
MQL5 Cookbook: Implementazione di un array associativo o di un dizionario per l'accesso rapido ai dati

Sommario
- INTRODUZIONE
- CAPITOLO 1. TEORIA DELL'ORGANIZZAZIONE DEI DATI
- CAPITOLO 2. TEORIA DELL'ORGANIZZAZIONE ASSOCIATIVA DI ARRAY
- CAPITOLO 3. SVILUPPO PRATICO DI UN ARRAY ASSOCIATIVO
- CAPITOLO 4. TEST E VALUTAZIONE DELLE PRESTAZIONI
- CAPITOLO 5. DOCUMENTAZIONE DELLA CLASSE DI CDICTIONARY
- CONCLUSIONE
Introduzione
Questo articolo descrive una classe per una comoda archiviazione delle informazioni, ovvero un array associativo o un dizionario. Questa classe consente di accedere alle informazioni tramite una chiave.
L'array associativo assomiglia a un array regolare. Ma invece di un indice utilizza una chiave univoca, ad esempio l'enumerazione ENUM_TIMEFRAMES o del testo. Non importa cosa rappresenti una chiave. È l'unicità della chiave che conta. Questo algoritmo di memorizzazione dei dati semplifica notevolmente molti aspetti della programmazione.
Ad esempio, una funzione, che richiederebbe un codice di errore e stamperebbe un testo equivalente all'errore, potrebbe essere la seguente:
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
Esamineremo in seguito le caratteristiche specifiche di questo codice.
Prima di dare una descrizione diretta della logica interna degli array associativi, prenderemo in considerazione i dettagli dei due metodi principali di memorizzazione dei dati, ovvero gli array e le liste. Il nostro dizionario si baserà su questi due tipi di dati, ecco perché dovremmo avere una buona comprensione delle loro caratteristiche specifiche. Il capitolo 1 è dedicato alla descrizione dei tipi di dati. Il secondo capitolo è dedicato alla descrizione dell'array associativo e ai metodi per lavorarci.
Capitolo 1. Teoria dell'organizzazione dei dati
1.1. Algoritmo di organizzazione dei dati. Ricerca del miglior contenitore di archiviazione dati
La ricerca, l'archiviazione e la rappresentazione delle informazioni sono le principali funzioni imposte ai moderni computer. L'interazione uomo-computer di solito include la ricerca di alcune informazioni o la creazione e l'archiviazione di informazioni per un utilizzo futuro. L'informazione non è un concetto astratto. In un certo senso, c'è un certo concetto sotto questa parola. Ad esempio, una cronologia delle quotazioni di un simbolo è una fonte di informazioni per qualsiasi trader che fa o sta per concludere un accordo su questo simbolo. La documentazione del linguaggio di programmazione o il codice sorgente di alcuni programmi possono servire come fonte di informazioni per un programmatore.
Alcuni file grafici (ad esempio, un'immagine realizzata con una fotocamera digitale) possono essere una fonte di informazioni per persone estranee alla programmazione o al trading. È evidente che questi tipi di informazioni hanno strutture e natura diverse. Di conseguenza, gli algoritmi di memorizzazione, rappresentazione ed elaborazione di queste informazioni saranno diversi.
Ad esempio, è più semplice presentare un file grafico come matrice bidimensionale (array bidimensionale) nella quale ogni elemento o cella memorizzerà informazioni sul colore di una piccola area dell'immagine — pixel. I dati delle quotazioni hanno un'altra natura. Essenzialmente, questo è un flusso di dati omogenei in formato OHLCV. È meglio presentare questo flusso come un array o una sequenza ordinata di strutture il quale rappresenta un certo tipo di dati nel linguaggio di programmazione che combina diversi tipi di dati. La documentazione o un codice sorgente è solitamente rappresentato come testo normale. Questo tipo di dati può essere definito e archiviato come una sequenza ordinata di stringhe, dove ogni stringa è una sequenza arbitraria di simboli.
Il tipo di contenitore in cui archiviare i dati dipende dal tipo di dati. Usando i termini della programmazione orientata agli oggetti, è più facile definire un contenitore come una certa classe che memorizza questi dati e ha algoritmi (metodi) speciali per manipolarli. Esistono diversi tipi di contenitori di archiviazione dati (classi). Si basano su una diversa organizzazione dei dati. Ma alcuni algoritmi di organizzazione dei dati consentono di combinare diversi paradigmi di archiviazione dei dati. In questo modo possiamo trarre vantaggio dalla combinazione dei vantaggi di tutti i tipi di archiviazione.
Si seleziona uno o un altro contenitore per archiviare, elaborare e ricevere dati a seconda di un presunto metodo di manipolazione e della loro natura. È importante rendersi conto che non esistono contenitori di dati altrettanto efficienti. I punti deboli di un contenitore di dati sono il rovescio dei suoi vantaggi.
Ad esempio, è possibile accedere rapidamente a qualsiasi elemento dell'array. Tuttavia, è necessaria un'operazione dispendiosa in termini di tempo per l'inserimento di un elemento in un punto a caso dell'array, poiché in questo caso è richiesto il ridimensionamento completo dell'array. E viceversa, l'inserimento di un elemento in un elenco con collegamento singolo è un'operazione efficace e ad alta velocità, ma l'accesso a un elemento casuale può richiedere molto tempo. Se fosse necessario inserire spesso nuovi elementi, ma non hai bisogno di un accesso frequente a questi elementi, l'elenco con link singolo sarà il tuo contenitore giusto. E scegli un array come classe di dati se è richiesto un accesso frequente a elementi casuali.
Per capire quale tipo di archiviazione dati è preferibile, è necessario avere familiarità con la disposizione di un determinato contenitore. Questo articolo è dedicato all'array associativo o al dizionario, un contenitore di archiviazione dati specifico basato sulla combinazione di un array e di un elenco. Ma vorrei ricordare che il dizionario può essere implementato in modi diversi a seconda di un determinato linguaggio di programmazione, dei suoi mezzi, capacità e regole di programmazione accettate.
Ad esempio, l'implementazione del dizionario C# è diversa da C++. Questo articolo non descrive l'implementazione adattata del dizionario per С++. La versione descritta dell'array associativo è stata creata da zero per il linguaggio di programmazione MQL5 e considera le sue caratteristiche speciali e la pratica di programmazione comune. Sebbene la loro implementazione sia diversa, le caratteristiche generali ei metodi di funzionamento dei dizionari dovrebbero essere simili. In questo contesto, la versione descritta mostra pienamente tutte queste caratteristiche e modalità.
Nel frattempo creeremo gradualmente l'algoritmo del dizionario, mentre discuteremo sulla natura degli algoritmi di memorizzazione dei dati. E alla fine dell'articolo avremo una versione completa dell'algoritmo e saremo pienamente consapevoli del suo principio di funzionamento.
Non esistono contenitori altrettanto efficienti per diversi tipi di dati. Consideriamo un semplice esempio: un quaderno di carta. Può essere considerato anche come un contenitore/classe utilizzato nella nostra quotidianità. Tutte le sue note sono inserite secondo un elenco preliminarmente redatto (in questo caso alfabetico). Se conosci il nome di un abbonato, puoi facilmente trovare il suo numero di telefono, poiché devi solo aprire il taccuino.
1.2. Array e indirizzamento diretto dei dati
Un array è il modo più semplice e allo stesso tempo più efficace per memorizzare le informazioni. In programmazione, un array è una raccolta di elementi dello stesso tipo, posizionati uno dopo l'altro nella memoria. Grazie a queste proprietà possiamo calcolare l'indirizzo di ogni elemento dell'array.
Infatti, se tutti gli elementi hanno lo stesso tipo, avranno tutti la stessa dimensione. Poiché i dati dell'array sono organizzati continuamente, possiamo calcolare un indirizzo di un elemento casuale e fare riferimento direttamente a questo elemento se conosciamo la dimensione di un elemento di base. Una formula generale per il calcolo dell'indirizzo dipende da un tipo di dati e da un indice.
Ad esempio, puoi calcolare un indirizzo del quinto elemento nell'array degli elementi di tipo uchar usando la seguente formula generale che esce dalle proprietà dell'organizzazione dei dati dell'array:
indirizzo casuale dell’elemento = indirizzo del primo elemento + (indice dell'elemento casuale nell'array * dimensione del tipo di array)
L'indirizzamento dell'array parte da zero, per questo l'indirizzo del primo elemento corrisponde all'indirizzo dell'elemento dell'array con indice 0. Di conseguenza, il quinto elemento avrà indice 4. Supponiamo che l'array memorizzi elementi di tipo uchar. Questo è il tipo di dati di base in molti linguaggi di programmazione. Ad esempio, è presente in tutti i linguaggi di tipo C. MQL5 non fa eccezione. Ogni elemento dell'array di tipo uchar occupa 1 byte o 8 bit di memoria.
Ad esempio, secondo la formula precedentemente menzionata, l'indirizzo del quinto elemento nell'array uchar sarà il seguente:
indirizzo del quinto elemento = indirizzo del primo elemento + (4 * 1 byte);
In altre parole, il quinto elemento dell'array uchar sarà 4 byte più alto del primo elemento. È possibile fare riferimento a ciascun elemento dell'array direttamente dal suo indirizzo durante l'esecuzione del programma. Tale aritmetica degli indirizzi consente di ottenere un accesso molto veloce a ciascun elemento dell'array. Ma tale organizzazione dei dati presenta degli svantaggi.
Uno di questi è che non è possibile memorizzare elementi di tipi diversi nell'array. Tale limitazione è la conseguenza dell'indirizzamento diretto. Sicuramente, diversi tipi di dati variano nelle dimensioni, il che significa che il calcolo di un indirizzo di un determinato elemento utilizzando la formula sopra menzionata diventa impossibile. Ma questa limitazione può essere superata in modo intelligente, se l'array non memorizza elementi ma puntatori.
Sarà più semplice se rappresenti un puntatore come collegamento (come scorciatoie in Windows). Il puntatore si riferisce a un determinato oggetto nella memoria, ma il puntatore stesso non è un oggetto. In MQL5 il puntatore può fare riferimento solo a una classe. Nella programmazione orientata agli oggetti, una classe è un particolare tipo di dati che può includere un insieme arbitrario di dati e metodi ed essere creato da un utente per un'efficace strutturazione del programma.
Ogni classe è un tipo di dati univoco definito dall'utente. I puntatori che fanno riferimento a classi diverse non possono essere posizionati in un array. Ma indipendentemente dalla classe di riferimento, il puntatore ha sempre la stessa dimensione, poiché contiene solo un indirizzo di oggetto nello spazio degli indirizzi del sistema operativo che è comune a tutti gli oggetti allocati.
1.3. Concetto del nodo spiegato con l’esempio della classe semplice CObjectCustom
Ora abbiamo le conoscenze per progettare il nostro primo puntatore universale. L'idea è quella di creare un array di puntatori universale in cui ogni puntatore farebbe riferimento al suo tipo particolare. I tipi sarebbero diversi, ma a causa del fatto che sono indicati dallo stesso puntatore, questi tipi potrebbero essere archiviati in un contenitore/array. Creiamo la prima versione del nostro puntatore.
Questo puntatore sarà rappresentato dal tipo più semplice che chiameremo CObjectCustom:
class CObjectCustom
{
}; Sarebbe davvero difficile inventare una classe più semplice di CObjectCustom, in quanto non contiene dati o metodi. Ma tale implementazione è sufficiente per il momento.
Ora useremo uno dei concetti principali della programmazione orientata agli oggetti: l'ereditarietà. L'ereditarietà fornisce un modo speciale per stabilire l'identità tra gli oggetti. Ad esempio, possiamo dire a un compilatore che qualsiasi classe è un derivato di CObjectCustom.
Ad esempio, una classe di esseri umani (СHuman), una classe di Expert Advisors (CExpert) e una classe di condizioni meteorologiche (CWeather) rappresentano un concetto più generale della classe CObjectCustom. Forse questi concetti non sono effettivamente in relazione nella vita reale: il tempo metereologico non ha nulla in comune con le persone e gli Expert Advisor non sono associati al tempo. Ma siamo noi che creiamo collegamenti nel mondo della programmazione, e se questi collegamenti sono utili per i nostri algoritmi, non c'è motivo per cui non possiamo crearli.
Creiamo altre classi allo stesso modo: una classe di auto (CCar), una classe di numeri (CNumber), una classe di barra dei prezzi (CBar), una classe di quotazione (CQuotes), una classe di società MetaQuotes (CMetaQuotes) e una classe che descrive una nave (Cnave). Analogamente alle classi precedenti, queste classi non sono effettivamente connesse, ma discendono tutte dalla classe CObjectCustom.
Creiamo una libreria di classi per questi oggetti combinando tutte queste classi in un unico file: ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
Ora è giunto il momento di combinare queste classi in un array.
1.4. Array di puntatori al nodo con l'esempio della classe CArrayCustom
Per combinare le classi, avremo bisogno di un array speciale.
Nel caso più semplice sarà sufficiente scrivere:
CObjectCustom array[];
Questa stringa crea un array dinamico che memorizza elementi di tipo CObjectCustom. Dato che tutte le classi, che abbiamo definito nella sezione precedente, sono derivate da CObjectCustom, possiamo memorizzare qualsiasi di queste classi in questo array. Ad esempio, possiamo localizzare persone, auto e navi lì. Ma la dichiarazione dell'array CObjectCustom non sarà sufficiente per questo scopo.
Il fatto è che quando dichiariamo l'array nel modo normale, tutti i suoi elementi vengono riempiti automaticamente al momento dell'inizializzazione dell'array. Quindi, dopo aver dichiarato l'array, tutti i suoi elementi saranno occupati dalla classe CObjectCustom.
Possiamo verificarlo se modifichiamo leggermente CObjectCustom:
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
Eseguiamo un codice di prova come script per verificare questa particolarità:
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
Nella funzione OnStart() abbiamo inizializzato un array composto da tre elementi di CObjectCustom.
Il compilatore ha riempito questo array con gli oggetti corrispondenti. Puoi verificarlo se leggi il registro del terminale:
2015.02.12 12:26:32.964 Prova (USDCHF,H1) Oggetto n. 2 - CObjectCustom
2015.02.12 12:26:32.964 Prova (USDCHF,H1) Oggetto n. 1 - CObjectCustom
2015.02.12 12:26:32.964 Prova (USDCHF,H1) Oggetto #0 - CObjectCustom
Ciò significa che l'array è riempito dal compilatore e non possiamo individuare altri elementi lì, ad esempio CWeather o CExpert.
Questo codice non verrà compilato:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
Il compilatore darà un messaggio di errore:
'=' - structure have objects and cannot be copied Test.mq5 18 13
Ciò significa che l'array ha già degli oggetti e che i nuovi oggetti non possono essere copiati lì.
Ma possiamo superare questa impasse! Come accennato in precedenza, dovremmo lavorare non con oggetti ma con puntatori a questi oggetti.
Riscrivi il codice nella funzione OnStart() in modo che possa funzionare con i puntatori:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
Ora il codice è compilato e non si verificano errori. Cos'è successo? Innanzitutto, abbiamo sostituito l'inizializzazione dell'array CObjectCustom con l'inizializzazione dell'array di puntatori a CObjectCustom.
In questo caso il compilatore non crea nuovi oggetti CObjectCustom quando inizializza l'array ma lo lascia vuoto. In secondo luogo, ora usiamo un puntatore all'oggetto CWeather invece dell'oggetto stesso. Usando la parola chiave new abbiamo creato l'oggetto CWeather e l'abbiamo assegnato al nostro puntatore 'meteo', quindi abbiamo messo il puntatore 'meteo' (ma non l'oggetto) nell'array.
Ora mettiamo il resto degli oggetti nell'array in modo simile.
A tal fine scrivi il seguente codice:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
Questo codice funzionerà, ma è piuttosto rischioso poiché manipoliamo direttamente gli indici dell'array.
Se calcoliamo male la dimensione del nostro array arrayObj o dell'indirizzo con un indice sbagliato, il nostro programma finirà con un errore critico. Ma questo codice è adatto ai nostri scopi dimostrativi.
Presentiamo questi elementi come uno schema:
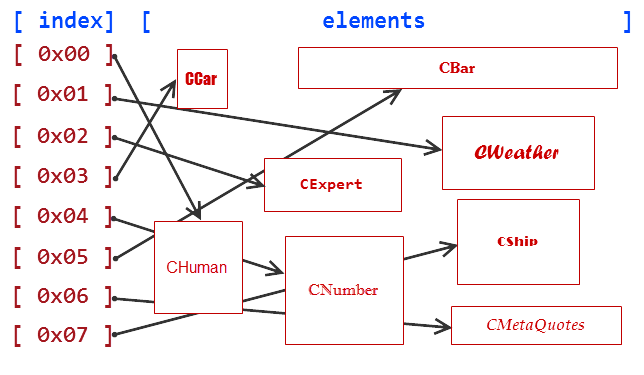
Fig. 1. Schema di memorizzazione dei dati nell'array di puntatori
Gli elementi, creati dall'operatore 'nuovo', sono memorizzati in una parte speciale della memoria ad accesso casuale chiamata heap. Questi elementi non sono ordinati come si può chiaramente vedere nello schema di cui sopra.
Il nostro array di puntatori arrayObj ha un'indicizzazione rigorosa, che consente di accedere rapidamente a qualsiasi elemento utilizzando il suo indice. Ma ottenere l'accesso a tale elemento non sarà sufficiente, poiché l'array di puntatori non sa a quale particolare oggetto esso punta. Il puntatore CObjectCustom può puntare a CWeather, CBar o CMetaQuotes, poiché sono tutti CObjectCustom. Quindi è necessario il cast esplicito di un oggetto nel suo tipo effettivo per ottenere il tipo di elemento.
Ad esempio, si può fare come segue:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
In questo codice abbiamo creato l'oggetto CHuman e l'abbiamo posizionato nell'array arrayObj come CObjectCustom. Quindi abbiamo estratto CObjectCustom e lo abbiamo convertito in CHuman, che in realtà è lo stesso. Nell'esempio la conversione non ha avuto errori in quanto ci siamo ricordati del tipo. In una situazione di programmazione reale è molto difficile tracciare un tipo per ogni oggetto in quanto potrebbero esserci centinaia di tipi e il numero di oggetti potrebbe essere superiore a un milione.
Ecco perché dovremmo fornire alla classe ObjectCustom un metodo Type() aggiuntivo che restituisce un modificatore di un tipo di oggetto effettivo. Un modificatore è un certo numero univoco che descrive il nostro oggetto permettendo di fare riferimento al tipo con il suo nome. Ad esempio, possiamo definire i modificatori utilizzando la direttiva del preprocessore #define. Se conosciamo il tipo di oggetto specificato dal modificatore, possiamo sempre convertire in sicurezza il suo tipo in quello effettivo. Così, ci siamo avvicinati alla creazione di tipi sicuri.
1.5. Controllo e sicurezza dei tipi
Non appena iniziamo a convertire un tipo in un altro, la sicurezza di tale conversione diventa una pietra angolare della programmazione. Non vorremmo che il nostro programma finisse con un errore critico, no? Ma sappiamo già quale sarà lo standard per controllare la sicurezza per i nostri tipi: modificatori speciali. Se conosciamo il modificatore, possiamo convertirlo nel tipo richiesto. A questo scopo abbiamo bisogno di integrare la nostra classe CObjectCustom con diverse aggiunte.
Prima di tutto, creiamo identificatori di tipo per poter creare dei nomi. A questo scopo creeremo un file separato con l'enumerazione richiesta:
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip
Ora cambieremo i codici di classe aggiungendo CObjectCustom alla variabile che memorizza il tipo di oggetto come numero. Nascondilo nella sezione privata, così nessuno potrà cambiarlo.
Oltre a ciò, aggiungeremo un costruttore speciale disponibile per le classi derivate da CObjectCustom. Questo costruttore consentirà agli oggetti di designare il proprio tipo durante la creazione.
Il codice comune sarà il seguente:
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
Come possiamo vedere, ogni tipo derivato da CObjectCustom ora imposta il proprio tipo nel suo costruttore durante la creazione. Il tipo non può essere modificato una volta impostato, poiché il campo in cui è memorizzato è privato e disponibile solo per CObjectCustom. Ciò ti impedirà di manipolare i tipi errati. Se la classe non chiama il costruttore protetto CObjectCustom, il suo tipo, TYPE_OBJECT, sarà il tipo predefinito.
Quindi, è tempo di imparare come estrarre i tipi da arrayObj ed elaborarli. A questo scopo forniremo alle classi CHuman e CWeather i metodi pubblici Run() e Temp(). Dopo aver estratto la classe da arrayObj, la convertiremo nel tipo richiesto e inizieremo a lavorarci in modo corretto.
Se il tipo, memorizzato nell'array CObjectCustom, è sconosciuto, lo ignoreremo scrivendo un messaggio "tipo sconosciuto":
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
Questo codice visualizzerà il seguente messaggio:
2015.02.13 15:11:24.703 Prova (USDCHF,H1) tipo sconosciuto.
2015.02.13 15:11:24.703 Prova (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Prova (USDCHF,H1) Gestito da un umano...
Quindi, abbiamo ottenuto il risultato cercato. Ora possiamo memorizzare qualsiasi tipo di oggetto nell'array CObjectCustom, ottenere un rapido accesso a questi oggetti tramite i loro indici nell'array e convertirli correttamente nei loro tipi effettivi. Ma ci mancano ancora molte cose: abbiamo bisogno di una corretta cancellazione degli oggetti dopo la fine del programma: dobbiamo cancellare da soli gli oggetti che si trovano nell'heap usando l'operatore delete.
Inoltre, abbiamo bisogno di ridimensionare in sicurezza l'array se l'array è completamente riempito. Ma non ricreeremo la ruota. Il set di strumenti standard MetaTrader 5 include classi che implementano tutte queste funzionalità.
Queste classi sono basate sul contenitore/classe universale CObject. Analogamente alla nostra classe, ha il metodo Type(), che restituisce il tipo effettivo della classe, e altri due puntatori importanti del tipo CObject: m_prev e m_next. Il loro scopo sarà descritto nella sezione successiva dove discuteremo un altro metodo di memorizzazione dei dati, ovvero una lista doppiamente collegata, attraverso l'esempio del contenitore CObject e della classe CList.
1.6. La classe CList come esempio di lista con doppio collegamento
Un array con elementi di tipo arbitrario soffre di un solo grande difetto: ci vuole molto tempo e fatica se si vuole inserire un nuovo elemento, specialmente se questo elemento deve essere inserito al centro dell'array. Gli elementi si trovano in una sequenza, quindi per l'inserimento è necessario ridimensionare l'array per aumentare di uno il numero totale di elementi e quindi riorganizzare tutti gli elementi che seguono l'oggetto inserito in modo che i loro indici corrispondano ai loro nuovi valori.
Supponiamo di avere un array composto da 7 elementi e di voler inserire un altro elemento in quarta posizione. Uno schema di inserimento approssimativo sarà il seguente:

Fig. 2. Ridimensionamento dell'array e inserimento di un nuovo elemento
Esiste uno schema di memorizzazione dei dati che consente l'inserimento e l'eliminazione di elementi in modo rapido ed efficace. Tale schema è chiamato elenco a collegamento singolo o a doppio collegamento. L'elenco ricorda una normale coda. Quando siamo in coda abbiamo solo bisogno di seguire la persona davanti a noi (non abbiamo bisogno di vedere una persona che è in piedi davanti quella che stiamo seguendo). Inoltre, non abbiamo bisogno di conoscere una persona in piedi dopo di noi, poiché questa persona deve controllare la sua posizione in coda.
Una coda è un classico esempio di elenco con collegamento singolo. Ma le liste possono anche essere doppiamente collegate. In questo caso ogni persona in coda conosce non solo la persona prima, ma anche la persona dietro. Quindi, se chiedi a ogni persona, puoi spostarti in entrambe le direzioni della coda.
Standard CList disponibile nella Standard Library offre proprio questo algoritmo. Proviamo a fare una coda di classi già note. Ma questa volta deriveranno da CObject standard e non da CObjectCustom.
Questo può essere schematicamente mostrato come segue:

Fig. 3. Schema di una lista doppiamente collegata
Quindi questo è un codice sorgente che crea tale schema:
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
Le nostre classi ora hanno due puntatori da CObject: uno fa riferimento all'elemento precedente, l'altro all'elemento successivo. Il puntatore all'elemento precedente del primo elemento nell'elenco è uguale a NULL. L'elemento alla fine dell'elenco ha un puntatore all'elemento successivo che è anche uguale a NULL. Quindi possiamo enumerare gli elementi uno per uno enumerando così l'intera coda.
Le funzioni EnumerateAll() e ReverseEnumerateAll() eseguono l'enumerazione di tutti gli elementi nell'elenco.
Il primo enumera l'elenco dall'inizio alla fine, il secondo - dalla fine all'inizio. Il codice sorgente di queste funzioni è il seguente:
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
Come funziona questo codice? In effetti, è abbastanza semplice. All'inizio otteniamo un riferimento al primo nodo nella funzione EnumerateAll(). Quindi stampiamo un numero di sequenza di questo nodo nel ciclo for e ci spostiamo al nodo successivo usando il comando node = node.Next(). Non dimenticare di ripetere di uno l'indice corrente dell'elemento (i++). L'enumerazione continua finché il nodo corrente non è uguale a NULL. Il codice nel secondo blocco di for ne è responsabile: node != NULL.
La versione inversa di questa funzione ReverseEnumerateAll() si comporta in modo simile con l'unica differenza che inizialmente ottiene l'ultimo elemento della lista CObject* node = list.GetLastNode(). Nel ciclo for non ottiene il successivo, ma l'elemento precedente della lista node = node.Prev().
Dopo aver lanciato il codice riceveremo il seguente messaggio:
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) enumerazione completa.
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 0
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 1
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 2
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 3
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) <<< enumera dalla fine all'inizio <<<
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 3
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 2
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 1
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) Elemento a 0
2015.02.13 17:52:02.974 TestList (USD/CHF, D1) >>> enumera dall'inizio alla fine >>>
Puoi facilmente inserire nuovi elementi nell'elenco. Basta cambiare i puntatori degli elementi precedenti e successivi in modo tale che si riferiscano a un nuovo elemento e questo nuovo elemento si riferisca all'oggetto precedente e successivo.
Lo schema è più semplice di quanto sembri:

Fig. 4. Inserimento di un nuovo elemento in una lista con doppio collegamento
Il principale svantaggio dell'elenco è l'impossibilità di fare riferimento a ciascun elemento in base al suo indice.
Ad esempio, se vuoi fare riferimento a CExpert come mostrato in Fig. 4, devi prima accedere a CCar, dopodiché puoi passare a CExpert. Lo stesso vale per CWeather. È più vicino alla fine dell'elenco, quindi sarà più facile accedervi dalla fine. A tal fine è necessario fare riferimento prima a CHip e poi a CWeather.
Lo spostamento tramite puntatori è un'operazione più lenta rispetto all'indicizzazione diretta. Le moderne unità centrali di elaborazione sono ottimizzate per il funzionamento in particolare con gli array. Questo è il motivo per cui in pratica gli array potrebbero essere preferibili anche se le liste potrebbero funzionare più velocemente.
Capitolo 2. Teoria dell'organizzazione degli array associativi
2.1. Gli array associativi nella nostra vita quotidiana
Abbiamo sempre a che fare con degli array associativi nella nostra vita quotidiana. Ma non ce ne rendiamo conto. L'esempio più semplice dell'array associativo o del dizionario è una normale rubrica telefonica. Ogni numero di telefono nel libro è associato al nome di una determinata persona. Il nome della persona in tale libro è una chiave univoca e il numero di telefono è un semplice valore numerico. Ogni persona nella rubrica può avere più di un numero di telefono. Ad esempio, una persona può avere numeri di telefono di casa, cellulare e azienda.
In generale, ci può essere una quantità illimitata di numeri, ma il nome della persona è unico. Ad esempio, due persone di nome Alexander nella tua rubrica ti confonderanno. A volte potremmo comporre un numero sbagliato. Ecco perché le chiavi (in questo caso i nomi) devono essere univoche per evitare tale situazione. Ma allo stesso tempo il dizionario deve saper risolvere le collisioni e resistervi. Due nomi identici non distruggeranno la rubrica. Quindi il nostro algoritmo dovrebbe sapere come elaborare tali situazioni.
Usiamo diversi tipi di dizionari nella vita reale. Ad esempio, la rubrica è un dizionario in cui una linea univoca (nome dell'abbonato) è una chiave e un numero è un valore. Il dizionario dei termini stranieri ha un'altra struttura. Una parola inglese sarà una chiave e la sua traduzione sarà un valore. Entrambi questi array associativi si basano sugli stessi metodi di gestione dei dati, ecco perché il nostro dizionario deve essere multiuso e consentire di archiviare e confrontare qualsiasi tipo.
Nella programmazione, può anche essere conveniente creare i propri dizionari e "quaderni".
2.2. Array associativi primari basati sull'operatore switch-case o un semplice array
Puoi facilmente creare un semplice array associativo. Basta utilizzare strumenti standard del linguaggio MQL5, ad esempio l'operatore switch o un array.
Diamo un'occhiata a tale codice più da vicino:
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
In questo caso l'operatore switch-case agisce come un dizionario. Ogni valore di ENUM_TIMEFRAMES ha un valore stringa che descrive questo periodo. A causa del fatto che l'operatore switch è un passaggio commutato (in russo), l'accesso alla variante richiesta del caso è istantaneo e le altre varianti del caso non sono enumerate . Ecco perché questo codice è altamente efficiente.
Ma il suo svantaggio è che, prima, devi riempire tutti i valori, che devono essere restituiti con l'uno o l'altro valore di ENUM_TIMEFRAMES, manualmente. In secondo luogo, lo switch può funzionare solo con valori interi. Ma sarebbe più difficile scrivere una funzione inversa che potrebbe restituire il tipo di intervallo di tempo a seconda di una stringa trasferita. Il terzo svantaggio di tale approccio è che questo metodo non è sufficientemente flessibile. È necessario specificare in anticipo tutte le possibili varianti. Ma spesso è necessario inserire i valori nel dizionario in modo dinamico man mano che i nuovi dati diventano disponibili.
Il secondo metodo "frontale" di memorizzazione della coppia "chiave-valore" prevede la creazione di un array in cui una chiave viene utilizzata come indice e un valore è un elemento dell'array .
Ad esempio, proviamo a risolvere il compito simile, vale a dire restituire la rappresentazione della stringa del timeframe:
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
Questo codice rappresenta il riferimento per indice in cui ENUM_TIMFRAMES è specificato come indice. Prima di restituire il valore, la funzione controlla se l'array è riempito con un elemento richiesto. In caso contrario, la funzione delega il riempimento a una funzione speciale - InitTimeframes(). Presenta gli stessi svantaggi dell'operatore di commutazione.
Inoltre, tale struttura del dizionario richiede l'inizializzazione di un array con valori grandi. Quindi il valore del modificatore PERIOD_MN1 è 49153. Significa che abbiamo bisogno di 49153 celle per memorizzare solo nove intervalli di tempo. Altre celle rimangono vuote. Questo metodo di allocazione dei dati è lungi dall'essere compatto, ma potrebbe essere appropriato quando l'enumerazione consiste in un intervallo di numeri piccolo e successivo.
2.3. Conversione dei tipi di base in una chiave univoca
Poiché gli algoritmi utilizzati nel dizionario sono simili indipendentemente da determinati tipi di chiavi e valori, è necessario eseguire l'allineamento dei dati, in modo che diversi tipi di dati possano essere elaborati da un algoritmo. Il nostro algoritmo di dizionario sarà universale e consentirà di memorizzare valori in cui qualsiasi tipo di base può essere specificato come chiave, ad esempio int, enum, double o anche string.
In realtà, in MQL5 qualsiasi tipo di dati di base può essere rappresentato come un numero ulong senza segno. Ad esempio, i tipi di dati short o ushort sono versioni "brevi" di ulong.
Con l'espressa comprensione che il tipo ulong memorizza il valore ushort, puoi sempre effettuare una conversione sicura di tipo esplicito:
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)
Lo stesso vale per i tipi char e int e i loro analoghi senza segno, poiché ulong può memorizzare qualsiasi tipo, la cui dimensione è minore o uguale a ulong. I tipi Datetime, enum e color si basano su un numero uint intero a 32 bit, il che significa che possono essere convertiti in tutta sicurezza in ulong. Il tipo bool possiede solo due valori: 0, che significa falso e 1, che significa vero. Pertanto, i valori di tipo bool possono essere memorizzati anche nella variabile di tipo ulong. Inoltre, molte funzioni del sistema MQL5 si basano su questa caratteristica.
Ad esempio, la funzione AccountInfoInteger() restituisce il valore intero del tipo long, che può anche essere un numero di conto del tipo ulong e un valore booleano di autorizzazione al commercio - ACCOUNT_TRADE_ALLOWED.
Ma MQL5 ha tre tipi di base che si distinguono dai tipi interi. Non possono essere convertiti direttamente nel tipo intero ulong. Tra questi tipi ci sono i tipi a virgola mobile, come double e float, e le stringhe. Ma alcune semplici azioni possono convertirli in chiavi/valori interi univoci.
Ciascun valore in virgola mobile può essere impostato come una base elevata a una potenza arbitraria, in cui sia la base che la potenza sono memorizzate separatamente come valore intero. Questo tipo di metodo di archiviazione viene utilizzato nei valori double e float. Il tipo float utilizza 32 cifre per memorizzare mantissa e potenza, il tipo double utilizza 64 cifre.
Se proviamo a convertirli direttamente nel tipo ulong, un valore verrà semplicemente arrotondato. In questo caso 3.0 e 3.14159 daranno lo stesso valore ulong — 3. Questo non è appropriato per noi, poiché avremo bisogno di chiavi diverse per questi due diversi valori. Una caratteristica non comune, che può essere utilizzata nei linguaggi di tipo C, viene in soccorso. Si chiama conversione della struttura. È possibile convertire due strutture diverse se hanno la stessa dimensione (conversione di una struttura in un'altra).
Analizziamo questo esempio su due strutture di cui una memorizza il valore di tipo ulong, e l'altra memorizza il valore di tipo double:
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
Questo codice copia byte per byte la struttura DoubleValue nella struttura ULongValue. Poiché hanno le stesse dimensioni e lo stesso ordine delle variabili, il valore double di dValue.value viene copiato byte per byte nella variabile ulong di lValue.value.
Dopodiché viene stampato il valore di questa variabile. Se cambiamo dValue.value in 3.14160, anche lValue.value verrà modificato.
Ecco il risultato che verrà visualizzato dalla funzione printf():
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
Il tipo float è una versione breve del tipo double. Di conseguenza, prima di convertire il tipo float nel tipo ulong è possibile estendere in sicurezza il tipo float al doppio:
float fl = 3.14159f; double dbl = fl;
Dopodiché converti double nel tipo ulong tramite la conversione della struttura.
2.4. Hashing delle stringhe e utilizzo di un hash come chiave
Negli esempi precedenti le chiavi erano rappresentate da un tipo di dati: stringhe. Tuttavia, potrebbero esserci situazioni diverse. Ad esempio, le prime tre cifre di un numero di telefono indicano un operatore telefonico. In questo caso in particolare queste tre cifre rappresentano una chiave. D'altro canto, ogni stringa può essere rappresentata come un numero univoco. Ogni cifra indicherebbe un numero progressivo di una lettera dell'alfabeto. Pertanto, possiamo convertire la stringa in un numero univoco e utilizzare questo numero come chiave intera per il suo valore associato.
Questo metodo è buono ma non è abbastanza multiuso. Se usiamo una stringa contenente centinaia di simboli come chiave, il numero sarà incredibilmente grande. Sarà impossibile catturarlo in una semplice variabile di qualsiasi tipo. Le funzioni hash ci aiuteranno a risolvere questo problema. La funzione hash è un particolare algoritmo che accetta qualsiasi tipo di dati (ad esempio una stringa) e restituisce un numero univoco che caratterizza questa stringa.
Anche se viene modificato un simbolo dei dati di ingresso, il numero sarà assolutamente diverso. I numeri restituiti da questa funzione hanno un intervallo fisso. Ad esempio, la funzione hash Adler32() accetta il parametro sotto forma di una stringa arbitraria e restituisce un numero nell'intervallo da 0 a 2 elevato alla potenza di 32. Questa funzione è piuttosto semplice, ma si adatta bene ai nostri compiti.
C'è il suo codice sorgente in MQL5:
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
Vediamo quali numeri restituisce a seconda di una stringa trasferita.
A questo scopo scriveremo un semplice script che chiama questa funzione e trasferisce diverse stringhe:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
Questo output di script ha rivelato quanto segue:
2015.02.16 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Pace - 91685343
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Ciao mondo! - 487130206
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Ciao mondo - 413860925
Come possiamo vedere, ogni stringa ha un numero univoco corrispondente. Rivolgi l'attenzione alle stringhe "Hello world" e "Hello world!" - sono quasi identiche. L'unica differenza è un punto esclamativo alla fine della seconda stringa.
Ma i numeri forniti da Adler32() erano assolutamente diversi in entrambi i casi.
Ora sappiamo come convertire il tipo di stringa nel valore uint senza segno e possiamo memorizzare il suo hash intero invece della chiave del tipo di stringa. Se due stringhe avranno un hash, è molto probabile che sia la stessa stringa. Pertanto, una chiave per un valore non è una stringa ma un hash intero generato sulla base di questa stringa.
2.5. Calcolare un indice con una chiave. List array
Ora sappiamo come convertire qualsiasi tipo di base di MQL5 nel tipo ulong unsigned. Esattamente questo tipo sarà una vera chiave a cui corrisponderà il nostro valore. Ma non basta avere una chiave univoca del tipo ulong. Ovviamente se conosciamo una chiave univoca di ogni oggetto, potremmo inventare un metodo di memorizzazione primitivo basato sull'operatore switch-case o un array di lunghezza arbitraria.
Tali metodi sono stati descritti nella sezione 2.2 del presente capitolo. Ma non sono abbastanza flessibili ed efficienti. Per quanto riguarda switch-case, non sembra possibile descrivere tutte le varianti di questo operatore.
Come se ci fossero decine di migliaia di oggetti, dovremo descrivere l'operatore switch, composto da decine di migliaia di chiavi, in fase di compilazione, cosa impossibile. Il secondo metodo utilizza un array in cui la chiave di un elemento è anche il suo indice. Permette di ridimensionare l'array in maniera dinamica aggiungendo gli elementi necessari. In tal modo possiamo costantemente fare riferimento ad esso per il suo indice che sarà la chiave dell'elemento.
Facciamo una bozza di questa soluzione:
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
Ma nella vita reale questo codice pone dei problemi, non li risolve. Supponiamo che una funzione hash produca un hash grande. Come nell'esempio dato l'indice dell'array è uguale al suo hash, dobbiamo ridimensionare l'array che lo renderà enorme. E non significa necessariamente che ci riusciremo. Vuoi memorizzare una stringa in un contenitore la cui dimensione può raggiungere diversi gigabyte?
Il secondo problema è che in caso di collisioni il valore precedente verrà sostituito con uno nuovo. Dopotutto, non è improbabile che la funzione Adler32() restituisca una chiave hash per due stringhe diverse. Vuoi perdere una parte dei tuoi dati solo perché vuoi consultarli rapidamente usando una chiave? La risposta a queste domande è ovvia: no, non lo fai. Per evitare tali situazioni, dobbiamo modificare l'algoritmo di archiviazione e sviluppare un contenitore ibrido speciale basato su un array di elenchi.
Un array di elenchi combina le migliori caratteristiche di array ed elenchi. Queste due classi sono rappresentate nella libreria standard. Vale la pena ricordare che gli array consentono di fare riferimento ai loro elementi indefiniti in modo molto rapido, ma gli array stessi si ridimensionano a un ritmo lento. Ma gli elenchi consentono di aggiungere e rimuovere nuovi elementi in men che non si dica, ma l'accesso a ciascun elemento di un elenco è un'operazione piuttosto lenta.
Un array di liste può essere rappresentato come segue:

Fig. 5. Schema di un array di elenchi
È evidente dallo schema che un array di elenchi è un array il cui elemento ha la forma di un elenco. Vediamo quali vantaggi offre. Innanzitutto, possiamo fare rapidamente riferimento a qualsiasi elenco tramite il suo indice. D'altra parte, se memorizziamo ogni elemento di dati in un elenco, saremo in grado di aggiungere e rimuovere prontamente elementi dall'elenco senza ridimensionare l'array. L'indice dell'array può essere vuoto o uguale a NULL. Ciò significa che gli elementi corrispondenti a questo indice non sono stati ancora aggiunti.
La combinazione di un array e di un elenco offre un'altra opportunità non comune. Possiamo memorizzare due o più elementi utilizzando un indice. Per comprenderne la necessità, possiamo supporre di dover memorizzare 10 numeri in un array con 3 elementi. Come possiamo vedere ci sono più numeri che elementi nell'array. Risolveremo questo problema memorizzando le liste in un array. Supponiamo di aver bisogno di una delle tre liste allegate a uno dei tre indici di array per memorizzare uno o un altro numero.
Per determinare l'indice della lista, dobbiamo trovare un resto nella divisione del nostro numero per la quantità di elementi nell'array:
indice array = numero % elementi nell'array;
Ad esempio, l'indice dell'elenco per il numero 2 sarà il seguente: 2%3 = 2. Ciò significa che l'indice 2 verrà memorizzato nell'elenco per indice. Il numero 3 verrà memorizzato dall'indice 3%3 = 0. Il numero 7 verrà memorizzato dall'indice 7%3 = 1. Dopo aver determinato l'indice dell'elenco, è sufficiente aggiungere questo numero alla fine dell'elenco.
Azioni simili sono necessarie per estrarre il numero dall'elenco. Supponiamo di voler estrarre il numero 7 dal contenitore. A questo scopo dobbiamo scoprire in quale contenitore si trova: 7%3=1. Dopo aver determinato che il numero 7 può essere localizzato nell'elenco in base all'indice 1, dovremo ordinare l'intero elenco e restituire questo valore se uno degli elementi è uguale a 7.
Se possiamo memorizzare più elementi utilizzando un indice, non dobbiamo creare enormi array per memorizzare piccole quantità di dati. Supponiamo di dover memorizzare il numero 232.547.879 in un array composto da 0-10 cifre e con tre elementi. Questo numero avrà il suo indice di lista pari a (232.547.879 % 3 = 2).
Se sostituiamo i numeri con l'hash, saremo in grado di trovare un indice di qualsiasi elemento che deve trovarsi nel dizionario. Perché l'hash è un numero. Inoltre, grazie alla possibilità di memorizzare più elementi in un elenco, l'hash non deve essere univoco. Gli elementi con lo stesso hash saranno in un elenco. Se abbiamo bisogno di estrarre un elemento tramite la sua chiave, confronteremo questi elementi ed estrarremo quello corrispondente alla chiave.
Ciò è possibile poiché due elementi con lo stesso hash avranno due chiavi univoche. L'unicità delle chiavi può essere controllata dalla funzione che aggiunge un elemento al dizionario. Semplicemente non aggiungerà un nuovo elemento se la sua chiave corrispondente è già nel dizionario. Questo è come un controllo sulla corrispondenza di un abbonato a un solo numero di telefono.
2.6. Ridimensionamento dell'array, riduzione della lunghezza dell'elenco
Più piccolo è l'array di liste e più elementi aggiungiamo, più lunghe saranno le catene di liste formate dall'algoritmo. Come è stato detto nel primo capitolo, l'accesso a un elemento di questa catena è un'operazione inefficiente. Più breve è il nostro elenco, più il nostro contenitore sembrerà un array che fornisce l'accesso a ciascun elemento tramite un indice. Dobbiamo puntare a liste brevi e array lunghi. Un array perfetto per dieci elementi è un array composto da dieci elenchi ognuno dei quali avrà un elemento.
La peggiore variante sarà un array di dieci elementi di lunghezza in una lista. Poiché tutti gli elementi vengono aggiunti dinamicamente al nostro contenitore durante il flusso del programma, non possiamo prevedere quanti elementi verranno aggiunti. Ecco perché dobbiamo pensare al ridimensionamento dinamico dell'array. E inoltre, il numero di catene nelle liste dovrebbe tendere a un elemento. È ovvio che per questo scopo la dimensione dell'array dovrebbe essere mantenuta uguale al numero totale di elementi. L'aggiunta permanente di elementi richiede il ridimensionamento permanente dell'array.
La situazione è complicata anche dal fatto che insieme al ridimensionamento dell'array dovremo ridimensionare tutte le liste, in quanto l'indice della lista, a cui potrebbe appartenere l'elemento, può essere modificato dopo il ridimensionamento. Ad esempio, se l'array ha tre elementi, il numero 5 verrà memorizzato nel secondo indice (5%3 = 2). Se sono presenti sei elementi, il numero 5 verrà memorizzato nel quinto indice (5%6=5). Quindi, il ridimensionamento del dizionario è un'operazione lenta. Dovrebbe essere eseguito il meno possibile. D'altra parte, se non lo eseguiamo affatto, le catene cresceranno con ogni nuovo elemento e l'accesso a ciascun elemento diventerà sempre meno efficiente.
Possiamo creare un algoritmo che implementi un compromesso tra la quantità di ridimensionamenti dell'array e la lunghezza media della catena. Si baserà sul fatto che ogni ridimensionamento successivo aumenterà due volte la dimensione corrente dell'array. Quindi, se il dizionario ha inizialmente due elementi, il primo ridimensionamento aumenterà la sua dimensione di 4 (2^2), il secondo - di 8 (2^3), il terzo - di 16 (2^3). Dopo il sedicesimo ridimensionamento ci sarà spazio per 65 536 catene (2^16). Ogni ridimensionamento verrà eseguito se la quantità di elementi aggiunti coincide con la potenza ricorrente di due. Pertanto, la memoria principale effettiva richiesta totale, non supererà la memoria richiesta per memorizzare tutti gli elementi più di due volte. D'altra parte, la legge logaritmica aiuterà ad evitare frequenti ridimensionamenti dell'array.
Allo stesso modo, rimuovendo gli elementi dall'elenco possiamo ridurre le dimensioni dell'array e risparmiare memoria principale allocata.
Capitolo 3. Sviluppo pratico di un array associativo
3.1. La classe modello CDictionary, i metodi AddObject e DeleteObjectByKey e il contenitore KeyValuePair
Il nostro array associativo deve essere multiuso e permettere di lavorare con tutti i tipi di chiavi. Allo stesso tempo useremo oggetti basati su CObject standard come valori. Poiché possiamo individuare qualsiasi variabile di base nelle classi, il nostro dizionario sarà una soluzione completa. Naturalmente, potremmo creare diverse classi di dizionari. Potremmo usare un tipo di classe separato per ogni tipo di base.
Ad esempio potremmo creare le seguenti classi:
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...
Ma MQL5 ha troppi tipi basic. Inoltre, dovremmo correggere ogni errore di codice molte volte, poiché tutti i tipi hanno un codice principale. Utilizzeremo modelli per evitare duplicazioni. Avremo una classe, ma questa elaborerà diversi tipi di dati contemporaneamente. Ecco perché i metodi principali delle classi saranno template.
Prima di tutto, creiamo il nostro primo metodo modello — Add(). Questo metodo aggiungerà un elemento con una chiave arbitraria al nostro dizionario. La classe del dizionario si chiamerà CDictionary. Oltre all'elemento, il dizionario conterrà un array di puntatori agli elenchi CList. E memorizzeremo elementi in queste catene:
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
Il metodo AddObject() funziona come segue. Innanzitutto controlla se il dizionario ha un elemento con una chiave che deve essere aggiunta. Il metodo ContieneKey() esegue questo controllo. Se il dizionario ha già la chiave, non verrà aggiunto un nuovo elemento, poiché causerà incertezze dato che due elementi corrisponderanno a una chiave.
Quindi il metodo apprende la dimensione dell'array in cui sono archiviate le catene CList. Se la dimensione dell'array è uguale al numero di elementi, è il momento di effettuare un ridimensionamento. Questa attività è delegata al metodo Resize().
I passaggi successivi sono semplici. Se secondo l'indice determinato la catena CList non esiste ancora, questa catena deve essere creata. L'indice è determinato in anticipo dal metodo ContieneKey(). Salva l'indice determinato nella variabile m_index. Quindi il metodo aggiunge un nuovo elemento alla fine dell'elenco. Ma prima di questo l'elemento è impacchettato in un contenitore speciale - KeyValuePair. Si basa su CObject standard e espande quest'ultimo con puntatori e dati aggiuntivi. La disposizione delle classi dei container sarà descritta più avanti. Insieme a puntatori aggiuntivi, il contenitore memorizza anche una chiave originale dell'oggetto e il suo hash.
Il metodo AddObject() è un metodo modello:
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
Questo record indica che il tipo di argomento chiave è sostitutivo e il suo tipo effettivo viene determinato in fase di compilazione.
Ad esempio, il metodo AddObject() può essere attivato nel suo codice come segue:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
Ognuna di queste attivazioni funzionerà perfettamente grazie ai modelli.
C'è anche il metodo DeleteObjectByKey() che rimane opposto al metodo AddObject(). Questo metodo elimina un oggetto dal dizionario tramite la sua chiave.
Ad esempio, puoi eliminare un oggetto con il tasto "Auto" se esiste:
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
Il codice è molto simile al codice del metodo AddObject(), quindi non lo illustreremo qui.
I metodi AddObject() e DeleteObjectByKey() non funzionano direttamente con gli oggetti. Invece di questo, impacchettano ogni oggetto nel contenitore KeyValuePair basato sulla classe CObject standard. Questo contenitore ha puntatori aggiuntivi, che consentono di mettere in relazione gli elementi, e ha anche una chiave originale e un hash determinato per l'oggetto. Il contenitore verifica anche l’uguaglianza della chiave passata che consente di evitare collisioni. Ne parleremo nella prossima sezione dedicata al metodo ContainsKey().
Ora illustreremo il contenuto di questa classe:
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. Identificazione del tipo di runtime basato su typename, campionamento hash
Ora che sappiamo come usare tipi indefiniti nei nostri metodi, dovremo determinare il loro hash. Per tutti i tipi interi un hash sarà uguale al valore di questo tipo espanso al tipo ulong.
Per calcolare l'hash per i tipi double e float, è necessario utilizzare il casting tramite strutture, descritto nella sezione "Conversione dei tipi di base in una chiave univoca". Una funzione hash dovrebbe essere usata per le stringhe. Ad ogni modo, ogni tipo di dati richiede il proprio metodo di campionamento dell'hash. Quindi tutto ciò di cui abbiamo bisogno è determinare il tipo trasferito e attivare un metodo di campionamento dell'hash in base a questo tipo. Per questo scopo avremo bisogno di una direttiva speciale typename.
Un metodo che determina l'hash in base alla chiave si chiama GetHashByKey().
Include:
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
La sua logica è semplice. Usando la direttiva typename il metodo ottiene il nome della stringa del tipo trasferito. Se la stringa viene trasferita come chiave, typename restituirà il valore "string", nel caso del valore int restituirà "int". Lo stesso accadrà con qualsiasi altro tipo. Pertanto, tutto ciò che dobbiamo fare è confrontare il valore restituito con le costanti stringa richieste e attivare il gestore corrispondente se questo valore coincide con una delle costanti.
Se la chiave è di tipo string, il suo hash viene calcolato dalla funzione Adler32(). Se la chiave è rappresentata da tipi reali, questi vengono convertiti nell'hash a causa della conversione della struttura. Tutti gli altri tipi si convertono esplicitamente nel tipo ulong che diventerà l'hash.
3.3. Il metodo ContainsKey(). Reazione alla collisione di hash
Il problema principale di qualsiasi funzione di hashing risiede nelle collisioni, situazioni in cui chiavi diverse forniscono lo stesso hash. In tal caso se gli hash coincidono, sorgerà l'ambiguità (due oggetti saranno simili in termini di logica del dizionario). Per evitare tale situazione è necessario controllare i tipi di chiave effettivi e richiesti e restituire un valore positivo solo se le chiavi effettive coincidono. Ecco come funziona il metodo ContieneKey(). Restituisce vero se esiste un oggetto con la chiave richiesta, altrimenti restituisce falso.
Forse questo è il metodo più utile e conveniente dell'intero dizionario. Permette di sapere se esiste un oggetto con una chiave definita:
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
Ad esempio, il codice precedente verifica la disponibilità dell'oggetto di tipo CCar e aggiunge CCar, se tale oggetto non esiste. Questo metodo consente anche di verificare l'unicità della chiave di ogni nuovo oggetto aggiunto.
Se la chiave dell'oggetto è già utilizzata, il metodo AddObject() semplicemente non aggiungerà questo nuovo oggetto al dizionario.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
Questo è un metodo così universale che è ampiamente utilizzato sia dagli utenti che da altri metodi di classe.
Il suo contenuto:
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
Innanzitutto il metodo trova un hash usando GetHashByKey(). Quindi, basandosi sull'hash, ottiene un indice della catena CList, dove può trovarsi un oggetto con l'hash specificato. Se non esiste tale catena, non esiste nemmeno l'oggetto con tale chiave. In questo caso interromperà anticipatamente la sua operazione e restituirà false (oggetto con tale chiave non esiste). Se la catena esiste, viene avviata l'enumerazione.
Ogni elemento di questa catena è rappresentato dall'oggetto di tipo KeyValuePair, che viene offerto per confrontare una chiave trasferita effettiva con una chiave memorizzata da un elemento. Se le chiavi sono le stesse, il metodo restituisce true (esiste un oggetto con tale chiave). Il codice, che verifica l'uguaglianza delle chiavi, viene fornito nell'elenco della classe KeyValuePair.
3.4. Allocazione dinamica e deallocazione della memoria
Il metodo Resize() è responsabile dell'allocazione dinamica e deallocazione della memoria nel nostro array associativo. Questo metodo viene attivato ogni volta che il numero di elementi è uguale alla dimensione m_array. Si attiva anche quando gli elementi vengono eliminati dall'elenco. Questo metodo sovrascrive gli indici di archiviazione per tutti gli elementi, quindi funziona in modo eccezionalmente lento.
Per evitare l'attivazione frequente del metodo Resize(), il volume della memoria allocata viene aumentato due volte ogni volta rispetto al volume precedente. In altre parole, se vogliamo che il nostro dizionario memorizzi 65.536 elementi, il metodo Resize() verrà attivato 16 volte (2^16). Dopo venti attivazioni il dizionario potrebbe contenere oltre un milione di elementi (1.048.576). Il metodo FindNextLevel() è responsabile della crescita esponenziale degli elementi richiesti.
Ecco il codice sorgente del metodo Resize():
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
Questo metodo funziona sia sul lato superiore che su quello inferiore. Quando sono presenti meno elementi di quelli che può contenere un array effettivo, viene avviato un codice di riduzione degli elementi. E viceversa, quando l'array corrente non è sufficiente, l'array viene ridimensionato per più elementi. Questo codice richiede molte risorse di elaborazione.
L'intero array deve essere ridimensionato, ma tutti i suoi elementi devono essere precedentemente rimossi in una copia temporanea dell'array. Quindi è necessario determinare nuovi indici per tutti gli elementi. Solo dopo sarà possibile individuare questi elementi nei loro nuovi punti.
3.5. Tratti finali: ricerca di oggetti e un pratico indicizzatore
Pertanto, la nostra classe CDictionary ha già i metodi principali per lavorarci. Possiamo usare il metodo ContieneKey() se vogliamo sapere se esiste un oggetto con una certa chiave. Possiamo aggiungere un oggetto al dizionario usando il metodo AddObject(). Possiamo anche eliminare un oggetto dal dizionario utilizzando il metodo DeleteObjectByKey().
Ora dobbiamo solo fare una comoda enumerazione di tutti gli oggetti nel contenitore. Come già sappiamo, tutti gli elementi sono memorizzati lì in un ordine particolare in base alle loro chiavi. Ma sarebbe conveniente enumerare tutti gli elementi nello stesso ordine in cui li abbiamo aggiunti all'array associativo. A questo scopo il contenitore KeyValuePair ha due puntatori aggiuntivi agli elementi aggiunti precedentemente e successivamente del tipo KeyValuePair. Possiamo eseguire un'enumerazione sequenziale grazie a questi puntatori.
Ad esempio, se aggiungiamo elementi al nostro array associativo come segue:
CNumero CNave CMeteo CHuman CExpert CCar
anche l'enumerazione di questi elementi sarà sequenziale, in quanto verrà eseguita utilizzando riferimenti a KeyValuePair, come mostrato in Fig. 6:

Fig. 6. Schema di enumerazione sequenziale di array
Per eseguire tale enumerazione vengono utilizzati cinque metodi.
Ecco il loro contenuto e una breve descrizione:
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
Grazie a questi semplici iteratori possiamo eseguire un'enumerazione sequenziale degli elementi aggiunti:
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
Questo codice produrrà valori stringa di oggetti nello stesso ordine in cui sono stati aggiunti al dizionario:
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
Modificadue stringhe del codice nella funzione OnStart() per restituire tutti gli elementi in ordine inverso:
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
Di conseguenza, i valori emessi vengono invertiti:
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
Capitolo 4. Test e valutazione delle prestazioni
4.1. Scrivere test e valutare le prestazioni
La valutazione delle prestazioni è un ingrediente fondamentale della progettazione di una classe, soprattutto se si tratta di una classe per l'archiviazione dei dati. Dopotutto, i programmi più diversi possono trarre vantaggio da questa classe. Gli algoritmi di questi programmi possono essere critici per la velocità e richiedere prestazioni elevate. Ecco perché è così importante sapere come valutare le prestazioni e ricercare i punti deboli di tali algoritmi.
Per cominciare, scriveremo un semplice test che misura la velocità di aggiunta ed estrazione di elementi dal dizionario. Questo test sembrerà uno script.
Il suo codice sorgente è allegato di seguito:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
Questo codice aggiunge in sequenza elementi al dizionario e poi fa riferimento ad essi misurando la loro velocità. Dopo questo ogni elemento viene eliminato utilizzando il metodo DeleteObjectByKey(). La funzione di sistema GetTickCount() misura la velocità.
Utilizzando questo script, abbiamo creato un diagramma che illustra le dipendenze temporali di questi tre metodi principali:
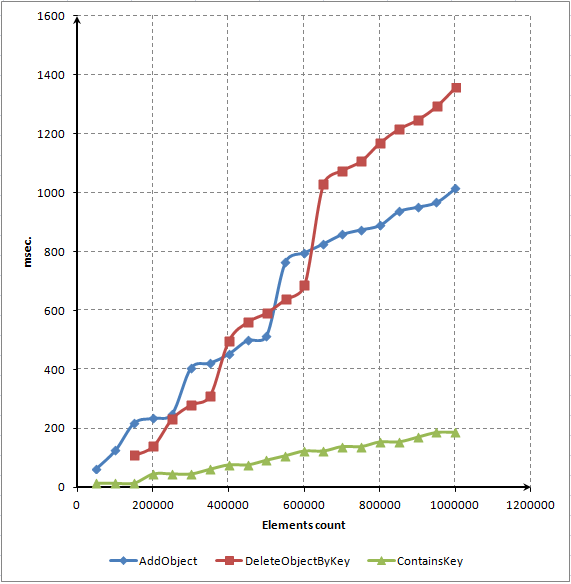
Fig. 7. Diagramma a punti della dipendenza tra il numero di elementi e il tempo di funzionamento dei metodi in millisecondi
Come puoi vedere, la maggior parte del tempo viene spesa per individuare ed eliminare elementi dal dizionario. Tuttavia, ci aspettavamo che gli elementi sarebbero stati eliminati molto più velocemente. Cercheremo di migliorare le prestazioni del metodo utilizzando un profiler di codice. Questa procedura verrà descritta nella sezione successiva.
Rivolgi l'attenzione al diagramma del metodo ContainsKey(). È lineare. Ciò significa che l'accesso a un elemento casuale richiede circa un periodo di tempo indipendentemente dal numero di questi elementi nell'array. Questa è una caratteristica indispensabile per un vero array associativo.
Per illustrare questa funzionalità mostreremo un diagramma di dipendenza tra il tempo medio di accesso a un elemento e un numero di elementi nell'array:
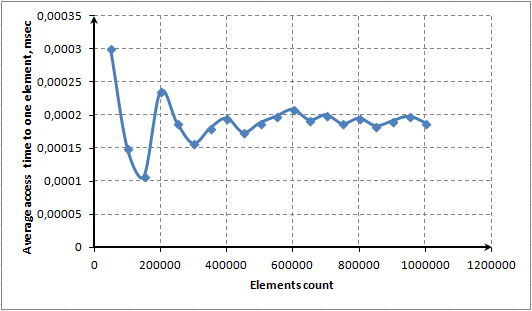
Fig. 8. Tempo medio di accesso a un elemento utilizzando il metodo ContieneKey()
4.2. Profiling del codice Velocità verso la gestione automatica della memoria
La profilazione del codice è una tecnica speciale che misura il dispendio di tempo di tutte le funzioni. Basta avviare qualsiasi programma MQL5 facendo clic su ![]() in MetaEditor.
in MetaEditor.
Faremo lo stesso e invieremo il nostro script per la profilazione. Dopo un po' il nostro script viene eseguito e otteniamo un profilo temporale di tutti i metodi eseguiti durante il funzionamento dello script. Lo screenshot qui sotto mostra che la maggior parte del tempo è stata spesa per eseguire tre metodi: AddObject() (40% delle volte), GetObjectByKey() (7% delle volte) e DeleteObjectByKey() (53% delle volte):
")
Fig. 9. Profilazione del codice nella funzione OnStart()
E oltre il 60% della chiamata DeleteObjectByKey() è stato speso per chiamare il metodo Compress().
Ma questo metodo è quasi vuoto, il tempo principale viene impiegato per chiamare il metodo Resize().
Include:
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
Il problema è chiaro. Quando eliminiamo tutti gli elementi, il metodo Resize() viene lanciato occasionalmente. Questo metodo riduce le dimensioni dell'array rilasciando lo spazio di archiviazione in modo dinamico.
Disattiva questo metodo se desideri eliminare gli elementi più velocemente. Ad esempio, è possibile introdurre nella classe il metodo speciale AutoFreeMemory(), impostando il flag di compressione. Verrà impostato di default e in tal caso la compressione verrà eseguita automaticamente. Ma se abbiamo bisogno di velocità aggiuntiva, eseguiremo la compressione manualmente in un momento ben scelto. A questo scopo renderemo pubblico il metodo Compress().
Se la compressione è disabilitata, gli elementi vengono eliminati tre volte più velocemente:
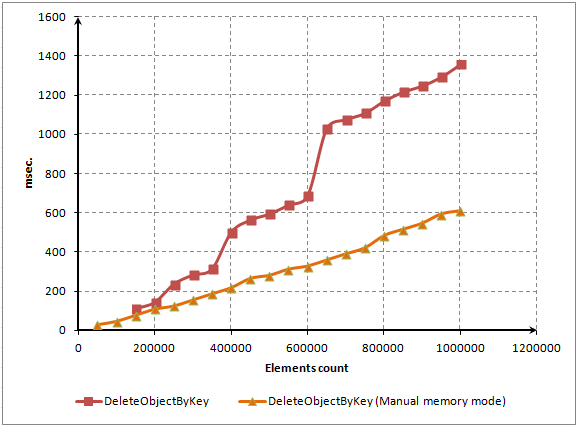
Fig. 10. Tempo di cancellazione dell'elemento con monitoraggio umano della memoria occupata (confronto)
Il metodo Resize() viene chiamato non solo per la compressione dei dati ma anche quando ci sono troppi elementi e abbiamo bisogno di un array più grande. In questo caso non possiamo evitare di chiamare il metodo Resize(). Deve essere chiamato per non creare catene CList lunghe e lente in futuro. Ma possiamo specificare in anticipo il volume richiesto del nostro dizionario.
Ad esempio, una serie di elementi aggiunti è spesso nota in anticipo. Conoscendo il numero di elementi, il dizionario creerà preliminarmente un array della dimensione richiesta, quindi non saranno necessari ridimensionamenti aggiuntivi durante il riempimento dell'array.
A questo scopo aggiungeremo un altro costruttore che accetterà gli elementi richiesti:
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
Il metodo private Init() esegue l'operazione principale:
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
I nostri miglioramenti sono finiti. Ora è giunto il momento di valutare le prestazioni del metodo AddObject() con la dimensione dell'array inizialmente specificata. A questo scopo cambieremo due prime stringhe della funzione OnStart() del nostro script:
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
In questo caso END è rappresentato da un numero grande pari a 1.000.000 di elementi.
Queste innovazioni hanno notevolmente accelerato le prestazioni del metodo AddObject():

Fig. 11. Tempo per l’aggiunta di elementi con la dimensione dell'array preimpostata
Risolvendo problemi di programmazione reali, dobbiamo sempre scegliere tra l'ingombro della memoria e la velocità delle prestazioni. Ci vuole molto tempo per liberare la memoria. Ma in questo caso avremo più memoria disponibile. Se manteniamo tutto così com'è, il tempo della CPU non sarà speso per ulteriori complicati problemi di calcolo, ma avremo meno memoria disponibile. Utilizzando i contenitori, la programmazione orientata agli oggetti consente di allocare risorse tra la memoria della CPU e il tempo della CPU in modo flessibile selezionando una determinata politica di esecuzione per ogni particolare problema.
Tutto sommato, le prestazioni della CPU sono ridimensionate molto peggio della capacità di memoria. Ecco perché nella maggior parte dei casi diamo la preferenza alla velocità di esecuzione piuttosto che al footprint di memoria. Inoltre, il controllo della memoria da parte dell'utente è più efficiente di un controllo automatizzato, poiché di solito non conosciamo lo stato finito dell'attività.
Ad esempio, nel caso del nostro script sappiamo in anticipo che alla fine dell'enumerazione il numero totale di elementi sarà nullo, poiché il metodo DeleteObjectByKey() li cancellerà tutti al termine dell'attività. Questo è il motivo per cui non è necessario comprimere automaticamente l'array. Sarà sufficiente cancellarlo alla fine chiamando il metodo Compress().
Ora, quando disponiamo di buone metriche lineari per l'aggiunta e l'eliminazione di elementi dall'array, potremo analizzare un tempo medio di aggiunta ed eliminazione di un elemento in base al numero totale di elementi:
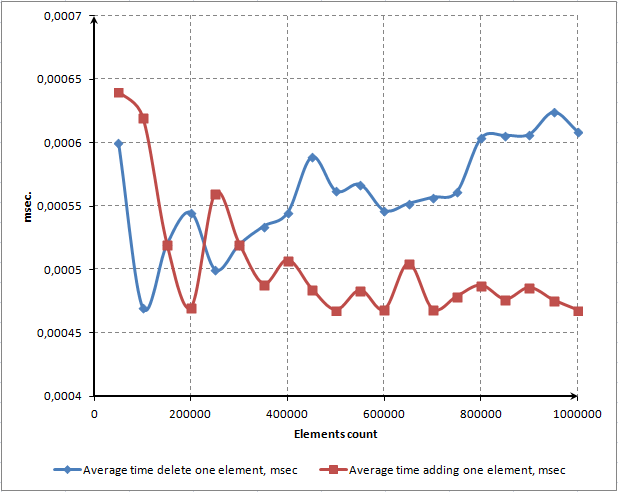
Fig. 12. Tempo medio di aggiunta ed eliminazione di un elemento
Possiamo vedere che il tempo medio di aggiunta di un elemento è piuttosto stazionario e non dipende dal numero totale di elementi nell'array. Il tempo medio di cancellazione di un elemento si sposta leggermente verso l'alto, il che è indesiderabile. Ma non possiamo dire con precisione se ci troviamo di fronte a risultati all'interno del tasso di errore o se questa è una tendenza regolare.
4.3. Prestazioni di CDictionary rispetto allo standard CARrayObj
È giunto il momento per il test più interessante: confronteremo il nostro CDictionary con la classe standard CArrayObj. Il CArrayObj non ha meccanismi per l'allocazione manuale della memoria come l'indicazione di una dimensione presunta in fase di costruzione, ecco perché disabiliteremo il controllo manuale della memoria in CDictionary e verrà abilitato il meccanismo AutoFreeMemory().
I punti di forza e di debolezza di ogni classe sono stati descritti nel primo capitolo. CDictionary permette di aggiungere un elemento in un punto indefinito e di estrarlo dal dizionario in maniera molto rapida. Ma CARrayObj permette di fare un'enumerazione molto veloce di tutti gli elementi. L'enumerazione in CDictionary sarà più lenta, poiché verrà eseguita mediante lo spostamento di un puntatore, e questa operazione è più lenta dell'indicizzazione diretta.
Quindi eccoci qui. Per cominciare, creiamo una nuova versione del nostro test:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
Utilizza le macro TEST_ARRAY. Se è identificato, il test esegue operazioni su CArrayObj, altrimenti operazioni su CDictionary. Il primo test per l'aggiunta di nuovi elementi è vinto da CDictionary.
Il suo modo di riallocare la memoria sembra migliore in questo caso particolare:
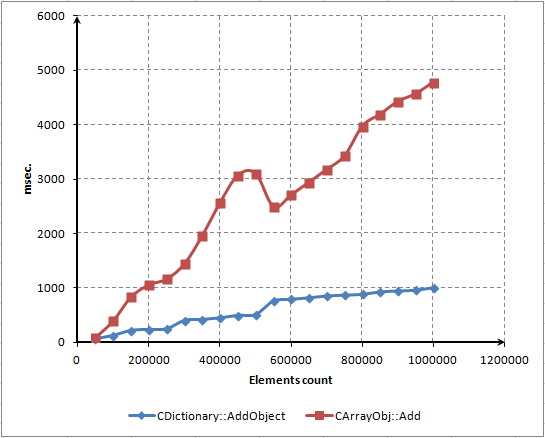
Fig. 13. Tempo impiegato per aggiungere nuovi elementi a CARrayObj e CDictionary (confronto)
È fondamentale sottolineare che l'operazione più lenta è stata causata da un particolare modo di riallocazione della memoria in CArrayObj.
È descritto da una sola stringa del codice sorgente:
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize); Questo è un algoritmo lineare di allocazione della memoria. Viene chiamato per impostazione predefinita dopo aver riempito ogni 16 elementi. CDictionary utilizza un algoritmo esponenziale: ogni successiva riallocazione della memoria alloca il doppio della memoria rispetto alla chiamata precedente. Questo diagramma illustra perfettamente il dilemma tra prestazioni e memoria utilizzata. Il metodo Reserve() della classe CArrayObj è più economico e richiede meno memoria ma funziona più lentamente. Il metodo Resize() della classe CDictionary funziona più velocemente ma richiede più memoria e metà di questa memoria potrebbe rimanere inutilizzata.
Eseguiamo l'ultima prova. Calcoleremo il tempo per l'enumerazione completa dei contenitori CArrayObj e CDictionary. CArrayObj utilizza l'indicizzazione diretta e CDictionary utilizza il riferimento. CArrayObj consente di fare riferimento a qualsiasi elemento tramite il suo indice, ma in CDictionary il riferimento a qualsiasi elemento tramite il suo indice è ostacolato. L'enumerazione sequenziale è altamente competitiva con l'indicizzazione diretta:
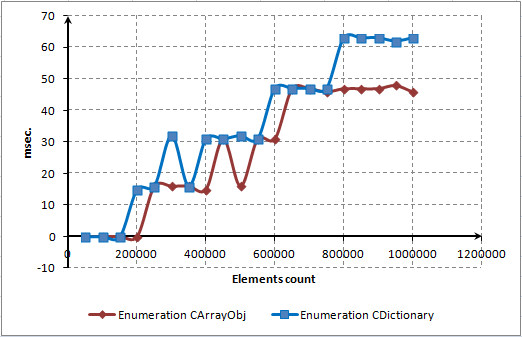
Fig. 14. Tempo per l'enumerazione completa di CArrayObj e CDictionary
Gli sviluppatori del linguaggio MQL5 hanno fatto un ottimo lavoro e ottimizzato i riferimenti. Sono altamente competitivi in velocità con l'indicizzazione diretta che è illustrata nel diagramma.
È importante rendersi conto che l'enumerazione degli elementi richiede così poco tempo che è quasi sull'orlo della risoluzione della funzione GetTickCount(). È difficile utilizzarlo per misurare intervalli di tempo inferiori a 15 millisecondi.
4.4. Raccomandazioni generali per l'utilizzo di CArrayObj, CList e CDictionary
Creeremo una tabella in cui descriveremo i principali compiti che possono verificarsi nella programmazione e le caratteristiche dei contenitori che devono essere conosciuti per risolvere questi compiti.
Le funzionalità con buone prestazioni delle attività sono scritte in verde, le funzionalità che non consentono di completare le attività in modo efficiente sono scritte in rosso.
| Scopo | CArrayObj | CList | CDdizionario |
|---|---|---|---|
| Sequenziale aggiunta di nuovi elementi alla fine del contenitore. | Il contenitore deve allocare nuova memoria per un nuovo elemento. Non è richiesto il trasferimento di elementi esistenti a nuovi indici. CARrayObj eseguirà questa operazione molto rapidamente. | Il contenitore ricorda il primo, l'attuale e l'ultimo elemento. Per questo motivo un nuovo elemento verrà allegato alla fine dell'elenco (l'ultimo elemento ricordato) molto rapidamente. | Il dizionario non ha concetti come "fine" o "inizio". Un nuovo elemento viene collegato molto rapidamente e non dipende da un numero di elementi. |
| Accesso a un elemento arbitrario tramite il suo indice. | A causa dell'indicizzazione diretta, l'accesso viene ottenuto molto rapidamente, richiede O (1) di tempo. | L'accesso a ciascun elemento si ottiene tramite l'enumerazione di tutti gli elementi precedenti. Questa operazione richiede O(n) di tempo. | L'accesso a ciascun elemento si ottiene tramite l'enumerazione di tutti gli elementi precedenti. Questa operazione richiede O(n) di tempo. |
| Accesso a un elemento arbitrario tramite la sua chiave. | Non disponibile | Non disponibile | Calcolare un hash e un indice tramite una chiave è un'operazione efficiente e veloce. L'efficienza della funzione di hashing è molto importante per le chiavi stringa. Questa operazione richiede O(1) di tempo. |
| I nuovi elementi vengono aggiunti/cancellati da un indice indefinito. | CArrayObj non deve solo allocare memoria per un nuovo elemento, ma anche rimuovere tutti gli elementi il cui indice è maggiore di un indice dell'elemento inserito. Ecco perché CARrayObj è un'operazione lenta. | L'elemento viene aggiunto o eliminato da CList molto rapidamente, ma è possibile accedere all'indice necessario per O(n). Questa è un'operazione lenta. | In CDictionary, l'accesso all'elemento tramite il suo indice viene eseguito in base all'elenco CList e richiede molto tempo. Ma l'aggiunta e l'eliminazione vengono eseguite molto velocemente. |
| I nuovi elementi vengono aggiunti/cancellati da una chiave non definita. | Non disponibile | Non disponibile | Poiché ogni nuovo elemento viene inserito in CList, i nuovi elementi vengono aggiunti ed eliminati molto velocemente poiché l'array non deve essere ridimensionato dopo ogni aggiunta/eliminazione. |
| Utilizzo e gestione della memoria. | È richiesto il ridimensionamento dinamico dell'array. Questa è un'operazione ad alta intensità di risorse, richiede o molto tempo o molta memoria. | La gestione della memoria non viene utilizzata. Ogni elemento richiede la giusta quantità di memoria. | È richiesto il ridimensionamento dinamico dell'array. Questa è un'operazione ad alta intensità di risorse, richiede o molto tempo o molta memoria. |
| Enumerazione degli elementi. Operazioni che devono essere eseguite per ogni elemento del vettore. | Eseguito molto velocemente grazie all'indicizzazione diretta degli elementi. Ma in alcuni casi l'enumerazione deve essere eseguita in ordine inverso (ad esempio, quando si elimina in sequenza l'ultimo elemento). | Poiché è necessario enumerare tutti gli elementi una sola volta, il riferimento diretto è un'operazione rapida. | Poiché è necessario enumerare tutti gli elementi una sola volta, il riferimento diretto è un'operazione rapida. |
Capitolo 5. Documentazione della classe del CDictionary
5.1. Metodi chiave per aggiungere, eliminare e accedere agli elementi
5.1.1. Il metodo AddObject()
Aggiunge un nuovo elemento del tipo CObject con il tasto T. Qualsiasi tipo di base può essere utilizzato come chiave.
template<typename T> bool AddObject(T key,CObject *value);
Parametri
- [in] key – chiave univoca rappresentata da uno dei tipi di base (stringa, ulong, char, enum ecc.).
- [in] value - oggetto con CObject come tipo di base.
Returned value
Restituisce vero, se l'oggetto è stato aggiunto al contenitore, altrimenti restituisce falso. Se la chiave dell'oggetto aggiunto esiste già nel contenitore, il metodo restituirà un valore negativo e l'oggetto non verrà aggiunto.
5.1.2. Il metodo ContieneKey()
Verifica se nel contenitore è presente un oggetto con una chiave uguale a T Key. Qualsiasi tipo di base può essere utilizzato come chiave.
template<typename T> bool ContainsKey(T key);
Parametri
- [in] key – chiave univoca rappresentata da uno dei tipi di base (stringa, ulong, char, enum ecc.).
Restituisce vero, se l'oggetto con la chiave selezionata esiste nel contenitore. Altrimenti restituisce 0.
5.1.3. Il metodo DeleteObjectByKey()
Elimina un oggetto tramite il tasto T preimpostato. Qualsiasi tipo di base può essere utilizzato come chiave.
template<typename T> bool DeleteObjectByKey(T key);
Parametri
- [in] key – chiave univoca rappresentata da uno dei tipi di base (stringa, ulong, char, enum ecc.).
Returned value
Restituisce vero, se l'oggetto con la chiave preimpostata è stato eliminato. Restituisce false, se l'oggetto con la chiave preimpostata non esiste o la sua eliminazione non è riuscita.
5.1.4. Il metodo GetObjectByKey()
Restituisce un oggetto tramite il tasto T preimpostato. Qualsiasi tipo di base può essere utilizzato come chiave.
template<typename T> CObject* GetObjectByKey(T key);
Parametri
- [in] key – chiave univoca rappresentata da uno dei tipi di base (stringa, ulong, char, enum ecc.).
Returned value
Restituisce un oggetto corrispondente alla chiave preimpostata. Restituisce NULL, se l'oggetto con la chiave preimpostata non esiste.
5.2. Metodi di gestione della memoria
5.2.1. CDictionary() costruttore
Il costruttore di base crea l'oggetto CDictionary con la dimensione iniziale dell'array di base pari a 3 elementi.
L'array viene aumentato o compresso automaticamente con il riempimento del dizionario o l'eliminazione di elementi da esso.
CDictionary();
5.2.2. Costruttore di CDictionary (capacità int)
Il costruttore crea l'oggetto CDictionary con la dimensione iniziale dell'array di base uguale a 'capacity'.
L'array viene aumentato o compresso automaticamente con il riempimento del dizionario o l'eliminazione di elementi da esso.
CDictionary(int capacity);
Parametri
- [in] capacity – numero di elementi iniziali.
Nota
L'impostazione del limite della dimensione dell'array immediatamente dopo la sua inizializzazione ti aiuterà a evitare le chiamate del metodo Resize() e quindi ad aumentare l'efficienza durante l'inserimento di nuovi elementi.
Tuttavia, è necessario notare che se si eliminano elementi con (AutoMemoryFree(true)) abilitato, il contenitore verrà automaticamente compresso nonostante l'impostazione della capacità. Per evitare la compressione anticipata, eseguire la prima operazione di eliminazione degli oggetti dopo che i contenitori sono stati completamente riempiti oppure, se non è possibile, disabilitare (AutoMemoryFree(false)).
5.2.3. Il metodo FreeMode (modalità bool)
Imposta la modalità di eliminazione degli oggetti esistenti nel contenitore.
Se la modalità di cancellazione è abilitata, anche il contenitore è soggetto alla procedura di 'cancellazione' dopo che l'oggetto è stato cancellato. Il suo distruttore viene attivato e diventa non disponibile. Se la modalità di cancellazione è disabilitata, il distruttore dell'oggetto non viene attivato e rimane disponibile da altri punti del programma.
void FreeMode(bool free_mode);
Parametri
- [in] free_mode – indicatore della modalità di eliminazione degli oggetti.
5.2.4. Il metodo FreeMode()
Restituisce l'indicatore dell'eliminazione degli oggetti che si trovano nel contenitore (vedere FreeMode(bool mode)).
bool FreeMode(void);
Returned value
Restituisce true se l'oggetto viene eliminato dall'operatore delete dopo che è stato eliminato dal contenitore. Altrimenti restituisce 0.
5.2.5. Il metodo AutoFreeMemory(bool autoFree)
Imposta l'indicatore di gestione automatica della memoria. La gestione automatica della memoria è abilitata per impostazione predefinita. In tal caso l'array viene compresso automaticamente (ridimensionato da una dimensione maggiore a una più piccola). Se disabilitato, l'array non viene compresso. Aumenta in modo significativo la velocità di esecuzione del programma, poiché non è necessario chiamare il metodo Resize() ad alta intensità di risorse. Ma in questo caso bisogna tenere d'occhio la dimensione dell'array e comprimerlo manualmente tramite il metodo Compress().
void AutoFreeMemory(bool auto_free);
Parametri
- [in] auto_free – indicatore della modalità di gestione della memoria.
Returned value
Restituisce true, se è necessario abilitare la gestione della memoria e chiamare automaticamente il metodo Compress(). Altrimenti restituisce 0.
5.2.6. Il metodo AutoFreeMemory()
Restituisce l'indicatore che specifica se viene utilizzata la modalità di gestione automatica della memoria (vedere il metodo FreeMode(bool free_mode)).
bool AutoFreeMemory(void);
Returned value
Restituisce true, se viene utilizzata la modalità di gestione della memoria. Altrimenti restituisce 0.
5.2.7. Il metodo Compress()
Comprime il dizionario e ridimensiona gli elementi. L'array viene compresso solo se possibile.
Questo metodo deve essere chiamato solo se la modalità di gestione automatica della memoria è disabilitata.
void Compress(void);
5.2.8. Il metodo Clear()
Elimina tutti gli elementi nel dizionario. Se l'indicatore di gestione della memoria è abilitato, viene chiamato il distruttore per ogni elemento da eliminare.
void Clear(void);
5.3. Metodi di ricerca nel dizionario
Tutti gli elementi del dizionario sono interconnessi. Ogni nuovo elemento si collega al precedente. Diventa così possibile la ricerca sequenziale di tutti gli elementi del dizionario. In tal caso il riferimento è effettuato da una lista collegata. I metodi in questa sezione facilitano la ricerca e rendono più conveniente l'iterazione del dizionario.
Puoi usare la seguente costruzione durante la ricerca nel dizionario:
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }
5.3.1. Il metodo GetFirstNode()
Restituisce il primo elemento aggiunto al dizionario.
CObject* GetFirstNode(void); Returned value
Restituisce il puntatore all'oggetto di tipo CObject, che è stato principalmente aggiunto al dizionario.
5.3.2. Il metodo GetLastNode()
Restituisce l'ultimo elemento del dizionario.
CObject* GetLastNode(void); Returned value
Restituisce il puntatore all'oggetto di tipo CObject, che è stato aggiunto al dizionario alla fine.
5.3.3. Metodo GetCurrentNode()
Restituisce l'elemento attualmente selezionato. L'elemento deve essere preselezionato da uno dei metodi di ricerca degli elementi sul dizionario o dal metodo di accesso all'elemento del dizionario (ContainsKey(), GetObjectByKey()).
CObject* GetLastNode(void); Returned value
Restituisce il puntatore all'oggetto di tipo CObject, che è stato aggiunto al dizionario alla fine.
5.3.4. Il metodo GetNextNode()
Restituisce l'elemento che segue quello corrente. Restituisce NULL se l'elemento corrente è l'ultimo o non è selezionato.
CObject* GetLastNode(void); Returned value
Restituisce il puntatore all'oggetto di tipo CObject, che segue quello corrente. Restituisce NULL se l'elemento corrente è l'ultimo o non è selezionato.
5.3.5. Il metodo GetPrevNode()
Restituisce l'elemento precedente a quello corrente. Restituisce NULL se l'elemento corrente è il primo o non è selezionato.
CObject* GetPrevNode(void); Returned value
Restituisce il puntatore all'oggetto di tipo CObject, precedente a quello corrente. Restituisce NULL se l'elemento corrente è il primo o non è selezionato.
Conclusione
Abbiamo considerato le caratteristiche principali dei contenitori di dati diffusi. Ogni contenitore di dati dovrebbe essere utilizzato dove le sue caratteristiche consentono di risolvere il problema nel modo più efficiente.
Gli array regolari dovrebbero essere usati dove l'accesso sequenziale a un elemento è sufficiente per risolvere il problema. I dizionari e gli array associati sono migliori da usare dove è richiesto l'accesso a un elemento tramite la sua chiave univoca. Le liste sono da utilizzare in caso di frequenti sostituzioni di elementi: cancellazione, inserimento, aggiunta di nuovi elementi.
Il dizionario consente di risolvere problemi algoritmici impegnativi in modo semplice e piacevole. Laddove altri contenitori di dati richiedono funzionalità di elaborazione aggiuntive, il dizionario consente di organizzare l'accesso agli elementi esistenti nel modo più efficace. Ad esempio, basandosi sul dizionario, è possibile creare un modello di evento in cui ogni evento del tipo OnChartEvent() viene consegnato alla classe che gestisce l'uno o l'altro elemento grafico. A tal fine è sufficiente associare ad ogni istanza di classe il nome dell'oggetto gestito da questa classe.
Essendo il dizionario un algoritmo universale, può essere applicato nei più svariati campi. Questo articolo chiarisce che il suo funzionamento si basa su algoritmi piuttosto semplici ma robusti che rendono la sua applicazione comoda ed efficace.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/1334
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

 Tecnica di test (ottimizzazione) e alcuni criteri per la selezione dei parametri dell'Expert Advisor
Tecnica di test (ottimizzazione) e alcuni criteri per la selezione dei parametri dell'Expert Advisor
 Studiare la classe CCanvas. Come disegnare oggetti trasparenti
Studiare la classe CCanvas. Come disegnare oggetti trasparenti
 La regola d'oro dei trader
La regola d'oro dei trader
 Trading bidirezionale e copertura delle posizioni in MetaTrader 5 utilizzando l'API HedgeTerminal, parte 2
Trading bidirezionale e copertura delle posizioni in MetaTrader 5 utilizzando l'API HedgeTerminal, parte 2
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
non deve funzionare correttamente in generale.
il modo corretto per eseguire cancellazioni multiple da un array associativo è raccogliere un array di chiavi da cancellare, quindi cancellare per chiave.
Questo è il punto, anche questo metodo causa improvvisamente uno strano bug. È ovviamente un errore. Lo esaminerò.
Per ora, posso consigliarvi di creare un nuovo dizionario e di aggiungervi i valori che non devono essere eliminati. Quindi cancellare quello vecchio. Questo funzionerà al 100%.
Ecco come procedere:
1. aggiornare la versione del Dizionario a quella allegata a questo post.
2. Eseguire uno script di prova per eliminare anche gli elementi.
L'eliminazione dovrebbe avvenire in due passaggi:
Per quanto riguarda il metodo DeleteCurrentObject():
Questo metodo deve essere usato solo insieme alla funzione ContainsKey(). L'unico motivo per cui è disponibile come pubblico è che in questo caso la chiamata al metodo fa risparmiare tempo al riposizionamento del puntatore. Cioè, il tipico e unico caso di utilizzo è 1. Controllare se c'è una chiave, 2. Controllare se c'è una chiave. Controllare se c'è una chiave, 2. Se c'è, cancellarla rapidamente con questo metodo.
È comprensibile, ma anche in questo caso la carrozzeria non è necessaria.
È tecnicamente possibile eseguire una rimozione in un unico passaggio, come si prevede. Ma sarebbe complicato. Ecco perché non ancora, solo in due passaggi. Dal punto di vista del dizionario come struttura dati distribuita, la cancellazione in due passaggi è una soluzione più canonicamente corretta. Solo a livello di utente sembra che la cancellazione sia sequenziale, in realtà è tutto diverso. In termini di prestazioni, la cancellazione in un solo passaggio non porterà alcun beneficio. In termini di comodità, sì, potrebbe essere più conveniente.
È tecnicamente possibile eseguire una rimozione in un unico passaggio, come previsto. Ma sarebbe complicato. Per questo motivo non è ancora possibile, ma solo in due passaggi. Dal punto di vista del dizionario come struttura dati distribuita, l'eliminazione in due passaggi è più canonicamente corretta. Solo a livello di utente sembra che la cancellazione sia sequenziale, in realtà è tutto diverso. In termini di prestazioni, la cancellazione in un solo passaggio non porterà alcun beneficio. In termini di comodità, sì, potrebbe essere più conveniente.
Grazie.
Credo di aver trovato un errore quando si elimina un elemento e si cerca di raggiungere l'ultimo elemento:
L'errore nel CDictionary.mqh sarà:
accessoal puntatore non valido in 'Dictionary.mqh' (463,9)
Qualcuno può confermarlo? Qualche idea su come risolvere il problema?
Si trattava di un bug nelle righe 500 e 501 dell'implementazione del controllo dei puntatori.
È stato risolto utilizzando CheckPointer() integrato.