de seguimiento y control del progreso del aprendizaje.
Es importante evaluar periódicamente el progreso del modelo y los resultados del entrenamiento. Esto ayudará a ver los progresos realizados y a identificar posibles problemas o puntos débiles. Las evaluaciones periódicas permiten realizar ajustes oportunos en su aprendizaje y evitar la procrastinación de tareas.
Ofrecer al modelo una amplia variedad de tareas y un entorno estimulante puede ayudar a evitar la procrastinación. La variación de tareas ayudará a mantener al modelo interesado y motivado, mientras que un entorno estimulante, como competiciones o elementos de juego, puede fomentar la participación activa y la progresión del modelo.
Los patrones de procrastinación pueden relacionarse con la falta de actualización y mejora. Resulta importante analizar periódicamente los resultados y mejorar iterativamente el modelo a partir de los comentarios y las nuevas ideas. El desarrollo gradual de patrones y el progreso visible pueden ayudarle a hacer frente a la procrastinación.
Crear un entorno de aprendizaje positivo y de apoyo para el modelo supone un aspecto esencial del entrenamiento de modelos mediante refuerzo. Las investigaciones demuestran que los ejemplos positivos contribuyen a un entrenamiento del modelo más eficaz y dirigido, ya que el modelo busca la elección más óptima, y las penalizaciones por acciones erróneas conducen a una menor probabilidad de elegir acciones erróneas. Al mismo tiempo, las recompensas positivas indican explícitamente al modelo la elección correcta y aumentan sustancialmente la probabilidad de que esas acciones se repitan.
Cuando un modelo recibe una recompensa positiva por una determinada acción, le prestará más atención y se inclinará a repetir esa acción en un futuro. Este mecanismo de motivación ayudará al modelo a buscar e identificar las estrategias más acertadas para alcanzar sus objetivos.
Por último, para solucionar de forma eficaz la procrastinación del modelo, es necesario analizar las causas subyacentes de la misma. Identificar sus causas específicas nos permitirá tomar medidas concretas para su solución. Esto puede incluir la auditoría de los procesos de aprendizaje, la detección de zonas de dificultad, problemas de recursos o ajustes subóptimos del modelo.
Ser consciente de las condiciones cambiantes y adaptarse a las mismas puede ayudarle a evitar la procrastinación. Actualizar periódicamente el modelo según los nuevos datos y cambios en la tarea de aprendizaje ayudará a que siga siendo pertinente y eficaz. Además, la consideración de factores como nuevos requisitos o limitaciones permitirá al modelo adaptarse y evitar el estancamiento.
Establecer pequeños objetivos y etapas intermedios puede ayudar a dividir una gran tarea en partes más manejables y alcanzables. Esto ayudará al modelo a percibir los progresos y le mantendrá motivado mientras aprende.
Para superar con éxito la procrastinación en un modelo de aprendizaje por refuerzo, deberemos utilizar diversos enfoques y estrategias. Este enfoque global ayudará al modelo a superar la procrastinación y lograr los mejores resultados en su aprendizaje. Mediante la combinación de diversas técnicas, como la mejora del entorno de entrenamiento, el establecimiento de objetivos claros, la evaluación periódica de los progresos y el uso de la motivación, el modelo podrá superar la procrastinación y avanzar hacia la consecución de sus objetivos de aprendizaje.
2. Pasos prácticos para la solución
Una vez analizados los aspectos teóricos del problema, ahora pasaremos a su aplicación práctica.
En el artículo anterior dejamos nuestro modelo con un comentario sobre la necesidad de realizar más entrenamientos para minimizar las operaciones perdedoras. Sin embargo, mientras proseguíamos el entrenamiento, nos encontramos con una situación en la que el asesor experto no hacía ni una sola operación durante todo el periodo de entrenamiento.
Este fenómeno, denominado "procrastinación del modelo", es un grave problema que requiere atención y solución por nuestra parte.

2.1. Análisis causal
Para superar el modelo de procrastinación en el aprendizaje por refuerzo, es importante comenzar por el análisis de la situación actual e identificar las causas de este fenómeno. El análisis nos ayudará a comprender por qué el modelo no realiza transacciones y qué puede ajustarse para mejorar su rendimiento.
El modelo entrenado se prueba utilizando el asesor experto "Test.mq5", que realiza una selección codiciosa de agente y acción. Debemos tener en cuenta que cada ejecución posterior del asesor experto con los mismos parámetros y periodo de prueba dará lugar a la reproducción de la pasada anterior con alta precisión. Esto nos permitirá añadir puntos de control y analizar el rendimiento del asesor en cada ejecución.
Añadir puntos de control y analizar el rendimiento del asesor en cada ejecución nos ofrecerá una mayor robustez y confianza en el resultado del entrenamiento del modelo con refuerzo. Así podremos entender mejor cómo aplicará el modelo sus conocimientos y predicciones sobre datos reales, y también hacer las inferencias y ajustes oportunos para mejorar su rendimiento.
Para evaluar el rendimiento del planificador, introduciremos el vector ModelsCount, que contendrá el número de veces que se ha seleccionado cada agente. Para ello, declararemos el vector ModelsCount en el bloque de variables globales:
vector<float> ModelsCount;
Después, en la función OnInit, inicializaremos este vector con un tamaño correspondiente al número de agentes que se van a utilizar:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); //--- return(INIT_SUCCEEDED); }
En la función OnTick, después de cada pasada directa del planificador, incrementaremos el contador del agente correspondiente en el vector ModelsCount:
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ....... //--- if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; Schedule.getResults(Result); int model = GetAction(Result, 0, 1); ModelsCount[model]++; //--- ........ ........ }
Por último, al desinicializar el asesor, mostraremos los resultados del recuento en el diario de registro:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Print(ModelsCount); delete Result; }
Por ello, añadiremos una función para contar el número de selecciones de cada agente y enviar los resultados del recuento al registro cuando se desinicialice el asesor. Esto nos permitirá evaluar el rendimiento del planificador y obtener información sobre la frecuencia con la que se ha seleccionado cada agente durante la ejecución del asesor.
Después de añadir nuestro primer punto de control, ejecutaremos el asesor en el simulador de estrategias sin cambiar los parámetros ni el periodo de prueba. Los resultados han confirmado nuestros temores. Observamos que el planificador solo ha utilizado un agente a lo largo de nuestras pruebas.

Esta observación indica que el planificador puede estar sesgado a favor de un agente concreto, ignorando la investigación de otros agentes disponibles. Este sesgo puede obstaculizar la eficacia de nuestro modelo de aprendizaje por refuerzo y limitar su capacidad para detectar estrategias con mayor eficacia.
Para resolver este problema, deberemos investigar las razones por las que el planificador prefiere utilizar un solo agente.
Para seguir analizando las razones de este comportamiento del modelo, añadiremos dos puntos de control adicionales. Ahora nos centraremos en la dinámica de cambio de las distribuciones en la salida de los modelos según las condiciones cambiantes del entorno. Para ello, introduciremos dos vectores adicionales: prev_scheduler y prev_actor. En estos vectores guardaremos los resultados de la pasada anterior del planificador y de los agentes respectivamente.
vector<float> prev_scheduler; vector<float> prev_actor;
Esto nos permitirá comparar las distribuciones actuales con las anteriores y estimar sus cambios. Si observamos que las distribuciones cambian significativamente con el tiempo o en respuesta a cambios en el entorno, esto podría indicar que el modelo puede resultar demasiado sensible a los cambios o inestable en sus estrategias.
La adición de estos vectores a nuestro modelo nos permite obtener información más detallada sobre la dinámica de cambio de las estrategias y distribuciones, lo que a su vez nos ayuda a comprender las razones que favorecen a un agente concreto y a tomar medidas para solucionarlo.
Como en el caso anterior, inicializaremos los vectores en el método OnInit para prepararlos para el control de datos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); prev_scheduler.Init(Models); prev_actor.Init(Result.Total()); //--- return(INIT_SUCCEEDED); }
El control real de los datos se realiza en el método OnTick.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return; Actor.getResults(Result); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; vector<float> temp; Schedule.getResults(Result); Result.GetData(temp); float delta = MathAbs(prev_scheduler - temp).Sum(); int model = GetAction(Result, 0, 1); prev_scheduler = temp; Actor.getResults(Result); Result.GetData(temp); delta = MathAbs(prev_actor - temp).Sum(); prev_actor = temp; ModelsCount[model]++; //--- ........ ........ //--- }
En este caso, queremos evaluar cómo influye un cambio en las condiciones del entorno en el resultado del modelo. Como resultado de este experimento, esperamos ver una distribución de probabilidad única en la salida del modelo para cada vela de la muestra de prueba. Es decir, queremos observar cambios en las estrategias del modelo en respuesta a los cambios en las condiciones del mercado.
No enviaremos los análisis al diario de registro, ya que esto redundaría en una gran cantidad de información. En su lugar, usaremos el modo de depuración para ver cómo cambian los valores. Para reducir la cantidad de valores a comparar, solo comprobaremos el desvío total de los vectores.
Desgraciadamente, durante la prueba no hemos encontrado desvíos. Esto significa que la distribución de probabilidad del resultado del modelo sigue siendo prácticamente la misma en todos los estados del entorno.
Esta observación indica que el modelo no se adapta a un entorno cambiante y no considera las diferencias en las condiciones del mercado. Existen varias razones posibles para este comportamiento del modelo y distintos enfoques para resolverlas:
- Limitaciones del conjunto de datos de entrenamiento: Si el conjunto de datos de entrenamiento no contiene una variedad suficiente de situaciones, es posible que el modelo no aprenda a responder a las nuevas condiciones de forma adecuada. Una solución podría ser ampliar y diversificar el conjunto de datos de entrenamiento para incluir una gama más amplia de escenarios y condiciones de mercado cambiantes.
- Entrenamiento insuficiente del modelo: Puede que el modelo no se haya entrenado lo suficiente o que no haya pasado por suficientes épocas de entrenamiento para adaptarse a diferentes entornos. En tal caso, ampliar la duración del entrenamiento o usar métodos adicionales como el reentrenamiento (fine-tuning) puede ayudar al modelo a adaptarse mejor.
- Falta de complejidad del modelo: Es posible que el modelo no sea lo bastante sofisticado para captar diferencias sutiles en los estados del entorno. En este caso, aumentar el tamaño y la complejidad del modelo, por ejemplo, añadiendo más capas o aumentando el número de neuronas, puede ayudar al modelo a captar y procesar mejor las diferencias en los datos.
- Elección incorrecta de la arquitectura del modelo: Quizá la arquitectura actual del modelo no sea la adecuada para adaptarse a un entorno cambiante. En tal caso, revisar la arquitectura del modelo podría mejorar su capacidad de adaptación a los cambios del entorno.
- Función de recompensa no adecuada: Es posible que la función de recompensa del modelo no sea lo suficientemente informativa o adecuada: en tal caso, revisar la función de recompensa y añadirle factores más relevantes puede ayudar al modelo a tomar decisiones más inteligentes en un entorno cambiante.
Todos los planteamientos mencionados requieren experimentación, pruebas y ajustes adicionales con el modelo para lograr una mejor adaptación al entorno cambiante y mejorar su rendimiento.
Para averiguar en qué punto exacto de nuestros modelos se pierde información sobre los cambios de estado del sistema, deberemos analizar la arquitectura de cada capa. En el modo de depuración, comprobaremos el cambio en los resultados a la salida de cada capa de nuestros modelos.
Comenzaremos con la capa CNeuronBaseOCL totalmente conectada. En esta capa, comprobaremos si se guarda la información sobre el cambio de estado del sistema. A continuación, comprobaremos la capa de normalización de datos por lotes CNeuronBatchNormOCL para asegurarnos de que no distorsiona los datos de cambio de estado. Luego, analizaremos la capa convolucional CNeuronConvOCL para ver cómo gestiona la información sobre los cambios en el estado del sistema. Por último, analizaremos la capa multimodelo completamente conectada CNeuronMultiMultiModel para determinar cómo tiene en cuenta el cambio de estado entre modelos.
Realizar este análisis nos ayudará a identificar en qué capa de la arquitectura del modelo se pierde información sobre el estado cambiante del sistema y qué capas pueden optimizarse o cambiarse para mejorar el rendimiento del modelo a la hora de adaptarse al entorno cambiante.
Para controlar y monitorear la salida de cada capa del modelo, implementaremos el vector prev_output en la clase CNeuronBaseOCL. Recordemos que esta clase es la clase básica para todas las demás clases de capas neuronales, y todas las demás capas la heredan. Añadiendo un vector al cuerpo de esta clase, nos aseguramos de que esté presente en todas las capas del modelo.
class CNeuronBaseOCL : public CObject { protected: ........ ........ vector<float> prev_output;
En el método de inicialización de la clase, estableceremos un tamaño del vector igual al número de neuronas de esta capa.
bool CNeuronBaseOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { ........ ........ //--- prev_output.Init(numNeurons); //--- ........ ........ //--- return true; }
En el método feedForward, encargado de realizar una pasada directa del modelo, añadiremos un punto de control al final del método una vez completadas todas las iteraciones. Debemos señalar que todas las operaciones de este método se realizan en el contexto de OpenCL. Para controlar los datos, necesitaremos cargar los resultados de las operaciones en la memoria principal, pero esto puede ocupar un tiempo considerable. Ya hemos intentado minimizar esta carga con anterioridad, dejando solo la carga de los resultados del modelo. En este caso, deberemos cargar los resultados de cada capa neuronal. No obstante, este bloque de código puede eliminarse o comentarse más adelante si no necesitamos controlar los datos.
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { ........ ........ //--- vector<float> temp; Output.GetData(temp); float delta=MathAbs(temp-prev_output).Sum(); prev_output=temp; //--- return true; }
También añadiremos un control similar a los métodos de pasada directa de todas las clases de capas neuronales analizadas. Esto nos permitirá controlar los valores a la salida de cada capa e identificar el posible lugar dónde se está "perdiendo" el cambio en el estado del sistema. Añadiendo los bloques de código apropiados a los métodos de pasada directa de cada clase de capa, podremos almacenar y analizar los resultados de la capa en cada iteración del entrenamiento del modelo.
El control de datos lo realizaremos en el modo de depuración.
Tras analizar los resultados, hemos descubierto que el bloque de preprocesamiento de datos, compuesto por una capa de datos de origen, una capa de normalización por lotes y dos bloques consecutivos de capas neuronales (de convolución y completamente conectada), no funciona correctamente. Asimismo, hemos observado que, tras la segunda capa de convolución, el modelo no responde a los cambios de estado del sistema analizado.
CNeuronBaseOCL -> CNeuronBatchNormOCL -> CNeuronConvOCL -> CNeuronBaseOCL -> CNeuronConvOCL -> CNeuronBaseOCL
Esto se observa tanto en los agentes como en el planificador, en el que utilizábamos un bloque de preprocesamiento de datos similar. Los resultados de la prueba han resultado idénticos en ambos casos.
Aunque esta arquitectura había mostrado resultados positivos en experimentos anteriores, en este caso ha resultado ineficaz. Así pues, nos vemos en la necesidad de introducir cambios en la arquitectura de los modelos utilizados.
2.2. Cambiando la arquitectura de los modelos
Tras realizar el análisis pertinente, hemos concluido que la arquitectura del modelo actual resulta ineficiente. Ahora deberemos dar un paso atrás y contemplar la arquitectura creada anteriormente desde una nueva perspectiva para evaluar posibles formas de optimizarla.
En el modelo actual, introduciremos la situación del mercado y el estado de nuestra cuenta como datos de entrada para los agentes, que analizarán la situación y sugerirán posibles acciones. Luego añadiremos el resultado de los agentes a los datos de origen recogidos previamente y lo transmitiremos como entrada al planificador, que seleccionará un agente para realizar la acción.
Imaginemos ahora un departamento de inversiones en el que los empleados analizan la situación del mercado y comunican los resultados de sus análisis al jefe del departamento. Este combina dichos resultados con los datos de origen y realiza análisis adicionales para seleccionar a un agente cuya predicción coincida con la suya. No obstante, este planteamiento puede reducir la eficacia del departamento.
Con este tipo de organización del trabajo, el jefe del departamento no solo tiene que analizar él mismo la situación del mercado, sino también estudiar los resultados del trabajo de los empleados. Esto añade una carga laboral adicional y no siempre tiene valor práctico en la toma de decisiones. El intento de proporcionar toda la información posible en cada etapa puede hacer que se pierda la idea básica de los modelos jerárquicos, que consiste en dividir la tarea en componentes más pequeños.
En este contexto, el rendimiento de un departamento de este tipo, basado por analogía en nuestro modelo, puede ser inferior al del propio jefe de departamento, ya que no solo tiene que ocuparse de analizar la situación del mercado, sino también de comprobar el rendimiento de los empleados, que pueden ser menos eficaces en la toma de decisiones.
Del escenario presentado se desprende que la eficacia del departamento de inversiones mejorará si dividimos el análisis de la situación del mercado entre los agentes y el planificador. En este modelo, los agentes se especializarán en el análisis del mercado, mientras que el planificador se encargará de tomar decisiones basándose en las previsiones de los agentes, sin tener que realizar su propio análisis de la situación del mercado.
Los agentes se encargarán de analizar los datos del mercado, lo cual incluirá la realización de análisis técnicos y fundamentales. Asimismo, investigarán y evaluarán la situación actual del mercado, identificarán las tendencias y sugerirán posibles líneas de actuación. Sin embargo, a la hora de realizar su análisis, no tendrán en cuenta el estatus.
El planificador, a su vez, será el responsable de la gestión de riesgos y la toma de decisiones basadas en el análisis de los agentes. Para ello, utilizará las previsiones y recomendaciones facilitadas por los agentes y realizará análisis adicionales de la cuenta y otros factores relacionados con la gestión de riesgos. Basándose en la información obtenida, el planificador tomará la decisión final sobre las acciones específicas dentro de la estrategia de inversión.
Esta separación de funciones permite a los agentes centrarse en el análisis del mercado sin distraerse con el estado de las cuentas, lo cual aumentará su especialización y la precisión de sus previsiones. El planificador, por su parte, puede centrarse en la evaluación del riesgo y la toma de decisiones basadas en las previsiones de los agentes, lo cual le permite gestionar el portafolio con eficacia y minimizar el riesgo.
Este planteamiento mejorará la toma de decisiones en el departamento de inversiones, ya que cada miembro del equipo se centrará en su especialidad, lo que dará lugar a análisis y previsiones más precisos. Esto puede mejorar el rendimiento de nuestro modelo y posibilitar decisiones de inversión más fundamentadas y acertadas.
Considerando la información presentada, procederemos a revisar la arquitectura de nuestro modelo. En primer lugar, realizaremos cambios en la capa de datos de entrada del agente para que se centre únicamente en analizar la situación del mercado, eliminando las neuronas encargadas de analizar el estado de la cuenta;
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *scheduler) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * 12); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
así, en el bloque de preprocesamiento de datos, eliminaremos las capas totalmente conectadas, dejando solo la capa de normalización por lotes y 2 capas de convolución.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El bloque de decisión permanecerá inalterado.
Asimismo, hemos tomado la decisión de cambiar la arquitectura del Crítico. Al igual que antes, el Crítico analizará tanto las condiciones del mercado como el estado de las cuentas. Esto se debe a que el valor del siguiente estado dependerá no solo de la última acción realizada, sino también de las acciones anteriores expresadas en las posiciones abiertas y el beneficio o las pérdidas acumulados.
También hemos llegado a la conclusión de que el valor del estado posterior no debería depender de la estrategia elegida. Nuestro objetivo es maximizar los beneficios potenciales, independientemente de la estrategia concreta empleada. Considerando esto, hemos introducido algunos cambios en el modelo del Crítico.
Concretamente, hemos simplificado la arquitectura del Crítico eliminando las capas multimodelo completamente conectadas. En su lugar, hemos añadido un modelo de decisión totalmente parametrizado. Esto nos permitirá conseguir un enfoque más general y flexible en el que la estrategia no influya directamente en la evaluación del valor del estado.
Este cambio en la arquitectura del modelo del Crítico nos ayudará a separar el análisis de la situación del mercado y la toma de decisiones, lo cual simplificará el proceso y nos permitirá centrarnos en la maximización del beneficio independientemente de la estrategia elegida.
Además, en el bloque de preprocesamiento de datos, hemos realizado cambios similares a los cambios en la arquitectura del agente: hemos simplificado la arquitectura eliminando las capas completamente conectadas y dejando solo la capa de normalización por lotes y dos capas de convolución.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (int)(HistoryBars * 12 + 9); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 150; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.optimization = ADAM; descr.activation = TANH; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = TANH; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
A continuación, hemos realizado una importante simplificación de la arquitectura del planificador. La renuncia al análisis de la situación del mercado ha reducido considerablemente el tamaño de la capa de datos de entrada. Como resultado, nos hemos deshecho casi por completo del bloque de preprocesamiento de datos, dejando únicamente la capa de normalización por lotes. Hemos decidido utilizar la normalización por lotes para analizar los valores absolutos del estado de la cuenta. Actualmente utilizamos valores completamente normalizados de la salida del modelo de agentes. En el futuro, es posible que pasemos a valores relativos del estado de la cuenta y eliminemos la capa de normalización de datos.
En el bloque de decisión, aplicaremos un modelo de perceptrón simple con una capa SoftMax en la salida. Este modelo nos permitirá obtener una distribución de la probabilidad sobre los diferentes Agentes y seleccionar la acción más adecuada según estas probabilidades.
Esta simplificación de la arquitectura del planificador nos permitirá tomar decisiones de forma más eficiente considerando únicamente los resultados de los análisis de los agentes. Esto reducirá la complejidad computacional y la dependencia respecto a datos adicionales.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (9 + 40); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 10; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 10; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
Durante el entrenamiento del modelo, usaremos tres asesores: cada uno de ellos desempeñará una función diferente. Para evitar confusiones y reducir la posibilidad de errores, hemos decidido trasladar la función de descripción de la arquitectura del modelo al archivo "Trajectory.mqh", que forma parte de la biblioteca que describe las clases y estructuras utilizadas en nuestro modelo. Esto nos permite utilizar una única arquitectura de modelos en todos los asesores y posibilita la sincronización automática de los cambios en el funcionamiento de los tres asesores.
Asimismo, hemos modificado la estructura de los modelos, incluida la separación del flujo de datos de entrada, lo cual ha requerido cambios en la estructura de la descripción del estado actual. Hemos reservado un array aparte para registrar el estado de la cuenta, de modo que pueda considerarse en los análisis y la toma de decisiones. Este cambio permitirá gestionar y utilizar mejor la información sobre el estado de la cuenta durante el entrenamiento y el funcionamiento de los modelos.
struct SState { float state[HistoryBars * 12]; float account[9]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); } };
Como resultado de los cambios en la estructura del modelo, también hemos tenido que realizar cambios en los métodos de gestión de archivos. El código completo de la estructura actualizada y los métodos vinculados está disponible en el archivo adjunto para su revisión.
2.3. Cambios en el proceso de recogida de datos
En el siguiente paso, realizaremos cambios en el proceso de recogida de datos, que se llevará a cabo en el asesor experto "Research.mq5".
Como ya hemos dicho, el uso de ejemplos positivos en el entrenamiento del modelo aumenta su eficacia. Por lo tanto, hemos introducido una restricción sobre la rentabilidad mínima de las transacciones que deben guardarse en la base de datos de ejemplo. El nivel de esta rentabilidad mínima vendrá determinado por el parámetro externo "ProfitToSave".
Además, hemos introducido parámetros externos para limitar los niveles de take profit y stop loss y así reducir la incidencia de las posiciones largas. Los valores de estos parámetros se fijarán en la divisa del depósito y permitirán limitar la duración del mantenimiento de la posición y controlar indirectamente el volumen de las posiciones abiertas.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input double ProfitToSave = 10; input double MoneyTP = 10; input double MoneySL = 5;
Los cambios en las estructuras de almacenamiento de datos y en las arquitecturas de los modelos nos han obligado a modificar las operaciones de recopilación y preparación de datos para la pasada directa de los modelos. Al igual que antes, empezaremos a recopilar los datos sobre el estado del mercado en el array "state",
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
y luego almacenaremos la información del estado de la cuenta en el array "account".
//--- sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
Para la pasada directa, con la arquitectura actualizada del modelo de Agente, solo necesitaremos el estado del mercado del array "state".
State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return;
Para proporcionar los datos de entrada para la pasada directa del Planificador, necesitaremos combinar los datos del estado de la cuenta y los resultados de la pasada directa del modelo de agente.
Actor.getResults(Result); State1.AssignArray(sState.account); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return;
Como resultado de la pasada directa de los dos modelos, muestrearemos y seleccionaremos una acción. Este proceso se mantendrá sin cambios. No obstante, añadiremos el análisis de las ganancias y las pérdidas acumuladas. Si el valor de las ganancias o pérdidas acumuladas alcanza los umbrales indicados, indicaremos la acción de cierre de todas las posiciones.
Debemos señalar que nuestro modelo solo incluye la acción de cierre de todas las posiciones. Por lo tanto, al analizar las pérdidas y ganancias acumuladas, sumaremos el valor de todas las posiciones, independientemente de su dirección.
int act = GetAction(Result, Schedule.getSample(), Models); double profit = buy_profit + sell_profit; if(profit >= MoneyTP || profit <= -MathAbs(MoneySL)) act = 2;
También hemos introducido cambios en la función de recompensa: hemos optado por excluir el impacto de los cambios en la propia equidad, lo cual ha dado lugar a una recompensa más escasa. Sin embargo, reconocemos que durante el comercio en los mercados financieros, solo el cambio en el balance tiene valor en última instancia. Esto se ha tenido en cuenta al ajustar la función de recompensa.
El código completo de todos los métodos y funciones del asesor experto se puede encontrar en el archivo adjunto.
2.4. Cambios en el proceso de aprendizaje
También hemos introducido cambios en el entrenamiento de los modelos, haciendo hincapié en el entrenamiento paralelo de todos los modelos y agentes. En concreto, hemos cambiado nuestro enfoque sobre la transmisión de recompensas en la pasada inversa. Antes solo especificábamos la recompensa para el agente seleccionado, pero ahora queremos transmitir la distribución de recompensas completa a todos los agentes. Esto permitirá al Planificador evaluar de forma más completa el posible impacto de cada agente y reducir la probabilidad de seleccionar un único agente para todos los estados, que es lo que hemos observado antes.
Por la teoría de probabilidad, sabemos que la probabilidad de un suceso complejo es igual al producto de las probabilidades de sus componentes. En nuestro caso, tenemos la distribución de probabilidad de las elecciones de los agentes y la distribución de probabilidad de la elección de acciones de cada agente. En la base de datos de ejemplos, también tenemos acciones específicas y sus correspondientes recompensas del sistema. Para preparar los datos para la pasada inversa del planificador, multiplicaremos los elementos del vector de probabilidades de la selección de un agente por los elementos del vector de probabilidades de que dicha acción sea elegida por cada agente.
Para transmitir la recompensa completa al planificador, aplicaremos la función SoftMax para normalizar las probabilidades resultantes y, a continuación, multiplicaremos el vector resultante por la recompensa externa. En este caso, ajustaremos preliminarmente la recompensa externa según el valor del estado, lo cual nos permitirá estimar la desviación respecto a la trayectoria óptima.
void Train(void) { ........ ........ Actor.getResults(ActorResult); Critic.getResults(CriticResult); State1.AssignArray(Buffer[tr].States[i].account); State1.AddArray(ActorResult); if(!Scheduler.feedForward(GetPointer(State1), 12, false)) return; Scheduler.getResults(SchedulerResult); //--- ulong actions = ActorResult.Size() / Models; matrix<float> temp; temp.Init(1, ActorResult.Size()); temp.Row(ActorResult, 0); temp.Reshape(Models, actions); float reward=(Buffer[tr].Revards[i] - CriticResult.Max())/100; int action=Buffer[tr].Actions[i]; SchedulerResult=SchedulerResult*temp.Col(action); SchedulerResult.Activation(SchedulerResult,AF_SOFTMAX); SchedulerResult = SchedulerResult * reward; Result.AssignArray(SchedulerResult); //--- if(!Scheduler.backProp(GetPointer(Result))) return;
Para entrenar al Crítico, simplemente transmitiremos una recompensa externa no ajustada para la acción correspondiente.
CriticResult[action] = Buffer[tr].Revards[i]; Result.AssignArray(CriticResult); //--- if(!Critic.backProp(GetPointer(Result), 0.0f, NULL)) return;
Al tratar con modelos de agentes, tendremos en cuenta que el uso de cualquier estrategia puede dar lugar tanto a ganancias como a pérdidas. En algunos casos, tras una entrada fallida en una posición, será importante tener la determinación de salir a tiempo y limitar las pérdidas. Por lo tanto, no podemos descartar por completo las acciones con recompensas negativas, porque en algunos casos otras acciones podrían tener un efecto negativo aún mayor. Lo mismo ocurrirá con las recompensas positivas.
Al preparar los datos para la pasada inversa de los modelos de agentes, simplemente ajustaremos los resultados de la última pasada directa para tener en cuenta la probabilidad de que cada agente elija una acción y la recompensa externa del sistema. Para mantener la integridad de la distribución de probabilidad de cada agente, normalizaremos la distribución ajustada utilizando la función SoftMax.
//--- for(int r = 0; r < Models; r++) { vector<float> row = temp.Row(r); row[action] += row[action] * reward; row.Activation(row, AF_SOFTMAX); temp.Row(row, r); } temp.Reshape(1, ActorResult.Size()); Result.AssignArray(temp.Row(0)); //--- if(!Actor.backProp(GetPointer(Result))) return;
En los archivos adjuntos podrá ver el código completo de todos los asesores expertos, así como sus funciones utilizadas durante el trabajo.
Para iniciar el proceso de entrenamiento del modelo, ejecutaremos el asesor experto "Research.mq5" en el modo de optimización del simulador de estrategias, similar al descrito en el artículo sobre el algoritmo Go-Explore. La principal diferencia en este caso será la especificación de un nivel mínimo de rendimiento de la pasada que determinará los ejemplos almacenados en la base de datos. Esto ayudará a aumentar la eficacia del entrenamiento del modelo, ya que nos centraremos en los ejemplos positivos.
Sin embargo, cabe destacar un detalle importante: Para lograr una exploración más diversa del entorno y aumentar la cobertura de las estrategias de comportamiento, podemos incorporar la optimización de los parámetros de take profit y stop loss al proceso de recopilación de ejemplos. Esto permitirá a nuestro modelo aprender más estrategias diferentes y encontrar puntos óptimos de salida de las posiciones.

Tras crear una base de datos de ejemplos, iniciaremos el proceso de entrenamiento de modelos utilizando el asesor experto "Study2.mq5". Para ello, adjuntaremos el asesor experto al gráfico del instrumento seleccionado y especificaremos el número de iteraciones que determinará cuántas veces se actualizarán los parámetros del modelo.
La ejecución del asesor experto "Study2.mq5" en un gráfico permite al modelo utilizar los ejemplos recopilados para entrenarse y ajustar sus parámetros. Durante el proceso de aprendizaje, el modelo mejorará y se adaptará al entorno del mercado para tomar decisiones más precisas y aumentar su eficacia.
Comprobaremos los resultados del entrenamiento del modelo usando una única ejecución en el simulador de estrategias del asesor experto "Test.mq5". Es de esperar que tras la primera iteración de entrenamiento del modelo, su resultado diste mucho del esperado: podría no ser rentable.


O incluso generar beneficios, pero la línea de balance estará muy lejos de nuestras expectativas.

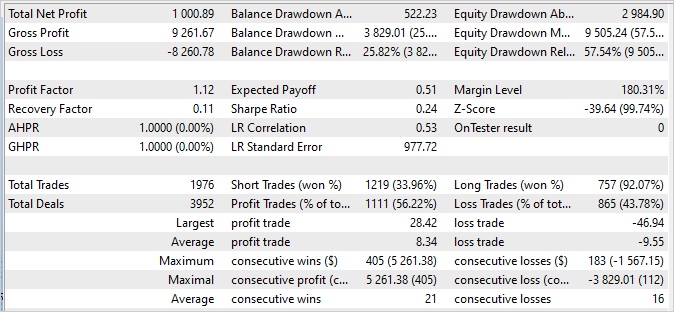
Dicho esto, podemos ver cómo nuestro Planificador usa casi todos los agentes en cierta medida.


Para detectar acciones erróneas del modelo, añadiremos un bloque para recoger información sobre los estados visitados, las acciones realizadas y las recompensas externas recibidas en nuestro asesor de prueba "Test.mq5". Este bloque de recogida de datos es similar al usado en el asesor para recoger ejemplos.
Debemos señalar que en el asesor de prueba utilizamos una selección codiciosa de agentes y acciones. Esto significa que todos los pasos que se dan están determinados por la estrategia de nuestro modelo, y por lo tanto, añadiremos todas las pasadas a la base de datos de ejemplos independientemente de su rentabilidad. La incorporación de dichos datos a nuestra base de datos de ejemplos nos permitirá ajustar y optimizar la estrategia comercial de nuestro modelo.
Recopilando información sobre los estados visitados, las acciones realizadas y las recompensas recibidas, podremos analizar el rendimiento del modelo y determinar qué acciones llevan a resultados deseables y cuáles a resultados indeseables. Esta información nos permitirá mejorar la eficacia de los modelos y la precisión de sus decisiones en las posteriores iteraciones de su entrenamiento.
Para ampliar la base de ejemplos positivos y obtener más datos para entrenar nuestro modelo, será esencial ejecutar el asesor de recopilación de ejemplos en el modo de optimización del simulador de estrategias.
No obstante, debemos señalar la necesidad de alternar los procesos de recogida de ejemplos y de entrenamiento de modelos. Durante la recogida de ejemplos, muestreamos acciones partiendo de la distribución de probabilidad generada por el modelo. Esto significa que la recolección de ejemplos tendrá cierta direccionalidad, y los nuevos ejemplos estarán a poca distancia de la elección de acción codiciosa. Esto permitirá una exploración más completa del entorno en una dirección determinada y enriquecerá la base de ejemplos con datos útiles.
La alternancia entre la recogida de ejemplos y el entrenamiento del modelo permitirá a este hacer un uso eficaz de los nuevos datos, mejorando su estrategia según la información obtenida. De este modo, con cada nueva iteración, el modelo adquirirá más experiencia y se adaptará a la dirección requerida de la negociación.
3. Simulación
Tras realizar varias iteraciones de recopilación de ejemplos, entrenamiento y pruebas, hemos conseguido un modelo capaz de generar beneficios en la muestra de entrenamiento con un factor de beneficio de 114,53. En los 4 primeros meses de 2023 en los que hemos entrenado el modelo, se han realizado 286 transacciones. De ellas, solo 16 han resultado no rentables. El factor de recuperación de la muestra de entrenamiento ha sido de 1,3, lo que indica la capacidad del modelo para recuperarse rápidamente de las pérdidas.
El tiempo de mantenimiento de las posiciones abiertas se ha distribuido uniformemente entre 1 y 198 horas, con un tiempo medio de mantenimiento de 72 horas y 59 minutos. Esto indica que el modelo puede tomar decisiones tanto a corto como a largo plazo, según las condiciones actuales del mercado.
En conjunto, estos resultados sugieren que el modelo presenta una alta rentabilidad, una baja proporción de transacciones perdedoras, capacidad de recuperación rápida y flexibilidad en el tiempo de mantenimiento de la posición. Entonces podemos ver que se trata de una confirmación positiva de la eficacia del modelo y de su potencial de aplicación en condiciones comerciales reales.



Debemos destacar que el gráfico de balance de las 2 semanas siguientes, que no se encuentran en la muestra de entrenamiento, demuestra estabilidad y ninguna diferencia significativa respecto al gráfico de la muestra de entrenamiento. Si bien las cifras son un poco más bajas, siguen siendo decentes:
- El factor de beneficio es de 15,64, lo cual indica que el modelo es muy rentable con respecto al riesgo.
- El factor de recuperación es de 1,07, lo que indica la capacidad del modelo para recuperarse de las transacciones perdedoras.
- De las 89 operaciones realizadas, 80 se han cerrado con beneficio, lo que indica una elevada proporción de transacciones con éxito.
Estos resultados confirman la estabilidad y solidez del modelo con los datos comerciales posteriores. Aunque los valores pueden diferir ligeramente de la muestra de entrenamiento, siguen siendo impresionantes y confirman el potencial del modelo para comerciar con éxito en el mundo real.


Los informes del simulador de estrategias se encuentran en el anexo.
Conclusión
En este artículo hemos analizado el problema de la procrastinación de modelos y sugerido enfoques eficaces para superarlo. Utilizando el algoritmo Scheduled Auxiliary Control, hemos desarrollado un enfoque para entrenar modelos de comercio automatizado en los mercados financieros.
Asimismo, hemos presentado una arquitectura jerárquica compuesta por varios modelos que interactúan entre sí. Cada modelo es responsable de determinados aspectos de la toma de decisiones. Esta estructura modular nos permite superar eficazmente la procrastinación dividiendo las tareas en subtareas más pequeñas pero interrelacionadas.
También hemos estudiado la recopilación de ejemplos y algunas técnicas de entrenamiento y prueba de modelos que nos permiten entrenar eficazmente los modelos con datos reales y adaptarlos a las condiciones cambiantes del mercado. La incorporación de una amplia variedad de estrategias y el análisis de las ganancias y pérdidas acumuladas nos permite tomar decisiones con conocimiento de causa y minimizar los riesgos.
Los resultados de nuestros experimentos demuestran que el enfoque propuesto puede superar la procrastinación y lograr un comercio estable y rentable. Además, los modelos muestran una alta rentabilidad y estabilidad en los datos de entrenamiento y los datos posteriores, lo que valida su rendimiento en el mundo real.
En general, nuestro planteamiento permite a los modelos aprender y adaptarse eficazmente a las condiciones del mercado y tomar decisiones con conocimiento de causa. Un mayor desarrollo y optimización de este planteamiento puede llevar a una rentabilidad y estabilidad aún mayores en el comercio automatizado en los mercados financieros.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de ejemplos |
| 2 | Study2.mql5 | Asesor | Asesor de entrenamiento de modelos |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | FQF.mqh | Biblioteca de clases | Biblioteca de clases de organización de modelos completamente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
…
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12638
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola, Dimitri. Gracias por el nuevo trabajo. Yo también estaba tratando de obtener una línea recta en el gráfico. Ahora entiendo por qué. ¿Puedes decirme qué resultados del Estudio2 pueden considerarse aceptables? La prueba no muestra ninguna acción significativa todavía, abrió una compra y rellena en cada barra.
Por cierto, la carpeta NeuroNet_DNG tuvo que ser arrastrado desde el último EA. Si ha realizado cambios en él, me estoy golpeando la cabeza contra la pared.
Las últimas versiones de los archivos están en el archivo adjunto
Dmitry hola. ¿Me puede decir cuánto ha entrenado a este Asesor Experto para que empezara a hacer por lo menos algunos oficios significativos, incluso en menos. Acabo de tener o bien no tratar de negociar en absoluto, o se abre un montón de operaciones y no puede pasar todo el período de 4 meses. Al mismo tiempo, el saldo se queda quieto y la equidad está flotando. Utiliza uno o dos agentes, el resto son ceros. La muestra inicial probó diferentes.
-de 50 $ por ejemplo 30-40 ejemplos al principio y luego después de cada pase de Stady2 (100000 por defecto), y luego añadió 1-2 ejemplos en un ciclo.
-desde 35$ por ejemplo 130-150 ejemplos al principio y luego después de cada pasada de Stady2 (100000 por defecto), y además añadí 1-2 ejemplos en un ciclo.
- A partir de 50 $ con 15 ejemplos al principio y no añadió nada para entrenar Stady2 en 500000 y 2000000 .
Con todas las variantes el resultado es el mismo - no funciona, no aprende. Por otra parte, después de 2-3 millones de iteraciones, por ejemplo, bien puede mostrar nada de nuevo - simplemente no operar.
¿Cuánto (en cifras) debe ser entrenado para empezar a abrir y cerrar operaciones en absoluto?
¡Hola Dmitry! ¡Fuiste un gran profesor y mentor!
350668273_1631799953971007_1316803797828649367_n.png (1115×666) (fbcdn.net)Después de un entrenamiento exitoso, pude lograr una tasa de ganancias del 99%. Sin embargo, sólo vendió oficios. no comprar operaciones
Aquí está una captura de pantalla:
350733414_605596475011106_6366687350579423076_n.png (1909×682) (fbcdn.net)
Dmitriy,
Sigo tus artículos para aprender todo lo posible ya que tus conocimientos y experiencia me superan. Después de leer el artículo, se me ocurrió que aunque el modelo final presentado es excelente para identificar operaciones cortas y totalmente fallido para identificar operaciones largas, podría ser parte de una solución de trading de dos niveles.¿Cree que el modelo largo podría desarrollarse invirtiendo algunas de las suposiciones o es necesario un modelo completamente nuevo, como toe Go Explore en el artículo 39?
Saludos en sus esfuerzos actuales y apoyo para sus futuros esfuerzos.