
Usando OpenCL para testar padrões de candles

Introdução
Quando se começa a dominar a OpenCL, surge a pergunta 'onde aplicá-la'. Na prática, ótimos exemplos como multiplicação de arrays ou classificação de grandes volumes de dados não encontram implementação na hora de construir indicadores ou sistemas de negociação automatizados. Além disso, existem outras formas de implementação, como a de trabalhar com redes neurais, no entanto, isso requer certo conhecimento que exige muito tempo e não garante bons resultados na negociação. Tudo isso é algo muito negativo para os gostam de sentir todo o poder da OpenCL com a ajuda de exemplos de tarefas básicas.
Neste artigo, consideraremos o uso de OpenCL para resolver como buscar de padrões de candles e testá-los com base no histórico. Desenvolveremos um algoritmo para testar - de uma passagem só - e otimizar dois parâmetros no modo "OHLC em M1". Depois, compararemos o desempenho do testador de estratégias embutido com o do testador escrito em OpenCL, e descobriremos qual deles é mais rápido.
Eu suponho que o leitor já conheça os fundamentos da OpenCL. Caso contrário, recomendo ler o artigo "OpenCL: ponte para mundos paralelos" e "OpenCL: da programação ingênua até a mais perceptível". E é sempre bom ter ao nosso alcance o documento "The OpenCL Specification Version 1.2". O artigo será focado no algoritmo para construir o testador, sem tocar os fundamentos da programação em OpenCL.
- Introdução
- 1. Implementação em MQL5
- 2. Implementação em OpenCL
- 2.1 Carregando dados de preços
- 2.2 Teste simples
- 2.2.1. Busca de padrões em OpenCL
- 2.2.2. Transferindo ordens para o timeframe M1
- 2.2.3. Obtendo resultados de operações
- 2.3. Iniciando o teste
- 2.4. Otimização
- 2.4.1. Preparando ordens
- 2.4.2. Obtendo resultados de operações
- 2.4.3. Buscando padrões e gerando resultados de teste
- 2.5. Iniciando a otimização
- 3. Comparando o desempenho
- 3.1. Otimização no par EURUSD
- 3.2. Otimização no par GBPUSD
- 3.3. Otimização no par USDJPY
- 3.4. Tabela de desempenho
- Fim do artigo
1. Implementação em MQL5
Para garantir que a implementação do testador em OpenCL funcione corretamente, é preciso apoiar-se em algo. Por isso, primeiro escreveremos um EA em MQL5, compararemos seus resultados de teste e de otimização - de um testador regular - com os de um testador criado em OpenCL.
- Pinbar de baixa
- Pinbar de alta
- Engolfamento de baixa
- Engolfamento de alta
A estratégia será simples:
- Pinbar de baixa ou pinbar de alta — venda
- Pinbar de alta ou pinbar de baixa — compra
- Número de posições abertas — ilimitado
- Tempo máximo de bloqueio da posição aberta — limitado, definido pelo usuário
- Níveis de Take Profit e Stop Loss são fixos, e definidos pelo usuário.
A presença do padrão será verificada em barras totalmente fechadas. Em outras palavras, quando surge uma nova barra, procuraremos um padrão nas três anteriores.
As condições para encontrar o padrão serão as seguintes:

Fig. 1. Padrões "Pinbar de baixa" (a) e "Pinbar de alta" (b)
Para pinbar de baixa (Fig. 1, a):
- A sombra superior ("Cauda") da primeira barra é maior do que o valor de referência especificado: tail>=Reference
- A barra zero é de alta: Close[0]>Open[0]
- A segunda barra é de baixa: Open[2]>Close[2]
- O preço High da primeira barra é um mínimo local: High[1]>MathMax(High[0],High[2])
- O corpo da primeira barra é menor do que sua sombra superior: MathAbs(Open[1]-Close[1])<tail
- "Cauda" tail = High[1]-max(Open[1],Close[1])
Para pinbar de alta (Fig. 1, b):
- A sombra inferior ("Cauda") da primeira barra é maior do que o valor de referência especificado: tail>=Reference
- A barra zero é de baixa: Open[0]>Close[0]
- A segunda barra é de alta: Close[2]>Open[2]
- O preço Low da primeira barra é um mínimo local: Low[1]<MathMin(Low[0],Low[2])
- O corpo da primeira barra é menor do que sua sombra inferior: MathAbs(Open[1]-Close[1])<tail
"Cauda" tail = min(Open[1],Close[1])-Low[1]

Fig. 2. Padrões "Engolfamento de baixa" (a) e "Engolfamento de alta" (b)
Para engolfamento de baixa (Fig. 2, a):
- A primeira barra é de alta, seu corpo é maior do que o valor de referência especificado: (Close[1]-Open[1])>=Reference
- O preço High da barra zero é menor do que o preço de fechamento da primeira barra: High[0]<Close[1]
- O preço de abertura da segunda barra é maior do que o preço de fechamento da primeira barra: Open[2]>CLose[1]
- O preço de fechamento da segunda barra é menor do que o preço de abertura da primeira barra: Close[2]<Open[1]
Para engolfamento de alta (Fig. 2, b):
- A primeira barra é de baixa, seu corpo é maior do que o valor de referência especificado: (Open[1]-Close[1])>=Reference
- O preço Low da barra zero é maior do que o preço de fechamento da primeira barra: Low[0]>Close[1]
- O preço de abertura da segunda barra é menor do que o preço de fechamento da primeira barra: Open[2]<Close[1]
- O preço de fechamento da segunda barra é maior do que o preço de abertura da primeira barra: Close[2]>Open[1]
1.1 Busca de padrões
ENUM_PATTERN Check(MqlRates &r[],uint flags,double ref) { //--- pinbar de baixa if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-MathMax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>MathMax(H(0),H(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- pinbar de alta if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=MathMin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<MathMin(L(0),L(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- engolfamento de baixa if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- engolfamento de alta if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- nada encontrado return PAT_NONE; }
Aqui você deve prestar atenção ao enumerador ENUM_PATTERN, cujos valores são sinalizadores que podem ser combinados e passados como um único argumento usando bit a bit OU:
enum ENUM_PATTERN { PAT_NONE=0, PAT_PINBAR_BEARISH = (1<<0), PAT_PINBAR_BULLISH = (1<<1), PAT_ENGULFING_BEARISH = (1<<2), PAT_ENGULFING_BULLISH = (1<<3) };
Além disso, para um registro mais compacto de condições, são incluídas macros:
#define O(i) (r[i].open) #define H(i) (r[i].high) #define L(i) (r[i].low) #define C(i) (r[i].close)
A função Check() será chamada a partir da função IsPattern(), que é projetada para verificar a presença desses padrões durante a abertura de uma nova barra:
ENUM_PATTERN IsPattern(uint flags,uint ref) { MqlRates r[]; if(CopyRates(_Symbol,_Period,1,PBARS,r)<PBARS) return 0; ArraySetAsSeries(r,false); return Check(r,flags,double(ref)*_Point); }
1.2 Compilação do EA
Para começar, vamos definir os parâmetros de entrada. Em primeiro lugar, em termos de determinação de padrões, temos um valor de referência. Ele é o comprimento mínimo da "cauda" para uma pinbar ou interseção de corpos para engolfamento. Vamos defini-lo em pontos:
input int inp_ref=50;
Em segundo lugar, trata-se do conjunto de padrões com os quais trabalhamos. Por conveniência, não usaremos o registro de sinalizadores nos parâmetros de entrada, mas escreveremos em quatro parâmetros do tipo bool:
input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true;
Eles serão coletados por nós numa variável não assinada na função de inicialização:
p_flags = 0; if(inp_bullish_pin_bar==true) p_flags|=PAT_PINBAR_BULLISH; if(inp_bearish_pin_bar==true) p_flags|=PAT_PINBAR_BEARISH; if(inp_bullish_engulfing==true) p_flags|=PAT_ENGULFING_BULLISH; if(inp_bearish_engulfing==true) p_flags|=PAT_ENGULFING_BEARISH;
Em seguida, são especificados: o tempo admissível para o bloqueio da posição expresso em horas, o Take Profit, o Stop Loss e o volume do lote:
input int inp_timeout=5; input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true; input double inp_lot_size=1;Para a negociação, vamos usar a classe CTrade da biblioteca padrão. Para medir a velocidade do testador, usaremos a classe CDuration, que permite medir os intervalos de tempo entre os pontos de controle do programa em microssegundos e exibir de forma clara. Neste caso, vamos medir o tempo entre as funções OnInit() e OnDeinit(). O código completo da classe está contido no arquivo Duration.mqh que está no anexo.
CDuration time; int OnInit() { time.Start(); // ... return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { time.Stop(); Print("O teste dourou "+time.ToStr()); }
O trabalho do EA é extremamente simples e consiste no seguinte.
Na função OnTick(), posições abertas são processadas em primeiro lugar. Ela fecha forçosamente uma posição se o seu tempo de espera exceder o valor especificado nos parâmetros de entrada. Em seguida, é verificada a abertura de uma nova barra. Se a verificação passar, checamos a presença do padrão usando a função IsPattern(). Ao encontrar um padrão, abrimos uma posição para comprar ou vender de acordo com a estratégia. O código completo da função OnTick() é mostrado abaixo:
void OnTick() { //--- processamento de posições abertas int total= PositionsTotal(); for(int i=0;i<total;i++) { PositionSelect(_Symbol); datetime t0=datetime(PositionGetInteger(POSITION_TIME)); if(TimeCurrent()>=(t0+(inp_timeout*3600))) { trade.PositionClose(PositionGetInteger(POSITION_TICKET)); } else break; } if(IsNewBar()==false) return; //--- verificando a presença de padrão ENUM_PATTERN pat=IsPattern(p_flags,inp_ref); if(pat==PAT_NONE) return; //--- abertura de posições double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); if((pat&(PAT_ENGULFING_BULLISH|PAT_PINBAR_BULLISH))!=0)//compra trade.Buy(inp_lot_size,_Symbol,ask,NormalizeDouble(ask-inp_sl*_Point,_Digits),NormalizeDouble(ask+inp_tp*_Point,_Digits),DoubleToString(ask,_Digits)); else//venda trade.Sell(inp_lot_size,_Symbol,bid,NormalizeDouble(bid+inp_sl*_Point,_Digits),NormalizeDouble(bid-inp_tp*_Point,_Digits),DoubleToString(bid,_Digits)); }
1.3 Teste
Para começar, iniciaremos uma otimização para ter uma ideia de quais parâmetros de entrada esse EA pode usar para negociar com lucro ou, pelo menos, para abrir algumas posições. Vamos otimizar dois parâmetros, nomeadamente o valor de referência para padrões e o nível de Stop Loss em pontos. Definimos 50 pontos para o Take Profit, selecionamos todos os padrões para teste.
Vamos realizar a otimização no par EURUSD e no período gráfico M5. Intervalo de tempo: 01.01.2018 — 01.10.2018. Otimização rápida (algoritmo genético), modo de negociação "OHLC em M1".
Os valores dos parâmetros otimizados serão escolhidos numa ampla faixa com inúmeras gradações:
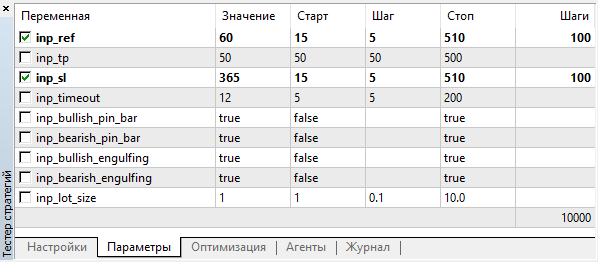
Fig. 3. Parâmetros de otimização
Concluída a otimização, os resultados serão classificados por lucro:
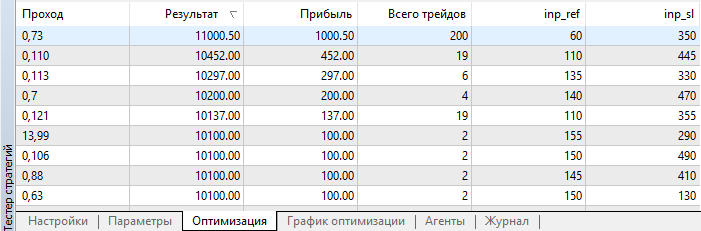
Fig. 4. Resultados da otimização
Como se pode ver, o melhor resultado (lucro de 1000,50) foi obtido com um valor de referência de 60 pontos e um nível de Stop Loss de 350 pontos. Vamos começar a testar com esses parâmetros e prestar atenção ao seu tempo de execução.
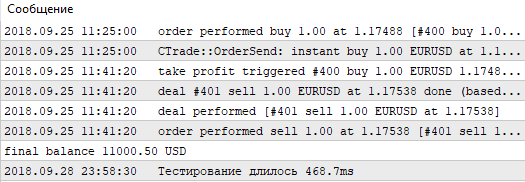
Fig. 5. Tempo de teste com passagem simples e testador regular
Vamos nos lembrar desses valores e continuar testando a mesma estratégia, mas sem testador geral. Vamos escrever o nosso usando os recursos da OpenCL.
2. Implementação em OpenCL
Para trabalhar com OpenCL, vamos usar a classe COpenCL da biblioteca padrão com pequenas modificações. O objetivo da alteração é obter o máximo de informações possíveis sobre os erros que ocorrem, mas não sobrecarregar o código com o console e as condições. Para fazer isso, criamos a classe COpenCLx, código completo está contido no arquivo anexado OpenCLx.mqh:
class COpenCLx : public COpenCL { private: COpenCL *ocl; public: COpenCLx(); ~COpenCLx(); STR_ERROR m_last_error; // estrutura do último erro COCLStat m_stat; // estatística OpenCL //--- trabalhando com buffers bool BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line); template<typename T> bool BufferFromArray(const ENUM_BUFFERS buffer_index,T &data[],const uint data_array_offset,const uint data_array_count,const uint flags,const string function,const int line); template<typename T> bool BufferRead(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); template<typename T> bool BufferWrite(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); //--- definindo argumentos template<typename T> bool SetArgument(const ENUM_KERNELS kernel_index,const int arg_index,T value,const string function,const int line); bool SetArgumentBuffer(const ENUM_KERNELS kernel_index,const int arg_index,const ENUM_BUFFERS buffer_index,const string function,const int line); //--- trabalhando com o kernel bool KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line); bool Execute(const ENUM_KERNELS kernel_index,const int work_dim,const uint &work_offset[],const uint &work_size[],const string function,const int line); //--- bool Init(ENUM_INIT_MODE mode); void Deinit(void); };
Como podemos ver, a classe contém um ponteiro para o objeto COpenCL, bem como vários métodos que servem como wrappers para métodos de classe COpenCL com o mesmo nome. Cada um desses métodos tem entre os argumentos o nome da função e a string da qual ele foi chamado. Além disso, em vez de índices e buffers de kernel, são usados enumeradores. Isso é feito para que, na mensagem de erro, possa se aplicar EnumToString(), o que é muito mais informativo do que apenas um índice.
Consideraremos um desses métodos em mais detalhes.
bool COpenCLx::KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"Objeto OpenCL não existe",function,line); return false; } //--- Inicialização do kernel ::ResetLastError(); if(!ocl.KernelCreate(kernel_index,kernel_name)) { string comment="Erro ao criar o kernel "+EnumToString(kernel_index)+", nome \""+kernel_name+"\""; SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_KERNEL_CREATE,comment,function,line); return(false); } //--- return true; }
Neste ponto, é verificado se objeto da classe COpenCL existe e o método para criar o kernel é bem-sucedido. Mas, em ver de imprimir o texto da função Print(), as mensagens são enviadas para macros, juntamente com um código de erro, um nome de função e uma string de chamada. Essas macros armazenam informações de erro no membro da classe m_last_error, cuja estrutura é mostrada abaixo:
struct STR_ERROR { int code; // código string comment; // comentários string function; // função em que ocorreu o erro int line; // string em que ocorreu o erro };
Existem quatro macros no total. Vamos examiná-las em ordem.
A macro SET_ERR grava o último erro de execução, a função e a linha a partir da qual foi chamado, e o comentário que é passado como parâmetro:
#define SET_ERR(c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
Macro SET_ERRx semelhante à macro SET_ERR:
#define SET_ERRx(c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
Ela difere em que o nome da função e a string são passados como parâmetros. Por que isso é feito? Imagine que no método KernelCreate() ocorreu um erro. Ao usar a macro SET_ERR, vamos ver o nome do método KernelCreate(), mas é muito mais útil saber de onde foi chamado o método. Para isso, a função e a string de chamada desse método são passadas como argumentos e esses argumentos são substituídos na macro.
Em seguida, a macro SET_UERR. Ela se destina a gravar erros personalizados:
#define SET_UERR(err,c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
Nela, em vez de chamar GetLastError(), o código de erro é passado como um parâmetro. O resto é semelhante à macro SET_ERR.
A macro SET_UERRx é projetada para gravar erros personalizados com a transferência do nome da função e da string de chamada como parâmetros:
#define SET_UERRx(err,c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
No caso de um erro, temos todas as informações necessárias em nossas mãos. A diferença mais importante em relação ao erros que são enviados para o console a partir da classe COpenCL é a concretização. Basta comparar a exibição a partir da classe COpenCL (linha superior) e a exibição estendida a partir da classe COpenCLx (duas linhas inferiores):

Fig. 6. Erro ao criar o kernel
Consideremos outro exemplo de método de encapsulamento, particularmente o método de criação de buffer:
bool COpenCLx::BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"Objeto OpenCL não existe",function,line); return false; } //--- monitoramento de memória livre if((m_stat.gpu_mem_usage+=size_in_bytes)==false) { CMemsize cmem=m_stat.gpu_mem_usage.Comp(size_in_bytes); SET_UERRx(UERR_NO_ENOUGH_MEM,"Não há memória livre da GPU. Não há suficiente "+cmem.ToStr(),function,line); return false; } //--- criação de buffer ::ResetLastError(); if(ocl.BufferCreate(buffer_index,size_in_bytes,flags)==false) { string comment="Erro ao criar buffer "+EnumToString(buffer_index); SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_BUFFER_CREATE,comment,function,line); return(false); } //--- return(true); }
Nele, além de verificar a existência de um objeto da classe COpenCL e o resultado da operação, há também uma função de registro e verificação de memória livre. Como lidaremos com quantidades relativamente grandes de memória (centenas de megabytes), é preciso controlar seu consumo. A classe СMemsize é encarregada disso. O código completo do que está contido no arquivo Memsize.mqh.
Aqui há uma coisa desagradável. Apesar da depuração, o código se torna incômodo. Por exemplo, o código de criação do buffer ficaria assim:
if(BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE,__FUNCTION__,__LINE__)==false) return false;
Há muita informação desnecessária que dificulta o foco no algoritmo. Nesse momento, as macros vêm em nosso auxílio. Cada um dos métodos de encapsulamento é duplicado por uma macro, o que torna sua chamada mais compacta. Para o método BufferCreate(), trata-se da macro _BufferCreate:
#define _BufferCreate(buffer_index,size_in_bytes,flags) \ if(BufferCreate(buffer_index,size_in_bytes,flags,__FUNCTION__,__LINE__)==false) return false
Graças a ela, a chamada para o método de criação de buffer toma a forma:
_BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
A criação de kernels assume a forma:
_KernelCreate(k_FIND_PATTERNS,"find_patterns");
Aqui é preciso observar que a maioria dessas macros termina em "return false", exceto _KernelCreate, que termina com "break". Isso deve ser considerado ao criar o código. Todas as macros são definidas no arquivo OCLDefines.mqh.
A classe também contém métodos para inicialização e desinicialização. O primeiro, exceto pela criação de um objeto da classe COpenCL, ele também verifica o suporte a double, cria kernels e obtém o tamanho da memória disponível:
bool COpenCLx::Init(ENUM_INIT_MODE mode) { if(ocl) Deinit(); //--- criação de objeto de classe COpenCL ocl=new COpenCL; while(!IsStopped()) { //--- inicialização de OpenCL ::ResetLastError(); if(!ocl.Initialize(cl_tester,true)) { SET_ERR("Erro de inicialização de OpenCL"); break; } //--- verificação de suporte para trabalhar com double if(!ocl.SupportDouble()) { SET_UERR(UERR_DOUBLE_NOT_SUPP,"O trabalho com double (cl_khr_fp64) é suportado pelo dispositivo"); break; } //--- configurando o número de kernels if(!ocl.SetKernelsCount(OCL_KERNELS_COUNT)) break; //--- criando kernels if(mode==i_MODE_TESTER) { _KernelCreate(k_FIND_PATTERNS,"find_patterns"); _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_ORDER_TO_M1,"order_to_M1"); _KernelCreate(k_TESTER_STEP,"tester_step"); }else if(mode==i_MODE_OPTIMIZER){ _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_TESTER_OPT_PREPARE,"tester_opt_prepare"); _KernelCreate(k_TESTER_OPT_STEP,"tester_opt_step"); _KernelCreate(k_FIND_PATTERNS_OPT,"find_patterns_opt"); } else break; //--- criando buffers if(!ocl.SetBuffersCount(OCL_BUFFERS_COUNT)) { SET_UERR(UERR_SET_BUF_COUNT,"Erro ao criar buffers"); break; } //--- obtendo o tamanho da RAM long gpu_mem_size; if(ocl.GetGlobalMemorySize(gpu_mem_size)==false) { SET_UERR(UERR_GET_MEMORY_SIZE,"Erro ao obter o tamanho da RAM"); break; } m_stat.gpu_mem_size.Set(gpu_mem_size); m_stat.gpu_mem_usage.Max(gpu_mem_size); return true; } Deinit(); return false; }
O argumento mode define o modo de inicialização. Isso pode ser otimização ou teste simples. Dependendo disso, são criados diferentes kernels.
Enumeradores de kernels e buffers são declarados no arquivo OCLInc.mqh. No mesmo local, os códigos fonte dos kernels são anexados na forma de recurso, como uma string cl_tester.
Método Deinit() exclui programas e objetos OpenCL:
void COpenCLx::Deinit() { if(ocl!=NULL) { //--- removendo objetos OpenCL ocl.Shutdown(); delete ocl; ocl=NULL; } }
Agora que todo o necessário foi criado, pode-se começar a trabalhar. Adicionalmente, há um código relativamente compacto e, ao mesmo tempo, informações abrangentes sobre erros.
Mas primeiro é preciso carregar os dados com os quais vamos trabalhar. Isso não é tão fácil quanto parece à primeira vista.
2.1 Carregando dados de preços
A classe CBuffering é responsável pelo carregamento de dados.
class CBuffering { private: string m_symbol; ENUM_TIMEFRAMES m_period; int m_maxbars; uint m_memory_usage; //memória usada bool m_spread_ena; //carregar o buffer do spread datetime m_from; datetime m_to; uint m_timeout; //tempo limite de carregamento em milissegundos ulong m_ts_abort; //carimbo de data/hora em microssegundos, quando necessário interromper a operação //--- carregamento forçado bool ForceUploading(datetime from,datetime to); public: CBuffering(); ~CBuffering(); //--- quantidade de dados nos buffers int Depth; //--- buffers double Open[]; double High[]; double Low[]; double Close[]; double Spread[]; datetime Time[]; //--- obtendo o limite de tempo real dos dados carregados datetime TimeFrom(void){return m_from;} datetime TimeTo(void){return m_to;} //--- int Copy(string symbol,ENUM_TIMEFRAMES period,datetime from,datetime to,double point=0); uint GetMemoryUsage(void){return m_memory_usage;} bool SpreadBufEnable(void){return m_spread_ena;} void SpreadBufEnable(bool ena){m_spread_ena=ena;} void SetTimeout(uint timeout){m_timeout=timeout;} };
Não aprofundaremos seu trabalho, já que o carregamento de dados não está diretamente relacionado ao tópico do artigo. Apenas consideremos brevemente seu uso.
A classe contém os buffers Open[], High[], Low[], Close[], Time[] e Spread[]. É possível trabalhar com eles, após um processamento bem-sucedido do método Copy(). Observe que o buffer Spread[] tem o tipo double e é expresso na diferença de preço. Além disso, a cópia do buffer Spread[] é desativada inicialmente e, se necessário, deve ser ativada usando o método SpreadBufEnable();
Para carregamento, é usado o método Copy(). O argumento predefinido point é usado apenas para converter o spread de pontos em diferença de preço. Se a cópia do spread estiver desativada, esse argumento não será usado.
As principais razões pelas quais foi necessário criar uma classe separada para o carregamento de dados são:
- Não se podem carregar mais do que TERMINAL_MAXBARS dados, usando a função CopyTime() e seus semelhantes.
- Nenhuma garantia de que o terminal tem esses dados localmente.
A classe CBuffering sabe copiar grandes quantidades de dados que excedam TERMINAL_MAXBARS, bem como iniciar o carregamento de dados ausentes a partir do servidor e aguardar sua conclusão. É por causa dessa expectativa que o método SetTimeout() é projetado para definir o tempo máximo de carregamento de dados (incluindo espera) em milissegundos. Por padrão, o construtor de classe é definido como 5000, ou seja, 5 segundos. Definir o tempo limite como zero desativará seu uso. Isso é altamente indesejável, mas em alguns casos pode ser útil.
Ao mesmo tempo, ainda se aplicam algumas restrições: os dados do período M1 não são baixados por um período de mais de um ano, o que, até certo ponto, reduz o alcance do nosso testador.
2.2 Teste simples
O processo de teste simples consistirá nos seguintes pontos:
- Carregamento de buffers de timeseries
- Inicialização de OpenCL
- Cópia de buffers de timeseries para buffers OpenCL
- Inicialização do kernel que encontra padrões no gráfico atual e adiciona os resultados ao buffer de ordens como pontos de entrada no mercado
- Inicialização do kernel que transfere ordens para o gráfico M1
- Inicialização do kernel que conta os resultados das operações pelas ordens no gráfico M1 e os coloca no buffer
- Processamento do buffer de resultados e cálculo dos resultados do teste
- Desinicialização de OpenCL
- Exclusão de buffers de timeseries
A classe CBuffering é responsável pelo carregamento de timeseries. Em seguida, esses dados precisam ser copiados para os buffers OpenCL, para que os kernels possam trabalhar com eles. O método LoadTimeseriesOCL() é destinado a esse propósito, e o seu código está abaixo:
bool CTestPatterns::LoadTimeseriesOCL() { //--- buffer Open: _BufferFromArray(buf_OPEN,m_sbuf.Open,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- buffer High: _BufferFromArray(buf_HIGH,m_sbuf.High,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Low: _BufferFromArray(buf_LOW,m_sbuf.Low,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Close: _BufferFromArray(buf_CLOSE,m_sbuf.Close,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Time: _BufferFromArray(buf_TIME,m_sbuf.Time,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Open (M1): _BufferFromArray(buf_OPEN_M1,m_tbuf.Open,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- buffer High (M1): _BufferFromArray(buf_HIGH_M1,m_tbuf.High,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Low (M1): _BufferFromArray(buf_LOW_M1,m_tbuf.Low,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Close (M1): _BufferFromArray(buf_CLOSE_M1,m_tbuf.Close,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Spread (M1): _BufferFromArray(buf_SPREAD_M1,m_tbuf.Spread,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- buffer Time (M1): _BufferFromArray(buf_TIME_M1,m_tbuf.Time,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- cópia bem-sucedida return true; }
Assim, os dados são carregados. Chegamos perto da implementação do algoritmo de teste.
2.2.1 Busca de padrões em OpenCL
O código de definição de padrão em OpenCL não é muito diferente do código em MQL5:
//--- padrões #define PAT_NONE 0 #define PAT_PINBAR_BEARISH (1<<0) #define PAT_PINBAR_BULLISH (1<<1) #define PAT_ENGULFING_BEARISH (1<<2) #define PAT_ENGULFING_BULLISH (1<<3) //--- preços #define O(i) Open[i] #define H(i) High[i] #define L(i) Low[i] #define C(i) Close[i] //+------------------------------------------------------------------+ //| Verificando a presença de padrões | //+------------------------------------------------------------------+ uint Check(__global double *Open,__global double *High,__global double *Low,__global double *Close,double ref,uint flags) { //--- pinbar de baixa if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-fmax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>fmax(H(0),H(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //--- pinbar de alta if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=fmin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<fmin(L(0),L(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //--- engolfamento de baixa if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //--- engolfamento de alta if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //--- nada encontrado return PAT_NONE; }
Uma das pequenas diferenças é que a transferência de buffers é feita por ponteiro, e não por referência. Além disso, a presença de um modificador __global que indica que os buffers de timeseries estão na memória global. Todos os buffers OpenCL que criarmos estão na memória global.
A funçãoCheck() chama o kernel find_patterns():
__kernel void find_patterns(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global int *Order, // buffer de ordens __global int *Count, // número de ordens no buffer const double ref, // parâmetros do padrão const uint flags) // que padrões procurar { //--- funcionamento numa dimensão //--- índice da barra size_t x=get_global_id(0); //--- tamanho do espaço de busca do padrão size_t depth=get_global_size(0)-PBARS; if(x>=depth) return; //--- verificando a presença de padrões uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref,flags); if(res==PAT_NONE) return; //--- definindo ordens if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) {//sell int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL; } else if(res==PAT_PINBAR_BULLISH || res==PAT_ENGULFING_BULLISH) {//buy int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_BUY; } }
É isso que vamos usar para procurar padrões e colocar ordens num buffer especialmente designado.
O kernerl find_patterns() funciona num espaço de tarefas unidimensional. Após iniciado, será criado o número de work-items que indicaremos no tamanho do espaço de tarefas para a dimensão 0. Nesse caso, é o número de barras no período atual. Para entender qual barra está sendo processada, é preciso obter o índice da tarefa:
size_t x=get_global_id(0);Onde zero é o índice de dimensão.
Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL;
Para obter este número de sequência, usamos a função atômica atomic_inc(). O fato é que, ao executar a tarefa, não temos ideia nem das tarefas e nem de com quais barras foram concluídas. Estes são cálculos paralelos e não há absolutamente nenhuma sequência. Além disso, o número da tarefa não está relacionado ao número de tarefas já concluídas. Portanto, não sabemos quantas ordens já foram colocadas no buffer. No momento de tentarmos ler seu número - na célula 0 do buffer Count[] - outra tarefa pode escrever algo nesse lugar. Para sair de tais situações, são usadas funções atômicas.
No nosso caso, a função atomic_inc(), primeiro, impede que outras tarefas acessem a célula Count[0], depois, aumenta seu valor numa unidade e retorna o valor anterior como resultado.
int i=atomic_inc(&Count[0]);
Claro, isso desacelera o trabalho, porque enquanto o acesso a Count[0] é bloqueado, outras tarefas aguardam. Mas, em alguns casos, como no nosso, simplesmente não há outra saída.
Depois que todas as tarefas forem concluídas, obteremos o buffer de ordens Order[] gerado e seu número na célula Count[0].
2.2.2 Transferindo ordens para o timeframe M1
Assim, encontramos padrões no período atual, mas os testes devem ser feitos no período M1. Isto significa que para todos os pontos de entrada encontrados no período atual, é necessário encontrar as barras correspondentes no período M1. Usando o fato de que a negociação por padrões fornece um número relativamente pequeno de pontos de entrada, mesmo em pequenos intervalos de tempo, escolheremos um modo bastante difícil, mas, neste caso, bastante adequado -
a pesquisa detalhada. Vamos comparar o tempo de cada ordem encontrada com o tempo de cada barra do período M1. Para fazer isso, criamos o kernel order_to_M1():
__kernel void order_to_M1(__global ulong *Time,__global ulong *TimeM1, __global int *Order,__global int *OrderM1, __global int *Count, const ulong shift) // deslocamento do tempo em segundos { //--- funciona em duas dimensões size_t x=get_global_id(0); //índice do índice Time em Order if(OrderM1[x*2]>=0) return; size_t y=get_global_id(1); //índice em TimeM1 if((Time[Order[x*2]]+shift)==TimeM1[y]) { atomic_inc(&Count[1]); //--- considerando índices pares colocamos os índices no buffer TimeM1 OrderM1[x*2]=y; //--- considerando índices impares colocamos operações (OP_BUY/OP_SELL) OrderM1[(x*2)+1]=Order[(x*2)+1]; } }
Aqui já existe um espaço de tarefas bidimensional. A dimensão do espaço 0 é igual ao número de ordens colocadas, enquanto a dimensão do espaço 1 é igual ao número de barras do período M1. Se o tempo de abertura da barra de ordem e da barra M1 coincidirem, a operação da ordem atual é copiada para o buffer OrderM1[] e o índice de barras encontrado é definido na série temporal do período M1.
Mas há duas coisas que não devem ser tão evidentes.
- A primeira é a função atômica atomic_inc() que, por algum motivo, conta os pontos de entrada encontrados no período M1. Na dimensão 0, cada ordem trabalha com seu índice, enquanto na dimensão 1 não pode haver mais de uma correspondência. Assim, a tentativa de compartilhar é completamente excluída. Por que então é preciso contar?
- A segunda coisa é o argumento shift que é adicionado ao tempo da barra do período atual.
Existem razões especiais para isso. No mundo, nem tudo é perfeito. A presença de uma barra no gráfico M5 com o tempo de abertura 01:00:00 não significa que a barra esteja no gráfico M1 com o mesmo tempo de abertura.
A barra correspondente no gráfico M1 pode ter hora de abertura de 01:01:00 e 01:04:00. Ou seja, o número de variações será igual à proporção da duração dos períodos. É para este propósito que é implementada a função para contar o número de pontos de entrada encontrados no período M1:
atomic_inc(&Count[1]);
Se após a conclusão do trabalho do kernel, o número de ordens encontradas em M1 for igual ao número de ordens encontradas no período atual, então a tarefa foi completada por completo. Caso contrário, será preciso reiniciar com um valor de argumento shift diferente. Pode haver tantas inicializações como os períodos M1 contém o período atual.
Para reiniciar com um valor de argumento shift diferente de zero, os pontos de entrada encontrados não foram reescritos usando outros valores, foi verificado o seguinte:
if(OrderM1[x*2]>=0) return;
Mas, para que isso funcione, antes de iniciar o kernel, deve-se preencher o buffer OrderM1[] com o valor -1. Para fazer isso, criamos um kernel de preenchimento de buffer array_fill():
__kernel void array_fill(__global int *Buf,const int value) { //--- funcionamento numa dimensão size_t x=get_global_id(0); Buf[x]=value; }
2.2.3 Obtendo resultados de operações
Depois que os pontos de entrada para M1 são encontrados, pode-se começar a obter os resultados das operações. Para fazer isso, precisa-se de um kernel que acompanhe a abertura de posições. Em outras palavras, deve-se esperar até que eles fechem por uma das seguintes razões:
- Atingimento do nível de Take Profit
- Atingimento do nível de Stop Loss
- Expiração do tempo máximo de bloqueio de uma posição aberta
- Fim do período de teste
O espaço de tarefas para o kernel será unidimensional e seu tamanho será igual ao número de ordens. O kernel iterará as barras, começando pela barra de abertura de posição, e verificará as condições descritas acima. Dentro da barra, os ticks serão modelados em modo "1 minute OHLC", descrito na seção "Testando estratégias de negociação", na documentação.
É importante que algumas posições sejam fechadas quase imediatamente após a abertura, algumas mais tarde, e algumas por tempo limite ou final do teste. Isso significa que o tempo de execução da tarefa para diferentes pontos de entrada será significativamente diferente.
A prática mostrou que manter uma posição antes de fechar após uma passagem não é eficaz. Resultados significativamente melhores em velocidade podem ser obtidos se dividido o espaço de teste (ou seja, o número de barras antes do fechamento forçado após a posição ter sido mantida) em várias partes e se executado o processamento em várias passagens.
As tarefas que não são concluídas no passagem atual são adiadas para o próximo. Assim, com cada passagem o tamanho do espaço da tarefa diminuirá. Mas, para implementar isso, é preciso usar outro buffer para armazenar índices de tarefa. Cada tarefa é um índice do ponto de entrada no buffer de ordens. Na primeira inicialização, o conteúdo do buffer de tarefas corresponderá totalmente ao buffer de ordens. Com as próximas inicializações, ele conterá índices das ordens cujas posições ainda não foram fechadas. Para poder trabalhar com o buffer de tarefas e, ao mesmo tempo, adicionar tarefas para a próxima execução, ele deve ter dois bancos: um banco para trabalho na inicialização atual e outro para gerar tarefas para o próximo.
No trabalho, isso ficará assim. Suponhamos que tenhamos 1 000 pontos de entrada para os quais precisamos obter os resultados das operações. O tempo de bloqueio de uma posição aberta é equivalente a 800 barras. Nós decidimos dividir o teste em 4 passagens. Graficamente, será como mostrado na Fig. 7.
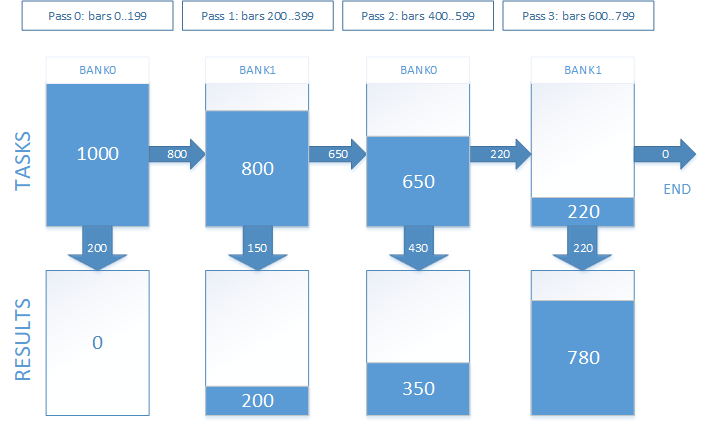
Fig. 7. Manutenção de posições abertas em várias passagens
Foi experimentalmente determinado que o número ideal de passagens é igual a 8, enquanto o tempo limite de bloqueio de posição aberta ideal é igual a 12 horas (ou 720 barras de minutos). Este é o valor padrão. Ele irá variar para diferentes valores de tempo limite e diferentes dispositivos OpenCL. É recomendado, para obter o desempenho máximo.
Assim, além dos timeseries, o buffer de tarefas Tasks[] e o número do banco de tarefas com o qual trabalhamos já foram adicionados aos argumentos do kernel. Além disso, adicionamos o buffer Res[] para salvar os resultados.
A quantidade de dados reais no buffer de tarefa é retornada por meio do buffer Left[], que tem um tamanho de dois elementos, para cada um dos bancos, respectivamente.
Como o teste é realizado em partes, entre os argumentos do kernel, é preciso passar a partir de qual e para qual barra acompanhar a posição. Esse é um valor relativo que é somado ao índice da barra de abertura de posição para obter o índice absoluto da barra atual no timeseries. Além disso, é necessário transferir para o kernel o índice de barras máximo admissível no timeseries de modo a não ir além dos buffers.
Como resultado, o conjunto de argumentos do kernel tester_step(), que trata da manutenção de posições abertas, assume a seguinte forma:
__kernel void tester_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1, // expresso em diferença de preço, não, em pontos __global ulong *TimeM1, __global int *OrderM1, // buffer de ordens, onde [0] é o índice em OHLC(M1), [1] é a operação (Buy/Sell) __global int *Tasks, // buffer de tarefas (posições abertas), contém índices para ordens no buffer OrderM1 __global int *Left, // número de tarefas restantes, dois elementos: [0] - para bank0, [1] - para bank1 __global double *Res, // buffer de resultados const uint bank, // banco atual const uint orders, // número de ordens em OrderM1 const uint start_bar, // barra processada para a conta (como deslocamento a partir do índice de OrderM1 especificado) const uint stop_bar, // para qual barra processar (inclusive) const uint maxbar, // índice de barras máximo permitido (a última barra do array) const double tp_dP, // TP na diferença de preço const double sl_dP, // SL na diferença de preço const ulong timeout) // tempo - após a abertura - para fechamento forçoso da operação (em segundos)
O kernel tester_step() funciona numa dimensão. A dimensão das tarefas desta dimensão será alterado com cada chamada, começando com o número de ordens e diminuindo com cada passagem.
No início do código do kernel, obtemos o ID da tarefa:
size_t id=get_global_id(0);Em seguida, com base no índice do banco atual, que é passado pelo argumento bank, consideramos o índice do seguinte:
uint bank_next=(bank)?0:1;
Calculamos o índice da ordem com a qual vamos trabalhar. Na primeira inicialização (quando start_bar é igual a zero), o buffer da tarefa corresponde ao buffer da ordem, portanto, o índice da ordem é igual ao índice da tarefa. Nas seguintes inicializações, o índice da ordem é obtido do buffer da tarefa, levando em consideração o banco atual e o índice da tarefa:
if(!start_bar) idx=id; else idx=Tasks[(orders*bank)+id];
Conhecendo o índice da ordem, obtemos o índice da barra no timeseries e o código de operação:
//--- índice da barra no buffer M1 no qual foi aberta a posição uint iO=OrderM1[idx*2]; //--- operação (OP_BUY/OP_SELL) uint op=OrderM1[(idx*2)+1];
Com base no valor do argumento timeout consideramos o tempo de fechamento forçado da posição:
ulong tclose=TimeM1[iO]+timeout;Em seguida vem o processamento da posição aberta. Consideremos o exemplo da operação BUY (para operações SELL similarmente).
if(op==OP_BUY) { //--- preço de abertura da posição double open=OpenM1[iO]+SpreadM1[iO]; double tp = open+tp_dP; double sl = open-sl_dP; double p=0; for(uint j=iO+start_bar; j<=(iO+stop_bar); j++) { for(uint k=0;k<4;k++) { if(k==0) { p=OpenM1[j]; if(j>=maxbar || TimeM1[j]>=tclose) { //--- fechamento forçado por causa do tempo Res[idx]=p-open; return; } } else if(k==1) p=HighM1[j]; else if(k==2) p=LowM1[j]; else p=CloseM1[j]; //--- verificando se TP ou SL foi ativado if(p<=sl) { Res[idx]=sl-open; return; } else if(p>=tp) { Res[idx]=tp-open; return; } } } }
Se nenhuma das condições para sair do kernel foi ativada, a tarefa é adiada para a próxima passagem:
uint i=atomic_inc(&Left[bank_next]);
Tasks[(orders*bank_next)+i]=idx;
Após desencadeadas todas as passagens, o buffer Res[] conterá os resultados de todas as operações. Para obter o resultado do teste, é necessário somá-los.
Agora que o algoritmo está limpo e os kernels estão prontos, pode-se começar a iniciá-los.
2.3 Iniciando o teste
Para fazer isso, será útil a classe CTestPatterns:
class CTestPatterns : private COpenCLx { private: CBuffering *m_sbuf; // série temporal do timeframe atual CBuffering *m_tbuf; // série temporal do timeframe M1 int m_prepare_passes; uint m_tester_passes; bool LoadTimeseries(datetime from,datetime to); bool LoadTimeseriesOCL(void); bool test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); bool optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); void buffers_free(void); public: CTestPatterns(); ~CTestPatterns(); //--- inicialização de teste simples bool Test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); //--- inicialização de otimização bool Optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); //--- obtendo um ponteiro para as estatísticas de execução do programa COCLStat *GetStat(void){return &m_stat;} //--- obtendo o código do último erro int GetLastError(void){return m_last_error.code;} //--- obtendo a estrutura do último erro STR_ERROR GetLastErrorExt(void){return m_last_error;} //--- redefinindo o último erro void ResetLastError(void); //--- número de passagens para inicialização do kernel de teste void SetTesterPasses(uint tp){m_tester_passes=tp;} //--- número de passagenspara inicialização do kernel de preparação de ordens void SetPrepPasses(int p){m_prepare_passes=p;} };
Consideremos em mais detalhes o método Test():
bool CTestPatterns::Test(STR_TEST_RESULT &result,datetime from,datetime to,STR_TEST_PARS &par) { ResetLastError(); m_stat.Reset(); m_stat.time_total.Start(); //--- carregamento de dados da série temporal m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- inicialização de OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_TESTER)==false) return false; m_stat.time_ocl_init.Stop(); //--- inicialização de teste bool result=test(stat,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return result; }
Na entrada, tem tanto um intervalo de datas no qual é necessário testar a estratégia como uma referência à estrutura dos parâmetros e aos resultados do teste.
Se o trabalho for bem-sucedido, o método retornará "true" e gravará os resultados no argumento result. Se ocorrer um erro durante a execução, o método retornará "false" e, para obter os detalhes do erro, será necessário chamar GetLastErrorExt().
Primeiro, carregamos os dados da timeseries. Em seguida, inicializamos OpenCL. Isso inclui a criação de objetos e kernels. Se tudo correu bem, chamamos o método test(), nele é implementado todo o algoritmo de teste. Essencialmente, o método Test() serve como um encapsulamento para test(). Isso é feito para sempre desinicializar e liberar os buffers de timeseries em qualquer saída do método teste.
No método test() tudo começa com o carregamento dos buffers de timeseries nos buffers de OpenCL:if(LoadTimeseriesOCL()==false) return false;
Isso é feito usando o método LoadTimeseriesOCL(), que já foi discutido acima.
O primeiro é o kernel find_patterns(), que corresponde ao enumerador k_FIND_PATTERNS. Mas antes da inicialização, é necessário criar buffers de ordens e resultados:
_BufferCreate(buf_ORDER,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
O buffer de ordens tem um tamanho duas vezes maior que o número de barras no período atual. Como não sabemos quantos padrões serão encontrados, assumimos que o padrão será encontrado em cada barra. Esta precaução parece à primeira vista absurda, dados os padrões com os quais estamos trabalhando no momento. Mas, no futuro, ao adicionar outros padrões, isso pode evitar muitos problemas.
Em seguida, definimos os argumentos:
_SetArgumentBuffer(k_FIND_PATTERNS,0,buf_OPEN); _SetArgumentBuffer(k_FIND_PATTERNS,1,buf_HIGH); _SetArgumentBuffer(k_FIND_PATTERNS,2,buf_LOW); _SetArgumentBuffer(k_FIND_PATTERNS,3,buf_CLOSE); _SetArgumentBuffer(k_FIND_PATTERNS,4,buf_ORDER); _SetArgumentBuffer(k_FIND_PATTERNS,5,buf_COUNT); _SetArgument(k_FIND_PATTERNS,6,double(par.ref)*_Point); _SetArgument(k_FIND_PATTERNS,7,par.flags);
Para o kernel find_patterns(), definimos um espaço de tarefa unidimensional com um deslocamento inicial de zero:
uint global_size[1]; global_size[0]=m_sbuf.Depth; uint work_offset[1]={0};
Iniciamos a execução do kernel find_patterns():
_Execute(k_FIND_PATTERNS,1,work_offset,global_size);Observe que a saída desde o método Execute() não significa que o programa seja executado. Ainda pode ser executada ou enfileirada para execução. Para saber seu status atual, é necessário usar a função CLExecutionStatus(). Se for preciso aguardar a conclusão do programa, poderá consultar periodicamente seu estado. Ou será possível ler o buffer no qual o programa coloca os resultados. No segundo caso, no método de leitura do buffer BufferRead() será esperado que o programa conclua sua execução.
_BufferRead(buf_COUNT,count,0,0,2);
Agora o buffer count[] no índice 0 contém o número de padrões encontrados ou o número de ordens colocadas no buffer correspondente. O próximo passo é encontrar os pontos de entrada correspondentes no período M1. O Kernel order_to_M1() acumulará a quantidade encontrada no mesmo buffer count[], mas no índice 1. A ativação da condição (count[0]==count[1]) será considerada uma finalização bem-sucedida.
Mas primeiro é preciso criar um buffer de ordens para o M1 e preenchê-lo com o valor -1. Como já sabemos o número de ordens, especificamos o tamanho exato do buffer sem margem:
int len=count[0]*2; _BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
Definimos argumentos para o kernel array_fill():
_SetArgumentBuffer(k_ARRAY_FILL,0,buf_ORDER_M1); _SetArgument(k_ARRAY_FILL,1,int(-1));
Estabelecemos um espaço unidimensional de tarefas com um deslocamento inicial igual a zero e um tamanho igual ao tamanho do buffer. Executamos:
uint opt_init_work_size[1]; opt_init_work_size[0]=len; uint opt_init_work_offset[1]={0}; _Execute(k_ARRAY_FILL,1,opt_init_work_offset,opt_init_work_size);
O próximo passo é preparar a execução do kernel order_to_M1():
//--- definido argumentos _SetArgumentBuffer(k_ORDER_TO_M1,0,buf_TIME); _SetArgumentBuffer(k_ORDER_TO_M1,1,buf_TIME_M1); _SetArgumentBuffer(k_ORDER_TO_M1,2,buf_ORDER); _SetArgumentBuffer(k_ORDER_TO_M1,3,buf_ORDER_M1); _SetArgumentBuffer(k_ORDER_TO_M1,4,buf_COUNT); //--- O espaço de tarefas para o kernel k_ORDER_TO_M1 é bidimensional uint global_work_size[2]; //--- a 1ª dimensão são ordens deixadas pelo kernel k_FIND_PATTERNS global_work_size[0]=count[0]; //--- a 2ª dimensão são todas as barras do gráfico M1 global_work_size[1]=m_tbuf.Depth; //--- o deslocamento inicial no espaço de tarefas para ambas as dimensões é zero uint global_work_offset[2]={0,0};
O argumento sob o índice 5 não foi definido, porque seu valor será diferente e sua instalação será feita imediatamente antes de iniciar a execução do kernel. Pelo motivo acima, o kernel order_to_M1() pode precisar ser executado várias vezes com diferentes valores de deslocamento em segundos. O número máximo de inicialização será limitado pela relação entre a duração dos períodos do gráfico atual e o gráfico M1:
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1);
O ciclo inteiro ficará assim:
for(int s=0;s<maxshift;s++) { //--- definindo o deslocamento para a passagem atual _SetArgument(k_ORDER_TO_M1,5,ulong(s*60)); //--- executando do kernel _Execute(k_ORDER_TO_M1,2,global_work_offset,global_work_size); //--- lendo resultados _BufferRead(buf_COUNT,count,0,0,2); //--- no gráfico atual é encontrado o número de ordens para o índice 0 //--- no gráfico M1 é encontrado o número de barras correspondentes para o índice 1 //--- se os dois valores coincidirem, saímos do ciclo if(count[0]==count[1]) break; //--- caso contrário, realizamos a próxima iteração e iniciamos o kernel com um deslocamento diferente } //--- se não sairmos do ciclo pelo 'break', verificamos novamente a correspondência do numero de ordens if(count[0]!=count[1]) { SET_UERRt(UERR_ORDERS_PREPARE,"Erro ao preparar ordens M1"); return false; }
Chegou a hora de iniciar o kernel tester_step(), que calculará os resultados das operações abertas pelos pontos de entrada encontrados. Primeiro, criamos os buffers ausentes e configuramos os argumentos:
//--- criamos o buffer Tasks, no qual será gerado o número de tarefas para a próxima passagem _BufferCreate(buf_TASKS,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); //--- criamos o buffer Result, no qual serão adicionados os resultados das operações _BufferCreate(buf_RESULT,m_sbuf.Depth*sizeof(double),CL_MEM_READ_WRITE); //--- definimos os argumentos para o kernel de teste simples _SetArgumentBuffer(k_TESTER_STEP,0,buf_OPEN_M1); _SetArgumentBuffer(k_TESTER_STEP,1,buf_HIGH_M1); _SetArgumentBuffer(k_TESTER_STEP,2,buf_LOW_M1); _SetArgumentBuffer(k_TESTER_STEP,3,buf_CLOSE_M1); _SetArgumentBuffer(k_TESTER_STEP,4,buf_SPREAD_M1); _SetArgumentBuffer(k_TESTER_STEP,5,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_STEP,6,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_STEP,7,buf_TASKS); _SetArgumentBuffer(k_TESTER_STEP,8,buf_COUNT); _SetArgumentBuffer(k_TESTER_STEP,9,buf_RESULT); uint orders_count=count[0]; _SetArgument(k_TESTER_STEP,11,uint(orders_count)); _SetArgument(k_TESTER_STEP,14,uint(m_tbuf.Depth-1)); _SetArgument(k_TESTER_STEP,15, double(par.tp)*_Point); _SetArgument(k_TESTER_STEP,16, double(par.sl)*_Point); _SetArgument(k_TESTER_STEP,17,ulong(par.timeout));
Em seguida, recalculamos o tempo máximo de bloqueio da posição no número de barras no gráfico M1:
uint maxdepth=(par.timeout/PeriodSeconds(PERIOD_M1))+1;
Em seguida, verificamos o número especificado de passagens da execução do kernel. Por padrão, seu valor é 8, mas para selecionar o desempenho ideal para diferentes dispositivos OpenCL, é permitido definir outros valores usando o método SetTesterPasses().
if(m_tester_passes<1) m_tester_passes=1; if(m_tester_passes>maxdepth) m_tester_passes=maxdepth; uint step_size=maxdepth/m_tester_passes;
Definimos o tamanho do espaço de tarefas para uma única dimensão e iniciamos o ciclo para calcular os resultados das operações:
global_size[0]=orders_count; m_stat.time_ocl_test.Start(); for(uint i=0;i<m_tester_passes;i++) { //--- definindo o índice do banco atual _SetArgument(k_TESTER_STEP,10,uint(i&0x01)); uint start_bar=i*step_size; //--- definindo o índice da barra, a partir da qual começará o teste na passagem atual _SetArgument(k_TESTER_STEP,12,start_bar); //--- definindo o índice da barra, na qual terminará o teste na passagem atual (inclusive) uint stop_bar=(i==(m_tester_passes-1))?(m_tbuf.Depth-1):(start_bar+step_size-1); _SetArgument(k_TESTER_STEP,13,stop_bar); //--- redefinindo o número de tarefas no próximo banco //--- nele será gerado o número de ordens restante para a próxima passagem count[(~i)&0x01]=0; _BufferWrite(buf_COUNT,count,0,0,2); //--- executando o kernel de teste _Execute(k_TESTER_STEP,1,work_offset,global_size); //--- lendo o número de ordens restantes para a próxima passagem _BufferRead(buf_COUNT,count,0,0,2); //--- configurando o novo número de tarefas que é igual ao número de ordens global_size[0]=count[(~i)&0x01]; //--- se não houver tarefas, saímos do ciclo if(!global_size[0]) break; } m_stat.time_ocl_test.Stop();
Criamos um buffer para ler os resultados das operações:
double Result[]; ArrayResize(Result,orders_count); _BufferRead(buf_RESULT,Result,0,0,orders_count);
Para obter resultados que podem ser comparados com os resultados de um testador regular, os valores de leitura precisarão ser divididos em _Point. O código para calcular o resultado e as estatísticas de teste é dado abaixo:
m_stat.time_proc.Start(); result.trades_total=0; result.gross_loss=0; result.gross_profit=0; result.net_profit=0; result.loss_trades=0; result.profit_trades=0; for(uint i=0;i<orders_count;i++) { double r=Result[i]/_Point; if(r>=0) { result.gross_profit+=r; result.profit_trades++; }else{ result.gross_loss+=r; result.loss_trades++; } } result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; m_stat.time_proc.Stop();
Vamos escrever um pequeno script que nos permita iniciar nosso testador.
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- configurando parâmetros de teste STR_TEST_PARS pars; pars.ref= 60; pars.sl = 350; pars.tp = 50; pars.flags=15; // todos os padrões pars.timeout=12*3600; //--- estrutura de resultados STR_TEST_RESULT res; //--- inicialização de teste tpat.Test(res,from,to,pars); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- resultados de teste Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //--- estatísticas de execução COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
Como período de teste, símbolo e timeframe são escolhidos aqueles com os quais começamos a testar o EA escrito em MQL5. Os valores do valor de referência e o nível de Stop Loss são definidos para aqueles que foram encontrados no processo de otimização. Resta executar o script e comparar o resultado com o resultado do testador regular.
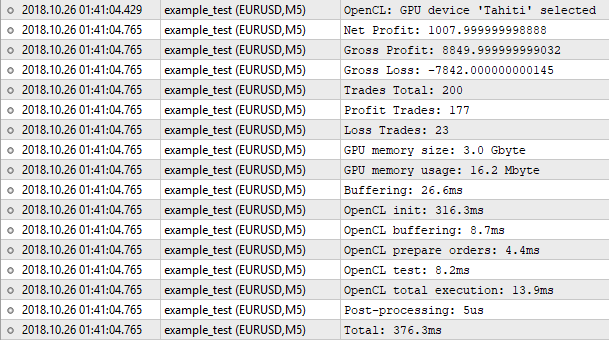
Fig. 8. Resultados do testador criado em OpenCL
O número de trades é o mesmo. Mas o valor do lucro líquido - não. O testador regular mostra 1000,50 e o nosso exibe 1007,99. O que está acontecendo é o seguinte. Para conseguir os mesmos resultados, é necessário considerar, no mínimo, o swap. Mas a sua implementação no nosso testador não será justificada. Para uma estimativa aproximada, em que o teste no modo OHLC é aplicado em M1, tais coisas sem importância podem ser ignoradas. O importante é que o resultado é muito próximo, portanto, nosso algoritmo funciona corretamente.
Agora prestemos atenção às estatísticas de execução do programa. A memória ocupou apenas 16 megabytes. O tempo foi gasto, sobretudo, na inicialização da OpenCL. Todo o processo de teste levou 376 milissegundos, o que comparado com o testador regular é quase o mesmo. Aqui não vale a pena esperar melhoria no desempenho. Com 200 operações, a maior parte do tempo é gasto em coisas gerais: inicialização, cópia de buffers e assim por diante. Para sentir a diferença, são precisos de centenas de vezes mais ordens para testes. É hora de passar para a otimização.
2.4. Otimização
O algoritmo de otimização será semelhante ao algoritmo de teste simples, mas terá uma grande diferença. Se, no testador, primeiro procuramos padrões e depois lemos os resultados das operações, então agora será o oposto. Primeiro calculamos os resultados das operações e, em seguida, procedemos à pesquisa de padrões. Existe uma razão para isso.
Temos dois parâmetros otimizados. O primeiro é o valor de referência para encontrar padrões. O segundo é o nível Stop Loss, que participa do processo de cálculo do resultado da operação. Ou seja, um deles afeta o número de pontos de entrada, enquanto o segundo - os resultados das operações e a duração do acompanhamento da posição aberta. Se mantivermos a mesma sequência de ações que no algoritmo de teste simples, não poderemos evitar o novo teste dos mesmos pontos de entrada, e isso é uma enorme perda de tempo, uma vez que um pimbar com “cauda” de 300 pontos será encontrada para quaisquer valores de apoio, que é igual ou menor que esse valor.
Por essa razão, no nosso caso, é muito melhor calcular os resultados das operações com pontos de entrada em cada barra (incluindo compra e venda) e, em seguida, operar com esses dados no processo de pesquisa de padrão. Assim, a sequência de ações durante a otimização será a seguinte:
- Carregamento de buffers de timeseries
- Inicialização de OpenCL
- Cópia de buffers de timeseries para buffers OpenCL
- Inicialização do kernel de preparação de ordens (para cada barra do período atual, dois pedidos - compra e venda)
- Inicialização do kernel que transfere ordens para o gráfico M1
- Inicialização do kernel que conta os resultados das operações por ordens
- Inicialização do kernel que encontra padrões e gera resultados de teste para cada combinação de parâmetros otimizados a partir dos resultados finais das operações
- Processamento do buffer de resultados e busca de parâmetros otimizados que correspondem ao melhor resultado
- Desinicialização de OpenCL
- Exclusão de buffers de timeseries
Além disso, o número de tarefas para pesquisa de padrões será multiplicado pelo número de valores do valor de referência, enquanto o número de tarefas para calcular os resultados das operações será multiplicado pelo número de valores do nível Stop Loss.
2.4.1 Preparando ordens
Assumimos que os padrões procurados podem ser encontrados em qualquer barra. Isso significa que em cada barra é preciso definir uma ordem para comprar e vender. O tamanho do buffer de ordem pode ser expresso através da fórmula:
N = Depth*4*SL_count;
onde Depth é o tamanho do buffer de timeseries, enquanto SL_count é a quantidade de valores Stop Loss.
Além disso, os índices de barras devem ser da timeseries M1. O kernel tester_opt_prepare() buscará nas timeseries M1 barras com tempo de abertura igual ao tempo de abertura de barras do período atual e irá colocá-las no buffer de ordens no formato especificado acima. Em geral, seu trabalho será muito similar ao trabalho do kernel order_to_M1():
__kernel void tester_opt_prepare(__global ulong *Time,__global ulong *TimeM1, __global int *OrderM1,// buffer de ordens __global int *Count, const int SL_count, // número de valores de SL const ulong shift) // deslocamento do tempo em segundos { //--- funciona em duas dimensões size_t x=get_global_id(0); //índice em Time if(OrderM1[x*SL_count*4]>=0) return; size_t y=get_global_id(1); //índice em TimeM1 if((Time[x]+shift)==TimeM1[y]) { //--- de caminho encontro o índice máximo de barra para o timeframe М1 atomic_max(&Count[1],y); uint offset=x*SL_count*4; for(int i=0;i<SL_count;i++) { uint idx=offset+i*4; //--- para cada barra adiciono duas ordens: compra e venda OrderM1[idx++]=y; OrderM1[idx++]=OP_BUY |(i<<2); OrderM1[idx++]=y; OrderM1[idx] =OP_SELL|(i<<2); } atomic_inc(&Count[0]); } }
Mas haverá uma diferença importante que consistirá em encontrar o índice máximo da timeseries M1. Agora vou explicar por que isso é feito.
No caso de testes de passagem única, lidávamos com um número relativamente pequeno de ordens. O número de tarefas, que era igual ao número de ordens multiplicado pelo tamanho do buffer das timeseries M1, também era pequeno. Se levarmos em conta os dados em que realizamos o teste, esses dados são 200 ordens multiplicadas por 279 039 barras M1, o que, em última análise, dá 55,8 milhões de tarefas.
Na situação atual, o número de tarefas será muito maior. Por exemplo, isso é 279 039 barras M1 multiplicadas por 55 843 barras do período atual (M5), o que é igual a 15,6 bilhões de tarefas. Também vale a pena considerar que é necessário que executar este Kernel novamente com um valor de deslocamento de tempo diferente. Aqui o método de pesquisa detalhada é dispendioso.
Para resolver esse problema, ainda deixamos a pesquisa detalhada, mas dividimos o intervalo de processamento das barras do período atual em várias partes. Também limitamos o alcance das barras de minutos correspondentes. Mas, como o valor calculado do índice do limite superior do intervalo de barras de minutos será, na maioria dos casos, maior que o real, então, por meio de Count[1], retornaremos o índice máximo da barra de minutos para iniciar a próxima passagem a partir desse ponto.
2.4.2 Obtendo resultados de operações
Uma vez preparadas as ordens, pode-se começar a receber os resultados das operações.
Kernel tester_opt_step() será muito semelhante ao tester_step(). Por isso, não vou dar o código inteiro, vou considerar apenas as diferenças. Primeiro, os parâmetros de entrada foram alterados:
__kernel void tester_opt_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1,// expresso em diferença de preço, mas, não, em pontos __global ulong *TimeM1, __global int *OrderM1, // buffer de ordens, onde [0] é o índice em OHLC(M1), [1] é a operação (Buy/Sell) __global int *Tasks, // buffer de tarefas (posições abertas), contém índices para ordens no buffer OrderM1 __global int *Left, // número de tarefas restantes, dois elementos: [0] - para bank0, [1] - para bank1 __global double *Res, // o buffer de resultados são acumulados à medida que são recebidos const uint bank, // banco atual const uint orders, // número de ordens em OrderM1 const uint start_bar, // número de série da barra processada (como um deslocamento do índice especificado em OrderM1) - "i" do ciclo que inicia o kernel const uint stop_bar, // última barra a ser processada (inclusive) - para a maioria dos casos será igual ao valor bar const uint maxbar, // índice de barras máximo permitido (a última barra do array) const double tp_dP, // TP na diferença de preço const uint sl_start, // SL em pontos - valor inicial const uint sl_step, // SL em pontos - passo const ulong timeout, // tempo após o qual a operação é forçosamente fechada (em segundos) const double point) // _Point
Em vez do argumento sl_dP, através do qual o valor do SL expresso em diferença de preço foi passado, foram adicionados dois argumentos: sl_start e sl_step, bem como o argumento point. Agora, para calcular o valor do nível SL, é necessário aplicar a fórmula:
SL = (sl_start+sl_step*sli)*point;
onde sli é o índice do valor de Stop Loss que está contido na ordem.
A segunda diferença está no o código para obter o índice de sli a partir do buffer de ordem:
//--- operação (bits 1:0) e índice de SL (bits 9:2) uint opsl=OrderM1[(idx*2)+1]; //--- obtemos o índice de SL uint sli=opsl>>2;
O resto do código é idêntico ao kernel tester_step().
Após a execução, receberemos no buffer Res[], os resultados de compra e venda para cada barra e cada valor de Stop Loss.
2.4.3 Buscando padrões e gerando resultados de teste
Ao contrário dos testes, aqui vamos resumir os resultados das operações diretamente no kernel. Isso tem um certo inconveniente, quer dizer, é preciso converter os resultados em tipo inteiro, o que necessariamente faz com que se perda precisão. É por essa razão que o argumento point deve passar o valor _Point dividido por 100.
Como as funções atômicas não funcionam com o tipo double, os resultados devem ser convertidos no tipo int forçosamente. Para somar os resultados, vamos usar atomic_add().
O kernel find_patterns_opt() irá trabalhar num espaço de tarefas tridimensional:
- Dimensão 0: índice de barras no timeframe atual
- Dimensão 1: índice do valor do valor de referência para os padrões
- Dimensão 2: índice do valor do nível Stop Loss
No decorrer do trabalho, será gerado um buffer de resultados, que conterá estatísticas de teste para cada combinação de nível Stop Loss e valor de referência. Aqui estatística de teste se refere à estrutura que contém os seguintes valores:
- Lucro total
- Perda total
- Número de operações lucrativas
- Número de operações não lucrativas
Todas elas têm o tipo int. Com base neles, também pode-se calcular o lucro líquido e o número total de operações. O código do kernel é mostrado abaixo:
__kernel void find_patterns_opt(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global double *Test, // buffer de resultados de teste para cada barra, tamanho 2*x*z ([0]-buy, [1]-sell ... ) __global int *Results, // buffer de resultados, tamanho 4*y*z const double ref_start, // parâmetro de padrão const double ref_step, // const uint flags, // quais padrões buscar const double point) // _Point/100 { //--- funciona em três dimensões //--- índice da barra size_t x=get_global_id(0); //--- índice do valor de ref size_t y=get_global_id(1); //--- índice do valor de SL size_t z=get_global_id(2); //--- número de barras size_t x_sz=get_global_size(0); //--- número de valores de ref size_t y_sz=get_global_size(1); //--- número de valores de sl size_t z_sz=get_global_size(2); //--- tamanho do espaço de busca do padrão size_t depth=x_sz-PBARS; if(x>=depth)//não abro perto do final do buffer return; // uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref_start+ref_step*y,flags); if(res==PAT_NONE) return; //--- calculamos o índice do resultado da operação no buffer Test[] int ri; if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) //sell ri = (x+PBARS)*z_sz*2+z*2+1; else //buy ri=(x+PBARS)*z_sz*2+z*2; //--- obtemos o resultado pelo índice calculado e convertemos em centavos int r=Test[ri]/point; //--- calculamos o índice de resultados de teste no buffer Results[] int idx=z*y_sz*4+y*4; //--- adicionamos o resultado da operação para o padrão atual if(r>=0) {//--- profit //--- somamos o lucro total em centavos atomic_add(&Results[idx],r); //--- aumentamos o número de operações lucrativas atomic_inc(&Results[idx+2]); } else {//--- loss //--- somamos a perda total em centavos atomic_add(&Results[idx+1],r); //--- aumentamos o número de operações perdedoras atomic_inc(&Results[idx+3]); } }
O buffer Test[] nos argumentos é o resultado obtido após a execução do kernel tester_opt_step().
2.5 Iniciando a otimização
O código de inicialização para executar kernels a partir da MQL5 durante o processo de otimização é construído da mesma forma que o processo de teste. O método público Optimize() é um encapsulamento do método optimize() em que é implementada a ordem de preparação e inicialização da execução de kernels.
bool CTestPatterns::Optimize(STR_TEST_RESULT &result,datetime from,datetime to,STR_OPT_PARS &par) { ResetLastError(); if(par.sl.step<=0 || par.sl.stop<par.sl.start || par.ref.step<=0 || par.ref.stop<par.ref.start) { SET_UERR(UERR_OPT_PARS,"Parâmetros de otimização incorretos"); return false; } m_stat.Reset(); m_stat.time_total.Start(); //--- carregamento de dados da série temporal m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //--- inicialização de OpenCL m_stat.time_ocl_init.Start(); if(Init(i_MODE_OPTIMIZER)==false) return false; m_stat.time_ocl_init.Stop(); //--- inicialização de otimização bool res=optimize(result,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return res; }
Não consideraremos em detalhes cada string, analisaremos apenas os lugares que são diferentes, particularmente a inicialização do kernel tester_opt_prepare().
Para começar, criamos um buffer para controlar o número de barras processadas e retornar o índice de barras máximo M1:
int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
Em seguida, definimos os argumentos e o tamanho do espaço de tarefas.
_SetArgumentBuffer(k_TESTER_OPT_PREPARE,0,buf_TIME); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,1,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,2,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,3,buf_COUNT); _SetArgument(k_TESTER_OPT_PREPARE,4,int(slc)); // número de valores de SL //--- o kernel k_TESTER_OPT_PREPARE terá um espaço de tarefas bidimensional uint global_work_size[2]; //--- a dimensão 0 é ordens para o período atual global_work_size[0]=m_sbuf.Depth; //--- a 1ª dimensão são todas as barras М1 global_work_size[1]=m_tbuf.Depth; //--- para a primeira inicialização, definimos o deslocamento no espaço de tarefas como zero para ambas as dimensões uint global_work_offset[2]={0,0};
O deslocamento no espaço de tarefas da primeira dimensão será aumentado após o processamento de parte das barras. Seu valor será igual ao valor máximo da barra M1, que retornará o kernel aumentado em 1.
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1); int prep_step=m_sbuf.Depth/m_prepare_passes; for(int p=0;p<m_prepare_passes;p++) { //compensação para o espaço de tarefas do período atual global_work_offset[0]=p*prep_step; //compensação para o espaço de tarefas do período M1 global_work_offset[1]=count[1]; //dimensão de tarefas para o período atual global_work_size[0]=(p<(m_prepare_passes-1))?prep_step:(m_sbuf.Depth-global_work_offset[0]); //dimensão das tarefas para o período M1 uint sz=maxshift*global_work_size[0]; uint sz_max=m_tbuf.Depth-global_work_offset[1]; global_work_size[1]=(sz>sz_max)?sz_max:sz; // count[0]=0; _BufferWrite(buf_COUNT,count,0,0,2); for(int s=0;s<maxshift;s++) { _SetArgument(k_TESTER_OPT_PREPARE,5,ulong(s*60)); //--- executando o kernel _Execute(k_TESTER_OPT_PREPARE,2,global_work_offset,global_work_size); //--- leio resultados (o número deve corresponder ao с m_sbuf.Depth) _BufferRead(buf_COUNT,count,0,0,2); if(count[0]==global_work_size[0]) break; } count[1]++; } if(count[0]!=global_work_size[0]) { SET_UERRt(UERR_ORDERS_PREPARE,"Erro ao preparar ordens M1"); return false; }
O parâmetro m_prepare_passes indica o número de passagens em que deve ser dividido o processo de preparação das ordens. O valor padrão é 64, pode-se alterar usando o método SetPrepPasses().
Uma vez lidos os resultados do teste no buffer OptResults[], são buscados os parâmetros otimizados com os quais foi obtido o máximo lucro líquido.
int max_profit=-2147483648; uint idx_ref_best= 0; uint idx_sl_best = 0; for(uint i=0;i<refc;i++) for(uint j=0;j<slc;j++) { uint idx=j*refc*4+i*4; int profit=OptResults[idx]+OptResults[idx+1]; //sum+=profit; if(max_profit<profit) { max_profit=profit; idx_ref_best= i; idx_sl_best = j; } }
Em seguida, recalculamos os resultados em double e definimos os valores procurados relativamente a parâmetros a serem otimizados na estrutura correspondente.
uint idx=idx_sl_best*refc*4+idx_ref_best*4; result.gross_profit=double(OptResults[idx])/100; result.gross_loss=double(OptResults[idx+1])/100; result.profit_trades=OptResults[idx+2]; result.loss_trades=OptResults[idx+3]; result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; //--- par.ref.value= int(par.ref.start+idx_ref_best*par.ref.step); par.sl.value = int(par.sl.start+idx_sl_best*par.sl.step);
Deve-se ter em mente que a conversão de int em double e vice-versa afetará necessariamente os valores dos resultados, e eles diferirão ligeiramente daqueles obtidos no teste simples.
Vamos escrever um pequeno script para executar a otimização:
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatterns tpat; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //--- definindo parâmetros de otimização STR_OPT_PARS optpar; optpar.ref.start = 15; optpar.ref.step = 5; optpar.ref.stop = 510; optpar.sl.start = 15; optpar.sl.step = 5; optpar.sl.stop = 510; optpar.flags=15; optpar.tp=50; optpar.timeout=12*3600; //--- estrutura de resultados STR_TEST_RESULT res; //--- inicialização de otimização tpat.Optimize(res,from,to,optpar); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //--- valores de parâmetros otimizados Print("Ref: ",optpar.ref.value,", SL: ",optpar.sl.value); //--- resultados de teste Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //--- estatísticas de execução COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
Os parâmetros de entrada são substituídos pelos mesmos que usamos ao otimizar um testador regular. Inicializamos:
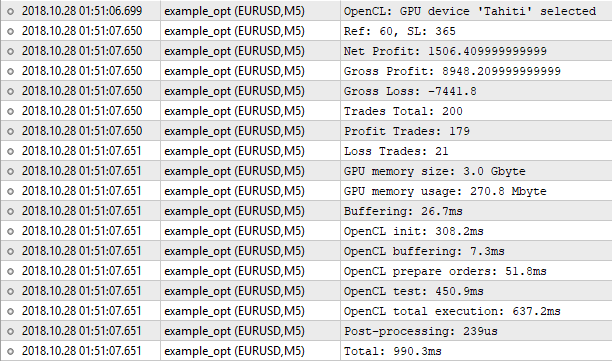
Fig. 9. Otimização no testador em OpenCL
Vemos que os resultados não coincidem completamente com aqueles que foram encontrados pelo testador regular. Por que aconteceu isso? Será mesmo que a precisão na conversão de double em int e vice-versa desempenhou um papel decisivo? Teoricamente, se os resultados diferissem em frações após o ponto decimal, isso poderia acontecer. Mas os resultados diferem significativamente.
O testador regular encontrou os valores Ref = 60 e SL = 350 com um lucro líquido de 1000,50. Nosso testador OpenCL encontrou os valores Ref = 60 e SL = 365 com um lucro líquido de 1506,40. Vamos tentar executar um testador regular com os valores encontrados pelo testador OpenCL:

Fig. 10. Verificação de resultados de otimização encontrados pelo testador OpenCL
O resultado é muito parecido com o nosso, o que significa que não se trata de uma perda de precisão. O que aconteceu é que o algoritmo genético perdeu ignorou esta combinação de parâmetros otimizados. Vamos executar o testador embutido no modo de otimização lenta, com uma busca exaustiva de parâmetros.
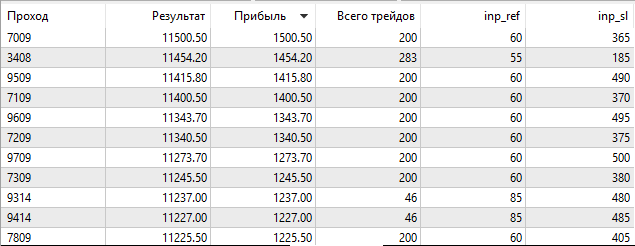
Fig. 11. Execução do testador embutido no modo de otimização lenta
Vemos que no modo de busca exaustiva, o testador embutido encontrou os mesmos valores procurados Ref = 60 e SL = 365, como nosso testador OpenCL. Isso significa que o algoritmo de otimização implementado por nós funciona corretamente.
3. Comparação de desempenho
É hora de comparar o desempenho do testador regular e o testador criado usando a OpenCL.
Vamos comparar o tempo gasto na otimização dos parâmetros da estratégia descrita acima. Iniciaremos o testador embutido em dois modos: otimização rápida (algoritmo genético) e lenta (busca exaustiva de parâmetros). A inicialização será realizada num PC com as seguintes características:
| Sistema operacional | Windows 10 (build 17134) x64 |
| Processador | AMD FX-8300 Eight-Core Processor, 3600MHz |
| Memória RAM | 24574 Mb |
| Tipo de mídia na qual está instalado o MetaTrader | HDD |
Para agentes de teste, foram alocados 6 dos 8 núcleos.
O testador OpenCL será executado na placa de vídeo AMD Radeon HD 7950 com uma capacidade de memória de 3Gb e uma frequência de GPU de 800Mhz.
Vamos realizar a otimização em três pares: EURUSD, GBPUSD e USDJPY. Além disso, em cada par, vamos executá-lo em quatro intervalos de tempo para cada um dos modos de otimização, para os quais tomamos as seguintes abreviações:
| Modo de otimização | Descrição |
|---|---|
| Tester Fast | Testador de estratégia embutido, algoritmo genético |
| Tester Slow | Testador de estratégia embutido, busca exaustiva de parâmetros |
| Tester OpenCL | Testador criado usando a OpenCL |
Designações de faixa de teste:
| Período | Intervalo de datas |
|---|---|
| 1 mês | 2018.09.01 - 2018.10.01 |
| 3 meses | 2018.07.01 - 2018.10.01 |
| 6 meses | 2018.04.01 - 2018.10.01 |
| 9 meses | 2018.01.01 - 2018.10.01 |
Dos resultados obtidos, para nós serão importantes os valores dos parâmetros buscados, o valor do lucro líquido, o número de operações e o tempo gasto na otimização.
3.1. Otimização no par EURUSD
Período H1, 1 mês:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 15 | 15 | 15 |
| Stop Loss | 330 | 510 | 500 |
| Lucro líquido | 942.5 | 954.8 | 909.59 |
| Número de trades | 48 | 48 | 47 |
| Duração da otimização | 10 seg | 6 min 2 seg | 405,8 ms |
Período H1, 3 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 50 | 65 | 70 |
| Stop Loss | 250 | 235 | 235 |
| Lucro líquido | 1233.8 | 1503.8 | 1428.35 |
| Número de trades | 110 | 89 | 76 |
| Duração da otimização | 9 seg | 8 min 8 seg | 457,9 ms |
Período H1, 6 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 15 | 20 | 20 |
| Stop Loss | 455 | 435 | 435 |
| Lucro líquido | 1641.9 | 1981.9 | 1977.42 |
| Número de trades | 325 | 318 | 317 |
| Duração da otimização | 15 seg | 11 min 13 seg | 405,5 ms |
Período H1, 9 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 15 | 15 | 15 |
| Stop Loss | 440 | 435 | 435 |
| Lucro líquido | 1162.0 | 1313.7 | 1715.77 |
| Número de trades | 521 | 521 | 520 |
| Duração da otimização | 20 seg | 16 min 44 seg | 438,4 ms |
Período M5, 1 mês:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 135 | 45 | 45 |
| Stop Loss | 270 | 205 | 205 |
| Lucro líquido | 47 | 417 | 419.67 |
| Número de trades | 1 | 39 | 39 |
| Duração da otimização | 7 seg | 9 min 27 seg | 418 ms |
Período M5, 3 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 120 | 70 | 70 |
| Stop Loss | 440 | 405 | 405 |
| Lucro líquido | 147 | 342 | 344.85 |
| Número de trades | 3 | 16 | 16 |
| Duração da otimização | 11 seg | 8 min 25 seg | 585,9 ms |
Período M5, 6 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 85 | 70 | 70 |
| Stop Loss | 440 | 470 | 470 |
| Lucro líquido | 607 | 787 | 739.6 |
| Número de trades | 22 | 47 | 46 |
| Duração da otimização | 21 seg | 12 min 03 seg | 796,3 ms |
Período M5, 9 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 60 | 60 | 60 |
| Stop Loss | 495 | 365 | 365 |
| Lucro líquido | 1343.7 | 1500.5 | 1506.4 |
| Número de trades | 200 | 200 | 200 |
| Duração da otimização | 20 seg | 16 min 44 seg | 438,4 ms |
3.2. Otimização no par GBPUSD
Período H1, 1 mês:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 175 | 90 | 90 |
| Stop Loss | 435 | 185 | 185 |
| Lucro líquido | 143.40 | 173.4 | 179.91 |
| Número de trades | 3 | 13 | 13 |
| Duração da otimização | 10 seg | 4 min 33 seg | 385,1 ms |
Período H1, 3 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 175 | 145 | 145 |
| Stop Loss | 225 | 335 | 335 |
| Lucro líquido | 93.40 | 427 | 435.84 |
| Número de trades | 13 | 19 | 19 |
| Duração da otimização | 12 seg | 7 min 37 seg | 364,5 ms |
Período H1, 6 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 165 | 170 | 165 |
| Stop Loss | 230 | 335 | 335 |
| Lucro líquido | 797.40 | 841.2 | 904.72 |
| Número de trades | 31 | 31 | 32 |
| Duração da otimização | 18 seg | 11 min 3 seg | 403,6 ms |
Período H1, 9 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 165 | 165 | 165 |
| Stop Loss | 380 | 245 | 245 |
| Lucro líquido | 1303.8 | 1441.6 | 1503.33 |
| Número de trades | 74 | 74 | 75 |
| Duração da otimização | 24 seg | 19 min 23 seg | 428,5 ms |
Período M5, 1 mês:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 335 | 45 | 45 |
| Stop Loss | 450 | 485 | 485 |
| Lucro líquido | 50 | 484.6 | 538.15 |
| Número de trades | 1 | 104 | 105 |
| Duração da otimização | 12 seg | 9 min 42 seg | 412,8 ms |
Período M5, 3 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 450 | 105 | 105 |
| Stop Loss | 440 | 240 | 240 |
| Lucro líquido | 0 | 220 | 219.88 |
| Número de trades | 0 | 16 | 16 |
| Duração da otimização | 15 seg | 8 min 17 seg | 552,6 ms |
Período M5, 6 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 510 | 105 | 105 |
| Stop Loss | 420 | 260 | 260 |
| Lucro líquido | 0 | 220 | 219.82 |
| Número de trades | 0 | 23 | 23 |
| Duração da otimização | 24 seg | 14 min 58 seg | 796,5 ms |
Período M5, 9 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 185 | 195 | 185 |
| Stop Loss | 205 | 160 | 160 |
| Lucro líquido | 195 | 240 | 239.92 |
| Número de trades | 9 | 9 | 9 |
| Duração da otimização | 25 seg | 20 min 58 seg | 4,4 ms |
3.3. Otimização no par USDJPY
Período H1, 1 mês:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 60 | 50 | 50 |
| Stop Loss | 425 | 510 | 315 |
| Lucro líquido | 658.19 | 700.14 | 833.81 |
| Número de trades | 18 | 24 | 24 |
| Duração da otimização | 6 seg | 4 min 33 seg | 387,2 ms |
Período H1, 3 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 75 | 55 | 55 |
| Stop Loss | 510 | 510 | 460 |
| Lucro líquido | 970.99 | 1433.95 | 1642.38 |
| Número de trades | 50 | 82 | 82 |
| Duração da otimização | 10 seg | 6 min 32 seg | 369 ms |
Período H1, 6 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 150 | 150 | 150 |
| Stop Loss | 345 | 330 | 330 |
| Lucro líquido | 273.35 | 287.14 | 319.88 |
| Número de trades | 14 | 14 | 14 |
| Duração da otimização | 17 seg | 11 min 25 seg | 409,2 ms |
Período H1, 9 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 190 | 190 | 190 |
| Stop Loss | 425 | 510 | 485 |
| Lucro líquido | 244.51 | 693.86 | 755.84 |
| Número de trades | 16 | 16 | 16 |
| Duração da otimização | 24 seg | 17 min 47 seg | 445,3 ms |
Período M5, 1 mês:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 30 | 35 | 35 |
| Stop Loss | 225 | 100 | 100 |
| Lucro líquido | 373.60 | 623.73 | 699.79 |
| Número de trades | 53 | 35 | 35 |
| Duração da otimização | 7 seg | 4 min 34 seg | 415,4 ms |
Período M5, 3 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 45 | 40 | 40 |
| Stop Loss | 335 | 250 | 250 |
| Lucro líquido | 1199.34 | 1960.96 | 2181.21 |
| Número de trades | 71 | 99 | 99 |
| Duração da otimização | 12 seg | 8 min | 607,2 ms |
Período M5, 6 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 130 | 40 | 40 |
| Stop Loss | 400 | 130 | 130 |
| Lucro líquido | 181.12 | 1733.9 | 1908.77 |
| Número de trades | 4 | 229 | 229 |
| Duração da otimização | 19 seg | 12 min 31 seg | 844 ms |
Período M5, 9 meses:
| Resultado | Tester Fast | Tester Slow | Tester OpenCL |
|---|---|---|---|
| Reference | 35 | 30 | 30 |
| Stop Loss | 460 | 500 | 500 |
| Lucro líquido | 3701.30 | 5612.16 | 6094.31 |
| Número de trades | 681 | 1091 | 1091 |
| Duração da otimização | 34 seg | 18 min 56 seg | 1 seg |
3.4. Tabela de desempenho
Com base nos resultados obtidos, fica claro que o testador regular no modo de otimização rápida (algoritmo genético) geralmente omite os melhores resultados. Portanto, é mais justo que o desempenho em relação ao testador OpenCL seja comparado no modo de busca exaustiva de parâmetros. Para maior clareza, elaboramos uma tabela de resumo mostrando o tempo gasto em otimização.
| Condições de otimização | Tester Slow | Tester OpenCL | Ratio |
|---|---|---|---|
| EURUSD, H1, 1 mês | 6 min 2 seg | 405,8 ms | 891 |
| EURUSD, H1, 3 meses | 8 min 8 seg | 457,9 ms | 1065 |
| EURUSD, H1, 6 meses | 11 min 13 seg | 405,5 ms | 1657 |
| EURUSD, H1, 9 meses | 16 min 44 seg | 438,4 ms | 2292 |
| EURUSD, M5, 1 mês | 9 min 27 seg | 418 ms | 1356 |
| EURUSD, M5, 3 meses | 8 min 25 seg | 585,9 ms | 861 |
| EURUSD, M5, 6 meses | 12 min 3 seg | 796,3 ms | 908 |
| EURUSD, M5, 9 meses | 17 min 39 seg | 1 seg | 1059 |
| GBPUSD, H1, 1 mês | 4 min 33 seg | 385,1 ms | 708 |
| GBPUSD, H1, 3 meses | 7 min 37 seg | 364,5 ms | 1253 |
| GBPUSD, H1, 6 meses | 11 min 3 seg | 403,6 ms | 1642 |
| GBPUSD, H1, 9 meses | 19 min 23 seg | 428,5 ms | 2714 |
| GBPUSD, M5, 1 mês | 9 min 42 seg | 412,8 ms | 1409 |
| GBPUSD, M5, 3 meses | 8 min 17 seg | 552,6 ms | 899 |
| GBPUSD, M5, 6 meses | 14 min 58 seg | 796,4 ms | 1127 |
| GBPUSD, M5, 9 meses | 20 min 58 seg | 970,4 ms | 1296 |
| USDJPY, H1, 1 mês | 4 min 33 seg | 387,2 ms | 705 |
| USDJPY, H1, 3 meses | 6 min 32 seg | 369 ms | 1062 |
| USDJPY, H1, 6 meses | 11 min 25 seg | 409,2 ms | 1673 |
| USDJPY, H1, 9 meses | 17 min 47 seg | 455,3 ms | 2396 |
| USDJPY, M5, 1 mês | 4 min 34 seg | 415,4 ms | 659 |
| USDJPY, M5, 3 meses | 8 min | 607,2 ms | 790 |
| USDJPY, M5, 6 meses | 12 min 31 seg | 844 ms | 889 |
| USDJPY, M5, 9 meses | 18 min 56 seg | 1 seg | 1136 |
Fim do artigo
Neste artigo, implementamos um algoritmo para construir um testador para uma estratégia de negociação simples usando a OpenCL. Obviamente, esta implementação é apenas uma das soluções possíveis e, por enquanto, tem muitos inconvenientes, entre elas estão:
- Trabalho - no modo OHLC em M1 - adequado apenas para estimativa aproximada
- Nenhum registro de swaps e comissões
- Trabalho incorreto com pares de moedas
- Não tem Trailing-Stop
- Não registra o número de posições simultaneamente abertas
- Nenhum valor de drawdown entre os parâmetros de retorno
No entanto, esse algoritmo pode nós ajudar seriamente nos casos em que é preciso avaliar de maneira rápida e aproximada o desempenho dos padrões mais simples, pois permite fazer isso mil vezes mais rápido do que o testador embutido sendo executado no modo de busca exaustiva de parâmetros e dezenas de vezes mais rápido do que o testador usando algoritmo genético.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/4236
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Reversão: criemos um ponto de entrada e programemos um algoritmo de negociação manual
Reversão: criemos um ponto de entrada e programemos um algoritmo de negociação manual
 WebRequest multi-threaded assíncrono em MQL5
WebRequest multi-threaded assíncrono em MQL5
 Aplicando a teoria da probabilidade na negociação de gaps
Aplicando a teoria da probabilidade na negociação de gaps
 Padrões de reversão: Testando o padrão 'topo/fundo duplo'
Padrões de reversão: Testando o padrão 'topo/fundo duplo'
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Em primeiro lugar, no núcleo tester_step, precisamos adicionar mais um argumento que nos permitirá obter o tempo de fechamento de uma negociação (pode ser o índice da barra M1, onde a negociação foi fechada, ou o tempo de manutenção de uma posição expresso no número de barras de M1) com indexação, como no buffer de resultados __global double *Res.
Além disso, dependendo do fato de sua pergunta se referir a um único teste ou à otimização:
1. teste. No loop em que o lucro total é resumido, você precisa adicionar condições que excluirão a sobreposição de posições abertas usando os horários de fechamento (que serão retornados pelo tester_step finalizado).
2. otimização. Aqui, em vez do kernel find_patterns_opt, que resume os lucros, precisamos usar find_patterns, que simplesmente retornará os pontos de entrada. Levando em conta as condições de inadmissibilidade de abrir mais de uma negociação por vez, teremos de resumir o lucro no código mql5. No entanto, isso pode levar algum tempo (você deve tentar), porque, nesse caso, o que foi executado em paralelo será executado sequencialmente (o número de passagens de otimização é multiplicado pela profundidade da otimização). Outra opção de compromisso possível é adicionar um kernel que contará o lucro para uma passagem (levando em conta a condição do número de posições abertas simultaneamente), mas, com base em minha própria prática, posso dizer que é uma má ideia executar kernels "pesados". O ideal é se esforçar para manter o código do kernel o mais simples possível e executar o maior número possível deles.
Boa tarde.
Obrigado por sua resposta rápida. Eu estava interessado, em primeiro lugar, na resposta sobre otimização, como a ideia de aplicar o código na prática, a propósito, pensei que parcialmente eu teria que escrever no código mql. Muito obrigado pelo artigo, pois não há nada parecido com ele! Além disso, se modificarmos um pouco o tester_step (e o tester_step_opt), adicionando à condição de tempo p>open to buy (ou seja if(j>=maxbar || (TimeM1[j]>=tclose && p>open)) e para vender if(j>=maxbar || (TimeM1[j]>=tclose && p<open))), você terá uma estratégia para negociação de opções.
...Também acrescentarei algumas palavras ao meu comentário anterior sobre a estratégia de opções. Aqui, precisamos adicionar a variável Option Expiration Time (ao mesmo tempo, StopLoss e TakeProfit não são necessários para opções durante a otimização), portanto, modificamos o código em tester_opt_step da seguinte forma:
Boa tarde. Ao executar a otimização do OpenCL para o USDRUB de acordo com seu artigo, encontrei esse problema - os resultados da otimização são sempre positivos, sempre um lucro, ou seja, parece que há um estouro para uma variável do tipo int, na qual o resultado é gerado, enquanto que para o EURUSD a otimização funciona corretamente. Talvez seja também uma questão de cinco dígitos para o USDRUB. Você poderia me dizer como corrigir esse problema?
No artigo, você escreveu:
В нашем случае функция atomic_inc() для начала запрещает доступ другим задачам к ячейке Count[0], затем увеличивает её значение на единицу, а предыдущее возвращает в виде результата.
Pelo que entendi, essa função funciona somente com uma matriz do tipo int, mas se eu tiver uma matriz de um tipo diferente, por exemplo, ushort, o que devo fazer?