
Le MQL5 Cookbook : Implémentation d'un tableau associatif ou d'un dictionnaire pour un accès rapide aux données

Table des matières
- INTRODUCTION
- CHAPITRE 1. THÉORIE DE L'ORGANISATION DES DONNÉES
- CHAPITRE 2. THÉORIE DE L'ORGANISATION DU TABLEAU ASSOCIATIF
- CHAPITRE 3. DÉVELOPPEMENT PRATIQUE D'UN TABLEAU ASSOCIATIF
- CHAPITRE 4. TEST ET ÉVALUATION DES PERFORMANCES
- CHAPITRE 5. DOCUMENTATION DE LA CLASSE CDICTIONARY
- CONCLUSION
Introduction
Cet article décrit une classe pour le stockage pratique d'informations, à savoir un tableau associatif ou un dictionnaire. Cette classe permet d'accéder à l'information par sa clé.
Le tableau associatif ressemble à un tableau normal. Mais au lieu d'un index, il utilise une clé unique, par exemple, l'énumération ENUM_TIMEFRAMES ou du texte. Peu importe ce qui représente une clé. C'est l'unicité de la clé qui compte. Cet algorithme de stockage de données simplifie considérablement de nombreux aspects de la programmation.
Par exemple, une fonction, qui prendrait un code d'erreur et imprimerait un équivalent textuel de l'erreur, pourrait être comme suit :
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
Nous examinerons les caractéristiques spécifiques de ce code plus tard.
Avant de traiter une description directe de la logique interne des tableaux associatifs, nous examinerons les détails de deux méthodes principales de stockage de données, à savoir les tableaux et les listes. Notre dictionnaire sera basé sur ces deux types de données, c'est pourquoi nous devons avoir une bonne compréhension de leurs spécificités. Le chapitre 1 est consacré à la description des types de données. Le deuxième chapitre est consacré à la description du tableau associatif et aux méthodes de travail avec celui-ci.
Chapitre 1. Théorie de l'organisation des données
1.1. Algorithme d'organisation des données. Recherche du meilleur conteneur de stockage de données
La recherche, le stockage et la représentation des informations sont les principales fonctions imposées aux ordinateurs modernes. L'interaction homme-machine comprend généralement soit la recherche d'informations, soit la création et le stockage d'informations pour une utilisation ultérieure. L'information n'est pas un concept abstrait. Dans un sens réel, il y a un certain concept sous ce mot. Par exemple, un historique de cotation d'un symbole est une source d'informations pour tout trader qui conclut ou va conclure une transaction sur ce symbole. La documentation du langage de programmation ou le code source d'un programme peut servir de source d'informations pour un programmeur.
Certains fichiers graphiques (par exemple, une photo prise avec un appareil photo numérique) peuvent être une source d'informations pour des personnes sans rapport avec la programmation ou le trading. Il est évident que ces types d'informations ont des structures différentes et leur propre nature. Par conséquent, les algorithmes de stockage, de représentation et de traitement de ces informations seront différents.
Par exemple, il est plus facile de présenter un fichier graphique sous forme de matrice bidimensionnelle (tableau bidimensionnel) dont chaque élément ou cellule stockera des informations sur la couleur d'une petite zone d'image — pixel. Les données de cotation ont une autre nature. Il s'agit essentiellement d'un flux de données homogènes au format OHLCV. Il est préférable de présenter ce flux sous la forme d'un tableau ou d'une séquence ordonnée de structures qui est un certain type de données dans le langage de programmation combinant plusieurs types de données. La documentation ou un code source est généralement représenté sous forme de texte brut. Ce type de données peut être défini et stocké sous la forme d'une séquence ordonnée de chaînes, où chaque chaîne est une séquence arbitraire de symboles.
Le type d'un conteneur pour stocker des données dépend du type de données. En utilisant les termes de la programmation orientée objet, il est plus facile de définir un conteneur comme une certaine classe qui stocke ces données et dispose d'algorithmes (méthodes) spéciaux pour les manipuler. Il existe plusieurs types de tels conteneurs de stockage de données (classes). Ils reposent sur une organisation différente des données. Mais certains algorithmes d'organisation des données permettent de combiner différents paradigmes de stockage de données. Ainsi, nous pouvons profiter de la combinaison des avantages de tous les types de stockage.
Vous sélectionnez l'un ou l'autre conteneur pour stocker, traiter et recevoir des données en fonction d'un mode supposé de leur manipulation et de leur nature. Il est important de réaliser qu'il n'existe pas de conteneurs de données aussi efficaces. Les faiblesses d'un conteneur de données sont le revers de ses avantages.
Par exemple, vous pouvez accéder rapidement à n'importe quel élément du tableau. Cependant, une opération longue est nécessaire pour insérer un élément dans un emplacement de tableau aléatoire, car un redimensionnement complet du tableau est requis dans ce cas. Et à l'inverse, insérer un élément dans une liste à chaînage simple est une opération efficace et rapide, mais accéder à un élément aléatoire peut prendre beaucoup de temps. S'il est nécessaire d'insérer fréquemment de nouveaux éléments, mais que vous n'avez pas besoin d'accéder fréquemment à ces éléments, la liste à liaisons simples sera votre bon conteneur. Et choisissez un tableau comme classe de données si un accès fréquent à des éléments aléatoires est requis.
Afin de comprendre quel type de stockage de données est préférable, vous devez vous familiariser avec la disposition de tout conteneur donné. Cet article est consacré au tableau associatif ou au dictionnaire - un conteneur de stockage de données spécifique basé sur la combinaison d'un tableau et d'une liste. Mais je voudrais mentionner que le dictionnaire peut être implémenté de différentes manières en fonction d'un certain langage de programmation, de ses moyens, de ses capacités et des règles de programmation acceptées.
Par exemple, l'implémentation du dictionnaire C# diffère du C++. Cet article ne décrit pas l'implémentation adaptée du dictionnaire pour le С++. La version décrite du tableau associatif a été créée à partir de zéro pour le langage de programmation MQL5 et prend en compte ses caractéristiques spéciales et ses pratiques de programmation courantes. Bien que leur implémentation diffère, les caractéristiques générales et les méthodes de fonctionnement des dictionnaires devraient être similaires. Dans ce contexte, la version décrite présente pleinement toutes ces caractéristiques et méthodes.
Pendant ce temps, nous créerons progressivement l'algorithme du dictionnaire et discuterons de la nature des algorithmes de stockage de données. Et à la fin de l'article, nous aurons une version complète de l'algorithme et serons pleinement conscients de son principe de fonctionnement.
Il n'existe pas de conteneurs aussi efficaces pour différents types de données. Prenons un exemple simple : un cahier en papier. Il peut également être considéré comme un conteneur/classe utilisé dans notre vie de tous les jours. Toutes ses notes sont saisies selon une liste préalablement constituée (alphabet dans ce cas). Si vous connaissez le nom d'un abonné, vous pouvez facilement trouver son numéro de téléphone, car il vous suffit d'ouvrir le cahier.
1.2. Tableaux et adressage direct des données
Un tableau est le moyen le plus simple et en même temps le plus efficace de stocker des informations. En programmation, un tableau est une collection d'éléments de même type, situés immédiatement les uns après les autres dans la mémoire. Grâce à ces propriétés, nous pouvons calculer l'adresse de chaque élément du tableau.
En effet, si tous les éléments ont le même type, ils auront tous la même taille. Comme les données du tableau sont localisées en permanence, nous pouvons calculer l'adresse d'un élément aléatoire et nous référer directement à cet élément si nous connaissons la taille d'un élément de base. Une formule générale de calcul de l'adresse dépend d'un type de données et d'un index.
Par exemple, vous pouvez calculer une adresse du cinquième élément dans le tableau des éléments de type uchar à l'aide de la formule générale suivante issue des propriétés de l'organisation des données du tableau :
adresse de l'élément aléatoire = l'adresse du premier élément + (index de l'élément aléatoire dans le tableau * taille du type de tableau)
L'adressage du tableau part de zéro, c'est pourquoi l'adresse du premier élément correspond à l'adresse de l'élément du tableau ayant l'index 0. Par conséquent, le cinquième élément aura l'index 4. Supposons que le tableau stocke des éléments de type uchar. C'est le type de données de base dans de nombreux langages de programmation. Par exemple, il est présent dans tous les langages de type C. MQL5 ne fait pas exception. Chaque élément du tableau de type uchar occupe 1 octet ou 8 bits de mémoire.
Par exemple, selon la formule mentionnée précédemment, l'adresse du cinquième élément dans le tableau uchar sera la suivante :
l'adresse du cinquième élément = l'adresse du premier élément + (4 * 1 octet) ;
En d'autres termes, le cinquième élément du tableau uchar sera de 4 octets de plus que le premier élément. Vous pouvez faire référence à chaque élément du tableau directement par son adresse lors de l'exécution du programme. Une telle arithmétique d'adresse permet d'accéder très rapidement à chaque élément du tableau. Mais une telle organisation des données présente des inconvénients.
L'un d'eux est que vous ne pouvez pas stocker des éléments de types différents dans le tableau. Une telle limitation est la conséquence de l'adressage direct. Certes, différents types de données varient en taille, ce qui signifie que le calcul d'une adresse d'un certain élément à l'aide de la formule mentionnée ci-dessus s'avère impossible. Mais cette limitation peut être intelligemment surmontée si le tableau ne stocke pas des éléments mais des pointeurs vers eux.
Ce sera le moyen le plus simple si vous représentez un pointeur sous forme de lien (sous forme de raccourcis sous Windows). Le pointeur fait référence à un certain objet dans la mémoire, mais le pointeur lui-même n'est pas un objet. En MQL5, le pointeur ne peut faire référence qu'à une classe. Dans la programmation orientée objet, une classe est un type de données particulier qui peut inclure un ensemble arbitraire de données et de méthodes et être créé par un utilisateur pour une structuration efficace du programme.
Chaque classe est un type de données unique défini par l'utilisateur. Les pointeurs faisant référence à différentes classes ne peuvent pas être situés dans un même tableau. Mais quelle que soit la classe référencée, le pointeur a toujours la même taille, car il ne contient qu'une adresse d'objet dans l'espace d'adressage du système d'exploitation qui est commun à tous les objets alloués.
1.3. Concept du nœud par l'exemple de la classe simple CObjectCustom
Nous en savons maintenant assez pour concevoir notre premier pointeur universel. L'idée est de créer un tableau de pointeurs universel où chaque pointeur ferait référence à son type particulier. Les types réels seraient différents, mais du fait qu'ils sont référencés par le même pointeur, ces types pourraient être stockés dans un conteneur/tableau. Créons la première version de notre pointeur.
Ce pointeur sera représenté par le type le plus simple que nous nommerons CObjectCustom :
class CObjectCustom
{
}; Il serait vraiment difficile d'inventer une classe plus simple que CObjectCustom, car elle ne contient aucune donnée ni méthode. Mais une telle implémentation est suffisante pour le moment.
Nous allons maintenant utiliser l'un des principaux concepts de la programmation orientée objet : l'héritage. L'héritage fournit un moyen spécial d'établir l'identité entre les objets. Par exemple, nous pouvons dire à un compilateur que n'importe quelle classe est un dérivé de CObjectCustom.
Par exemple, une classe d'êtres humains (СHuman), une classe d'Expert Advisors (CExpert) et une classe de météo (CWeather) représentent un concept plus général de la classe CObjectCustom. Peut-être que ces concepts ne sont pas réellement connectés dans la vie réelle : la météo n'a rien en commun avec les gens, et les Expert Advisors ne sont pas associés à la météo. Mais c'est nous qui établissons des liens dans le monde de la programmation, et si ces liens sont bons pour nos algorithmes, il n'y a aucune raison pour que nous ne puissions pas les créer.
Créons d'autres classes de la même manière : une classe de voiture (CCar), une classe de nombre (CNumber), une classe de barre de prix (CBar), une classe de cotation (CQuotes), une classe d'entreprise MetaQuotes (CMetaQuotes) et une classe décrivant un navire (CShip). Semblables aux classes précédentes, ces classes ne sont pas réellement connectées, mais elles sont toutes descendantes de la classe CObjectCustom.
Créons une bibliothèque de classes pour ces objets combinant toutes ces classes dans un seul fichier : ObjectsCustom.mqh :
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
Il est maintenant temps de combiner ces classes en un seul tableau.
1.4. Tableaux de pointeurs de nœuds par l'exemple de la classe CArrayCustom
Pour combiner des classes, nous aurons besoin d'un tableau spécial.
Dans le cas le plus simple il suffira d'écrire :
CObjectCustom array[];
Cette chaîne crée un tableau dynamique qui stocke les éléments de type CObjectCustom. Du fait que toutes les classes, que nous avons définies dans la section précédente, sont dérivées de CObjectCustom, nous pouvons stocker n'importe laquelle de ces classes dans ce tableau. Par exemple, nous pouvons y localiser des personnes, des voitures et des navires. Mais la déclaration du tableau CObjectCustom ne suffira pas à cet effet.
Le fait est que lorsque nous déclarons le tableau de manière normale, tous ses éléments sont remplis automatiquement au moment de l'initialisation du tableau. Ainsi, après avoir déclaré le tableau, tous ses éléments seront occupés par la classe CObjectCustom.
Nous pouvons vérifier cela si nous modifions légèrement CObjectCustom :
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
Exécutons un code de test en tant que script pour vérifier cette particularité :
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
Dans la fonction OnStart(), nous avons initialisé un tableau composé de trois éléments de CObjectCustom.
Le compilateur a rempli ce tableau avec les objets correspondants. Vous pouvez le vérifier si vous lisez le journal du terminal :
12.02.2015 12:26:32.964 Test (USDCHF,H1) Object #2 - CObjectCustom
12.02.2015 12:26:32.964 Test (USDCHF,H1) Objet #1 - CObjectCustom
12.02.2015 12:26:32.964 Test (USDCHF,H1) Object #0 - CObjectCustom
Cela signifie que le tableau est rempli par le compilateur, et nous ne pouvons pas y localiser d'autres éléments, par exemple CWeather ou CExpert.
Ce code ne sera pas compilé :
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
Le compilateur donnera un message d'erreur :
'=' - structure have objects and cannot be copied Test.mq5 18 13
Cela signifie que le tableau contient déjà des objets et que de nouveaux objets ne peuvent pas y être copiés.
Mais nous pouvons sortir de cette impasse ! Comme mentionné ci-dessus, nous ne devons pas travailler avec des objets mais avec des pointeurs vers ces objets.
Réécrivez le code dans la fonction OnStart() de manière à ce qu'il puisse fonctionner avec des pointeurs :
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
Maintenant, le code est compilé et aucune erreur ne se produit. Que s'est-il passé ? Premièrement, nous avons remplacé l'initialisation du tableau CObjectCustom par l'initialisation du tableau de pointeurs vers CObjectCustom.
Dans ce cas, le compilateur ne crée pas de nouveaux objets CObjectCustom lors de l'initialisation du tableau mais le laisse vide. Deuxièmement, nous utilisons maintenant un pointeur vers l'objet CWeather au lieu de l'objet lui-même. En utilisant le mot-clé nouveau, nous avons créé l'objet CWeather et l'avons affecté à notre pointeur 'weather', puis nous avons placé le pointeur 'weather' (mais pas l'objet) dans le tableau.
Mettons maintenant le reste des objets du tableau dans la même veine.
Pour cela, écrivez le code suivant :
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
Ce code fonctionnera, mais il est assez risqué car nous manipulons directement les index du tableau.
Si nous calculons mal la taille de notre tableau arrayObj ou l’adresse par un mauvais index, notre programme se retrouvera avec une erreur critique. Mais ce code convient à nos fins de démonstration.
Présentons ces éléments sous forme de schéma :
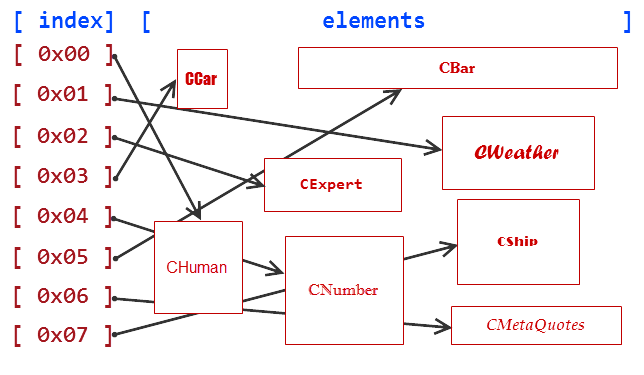
Fig. 1. Schéma de stockage des données dans le tableau de pointeurs
Les éléments, créés par l'opérateur 'nouveau', sont stockés dans une partie spéciale de la mémoire vive qui s'appelle un tas. Ces éléments ne sont pas ordonnés comme on peut le voir clairement sur le schéma ci-dessus.
Notre tableau de pointeurs arrayObj a une indexation stricte, ce qui permet d'accéder rapidement à n'importe quel élément en utilisant son index. Mais accéder à un tel élément ne suffira pas, car le tableau de pointeurs ne sait pas vers quel objet particulier il pointe. Le pointeur CObjectCustom peut pointer vers CWeather ou CBar, ou CMetaQuotes, car ils sont tous CObjectCustom. Un transtypage explicite d'un objet vers son type réel est donc requis pour obtenir le type d'élément.
Par exemple, cela peut être fait comme suit :
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
Dans ce code, nous avons créé l'objet CHman et l'avons placé dans le tableau arrayObj en tant que CObjectCustom. Ensuite, nous avons extrait CObjectCustom et l'avons converti en CHman, ce qui est en fait le même. Dans l'exemple, la conversion n'a eu aucune erreur car nous nous sommes souvenus du type. Dans une situation de programmation réelle, il est très difficile de suivre un type de chaque objet car il peut y avoir des centaines de ces types et le nombre d'objets peut dépasser le million.
C'est pourquoi nous devons fournir à la classe ObjectCustom une méthode Type() supplémentaire qui renvoie un modificateur d'un type d'objet réel. Un modificateur est un certain numéro unique qui décrit notre objet permettant de désigner le type par son nom. Par exemple, nous pouvons définir des modificateurs à l'aide de la directive de préprocesseur #define. Si nous connaissons le type d'objet spécifié par le modificateur, nous pouvons toujours convertir en toute sécurité son type dans le type réel. Ainsi, nous nous sommes rapprochés de la création de types sûrs.
1.5. Contrôle et sécurité des types
Dès que nous commençons à convertir un type en un autre, la sécurité d'une telle conversion devient la pierre angulaire de la programmation. Nous ne voudrions pas que notre programme se termine par une erreur critique, n'est-ce pas ? Mais nous savons déjà quelle sera la base de sécurité pour nos types - des modificateurs spéciaux. Si nous connaissons le modificateur, nous pouvons le convertir en un type requis. Pour cela, nous devons compléter notre classe CObjectCustom avec plusieurs ajouts.
Tout d'abord, créons des identificateurs de type pour y faire référence par leur nom. À cette fin, nous allons créer un fichier séparé avec l'énumération requise :
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip
Nous allons maintenant modifier les codes de classe en ajoutant CObjectCustom à la variable qui stocke le type d'objet sous forme de nombre. Cachez-le dans la section privée, afin que personne ne puisse le modifier.
À côté de cela, nous ajouterons un constructeur spécial disponible pour les classes dérivées de CObjectCustom. Ce constructeur permettra aux objets de désigner leur type lors de la création.
Le code commun sera comme suit :
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
Comme nous pouvons le voir, chaque type dérivé de CObjectCustom définit désormais son propre type dans son constructeur lors de la création. Le type ne peut pas être modifié une fois qu'il est défini, car le champ, où il est stocké, est privé et disponible uniquement pour CObjectCustom. Cela vous évitera une mauvaise manipulation de type. Si la classe n'appelle pas le constructeur protégé CObjectCustom, son type - TYPE_OBJECT - sera le type par défaut.
Il est donc temps d'apprendre à extraire des types de arrayObj et à les traiter. À cette fin, nous fournirons aux classes CHman et CWeather les méthodes publiques Run() et Temp() correspondantes. Après avoir extrait la classe de arrayObj, nous la convertirons en type requis et commencerons à l'utiliser correctement.
Si le type, stocké dans le tableau CObjectCustom, est inconnu, nous l'ignorerons en écrivant un message « type inconnu » :
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
Ce code affichera le message suivant :
13.02.2015. 15:11:24.703 Test (USDCHF,H1) type inconnu.
13.02.2015. 15:11:24.703 Test (USDCHF,H1) 32.0
13.02.2015. 15:11:24.703 Test (USDCHF,H1) Exécuté par l’humain...
Nous avons donc obtenu le résultat recherché. Maintenant, nous pouvons stocker tous les types d'objets dans le tableau CObjectCustom, accéder rapidement à ces objets par leurs index dans le tableau et les convertir correctement dans leurs types réels. Mais il nous manque encore beaucoup de choses : nous avons besoin d'une suppression correcte des objets après la fin du programme, car nous devons supprimer nous-mêmes les objets situés dans le tas en utilisant l'opérateur supprimer.
De plus, nous avons besoin de moyens de redimensionnement sécurisé du tableau si le tableau est entièrement rempli. Mais nous n'allons pas recréer la roue. L'ensemble d'outils standard de MetaTrader 5 comprend des classes qui implémentent toutes ces fonctionnalités.
Ces classes sont basées sur le conteneur/classe universel CObject. De la même manière que notre classe, elle dispose de la méthode Type(), qui renvoie le type réel de la classe, et deux pointeurs plus importants du type CObject : m_prev et m_next. Leur objectif sera décrit dans la section suivante où nous aborderons une autre méthode de stockage de données, à savoir une liste à liaisons doubles, à travers l'exemple du conteneur CObject et de la classe CList.
1.6. La classe CList comme exemple de liste à deux liaisons
Un tableau avec des éléments de type arbitraire souffre d'un seul défaut majeur : cela prend beaucoup de temps et d'efforts si vous voulez insérer un nouvel élément, surtout si cet élément doit être inséré au milieu du tableau. Les éléments sont situés dans une séquence, donc pour l'insertion, vous devez redimensionner le tableau pour augmenter le nombre total d'éléments d'un, puis réorganiser tous les éléments qui suivent l'objet inséré de manière à ce que leurs index correspondent à leurs nouvelles valeurs.
Supposons que nous ayons un tableau composé de 7 éléments et que nous voulions insérer un élément de plus en quatrième position. Un schéma d'insertion approximatif sera le suivant :

Fig. 2. Redimensionnement du tableau et insertion d'un nouvel élément
Il existe un schéma de stockage de données qui permet une insertion et une suppression rapides et efficaces des éléments. Un tel schéma est appelé une liste à liaisons simples ou une liste à liaisons doubles. La liste rappelle une file d'attente ordinaire. Lorsque nous sommes dans une file d'attente, nous avons seulement besoin de connaître une personne que nous suivons (nous n'avons pas besoin de connaître une personne qui se tient devant elle). Nous n'avons pas non plus besoin de connaître une personne qui se tient derrière nous, car cette personne doit contrôler sa position dans la file d'attente.
Une file d'attente est un exemple classique de liste à liaisons simples. Mais les listes peuvent aussi être doublement liées. Dans ce cas, chaque personne dans une file d'attente connaît non seulement une personne avant mais aussi une personne après elle. Donc si vous interrogez chaque personne, vous pouvez vous déplacer dans les deux sens de la file d'attente.
La CList standard disponible dans la bibliothèque standard propose précisément cet algorithme. Essayons de faire une file d'attente à partir de classes déjà connues. Mais cette fois, elles dériveront de CObject standard et non de CObjectCustom.
Ceci peut être schématisé comme suit :

Fig. 3. Schéma d'une liste à liaisons doubles
Voici donc un code source qui crée un tel schéma :
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
Nos classes ont maintenant deux pointeurs de CObject: l'un fait référence à l'élément précédent, l'autre à l'élément suivant. Le pointeur vers l'élément précédent du premier élément de la liste est égal à ZÉRO. L'élément à la fin de la liste a un pointeur vers l'élément suivant qui est également égal à ZÉRO. Nous pouvons donc énumérer les éléments un par un, énumérant ainsi toute la file d'attente.
Les fonctions EnumerateAll() et ReverseEnumerateAll() effectuent l'énumération de tous les éléments de la liste.
Le premier énumère la liste du début à la fin, le second - de la fin au début. Le code source de ces fonctions est le suivant :
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
Comment fonctionne ce code ? En fait, c'est assez simple. Au début, nous obtenons une référence au premier nœud dans la fonction EnumerateAll(). Ensuite, nous imprimons un numéro de séquence de ce nœud dans la boucle pour et passons au nœud suivant en utilisant la commande node = node.Next(). N'oubliez pas d'itérer l'index courant de l'élément de un (i++). L'énumération continue jusqu'à ce que le nœud actuel soit égal à ZÉRO. Le code dans le deuxième bloc de pour est responsable de cela : node != NULL.
La version inversée de cette fonction ReverseEnumerateAll() se comporte de manière similaire à la seule différence qu'elle obtient d'abord le dernier élément de la liste CObject* node = list.GetLastNode(). Dans la boucle pour, elle n'obtient pas le suivant, mais l'élément précédent de la liste node = node.Prev().
Après avoir lancé le code, nous recevrons le message suivant :
13.02.2015 17:52:02.974 TestList (USDCHF,D1) énumération terminée.
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 0
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 1
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 2
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 3
13.02.2015 17:52:02.974 TestList (USDCHF,D1) <<< énumérer de la fin au début <<<
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 3
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 2
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 1
13.02.2015 17:52:02.974 TestList (USDCHF,D1) Élément à 0
13.02.2015 17:52:02.974 TestList (USDCHF,D1) >>> énumérer du début à la fin >>>
Vous pouvez facilement insérer de nouveaux éléments dans la liste. Modifiez simplement les pointeurs des éléments précédents et suivants de manière à ce qu'ils fassent référence à un nouvel élément et que ce nouvel élément fasse référence aux objets précédent et suivant.
Le schéma semble plus simple qu'il ne paraît :

Fig. 4. Insertion d'un nouvel élément dans une liste à liaisons doubles
Le principal inconvénient de la liste est l'impossibilité de référencer chaque élément par son index.
Par exemple, si vous souhaitez vous référer à CExpert comme illustré à la Fig. 4, vous devez d'abord accéder à CCar, puis vous pourrez passer à CExpert. Il en est de même pour CWeather. Il est plus proche de la fin de la liste, il sera donc plus facile d'y accéder depuis la fin. À cette fin, vous devez d'abord vous référer à CShip, puis à CWeather.
Le déplacement par pointeurs est une opération plus lente par rapport à l'indexation directe. Les unités centrales modernes sont optimisées pour un fonctionnement en particulier avec des tableaux. C'est pourquoi, en pratique, les tableaux peuvent être plus préférables même si les listes fonctionnent potentiellement plus rapidement.
Chapitre 2. Théorie de l'organisation du tableau associatif
2.1. Les tableaux associatifs dans notre quotidien
Nous sommes en permanence confrontés à des tableaux associatifs dans notre quotidien. Mais ils nous semblent si évidents que nous les percevons comme une évidence. L'exemple le plus simple du tableau associatif ou du dictionnaire est un annuaire téléphonique habituel. Chaque numéro de téléphone dans le livre est associé au nom d'une certaine personne. Le nom de la personne dans un tel livre est une clé unique, et le numéro de téléphone est une simple valeur numérique. Chaque personne dans l'annuaire téléphonique peut avoir plus d'un numéro de téléphone. Par exemple, une personne peut avoir des numéros de téléphone personnel, mobile et professionnel.
De manière générale, il peut y avoir un nombre illimité de numéros, mais le nom de la personne est unique. Par exemple, deux personnes nommées Alexandre dans votre annuaire vous confondront. Parfois, nous pouvons composer un mauvais numéro. C'est pourquoi les clés (les noms dans ce cas) doivent être uniques pour éviter une telle situation. Mais en même temps le dictionnaire doit savoir résoudre les collisions et y résister. Deux noms identiques ne détruiront pas le répertoire téléphonique. Notre algorithme doit donc savoir comment traiter de telles situations.
Nous utilisons plusieurs types de dictionnaires dans la vie réelle. Par exemple, le répertoire téléphonique est un dictionnaire où une ligne unique (nom de l'abonné) est une clé et un nombre est une valeur. Le dictionnaire de termes étrangers a une autre structure. Un mot anglais sera une clé, et sa traduction sera une valeur. Ces deux tableaux associatifs reposent sur les mêmes méthodes de traitement des données, c'est pourquoi notre dictionnaire doit être polyvalent et permettre de stocker et de comparer tous types.
En programmation, il peut aussi être pratique de créer ses propres dictionnaires et « cahiers ».
2.2. Tableaux associatifs primaires basés sur l'opérateur switch-case ou un tableau simple
Vous pouvez facilement créer un tableau associatif simple. Il suffit d'utiliser des outils standards du langage MQL5, par exemple, l'opérateur de changement ou un tableau.
Regardons ce code de plus près :
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
Dans ce cas, l'opérateur switch-case agit comme un dictionnaire. Chaque valeur de ENUM_TIMEFRAMES a une valeur de chaîne décrivant cette période. Étant donné que l'opérateur de changement est un passage changé (en russe), l'accès à la variante de casse requise est instantané et les autres variantes de casse ne sont pas énumérées . C'est pourquoi ce code est très efficace.
Mais son inconvénient est que, d'abord, vous devez remplir toutes les valeurs qui doivent être manuellement renvoyées avec l'une ou l'autre valeur de ENUM_TIMEFRAMES. Deuxièmement, le changement ne peut fonctionner qu'avec des valeurs entières. Mais il serait plus difficile d'écrire une fonction inverse qui pourrait renvoyer le type de cadre temporel en fonction d'une chaîne transférée. Le troisième inconvénient d'une telle approche est que cette méthode n'est pas assez flexible. Vous devez spécifier toutes les variantes possibles à l'avance. Mais vous devez souvent remplir les valeurs du dictionnaire de manière dynamique à mesure que de nouvelles données deviennent disponibles.
La deuxième méthode « frontale » de stockage de paires « clé-valeur » consiste à créer un tableau dans lequel une clé est utilisée comme index et une valeur est un élément du tableau.
Par exemple, essayons de résoudre la tâche similaire, à savoir renvoyer une représentation sous forme de chaîne de période :
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
Ce code décrit la référence par index où ENUM_TIMFRAMES est spécifié comme index. Avant de renvoyer la valeur, la fonction vérifie si le tableau est rempli avec un élément requis. Sinon, la fonction délègue le remplissage à une fonction spéciale - InitTimeframes(). Elle présente les mêmes inconvénients que l'opérateur de changement.
De plus, une telle structure de dictionnaire nécessite l'initialisation d'un tableau avec de grandes valeurs. Ainsi la valeur du modificateur PERIOD_MN1 est 49153. Cela signifie que nous avons besoin de 49153 cellules pour ne stocker que neuf périodes. Les autres cellules restent vides. Cette méthode d'allocation des données est loin d'être compacte, mais elle peut être appropriée lorsque le dénombrement consiste en une petite plage successive de nombres.
2.3. Conversion des types de base en une clé unique
Comme les algorithmes utilisés dans le dictionnaire sont similaires quels que soient certains types de clés et de valeurs, nous devons effectuer un alignement des données, afin que différents types de données puissent être traités par un seul algorithme. Notre algorithme de dictionnaire sera universel et permettra de stocker des valeurs où n'importe quel type de base peut être spécifié comme clé, par exemple int, enum, double ou même string.
En fait, dans MQL5, tout type de données de base peut être représenté par un nombre ulong non signé. Par exemple, les types de données short ou ushort sont des versions « courtes » de ulong.
En comprenant expressément que le type ulong stocke la valeur ushort, vous pouvez toujours effectuer une conversion de type explicite en toute sécurité :
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)
Il en va de même pour les types char et int et leurs analogues non signés, car ulong peut stocker n'importe quel type, dont la taille est inférieure ou égale à ulong. Les types datetime, enum et color sont basés sur un nombre uint entier de 32 bits, ce qui signifie qu'ils peuvent être convertis en toute sécurité en ulong. Le type bool ne possède que deux valeurs : 0, qui signifie faux, et 1, qui signifie vrai. Ainsi, des valeurs de type bool peuvent également être stockées dans la variable de type ulong. En outre, de nombreuses fonctions du système MQL5 sont basées sur cette fonctionnalité.
Par exemple, la fonction AccountInfoInteger() renvoie la valeur entière de type long, qui peut également être un numéro de compte de type ulong et une valeur booléenne d'autorisation de négocier - ACCOUNT_TRADE_ALLOWED.
Mais MQL5 a trois types de base qui se distinguent des types entiers. Ils ne peuvent pas être directement convertis au type entier ulong. Parmi ces types figurent les types à virgule flottante, tels que double et flottant, et chaînes. Mais certaines actions simples peuvent les convertir en clés/valeurs entières uniques.
Chaque valeur à virgule flottante peut être définie comme une base élevée à une puissance arbitraire, où la base et la puissance sont stockées séparément sous forme de valeur entière. Ce type de méthode de stockage est utilisé dans les valeurs doubles et flottantes. Le type flottant utilise 32 chiffres pour stocker la mantisse et la puissance, le type double utilise 64 chiffres.
Si nous essayons de les convertir directement au type ulong, une valeur sera simplement arrondie. Dans ce cas 3,0 et 3,14159 donneront la même valeur ulong — 3. Ceci est inapproprié pour nous, car nous aurons besoin de clés différentes pour ces deux valeurs différentes. Une fonctionnalité peu courante, utilisable dans les langages de type C, vient à la rescousse. On appelle cela la conversion de structure. Deux structures différentes peuvent être converties si elles ont une taille (convertissant une structure à une autre).
Analysons cet exemple sur deux structures dont l'une stocke la valeur de type ulong, et une autre stocke la valeur de type double :
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
Ce code copie la structure DoubleValue dans la structure ULongValue octet par octet. Comme elles ont la même taille et le même ordre de variables, la double valeur de dValue.value est copiée octet par octet dans la variable ulong de lValue.value.
Après cela, cette valeur de variable est imprimée. Si nous modifions dValue.value en 3,14160, lValue.value sera également modifiée.
Voici le résultat qui sera affiché par la fonction printf() :
16.02.2015 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
16.02.2015 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
Le type flottant est une version courte du type double. Par conséquent, avant de convertir le type flottant en type ulong, vous pouvez en toute sécurité étendre le type flottant au type double :
float fl = 3.14159f; double dbl = fl;
Après cela, convertissez le double en type ulong via la conversion de structure.
2.4. Hachage de chaîne et utilisation d'un hachage comme clé
Dans les exemples ci-dessus, les clés étaient représentées par un seul type de données : des chaînes. Cependant, il peut y avoir des situations différentes. Par exemple, les trois premiers chiffres d'un numéro de téléphone indiquent un opérateur téléphonique. Dans ce cas particulièrement ces trois chiffres représentent une clé. De l'autre côté, chaque chaîne peut être représentée comme un numéro unique dont chaque chiffre signifie un numéro de séquence d'une lettre de l'alphabet. Ainsi, nous pouvons convertir la chaîne en nombre unique et utiliser ce nombre comme clé entière de sa valeur associée.
Cette méthode est bonne mais pas assez polyvalente. Si nous utilisons une chaîne contenant des centaines de symboles comme clé, le nombre sera incroyablement grand. Il sera impossible de le capturer dans une simple variable de n'importe quel type. Les fonctions de hachage nous aideront à résoudre ce problème. La fonction de hachage est un algorithme particulier qui accepte tous les types de données (par exemple, une chaîne) et renvoie un nombre unique caractérisant cette chaîne.
Même si un symbole de données d'entrée est modifié, le nombre sera absolument différent. Les nombres renvoyés par cette fonction ont une plage fixe. Par exemple, la fonction de hachage Adler32() accepte le paramètre sous la forme d'une chaîne arbitraire et renvoie un nombre compris entre 0 et 2 élevé à la puissance 32 . Cette fonction est assez simple, mais elle convient parfaitement à nos tâches.
Il y a son code source en MQL5 :
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
Voyons quels nombres elle renvoie en fonction d'une chaîne transférée.
Pour cela, nous écrirons un script simple qui appelle cette fonction et transfère différentes chaînes :
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
Cette sortie de script a révélé ce qui suit :
16.02.2015 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
16.02.2015 13:29:12.576 TestList (USDCHF,H1) Peace - 91685343
16.02.2015 13:29:12.576 TestList (USDCHF,H1) Hello world! - 487130206
16.02.2015 13:29:12.576 TestList (USDCHF,H1) Hello world - 413860925
Comme nous pouvons le voir, chaque chaîne a un numéro unique correspondant. Faites attention aux chaînes « Hello world » et « Hello world ! » - elles sont presque identiques. La seule différence est un point d'exclamation à la fin de la deuxième chaîne.
Mais les nombres donnés par Adler32() étaient absolument différents dans les deux cas.
Nous savons maintenant comment convertir le type de chaîne en valeur uint non signée, et nous pouvons stocker son hachage entier au lieu de la clé de type de chaîne. Si deux chaînes ont un hachage, il est fort probable qu'il s'agisse de la même chaîne. Ainsi, une clé d'une valeur n'est pas une chaîne mais un hachage d'entier généré à partir de cette chaîne.
2.5. Figurer un index par une clé. Tableau de liste
Nous savons maintenant comment convertir n'importe quel type de base de MQL5 en type ulong non signé. Exactement ce type sera une clé réelle à laquelle notre valeur correspondra. Mais il ne suffit pas d'avoir une clé unique de type ulong. Bien sûr, si nous connaissons une clé unique pour chaque objet, nous pourrions inventer une méthode de stockage primitive basée sur l'opérateur switch-case ou un tableau d'une longueur arbitraire.
De telles méthodes ont été décrites dans la section 2.2 du présent chapitre. Mais elles ne sont pas assez flexibles et efficaces. Quant au switch-case, il ne semble pas possible de décrire toutes les variantes de cet opérateur.
Comme s'il existait des dizaines de milliers d'objets, nous devrons décrire l'opérateur de changement, constitué de dizaines de milliers de clés, au stade de la compilation, ce qui est impossible. La deuxième méthode utilise un tableau où la clé d'un élément est également son index. Elle permet de redimensionner le tableau de manière dynamique en ajoutant les éléments nécessaires. Ainsi on pourra s'y référer à tout moment par son index qui sera la clé de l'élément.
Faisons une ébauche de cette solution :
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
Mais dans la vraie vie ce code pose plutôt des problèmes, mais ne les résout pas. Supposons qu'une fonction de hachage produira un gros hachage. Comme dans l'exemple donné, l'index du tableau est égal à son hachage, nous devons redimensionner le tableau, ce qui le rendra énorme. Et cela ne signifie pas nécessairement que nous réussirons. Souhaitez-vous stocker une chaîne dans un conteneur dont la taille peut atteindre plusieurs gigaoctets ?
Le deuxième problème est qu'en cas de collision, la valeur précédente sera remplacée par une nouvelle. Après tout, il n'est pas improbable que la fonction Adler32() renvoie une clé de hachage pour deux chaînes différentes. Souhaitez-vous perdre une partie de vos données simplement parce que vous souhaitez vous y référer rapidement à l'aide d'une clé ? La réponse à ces questions est évidente - non, vous ne le souhaitez pas. Afin d'éviter de telles situations, nous devons modifier l'algorithme de stockage et développer un conteneur hybride spécial basé sur un tableau de listes.
Un tableau de liste combine les meilleures fonctionnalités des tableaux et des listes. Ces deux classes sont représentées dans la bibliothèque standard. Il convient de rappeler que les tableaux permettent de se référer à leurs éléments indéfinis de manière très rapide, mais les tableaux eux-mêmes se redimensionnent lentement. Cependant, les listes permettent d'ajouter et de supprimer de nouveaux éléments en un rien de temps, mais l'accès à chaque élément d'une liste est une opération plutôt lente.
Un tableau de liste peut être représenté comme suit :

Fig. 5. Schéma d'un tableau de liste
Il ressort du schéma qu'un tableau de liste est un tableau dont chaque élément a une forme de liste. Voyons quels avantages il offre. Tout d'abord, on peut rapidement se référer à n'importe quelle liste par son index. D'autre part, si nous stockons chaque élément de données dans une liste, nous pourrons rapidement ajouter et supprimer des éléments de la liste sans redimensionner le tableau. L'index du tableau peut être vide ou égal à ZÉRO. Cela signifie que les éléments correspondant à cet index n'ont pas encore été ajoutés.
La combinaison d'un tableau et d'une liste offre une autre opportunité rare. Nous pouvons stocker deux ou plusieurs éléments en utilisant un seul index. Pour comprendre sa nécessité, on peut supposer qu'il faut stocker 10 nombres dans un tableau à 3 éléments. Comme nous pouvons le voir, il y a plus de nombres que d'éléments dans le tableau. Nous allons résoudre ce problème de stockage des listes dans un tableau. Supposons que nous aurons besoin de l'une des trois listes attachées à l'un des trois index de tableau pour stocker l'un ou l'autre nombre.
Pour déterminer l'index de la liste, nous devons trouver un reste dans la division de notre nombre par le nombre d'éléments du tableau :
index de tableau = % du nombre d'éléments dans le tableau ;
Par exemple, l'index de liste pour le numéro 2 sera le suivant : 2%3 = 2. Cela signifie que l'index 2 sera stocké dans la liste par index. Le numéro 3 sera stocké par l'index 3%3 = 0. Le numéro 7 sera stocké par l'index 7%3 = 1. Après avoir déterminé l'index de la liste, il nous suffit d'ajouter ce numéro à la fin de la liste.
Des actions similaires sont nécessaires pour extraire le numéro de la liste. Supposons que nous voulions extraire le numéro 7 du conteneur. Pour cela, nous devons savoir dans quel conteneur il se trouve : 7%3=1. Après avoir déterminé que le nombre 7 peut être localisé dans la liste par l'index 1, nous devrons trier toute la liste et renvoyer cette valeur si l'un des éléments est égal à 7.
Si nous pouvons stocker plusieurs éléments à l'aide d'un index, nous n'avons pas besoin de créer d'énormes tableaux pour stocker une petite quantité de données. Supposons que nous devons stocker le nombre 232 547 879 dans un tableau composé de 0 à 10 chiffres et comportant trois éléments. Ce numéro aura son index de liste égal à (232 547 879 % 3 = 2).
Si nous remplaçons les nombres par un hachage, nous pourrons trouver un index de n'importe quel élément qui doit être situé dans le dictionnaire. Parce que le hachage est un nombre. De plus, grâce à la possibilité de stocker plusieurs éléments dans une liste, le hachage n'a pas à être unique. Les éléments avec le même hachage seront dans une seule liste. Si nous devons extraire un élément par sa clé, nous comparerons ces éléments et extrairons celui correspondant à la clé.
Ceci est possible car deux éléments avec le même hachage auront deux clés uniques. L'unicité des clés peut être contrôlée par la fonction qui ajoute un élément au dictionnaire. Elle n'ajoutera tout simplement pas de nouvel élément si sa clé correspondante est déjà dans le dictionnaire. C'est comme un contrôle de la correspondance d'un abonné à un seul numéro de téléphone.
2.6. Redimensionnement du tableau, minimisant la longueur de la liste
Plus le tableau de liste est petit et plus nous ajoutons d'éléments, plus l'algorithme formera de longues chaînes de listes. Comme cela a été dit dans le premier chapitre, l'accès à un élément de cette chaîne est une opération inefficace. Plus notre liste est courte, plus notre conteneur ressemblera à un tableau qui donne accès à chaque élément par un index. Nous devons viser des listes courtes et des tableaux longs. Un tableau parfait pour dix éléments est un tableau composé de dix listes dont chacune aura un élément.
La pire variante sera un tableau de dix éléments composé d'une liste. Comme tous les éléments sont ajoutés dynamiquement à notre conteneur pendant le déroulement du programme, nous ne pouvons pas prévoir combien d'éléments seront ajoutés. C'est pourquoi nous devons réfléchir au redimensionnement dynamique du tableau. Et de plus, le nombre de chaînes dans les listes doit tendre vers un élément. Il est évident qu'à cette fin, la taille du tableau doit être maintenue égale au nombre total d'éléments. L'ajout permanent d'éléments nécessite un redimensionnement permanent du tableau.
La situation est également compliquée par le fait qu'en plus du redimensionnement du tableau, nous devrons redimensionner toutes les listes, car l'index de liste auquel l'élément pourrait appartenir peut être modifié après le redimensionnement. Par exemple, si le tableau a trois éléments, le numéro 5 sera stocké dans le deuxième index (5%3 = 2). S'il y a six éléments, le numéro 5 sera stocké dans le cinquième index (5%6=5). Ainsi, le redimensionnement du dictionnaire est une opération lente. Il doit être effectué le moins souvent possible. En revanche, si nous ne le faisons pas du tout, les chaînes s'agrandiront avec chaque nouvel élément, et l'accès à chaque élément deviendra de moins en moins efficace.
Nous pouvons créer un algorithme qui implémente un compromis raisonnable entre la quantité de redimensionnement du tableau et la longueur moyenne de la chaîne. Il sera basé sur le fait que chaque redimensionnement suivant augmentera deux fois la taille actuelle du tableau. Ainsi, si le dictionnaire a initialement deux éléments, le premier redimensionnement augmentera sa taille de 4 (2^2), le second - de 8 (2^3), le troisième - de 16 (2^3). Après le seizième redimensionnement, il y aura de la place pour 65 536 chaînes (2^16). Chaque redimensionnement sera effectué si la quantité d'éléments ajoutés coïncide avec la puissance récurrente de deux. Ainsi, la mémoire principale réelle totale requise ne dépassera pas la mémoire requise pour stocker tous les éléments plus de deux fois. D'autre part, la loi logarithmique permettra d'éviter des redimensionnements fréquents du tableau.
De même, en supprimant des éléments de la liste, nous pouvons réduire la taille du tableau et, ce faisant, économiser la mémoire principale allouée.
Chapitre 3. Développement pratique d'un tableau associatif
3.1. La classe modèle CDictionary, les méthodes AddObject et DeleteObjectByKey et le conteneur KeyValuePair
Notre tableau associatif doit être polyvalent et permettre de travailler avec tous types de clés. En même temps, nous utiliserons des objets basés sur le CObject standard comme valeurs. Puisque nous pouvons localiser toutes les variables de base dans les classes, notre dictionnaire sera une solution unique. Bien sûr, nous pourrions créer plusieurs classes de dictionnaires. Nous pourrions utiliser un type de classe distinct pour chaque type de base.
Par exemple, nous pourrions créer les classes suivantes :
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...
Mais MQL5 a trop de types de base. De plus, nous devrions corriger chaque erreur de code plusieurs fois, car tous les types ont un code de base. Nous utiliserons des modèles pour éviter les doublons. Nous aurons une classe, mais elle traitera plusieurs types de données simultanément. C'est pourquoi les principales méthodes de classes seront des modèles.
Tout d'abord, créons notre première méthode de modèle - Add(). Cette méthode ajoutera un élément avec une clé arbitraire à notre dictionnaire. La classe de dictionnaire sera nommée CDictionary. En plus de l'élément, le dictionnaire contiendra un tableau de pointeurs vers les listes CList. Et nous allons stocker des éléments dans ces chaînes :
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
La méthode AddObject() fonctionne comme suit. Elle vérifie d'abord si le dictionnaire a un élément avec une clé qui doit être ajouté. La méthode ContainsKey() effectue cette vérification. Si le dictionnaire possède déjà la clé, un nouvel élément ne sera pas ajouté, car cela entraînera des incertitudes étant donné que deux éléments correspondront à une clé.
Ensuite, la méthode apprend à connaître la taille du tableau dans lequel les chaînes CList sont stockées. Si la taille du tableau est égale au nombre d'éléments, il est temps de faire un redimensionnement. Cette tâche est déléguée à la méthode Resize().
Les prochaines étapes sont simples. Si selon l'index déterminé la chaîne CList n'existe pas encore, cette chaîne doit être créée. L'index est déterminé au préalable par la méthode ContainsKey(). Elle enregistre l'index déterminé dans la variable m_index. Ensuite, la méthode ajoute un nouvel élément à la fin de la liste. Mais avant cela, l'élément est emballé dans un conteneur spécial - KeyValuePair. Il est basé sur le CObject standard et étend ce dernier avec des pointeurs et des données supplémentaires. L'arrangement des classes de conteneurs sera décrit un peu plus tard. Outre des pointeurs supplémentaires, le conteneur stocke également une clé d'origine de l'objet et son hachage.
La méthode AddObject() est une méthode modèle :
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
Cet enregistrement signifie que le type d'argument clé est substitutif et que son type réel est déterminé au moment de la compilation.
Par exemple, la méthode AddObject() peut être activée dans son code comme suit :
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
Chacune de ces activations fonctionnera parfaitement grâce aux modèles.
Il existe également la méthode DeleteObjectByKey() qui reste opposée à la méthode AddObject(). Cette méthode supprime un objet du dictionnaire par sa clé.
Par exemple, vous pouvez supprimer un objet avec la clé « Voiture » s'il existe :
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
Le code est très similaire au code de la méthode AddObject(), nous ne l'illustrons donc pas ici.
Les méthodes AddObject() et DeleteObjectByKey() ne fonctionnent pas directement avec les objets. Au lieu de cela, ils emballent chaque objet dans le conteneur KeyValuePair en fonction de la classe CObject standard. Ce conteneur possède des pointeurs supplémentaires, qui permettent de relier des éléments, et possède également une clé d'origine et un hachage déterminé pour l'objet. Le conteneur teste également l'égalité de la clé transmise, ce qui permet d'éviter les collisions. Nous en discuterons dans la prochaine section consacrée à la méthode ContainsKey().
Nous allons maintenant illustrer le contenu de cette classe :
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. Identification du type d'exécution basée sur le nom de type, l’échantillonnage de hachage
Maintenant, lorsque nous saurons prendre des types non définis dans nos méthodes, nous devrons déterminer leur hachage. Pour tous les types entiers, un hachage sera égal à la valeur de ce type étendu au type ulong.
Pour calculer le hachage pour les types double et flottant, nous devons utiliser un transcrypage via des structures, décrites dans la section « Conversion des types de base en une clé unique ». Une fonction de hachage doit être utilisée pour les chaînes. Quoi qu'il en soit, chaque type de données nécessite sa propre méthode d'échantillonnage par hachage. Il suffit donc de déterminer le type transféré et d'activer une méthode d'échantillonnage de hachage en fonction de ce type. À cette fin, nous aurons besoin d'une directive spéciale nom de type.
Une méthode qui détermine le hachage en fonction de la clé s'appelle GetHashByKey().
Elle comprend :
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
Sa logique est simple. En utilisant la directive nom de type, la méthode obtient le nom de chaîne du type transféré. Si la chaîne est transférée en tant que clé, le nom de type renverra la valeur de la « chaîne », dans le cas de la valeur int, il renverra « int ». La même chose se produira avec tout autre type. Ainsi, tout ce que nous avons à faire est de comparer la valeur renvoyée avec les constantes de chaîne requises et d'activer le gestionnaire correspondant si cette valeur coïncide avec l'une des constantes.
Si la clé est le type de chaîne, son hachage est calculé par la fonction Adler32(). Si la clé est représentée par des types réels, ils sont convertis en hachage grâce à la conversion de structure. Tous les autres types se convertissent explicitement en type ulong qui deviendra le hachage.
3.3. La méthode ContainsKey(). Réaction à la collision de hachage
Le principal problème de toute fonction de hachage réside dans les collisions - des situations où différentes clés donnent le même hachage. Dans ce cas, si les hachages coïncident, une ambiguïté surviendra (deux objets seront similaires en termes de logique de dictionnaire). Pour éviter une telle situation, nous devons vérifier les types de clés réels et demandés et renvoyer une valeur positive uniquement si les clés réelles coïncident. C'est ainsi que fonctionne la méthode ContainsKey(). Elle renvoie vrai si un objet ayant la clé demandée existe, sinon elle renvoie faux.
C'est peut-être la méthode la plus utile et la plus pratique de tout le dictionnaire. Elle permet de savoir si un objet avec une clé définie existe :
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
Par exemple, le code ci-dessus vérifie la disponibilité de l'objet de type CCar et ajoute CCar, si cet objet n'existe pas. Cette méthode permet également de vérifier l'unicité de la clé de chaque nouvel objet ajouté.
Si la clé d'objet est déjà utilisée, la méthode AddObject() n'ajoutera tout simplement pas ce nouvel objet au dictionnaire.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
C'est une méthode tellement universelle qu'elle est abondamment utilisée à la fois par les utilisateurs et par d'autres méthodes de classe.
Son contenu :
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
D'abord, la méthode trouve un hachage à l'aide de GetHashByKey(). En se basant sur le hachage, elle obtient un index de la chaîne CList, où un objet avec le hachage donné peut être localisé. S'il n'y a pas une telle chaîne, l'objet avec une telle clé n'existe pas non plus. Dans ce cas, elle terminera prématurément son opération et renverra faux (l'objet avec une telle clé n'existe pas). Si la chaîne existe, elle commence à être énumérée.
Chaque élément de cette chaîne est représenté par l'objet de type KeyValuePair, qui est proposé pour comparer une clé réellement transférée avec une clé stockée par un élément. Si les clés sont les mêmes, la méthode renvoie vrai (l'objet ayant une telle clé existe). Le code, qui teste l'égalité des clés, est donné dans la liste de la classe KeyValuePair.
3.4. Allocation et désallocation dynamiques de la mémoire
La méthode Redimensionner() est responsable de l'allocation dynamique et de la désallocation de la mémoire dans notre tableau associatif. Cette méthode est activée à chaque fois que le nombre d'éléments est égal à la taille m_array. Elle est également activée lorsque des éléments sont supprimés de la liste. Cette méthode remplace les index de stockage pour tous les éléments, elle fonctionne donc exceptionnellement lentement.
Pour éviter une activation fréquente de la méthode Redimensionner(), le volume de mémoire allouée est augmenté deux fois à chaque fois par rapport à son volume précédent. Autrement dit, si nous voulons que notre dictionnaire stocke 65 536 éléments, la méthode Redimensionner() sera activée 16 fois (2^16). Après vingt activations, le dictionnaire pouvait contenir plus d'un million d'éléments (1 048 576). La méthode FindNextLevel() est responsable de la croissance exponentielle des éléments requis.
Voici le code source de la méthode Redimensionner() :
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
Cette méthode fonctionne à la fois sur les côtés supérieurs et inférieurs. Lorsqu'il y a moins d'éléments qu'un tableau réel ne peut en contenir, un code de réduction d'élément est lancé. Et inversement lorsque le tableau actuel n'est pas suffisant, le tableau est redimensionné pour plus d'éléments. Ce code nécessite beaucoup de ressources de calcul.
L'ensemble du tableau doit être redimensionné, mais tous ses éléments doivent être préalablement supprimés dans une copie temporaire du tableau. Ensuite, vous devez déterminer de nouveaux index pour tous les éléments et seulement après cela, vous pourrez localiser ces éléments à leurs nouveaux emplacements.
3.5. Coups de finition : recherche d'objets et indexeur pratique
Ainsi, notre classe CDictionary possède déjà les principales méthodes pour travailler avec elle. Nous pouvons utiliser la méthode ContainsKey() si nous voulons savoir si un objet avec une certaine clé existe. Nous pouvons ajouter un objet au dictionnaire en utilisant la méthode AddObject(). Nous pouvons également supprimer un objet du dictionnaire en utilisant la méthode DeleteObjectByKey().
Il ne nous reste plus qu'à faire une énumération pratique de tous les objets du conteneur. Comme nous le savons déjà, tous les éléments y sont stockés dans un ordre particulier en fonction de leurs clés. Mais il serait pratique d'énumérer tous les éléments dans le même ordre dans lequel nous les avons ajoutés au tableau associatif. À cette fin, le conteneur KeyValuePair a deux pointeurs supplémentaires vers les éléments ajoutés précédents et suivants du type KeyValuePair. Nous pouvons effectuer une énumération séquentielle grâce à ces pointeurs.
Par exemple, si nous avons ajouté des éléments à notre tableau associatif comme suit :
CNumber CShip CWeather CHuman CExpert CCar
l'énumération de ces éléments sera également séquentielle, car elle sera effectuée en utilisant des références à KeyValuePair, comme l’indique la figure 6 :

Fig. 6. Schéma d'énumération de tableau séquentiel
Cinq méthodes sont utilisées pour effectuer ce dénombrement.
Voici leur contenu et une brève description :
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
Grâce à ces itérateurs simples, nous pouvons effectuer une énumération séquentielle des éléments ajoutés :
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
Ce code affichera les valeurs de la chaîne des objets dans le même ordre dans lequel elles ont été ajoutées au dictionnaire :
24.02.2015 14:08:29.537 TestDict (USDCHF,H1) 6 : CCar
24.02.2015 14:08:29.537 TestDict (USDCHF,H1) 5 : CExpert
24.02.2015 14:08:29.537 TestDict (USDCHF,H1) 4 : CHuman
24.02.2015 14:08:29.537 TestDict (USDCHF,H1) 3 : CWeather
24.02.2015 14:08:29.537 TestDict (USDCHF,H1) 2 : CSship
24.02.2015 14:08:29.537 TestDict (USDCHF,H1) 1 : CNumber
Modifiez deux chaînes de code dans la fonction OnStart() pour afficher tous les éléments à l'envers :
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
En conséquence, les valeurs sorties sont inversées :
24.02.2015 14:11:01.021 TestDict (USDCHF,H1) 6 : CNumber
24.02.2015 14:11:01.021 TestDict (USDCHF,H1) 5 : CSship
24.02.2015 14:11:01.021 TestDict (USDCHF,H1) 4 : CWeather
24.02.2015 14:11:01.021 TestDict (USDCHF,H1) 3 : CHuman
24.02.2015 14:11:01.021 TestDict (USDCHF,H1) 2 : CExpert
24.02.2015 14:11:01.021 TestDict (USDCHF,H1) 1 : CCar
Chapitre 4. Test et évaluation des performances
4.1. Rédaction de tests et évaluation des performances
L'évaluation des performances est un ingrédient essentiel de la conception d'une classe, surtout si nous parlons d'une classe pour le stockage de données. Après tout, les programmes les plus divers peuvent profiter de cette classe. Les algorithmes de ces programmes peuvent être critiques pour la vitesse et nécessitent des performances élevées. C'est pourquoi il est si important de savoir évaluer les performances et rechercher les faiblesses de tels algorithmes.
Pour commencer, nous allons écrire un test simple qui mesure la vitesse d'ajout et d'extraction d'éléments du dictionnaire. Ce test ressemblera à un script.
Son code source est joint ci-dessous :
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
Ce code ajoute séquentiellement des éléments au dictionnaire et se réfère ensuite à eux en mesurant leur vitesse. Après cela, chaque élément est supprimé à l'aide de la méthode DeleteObjectByKey(). La fonction système GetTickCount() mesure la vitesse.
À l'aide de ce script, nous avons créé un diagramme illustrant les dépendances temporelles de ces trois méthodes principales :
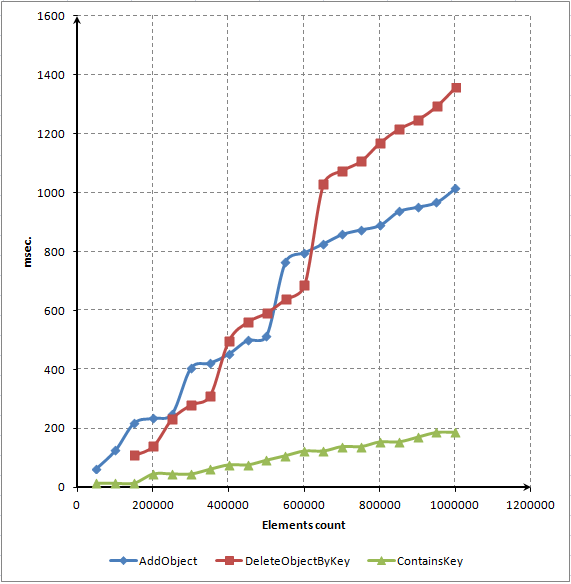
Fig. 7. Diagramme à points de dépendance entre le nombre d'éléments et le temps de fonctionnement des méthodes en millisecondes
Comme vous pouvez le constater, la plupart du temps est consacré à la localisation et à la suppression d'éléments du dictionnaire. Néanmoins, nous nous attendions à ce que les éléments soient supprimés beaucoup plus rapidement. Nous allons essayer d'améliorer les performances de la méthode en utilisant un profileur de code. Cette procédure sera décrite dans la section suivante.
Faites attention au diagramme de la méthode ContainsKey(). Il est linéaire. Cela signifie que l'accès à un élément aléatoire nécessite approximativement un temps, quel que soit le nombre de ces éléments dans le tableau. C'est une fonctionnalité indispensable d'un véritable tableau associatif.
Pour illustrer cette fonctionnalité, nous allons montrer un diagramme de dépendance entre le temps d'accès moyen à un élément et un certain nombre d'éléments dans le tableau :
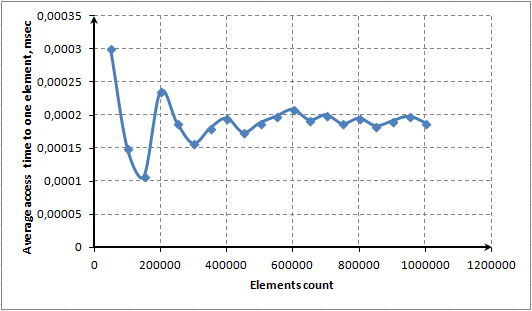
Fig. 8. Temps d'accès moyen à un élément à l'aide de la méthode ContainsKey()
4.2. Profilage de code. Vitesse vers la gestion automatique de la mémoire
Le profilage de code est une technique spéciale qui mesure les dépenses en temps de toutes les fonctions. Lancez simplement n'importe quel programme MQL5 en cliquant ![]() dans MetaEditor.
dans MetaEditor.
Nous ferons de même et enverrons notre script pour le profilage. Après un certain temps, notre script est exécuté et nous obtenons un profil temporel de toutes les méthodes exécutées pendant le fonctionnement du script. La capture d'écran ci-dessous montre que la plupart du temps a été consacré à l'exécution de trois méthodes : AddObject() (40 % du temps), GetObjectByKey() (7 % du temps) et DeleteObjectByKey() (53 % du temps) :
")
Fig. 9. Profilage de code dans la fonction OnStart()
Et plus de 60 % de l'appel DeleteObjectByKey() ont été effectués pour appeler la méthode Compress().
Mais cette méthode est presque vide, le temps principal est passé à appeler la méthode Redimensionner().
Elle comprend :
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
Le problème est clair. Lorsque nous supprimons tous les éléments, la méthode Redimensionner() est occasionnellement lancée. Cette méthode réduit la taille du tableau en libérant dynamiquement le stockage.
Désactivez cette méthode si vous souhaitez supprimer des éléments plus rapidement. Par exemple, vous pouvez introduire la méthode spéciale AutoFreeMemory(), définissant l'indicateur de compression, dans la classe. Elle sera définie par défaut, et dans ce cas la compression sera effectuée automatiquement. Mais si nous avons besoin de vitesse supplémentaire, nous effectuerons la compression manuellement à un moment bien choisi. Pour cela, nous rendrons publique la méthode Compress().
Si la compression est désactivée, les éléments sont supprimés trois fois plus rapidement :
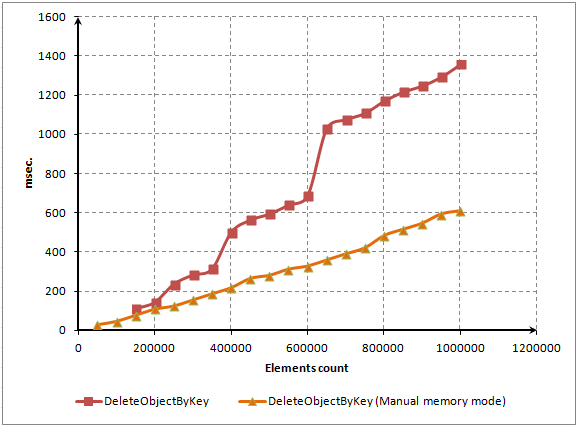
Fig. 10. Temps de suppression d'élément avec surveillance humaine du stockage occupé (comparaison)
La méthode Redimensionner() est appelée non seulement pour la compression des données, mais aussi lorsqu'il y a trop d'éléments et que nous avons besoin d'un tableau plus grand. Dans ce cas, nous ne pouvons pas éviter d'appeler la méthode Redimensionner(). Elle doit être appelée afin de ne pas créer de chaînes CList longues et lentes à l'avenir. Mais nous pouvons spécifier le volume requis de notre dictionnaire à l'avance.
Par exemple, un certain nombre d'éléments ajoutés est souvent connu à l'avance. Connaissant le nombre d'éléments, le dictionnaire créera au préalable un tableau de la taille requise, donc des redimensionnements supplémentaires lors du remplissage du tableau ne seront pas nécessaires.
À cette fin, nous ajouterons un autre constructeur qui acceptera les éléments requis :
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
La méthode privée Init() effectue l'opération principale :
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
Nos améliorations sont faites. Il est maintenant temps d'évaluer les performances de la méthode AddObject() avec la taille de tableau initialement spécifiée. Pour cela nous allons changer deux premières chaînes de la fonction OnStart() de notre script :
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
Dans ce cas, END est représenté par un grand nombre égal à 1 000 000 d'éléments.
Ces innovations ont considérablement accéléré les performances de la méthode AddObject() :

Fig. 11. Temps d'ajout d'éléments avec la taille de tableau prédéfinie
Pour résoudre de vrais problèmes de programmation, nous devons toujours choisir entre empreinte mémoire et vitesse de performance. Il faut beaucoup de temps pour libérer la mémoire. Mais dans ce cas, nous aurons plus de mémoire disponible. Si nous gardons tout tel quel, le temps CPU ne sera pas dépensé pour des problèmes de calcul compliqués supplémentaires, mais en même temps, nous aurons moins de mémoire disponible. En utilisant des conteneurs, la programmation orientée objet permet d'allouer des ressources entre la mémoire CPU et le temps CPU de manière flexible en sélectionnant une certaine politique d'exécution pour chaque problème particulier.
Dans l'ensemble, les performances du processeur sont bien pires que la capacité de la mémoire. C'est pourquoi dans la plupart des cas, nous privilégions la vitesse d'exécution plutôt que l'empreinte mémoire. De plus, le contrôle de la mémoire au niveau de l'utilisateur est plus efficace qu'un contrôle automatisé, car nous ne connaissons généralement pas l'état fini de la tâche.
Par exemple, dans le cas de notre script, nous savons qu'à la fin de l'énumération, le nombre total d'éléments sera nul, car la méthode DeleteObjectByKey() les supprimera tous au moment de la fin de la tâche. C'est pourquoi nous n'avons pas besoin de compresser le tableau automatiquement. Il suffira de l'effacer à la toute fin en appelant la méthode Compress().
Maintenant, lorsque nous avons de bonnes métriques linéaires d'ajout et de suppression d'éléments du tableau, nous analyserons un temps moyen d'ajout et de suppression d'un élément en fonction du nombre total d'éléments :
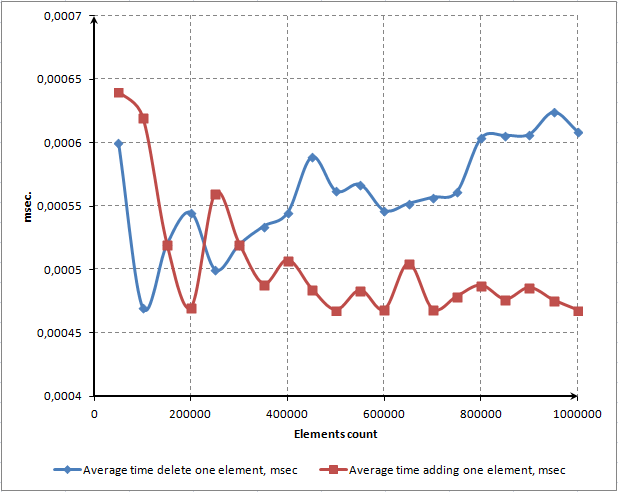
Fig. 12. Temps moyen d'ajout et de suppression d'un élément
Nous pouvons voir que le temps moyen d'ajout d'un élément est assez fixe et ne dépend pas du nombre total d'éléments dans le tableau. Le temps moyen de suppression d'un élément augmente légèrement, ce qui n'est pas souhaitable. Mais nous ne pouvons pas dire avec précision si nous traitons des résultats à l'intérieur du taux d'erreur ou s'il s'agit d'une tendance régulière.
4.3. Performances de CDictionary par rapport au CArrayObj standard
Il est temps pour le test le plus intéressant : nous allons comparer notre CDictionary avec la classe standard CArrayObj. La CArrayObj n'a pas de mécanismes d'allocation de mémoire manuelle comme l'indication d'une taille hypothétique dans la phase de construction, c'est pourquoi nous désactiverons le contrôle manuel de la mémoire dans CDictionary et le mécanisme AutoFreeMemory() sera activé.
Les forces et les faiblesses de chaque classe ont été décrites dans le premier chapitre. CDictionary permet d'ajouter un élément à un endroit indéfini ainsi que de l'extraire du dictionnaire de manière très rapide. Mais CArrayObj permet de faire une énumération très rapide de tous les éléments. L'énumération dans CDictionary sera plus lente, car elle sera effectuée au moyen d'un déplacement par un pointeur, et cette opération est plus lente que l'indexation directe.
Alors on y va. Pour commencer, créons une nouvelle version de notre test :
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
Elle utilise les macros TEST_ARRAY. S'il est identifié, le test effectue des opérations sur CArrayObj, sinon les opérations sont effectuées sur CDictionary. Le premier test d'ajout de nouveaux éléments est remporté par CDictionary.
Son mode de réallocation de mémoire s'est révélé meilleur dans ce cas particulier :
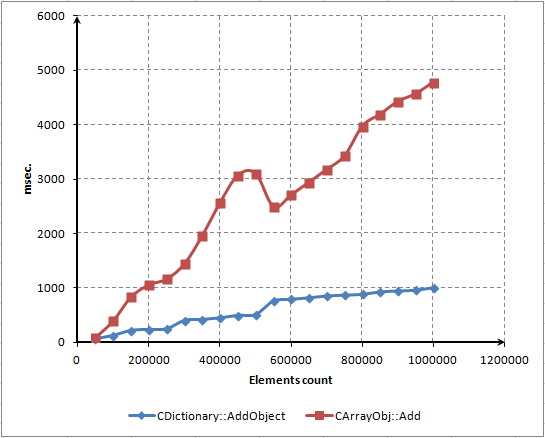
Fig. 13. Temps passé à ajouter de nouveaux éléments à CArrayObj et CDictionary (comparaison)
Il est essentiel de souligner que le ralentissement du fonctionnement a été causé par un mode particulier de réallocation de mémoire dans CArrayObj.
Cela est décrit par une seule chaîne du code source :
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize); Il s'agit d'un algorithme linéaire d'allocation de mémoire. Il est appelé par défaut après avoir rempli tous les 16 éléments. CDictionary utilise un algorithme exponentiel : chaque prochaine réallocation de mémoire alloue deux fois plus de mémoire que l'appel précédent. Ce schéma illustre parfaitement le dilemme entre performances et mémoire utilisée. La méthode Réserve() de la classe CArrayObj est plus économique et nécessite moins de mémoire mais fonctionne plus lentement. La méthode Redimensionner() de la classe CDictionary fonctionne plus rapidement mais nécessite plus de mémoire, et la moitié de cette mémoire peut rester inutilisée.
Faisons le dernier test. Nous calculerons le temps nécessaire à l'énumération complète des conteneurs CArrayObj et CDictionary. CArrayObj utilise l'indexation directe et CDictionary utilise le référencement. CArrayObj permet de faire référence à n'importe quel élément par son index, mais dans CDictionary, la référence à n'importe quel élément par son index est entravée. Le énumération séquentielle est très compétitive avec l'indexation directe :
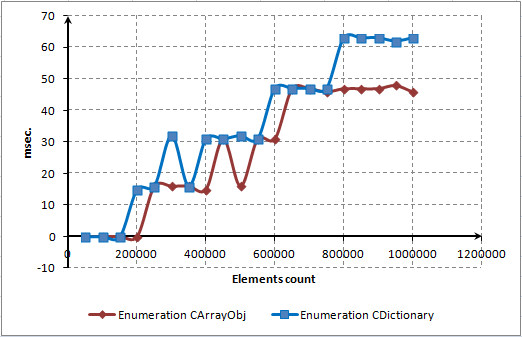
Fig. 14. Temps pour l'énumération complète de CArrayObj et CDictionary
Les développeurs du langage MQL5 ont fait un excellent travail et optimisé les références. Elles sont très compétitives en vitesse avec une indexation directe qui est illustrée dans le schéma.
Il est important de réaliser que l'énumération des éléments prend si peu de temps qu'elle est presque sur le point de la résolution de la fonction GetTickCount(). Elle est difficilement utilisable pour mesurer des intervalles de temps inférieurs à 15 millisecondes.
4.4. Recommandations générales lors de l'utilisation de CArrayObj, CList et CDictionary
Nous allons faire un tableau où nous décrirons les principales tâches qui peuvent se produire dans la programmation et les fonctionnalités des conteneurs qui doivent être connues pour résoudre ces tâches.
Les fonctionnalités avec de bonnes performances de tâche sont écrites en vert, les fonctionnalités, qui ne permettent pas de terminer les tâches efficacement, sont écrites en rouge.
| But | CArrayObj | CList | CDictionary |
|---|---|---|---|
| Ajout séquentiel de nouveaux éléments à la fin du conteneur. | Le conteneur doit allouer une nouvelle mémoire pour un nouvel élément. Le transfert d'éléments existants vers de nouveaux index n'est pas requis. CArrayObj effectuera cette opération très rapidement. | Le conteneur mémorise le premier, l’actuel et le dernier élément. De ce fait, un nouvel élément sera attaché à la fin de la liste (le dernier élément mémorisé) très rapidement. | Le dictionnaire n'a pas de concepts tels que « fin » ou « début ». Un nouvel élément est attaché très rapidement et ne dépend pas d'un nombre d'éléments. |
| Accès à un élément arbitraire par son index. | En raison de l'indexation directe, l'accès est obtenu très rapidement, cela prend O(1) de temps. | L'accès à chaque élément est obtenu via l'énumération de tous les éléments précédents. Cette opération prend O(n) de temps. | L'accès à chaque élément est obtenu via l'énumération de tous les éléments précédents. Cette opération prend O(n) de temps. |
| Accès à un élément arbitraire par sa clé. | Pas disponible | Pas disponible | La détermination d'un hachage et d'un index par une clé est une opération efficace et rapide. L'efficacité de la fonction de hachage est très importante pour les clés de la chaîne. Cette opération prend O(1) de temps. |
| Les nouveaux éléments sont ajoutés/supprimés par un index non défini. | CArrayObj doit non seulement allouer de la mémoire pour un nouvel élément mais aussi supprimer tous les éléments dont les index sont supérieurs à un index de l'élément inséré. C'est pourquoi CArrayObj est une opération lente. | L'élément est ajouté ou supprimé de CList très rapidement, mais l'index nécessaire est accessible pour O(n). C'est une opération lente. | Dans CDictionary, l'accès à l'élément par son index se fait à partir de la liste CList et prend beaucoup de temps. Mais l'ajout et la suppression sont effectués très rapidement. |
| Les nouveaux éléments sont ajoutés/supprimés par une clé non définie. | Pas disponible | Pas disponible | Comme chaque nouvel élément est inséré dans CList, de nouveaux éléments sont ajoutés et supprimés très rapidement car le tableau n'a pas besoin d'être redimensionné après chaque ajout/suppression. |
| Utilisation et gestion de la mémoire. | Un redimensionnement dynamique du tableau est requis. C'est une opération nécessitant d’énormes ressources, elle nécessite soit beaucoup de temps, soit beaucoup de mémoire. | La gestion de la mémoire n'est pas utilisée. Chaque élément utilise la bonne quantité de mémoire. | Un redimensionnement dynamique du tableau est requis. C'est une opération nécessitant d’énormes ressources, elle nécessite soit beaucoup de temps, soit beaucoup de mémoire. |
| Énumération des éléments. Les opérations qui doivent être effectuées pour chaque élément du vecteur. | Très rapide grâce à l'indexation directe des éléments. Mais dans certains cas, l'énumération doit être effectuée dans l'ordre inverse (par exemple, lors de la suppression séquentielle du dernier élément). | Comme nous devons énumérer tous les éléments une seule fois, le référencement direct est une opération rapide. | Comme nous devons énumérer tous les éléments une seule fois, le référencement direct est une opération rapide. |
Chapitre 5. Documentation de la classe CDictionary
5.1. Méthodes clés pour ajouter, supprimer et accéder aux éléments
5.1.1. La méthode AddObject()
Ajoute un nouvel élément du type CObject avec la touche T. Tout type de base peut être utilisé comme clé.
template<typename T> bool AddObject(T key,CObject *value);
Paramètres
- [in] clé - clé unique représentée par l'un des types de base (chaîne, ulong, char, enum, etc.).
- [in] valeur - objet avec CObject comme type de base.
Valeur renvoyée
Renvoie vrai, si l'objet a été ajouté au conteneur, sinon renvoie faux. Si la clé de l'objet ajouté existe déjà dans le conteneur, la méthode renverra une valeur négative et l'objet ne sera pas ajouté.
5.1.2. La méthode ContainsKey()
Vérifie s'il y a un objet avec une clé égale à la touche T dans le conteneur. Tout type de base peut être utilisé comme clé.
template<typename T> bool ContainsKey(T key);
Paramètres
- [in] clé - clé unique représentée par l'un des types de base (chaîne, ulong, char, enum, etc.).
Renvoie vrai, si l'objet dont la clé est vérifiée existe dans le conteneur. Sinon renvoie faux.
5.1.3. La méthode DeleteObjectByKey()
Supprime un objet par la touche T prédéfinie. Tout type de base peut être utilisé comme clé.
template<typename T> bool DeleteObjectByKey(T key);
Paramètres
- [in] clé - clé unique représentée par l'un des types de base (chaîne, ulong, char, enum, etc.).
Valeur renvoyée
Renvoie vrai, si l'objet dont la clé est prédéfinie a été supprimé. Renvoie faux, si l'objet dont la clé est prédéfinie n'existe pas ou si sa suppression a échoué.
5.1.4. La méthode GetObjectByKey()
Renvoie un objet par la touche T prédéfinie. Tout type de base peut être utilisé comme clé.
template<typename T> CObject* GetObjectByKey(T key);
Paramètres
- [in] clé - clé unique représentée par l'un des types de base (chaîne, ulong, char, enum, etc.).
Valeur renvoyée
Renvoie un objet correspondant à la clé prédéfinie. Renvoie ZÉRO, si l'objet avec la clé prédéfinie n'existe pas.
5.2. Méthodes de gestion de la mémoire
5.2.1. Constructeur CDictionary()
Le constructeur de base crée l'objet CDictionary avec une taille initiale du tableau de base égale à 3 éléments.
Le tableau est augmenté ou compressé automatiquement en remplissant le dictionnaire ou en supprimant des éléments.
CDictionary();
5.2.2. Constructeur CDictionary(int capacity)
Le constructeur crée l'objet CDictionary avec une taille initiale du tableau de base égale à 'capacité'.
Le tableau est augmenté ou compressé automatiquement en remplissant le dictionnaire ou en supprimant des éléments.
CDictionary(int capacity);
Paramètres
- [in] capacité - nombre d'éléments initiaux.
Remarque
Définir une limite de taille de tableau immédiatement après son initialisation vous aidera à éviter les appels de la méthode Redimensionner() et ainsi augmenter l'efficacité lors de l'insertion de nouveaux éléments.
Cependant, il faut noter que si vous supprimez des éléments avec activé (AutoMemoryFree(true)), le conteneur sera automatiquement compressé malgré le paramètre capacité. Pour éviter une compression précoce, effectuez la première opération de suppression d'objet une fois que les conteneurs sont complètement remplis, ou si cela ne peut pas être fait, désactivez (AutoMemoryFree(false)).
5.2.3. La méthode FreeMode (mode booléen)
Définit le mode de suppression des objets existants dans le conteneur.
Si le mode de suppression est activé, le conteneur est également soumis à la procédure 'suppression' après la suppression de l'objet. Son destructeur est activé et il devient indisponible. Si le mode de suppression est désactivé, le destructeur de l'objet n'est pas activé et il reste disponible à partir d'autres points du programme.
void FreeMode(bool free_mode);
Paramètres
- [in] free_mode - indicateur de mode de suppression d'objet.
5.2.4. La méthode FreeMode()
Renvoie l'indicateur de suppression des objets situés dans le conteneur (voir FreeMode(bool mode)).
bool FreeMode(void);
Valeur renvoyée
Renvoie vrai si l'objet est supprimé par l'opérateur suppression après avoir été supprimé du conteneur. Sinon renvoie faux.
5.2.5. La méthode AutoFreeMemory(bool autoFree)
Définit l'indicateur de gestion automatique de la mémoire. La gestion automatique de la mémoire est activée par défaut. Dans ce cas, le tableau est compressé automatiquement (redimensionné de la plus grande à la plus petite). Si elle est désactivée, le tableau n'est pas compressé. Cela augmente considérablement la vitesse d'exécution du programme, car la méthode Redimensionner() nécessitant d’énormes ressources n'a pas besoin d'être appelée. Mais dans ce cas, vous devez avoir un œil sur la taille du tableau et le compresser manuellement à l'aide de la méthode Compress().
void AutoFreeMemory(bool auto_free);
Paramètres
- [in] auto_free - indicateur de mode de gestion de la mémoire.
Valeur renvoyée
Renvoie vrai si vous devez activer la gestion de la mémoire et appeler automatiquement la méthode Compress(). Sinon renvoie faux.
5.2.6. La méthode AutoFreeMemory()
Renvoie l'indicateur qui précise si le mode de gestion automatisée de la mémoire est utilisé (voir la méthode FreeMode(bool free_mode)).
bool AutoFreeMemory(void);
Valeur renvoyée
Renvoie vrai, si le mode de gestion de la mémoire est utilisé. Sinon renvoie faux.
5.2.7. La méthode Compress()
Compresse le dictionnaire et redimensionne les éléments. Le tableau n'est compressé que si cela est possible.
Cette méthode ne doit être appelée que si le mode de gestion automatisée de la mémoire est désactivé.
void Compress(void);
5.2.8. La méthode Clear()
Supprime tous les éléments du dictionnaire. Si l'indicateur de gestion de la mémoire est activé, le destructeur est appelé pour chaque élément en cours de suppression.
void Clear(void);
5.3. Méthodes de recherche dans le dictionnaire
Tous les éléments du dictionnaire sont interconnectés. Chaque nouvel élément est relié au précédent. Ainsi, la recherche séquentielle de tous les éléments du dictionnaire devient possible. Dans ce cas, la référence est effectuée par une liste chaînée. Les méthodes de cette section facilitent la recherche et rendent l'itération du dictionnaire plus pratique.
Vous pouvez utiliser la construction suivante lors de la recherche dans le dictionnaire :
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }
5.3.1. La méthode GetFirstNode()
Renvoie le tout premier élément ajouté au dictionnaire.
CObject* GetFirstNode(void); Valeur renvoyée
Renvoie le pointeur vers l'objet de type CObject, qui a été principalement ajouté au dictionnaire.
5.3.2. La méthode GetLastNode()
Renvoie le dernier élément du dictionnaire.
CObject* GetLastNode(void); Valeur renvoyée
Renvoie le pointeur vers l'objet de type CObject, qui a été ajouté au dictionnaire à la toute fin.
5.3.3. Méthode GetCurrentNode()
Renvoie l'élément actuellement sélectionné. L'élément doit être préalablement sélectionné par l'une des méthodes de recherche d'éléments sur le dictionnaire ou par la méthode d'accès à l'élément du dictionnaire (ContainsKey(), GetObjectByKey()).
CObject* GetLastNode(void); Valeur renvoyée
Renvoie le pointeur vers l'objet de type CObject, qui a été ajouté au dictionnaire à la toute fin.
5.3.4. La méthode GetNextNode()
Renvoie l'élément qui suit l'élément actuel. Renvoie ZÉRO si l'élément actuel est le dernier ou n'est pas sélectionné.
CObject* GetLastNode(void); Valeur renvoyée
Renvoie le pointeur vers l'objet de type CObject, qui suit l'objet actuel. Renvoie ZÉRO si l'élément actuel est le dernier ou n'est pas sélectionné.
5.3.5. La méthode GetPrevNode()
Renvoie l'élément qui précède l'élément actuel. Renvoie ZÉRO si l'élément actuel est le premier ou n'est pas sélectionné.
CObject* GetPrevNode(void); Valeur renvoyée
Renvoie le pointeur vers l'objet de type CObject, qui est antérieur à l'objet actuel. Renvoie ZÉRO si l'élément actuel est le premier ou n'est pas sélectionné.
Conclusion
Nous avons examiné les principales caractéristiques des conteneurs de données répandus. Chaque conteneur de données doit être utilisé là où ses fonctionnalités permettent de résoudre le problème de la manière la plus efficace.
Des tableaux réguliers doivent être utilisés lorsque l'accès séquentiel à un élément est suffisant pour résoudre le problème. Il est préférable d'utiliser les dictionnaires et les tableaux associés lorsque l'accès à un élément par sa clé unique est requis. Les listes sont mieux à utiliser en cas de remplacement fréquent d'éléments : suppression, insertion, ajout de nouveaux éléments.
Le dictionnaire permet de résoudre des problèmes algorithmiques difficiles d'une manière agréable et simple. Là où d'autres conteneurs de données nécessitent des fonctionnalités de traitement supplémentaires, le dictionnaire permet d'organiser l'accès aux éléments existants de la manière la plus efficace. Par exemple, en vous basant sur le dictionnaire, vous pouvez faire un modèle d'événement où chaque événement de type OnChartEvent() est livré à la classe qui gère l'un ou l'autre élément graphique. Pour cela, il suffit d'associer à chaque instance de classe le nom de l'objet géré par cette classe.
Le dictionnaire étant un algorithme universel, il peut être appliqué dans les domaines les plus divers. Cet article précise que son fonctionnement est basé sur des algorithmes assez simples mais robustes qui rendent son application pratique et efficace.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/1334
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Étudier la classe CCanvas. Comment dessiner des objets transparents
Étudier la classe CCanvas. Comment dessiner des objets transparents
 Trading bidirectionnel et couverture des positions dans MetaTrader 5 à l’aide du HedgeTerminalAPI, Partie 2
Trading bidirectionnel et couverture des positions dans MetaTrader 5 à l’aide du HedgeTerminalAPI, Partie 2
 Technique de test (optimisation) et quelques critères de sélection des paramètres de l'Expert Advisor
Technique de test (optimisation) et quelques critères de sélection des paramètres de l'Expert Advisor
 Trading bidirectionnel et couverture des positions dans MetaTrader 5 à l’aide du panneau HedgeTerminal, Partie 1
Trading bidirectionnel et couverture des positions dans MetaTrader 5 à l’aide du panneau HedgeTerminal, Partie 1
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
il n'est pas nécessaire qu'il fonctionne correctement en général.
la bonne façon d'effectuer des suppressions multiples à partir d'un tableau associatif est de collecter un tableau de clés à supprimer, puis de supprimer par clé.
C'est là que le bât blesse, car même cette méthode provoque soudain un étrange bogue. Il s'agit manifestement d'une erreur. Je vais me pencher sur la question.
Pour l'instant, je peux vous conseiller de créer un nouveau dictionnaire, et d'y ajouter les valeurs qui ne doivent pas être supprimées. Ensuite, effacez l'ancien dictionnaire. Cela fonctionnera à 100 %.
Voici ce qu'il faut faire :
1. mettre à jour la version du dictionnaire avec celle qui est jointe à ce message.
2. Exécuter un script de test pour supprimer les éléments pairs.
La suppression doit se faire en deux passes :
En ce qui concerne la méthode DeleteCurrentObject():
Cette méthode ne doit être utilisée qu'en conjonction avec la fonction ContainsKey(). La seule raison pour laquelle elle est disponible en tant que méthode publique est que, dans ce cas, l'appel à la méthode permet de gagner du temps sur le repositionnement du pointeur. En d'autres termes, le seul cas typique d'utilisation de cette méthode est le suivant : 1. Vérifier s'il y a une clé, 2. si c'est le cas, la supprimer rapidement avec cette méthode.
C'est compréhensible, mais là encore, la carrosserie n'est pas nécessaire.
Il est techniquement possible de procéder à une dépose en un seul passage, comme vous le souhaitez. Mais ce serait compliqué. C'est pourquoi il n'est pas encore possible de le faire en deux passes. Du point de vue du dictionnaire en tant que structure de données distribuée, la suppression en deux passes est une solution plus correcte d'un point de vue canonique. Ce n'est qu'au niveau de l'utilisateur qu'il semble que la suppression est séquentielle, alors qu'en réalité tout est différent. En termes de performances, la suppression en une seule passe n'apportera aucun avantage. En termes de commodité, oui, elle peut être plus pratique.
Il est techniquement possible de procéder à un retrait en un seul passage, comme vous le souhaitez. Mais ce serait compliqué. C'est pourquoi il n'est pas encore possible de procéder à une suppression en deux passes. Du point de vue du dictionnaire en tant que structure de données distribuée, la suppression en deux passes est plus correcte d'un point de vue canonique. Ce n'est qu'au niveau de l'utilisateur qu'il semble que la suppression est séquentielle, alors qu'en réalité tout est différent. En termes de performances, la suppression en une seule passe n'apporte aucun avantage. En termes de commodité, oui, elle peut être plus pratique.
Je vous remercie.
Je pense avoir trouvé un bug en supprimant un élément et en essayant d'atteindre le dernier élément :
L'erreur dans le CDictionary.mqh sera :
accès aupointeur invalide dans 'Dictionary.mqh' (463,9)
Quelqu'un peut-il le confirmer ? Comment corriger cette erreur ?
Il s'agit d'un bogue à la ligne 500 && 501 sur l'implémentation de la vérification des pointeurs.
Corrigé en utilisant la fonction intégrée CheckPointer().