
Uso del algoritmo de aprendizaje automático PatchTST para predecir la acción del precio durante las próximas 24 horas
Introducción
Me encontré por primera vez con un algoritmo llamado PatchTST cuando comencé a investigar los avances de IA asociados con las predicciones de series de tiempo en Huggingface.co. Como sabrá cualquiera que haya trabajado con grandes modelos lingüísticos (LLM), la invención de los transformadores ha supuesto un cambio radical en el desarrollo de herramientas para el procesamiento del lenguaje natural, las imágenes y el vídeo. ¿Pero qué pasa con las series temporales? ¿Es algo que simplemente quedó atrás? ¿O la mayor parte de la investigación se realiza simplemente a puertas cerradas? Resulta que hay muchos modelos más nuevos que aplican transformadores con éxito para predecir series de tiempo. En este artículo, analizaremos una de esas implementaciones.
Lo impresionante de PatchTST es lo rápido que es entrenar un modelo y lo fácil que es usar el modelo entrenado con MQL. Admito abiertamente que soy nuevo en el concepto de redes neuronales. Pero al pasar por este proceso y abordar la implementación de PatchTST descrita en este artículo para MQL5, sentí que di un gran paso adelante en mi aprendizaje y comprensión de cómo se desarrollan, solucionan problemas, entrenan y utilizan estas redes neuronales complejas. Es como coger a un niño, que apenas está aprendiendo a andar, y ponerlo en un equipo de fútbol profesional, esperando que marque el gol de la victoria en la final de la Copa del Mundo.
Descripción general de PatchTST
Después de descubrir PatchTST, comencé a investigar el artículo que explica su diseño: "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers". El título era interesante. A medida que comencé a leer más sobre el documento, pensé: “¡Vaya! Esta parece una estructura fascinante: tiene muchos elementos que siempre quise aprender”. Naturalmente, quise probarlo y ver cómo funcionan las predicciones. Esto es lo que me hizo interesarme aún más en este algoritmo:
- Puede predecir la apertura, el máximo, el mínimo y el cierre utilizando PatchTST. Con PatchTST, sentí que podía alimentarlo con todos los datos a medida que llegaban: apertura, máximo, mínimo, cierre e incluso volumen. Se puede esperar que encuentre patrones en los datos porque todos los datos se convierten en algo llamado "parches". Más adelante en este artículo hablaremos más sobre qué son estos parches. Por ahora, solo es importante saber que los parches son atractivos y ayudan a mejorar las predicciones.
- Requisitos mínimos de preprocesamiento de datos con PatchTST. Cuando comencé a profundizar en el algoritmo, me di cuenta de que los autores utilizan algo llamado "RevIn", que es la normalización de instancia inversa. RevIn proviene de un artículo titulado: "REVERSIBLE INSTANCE NORMALIZATION FOR ACCURATE TIME-SERIES FORECASTING AGAINST DISTRIBUTION SHIFT". RevIn intenta abordar el problema del cambio de distribución en la previsión de series temporales. Como traders algorítmicos, estamos muy familiarizados con la sensación que sentimos cuando nuestro EA entrenado ya no parece predecir el mercado y nos vemos obligados a volver a optimizar y actualizar nuestros parámetros. Considere RevIn como una forma de hacer lo mismo.
- Este método básicamente toma los datos que se le pasan y los normaliza utilizando la siguiente fórmula:
x = (x - mean) / std
Luego, cuando el modelo tiene que hacer una predicción, desnormaliza los datos utilizando la propiedad opuesta:
x = x * std + mean
RevIn también tiene otra propiedad llamada affine_bias. En los términos más sencillos posibles, se trata de un parámetro que se puede aprender y que se ocupa de la asimetría, la curtosis, etc. que pueda haber en el conjunto de datos.
x = x * affine_weight + affine_bias
La estructura de PatchTST puede resumirse como sigue:
Datos de entrada -> RevIn -> Descomposición de series -> Componente de tendencia -> PatchTST Backbone -> TSTi Encoder -> Flatten_Head -> Pronosticador de tendencia -> Componente residual -> Añadir tendencia y residual -> Predicción final
Entendemos que nuestros datos se extraerán mediante MT5. También hemos discutido cómo funciona RevIn.
Así es como funciona PatchTST: digamos que extraes 80.000 barras de datos EURUSD para el período de tiempo H1. Eso equivale aproximadamente a 13 años de datos. Con PatchTST, segmentas los datos en algo llamado “parches”. A modo de analogía, piense en los parches como algo similar a cómo funcionan los Transformadores de Visión (Vision Transformers,ViTs) para imágenes, pero adaptados para datos de series de tiempo. Entonces, por ejemplo, si la longitud del parche es 16, cada parche contendría 16 valores de precios consecutivos. Esto es como mirar pequeños fragmentos de la serie temporal a la vez, lo que ayuda al modelo a centrarse en los patrones locales antes de considerar el patrón global.
A continuación, los parches incluyen codificación posicional para preservar el orden de la secuencia, lo que ayuda al modelo a recordar la posición de cada parche en la secuencia.
El transformador pasa los parches normalizados y codificados a través de una pila de capas de codificador. Cada capa del codificador contiene una capa de atención de múltiples cabezales y una capa de avance. La capa de atención de múltiples cabezales permite que el modelo preste atención a diferentes partes de la secuencia de entrada, mientras que la capa de avance permite que el modelo aprenda transformaciones no lineales complejas de los datos.
Por último, tenemos los componentes de tendencia y residual. Las mismas capas de parcheo, normalización, codificación posicional y transformación se aplican tanto al componente de tendencia como al componente residual. Luego, sumamos los resultados de los componentes de tendencia y residuales para producir el pronóstico final.
Problemas con el repositorio oficial de PatchTST
El repositorio oficial de PatchTST se puede encontrar en GitHub en el siguiente enlace: PatchTST (ICLR 2023). Hay dos versiones diferentes disponibles: supervisada y no supervisada. Para este artículo, utilizaremos el enfoque de aprendizaje supervisado. Como sabemos, para utilizar cualquier modelo con MQL5, necesitamos una forma de convertirlo al formato ONNX. Sin embargo, los autores de PatchTST no tuvieron esto en cuenta. Tuve que hacer las siguientes modificaciones a su código base para que el modelo funcionara con MQL5:
Código original:
class PatchTST_backbone(nn.Module): def __init__(self, c_in:int, context_window:int, target_window:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024, n_layers:int=3, d_model=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None, d_ff:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:bool='auto', padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False, pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None, pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False, verbose:bool=False, **kwargs): super().__init__() # RevIn self.revin = revin if self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last) # Patching self.patch_len = patch_len self.stride = stride self.padding_patch = padding_patch patch_num = int((context_window - patch_len)/stride + 1) if padding_patch == 'end': # can be modified to general case self.padding_patch_layer = nn.ReplicationPad1d((0, stride)) patch_num += 1 # Backbone self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len, n_layers=n_layers, d_model=d_model, n_heads=n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var, attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn, pe=pe, learn_pe=learn_pe, verbose=verbose, **kwargs) # Head self.head_nf = d_model * patch_num self.n_vars = c_in self.pretrain_head = pretrain_head self.head_type = head_type self.individual = individual if self.pretrain_head: self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # custom head passed as a partial func with all its kwargs elif head_type == 'flatten': self.head = Flatten_Head(self.individual, self.n_vars, self.head_nf, target_window, head_dropout=head_dropout) def forward(self, z): # z: [bs x nvars x seq_len] # norm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'norm') z = z.permute(0,2,1) # do patching if self.padding_patch == 'end': z = self.padding_patch_layer(z) z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len] z = z.permute(0,1,3,2) # z: [bs x nvars x patch_len x patch_num] # model z = self.backbone(z) # z: [bs x nvars x d_model x patch_num] z = self.head(z) # z: [bs x nvars x target_window] # denorm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'denorm') z = z.permute(0,2,1) return z
El código anterior es la columna vertebral principal. Como puedes ver, el código utiliza una función llamada Unfold en la línea:
z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len]
ONNX no admite la conversión de Unfold. Recibirás un error como el siguiente:
Unsupported: ONNX export of operator Unfold, input size not accessible. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues
Entonces tuve que reemplazar esta sección del código con:
# Manually unfold the input tensor batch_size, n_vars, seq_len = z.size() patches = [] for i in range(0, seq_len - self.patch_len + 1, self.stride): patches.append(z[:, :, i:i+self.patch_len])
Tenga en cuenta que el reemplazo anterior es un poco menos eficiente porque utiliza un bucle for para entrenar una red neuronal. Las ineficiencias pueden acumularse a lo largo de muchas épocas y en grandes conjuntos de datos. Pero esto es necesario porque de lo contrario, el modelo simplemente no podrá convertirse y no podremos usarlo con MQL5.
He abordado específicamente esta cuestión. Hacer esto tomó el mayor tiempo. Luego puse todo junto en un archivo llamado patchTST.py, que se puede encontrar en el archivo ZIP adjunto a este artículo. Este es el archivo que usaremos para el entrenamiento de nuestro modelo.
Requisitos para trabajar con PatchTST en Python
En esta sección, te daré los requisitos para trabajar con PatchTST en Python. Estos requisitos se pueden resumir a continuación:
Crear un entorno virtual:
python -m venv myenv
Activar el entorno virtual (Windows)
.\myenv\Scripts\activate
Instale el archivo requirements.txt incluido en el archivo ZIP adjunto a este artículo:
pip install -r requirements.txt
En concreto, los requisitos para ejecutar este proyecto son:
MetaTrader5
pandas
numpy
torch
plotly
datetime Desarrollo de código de entrenamiento modelo paso a paso
Para el siguiente código, puedes seguirme usando un cuaderno Jupyter que he incluido en el archivo ZIP: PatchTST Step-By-Step.ipynb. A continuación resumiremos los pasos:
-
Importar las bibliotecas necesarias: Importar las bibliotecas necesarias, incluidas MetaTrader 5, Pandas, Numpy, Torch y el modelo PatchTST.
# Step 1: Import necessary libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from torch.utils.data import TensorDataset, DataLoader from patchTST import Model as PatchTST
-
Inicializar y recuperar datos de MetaTrader 5: La función fetch_mt5_data inicializa MT5, obtiene los datos para el símbolo, el período de tiempo y el número de barras dados, luego devuelve un marco de datos con las columnas de apertura, máximo, mínimo y cierre.
# Step 2: Initialize and fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch data data = fetch_mt5_data('EURUSD', 'H1', 80000)
-
Preparar datos de pronóstico utilizando una ventana deslizante: La función prepare_forecasting_data crea el conjunto de datos utilizando un enfoque de ventana deslizante, generando secuencias de datos históricos (X) y los datos futuros correspondientes (y).
# Step 3: Prepare forecasting data using sliding window def prepare_forecasting_data(data, seq_length, pred_length): X, y = [], [] for i in range(len(data) - seq_length - pred_length): X.append(data.iloc[i:(i + seq_length)].values) y.append(data.iloc[(i + seq_length):(i + seq_length + pred_length)].values) return np.array(X), np.array(y) seq_length = 168 # 1 week of hourly data pred_length = 24 # Predict next 24 hours X, y = prepare_forecasting_data(data, seq_length, pred_length)
-
Dividir los datos en conjuntos de entrenamiento y prueba: Dividir los datos en conjuntos de entrenamiento y prueba, con un 80 % para entrenamiento y un 20 % para prueba.
# Step 4: Split data into training and testing sets split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:]
-
Convertir datos en tensores de PyTorch: Conversión de las matrices NumPy en tensores PyTorch, que son necesarios para el entrenamiento con PyTorch. Establece una semilla manual para la antorcha, para la reproducibilidad de los resultados.
# Step 5: Convert data to PyTorch tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) torch.manual_seed(42)
-
Configurar el dispositivo para cálculo: Configurar el dispositivo en CUDA si está disponible, de lo contrario, utilizar la CPU. Esto es esencial para aprovechar la aceleración de la GPU durante el entrenamiento, especialmente si está disponible.
# Step 6: Set device for computation device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")
-
Crear un cargador de datos para los datos de entrenamiento: Creación de un cargador de datos para gestionar el procesamiento por lotes y la mezcla de los datos de entrenamiento.
# Step 7: Create DataLoader for training data train_dataset = TensorDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
-
Definir la clase de configuración para el modelo: Definir una clase de configuración Config para almacenar todos los hiperparámetros y configuraciones necesarios para el modelo PatchTST.
# Step 8: Define the configuration class for the model class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = pred_length self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 configs = Config()
-
Inicializar el modelo PatchTST: Inicializa el modelo PatchTST con la configuración definida y lo mueve al dispositivo seleccionado.
# Step 9: Initialize the PatchTST model model = PatchTST( configs=configs, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ).to(device)
-
Definir optimizador y función de pérdida: Configuración del optimizador (Adam) y la función de pérdida (error cuadrático medio) para entrenar el modelo.
# Step 10: Define optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=0.001) loss_fn = torch.nn.MSELoss() num_epochs = 100
-
Entrenar el modelo: Entrenamiento del modelo durante el número especificado de épocas. Para cada lote de datos, el modelo realiza un pase hacia adelante, calcula la pérdida, realiza un pase hacia atrás para calcular gradientes y actualiza los parámetros del modelo.
# Step 11: Train the model for epoch in range(num_epochs): model.train() total_loss = 0 for batch_X, batch_y in train_loader: optimizer.zero_grad() batch_X = batch_X.to(device) batch_y = batch_y.to(device) outputs = model(batch_X) outputs = outputs[:, -pred_length:, :4] loss = loss_fn(outputs, batch_y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.10f}")
-
Guardar el modelo en formato PyTorch: Guardar el diccionario de estados del modelo entrenado en un archivo. Podemos usar este archivo para hacer predicciones directamente en Python.
# Step 12: Save the model in PyTorch format torch.save(model.state_dict(), 'patchtst_model.pth')
-
Preparar una entrada ficticia para la exportación ONNX: Creación de un tensor de entrada ficticio para usar para exportar el modelo al formato ONNX.
# Step 13: Prepara una entrada ficticia para exportar ONNX dummy_input = torch.randn(1, seq_length, 4).to(device)
-
Exportar el modelo al formato ONNX: Exportar el modelo entrenado al formato ONNX. Necesitaremos este fichero para realizar predicciones con MQL5.
# Step 14: Export the model to ONNX format torch.onnx.export(model, dummy_input, "patchtst_model.onnx", opset_version=13, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}) print("Model trained and saved in PyTorch and ONNX formats.")
Resultados del entrenamiento de modelos
Estos son los resultados que he obtenido al entrenar el modelo.
Epoch 1/100, Loss: 0.0000283705 Epoch 2/100, Loss: 0.0000263274 Epoch 3/100, Loss: 0.0000256321 Epoch 4/100, Loss: 0.0000252389 Epoch 5/100, Loss: 0.0000249340 Epoch 6/100, Loss: 0.0000246715 Epoch 7/100, Loss: 0.0000244293 Epoch 8/100, Loss: 0.0000241942 Epoch 9/100, Loss: 0.0000240157 Epoch 10/100, Loss: 0.0000236776 Epoch 11/100, Loss: 0.0000233954 Epoch 12/100, Loss: 0.0000230437 Epoch 13/100, Loss: 0.0000226635 Epoch 14/100, Loss: 0.0000221875 Epoch 15/100, Loss: 0.0000216960 Epoch 16/100, Loss: 0.0000213242 Epoch 17/100, Loss: 0.0000208693 Epoch 18/100, Loss: 0.0000204956 Epoch 19/100, Loss: 0.0000200573 Epoch 20/100, Loss: 0.0000197222 Epoch 21/100, Loss: 0.0000193516 Epoch 22/100, Loss: 0.0000189223 Epoch 23/100, Loss: 0.0000186635 Epoch 24/100, Loss: 0.0000184025 Epoch 25/100, Loss: 0.0000180468 Epoch 26/100, Loss: 0.0000177854 Epoch 27/100, Loss: 0.0000174621 Epoch 28/100, Loss: 0.0000173247 Epoch 29/100, Loss: 0.0000170032 Epoch 30/100, Loss: 0.0000168594 Epoch 31/100, Loss: 0.0000166609 Epoch 32/100, Loss: 0.0000164818 Epoch 33/100, Loss: 0.0000162424 Epoch 34/100, Loss: 0.0000161265 Epoch 35/100, Loss: 0.0000159775 Epoch 36/100, Loss: 0.0000158510 Epoch 37/100, Loss: 0.0000156571 Epoch 38/100, Loss: 0.0000155327 Epoch 39/100, Loss: 0.0000154742 Epoch 40/100, Loss: 0.0000152778 Epoch 41/100, Loss: 0.0000151757 Epoch 42/100, Loss: 0.0000151083 Epoch 43/100, Loss: 0.0000150182 Epoch 44/100, Loss: 0.0000149140 Epoch 45/100, Loss: 0.0000148057 Epoch 46/100, Loss: 0.0000147672 Epoch 47/100, Loss: 0.0000146499 Epoch 48/100, Loss: 0.0000145281 Epoch 49/100, Loss: 0.0000145298 Epoch 50/100, Loss: 0.0000144795 Epoch 51/100, Loss: 0.0000143969 Epoch 52/100, Loss: 0.0000142840 Epoch 53/100, Loss: 0.0000142294 Epoch 54/100, Loss: 0.0000142159 Epoch 55/100, Loss: 0.0000140837 Epoch 56/100, Loss: 0.0000140005 Epoch 57/100, Loss: 0.0000139986 Epoch 58/100, Loss: 0.0000139122 Epoch 59/100, Loss: 0.0000139010 Epoch 60/100, Loss: 0.0000138351 Epoch 61/100, Loss: 0.0000138050 Epoch 62/100, Loss: 0.0000137636 Epoch 63/100, Loss: 0.0000136853 Epoch 64/100, Loss: 0.0000136191 Epoch 65/100, Loss: 0.0000136272 Epoch 66/100, Loss: 0.0000135552 Epoch 67/100, Loss: 0.0000135439 Epoch 68/100, Loss: 0.0000135200 Epoch 69/100, Loss: 0.0000134461 Epoch 70/100, Loss: 0.0000133950 Epoch 71/100, Loss: 0.0000133979 Epoch 72/100, Loss: 0.0000133059 Epoch 73/100, Loss: 0.0000133242 Epoch 74/100, Loss: 0.0000132816 Epoch 75/100, Loss: 0.0000132145 Epoch 76/100, Loss: 0.0000132803 Epoch 77/100, Loss: 0.0000131212 Epoch 78/100, Loss: 0.0000131809 Epoch 79/100, Loss: 0.0000131538 Epoch 80/100, Loss: 0.0000130786 Epoch 81/100, Loss: 0.0000130651 Epoch 82/100, Loss: 0.0000130255 Epoch 83/100, Loss: 0.0000129917 Epoch 84/100, Loss: 0.0000129804 Epoch 85/100, Loss: 0.0000130086 Epoch 86/100, Loss: 0.0000130156 Epoch 87/100, Loss: 0.0000129557 Epoch 88/100, Loss: 0.0000129013 Epoch 89/100, Loss: 0.0000129018 Epoch 90/100, Loss: 0.0000128864 Epoch 91/100, Loss: 0.0000128663 Epoch 92/100, Loss: 0.0000128411 Epoch 93/100, Loss: 0.0000128514 Epoch 94/100, Loss: 0.0000127915 Epoch 95/100, Loss: 0.0000127778 Epoch 96/100, Loss: 0.0000127787 Epoch 97/100, Loss: 0.0000127623 Epoch 98/100, Loss: 0.0000127452 Epoch 99/100, Loss: 0.0000127141 Epoch 100/100, Loss: 0.0000127229
Los resultados se pueden visualizar de la siguiente manera:

También obtenemos el siguiente resultado sin errores ni advertencias, lo que indica que nuestro modelo se ha convertido correctamente al formato ONNX.
Model trained and saved in PyTorch and ONNX formats.
Generación de predicciones con Python paso a paso
Ahora veamos el código de predicción:
- Paso 1. Importar bibliotecas necesarias: Comenzamos importando todas las librerías necesarias.
# Import required libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from datetime import datetime, timedelta import plotly.graph_objects as go from plotly.subplots import make_subplots from patchTST import Model as PatchTST
- Paso 2. Obtener datos de MetaTrader 5: Definimos una función para obtener datos de MetaTrader 5 y convertirlos en un DataFrame. Obtenemos 168 barras anteriores porque eso es lo que se requiere para obtener una predicción con nuestro modelo.
# Function to fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch the latest week of data historical_data = fetch_mt5_data('EURUSD', 'H1', 168)
- Paso 3. Preparar datos de entrada: Definimos una función para preparar los datos de entrada para el modelo tomando las últimas filas de datos seq_length. Al extraer datos, solo necesitamos las últimas 168 horas de datos de 1 hora para hacer predicciones para las próximas 24 horas. Esto se debe a que así es como entrenamos el modelo.
# Function to prepare input data def prepare_input_data(data, seq_length): X = [] X.append(data.iloc[-seq_length:].values) return np.array(X) # Prepare the input data seq_length = 168 # 1 week of hourly data input_data = prepare_input_data(historical_data, seq_length)
- Paso 4. Definir configuración: Definimos una clase de configuración para establecer los parámetros para el modelo. Estas configuraciones son las mismas que usamos para entrenar el modelo.
# Define the configuration class class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = 24 # Predict next 24 hours self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 # Initialize the configuration config = Config()
- Paso 5. Cargar el modelo entrenado: Definimos una función para cargar el modelo PatchTST entrenado. Éstas son las mismas configuraciones que usamos para entrenar el modelo.
# Function to load the trained model def load_model(model_path, config): model = PatchTST( configs=config, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ) model.load_state_dict(torch.load(model_path)) model.eval() return model # Load the trained model model_path = 'patchtst_model.pth' device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = load_model(model_path, config).to(device)
- Paso 6. Hacer predicciones: Definimos una función para realizar predicciones utilizando el modelo cargado y los datos de entrada.
# Function to make predictions def predict(model, input_data, device): with torch.no_grad(): input_data = torch.tensor(input_data, dtype=torch.float32).to(device) output = model(input_data) return output.cpu().numpy() # Make predictions predictions = predict(model, input_data, device)
- Paso 7. Posprocesamiento y visualización: Procesamos las predicciones, creamos un marco de datos y visualizamos los datos históricos y predichos utilizando Plotly.
# Ensure predictions have the correct shape if predictions.shape[2] != 4: predictions = predictions[:, :, :4] # Adjust based on actual number of columns required # Check the shape of predictions print("Shape of predictions:", predictions.shape) # Create a DataFrame for predictions pred_index = pd.date_range(start=historical_data.index[-1] + pd.Timedelta(hours=1), periods=24, freq='H') pred_df = pd.DataFrame(predictions[0], columns=['open', 'high', 'low', 'close'], index=pred_index) # Combine historical data and predictions combined_df = pd.concat([historical_data, pred_df]) # Create the plot fig = make_subplots(rows=1, cols=1, shared_xaxes=True, vertical_spacing=0.03, subplot_titles=('EURUSD OHLC')) # Add historical candlestick fig.add_trace(go.Candlestick(x=historical_data.index, open=historical_data['open'], high=historical_data['high'], low=historical_data['low'], close=historical_data['close'], name='Historical')) # Add predicted candlestick fig.add_trace(go.Candlestick(x=pred_df.index, open=pred_df['open'], high=pred_df['high'], low=pred_df['low'], close=pred_df['close'], name='Predicted')) # Add a vertical line to separate historical data from predictions fig.add_vline(x=historical_data.index[-1], line_dash="dash", line_color="gray") # Update layout fig.update_layout(title='EURUSD OHLC Chart with Predictions', yaxis_title='Price', xaxis_rangeslider_visible=False) # Show the plot fig.show() # Print predictions (optional) print("Predicted prices for the next 24 hours:", predictions)
Código de entrenamiento y predicción en Python
Si no está interesado en ejecutar la base de código en un cuaderno Jupyter, he proporcionado un par de archivos que puede ejecutar directamente en los archivos adjuntos:
- model_training.py
- model_prediction.py
Puede configurar el modelo como desee y ejecutarlo sin usar Jupyter.
Resultados de la predicción
Después de entrenar el modelo y ejecutar el código de predicción en Python, obtuve el siguiente gráfico. Las predicciones se crearon aproximadamente a las 12:30 a. m. (CEST + 3) del 8/7/2024. Esto es justo en la apertura del domingo por la noche/lunes por la mañana. Podemos ver un hueco (gap) en el gráfico porque el EURUSD abrió con un hueco. El modelo predice que el EURUSD debería experimentar una tendencia alcista durante la mayor parte del tiempo, posiblemente llenando este hueco (gap). Una vez que se haya llenado el hueco (gap), el precio de la acción debería volverse hacia abajo cerca del final del día.

También imprimimos el valor bruto de los resultados, que se puede ver a continuación:
Predicted prices for the next 24 hours: [[[1.0789319 1.08056 1.0789403 1.0800443] [1.0791171 1.080738 1.0791024 1.0802013] [1.0792702 1.0807946 1.0792127 1.0802455] [1.0794896 1.0809869 1.07939 1.0804181] [1.0795166 1.0809793 1.0793561 1.0803629] [1.0796498 1.0810834 1.079427 1.0804263] [1.0798903 1.0813211 1.0795883 1.0805805] [1.0800778 1.081464 1.0796818 1.0806502] [1.0801392 1.0815498 1.0796598 1.0806476] [1.0802988 1.0817037 1.0797216 1.0807337] [1.080521 1.0819166 1.079835 1.08086 ] [1.0804708 1.0818571 1.079683 1.0807351] [1.0805807 1.0819991 1.079669 1.0807738] [1.0806456 1.0820425 1.0796478 1.0807805] [1.080733 1.0821087 1.0796758 1.0808226] [1.0807986 1.0822101 1.0796862 1.08086 ] [1.0808219 1.0821983 1.0796905 1.0808747] [1.0808604 1.082247 1.0797052 1.0808727] [1.0808146 1.082188 1.0796149 1.0807893] [1.0809066 1.0822624 1.0796828 1.0808471] [1.0809724 1.0822903 1.0797662 1.0808889] [1.0810378 1.0823163 1.0797914 1.0809084] [1.0810691 1.0823379 1.0798224 1.0809308] [1.0810966 1.0822875 1.0797993 1.0808865]]]
Incorporación del modelo preentrenado a MQL5
En esta sección, crearemos un precursor de un indicador que nos ayudará a visualizar la acción del precio prevista en nuestros gráficos. He hecho deliberadamente el guión rudimentario y abierto porque nuestros lectores pueden tener diferentes objetivos y diferentes estrategias sobre cómo utilizar estas complejas redes neuronales. El indicador está desarrollado en el formato de asesor experto MQL5. Aquí está el script completo:
//+------------------------------------------------------------------+ //| PatchTST Predictor | //| Copyright 2024 | //+------------------------------------------------------------------+ #property copyright "Copyright 2024" #property link "https://www.mql5.com" #property version "1.00" #resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[] #define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4 long ModelHandle = INVALID_HANDLE; datetime ExtNextBar = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load the ONNX model ModelHandle = OnnxCreateFromBuffer(PatchTSTModel, ONNX_DEFAULT); if (ModelHandle == INVALID_HANDLE) { Print("Error creating ONNX model: ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {1, SEQ_LENGTH, INPUT_FEATURES}; if (!OnnxSetInputShape(ModelHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting input shape: ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {1, PRED_LENGTH, INPUT_FEATURES}; if (!OnnxSetOutputShape(ModelHandle, 0, output_shape)) { Print("Error setting output shape: ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if (ModelHandle != INVALID_HANDLE) { OnnxRelease(ModelHandle); ModelHandle = INVALID_HANDLE; } } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Prepare input data float input_data[]; if (!PrepareInputData(input_data)) { Print("Error preparing input data"); return; } // Make prediction float predictions[]; if (!MakePrediction(input_data, predictions)) { Print("Error making prediction"); return; } // Draw hypothetical future bars DrawFutureBars(predictions); } //+------------------------------------------------------------------+ //| Prepare input data for the model | //+------------------------------------------------------------------+ bool PrepareInputData(float &input_data[]) { MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(_Symbol, PERIOD_H1, 0, SEQ_LENGTH, rates); if (copied != SEQ_LENGTH) { Print("Failed to copy rates data. Copied: ", copied); return false; } ArrayResize(input_data, SEQ_LENGTH * INPUT_FEATURES); for (int i = 0; i < SEQ_LENGTH; i++) { input_data[i * INPUT_FEATURES + 0] = (float)rates[SEQ_LENGTH - 1 - i].open; input_data[i * INPUT_FEATURES + 1] = (float)rates[SEQ_LENGTH - 1 - i].high; input_data[i * INPUT_FEATURES + 2] = (float)rates[SEQ_LENGTH - 1 - i].low; input_data[i * INPUT_FEATURES + 3] = (float)rates[SEQ_LENGTH - 1 - i].close; } return true; } //+------------------------------------------------------------------+ //| Make prediction using the ONNX model | //+------------------------------------------------------------------+ bool MakePrediction(const float &input_data[], float &output_data[]) { ArrayResize(output_data, PRED_LENGTH * INPUT_FEATURES); if (!OnnxRun(ModelHandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Error running ONNX model: ", GetLastError()); return false; } return true; } //+------------------------------------------------------------------+ //| Draw hypothetical future bars | //+------------------------------------------------------------------+ void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Para ejecutar el script anterior, tenga en cuenta cómo se define la siguiente línea:
#resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[]
Esto significa que dentro de la carpeta del Asesor Experto, necesitaremos crear una subcarpeta titulada PatchTST. Dentro de la subcarpeta PatchTST, necesitaremos guardar el archivo ONNX del entrenamiento del modelo. Sin embargo, el EA principal se almacenará en la propia carpeta raíz.
Los parámetros que usamos para entrenar nuestro modelo también están definidos en la parte superior del script:
#define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4
En nuestro caso, queremos utilizar 168 barras anteriores, introducirlas en el modelo ONNX y obtener una predicción para las próximas 24 barras en el futuro. Tenemos 4 características de entrada: open, high, low, and close.
Además, tenga en cuenta el siguiente código dentro de la función OnTick():
if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds();
Dado que los modelos ONNX consumen mucha potencia de procesamiento de una computadora, este código garantizará que solo se genere una nueva predicción una vez por barra. En nuestro caso, como trabajamos con barras horarias, las predicciones se actualizarán una vez por hora.
Finalmente, en este código, dibujaremos las barras de futuros en la pantalla, mediante el uso de las funciones de dibujo de MQL5:
void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Después de implementar este código en MQL5, compilar el modelo y colocar el EA resultante en el marco temporal H1, debería ver algunas barras adicionales agregadas en el futuro en su gráfico. En mi caso se ve así:
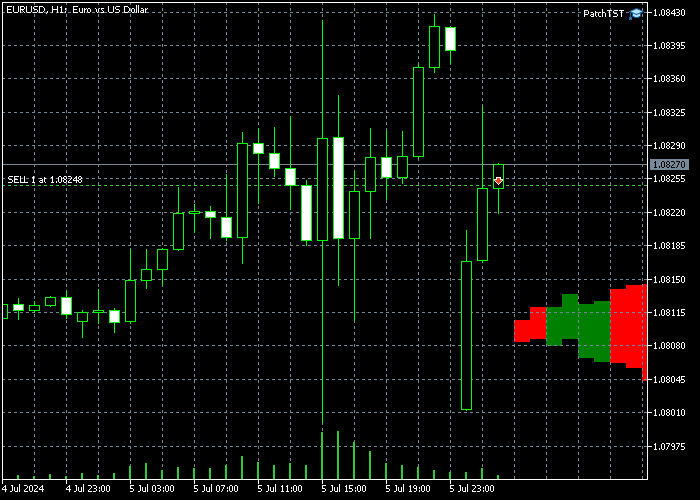
Tenga en cuenta que si no ve las barras recién dibujadas a la derecha, es posible que deba hacer clic en el botón "Desplazamiento del gráfico desde el borde derecho". ![]()
Conclusión
En este artículo, adoptamos un enfoque paso a paso para entrenar el modelo PatchTST, que se introdujo en 2023. Obtuvimos una idea general de cómo funciona el algoritmo PatchTST. El código base tenía algunos problemas relacionados con la conversión de ONNX. En concreto, el operador "Unfold" no es compatible, por lo que resolvimos este problema para que el código sea más compatible con ONNX. También mantuvimos el propósito del artículo amigable para el comerciante al enfocarnos en los conceptos básicos del modelo, extraer los datos, entrenar el modelo y obtener una predicción para las próximas 24 horas. Luego implementamos la predicción en MQL5, para que podamos usar el modelo completamente entrenado con nuestros indicadores y asesores expertos favoritos. Estoy encantado de compartir todo mi código con la comunidad MQL5 en el archivo ZIP adjunto. Si tiene alguna pregunta o comentario, no dude en hacérmelo saber.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15198
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
A menudo me encuentro con que los resultados predichos de este modelo no son del todo coherentes con la situación real. No he hecho ningún cambio en el código de este modelo. ¿Podría orientarme? Muchas gracias.
Gracias por compartir su experiencia con el modelo. Ha planteado una cuestión válida sobre la coherencia de las predicciones. El modelo PatchTST funciona mejor cuando se integra en un enfoque de negociación global que tenga en cuenta múltiples factores del mercado. Le recomiendo que utilice las predicciones del modelo de manera más eficaz:
Algunas observaciones personales adicionales:
Las predicciones del modelo deben utilizarse como un componente de su análisis y no como el único elemento decisorio. Si incorpora estos elementos, podrá mejorar potencialmente la coherencia de los resultados de sus operaciones cuando utilice el modelo PatchTST.
Espero que le sirva de ayuda.
Fair Value Gap (FVG) Script que he mencionado (estos gaps funcionan de forma muy parecida a las zonas de oferta y demanda, según mi experiencia):
Gracias por su interés. Sí, esos cambios en los parámetros funcionarían en principio, pero hay algunas consideraciones importantes al cambiar a datos M1:
1. Volumen de datos: Entrenar con 10080 minutos (1 semana) de datos M1 significa manejar significativamente más puntos de datos que con H1. Esto supondrá:
2. Ajustes en la arquitectura del modelo: En el paso 8 del entrenamiento del modelo y el paso 4 del código de predicción, es posible que desee ajustar otros parámetros para acomodar la secuencia de entrada más grande:
3. 3. Calidad de la predicción: Aunque obtendrá predicciones más detalladas, tenga en cuenta que los datos M1 suelen contener más ruido. Es posible que desee experimentar con diferentes longitudes de secuencia y ventanas de predicción para encontrar el equilibrio óptimo.Gracias por la información. Mi ordenador es razonablemente capaz, con 256 GB y 64 núcleos físicos. Sin embargo, no le vendría mal una GPU mejor.
En cuanto actualice la GPU, probaré los ajustes de configuración actualizados.
Gracias por compartir su experiencia con el modelo. Usted plantea un punto válido sobre la consistencia de la predicción. El modelo PatchTST funciona mejor cuando se integra en un enfoque de negociación global que tenga en cuenta múltiples factores del mercado. Le recomiendo que utilice las predicciones del modelo de manera más eficaz:
Algunas observaciones personales adicionales:
Las predicciones del modelo deben utilizarse como un componente de su análisis y no como el único elemento decisorio. Al incorporar estos elementos, puede mejorar potencialmente la coherencia de los resultados de sus operaciones cuando utilice el modelo PatchTST.
Espero que le sirva de ayuda.
Fair Value Gap (FVG) Script que he mencionado (estos gaps funcionan de forma muy parecida a las zonas de oferta y demanda, según mi experiencia):
Muchas gracias por su paciente respuesta y por compartirla desinteresadamente. Nunca había visto respuestas tan detalladas y profesionales. Leeré su artículo repetidamente. Estos conocimientos son especialmente valiosos para mí. Mis mejores deseos para usted.
Muchas gracias. ¡¡Sus amables palabras significan mucho!! Si necesita más ayuda, no dude en ponerse en contacto con nosotros.