
Das MQL5-Kochbuch: Implementierung eines Assoziativen Arrays oder eines Lexikons für raschen Datenzugriff

Inhaltsverzeichnis
- EINLEITUNG
- KAPITEL 1 DATENORGANISATION - THEORIE
- KAPITEL 2 ORGANISTION ASSOZIATIVER (INHALTSORIENTIERTER) ARRAYS - THEORIE
- KAPITEL 3 PRAKTISCHE ENTWICKLUNG EINES ASSOZIATIVEN ARRAYS
- KAPITEL 4 LEISTUNGSTEST UND BEWERTUNG
- KAPITEL 5 CDICTIONARY-KLASSE - DOKUMENTATION
- FAZIT
Einleitung
Dieser Beitrag beschreibt eine Klasse zur bequemen Informationsspeicherung - nämlich ein assoziatives oder inhaltsorientiertes Array oder ein Lexikon. Diese Klasse erlaubt den Zugriff auf Information mittels ihres Schlüssels .
Das assoziative Array ähnelt einem normalen Array. Doch statt eines Index, arbeitet es mit einem eindeutigen Schlüssel, der ENUM_TIMEFRAMES-Aufzählung oder einem Text. Dabei spielt es keine Rolle, was einen Schlüssel darstellt. Die Eindeutigkeit des Schlüssels ist wichtig. Dieser Algorithmus zur Datenspeicherung vereinfacht viele Programmierungsaspekte ganz erheblich.
So könnte z.B. eine Funktion, die einen Fehlercode aufnehmen und einem, dem Fehler entsprechenden Text, ausdruckten kann, folgendermaßen aussehen:
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
Die spezifischen Merkmale dieses Codes sehen wir uns später erst an.
Bevor wir zu einer klaren Beschreibung der internen Logik eines assoziativen Arrays kommen, müssen wir uns zunächst detailliert zwei Hauptmethoden zur Datenspeicherung ansehen - Arrays und Listen. Unser Lexikon beruht auf diesen zwei Datentypen, daher sollten wir ihre spezifischen Merkmale auch wirklich gut kennen. Kapitel 1 beschäftigt sich mit der Beschreibung von Datentypen. Kapitel 2 widmet sich der Beschreibung des assoziativen Arrays und den Methoden, wie man mit ihm arbeitet.
KAPITEL 1 Datenorganisation - Theorie
1.1 Algorithmus zur Datenorganisation. Den besten Daten-Speicherbehälter finden
Die Hauptfunktionen, die moderne Computer leisten müssen, sind Suche, Speicherung und Darstellung von Informationen. Die Interaktion zwischen Mensch und Computer umfasst entweder die Suche nach gewissen Informationen oder die Erzeugung und Speicherung von Informationen für ihre spätere Nutzung. Information ist kein abstraktes Konzept - denn in Wirklichkeit liegt diesem Begriff ein bestimmtes Konzept zugrunde. So ist z.B. die Historie einer Symbol-Notierung eine Informationsquelle für jeden Händler, der auf diesem Symbol einen Abschluss ausführt oder ausführen wird. Die Dokumentation der Programmiersprache oder ein Quellcode eines Programms kann einem Programmierer ebenfalls als Informationsquelle dienen.
Einige Grafikdateien (z.B. ein mit einer Digitalkamera aufgenommenes Foto) kann für Menschen, die nichts mit Programmieren oder Handel am Hut haben, ebenfalls so eine Informationsquelle sein. Und es ist ganz klar, dass diese Arten von Information unterschiedliche Strukturen und ihre eigenen Arten haben. Folglich unterscheiden sich auch die Algorithmen zur Speicherung, Darstellung und Verarbeitung dieser Informationen.
So ist es z.B. wesentlich einfacher eine Grafikdatei als eine zweidimensionale Matrix (zweidimensionales Array) darzustellen, dessen jedes Element oder Zelle Informationen über die Farbe eines kleinen Bildbereichs speichert — ds Pixel nämlich. Daten zu Kursnotierungen besitzen eine andere Art, sie sind im Grunde ein Strom homogener Daten im OHLCV-Format. Dieser Datenstrom lässt sich wesentlich besser als Array oder eine geordnete Sequenz an Strukturen darstellen, also ein bestimmter Datentyp in der Programmiersprache, der unterschiedliche Datentypen kombiniert. Dokumentationen oder ein Quellcode werden meist als reiner Text dargestellt. Diese Datentypen können als eine geordnete Sequenz von Strings festgelegt und gespeichert werden, wo jeder String eine zufällige Abfolge von Symbolen ist.
Der Typ des Behälters zur Datenspeicherung hängt vom Datentyp ab. Mit Hilfe der Begriffe des Objekt-orientierten Programmierens kann man einen Behälter leichter definieren - und zwar als eine bestimmte Klasse, die diese Daten speichert und zu ihrer Bearbeitung spezielle Algorithmen (Methoden) besitzt. Von diesen Datenspeicherbehältern gibt es verschiedene Typen (Klassen). Sie beruhen auf unterschiedlicher Datenorganisation. Einige Algorithmen zur Datenorganisation erlauben die Kombination verschiedener Paradigmen zur Datenspeicherung. Also können wir von der Kombination der Vorteile aller Speicherungsarten profitieren.
Man wählt zur Speicherung, Verarbeitung und zum Abruf von Daten den einen oder den anderen Behälter, je nach der vermeintlichen Methode der Bearbeitung der Daten und ihrer Art. Hierbei ist es wichtig zu verstehen, dass es keine durchgängig effizienten Datenbehälter gibt. Die Schwächen eines Datenbehälters sind der Preis, den man für seiner Vorteile zu zahlen hat.
So kann man z.B. schnell Zugriff auf jedes der Array-Elemente bekommen. Doch das Einfügen eines Elements in einen zufälligen Array-Ort ist hingegen ein zeitaufwendiger Vorgang, da in diesem Fall eine komplette Größenumstellung des Arrays erforderlich ist. Und umgekehrt ist das Einfügen eines Elements in eine einfach-verknüpfte Liste ein effektiver und extrem rascher Vorgang, doch der Zugriff auf ein zufälliges Element dort kann viel Zeit in Anspruch nehmen. Muss man neue Elemente sehr häufig einfügen, braucht jedoch keinen ebenso häufigen Zugriff auf diese Elemente, dann ist die einfach-verknüpfte Liste der richtige Behälter. Braucht man häufigen Zugriff auf zufällige Elemente, dann sollte man ein Array als eine Datenklasse wählen.
Um wirklich zu verstehen, welche Art der Datenspeicherung am besten ist, sollte man die Anordnung jedes gegebenen Behälters kennen. Dieser Beitrag beschäftigt sich mit dem assoziativen Array oder Lexikon — einem bestimmten Behälter zur Datenspeicherung, auf Basis der Kombination eines Array und einer Liste. Lassen Sie mich hier darauf hinweisen, dass das Lexikon auf unterschiedliche arten implementiert werden kann, je nach der bestimmten Programmiersprache, seinen Mitteln, Fähigkeiten und akzeptierten Programmierregeln.
So unterscheidet sich z.B. die Implementierung des C# Lexikons von der des C++ Lexikons. In diesem Beitrag geht es nicht um die angepasste Implementierung des Lexikons für С++. Die hier beschriebene Version des assoziativen Arrays wurde von Grund auf für die MQL5 Programmiersprache erstellt und betrachtet seine spezifischen Merkmale und die geläufige Programmierpraxis. Zwar unterscheidet sich die Implementierung der Lexika, doch ihre allgemeinen Charakteristika und Arbeitsmethoden sollten gleich sein. Vor diesem Hintergrund zeigt die beschriebene Version all diese Charakteristika und Methoden in Gänze.
Wir erstellen nach und nach die Lexikon-Algorithmen und sprechen dabei gleichzeitig über die Art der Algorithmen zur Datenspeicherung. Am Schluss dieses Beitrags haben wir dann eine vollständige Version des Algorithmus vor uns und kennen sein Funktionsprinzip aus dem Eff-Eff.
Es gibt für unterschiedliche Datentypen keine durchgängig effizienten Datenbehälter. Betrachten wir uns dazu ein einfaches Beispiel: ein Notizbuch. Das kann man auch als einen Behälter oder eine Klasse betrachten, die wir in unserem Alltag verwenden. Alles was wir dort notieren, wird gemäß einer vorläufig angelegten Liste eingetragen (in diesem Falle alphabetische Auflistung). Wenn Sie den Namen eines Abonnenten kennen, finden Sie ganz leicht seine/ihre Telefonnummer, denn Sie müssen dazu nur das Notizbuch öffnen und unter dem Anfangsbuchstaben seines Namens nachsehen.
1.2 Direktes Ansprechen von Arrays und Daten
Ein Array ist die einfachste, und zugleich effektivste Art, Informationen zu speichern. Beim Programmieren ist ein Array eine Sammlung der Elemente des gleichen Typs, die in seinem Speicher direkt, eins nach dem anderen, zu finden sind. Aufgrund dieser Eigenschaften können wir die "Adresse" jedes Elements im Array berechnen.
Denn in der Tat, sind alle Elemente vom gleichen Typ, haben sie auch die gleiche Größe. Da Array-Daten kontinuierlich zu finden sind, können wir die Adresse eines zufälligen Elements berechnen und, wenn wir die grundsätzliche Größe des Elements kennen, direkt auf dieses Element verweisen. Eine allgemeine Berechnungsformel der Adresse hängt vom Datentyp und einem Index ab.
So kann man z.B. die Adresse des fünften Elements im Array mit Elementen vom Typ uchar mit Hilfe der folgenden allgemeinen Formel berechnen, die sich aus den Eigenschaften der Array-Datenorganisation ergibt:
zufällige Adresse des Elements = Adresse des ersten Elements + (Index des zufälligen Elements im Array * Array -Typengröße)
Array-Adressierung beginnt bei Null - deshalb entspricht die Adresse des ersten Elements der Adresse des Array-Elements mit dem Index "0". Logischerweise hat das vierte Elemente dann einen Index "4". Nehmen wir an, das Array speichert Elemente vom Typ uchar - dem grundsätzlichen Datentyp in vielen Progammiersprachen. Er ist beispielsweise in allen C-Sprachen vorhanden. Und MQL5 ist da keine Ausnahme. Jedes Element des Arrays vom Typ uchar belegt 1 Byte oder 8 Bits Speicherplatz.
Also ist die Adresse des fünften Elements im uchar-Array, laut der vorhin angesprochenen Formel folgende:
Adresse des fünften Elements = Adresse des ersten Elements + (4 * 1 Byte);
Mit anderen Worten: das fünfte Elemente des uchar-Arrays ist 4 Bytes höher als das erste. Während das Programm ausgeführt wird, kann man auf jedes Array-Element direkt per seiner Adresse verweisen. So eine Adressen-Arithmetik erlaubt einen wirklich raschen Zugriff auf jedes Array-Element. Doch eine derartige Datenorganisation hat auch ihre Nachteile.
So ein Nachteil ist beispielsweise, dass man keine Elemente unterschiedlicher Typen in dem Array speichern kann. Eine solche Einschränkung ist die Folge des direkten Ansprechens. Klar unterscheiden sich unterschiedliche Datentypen in ihrer Größe, was bedeutet, dass die Berechnung einer Adresse eines bestimmten Elements mit Hilfe der oben angesprochenen Formel schlichtweg unmöglich wird. Doch diese Einschränkung kann man elegant umgehen, wenn das Array keine Elemente, sondern Zeiger auf die Elemente speichert.
Und am einfachsten ist hierbei, einen Zeiger als einen Link darzustellen (wie Kurzbefehle in Windows). Der Zeiger verweist auf ein bestimmtes Objekt im Speicher, doch der Zeiger an sich ist kein Objekt.. In MQL5 kann der Zeiger nur auf eine Klasse verweisen. Im Objekt-orientierten Programmieren ist eine Klasse ein bestimmter Datentyp, der ein beliebiges Datenset und Methoden enthalten kann und vom Benutzer für effektive Programmstrukturierung erzeugt werden kann.
Jede Klasse ist ein eindeutig benutzerdefinierter Datentyp. Zeiger, die auf unterschiedliche Klassen verweisen, können nicht in einem Array untergebracht werden. Doch ungeachtet der Klasse, auf die verwiesen wird, besitzt der Zeiger immer die gleiche Größe, da er nur eine Objektadresse im Adressbereich des Betriebssystems enthält, die für alle zugewiesenen Objekte identisch ist.
1.3 Das Knoten-Konzept anhand des Beispiels der CObjectCustom einfachen Klasse
So, jetzt wissen wir genug, um unseren ersten universellen Zeiger erstellen zu können. Was wir wollen, ist, ein Array universeller Zeiger anzulegen, in dem jeder Zeiger auf seinen bestimmten Typ verweisen würde. Die tatsächlichen Typen wären dabei unterschiedlich, doch angesichts der Tatsache, dass auf sie ja vom selben Zeiger verwiesen wird, könnte man diese Typen in einem Behälter/Array unterbringen. Also erstellen wir die erste Version unseres Zeigers an.
Er wird vom einfachsten Typ dargestellt, den wir CObjectCustom nennen:
class CObjectCustom
{
};
Eine Klasse zu erfinden, die noch einfacher als CObjectCustom ist, geht schon fast gar nicht mehr, denn sie enthält keinerlei Daten oder Methoden. Doch eine solche Implementierung reicht uns für jetzt vollkommen aus.
Jetzt bedienen wir uns auch eines der Hauptkonzepte des Objekt-orientiertes Programmierens — Vererbung. Vererbung bietet eine spezielle Art wie man die Identität zwischen Objekten einrichten kann. So können wir z.B. einem Compiler sagen, dass jede Klasse ein Nachkomme von CObjectCustom ist.
Das allgemeinere Konzept der CObjectCustom Klasse lässt sich z.B. gut an einer Klasse an Menschen (CHuman), einer Klasse an Exert Advisors (CExpert) und einer Klasse an Wetter (CWeather) veranschaulichen . Diese Konzepte sind vielleicht im wirklichen Leben nicht tatsächlich miteinander verknüpft - Wetter hat ja nichts mit Menschen gemein, und Expert Advisors hängen nicht mit Wetter zusammen. Doch in der Welt des Programmierens richten wir ja die Verknüpfungen ein, und wenn sie für unsere Algorithmen geeignet sind, gibt es keinen Grund, sie nicht zu erzeugen.
Also erzeugen wir auf die gleiche Art noch ein paar mehr Klassen: eine Klasse an Autos (CCar), eine an Zahlen (CNumber), eine Klasse an Kurs-Bars (CBar), eine an Notierungen (CQuotes), eine Klasse des MetaQuotes Unternehmens (CMetaQuotes) und eine Klasse zur Beschreibung eines Schiffs (CShip). Ganz ähnlich wie die vorausgegangenen Klassen, sind auch sie nicht wirklich miteinander verknüpft, doch sind sie alle Nachkommen der CObjectCustom Klasse.
Legen wir nun für diese Objekte einen Klassen-Library an, die all diese Klassen in einer Datei vereint: ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
Nun ist es an der Zeit, diese Klassen auch in einem Array zu kombinieren.
1.4 Arrays mit Knoten-Zeiger anhand des Beispiels der CArrayCustom Klasse
Um Klassen zu kombinieren, brauchen wir ein spezielles Array.
Im einfachsten Fall, genügt es folgendes zu schreiben:
CObjectCustom array[];
Dieser String erzeugt ein dynamisches Array, das Elemente vom Typ CObjectCustom speichert. Aufgrund der Tatsache, dass alle Klassen, die wir im vorangegangenen Abschnitt definiert haben, von CObjectCustom abgeleitet sind, können wir in diesem Array jede dieser Klassen speichern. Wir können also Menschen, Autos und Schiffe hier unterbringen. Doch die Deklarierung des CObjectCustom Arrays reicht zu diesem Zweck allein nicht aus.
Denn wenn wir das Array auf normale Weise deklarieren, werden im Moment der Array-Initialisierung alle Elemente automatisch befüllt. Also werden all seine Elemente, nachdem wir das Array deklariert haben, von der CObjectCustom Klasse belegt sein.
Das können wir nachprüfen, wenn wir CObjectCustom nur leicht ändern:
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
Lassen wir einen Test-Code als Script ablaufen, um diese Besonderheit zu prüfen:
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
In der OnStart() Funktion haben wir ein Array initialisiert, das aus drei Elementen von CObjectCustom bestand.
Der Compiler hat das Array dann mit entsprechenden Objekten befüllt. Sie können das im Protokoll des Terminals nachlesen:
12.02.2015 12:26:32.964Test (USDCHF,H1)Objekt #2 - CObjectCustom
12.02.2015 12:26:32.964Test (USDCHF,H1)Objekt #1 - CObjectCustom
12.02.2015 12:26:32.964Test (USDCHF,H1)Objekt #0 - CObjectCustom
Das heißt also: das Array wurde vom Compiler befüllt und wir können dort jetzt keine weiteren Elemente mehr unterbringen, wie z.B. CWeather oder CExpert.
Dieser Code wird nicht erstellt:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
Der Compiler liefert uns eine Fehlermeldung:
'=' - structure have objects and cannot be copied Test.mq5 18 13
Das bedeutet, dass das Array bereits Objekte besitzt und dort keine neuen Objekte mehr hin kopiert werden können.
Doch auch dieses Problem können wir knacken! Wie bereits erwähnt, sollten wir nicht mit Objekten, sondern mit Zeigern auf diese Objekte arbeiten.
Also schreiben wir den Code in der OnStart() Funktion so um, dass er mit Zeigern arbeiten kann
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
Jetzt wird der Code erstellt und es gibt keine Fehlermeldungen. Was hat sich geändert? Erstens haben wir die CObjectCustom Array-Initialisierung durch die Initialisierung des Arrays der Zeiger auf CObjectCustom ersetzt.
In diesem Fall erzeugt der Compiler bei der Initialisierung das Arrays keine neuen CObjectCustom Objekte, sondern läßt es leer. Und zweitens verwenden wir nun einen Zeiger auf das Objekt CWeather, anstatt das Objekt selbst. Mit Hilfe des Schlüsselworts neu haben wir das Objekt CWeather erzeugt und es unserem Zeiger 'Wetter' zugewiesen und haben dann den Zeiger 'Wetter' (und eben nicht das Objekt) in das Array abgelegt.
Platzieren wir jetzt die übrigen Objekte auf ähnliche Weise ins Array.
Dazu schreiben wir den folgenden Code:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
Der Code wird funktionieren, doch ist das ziemlich heikel, das wird direkt an den Indices des Arrays herumtun.
Wenn wir uns in der Größe unseres arrayObj Arrays verrechnen oder es mittels eines falschen Index adressieren, führt das zu einem schwerwiegenden Fehler in unserem Programm. Doch dieser Code genügt für diesen Beitrag zur Veranschaulichung.
Stellen wir diese Elemente schematisch dar:
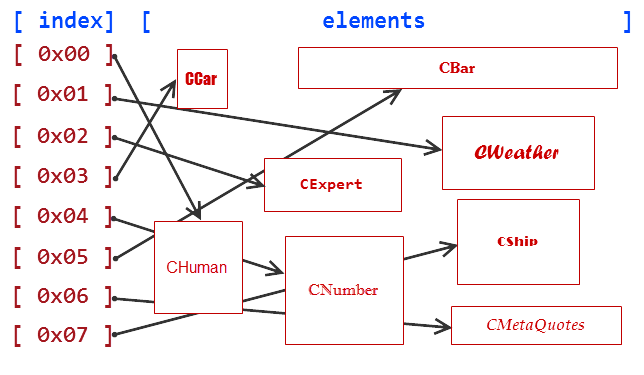
Abb. 1 Schema der Datenspeicherung im Zeiger-Array
Vom Operator 'neu' erzeugte Elemente werden in einem speziellen Teil des RAM abgelegt, dem sog. Freispeicher. Diese Elemente sind ungeordnet und sind im obigen Schema deutlich zu erkennen.
Unser arrayObj Zegier-Array hat eine strenge Indizierung mit der man rasch Zugriff auf jedes Element bekommt, das seinen Index verwendet. Doch Zugriff auf so ein Element reicht nicht aus, da das Zeiger-Array nicht weiß auf welches bestimmte Objekt es zeigt. Der CObjectCustom Zeiger kann nämlich auf CWeather oder CBar oder CMetaQuotes zeigen, da sie alle ja CObjectCustom sind. Daher ist ein expliziter Abdruck eines Objekts auf seinen aktuellen Typ notwendig, um den Element-Typ zu bekommen
Und das geht z.B. so:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
In diesem Code haben wir das CHuman Objekt erzeugt und es als CObjectCustom in das arrayObj Array platziert. Anschließend haben wir CObjectCustom extrahiert und zu CHuman umgewandelt, was in dr Tat das gleche ist. Und unsere Beispielumwandlung führte zu keinen Fehlern, da wir uns an den Typ erinnert haben. In einer echten Programmiersituation ist es nahezu unmöglich einen Typ jedes Objekts nach zu verfolgen, da es Hunderte solcher Typen und mehr als eine Million Objekte geben kann.
Aus diesem Grund sollten wir die ObjectCustom Klasse mit der zusätzlichen Type() Methode ausstatten, die einen Modifikator eines tatsächlichen Objekttyps liefert. Ein Modifikator ist eine bestimmte eindeutige Ziffer, die unser Objekt beschreibt, sodass auf seinen Typ via seinem Namen verwiesen werden kann. Wir können z.B. Modifikatoren mittels der Präprozessor-Direktive #define definieren. Wenn wir dann den vom Modifikator spezifizierten Objekttyp kennen, können wir immer seinen Typ in den tatsächlichen umwandeln. Und somit sind wir der Erzeugung von sicheren Typen schon ganz nahe.
1.5 Prüfung und Sicherheit von Typen
Sobald wir mit der Umwandlung eines Typs in einen anderen beginnen, spielt die Sicherheit einer solchen Umwandlung bei der Programmierung eine eminent wichtige Rolle. Wir wollen ja nicht, dass unser Programm einen schwerwiegenden Fehler erfährt, oder? Doch wir wissen bereits, was die Sicherheitsgrundlage für unsere Typen sein wird — spezielle Modifikatoren. Wenn wir den Modifikator kennen, können wir ihn in den erforderlichen Typ umwandeln. Und dazu müssen wir unsere CObjectCustom Klasse mit einigen Zusätzen versehen
Zuerst müssen Typ-Identifikatoren anlegen, die auf sie per Name verweisen. Aus diesem Grund legen wir eine extra Datei mit der notwendigen Aufzählung an:
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip
Jetzt verändern wir die Klassen-Codes, indem wir der Variable, die Objekttypen als Ziffer speichert, CObjectCustom hinzufügen. Das verbergen wir im privaten Bereich, damit niemand es sehen kann.
Darüber hinaus fügen wir einen speziellen Konstruktor hinzu, der für Klassen, die von CObjectCustom begleitet werden, verfügbar ist. Dieser Konstruktor gestattet Objekten während ihrer Erzeugung ihren Typ zu benennen.
Der übliche Code hierfür sieht so aus:
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
Wie wir erkennen können, richtet nun jeder, von CObjectCustom abgeleitete Typ, während er erzeugt wird, seinen eigenen Typ in seinem Konstruktor ein. Einmal eingerichtet, kann der Typ nicht mehr verändert werden, da das Feld, in dem er gespeichert ist, privat ist und nur für CObjectCustom zugänglich. Damit wird verhindert, dass man den falschen Typ bearbeitet. Wenn die Klasse nicht den geschützten Konstruktor CObjectCustom aufruft, wird sein Typ - TYPE_OBJECT - der Standardtyp sein.
Jetzt beschäftigen wir uns damit, wie man Typen aus arrayObj extrahiert und sie verarbeitet. Dazu statten wir die CHuman und CWeather Klassen mit public Run() bzw. Temp() Methoden aus. Nachdem die Klasse aus arrayObj extrahiert worden ist, wandeln wir sie in den erforderlichen Typ um und beginnen mit ihr auf korrekte Weise zu arbeiten.
Ist der im CObjectCustom Array gespeicherte Typ unbekannt, ignorieren wir ihn einfach und verfassen die Meldung "unbekannter Typ":
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
Der Code zeigt uns die folgende Meldung:
13.02.2015 15:11:24.703Test (USDCHF,H1)unbekannter Typ.
13.02.2015 15:11:24.703Test (USDCHF,H1)32.0
13.02.2015 15:11:24.703Test (USDCHF,H1)Human läuft...
Also haben wir das gewünschte Ergebnis erreicht, denn jetzt können wir alle Typen von Objekten im CObjectCustom Array speichern, mittels ihrer Indices im schnell im Array auf sie zugreifen und sie zudem auch korrekt in ihre tatsächlichen Typen umwandeln. Doch immer noch fehlen uns viele Dinge: wir brauchen noch eine korrekte Löschung nach Programmbeendigung, da wir die im Freispeicher befindlichen Objekte selbst mit Hilfe des löschen-Operators löschen müssen.
Des weiteren brauchen wir eine Möglichkeit für eine sichere Größenneuanordnung des Arrays, sollte es komplett voll sein. Aber wir werden das Rad hier nicht neu erfinden. Das Standardset an Tools in MetaTrader 5 umfasst Klassen, die all diese Merkmale implementieren Merkmale.
Diese Klassen beruhen auf dem universellen CObject Behälter/Klasse. Ganz ähnlich unserer Klasse besitzt er die Type() Methode, die den tatsächlichen Typ der Klasse liefert sowie zwei weitere wichtige Zeiger auf den CObject Typ - nämlich m_prev und m_next. Welchen Zweck sie erfüllen, wird im folgenden Abschnitt beschrieben, wo wir uns anhand des Beispiels des CObject Behälters und der CList Klasse eine weitere Methode zur Datenspeicherung ansehen, nämlich eine doppelt-verknüpfte Liste.
1.6 Die CList-Klasse als Beispiel für eine doppelt verknüpfte Liste
Ein Array mit Elementen beliebigen Typs leidet nur unter einem großen Nachteil - wenn man ein neues Element einfügen will, dann ist das zeitaufwendig und mühevoll, insbesondere wenn dieses Element in der Mitte des Arrays eingefügt werden muss. Die Elemente sind in einer Reihenfolge untergebracht, daher muss für ein Einfügen die Größe des Arrays neu angeordnet werden, um die Gesamtzahl der Elemente um eins zu erhöhen und dann alle Elemente, die dem frisch eingefügten folgen, neu anzuordnen, das ihre Indices ihren neuen Werten entsprechen.
Nehmen wir also an, wir haben ein Array aus 7 Elementen und möchten an der vierten Stelle ein weiteres Element einfügen. Ein annäherndes Schema dieser Einfügung sieht so aus:

Abb. 2 Neuanordnung der Größe des Arrays und Einfügen eines neuen Elements
Es gibt jedoch ein Schema zur Datenspeicherung, das das schnelle und effektive Einfügen und Löschen von Elementen ermöglicht, nämlich die sog. einfach-verknüpfte oder doppelt-verknüpfte Liste. Die Liste bleibt dabei ein ganz normale Warteschlange. Und wie Sie wissen: wenn wir in einer Warteschlange stehen, dann müssen wir nur weissen, wer vor uns steht, also wem wir zu folgen haben, wer vor dieser Person steht, interessiert uns dabei gar nicht. Wir müssen auch nicht wissen, wer hinter uns steht, da diese Person für seine/ihre Position in der Warteschlange selbst verantwortlich ist.
Eine Warteschlange ist das klassische Beispiel für eine einfach-verknüpfte Liste. Doch Listen können auch doppelt-verknüpft sein. In diesem Fall kennt jede Person in der Schlange nicht nur die Person vor ihr, sondern auch die hinter ihr. Wenn Sie also jede dieser beiden Personen fragen, können Sie sich in der Schlange in beide Richtungen bewegen.
Und die in der Standard-Library vorhandene Standard CList bietet genau diesen Algorithmus Bilden wir also aus den bereits bekannten Klassen eine Warteschlange. Diesmal werden sie alle von CObject und nicht von CObjectCustom abgeleitet.
Schematisch lässt sich dies wie folgt darstellen:

Abb. 3 Schema einer doppelt-verknüpften Liste
Und das ist der Quellcode, der so ein Schema erzeugt:
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
Unsere Klassen haben jetzt zwei Zeiger von CObject: einer verweist auf das vorausgehende und der andere auf das folgende, nächste Element. Der Zeiger auf das vorausgehende Element des ersten Elements in der Liste = NULL. Das Element am Ende der Liste hat einen Zeiger auf das folgende, nächste Element, der natürlich auch = NULL ist. Also können nun die Elemente eins nach dem anderen aufzählen und somit die gesamte Schlange aufzählen.
Die EnumerateAll() und ReverseEnumerateAll() Funktionen übernehmen die Aufzählung aller Elemente in der Liste.
Die erste Funktion führt die Aufzählung der Liste von Anfang bis Ende aus, die zweit vom Ende bis zum Anfang. Der Quellcode dieser Funktionen sieht so aus:
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
Wie arbeitet dieser Code? Eigentlich echt einfach Zu Anfang bekommen wir einen Verweis auf den ersten Knoten in der EnumerateAll() Funktion. Dann drucken wir eine Sequenznummer dieses Knotens in die für Schleife und gehen mittels command node = node.Next() zum nächsten Knoten. Bitte nicht vergessen, den aktuellen Index des Elements um einen (i++) wiederholt durchzugehen. Die Aufzählung dauert solange, bis der aktuelle Knoten = NULL ist. Der Code im zweiten Block von 'für' ist hierfür zuständig: node != NULL.
Die umgekehrte Version dieser Funktion, nämlich ReverseEnumerateAll(), verhält sich ähnlich, mit dem einzigen Unterschied, dass sie sich zuerst mit dem letzten Element der Liste beschäftigt - CObject* node = list.GetLastNode(). In der 'für' Schleife geht sie daher nicht zum nächsten, sondern zum vorigen Element der Liste - node = node.Prev().
Nach Start des Codes erhalten wir folgende Meldung:
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Aufzählung abgeschlossen.
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 0
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 1
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 2
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 3
13.02.1015 17:52:02.974TestListe (USDCHF,D1)<<< aufzählen von Ende bis Anfang <<<
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 3
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 2
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 1
13.02.1015 17:52:02.974TestListe (USDCHF,D1)Element bei 0
13.02.1015 17:52:02.974TestListe (USDCHF,D1)>>> aufzählen von Anfang bis Ende >>>
In der Liste lassen sich neue Elemente leicht einfügen. Dazu müssen nur die Zeiger der vorausgehenden und folgenden Elemente so verändert werden, dass sie auf ein neues Element verweisen würden, und dieses neue Element würde dann auf die vorausgehenden und folgenden Objekte verweisen.
Das Schema sieht viel leichter aus als es meine Erklärung vermuten lässt:

Abb. 4 Einfügen eines neuen Elements in einer doppelt-verknüpften Liste
Der Hauptnachteil der Liste liegt darin, dass es hier nicht möglich ist, auf jedes Element mittels seines Index zu verweisen.
Möchte man z.B., so wie in Abb. 4 gezeigt, auf CExpert verweisen, muss man erst auf CCar zugreifen, und kann dann erst zu CExpert weitergehen. Das gleiche gilt für CWeather. Es liegt allerdings näher am Ende der Liste, als kann man vom Ende her schneller darauf zugreifen. Und genau deshalb muss man zuerst auf CShip verweisen und dann erst auf CWeather.
Verglichen mit der direkten Indizierung ist das Bewegen von Zeigern ein langsamerer Vorgang. Moderne zentrale Prozessoreinheiten sind für Abläufe, insbesondere im Zusammenhang mit Arrays, allerdings optimiert. Aus diesem Grund sind in der Praxis Arrays vermutlich vorzuziehen, selbst obwohl Listen möglicherweise schneller arbeiten könnten.
KAPITEL 2 Die Organisation assoziativer (inhaltsorientierter) Arrays - Theorie
2.1 Die Rolle assoziativer Arrays im täglichen Leben
In unserem täglichen Leben haben wir ständig mit assoziativen Arrays zu tun. Für uns eine so klare Sache, dass wir sie als selbstverständlich ansehen. Das einfachste Beispiel eines assoziativen Arrays oder Lexikons ist das Telefonbuch. Jede Telefonnummer darin hängt mit dem Namen einer bestimmten Person zusammen. Dieser Name im Telefonbuch ist ein eindeutiger Schlüssel und die dazu gehörende Telefonnummer ist ein einfacher Zahlenwert. Jede Person kann ja durchaus auch mehr als nur ein Telefonnummer haben, z.B. eine private, geschäftliche und Mobiltelefonnummer.
Ganz allgemein kann die Menge an Telefonnummern unbegrenzt sein, doch der Name der dazu gehörenden Person bleibt immer der gleiche - er ist eindeutig. Zwei Menschen, die in Ihrem Telefonbuch beide Alexander heißen, könnten uns verwirren, und manchmal verwählen wir uns ja auch. Und deshalb müssen die Schlüssel (in dem Fall die Namen) eindeutig sein, um dies zu vermeiden. Doch gleichzeitig muss das Lexikon wissen, wie es Kollisionen behebt und wie es sie möglichst vermeiden kann. Zwei identische Namen machen unser Telefonbuch nicht gleich nutzlos. Also muss unser Algorithmus wissen, wie er mit solchen Situationen umgeht.
Im wirklichen Leben verwenden wir mehrere Arten an Lexika: das Telefonbuch ist so ein Lexikon mit einer eindeutigen Zeile (Name der Person) als Schlüssel, und einer entsprechenden Ziffer als Wert. Fremdwörterbücher sind anders aufgebaut. Das englische Wort ist hier der Schlüssel und seine Übersetzung ist sein Wert. Beide assoziativen Arrays beruhen auf denselben Methoden des Umgangs mit Daten, und deshalb muss unser Lexikon mehrere Zwecke erfüllen können und uns ermöglichen, jeden Typ zu speichern und zu vergleichen.
Beim Programmieren kann es durchaus bequem sein, sich seine eigenen Lexika und "Notizbücher" selbst anzulegen.
2.2 Primäre assoziative Arrays auf Basis des Switch-Case Operators oder einem einfachen Array
Ein einfaches assoziatives Array lässt sich ganz leicht selbst anlegen. Man nimmt einfach die Standard-Tools der MQL5-Sprache, z.B. den Switch-Operator oder ein Array.
Sehen wir uns so einen Code mal näher an:
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
In diesem Fall agiert der Switch-Case-Operator wie ein Lexikon: jeder Wert von ENUM_TIMEFRAMES besitzt einen String-Wert, der diesen Zeitraum beschreibt. Aufgrund der Tatsache, dass der Switch-Operator eine umgeschaltete Passage (in russisch) ist, erfolgt der Zugriff auf die erforderliche Case-Variante unverzüglich und andere Case-Varianten werden nicht aufgezählt. Und deshalb ist dieser Code höchst effizient.
Sein Nachteil jedoch liegt darin, dass man erstens alle Werte manuell eintragen muss, die dann mit einem oder dem anderen Wert von ENUM_TIMEFRAMES geliefert werden müssen. Zweitens kann ein Switch nur mit ganzzahligen Werten arbeiten. Doch eine Umkehrfunktion zu schreiben, die den Typ des Zeitrahmens je nach dem übertragenen String liefern würde, wäre weitaus komplizierter. Und drittens ist diese Methode nicht flexibel genug, da man alle möglichen Varianten im Voraus spezifizieren muss. Doch oft muss man Werte dynamisch in das Lexikon füllen, immer dann nämlich, wenn neue Daten auftauchen.
Die zweite "frontale" Methode der Speicherung des Paars 'Schlüssel-Wert' bedeutet, ein Array anzulegen, wo ein Schlüssel als Index verwendet wird und ein Wert ein Element des Arrays ist.
Versuchen wir z.B. die ähnliche Aufgabe, nämlich die Lieferung der Darstellung des Zeitrahmen-Strings zu bewältigen:
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
Dieser Code stellt den Verweis per Index dar, wo ENUM_TIMFRAMES als ein solcher Index spezifiziert ist. Bevor der Wert geliefert wird, prüft die Funktion, ob das Array mit dem benötigten Element befüllt ist. Wenn nicht, delegiert die Funktion das entsprechende Befüllen an eine spezielle Funktion - InitTimeframes(). Sie hat jedoch die gleichen Nachteile wie der Switch-Operator.
Darüber hinaus verlangt eine derartige Lexikon-Struktur die Initialisierung eines Arrays mit großen Werten. Der Wert des PERIOD_MN1 Modifikators ist 49153. Das heißt, wir brauchen 49153 Zellen zur Speicherung von nur neun Zeitrahmen. Andere Zellen bleiben leer. Diese Methode der Datenzuweisung ist alles andere als kompakt, doch durchaus geeignet, wenn Aufzählungen aus einem kleinen und aufeinander folgenden Bereichen an Zahlen bestehen.
2.3 Umwandlung von Basistypen in einen eindeutigen Schlüssel
Da die im Lexikon verwendeten Algorithmen alle ähnlich sind, ungeachtet bestimmter Schlüsseltypen und Werte, müssen wir eine Datenanpassung ausführen, damit unterschiedliche Daten auch von einem Algorithmus verarbeitet werden können. Unser Lexikon-Algorithmus wird universell sein und die Speicherung von Werten zulassen, wo jeder Basistyp als ein Schlüssel spezifiziert werden kann, z.B.: int, enum, double oder sogar string.
In MQL5 kann jeder Basisdatentyp als eine unsignierte ulong Ziffer dargestellt werden. So sind short oder ushort Datentpyen "kurze" Versionen von ulong.
Mit dem ausdrücklichen Verständnis, dass der 'ulong'-Typus den 'ushort'-Wert speichert, ist eine sichere explizite Typenumwandlung immer möglich:
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)
Das gleiche trifft zu auf die char und int Typen und ihre unsignierten analogen Ziffern, da ulong jeden Typ speichern kann, dessen Größe < oder = ulong ist. Die Datetime, Enum und Farb-Typen beruhen auf einer ganzzahligen, 32-Bit uint Ziffer, d.h. auch sie können sicher in 'ulong' umgewandelt werden. Der bool Type besitzt nur zwei Werte: "0" für 'false' und "1" für 'true'. Also können Werte des bool Typs ebenfalls in der Variable vom Typ ulong gespeichert werden. Übrigens beruhen viele MQL5 Systemfunktionen auf diesem Merkmal.
So liefert die AccountInfoInteger() Funktion z.B. den ganzzahligen Wert des 'long'-Typs, der auch eine Kontonummer des 'ulong'-Typs und ein boole'scher Wert einer Erlaubnis zum Handel sein kann - ACCOUNT_TRADE_ALLOWED.
Doch MQL5 hat drei Basistypen, die sich von den ganzzahligen Typen unterscheiden. Die können nicht direkt in einen ganzzahligen 'ulong'-Typ umgewandelt werden. Zu diesen Typen gehören 'gleitender Punkt', wie z.B. double und gleitend und Strings. Doch mittels einfacher Maßnahmen lassen sie sich in eindeutige, ganzzahlige Schlüssel/Werte umwandeln.
Jeder Wert eines gleitenden Punkts kann als Grundwert angelegt werden, mit einer beliebigen Ziffer potenziert, wobei sowohl Grundwert als auch Potenz separat als ganzzahliger Wert gespeichert werden. Diese Speichermethode wird für 'double' und 'gleitende' Werte verwendet. Der 'gleitende'-Typ verwendet 32 Stellen zur Speicherung von Mantisse und Potenz; der 'double'-Typ 64 Stellen.
Bei ihrer direkten Umwandlung in den 'ulong'-Typ wird ihr Wert einfach aufgerundet. In diesem Fall ergeben 3,0 und 3,14159 denselben 'ulong'-Wert — 3. Für uns ist das ungeeignet, da wir ja verschiedene Schlüssel für diese zwei unterschiedlichen Werte brauchen. Und hier hilft uns ein ungewöhnliches Merkmal, das in den C-Programmiersprachen benutzt werden kann, die sog. Strukturumwandlung. Zwei unterschiedliche Strukturen können umgewandelt werden, wenn sie eine Größe besitzen (eine Struktur wird zur anderen umgewandelt).
Sehen wir uns das Beispiel an zwei Strukturen genauer an. Eine speichert den Wert des ulong-Typs, die andere den des double-Typs:
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
Dieser Code kopiert die DoubleValue Struktur Byte per Byte in die ULongValue Struktur. Da sie die gleiche Größe und Anordnung der Variablen haben, wird der 'double'-Wert dValue.value Byte per Byte in die 'ulong'-Variable des lValue.value Werts kopiert.
Anschließend wird der Wert der Variable ausgedruckt. Sobald wir dValue.value zu 3,14160 ändern, wird lValue.value ebenfalls geändert.
Und mit Hilfe der printf() Funktion wird dann folgendes Ergebnis angezeigt:
16.02.2015 15:37:50.646TestListe (USDCHF,H1)4614256673094690983
16.02.2015 15:37:50.646TestListe (USDCHF,H1)4614256650576692846
Der 'gleitend'-Typ ist die Kurzversion des 'double'-Typs. Bevor man also den 'gleitend'-Typ in den 'ulong'-Typ umwandelt kann entsprechend der 'gleitend'-Typ sicher auf 'double' erweitert werden:
float fl = 3.14159f; double dbl = fl;
Danach wird mittels der Strukturumwandlung double in ulong umgewandelt.
2.4 String-Hashing und Einsatz eines Hash (Raute) als Schlüssel
In den obigen Beispielen wurden Schlüssel durch einen Datentyp dargestellt — Strings. Doch kann es allerdings auch andere Situationen geben, beispielsweise, dass die ersten drei Stellen einer Telefonnummer einen Telefonanbieter bezeichnen. In diesem Fall stellen genau diese drei Stellen einen Schlüssel dar. Auf der anderen Seite kann jeder String als eine eindeutige Ziffer dargestellt werden, dessen jede Stelle eine Sequenzzahl eines Buchstabens im Alphabet bedeutet. Also können wir den String in eine eindeutige Ziffer umwandeln und diese Ziffer als einen ganzzahligen Schlüssel zu seinem mit ihm zusammenhängenden Wert verwenden.
Diese Methode ist gar nicht schlecht, aber noch nicht ausreichend Mehrzweck-dienlich. Wenn wir einen String als Schlüssel verwenden, der Hunderte an Symbolen enthält, wird diese Ziffer unglaublich lang, und damit wird es unmöglich, sie in einem einfachen Wert jeden Typs zu erfassen. Dieses Problem lässt sich mit Hash-Funktionen lösen. Eine Hash-Funktion ist ein bestimmter Algorithmus, der jeden Datentyp akzeptiert (z.B. einen String) und eine eindeutige Ziffer liefert, die diesen String charakterisiert.
Und selbst wenn ein Symbol der Eintrittsdaten verändert wird, wird diese Ziffer absolut anders sein. Die von dieser Funktion gelieferten Zahlen haben einen festen Bereich. So akzeptiert z.B. die Adler32() Hash-Funktion Parameter in Form eines beliebigen Strings und liefert eine Ziffer im Bereich von 0 - 2 hoch 32. Diese Funktion ist reichlich simpel, doch bestens für unsere Aufgaben geeignet.
Hier kommt ihr Quellcode in MQL5:
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
Sehen wir uns mal an, welche Ziffern sie, je nach einem übertragenen String liefert.
Dazu schreiben wir ein einfaches Script, das diese Funktion aufruft und unterschiedliche Strings liefert:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
Die Script-Ausgabe ergab folgendes:
16.02.2015 13:29:12.576TestListe (USDCHF,H1)MetaTrader - 352191466
16.02.2015 13:29:12.576TestListe (USDCHF,H1)Frieden - 91685343
16.02.2015 13:29:12.576TestListe (USDCHF,H1)Hallo Welt! - 487130206
16.02.2015 13:29:12.576TestListe (USDCHF,H1)Hallo Welt - 413860925
Wir sehen also: jeder String hat eine entsprechende, eindeutige Ziffer. Bitte beachten Sie "Hallo Welt" und "Hallo Welt" - beide sind fast identisch. Der einzige Unterschied ist das Ausrufezeichen am Ende des ersten Strings.
Doch die von Adler32() erhaltenen Ziffern waren bei beiden absolut gleich.
Wir wissen jetzt also, wie man den String-Typ in einen unsignierten uint-Wert umwandeln kann und wir können seinen ganzzahligen Hash, anstatt den Schlüssel vom Typ string speichern. Wenn zwei Strings einen Hash haben, dann bedeutet das höchstwahrscheinlich, dass es sich um den gleichen String handelt. Also: ein Schlüssel zu einem Wert ist kein String, sondern ein ganzzahliger Hash, der auf Grundlage dieses Strings generiert wurde.
2.5 Einen Index durch einen Schlüssel ermitteln. Listen-Array
Wir wissen jetzt, wie die Umwandlung jedes Basistyps von MQL5 in einen unsignierten ulong Typ geht. Und genau dieser Typ wird ein tatsächlicher Schlüssel sein, dem unser Wert entsprechen wird. Doch es reicht noch nicht aus, nur einen eindeutigen Schlüssel des 'ulong'-Typs zu haben. Klar: wenn wir einen eindeutigen Schlüssel jedes Objekts kennen, könnten wir eine primitive Speichermethode auf Basis des Switch-Case Operators oder eines Arrays beliebiger Länge entwickeln.
Solche Methoden sind im Abschnitt 2.2 des vorigen Kapitels beschrieben worden. Doch leider sind sie weder flexibel noch effizient genug. Bei Switch-Case ist es beispielsweise nicht möglich, alle Varianten dieses Operators zu beschreiben.
Und da es viele Tausend Objekte gibt, müssen wir den Switch-Operator beschreiben, der zum Zeitpunkt seiner Erstellung aus ebenso vielen tausend Schlüsseln besteht - und das geht einfach nicht. Die zweite Methode wäre, ein Array zu verwenden, wo der Schlüssel eines Elements zugleich auch sein Index wäre. Damit könnte man das Array größenmäßig dynamisch anpassen und die notwendigen Elemente hinzufügen. Dadurch könnten wir, via seines Index, der der Schlüssel des Elements ist, konstant auf das Array verweisen.
Machen wir kurz einen Entwurf dieser Lösung:
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
Doch im wirklichen Leben stellt dieser Code eher Probleme dar, anstatt sie zu lösen. Nehmen wir an, dass eine Hash-Funktion auch einen großen Hash ausgibt. Da im gegebenen Beispiel der Array-Index = seinem Hash ist, müssen wir die Größe des Arrays anpassen und es wird einfach riesig. Und das heißt noch lange nicht, dass wir gewonnen haben. Möchten Sie wirklich einen String in einem Behälter speichern, dessen Größe leicht einige GB haben kann?
Das zweite Problem ist, dass im Falle von Kollisionen der vorherige Wert durch einen neuen ersetzt wird. Denn es ist absolut nicht unwahrscheinlich, dass die Adler32() Funktion für zwei unterschiedliche Strings einen Hash-Schlüssel liefert. Wollen Sie wirklich einen Teil Ihrer Daten verlieren, nur weil Sie schnell, mit Hilfe eines Schlüssels, auf sie verweisen wollen? Die Antwort liegt ja wohl auf der Hand — nein, wollen Sie nicht!. Und um genau solche Situationen zu vermeiden, müssen wir den Speicherungs-Algorithmus verändern und einen, speziell für diesen Zweck geeigneten, Hybridbehälter auf Grundlage eines Listen-Arrays entwickeln.
Ein Listen-Array vereint die besten Merkmale von Arrays und Listen. Diese beiden Klassen sind in der Standard Library dargestellt. Ich erinnere hier nochmals daran, dass man mit Arrays sehr rasch auf ihre undefinierten Elemente verwiesen kann, doch die Größenanpassung der Arrays an sich extrem lange dauert. Listen hingegen erlauben das Hinzufügen und Entfernen neuer Elemente im Handumdrehen, doch der Zugriff auf jedes Element einer Liste nimmt wiederum viel Zeit in Anspruch.
Ein Listen-Array kann folgendermaßen dargestellt werden:

Abb. 5 Schema eines Listen-Arrays
Aus diesem Schema eines Listen-Arrays wird ersichtlich, dass ein Listen-Array ein Array ist, dessen jedes Element die Form einer Liste besitzt. Und welche Vorteile haben wir davon?. Zu allererst können wir sehr rasch auf jede Liste via ihres Index verweisen. Und, wenn wir jedes Datenelement in einer Liste speichern, können wir sofort Elemente in die Liste hinzufügen oder aus ihr entfernen, ohne dabei die Größe des Array anrühren zu müssen. Der Array-Index kann dabei leer oder = NULL sein. Das heißt: Elemente, die diesem Index entsprechen, sind noch nicht hinzugefügt worden.
Die Kombination von Array und Liste bietet noch eine weitere ungewöhnliche Möglichkeit: wir können dort zwei oder mehr Elemente mit Hilfe eines Index speichern. Um die Notwendigkeit hierfür zu verstehen, nehmen wir einfach mal an, dass wir 10 Zahlen in einem Array mit 3 Elementen speichern müssen - also mehr Zahlen als Elemente in diesem Array. Diese Problem lösen wir, indem wir Listen in einem Array speichern. Angenommen, wir brauchen eine der drei Listen, die an einen der drei Array-Indices angehängt ist, um die eine oder andere Ziffer zu speichern.
Um den Listenindex festzustellen, müssen wir den Rest durch Dividieren unserer Ziffer durch die Menge der Element im Array ermitteln:
Array-Index = Anzahl der Elemente (%) im Array;
Beispiel: der Listenindex für Ziffer 2 ist folgender: 2%3 = 2. D.h.: Index 2 wird in der Liste nach Index gespeichert. Ziffer 3 wird nach Index 3%3 = 0 gespeichert und Ziffer 7 nach Index 7%3 = 1. Nachdem wir den Listenindex festgelegt haben, müssen wir nur noch diese Ziffer am Ende der Liste hinzufügen.
Ähnliches muss getan werden, will man die Ziffer wieder aus der Liste extrahieren. Angenommen, wir wollen die Ziffer 7 aus dem Behälter extrahieren. Dazu müssen wir zunächst feststellen, in welchem Behälter sie sich überhaupt befindet: 7%3=1. Nachdem wir festgelegt haben, dass Ziffer 7 in der Liste per Index 1 zu finden ist, müssen wir die gesamte Liste sortieren und diesen Wert liefern, sollte eines der Elemente = 7 sein.
Wenn wir mehrere Element mit Hilfe eines Index speichern können, müssen wir eben keine Riesen-Arrays zu Speicherung kleiner Datenmengen mehr anlegen. Angenommen, wir müssen die Ziffer 232.547.879 in einem Array speichern, das aus 0-10 stellen besteht und 3 Element besitzt. Diese Ziffer hat ihren Listenindex = (232.547.879 % 3 = 2).
Wenn wir Ziffern durch Hash ersetzen, müssen wir einen Index jedes Elements finden können, das im Lexikon untergebracht werden muss. Denn Hash ist ja eine Ziffer. Darüber hinaus muss Hash, infolge der Möglichkeit, mehrere Elemente in einer Liste speichern zu können, nicht notwendigerweise eindeutig sein. Elemente mit demselben Hash befinden sich in einer Liste. Wenn wir ein Element mittels seines Schlüssels extrahieren müssen, vergleichen wir diese Elemente und extrahieren dasjenige, das dem Schlüssel entspricht.
Dies geht, da ja zwei Elemente mit demselben Hash zwei eindeutige Schlüssel haben. Die Eindeutigkeit von Schlüsseln kann durch die Funktion kontrolliert werden, die ein Element in das Lexikon hinzufügt. Denn diese Funktion fügt schlichtweg kein neues Element hinzu, wenn sein entsprechender Schlüssel sich bereits im Lexikon befindet. Das ist quasi wie eine Kontrolle der Korrespondenz mit einer Person nur via einer Telefonnummer.
2.6 Größe des Arrays anpassen, Listenlänge minimieren
Je kleiner das Listen-Array ist und je mehr Elemente wir hinzufügen, umso längere Listenketten erzeugt der Algorithmus. Wie bereits im 1. Kapitel angesprochen, ist der Zugriff auf diese Kette ein sehr ineffiziente Angelegenheit. Je kürzer unsere Liste ist, umso eher sieht unser Behälter wie ein Array aus, das Zugriff auf jedes Element mittels eines Index ermöglicht. Also müssen wir uns auf kurze Listen und lange Arrays konzentrieren. Das perfekte Array für zehn Elemente ist daher ein Array, das aus zehn Listen besteht, von denen jede einzelne nur ein Element enthält.
Die schlimmste Variante wäre ein Array mit zehn Elementen Länge, das nur aus einer Liste besteht. Da ja alle Elemente während der Arbeit des Programms unserem Behälter dynamisch hinzugefügt werden, können wir nicht vorhersagen, wie viele Elemente hinzugefügt werden. Und daher müssen wir über eine dynamische Größenanpassung des Arrays nachdenken. Darüber hinaus sollte die Anzahl der Ketten in Listen in Richtung ein Element gehen. Es liegt auf der Hand, dass zu diesem Zweck die Arraygröße gleich der Gesamtzahl der Elemente gehalten werden sollte. Also: ständiges Hinzufügen von Elementen verlangt ein ständige Größenanpassung des Arrays.
Die Situation wird zudem noch durch die Tatsache verkompliziert, dass neben der Größenanpassung des Arrays, wird dies auch bei allen Listen tun müssen, da der Listenindex zu dem das Element gehören könnte, nach der Arrayanpassung verändert werden könnte. Wenn das Array z.B. drei Elemente aufweist, wird Nummer 5 im zweiten Index gespeichert (5%3 = 2). Sind sechs Elemente vorhanden, wird Nummer 5 im fünften Index gespeichert (5%6 = 5). Sie sehen - die Größenanpassung des Lexikons ist eine langsame Sache und sollte daher so selten wie möglich ausgeführt werden. Andererseits: wenn wir sie überhaupt nicht durchführen, werden die Ketten mit jedem neuen Element immer länger und der Zugriff auf jedes Element wird immer ineffizienter.
Wir erzeugen also einen Algorithmus, der einen vernünftigen Kompromiss zwischen der Menge der Array-Größenanpassungen und der durchschnittlichen Länge der Kette umsetzt. Dieser Algorithmus beruht auf der Tatsache, dass jede nächste Größenanpassung die aktuelle Größe des Arrays ums Doppelte erhöht. Hatte also das Lexikon anfänglich zwei Elemente, wächst seine Größe infolge der ersten Größenanpassung um 4 (2^2), bei der zweiten um 8 (2^3) und bei der dritten um 16 (2^3). Nach sechzehn Größenanpassungen braucht man Platz für 65.536 Ketten (2^16). Jede Größenanpassung wird durchgeführt, wenn die Menge der hinzugefügten Elemente mit der immer wiederkehrenden Potenz (hoch 2) zusammenfällt. Daher übersteigt der erforderliche Hauptspeicherplatz den zur Speicherung aller Elemente erforderlichen Speicherplatz nicht um mehr als das Doppelte. Auf der anderen Seite hilft uns das logarithmische Gesetz dabei, häufige Größenanpassungen des Arrays zu vermeiden.
Ganz ähnlich verhält es sich beim Entfernen von Elementen aus der Liste: hier können wir die Größe des Arrays reduzieren und sparen dadurch ebenfalls zugewiesenen Hauptspeicherplatz.
KAPITEL 3 Praktische Entwicklung eines assoziativen Arrays
3.1 Die CDictionary Template-Klasse, die AddObject und die DeleteObjectByKey Methoden und der KeyValuePair Behälter
Unser assoziatives Array muss viele Zwecke erfüllen können und uns die Arbeit mit allen Arten von Schlüsseln erlauben. Gleichzeitig verwenden wir Objekte auf Basis des Standard CObject als Werte. Da wir in Klassen ja jede Basisvariable finden können, ist unser Lexikon eine One-Stop Lösung. Natürlich könnten wir unterschiedliche Klassen an Lexika erzeugen und für jeden Basistyp einen extra Klassentyp verwenden.
Wir könnten beispielsweise die folgenden Klassen erzeugen:
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...
Doch MQL5 hat zu viele Basistypen. Des weiteren müssten wir jeden Codefehler mehrmals bereinigen, da ja alle Typen einen Kerncode besitzen. Um diese Duplizierung zu vermeiden, arbeiten wir mit Templates. Wir haben eine Klasse, die aber mehrere Datentypen simultan verarbeiten kann. Aus diesem Grund sind die Hauptmethoden der Klassen ein Template.
Beginnen wir als zuerst unsere erste Template-Methode zu erzeugen — Add(). Diese Methode fügt unserem Lexikon ein Element mit einem beliebigen Schlüssel hinzu. Die Lexikonklasse soll CDictionary heißen. Neben mit dem Element enthält das Lexikon ein Array mit Zeigern auf die CList Listen. Und in diesen Ketten speichern wir Elemente:
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
Die AddObject() Methode funktioniert so: Sie prüft zunächst, ob das Lexikon ein Element mit einem Schlüssel enthält, das hinzugefügt werden muss. Die ContainsKey() Methode übernimmt diese Prüfung. Wenn das Lexikon diesen Schlüssel bereits hat, wird kein neues Element hinzugefügt, da dies zu Unsicherheiten führt, da ja zwei Element nun einem Schlüssel entsprechen könnten.
Dann informiert sich die Methode über die Größe des Arrays, wo die CList Ketten gespeichert sind. Ist die Arraygröße gleich der Anzahl der Elemente, muss sie neu angepasst werden. Diese Aufgabe wird an die Resize() Methode delegiert.
Die nächsten Schritte sind einfach. Wenn, gemäß des bestimmten Index, die CList Kette noch nicht besteht, dann muss sie erzeugt werden Der Index dazu wird zuvor mittels der ContainsKey() Methode bestimmt. Sie speichert den bestimmten Index in der m_index Variable. Danach fügt die Methode am Ende der Liste ein neues Element hinzu. Doch zuvor wird dieses Element in einen speziellen Behälter gepackt — KeyValuePair. Er beruht auf Standard-CObject und erweitert den zweiteren durch zusätzliche Zeiger und Daten. Auf die Anordnung der Behälterklasse kommen wir gleich zu sprechen. Der Behälter speichert, zusammen mit den zusätzlichen Zeigern, auch einen Originalschlüssel des Objekts und seinen Hash.
Die AddObject() Methode ist ein Template-Methode:
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
Dieser Eintrag bedeutet, dass der Typ der Schlüsselbegründung ersatzweise ist und sein tatsächlicher Typ erst zum Zeitpunkt der Erstellung bestimmt wird.
So kann z.B. die AddObject() Methode in seinem Code folgendermaßen aktiviert werden:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
Jede dieser Aktivierungen wird wegen der Templates problemlos funktionieren.
Es gibt auch dieDeleteObjectByKey() Methode, die genau das Gegenteil der AddObject() Methode macht. Diese Methode löscht ein Objekt nach seinem Schlüssel aus dem Lexikon.
So kann man z.B. ein Objekt mit dem Schlüssel "Auto" löschen, falls es dies gibt:
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
Der Code ähnelt stark dem Code der AddObject() Methode, daher zeigen wir ihn hier nicht.
Die AddObject() und DeleteObjectByKey() Methoden arbeiten nicht direkt mit Objekten. Stattdessen packen sie auf Basis der Standard CObject-Klasse jedes Objekt in den KeyValuePair Behälter. Dieser Behälter besitzt zusätzliche Zeiger, mit denen man Elemente miteinander in Beziehung setzen kann und zudem einen Originalschlüssel und einen für das Objekt bestimmten Hash. Der Behälter testet auch den übertragenen Schlüssel auf Gleichheit, damit solche Kollisionen vermieden werden können. Darauf kommen wir im nächsten Abschnitt zu sprechen, in dem es um die ContainsKey() Methode geht.
Jetzt stellen wir erst einmal den Inhalt dieser Klasse dar:
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2 Laufzeit-Typ Identifikation auf Basis des Typennamens, Hash-Sampling
Wenn wir also wissen, wie man undefinierte Methoden in unsere Typen aufnimmt, müssen wir ihren Hash bestimmen. Für alle ganzzahligen Typen ist ein Hash gleich des Werts des Typs, der auf den ulong-Typ erweitert wurde.
Zur Berechnung des Hash für die double und gleitend-Typen, müssen wir Abdruck via Strukturen verwenden, so wie im abschnitt "Umwandlung von Basistypen in einen eindeutigen Schlüssel" beschrieben. Für Strings sollte eine Hash-Funktion verwendet werden. Egal, jeder Datentyp benötigt seine eigene Methode zum Hash-Sampling. Daher müssen wir nur den übertragenen Typ bestimmen und, abhängig von diesem Typ, eine Methode des Hash-Sampling aktivieren. Und dazu brauchen wir eine spezielle Direktive, nämlich Typenname.
Eine Methode zur Bestimmung des Hash auf Basis des Schlüssel, heißt GetHashByKey().
Sie umfasst:
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
Ihre Logik ist simpel. Unter Verwendung der Direktive 'Typenname' erhält die Methode den Stringnamen des übertragenen Typs. Wird der String als ein Schlüssel übertragen, liefert 'Typenname' den Wert des "Strings", im Falle eines 'int'-Werts liefert sie "int". Und das passiert für jeden anderen Typ ganz genauso. Daher müssen wir nur noch den gelieferten Wert mit den erforderlichen String-Konstanten vergleichen und den entsprechenden Handler aktivieren, sollte dieser Wert mit einer der Konstanten zusammenfallen.
Ist der Schlüssel vom Typ String, wird sein Hash von der Adler32() Funktion berechnet. Wird der Schlüssel durch echte Typen dargestellt, werden sie infolge der Strukturumwandlung in den Hash konvertiert. Alle anderen Typen wandeln sich explizit in den ulong-Typ um, der dann zum Hash wird.
3.3 Die ContainsKey() Methode. Reaktion auf Hash-Kollision
Das Hauptproblem jeder Hashing-Funktion besteht in den Kollisionen — Situationen, in denen unterschiedliche Schlüssel den gleichen Hash ergeben. Wenn sich in solchen Fällen Hash gleichen, kommt es zu Zweideutigkeiten (zwei Objekte sind in Bezug auf die Lexikon-Logik eben ähnlich). Und um dies zu vermeiden, müssen wir die tatsächlichen und benötigten Schlüsseltypen prüfen und einen positiven Wert liefern, sollten sich tatsächliche Schlüssel in der Tat gleichen. Und so funktioniert die ContainsKey() Methode. Wenn ein Objekt mit dem benötigten Schlüsseltyp tatsächlich besteht, liefert sie 'true'; ansonsten 'false'
Diese Methode ist vielleicht die nützlichste und bequemste Methode im gesamten Lexikon. Denn mit ihrer Hilfe erfährt man, ob ein Objekt mit einem bestimmten Schlüssel wirklich existiert:
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
So prüft der o.g. Code z.B. das Vorhandensein des Objekts des Typs CCar und fügt CCar hinzu, sollte so ein Objekt nicht existieren. Mit dieser Methode kann man auch die Eindeutigkeit eines Schlüssels jedes neuen Objekts prüfen, das hinzugefügt wird.
Gibt es den Objekt-Schlüssel bereits, fügt die AddObject() Methode dieses neue Objekt einfach nicht dem Lexikon hinzu.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
Das ist so eine universelle Methode, dass sie sowohl von Benutzern als auch anderen Klassen-Methoden sehr oft verwendet wird.
Ihr Inhalt:
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
Zuerst findet die Methode mit Hilfe von GetHashByKey() einen Hash. Anschließend holt sie sich, auf Basis des Hash, einen Index der CList-Kette, in der ein Objekt mit dem gegebenen Hash eventuell vorhanden sein könnte. Gibt es so eine Kette nicht, gibt es auch das Objekt mit so einem Schlüssel nicht. In diesem Fall beendet die Methode ihre Arbeit vorzeitig und liefert 'false' (ein Objekt mit so einem Schlüssel gibt es nicht) Wenn die Kette besteht, wird mit ihrer Aufzählung begonnen.
Jedes Element dieser Kette wird vom Objekt des Typs KeyValuePair repräsentiert, dem dann angeboten wird, einen aktuell übertragenen Schlüssel mit einem durch ein Element gespeicherten Schlüssel zu vergleichen. Sind die Schlüssel die gleichen, liefert die Methode 'true' (ein Objekt mit so einem Schlüssel gibt es). Der Code, der die Schlüssel auf ihre Gleichheit prüft, ist in der Auflistung der KeyValuePair Klasse angegeben.
3.4 Dynamische Speicherzuweisung und Freigabe
Die Resize() Methode ist für die dynamische Zuweisung und Freigabe von Speicher in unserem assoziativen Array verantwortlich. Diese Methode wird jedes Mal aktiviert,wenn die Anzahl der Elemente = der m_array Größe ist. Sie wird auch aktiviert, wenn Elemente aus der Liste gelöscht werden. Diese Methode hebt die Speicher-Indices für alle Elemente auf, daher arbeitet sie extrem langsam.
Um eine häufige Aktivierung der Resize() Methode zu vermeiden, wird das Volumen des zugewiesenen Speicher jedes Mal ums Doppelte, verglichen mit seinem vorigen Volumen, erhöht. Anders gesagt: Wenn unser Lexikon 65.536 Elemente speichern soll, wird die Resize() Methode 16 Mal aktiviert (2^16). Nach 20 derartigen Aktivierungen könnten unser Lexikon mehr als 1 Million Elemente enthalten (1.048.576). Für dieses exponentielle Wachstum der erforderlichen Elemente ist die FindNextLevel() Methode verantwortlich.
Und hier kommt der Quellcode für die Resize() Methode:
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
Sie funktioniert sowohl auf höhere als auch auf niedrigere Seite. Sind also weniger Elemente vorhanden sind, als das aktuelle Array aufnehmen kann, wird ein Code zur Element-Reduktion aktiviert. Und umgekehrt: sollte das aktuelle Array nicht ausreichen, wird seine Größe für mehr Elemente angepasst. Dieser Code braucht eine ganze Menge an Rechnerressourcen.
Das ganze Array muss nämlich größenmäßig angepasst werden, doch all seine Elemente sollten zuvor in eine zwischenzeitliche Kopie des Arrays verschoben werden. Danach muss man neue Indices für alle Elemente festlegen und nur dann kann man später nämlich diese Elemente auch an ihren neuen Positionen wieder finden.
3.5 Feinarbeiten: Objekte suchen und ein bequemer Indexer
Unsere CDictionary Klasse besitzt nun also bereits die Hauptmethoden, die für eine Arbeit mit ihr vonnöten sind. Wir können die ContainsKey() Methode verwenden, wenn wir wissen müssen, ob ein Objekte mit einem bestimmten Schlüssel auch besteht. Wir können mit Hilfe der AddObject() Methode ein Objekt dem Lexikon hinzufügen. Wir können auch ein Objekt aus dem Lexikon löschen, und zwar mit Hilfe der DeleteObjectByKey() Methode.
Jetzt müssen wir nur noch eine bequeme Aufzählung alle Objekte im Behälter anlegen. Wie wir bereits wissen, sind dort alle Elemente in eiern bestimmten Ordnung, gemäß ihrer Schlüssel abgelegt. Doch es wäre wundervoll, wenn man sie alle in der gleichen Reihenfolge aufzählen könnten, in der sich dem assoziativen Array hinzugefügt wurden. Und zu diesem Zweck besitzt der KeyValuePair-Behälter zwei zusätzliche Zeiger auf die zuvor und als nächstes hinzugefügten Elemente des Typs KeyValuePair. Dank dieser Zeiger können wir eine sequentielle Aufzählung durchführen.
Wenn wir beispielsweise unserem assoziativen Array neue Elemente folgendermaßen hinzugefügt haben:
CNumber --> CShip --> CWeather --> CHuman --> CExpert --> CCar
wird die Aufzählung dieser Elemente ebenfalls, mit Hilfe der Verweise auf KeyValuePair, sequentiell, also in einer Reihenfolge, ablaufen. Dies zeigt Abb. 6:

Abb. 6 Schema der sequentiellen Array-Aufzählung
Zur Ausführung einer derartigen Aufzählung werden fünf Methoden verwendet.
Hier kommen ihre Inhalte und eine Kurzbeschreibung:
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
Aufgrund dieser einfachen Durchläufe können wir eine sequentielle Aufzählung hinzugefügter Elemente ausführen:
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
Diese Code gibt String-Werte von Objekten in der gleichen Reihenfolge aus, in der sie dem Lexikon hinzugefügt wurden:
24.02.2015 14:08:29.537TestLex (USDCHF,H1)6: CCar
24.02.2015 14:08:29.537TestLex (USDCHF,H1)5: CExpert
24.02.2015 14:08:29.537TestLex (USDCHF,H1)4: CHuman
24.02.2015 14:08:29.537TestLex (USDCHF,H1)3: CWeather
24.02.2015 14:08:29.537TestLex (USDCHF,H1)2: CShip
24.02.2015 14:08:29.537TestLex (USDCHF,H1)1: CNumber
Zur Ausgabe all dieser Elemente rückwärts, muss man zwei Strings des Codes der OnStart() Funktion ändern:
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
Und entsprechend werden dann die Ausgabewerte von hinten nach vorne angezeigt:
24.02.2015 14:11:01.021TestLex (USDCHF,H1)6: CNumber
24.02.2015 14:11:01.021TestLex (USDCHF,H1)5: CShip
24.02.2015 14:11:01.021TestLex (USDCHF,H1)4: CWeather
24.02.2015 14:11:01.021TestLex (USDCHF,H1)3: CHuman
24.02.2015 14:11:01.021TestLex (USDCHF,H1)2: CExpert
24.02.2015 14:11:01.021TestLex (USDCHF,H1)1: CCar
KAPITEL 4 Leistungstest und Bewertung
4.1 Tests schreiben und Leistung bewerten
Die Bewertung der Leistung ist ein ganz wichtiger Bestandteil beim Design einer Klasse, v.a. wenn es um eine Klasse für die Datenspeicherung geht. Denn schließlich profitieren alle möglichen Programme von dieser Klasse. Die Algorithmen dieser Programme sind für die Geschwindigkeit äußerst wichtig und erfordern eine hohe Leistung. Deshalb ist es ja so wichtig, genau zu wissen, wie man die Leistung bewertet und exakt nach Schwachpunkten bei diesen Algorithmen Ausschau zu halten.
Zunächst einmal schreiben wir einen einfachen Test mit dem Geschwindigkeit gemessen wird, mit der Elemente dem Lexikon hinzugefügt und aus ihm extrahiert werden. Dieser Test sieht wie ein Script aus.
Sein Quellcode ist unten angehängt:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
Dieser Code fügt dem Lexikon Elemente in einer Reihenfolge hinzu und verweist dann auf sie, um so ihre Geschwindigkeit zu messen. Anschließend wird jedes Element mit Hilfe der DeleteObjectByKey() Methode gelöscht. Die Geschwindigkeit hierbei wird mittels der GetTickCount() Systemfunktion gemessen
Unter Verwendung dieses Scripts haben wir ein Diagramm angelegt, dass die zeitlichen Abhängigkeiten dieser drei Hauptmethoden veranschaulicht:
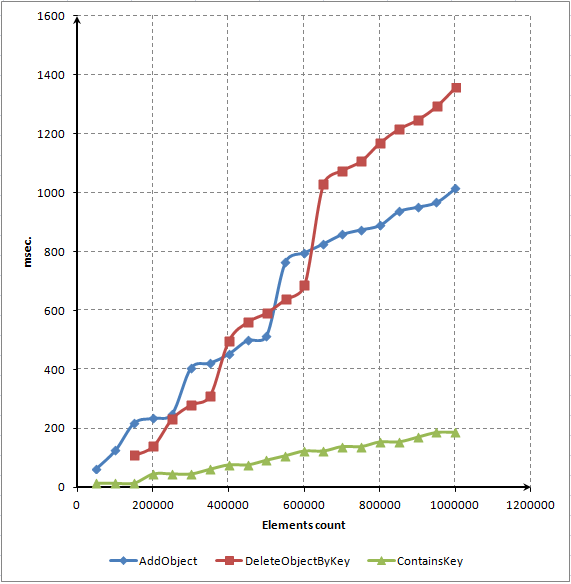
Abb. 7 Punktdiagramm der Abhängigkeit zwischen der Anzahl der Elemente und der Ablaufgeschwindigkeit der Methoden in Millisekunden
Wie man gut erkennen kann, dauert das Finden und Löschen von Elementen aus dem Lexikon am längsten. Wir haben aber doch erwartet, dass Elemente weitaus schneller gelöscht werden würden. Wir versuchen, die Leistung dieser Methode mittels eines Code-Profilers zu steigern. Wie das geht, wird im nächsten Abschnitt beschrieben.
Beachten Sie genau das Diagramm der ContainsKey() Methode - es ist ein lineares Diagramm. Das bedeutet, dass Zugriff auf ein zufälliges Element ungefähr eine gewisse Zeit erfordert, ungeachtet der Anzahl dieser Elemente im Array. Und für jedes echte assoziative Array ist dieses Merkmal ein absolutes MUSS.
Zur Veranschaulichung dieses Merkmals, zeigen wir ein Diagramm der Abhängigkeit zwischen der durchschnittlichen Zugriffszeit auf ein Element und einer Anzahl Elemente im Array
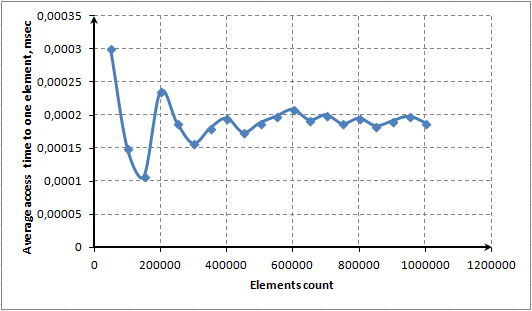
Abb. 8 Durchschnittliche Zugriffszeit auf ein Element mit Hilfe der ContainsKey() Methode
4.2 Code-Profilerstellung. Geschwindigkeit hinsichtlich automatischer Speicherverwaltung
Die Code-Profilerstellung ist eine spezielle Technik, die den Zeitaufwand bei allen Funktionen misst. Dazu startet man einfach irgendein MQL5 Programm, indem man im MetaEditor ![]() anklickt.
anklickt.
Das machen wir auch und schicken unser Script zur Profilerstellung ab. Es wird dann nach einer Weile ausgeführt und wir erhalten ein Zeitprofil aller Methoden, die während des Scriptablaufs ausgeführt wurden. Der Screenshot unten zeigt, dass die Ausführung dreier Methoden die meiste Zeit gekostet hat: AddObject() (40% der Zeit), GetObjectByKey() (7% der Zeit) und DeleteObjectByKey() (53% der Zeit):
 Funktion")
Abb. 9 Code-Profilerstellung in der OnStart() Funktion
Und mehr als 60% der Zeit des DeleteObjectByKey() Aufrufs ging für den Aufruf der Compress() Methode drauf.
Doch diese Methode ist fast leer, daher wurde hauptsächlich Zeit für den Aufruf der Resize() Methode gebraucht.
Sie umfasst:
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
Das Problem ist also klar. Wenn wir alle Elemente löschen, wird die Resize() Methode ab und zu gestartet. Sie verringert die Arraygröße dynamisch und gibt Speicherplatz frei.
Wenn man Elemente rascher löschen möchte, sollte man diese Methode deaktivieren. So kann man z.B. die spezielle AutoFreeMemory() Methode in dr Klasse einführen, die einen Komprimierungsmarker setzt. Sie ist standardmäßig bereits eingestellt; in diesem Fall wird die Komprimierung automatisch durchgeführt. Doch wenn man mehr Geschwindigkeit möchte, führt man eine Komprimierung in einem guten Moment am besten manuell aus. Deshalb machen wir die Compress() Methode public.
Ist Komprimierung deaktiviert, werden Elemente dreimal schneller gelöscht:
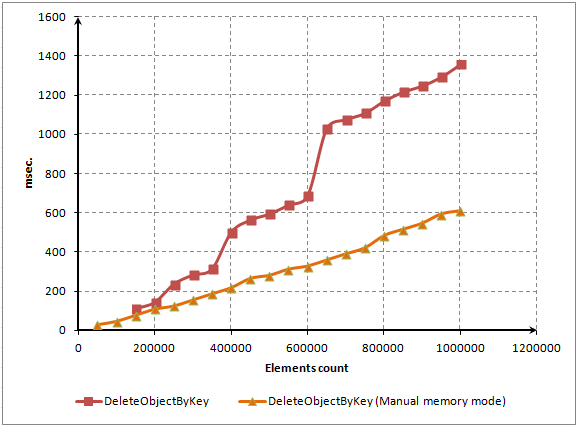
Abb. 10 Löschen von Elementen bei menschlicher Kontrolle des belegten Speicherplatzes (Vergleich)
Die Resize() Methode wird nicht nur zur Datenkomprimierung aufgerufen, sondern auch bei zu vielen Elementen und man ein größeres Array benötigt. In unserem Fall kommen wir um einen Aufruf der Resize() Methode nicht herum. Sie muss aufgerufen werden, damit in Zukunft keine langen und langsamen CList Ketten erzeugt werden. Doch wir können das notwendige Volumen unserer Lexikons auf im voraus festlegen.
So kennt man z.B. oft die Anzahl der hinzugefügten Elemente bereits im Vorfeld. Und wenn das Lexikon die Anzahl der Elemente kennt, erzeugt es bereits im voraus ein Array mit der notwendigen Größe, sodass extra Größenanpassungen während seines Füllens entfallen.
Aus diesem Grund müssen wir noch einen Konstruktor mehr hinzufügen, der die benötigten Elemente akzeptiert:
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
Dies wird hauptsächlich von der Init() Methode ausgeführt:
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
Unsere Verbesserungen sind hiermit abgeschlossen. Jetzt können wir also die Leistung der AddObject() Methode mit der anfangs festgelegten Arraygröße testen. Dazu ändern wir zwei erste Strings der OnStart() Funktion unseres Scripts:
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
END wird hier durch eine große Ziffer dargestellt, die 1.000.000 Elemente entspricht.
Diese Neuerungen wirken sich erheblich auf die Leistungsgeschwindigkeit der AddObject() Methode aus:

Abb. 11 Benötigte Zeit für das Hinzufügen von Elementen bei vorab eingerichteter Arraygröße
Bei der Lösung von echten Programmierproblemen müssen wir uns stets zwischen Speicherbedarf und Leistungsgeschwindigkeit entscheiden. Speicher freizugeben dauert immer ganz schön lange, doch in unserem Fall werden wir mehr freien Speicher erhalten. Wenn wir alles so lassen, wie es ist, wird die CPU-Zeit nicht mit zusätzlichen komplizierten Rechneraufgaben vergeudet, doch wir haben zugleich auch weniger freien Speicher. Objekt-orientiertes Programmieren erlaubt, mit Hilfe von Behältern, eine Zuweisung von Ressourcen zwischen CPU-Speicher und der CPU-Zeit auf flexible Art und Weise, indem eine gewisse Ausführungsrichtlinie für jedes einzelne Problem gewählt wird.
Alles in allem ist die CPU-Leistung weit schlechter skaliert als die Speicherkapazität. Und darum ist uns wir in den meisten Fällen die Geschwindigkeit der Ausführung lieber als die Speicherkapazität. Übrigens ist die Kontrolle von Speicher durch Benutzer wesentlich effizienter als eine automatisierte Kontrolle, da wir ja nur selten den endgültigen Status der Aufgabe kennen.
Bei unserem Script wissen wir z.B: im voraus, dass am Ende dr Aufzählung die Gesamtzahl der Elemente null sein wird, da sie alle von der DeleteObjectByKey() Methode gelöscht werden, wenn die Aufgabe abgeschlossen ist. Deshalb müssen wir unser Array auch nicht automatisch komprimieren, es genügt es am Ende mittels Aufruf der Compress() Methode zu leeren.
Wenn wir also gute lineare Kennzahlen bzgl. Hinzufügen und Löschen von Elementen aus dem Array haben, können wir dann die Durchschnittszeit fürs Hinzufügen und Löschen eines Elements, je nach der Gesamtzahl der Elemente analysieren:
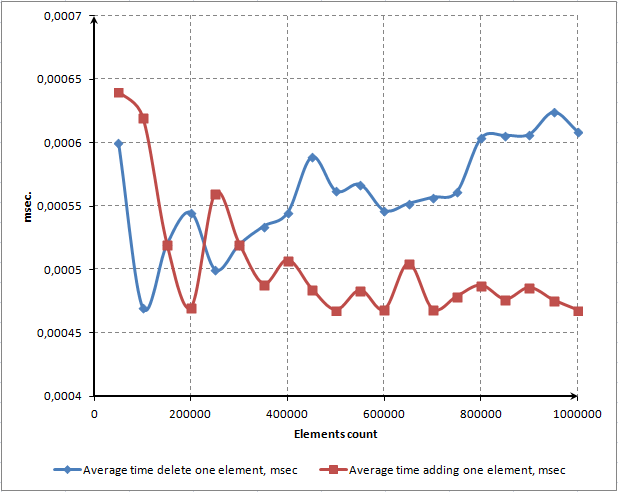
Abb. 12 Durchschnittszeit für das Hinzufügen und Löschen eines Elements
Wir sehen hier, dass die Durchschnittszeit für das Hinzufügen eines Elements ziemlich unverändert ist und nicht von der Gesamtzahl der Elemente im Array abhängt. Die Durchschnittszeit für das Löschen eines Elements steigt allerdings leicht nach oben, was nicht wünschenswert ist. Doch können wir nicht genau sagen, ob wir es hier mit Ergebnissen innerhalb der Fehlerrate zu tun haben oder ob es sich um eine regelmäßige Tendenz handelt.
4.3 Leistung von CDictionary, verglichen mit Standard-CArrayObj
Und jetzt ist es Zeit für den interessantesten Test - dem Vergleich unseres CDictionary mit der CArrayObj Standardklasse. CArrayObj besitzt keine Mechanismen zur manuellen Speicherplatzzuweisung wie die Angabe einer angenommenen Größe bereits in der Bauphase. Deshalb müssen wir die manuelle Speicherplatzkontrolle in CDictionary deaktivieren und stattdessen den AutoFreeMemory() Mechanismus aktivieren.
Die Stärken und Schwächen beider Klassen wurden im 1. Kapitel beschrieben. Mittels CDictionary kann man ein Element an einen nicht festgelegten Platz hinzufügen und es auch aus dem Lexikon extrahieren - und zwar ziemlich rasch. Doch CArrayObj erlaubt eine ebenfalls ziemlich schnelle Aufzählung aller Elemente. Die Aufzählung in CDictionary wird langsamer sein, da sie ja mit Hilfe der Zeigerbewegeung ausgeführt wird und dies weitaus langsamer als direkte Indizierung ist.
Los geht's. Zuerst erzeugen wir eine neue Version unseres Tests:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
Sie arbeitet mit den TEST_ARRAY Makros. Wird sie identifiziert, führt der Test Abläufe auf CArrayObj aus; ansonsten werden Abläufe auf CDictionary ausgeführt. Im ersten Test für das Hinzufügen neuer Elemente heißt der Sieger CDictionary.
Die Art und Weise wie diese Klasse Speicherplatz zuweist, hat sich in diesem speziellen Fall als überlegen erwiesen:
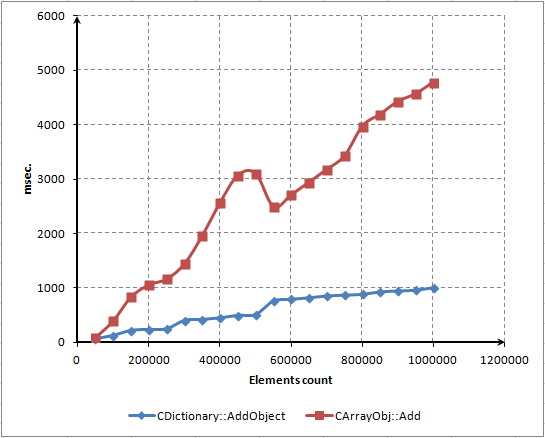
Abb. 13 Benötigte Zeit für das Hinzufügen neuer Elemente in CArrayObj und CDictionary (Vergleich)
Es ist wichtig hierbei zu unterstreichen, dass der Grund für den langsameren Ablauf in der besonderen Art der Speicherzuweisung in CArrayObj liegt.
Das wird durch nur einen String des Quellcodes beschrieben:
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize);
Dies ist ein linearer Algorithmus der Speicherzuweisung, der standardmäßig nach dem Füllen von jeweils 16 Elementen aufgerufen wird. CDictionary arbeitet mit einem exponentiellen Algorithmus: bei jeder nächsten Speicherzuweisung wird immer doppelt so viel Speicher zugewiesen, wie beim vorherigen Aufruf. Dieses Diagramm zeigt perfekt das Dilemma zwischen Leistung und belegtem Speicher. Die Reserve() Methode der CArrayObj Klasse ist wesentlich ökonomischer und belegt weniger Speicher - aber sie ist halt auch langsamer. Die Resize() Methode der CDictionary Klasse ist schneller, benötigt jedoch mehr Speicher, von dem durchaus die Hälfte gar nicht verwendet wird.
Führen wir den letzten Test durch: die Berechnung der Zeit für eine vollständige Aufzählung der CArrayObj und CDictionary Behälter. CArrayObj arbeitet hier mit direkter Indizierung, CDictionary mit Verweisen. CArrayObj erlaubt einen Verweis auf jedes Element per seinem Index, in CDictionary jedoch ist der Verweis auf ein Element per Index beeinträchtigt. Sequentielle Aufzählung mit direkter Indizierung ist zeitlich ziemlich interessant:
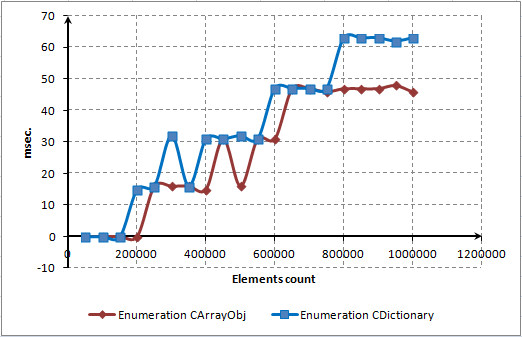
Abb. 14 die Zeit für eine vollständige Aufzählung von CArrayObj und CDictionary
Die Entwickler der MQL5-Sprache haben tolle Arbeit geleistet und Verweise optimiert: was Geschwindigkeit angeht, kommen sie der direkten Indizierung schon ziemlich nahe, wie man im Diagramm ablesen kann.
Hier ist es wichtig zu erkennen, dass die Aufzählung der Elemente in so kurzer Zeit vonstatten geht, dass sie schon fast die Auflösung der GetTickCount() Funktion bedeutet. Zur Messung von Zeitintervallen unter 15 Millisekunden kann diese Funktion nur schwer verwendet werden.
4.4 Allgemeine Empfehlungen bei der Arbeit mit CArrayObj, CList und CDictionary
Wir legen eine Tabelle an, in der wir die Hauptaufgaben, die beim Programmieren anstehen sowie die Merkmale der Behälter beschreiben, die man zur Lösung dieser Aufgaben kennen muss.
Die Merkmale mit einer guten Aufgabenleistung sind in Grün und die Merkmale, die einen effizienten Abschluss der Aufgaben nicht ermöglichen, in Rot gehalten.
| Zweck | CArrayObj | CList | CDictionary |
|---|---|---|---|
| Sequentielles Hinzufügen neuer Elemente am Ende des Behälters. | Der Behälter muss für jedes neue Element auch neuen Speicher zuweisen. Eine Übertragung bestehender Elemente in neue Indices ist nicht nötig. Dieser Vorgang wird von CArrayObj sehr rasch ausgeführt. | Der Behälter merkt sich das erste, das aktuelle und das letzte Element. Aufgrund dieser Tatsache wird ein neues Element sehr rasch ans Ende der Liste angehängt (das letzte, gemerkte Element). | Das Lexikon kennt derartige Konzept wie "Ende" oder "Anfang" nicht. Ein neues Element wird sehr rasch angehängt und dies ist nicht von der Anzahl der Elemente abhängig. |
| Zugriff auf ein beliebiges Element via seines Index. | Aufgrund der direkten Indizierung erfolgt ein Zugriff extrem rasch - nur O(1) an Zeit. | Der Zugriff auf jedes Element erfolgt via Aufzählung aller vorangehenden Elemente. Dies dauert O(n) an Zeit. | Der Zugriff auf jedes Element erfolgt via Aufzählung aller vorangehenden Elemente. Dies dauert O(n) an Zeit. |
| Zugriff auf ein beliebiges Element via seines Schlüssels. | Nicht möglich | Nicht möglich | Die Berechnung eines Hash und eines Index per Schlüssel ist ein schneller und effizienter Vorgang. Für String-Schlüssel ist die Wirksamkeit der Hashing-Funktion sehr wichtig. Dieser Vorgang dauert O(1) an Zeit. |
| Neue Elemente werden per nicht definiertem Index hinzugefügt/gelöscht. | CArrayObj muss nicht nur Speicherplatz für ein neues Element zuweisen, sondern auch alle Elemente entfernen, deren Indices höher sind als der Index eines eingefügten Elements. Aus diesem Grund ist CArrayObj sehr langsam. | Das Element wird CList sehr schnell hinzugefügt (oder daraus gelöscht), doch kann auf den notwendigen Index für O(n) zugegriffen werden. Dies dauert extrem lange. |
In CDictionary erfolgt der Zugriff auf das Element per seinem Index auf Basis der CList Liste und dauert sehr lange. Doch hinzufügen und Löschen geht ziemlich schnell. |
| Neue Elemente werden per nicht definiertem Schlüssel hinzugefügt/gelöscht. | Nicht möglich | Nicht möglich | Da ja jedes neue Element in CList eingefügt wird, werden neue Elemente sehr schnell hinzugefügt und gelöscht, da das Array nicht nach so einem hinzufügen/Löschen größenmäßig neu angepasst werden muss. |
| Speicherbelegung und Verwaltung. | Eine dynamische Anpassung der Arraygröße ist erforderlich. Dies ist ein Ressourcen-intensiver Vorgang - er verlangt entweder viel Zeit oder viel Speicher. | Speicherverwaltung wird nicht verwendet. Jedes Element belegt die richtige Speichermenge. | Eine dynamische Anpassung der Arraygröße ist erforderlich. Dies ist ein Ressourcen-intensiver Vorgang - er verlangt entweder viel Zeit oder viel Speicher. |
| Aufzählung von Elementen. Vorgänge, die für jedes Element des Vektors ausgeführt werden müssen. | Geht sehr schnell wegen direkter Element-Indizierung. In manchen Fällen jedoch muss eine Aufzählung in umgekehrter Richtung erfolgen (z.B. wenn am sequentiell das letzte Element löscht). | Da wir alle Elemente nur einmal aufzählen müssen, ist der direkte Verweis ein schneller Vorgang. | Da wir alle Elemente nur einmal aufzählen müssen, ist der direkte Verweis ein schneller Vorgang. |
KAPITEL 5 CDictionary-Klasse - Dokumentation
5.1 Wichtigste Methoden zum Hinzufügen, Löschen und Zugriff auf Elemente
5.1.1 Die AddObject() Methode
Fügt ein Element des Typs CObject mit T-Schlüssel ein. Dabei kann als Schlüssel jeder Basistyp verwendet werden.
template<typename T> bool AddObject(T key,CObject *value);
Parameter
- [in] Schlüssel – eindeutiger Schlüssel, von einem der Basistypen (String, ulong, char, enum etc.) repräsentiert.
- [in] Wert - Objekt mit CObject als Basistyp.
Gelieferter Wert
Liefert 'true' wenn das Objekt zum Behälter hinzugefügt wurde; ansonsten 'false'. Besteht der Schlüssel des hinzugefügten Objekts bereits im Behälter, liefert die Methode einen negativen Wert und das Objekt wird nicht hinzugefügt.
5.1.2 Die ContainsKey() Methode
Prüft, ob es ein Objekt mit einem Schlüssel gibt, der dem T-Schlüssel im Behälter entspricht. Dabei kann als Schlüssel jeder Basistyp verwendet werden.
template<typename T> bool ContainsKey(T key);
Parameter
- [in] Schlüssel – eindeutiger Schlüssel, von einem der Basistypen (String, ulong, char, enum etc.) repräsentiert.
Liefert 'true', wenn das Objekt mit dem überprüften Schlüssel bereits im Behälter besteht. Ansonsten 'false'.
5.1.3 Die DeleteObjectByKey() Methode
Löscht ein Objekt nach voreingestelltem T-Schlüssel. Dabei kann als Schlüssel jeder Basistyp verwendet werden.
template<typename T> bool DeleteObjectByKey(T key);
Parameter
- [in] Schlüssel – eindeutiger Schlüssel, von einem der Basistypen (String, ulong, char, enum etc.) repräsentiert.
Gelieferter Wert
Liefert 'true', wenn das Objekt mit dem voreingestellten Schlüssel gelöscht worden ist. Liefert 'false', wenn das Objekt mit dem voreingestellten Schlüssel nicht besteht oder sein Löschen fehlgeschlagen ist.
5.1.4 Die GetObjectByKey() Methode
Liefert ein Objekt nach voreingestelltem T-Schlüssel.. Dabei kann als Schlüssel jeder Basistyp verwendet werden.
template<typename T> CObject* GetObjectByKey(T key);
Parameter
- [in] Schlüssel – eindeutiger Schlüssel, von einem der Basistypen (String, ulong, char, enum etc.) repräsentiert.
Gelieferter Wert
Liefert ein Objekt, das zum voreingestellten Schlüssel passt. Liefert NULL, wenn das Objekt mit dem voreingestellten Schlüssel nicht besteht.
5.2 Methoden zur Speicherplatzverwaltung
5.2.1 Der CDictionary() Konstruktor
Dieser Basis-Konstruktor erzeugt das CDictionary-Objekt mit einer Anfangsgröße des Basis-Arrays = 3 Elemente.
Das Array wird durch Füllen des Lexikons mit seinen Elementen oder dem Löschen seiner Elemente automatisch erweitert oder komprimiert.
CDictionary();
5.2.2. Der CDictionary(int capacity) Konstruktor
Dieser Basis-Konstruktor erzeugt das CDictionary-Objekt mit einer Anfangsgröße des Basis-Arrays = 'Kapazität'.
Das Array wird durch Füllen des Lexikons mit seinen Elementen oder dem Löschen seiner Elemente automatisch erweitert oder komprimiert.
CDictionary(int capacity);
Parameter
- [in] Kapazität – Anzahl der ursprünglichen Elemente.
Hinweis
Wenn Sie unmittelbar nach der Initialisierung des Arrays eine Größenbeschränkung einrichten, hilft Ihnen dies, Aufrufe der Resize() Methode zu vermeiden und erhöht damit die Effizienz beim Einfügen neuer Elemente.
Hier sei jedoch angemerkt, dass beim Löschen von Elementen mit aktivierter (AutoMemoryFree(true)), der Behälter automatisch komprimiert wird - ungeachtet wie seine Kapazität eingestellt wurde. Um eine frühe Komprimierung zu vermeiden, sollten Sie das erste Löschen von Objekten erst dann ausführen, wenn die Behälter komplett gefüllt sind, oder, wenn dies nicht geht, (AutoMemoryFree(false)) aktivieren.
5.2.3 Die FreeMode(bool mode) Methode
Legt den Modus des Löschens von im Behälter bestehenden Objekten fest.
Ist der Löschen-Modus aktiviert, unterliegt der Behälter ebenfalls einem 'Löschen', nachdem das Objekt gelöscht worden ist. Sein Destruktor wird aktiviert und das Objekt steht nicht mehr zur Verfügung. Ist der Löschen-Modus deaktiviert, ist der Destruktor des Objekts nicht aktiviert und es kann weiterhin von anderen Punkten des Programms verwendet werden.
void FreeMode(bool free_mode);
Parameter
- [in] free_mode – Indikator des Löschen-Modus des Objekts.
5.2.4 Die FreeMode() Methode
Liefert den Indikator zum Löschen von Objekten, die sich im Behälter befinden (vgl. FreeMode(bool mode)).
bool FreeMode(void);
Gelieferter Wert
Liefert 'true', wenn das Objekt vom Löschen-Operator gelöscht wurde, nachdem es aus dem Behälter gelöscht wurde. Ansonsten 'false'.
5.2.5 Die AutoFreeMemory(bool autoFree) Methode
Richtet den Indikator für automatische Speicherplatzverwaltung ein. Automatische Speicherplatzverwaltung ist standardmäßig aktiviert. In so einem Fall wird das Array automatisch komprimiert (d.h. seine Größe verändert sich von größer auf kleiner). Wenn deaktiviert, wird das Array nicht komprimiert. Dies steigert die Geschwindigkeit der Programmausführung ganz erheblich, da die Ressourcen-intensive Resize()-Methode nicht aufgerufen werden muss. Doch hier müssen Sie stets die Array-Größe im Auge behalten und es manuell mittels der Compress() Methode komprimieren.
void AutoFreeMemory(bool auto_free);
Parameter
- [in] auto_free – Indikator für den Speicherplatzverwaltungs-Modus.
Gelieferter Wert
Liefert 'true', wenn die Speicherplatzverwaltung aktiviert und die Compress() Methode automatisch aufgerufen werden muss. Ansonsten 'false'.
5.2.6 Die AutoFreeMemory() Methode
Liefert den Indikator, der angibt, ob der automatische Speicherplatzverwaltungs-Modus verwendet wird (vgl. die FreeMode(bool free_mode) Methode).
bool AutoFreeMemory(void);
Gelieferter Wert
Liefert 'true', wenn der Speicherplatzverwaltungs-Modus verwendet wird. Ansonsten 'false'.
5.2.7 Die Compress() Methode
Komprimiert das Lexikon und verändert die Größe der Elemente. Das Array wird nur dann komprimiert, wenn dies auch wirklich möglich ist.
Diese Methode sollte nur dann aufgerufen werden, wenn der automatische Speicherplatzverwaltungs-Modus deaktiviert ist.
void Compress(void);
5.2.8 Die Clear() Methode
Löscht alle Elemente im Lexikon. Wir der Speicherplatzverwaltungs-Indikator aktiviert, wird der Destruktor für jedes Element, das zu löschen ist, aufgerufen.
void Clear(void);
5.3 Methoden zur Suche im Lexikon
Alle Elemente des Lexikons sind miteinander verbunden. Jedes neue Element verknüpft sich mit einem vorhergehenden. Dadurch wird eine sequentielle Suche aller Elemente des Lexikons ermöglicht. In so einem Fall wird der Verweis durch eine verknüpfte Liste ausgeführt. Die Methoden im folgenden Abschnitt erleichtern die Suche und machen das wiederholte Durchlaufen des Lexikons bequemer.
Zur Suche im Lexikon können Sie die folgende Konstruktion verwenden:
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }
5.3.1 The GetFirstNode() Methode
Liefert das allererste Element, das dem Lexikon hinzugefügt wurde.
CObject* GetFirstNode(void);
Gelieferter Wert
Liefert den Zeiger auf das Objekt des CObject Typs, das dem Lexikon ganz am Anfang hinzugefügt wurde.
5.3.2 The GetLastNode() Methode
Liefert das letzte Element des Lexikons.
CObject* GetLastNode(void);
Gelieferter Wert
Liefert den Zeiger auf das Objekt des CObject Typs, das dem Lexikon ganz zum Schluss hinzugefügt wurde.
5.3.3 GetCurrentNode() Methode
Liefert das aktuell ausgewählte Element. Dieses Element sollten von einer der Suchmethoden nach Elementen im Lexikon oder von der Zugriffsmethode auf das Element des Lexikons (ContainsKey(), GetObjectByKey()) bereits vorab ausgewählt worden sein.
CObject* GetLastNode(void);
Gelieferter Wert
Liefert den Zeiger auf das Objekt des CObject Typs, das dem Lexikon ganz zum Schluss hinzugefügt wurde.
5.3.4 Die GetNextNode() Methode
Liefert das Element, das auf das aktuelle Element folgt. Liefert NULL, wenn das aktuelle Element das letzte ist oder wenn es nicht ausgewählt wurde.
CObject* GetLastNode(void);
Gelieferter Wert
Liefert den Zeiger auf das Objekt des CObject Typs, das auf das aktuelle Element folgt. Liefert NULL, wenn das aktuelle Element das letzte ist oder wenn es nicht ausgewählt wurde.
5.3.5 Die GetPrevKNode() Methode
Liefert das Element, das dem aktuellen Element vorangeht. Liefert NULL, wenn das aktuelle Element das erste ist oder wenn es nicht ausgewählt wurde.
CObject* GetPrevNode(void);
Gelieferter Wert
Liefert den Zeiger auf das Objekt des CObject Typs, das dem aktuelle Element vorangeht. Liefert NULL, wenn das aktuelle Element das erste ist oder wenn es nicht ausgewählt wurde.
Fazit
Wir haben nun die Hauptmerkmale von weit verbreiteten Datenbehälter betrachtet. Jeder Datenbehälter sollte dann verwendet werden, wenn seine Merkmale ein Problem auf maximal effiziente Weise lösen können.
Reguläre Arrays sollte dann verwendet werden, wenn ein sequentieller Zugriff auf ein Element zur Lösung eines Problems ausreicht. Der Einsatz von Lexika und damit zusammenhängenden Arrays eignet sich besser, wenn der Zugriff auf ein Element durch seinen eindeutigen Schlüssel erforderlich ist. Der Einsatz von Listen eignet sich besser in Fällen häufigen Austauschs von Elementen - Löschen, Einfügen, Hinzufügen neuer Elemente.
Mit Hilfe des Lexikons kann man anspruchsvolle algorithmische Probleme ganz einfach und bequem lösen. Dort wo andere Datenbehälter zusätzliche Verarbeitungsmerkmale verlangen, kann man mit dem Lexikon den Zugriff auf bestehende Elemente höchst effektiv anordnen. So kann man z.B. auf Basis des Lexikons, ein Ereignismodell erstellen, wo jedes Ereignis des Typs OnChartEvent() an die Klasse geliefert wird, die ein oder mehrere grafische Elemente verwaltet. Zu diesem Zweck müssen Sie nur jede Klassen-Instanz mit dem Namen des, von dieser Klasse verwalteten Objekts, zusammenbringen.
Da das Lexikon ja ein universeller Algorithmus, kann es auf maximal viele Felder angewendet werden, Dieser Artikel macht deutlich, dass die Abläufe des Lexikons auf einem recht einfachen, doch stabilen Algorithmus beruht, mit dessen Hilfe seine Anwendung bequem und wirkungsvoll wird.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/1334
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Gegenläufig gerichteter Handel und Sicherung von Positionen in MetaTrader 5 mithilfe der HedgeTerminalApi, Teil 2
Gegenläufig gerichteter Handel und Sicherung von Positionen in MetaTrader 5 mithilfe der HedgeTerminalApi, Teil 2
 Die Betrachtung der CCanvas-Klasse. Wie man transparente Objekte zeichnet
Die Betrachtung der CCanvas-Klasse. Wie man transparente Objekte zeichnet
 Grundlagen der Börsenkursbildung am Beispiel des Terminhandelsbereichs der Moskauer Börse
Grundlagen der Börsenkursbildung am Beispiel des Terminhandelsbereichs der Moskauer Börse
 Das MQL5-Kochbuch: ОСО-Orders
Das MQL5-Kochbuch: ОСО-Orders
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
es muss im Allgemeinen nicht richtig funktionieren.
Der korrekte Weg, um mehrere Löschungen aus einem assoziativen Array durchzuführen, besteht darin, ein Array der zu löschenden Schlüssel zu sammeln und dann nach Schlüssel zu löschen.
Das ist die Sache, auch diese Methode verursacht plötzlich einen seltsamen Fehler. Es ist offensichtlich ein Fehler. Ich werde dem nachgehen.
Fürs Erste kann ich Ihnen raten, ein neues Wörterbuch zu erstellen und ihm die Werte hinzuzufügen, die nicht gelöscht werden müssen. Löschen Sie dann das alte Wörterbuch. Das wird zu 100% funktionieren.
So geht's:
1. Aktualisieren Sie die Version des Wörterbuchs auf die an diesen Beitrag angehängte Version.
2. Führen Sie ein Testskript aus, um auch Elemente zu löschen.
Die Löschung sollte in zwei Durchgängen erfolgen:
Bezüglich der Methode DeleteCurrentObject():
Diese Methode sollte nur in Verbindung mit der Funktion ContainsKey() verwendet werden. Der einzige Grund, warum sie als öffentlich verfügbar ist, ist, dass der Methodenaufruf in diesem Fall Zeit bei der Neupositionierung des Zeigers spart. Das heißt, der typische und einzige Fall seiner Verwendung ist 1. Prüfen, ob ein Schlüssel vorhanden ist, 2. wenn ja, diesen schnell mit dieser Methode löschen.
Das ist zwar verständlich, aber auch wieder unnötige Karosseriearbeit.
Es ist technisch möglich, den Ausbau in einem Arbeitsgang durchzuführen, wie Sie es erwarten. Aber es wäre kompliziert. Deshalb noch nicht, nur in zwei Durchgängen. Aus der Sicht des Wörterbuchs als verteilte Datenstruktur ist die Löschung in zwei Durchgängen eine kanonisch korrektere Lösung. Nur auf der Benutzerebene sieht es so aus, als ob die Löschung sequentiell erfolgt, in Wirklichkeit ist alles anders. In Bezug auf die Leistung bringt die Löschung in einem Durchgang keine Vorteile. Was die Bequemlichkeit angeht, so kann es durchaus bequemer sein.
Es ist technisch möglich, die Entfernung in einem Durchgang durchzuführen, wie Sie erwarten. Aber es wäre kompliziert. Deshalb noch nicht, nur in zwei Durchgängen. Aus der Sicht des Wörterbuchs als verteilte Datenstruktur ist die Löschung in zwei Durchgängen kanonisch korrekter. Nur auf der Benutzerebene sieht es so aus, als ob die Löschung sequentiell erfolgt, in Wirklichkeit ist alles anders. In Bezug auf die Leistung bringt das Löschen in einem Durchgang keine Vorteile. Was die Bequemlichkeit angeht, so kann es durchaus bequemer sein.
Ich danke Ihnen.
Ich glaube, ich habe einen Fehler gefunden, wenn ich ein Element lösche und versuche, zum letzten Element zu gelangen:
Fehler in der CDictionary.mqh wird sein:
ungültiger Zeigerzugriff in 'Dictionary.mqh' (463,9)
Kann jemand dies bestätigen? Hat jemand eine Idee, wie man das beheben kann?
Es war ein Fehler in Zeile 500 && 501 bei der Implementierung der Zeigerüberprüfung.
Behoben mit der eingebauten CheckPointer().