
Redes neuronales en el trading: Inyección de información global en canales independientes (InjectTST)

Introducción
Recientemente, los modelos de pronóstico de series temporales multimodales basados en la arquitectura del Transformer se han vuelto ampliamente utilizados y gradualmente se están convirtiendo en una de las arquitecturas más populares para el modelado de series temporales. Y cada vez más modelos usan enfoques de canales independientes, donde el modelo secuencia cada canal por separado de los demás.
La independencia del canal posee dos ventajas:
- Supresión de ruido: los modelos independientes del canal pueden centrarse en predecir canales individuales sin distraerse con el ruido de otros canales.
- Mitigación de la desviación de la distribución: la independencia del canal puede aliviar el problema de la desviación de la distribución de las series temporales.
Al mismo tiempo, la mezcla de canales resulta menos efectiva para combatir estos problemas, lo cual conduce a una disminución del rendimiento del modelo. Sin embargo, la mezcla de canales tiene algunas ventajas únicas:
- Alta capacidad de información: los modelos de mezcla de canales se destacan por capturar dependencias entre canales y pueden ofrecer más información para predecir valores posteriores.
- Especificidad del canal: La optimización de múltiples canales en los modelos de mezcla de canales se realiza simultáneamente, lo cual permite que el modelo capture completamente las características distintivas de cada canal.
Además, como el enfoque de independencia del canal analiza canales individuales utilizando un modelo común, el modelo no puede distinguir entre canales y aprende principalmente los patrones comunes de múltiples canales. Esto genera una pérdida de especificidad del canal y un posible impacto en la previsión de series temporales multimodales.
Por consiguiente, el desarrollo de un modelo eficaz que tenga las ventajas tanto de la independencia del canal como de la mezcla de canales, que pueda explotar las ventajas de ambos enfoques (reducción de ruido, mitigación de la deriva de la distribución, alta capacidad de información y especificidad del canal), es la clave para mejorar aún más el desempeño de pronóstico de series temporales multimodales.
Sin embargo, desarrollar un modelo para dicho modelo supone un rompecabezas complejo. En primer lugar, los modelos independientes del canal están inherentemente en desacuerdo con las dependencias del canal. Si bien ajustar un modelo general para cada canal puede resolver el problema de la especificidad del canal, esto implica costes significativos a nivel de entrenamiento. En segundo lugar, los métodos existentes de reducción de ruido y resolución de deriva todavía no pueden hacer que los marcos de mezcla de canales sean tan robustos como los modelos de canales independientes.
Una de las opciones para solucionar estos problemas se propone en el artículo "InjectTST: A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting", que presenta un método para inyectar información global de una serie temporal multimodal en canales individuales (InjectTST). Los autores del método evitan el modelado explícito de dependencias entre canales para pronosticar las series temporales multimodales. En lugar de ello, mantienen la estructura de independencia del canal como base y la información global (mezcla de canales) se introduce en cada canal de manera selectiva. Y esto permite una mezcla implícita de canales.
Cada canal individual puede recibir selectivamente información global útil y evitar información ruidosa, lo cual permite mantener una alta capacidad de información y supresión de ruido. Como la independencia del canal se mantiene como base, también podemos reducir la desviación de la distribución.
Además, para resolver el problema de especificidad del canal, los autores del método añaden un identificador de canal a InjectTST.
1. Algoritmo InjectTST
Para construir los valores de pronóstico de Y para un horizonte de planificación T dado, analizaremos los valores históricos de una serie de tiempo multimodal X, que contendrá L pasos temporales. Y cada paso temporal será un vector con dimensionalidad M.
Para resolver este problema aprovechando las ventajas de la independencia del canal y su mezcla, se usará un complejo algoritmo InjectTST multinivel.
En la primera etapa del algoritmo, aplicaremos el mecanismo de segmentación de los datos iniciales en una línea troncal independiente del canal, después de lo cual se realizará una proyección lineal con codificación posicional entrenable.
La plataforma independiente del canal procesará los canales utilizando un modelo común. Como resultado, el modelo no podrá distinguir entre canales y aprenderá principalmente patrones de canales generales sin especificidad del canal. Para resolver este problema, los autores del método InjectTST introducen un identificador de canal, que supone un tensor entrenable.
Tras la proyección lineal de parches, a los tokens se les añadirán tensores tanto con codificación posicional como con un identificador de canal.
Los datos de origen preparados de esta forma se transmitirán al codificador del Transformer para una representación de alto nivel.
Tenga en cuenta que en este caso el codificador del Transformer opera en una línea troncal de canales independientes, es decir, solo se analizarán los tokens de canales individuales. La información entre canales no se mezclará.
El identificador de canal representará las características distintivas de cada canal, permitiendo al modelo distinguir entre canales y obtener una representación única para cada uno de ellos.
En paralelo con la línea troncal del canal independiente en la ruta de mezcla de canales, la secuencia original X pasará primero por el módulo de mezcla global para obtener información global. El objetivo principal de InjectTST consistirá en inyectar información global en cada canal, por lo que obtener información global será una cuestión crítica. Los autores del método presentan en su trabajo dos tipos de módulos de mezcla global, llamados CaT (canal como token) y PaT (parche como token).
El módulo CaT asigna directamente cada canal a un token. En resumen, la proyección lineal se aplica a todos los valores del canal.
El módulo de mezcla global PaT toma los parches como entrada. En primer lugar, se agruparán los parches relacionados con los pasos temporales correspondientes de la secuencia multimodal analizada. Luego se aplicará una proyección lineal a los parches agrupados, que básicamente combinará la información a nivel de parches. Tras esto, se agregará la codificación posicional y los datos se transmitirán al codificador del Transformer para una mayor fusión de información entre parches y la información global.
Los experimentos realizados por los autores del método muestran que PaT es más estable, mientras que CaT destaca en algunos conjuntos de datos especiales.
Uno de los desafíos del método InjectTST es la necesidad de inyectar información global en cada canal con un impacto mínimo en la fiabilidad del modelo. En el Transformer original, la atención cruzada hace que la secuencia objetivo se centre de forma selectiva y libre en la información contextual de otra fuente según su relevancia. Gracias a esta comprensión, el constructo de atención cruzada también podrá ser adecuado para inyectar información global en una serie temporal multimodal. Por consiguiente, la información global mezclada con los canales podrá verse como contexto. Los autores del método usan un constructo de atención cruzada para introducir información global en cada canal.
Aquí vale la pena añadir que los autores del método introducen una conexión residual opcional para el módulo de atención contextual. En casos generales, el acoplamiento residual hace que el modelo resulte un poco inestable. No obstante, podemos mejorar significativamente el rendimiento en algunos conjuntos de datos especiales.
En general, la información global se ingresará al módulo de atención contextual en forma de Key y Value, mientras que la información del canal estará en forma de Query.
Después de la atención cruzada, los datos se enriquecerán con información global. Y para generar los valores predichos, se agregará una carga lineal.
Los autores de InjectTST proponen un proceso de entrenamiento de tres etapas. En la etapa de pre-entrenamiento, las series temporales originales se enmascaran aleatoriamente, y el objetivo es predecir las partes enmascaradas. En la etapa de ajuste fino de la cabeza de pre-entrenamiento, InjectTST se reemplaza por la cabeza de predicción y se ajusta la cabeza de predicción. En esta etapa, el resto de la red estará congelada. Y en la etapa de ajuste fino, se afinará toda la red InjectTST.
A continuación le presentamos la visualización del método por parte del autor.
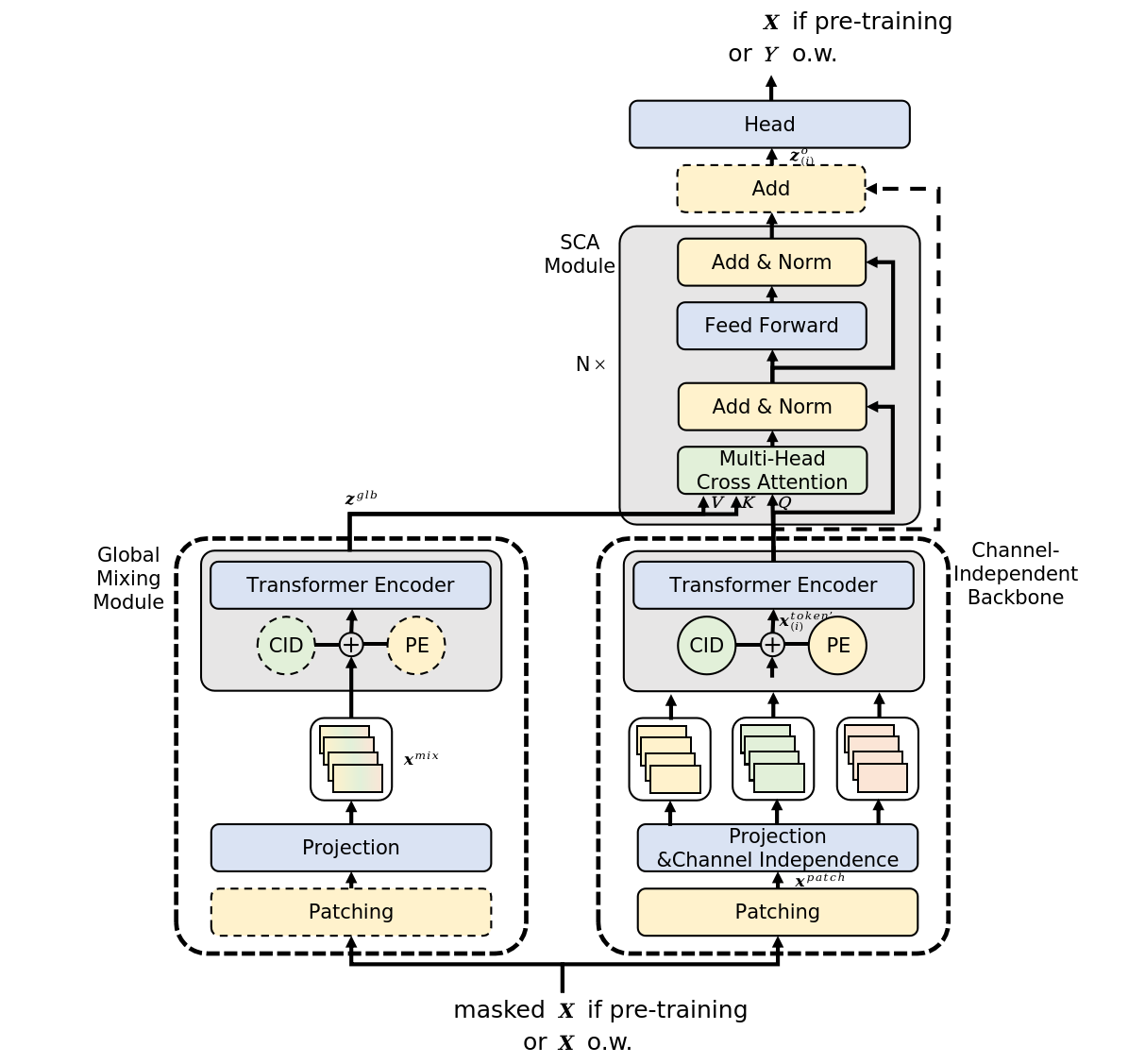
2. Implementación con MQL5
Tras familiarizarnos con los aspectos teóricos del método InjectTST, procederemos a la implementación práctica de nuestra visión de los enfoques propuestos utilizando MQL5.
Aquí cabe señalar que la opción de implementación propuesta en este artículo no es la única correcta. Además, la opción de implementación propuesta representa mi comprensión personal de los materiales presentados en el artículo del autor y puede diferir de la visión de los autores de los enfoques propuestos. Y lo mismo puede decirse de los resultados obtenidos.
Comenzando a trabajar en la implementación de los enfoques propuestos, vale la pena señalar que ya hemos considerado antes varios modelos basados en el Transformer utilizando el paradigma de canal independiente. Pero en ellos solo se ha realizado la previsión para canales independientes, mientras que el bloque del Transformer se ha utilizado para estudiar las dependencias entre canales, lo cual puede compararse con los enfoques del módulo de mezcla global CaT.
Sin embargo, los autores del método usan la arquitectura Transformer en la línea troncal de los canales independientes, evitando flujos de información entre canales en esta etapa. Teóricamente, podemos implementar este algoritmo organizando un ciclo de procesamiento de datos de secuencias unitarias individuales. No obstante, este enfoque es extensivo y provoca un aumento en el número de operaciones secuenciales, que aumenta con el número de variables analizadas en datos de fuentes multimodales.
En nuestro trabajo nos esforzaremos por realizar el máximo número posible de operaciones en flujos paralelos. Por ello, en el marco de esta implementación, crearemos una nueva capa con la capacidad de analizar de forma independiente canales individuales.
2.1 Bloque de análisis independiente para canales individuales
Implementaremos la funcionalidad de análisis independiente de canales individuales en la clase CNeuronMVMHAttentionMLKV, que heredará la funcionalidad básica de otro bloque multicapa de atención multiencabeza CNeuronMLMHAttentionOCL. A continuación, mostraremos la estructura de la nueva clase.
class CNeuronMVMHAttentionMLKV : public CNeuronMLMHAttentionOCL { protected: uint iLayersToOneKV; ///< Number of inner layers to 1 KV uint iHeadsKV; ///< Number of heads KV uint iVariables; ///< Number of variables CCollection KV_Tensors; ///< The collection of tensors of Keys and Values CCollection K_Tensors; ///< The collection of tensors of Keys CCollection K_Weights; ///< The collection of Matrix of K weights to previous layer CCollection V_Tensors; ///< The collection of tensors of Values CCollection V_Weights; ///< The collection of Matrix of V weights to previous layer CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMVMHAttentionMLKV(void) {}; ~CNeuronMVMHAttentionMLKV(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMVMHAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
En esta clase añadiremos 3 variables:
- iLayersToOneKV — número de capas para 1 tensor Key-Value ;
- iHeadsKV — número de cabezas de atención en el tensor Key-Value ;
- iVariables — número de secuencias unitarias en la serie temporal multimodal.
Además, añadiremos 5 colecciones de búferes de datos cuyo propósito aprenderemos a medida que avancemos en la implementación. Todos los objetos internos se declararán estáticamente, lo que permitirá dejar el constructor y el destructor de la clase "vacíos". La inicialización directa de todas las variables y objetos internos se realizará en el método Init.
bool CNeuronMVMHAttentionMLKV::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
En los parámetros de este método esperamos recibir las constantes principales que nos permitan identificar de forma única la arquitectura de la clase inicializada. Entre ellas:
- window — tamaño del vector que representa un elemento de la secuencia de una serie de tiempo unitaria;
- window_key — tamaño del vector de la representación interna de la entidad Key de un elemento de la secuencia de serie temporal unitaria;
- heads — número de cabezas de atención de la entidad Query;
- heads_kv — número de cabezas de atención en el tensor Key-Value concatenado;
- units_count — tamaño de la secuencia que se está analizando;
- layers: número de capas anidadas en el bloque;
- layers_to_one_kv — número de capas anidadas que trabajarán con un tensor Key-Vakue;
- variables — número de secuencias unitarias en la serie temporal multimodal.
En el cuerpo del método, llamaremos inmediatamente al método homónimo de la clase básica padre, en el que se realizará la inicialización de las variables y objetos heredados. Además, este método ya implementaremos los controles mínimos necesarios de los datos recibidos del programa que realiza la llamada.
Después de la ejecución exitosa del método de la clase padre, guardaremos los parámetros recibidos en variables internas.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1); iVariables = variables;
Aquí definiremos las principales constantes que determinan la arquitectura de los objetos anidados.
uint num_q = iWindowKey * iHeads * iUnits * iVariables; //Size of Q tensor uint num_kv = iWindowKey * iHeadsKV * iUnits * iVariables; //Size of KV tensor uint q_weights = (iWindow * iHeads + 1) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = (iWindow * iHeadsKV + 1) * iWindowKey; //Size of weights' matrix of K/V tenzor uint scores = iUnits * iUnits * iHeads * iVariables; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits * iVariables; //Size of multi-heads self-attention uint out = iWindow * iUnits * iVariables; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 weights' matrix uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Y ahora, tal vez, deberíamos decir algunas palabras sobre los enfoques que proponemos para implementar en esta clase. En primer lugar, hemos tomado la decisión de construir una nueva clase sin realizar cambios en el programa OpenCL. En otras palabras, a pesar de los nuevos requisitos, estamos construyendo la clase completamente sobre los kernels existentes.
Para ello, primero separaremos la generación de entidades Key y Value. Permítame recordarle que anteriormente se generaban dentro de una pasada directa de la capa convolucional y se escribían en el búfer secuencialmente para cada elemento de la secuencia. Este enfoque resulta aceptable para generar atención global. En el caso de organizar el trabajo dentro de canales separados, obtendremos una secuencia Key/Value alterna para canales separados, lo cual no resulta del todo cómodo para el análisis posterior y “no encaja” en el funcionamiento de los algoritmos que hemos creado anteriormente. Entonces generaremos entidades por separado y luego las concatenaremos en un solo tensor.
Vale la pena señalar aquí que hemos dividido la generación de entidades en 2 etapas cuyo número no dependerá del número de variables analizadas ni del número de cabezas de atención.
El segundo punto es que los autores del método InjectTST prevén el uso de un codificador del Transformer para todos los canales. Por eso también usaremos las mismas matrices de peso para todos los canales. Por ello, con un cambio en el número de canales, el tamaño de las matrices de peso no cambiará.
Con esto finalizaremos nuestro trabajo preparatorio y organizaremos un ciclo con un número de iteraciones igual al número de capas anidadas.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
En el cuerpo del ciclo, organizaremos un ciclo anidado para crear búferes con los resultados de las operaciones intermedias y los gradientes de error correspondientes.
for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Aquí primero crearemos un búfer del tensor Query. El algoritmo de creación será idéntico para todos los búferes. Primero crearemos una nueva instancia del objeto de búfer. Lo inicializaremos con valores cero en un tamaño determinado. Después de eso, crearemos una copia del búfer en el contexto OpenCL y agregaremos el puntero al búfer a la colección correspondiente. En este caso, además, deberemos necesariamente supervisar el progreso de las operaciones en cada paso.
Como planeamos utilizar 1 tensor Key-Value para el análisis en varias capas anidadas, crearemos los búferes correspondientes con una frecuencia determinada.
//--- Initilize KV tensor if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(2 * num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; }
Vale la pena señalar que en esta etapa crearemos 3 búferes: Key, Value y Key-Value concatenados.
El siguiente paso será crear un búfer de coeficientes de atención.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
A continuación vendrá el búfer de resultados de atención multicabeza.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Y luego estarán los búferes de compresión de la atención multicabeza y el bloque FeedForward.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Tras inicializar los búferes de resultados intermedios y sus gradientes, procederemos a inicializar las matrices de peso. El algoritmo para su inicialización será similar a la creación de búferes de datos, solo que la matriz se rellenará con valores aleatorios.
La primera matriz generada es la matriz de pesos de la entidad Query.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < q_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
La frecuencia de creación de las matrices de pesos de las entidades Key y Value será similar a la frecuencia de los búferes de las entidades correspondientes.
//--- Initilize K weights if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; }
Asimismo, añadiremos una matriz de compresión de cabezas de atención.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Y el bloque FeedForward.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Después de eso, crearemos otro ciclo anidado en el que agregaremos búferes de momentos al nivel del coeficiente de peso. La cantidad de búferes creados dependerá del método de actualización de parámetros.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? q_weights : iWindowKey * iHeads), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false; if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
Al final del método de inicialización, agregaremos un búfer para almacenar los datos temporales y retornar el resultado lógico de las operaciones realizadas al programa que realiza la llamada.
if(!Temp.BufferInit(MathMax(2 * num_kv, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- return true; }
Tras inicializar el objeto, pasaremos a organizar los algoritmos de pasada directa. Y aquí vale la pena decir algunas palabras sobre el uso de kernels creados previamente. En particular, sobre el kernel de pasada directa del bloque de atención cruzada MH2AttentionOut, el algoritmo para colocarlo en la cola de ejecución se implementará en el método AttentionOut. Diremos inmediatamente que el algoritmo para colocar el kernel en la cola de ejecución no ha cambiado. Pero nuestra tarea consistirá en implementar el análisis de canales independientes utilizando este algoritmo.
Primero, veremos cómo funciona nuestro kernel con cabezas de atención individuales. Y este las procesa independientemente en flujos separados. Pienso que esto es exactamente lo que necesitamos. Diremos entonces que los canales individuales serán las propias cabezas de atención.
bool CNeuronMVMHAttentionMLKV::AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads * iVariables}; uint local_work_size[3] = {1, iUnits, 1};
De lo contrario, el algoritmo del método seguirá siendo el mismo. Transmitiremos los parámetros necesarios al kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, scores.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Con toda seguridad, ajustaremos el número de cabezas del tensor Key-Value.
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_heads_kv, (int)(iHeadsKV * iVariables))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
A continuación, colocaremos el kernel en la cola de ejecución.
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_mask, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Y finalizaremos el método. Pero esto será solo una parte del algoritmo de pasada directa. Y construiremos el algoritmo completo en el método feedForward.
bool CNeuronMVMHAttentionMLKV::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
En los parámetros, el método obtendrá el puntero al objeto de la capa neuronal anterior, que contendrá los datos iniciales de nuestro algoritmo. Como datos iniciales esperamos recibir un tensor tridimensional: la longitud de la secuencia * el número de secuencias unitarias * el tamaño de la ventana analizada de un elemento.
En el cuerpo del método, verificaremos la relevancia del puntero recibido y organizaremos un ciclo de iteración a través de las capas anidadas del módulo.
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
Aquí primero declararemos el puntero local al búfer de datos de origen en el que almacenaremos el puntero requerido. Después de esto, extraeremos de la colección el búfer de la entidad Query correspondiente a la capa analizada y escribiremos en él los datos generados en base a los datos de origen.
CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
El siguiente paso será verificar si necesitamos generar un nuevo tensor Key-Value. De ser necesario, determinaremos primero el desplazamiento en las colecciones correspondientes.
if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV;
Y extraeremos los punteros a los búferes que necesitemos.
kv = KV_Tensors.At(i_kv * 2); CBufferFloat *k = K_Tensors.At(i_kv * 2); CBufferFloat *v = V_Tensors.At(i_kv * 2);
Después de lo cual generaremos secuencialmente las entidades Key y Value.
if(IsStopped() || !ConvolutionForward(K_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, k, iWindow, iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !ConvolutionForward(V_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, v, iWindow, iWindowKey * iHeadsKV, None)) return false;
Y concatenaremos los tensores obtenidos a lo largo de la primera dimensión (elementos de la secuencia).
if(IsStopped() || !Concat(k, v, kv, iWindowKey * iHeadsKV * iVariables, iWindowKey * iHeadsKV * iVariables, iUnits)) return false; }
Tenga en cuenta que en esta versión de organización de los datos obtendremos un búfer de datos que puede representarse como un tensor de datos de cinco dimensiones: Units * [Key, Value] * Variable * HeadsKV * Window_Key. El tensor de entidad Query tendrá una dimensionalidad comparable, solo que en lugar de [Key, Value], tendremos [Query]. Al reunir las dimensiones Variable y Heads en una única dimensionalidad "Variable * Heads", obtendremos dimensionalidades de tensor comparables a la Multi-Heads Self-Attention tradicional.
Aquí deberemos recordar que en el lado del contexto OpenCL trabajaremos con búferes de datos unidimensionales. La descomposición de datos en un tensor multidimensional solo será declarativa para comprender la secuencia de datos. En general, la secuencia de datos en el búfer irá desde la última dimensión a la primera.
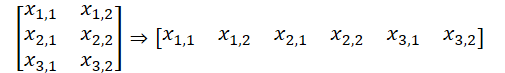
Esto nos permitirá utilizar kernels previamente creados de nuestro programa OpenCL para analizar canales independientes. Luego obtendremos los punteros a los búferes de datos requeridos de las colecciones y ejecutaremos el algoritmo Multi-Heads Self-Attention. Ya hemos ajustado el método requerido arriba.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
Luego, reformatearemos mentalmente los resultados de la atención multicabeza en un tensor de [Units * Variable] * Heads * Window_Key y proyectaremos los datos a la dimensionalidad de los datos de origen.
//--- Attention out calculation temp = FF_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
Después de lo cual sumaremos los resultados obtenidos con los datos de origen y normalizamos los valores obtenidos.
A continuación, realizaremos las operaciones del bloque FeedForward con el mismo estilo y pasaremos a la siguiente iteración del ciclo.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- return true; }
Tras completar con éxito las operaciones de todas las capas anidadas del bloque, finalizaremos el método y devolveremos el resultado lógico de las operaciones al programa que ha realizado la llamada.
Después de implementar métodos de pasada directa, generalmente pasamos a construir algoritmos de pasada inversa. Hoy me gustaría sugerirle que analice de forma independiente la opción de implementación propuesta, que encontrarán en el archivo adjunto. Durante la implementación de los métodos de pasada inversa, hemos utilizado los enfoques descritos anteriormente en la implementación de los métodos de pasada directa. Permítame recordarle que las operaciones de pasada inversa se llevan a cabo en estricta conformidad con el algoritmo de pasada directa, pero en orden inverso.
Además, en el archivo adjunto encontrará la implementación de la clase CNeuronMVCrossAttentionMLKV, cuyos algoritmos en su mayoría repiten algoritmos semejantes de la clase CNeuronMVMHAttentionMLKV, solo que complementados con herramientas de atención cruzada.
Y también quiero recordarle que las clases CNeuronMVMHAttentionMLKV y CNeuronMVCrossAttentionMLKV que implementamos suponen solo bloques de construcción de un algoritmo InjectTST más complejo; ya nos hemos familiarizado con los aspectos teóricos más arriba. Y la siguiente etapa de nuestro trabajo consistirá en crear una nueva clase, dentro de la cual implementaremos el algoritmo InjectTST.
2.2 Implementación de InjectTST
Ahora ensamblaremos el algoritmo InjectTST completo dentro de la clase CNeuronInjectTST, que heredará la funcionalidad básica de la clase padre de la capa neuronal completamente conectada CNeuronBaseOCL. A continuación, mostraremos la estructura de la nueva clase.
class CNeuronInjectTST : public CNeuronBaseOCL { protected: CNeuronPatching cPatching; CNeuronLearnabledPE cCIPosition; CNeuronLearnabledPE cCMPosition; CNeuronMVMHAttentionMLKV cChanelIndependentAttention; CNeuronMLMHAttentionMLKV cChanelMixAttention; CNeuronMVCrossAttentionMLKV cGlobalInjectionAttention; CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronInjectTST(void) {}; ~CNeuronInjectTST(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronInjectTST; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CBufferFloat *getWeights(void) override; };
En esta clase veremos una gran cantidad de objetos internos, pero no hay una sola variable. Esto se debe a que esta clase implementa, podría decirse, un “ensamblaje de nodos grandes” de un algoritmo, cuya funcionalidad principal estará construida por objetos internos. Y todas las constantes que definen la arquitectura del bloque se utilizarán solo en el método de inicialización de la clase y se almacenarán dentro de objetos anidados. Nos familiarizaremos con la funcionalidad de estos durante la implementación de los algoritmos.
Todos los objetos internos de la clase se declaran estáticamente, lo que nos permitirá dejar el constructor y el destructor de la clase vacíos, mientras que la inicialización de todos los objetos anidados y heredados se realizará en el método Init.
bool CNeuronInjectTST::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false; SetActivationFunction(None);
Como es habitual, en los parámetros de este método obtendremos las constantes principales que determinan la arquitectura del objeto creado. En el cuerpo del método, llamaremos inmediatamente al método homónimo de la clase padre, que ya implementará controles básicos para los parámetros recibidos y la inicialización de objetos heredados.
A continuación, inicializaremos los objetos internos en la secuencia de pasada directa del algoritmo InjectTST. En la visualización del autor del método presentado anteriormente, podemos ver fácilmente que los datos iniciales obtenidos se utilizan en 2 flujos de información: los bloques de canales independientes y la mezcla global. En ambos bloques, primero se segmentarán los datos de origen. En nuestra implementación, hemos decidido no duplicar el proceso de segmentación, sino realizarlo una vez antes de que los flujos de información se ramifiquen.
if(!cPatching.Init(0, 0, OpenCL, window, window, window, units_count, variables, optimization, iBatch)) return false; cPatching.SetActivationFunction(None);
Cabe señalar que en esta implementación usaremos parámetros iguales: el tamaño del segmento, el paso de la ventana del segmento y el tamaño de incorporación del segmento. Por lo tanto, el tamaño del búfer de datos de origen antes y después de la segmentación no ha cambiado. No obstante, la secuencia de datos en el búfer sí lo ha hecho. Y el tensor de datos bidimensional L * V ha sido reformateado al tridimensional L/p*V*p, donde L será la longitud de la secuencia multimodal de los datos de origen, V será el número de variables analizadas y p será el tamaño del segmento.
A los tokens de segmentos en el bloque de la línea troncal del canal independiente, los autores del método le añaden dos tensores entrenables: la codificación posicional y la identificación de canal. La suma de los dos números será un número, por lo que en nuestra implementación hemos decidido utilizar una única capa de codificación posicional entrenable que estudie la etiqueta posicional de cada elemento individual en el tensor de entrada.
if(!cCIPosition.Init(0, 1, OpenCL, window * units_count * variables, optimization, iBatch)) return false; cCIPosition.SetActivationFunction(None);
En el bloque de mezcla global, el algoritmo también ofrece codificación posicional. Inicializaremos una capa similar para la segunda línea troncal de flujo de información.
if(!cCMPosition.Init(0, 2, OpenCL, window * units_count * variables, optimization, iBatch)) return false; cCMPosition.SetActivationFunction(None);
Luego construiremos la estructura principal del canal independiente utilizando el bloque de atención del canal independiente CNeuronM V MHAttentionMLKV discutido anteriormente.
if(!cChanelIndependentAttention.Init(0, 3, OpenCL, window, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, variables, optimization, iBatch)) return false; cChanelIndependentAttention.SetActivationFunction(None);
Y para organizar el bloque de mezcla global, usaremos el bloque de atención previamente creado CNeuronM L MHAttentionMLKV.
if(!cChanelMixAttention.Init(0, 4, OpenCL, window * variables, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, optimization, iBatch)) return false; cChanelMixAttention.SetActivationFunction(None);
Nótese que en este caso el tamaño de la ventana del vector analizado de un elemento será igual al producto del tamaño del segmento y el número de variables analizadas, lo que se corresponderá con el paradigma de mezcla de canales.
La inyección de información global en los canales independientes se realizará dentro del bloque de atención cruzada.
if(!cGlobalInjectionAttention.Init(0, 5, OpenCL, window, window_key, heads, window * variables, heads_kv, units_count, units_count, layers, layers_to_one_kv, variables, 1, optimization, iBatch)) return false; cGlobalInjectionAttention.SetActivationFunction(None);
Tenga en cuenta que en este caso estableceremos el número de filas unitarias en el contexto en 1, ya que aquí estamos trabajando con canales mixtos.
Al final del método de inicialización, realizaremos un intercambio de búferes de datos, lo cual nos permitirá evitar el copiado innecesario entre los búferes de nuestra clase y los objetos internos.
if(!SetOutput(cGlobalInjectionAttention.getOutput(), true) || !SetGradient(cGlobalInjectionAttention.getGradient(), true) ) return false;
Asimismo, inicializaremos un búfer auxiliar para almacenar datos intermedios y retornaremos el resultado lógico de las operaciones al programa que realiza la llamada.
if(!cTemp.BufferInit(cPatching.Neurons(), 0) || !cTemp.BufferCreate(OpenCL) ) return false; //--- return true; }
Tras inicializar el objeto de la clase, pasaremos a construir el algoritmo de pasada directa para nuestra clase. Ya hemos discutido las principales etapas del algoritmo durante la implementación del método de inicialización. Ahora solo tenemos que describirlas en el método feedForward.
bool CNeuronInjectTST::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPatching.FeedForward(NeuronOCL)) return false;
En los parámetros del método recibiremos el puntero al objeto de la capa anterior, que nos pasará los datos de origen. Y transmitiremos inmediatamente el puntero recibido al método homónimo de la capa de segmentación de datos anidados.
Tenga en cuenta que en esta etapa no verificaremos la relevancia del puntero obtenido, ya que los controles necesarios se implementarán en el método de la capa de segmentación y no será necesario volver a verificarlo.
El siguiente paso será agregar codificación posicional a los datos segmentados,
if(!cCIPosition.FeedForward(cPatching.AsObject()) || !cCMPosition.FeedForward(cPatching.AsObject()) ) return false;
después de lo cual primero pasaremos los datos a través de un bloque de canales independientes.
if(!cChanelIndependentAttention.FeedForward(cCIPosition.AsObject())) return false;
Y luego a través del bloque de mezcla global.
if(!cChanelMixAttention.FeedForward(cCMPosition.AsObject())) return false;
Tenga en cuenta que, a pesar de la secuencia de ejecución, se trata de dos flujos de información independientes. Y la inyección de datos globales en canales independientes se realizará solo en el bloque de atención contextual.
if(!cGlobalInjectionAttention.FeedForward(cCIPosition.AsObject(), cCMPosition.getOutput())) return false; //--- return true; }
Ahora hemos sacado la cabeza de toma de decisiones fuera de la clase CNeuronInjectTST.
Como puede ver, el método de pasada directa ha resultado bastante conciso y legible. En otras palabras, como esperábamos de una implementación de “nodo grande” del algoritmo. Los métodos de pasada inversa se construirán de forma similar, así que le sugiero familiarizarse con ellos. Permítame recordarle que el código completo de todas las clases descritas y sus métodos se presenta en el archivo adjunto. Allí también encontrará el código completo de todos los programas usados en la preparación del artículo.
2.3 Arquitectura de los modelos entrenados
Arriba hemos implementado los algoritmos básicos del método InjectTST usando MQL5 y ahora podemos implementar los enfoques propuestos en nuestros propios modelos. El método que estamos analizando se propuso inicialmente para pronosticar series temporales. Y nosotros, de manera similar a como sucede con varios métodos de pronóstico de series temporales considerados previamente, intentaremos implementar los enfoques propuestos en el modelo del Codificador del estado del entorno. Como ya sabe, la descripción de la arquitectura de este modelo se presenta en el método CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
En los parámetros de este método obtendremos el puntero a un objeto de array dinámico para registrar la arquitectura del modelo. En el cuerpo del método, verificaremos directamente la relevancia del puntero recibido y, de ser necesario, crearemos un nuevo objeto de array dinámico. Y luego comenzaremos a describir la arquitectura del modelo que estamos creando.
La primera es la capa básica completamente conectada, que se usará para registrar los datos de origen.
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como siempre, planeamos suministrar al modelo datos de entrada sin procesar. Estos se someterán al procesamiento primario en la capa de normalización de datos por lotes, donde la información de diferentes distribuciones se llevará a una forma comparable.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación vendrá nuestra nueva capa de canales independientes con inyección global.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronInjectTST; descr.window = PatchSize; //Patch window descr.window_out = 8; //Window Key
Para especificar el tamaño del segmento, agregaremos la constante PatchSize. Y calcularemos el tamaño de la secuencia según la profundidad de la historia analizada y el tamaño del segmento.
prev_count = descr.count = (HistoryBars + descr.window - 1) / descr.window; //Units
Luego escribiremos el número de cabezas de atención para las entidades Query, Key y Value, así como el número de secuencias unitarias, en un array.
{
int temp[] =
{
4, //Heads
2, //Heads KV
BarDescr //Variables
};
ArrayCopy(descr.heads, temp);
}
Todos los bloques internos contendrán 4 capas plegadas.
descr.layers = 4; //Layers
Y un tensor Key-Value será relevante para 2 capas anidadas.
descr.step = 2; //Layers to 1 KV descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación deberemos agregar una cabeza para predecir los valores subsiguientes. Recordemos que a la salida del bloque InjectTST obtendremos un tensor de dimensionalidad L/p * V * p. Y para realizar un pronóstico de datos dentro de canales independientes, primero necesitaremos transponer los datos.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = PatchSize * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Y luego usaremos un MLP de dos capas para predecir los canales independientes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = PatchSize * BarDescr; descr.window = prev_count; descr.window_out = NForecast; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = PatchSize * NForecast; descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Al hacerlo, reduciremos la dimensionalidad de los datos a Variables * Forecast. Ahora podremos devolver los valores predichos a la representación de los datos de origen.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Y agregaremos las lecturas estadísticas eliminadas de los datos de origen durante la normalización.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Además, utilizaremos enfoques FreDF para ajustar loa valores predichos de series unitarias en el dominio de la frecuencia.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Las arquitecturas de los modelos del Actor y el Crítico se han mantenido sin cambios respecto al trabajo anterior. Por consiguiente, no nos detendremos ahora en describirlas con detalle.
Además, en la nueva arquitectura del Codificador del estado del entorno, no cambiaremos ni la capa de datos de origen ni los resultados. Todo esto nos permitirá utilizar todos los programas previamente creados para interactuar con el entorno y entrenar los modelos sin realizar cambios. En consecuencia, podremos utilizar la muestra de entrenamiento recopilada previamente para el entrenamiento inicial de los modelos.
Permítame recordarle que en el archivo adjunto encontrará el código completo de todas las clases y sus métodos, así como el código completo de todos los programas utilizados en la preparación del artículo.
3. Simulación
Más arriba hemos realizado los trabajos de implementación de los enfoques del método InjectTST utilizando herramientas MQL5. También hemos demostrado una variante de uso de la nueva clase en el modelo del Codificador del estado del entorno. Ahora podemos comenzar a probar la eficacia del modelo con datos históricos reales.
Al igual que antes, primero entrenaremos el modelo del Codificador del estado del entorno para predecir el próximo movimiento de precios durante un horizonte de planificación determinado. Durante el experimento, usaremos como muestra de entrenamiento los datos históricos de 2023 para el instrumento EURUSD y el marco temporal H1.
El Codificador de estado del entorno analizará únicamente los datos históricos del instrumento de precio, que no se verá afectado por las acciones del Agente. Por lo tanto, entrenaremos el modelo hasta que obtenemos los resultados deseados o el error de pronóstico alcance una meseta.
A continuación le mostramos una visualización comparativa de la trayectoria del movimiento del precio previsto y el precio objetivo.
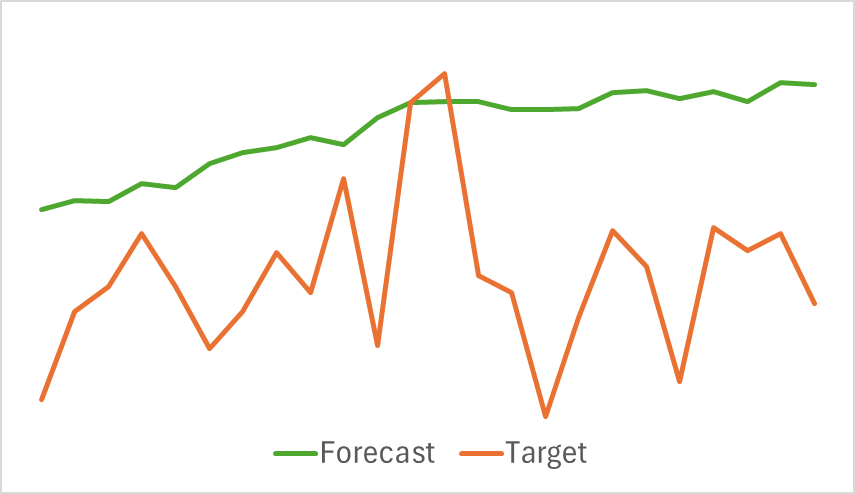
Como podemos ver en el gráfico presentado, la trayectoria prevista se desplaza hacia arriba y las fluctuaciones en ella son menos pronunciadas. Al mismo tiempo, podemos destacar la coincidencia de las direcciones de la tendencia general. Este podría no ser el mejor pronóstico para el movimiento de precios posterior al nivel de los modelos que hemos considerado anteriormente. Pero pasemos a la segunda etapa del entrenamiento del modelo y veamos si semejante Codificador ayudará a nuestro Actor a construir una estrategia rentable.
Los modelos del Actor y el Crítico se entrenarán iterativamente. En primer lugar, llevaremos a cabo varias épocas de entrenamiento del modelo en la muestra de entrenamiento existente. Luego, a medida que interactuemos con el entorno utilizando la política actual del Actor, actualizaremos el conjunto de entrenamiento. Esto nos permitirá enriquecer el conjunto de entrenamiento con recompensas de acciones reales de la distribución de la política actual del Actor. Y esto significa que durante el posterior entrenamiento de los modelos, podremos entrenar mejor la función de recompensa del Crítico y evaluar con mayor precisión las acciones del Actor, indicando el vector de corrección de la acción para mejorar la efectividad de la política actual. Las iteraciones se repetirán hasta obtener el resultado deseado.
Para evaluar la efectividad de la política de Actor entrenado, realizaremos una prueba del asesor de interacción con el entorno en el simulador de estrategias MetaTrader 5. Las pruebas se llevarán a cabo con los datos históricos de enero de 2024, manteniéndose iguales los demás parámetros. Los resultados de la prueba se muestran a continuación.
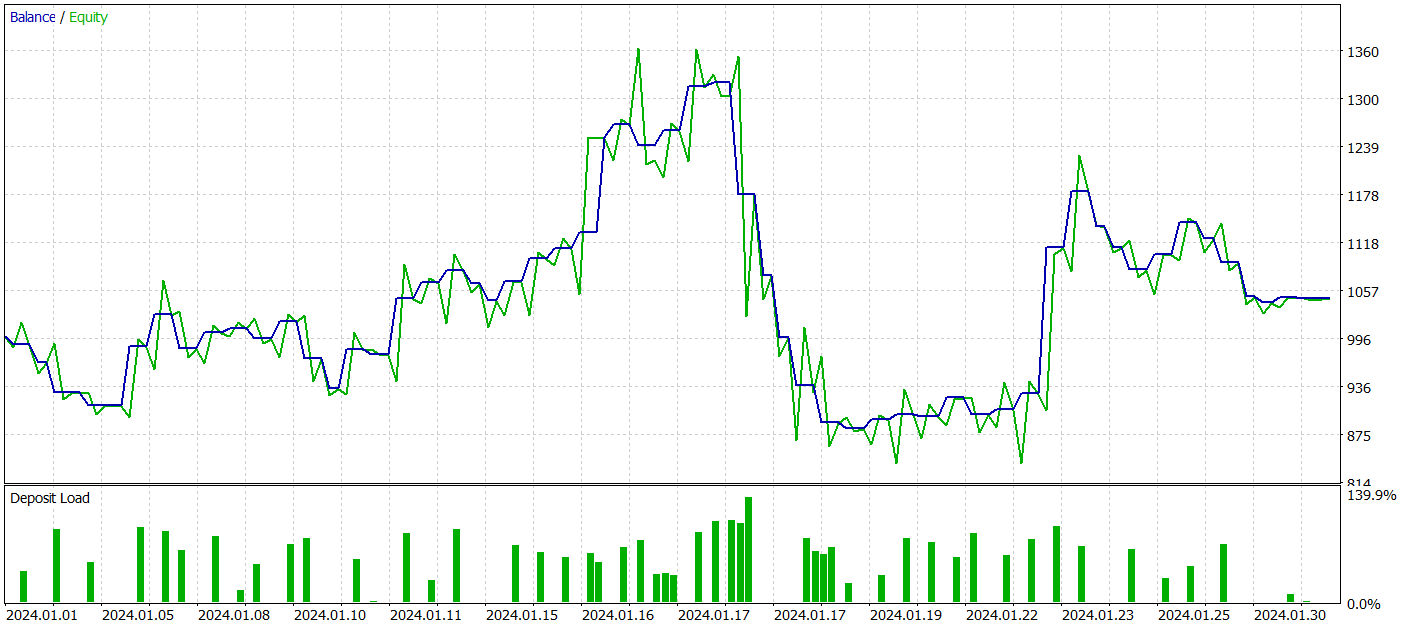
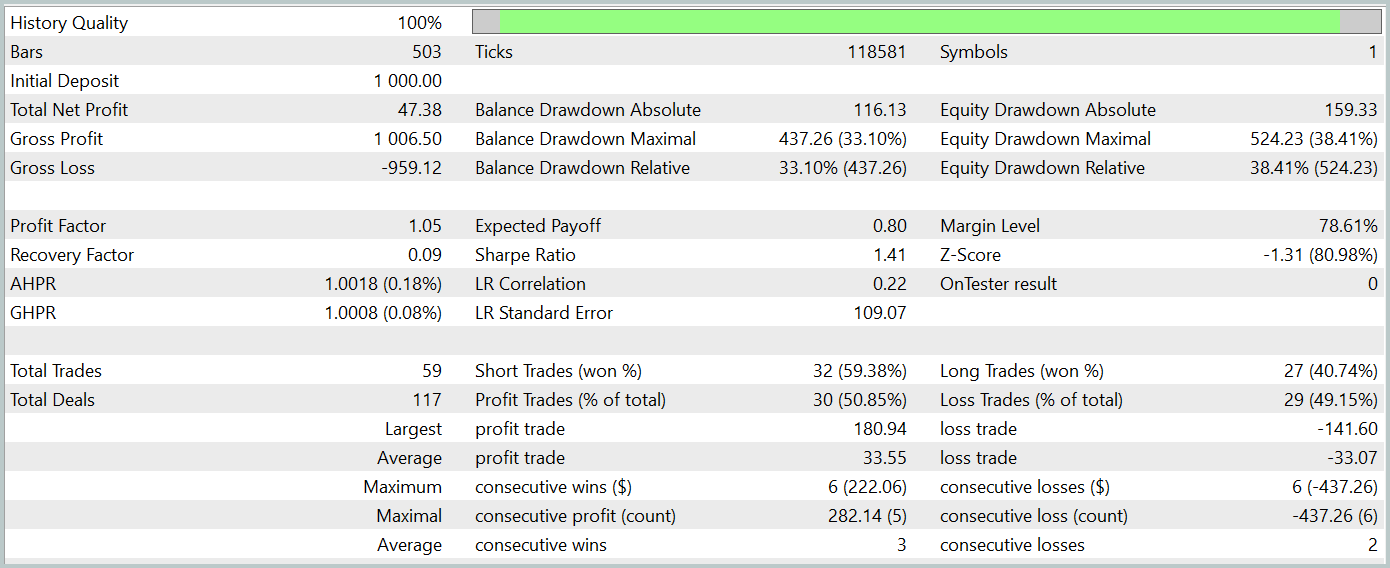
Durante el periodo de prueba, el modelo ha logrado generar un pequeño beneficio. Solo se han realizado 59 transacciones y 30 de ellas se han cerrado con ganancias. Las transacciones rentables máximas y promedio superan las cifras correspondientes a las posiciones perdedoras. Esto nos ha permitido obtener un factor de beneficio de 1,05. Sin embargo, el gráfico de balance no tiene una dirección claramente definida. Y durante las pruebas, se ha permitido una reducción del balance de más del 33%.
Conclusión
En este artículo, hemos presentado un nuevo método de pronóstico de series temporales, el InjectTST, diseñado para mejorar la calidad del pronóstico de series temporales largas inyectando información global en canales de datos independientes.
En la parte práctica del artículo, hemos implementado los enfoques propuestos utilizando MQL5 y los hemos introducido en el modelo del Codificador del estado del entorno. Hemos realizado un trabajo considerable, pero los resultados han quedado lejos de nuestras expectativas.
Deberemos efectuar un análisis detallado para encontrar las razones de estos resultados tan modestos. Pero es muy posible que una de las razones sea que el entrenamiento del modelo para predecir los estados posteriores del entorno se haya realizado, por así decirlo, "de frente". Sin embargo, los autores del método recomiendan un entrenamiento del modelo en tres etapas.
Enlaces
- InjectTST: A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15498
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso