
MQL5 Cookbook: Hızlı Veri Erişimi için İlişkisel Dizi veya Sözlük Uygulama

İçerik Tablosu
- GİRİŞ
- BÖLÜM 1. VERİ ORGANİZASYON TEORİSİ
- BÖLÜM 2. İLİŞKİSEL DİZİ ORGANİZASYON TEORİSİ
- BÖLÜM 3. İLİŞKİSEL DİZİNİN PRATİK GELİŞTİRİLMESİ
- BÖLÜM 4. PERFORMANSIN TESTİ VE DEĞERLENDİRİLMESİ
- BÖLÜM 5. CDICTIONARY SINIF BELGELERİ
- SONUÇ
Giriş
Bu makale, bilgilerin uygun şekilde saklanması için bir sınıfı, yani bir ilişkisel diziyi veya sözlüğü açıklamaktadır. Bu sınıf, anahtar ile bilgiye erişim elde edilmesine olanak tanır.
İlişkisel dizi, normal bir diziye benzer. Ancak endeks yerine benzersiz bir anahtar kullanır, örneğin ENUM_TIMEFRAMES numaralandırması veya bir metin. Bir anahtarı neyin temsil ettiği önemli değildir. Önemli olan anahtarın benzersizliğidir. Bu veri depolama algoritması, programlamanın birçok yönünü önemli ölçüde basitleştirir.
Örneğin bir hata kodu alacak ve hatanın metin eşdeğerini yazdıracak bir işlev aşağıdaki gibi olabilir:
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
Bu kodun belirli özelliklerini daha sonra inceleyeceğiz.
İlişkisel dizi dahili mantığının düz bir tanımını ele almadan önce, iki ana veri depolama yönteminin, yani dizilerin ve listelerin ayrıntılarını ele alacağız. Sözlüğümüz bu iki veri türünü temel alacaktır, bu yüzden onların belirli özelliklerini iyi anlamamız gerekir. Bölüm 1, veri türlerinin tanımına ayrılmıştır. İkinci bölüm, ilişkisel dizinin tanımına ve onunla çalışma yöntemlerine ayrılmıştır.
Bölüm 1. Veri Düzenleme Teorisi
1.1. Veri düzenleme algoritması. En iyi veri saklama kapsayıcısını arama
Bilginin aranması, depolanması ve temsili, modern bilgisayarın faydalandığı ana işlevlerdir. İnsan-bilgisayar etkileşimi genellikle ya bazı bilgilerin aranmasını ya da daha fazla kullanım için bilgilerin oluşturulmasını ve depolanmasını içerir. Bilgi soyut bir kavram değildir. Gerçek anlamda, bu kelimenin altında belli bir kavram vardır. Örneğin, bir sembol kotasyon geçmişi, bu sembol üzerinde bir alım satım yapan veya yapacak olan her yatırımcı için bir bilgi kaynağıdır. Programlama dili belgeleri veya bir programın kaynak kodu, bir programcı için bilgi kaynağı işlevi görebilir.
Bazı grafik dosyaları (örneğin dijital kamerayla yapılmış bir resim), programlama veya alım satımla ilgisi olmayan kişiler için bir bilgi kaynağı olabilir. Bu tür bilgilerin farklı yapılara ve kendilerine özgü niteliklere sahip oldukları açıktır. Sonuç olarak, bu bilgileri depolama, temsil etme ve işleme algoritmaları farklılık gösterecektir.
Örneğin, bir grafik dosyasını, her bir öğesi veya hücresi küçük bir görüntü alanının rengi hakkında bilgi depolayacak olan iki boyutlu bir matris (iki boyutlu dizi) olarak sunmak daha kolaydır — — piksel. Kotasyon verilerinin başka bir doğası vardır. Esasen bu, OHLCV formatında homojen bir veri akışıdır. Bu akışı bir dizi veya birkaç veri türünü birleştiren programlama dilinde belirli bir veri türü olan yapılar sıralı dizisi olarak sunmak daha iyidir. Belgeler veya bir kaynak kodu genellikle düz metin olarak gösterilir. Bu veri türü, sıralı bir dizeler dizisi olarak tanımlanabilir ve depolanabilir, burada her dize gelişigüzel bir sembol dizisidir.
Verileri depolamak için bir kapsayıcı türü, veri türüne bağlıdır. Nesne yönelimli programlama terimlerini kullanarak, bir kapsayıcıyı, bu verileri depolayan ve bunları işlemek için özel algoritmalara (yöntemlere) sahip belirli bir sınıf olarak tanımlamak daha kolaydır. Bu tür veri depolama kapsayıcılarının (sınıflarının) birkaç türü vardır. Farklı veri düzenlemelerine dayanırlar. Ancak bazı veri düzenleme algoritmaları, farklı veri depolama paradigmalarını birleştirmeye izin verir. Böylece tüm depolama türlerinin faydalarını birleştirme avantajından yararlanabiliriz.
Verileri depolamak, işlemek ve almak için sözde manipülasyon yöntemine ve doğasına bağlı olarak bir veya başka bir kapsayıcı seçersiniz. Eşit derecede verimli veri kapsayıcılarının olmadığını anlamak önemlidir. Bir veri kapsayıcısının zayıf yönleri, avantajlarının tersidir.
Örneğin dizi öğelerinden herhangi birine hızla erişebilirsiniz. Ancak, bu durumda tam dizi yeniden boyutlandırma talep edildiğinden, rastgele bir dizi noktasına bir öğe eklemek için zaman alıcı bir işlem gerekmektedir. Ve aksine, ayrı ayrı bağlantılı bir listeye bir öğe eklemek etkili ve yüksek hızlı bir işlemdir, ancak rastgele bir öğeye erişmek çok zaman alabilir. Sık sık yeni öğeler eklemek gerekirse, ancak bu öğelere sık erişmeniz gerekmiyorsa ayrı ayrı bağlantılı liste doğru kapsayıcınız olacaktır. Rastgele öğelere sık erişim gerekiyorsa veri sınıfı olarak bir dizi seçin.
Hangi veri depolama türünün tercih sebebi olduğunu anlamak için her bir kapsayıcının düzenine aşina olmalısınız. Bu makale, bir dizi ve bir listenin birleşimine dayanan belirli bir veri depolama kapsayıcısı olan ilişkisel diziye veya sözlüğe ayrılmıştır. Ancak belirli bir programlama diline, araçlarına, yeteneklerine ve kabul edilen programlama kurallarına bağlı olarak sözlüğün farklı şekillerde uygulanabileceğini belirtmek isterim.
Örneğin C# sözlük uygulaması C++'dan farklıdır. Bu makale, sözlüğün С++ için uyarlanmış uygulamasını açıklamamaktadır. İlişkisel dizinin açıklanan sürümü MQL5 programlama dili için sıfırdan oluşturulmuştur ve onun özel özelliklerini ve yaygın programlama uygulamasını dikkate alır. Uygulamaları farklılık gösterse de sözlüklerin genel karakteristikleri ve işleyiş yöntemleri benzer olmalıdır. Bu bağlamda açıklanan sürüm tüm bu karakteristikleri ve yöntemleri eksiksiz olarak sergilemektedir.
Bu zaman zarfında, yavaş yavaş sözlük algoritmasını oluşturacağız ve veri depolama algoritmalarının doğası hakkında konuşacağız. Ve makalenin sonunda algoritmanın tam bir sürümüne sahip olacağız ve çalışma prensibine tamamen hakim olacağız.
Farklı veri türleri için eşit derecede verimli kapsayıcı yoktur. Basit bir örnek ele alalım: bir kağıt defter. Günlük hayatımızda kullanılan bir kapsayıcı/sınıf olarak da düşünülebilir. Tüm notları önceden hazırlanmış bir listeye göre girilir (bu durumda alfabe). Bir abonenin adını biliyorsanız not defterini açmanız yeterli olduğundan, telefon numarasını kolayca bulabilirsiniz.
1.2. Diziler ve veri doğrudan adresleme
Bir dizi, bilgi depolamanın en basit ve aynı zamanda en verimli yoludur. Programlamada, bir dizi, bellekte hemen birbiri ardına yer alan aynı türdeki öğelerin bir koleksiyonudur.. Bu özelliklerden dolayı dizinin her bir öğesinin adresini hesaplayabiliriz.
Gerçekten de, tüm öğeler aynı türe sahipse hepsi aynı boyutta olacaktır. Dizi verileri sürekli olarak konumlandırıldığından, rastgele bir öğenin adresini hesaplayabilir ve temel bir öğenin boyutunu biliyorsak doğrudan bu öğeye başvurabiliriz. Adresi hesaplamak için genel bir formül, bir veri türüne ve bir indekse bağlıdır.
Örneğin, dizi veri düzenlemesi özelliklerinden çıkan aşağıdaki genel formülü kullanarak uchar türü öğelerin dizisindeki beşinci öğenin adresini hesaplayabilirsiniz:
rastgele öğe adresi = ilk öğe adresi + (dizideki rastgele öğenin indeksi * dizi türü boyutu)
Dizi adresleme sıfırdan başlar, bu nedenle ilk öğenin adresi, indeks 0'a sahip dizi öğesinin adresine karşılık gelir. Sonuç olarak, beşinci öğenin indeksi 4 olacaktır. Dizinin uchar türü öğeleri depoladığını varsayalım. Bu, birçok programlama dilindeki temel veri türüdür. Örneğin tüm C tipi dillerde bulunur. MQL5 bir istisna değildir. uchar türü dizinin her öğesi 1 bayt veya 8 bit bellek kaplar.
Örneğin, daha önce bahsedilen formüle göre uchar dizisindeki beşinci öğe adresi aşağıdaki gibi olacaktır:
beşinci öğe adresi = ilk öğe adresi + (4 * 1 bayt);
Başka bir deyişle, uchar dizisinin ilk öğesi, ilk öğeden 4 bayt daha yüksek olacaktır. Program yürütme sırasında her dizi öğesine doğrudan adresiyle başvurabilirsiniz. Bu tür adres aritmetiği, her dizi öğesine gerçekten hızlı erişim elde etmeyi sağlar. Ancak böyle bir veri düzenlemesinin dezavantajları vardır.
Bunlardan biri, dizide farklı türdeki öğeleri depolayamıyor olmanızdır. Bu sınırlama, doğrudan adreslemenin sonucudur. Elbette, farklı veri türlerinin boyutları değişir, bu da belirli bir öğenin adresini yukarıda belirtilen formülle hesaplamanın imkansız olduğu anlamına gelir. Ancak dizi, öğeleri değil de onlara işaretçileri depolarsa, bu sınırlama ustalıkla aşılabilir.
Bir işaretçiyi bağlantı olarak (Windows'ta kısayollar olarak) temsil etmeniz en kolay yol olacaktır. İşaretçi, bellekteki belirli bir nesneye başvurur ancak işaretçinin kendisi bir nesne değildir. MQL5'te işaretçi yalnızca bir sınıfa başvurabilir. Nesne yönelimli programlamada, bir sınıf, gelişigüzel bir dizi veri ve yöntem içerebilen ve etkin program yapılandırması için bir kullanıcı tarafından oluşturulabilen belirli bir veri türüdür.
Her sınıf benzersiz bir kullanıcı tanımlı veri türüdür. Farklı sınıflara başvuran işaretçiler bir dizide bulunamaz. Ancak, başvurulann sınıftan bağımsız olarak, işaretçi her zaman aynı boyuttadır çünkü işletim sisteminin adres alanında yalnızca, tahsis edilen tüm nesneler için ortak olan bir nesne adresi içerir.
1.3. CObjectCustom basit sınıfı örneğiyle düğüm kavramı
Artık ilk evrensel işaretçimizi tasarlamaya yetecek kadar bilgimiz var. Buradaki fikir, her bir işaretçinin kendi türüne başvuracağı evrensel bir işaretçi dizisi oluşturmaktır. Gerçek türler farklı olacaktır ancak aynı işaretçi tarafından başvuruldukları için bu türler bir kapsayıcı/dizide depolanabilir. İşaretçimizin ilk sürümünü oluşturalım.
Bu işaretçi, CObjectCustom olarak adlandıracağımız en basit türle temsil edilecektir:
class CObjectCustom
{
}; Herhangi bir veri veya yöntem içermediğinden, CObjectCustom'dan daha basit bir sınıf icat etmek gerçekten zor olurdu. Ancak böyle bir uygulama şimdilik yeterlidir.
Şimdi nesne yönelimli programlamanın ana kavramlarından birini kullanacağız — kalıtım. Kalıtım, nesneler arasında kimlik oluşturmanın özel bir yolunu sağlar. Örneğin, bir derleyiciye herhangi bir sınıfın CObjectCustom'un bir türevi olduğunu söyleyebiliriz.
Örneğin bir insan sınıfı (СHuman), bir Expert Advisor sınıfı (CExpert) ve bir hava durumu sınıfı (CWeather), CObjectCustom sınıfının daha genel konseptini temsil eder. Belki de bu kavramlar gerçek hayatta gerçekten bağlantılı değildir: havanın insanlarla hiçbir ortak yanı yoktur ve Expert Advisor'lar hava ile ilişkili değildir. Ama programlama dünyasında bağlantıları kuran biziz ve bu bağlantılar algoritmalarımız için iyiyse bunları oluşturamamamız için hiçbir neden yok.
Aynı şekilde birkaç sınıf daha oluşturalım: bir araba sınıfı (CCar), bir sayı sınıfı (CNumber), bir fiyat çubuğu sınıfı (CBar), bir kotasyon sınıfı (CQuotes), bir MetaQuotes şirket sınıfı (CMetaQuotes) ve bir gemiyi tanımlayan bir sınıf (CSship). Önceki sınıflara benzer şekilde, bu sınıflar aslında bağlantılı değildir ancak hepsi CObjectCustom sınıfının soyundan gelir.
Tüm bu sınıfları tek bir dosyada birleştirerek bu nesneler için bir sınıf kitaplığı oluşturalım: ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
Şimdi bu sınıfları tek bir dizide birleştirmenin zamanı geldi.
1.4. CArrayCustom sınıfının örneğine göre düğüm işaretçi dizileri
Sınıfları birleştirmek için özel bir diziye ihtiyacımız olacak.
En basit durumda şunu yazmak yeterli olacaktır:
CObjectCustom array[];
Bu dize, CObjectCustom türü öğeleri depolayan dinamik bir dizi oluşturur. Bir önceki bölümde tanımladığımız tüm sınıflar CObjectCustom'dan türetildiği için bu sınıflardan herhangi birini bu dizide depolayabiliriz. Örneğin, oradaki insanları, arabaları ve gemileri bulabiliriz. Ancak CObjectCustom dizisinin bildirilmesi bu amaç için yeterli olmayacaktır.
Mesele şu ki, diziyi normal şekilde bildirdiğimizde, dizi başlatma anında tüm öğeleri otomatik olarak doldurulur. Böylece diziyi bildirdikten sonra tüm öğeleri CObjectCustom sınıfı tarafından meşgul edilecektir.
CObjectCustom'u biraz değiştirirsek bunu kontrol edebiliriz:
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
Bu tuhaflığı kontrol etmek için bir test kodunu script dosyası olarak çalıştıralım:
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
OnStart() işlevinde, CObjectCustom'ın üç öğesinden oluşan bir dizi başlattık.
Derleyici bu diziyi karşılık gelen nesnelerle doldurdu. Terminalin günlüğünü okursanız kontrol edebilirsiniz:
2015.02.12 12:26:32.964 Test (USDCHF,H1) Nesne #2 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Nesne #1 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Nesne #0 - CObjectCustom
Bu, dizinin derleyici tarafından doldurulduğu ve orada CWeather veya CExpert gibi başka öğeleri bulamadığımız anlamına gelir.
Bu kod derlenmeyecek:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
Derleyici bir hata mesajı verecektir:
'=' - structure have objects and cannot be copied Test.mq5 18 13
Bu, dizinin zaten nesnelerinin bulunduğu ve yeni nesnelerin oraya kopyalanamayacağı anlamına gelir.
Ancak bu çıkmazı aşabiliriz! Yukarıda bahsedildiği gibi nesnelerle değil, bu nesnelere işaretçiler ile çalışmalıyız.
OnStart() işlevindeki kodu, işaretçilerle çalışabilecek şekilde yeniden yazın:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
Şimdi kod derlendi ve hatalar çıkmıyor. Ne oldu? İlk olarak, CObjectCustom dizisi başlatmayı, işaretçi dizisinin CObjectCustom'a başlatılmasıyla değiştirdik.
Bu durumda, derleyici diziyi başlatırken yeni CObjectCustom nesneleri oluşturmaz ancak onu boş bırakır. İkinci olarak, şimdi nesnenin kendisi yerine CWeather nesnesine bir işaretçi kullanıyoruz. yeni anahtar sözcüğünü kullanarak CWeather nesnesini yarattık ve onu 'weather' işaretçimize atadık ve sonra 'weather' işaretçisini (ancak nesneyi değil) diziye koyduk.
Şimdi dizideki nesnelerin geri kalanını benzer bir şekilde yerleştirelim.
Bu amaçla aşağıdaki kodu yazın:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
Bu kod işe yarayacaktır, ancak dizinin indekslerini doğrudan değiştirdiğimiz için oldukça risklidir.
arrayObj dizimizin veya adresimizin boyutunu yanlış bir indeks ile yanlış hesaplarsak programımız kritik bir hata verecektir. Ancak bu kod bizim tanıtım amacımız için uygundur.
Bu öğeleri şema halinde sunalım:
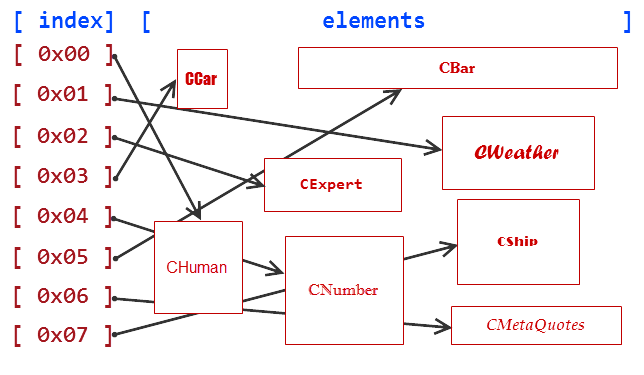
Şek. 1. İşaretçi dizisindeki veri depolama şeması
'Yeni' işleci tarafından oluşturulan öğeler, rastgele erişimli belleğin yığın olarak adlandırılan özel bir bölümünde depolanır. Bu öğeler, yukarıdaki şemada açıkça görülebileceği gibi sırasızdır.
arrayObj işaretçi dizimiz, indeksini kullanarak herhangi bir öğeye hızlı erişim elde etmeyi sağlayan katı indekslemeye sahiptir. Ancak, işaretçi dizisi hangi belirli nesneyi işaret ettiğini bilmediğinden, böyle bir öğeye erişim sağlamak yeterli olmayacaktır. CObjectCustom işaretçisi, hepsi CObjectCustom olduğundan CWeather veya CBar veya CMetaQuotes'a işaret edebilir. Bu nedenle, öğe türünü elde etmek için bir nesnenin gerçek türüne açık çevirimi gerekir.
Örneğin aşağıdaki gibi yapılabilir:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
Bu kodda CHuman nesnesini yarattık ve onu arrayObj dizisine as CObjectCustom'a yerleştirdik. Sonra CObjectCustom'u çıkardık ve aslında aynı olan CHuman'a dönüştürdük. Örnekte, türü unutmadığımız için dönüştürme hatası yoktu. Gerçek programlama durumunda, her nesnenin türünü izlemek çok zordur çünkü bu tür yüzlerce tür olabilir ve nesne sayısı bir milyondan fazla olabilir.
Bu nedenle, ObjectCustom sınıfını, gerçek bir nesne türünün değiştiricisini döndüren ek Tür() yöntemiyle donatmalıyız. Bir değiştirici, nesnemizi tanımlayan ve türe adıyla başvurmaya izin veren belirli bir benzersiz sayıdır. Örneğin önişlemci yönergesi #define kullanarak değiştiricileri tanımlayabiliriz. Değiştirici tarafından belirtilen nesne türünü biliyorsak, türünü her zaman güvenli bir şekilde gerçek olana dönüştürebiliriz. Böylece, güvenli türlerin yaratılmasına yaklaştık.
1.5. Türlerin kontrolü ve güvenliği
Bir türü diğerine dönüştürmeye başlar başlamaz, bu tür bir dönüşümün güvenliği programlamanın temel taşı haline gelir. Programımızın kritik bir hata vermesi hoşumuza gitmez, değil mi? Ancak türlerimiz için güvenlik temelinin ne olacağını zaten biliyoruz - özel değiştiriciler. Değiştiriciyi biliyorsak onu gereken türe dönüştürebiliriz. Bu amaçla CObjectCustom sınıfımızı birkaç eklemeyle tamamlamamız gerekiyor.
Her şeyden önce, adlarına göre başvurmak için tür tanımlayıcıları oluşturalım. Bu amaçla gerekli numaralandırma ile ayrı bir dosya oluşturacağız:
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip
Şimdi, nesne türünü sayı olarak depolayan değişkene CObjectCustom ekleyerek sınıf kodlarını değiştireceğiz. Özel bölümde saklayın, böylece kimse değiştiremez.
Bunun yanında, CObjectCustom'dan türetilen sınıflar için özel bir oluşturucu ekleyeceğiz. Bu oluşturucu, nesnelerin oluşturma sırasında türlerini belirlemelerine izin verecektir.
Ortak kod aşağıdaki gibi olacaktır:
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
Gördüğümüz gibi, CObjectCustom'dan türetilen her tür artık oluşturma sırasında oluşturucusunda kendi türünü belirler. Tür ayarlandıktan sonra değiştirilemez, çünkü depolandığı alan özeldir ve yalnızca CObjectCustom için kullanılabilir. Bu sizi yanlış tür manipülasyonundan koruyacaktır. Sınıf, korumalı oluşturucu CObjectCustom'u çağırmazsa türü - TYPE_OBJECT - varsayılan tür olacaktır.
Öyleyse arrayObj'den türlerin nasıl çıkarılacağını ve işleneceğini öğrenmenin zamanı geldi. Bu amaçla, CHuman ve CWeather sınıflarını buna bağlı olarak public Run() ve Temp() yöntemleriyle donatacağız. Sınıfı arrayObj'den çıkardıktan sonra, onu gerekli türe dönüştüreceğiz ve onunla uygun bir şekilde çalışmaya başlayacağız.
CObjectCustom dizisinde saklanan tür bilinmiyorsa "bilinmeyen tür" mesajı yazarak onu görmezden geleceğiz:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
Bu kod aşağıdaki mesajı gösterecektir:
2015.02.13 15:11:24.703 Test (USDCHF,H1) bilinmeyen tür.
2015.02.13 15:11:24.703 Test (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Test (USDCHF,H1) İnsan tarafından işletim...
Böylece, aradığımız sonucu elde ettik. Artık her tür nesneyi CObjectCustom dizisinde depolayabilir, dizideki indeksleri ile bu nesnelere hızlı erişim sağlayabilir ve onları gerçek türlerine doğru bir şekilde dönüştürebiliriz. Ancak hala birçok eksiğimiz var: Yığın içinde bulunan nesneleri sil işlecini kullanarak kendimiz silmemiz gerektiğinden, program sonlandırıldıktan sonra nesnelerin doğru şekilde silinmesine ihtiyacımız var.
Ayrıca, dizi tamamen doluysa güvenli dizi yeniden boyutlandırma araçlarına ihtiyacımız var. Ama tekerleği yeniden yaratmayacağız. Standart MetaTrader 5 araç seti, tüm bu özellikleri uygulayan sınıfları içerir.
Bu sınıflar, evrensel CObject kapsayıcısını/sınıfını temel alır. Sınıfımıza benzer şekilde, sınıfın gerçek türünü veren Tür() yöntemine ve CObject türünün daha önemli iki işaretçisine sahiptir: m_prev ve m_next. Amaçları, CObject kapsayıcısı ve CList sınıfı örneği üzerinden başka bir veri depolama yöntemi olan çift bağlantılı liste'yi konuşacağımız bir sonraki bölümde açıklanacaktır.
1.6. Çift bağlantılı liste örneği olarak CList sınıfı
Gelişigüzel türde öğelere sahip bir dizinin yalnızca bir büyük kusuru vardır: yeni bir öğe eklemek istiyorsanız, özellikle de bu öğenin dizinin ortasına eklenmesi gerekiyorsa çok zaman ve çaba gerektirir. Öğeler bir sıralamada bulunur, bu nedenle ekleme için diziyi yeniden boyutlandırarak toplam öğe sayısını bir artırmanız ve ardından eklenen nesneyi izleyen tüm öğeleri, indeksleri yeni değerlerine karşılık gelecek şekilde yeniden düzenlemeniz gerekmektedir.
7 öğeli bir dizimiz olduğunu ve dördüncü pozisyona bir öğe daha eklemek istediğimizi varsayalım. Yaklaşık bir yerleştirme şeması aşağıdaki gibi olacaktır:

Şek. 2. Dizi yeniden boyutlandırma ve yeni bir öğenin eklenmesi
Öğelerin hızlı ve etkili bir şekilde eklenmesini ve silinmesini sağlayan bir veri depolama şeması vardır. Böyle bir şemaya tek bağlantılı veya çift bağlantılı liste denir. Liste, sırada beklemeye benziyor. Sırada beklediğimizde sadece önümüzdeki kişiyi bilmemiz gerekir (onun önünde duran kişiyi tanımamız gerekmez). Ayrıca arkamızda duran kişiyi tanımamıza da gerek yok, çünkü bu kişinin sıradaki konumunu kendi kontrol etmesi gerekiyor.
Sıra, tek bağlantılı listenin klasik bir örneğidir. Ancak listeler çift bağlantılı da olabilir. Bu durumda sırada olan herkes sadece kendinden önceki kişiyi değil, kendisinden sonraki kişiyi de bilir. Yani herkese sorarsanız sıranın her iki yönünde de hareket edebilirsiniz.
Standart Kitaplıkta bulunan Standart CList tam olarak bu algoritmayı sunar. Bilinen sınıflardan bir sıra oluşturmaya çalışalım. Ancak bu sefer CObjectCustom'dan değil, standart CObject'den türetilecekler.
Bu şematik olarak aşağıdaki gibi gösterilebilir:

Şek. 3. Çift bağlantılı liste şeması
Yani bu, böyle bir şema oluşturan bir kaynak kodudur:
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
Sınıflarımızda artık CObject'den iki işaretçi var: biri önceki öğeye, diğeri ise sonraki öğeye başvuru yapıyor. Listedeki ilk öğenin önceki öğesinin işaretçisi NULL'a eşittir. Listenin sonundaki öğe, sıradaki öğenin işaretçisine sahiptir, bu da NULL'a eşittir. Dolayısıyla öğeleri tek tek numaralandırabiliriz, böylece tüm sırayı numaralandırabiliriz.
EnumerateAll() ve ReverseEnumerateAll() işlevleri, listedeki tüm öğelerin numaralandırmasını gerçekleştirir.
Birincisi listeyi baştan sona, ikincisi sondan başa numaralandırır. Bu işlevlerin kaynak kodu aşağıdaki gibidir:
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
Bu kod nasıl çalışır? Aslında bu oldukça basittir. Başlangıçta, EnumerateAll() işlevindeki ilk düğüme bir başvuru alıyoruz. Daha sonra for döngüsünde bu düğümün sıra numarasını yazdırıyor ve node = node.Next() komutunu kullanarak bir sonraki düğüme geçiyoruz. Öğenin geçerli dizinini birer birer (i++) yinelemeyi unutmayın. Numaralandırma, geçerli düğüm NULL'a eşit olana kadar devam eder. for öğesinin ikinci bloğundaki Kod bundan sorumludur: node != NULL.
Bu işlevin ters sürümü ReverseEnumerateAll() benzer şekilde işler, tek fark ilk başta CObject* node = list.GetLastNode() listesinin son öğesini almasıdır. for döngüsünde sıradakini değil, node = node.Prev() listesinin önceki öğesini alır.
Kodu başlattıktan sonra aşağıdaki mesajı alacağız:
2015.02.13 17:52:02.974 TestList(USDCHF,D1) numaralandırma tamamlandı.
2015.02.13 17:52:02.974 TestList(USDCHF,D1) Öğe 0'da
2015.02.13 17:52:02.974 TestList(USDCHF,D1) Öğe 1'de
2015.02.13 17:52:02.974 TestList(USDCHF,D1) 2'deki eleman
2015.02.13 17:52:02.974 TestList(USDCHF,D1) Öğe 3'te
2015.02.13 17:52:02.974 TestList(USDCHF,D1) <<< sondan başa numaralandırma <<<
2015.02.13 17:52:02.974 TestList(USDCHF,D1) Öğe 3'te
2015.02.13 17:52:02.974 TestList(USDCHF,D1) 2'deki eleman
2015.02.13 17:52:02.974 TestList(USDCHF,D1) Öğe 1'de
2015.02.13 17:52:02.974 TestList(USDCHF,D1) Öğe 0'da
2015.02.13 17:52:02.974 TestList(USDCHF,D1) >>> baştan sona numaralandır >>>
Listeye kolayca yeni öğeler ekleyebilirsiniz. Sadece önceki ve sonraki öğelerin işaretçilerini yeni bir öğeye başvuracak bulunacak şekilde değiştirin ve bu yeni öğe önceki ve sonraki nesnelere başvuracaktır.
Şema gözüktüğünden daha kolay görünüyor:

Şek. 4. Çift bağlantılı bir listeye yeni bir öğenin eklenmesi
Listenin ana dezavantajı, her bir öğeye indeksine göre referans vermenin imkansız olmasıdır.
Örneğin Şekil 4'te gösterildiği gibi CExpert'e başvurmak istiyorsanız önce CCar'a erişim sağlamanız gerekir ve bundan sonra CExpert'e geçebilirsiniz. Aynı durum CWeather için de geçerli. Listenin sonuna daha yakın olduğundan, sondan erişim sağlamak daha kolay olacaktır. Bunun için önce CSship'e, ardından CWeather'a başvurmanız gerekir.
İşaretçilerle hareket etmek, doğrudan indekslemeye kıyasla daha yavaş bir işlemdir. Modern merkezi işlem birimleri, özellikle dizilerle çalışmak üzere optimize edilmiştir. Bu nedenle, listeler potansiyel olarak daha hızlı çalışacak olsa bile pratikte diziler daha tercih edilesi olabilir.
Bölüm 2. İlişkisel Dizi Düzenleme Teorisi
2.1. Günlük hayatımızda ilişkisel diziler
Günlük hayatımızda sürekli olarak ilişkisel dizilerle karşı karşıyayız. Ama bize o kadar açık görünüyorlar ki, onları doğal olarak algılıyoruz. İlişkisel dizinin veya sözlüğün en basit örneği, olağan bir telefon rehberidir. Rehberdeki her telefon numarası, belirli bir kişinin adıyla ilişkilendirilir. Bu rehberdeki kişinin adı benzersiz bir anahtardır ve telefon numarası basit bir sayısal değerdir. Telefon rehberindeki her kişinin birden fazla telefon numarası olabilir. Örneğin, bir kişinin ev, cep telefonu ve iş telefonu numaraları olabilir.
Genel olarak konuşursak sınırsız sayıda numara olabilir, ancak kişinin adı benzersizdir. Örneğin telefon rehberinizde Alexander adında iki kişi kafanızı karıştıracaktır. Bazen yanlış bir numara çevirebiliriz. Bu nedenle, böyle bir durumdan kaçınmak için anahtarlar (bu durumda adlar) benzersiz olmalıdır. Ancak aynı zamanda sözlük, çakışmaları nasıl çözeceğini bilmeli ve bunlara karşı dirençli olmalıdır. İki aynı isim telefon rehberini bozmaz. Dolayısıyla algoritmamız bu tür durumları nasıl işleyeceğini bilmelidir.
Gerçek hayatta çeşitli sözlük türleri kullanırız. Örneğin telefon rehberi, benzersiz bir satırın (abone adı) bir anahtar ve bir sayının bir değer olduğu bir sözlüktür. Yabancı terim sözlüğünün başka bir yapısı vardır. İngilizce bir kelime bir anahtar olacak ve çevirisi bir değer olacak. Bu ilişkisel dizilerin her ikisi de aynı veri işleme yöntemlerine dayanmaktadır, bu nedenle sözlüğümüz çok amaçlı olmalı ve herhangi bir türü depolamaya ve karşılaştırmaya izin vermelidir.
Programlamada, kendi sözlüklerinizi ve "defterlerinizi" oluşturmak da pratik olabilir.
2.2. Switch-case işlecine veya basit bir diziye dayalı birincil ilişkisel diziler
Basit bir ilişkisel diziyi kolayca oluşturabilirsiniz. Yalnızca MQL5 dilinin standart araçlarını kullanın, örneğin switch işleci veya bir dizi.
Bu koda daha yakından bakalım:
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
Bu durumda switch-case operatörü bir sözlük gibi hareket eder. ENUM_TIMEFRAMESiçindekş her değer, bu dönemi açıklayan bir dize değerine sahiptir. Switch işlecinin switched passage (Rusça) olması nedeniyle, gerekli case varyantına erişim anlıktır ve vakanın diğer varyantları numaralandırılmaz. Bu kodun son derece verimli olmasının nedeni budur.
Ancak dezavantajı, ilk önce ENUM_TIMEFRAMES değerinden biri veya başka bir değeriyle verilmesi gereken tüm değerleri manuel olarak doldurmanız gerektiğidir. İkincisi, switch sadece tamsayı değerleri ile çalışabilir. Ancak, aktarılan bir dizgeye bağlı olarak zaman çerçevesi türünü verebilecek ters bir işlev yazmak daha zor olurdu. Bu yaklaşımın üçüncü dezavantajı, bu yöntemin yeterince esnek olmamasıdır. Tüm olası varyantları önceden belirtmelisiniz. Ancak, yeni veriler kullanıma sunuldukça sıklıkla sözlükteki değerleri dinamik olarak doldurmanız gerekir.
'Anahtar-değer' çifti depolamasının ikinci "önden" yöntemi, bir anahtarın bir indeks olarak kullanıldığı ve bir değerin bir dizi öğesi olduğu bir dizi oluşturmayı içerir.
Örneğin benzer bir görevi çözmeye çalışalım, yani zaman çerçevesi dizesi tasvirini almak için:
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
Bu kod, ENUM_TIMFRAMES'in bir indeks olarak belirtildiği dizine göre referansı gösterir. Değeri vermeden önce işlev, dizinin gerekli bir öğeyle dolu olup olmadığını kontrol eder. Değilse işlev doldurmayı özel bir işleve devreder - InitTimeframes(). switch işleciyle aynı dezavantajlara sahiptir.
Dahası, bu tür bir sözlük yapısı, büyük değerlere sahip bir dizinin başlatılmasını gerektirir. Dolayısıyla, PERIOD_MN1 değiştiricisinin değeri 49153'tür. Bu, yalnızca dokuz zaman çerçevesini depolamak için 49153 hücreye ihtiyacımız olduğu anlamına gelir. Diğer hücreler doldurulmadan kalır. Bu veri ayırma yöntemi, kompakt bir yöntem olmaktan uzaktır, ancak numaralandırma, küçük ve ardışık bir sayı aralığından oluştuğunda uygun olabilir.
2.3. Temel türlerin benzersiz bir anahtara dönüştürülmesi
Sözlükte kullanılan algoritmalar, belirli anahtar ve değer türlerinden bağımsız olarak benzer olduğundan, farklı veri türlerinin tek bir algoritma tarafından işlenebilmesi için veri hizalama gerçekleştirmemiz gerekir. Sözlük algoritmamız evrensel olacak ve örneğin int, enum, çift ve hatta dize gibi herhangi bir temel türün anahtar olarak belirtilebileceği değerleri depolamaya izin verecektir.
Aslında, MQL5'te herhangi bir temel veri türü, bazı işaretsiz ulong sayı olarak temsil edilebilir. Örneğin short veya ushort veri türleri, ulong'un "kısa" sürümleridir.
Ulong türünün ushort değerini sakladığını açıkça anlayarak, her zaman güvenli açık tür dönüşümü yapabilirsiniz:
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)
ulong, boyutu ulong'e eşit veya daha küçük olan herhangi bir türü depolayabileceğinden dolayı, char ve int türleri ve bunların işaretsiz analogları için de durum aynıdır. Datetime, enum ve renk türleri, 32-bit uint tamsayısını temel alır; bu, güvenli bir şekilde ulong'a dönüştürülebilecekleri anlamına gelir. bool türü yalnızca iki değere sahiptir: 0, yanlış anlamına gelir ve 1, doğru anlamına gelir. Böylece, bool türünün değerleri ulong türü değişkende de depolanabilir. Ayrıca, birçok MQL5 sistem işlevi bu özelliğe dayanmaktadır.
Örneğin AccountInfoInteger() işlevi, uzun türün tamsayı değerini verir; bu, aynı zamanda ulong türünde bir hesap numarası ve alım satım izninin Boole değeri - ACCOUNT_TRADE_ALLOWED olabilir.
Ancak MQL5›in, tamsayı türlerinden ayrı olarak üç temel türü vardır. Tamsayı ulong türüne doğrudan dönüştürülemezler. Bu türler arasında double ve float ve dizeler gibi kayan nokta türleri vardır. Ancak bazı basit eylemler onları benzersiz tamsayı anahtarlarına/değerlerine dönüştürebilir.
Her kayan nokta değeri, hem taban hem de kuvvetin bir tamsayı değeri olarak ayrı ayrı depolandığı, gelişigüzel bir güce yükseltilmiş bir taban olarak ayarlanabilir. Bu tür bir depolama yöntemi double ve float değerlerde kullanılır. Float türü, mantis ve kuvveti depolamak için 32 basamak kullanır, double tür 64 basamak kullanır.
Bunları doğrudan ulong türüne dönüştürmeye çalışırsak bir değer basitçe yuvarlanır. Bu durumda 3.0 ve 3.14159 aynı ulong değerini verir - 3. Bu iki farklı değer için farklı anahtarlara ihtiyacımız olacağından bu bizim için uygun değildir. C türü dillerde kullanılabilecek nadir bir özellik yardıma koşar. yapı dönüştürme olarak adlandırılır. Tek boyutu varsa (bir yapıyı diğerine dönüştürmek) iki farklı yapı dönüştürülebilir.
Bu örneği, biri ulong türü değerini, diğeri ise double türü değerini depolayan iki yapı üzerinde inceleyelim:
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
Bu kod, ULongValue yapısındaki DoubleValue yapısını bayt bayt kopyalar. Aynı boyut ve değişken sırasına sahip olduklarından, dValue.value'nin çift değeri, lValue.value'nun ulong değişkenine bayt bayt kopyalanır.
Bundan sonra bu değişken değeri yazdırılır. dValue.value'yu 3.14160 olarak değiştirirsek lValue.value de değişecektir.
printf() işlevi tarafından görüntülenecek olan sonuç:
2015.02.16 15:37:50.646 Test (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 Test (USDCHF,H1) 4614256650576692846
Float türü, double türünün kısa bir sürümüdür. Buna göre, float türünü ulong türüne dönüştürmeden önce, float türünü güvenli bir şekilde iki kata genişletebilirsiniz:
float fl = 3.14159f; double dbl = fl;
Bundan sonra, yapı dönüştürme yoluyla double'ı ulong türüne dönüştürün.
2.4. Dize hashleme ve hash'i anahtar olarak kullanma
Yukarıdaki örneklerde, anahtarlar tek bir veri türü ile temsil edilmiştir - dizeler. Ancak farklı durumlar olabilir. Örneğin bir telefon numarasının ilk üç hanesi bir telefon sağlayıcısını belirtir. Bu durumda özellikle bu üç rakam bir anahtarı temsil eder. Öte yandan, her dize, her basamağı alfabedeki bir harfin sıra numarası anlamına gelen benzersiz bir sayı olarak temsil edilebilir. Böylece dizeyi benzersiz sayıya dönüştürebilir ve bu sayıyı ilişkili değerine tamsayı anahtarı olarak kullanabiliriz.
Bu yöntem iyidir, ancak yeterince çok amaçlı değildir. Anahtar olarak yüzlerce sembol içeren bir dize kullanırsak sayı inanılmaz derecede büyük olacaktır. Onu herhangi bir türden basit bir değişkende yakalamak imkansız olacaktır. Hash işlevleri bu sorunu çözmemize yardımcı olacaktır. Hash işlevi, herhangi bir veri türünü (örneğin bir dize) kabul eden ve bu dizeyi karakterize eden benzersiz bir sayı veren özel bir algoritmadır.
Giriş verilerinin bir sembolü değiştirilse bile, sayı kesinlikle farklı olacaktır. Bu işlev tarafından verilen sayıların sabit bir aralığı vardır. Örneğin Adler32() hash işlevi, parametreyi gelişigüzel bir dize biçiminde kabul eder ve 32'nin kuvvetine yükseltilmiş 0 ila 2 aralığında bir sayı verir. Bu işlev oldukça basittir, ancak işimize gayet uygundur.
MQL5'te kaynak kodu var:
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
Aktarılan bir dizeye bağlı olarak hangi sayıları verdiğini görelim.
Bu amaçla, bu işlevi çağıran ve farklı dizeleri aktaran basit bir script dosyası yazacağız:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
Bu script dosyası çıktısı aşağıdakileri ortaya çıkardı:
2015.02.16 13:29:12.576 Test (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 Test (USDCHF,H1) Peace - 91685343
2015.02.16 13:29:12.576 Test (USDCHF,H1) Hello world! - 487130206
2015.02.16 13:29:12.576 Test (USDCHF,H1) Hello world - 413860925
Görebileceğimiz üzere, her dizenin karşılık gelen benzersiz bir numarası vardır. Dikkatinizi "Hello world" ve "Hello world!" dizelerine verin. Bunlar eredeyse aynı. Buradaki tek fark, ikinci dizenin sonundaki ünlem işaretidir.
Ancak Adler32() tarafından verilen sayılar her iki durumda da kesinlikle farklıydı.
Artık dize türünü işaretsiz uint değerine nasıl dönüştüreceğimizi biliyoruz ve string türü anahtar yerine hash'ini depolayabiliriz. İki dizenin bir hash'i olacaksa büyük olasılıkla aynı dizedir. Bu nedenle, bir değerin anahtarı bir dize değil, bu dize temelinde oluşturulan bir tamsayı hash'idir.
2.5. Bir anahtarla indeks bulma. Liste dizisi
Artık herhangi bir temel MQL5 türünü ulong işaretsiz türe nasıl dönüştüreceğimizi biliyoruz. Tam olarak bu tür, değerimizin karşılık geleceği gerçek bir anahtar olacaktır. Ancak ulong türünde benzersiz bir anahtara sahip olmak yeterli değildir. Elbette, her nesnenin benzersiz anahtarını biliyorsak, switch-case işlecine veya gelişigüzel uzunlukta bir diziye dayalı bazı ilkel depolama yöntemleri uydurabiliriz.
Bu tür yöntemler, mevcut bölümün 2.2 bölümünde açıklanmıştır. Ancak yeterince esnek ve verimli değiller. Switch-case ile ilgili olarak, bu işlecin tüm varyantlarını açıklamak mümkün görünmemektedir.
Sanki onbinlerce nesne varmış gibi, onbinlerce anahtardan oluşan switch işlecini derleme aşamasında anlatmak zorunda kalacağız ki bu imkansız. İkinci yöntem, bir öğenin anahtarının aynı zamanda indeksi olduğu bir dizi kullanmaktır. Gerekli öğeleri ekleyerek diziyi dinamik bir şekilde yeniden boyutlandırmaya izin verir. Böylece, sürekli olarak öğenin anahtarı olacak olan indeksi baz alarak başvurabiliriz.
Bu çözümün bir taslağını yapalım:
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
Ancak gerçek hayatta bu kod sorunları çözmek yerine daha ziyade sorun yaratır. Bir hash işlevinin büyük bir hash üreteceğini varsayalım. Verilen örnekte olduğu gibi, dizi indeksi hash değerine eşittir, onu devasa yapacak olan diziyi yeniden boyutlandırmamız gerekiyor. Bu kesinlikle başarılı olacağımız anlamına gelmez. Boyutu birkaç gigabayta ulaşabilen bir kapsayıcıda tek bir dize saklamak ister misiniz?
İkinci sorun, çakışma durumunda önceki değerin yenisiyle değiştirilecek olmasıdır. Sonuçta, Adler32() işlevinin iki farklı dize için tek hash anahtarı vermesi ihtimal dışı değildir. Bir anahtar kullanarak hızlı bir şekilde başvurmak istediğiniz için verilerinizin bir kısmını kaybetmek mi istiyorsunuz? Bu soruların cevabı açık: hayır, istemezsiniz. Bu gibi durumlardan kaçınmak için depolama algoritmasını değiştirmeli ve bir liste dizisine dayalı özel amaçlı bir hibrit kapsayıcı geliştirmeliyiz.
Liste dizisi, dizilerin ve listelerin en iyi özelliklerini birleştirir. Bu iki sınıf Standart Kitaplıkta temsil edilir. Dizilerin tanımsız öğelerine çok hızlı bir şekilde başvurmaya izin verdiğini, ancak dizilerin kendilerinin yavaş bir hızda yeniden boyutlandırıldığını hatırlatmakta fayda var. Bununla birlikte listeler, yeni öğelerin hemen eklenmesine ve çıkarılmasına izin verir ancak bir listenin her bir öğesine erişim oldukça yavaş bir işlemdir.
Bir liste dizisi aşağıdaki gibi temsil edilebilir:

Şek. 5. Bir liste dizisinin şeması
Bir liste dizisinin, her öğesi bir liste biçimine sahip olan bir dizi olduğu şemadan açıkça görülmektedir. Bakalım ne gibi avantajlar sağlıyor. Her şeyden önce, indeksine göre herhangi bir listeye hızlı bir şekilde başvurabiliriz. Diğer bir konu, her bir veri öğesini bir listede depolarsak, diziyi yeniden boyutlandırmadan listeye hızla öğe ekleyip çıkarabileceğiz. Dizi indeksi boş veya NULL'a eşit olabilir. Bu, bu indekse karşılık gelen öğelerin henüz eklenmediği anlamına gelir.
Bir dizi ve bir listenin kombinasyonu, alışılmadık bir fırsat daha sunar. Bir indeks kullanarak iki veya daha fazla öğeyi saklayabiliriz. Gerekliliğini anlamak için 3 öğeli bir dizide 10 sayı depolamamız gerektiğini varsayabiliriz. Gördüğümüz gibi dizide öğeden çok sayı var. Listeleri bir dizide saklayarak bu sorunu çözeceğiz. Bir veya başka bir sayıyı depolamak için üç dizi indeksinden birine eklenmiş üç listeden birine ihtiyacımız olacağını varsayalım.
Liste indeksini belirlemek için, sayımızın dizideki öğe miktarına bölünmesinde kalanı bulmamız gerekir:
dizi indeksi = dizideki % öğe sayısı;
Örneğin 2 sayısı için liste indeksi aşağıdaki gibi olacaktır: 2%3 = 2. Bu, indeks 2'nin listede indekse göre depolanacağı anlamına gelir. 3 sayısı, 3%3 = 0 indeksine göre depolanacaktır. 7 sayısı, 7%3 = 1 indeksine göre depolanacaktır. Liste indeksini belirledikten sonra bu numarayı listenin sonuna eklememiz yeterli.
Numarayı listeden çıkarmak için benzer eylemler gereklidir. 7 sayısını kapsayıcıdan çıkarmak istediğimizi varsayalım. Bu amaçla, hangi kapsayıcıda bulunduğunu tespit etmemiz gerekiyor: 7%3=1. 7 sayısının listede indeks 1'e göre bulunabileceğini belirledikten sonra, tüm listeyi sıralamamız ve öğelerden biri 7'ye eşitse bu değeri vermemiz gerekecek.
Tek bir indeks kullanarak birkaç öğeyi depolayabilirsek az miktarda veriyi depolamak için büyük diziler oluşturmamız gerekmez. 232,547,879 sayısını 0-10 basamaktan oluşan ve üç öğeli bir dizide depolamamız gerektiğini varsayalım. Bu sayının liste indeksi (232.547.879 % 3 = 2) olacaktır.
Rakamları hash ile değiştirirsek sözlükte bulunması gereken herhangi bir öğenin indeksini bulabiliriz. Çünkü hash bir sayıdır. Dahası, birden fazla öğeyi tek bir listede depolama olasılığı nedeniyle, hash'in benzersiz olması gerekmez. Aynı hash'e sahip öğeler tek bir listede olacaktır. Bir öğeyi anahtarına göre çıkarmamız gerekirse bu öğeleri karşılaştırır ve anahtara karşılık gelen öğeyi çıkarırız.
Aynı hash'e sahip iki öğenin iki benzersiz anahtarı olacağından bu mümkündür. Anahtarların benzersizliği, sözlüğe öğe ekleyen işlev tarafından kontrol edilebilir. Karşılık gelen anahtarı zaten sözlükteyse yeni bir öğe eklemeyecektir. Bu, bir abonenin yalnızca bir telefon numarasıyla uyuşması hususunda bir kontrol gibidir.
2.6. Dizi yeniden boyutlandırma, liste uzunluğunu en aza indirme
Liste dizisi ne kadar küçükse ve ne kadar çok öğe eklersek algoritma tarafından o kadar uzun liste zincirleri oluşturulacaktır. Birinci bölümde bahsedildiği gibi, bu zincirin bir öğesine erişim verimsiz bir işlemdir. Listemiz ne kadar kısa olursa kapsayıcımız o kadar çok indekse göre her öğeye erişim sağlayan bir dizi gibi görünecektir. Kısa listeleri ve uzun dizileri hedeflememiz gerekiyor. On öğe için mükemmel dizi, her biri bir öğeye sahip olacak on listeden oluşan bir dizidir.
En kötü varyant, bir listeden oluşan on öğe uzunluğunda bir dizi olacaktır. Programın akışı sırasında tüm öğeler dinamik olarak kapsayıcımıza eklendiğinden, kaç öğenin ekleneceğini öngöremiyoruz. Bu yüzden dizinin dinamik yeniden boyutlandırılması üzerine düşünmemiz gerekiyor. Dahası, listelerdeki zincir sayısı tek bir tek öğe eğilimi göstermelidir. Bunun için dizi boyutunun toplam öğe sayısına eşit tutulması gerektiği açıktır. Öğelerin kalıcı olarak eklenmesi, dizinin kalıcı olarak yeniden boyutlandırılmasını gerektirir.
Durum ayrıca, dizi yeniden boyutlandırma ile birlikte tüm listeleri yeniden boyutlandırmamız gerekeceği için karmaşıktır çünkü öğenin ait olabileceği liste indeksi yeniden boyutlandırmadan sonra değiştirilebilir. Örneğin, dizinin üç öğesi varsa 5 sayısı ikinci indeksde saklanacaktır (5%3 = 2). Altı öğe varsa 5 sayısı beşinci indekste saklanacaktır (5%6=5). Bu nedenle, sözlük yeniden boyutlandırma yavaş bir işlemdir. Mümkün olduğunca nadiren yapılmalıdır. Öte yandan, bunu hiç yapmazsak her yeni öğeyle zincirler büyüyecek ve her öğeye erişim giderek daha az verimli hale gelecektir.
Dizi yeniden boyutlandırma miktarı ile zincirin ortalama uzunluğu arasında makul bir uzlaşma uygulayan bir algoritma oluşturabiliriz. Her bir sonraki yeniden boyutlandırmanın dizinin mevcut boyutunu iki kez artıracağı gerçeğine dayanacaktır. Bu nedenle, sözlük başlangıçta iki öğeye sahipse, ilk yeniden boyutlandırma boyutunu 4 (2^2), ikinci - 8 (2^3), üçüncü - 16 (2^3) artıracaktır. On altıncı yeniden boyutlandırmadan sonra 65 536 zincir (2^16) için yer olacaktır. Her yeniden boyutlandırma, eklenen öğelerin miktarı ikinin yinelenen kuvvetiyle örtüşürse gerçekleştirilecektir. Bu nedenle, gerekli toplam gerçek ana bellek, tüm öğelerin depolanması için gereken belleği ikiden fazla aşmayacaktır. Öte yandan logaritmik yasa, dizinin sık sık yeniden boyutlandırılmasını önlemeye yardımcı olacaktır.
Benzer şekilde, listeden öğeleri kaldırarak dizinin boyutunu küçültebiliriz ve bunu yaparak tahsis edilen ana bellekten tasarruf edebiliriz.
Bölüm 3. İlişkisel Dizinin Pratik Geliştirilmesi
3.1. Şablon CDictionary sınıfı, AddObject ve DeleteObjectByKey yöntemleri ve KeyValuePair kapsayıcısı
İlişkisel dizimiz çok amaçlı olmalı ve her tür anahtarla çalışabilmelidir. Aynı zamanda, değerler olarak standart CObject tabanlı nesneleri kullanacağız. Herhangi bir temel değişkeni sınıflarda bulabileceğimiz için sözlüğümüz tek başına çözüm olacaktır. Elbette, birkaç sözlük sınıfı oluşturabiliriz. Her temel tür için ayrı bir sınıf türü kullanabiliriz.
Örneğin aşağıdaki sınıfları oluşturabiliriz:
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...
Ancak MQL5'in çok fazla temel türü vardır. Dahası, tüm türlerin bir çekirdek kodu olduğundan, her kod hatasını birçok kez düzeltmemiz gerekir. Tekrarı önlemek için şablonlar kullanacağız. Bir sınıfımız olacak, ancak aynı anda birkaç veri türünü işleyecek. Bu nedenle sınıfların ana yöntemleri şablon olacaktır.
Her şeyden önce, ilk şablon yöntemimizi oluşturalım - Add(). Bu yöntem, sözlüğümüze gelişigüzel bir anahtarlı öğe ekleyecektir. Sözlük sınıfı CDictionary olarak adlandırılacaktır. Öğenin yanı sıra sözlük, CList listelerine yönelik bir dizi işaretçi içerecektir. Bu zincirlerde öğeleri saklayacağız:
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
AddObject() yöntemi aşağıdaki gibi çalışır. İlk olarak sözlüğün eklenmesi gereken anahtarlı bir öğeye sahip olup olmadığını kontrol eder. ContainerKey() yöntemi bu denetimi gerçekleştirir. Sözlükte zaten anahtar varsa iki öğenin bir anahtara karşılık gelmesi belirsizliklere neden olacağından yeni bir öğe eklenmeyecektir.
Ardından yöntem, CList zincirlerinin depolandığı dizinin boyutunu öğrenir. Dizi boyutu öğelerin sayısına eşitse yeniden boyutlandırma zamanı gelmiştir. Bu görev, Resize() yöntemine devredilmiştir.
Sonraki adımlar basittir. Belirlenen indekse göre CList zinciri henüz mevcut değilse bu zincir oluşturulmalıdır. Dizin, önceden ContainerKey() yöntemiyle belirlenir. Belirlenen indeksi m_index değişkenine kaydeder. Ardından yöntem, listenin sonuna yeni bir öğe ekler. Ancak bundan önce öğe özel bir kapsayıcıda paketlenir — KeyValuePair. Standart CObject'e dayanır ve ikincisini ek işaretçiler ve verilerle genişletir. Kapsayıcı sınıf düzenlemesi biraz sonra anlatılacaktır. Kapsayıcı, ek işaretçilerle birlikte, nesnenin orijinal anahtarını ve hash'i de depolar.
AddObject() yöntemi bir şablon yöntemidir:
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
Bu kayıt, anahtar değişken türünün değiştirmeli olduğu ve gerçek türünün derleme zamanında belirlendiği anlamına gelir.
Örneğin AddObject() yöntemi kodunda aşağıdaki gibi etkinleştirilebilir:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
Bu aktivasyonlardan her biri, şablonlar sayesinde mükemmel şekilde çalışacaktır.
AddObject() yönteminin tam tersi olan DeleteObjectByKey() yöntemi de vardır. Bu yöntem, bir nesneyi anahtarıyla sözlükten siler.
Örneğin varsa, bir nesneyi "Araba" anahtarıyla silebilirsiniz:
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
Kod, AddObject() yöntem koduna çok benzer, bu yüzden burada göstermeyeceğiz.
AddObject() ve DeleteObjectByKey() yöntemleri, nesnelerle doğrudan çalışmaz. Bunun yerine her nesneyi standart CObject sınıfına dayalı olarak KeyValuePair kapsayıcısına paketlerler. Bu kapsayıcı, öğeleri ilişkilendirmeyi sağlayan ek işaretçilere sahiptir ve ayrıca orijinal bir anahtara ve nesne için belirlenmiş bir hash'e sahiptir. Kap, aynı zamanda, çakışmaları önlemeye izin veren eşitlik için geçirilen anahtarı test eder. Bunu, ContainerKey() yöntemine ayrılmış bir sonraki bölümde ele alacağız.
Şimdi bu sınıfın içeriğini göstereceğiz:
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. Tür adına dayalı çalışma zamanı türü tanımlaması; hash örnekleme
Artık yöntemlerimizde tanımsız türleri nasıl alacağımızı bildiğimize göre, onların hash'lerini belirlememiz gerekecek. Tüm tamsayı türleri için bir hash, bu türün ulong türüne genişletilen değerine eşit olacaktır.
double ve float türleri için hash'i hesaplamak için "Temel türlerin benzersiz bir anahtara dönüştürülmesi" bölümünde açıklanan yapılar aracılığıyla çevirimi kullanmamız gerekir. Dizeler için bir hash işlevi kullanılmalıdır. Her neyse, her veri türü kendi hash örnekleme yöntemini gerektirir. Yani tek ihtiyacımız olan transfer türünü belirlemek ve bu türe bağlı olarak bir hash örnekleme metodunu etkinleştirmektir. Bunun için özel bir yönergeye ihtiyacımız olacak typename.
Anahtarı temel alarak hash değerini belirleyen bir yönteme GetHashByKey() adı verilir.
Şunları içerir:
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
Mantığı basittir. Yöntem, typename yönergesini kullanarak aktarılan türün dize adını alır. Dize bir anahtar olarak aktarılırsa, typename "dize" değerini, int değeri olması durumunda "int" değerini verir. Aynısı diğer türlerde de olacaktır. Dolayısıyla, tüm yapmamız gereken, verilen değeri gerekli dize sabitleriyle karşılaştırmak ve bu değer sabitlerden biriyle çakışıyorsa karşılık gelen işleyiciyi etkinleştirmek.
Anahtar dize türündeyse hash Adler32() işlevi tarafından hesaplanır. Anahtar gerçek türlerle temsil ediliyorsa yapı dönüşümü sayesinde bunlar hash'e dönüştürülür. Diğer tüm türler açıkça, hash olacak ulong türüne dönüşür.
3.3. ContainsKey() yöntemi. Hash çarpışmasına tepki
Herhangi bir hash işlevinin ana sorunu, farklı anahtarların aynı karma değerini verdiği çakışmalarda yatar. Böyle bir durumda hash'ler çakışırsa belirsizlik ortaya çıkacaktır (iki nesne sözlük mantığı açısından benzer olacaktır). Böyle bir durumdan kaçınmak için, gerçek ve istenen anahtar türlerini kontrol etmemiz ve yalnızca gerçek anahtarlar çakışırsa pozitif bir değer vermemiz gerekir. ContainerKey() yöntemi bu şekilde çalışır. İstenen anahtara sahip bir nesne varsa doğru, aksi takdirde yanlış verir.
Belki de bu, tüm sözlükteki en kullanışlı ve pratik yöntemdir. Kesin bir anahtarı olan bir nesnenin var olup olmadığını bilmeyi sağlar:
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
Örneğin, yukarıdaki kod CCar türü nesnenin kullanılabilirliğini kontrol eder ve böyle bir nesne yoksa CCar'ı ekler. Bu yöntem ayrıca eklenen her yeni nesnenin anahtar benzersizliğini kontrol etmeyi sağlar.
Nesne anahtarı zaten kullanılmışsa AddObject() yöntemi bu yeni nesneyi sözlüğe eklemeyecektir.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
Bu o kadar evrensel bir metottur ki, hem kullanıcılar hem de diğer sınıf yöntemleri tarafından bolca kullanılmaktadır.
İçeriği:
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
İlk olarak yöntem GetHashByKey() kullanarak bir hash bulur. Hash'i temel almak yerine, verilen hash'e sahip bir nesnenin bulunabileceği CList zincirinin bir indeksini alır. Böyle bir zincir yoksa böyle bir anahtara sahip nesne de yoktur. Bu durumda, çalışmasını erken sonlandıracak ve false verecektir (böyle bir anahtara sahip nesne mevcut değildir). Zincir varsa numaralandırılmaya başlanır.
Bu zincirin her bir öğesi, aktarılan gerçek bir anahtarı bir öğe tarafından depolanan bir anahtarla karşılaştırmak için sunulan KeyValuePair türü nesne tarafından temsil edilir. Anahtarlar aynıysa yöntem yanlış verir (böyle bir anahtara sahip nesne var). Anahtarların eşitliğini test eden kod KeyValuePair sınıfının listesinde verilmiştir.
3.4. Dinamik ayırma ve belleğin serbest bırakılması
Yeniden boyutlandırma() yöntemi, ilişkisel dizimizde belleğin dinamik olarak tahsis edilmesinden ve serbest bırakılmasından sorumludur. Bu yöntem, öğe sayısı m_array boyutuna eşit olduğunda her zaman etkinleştirilir. Listeden öğeler silindiğinde de etkinleştirilir. Bu yöntem, tüm öğeler için depolama indekslerini geçersiz kılar, bu nedenle son derece yavaş çalışır.
Resize() yönteminin sık sık etkinleştirilmesini önlemek için ayrılan belleğin hacmi, önceki hacime kıyasla her seferinde iki kez artırılır. Başka bir deyişle, sözlüğümüzün 65.536 öğe depolamasını istiyorsak Resize() yöntemi 16 kez (2^16) etkinleştirilecektir. Yirmi defa etkinleştirmeden sonra sözlük bir milyondan fazla öğe içerebilir (1.048.576). FindNextLevel() yöntemi, gerekli öğelerin üstel büyümesinden sorumludur.
Resize() yönteminin kaynak kodu şöyledir:
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
Bu yöntem hem üst hem de alt taraflara çalışır. Gerçek bir dizinin içerebileceğinden daha az öğe olduğunda, bir öğe azaltma kodu başlatılır. Tersine, mevcut dizi yeterli olmadığında, dizi daha fazla öğe için yeniden boyutlandırılır. Bu kod çok fazla bilgi işlem kaynağı gerektirir.
Tüm dizinin yeniden boyutlandırılması gerekir, ancak tüm öğeleri önceden dizinin geçici bir kopyasına kaldırılmalıdır. Daha sonra tüm öğeler için yeni indeksler belirlemeniz gerekir ve ancak bundan sonra bu öğeleri yeni noktalarına yerleştirebilirsiniz.
3.5. Bitirme vuruşları: nesneleri arama ve kullanışlı bir dizin oluşturucu
Bu nedenle, CDictionary sınıfımız zaten onunla çalışmak için ana yöntemlere sahiptir. Belirli bir anahtara sahip bir nesnenin var olup olmadığını bilmek istiyorsak ContainerKey() yöntemini kullanabiliriz. AddObject() yöntemini kullanarak sözlüğe bir nesne ekleyebiliriz. Ayrıca DeleteObjectByKey() yöntemini kullanarak bir nesneyi sözlükten silebiliriz.
Şimdi sadece kapsayıcıdaki tüm nesnelerin uygun bir listesini yapmamız gerekiyor. Bildiğimiz gibi, tüm öğeler orada anahtarlarına göre belirli bir sırayla depolanır. Ancak tüm öğeleri ilişkisel diziye eklediğimiz aynı sırayla depolamak pratik olacaktır. Bu amaçla KeyValuePair kapsayıcısında, KeyValuePair türünün önceki ve sonraki eklenen öğelerine yönelik iki ek işaretçi bulunur. Bu işaretçiler sayesinde sıralı bir numaralandırma gerçekleştirebiliriz.
Örneğin ilişkisel dizimize aşağıdaki gibi öğeler eklersek:
CNumber CShip CWeather CHuman CExpert CCar
Şekil 6'da gösterildiği gibi KeyValuePair referansları kullanılarak gerçekleştirileceğinden, bu elemanların numaralandırılması da sıralı olacaktır:

Şek. 6. Sıralı dizi numaralandırma şeması
Bu tür bir numaralandırmayı gerçekleştirmek için beş yöntem kullanılır.
İçerikleri ve kısa açıklamaları şöyledir:
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
Bu basit yineleyiciler sayesinde, eklenen öğelerin sıralı bir numaralandırmasını gerçekleştirebiliriz:
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
Bu kod, nesnelerin dize değerlerini sözlüğe eklendikleri sırada çıkartır:
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
Tüm öğeleri geriye doğru çıkarmak için OnStart() işlevindeki kodun iki dizesini değiştirin:
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
Buna göre, çıktı değerleri ters çevrilir:
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
Bölüm 4. Performansın Testi ve Değerlendirilmesi
4.1. Test yazma ve performansı değerlendirme
Performans değerlendirmesi, özellikle veri depolama için bir sınıftan bahsediyorsak bir sınıf tasarlamanın temel bir bileşenidir. Sonuçta, en kapsamlı programlar bu sınıftan yararlanabilir. Bu programların algoritmaları hız için kritik olabilir ve yüksek performans gerektirebilir. Bu nedenle, bu tür algoritmaların performansının nasıl değerlendirileceğini ve zayıf yönlerinin nasıl aranacağını bilmek çok önemlidir.
Başlangıç olarak, sözlükten öğe ekleme ve çıkarma hızını ölçen basit bir test yazacağız. Bu test bir script dosyası gibi görünecek.
Kaynak kodu aşağıda eklenmiştir:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
Bu kod sırayla sözlüğe öğeler ekler ve ardından hızlarını ölçmek için onlara başvurur. Bundan sonra her öğe DeleteObjectByKey() yöntemi kullanılarak silinir. GetTickCount() sistem işlevi hızı ölçer.
Bu script dosyasını kullanarak, bu üç ana yöntemin zaman bağımlılıklarını gösteren bir diyagram oluşturduk:
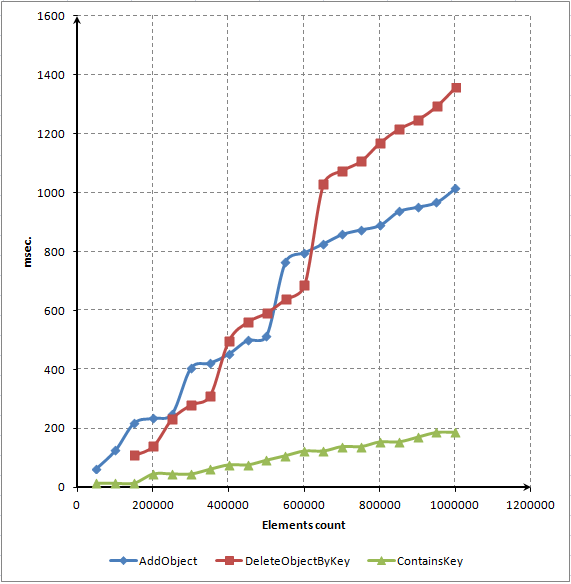
Şek. 7. Öğe sayısı ve yöntemlerin çalışma süresi arasındaki bağımlılığın milisaniye cinsinden nokta diyagramı
Gördüğünüz gibi, zamanın çoğu sözlükten öğeleri bulmak ve silmek için harcanıyor. Bununla birlikte, öğelerin çok daha hızlı silinmesini bekliyorduk. Bir kod profili oluşturucu kullanarak yöntemin performansını artırmaya çalışacağız. Bu prosedür bir sonraki bölümde açıklanacaktır.
ContainerKey() yönteminin diyagramına dikkat edin. Doğrusal. Bu, dizideki bu öğelerin sayısı ne olursa olsun, rastgele bir öğeye erişimin yaklaşık olarak bir süre gerektirdiği anlamına gelir. Bu, gerçek bir ilişkisel dizinin olmazsa olmaz bir özelliğidir.
Bu özelliği göstermek için bir öğeye ortalama erişim süresi ile dizideki birkaç öğe arasındaki bağımlılığın bir diyagramını göstereceğiz:
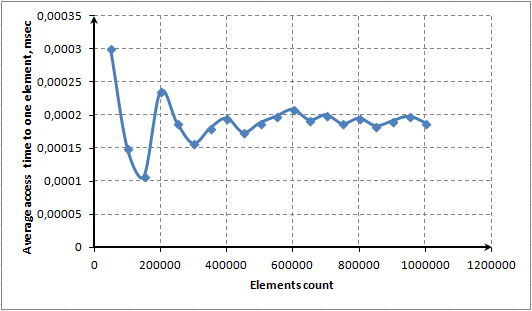
Şek. 8. ContainerKey() yöntemini kullanarak bir öğeye ortalama erişim süresi
4.2. Kod profilleme. Otomatik bellek yönetimine giden hız
Kod profilleme, tüm işlevlerin zaman harcamalarını ölçen özel bir tekniktir. MetaEditor'da ![]() öğesini tıklayarak herhangi bir MQL5 programını başlatmanız yeterlidir.
öğesini tıklayarak herhangi bir MQL5 programını başlatmanız yeterlidir.
Aynısını yapacağız ve script dosyamızı profilleme için göndereceğiz. Bir süre sonra script dosyamız gerçekleştirilir ve script dosyasının çalışması sırasında gerçekleştirilen tüm yöntemlerin bir zaman profilini alırız. Aşağıdaki ekran görüntüsü, zamanın çoğunun üç yöntemi gerçekleştirmek için harcandığını göstermektedir: AddObject() (zamanın %40'ı), GetObjectByKey() (zamanın %7'si) ve DeleteObjectByKey() (zamanın %53'ü):
 işlevinde kod profilleme")
Şek. 9. OnStart() işlevinde kod profilleme
Ve DeleteObjectByKey() çağrısının %60'ından fazlası Compress() yöntemini çağırmak için harcandı.
Ancak bu yöntem neredeyse boştur, ana zaman Resize() yöntemini çağırmak için harcanır.
Şunları içerir:
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
Sorun açık. Tüm öğeleri sildiğimizde, zaman zaman Resize() yöntemi başlatılır. Bu yöntem, depolamayı dinamik olarak serbest bırakarak dizi boyutunu azaltır.
Öğeleri daha hızlı silmek istiyorsanız bu yöntemi devre dışı bırakın. Örneğin, sıkıştırma bayrağını ayarlayarak özel AutoFreeMemory() yöntemini sınıfa tanıtabilirsiniz. Varsayılan olarak ayarlanacaktır ve böyle bir durumda sıkıştırma otomatik olarak gerçekleştirilecektir. Ancak ek hıza ihtiyacımız olursa sıkıştırma işlemini iyi seçilmiş bir anda manuel olarak gerçekleştireceğiz. Bu amaçla Compress() yöntemini public yapacağız.
Sıkıştırma devre dışı bırakılırsa öğeler üç kat daha hızlı silinir:
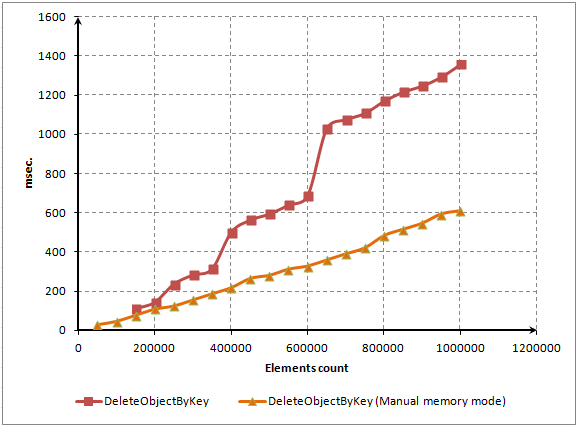
Şek. 10. Meşgul edilen depolama insan gözetimindeyken öğe silme süresi (karşılaştırma)
Resize() yöntemi yalnızca veri sıkıştırma için değil, aynı zamanda çok fazla öğe olduğunda ve daha büyük bir diziye ihtiyacımız olduğunda da çağrılır. Bu durumda Resize() yöntemini çağırmaktan kaçınamayız. İleride uzun ve yavaş CList zincirleri oluşturmamak için çağrılması gerekir. Ancak sözlüğümüzün gerekli hacmini önceden belirleyebiliriz.
Örneğin bir dizi eklenen öğe genellikle önceden bilinir. Öğe sayısını bilerek, sözlük önceden gerekli boyutta bir dizi oluşturacaktır, böylece diziyi doldururken ekstra yeniden boyutlandırma gerekli olmayacaktır.
Bu amaçla, gerekli öğeleri kabul edecek bir oluşturucu daha ekleyeceğiz:
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
Özel Init() yöntemi ana işlemi gerçekleştirir:
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
İyileştirmelerimiz tamamlandı. Şimdi, başlangıçta belirtilen dizi boyutuyla AddObject() yönteminin performansını değerlendirmenin zamanı geldi. Bu amaçla, script dosyamızın OnStart() işlevinin ilk iki dizesini değiştireceğiz:
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
Bu durumda END, 1.000.000 öğeye eşit büyük bir sayı ile temsil edilir.
Bu yenilikler, AddObject() yönteminin performansını önemli ölçüde hızlandırdı:

Şek. 11. Önceden ayarlanmış dizi boyutuyla öğeleri ekleme zamanı
Gerçek programlama problemlerini çözerken, her zaman bellek ayak izi ve performans hızı arasında seçim yapmak zorundayız. Belleği boşaltmak önemli miktarda zaman alır. Ancak bu durumda daha fazla kullanılabilir belleğe sahip olacağız. Her şeyi olduğu gibi tutarsak, CPU zamanı ek karmaşık hesaplama sorunları için harcanmaz, ancak aynı zamanda daha az kullanılabilir belleğe sahip oluruz. Kapsayıcıları kullanarak, nesne yönelimli programlama, kaynakları CPU belleği ile CPU zamanı arasında esnek bir şekilde tahsis etmeyi sağlar ve her belirli sorun için belirli bir yürütme politikası seçer.
Sonuç olarak, CPU performansı bellek kapasitesinden çok daha kötü ölçeklenir. Bu nedenle çoğu durumda bellek ayak izinden ziyade yürütme hızını tercih ederiz. Ayrıca, genellikle görevin sonlu durumunu bilmediğimiz için, kullanıcı düzeyinde bellek kontrolü otomatik kontrolden daha verimlidir.
Örneğin, script dosyamız durumunda, DeleteObjectByKey() yöntemi görevin sonuna kadar hepsini sileceğinden, numaralandırmanın sonunda toplam öğe sayısının boş olacağını önceden biliyoruz. Bu yüzden diziyi otomatik olarak sıkıştırmamıza gerek yok. En sonunda Compress() yöntemini çağırarak temizlemeniz yeterli olacaktır.
Şimdi, diziden öğe eklemek ve silmek için iyi doğrusal metriklere sahip olduğumuzda, toplam öğe sayısına bağlı olarak ortalama öğe ekleme ve silme süresini analiz edeceğiz:
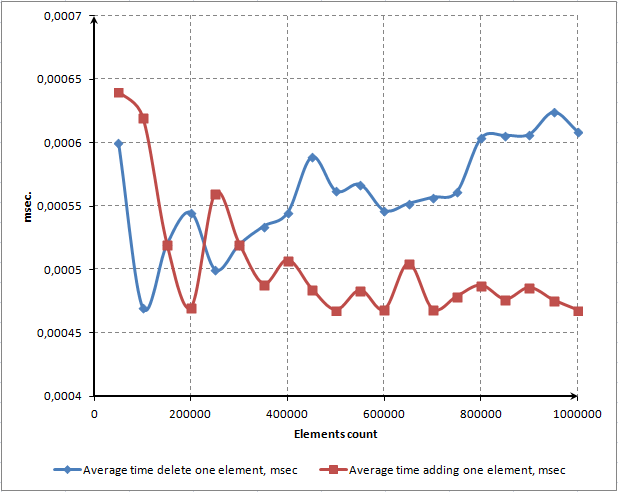
Şek. 12. Bir öğe ekleme ve silme için ortalama süre
Ortalama öğe ekleme süresinin oldukça durağan olduğunu ve dizideki toplam öğe sayısına bağlı olmadığını görebiliriz. Bir öğeyi ortalama silme süresi hafifçe yukarı doğru hareket eder ve bu istenmeyen bir durumdur. Ama sonuçlarla hata oranı dahilinde mi olduğunu yoksa bunun düzenli bir eğilim mi olduğunu kesin olarak söyleyemiyoruz.
4.3. CDictionary performansının standart CArrayObj ile karşılaştırması
En ilginç testin zamanı geldi: CDictionary'mizi standart CARrayObj sınıfıyla karşılaştıracağız. CArrayObj, yapım aşamasında varsayılan bir boyutun belirtilmesi gibi manuel bellek tahsisi için mekanizmalara sahip değildir, bu nedenle CDictionary'de manuel bellek kontrolünü devre dışı bırakacağız ve AutoFreeMemory() mekanizması etkinleştirilecektir.
Her sınıfın güçlü ve zayıf yönleri birinci bölümde açıklanmıştır. CDictionary, tanımsız bir noktaya öğe eklemenin yanı sıra onu sözlükten çok hızlı bir şekilde çıkarmayı sağlar. Ancak CArrayObj, tüm öğelerin çok hızlı bir şekilde numaralandırılmasını sağlar. CDictionary'de numaralandırma, bir işaretçi tarafından hareket ettirilerek gerçekleştirileceği için daha yavaş olacaktır ve bu işlem doğrudan indekslemeye göre daha yavaştır.
İşte başlıyoruz. Başlangıç için testimizin yeni bir sürümünü oluşturalım:
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
TEST_ARRAY makrolarını kullanır. Test tanımlanırsa işlemler CArrayObj üzerinde gerçekleştirir, aksi takdirde işlemler CDictionary üzerinde gerçekleştirilir. Yeni öğeler eklemek için ilk testi CDictionary kazandı.
Bu özel durumda, bellek yeniden tahsis yönteminin daha iyi olduğu ortaya çıktı:
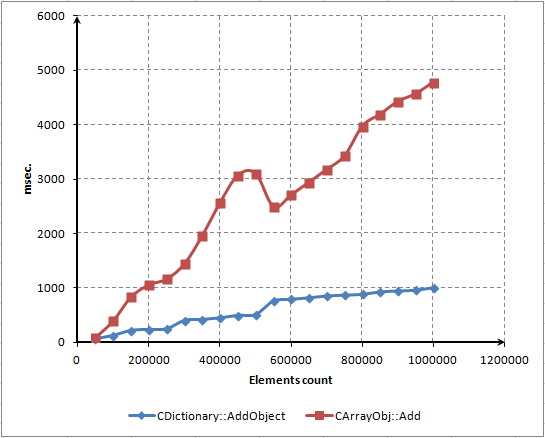
Şek. 13. CArrayObj ve CDictionary'ye yeni öğeler eklemek için harcanan süre (karşılaştırma)
CARrayObj içindeki belirli bir bellek yeniden tahsis yönteminin daha yavaş çalışmaya neden olduğunun altını çizmek çok önemlidir.
Kaynak kodun yalnızca bir dizesiyle tanımlanır:
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize); Bu, doğrusal bir bellek ayırma algoritmasıdır. Her 16 öğeyi doldurduktan sonra varsayılan olarak çağrılır. CDictionary, üstel bir algoritma kullanır: sıradaki her bellek yeniden tahsisi, önceki çağrının iki katı bellek ayırır. Bu diyagram, performans ve kullanılan bellek arasındaki ikilemi mükemmel bir şekilde göstermektedir. CArrayObj sınıfının Rezerv() yöntemi daha ekonomiktir ve daha az bellek gerektirir ancak daha yavaş çalışır. CDictionary sınıfının Yeniden boyutlandırma() yöntemi daha hızlı çalışır ancak daha fazla bellek gerektirir ve bu belleğin yarısı hiç kullanılmamış halde kalabilir.
Son testi yapalım. CARrayObj ve CDictionary kapsayıcılarının tam numaralandırması için süreyi hesaplayacağız. CArrayObj doğrudan dizin oluşturmayı, CDictionary ise referanslamayı kullanır. CArrayObj, herhangi bir öğeye dizinine göre başvurmaya izin verir, ancak CD Sözlüğü'nde herhangi bir öğeye indeksine göre başvuru yapılması engellenir. Sıralı numaralandırma, doğrudan indeksleme ile oldukça rekabetçidir:
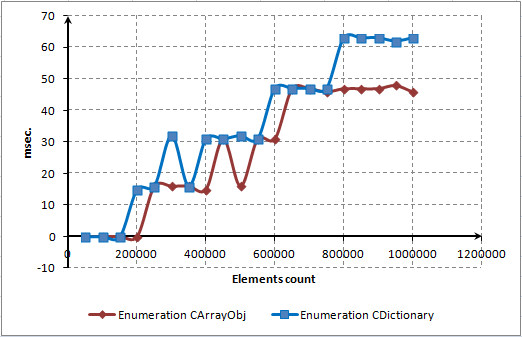
Şek. 14. CArrayObj ve CDictionary'nin tam numaralandırma süresi
MQL5 dil geliştiricileri harika bir iş çıkardı ve referansları optimize etti. Diyagramda gösterilen doğrudan indeksleme ile hız açısından oldukça rekabetçidirler.
Öğe numaralandırmanın çok kısa sürdüğünü ve GetTickCount() işlevinin neredeyse çözümlenmenin eşiğinde olduğunu anlamak önemlidir. 15 milisaniyeden küçük zaman aralıklarını ölçmek için kullanılması zordur.
4.4. CArrayObj, CList ve CDictionary'yi kullanırken genel öneriler
Programlamada oluşabilecek temel görevleri ve bu görevleri çözmek için bilinmesi gereken kapsayıcıların özelliklerini anlatacağımız bir tablo yapacağız.
Görev performansı iyi olan özellikler yeşil, görevlerin verimli bir şekilde tamamlanmasına izin vermeyen özellikler kırmızı ile yazılmıştır.
| Amaç | CArrayObj | CList | CDictionary |
|---|---|---|---|
| Kapsayıcının sonuna sıralı olarak yeni öğeler ekleme. | Kapsayıcının yeni bir öğe için yeni bellek ayırması gerekiyor. Mevcut öğelerin yeni indekslere aktarılması gerekli değildir. CarrayObj bu işlemi çok hızlı bir şekilde gerçekleştirecektir. | Kapsayıcı ilk, geçerli ve son öğeleri hatırlar. Bu nedenle, yeni bir öğe listenin sonuna (son hatırlanan öğe) çok hızlı şekilde eklenecektir. | Sözlükte "bitiş" veya "başlangıç" gibi kavramlar yoktur. Yeni bir öğe çok hızlı şekilde eklenir ve bir dizi öğeye bağlı değildir. |
| İndeksine göre gelişigüzel bir öğeye erişim. | Doğrudan indeksleme nedeniyle erişim çok hızlı bir şekilde elde edilir, O(1) zaman alır. | Her öğeye erişim, önceki tüm öğelerin numaralandırılmasıyla elde edilir. Bu işlem O(n) zaman alır. | Her öğeye erişim, önceki tüm öğelerin numaralandırılmasıyla elde edilir. Bu işlem O(n) zaman alır. |
| Anahtarı ile gelişigüzel bir öğeye erişim. | Mevcut değil | Mevcut değil | Bir anahtarla bir hash ve dizin bulmak, verimli ve hızlı bir işlemdir. Hashing işlevi verimliliği dize anahtarları için çok önemlidir. Bu işlem O(1) zaman alır. |
| Yeni öğeler, tanımsız bir dizin tarafından eklenir/silinir. | CArrayObj, yalnızca yeni bir öğe için bellek ayırmakla kalmamalı, aynı zamanda indeksleri eklenen öğenin bir indeksinden daha yüksek olan tüm öğeleri kaldırmalıdır. CArrayObj bu nedenle yavaş bir işlemdir. | Öğe CList'te çok hızlı bir şekilde eklenir veya silinir, ancak O(n) içinde gerekli indekse erişilebilir. Bu yavaş bir işlemdir. | CDictionary'de, öğeye indeksine göre erişim, CList listesine göre gerçekleştirilir ve çok zaman alır. Ancak ekleme ve silme işlemleri çok hızlı yapılıyor. |
| Yeni öğeler, tanımsız bir anahtarla eklenir/silinir. | Mevcut değil | Mevcut değil | CList'e her yeni eleman eklendiğinden, her ekleme/silme işleminden sonra dizinin yeniden boyutlandırılması gerekmediğinden yeni elemanlar çok hızlı eklenir ve silinir. |
| Kullanım ve bellek yönetimi. | Dinamik dizi yeniden boyutlandırması gerekli. Bu yoğun kaynak gerektiren bir işlemdir, ya çok zaman ya da çok bellek gerektirir. | Bellek yönetimi kullanılmıyor. Her öğe doğru miktarda bellek alır. | Dinamik dizi yeniden boyutlandırması gerekli. Bu yoğun kaynak gerektiren bir işlemdir, ya çok zaman ya da çok bellek gerektirir. |
| Öğelerin numaralandırılması. Vektörün her bir öğesi için yapılması gereken işlemler. | Doğrudan öğe indeksleme sebebiyle çok hızlı gerçekleştirildi. Ancak bazı durumlarda numaralandırma ters sırada yapılmalıdır (örneğin son öğeyi sıralı olarak silerken). | Tüm öğeleri yalnızca bir kez numaralandırmamız gerektiğinden, doğrudan referans verme hızlı bir işlemdir. | Tüm öğeleri yalnızca bir kez numaralandırmamız gerektiğinden, doğrudan referans verme hızlı bir işlemdir. |
Bölüm 5. CDSözlük Sınıfı Belgeleri
5.1. Öğe eklemek, silmek ve öğelere erişmek için kilit yöntemler
5.1.1. AddObject() yöntemi
T Anahtarı ile CObject türünün yeni öğesini ekler. Herhangi bir temel türü anahtar olarak kullanılabilir.
template<typename T> bool AddObject(T key,CObject *value);
Parametreler
- [içinde] anahtar – temel türlerden biri tarafından temsil edilen benzersiz anahtar (dize, ulong, char, enum vb.).
- [içinde] değer - temel tür olarak CObject'i olan nesne.
Dönüştürülen değer
Nesne kapsayıcıya eklendiyse doğru, aksi takdirde yanlış verir. Eklenen nesnenin anahtarı kapsayıcıda zaten varsa yöntem negatif bir değer verir ve nesne eklenmez.
5.1.2. ContainerKey() yöntemi
Kapsayıcıda anahtarı T Anahtarına eşit olan bir nesne olup olmadığını kontrol eder. Herhangi bir temel türü anahtar olarak kullanılabilir.
template<typename T> bool ContainsKey(T key);
Parametreler
- [içinde] anahtar – temel türlerden biri tarafından temsil edilen benzersiz anahtar (dize, ulong, char, enum vb.).
Kontrol edilen anahtara sahip nesne kapsayıcıda varsa değerini verir. Aksi takdirde yanlış dönüşür.
5.1.3. DeleteObjectByKey() yöntemi
Ön ayarlı T Anahtarı ile bir nesneyi siler. Herhangi bir temel türü anahtar olarak kullanılabilir.
template<typename T> bool DeleteObjectByKey(T key);
Parametreler
- [içinde] anahtar – temel türlerden biri tarafından temsil edilen benzersiz anahtar (dize, ulong, char, enum vb.).
Dönüştürülen değer
Ön ayar anahtarına sahip nesne silinmişse doğru değerini verir. Ön ayar anahtarına sahip nesne yoksa veya silinmesi başarısız olursa false verir.
5.1.4. GetObjectByKey() yöntemi
Önceden ayarlanmış T Anahtarına göre bir nesne verir. Herhangi bir temel türü anahtar olarak kullanılabilir.
template<typename T> CObject* GetObjectByKey(T key);
Parametreler
- [içinde] anahtar – temel türlerden biri tarafından temsil edilen benzersiz anahtar (dize, ulong, char, enum vb.).
Dönüştürülen değer
Ön ayar anahtarına karşılık gelen bir nesne verir. Ön ayar anahtarına sahip nesne yoksa NULL verir.
5.2. Bellek yönetimi yöntemleri
5.2.1. CDictionary() oluşturucu
Temel oluşturucu, temel dizinin başlangıç boyutu 3 öğeye eşit olan CDictionary nesnesini oluşturur.
Dizi, sözlüğün doldurulmasıyla veya öğelerin silinmesiyle otomatik olarak artırılır veya sıkıştırılır.
CDictionary();
5.2.2. CDictionary(int kapasite) oluşturucu
Oluşturucu, temel dizinin başlangıç boyutu 'kapasite'ye eşit olan CDictionary nesnesini yaratır.
Dizi, sözlüğün doldurulmasıyla veya öğelerin silinmesiyle otomatik olarak artırılır veya sıkıştırılır.
CDictionary(int capacity);
Parametreler
- [içinde] kapasite – başlangıç öğelerinin sayısı.
Not
Dizi boyutu sınırını, başlatıldıktan hemen sonra ayarlamak, Resize() yönteminin çağrılarını önlemenize ve böylece yeni öğeler eklerken verimliliği artırmanıza yardımcı olur.
Ancak, (AutoMemoryFree(true)) etkin olan öğeleri silerseniz kapasite ayarına rağmen kapsayıcının otomatik olarak sıkıştırılacağına dikkat edilmelidir. Erken sıkıştırmayı önlemek için kapsayıcılar tamamen doldurulduktan sonra ilk nesne silme işlemini gerçekleştirin veya bu yapılamıyorsa devre dışı bırakın (AutoMemoryFree(false)).
5.2.3. FreeMode(bool modu) yöntemi
Kapsayıcıda bulunan nesneleri silme modunu ayarlar.
Silme modu etkinleştirilirse nesne silindikten sonra kapsayıcı da "sil" prosedürüne tabidir. İz silici etkinleştirildi ve kullanılamaz hale geldi. Silme modu devre dışı bırakılırsa nesnenin iz silicisi etkinleştirilmez ve programın diğer noktalarından erişilebilir olmaya devam eder.
void FreeMode(bool free_mode);
Parametreler
- [içinde] free_mode – nesne silme modu göstergesi.
5.2.4. FreeMode() yöntemi
Kapsayıcıda bulunan nesnelerin silinme göstergesini verir (bkz. FreeMode(bool modu)).
bool FreeMode(void);
Dönüştürülen değer
Nesne kapsayıcıdan silindikten sonra delete işleci tarafından silinirse doğru verir. Aksi takdirde yanlış dönüşür.
5.2.5. AutoFreeMemory(bool autoFree) yöntemi
Otomatik bellek yönetimi göstergesini ayarlar. Otomatik bellek yönetimi varsayılan olarak etkindir. Bu durumda dizi otomatik olarak sıkıştırılır (büyükten küçüğe yeniden boyutlandırılır). Devre dışı bırakılırsa dizi sıkıştırılmaz. Yoğun kaynak kullanan Resize() yönteminin çağrılması gerekmediğinden program yürütme hızını önemli ölçüde artırır. Ancak bu durumda dizi boyutuna dikkat etmeniz ve Compress() yöntemiyle manuel olarak sıkıştırmanız gerekir.
void AutoFreeMemory(bool auto_free);
Parametreler
- [içinde] auto_free – bellek yönetimi modu göstergesi.
Dönüştürülen değer
Bellek yönetimini etkinleştirmeniz ve otomatik olarak Compress() yöntemini çağırmanız gerekiyorsa doğru değerini verir. Aksi takdirde yanlış dönüşür.
5.2.6. AutoFreeMemory() yöntemi
Otomatik bellek yönetimi modunun kullanılıp kullanılmadığını belirten göstergeyi verir (bkz. FreeMode(bool free_mode) yöntemi).
bool AutoFreeMemory(void);
Dönüştürülen değer
Bellek yönetimi modu kullanılıyorsa doğru değerini verir. Aksi takdirde yanlış dönüşür.
5.2.7. Sıkıştır() yöntemi
Sözlüğü sıkıştırır ve öğeleri yeniden boyutlandırır. Dizi yalnızca mümkünse sıkıştırılabilir.
Bu yöntem, yalnızca otomatik bellek yönetimi modu devre dışı bırakılmışsa talep edilmelidir.
void Compress(void);
5.2.8. Temizleme() yöntemi
Sözlükteki tüm öğeleri siler. Bellek yönetimi göstergesi etkinleştirilirse, silinen her öğe için yıkıcı talep edilir.
void Clear(void);
5.3. Sözlük üzerinden arama yöntemleri
Tüm sözlük öğeleri birbirine bağlıdır. Her yeni öğe bir öncekine bağlanır. Böylece tüm sözlük öğelerinin sıralı olarak aranması mümkün hale gelir. Böyle bir durumda referans, bağlantılı bir liste tarafından gerçekleştirilir. Bu bölümdeki yöntemler aramayı kolaylaştırır ve sözlük yinelemesini daha uygun hale getirir.
Sözlük üzerinden arama yaparken aşağıdaki yapıyı kullanabilirsiniz:
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }
5.3.1. GetFirstNode() yöntemi
Sözlüğe eklenen ilk öğeyi dönüştürür.
CObject* GetFirstNode(void); Dönüştürülen değer
İşaretçiyi, öncelikle sözlüğe eklenmiş olan CObject türü nesneye dönüştürür.
5.3.2. GetLastNode() yöntemi
Sözlüğün son öğesini dönüştürür.
CObject* GetLastNode(void); Dönüştürülen değer
İşaretçiyi, en sonunda sözlüğe eklenmiş olan CObject türü nesneye dönüştürür.
5.3.3. GetCurrentNode() yöntemi
Geçerli seçili öğeyi dönüştürür. Öğe, sözlük üzerinden öğe arama yöntemlerinden biriyle veya sözlük öğesine erişim yöntemiyle (ContainsKey(), GetObjectByKey()) önceden seçilmelidir.
CObject* GetLastNode(void); Dönüştürülen değer
İşaretçiyi, en sonunda sözlüğe eklenmiş olan CObject türü nesneye dönüştürür.
5.3.4. GetNextNode() yöntemi
Geçerli öğeyi takip eden öğeye dönüştürür. Geçerli öğe sonuncuysa veya seçilmemişse NULL'a (BOŞA) dönüştürür.
CObject* GetLastNode(void); Dönüştürülen değer
İşaretçiyi, geçerli olanı takip eden CObject türü nesneye dönüştürür. Geçerli öğe sonuncuysa veya seçilmemişse NULL'a (BOŞA) dönüştürür.
5.3.5. GetPrevNode() yöntemi
Geçerli öğeden önceki öğeyi dönüştürür. Geçerli öğe ilkse veya seçilmemişse NULL'a (BOŞA) dönüştürür.
CObject* GetPrevNode(void); Dönüştürülen değer
İşaretçiyi, geçerli olandan önceki CObject türü nesneye dönüştürür. Geçerli öğe ilkse veya seçilmemişse NULL'a (BOŞA) dönüştürür.
Sonuç
Yaygın veri kapsayıcılarının temel özelliklerini inceledik. Her veri kapsayıcısı, özelliklerinin sorunu en verimli şekilde çözmesine izin verdiği yerlerde kullanılmalıdır.
Bir öğeye sıralı erişimin sorunu çözmek için yeterli olduğu durumlarda düzenli diziler kullanılmalıdır. Sözlükler ve ilişkili diziler, bir öğeye benzersiz anahtarıyla erişimin gerekli olduğu durumlarda daha iyidir. Listelerin sık öğe değişimi durumunda kullanılması daha iyidir: silme, ekleme, yeni öğe ekleme.
Sözlük, zorlu algoritmik problemlerin güzel ve basit bir şekilde çözülmesini sağlar. Diğer veri kapsayıcılarının ek işleme özellikleri gerektirdiği durumlarda, sözlük mevcut öğelere erişimi en etkili şekilde düzenlemeye olanak tanır. Örneğin sözlüğe dayanarak, OnChartEvent() türündeki her olayın bir veya başka bir grafik öğesini yöneten sınıfa teslim edildiği bir olay modeli oluşturabilirsiniz. Bu amaçla, her sınıf örneğini bu sınıf tarafından yönetilen nesnenin adıyla ilişkilendirmeniz yeterlidir.
Sözlük evrensel bir algoritma olduğu için çok çeşitli alanlarda uygulanabilir. Bu makale, çalışmasının, uygulamasını kullanışlı ve etkili kılan oldukça basit ama sağlam algoritmalara dayandığını açıklıyor.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/1334
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

 CCanvas Sınıfını incelemek. Şeffaf Nesneler Nasıl Çizilir
CCanvas Sınıfını incelemek. Şeffaf Nesneler Nasıl Çizilir
 HedgeTerminal API'sini Kullanarak MetaTrader 5'te İki Yönlü Alım Satım ve Pozisyonların Korunması, Bölüm 2
HedgeTerminal API'sini Kullanarak MetaTrader 5'te İki Yönlü Alım Satım ve Pozisyonların Korunması, Bölüm 2
 Test (Optimizasyon) Tekniği ve Expert Advisor Parametrelerinin Seçiminde Bazı Kriterler
Test (Optimizasyon) Tekniği ve Expert Advisor Parametrelerinin Seçiminde Bazı Kriterler
 MetaTrader 5'te HedgeTerminal Panelini Kullanarak İki Yönlü Alım Satım ve Pozisyonların Korunması, Bölüm 1
MetaTrader 5'te HedgeTerminal Panelini Kullanarak İki Yönlü Alım Satım ve Pozisyonların Korunması, Bölüm 1
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
genel olarak doğru çalışması gerekmez.
İlişkisel bir diziden birden fazla silme işlemi gerçekleştirmenin doğru yolu, silinecek anahtarların bir dizisini toplamak ve ardından anahtara göre silmektir.
Mesele şu ki, bu yöntem bile aniden garip bir hataya neden oluyor. Belli ki bir hata var. Bunu araştıracağım.
Şimdilik, size yeni bir sözlük oluşturmanızı ve silinmesine gerek olmayan değerleri eklemenizi tavsiye edebilirim. Sonra eskisini temizleyin. Bu %100 işe yarayacaktır.
İşte başlıyoruz:
1. Sözlük sürümünü bu yazıya eklenmiş olana güncelleyin.
2. Öğeleri bile silmek için bir test betiği çalıştırın.
Silme işlemi iki geçişte yapılmalıdır:
DeleteCurrentObject() yöntemi ile ilgili olarak:
Bu yöntem yalnızca ContainsKey() işlevi ile birlikte kullanılmalıdır. Public olarak kullanılabilir olmasının tek nedeni, bu durumda yöntem çağrısının işaretçinin yeniden konumlandırılmasında zaman kazandırmasıdır. Yani, tipik ve tek kullanım durumu 1. Bir anahtar olup olmadığını kontrol edin, 2. Varsa - bu yöntemle hızlı bir şekilde silin.
Bu anlaşılabilir bir şey ama yine de gereksiz bir kaporta işi.
Beklediğiniz gibi tek geçişli bir kaldırma işlemi yapmak teknik olarak mümkündür. Ancak bu karmaşık olacaktır. Bu yüzden henüz değil, sadece iki geçişte. Dağıtık bir veri yapısı olarak sözlük açısından bakıldığında, iki geçişli silme işlemi kanonik olarak daha doğru bir çözümdür. Sadece kullanıcı seviyesinde silme işlemi sıralı gibi görünür, gerçekte her şey farklıdır. Performans açısından, tek geçişli silme herhangi bir fayda sağlamayacaktır. Kolaylık açısından, evet, daha uygun olabilir.
Beklediğiniz gibi tek geçişli bir kaldırma işlemi yapmak teknik olarak mümkündür. Ancak bu karmaşık olacaktır. Bu yüzden henüz değil, sadece iki geçişte. Dağıtık bir veri yapısı olarak sözlük açısından bakıldığında, iki geçişli silme işlemi kanonik olarak daha doğrudur. Sadece kullanıcı seviyesinde silme işlemi sıralı gibi görünür, gerçekte her şey farklıdır. Performans açısından, tek geçişli silme herhangi bir fayda sağlamayacaktır. Kolaylık açısından, evet, daha uygun olabilir.
Teşekkürler.
Sanırım bir öğeyi silerken ve son öğeye ulaşmaya çalışırken bir hata buldum:
CDictionary.mqh dosyasında hata olacaktır:
'Dictionary.mqh' içindegeçersiz işaretçi erişimi (463,9)
Bunu doğrulayabilecek biri var mı? Nasıl düzeltileceği hakkında bir fikrin var mı?
İşaretçileri kontrol etme uygulamasında 500 && 501 satırında bir hata vardı.
Dahili CheckPointer() kullanılarak düzeltildi.