
Guia Prático MQL5: Implementando um Array Associativo ou um Dicionário para Acesso Rápido ao Dados

Índice
- INTRODUÇÃO
- CAPÍTULO 1. TEORIA DA ORGANIZAÇÃO DE DADOS
- CAPÍTULO 2. TEORIA DA ORGANIZAÇÃO DO ARRAY ASSOCIATIVO
- CAPÍTULO 3. DESENVOLVIMENTO PRÁTICO DE UM ARRAY ASSOCIATIVO
- CAPÍTULO 4. TESTE E AVALIAÇÃO DE DESEMPENHO
- CAPÍTULO 5. DOCUMENTAÇÃO DA CLASSE CDICTIONARY
- CONCLUSÃO
Introdução
Este artigo descreve uma classe para facilitar o armazenamento de informações, ou seja, um array associativo ou em um dicionário. Esta classe permite obter acesso a informações por sua chave.
O array associativo se assemelha a um array regular. Mas em vez de um índice, ele utiliza alguma chave única, por exemplo, a enumeração ENUM_TIMEFRAMES ou algum texto. Não importa o que a chave representa. A unicidade da chave que importa. Este algoritmo de armazenamento de dados simplifica significativamente muitos aspectos da programação.
Por exemplo, uma função, que daria um código de erro e imprime um texto equivalente ao erro, poderia ser o seguinte:
//+------------------------------------------------------------------+ //| Exibe a descrição do erro no terminal. | //| Exibe um "erro desconhecido" se o ID for desconhecido | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
Nós vamos olhar para as características específicas deste código mais tarde.
Antes de tratar diretamente uma descrição da lógica interna do array associativo, nós vamos considerar os detalhes dos dois métodos principais de armazenamento de dados, ou seja, arrays e listas. Nosso dicionário será com base nesses dois tipos de dados, é por isso que se deve ter uma boa compreensão de suas características específicas. O capítulo 1 é dedicado à descrição dos tipos de dados. O segundo capítulo é dedicado à descrição do array associativo e os métodos de trabalhar com ele.
Capítulo 1. Teoria da Organização de Dados
1.1. Algoritmo de organização de dados. Pesquisando o melhor container de armazenamento de dados
Busca, armazenamento e a representação da informação são as principais funções impostas a computadores modernos. A interação humano-computador geralmente inclui tanto a busca por alguma informação quanto a criação e armazenamento de informações para uso posterior. A informação não é um conceito abstrato. Em um sentido real, há um certo conceito subjacente a esta palavra. Por exemplo, uma cotação histórica do símbolo é uma fonte de informação para qualquer trader que faz ou irá fazer negociações com este símbolo. Documentação da linguagem de programação ou o código fonte de algum programa pode servir como uma fonte de informação para um programador.
Alguns arquivos gráficos (por exemplo, uma foto feita com uma câmera digital) pode ser uma fonte de informação para as pessoas que não se relacionam com programação ou negociação. É evidente que estes tipos de informações têm diferentes estruturas e a sua própria natureza. Consequentemente, os algoritmos de armazenamento, representação e processamento desta informação serão diferentes.
Por exemplo, é mais fácil de apresentar um arquivo gráfico como um array bidimensional (array bidimensional), cada elemento ou célula dele irá armazenar a informação sobre a cor de uma pequena área de imagem - pixel. Dados de cotações possuem uma outra natureza. Essencialmente, isto é uma transmissão de dados homogéneos em formato OHLCV. É melhor apresentar esta transmissão como um array ou uma seqüência ordenada de estruturas, que é um certo tipo de dados na linguagem de programação que combina vários tipos de dados. A documentação ou um código fonte é normalmente representado como um texto simples. Este tipo de dados pode ser definido e armazenado como uma sequência ordenada de strings, onde cada string é uma seqüência arbitrária de símbolos.
Tipo de um container para o armazenamento de dados depende do tipo de dados. Usando os termos de programação orientada a objetos, é mais fácil definir um container como uma certa classe, que armazena estes dados e possui algoritmos especiais (métodos) para manipulá-los. Existem vários tipos de containers de armazenamento de dados (classes). Eles são baseados em diferentes organizações de dados. Mas alguns algoritmos de organização de dados permitem combinar diferentes paradigmas de armazenamento de dados. Assim, podemos tirar vantagem de combinar os benefícios de todos os tipos de armazenamento.
Você seleciona um ou outro container para armazenar, processar e receber dados, dependendo de um suposto método de sua manipulação e sua natureza. É importante perceber que não existem containers de dados igualmente eficientes. As fraquezas de um contêiner de dados são o lado reverso de suas vantagens.
Por exemplo, você pode ganhar rapidamente o acesso a qualquer um dos elementos do array. No entanto, é necessária uma operação, que consome tempo, para a inserção de um elemento em um local aleatório do array, o redimensionamento do array é exigido nesse caso. E, por outro lado, a inserção de um elemento em uma lista encadeada simples é uma operação eficaz e de alta velocidade, mas acessar um elemento aleatório pode levar muito tempo. Se é necessário inserir novos elementos em ocasiões frequentes, mas você não precisa de acesso frequente a esses elementos, a lista encadeada simples será o seu container correto. E escolha um array como uma classe de dados, se for necessário o acesso frequente a elementos aleatórios.
A fim de compreender que tipo de armazenamento de dados é preferível, você deve estar familiarizado com arranjo de qualquer container dado. Este artigo é dedicado à um array associativo ou dicionário - um container de armazenamento de dados específico, baseado na combinação de um array e uma lista. Mas eu gostaria de mencionar que o dicionário pode ser implementado de maneiras diferentes, dependendo da linguagem de programação, seus meios, capacidades e regras de programação aceitas.
Por exemplo, a implementação de um dicionário em C# é diferente de C++. Este artigo não descreve a implementação adaptada de um dicionário para С++. A versão descrita de um array associativo foi criado a partir do zero para a linguagem de programação MQL5 e considera suas características especiais e prática de programação comum. Embora sua implementação difere dos dicionários, suas características em geral e os métodos de funcionamento devem ser semelhantes. Neste contexto, a versão descrita exibe por completo todas as características e métodos.
Nós iremos criar gradualmente o algoritmo do dicionário e, ao mesmo tempo, ir discorrendo sobre a natureza dos algoritmos de armazenamento de dados. E no final do artigo, vamos ter uma versão completa do algoritmo e estar plenamente conscientes do seu princípio de funcionamento.
Não há containers igualmente eficientes para os diferentes tipos de dados. Vamos considerar um exemplo simples: uma caderneta de papel. Ela também pode ser considerada como um container/classe usado na nossa vida cotidiana. Todas as suas notas são inseridas de acordo com uma lista feita preliminarmente (alfabeto, neste caso). Se você sabe do nome de um assinante, você pode facilmente encontrar o seu número de telefone, já que você só precisa abrir a caderneta.
1.2. Arrays e endereçamento direto de dados
Um array é o mais simples e ao mesmo tempo a forma mais eficaz para armazenar informação. Na programação, um array é uma coleção dos mesmos tipos de elementos, imediatamente localizado um após o outro na memória. Devido a essas propriedades pode-se calcular o endereço de cada elemento do array.
De fato, se todos os elementos têm o mesmo tipo, todos eles têm o mesmo tamanho. Como os dados do array são localizados continuamente, podemos calcular um endereço de um elemento aleatório e referir diretamente a este elemento, se sabemos o tamanho de um elemento básico. A fórmula geral para o cálculo do endereço depende do tipo de dados e do índice.
Por exemplo, você pode calcular o endereço do quinto elemento no array de elementos do tipo uchar usando a seguinte fórmula geral que sai das propriedades da organização de dados do array:
endereço do elemento aleatório = o endereço do primeiro elemento + (índice de elemento aleatório no array * tamanho do tipo do array)
O endereçamento do array começa do zero, é por isso que o endereço do primeiro elemento corresponde ao endereço do elemento do array que tem o índice 0. Por conseguinte, o quinto elemento terá índice 4. Vamos supor que os elementos armazenam elementos do tipo uchar. Este é o tipo de dados básico em muitas linguagens de programação. Por exemplo, ele está presente em todas as línguas do tipo C. MQL5 não é exceção. Cada elemento do array do tipo uchar ocupa 1 byte ou 8 bits de memória.
Por exemplo, de acordo com a fórmula anteriormente mencionada o quinto endereço do elemento no array uchar será o seguinte:
o endereço do quinto elemento = o endereço do primeiro elemento + (4 * 1 byte);
Em outras palavras, o primeiro elemento do array uchar será 4 bytes maior do que o primeiro elemento. Você pode referir-se a cada elemento do array diretamente pelo endereço durante a execução do programa. Tal aritmética para o endereço permite obter um acesso muito rápido a cada elemento do array. Mas tais organização de dados tem desvantagens.
Um deles é que você não pode armazenar elementos de diferentes tipos no array. Tal limitação é a conseqüência do endereçamento direto. Certamente, os diferentes tipos de dados variam em tamanho, o que significa que o cálculo de um endereço de um determinado elemento utilizando a fórmula acima mencionada torna-se impossível. Mas esta limitação pode ser superada de forma inteligente, se os arrays não armazenarem elementos, mas os ponteiros a eles.
Vai ser a maneira mais fácil se você representar um ponteiro como um link (como atalhos no Windows). O ponteiro refere-se a um certo objeto na memória, mas o ponteiro em si não é um objecto. Em MQL5 o ponteiro pode fazer referência a apenas uma classe. Na programação orientada a objeto, uma classe é um tipo de dados especial que pode incluir um conjunto arbitrário de dados e métodos e pode ser criada por um usuário para a eficaz estruturação do programa.
Cada classe é um tipo de dados único definido pelo usuário. Os ponteiros referentes a diferentes classes não podem ser localizados em um array. Mas, independentemente da classe a que se refere, o ponteiro sempre tem o mesmo tamanho, pois ele contém apenas um endereço de objeto no espaço de endereço do sistema operacional que é comum para todos os objetos alocados.
1.3. Conceito do nó pelo exemplo da classe simples CObjectCustom
Agora, nós já sabemos o suficiente para projetar o nosso primeiro ponteiro universal. A idéia é criar um array de ponteiro universal em que cada ponteiro remete para o seu tipo em particular. Tipos concretos seriam diferentes, mas devido ao fato de que eles são referidos pelo mesmo ponteiro, estes tipos podem ser armazenados em um container/array. Vamos criar a primeira versão do nosso ponteiro.
Este ponteiro será representado pelo tipo mais simples que nós chamaremos de CObjectCustom:
class CObjectCustom
{
};
Seria muito difícil inventar uma classe mais simples que CObjectCustom, já que esta não contém nenhum dado ou método. Mas tal implementação é suficiente por enquanto.
Agora vamos usar um dos principais conceitos da programação orientada a objetos - herança. A herança fornece uma maneira especial de estabelecer a identidade entre objetos. Por exemplo, podemos dizer a um compilador que qualquer classe é derivada de CObjectCustom.
Por exemplo, uma classe de seres humanos (СHuman), uma classe de Expert Advisors (CExpert) e uma classe de clima (CWeather) representam conceito mais gerais da classe CObjectCustom. Talvez esses conceitos não estão realmente ligado na vida real: o tempo não tem nada em comum com as pessoas, e Expert Advisors não estão associados com o clima. Mas isso depende de nós em estabelecer as ligações no mundo da programação, e se estas ligações são boas para nossos algoritmos, não há nenhuma razão pela qual não podemos criá-las.
Vamos criar mais algumas classes da mesma maneira: a classe de carro (CCAR), uma classe número (CNumber), uma classe de barra de preço (CBar), uma classe de cotação (CQuotes), uma classe da empresa MetaQuotes (CMetaQuotes), e uma classe descrevendo um navio (CShip). Similar às classes anteriores, essas classes não estão realmente ligadas, mas todas elas são descendentes da classe CObjectCustom.
Vamos criar uma biblioteca de classes para esses objetos que combinam todas essas classes em um único arquivo: ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Classe Base CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo os seres humanos. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo o tempo. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo os Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo os carros. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo os números. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo barras de preços. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo cotações. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo a empresa MetaQuotes. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Classe descrevendo navios. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
Agora é hora de combinar essas classes em um array.
1.4. Arrays de Nó ponteiro pelo exemplo da classe CArrayCustom
Para combinar as classes, vamos precisar de um array especial.
No caso mais simples será suficiente escrever:
CObjectCustom array[];
Essa linha cria um array dinâmico que armazena os elementos do tipo CObjectCustom. Devido ao fato de que todas as classes que definimos na secção anterior, são derivadas de CObjectCustom, nós podemos armazenar qualquer destas classes nessa matriz. Por exemplo, podemos localizar pessoas, carros e navios lá. Mas a declaração do array CObjectCustom não será suficiente para esta finalidade.
A negócio é que, quando nós declaramos um array de uma forma normal, todos os seus elementos são preenchidos automaticamente no momento da inicialização do array. Assim, depois de declarar o array, todos os seus elementos serão ocupados pela classe CObjectCustom.
Nós podemos verificar isso se modificarmos ligeiramente a CObjectCustom:
//+------------------------------------------------------------------+ //| Classe base CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
Vamos executar um código de teste em um script para verificar esta peculiaridade:
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
Na função OnStart() nós inicializamos um array composto por três elementos da CObjectCustom.
O compilador preencheu este array com os objetos correspondentes. Você pode verificá-lo se você ler o log do terminal:
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #2 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #1 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #0 - CObjectCustom
Isso significa que o array é preenchido pelo compilador, e nós não podemos localizar quaisquer outros elementos lá, por exemplo CWeather ou CExpert.
Este código não será compilado:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
O compilador irá exibir uma mensagem de erro:
'=' - structure have objects and cannot be copied Test.mq5 18 13
Isso significa que o array já possui objetos e novos objetos não podem ser copiados lá.
Mas nós podemos romper esse impasse! Como mencionado acima, nós devemos trabalhar não com os objetos, mas com os ponteiros para esses objetos.
Reescrever o código na função OnStart() de tal forma que é possível trabalhar com ponteiros:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
Agora o código é compilado e os erros não ocorrem. O que aconteceu? Em primeiro lugar, nós substituímos a inicialização do array CObjectCustom com a inicialização do array de ponteiros para CObjectCustom.
Neste caso, o compilador não criar novos objetos CObjectCustom ao inicializar o array, mas deixa ele vazio. Em segundo lugar, agora nós usamos um ponteiro para o objeto CWeather em vez do próprio objeto. Utilizando a chave new nós criamos o objeto CWeather e atribuímos ao nosso ponteiro 'weather' e, em seguida nós colocamos o ponteiro de 'weather' (mas não o objeto) no array.
Agora vamos colocar o resto dos objetos no array em uma disposição semelhante.
Para este efeito, escreva o seguinte código:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
Este código irá funcionar, mas é muito arriscado manipular diretamente os índices do array.
Se calculamos mal sobre o tamanho de nosso array arrayObj ou endereço por um índice errado, nosso programa irá acabar com um erro crítico. Mas esse código se adapta aos nossos fins de demonstração.
Vamos apresentar estes elementos como um esquema:
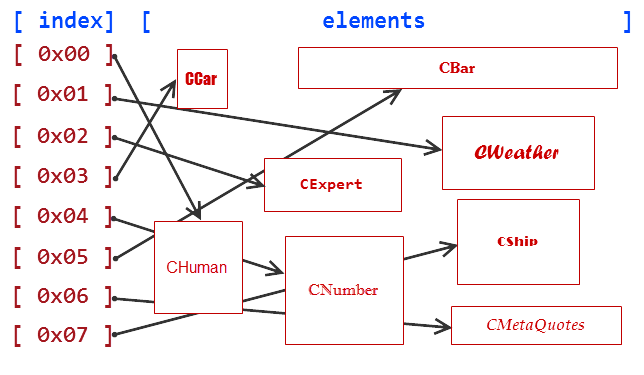
Fig. 1. Esquema de armazenamento de dados no array de ponteiros
Elementos, criado pelo operador 'new' , são armazenadas em uma parte especial da memória de acesso aleatória que é chamada de heap. Estes elementos não são ordenados como pode ser visto claramente no esquema acima.
Nosso array de ponteiros arrayObj possui indexação estrita, o que permite ter acesso rápido a qualquer elemento usando seu índice. Mas ter acesso a tal elemento não será suficiente, já que o array de ponteiro não sabe a que objeto em particular ele aponta. O ponteiro CObjectCustom pode apontar para CWeather ou CBar, ou CMetaQuotes, já que todos eles são CObjectCustom. Assim, é necessário explicitar a conversão de tipo de um objeto ao seu tipo atual para obter o tipo de elemento.
Por exemplo, isso pode ser feito a seguir:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
Neste código nós criamos o objeto Chuman e colocamos ele no array arrayObj como CObjectCustom. Em seguida, nós extraímos o CObjectCustom e convertemos ele em Chuman, que na verdade é o mesmo. Na conversão de exemplo não tiveram erros já que nos recordamos do tipo. Em uma situação real de programação, é muito difícil de rastrear um tipo de cada objeto já que pode haver centenas de tipos e o número de objetos pode ser maior que um milhão.
É por isso que devemos fornecer a classe ObjectCustom com o método adicional Type() que retorna um modificador do tipo real do objeto. O modificador é de um certo número único que descreve o nosso objeto permitindo fazer referência ao tipo pelo seu nome. Por exemplo, podemos definir os modificadores usando a diretiva pré-processador #define. Se nós sabemos o tipo de objeto especificado pelo modificador, nós podemos sempre converter com segurança seu tipo para o real. Assim, chegamos perto de uma criação de tipos seguros.
1.5. Verificação e segurança dos tipos
Assim que iniciarmos a conversão de um tipo para outro, a segurança de tal conversão torna-se um fundamento da programação. Nós não vamos gostar se o nosso programa terminar com um erro crítico, não é? Mas nós já sabemos o que será a base de segurança para os nossos tipos - modificadores especiais. Se sabemos o modificador podemos convertê-lo em um tipo exigido. Para este efeito, é preciso completar a nossa classe CObjectCustom com várias adições.
Primeiramente, vamos criar os identificadores de tipo para se referir a eles pelo nome. Para este efeito, vamos criar um arquivo separado com a enumeração necessária:
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // Tipo CObjectCustom Geral #define TYPE_HUMAN 1 // Classe CHuman #define TYPE_WEATHER 2 // Classe CWeather #define TYPE_EXPERT 3 // Classe CExpert #define TYPE_CAR 4 // Classe CCar #define TYPE_NUMBER 5 // Classe CNumber #define TYPE_BAR 6 // Classe CBar #define TYPE_MQ 7 // Classe CMetaQuotes #define TYPE_SHIP 8 // Classe CShip
Agora nós vamos mudar os códigos da classe adicionando CObjectCustom para a variável que armazena o tipo de objeto como um número. Esconda-o na seção privada, assim ninguém pode mudá-lo.
Ao lado disso, vamos adicionar um construtor especial disponível para as classes derivadas de CObjectCustom. Este construtor irá permitir que os objetos apontem o seu tipo durante a criação.
O código simples será o seguinte:
//+------------------------------------------------------------------+ //| Classe base CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Classe descrevendo os seres humanos. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Classe descrevendo o tempo. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
Como podemos ver, agora o todo tipo derivado de CObjectCustom define o seu próprio tipo em seu construtor durante a criação. O tipo não pode ser alterado uma vez que ele é definido, como o campo, onde é armazenado, é privado e disponível apenas para CObjectCustom. Isso irá prevenir você de manipular o tipo errado. Se a classe não chama o construtor protected CObjectCustom , o seu tipo - TYPE_OBJECT - será o tipo padrão.
Então, está na hora de aprender como extrair os tipos de arrayObj e processá-los. Para este efeito, vamos fornecer as classes Chuman e CWeather com os métodos públicos Run() e Temp() respectivamente. Depois de extrair a classe de arrayObj, vamos convertê-la no tipo desejado e começar a trabalhar com ele de maneira correta.
Se o tipo, armazenadas no array CObjectCustom, é desconhecido, nós vamos ignorá-lo e escrever a mensagem "unknown type":
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
Este código irá exibir a seguinte mensagem:
2015.02.13 15:11:24.703 Test (USDCHF,H1) unknown type.
2015.02.13 15:11:24.703 Test (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Test (USDCHF,H1) Human run...
Assim, nós obtivemos o resultado desejado. Agora nós podemos armazenar quaisquer tipos de objetos no array CObjectCustom, obter acesso rápido a esses objetos por seus índices no array e corretamente convertê-los para seus tipos reais. Mas ainda faltam muitas coisas: precisamos eliminar os objetos de forma correta após o término do programa, já que nós mesmo temos de excluir os objetos localizados no heap usando o operador delete.
Além disso, nós precisamos dos meios de redimensionar o array de forma segura caso o array esteja totalmente preenchido. Mas nós não vamos reinventar a roda. O conjunto padrão de ferramentas do MetaTrader 5 incluem classes que implementam todos esses recursos.
Estas classes são baseadas no container/classe universal CObject. Da mesma forma que a nossa classe, ele tem o método Type(), que retorna o tipo real da classe, e mais dois ponteiros importantes do tipo CObject: m_prev e m_next. O seu objetivo será descrito na secção seguinte, onde discutiremos outro método de armazenagem de dados, chamada de lista duplamente ligada, através do exemplo do container CObject e a classe CList.
1.6. A classe CList como um exemplo de uma lista duplamente ligada
Um array com elementos do tipo arbitrário sofre de apenas uma grande falha: ele leva muito tempo e esforço, se você desejar inserir um novo elemento, especialmente se este elemento tem que ser inserido no meio do array. Os elementos estão localizados numa sequência, de modo que para a inserção é necessário redimensionar o array para aumentar o número total de elementos por um e depois para reorganizar todos os elementos que seguem o objeto inserido assim como os seus índices que correspondem aos seus novos valores.
Vamos supor que temos um array constituído por 7 elementos e queremos inserir mais um elemento na quarta posição. Um esquema aproximado de inserção será o seguinte:

Fig. 2. Redimensionamento do aray e a inserção de um novo elemento
Há um esquema de armazenamento de dados que fornece a inserção e exclusão de elementos de forma rápida e eficaz. Esse esquema é chamado de lista encadeada simples ou duplamente encadeada. A lista lembra uma fila comum. Quando estamos em uma fila só precisamos conhecer uma pessoa que seguimos (não precisamos conhecer a pessoa que está a frente dele ou dela). Nós também não precisamos saber da pessoa que está atrás de nós, já que esta pessoa deve controlar a sua posição na fila.
Uma fila é um exemplo clássico de uma lista encadeada simples. Mas as listas também pode ser duplamente ligadas. Neste caso, todas as pessoas em uma fila sabe não só da pessoa anterior, mas também da pessoa depois dela ou dele. Então, se você perguntar a cada pessoa, você pode se mover em ambas as direções da fila.
A CList padrão, disponível na Biblioteca padrão, oferece precisamente este algoritmo. Vamos tentar fazer uma fila fora das classes já conhecidas. Mas desta vez elas vão derivar do CObject padrão e não a partir de CObjectCustom.
Isto pode ser esquematicamente mostrado a seguir:

Fig. 3. Esquema de uma lista duplamente ligada
Portanto, este é um código fonte que cria tal esquema:
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
Nossas classes têm agora dois ponteiros de CObject: um que faz referência ao elemento anterior, e o outro - para o elemento seguinte. O ponteiro para o elemento anterior ao primeiro elemento na lista é igual a NULL. O elemento no final da lista tem um apontador para o elemento seguinte que é igual a NULL também. Assim, podemos enumerar elementos um a um, enumerando, deste modo, toda a fila.
As funções EnumerateAll() e ReverseEnumerateAll() executam a enumeração de todos os elementos da lista.
O primeiro enumera a lista do início ao fim, o segundo - do final para o início. O código fonte dessas funções é a seguinte:
//+------------------------------------------------------------------+ //| Enumera a lista do início ao fim exibindo uma sequência | //| Número de cada elemento no terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumera a lista do fim ao início exibindo uma sequência | //| Número de cada elemento no terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
Como esse código funciona? De fato, ele é bem simples. No início, nós obtemos uma referência para o primeiro nó na função EnumerateAll(). Em seguida, imprimimos o número da sequência deste nó no loop for e movemos para o próximo nó usando o comando node = node.Next(). Não se esqueça de fazer uma iteração do índice atual do elemento por um (i++). A enumeração continua indo até o nó atual ser igual a NULL. O Código no segundo bloco do for é responsável para isso: node != NULL.
A versão reverso desta função ReverseEnumerateAll() se comporta de forma semelhante, com uma diferença única de que na primeira ele recebe o último elemento da lista CObject* node = list.GetLastNode (). No loop for ele obtém não o próximo, mas o elemento do nó anterior da lista node = node.Prev ().
Depois de lançar o código nós receberemos a seguinte mensagem:
2015.02.13 17:52:02.974 TestList (USDCHF,D1) enumerate complete.
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) <<< enumerate from end to begin <<<
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) >>> enumerate from begin to end >>>
Você pode facilmente introduzir novos elementos na lista. Basta alterar os ponteiros dos elementos anteriores e dos próximos de tal forma que eles vão se referir a um novo elemento, e esse novo elemento remete ao objeto anterior e ao próximo.
O esquema parece mais fácil do que parece:

Fig. 4. Inserção de um novo elemento em uma lista duplamente ligada
A principal desvantagem da lista é a impossibilidade de referenciar cada elemento pelo seu índice.
Por exemplo, se você quiser se referir a CExpert como mostrado na Fig. 4, primeiro você tem que ter acesso a CCAR, e após isso, você pode mover-se para CExpert. O mesmo é o caso para CWeather. Ele está mais próximo do fim da lista, de modo que será mais fácil de obter acesso a partir de sua extremidade. Para este efeito, você tem que se referir a CShip primeiro, e depois a CWeather.
Mover-se por ponteiros é uma operação mais lenta em comparação com a indexação direta. Unidades centrais de processamento modernos são otimizados para operar particularmente com arrays. É por isso que na prática os arrays podem ser mais preferíveis mesmo que a listas potencialmente devem trabalhar de forma mais rápida.
Chapter 2. Teoria da Organização do Array Associativo
2.1. Os arrays associativos em nosso dia-a-dia
Nós sempre estamos convivendo com os arrays associativos em nosso dia-a-dia. Mas eles nos parecem tão óbvio que nós percebemos eles como uma questão de disciplina. O exemplo mais simples de um array associativo ou de um dicionário é uma agenda de telefone habitual. Cada número de telefone no livro está associado a um nome de uma determinada pessoa. O nome da pessoa em tal livro é uma chave única, e o número de telefone é um valor numérico simples. Cada pessoa na lista telefônica pode ter mais de um número de telefone. Por exemplo, uma pessoa pode ter números de telefone de casa, celulares e de negócios.
De um modo geral, pode haver uma quantidade ilimitada de números, mas o nome da pessoa é único. Por exemplo, duas pessoas nomeadas Alexander em sua agenda de telefone irá confundi-lo. Às vezes, podemos marcar um número errado. É por isso que as teclas (nomes, neste caso) devem ser exclusivos para evitar tal situação. Mas, ao mesmo tempo, o dicionário deve saber como resolver colisões e ser resistente a elas. Dois nomes idênticos não vai destruir a agenda de telefone. Assim, nosso algoritmo deve saber como processar tais situações.
Usamos vários tipos de dicionários na vida real. Por exemplo, a lista telefônica é um dicionário onde uma linha única (nome do assinante) é uma chave, e um número é um valor. O dicionário de termos em estrangeiro tem outra estrutura. Uma palavra em Inglês será uma chave, e sua tradução será um valor. Ambos os arrays de associação baseiam-se nos mesmos métodos de tratamento de dados, que é por isso que o nosso dicionário deve ser polivalente e permitir armazenar e comparar todos os tipos.
Na programação, pode ser conveniente também criar seus próprios dicionários e "cadernos".
2.2. Arrays associativos primários com base no operador switch-case ou um array simples
Você pode facilmente criar um array associativo simples. Basta usar as ferramentas padrão da linguagem MQL5, por exemplo, o operador switch ou um array.
Vejamos mais de perto esse código:
//+------------------------------------------------------------------+ //| Retorna a representação de string do período dependendo | //| do valor do período de tempo que passou. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
Neste caso, o operador switch-case age como um dicionário. Cada valor de ENUM_TIMEFRAMES tem um valor de string de caracteres descrevendo este período. Devido ao fato de que o operador switch é uma passagem comutada (Em russo), o acesso a variante solicitada do caso é instantânea, e outras variantes do caso não são enumeradas. É por isso que este código é altamente eficiente.
Mas a sua desvantagem é que, primeiro, você tem que preencher todos os valores, que têm de ser devolvidos com um ou outro valor de ENUM_TIMEFRAMES, manualmente. Em segundo lugar, o switch pode operar apenas com valores inteiros. Mas seria mais difícil de escrever uma função inversa que poderia retornar o tipo de período de tempo dependendo de uma string transferida. A terceira desvantagem desta abordagem é que este método não é suficientemente flexível. Você deve especificar todas as variantes possíveis com antecedência. Mas você muitas vezes é obrigado a preencher os valores no dicionário dinamicamente à medida que os novos dados estiverem disponíveis.
O segundo método "frontal" do armazenamento do par "key-value" envolve a criação de um array onde uma chave é usada como um índice o valor é um elemento do array.
Por exemplo, vamos tentar resolver a tarefa semelhante, ou seja, para retornar a representação de string do período de tempo:
//+------------------------------------------------------------------+ //| Valores String que corresponde ao | //| período de tempo. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adicionando valores associativos ao array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Retorna a representação de string do período dependendo | //| Um valor do período de tempo que passou. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
Este código representa a referência pelo índice onde ENUM_TIMFRAMES é especificado como um índice. Antes de retornar o valor, a função verifica se o array é preenchido com um elemento requerido. Se não, a função delega o preenchimento para uma função especial - InitTimeframes(). Ele tem as mesmas desvantagens que o operador switch.
Além disso, tal estrutura dicionário requer a inicialização de um array com valores grandes. Assim, o valor do modificador PERIOD_MN1 é 49153. Isso significa que precisamos de 49.153 células para armazenar apenas nove intervalos de tempo. Outras células ficam por preencher. Este método de alocação de dados está longe de ser compacto, mas pode ser apropriado quando a enumeração consiste de uma pequena e sucessiva série de números.
2.3. A conversão de tipos base em uma chave única
Já que os algoritmos usados no dicionário são semelhantes, independentemente de certos tipos de chaves e valores, nós precisamos executar o alinhamento de dados, assim como diferentes tipos de dados podem ser processados por um algoritmo. O nosso algoritmo dicionário será universal e permite armazenar valores, onde qualquer tipo de base pode ser especificada como uma chave, por exemplo int, enum, double ou mesmo string.
Na verdade, em MQL5 qualquer tipo de base de dados pode ser representada como algum número sem sinal ulong. Por exemplo, os tipos de dados short ou ushort são versões "curtas" de ulong.
Com entendimento expresso que o tipo ulong armazena o valor ushort, você sempre pode fazer a conversão de tipo explícita de forma segura:
ulong ln = (ushort)103; // Salva o valor ushort no tipo ulong (103) ushort us = (ushort)ln; // Obtém o valor ushort a partir do tipo ulong (103)
O mesmo é o caso dos tipos char e int e seus análogos não assinados, como ulong que pode armazenar qualquer tipo, tamanho que seja igual ou menor a ulong. Os tipos Datetime, Enum e color são baseados no número inteiro uint de 32-bit, o que significa que eles podem ser convertidos com segurança para ULONG. O tipo bool possui apenas dois valores: 0, o que significa falso, e 1, que significa verdade. Assim, os valores do tipo bool também podem ser armazenadas na variável do tipo ulong. Além disso, um monte de funções do sistema MQL5 baseiam-se nesta função.
Por exemplo, a função AccountInfoInteger() retorna o valor inteiro do tipo long, que também pode ser um número da conta do tipo ulong e um valor booleano de permissão para negociação - ACCOUNT_TRADE_ALLOWED.
Mas a MQL5 tem três tipos básicos que se distinguem dos tipos inteiros. Eles não podem ser diretamente convertidos para o tipo integer ulong. Entre estes tipos temos os tipos de ponto flutuante, tal como double e float e strings. Mas algumas ações simples podem convertê-los em chaves/valores únicos de inteiros.
Cada valor de ponto flutuante pode ser estabelecido como uma base elevada a uma potência arbitrária, onde tanto a base como a potência são armazenados separadamente como um valor inteiro. Esse tipo de método de armazenamento é usado em valores do tipo double e float. O tipo float usa 32 dígitos para armazenar a base e a potência, o tipo double usa 64 dígitos.
Se tentarmos convertê-los diretamente para o tipo ulong, o valor será simplesmente arredondado. Neste caso 3.14159 e 3.0 dará o mesmo valor ulong - 3. Isto é inadequado para nós, já que vamos precisar de chaves diferentes para estes dois valores diferentes. Uma característica incomum, que pode ser utilizada em linguagens do tipo C, vem para nos salvar. Ela é chamada de conversão de estrutura. Duas estruturas diferentes podem ser convertidas se elas têm um tamanho (conversão de uma estrutura para outra).
Vamos analisar este exemplo em duas estruturas, sendo que uma delas armazena o valor do tipo ulong, e a outra armazena o valor do tipo double:
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
Este código copia a estrutura DoubleValue na estrutura ULongValue byte por byte. Como eles têm o mesmo tamanho e ordem de variáveis, o valor double de dValue.value é copiado byte por byte para a variável ulong de lValue.value.
Depois disso, o valor da variável é impresso. Se mudarmos dValue.value para 3.14160, lValue.value também será alterado.
Aqui está o resultado que será exibido pela função printf():
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
O tipo float é uma versão menor do tipo double. Assim, antes de converter o tipo float para o tipo ulong você pode estender com segurança o tipo float para double:
float fl = 3.14159f; double dbl = fl;
Após isso, ocorre a conversão do tipo double para ulong via conversão de estrutura.
2.4. Hash de string e usando uma hash como chave
Nos exemplos acima as chaves foram representadas por um tipo de dado - strings. No entanto, pode haver situações diferentes. Por exemplo, os três primeiros dígitos de um número de telefone indicam uma operadora de telefonia. Neste caso em particular, estes três dígitos representam uma chave. Por outro lado, cada string pode ser representada como um número único de cada dígito, que significa um número de sequência de uma letra do alfabeto. Assim, podemos converter a string para um número único e usar esse número como uma chave de inteiro ao seu valor associado.
Este método é bom, mas não o suficiente para múltiplos fins. Se usarmos uma string contendo centenas de símbolos como uma chave, o número será incrivelmente grande. Será impossível para capturá-lo em uma simples variável de qualquer tipo. As funções hash vão nos ajudar a resolver este problema. A função hash é um algoritmo especial que aceita qualquer tipo de dados (por exemplo, uma string) e retorna um número único caracterizando esta string.
Mesmo se um símbolo da entrada de dados for alterado, o número será absolutamente diferente. Os números retornados por esta função possuem um intervalo fixo. Por exemplo, a função hash Adler32() aceita parâmetros sob a forma de uma string arbitrária, e retorna um número no intervalo de 0 a 2 elevado à potência de 32. Esta função é muito simples, mas ela se adapta bem às nossas tarefas.
Aqui está o seu código fonte em MQL5:
//+------------------------------------------------------------------+ //| Aceita uma string e retorna um valor hash de 32-bit | //| que caracteriza essa string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
Vamos ver quais números ela retorna dependendo da string transferida.
Para este efeito, vamos escrever um script simples que chama essa função e transfere diferentes strings:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
Esta saída do script revelou o seguinte:
2015.02.16 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Peace - 91685343
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world! - 487130206
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world - 413860925
Como podemos ver, cada string tem um número correspondente único. Preste atenção para as strings "Hello world" e "Hello world!" - elas são quase idênticas. A única diferença é o ponto de exclamação no final da segunda string.
Mas os números dados por Adler32() eram absolutamente diferentes em ambos os casos.
Agora sabemos como converter o tipo string para o valor não assinado uint, podendo armazenar seu hash inteiro em vez da chave do tipo string. Se duas strings tiver o mesmo hash, é mais provável que ela seja a mesma string. Assim, a chave para um valor não é uma string, mas uma hash de inteiro gerada com base nesta string.
2.5. Descobrindo um índice por uma chave. Array lista
Agora sabemos como converter qualquer tipo básico da MQL5 para o tipo não assinado ulong. Este tipo será exatamente uma chave real a que o nosso valor irá corresponder. Mas ele não é o suficiente para ter uma chave única do tipo ulong. Claro que, se nós sabemos a chave única de cada objeto, poderíamos inventar algum método primitivo de armazenamento com base no operador switch-case ou um array de um comprimento arbitrário.
Tais métodos têm sido descritos na seção 2.2 do capítulo atual. Mas eles não são suficientemente flexíveis e eficazes. Quanto ao switch-case, não me parece possível descrever todas as variantes deste operador.
Já que há dezenas de milhares de objetos, nós teremos de descrever o operador switch, consistindo de dezenas de milhares de chaves, na fase de compilação, o que é impossível. O segundo método é utilizar um array, onde a chave de um elemento é também o seu índice. Ele permite redimensionar o array de uma forma dinâmica, adicionando os elementos necessários. Desse modo, podemos constantemente nos referir a ele pelo seu índice, que será a chave do elemento.
Vamos fazer um esboço desta solução:
//+------------------------------------------------------------------+ //| Array para armazenar strings por uma chave. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adiciona uma string de caracteres para o array associativo. | //| RESULTADOS: | //| Retorna true, se a string foi adicionada, caso contrário | //| retorna false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
Mas na vida real este código organiza os problemas, mas não resolve eles. Vamos supor que uma função hash irá mostrar um grande hash. Como no exemplo dado o índice do array é igual ao seu hash, nós temos que redimensionar o array que irá torná-lo grande. E isso não significa necessariamente que nós vamos conseguir. Você quer armazenar uma seqüência de caracteres em um container cujo o tamanho pode chegar a vários gigabytes?
O segundo problema é que no caso de haver colisões, o valor anterior será substituído por um novo. Afinal, não é improvável que a função Adler32() irá retornar uma chave hash para duas strings diferentes. Você quer perder uma parte de seus dados só porque você quer se referir a ele mais rapidamente usando uma chave? A resposta a estas perguntas é óbvia - não, você não quer. A fim de evitar tais situações, temos que modificar o algoritmo de armazenamento e desenvolver um container híbrido para fins especiais, com base em um array de lista.
Um array de lista combina as melhores características de arrays e listas. Estas duas classes são representados na Biblioteca Padrão. Vale a pena lembrar que os arrays permitem referir a seus elementos indefinidos de uma forma muito rápida, mas os arrays se redimensionam num ritmo lento. Mas as listas permitem adicionar e remover novos elementos em menos de nada, mas o acesso a cada um dos elementos de uma lista é uma operação bastante lento.
Uma lista de array pode ser representada a seguir:

Fig. 5. Esquema de um array lista
É evidente a partir do esquema que um aray lista é um array que cada elemento dela possui forma de uma lista. Vamos ver quais as vantagens que ela oferece. Em primeiro lugar, podemos nos referir rapidamente a qualquer lista pelo seu índice. Por outro lado, se nós armazenamos cada elemento de dados em uma lista, nós seremos capazes de adicionar e remover prontamente os elementos da lista, não redimensionando o array. O índice do array pode ser vazio ou igual a NULL. Isso significa que os elementos correspondentes a este índice não foram ainda adicionados.
A combinação de um array e uma lista oferece uma oportunidade mais incomum. Nós podemos armazenar dois ou mais elementos usando um índice. Para entender sua necessidade, nós podemos supor que precisamos armazenar 10 números em um array com três elementos. Como podemos ver, há mais números do que elementos no array. Vamos resolver este problema armazenando as listas em um array. Vamos supor que vamos precisar de uma das três listas anexadas a um dos três índices do array para armazenar um ou outro número.
Para determinar o índice da lista, precisamos descobrir o resto na divisão do nosso número pela quantidade de elementos no array:
índice do array = número % elementos no array;
Por exemplo, o índice da lista para o número 2 é a seguinte: 2 % 3 = 2. Isso significa que o índice 2 será armazenado na lista pelo índice. O número 3 será armazenado pelo índice de 3 % 3 = 0. O número 7 será armazenado pelo índice 7 % 3 = 1. Depois que determinarmos o índice da lista, nós só precisamos adicionar este número no fim da lista.
Ações similares são necessárias para extrair o número da lista. Vamos supor que queremos extrair o número 7 do container. Para isso, precisa descobrir em qual container se ele se encontra: 7 % 3 = 1. Depois de termos determinado que o número 7 pode ser localizado na lista pelo índice 1, nós teremos que resolver toda a lista e retornar esse valor se um dos elementos for igual a 7.
Se nós podemos armazenar vários elementos usando um índice, não precisamos criar arrays enormes para armazenar uma pequena quantidade de dados. Vamos assumir que precisamos armazenar o número 232547879 em um array composto por 0-10 dígitos e tendo três elementos. Este número irá ter o seu índice da lista igual a (232547879 % 3 = 2).
Se substituirmos os números com hash, seremos capazes de encontrar um índice de qualquer elemento que tem de ser localizado no dicionário. Porque a hash é um número. Além disso, devido à possibilidade de armazenar vários elementos de uma lista, a hash não precisa única. Elementos com o mesmo hash estará em uma lista. Se precisamos extrair um elemento por sua chave, comparamos estes elementos e extrai-se aquele correspondente à chave.
Isto é possível já que os dois elementos com o mesmo hash terão duas chaves únicas. A singularidade das chaves podem ser controladas pela função que adiciona um elemento ao dicionário. Ele simplesmente não vai adicionar um novo elemento, se a sua chave correspondente já estiver no dicionário. Isto é como um controle sobre a correspondência de um assinante apenas para um número de telefone.
2.6. Redimensionamento do array, minimizando o comprimento da lista
Quanto menor for o array lista e quanto maior for o número de elementos que adicionamos, as cadeias mais longas das listas serão formadas pelo algoritmo. Como já foi dito no primeiro capítulo, o acesso a um elemento desta cadeia é uma operação ineficaz. Quanto menor a nossa lista for, mais parecido será o nosso container com um array, que fornece acesso a cada elemento por um índice. Nós precisamos visar listas curtas e arrays longos. Um array perfeito para dez elementos é um array que consiste em dez listas, contendo um elemento cada uma.
A pior variante será um array de dez elementos de comprimento consistindo de uma lista. Já que todos os elementos são dinamicamente colocados no nosso container durante o fluxo do programa, nós não podemos prever como muitos elementos serão adicionados. É por isso que nós precisamos pensar sobre o redimensionamento dinâmico do array. E além disso, o número de cadeias em listas devem tender a um elemento. É óbvio que, para este efeito, o tamanho do array deve ser mantido igual ao número total de elementos. A adição permanente de elementos exige redimensionamento permanente do array.
A situação também é complicada pelo fato de que, juntamente com o redimensionamento do array nós vamos ter de redimensionar todas as listas, como o índice da lista, e o elemento que pode pertencer a ela, poderá ser alterado após o redimensionamento. Por exemplo, se o array tem três elementos, o número 5 será armazenado no segundo índice (5 % 3 = 2). Se existem seis elementos, o número 5 será armazenado no quinto índice (5 % 6 = 5). Assim, o redimensionamento do dicionário é uma operação lenta. Ela deve ser realizada o mais raramente possível. Por outro lado, se nós não realizarmos isso, as cadeias irão crescer para cada novo elemento, e o acesso a cada um dos elementos se tornarão cada vez menos eficaz.
Podemos criar um algoritmo que implemente um compromisso razoável entre o valor dos redimensionamento do array e comprimento médio da cadeia. Ele irá basear-se no fato de que cada novo redimensionamento irá aumentar o tamanho atual do array em duas vezes. Assim, se o dicionário inicialmente tem dois elementos, o primeiro redimensionamento irá aumentar o seu tamanho por 4 (2^2), a segunda - por 8 (2^3), a terceira - por 16 (2^3). Após o décimo sexto redimensionamento haverá espaço para 65536 cadeias (2^16). Cada redimensionamento será realizado se a quantidade de elementos adicionados coincidir com a potência recursiva de dois. Assim, o total da memória principal atual necessária não excederá a memória necessária para armazenar todos os elementos mais do que duas vezes. Por outro lado, a lei logarítmica ajuda a evitar redimensionamentos frequentes do array.
Da mesma forma, a remoção de elementos da lista pode reduzir o tamanho do array, fazendo com que a memória principal alocada fique guardada.
Capítulo 3. Desenvolvimento prático de um array associativo
3.1. A classe de modelo CDictionary, os métodos AddObject e DeleteObjectByKey e o container KeyValuePair
Nossa matriz associativa deve ser universal e permitir trabalhar com todos os tipos de chaves. Ao mesmo tempo, nós vamos utilizar objetos com base no padrão CObject como valores. Desde que nós consigamos localizar quaisquer variáveis básicas nas classes, nosso dicionário será uma solução única. Claro, nós poderíamos criar várias classes de dicionários. Nós poderíamos usar um tipo de classe separada para cada tipo de base.
Por exemplo, poderíamos criar as seguintes classes:
CDictionaryLongObj // Para armazenar pares <ulong, CObject*> CDictionaryCharObj // Para armazenar pares <char, CObject*> CDictionaryUcharObj // Para armazenar pares <uchar, CObject*> CDictionaryStringObj // Para armazenar pares <string, CObject*> CDictionaryDoubleObj // Para armazenar pares <double, CObject*> ...
Mas a MQL5 tem muitos tipos básicos. Além disso, teríamos que corrigir cada erro de código muitas vezes, como todos os tipos têm um código núcleo. Vamos usar modelos para evitar duplicações. Nós teremos uma classe, mas ele irá processar vários tipos de dados simultaneamente. É por isso que os métodos principais de classes serão modelo.
Primeiro de tudo, vamos criar o nosso primeiro método modelo - Add(). Este método estará adicionando um elemento com uma chave arbitrária para nosso dicionário. A classe dicionário será chamada de CDictionary. Juntamente com o elemento, o dicionário conterá uma matriz de ponteiros para as listas CList. E nós vamos armazenar os elementos nessas cadeias:
//+------------------------------------------------------------------+ //| Um array associativo ou um dicionário armazenando elementos como | //| <chave - valor> , em que uma chave pode ser representado | //| por qualquer tipo de base, | //| e o valor pode ser representado por um objeto do tipo CObject. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // Array lista. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adiciona um elemento do tipo CObject | //| com uma chave T ao dicionário | //| PARÂMETROS DE ENTRADA: | //| Chave T - qualquer tipo de base, por exemplo, int, double | //| ou string. | //| Valor - uma classe que deriva de CObject. | //| RETORNA: | //| true, se o elemento foi adicionado, caso contrário - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
O método AddObject() funciona da seguinte maneira. Em primeiro lugar, ele verifica se o dicionário tem um elemento com a chave que tem de ser adicionada. O método ContainsKey() realiza essa verificação. Se o dicionário já tem a chave, o novo elemento não será adicionado, uma vez que ele irá causar incertezas dado que os dois elementos irão corresponder a uma chave.
Em seguida, o método aprende sobre o tamanho do array onde as cadeias CList são armazenados. Se o tamanho do array é igual ao número de elementos, é hora de fazer um redimensionamento. Esta tarefa é delegada ao método Resize().
Os próximos passos são simples. Se de acordo com o índice determinado, a cadeia CList não existe ainda, esta cadeia tem de ser criada. O índice é determinado de antemão pelo método ContainsKey(). Ele salva o determinado índice na variável m_index. Em seguida, o método adiciona um novo elemento no fim da lista. Mas antes disso o elemento é embalado em um container especial - KeyValuePair. Ele baseia-se no CObject padrão e expande este último com ponteiros e dados adicionais. O arranjo da classe container será descrita um pouco mais tarde. Junto com ponteiros adicionais, o container também armazena uma chave original do objeto e seu hash.
O método AddObject() é um método modelo:
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
Este registro significa que o tipo de argumento da chave é substituível e seu tipo real é determinado em tempo de compilação.
Por exemplo, o método AddObject() pode ser ativado no seu código a seguir:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
Qualquer uma dessas ativações irá funcionar perfeitamente devido aos modelos.
Há também o método DeleteObjectByKey() que fica de frente para o método AddObject(). Esse método exclui um objeto do dicionário por sua chave.
Por exemplo, você pode excluir um objeto com a chave "Car", se existir:
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
O código é muito semelhante ao código do método AddObject(), por isso não vamos ilustrá-lo aqui.
Os métodos AddObject() e DeleteObjectByKey() não funcionam diretamente com os objetos. Em vez disso, eles embalam cada objeto para o container KeyValuePair com base na classe padrão CObject. Este recipiente tem ponteiros adicionais, que permitem relacionar os elementos, e também tem uma chave original e um determinado hash para o objeto. O container também testa a chave passada para igualdade, que permite evitar colisões. Vamos discutir isso na próxima seção, dedicada ao método ContainsKey().
Agora vamos ilustrar o conteúdo desta classe:
//+------------------------------------------------------------------+ //| Container para armazenar os elementos CObject | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Armazena uma chave de string double m_double_key; // Armazena uma chave de ponteiro flutuante ulong m_ulong_key; // Armazena uma chave de inteiro não assinado ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. Identificação do tipo de tempo de execução com base em typename e amostragem de hash
Agora, quando nós sabemos como tomar os tipos indefinidos em nossos métodos, nós teremos que determinar o seu hash. Para todos os tipos inteiros uma hash será igual ao valor deste tipo expandido para o tipo ulong.
Para calcular o hash para os tipos double e float, nós precisamos usar a conversão de estruturas, descrito na secção "Conversão de tipos base em uma chave única". Uma função hash deve ser usada para strings. De qualquer forma, cada tipo de dados requer seu próprio método de amostragem hash. Então, tudo o que precisamos é determinar o tipo transferido e ativar um método de amostragem hash dependendo deste tipo. Para isso, nós vamos precisar de uma diretiva especial typename.
O método que determina a paridade de hash na chave é chamado de GetHashByKey().
Ele inclui:
//+------------------------------------------------------------------+ //| Calcula uma base hash em uma chave transferida. A chave pode ser | //| representada por qualquer tipo base MQL. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
Sua lógica é simples. Usando a diretiva typename o método obtém o nome da string do tipo transferido. Se a string é transferida como uma chave, typename irá retornar o valor "string", no caso do valor int ela irá retornar "int". O mesmo irá acontecer com qualquer outro tipo. Assim, tudo o que temos a fazer é comparar o valor retornado com as constantes de strings necessárias e ativar o manipulador correspondente caso este valor coincidir com uma das constantes.
Se a chave é do tipo string , o hash é calculado pela função Adler32(). Se a chave está representada por tipos reais, eles são convertidos em hash para a devida conversão de estrutura. Todos os outros tipos convertem explicitamente no tipo ulong que se tornará o hash.
3.3. O método ContainsKey(). Reação de uma colisão de hashes
O principal problema de qualquer função hash está nas colisões - situações quando diferentes chaves dão o mesmo hash. Em tal caso, se a hash coincidir, ambiguidades surgirão (dois objetos serão semelhantes em termos da lógica do dicionário). Para evitar tal situação, é preciso verificar os tipos de chaves atuais e os solicitados, retornando um valor positivo apenas se as chaves se coincidirem. É assim que o método ContainsKey() funciona. Ele retorna true se um objeto contendo a chave solicitada existir, e de outra forma ele retorna false.
Talvez, este é o método mais útil e conveniente de todo o dicionário. Ele permite saber se um objeto com uma chave definida existe:
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
Por exemplo, o código acima verifica a disponibilidade do objeto do tipo CCAR e adiciona CCAR se tal objeto não existir. Este método também permite verificar a singularidade da chave de cada novo objeto que está sendo adicionado.
Se a chave do objeto já está sendo usada, o método AddObject() simplesmente não adicionará este novo objeto ao dicionário.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
Este é um método universal que é utilizado abundantemente tanto por usuários e outros métodos de classe.
Seu conteúdo:
//+------------------------------------------------------------------+ //| Verifica se o dicionário contém uma chave do tipo arbitrário T. | //| RETORNA: | //| Retorna true, se existir um objeto com esta chave, | //| Caso contrário retorna false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
Primeiro, o método encontra um hash usando GetHashByKey(). Depois, baseado na hash, ele obtém um índice da cadeia CList, onde um objeto com o hash dado pode ser localizado. Se não existir tal cadeia, o objeto com esta chave não existe. Neste caso, ele terminará mais cedo a sua operação e retornará false (objeto com tal chave não existe). Se a cadeia existir, ela começa a ser enumerada.
Cada elemento desta cadeia é representada pelo tipo de objeto KeyValuePair, que é oferecido para comparar uma chave atual transferida com uma chave armazenada por um elemento. Se as chaves são as mesmas, o método retorna verdadeiro (objeto com tal chave existe). O código, que testa as chaves para a igualdade, é dado na listagem da classe KeyValuePair.
3.4. Alocação dinâmica e desalocação de memória
O método Resize() é responsável pela alocação dinâmica e desalocação de memória em nosso array associativo. Este método é ativado cada vez que o número de elementos for igual ao tamanho m_array. Ele também é ativado quando os elementos são excluídos da lista. Esse método substitui os índices de armazenamento para todos os elementos, por isso, ele funciona de forma excepcionalmente lenta.
Para evitar a ativação frequente do método de Resize(), o volume de memória alocada é aumentada por dois cada vez que há uma comparação com o seu volume anterior. Em outras palavras, se nós queremos que nosso dicionário armazene 65536 elementos, o método Resize() será ativado 16 vezes (2^16). Depois de vinte ativações o dicionário pode conter mais de um milhão de elementos (1 048 576). O método FindNextLevel() é responsável pelo crescimento exponencial dos elementos exigidos.
Aqui está o código fonte do método Resize():
//+------------------------------------------------------------------+ //| Redimensiona o container de armazenamento de dados | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
Este método funciona tanto para os lado superior quanto para o inferior. Quando houver menos elementos que um array pode conter, um código de redução de elemento é iniciado. E, inversamente, quando o array atual não for suficiente, o array é redimensionado para mais elementos. Esse código requer uma grande quantidade de recursos computacionais.
Todo o array tem que ser redimensionado, mas todos os seus elementos devem ser previamente removidos para uma cópia temporária do array. Então, você precisa determinar novos índices para todos os elementos e somente após isso, você poderá localizar esses elementos em seus novos pontos.
3.5. Acabamentos finais: buscando objetos e um indexador conveniente
Assim, nossa classe CDictionary já tem os principais métodos para trabalhar com ela. Nós podemos usar o método ContainsKey() se queremos saber se um objeto com uma determinada chave existe. Nós podemos adicionar um objeto ao dicionário usando o método AddObject(). Nós também podemos excluir um objeto do dicionário usando o método DeleteObjectByKey().
Agora nós precisamos apenas fazer uma enumeração conveniente de todos os objetos no container. Como já sabemos, todos os elementos são armazenados lá em uma ordem específica de acordo com suas chaves. Mas seria conveniente enumerar todos os elementos na mesma ordem em que nós adicionamos eles ao array associativo. Para este efeito, o container KeyValuePair tem dois ponteiros adicionais, um para o elemento anterior e o outro para o próximo do tipo KeyValuePair. Podemos realizar uma enumeração sequencial devido a esses ponteiros.
Por exemplo, se nós adicionamos os elementos para o nosso array associativo da seguinte forma:
CNumber --> CShip --> CWeather --> CHuman --> CExpert --> CCar
a enumeração destes elementos também será sequencial, uma vez que ele irá ser realizado utilizando referências para o KeyValuePair, como mostrado na Fig. 6:

Fig. 6. Esquema de enumeração do array sequencial
Cinco métodos são usados para realizar tal enumeração.
Aqui está o seu conteúdo e uma breve descrição:
//+------------------------------------------------------------------+ //| Retorna o objeto atual. Retorna NULL se um objeto não foi | //| escolhido | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Retorna o objeto anterior. O objeto atual torna-se o | //| anterior após a chamada do método. Retorna NULL se um objeto | //| não foi escolhido. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Retorna o próximo objeto. O objeto atual se torna o próximo | //| após a chamada do método. Retorna NULL se um objeto não foi | //| escolhido. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Retorna o primeiro nó da lista de nós. Retorna NULL se o | //| dicionário não possuir nós. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Retorna o último nó da lista. Retorna NULL se o | //| dicionário não possuir nós. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
Devido a esses iteradores simples, nós podemos executar uma enumeração sequencial dos elementos adicionados:
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
Este código irá imprimir valores de string dos objetos na mesma ordem em que foram adicionadas ao dicionário:
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
Mudar duas strings do código na função OnStart() para a saída de todos os elementos para trás:
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
Por conseguinte, os valores de saída são invertidos:
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
Capítulo 4. Teste e Avaliação de Desempenho
4.1. Escrevendo testes e avaliando o desempenho
A avaliação de desempenho é um ingrediente central de projetar uma classe, especialmente se estamos falando de uma classe para armazenamento de dados. Apesar de tudo, os mais diversos programas podem tirar vantagem desta classe. Estes algoritmos dos programas podem ser críticos para acelerar e exigir um alto desempenho. É por isso que ele é tão importante para saber como avaliar o desempenho e buscar os pontos fracos de tais algoritmos.
Para começar, vamos escrever um teste simples que mede a velocidade da adição e extração dos elementos do dicionário. Este teste será semelhante a um script.
Seu código fonte está se encontra a seguir:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
Este código adiciona sequencialmente os elementos para o dicionário e, em seguida, se refere a eles para medir a sua velocidade. Após isso, cada elemento é excluído usando o método DeleteObjectByKey(). A função do sistema GetTickCount() mede a velocidade.
Usando esse script, fizemos um diagrama que descreve as dependências de tempo desses três métodos principais:
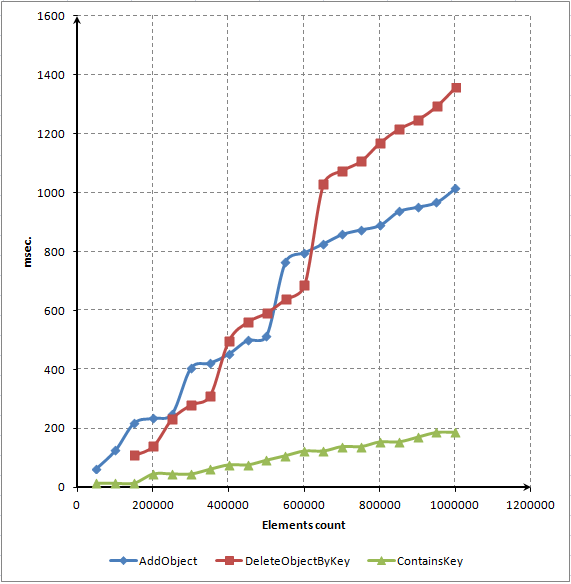
Fig. 7. Diagrama pontilhado de dependência entre o número de elementos e métodos, tempo da operação em milissegundos
Como você pode ver, a maior parte do tempo é gasto em localizar e excluir elementos do dicionário. No entanto, espera-se que os elementos sejam excluídos de forma muito mais rápida. Vamos tentar melhorar o desempenho do método utilizando um profiler de código. Este procedimento será descrito na próxima seção.
Preste atenção para o diagrama do método ContainsKey(). Ele é linear. Isso significa que o acesso a um elemento aleatório requer aproximadamente uma quantidade de tempo independente do número destes elementos no array. Esta é uma característica obrigatória de um array associativo real.
Para ilustrar esta característica nós vamos mostrar um diagrama de dependência entre o tempo médio de acesso a um elemento e um número de elementos no array:
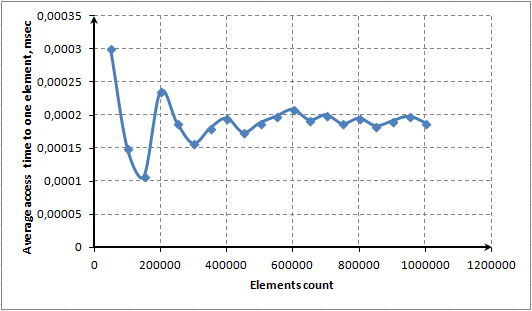
Fig. 8. Tempo médio de acesso a um elemento usando o método ContainsKey()
4.2. Profilando um código. A velocidade do gerenciamento automático de memória
O profiling de código é uma técnica especial que mede os gastos de tempo de todas as funções. Basta iniciar qualquer programa em MQL5 clicando no ![]() MetaEditor.
MetaEditor.
Nós vamos fazer o mesmo e enviar o nosso script para criação de profiling. Depois de um tempo o nosso script é executado e temos um profile de tempo de todos os métodos executados durante a operação do script. A figura abaixo mostra que a maior parte do tempo foi gasto para a realização de três métodos: AddObject() (40% do tempo), GetObjectByKey() (7% do tempo) e DeleteObjectByKey() (53% do tempo):
")
Fig. 9. Profiling de código na função OnStart()
E mais de 60% da chamada de DeleteObjectByKey() foi gasto para chamar o método Compress().
Mas este método está quase vazio, o tempo principal é gasto para chamar o método Resize().
Ele inclui:
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
O problema é claro. Quando apagamos todos os elementos, o método Resize() é ocasionalmente lançado. Este método reduz o tamanho do array liberando dinamicamente o armazenamento.
Desative este método se você deseja excluir mais rápido os elementos. Por exemplo, você pode introduzir o método especial AutoFreeMemory(), definindo o sinalizador de compressão, para a classe. Ele será definido por padrão e, em tal caso, a compactação será executada automaticamente. Mas se precisarmos de velocidade adicional, vamos realizar a compactação manualmente em um momento bem escolhido. Para este efeito, faremos o método público Compress().
Se a compressão está desabilitada, os elementos são apagados três vezes mais rápido:
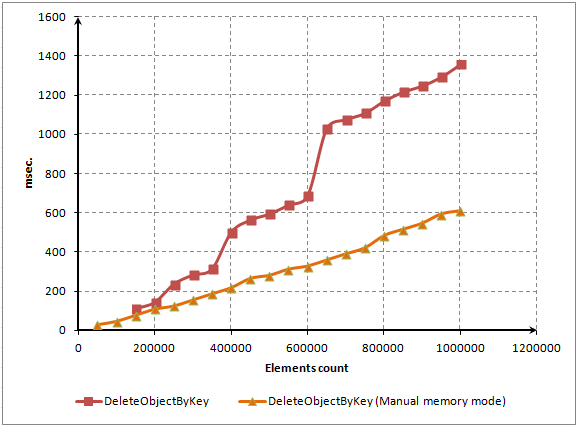
Fig. 10. Tempo de eliminação do elemento com monitoramento humano do armazenamento ocupado (comparação)
O método Resize() é chamado não só para a compressão de dados, mas também quando há muitos elementos e é necessário um leque maior. Neste caso não podemos evitar de chamar o método Resize(). Ele deve ser chamado a fim de não criar uma cadeia longa e lenta de CList no futuro. Mas nós podemos especificar o volume necessário de nosso dicionário com antecedência.
Por exemplo, um número de elementos adicionados é muitas vezes conhecido de antemão. Conhecendo o número de elementos, o dicionário preliminarmente vai criar um array do tamanho requerido, redimensionamentos adicionais durante o preenchimento do array não será necessário.
Para este efeito, vamos adicionar mais um construtor que aceita os elementos necessários:
//+------------------------------------------------------------------+ //| Cria um dicionário com a capacidade predefinida | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
O método privado Init() executa a operação principal:
//+------------------------------------------------------------------+ //| Inicializa o dicionário | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
Nossos melhorias estão feitas. Agora é hora de avaliar o desempenho do método AddObject() com o tamanho do array inicialmente especificado. Para este efeito, vamos mudar as duas primeiras strings da função OnStart() do nosso script:
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
Neste caso END é representado por um número grande igual a 1.000.000 elementos.
Essas inovações acelerou significativamente o desempenho do método AddObject():

Fig. 11. Tempo para adicionar os elementos com o tamanho do array predefinido
Ao resolver reais problemas de programação, nós sempre temos que escolher entre consumo de memória e velocidade de desempenho. Ele leva uma quantidade significativa de tempo para liberar a memória. Mas, neste caso, teremos mais memória disponível. Se nós mantermos tudo do jeito que está, o tempo de CPU não será gasto com problemas computacionais complexos adicionais, mas ao mesmo tempo nós teremos menos memória disponível. Utilizando containers, a programação orientada a objeto permite alocar recursos entre a memória do processador e o tempo de CPU de uma forma flexível, selecionando uma certa política de execução para cada problema em particular.
Ao todo, o desempenho da CPU é escalado de forma muito pior do que a capacidade de memória. É por isso que na maioria dos casos damos preferência para a velocidade de execução, em vez do consumo de memória. Além disso, o controle de memória em um nível de usuário é mais eficiente do que um controle automatizado, como nós geralmente não sabemos o estado finito da tarefa.
Por exemplo, no caso de nosso script, nós sabemos de antemão que o final da enumeração do número total de elementos será nulo, já que o método DeleteObjectByKey() apaga todos eles no momento do fim da tarefa. É por isso que nós não precisamos comprimir o array automaticamente. Isso será o suficiente para limpar ele no final, chamando o método Compress().
Agora, quando temos boas métricas lineares de adição e exclusão de elementos do array, nós vamos analisar um tempo médio de adição e excluir um elemento, dependendo do número total de elementos:
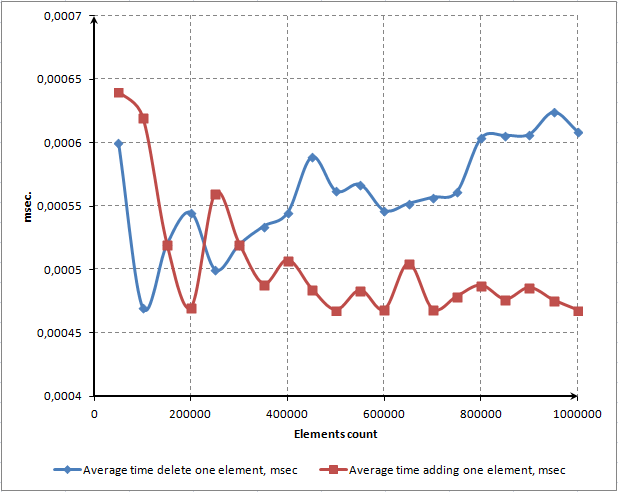
Fig. 12. A duração média de adicionar e excluir um elemento
Podemos ver que o tempo médio de adicionar um elemento é muito estacionário e não depende do número total de elementos no array. A duração média de excluir um elemento se move ligeiramente para cima, o que é indesejável. Mas nós não podemos dizer com precisão se nós lidamos com resultados com taxa de erro ou isto é uma tendência regular.
4.3. Desempenho do CDictionary em comparação com o CArrayObj padrão
Isso se trata de tempo para o teste mais interessante: vamos comparar nossa CDictionary com a classe padrão CArrayObj. Faz o CArrayObj não tem mecanismos para alocação de memória manual com indicação de um tamanho pressuposto na fase de construção, é por isso que vamos desativar o controle de memória manual em CDictionary e o mecanismo AutoFreeMemory() será habilitado.
Os pontos fortes e fracos de cada classe foram descritas no primeiro capítulo. CDictionary permite adicionar um elemento em um local indefinido, bem como extraí-lo do dicionário de uma maneira muito rápida. Mas CArrayObj permite fazer a enumeração muito rápida de todos os elementos. A enumeração no CDictionary será mais lenta, uma vez que ela irá ser realizada por meio de um ponteiro em movimento, e esta operação é mais lenta do que a indexação direta.
Então, vamos lá. Para começar, vamos criar uma nova versão do nosso teste:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- ÍNDICE --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
Ele usa as macros TEST_ARRAY. Se for identificado, o teste executa operações em CArrayObj, caso contrário, as operações são realizadas em CDictionary. O primeiro teste para a adição de novos elementos foi ganho por CDictionary.
Sua forma de realocação de memória apareceu ser melhor neste caso em particular:
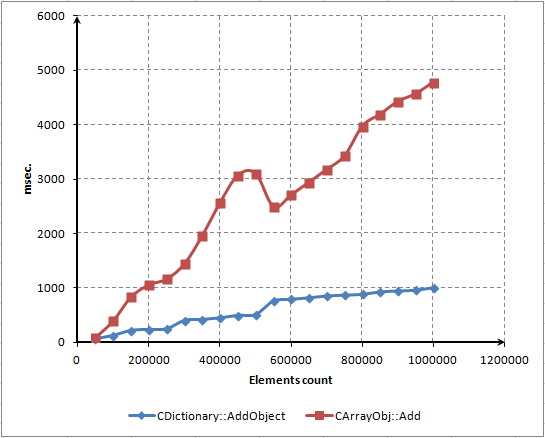
Fig. 13. O tempo gasto para a adição de novos elementos para CArrayObj e CDictionary (comparação)
É fundamental ressaltar que a operação mais lenta foi causada por uma forma particular de realocação de memória em CArrayObj.
Ele é descrito por uma única linha do código fonte:
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize); Este é um algoritmo linear de alocação de memória. Ele é chamado por padrão depois de preencher 16 elementos cada. CDictionary usa um algoritmo exponencial: a cada realocação de memória, ele aloca duas vezes mais memória que a chamada anterior. Este diagrama ilustra perfeitamente o dilema entre o desempenho e a memória utilizada. O método Reserve() da classe CArrayObj é mais econômico e requer menos memória, mas funciona de forma mais lenta. O método Resize() da classe CDictionary funciona mais rápido, mas requer mais memória, e metade dessa memória pode ficar sem uso.
Vamos realizar o último teste. Vamos calcular o tempo para enumeração completa dos containers CArrayObj e CDictionary. CArrayObj usa indexação direta, e CDictionary usa por referência. CArrayObj permite fazer referência a qualquer elemento pelo seu índice, mas em CDictionary a referência a qualquer elemento pelo seu índice é dificultada. A enumeração sequencial é altamente competitiva com a indexação direta:
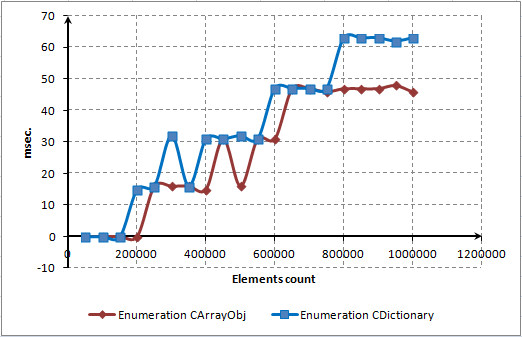
Fig. 14. Tempo para enumeração completa de CArrayObj e CDictionary
Os desenvolvedores da linguagem MQL5 fizeram um grande trabalho e otimizaram as referências. Eles são altamente competitivos em velocidade de indexação direta no qual é ilustrado no diagrama.
É importante perceber que a enumeração do elemento leva tão pouco tempo, que é quase à beira da resolução da função GetTickCount(). É difícil usá-lo para medir intervalos de tempo que são menos do que 15 milissegundos.
4.4. Recomendações gerais ao usar CArrayObj, CList e CDictionary
Vamos fazer uma tabela onde iremos descrever as principais tarefas que podem ocorrer em programação e as características dos containers que devem ser conhecidos para resolver essas tarefas.
Características com bom desempenho da tarefa são escritos em verdes, as que não permitem completar as tarefas de forma eficiente, são escritas em vermelho.
| Propósito | CArrayObj | CList | CDictionary |
|---|---|---|---|
| Adição sequencial de novos elementos na extremidade do container. | O container tem que dsitribuir uma nova memória para um novo elemento. A transferência de elementos existentes para os novos índices não é obrigatório. CArrayObj irá executar esta operação muito rapidamente. | O container se lembra da primeira, do atual e o último elementos. Devido a este fato, um novo elemento será ligado à extremidade da lista (o último elemento lembrado) muito rapidamente. | O dicionário não tem conceitos como "final" ou "início". Um novo elemento será ligado muito rapidamente e não dependerá de um número de elementos. |
| O acesso a um elemento arbitrário por seu índice. | Devido à indexação direta, o acesso é obtido muito rapidamente, ele leva O(1) de tempo. | O acesso a cada elemento é adquirida via enumeração de todos os elementos anteriores. Essa operação leva O(n) de tempo. | O acesso a cada elemento é adquirida via enumeração de todos os elementos anteriores. Essa operação leva O(n) de tempo. |
| O acesso a um elemento arbitrário por sua chave. | Não disponível | Não disponível | Descobrir um hash e um índice por uma chave é uma operação eficiente e rápida. Eficiência da função Hashing é muito importante para as chaves de strings. Essa operação leva O(1) de tempo. |
| Novos elementos são adicionados/removidos por um índice indefinido. | CArrayObj não tem que apenas distribuir memória para um novo elemento, mas também eliminar todos os elementos dos índices que são superiores que o índice do elemento inserido. É por isso que CArrayObj é uma operação lenta. | O elemento é adicionado ou excluído de CList muito rapidamente, mas o índice necessário pode ser acessado para O(n). Esta é uma operação lenta. | Em CDictionary, o acesso para o elemento pelo seu índice é realizado baseando-se na lista CList e leva muito tempo. Mas a adição e exclusão são realizados muito rápido. |
| Novos elementos são adicionados/removidos por uma chave indefinida. | Não disponível | Não disponível | Como todo novo elemento é inserido na CList, novos elementos são adicionados e excluídos muito rápido desde que o array não precisar ser redimensionado após cada adição/exclusão. |
| Uso e gerenciamento de memória. | Redimensionamento do array dinâmico se faz necessário. Esta é uma operação intensiva de recursos, é necessário ou muito tempo ou uma grande quantidade de memória. | O gerenciamento de memória não é usado. Cada elemento tem a quantidade certa de memória. | Redimensionamento do array dinâmico se faz necessário. Esta é uma operação intensiva de recursos, é necessário ou muito tempo ou uma grande quantidade de memória. |
| Enumeração de elementos. As operações que devem ser realizados para cada elemento do vetor. | Realizada de forma muito rápida devido à indexação direta do elemento. Mas, em alguns casos a enumeração deve ser realizada em ordem inversa (por exemplo, quando remover sequencialmente o último elemento). | Como precisamos enumerar todos os elementos de uma única vez, a referência direta é uma operação rápida. | Como precisamos enumerar todos os elementos de uma única vez, a referência direta é uma operação rápida. |
Capítulo 5. Documentação da Classe CDictionary
5.1. Principais métodos para adicionar, excluir e acessar os elementos
5.1.1. O método AddObject()
Adiciona novo elemento do tipo CObject com a chave T. Qualquer tipo de base pode ser usado como uma chave.
template<typename T> bool AddObject(T key,CObject *value);
Parâmetros
- [in] key – Chave única representada por um dos tipos de bases (string, ulong, char, enum etc.).
- [in] value - Objeto com CObject como um tipo base.
Valor retornado
Retorna true, se o objeto for adicionado ao container, caso contrário, retorna false. Se a chave do objeto adicionado já existe no container, o método vai devolver um valor negativo e o objeto não será adicionado.
5.1.2. O método ContainsKey()
Verifica se existe um objeto com uma chave igual a chave T no container. Qualquer tipo de base pode ser usado como uma chave.
template<typename T> bool ContainsKey(T key);
Parâmetros
- [in] key – Chave única representada por um dos tipos de bases (string, ulong, char, enum etc.).
Retorna true, se o objeto com a chave verificada existir no container. Caso contrário, retorna false.
5.1.3. O método DeleteObjectByKey()
Exclui um objeto pela chave T predefinida. Qualquer tipo de base pode ser usado como uma chave.
template<typename T> bool DeleteObjectByKey(T key);
Parâmetros
- [in] key – Chave única representada por um dos tipos de bases (string, ulong, char, enum etc.).
Valor retornado
Retorna true, se o objeto que tinha a chave predefinida for eliminado. Retorna false, se o objeto que tinha a chave predefinida não existir ou a sua remoção falhou.
5.1.4. O método GetObjectByKey()
Retorna um objeto pela chave T predefinida. Qualquer tipo de base pode ser usado como uma chave.
template<typename T> CObject* GetObjectByKey(T key);
Parâmetros
- [in] key – Chave única representada por um dos tipos de bases (string, ulong, char, enum etc.).
Valor retornado
Retorna um objeto que corresponde à chave predefinida. Retorna NULL, se o objeto com a chave memorizada não existir.
5.2. Métodos de gerenciamento de memória
5.2.1. Construtor CDictionary()
O construtor de base cria o objeto CDictionary com o tamanho inicial do array de base igual a três elementos.
O array é aumentado ou comprimido automaticamente com o dicionário de preenchimento ou a exclusão dos elementos dele.
CDictionary();
5.2.2. Construtor CDictionary(int capacity)
O construtor cria o objeto CDictionary com tamanho inicial do array de base igual a "capacity".
O array é aumentado ou comprimido automaticamente com o dicionário de preenchimento ou a exclusão dos elementos dele.
CDictionary(int capacity);
Parâmetros
- [in] capacity – Número de elementos iniciais.
Nota
Definir o limite do tamanho do array imediatamente após a sua inicialização irá ajudá-lo a evitar as chamadas do método Resize() e, assim, aumentar a eficiência ao inserir novos elementos.
No entanto, deve se notar que se você excluir os elementos habilitados (AutoMemoryFree (true)), o container será comprimido automaticamente apesar do ajuste de capacidade. Para evitar a compressão cedo, realize a primeira operação de eliminação de objeto depois dos containers serem totalmente preenchidos, ou se isso não pode ser feito, desative (AutoMemoryFree (false)).
5.2.3. O método FreeMode(bool mode)
Define o modo de exclusão de objetos existentes no container.
Se o modo de eliminação está habilitado, o recipiente também estrá sujeito ao procedimento de 'exclusão' após o objeto ser excluído. Seu destrutor é ativado e se torna indisponível. Se o modo de eliminação está desativado, o destrutor do objeto não é ativado e ele continua a ser disponível a partir de outros pontos do programa.
void FreeMode(bool free_mode);
Parâmetros
- [in] free_mode – Indicador do modo de remoção do objeto.
5.2.4. O método FreeMode()
Retorna o indicador de exclusão de objetos localizados no container (ver FreeMode (bool mode)).
bool FreeMode(void);
Valor retornado
Retorna true, se o objeto é excluído pelo operador delete depois de ter sido excluído do container. Caso contrário, retorna false.
5.2.5. O método AutoFreeMemory(bool autoFree)
Define o indicador automático de gerenciamento de memória. O gerenciamento automático de memória é ativado por padrão. Em tal caso, o array é comprimido automaticamente (redimensionado do maior tamanho para o menor). Se desabilitado, o array não é comprimido. Ele aumenta significativamente a velocidade de execução do programa, já que o método intensivo de recursos Resize() não tem de ser chamado. Mas, neste caso, você tem que ter um olho sobre o tamanho do array e comprimi-lo manualmente por meio do método de Compress().
void AutoFreeMemory(bool auto_free);
Parâmetros
- [in] auto_free – Indicador do modo de gerenciamento de memória.
Valor retornado
Retorna true, se você precisar ativar o gerenciamento de memória e chamar o método Compress() automaticamente. Caso contrário, retorna false.
5.2.6. O método AutoFreeMemory()
Retorna o indicador que especifica se o modo de gerenciamento de memória automática é usado (veja o método FreeMode(bool free_mode)).
bool AutoFreeMemory(void);
Valor retornado
Retorna true, se o modo de gerenciamento de memória é usado. Caso contrário, retorna false.
5.2.7. O método Compress()
Comprime o dicionário e redimensiona os elementos. O array é comprimido apenas se for possível.
Este método deve ser chamado somente se o modo de gerenciamento de memória automático está desativado.
void Compress(void);
5.2.8. O método Clear()
Exclui todos os elementos no dicionário. Se o indicador de gerenciamento de memória é ativado, o destrutor é chamado para cada elemento que está sendo excluído.
void Clear(void);
5.3. Métodos de busca no dicionário
Todos os elementos do dicionário estão interligados. Cada novo elemento é conectado com o anterior. Assim, a pesquisa sequencial de todos os elementos do dicionário se torna possível. Em tal caso a referência é realizada por uma lista ligada. Os métodos nesta seção facilitam a pesquisa e deixa a iteração do dicionário mais conveniente.
Você pode usar a seguinte construção, enquanto procura pelo dicionário:
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // Node significa o elemento atual do dicionário. }
5.3.1. O método GetFirstNode()
Retorna o primeiro elemento adicionado ao dicionário.
CObject* GetFirstNode(void); Valor retornado
Retorna o ponteiro para o objeto do tipo CObject, que foi adicionado em primeiro lugar com o dicionário.
5.3.2. O método GetLastNode()
Retorna o último elemento do dicionário.
CObject* GetLastNode(void); Valor retornado
Retorna o ponteiro para o objeto do tipo CObject, que foi adicionado ao dicionário no final.
5.3.3. O método GetCurrentNode()
Retorna o elemento atual selecionado. O elemento deve ser preliminarmente selecionado por um dos métodos de busca dos elementos sobre o dicionário ou pelo método de acesso para o elemento do dicionário (ContainsKey(), GetObjectByKey()).
CObject* GetLastNode(void); Valor retornado
Retorna o ponteiro para o objeto do tipo CObject, que foi adicionado ao dicionário no final.
5.3.4. O método GetNextNode()
Retorna o elemento que segue o atual. Retorna NULL se o elemento atual é o último ou não tiver sido selecionado.
CObject* GetLastNode(void); Valor retornado
Retorna o ponteiro para o objeto do tipo CObject, que segue o atual. Retorna NULL se o elemento atual é o último ou não tiver sido selecionado.
5.3.5. O método GetPrevNode()
Retorna o elemento que anterior ao atual. Retorna NULL se o elemento atual é o primeiro ou não tiver sido selecionado.
CObject* GetPrevNode(void); Valor retornado
Retorna o ponteiro para o objeto do tipo CObject , que é anterior ao atual. Retorna NULL se o elemento atual é o primeiro ou não tiver sido selecionado.
Conclusão
Nós consideramos as principais características dos containers de dados de forma difundida. Cada container de dados deve ser utilizado quando as suas características permitirem resolver o problema da maneira mais eficiente.
Arrays regulares devem ser usados onde o acesso sequencial para um elemento é suficiente para resolver o problema. Dicionários e arrays associativos são melhores para usar onde o acesso a um elemento por sua chave única é necessária. Listas são melhores para usar em caso de substituição frequente de um elemento: remoção, inserção, adição de novos elementos.
O dicionário permite resolver problemas algorítmicos desafiadores de uma forma agradável e simples. Onde outros recipientes de dados requerem recursos adicionais de processamento, o dicionário permite organizar o acesso a elementos existentes da forma mais eficaz. Por exemplo, baseando-se no dicionário, você pode fazer um modelo de evento, onde cada evento do tipo OnChartEvent() é entregue à classe que gere um ou outro elemento gráfico. Para este efeito, apenas associe cada instância de classe com o nome do objeto gerido por esta classe.
Já que o dicionário é um algoritmo universal, ele pode ser aplicado nas mais diversas áreas. Este artigo esclarece que o seu funcionamento é baseado em algoritmos bastante simples, mas ainda assim robustos, tornando a sua aplicação conveniente e eficaz.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/1334
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Negociação Bidirecional e de Cobertura de Posições no MetaTrader 5 Através da API HedgeTerminal, Parte 2
Negociação Bidirecional e de Cobertura de Posições no MetaTrader 5 Através da API HedgeTerminal, Parte 2
 Negociação Bidirecional e de cobertura de posições no MetaTrader 5 Através do Painel de HedgeTerminal, Parte 1
Negociação Bidirecional e de cobertura de posições no MetaTrader 5 Através do Painel de HedgeTerminal, Parte 1
 Estudando a Classe CCanvas. Como Desenhar Objetos Transparentes
Estudando a Classe CCanvas. Como Desenhar Objetos Transparentes
 Guia Prático MQL5: Ordens ОСО
Guia Prático MQL5: Ordens ОСО
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
não precisa funcionar corretamente em geral.
A maneira correta de realizar várias exclusões de uma matriz associativa é coletar uma matriz de chaves a serem excluídas e, em seguida, excluir por chave.
O problema é que até mesmo esse método causa um erro estranho. Obviamente, é um erro. Vou dar uma olhada nisso.
Por enquanto, posso aconselhá-lo a criar um novo dicionário e adicionar a ele os valores que não precisam ser excluídos. Em seguida, limpe o antigo. Isso funcionará 100%.
Aqui vai:
1. Atualize a versão do Dictionary para a que está anexada a esta postagem.
2. Execute um script de teste para excluir elementos pares.
A exclusão deve ser feita em duas passagens:
Com relação ao método DeleteCurrentObject():
Esse método só deve ser usado em conjunto com a função ContainsKey(). A única razão pela qual ele está disponível como público é que, nesse caso, a chamada do método economiza tempo no reposicionamento do ponteiro. Ou seja, o caso típico e único de seu uso é 1. Verificar se há uma chave, 2. Se houver, excluí-la rapidamente com esse método.
Isso é compreensível, mas, novamente, a carroceria é desnecessária.
Tecnicamente, é possível fazer uma remoção em uma única passagem, como você espera. Mas isso seria complicado. Por isso, ainda não é possível, apenas em duas passagens. Do ponto de vista do dicionário como uma estrutura de dados distribuída, a exclusão de duas passagens é uma solução canonicamente mais correta. Apenas no nível do usuário parece que a exclusão é sequencial, mas na realidade tudo é diferente. Em termos de desempenho, a exclusão de passagem única não trará nenhum benefício. Em termos de conveniência, sim, pode ser mais conveniente.
Tecnicamente, é possível fazer uma remoção em uma única passagem, como você espera. Mas isso seria complicado. Por isso, ainda não é possível, apenas em duas passagens. Do ponto de vista do dicionário como uma estrutura de dados distribuída, a exclusão de duas passagens é mais canonicamente correta. Somente no nível do usuário parece que a exclusão é sequencial; na realidade, tudo é diferente. Em termos de desempenho, a exclusão de passagem única não trará nenhum benefício. Em termos de conveniência, sim, pode ser mais conveniente.
Obrigado.
Acho que encontrei um erro ao excluir um elemento e tentar chegar ao último elemento:
O erro no CDictionary.mqh será:
acessoinválido aoponteiro em 'Dictionary.mqh' (463,9)
Alguém pode confirmar isso? Alguma ideia de como consertar?
Foi um erro na linha 500 && 501 na implementação da verificação dos ponteiros.
Corrigido usando o CheckPointer() embutido.