
MQL5秘笈之:采用关联数组或字典实现快速数据访问

内容简介
简介
本文介绍一个便捷的存储信息的类,称为关联属于或者字典。这个类允许通过密钥来访问其中的信息。
关联数组是一个常规数组。但是它使用某些具备唯一性的key来取代索引,如ENUM_TIMEFRAMES枚举值或者一些文本。用什么作为key并不关键。只要key是唯一的。这种数据存储算法能显著的简化许多编程工作。
例如,一个能够打印错误信息的函数,就能够如下实现:
//+------------------------------------------------------------------+ //| 在终端中显示错误描述 | //| 如果错误代码未知则显示“未知错误” | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
我们后面会仔细分析这段代码。
在介绍关联数组内部逻辑之前,我们来看看数据存储的两个主要方式,即数组和列表。我们的字典将基于这两个数据类型,因此我们要对他们的特性有深入的理解。第一张重点介绍数据类型。第二章介绍关联数组及其方法。
第一章数据组织理论
1.1. 数据组织算法。查找最佳数据存储容器
查找存储和信息表示是现代计算机的主要功能。人机交互通常包含信息查找或者信息创建和信息存储。信息不是抽象的概念。实际中,它有特定的含义。例如,一个货币的报价历史是任何交易者做单或准备做单的信息来源。编程语言文档或者某些程序的源代码可以作为程序员的信息来源。
某些图形文件(例如数字相机拍摄的照片)可以作为同编程或做交易无关的人群的信息来源。显然这些类型的信息分别具有它们自己的特征。因此,信息的存储、表示和处理算法也将随之不同。
例如,很容易将图形文件表示为一个二维矩阵(二维数组),每一个元素或者元组存储一小块图像的颜色信息 — 像素。报价数据另有特点。实质上这是一连串的OHLCV格式的数据流。最好将这个数据流表示成数组或者一个有序的结构体,一种编程语言中特定的数据类型,它可以由若干数据类型所组成。文档和源代码通常表示为纯文本形式。这种数据类型可以被定义和存储为有序的字符串类型,其中每个字符串是字符的任意序列。
容器类型根据数据类型存储数据。使用面向对象的编程方法,很容易定义一个容器如类来存储这些数据,并且具有特定的算法(方法)来对它们进行处理。类似的数据存储容器(类)有好几种类型。它们基于不同的数据结构。但一些数据结构算法允许合并不同的数据存储模式。因此我们利用这种所有存储类型组合的好处。
选择哪个容器来存储、处理以及接收数据取决于它们的方法和属性。没有效率相同的数据容器,意识到这点很重要。有优点也就有缺陷。
例如,你可以非常迅速的访问任何数组元素。然而,要在随机数组中的某个位置做插入操作就非常费时,以为这种情况下需要数组重构。相反,在单向链表中插入元素就非常高效和迅速了,但是要访问一个随机元素就可能要耗费多一些时间了。如果要频繁的插入新的元素,但是又不要经常访问它们,那么单向链表作为数据存储容器是正确的选择。如果需要频繁的访问随机元素,那么选择数组作为数据存储类。
为了了解何种数据存储类型更加有利,你应该熟悉所有容器的组成结构。本文致力于介绍关联数组和字典 — 一种特殊的数据存储容器,它基于数组和链表的组合。但是我要提醒的一点是,字典可以有不同的实现方式这取决于特定的编程语言,即可接受的编程规则和能力。
例如, C# 中字典的实现方式就和C++中的不一样。本文不介绍字典在C++中的实现。本文介绍的关联数组使用MQL5编程语言 编程实现,并考虑了它的特点和实际编程特性。虽然它们的实现有区别,但是字典的一般属性及操作方法都是类似的。本文中描述的版本充分展现了这些属性和方法。
我们将逐步创建字典算法并同时讨论数据存储算法的性质。最后在本文结束时我们将得到完整的算法并彻底了解其运作方式。
不同数据类型的处理效率不可能完全相同。让我们考虑一个简单的例子:纸质记事本。它可以看成是我们日常生活中使用的容器/类。所有的记录都按预设的列表存储(此处为字母顺序)。如果你知道订阅者的名字,你可以打开记事本方便的找到他或者她的电话号码。
1.2. 直接访问数组和数据
数组是最简单也是最有效的信息存储方式。在编程中,一个数组是同类元素的集合,在内存中一个接一个的分布。正是由于这个特点,我们可以计算数组每个元素的地址。
事实上,如果所有元素的类型都一样,它们也将有一样的大小。由于数组元素连续存储,如果我们知道元素的大小,就可以计算出任意元素的地址并直接访问它。计算地址的一般公式取决于数据类型和索引。
例如,我们可以使用下面的公式来计算uchar 类型数组的第五个元素的地址:
任意元素的地址 = 第一个元素的地址 + (任意元素在数组中的索引 * 数组元素类型大小)
第一个数组元素的地址对应为数组中索引为0的元素的地址。以此类推,第五个元素的索引为4. 让我们假设元素的类型为uchar类型。这是许多编程语言的基本数据类型。例如,它出现在C-类型语言中。MQL5也不例外。每一个uchar类型占用1个字节或者8个比特的内存。
例如,根据前面提到的公式,数组中第五个元素的地址如下:
第五个元素的地址 = 第一个元素的地址 + (4 * 1 字节);
换句话说,第五个元素的地址比第一个元素高4字节。你比可以在程序执行阶段通过地址直接访问元素。这种地址算法能够非常快的访问数组中的每个元素。但这样的数据结构也有弱点。
你不能将不同类型的元素存储在数组中。这种限制也是直接寻址的后果。不同的数据类型大小不同,也就是说无法通过上述公式来计算数组中特定元素的地址了。但是这个限制也能巧妙的客服,如果数组存储的不是元素而是指针 。
最简单的就是将指针看成是链接(犹如Windows中的快捷键)。指针指向内存中的特定对象,但是指针本身不是一个对象。在MQL5中,指针只能指向一个类。在面向对象的编程语言中,一个类是一种特殊的数据类型,它可以包含任意数据聚合和方法并且可以被用户创建用于高效的程序构建。
每个类都是用户定义的特定数据类型。指向不同类的指针不能放在一个数组中。但是不管指向哪个类,指针大小都是一样的,因为它仅包含对象在操作系统中的地址,所有对象的地址大小都是一样的。
1.3. 以CObjectCustom简单类为例介绍节点的概念
现在我们有足够的知识来设计第一个通用指针了。想法是创建一个通用指针数组,每个指针都指向特定的类型。数据的实际类型可能不同,但是由于都是被同样的指针所指向,这些类型可以存储在一个容器/数组中。创建我们的第一个指针版本。
这个指针将表示为最简单的类型,我们称为CObjectCustom:
class CObjectCustom
{
};
没有比CObjectCustom类更简单的了,因为它里面既没有数据也没有方法。但目前足够了。
现在我们使用面向对象编程中的主要思想 — 继承。继承提供了建立对象之间身份关系的一种特殊方式。例如,我们可以告诉编译器任何一个类都是CObjectCustom的子类。
例如,人类 (СHuman),EA类 (CExpert)和天气类 (CWeather)都是CObjectCustom类的具象类。也许这些概念在实际生活中很难联系在一起:天气和人类没有关系,EA和天气没有关系。但是这些使我们在程序世界中建立的联结,如果有助于我们的算法,没有理由不创建它们。
让我们以同样的方式创建更多的类:汽车类 (CCar),数字类 (CNumber),价格k线类 (CBar),报价类 (CQuotes),MetaQuotes公司类 (CMetaQuotes)以及描述船的类 (CShip)。同先前的类一样,这些类实际上没有关系,但是他们都是CObjectCustom的子类。
让我们在一个文件中为这些类创建一个类库ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| 基类 CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述人类的类。 | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述天气的类。 | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述EA的类。 | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述汽车的类。 | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述数字的类。 | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述价格K线的类。 | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述报价的类。 | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述MetaQuotes公司的类。 | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| 描述船的类。 | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
现在是时候将这些类组成为一个数组了。
1.4. 以CArrayCustom类为例介绍节点指针数组
要组合类,我们将需要一个特殊的数组。
最简单的就是:
CObjectCustom array[];
这个字符串创建一个动态数组来存储CObjectCustom类型的元素。由于之前我们定义的所有类都是继承自CObjectCustom,我们可以将这些类存储在数组中。例如,我们可以在此存储people、cars和ships类。但是为了实现这个目的,声明CObjectCustom数组还不够。
一般当我们声明数组时,其所有元素在数组初始化时被自动填充。因此,当我们声明数组后,其中的所有元素都被CObjectCustom类占据。
如果想要确认这点,我们可以对CObjectCustom类进行略微修改:
//+------------------------------------------------------------------+ //| 基类 CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
让我们运行一段测试脚本来进行检验:
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
在OnStart()函数中我们初始化一个包含三个CObjectCustom元素的数组。
编译器用相应的对象进行数组填充。你可以阅读日志来检查:
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #2 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #1 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #0 - CObjectCustom
这意味着数组由编译器填充,我们不能在此分配任何其他的元素,例如 CWeather 或 CExpert。
这段代码将不会编译通过:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
编译报错:
'=' - structure have objects and cannot be copied Test.mq5 18 13
这意味着数组已经有对象了,新的对象不能被复制到其中。
但是我们能够解决这一问题!如上所述,此处我们不应该采用对象而应使用对象的指针。
以指针形式重写OnStart()函数中的代码:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
现在代码不会报错了顺利通过编译。怎么回事呢?首先我们用CObjectCustom的指针数组初始化替代CObjectCustom数组的初始化。
这样编译器在初始化时不创建新的CObjectCustom对象,而是设置为空指针。其次,我们使用CWeather对象的指针而非对象本身。用关键字new我们创建CWeather对象并且用指针'weather' 指向它,然后我们将指针'weather'(而非对象本身)放入数组。
将剩余对象以同样的方式放入数组中。
代码如下:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
这段代码能够运行,但是这样做非常冒险,因为我们直接操作数组的索引。
如果我们计算arrayObj数组大小错误或者写错索引的话,程序将会出现严重错误。但是这段代码用做演示是合适的。
让我们展示这些元素:
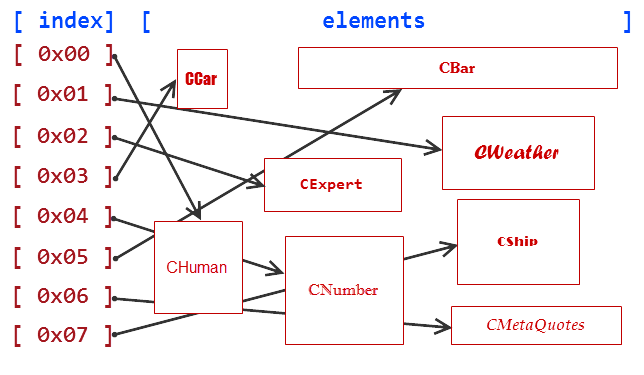
图 1. 用指针数组存储数据的方案
由操作符'new'创建的元素,保存在随机存储器的特定位置,称为堆。这些元素是无序的,如上清晰可见。
我们的arrayObj指针有严格的索引方式,使得能够通过索引快速的访问任何元素。但是访问这些元素还不够,因为指针数组不知道它所指向的对象。CObjectCustom可以指向CWeather 或CBar,或CMetaQuotes,因为它们都是CObjectCustom类型。因此,为了获取元素类型,需要精确 指向一个实际对象类型。
例如,实现如下:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
在这段代码中,我们创建CHuman对象,并将其作为CObjectCustom类型存入arrayObj数组中。然后我们解析CObjectCustom并将其转化为CHuman。因为我们指定了类型,此例中的代码没有报错。在实际编程中很难追踪每一个对象的类型,因为可能会有成百上千的类型并且对象的数量可能上百万。
这也是为什么我们要在ObjectCustom类最后增加额外的Type()方法,它返回实际对象类型的修饰符。修饰符是一个特定的数字,它描述了我们对象允许指向的类型。例如,我们能够使用预处理命令#define来定义修饰符。如果我们知道由修饰符确定的对象类型,我们总是能够安全的将其转化为实际类型。因此,接下来就要创建安全类型了。
1.5. 检查类型
一旦我们开始将一个类型转化为另一个类型,那么类型转换的安全性对于程序来说就非常重要了。我们不希望程序发生严重的错误,不是吗?我们已经知道什么是类型的安全基石 — 特定的修饰符。如果我们知道修饰符,就能够将其转化为想要的类型。为了达到这一目的,我们要为CObjectCustom类增加一些额外的功能。
首先,让我们创建类型标识符来通过名称引用它们。要实现这一目标我们将创建一个独立的文件来存放所需的枚举值:
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // 基类 CObjectCustom #define TYPE_HUMAN 1 // 类 CHuman #define TYPE_WEATHER 2 // 类 CWeather #define TYPE_EXPERT 3 // 类 CExpert #define TYPE_CAR 4 // 类 CCar #define TYPE_NUMBER 5 // 类 CNumber #define TYPE_BAR 6 // 类 CBar #define TYPE_MQ 7 // 类 CMetaQuotes #define TYPE_SHIP 8 // 类 CShip
现在我们将改变CObjectCustom类的代码,将其中的变量改为数字表示的对象类型。将其设为私有变量,使其它对象无法改变它。
除此之外,我们将增加一个特殊的构造函数,使得可以从CObjectCustom派生类。此构造方法将允许对象在创建过程中指定其类型。
常见的代码如下所示:
//+------------------------------------------------------------------+ //| 基类 CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| 描述人类的类。 | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| 描述天气的类 | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
如我们所见,在创建阶段任何从CObjectCustom派生的类现在都能在构造函数中设置自己的类型。类型一旦设置就无法更改,因为存储区是私有的,并且只能为CObjectCustom所用。这是为了防止错误的类型拷贝。如果类没有调用受保护的CObjectCustom的构造函数,TYPE_OBJECT - 将是它的默认类型。
所以,现在是时候学习如何从arrayObj提取类型和对其进行处理。为此,我们将分别为CHuman和CWeather类补充公共的run()和Temp()方法。在我们从arrayObj中提取类后,我们将其转化为需要的类型并且开始着手处理它。
如果存储在CObjectCustom数组中的类型未知,我们将忽略并写入“未知类型”:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
这段代码将输出如下信息:
2015.02.13 15:11:24.703 Test (USDCHF,H1) unknown type.
2015.02.13 15:11:24.703 Test (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Test (USDCHF,H1) Human run...
因此,看上去我们获得了想要的结果。现在我们可以将任何类型存储在CObjectCustom类型的数组中,根据索引快速访问这些对象并且将其转化为实际需要的类型。但我们仍旧缺不少东西:在程序结束后正确的销毁对象,使用delete操作符来删除堆中的对象。
另外,如果数组被完全填充满,我们需要安全的数组大小重构方法。但是我们没必要都重头来过。MetaTrader 5标准类库中已经包含了实现所有这些功能的工具。
这些类都是基于CObject通用容器/类的。同我们的类一样,它拥有Type()方法,返回类的实际类型,以及另外两个更重要的CObject类型指针:m_prev和m_next。它们的作用将会在下一节中介绍,在那里我们将通过CObject容器和CList类的例子,来讨论另一种称为双向链表的数据存储方式。
1.6. 双向链表的例子Clist类
含有任毅类型元素的数组有一个主要缺陷:如果你想要插入一个新的元素,尤其是在数组的中间位置,那么将耗费非常多的时间。元素按顺序排列,你不得不重新配分数组大小来增加一个数组元素用于插入,然后重新组织数组使得索引和新的值对应。
让我们假设有一个含有7个元素的数组,并且想要在第4个位置插入一个新的元素。一个大致的插入算法如下:

图 2. 调整数组大小并插入新元素
有一个数据存储方案,它能够快速有效的插入和删除元素。这种方案被称为单链接或双链表。这个列表是一个普通列队。当在列队中我们仅需知道前一个人是谁(我们无需知道他或她前面又是谁)。我们也无需知道在我们后面的是谁,他或她必须控制其自身在列队中的位置。
列队是单向链表的典型例子。然而列表也可以是双向的。这种情况下,每个人不仅知道前一个人是谁,还是知道他或她后面一个是谁。因此如果你要查找任何人,你从列队的任何一边开始都可以。
标准库中的CList类能够精确的实施这一算法。让我们从已知的类创建列队。但是这次它们将派生自CObject类而非CObjectCustom。
如下示意:

图 3. 双向链表
这就是创建双向链表的源代码:
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
我们的类有两个CObject类型的指针:一个指向前一个元素,另一个指向后一个元素。列表中第一个元素的前向指针为NULL。列表中最后一个元素的后向指针也为NULL。因此我们可以逐个遍历,直至列队的所有元素遍历完毕。
EnumerateAll() 和 ReverseEnumerateAll() 函数用于遍历列表中所有元素。
第一个函数从头至尾遍历列表,第二个从尾至头遍历。这些函数的源码如下:
//+------------------------------------------------------------------+ //| 从头至尾遍历列表在终端中 | //| 显示每一个元素。 | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| 从尾至头遍历列表在终端中 | //| 显示每一个元素。 | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
这个代码是如何运作的呢?实际上很简单。开始时在EnumerateAll()函数中我们得到第一个节点的引用。然后我们在for循环中打印此节点的编号,并使用命令node = node.Next()移动至下一个节点。别忘了将元素的当前索引号加1(i++)。知道当前节点为NULL停止遍历。for代码中的第二段用于确认:node != NULL。
ReverseEnumerateAll()函数的区别仅在于首先它获取列表中最后一个元素 CObject* node = list.GetLastNode()。在for循环中不是获取列表的下一个而是前一个元素 node = node.Prev()。
当执行代码后我们收到如下信息:
2015.02.13 17:52:02.974 TestList (USDCHF,D1) enumerate complete.
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) <<< enumerate from end to begin <<<
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) >>> enumerate from begin to end >>>
你可以很容易的插入新的元素到列表中。仅仅需要改变前一个或者后一个元素的指针,将它们指向新的元素,这个元素将指向它前一个和后一个元素。
办法非常很简单:

图 4. 在双向链表中插入新的元素
链表的最大缺点是无法根据索引访问其中的元素。
例如你想要引用图四中的CExpert,你得先访问CCar然后在访问CExpert。CWeather也一样。它靠近列表的末端,因此从尾部访问会更容易些。为此你必须线访问CShip,然后再是CWeather。
移动指针相比直接索引访问操作来的要慢。现代的中央处理单元的操作经过了优化,尤其是针对数组。这也是为何实际中更喜欢使用数组,尽管列表运行更快。
第二章关联数组组织理论
2.1. 日常生活中的关联数组
我们在日常生活中每天都会面对关联数组。但是它们太常见了,以至于我们认为它们是理所当然存在的了。最简单的关联数组或者字典的例子就是电话本了。本中每一个电话号码都和一个人的名字关联。电话本中的姓名是一个唯一的键,电话号码是一个简单的数值。电话号码本中的每个人都可能会有好几个号码。例如,一个人可能会有家庭电话,移动电话和公司电话号码。
一般来说,号码可能有无限多个,但是人的姓名是唯一的。例如,电话本中两个都叫Alexander的人可能会把你搞糊涂。有时候我们可能拨错号。这也就是为何key(本例中为人名)必须要唯一的原因。同时字典还需要知道如何解决冲突并避免之。两个一样的名字不会让电话本崩溃。我们的算法要知道如何处理这种情况。
日常生活中我们使用几种类型的字典。例如,电话本是一个字典,每个独立的行(名字)就是一个key,电话号码是数值。外文字典有着另一种结构。一个英文单词是一个key,它的翻译是值。这两类关联数组所基于的数据处理方式都是一样的,这也是为什么我们的字典必须能够有多种用途并且允许存储和比较任何类型。
在编程中,创建你自己的字典和“记事本”也不复杂。
2.2. 基于switch-case操作符的主关联数组或者简单数组
你可以很容易的创建一个简单的关联数组。使用MQL5语言中的标准工具库,例如,switch操作符或者数组。
让我们看看如下代码:
//+------------------------------------------------------------------+ //| 根据传入的时间框架值 | //| 返回时间框架的字符串表示 | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
在这种情况下,switch-case操作符的运作方式如一个字典。每一个ENUM_TIMEFRAMES有一个字符串值来描述时间框架。由于switch操作符是一个切换通道(在俄语中),访问所需的变量是即时的,其他变量不会被遍历。这就是为何这个代码非常高效。
但是它的缺点是,首先你必须手动填充每个ENUM_TIMEFRAMES所返回的值。其次,switch只能操作整型数值。但是要写一个相反的函数,根据字符串返回对应的之间框架就很难了。最后一个缺点就是这个方式的可扩展性不强。你必须预先确定所有可能的变量值。但是你往往需要当新的数据来到时动态的将值填充到字典中。
第二种“key-value”存储方式是创建数组,key被用于数组的索引,值为数组元素。
例如,让我们尝试解决类似问题,返回时间框架的字符串表示形式:
//+------------------------------------------------------------------+ //| 时间框架对应的 | //| 字符串值。 | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| 为数组添加关联值。 | | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| 根据传入的时间框架值 | //| 返回对应的字符串。 | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
这段代码描述了通过索引来应用数组元素,其中ENUM_TIMFRAMES是一个索引。在返回数值前,函数检查数组是否对想要的元素进行了赋值。如果没有,使用一个特殊的函数来赋值 - InitTimeframes()。它和switch操作符有一样的缺点。
此外,这样的字典结构需要用很大的数值来初始化数组。PERIOD_MN1的值是49153。也就是说我们需要49153个单元来存储9个时间框架。其他单元未被赋值。这种数据分配方式远不是一个紧凑的方案,但是当枚举值数量少并且是连续的数字时还是比较合适的。
2.3. 将基础类型转化为独特的key
由于若不考虑key的类型和值,用于字典的算法是类似的,因此我们需要执行数据对齐,这样不同的数据类型就能够由一个算法来处理了。我们的字典算法将是通用的,任何基本类型都能作为key,例如int, enum, double或者甚至是string。
实际上,在MQL5中任何基础类型都能被ulong数字来表示。例如,short 或者 ushort 是“短”版本的ulong。
当ulong类型存储ushort类型的值,你总是可以安全并精确的进行类型转换:
ulong ln = (ushort)103; // 将ushort类型值保存在ulong类型中(103) ushort us = (ushort)ln; // 从ulong类型中获取ushort类型值(103)
对于char 和 int类型也一样,它们的无符号类型ulong可以存储任何尺寸小于或等于ulong类型的数值。Datetime, enum 和color类型是基于32-bituint数字的,这就意味着它们可以被安全的转化为ulong类型。bool类型只有两个值:0,代表false,1,代表true。因此,bool类型的值也可以存储在ulong类型的变量中。另外,许多MQL5系统函数都是基于这个特性的。
例如,AccountInfoInteger()函数返回long类型的整型值,它可以是ulong类型的账号和是否允许交易的布尔值 - ACCOUNT_TRADE_ALLOWED。
但是MQL5有三个和整型不同的基本类型。它们可以直接被转化为ulong类型。其中就有浮点类型,如double和float,以及 strings。但是一些简单的操作就可以把它们转化为唯一的整型key/值。
每一个浮点数都可以用科学计数法表示,基数和乘数分别存储在为一个整型值。这种存储方法用于double和float值。float类型用32位来存储尾数和幂,double类型使用64位。
如果我们尝试将其直接转化为ulong类型,值将被简单的四舍五入。这种情况下,3.0 和 3.14159 将返回同样的值 — 3。这对我们来说是不合适的,因为对于两个不同的值我们需要不同的key。一个C语言中不常用的特性能够解决这个问题。它被称为结构转换。两个不同的结构体能够相互转换如果它们的大小一致(将一个结构体转换为另一个结构体)。
我们来分析这个一个两个结构体的例子,一个存储ulong类型的值,另一个存储double类型值:
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
这段代码按字节将DoubleValue结构体复制到ULongValue结构体中。由于它们由相同的大小和变量顺序,dValue.value的double类型值按字节复制到lValue.value的ulong类型值中。
之后这个变量值被打印出来。如果我们将dValue.value的值改为3.14160,lValue.value的值也将跟着变化。
这就是printf()函数打印出来的结果:
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
浮点类型是double类型的缩短版。相应的,在将float类型转换为ulong类型前你可以安全的将float类型扩展为double类型:
float fl = 3.14159f; double dbl = fl;
2.4. 哈希字符串和使用哈希数组作为key
在上面的例子中key由一个数据类型 — strings 来代表。然而,可能会有不同的情况。例如,电话号码的前三位代表号码供应商。这种情况下这三个数字代表了一个key。另一方面,每个字符串可以被一个唯一的数字所代表,每个数代表着字母表中字母的序号。因此,我们可以将字符串转换为唯一数字,并且使用此数字作为一个与其相关的整型key。
此方法虽然不错,但是不足以实现多种目。如果我们使用一个含有上百个字母的字符串作为key,那么数字就会很大。不可能将其装入任何类型的简单变量中。Hash函数将帮助我们解决这一问题。Hash函数是一种特殊的算法,适用于任何数据类型(例如,字符串),并且返回代表这个字符串的唯一数字。
既使输入数据的一个字母改变了,数字也会完全不同。这个函数返回的数字有一个固定的范围。例如,Adler32()hash函数接受任意字符串作为参数,返回一个0到2的32次方之间的数字。这个函数很简单但是很符合我们的需求。
下面是MQL5源代码:
//+------------------------------------------------------------------+ //| 返回代表字符串的32位哈希值 | //| | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
返回什么值取决于要转换的字符串。
为了实现这个目的,我们写一个简单的脚本来调用此函数并转换不同的字符串:
//+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
脚本的输出如下:
2015.02.16 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Peace - 91685343
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world! - 487130206
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world - 413860925
我们看到,每个字符串都有一个特别的数字与之对应。注意字符串"Hello world" 和 "Hello world!" - 他们几乎是一样的。唯一的不同就是第二个字符串最后多了个感叹号。
但是Adler32()返回的数字时完全不同的。
现在我们知道如何将字符串类型转换为无符号uint值了, 我们可以保存它的整型hash值而非string类型的key。如果两个字符串有同一个hash码,那么说明这两个字符串一模一样。因此,一个值的key不是一个字符串而是一个基于此字符串生成的整型hash码。
2.5. 根据密钥确定索引列表数组
现在我们知道怎样将MQL5基本类型转换为ulong类型了。事实上,我们的值就是和这个类型对应。但是有ulong类型的key还不够。当然,如果我们知道每个对象的唯一key,我们可以基于switch-case操作符创建一些私有的存储方法或者一个任意长度的字符串。
这种方法已经在前一章节的2.2节描述过了。但是他们的可扩展性还不够也不够高效。对于switch-case,要列举这个操作符的所有变量看上去是不可能的。
如果有成千上万的对象,我们就必须用成千上万的key来作为switch操作符中的枚举值,这在便一阶段是不可能的。第二种方法是使用数组,它的元素的key也是其索引。允许动态方式新增元素并重新分配数组大小。因此我们可以通过其索引,也就是其元素的key来频繁访问它。
让我们来搭建此解决方案的框架:
//+------------------------------------------------------------------+ //| 通过key存储字符串的数组 | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| 向关联数组中添加字符串。 | //| 结果: | //| 返回 true,如果字符串被成功添加,否则 | //| 返回 false。 | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
但是在现实中这段代码还不能解决问题。让我们假设一个hash函数输出一个很大的hash码。在给出的例子中数组索引等于其hash码,我们必须重新设置非常大的数组大小。但是很可能意味着失败。难道你希望将一个字符串存储在几个G大小的内存空间中?
第二个问题是如果遇到冲突,前值将被新值替代。总之,Adler32()函数还是有可能对两个不同的字符串返回同一个hash码的。你是否愿意仅仅为了使用key来快速访问丢失数据?针对这些问题的答案显而易见 — 不,你不会愿意。为了避免这种情况的发生,我们必须修改存储算法并基于链表数组开发一种特殊的混合存储容器。
链表数组结合了数组和列表的最佳特性。这两个类在标准类库中描述。要注意的是数组能够非常快的访问未定义元素,但是重新组织数组大小却很慢。但是链表可以很快的执行新增和删除元素操作,但是要访问每一个链表中的元素又很慢。
一个链表数组可以表示为如下形式:

图. 5. 链表数组
从上图中可以看到列表数组是一个每个元素都是列表的数组。让我们看看这有什么好处。首先,我们可以迅速的通过索引访问任何列表。另外,如果我们将数据元素存储在列表中,我们将能够及时从列表中添加和删除元素二不调整数组大小。数组索引可以是空或者NULL这意味着对应于这个索引的元素尚未被添加。
将数组和列表组合起来给我们带来了一个难得的机会。我们可以在一个索引中存储多个元素。为了便于理解,我们假设需要在只有3个元素的数组中存储10个数字。可见要存储的数字比数组元素多。我们将通过在数组中存储列表的方式解决此问题。让我们假定,我们需将三个列表之一连接到三个数组索引中的一个,来存储一个或另一个数。
为了确定列表索引,我们需要找出数组元素个数的除余数。
数组索引 = 数字 % 数组元素个数;
例如,数字2的列表索引将是: 2%3 = 2。这也意味着2将被存储在索引为2的列表中。3将被存储在索引为 3%3 = 0 的列表中。7将被存储在索引 7%3 = 1 的列表中。在确定了列表索引后,我们仅需要将数字添加到列表末端。
从列表中解析数据的方法类似。假设我们现在要解析数字7。为此我们需要找出它的位置: 7%3=1。在我们知道了数字7存储在索引为1的列表中后,我们将检索整个列表并返回等于7的元素的值。
如果我们能够使用一个索引存储几个元素,我们就无需为了存储少量的数据创建巨大的存储空间。让我们假设需要在具有三个元素的数组中存储数字232,547,879。这个数字的列表索引为(232,547,879 % 3 = 2)。
如果我们用hash码替换数字,我们就能为需要放置到字典中的任何一个元素找到一个索引。因为hash码是一个数字。另外,由于能够在一个列表中存储多个元素,hash码无需是唯一的。具有同一个hash码的元素将被存储在一个列表中。如果我们需要通过key解析一个元素,我们将比较这些元素并根据key解析对应的元素。
两个hash码一样的元素是可能有两个不同的key的。key的唯一性可以通过增加元素到字典中的函数来控制。如果对应的key已经在字典中存在,那么新的元素不会被添加。这就像控制一个用户只有一个电话号码与之对应一样。
2.6. 数组大小重构,最小化列表长度。
列表数组长度越小并且要添加的元素越多,那么算法将形成越长的列表链。如第一章所述,访问这种链表中的元素效率不高。我们的列表越短,我们的容器将看起来越像可以通过索引来访问的数组。我们要的是短的列表和长的数组。含有十个元素的完美数组是一个包含10个列表的数组,每个列表只有一个元素。
最坏的情况是一个仅有一个列表包含10个元素的数组。因为所有元素在程序运行时都是动态添加到我们的容器中的,我们不能预见有多少元素将被添加。这也是为何我们要动态分配数组长度的原因。另外,列表中的元素个数倾向于一个。为了实现这个目的,显然这就要求数组长度要等于元素个数。持续添加元素就需要不断的调整数组大小。
这种情况也很复杂,因为在调整数组大小的同时我们也必须调整所有列表长度,因为元素所属的列表索引可能会发生变化。例如,如果数组有三个元素,数字5将被存储在第二个索引中(5%3 = 2)。如果有留个元素,数字5将被存储在第5个索引中(5%6=5)。因此,字典大小调整是缓慢的操作。它应尽可能的少。另一方面,如果我们完全不执行这个操作,链表会随着新元素的增加而增加,那么访问每个元素将变得越来越低效。
我们可以创建一个算法,来合理的平衡数组长度和链表的平均长度。它将基于这样的事实,每一次数组大小调整都将是现在数组长度的两倍。因此如果字典初始只有两个元素,那么第一次调整后尺寸大小将为4 (2^2),第二次 - 8 (2^3),第三次 - 16 (2^3)。第16次调整后大小将为 65 536(2^16)。如果新增元素的数量正好等于当前数量的2次幂时调整数组大小。因此,实际需要的总内存将不会超过存储所有元素所需内存的两倍。另一方面,此算法将有助于避免频繁调整数组大小。
类似的,从列表中一处元素能够减少数组的大小并且节省内存空间。
第三章一个关联数组的开发实例
3.1. CDictionary类模板,AddObject和DeleteObjectByKey方法以及KeyValuePair容器
我们的关联数组必须是多功能的并且支持所有类型的key。同时我们将使用基于标准CObject类的对象作为变量。既然我们能够将任何基本类型变量都放在类中,我们的字典将提供一站式解决方案。当然,我们要能够创建多个字典类。可以为每个基本类型使用一个独立的类。
例如我们能够创建下面的类:
CDictionaryLongObj // 存储 <ulong, CObject*> CDictionaryCharObj // 存储 <char, CObject*> CDictionaryUcharObj // 存储 <uchar, CObject*> CDictionaryStringObj // 存储 <string, CObject*> CDictionaryDoubleObj // 存储 <double, CObject*> ...
但是MQL5中有太多的基本类型。还有,我们将不得不多次修正每一个代码错误,因为所有类型都有一个核心代码。我们将使用模板来避免重复。我们将只有一个类,但是它能够同时处理多个数据类型。这也是为何类的主要方法都是模板。
首先,让我们创建第一个模板方法 — Add()。这个而方法将会添加一个任意key的元素到字典中。字典类命名为 CDictionary。除元素本身外,字典还将包含指向CList列表的指针数组。我们将元素存储在这些链表中:
//+------------------------------------------------------------------+ //| 一个关联数组或者字典存储元素形如 | //| <key - value>,key可能被任何基本类型所表示 | //| 值可能被CObject类型对象表示。 | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // 列表数组。 template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| 添加一个带 T 的CObject类型元素key到字典中 | //| 输入参数: | //| T key - 任何基本类型,例如 int,double或者string。 | //| value - 从CObject类派生而来的类。 | //| 返回: | //| true,如果元素已添加,否则 - false。 | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
AddObject()方法运作方式如下。首先它检查是否有一个带key的元素要添加到字典中。ContainsKey()方法执行此项检测。如果字典中已经存在此key,新的元素将不会被添加,因为如果两个元素对应一个key会带来不确定性。
然后此方法获取到存储CList列表的数组大小。如果数组大小等于元素个数,那就是重新分配数组大小的时候了。这个操作在Resize()方法中实现。
下一步就简单了。如果根据确定的索引Clist链表尚不存在,那么就需要创建之。索引在此前由ContainsKey()方法确定。将索引存储在变量m_index中。然后在列表末端添加一个新元素。在此之前,这个元素被存储在一个特殊的容器中 — KeyValuePair。它是基于标准CObject的并且对其进行了扩展,增加了指针和数据。容器类的组织在稍后讨论。除了额外的指针,容器还包含一个对象的原始key和它的hash码。
AddObject()方法是一个模板方法:
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
这意味着key的类型为可替换的 ,并且其实际类型在编译的时候确定。
例如,AddObject()方法可以用如下代码激活:
//+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
由于模板的作用这些操作将完美的执行。
还有DeleteObjectByKey()方法,和AddObject()方法相反。这个方法从字典中通过元素的key删除一个对象。
例如,你可以删除key为“Car”的对象,如果对象存在的话。
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
代码和AddObject()方法的代码很类似,因此我们不再赘述。
AddObject()和DeleteObjectByKey()方法不直接操作对象。取而代之的是,它们把每个对象打包到基于标准CObject类KeyValuePair的容器中。这个容器有能够关联元素的指针,并且有一个对象的初始key和hash码。此容器也测试传入的key以避免冲突。我们将在下一章节中探讨处理冲突的ContainsKey()方法。
现在来看看这个类的代码:
//+------------------------------------------------------------------+ //| 存储CObject元素的容器 | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // 存储字符串类型的key double m_double_key; // 存储浮点数类型的key ulong m_ulong_key; // 存储无符号整型的key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. 基于类型明名称、hash采样,在运行时确定变量类型。
现在当我们要知道如果获取未定义方法时,我们需要确定它们的hash码。对于所有整型类型来说,一个hash码等于将此值扩展为ulong 类型后的值。
要计算double 和 float 类型的hash码,我们需要使用结构体,在“将基本类型转换为一个唯一key”章节中描述过。hash函数应该能被用于string类型。不管怎么说,任何数据类型都需要其自身的hash采样方法。因此我们要做的就是确定转换类型并且使用对应于此类型的hash采样方法。要实现这个目标我们将需要一个特殊的类型名称。
根据key确定hash码的方法称为GetHashByKey()。
它包含:
//+------------------------------------------------------------------+ //| 基于key计算hash码 | //| key可能被表征为任何MQL类型。 | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
它的逻辑很简单。使用类型名的方法获取传输类型的字符串名称。如果字符串作为key传输,类型名称将返回“string”值,如果是整型值将返回“int”。其他类型也一样。因此,我们要做的是比较返回值和字符串常量,如果其值和常量之一吻合则激活对应的函数句柄。
如果key是string类型, 那么它的hash码由Adler32()函数计算。如果key由实际类型表征,它们被转换成结构变换的hash码。所有其他类型都精确的转换为ulong类型的hash码。
3.3. ContainsKey()方法。哈希冲突的应对
任何hash函数的主要问题都是存在冲突 — 即当不同的key对应同一个hash码的情况。如果hash码冲突,就会产生混淆(两个对象在字典逻辑中将为同一个)。为了避免这种情况发生,我们需要检查实际和请求的key类型,仅当实际key冲突时返回一个正值。这就是ContainsKey()方法的运作原理。如果对象请求的key已经存在则返回true,否则返回false。
也许,这是整个字典中最有用和便捷的方法。它判断一个对象的key是否已经存在:
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
例如,上面的代码检查CCar类型对象是否存在,如果不存在则添加之。这个方法也检测每一个添加的新对象的key是否唯一。
如果对象的key已经存在,AddObject()方法就不会把这个新对象添加到字典中。
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
这就是被用户和其他类大量使用的通用方法。
如下:
//+------------------------------------------------------------------+ //| 检查字典中是否存在T类型的key | //| 返回: | //| 如果已经存在返回true, | //| 否则返回false。 | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
首先此方法使用GetHashByKey()查找hash码。然后基于hash它获得Clist链表的索引,给定hash码的对象就存储在这个索引中。如果没有这样的链表,那么具有此key的对象也不存在。这种情况下将提前终止操作并返回false(具有此key的对象不存在)。如果链表存在,则开始枚举。
链表中的每个元素被KeyValuePair类型的对象所表征,用于比较实际转换的key和元素中存储的key。如果key一样,函数返回true(已有此key的对象存在)。判断key是否相等的代码在KeyValuePair类中给出。
3.4. 动态分配和内存释放
在我们的关联数组中,Resize()方法用于动态分配和回收内存。此方法每当元素个数等于m_array大小时被调用。当元素被从列表中删除时也会调用。该方法将覆盖存所有存储元素的索引,所以它运行起来非常慢。
为了避免频繁调用Resize()方法,每次分配的内存都为原来大小的两倍。换句话说,如果我们的字典想要存储65,536个元素,Resize() 方法将被调用16次(2^16)。20次调用后,字典可能含有超过一百万个元素(1,048,576)。FindNextLevel()方法用于计算所需的指数级增长的元素个数。
这就是Resize()方法的源码:
//+------------------------------------------------------------------+ //| 重新分配存储空间大小 | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
此方法对于增加和减少内存空间都适用。当元素少于实际数组容量时,缩减空间的代码被调用。反之当当前数组空间不够时,数组将被重新分配大小用于存储更多的元素。这个操作消耗很多计算资源。
整个数组都得重新组织大小,再次之前所有的元素都必须先移动到另一个数组中暂存。然后你得确定所有元素的新的索引并只有在此之后你才能将这些元素放到新的位置中去。
3.5. 终极招数:搜索对象及一个简便的索引器
由于我们的CDictionary类已经有了用于运行的主要方法。如果我们想要知道特定key的对象是否存在,我们可以用ContainsKey()方法。我们可以使用AddObject()方法将一个对象添加到字典中。我们也能使用DeleteObjectByKey()方法将一个对象从字典中删除。
现在我们仅需要为所有对象创建一个便捷的枚举类型。正如和们所知,所有的元素都依据它们的key以某种特殊的方式存储在那里。但是如果我们以相同的顺序将它们添加到关联数组中将会有利于枚举所有元素。为了达到这个目的,KeyValuePair容器有两个额外的指针,指向前一个和后一个被添加的KeyValuePair类型元素。我们可以根据这些指针执行顺序枚举。
例如,如果我们如下向关联数组中添加元素:
CNumber --> CShip --> CWeather --> CHuman --> CExpert --> CCar
因为将通过KeyValuePair的引用来执行这些元素的枚举也将是按顺序的,如图6所示:

图. 6. 数组顺序枚举方案
执行这个枚举用到5个方法。
下面是它们的简述:
//+------------------------------------------------------------------+ //| 返回当前对象。如果对象未选中返回NULL | //| | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| 返回前一个对象。调用此方法后当前对象变为 | //| 前一个对象。如果对象 未选中返回NULL | //| | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| 返回下一个对象。当前对象变为下一个 | //| 调用此方法后,如果调用对象未选中,返回NULL | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| 返回节点列表中的第一个节点。返回NULL | //| 字典 中没有节点。 | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| 返回节点列表中的最后一个节点。返回NULL如果 | //| 字典 中没有节点。 | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
通过这些简单的迭代,我们可以执行一个所添加元素的顺序枚举:
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
这个代码将以相同的顺序输出已被添加到字典中的对象的字符串值:
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
改变OnStart()函数中两行代码,逆向输出所有元素:
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
相应的,输出内容逆向:
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
第四章。测试并评估性能
4.1. 写入测试及性能评估
性能评估是类设计的核心部分,尤其是用于存储数据的类。不管怎样,最多样化的程序可以利用这个类的优势。这些程序的算法对于提升运算速度非常关键,并且可能需要高的性能。这也是为何知道如何评估性能以及发现算法中的缺陷如此的重要。
一开始,我们将编写一个简单的测试脚本来评估在字典中添加及解析元素的速度。此测试程序看上去像是一个脚本。
源代码如下:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
这段代码顺序向字典中添加元素,然后再引用它们评估执行速度。此后使用DeleteObjectByKey()方法删除每个元素。GetTickCount()系统函数用于评估执行速度。
使用这个脚本,我们做了一个图来描绘这三种主要方法的时间依赖性:
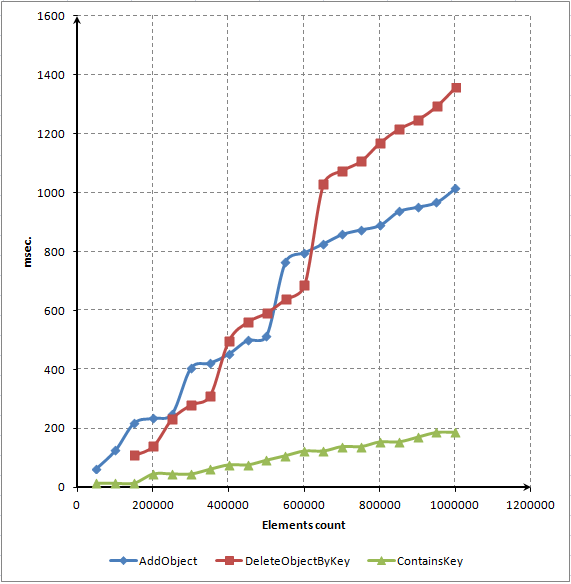
图. 7. Dot图展现了元素成员及函数运行时间之间依赖关系(毫秒)
你可以看到绝大多数时间都消耗在分配和从字典中删除元素上。然而,我们期望删除元素会更快些。我们将使用一个代码分析器来尝试提升该方法的性能。这个过程将在下一节中描述。
把注意力转到ContainsKey()方法的图上来。它是线性的。这就是说访问一个随机元素需要大约一份时间,不管数组中元素的数量有多少。这就是真实关联数组必须具备的特性。
为了揭示这个特性,我们将展示访问数组中一个元素和多个元素所需的平均时间之间的关系。
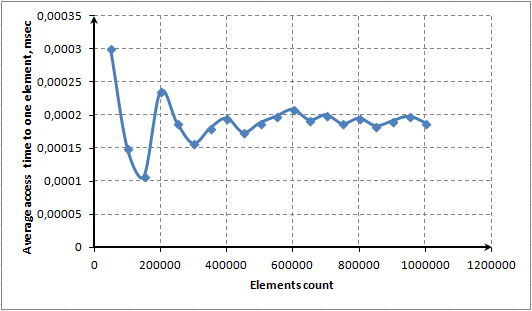
图. 8. 使用ContainsKey()方法访问一个元素的平均时间
4.2. 代码分析自动内存管理的速度
代码分析是一种特殊的技术,用于检测所有函数的时间消耗。只需在MetaEditor点击![]() 加载任意MQL5程序。
加载任意MQL5程序。
我们将用同样的方式来分析我们的脚本。一段时间后我们的脚本完成运行,我们得到脚本中所有方法的运行时间分析。截图显示最耗时的三个方法:AddObject() (耗费40%的时间),GetObjectByKey() (耗费7%的时间)以及DeleteObjectByKey() (耗费53%的时间)。
函数代码分析")
图. 9. OnStart()函数代码分析
Compress()方法消耗了超过60%的DeleteObjectByKey()函数运行时间。
但是此方法几乎是空的,时间主要都花在了Resize()方法上。
它包含:
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
问题清楚了。当我们删除所有元素时,Resize()方法偶尔被加载。这个方法动态减少数组大小以释放存储空间。
如果你想加快删除元素的速度就禁用这个方法。例如,你可以使用AutoFreeMemory()方法,在类中设置缩减标识。将它设为默认值,并且在这种情况下压缩会自动执行。但是如果我们需要获得额外的速度,就得手动在合适的时候执行压缩。我们把Compress() 方法设为公共方法来实现这一目的。
如果压缩被禁用,元素的删除速度将快三倍:
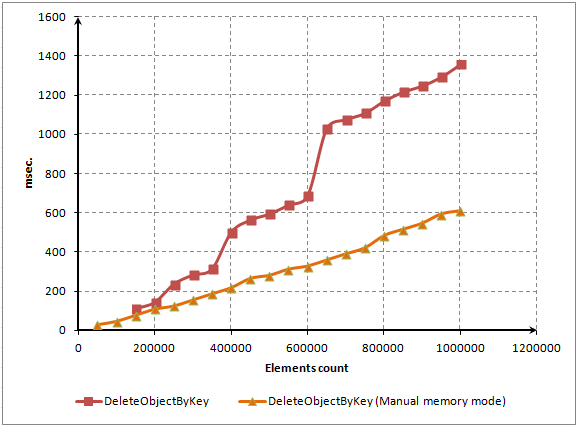
图. 10. 元素删除时间对比
Resize()方法不仅在数据压缩时被调用,而且当元素过多我们需要更大的数组时被调用。在这种情况下,我们无法避免Resize()方法的调用。为了将来创建的CList链表不冗长,它必须被调用。但是我们可以预先确定字典所需的空间大小。
例如,要添加的元素数量往往事先就能知道。知道元素的数量,就能为字典预先创建符合其大小的数组,因此就无需在数组填充阶段额外改调整其大小了。
为了实现这一目的,我们将添加一个额外的构造函数,用于接收所需的元素。
//+------------------------------------------------------------------+ //| 创建一个容量预先定义好的字典 | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
私有的Init()方法执行主要操作:
//+------------------------------------------------------------------+ //| 初始化字典 | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
我们的改进结束了。现在是评估已定义数组大小后,AddObject()方法性能的时候了。修改OnStart()函数的头两行:
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
在这种情况下END代表1,000,000个元素。
这些改进显著的提升了AddObject()方法的性能:

图. 11. 预设数组大小后添加元素所需的时间
解决实际变成问题我们惊颤刚不得不在内存占用和性能速度两者之间做选择。释放内存需要大量的时间。但是这种情况下我们将获得更多的内存。如果我们不干预,CPU就不会在复杂的计算问题上花费额外的时间,但是同时可用内存就会变少。使用容器的面向对象编程,为每个问题选择一种特定的执行策略,就能够在CPU缓存和CPU时间之间弹性的分配资源。
总而言之,CPU性能比内存占用更加关键。这也就是为什么大多数情况下我们优先选择提升执行速度,而不是内存占用。另外,用户侧的内存控制比自动控制更为高效,因为往往我们不清楚任务最重的状态。
例如,如果我们预先知道脚本最后所有元素都将为null,那么DeleteObjectByKey()方法将在任务的最后时刻删除它们。这就是为何我们无需自动缩减数组大小。在最后调用Compress()方法就够了。
现在当我们有了良好的从数组中添加和删除元素的线性指标,我们可以分析添加和删除一个元素的平均时间了。
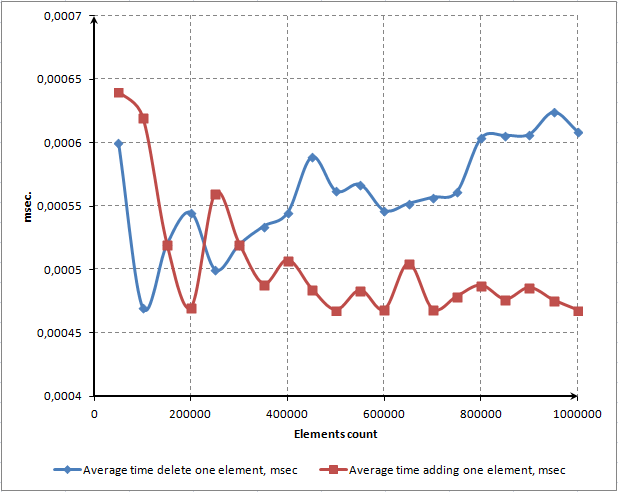
图. 12. 添加和删除一个元素的平均时间
可以看到添加一个元素的平均时间非常稳定,和数组中元素数量的多少没有关系。删除一个元素的平均时间缓缓的增长,这并不是我们希望的。但是我们不能肯定这是在误差范围内的结果还是常规趋势。
4.3. 传统的CArrayObj同CDictionary的性能对比
现在进行我们最感兴趣的测试:标准CArrayObj类的CDictionary。CArrayObj在创建阶段并没有类似累计分配空间提示的手动内存分配机制,这也就是为何我们在CDictionary将禁用手动内存分配,而启用AutoFreeMemory()机制。
每个类的优缺点在第一章中已经介绍过了。CDictionary允许在不确定的位置添加元素,并且从字典中快速的解析它。但是CArrayObj可是非常快速的枚举所有元素。在CDictionary中枚举会很慢,因为是通过指针的方式移动,这要慢于直接通过索引访问。
至此我们有了结论。让我们创建一个新版的测试程序:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| 脚本程序start函数 | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
它使用TEST_ARRAY宏。如果它被定义,则测试在CArrayObj上执行,否则在CDictionary上执行。添加新元素的第一个测试Dictionary胜出。
它的内存分配表现在这种特定情况下更好:
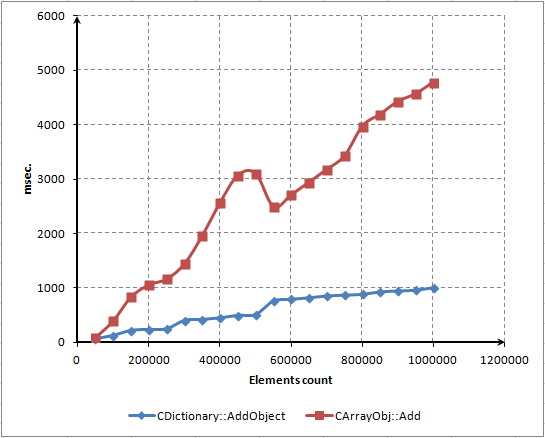
Fig. 13. 向CArrayObj和CDictionary中添加新元素的时间开销对比
要强调的是执行速度慢是由于CArrayObj特殊的内存分配机制引起的。
源代码中仅有一行描述了这个操作:
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize); 这是内存分配的线性算法。在每填充16个元素后被调用。CDictionary使用指数级算法:每下一次内存分配的大小都是前次的两倍。此图完美地演绎了性能和内存占用之间的两难选择。CArrayObj类的Reserve()方法更为高效且需要更少的内存,但是运行起来慢一些。CDictionary类的Resize() 方法执行起来更快但是需要更多的内存,并且所占用内存的一半可能都用不到。
让我们进行最后一个测试。我们将计算CArrayObj和CDictionary容器的全枚举所需时间。CArrayObj使用直接索引,CDictionary使用引用。CArrayObj可以通过索引访问任何元素,但是在CDictionary中通过索引引用任意元素是不允许的。通过直接索引的顺序枚举非常高效:
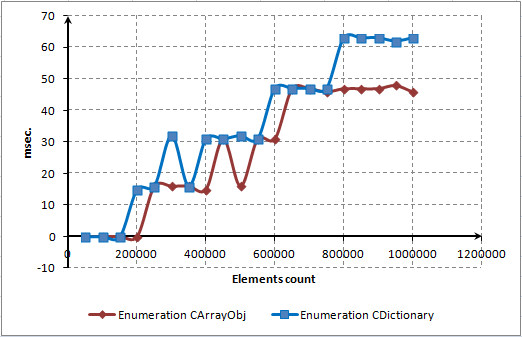
Fig. 14. CArrayObj和CDictionary的全枚举时间
MQL5语言开发者做的很好并优化了引用。如图所示,和直接索引相比它们的执行速度非常具有竞争力。
元素枚举耗时非常短几乎到了GetTickCount()函数能够分辨的边缘,意识到这点很重要。用它很难侦测到小于15毫秒的时间间隔。
4.4. 当使用CArrayObj, CList 和 CDictionary时的建议
我们将创建一个表格描述在编程中将遇到的主要任务以及解决这些问题必须要知道的容器的特性。
性能表现良好的特性用绿色表示,反之用红色表示。
| 目标 | CArrayObj | CList | CDictionary |
|---|---|---|---|
| 顺序在容器尾部添加新的元素。 | 容器必须为新的元素分配新的空间。无需将已有元素转移到新的索引中。CArrayObj能够非常快速的执行此番操作。 | 容器记忆第一个当前和最后一个元素。正因为如此,一个新的元素将会被非常快的添加到列表(最后一个元素)的后面。 | 字典没有诸如“结束”或“开始”的概念。新元素非常快的被添加到其中,和元素的数量没有关系。 |
| 通过其索引访问任意元素。 | 由于直接索引,访问非常快速,时间复杂度O(1)。 | 通过对所有前一个元素的枚举来实现每个元素的访问。时间复杂度O(n)。 | 通过对所有前一个元素的枚举来实现每个元素的访问。时间复杂度O(n)。 |
| 通过key访问任意元素。 | 不可用 | 不可用 | 通过key来确定hash码和索引是一种高效快速的操作方式。对于字符串key来说,hash码生成函数的效率非常重要。这个操作的时间复杂度为O(1)。 |
| 通过未定义的索引来添加/删除新元素。 | CArrayObj不仅为新元素分配内存,而且将索引大于被插入元素的所有元素都移除。这也就是CArrayObj执行较慢的原因。 | 元素在CList中添加或删除非常迅速,但是访问其索引的时间复杂度为O(n)。此操作非常慢。 | 在CDictionary中,通过索引访问元素的操作是基于CList列表的,它非常耗时。但是添加和删除元素的操作却非常快。 |
| 新的元素通过未定义过的key来添加/删除。 | 不可用 | 不可用 | 每个新元素被插入到CList中,数组无需在每次添加和删除操作后重新组织大小,因此元素的添加和删除执行起来非常快。 |
| CPU占用率和内存管理。 | 这就需要动态数组。这是一个资源密集型操作,要么需要非常多的时间,要么需要占用很多内存。 | 不使用内存管理。每个元素都占用一定的内存空间。 | 这就需要动态数组。这是一个资源密集型操作,要么需要非常多的时间,要么需要占用很多内存。 |
| 元素枚举。向量中每个元素必须要执行的操作。 | 由于直接索引访问,执行起来非常快。但某些情况下必须反向枚举(例如,顺序删除最后一个元素)。 | 因为我们仅需枚举所有元素一次,直接引用的执行速度很快。 | 因为我们仅需枚举所有元素一次,直接引用的执行速度很快。 |
第五章。CDictionary 类文档
5.1. 添加,删除和访问元素的方法
5.1.1. AddObject()方法
添加带T key的CObject类型的新元素。任何基本类型都可以作为key.
template<typename T> bool AddObject(T key,CObject *value);
参数
- [in] key – 由基本类型(string, ulong, char, enum etc.)代表的唯一key.
- [in] value - CObject对象作为基本类型。
返回值
如果对象已经添加到容器中返回true,否则返回false。如果被添加对象的key已经存在,函数将返回负数并且对象不会被添加。
5.1.2. ContainsKey()方法
检查容器中是否存在key为T key的对象。任何基本类型都可以作为key.
template<typename T> bool ContainsKey(T key);
参数
- [in] key – 由基本类型(string, ulong, char, enum etc.)代表的唯一key.
如果具有被检测key的对象已经存在于容器中,则返回true。否则返回false。
5.1.3. DeleteObjectByKey()方法
根据预设的T key删除对象。任何基本类型都可以作为key.
template<typename T> bool DeleteObjectByKey(T key);
参数
- [in] key – 由基本类型(string, ulong, char, enum etc.)代表的唯一key。
返回值
如果预设key对应的对象被删除,则返回true。如果对象不存在或者删除失败,则返回false。
5.1.4. GetObjectByKey()方法
返回T key代表的对象。任何基本类型都可以作为key.
template<typename T> CObject* GetObjectByKey(T key);
参数
- [in] key – 由基本类型(string, ulong, char, enum etc.)代表的唯一key。
返回值
返回预设key对应的对象。乳沟对象不存在,返回NULL。
5.2. 内存管理方法
5.2.1. CDictionary()构造函数
构造函数创建CDictionary对象,基本数组的初始大小等于3。
数组根据字典元素的填充和删除增加或减少空间。
CDictionary();
5.2.2. CDictionary(int capacity) 构造函数
构造函数创建CDictionary对象,数组初始大小等于“capacity”。
数组根据字典元素的填充和删除增加或减少空间。
CDictionary(int capacity);
参数
- [in] capacity – 初始元素个数。
注意
数组初始化后立即限制其大小有助于避免调用Resize()方法,可以提升新元素插入效率。
然而必须注意的是,如果你使用(AutoMemoryFree(true))来删除元素,不管capacity设置和值,容器都将自动缩小空间。为了避免过早的缩减,在容器被完全填充之后执行第一次对象删除操作,或者无法执行时禁用(AutoMemoryFree(false))。
5.2.3. FreeMode(bool mode)方法
设置删除容器中已有对象的方式。
如果启用删除模式,当对象被删除后容器仍旧维持“delete”模式。析构函数被激活并且对象变为不可用。如果删除模式被禁用,对象的析构函数不会被激活,仍旧可被程序的其他地方使用。
void FreeMode(bool free_mode);
参数
- [in] free_mode – 对象删除模式指标
5.2.4. FreeMode()方法
返回容器中删除元素的指标(参见 FreeMode(bool mode))。
bool FreeMode(void);
返回值
返回true,如果对象被delete操作符成功删除。否则返回false。
5.2.5. AutoFreeMemory(bool autoFree)方法
设置自动内存管理指标。默认启用自动内存管理启动。在这种情况下数组自动缩减(大小减少)。如果禁用,数组则不缩减。它将显著提升程序的执行速度,因为会消耗大量资源的Resize()方法不被调用。但这种情况下你必须时刻留意数组大小,通过Compress()方法手动缩减数组空间。
void AutoFreeMemory(bool auto_free);
参数
- [in] auto_free – 内存管理模式指标
返回值
如果你要启用内存管理并自动调用Compress()方法,返回true。否则返回false。
5.2.6. AutoFreeMemory()方法
返回是否自动内存管理模式的指标(参见FreeMode(bool free_mode)方法)。
bool AutoFreeMemory(void);
返回值
返回true,如果内存管理模式启用。否则返回false。
5.2.7. Compress()方法
缩减字典大小并重组元素。数组仅在可能时被压缩。
这个而方法仅可在自动内存管理模式被禁用时调用。
void Compress(void);
5.2.8. Clear()方法
删除自动中的所有元素。如果内存管理指标被启用,每个元素删除时析构函数被调用。
void Clear(void);
5.3. 字典搜索方法
所有字典中的元素是无关联的。每个新元素和前一个元素相关联。因此顺序搜索字典中所有元素成为可能。在这种情况下元素引用通过一个链表执行。本节的方法便于查找以及使得使字典迭代更方便。
当搜索字典时,你可以使用下面的构造函数:
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // 节点代表字典的当前元素。 }
5.3.1. GetFirstNode()方法
返回最早添加到字典中的元素。
CObject* GetFirstNode(void); 返回值
返回最先添加到字典中的CObject类型对象的指针。
5.3.2. GetLastNode()方法
返回字典中最后一个元素。
CObject* GetLastNode(void); 返回值
返回最后添加到字典中的CObject类型对象的指针。
5.3.3. GetCurrentNode()方法
返回当前选中的元素。元素必须通过字典搜索方法或者字典元素访问方法(ContainsKey(), GetObjectByKey())之一,预先选中。
CObject* GetLastNode(void); 返回值
返回最后添加到字典中的CObject类型对象的指针。
5.3.4. GetNextNode()方法
返回紧接当前元素的下一个元素。如果当前元素就是最后一个或者未被选中,则返回NULL。
CObject* GetLastNode(void); 返回值
返回当前元素下一个CObject类型对象的指针。如果当前元素就是最后一个或者未被选中,则返回NULL。
5.3.5. GetPrevNode()方法
返回当前元素的前一个元素。如果当前元素就是第一个或者未被选中,则返回NULL。
CObject* GetPrevNode(void); 返回值
返回当前元素前一个CObject类型对象的指针。如果当前元素就是第一个或者未被选中,则返回NULL。
总结
我们已经考虑了大量的数据容器的主要特征。每种数据容器都应该用在其能够最高效的解决问题的场合。
常规数组应该被用于顺序访问元素已经足够解决问题的场景。当需要通过唯一key来访问元素时,使用字典和关联数组就更加高效。如果经常需要进行元素替换操作:删除、插入、添加,那么最好使用列表。
字典能够简洁完美的解决棘手的算法问题。字典能够以最有效的方式访问已经存在的元素,而其他数据容器需要额外的处理功能。例如,基于字典你可以创建一个事件模型,每个OnChartEvent()类型的事件都被传递到管理图形元素的类中。为了实现这个目的,将每个类的实例和这个类管理的对象的名称关联起来。
因为字典是一种通用算法,它可以应用在非常广泛的地方。这篇文章阐明了字典算法的操作是非常简单而强大,这使得它的应用方便有效。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/1334
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 如何在莫斯科交易所安全地使用您的 EA 进行交易
如何在莫斯科交易所安全地使用您的 EA 进行交易
 使用 CCanvas 类绘制刻度表盘
使用 CCanvas 类绘制刻度表盘
一般情况下不一定要正确工作。
从关联数组中执行多次删除的正确方法是收集要删除的键的数组,然后按键删除。
问题就在这里,即使是这种方法也会突然出现一个奇怪的错误。这显然是个错误。我会研究一下。
目前,我建议你创建一个新的字典,并将不需要删除的值添加到其中。然后清除旧字典。这将 100% 有效。
开始吧:
1. 将字典版本更新为本帖子所附的版本。
2.运行测试脚本删除偶数元素。
删除应分两次完成:
关于DeleteCurrentObject() 方法:
该方法只能与 ContainsKey() 函数结合使用。将其作为公共方法的唯一原因是,在这种情况下,调用该方法可以节省重新定位指针的时间。也就是说,其典型且唯一的使用情况是:1.检查是否存在键,2. 如果存在,则使用该方法快速删除。
这是可以理解的,但同样也是不必要的车身装饰。
从技术上讲,可以按照您的期望进行一次拆卸。但会很复杂。这就是为什么现在还不行,只能分两次进行。从字典作为分布式数据结构 的角度来看,两次删除是一种更正确的解决方案。只是在用户层面上,删除似乎是按顺序进行的,而实际上一切都不同。就性能而言,单程删除不会带来任何好处。就方便性而言,是的,它可能更方便。
从技术上讲,可以按照你的期望进行一次清除。但会很复杂。这就是为什么现在还不能进行两次删除的原因。从字典作为分布式数据结构 的角度来看,两次删除更符合规范。只是在用户层面上,删除似乎是按顺序进行的,而实际上一切都不同。就性能而言,单程删除不会带来任何好处。就方便性而言,是的,它可能更方便。
谢谢。
我想我在删除一个元素并试图进入最后一个元素时发现了一个错误:
CDictionary.mqh 中会出现错误:
Dictionary.mqh 中的无效指针 访问 (463,9)
有人能确认这一点吗?有任何修复方法吗?
这是在第 500 && 501 行检查指针时出现的错误。
使用内置的 CheckPointer() 进行了修复。