
Redes neuronales: así de sencillo (Parte 39): Go-Explore: un enfoque diferente sobre la exploración

Introducción
Proseguimos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En artículos anteriores de esta serie, ya hemos analizado diversos algoritmos para explorar el entorno a través de la curiosidad y el desacuerdo en un conjunto de modelos. Ambos enfoques explotan recompensas intrínsecas para estimular al agente a realizar diferentes acciones en situaciones similares mientras explora nuevas áreas, pero el problema es que la recompensa intrínseca disminuye a medida que se explora el entorno, y en situaciones difíciles de recompensas poco comunes, o cuando el agente puede recibir sanciones en el camino hacia la recompensa, este enfoque puede no resultar muy efectivo. En este artículo, propongo al lector familiarizarse con un enfoque ligeramente distinto de estudio del entorno: el algoritmo Go-Explore.
1. El algoritmo de Go-Explore
Go-Explore es un algoritmo de aprendizaje por refuerzo diseñado para encontrar soluciones óptimas a problemas complejos que tengan un gran espacio de acción y estado. El algoritmo fue desarrollado por Adrien Ecoffet y descrito en el artículo "Go-Explore: a New Approach for Hard-Exploration Problems".
Este utiliza métodos de algoritmos evolutivos y aprendizaje automático para buscar eficazmente soluciones óptimas en problemas complejos e irresolubles.
El algoritmo comienza explorando una gran cantidad de caminos aleatorios, conocidos como "exploraciones básicas". Luego, usando un algoritmo evolutivo, guarda las mejores soluciones encontradas y las combina para crear nuevos caminos. Después, estos nuevos caminos se comparan con las mejores soluciones anteriores y, si son mejores, se mantienen. Dicho proceso se repite hasta encontrar la solución óptima.
Go-Explore también usa una técnica llamada "grabador" para guardar las mejores soluciones encontradas y reutilizarlas para crear nuevos caminos. Esto permite que el algoritmo encuentre soluciones aún más óptimas de las que se hallarían si se siguieran explorando caminos aleatorios.
Una de las principales ventajas de Go-Explore es su capacidad para hallar soluciones óptimas en problemas complejos e irresolubles donde otros algoritmos de aprendizaje por refuerzo pueden fallar. También es capaz de aprender de forma eficiente en condiciones de recompensa escasa, lo cual puede ser un problema para otros algoritmos.
En general, Go-Explore supone una herramienta poderosa a la hora de resolver problemas de aprendizaje por refuerzo y puede aplicarse de manera efectiva en diversos campos, incluidos la robótica, los juegos de computadora y la inteligencia artificial en general.
La idea principal detrás de Go-Explore es recordar y regresar a estados de perspectiva, y esto es fundamental para un funcionamiento eficaz en condiciones en las que el número de recompensas es reducido. Esta idea es tan flexible y amplia que se puede implementar de diversas maneras.
A diferencia de la mayoría de los algoritmos de aprendizaje por refuerzo, Go-Explore no se centra en resolver directamente el problema objetivo, sino en encontrar estados y acciones relevantes en el espacio de estados que puedan redundar en el logro del estado objetivo. Para ello, el algoritmo tiene dos fases principales: búsqueda y reutilización.
La primera fase consiste en recorrer todos los estados en el espacio de estados y escribir cada estado visitado en un "mapa" de estados. Después de ello, el algoritmo comienza a estudiar con más detalle cada estado visitado y a recopilar información sobre acciones que pueden conducir a otros estados interesantes.
La segunda fase consiste en reutilizar los estados y acciones previamente aprendidos para encontrar nuevas soluciones. El algoritmo guarda las trayectorias más exitosas y las usa para generar nuevos estados que pueden conducir a soluciones aún más exitosas.
El algoritmo Go-Explore funciona así:
- Recopilación de la base de ejemplos (archive): el agente inicia el juego, registra cada logro y lo guarda en el archivo. En lugar de almacenar los propios estados, el archivo contiene descripciones de las acciones que llevaron al logro del estado en particular.
- Exploración iterativa (iterative exploration): en cada iteración, el agente selecciona un estado aleatorio del archivo y reproduce el juego desde ese estado. Luego guarda los nuevos estados que logra alcanzar y los añade al archivo, junto con una descripción de las acciones que llevaron a esos estados.
- Aprendizaje de los ejemplos: después de una exploración iterativa, el algoritmo aprende de los ejemplos que ha recopilado utilizando algún tipo de algoritmo de aprendizaje por refuerzo.
- Repetición: el algoritmo repite la exploración iterativa y el aprendizaje de ejemplos hasta alcanzar el nivel de rendimiento deseado.
El objetivo del algoritmo Go-Explore consiste en minimizar el número de repeticiones del juego necesarias para lograr un alto nivel de rendimiento. Esto permite al agente explorar un gran espacio de estados usando una base de datos de ejemplo, lo cual acelera el proceso de aprendizaje y logra un mayor rendimiento.
En general, Go-Explore es un algoritmo bastante potente y eficiente que muestra buenos resultados en la resolución de problemas complejos de aprendizaje por refuerzo.
2. Implementación usando MQL5
En nuestra implementación, a diferencia de todo lo visto antes, no combinaremos el algoritmo completo en un solo programa. Las etapas del algoritmo Go-Explore son tan diferentes que resulta más eficaz crear un programa independiente para cada paso.
2.1. Fase 1 - investigación
En primer lugar, crearemos un programa para implementar la primera fase del algoritmo: la exploración del entorno y la recopilación de la base de datos con ejemplos. Antes de comenzar la implementación, debemos determinar los conceptos básicos del algoritmo a construir.
Al comenzar a estudiar el entorno, tenemos que explorar todos sus estados de la forma más completa posible. En esta etapa, no pretendemos encontrar la estrategia óptima, y aquí, por extraño que parezca, no utilizaremos una red neuronal. Después de todo, no estamos buscando una estrategia u optimizando la política. De esto se encargará la segunda fase. En este punto, simplemente realizaremos acciones aleatorias con varios agentes y registraremos todos los estados del sistema que visita cada uno de los agentes.
Pero de esta manera obtendremos un montón de estados aleatorios no relacionados, ¿qué pasará entonces con la exploración del entorno? Al fin y al cabo, cada agente realizará solo una acción de cada estado, sin reconocer los aspectos positivos y negativos de otras acciones. El siguiente paso del algoritmo vendrá aquí en nuestra ayuda. Nosotros, al actuando al azar o usando alguna política que definamos, seleccionaremos de la base de estados. Repetiremos todos los pasos hasta alcanzar este estado, y luego volveremos a determinar aleatoriamente las acciones del agente hasta llegar al final del episodio estudiado. Asimismo, añadiremos nuevos estados a nuestra base de datos de ejemplos.
Estos dos pasos del algoritmo comprenderán la primera fase, la exploración.
Debemos prestar atención a un aspecto más. Para realizar una exploración eficaz, necesitaremos utilizar varios agentes, y aquí, para iniciar en paralelo varios agentes independientes, utilizaremos el optimizador multiproceso del simulador de estrategias. Según los resultados de cada pasada, el agente transmitirá su base de estados acumulada a un único centro para su generalización.
Tras determinar los puntos principales del algoritmo en construcción, podemos comenzar a implementarlo, y comenzaremos creando una estructura para registrar el estado y el camino para lograrlo. Aquí nos encontramos con la primera limitación: en el simulador de estrategias, para transmitir los resultados de cada pasada, el simulador permite transmitir un array de cualquier tipo, pero no debe contener estructuras complejas que utilicen valores de cadena y arrays dinámicos. Esto significa que no podemos usar arrays dinámicos para describir el camino y el estado del sistema. Necesitamos determinar su dimensión directamente. Para lograr una mayor flexibilidad a la hora de organizar el programa, sacaremos los valores principales a las constantes. En ellas definiremos la profundidad de la historia analizada en barras (HistoryBars) y el tamaño del búfer de ruta (Buffer_Size). Podemos utilizar nuestros propios valores según sea necesario para resolver un problema específico.
#define HistoryBars 20 #define Buffer_Size 600 #define FileName "GoExploer"
Además, especificaremos directamente el nombre del archivo para escribir la base de ejemplos.
Escribiremos directamente los datos en el formato de estructura Cell. En él crearemos 2 arrays. Un array de valores enteros para registrar el camino para llegar al estado: actions. Y otro de valores reales para registrar la descripción del estado alcanzado: state. Como nos vemos obligados a utilizar arrays de datos estáticos, introduciremos la variable total_actions para indicar el tamaño del camino recorrido. Asimismo, añadiremos una variable de valor real para registrar el valor del peso de estado. Lo usaremos para priorizar la selección de estados para su posterior estudio.
//+------------------------------------------------------------------+ //| Cell | //+------------------------------------------------------------------+ struct Cell { int actions[Buffer_Size]; float state[HistoryBars * 12 + 9]; int total_actions; float value; //--- Cell(void); //--- bool Save(int file_handle); bool Load(int file_handle); };
Ahora inicializaremos las variables y arrays creados en el constructor de la estructura. Al crear la estructura, rellenaremos el array de ruta con el valor "-1", mientras que el array de estado y las variables serán valores nulos.
Cell::Cell(void) { ArrayInitialize(actions, -1); ArrayInitialize(state, 0); value = 0; total_actions = 0; }
Debemos recordar que guardaremos los estados recopilados en el archivo de base de datos de ejemplos. Por ello, crearemos los métodos para trabajar con archivos. El método de almacenamiento de datos se construye según el algoritmo que ya conocemos, y que hemos usado más de una vez para registrar los datos de las clases generadas.
En los parámetros del método, obtendremos el identificador del archivo para escribir los datos e inmediatamente comprobaremos su valor. Si recibimos un identificador incorrecto, finalizaremos el método con un resultado false.
Tras pasar exitosamente por el bloque de control, escribiremos "999" en el archivo para identificar nuestra estructura. Después de ello, almacenaremos los valores de las variables y los arrays. Para leer posteriormente los arrays de forma correcta, antes de escribir sus datos, deberemos especificar la dimensionalidad del array. Para ahorrar espacio en el disco, almacenaremos solo los datos del camino real y no todo el array actions. Y como ya hemos almacenado el valor de la variable total_actions, no especificaremos el tamaño de este array. Al guardar el array de estado, primero especificaremos el tamaño del array, y solo entonces guardaremos su contenido. Asegúrese de controlar el proceso de cada operación. Tras guardar con éxito todos los datos, saldremos del método con el resultado true.
bool Cell::Save(int file_handle) { if(file_handle <= 0) return false; if(FileWriteInteger(file_handle, 999) < INT_VALUE) return false; if(FileWriteFloat(file_handle, value) < sizeof(float)) return false; if(FileWriteInteger(file_handle, total_actions) < INT_VALUE) return false; for(int i = 0; i < total_actions; i++) if(FileWriteInteger(file_handle, actions[i]) < INT_VALUE) return false; int size = ArraySize(state); if(FileWriteInteger(file_handle, size) < INT_VALUE) return false; for(int i = 0; i < size; i++) if(FileWriteFloat(file_handle, state[i]) < sizeof(float)) return false; //--- return true; }
El método para leer datos del archivo Load se construye de forma similar. En él se realizan operaciones de lectura de datos manteniendo claramente la secuencia de su escritura. El código completo del asesor se encuentra en el archivo adjunto.
Después de crear la estructura para describir un estado del sistema y la forma de lograrlo, procederemos a crear un asesor experto para implementar la primera fase del algoritmo Go-Explore. Así, ahora llamaremos al asesor experto Faza1.mq5. Aunque realizaremos acciones aleatorias sin analizar la situación del mercado, usaremos indicadores para describir el estado del sistema. Por consiguiente, transferiremos sus parámetros desde los asesores expertos anteriores. La variable externa Start se utilizará para indicar el estado de la base de ejemplos. Volveremos sobre ello un poco más tarde.
input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input int Start = 100; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price bool TrainMode = true;
Tras especificar los parámetros externos, crearemos las variables globales. Aquí crearemos 2 arrays de estructuras que describen el estado del sistema. El primero (Base) se utilizará para registrar los estados de la pasada actual. El segundo (Total) se utilizará para registrar la base de datos de ejemplos completa.
Aquí también declararemos los objetos para realizar transacciones y descargar los datos históricos. Son exactamente iguales a los que usábamos antes.
Para los propósitos del algoritmo creado, crearemos:
- action_count — contador de operaciones;
- actions — array para registrar las acciones realizadas durante la sesión;
- StartCell — estructura de la descripción del estado para iniciar el estudio;
- bar — contador de pasos desde el inicio del asesor.
Cell Base[Buffer_Size]; Cell Total[]; CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- int action_count = 0; int actions[Buffer_Size]; Cell StartCell; int bar = -1;
En la función OnInit, primero inicializaremos los objetos de indicadores y las operaciones comerciales. Esta funcionalidad resulta completamente idéntica a la de los asesores expertos anteriormente analizados.
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Luego intentaremos cargar la base de datos de ejemplos que puede haber sido creada durante anteriores inicios del asesor. Ambas opciones resultan aceptables aquí. Si logramos cargar la base de ejemplos, intentamos leer de ella el elemento con el índice establecido en la variable externa Start. Si no existe tal elemento, tomaremos un elemento aleatorio y lo copiaremos en la estructura StartCell. Este será el punto de partida de nuestra exploración. Si la base de datos de ejemplos no está cargada, comenzaremos la exploración desde el principio.
//--- if(LoadTotalBase()) { int total = ArraySize(Total); if(total > Start) StartCell = Total[Start]; else { total = (int)(((double)MathRand() / 32768.0) * (total - 1)); StartCell = Total[total]; } } //--- return(INIT_SUCCEEDED); }
Hemos utilizado un sistema tan ramificado para crear el punto de partida de la exploración para poder organizar varios escenarios sin cambiar el código del asesor.
Una vez completadas todas las operaciones, finalizaremos el funcionamiento de la función de inicialización del asesor experto con el resultado INIT_SUCCEEDED.
Para cargar la base de ejemplos usaremos la función LoadTotalBase. Para completar una descripción del proceso de inicialización, veremos directamente su algoritmo. Esta función no tiene parámetros. En su lugar, usaremos la constante de nombre de archivo previamente definida FileName.
Aquí debemos señalar que el archivo se utilizará tanto en la primera como en la segunda fase del algoritmo. Por ello, declararemos la constante FileName en el archivo de estructura de descripción del estado.
En el cuerpo de la función, primero abriremos el archivo para leer datos y verificaremos el resultado de la operación según el valor del identificador.
Tras abrir el archivo con éxito, leeremos el número de elementos en la base de datos de ejemplos. Asimismo, cambiaremos el tamaño del array para leer los datos, y organizaremos un ciclo de lectura de datos de el archivo. Para leer cada estructura individual, usaremos el método Load creado previamente de la estructura de almacenamiento del estado de nuestro sistema.
En cada iteración, controlaremos el proceso de realización de las operaciones, y antes de salir de la función en cualquiera de las opciones, nos aseguraremos de cerrar el archivo abierto previamente para leer los datos.
bool LoadTotalBase(void) { int handle = FileOpen(FileName + ".bd", FILE_READ | FILE_BIN | FILE_COMMON); if(handle < 0) return false; int total = FileReadInteger(handle); if(total <= 0) { FileClose(handle); return false; } if(ArrayResize(Total, total) < total) { FileClose(handle); return false; } for(int i = 0; i < total; i++) if(!Total[i].Load(handle)) { FileClose(handle); return false; } FileClose(handle); //--- return true; }
Después de crear el algoritmo de inicialización del asesor, pasaremos al método de procesamiento de ticks: OnTick. El terminal llama a este método cuando ocurre un nuevo evento de tick en el gráfico del asesor. Solo necesitaremos procesar el evento de apertura de una nueva vela. Para implementar este control, utilizaremos la función IsNewBar. Está completamente copiada de los anteriores asesores, por lo que no nos detendremos en su algoritmo.
void OnTick() { //--- if(!IsNewBar()) return;
A continuación, aumentaremos el contador de pasos desde el inicio del asesor y compararemos su valor con el número de pasos hasta el inicio de la exploración. Si aún no hemos alcanzado el estado de inicio de la exploración, entonces realizaremos la siguiente acción desde el camino hasta el estado objetivo y luego la finalizaremos. Luego esperaremos la apertura de una nueva vela.
bar++; if(bar < StartCell.total_actions) { switch(StartCell.actions[bar]) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; } return; }
Tras alcanzar el estado de inicio de la exploración, copiaremos el camino recorrido en el conjunto de acciones del agente actual,
if(bar == StartCell.total_actions) ArrayCopy(actions, StartCell.actions, 0, 0, StartCell.total_actions);
y actualizaremos los datos históricos de los indicadores.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Después de ello, crearemos un array con la descripción actual del estado del sistema, en el que escribiremos los datos históricos de los indicadores y los valores de precio, así como información sobre el estado de la cuenta y las posiciones abiertas.
float state[249]; MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- state[b * 12] = (float)Rates[b].close - open; state[b * 12 + 1] = (float)Rates[b].high - open; state[b * 12 + 2] = (float)Rates[b].low - open; state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; state[b * 12 + 4] = (float)sTime.hour; state[b * 12 + 5] = (float)sTime.day_of_week; state[b * 12 + 6] = (float)sTime.mon; state[b * 12 + 7] = rsi; state[b * 12 + 8] = cci; state[b * 12 + 9] = atr; state[b * 12 + 10] = macd; state[b * 12 + 11] = sign; } //--- state[240] = (float)AccountInfoDouble(ACCOUNT_BALANCE); state[240 + 1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); state[240 + 2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); state[240 + 3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); state[240 + 4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } state[240 + 5] = (float)buy_value; state[240 + 6] = (float)sell_value; state[240 + 7] = (float)buy_profit; state[240 + 8] = (float)sell_profit;
Después de eso, realizaremos una acción aleatoria,
//--- int act = SampleAction(4); switch(act) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; }
y guardaremos el estado actual en un array de estados visitados del agente actual.
Tenga en cuenta que como número de pasos hasta el estado actual, indicaremos la suma de pasos hasta el estado de inicio de la exploración y los pasos aleatorios de la misma. Luego guardaremos los estados antes de comenzar la exploración, puesto que ya están guardados en nuestra base de datos de ejemplos. Al mismo tiempo, necesitaremos almacenar el camino completo hasta cada estado.
Como valor del estado indicaremos la magnitud inversa del cambio en la equidad de la cuenta. Lo usaremos como guía para priorizar estados para la exploración. El propósito de esta priorización es encontrar medidas para minimizar las pérdidas; esto potencialmente dará como resultado un aumento en las ganancias totales. Además, posteriormente podremos usar la magnitud inversa de este valor como recompensa al realizar el entrenamiento con la política en la segunda fase del algoritmo Go-Explore.
//--- copy cell actions[action_count] = act; Base[action_count].total_actions = action_count+StartCell.total_actions; if(action_count > 0) { ArrayCopy(Base[action_count].actions, actions, 0, 0, Base[action_count].total_actions+1); Base[action_count - 1].value = Base[action_count - 1].state[241] - state[241]; } ArrayCopy(Base[action_count].state, state, 0, 0); //--- action_count++; }
Después de guardar los datos del estado actual, incrementaremos el contador de pasos y procederemos a esperar la siguiente vela.
Ya hemos creado un algoritmo de agente para explorar el entorno. Ahora tenemos que organizar el proceso de recopilación de datos de todos los agentes en una única base de datos de ejemplos. Para ello, una vez finalizadas las pruebas, cada agente deberá enviar los datos recopilados al centro de generalización. Organizaremos esta funcionalidad en el método OnTester. Este es llamado por el simulador de estrategias al final de cada pasada.
Aquí hemos decidido conservar solo las pasadas rentables. Esto reducirá sustancialmente el tamaño de la base de datos de ejemplos y acelerará el proceso de aprendizaje. Si deseamos entrenar la política con la mayor precisión posible y no estamos limitados por los recursos, podemos guardar todos las pasadas. Esto ayudará a que nuestra política comprenda mejor el entorno.
Primero comprobaremos la rentabilidad de la pasada, y, de ser necesario, enviaremos los datos usando la función FrameAdd.
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); action_count--; if(profit > 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), action_count, profit, Base); //--- return(ret); }
Tenga en cuenta que antes de realizar el envío, reduciremos el número de pasos en 1, ya que desconocemos los resultados de la última acción.
Para organizar el proceso de recopilación de datos en una base de datos de ejemplos común, utilizaremos 3 funciones. Primero, al inicializar el proceso de optimización, cargaremos la base de datos de ejemplos, si hemos creado alguna previamente. Esta operación se realizará en la función OnTesterInit.
//+------------------------------------------------------------------+ //| TesterInit function | //+------------------------------------------------------------------+ void OnTesterInit() { //--- LoadTotalBase(); }
Luego, procesaremos cada pasada en la función OnTesterPass. Aquí organizaremos la recopilación de datos de todos los frames disponibles y los añadiremos al array de la base de ejemplos común. La función FrameNext leerá el siguiente frame, y si los datos se cargan correctamente, retornará true. En caso de error al leer los datos del frame, retornará false. Gracias a esta propiedad, podremos organizar un ciclo de lectura de datos y añadirlos a nuestro array común.
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; Cell array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Total); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(ArrayResize(Total, total + (int)id, 10000) < 0) return; ArrayCopy(Total, array, total, 0, (int)id); } }
Al final del proceso de optimización, se llamará a la función OnTesterDeinit. Aquí, primero clasificaremos nuestro conjunto de datos en orden descendente según el valor de la descripción del estado. Esto nos permitirá mover al comienzo del array los elementos que dan la máxima pérdida.
//+------------------------------------------------------------------+ //| TesterDeinit function | //+------------------------------------------------------------------+ void OnTesterDeinit() { //--- bool flag = false; int total = ArraySize(Total); printf("total %d", total); Cell temp; Print("Start sorting..."); do { flag = false; for(int i = 0; i < (total - 1); i++) if(Total[i].value < Total[i + 1].value) { temp = Total[i]; Total[i] = Total[i + 1]; Total[i + 1] = temp; flag = true; } } while(flag); Print("Saving..."); SaveTotalBase(); Print("Saved"); }
Después de ello, guardaremos la base de ejemplos en un archivo usando el método SaveTotalBase. Su algoritmo está construido de forma similar al método LoadTotalBase anteriormente analizado: encontrará su código completo, así como todas estas funciones, en el archivo adjunto.
Con esto damos por finalizado el trabajo con la primera fase del asesor experto. Ahora lo compilaremos y pasaremos al simulador de estrategias. Luego seleccionaremos el asesor experto Faza1.ex5 que hemos creado, el instrumento, el periodo de prueba (en nuestro caso, entrenamiento) y la optimización lenta con una búsqueda de todas las opciones.
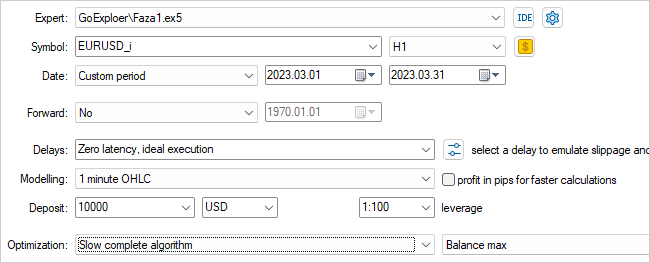
Optimizaremos según un parámetro Start cada vez. Con su ayuda determinaremos el número de agentes en ejecución. En la etapa inicial, comenzaremos con un pequeño número de agentes. Esto nos ofrecerá un pasada rápida para crear una base de datos de ejemplos inicial.
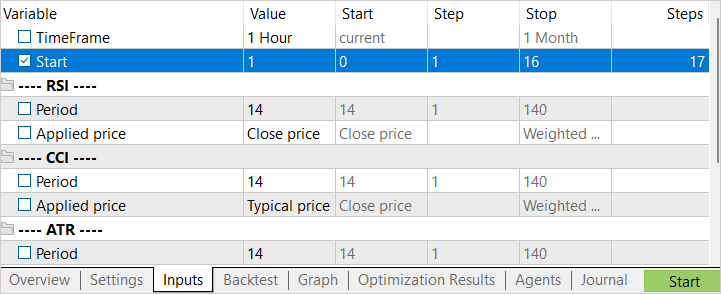
Tras completar la primera etapa de optimización, aumentaremos el número de agentes de prueba. Y aquí hay dos enfoques para el siguiente inicio. Si queremos tratar de encontrar la mejor acción en los estados menos rentables, entonces especificaremos el intervalo de optimización del parámetro Start desde "0". Para seleccionar estados aleatorios como punto de partida del estudio, estableceremos un valor inicial deliberadamente grande de optimización de parámetros. El valor final de la optimización de los parámetros dependerá del número de agentes iniciados. El valor en la columna Steps se corresponderá con la cantidad de agentes iniciados en el proceso de optimización (aprendizaje).
2.2. Fase 2: política de entrenamiento a partir de los ejemplos
Mientras nuestro primer asesor experto trabaja en la creación de una base de datos de ejemplos, procederemos a trabajar en la segunda fase del asesor experto.
Aquí vale la pena decir que en nuestra implementación nos hemos desviado un poco del proceso de entrenamiento de políticas en la fase 2 que proponían los autores del artículo. En el artículo se proponía utilizar un método de simulación de entrenamiento de políticas cuando se utiliza un enfoque modificado de los algoritmos de aprendizaje por refuerzo conocidos. En una sección separada, se entrenará al agente para que repita las acciones de una estrategia exitosa a partir de la base de datos de ejemplos, y luego se aplicará el enfoque estándar de aprendizaje por refuerzo. En la primera etapa, el segmento de demostración del "maestro" es máximo, y el agente debe obtener un resultado no peor que el del "maestro". A medida que avance el aprendizaje, el intervalo del "maestro" se reducirá, y el agente deberá aprender a optimizar la estrategia del maestro.
En mi implementación, hemos dividido esta fase en 2 etapas. En la primera etapa, entrenaremos al agente de manera similar al proceso de aprendizaje supervisado, solo que no indicaremos la acción correcta, y ajustaremos el valor de la recompensa prevista. Para esta etapa, crearemos el asesor experto Faza2.mq5.
En el código de este asesor experto, incluiremos el elemento de descripción del estado del sistema y la clase del modelo FQF completamente parametrizado.
//+------------------------------------------------------------------+ //| Includes | //+------------------------------------------------------------------+ #include "Cell.mqh" #include "..\RL\FQF.mqh" //+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 100000;
Este tendrá pocos parámetros externos: solo indicaremos el número de iteraciones de entrenamiento del modelo.
Entre los parámetros globales, declararemos la clase de modelo, el objeto de descripción de estado y el array de recompensas, así como un array para cargar la base de ejemplos.
CNet StudyNet; //--- float dError; datetime dtStudied; bool bEventStudy; //--- CBufferFloat State1; CBufferFloat *Rewards; Cell Base[];
En el método de inicialización del asesor experto, primero cargaremos la base de ejemplos. En dicho caso, este será uno de los puntos clave. Si se da un error al cargar la base de datos de ejemplos, no dispondremos de los datos de origen para entrenar el modelo. Por lo tanto, en caso de error al realizar la carga, saldremos de la función con el resultado INIT_FAILED.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!LoadTotalBase()) return(INIT_FAILED); //--- if(!StudyNet.Load(FileName + ".nnw", dError, dError, dError, dtStudied, true)) { CArrayObj *model = new CArrayObj(); if(!CreateDescriptions(model)) { delete model; return INIT_FAILED; } if(!StudyNet.Create(model)) { delete model; return INIT_FAILED; } delete model; } if(!StudyNet.TrainMode(true)) return INIT_FAILED; //--- bEventStudy = EventChartCustom(ChartID(), 1, 0, 0, "Init"); //--- return(INIT_SUCCEEDED); }
Después de cargar la base de datos de ejemplos, inicializaremos el modelo para entrenar. Como de costumbre, primero intentaremos cargar el modelo previamente entrenado, y en caso de que la carga del modelo falle por algún motivo, inicializaremos la creación de un nuevo modelo con pesos aleatorios. La descripción del modelo se especificará en la función CreateDescriptions.
Tras inicializar exitosamente el modelo, crearemos un evento personalizado para iniciar el proceso de entrenamiento del modelo. Hemos usado el mismo enfoque al entrenar los modelos supervisados.
Luego finalizaremos el funcionamiento de la función de inicialización del asesor experto.
Tenga en cuenta que en este asesor experto no hemos creado objetos para cargar los datos e indicadores históricos de precio. Todo el proceso de aprendizaje se basa en ejemplos, y en él guardaremos todas las descripciones del estado del sistema, incluida la información sobre la cuenta y las posiciones abiertas.
El evento personalizado que creamos se gestionará en la función OnChartEvent. Aquí solo verificaremos el evento esperado y llamaremos a la función de entrenamiento del modelo.
//+------------------------------------------------------------------+ //| ChartEvent function | //+------------------------------------------------------------------+ void OnChartEvent(const int id, const long &lparam, const double &dparam, const string &sparam) { //--- if(id == 1001) Train(); }
El proceso de entrenamiento del modelo en sí estará organizado en la función Train. Esta función no tiene parámetros. En el cuerpo de la función, primero determinaremos el tamaño de la base de ejemplos y almacenaremos en una variable local el número de milisegundos transcurridos desde que se inició el sistema. Usaremos este valor para crear informes periódicos para el usuario sobre el progreso del proceso de entrenamiento del modelo.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total = ArraySize(Base); uint ticks = GetTickCount();
Después de un pequeño trabajo preparatorio, organizaremos un ciclo de entrenamiento para el modelo. El número de iteraciones del ciclo se corresponderá col valor de la variable externa. Al mismo tiempo, preveremos la interrupción forzosa del ciclo y el cierre del programa a petición del usuario. Esto nos permitirá controlar el valor de la función IsStopped. Si el usuario fuerza el cierre del programa, la función indicada retornará true.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int i = 0; int count = 0; int total_max = 0; i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 1)); State1.AssignArray(Base[i].state); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
En el cuerpo del ciclo, seleccionaremos aleatoriamente un ejemplo de la base de datos y copiaremos el estado al búfer de datos. Luego realizaremos una pasada directa del modelo,
if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return;
y extraeremos la acción realizada en el ejemplo actual. Acto seguido, cargaremos los resultados de la pasada directa, y actualizaremos la recompensa por la acción completada.
int action = Base[i].total_actions; if(action < 0) { iter--; continue; } action = Base[i].actions[action]; if(action < 0 || action > 3) action = 3; StudyNet.getResults(Rewards); if(!Rewards.Update(action, -Base[i].value)) return;
Debemos prestar atención a dos puntos: si no hay ninguna acción en el ejemplo (se selecciona el estado inicial), reduciremos el contador de iteraciones y seleccionaremos un nuevo ejemplo, y al actualizar la recompensa, tomaremos el valor value con el signo opuesto. ¿Recuerda? Al guardar al estado, implementamos un valor positivo para reducir la equidad. Y este es un momento negativo.
Tras actualizar la recompensa, realizaremos una pasada inversa del modelo y actualizaremos los pesos.
if(!StudyNet.backProp(GetPointer(Rewards))) return; if(GetTickCount() - ticks > 500) { Comment(StringFormat("%.2f%% -> Error %.8f", iter * 100.0 / (double)(Iterations), StudyNet.getRecentAverageError())); ticks = GetTickCount(); } }
Al final de las iteraciones del ciclo, comprobaremos si es necesario actualizar la información del proceso de entrenamiento para el usuario. En este ejemplo, actualizaremos la información en el campo de comentarios del chat cada 0,5 segundos.
Con esto damos por finalizadas las operaciones en el cuerpo del ciclo y podemos pasar a un nuevo ejemplo de la base.
Después de completar todas las iteraciones del ciclo, limpiaremos el campo de comentarios, enviaremos información al registro e inicializaremos el cierre del asesor experto.
Comment(""); //--- PrintFormat("%s -> %d -> %10.7f", __FUNCTION__, __LINE__, StudyNet.getRecentAverageError()); ExpertRemove(); //--- }
Cuando el asesor experto finalice su trabajo en su método de desinicialización, eliminaremos los objetos dinámicos utilizados y guardaremos el modelo entrenado en el disco.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!!Rewards) delete Rewards; //--- StudyNet.Save(FileName + ".nnw", 0, 0, 0, 0, true); }
Después de recopilar la base de ejemplos del asesor de la primera fase, solo necesitaremos adjuntar al gráfico el asesor de la segunda fase y comenzará el proceso de entrenamiento del modelo. Tenga en cuenta que, a diferencia del asesor de la primera fase, el asesor de la segunda fase no lo iniciaremos en el simulador de estrategias, sino que lo adjuntaremos a un gráfico real. En los parámetros del asesor, especificaremos el número de iteraciones del ciclo del proceso de aprendizaje y monitorearemos el proceso.
Para lograr el resultado óptimo, se permitirá la repetición de iteraciones de la primera y segunda fase. En este caso, podemos repetir primero la primera fase N veces y luego la segunda M veces, o bien podemos repetir el ciclo de iteraciones la primera fase + la segunda fase varias veces.
Para ajustar la política utilizaremos el tercer asesor experto GE-lerning.mq5. En él organizaremos el clásico algoritmo de aprendizaje por refuerzo. No nos detendremos ahora en todas las funciones del asesor: su código completo está disponible en el archivo adjunto. Consideremos solo la función de procesamiento de ticks OnTick.
Como en el asesor de la primera fase, procesaremos solo el evento de apertura de una nueva vela, y en ausencia de ello, simplemente finalizaremos el funcionamiento de la función anticipándonos al momento adecuado.
Cuando ocurra un nuevo evento de apertura de vela, primero guardaremos el último estado, la acción realizada y el cambio en el valor en el búfer de reproducción de experiencias, y reescribiremos el indicador de acciones en la variable global para monitorear el cambio en la siguiente vela.
void OnTick() { if(!IsNewBar()) return; //--- float current = (float)AccountInfoDouble(ACCOUNT_EQUITY); if(Equity >= 0 && State1.Total() == (HistoryBars * 12 + 9)) cReplay.AddState(GetPointer(State1), Action, (double)(current - Equity)); Equity = current;
Luego, actualizaremos la historia de valores y de los indicadores de precio,
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
y formaremos una descripción del estado actual del sistema. Aquí deberemos tener cuidado de que la descripción generada del estado del sistema se corresponda plenamente con el proceso similar en el asesor experto de la primera fase. Después de todo, la explotación y el ajuste preciso deben realizarse con datos comparables a los datos de la muestra de entrenamiento.
State1.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[b].close - open) || !State1.Add((float)Rates[b].high - open) || !State1.Add((float)Rates[b].low - open) || !State1.Add((float)Rates[b].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } //--- if(!State1.Add((float)AccountInfoDouble(ACCOUNT_BALANCE)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_EQUITY)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_MARGIN_FREE)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_PROFIT))) return; //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); return; } } if(!State1.Add((float)buy_value) || !State1.Add((float)sell_value) || !State1.Add((float)buy_profit) || !State1.Add((float)sell_profit)) return;
Posteriormente realizaremos una pasada directa del modelo. Según los resultados de la pasada directa, determinaremos y realizaremos una acción.
if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return; Action = StudyNet.getAction(); switch(Action) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; }
Tenga en cuenta que en este caso no usaremos ninguna política de exploración, sino que seguiremos estrictamente la política aprendida.
Al final de la función de procesamiento de ticks, verificaremos la hora. Y una vez al día, a medianoche, actualizaremos la política del agente utilizando el búfer de reproducción de experiencias.
MqlDateTime time; TimeCurrent(time); if(time.hour == 0) { int repl_action; double repl_reward; for(int i = 0; i < 10; i++) { if(cReplay.GetRendomState(pstate1, repl_action, repl_reward, pstate2)) return; if(!StudyNet.feedForward(pstate1, 12, true)) return; StudyNet.getResults(Rewards); if(!Rewards.Update(repl_action, (float)repl_reward)) return; if(!StudyNet.backProp(GetPointer(Rewards), DiscountFactor, pstate2, 12, true)) return; } } //--- }
El código completo de todos los asesores se puede encontrar en el archivo adjunto.
3. Simulación
Las pruebas del trabajo de los tres asesores expertos creados se han realizado secuencialmente, según el algoritmo Go-Explore:
- Hemos ejecutado varios inicios sucesivos de la primera fase del asesor experto en el modo de optimización del simulador de estrategias para crear una base de datos de ejemplos.
- Hemos realizado varias iteraciones de entrenamiento con políticas usando el asesor de la segunda fase.
- También hemos llevado a cabo el ajuste final en el simulador de estrategias mediante algoritmos de aprendizaje por refuerzo.
Al igual que en los demás artículos de la serie, todas las pruebas se han realizado usando los datos históricos del instrumento EURUSD, con el marco temporal H1. Los parámetros del indicador se han usado por defecto sin ningún ajuste.
Como resultado de las pruebas, hemos obtenido resultados bastante buenos que se presentan en las capturas de pantalla a continuación.


En las imágenes presentadas, vemos un gráfico bastante uniforme del crecimiento del balance. En la práctica, según los datos de la prueba, hemos obtenido un factor de beneficio de 6,0 y un factor de recuperación de 3,34. De las 30 transacciones realizadas, 22 han sido rentables, lo que cual supone el 73,3%. El beneficio medio por transacción es 2 veces superior al promedio de las operaciones perdedoras, mientras que el beneficio máximo por operación supera en 3,5 veces la operación con una pérdida máxima.
Cabe señalar que el asesor solo ha realizado transacciones de compra y las ha cerrado sin reducciones significativas. El motivo de la falta de transacciones cortas es un tema que requiere investigación adicional.
Los resultados de las pruebas son prometedores, pero se han obtenido en un corto intervalo de tiempo. Para confirmar los resultados del algoritmo, deberemos realizar experimentos adicionales en un intervalo de tiempo más largo.
Conclusión
En este artículo, hemos presentado el algoritmo Go-Explore, que supone un nuevo enfoque para resolver problemas complejos de aprendizaje por refuerzo. Se basa en la idea de recordar y revisar los estados con buenas perspectivas en el espacio de estados, lo cual permite lograr el rendimiento deseado más rápidamente. La principal diferencia entre Go-Explore y otros algoritmos es su enfoque a la hora de encontrar estados y acciones relevantes, en lugar de resolver directamente el problema objetivo.
Hemos creado tres asesores expertos que se inician de forma secuencial, y cada uno de ellos realiza su propia funcionalidad del algoritmo para lograr el objetivo general de aprendizaje de políticas. La política aquí se refiere a una estrategia comercial.
El algoritmo se ha puesto a prueba con datos históricos y ha mostrado uno de los mejores resultados. Sin embargo, los resultados se han logrado en el simulador de estrategias en un periodo de tiempo corto. Por lo tanto, antes de utilizar el asesor experto en cuentas reales, deberemos probarlo minuciosamente y entrenar el modelo durante un periodo de tiempo más largo y representativo.
Enlaces
- Go-Explore: a New Approach for Hard-Exploration Problems
- Redes neuronales: así de sencillo (Parte 35): Módulo de curiosidad intrínseca (Intrinsic Curiosity Module)
- Redes neuronales: así de sencillo (Parte 36): Modelos relacionales de aprendizaje por refuerzo (Relational Reinforcement Learning)
- Redes neuronales: así de sencillo (Parte 37): Atención dispersa (Sparse Attention)
- Redes neuronales: así de sencillo (Parte 38): Exploración auto-supervisada por desacuerdo (Self-Supervised Exploration via Disagreement)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Faza1.mq5 | Asesor | Asesor de primera fase |
| 2 | Faza2.mql5 | Asesor | Asesor de segunda fase |
| 3 | GE-lerning.mq5 | Asesor | Asesor de ajuste preciso de políticas |
| 4 | Cell.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | FQF.mqh | Biblioteca de clases | Biblioteca de clases de organización de modelos completamente parametrizada |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12558
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Tengo este error
2023.05.07 20:04:44.281 Core 01 pass 359 probado con error "critical runtime error 502 in OnTester function(array out of range, module Experts\GoExploer\Faza1.ex5, file Faza1.mq5, line 223, col 12)" en 0:00:00.202
//--- copiar celda
acciones[recuento_acciones] = act;
Base[action_count].total_actions = action_count+StartCell.total_actions;
¿como solucionarlo?
Si el error crece constantemente, intenta reducir el coeficiente de entrenamiento.
Tengo este error.
2023.05.07 20:04:44.281 Core 01 pass 359 probado con error "critical runtime error 502 in OnTester function (array out of range, module Experts\GoExploer\Faza1.ex5, file Faza1.mq5, line 223, col 12)" en 0:00:00.202
//--- copiar celda
actions[action_count] = act;
Base[action_count].total_actions = action_count+StartCell.total_actions;
¿cómo solucionarlo?
¿Cuál es el periodo de estudio?
¿Cuál es el periodo de estudio?
Datos H1, del 1 abr 2023~ 30 abr 2023