
OpenCL を使用したローソク足パターンのテスト

イントロダクション
トレーダーが OpenCL を始めるとき、どこで適用するかという問題に直面します。 マトリックスの乗算や大量のデータのソートといった実例は、インジケータや自動トレードシステムの開発には広く使用されていません。 ニューラルネットワークを使用するもう1つの一般的なアプリケーションでは、特定の領域の知識が必要です。 ニューラルネットワークを研究しても、トレードの結果が保証されることはなく、一般的なプログラマーに多くの時間を要求します。 このような状況では、初歩的な タスクを解く際に、OpenCL のパワーを実感したい人のモチベーションを下げます。
この記事では、アルゴリズムトレードの最もシンプルなタスクを解決するために、OpenCL の使用を検討します。ローソク足パターンを見つけて、ヒストリー上でテストします。 単一パスをテストし、 "1 分 OHLC " トレーディングモードで2つのパラメータを最適化するアルゴリズムを開発します。 その後、ビルトインストラテジーテスターの性能を OpenCL one と比較して、どの程度高速であるかを調べます。
読者がすでに OpenCL の基本に精通していることを前提とします。 それ以外の場合は、記事「opencl: パラレルワールドへのブリッジ」と「opencl: ナイーブからより洞察に富んだプログラミングへ」を読むことをお勧めします。 OpenCL 仕様バージョン 1.2を手元にあると良いでしょう。 この記事では、OpenCL プログラミングの基本にこだわることなくテスターを構築するアルゴリズムに焦点を当てます。
- イントロダクション
- 1. MQL5 での実装
- 2. OpenCL での実装
- 3. パフォーマンス比較
- 結論
1. MQL5 での実装
OpenCL のテスターの実装が正しく動作することを確認するためにあるものに頼る必要があります。 まず、MQL5のEAを開発します。 次に、テストの結果と、OpenCL テスターが取得した正規のテスターを使用して最適化を比較します。
- 弱気ピンバー
- 強気ピンバー
- 弱気反転
- 強気反転
戦略はシンプルです。
- 弱気ピンバーまたは弱気反転—売る
- 強気ピンバーまたは強気反転-買い
- 同時に開かれたポジションの数-無制限
- 最大ポジション保持時間-制限付き、ユーザ定義
- テイクプロフィットおよび ストップロス レベル-固定、ユーザ定義
パターンの存在は、完全に閉じられた足でチェックされます。 つまり、新しいものが出現するとすぐに、3つ前の足でパターンを詳しく見ることができます。
パターン検出条件は次のとおりです。

図1. 「弱気ピンバー」 (a) および「強気ピンバー」 (b) パターン
弱気ピンバーの場合 (図1、a):
- 最初の足の上の影 ("tail") が、指定されたレファレンス値より大きい: tail > = レファンレンス
- ゼロバーは強気である: Close[0]>Open[0]
- 2番目の足は弱気: Open[2] > Close[2]
- 最初の足の高値は、ローカルの最大値であり、High[1] > MathMax (High[0],High[2])
- 最初の足の本体は、その上の影よりも小さくなっています: MathAbs(Open[1]-Close[1])<tail< a0/>
- tail = High[1]-max(Open[1],Close[1])
強気ピンバーの場合 (図1、b):
- 最初の足の下の影 ("tail") が、指定されたレファレンス値よりも大きい: tail > = レファレンス
- ゼロバーは弱気: Open[0]>Close[0]
- 2番目の足は強気: Close[2]>Open[2]
- 最初の足の安値は、ローカルの最小値:Low[1]<MathMin(Low[0],Low[2])
- 最初の足の本体は、下の影よりも小さい: MathAbs(Open[1]-Close[1])<tail
-
tail = min(Open[1],Close[1])-Low[1]

図2. 「弱気反転」と「強気反転」 (b)
弱気反転 (図2、a):
- 最初の足は強気で、そのボディは指定されたレファレンス値よりも大きくなります (Close[1]-Open[1])>=Reference。
- ゼロバーの高値は、最初の足の終値よりも低い。:High[0]<Close[1]
- 2番目の足の始値は、最初の足の終値を超えている:Open[2]>CLose[1]
- 2番目の足の終値は、最初の足の始値よりも低い:Close[2]<Open[1]
強気反転 (図2、b):
- 最初の足は弱気で、そのボディは指定されたレファレンス値よりも大きい: (Open[1]-Close[1])>=Reference
- ゼロバーの安値は、最初の足の終値よりも高い: Low[0]>Close[1]
- 2番目の足の始値は、最初の足の終値よりも低い。:Open[2]<Close[1]
- 2番目の足の終値は、最初の足の始値を超える:Close[2]>Open[1]
1.1 パターンの検索
ENUM_PATTERN Check(MqlRates &r[],uint flags,double ref) { //---弱気ピンバー if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-MathMax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>MathMax(H(0),H(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //---強気ピンバー if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=MathMin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<MathMin(L(0),L(2)) && MathAbs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //---弱気反転 if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //---強気反転 if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //---何も見つからない return PAT_NONE; }
ここでは、ENUM_PATTERN 列挙子に注意を払う必要があります。 その値は、ビットワイズ ORを使用して1つの引数として結合して渡すことができるフラグです。
enum ENUM_PATTERN { PAT_NONE=0, PAT_PINBAR_BEARISH = (1<<0), PAT_PINBAR_BULLISH = (1<<1), PAT_ENGULFING_BEARISH = (1<<2), PAT_ENGULFING_BULLISH = (1<<3) };
また、マクロはよりコンパクトな記録に導入されました:
#define O(i) (r[i].open) #define H(i) (r[i].high) #define L(i) (r[i].low) #define C(i) (r[i].close)
Check() 関数は、新しい足を開くときに指定されたパターンの存在をチェックするためのIsPattern()関数から呼び出されます。
ENUM_PATTERN IsPattern(uint flags,uint ref) { MqlRates r[]; if(CopyRates(_Symbol,_Period,1,PBARS,r)<PBARS) return 0; ArraySetAsSeries(r,false); return Check(r,flags,double(ref)*_Point); }
1.2 EAの組み立て
最初に、インプットパラメータを定義する必要があります。 パターン定義条件にレファレンス値があります。 ピンバーの "tail" の最小長、または反転の間にボディがクロスする領域です。 ポイントで指定します。
input int inp_ref=50;
また、扱うパターンのセットがあります。 より便利にするために、インプットでフラグのレジスタを使用しません。 代わりに、4つの bool 型パラメータに分割します。
input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true;
初期化関数の符号なし変数にアセンブルします。
p_flags = 0; if(inp_bullish_pin_bar==true) p_flags|=PAT_PINBAR_BULLISH; if(inp_bearish_pin_bar==true) p_flags|=PAT_PINBAR_BEARISH; if(inp_bullish_engulfing==true) p_flags|=PAT_ENGULFING_BULLISH; if(inp_bearish_engulfing==true) p_flags|=PAT_ENGULFING_BEARISH;
次に、許容可能なポジション保持時間を時間、TP、SLレベル、およびロットボリュームで設定します。
input int inp_timeout=5; input bool inp_bullish_pin_bar = true; input bool inp_bearish_pin_bar = true; input bool inp_bullish_engulfing = true; input bool inp_bearish_engulfing = true; input double inp_lot_size=1;トレードに対して、標準ライブラリから CTrade クラスを使用します。 テスターの速度を定義するために、プログラム実行のコントロールポイント間の時間間隔をマイクロ秒単位で測定し、容易な形式で表示できるCDurationクラスを使用します。 この場合、 OnInit()とOnDeinit()関数の間の時間を測定します。 完全なクラスコードは、添付されたDurationファイルに含まれます。
CDuration time; int OnInit() { time.Start(); //... ... return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { time.Stop(); Print("Test lasted "+time.ToStr()); }
EAのタスクは簡単で、次のもので構成されています。
OnTick()関数の主なタスクは、オープンポジションの処理です。 保持時間がインプットで指定された値を超えた場合、ポジションをクローズします。 続いて、新しい足の始値を確認します。 チェックが渡された場合は、 IsPattern()関数を使用してパターンの存在をチェックします。 パターンを見つけるときは、戦略に従って買いまたは売りポジションを開きます。 以下にOnTick()関数コードを示します。
void OnTick() { //---オープンポジションの処理 int total= PositionsTotal(); for(int i=0;i<total;i++) { PositionSelect(_Symbol); datetime t0=datetime(PositionGetInteger(POSITION_TIME)); if(TimeCurrent()>=(t0+(inp_timeout*3600))) { trade.PositionClose(PositionGetInteger(POSITION_TICKET)); } else break; } if(IsNewBar()==false) return; //---パターンが存在するかどうかを確認する ENUM_PATTERN pat=IsPattern(p_flags,inp_ref); if(pat==PAT_NONE) return; //---オープンポジション double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); if((pat&(PAT_ENGULFING_BULLISH|PAT_PINBAR_BULLISH))!=0)//買い trade.Buy(inp_lot_size,_Symbol,ask,NormalizeDouble(ask-inp_sl*_Point,_Digits),NormalizeDouble(ask+inp_tp*_Point,_Digits),DoubleToString(ask,_Digits)); else//売り trade.Sell(inp_lot_size,_Symbol,bid,NormalizeDouble(bid+inp_sl*_Point,_Digits),NormalizeDouble(bid-inp_tp*_Point,_Digits),DoubleToString(bid,_Digits)); }
1.3 テスト
まず第一に、収益性のある、または少なくともオープンポジションでトレードするEAの最適なインプット値を見つけるために、最適化を起動します。 2つのパラメータ (パターンの基準値とポイントの ストップロス レベル) を最適化します。 TPレベルを50ポイントに設定し、テストするすべてのパターンを選択します。
最適化は EURUSD M5で実行する必要があります。 時間間隔: 01.01.2018 —01.10.2018. 高速最適化 (遺伝的アルゴリズム)、トレードモード: 「1分 OHLC 」。
最適化されたパラメータの値は、多数の階調を持つ広い範囲で選択します。
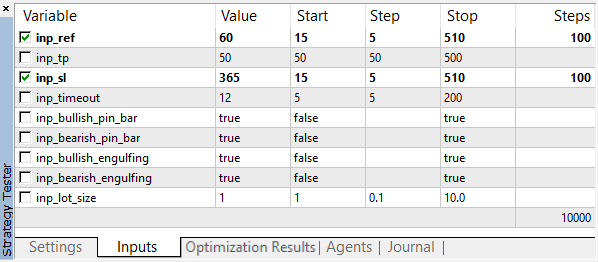
図3. Optimization parameters
最適化の完了後、結果は利益によってソートされます。
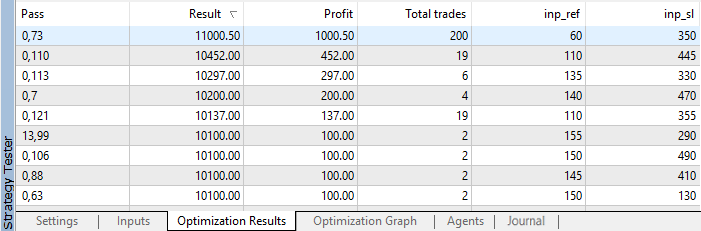
図4. 最適化の結果
ご覧の通り、1000.50 の利益との最良の結果は60ポイントの基準値と350ポイントの ストップロス レベルで受信されました。 パラメータを使用してテストを開始し、その実行時間に注意を払います。
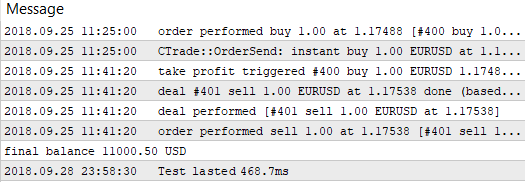
図5. ビルトインテスターによるシングルパステスト時間
これらの値を覚えて、通常のテスターを介さずに同じ戦略のテストに進みます。 OpenCL 関数を使用してカスタムテスターを開発してみましょう。
2. OpenCL での実装
OpenCL を使用するには、小さな変更を加えた標準ライブラリの COpenCL クラスを使います。 改善の目的は、発生するエラーについて可能な限り多くの情報を取得することです。 ただし、そうしている間は、条件によってコードをオーバーロードし、コンソールにデータを出力するべきではありません。 これを行うには、 COpenCLxクラスを作成します。 その完全なコードは、下に添付されているOpenCLxファイルにあります。
class COpenCLx : public COpenCL { private: COpenCL *ocl; public: COpenCLx(); ~COpenCLx(); STR_ERROR m_last_error; //直近のエラー構造 COCLStat m_stat; //OpenCL 統計 //---バッファを使用する bool BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line); template<typename T> bool BufferFromArray(const ENUM_BUFFERS buffer_index,T &data[],const uint data_array_offset,const uint data_array_count,const uint flags,const string function,const int line); template<typename T> bool BufferRead(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); template<typename T> bool BufferWrite(const ENUM_BUFFERS buffer_index,T &data[],const uint cl_buffer_offset,const uint data_array_offset,const uint data_array_count,const string function,const int line); //---引数の設定 template<typename T> bool SetArgument(const ENUM_KERNELS kernel_index,const int arg_index,T value,const string function,const int line); bool SetArgumentBuffer(const ENUM_KERNELS kernel_index,const int arg_index,const ENUM_BUFFERS buffer_index,const string function,const int line); //---カーネルで機能する bool KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line); bool Execute(const ENUM_KERNELS kernel_index,const int work_dim,const uint &work_offset[],const uint &work_size[],const string function,const int line); //--- bool Init(ENUM_INIT_MODE mode); void Deinit(void); };
ご覧のように、このクラスには、COpenCL オブジェクトへのポインタと、同じ名前のCOpenCLクラスメソッドのラッパーとして使用するメソッドがあります。 各メソッドには、関数の名前と、引数の中から呼び出された文字列があります。 さらに、列挙子は、カーネルのインデックスとバッファの代わりに使用します。 これは、単なるインデックスよりもはるかに有益なエラーメッセージでEnumToString()を適用できるようにするために行われます。
これらのメソッドをさらに詳しく見てみましょう。
bool COpenCLx::KernelCreate(const ENUM_KERNELS kernel_index,const string kernel_name,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL object does not exist",function,line); return false; } //---カーネル実行の起動 ::ResetLastError(); if(!ocl.KernelCreate(kernel_index,kernel_name)) { string comment="Failed to create kernel "+EnumToString(kernel_index)+", name \""+kernel_name+"\""; SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_KERNEL_CREATE,comment,function,line); return(false); } //--- return true; }
ここに2つのチェックがあります: COpenCL クラスオブジェクトの存在とカーネル作成メソッド。 ただし、 Print()関数を使用してテキストを表示する代わりに、メッセージはエラーコード、関数名、および呼び出し文字列と共にマクロに渡されます。 これらのマクロは、エラー情報をm_last_errorクラスエラーに格納します。 その構造は以下のように表示されます。
struct STR_ERROR { int code; //コード string comment; //コメント string function; //エラーが発生した関数 int line; //エラーが発生した文字列 };
そのようなマクロは全部で4つあります。 1つずつ考えてみましょう。
SET_ERR マクロは、直近の実行エラー、関数、および呼び出し元の文字列、およびパラメータとして渡されたコメントを書き込みます。
#define SET_ERR(c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
SET_ERRx マクロは、 SET_ERRに似ています。
#define SET_ERRx(c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=::GetLastError(); m_last_error.comment=c;} while(0)
関数名と文字列がパラメータとして渡される点で異なります。 なぜこれが行われたのでしょうか。 仮にKernelCreate() メソッドでエラーが発生したと仮定します。 SET_ERRマクロを使用する場合、 KernelCreate()メソッド名を見ることができますが、メソッドが呼び出された場所を知る方がはるかに便利です。 これを実現するために、関数とメソッドの呼び出し文字列を、マクロに挿入する引数として渡します。
SET_UERR マクロは次に進みます。 これは、カスタムエラーを記述するためのものです。
#define SET_UERR(err,c) do {m_last_error.function = __FUNCTION__; \ m_last_error.line =__LINE__; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
マクロでは、エラーコードは GetLastError() を呼び出すのではなく、パラメータとして渡されます。 他の面では、 SET_ERRマクロと似ています。
SET_UERRx マクロは、カスタムエラーを書き込んで、関数名と呼び出し文字列をパラメータとして渡すためのものです。
#define SET_UERRx(err,c,f,l) do {m_last_error.function = f; m_last_error.line = l; \ m_last_error.code=ERR_USER_ERROR_FIRST+err; m_last_error.comment=c;} while(0)
したがって、エラーが発生した場合は、必要な情報がすべて用意されています。 COpenCL クラスからコンソールに送信されるエラーとは異なり、ターゲットカーネルの仕様であり、その作成方法が呼び出された場所です。 COpenCLクラス (上の文字列) とCOpenCLxクラス (2 つの下の行) からの拡張出力の出力を比較します。

図6. カーネル作成エラー
ラッパーメソッドの別の例として、バッファ作成メソッドを考えてみましょう。
bool COpenCLx::BufferCreate(const ENUM_BUFFERS buffer_index,const uint size_in_bytes,const uint flags,const string function,const int line) { if(ocl==NULL) { SET_UERRx(UERR_NO_OCL,"OpenCL object does not exist",function,line); return false; } //---空きメモリの検討と確認 if((m_stat.gpu_mem_usage+=size_in_bytes)==false) { CMemsize cmem=m_stat.gpu_mem_usage.Comp(size_in_bytes); SET_UERRx(UERR_NO_ENOUGH_MEM,"No free GPU memory. Insufficient "+cmem.ToStr(),function,line); return false; } //---バッファを作成する ::ResetLastError(); if(ocl.BufferCreate(buffer_index,size_in_bytes,flags)==false) { string comment="Failed to create buffer "+EnumToString(buffer_index); SET_ERRx(comment,function,line); if(!m_last_error.code) SET_UERRx(UERR_BUFFER_CREATE,comment,function,line); return(false); } //--- return(true); }
COpenCL クラスオブジェクトと操作結果の存在を確認すること以外に、アカウンティングと空きメモリのチェックの関数も含まれています。 比較的大量のメモリ (数百メガバイト) を扱うため、消費のプロセスを制御する必要があります。 このタスクはСMemsizeに割り振られています。 完全なコードは、 Memsizeファイルに含まれています。
しかし、これには欠点があります。 便利なデバッグそれにも関わらず、コードは面倒になります。 たとえば、バッファの作成コードは次のようになります。
if(BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE,__FUNCTION__,__LINE__)==false) return false;
不必要な情報が多すぎて、アルゴリズムに焦点を当てるのが難しくなります。 マクロは再びここで役に立ちます。 各ラッパーメソッドは、その呼び出しをよりコンパクトにするマクロによって複製されます。 BufferCreate() メソッドの場合は、 _BufferCreateマクロです。
#define _BufferCreate(buffer_index,size_in_bytes,flags) \ if(BufferCreate(buffer_index,size_in_bytes,flags,__FUNCTION__,__LINE__)==false) return false
マクロのおかげで、バッファ作成メソッドの呼び出しは次の形式をとります。
_BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
カーネルの作成は次のようになります。
_KernelCreate(k_FIND_PATTERNS,"find_patterns");
マクロのほとんどは return false で終了しますが、 _KernelCreateは中断して終了します。 これはコードを開発するときに考慮する必要があります。 すべてのマクロは、 OCLDefinesファイルに定義されています。
このクラスには、初期化と初期化解除メソッドも含まれています。 COpenCL クラスオブジェクトの作成とは別に、最初のものも ' double ' のサポートをチェックし、カーネルを作成し、使用可能なメモリのサイズを受け取ります。
bool COpenCLx::Init(ENUM_INIT_MODE mode) { if(ocl) Deinit(); //---COpenCL クラスのオブジェクトを作成します。 ocl=new COpenCL; while(!IsStopped()) { //---OpenCL の初期化 ::ResetLastError(); if(!ocl.Initialize(cl_tester,true)) { SET_ERR("OpenCL initialization error"); break; } //---' double ' でのタスクがサポートされているかどうかを確認 if(!ocl.SupportDouble()) { SET_UERR (UERR_DOUBLE_NOT_SUPP (cl_khr_fp64) でのタスクは、デバイスでサポートされていません ")。 break; } //---カーネルの数を設定する if(!ocl.SetKernelsCount(OCL_KERNELS_COUNT)) break; //---カーネルの作成 if(mode==i_MODE_TESTER) { _KernelCreate(k_FIND_PATTERNS,"find_patterns"); _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_ORDER_TO_M1,"order_to_M1"); _KernelCreate(k_TESTER_STEP,"tester_step"); }else if(mode==i_MODE_OPTIMIZER){ _KernelCreate(k_ARRAY_FILL,"array_fill"); _KernelCreate(k_TESTER_OPT_PREPARE,"tester_opt_prepare"); _KernelCreate(k_TESTER_OPT_STEP,"tester_opt_step"); _KernelCreate(k_FIND_PATTERNS_OPT,"find_patterns_opt"); } else break; //---バッファの作成 if(!ocl.SetBuffersCount(OCL_BUFFERS_COUNT)) { SET_UERR(UERR_SET_BUF_COUNT,"Failed to create buffers"); break; } //---RAM サイズを受け取る long gpu_mem_size; if(ocl.GetGlobalMemorySize(gpu_mem_size)==false) { SET_UERR(UERR_GET_MEMORY_SIZE,"Failed to receive RAM value"); break; } m_stat.gpu_mem_size.Set(gpu_mem_size); m_stat.gpu_mem_usage.Max(gpu_mem_size); return true; } Deinit(); return false; }
mode 引数は、初期化モードを設定します。 最適化または単一のテストである可能性があります。 基づいて様々なカーネルが作成されます。
カーネルとバッファの列挙子は、OCLInc.mqh ファイルで宣言されています。 カーネルのソースコードは、 cl_tester文字列のように、そこにリソースとして添付されます。
Deinit() メソッドは OpenCL プログラムとオブジェクトを削除します。
void COpenCLx::Deinit() { if(ocl!=NULL) { //---OpenCL オブジェクトの削除 ocl.Shutdown(); delete ocl; ocl=NULL; } }
さて。すべての簡便性が開発されたので、主なタスクを開始しましょう。 すでに比較的コンパクトなコードとエラーに関する包括的情報があります。
しかし、まずは機能するデータをアップロードする必要があります。 見かけほど簡単ではありません。
2.1 価格データのアップロード
CBuffering クラスは、データをアップロードします。
class CBuffering { private: string m_symbol; ENUM_TIMEFRAMES m_period; int m_maxbars; uint m_memory_usage; //使用メモリ量 bool m_spread_ena; //スプレッドバッファのアップロード datetime m_from; datetime m_to; uint m_timeout; //アップロードのタイムアウト (ミリ秒) ulong m_ts_abort; //操作を中断する必要があるときのマイクロ秒単位の時間ラベル //---強制アップロード bool ForceUploading(datetime from,datetime to); public: CBuffering(); ~CBuffering(); //---バッファ内のデータ量 int Depth; //---バッファ double Open[]; double High[]; double Low[]; double Close[]; double Spread[]; datetime Time[]; //---アップロードされたデータのリアルタイムの境界を取得する datetime TimeFrom(void){return m_from;} datetime TimeTo(void){return m_to;} //--- int Copy(string symbol,ENUM_TIMEFRAMES period,datetime from,datetime to,double point=0); uint GetMemoryUsage(void){return m_memory_usage;} bool SpreadBufEnable(void){return m_spread_ena;} void SpreadBufEnable(bool ena){m_spread_ena=ena;} void SetTimeout(uint timeout){m_timeout=timeout;} };
データのアップロードは現在のトピックに直接関係していないため、あまりこだわりません。 とにかく、そのアプリケーションを検討する必要があります。
このクラスには、バッファの Open[], High[], Low[], Close[], Time[], Spread[] があります。 Copy() メソッドが正常に動作した後で、操作できます。 Spread[] バッファは「ダブル」タイプであり、ポイントではなく価格差で表現されていることに注意してください。 また、Spread[] バッファのコピーは、最初は無効になっています。 必要に応じて、 SpreadBufEnable()メソッドを使用して有効にする必要があります。
Copy() メソッドは、アップロードに使用します。 プリセットポイント引数は、ポイントから価格差へのスプレッドを再計算するためにのみ使用します。 スプレッドコピーがオフの場合、この引数は使用されません。
データをアップロードするための別のクラスを作成する主な理由は次のとおりです。
- CopyTime()関数等を用いてTERMINAL_MAXBARSを超える量でデータをダウンロードすることができません。
- ターミナルがローカルにデータを持っているという保証はありません。
CBuffering クラスは、TERMINAL_MAXBARS を超える大量のデータをコピーするだけでなく、サーバーから不足しているデータのアップロードを開始し、終了するのを待つことができます。 この待機により、最大データアップロード時間 (待機を含む) をミリ秒単位で設定するためのSetTimeout()メソッドに注意を払う必要があります。 デフォルトでは、クラスコンストラクタは 5000 (5 秒) です。 タイムアウトを0に設定すると無効になります。 望ましくありませんが、場合によっては役に立つことがあります。
しかし、制限があります: M1 期間データは、ある程度はテスターの範囲を狭く、1年を超える期間にアップロードされていません。
2.2 単一のテスト
単一のテストは、次の点で構成されます。
- 時系列バッファのダウンロード
- OpenCL の初期化
- OpenCL バッファへの時系列バッファのコピー
- 現在のチャート上のパターンを検出し、相場参入ポイントとしてオーダーバッファに結果を追加するカーネルを起動する
- M1 チャートにオーダーを移動するカーネルの起動
- チャート M1 上のオーダーによってトレード結果をカウントし、をバッファに追加するカーネルを起動する
- 結果バッファの処理とテスト結果の計算
- Deinitializing OpenCL
- 時系列バッファの削除
CBuffering は、時系列をダウンロードします。 次に、データを OpenCL バッファにコピーして、カーネルがを処理できるようにする必要があります。 このタスクは、 LoadTimeseriesOCL()メソッドに割り当てられます。 そのコードは以下に提供されます:
bool CTestPatterns::LoadTimeseriesOCL() { //---オープンバッファ: _BufferFromArray(buf_OPEN,m_sbuf.Open,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //---高値バッファ: _BufferFromArray(buf_HIGH,m_sbuf.High,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //---安値バッファ: _BufferFromArray(buf_LOW,m_sbuf.Low,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //---クローズバッファ: _BufferFromArray(buf_CLOSE,m_sbuf.Close,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //---時間バッファ: _BufferFromArray(buf_TIME,m_sbuf.Time,0,m_sbuf.Depth,CL_MEM_READ_ONLY); //--- Open (M1) buffer: _BufferFromArray(buf_OPEN_M1,m_tbuf.Open,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- High (M1) buffer: _BufferFromArray(buf_HIGH_M1,m_tbuf.High,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Low (M1) buffer: _BufferFromArray(buf_LOW_M1,m_tbuf.Low,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Close (M1) buffer: _BufferFromArray(buf_CLOSE_M1,m_tbuf.Close,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Spread (M1) buffer: _BufferFromArray(buf_SPREAD_M1,m_tbuf.Spread,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- Time (M1) buffer: _BufferFromArray(buf_TIME_M1,m_tbuf.Time,0,m_tbuf.Depth,CL_MEM_READ_ONLY); //--- copying successful return true; }
そのため、データはダウンロードされています。 今度は、テストアルゴリズムを実装します。
2.2.1 OpenCL でのパターンの検索
OpenCL のパターン定義コードは、MQL5 のコードとは大きく異なります。
//---パターン #define PAT_NONE 0 #define PAT_PINBAR_BEARISH (1<<0) #define PAT_PINBAR_BULLISH (1<<1) #define PAT_ENGULFING_BEARISH (1<<2) #define PAT_ENGULFING_BULLISH (1<<3) //---価格 #define O(i) Open[i] #define H(i) High[i] #define L(i) Low[i] #define C(i) Close[i] //+------------------------------------------------------------------+ //|パターンの存在をチェックする | //+------------------------------------------------------------------+ uint Check(__global double *Open,__global double *High,__global double *Low,__global double *Close,double ref,uint flags) { //---弱気ピンバー if((flags&PAT_PINBAR_BEARISH)!=0) {// double tail=H(1)-fmax(O(1),C(1)); if(tail>=ref && C(0)>O(0) && O(2)>C(2) && H(1)>fmax(H(0),H(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BEARISH; } //---強気ピンバー if((flags&PAT_PINBAR_BULLISH)!=0) {// double tail=fmin(O(1),C(1))-L(1); if(tail>=ref && O(0)>C(0) && C(2)>O(2) && L(1)<fmin(L(0),L(2)) && fabs(O(1)-C(1))<tail) return PAT_PINBAR_BULLISH; } //---弱気反転 if((flags&PAT_ENGULFING_BEARISH)!=0) {// if((C(1)-O(1))>=ref && H(0)<C(1) && O(2)>C(1) && C(2)<O(1)) return PAT_ENGULFING_BEARISH; } //---強気反転 if((flags&PAT_ENGULFING_BULLISH)!=0) {// if((O(1)-C(1))>=ref && L(0)>C(1) && O(2)<C(1) && C(2)>O(1)) return PAT_ENGULFING_BULLISH; } //---何も見つからない return PAT_NONE; }
小さな差として、バッファがレファレンスではなくポインタによって渡されることです。 また、時系列バッファがグローバルメモリにあることを示す __global 修飾子があります。 作成するすべての OpenCL バッファは、グローバルメモリに配置されています。
Check() 関数は、 find_patterns()カーネルを呼び出します。
__kernel void find_patterns(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global int *Order, //オーダーバッファ __global int *Count, //バッファ内のオーダー数 const double ref, //パターンパラメータ const uint flags) //検索するパターン { //---1つのディメンションで機能する //---足インデックス size_t x=get_global_id(0); //---パターン検索スペースのサイズ size_t depth=get_global_size(0)-PBARS; if(x>=depth) return; //---パターンが存在するかどうかを確認 uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref,flags); if(res==PAT_NONE) return; //---オーダーの設定 if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) {//売り int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL; } else if(res==PAT_PINBAR_BULLISH || res==PAT_ENGULFING_BULLISH) {//買い int i=atomic_inc(&Count[0]); Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_BUY; } }
パターンを検索し、特別に指定されたバッファ内のオーダーを見つけるために使用します。
find_patterns() カーネルは、1次元のタスク空間で動作します。 起動時に、ディメンション0のタスクスペースで指定するタスク項目の数を作成します。 この場合、現在の期間の足の数です。 どの足が処理されているかを理解するには、タスクインデックスを取得する必要があります。
size_t x=get_global_id(0);
ここで、ゼロは測定インデックスです。
Order[i*2]=x+PBARS; Order[(i*2)+1]=OP_SELL;
オーダーのシリアル番号を取得するには、atomic_inc() アトミック関数を使用します。 タスクを実行すると、すでに完了しているタスクとバーはわかりません。 並列計算であり、ここではシークエンスも全くありません。 タスクインデックスは、既に完了したタスクの数とは関係ありません。 したがって、バッファに既に配置されているオーダーの数はわかりません。 Count[] バッファのセル0にある番号を読み取ると、別のタスクが同時にそこに何かを書き込むことがあります。 これを避けるために、アトミック関数を使用します。
この場合、atomic_inc() 関数は、Count[0] セルへの他のタスクのアクセスを無効にします。 その後、1つずつ値が増加し、結果として前の値が返されます。
int i=atomic_inc(&Count[0]);
もちろん、他のタスクがCount[0] へのアクセスがブロックされるまで待たなければならないため、タスクが遅くなります。 しかし、場合によっては (今回のように)、他の解決策はありません。
すべてのタスクが完了した後、Count[0] セル内のオーダーとその数のバッファの形成されたオーダーを取得します。
2.2.2 M1 タイムフレームへのオーダーの移動
さて、現在の時間枠にパターンを発見したが、テストは M1 の時間枠で行われるべきです。 現在の期間に見つかったすべてのエントリポイントについて、M1 に適切な足があることを意味します。 トレードパターンは小さな時間枠でも比較的少数のエントリポイントを提供するので、かなり大まかでありながら適切な方法 (列挙) を選択します。 それぞれの M1 タイムフレーム足の時間と、見つかった各オーダーの時間を比較します。 これを行うには、order_to_M1() カーネルを作成します。
__kernel void order_to_M1(__global ulong *Time,__global ulong *TimeM1, __global int *Order,__global int *OrderM1, __global int *Count, const ulong shift) //秒単位のタイムシフト { //---2次元でのタスク size_t x=get_global_id(0); //時間インデックスのオーダー if(OrderM1[x*2]>=0) return; size_t y=get_global_id(1); //TimeM1 のインデックス if((Time[Order[x*2]]+shift)==TimeM1[y]) { atomic_inc(&Count[1]); //---偶数のインデックスによって TimeM1 バッファ内のインデックスを設定します。 OrderM1[x*2]=y; //---奇数のインデックスによって設定 (OP_BUY/OP_SELL) 操作 OrderM1[(x*2)+1]=Order[(x*2)+1]; } }
ここでは、2次元のタスクスペースがあります。 0の空間ディメンションは、配置されたオーダーの数と同じですが、スペース1の次元は M1 期間の足の数と等しくなります。 オーダーバーと m1 足のオープン時間が一致すると、現在のオーダーの操作が OrderM1 [] バッファにコピーされ、m1 期間の時系列で検出された足インデックスが設定されます。
一見して存在してはならない2つのことがあります。
- 最初のものは atomic_inc() アトミック関数であり、何らかの理由で M1 期間に見つかったエントリポイントをカウントします。 ディメンション0では、各オーダーはインデックスと連動しますが、インデックス1には複数の一致が存在することはできません。 共有アクセスの試行が完全に問題になっていることを意味します。 なぜ数える必要があるのでしょうか?
- 2つ目は、現在の期間足時間に追加された shift 引数です。
これには特別な理由があります。 世界は完璧ではありません。 01:00:00 のオープン時間と M5 チャート上の足の存在は、同じオープン時間の足が M1 チャート上に存在することを意味するものではありません。
M1 チャート上の適切な足は、01:01:00、または01:04:00 のいずれかのオープン時間を持つことがあります。 つまり、バリエーションの数は、時間枠の期間の比率です。 M1 に検出されたエントリポイントの数を数える関数はために導入されます:
atomic_inc(&Count[1]);
カーネル操作の完了後、見つかった M1 オーダーの数が現在のタイムフレームで検出されたオーダーの数と等しい場合、タスクは完全に完了します。 それ以外の場合は、別の shift 引数を指定して再起動する必要があります。 現在の期間に含まれる M1 期間の数と同数の再起動がある場合があります。
以下のチェックが導入され、ゼロ以外の shift 引数値を使用した再始動時に、検出されたインプット・ポイントが他の値によって書き直されないようになっています。
if(OrderM1[x*2]>=0) return;
動作させるには、カーネルを起動する前に、OrderM1 [] バッファに-1 をインプットしてください。 これを行うには、array_fill() バッファ塗りつぶしカーネルを作成します。
__kernel void array_fill(__global int *Buf,const int value) { //---1つのディメンションで動作 size_t x=get_global_id(0); Buf[x]=value; }
2.2.3 トレード結果の取得
M1 エントリポイントが見つかったら、トレード結果の取得を開始できます。 これを行うには、オープンポジションに付随するカーネルが必要です。 つまり、次の4つの理由のいずれかが終了するまで待つ必要があります。
- TPへの到達
- SLへの到達
- オープンポジション最大保持時間の満了
- テスト期間の終了
カーネルのタスクは1次元であり、そのサイズはオーダー数と同じです。 カーネルは、足を開いているポジションから開始し、上記の条件を確認します。 足の内部では、ドキュメントの「トレーディングストラテジーのテスト」セクションで説明されている "1 minute OHLC " モードでティックがシミュレートされるようになっています。
重要なことは、ポジションは、オープン直後に閉じられているか、後で閉じられるか、タイムアウトによって閉じられるか、またはテストが終了するということです。 異なるエントリポイントのタスク実行時間が大幅に異なることを意味します。
実際の練習では、1つのパスで閉じる前のポジションに付随することは効率的ではないことが示されています。 対照的に、テスト空間 (ポジション保持タイムアウトによる強制終了の前の足の数) を部分に分割し、パスでハンドリングを行うと、性能の面で有意に良好な結果が得られます。
現在のパスで完了していないタスクは、次のものまで延期されます。 したがって、タスクスペースのサイズは、パスごとに減少します。 ただし、実装するには、タスクのインデックスを格納する別のバッファを使用する必要があります。 各タスクは、オーダーバッファ内のエントリポイントのインデックスです。 最初の起動時に、タスクバッファの内容はオーダーバッファに完全に対応します。 次回の起動時には、オーダーのインデックスが含まれ、そのポジションはまだクローズされていません。 タスクバッファでタスクし、同時にそこに次の実行のタスクを格納するためには、2つのバンクを持っている必要があります: 1 つのバンクは、現在の起動時に使用され、別のは、次のものタスクを形成するために使用します。
実際のタスクでは、次のようになります。 トレード結果を取得する必要がある1000エントリポイントがあると仮定します。 オープンポジションの保持時間は、800足に相当します。 テストを4パスに分けることにしました。 図7に表示されているように見えます。
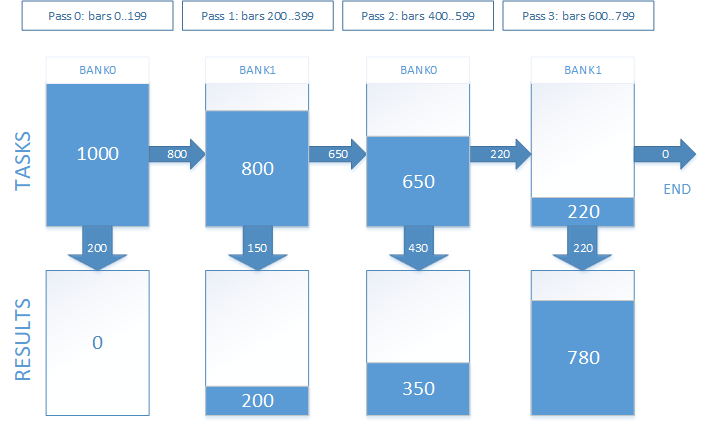
図7. 複数のパスでのオープンポジションの追跡
試行錯誤によって、12時間 (または720分足) のポジション保持タイムアウトに対して、最適なパス数が8になるように決定しました。 これがデフォルト値です。 異なるタイムアウト値と OpenCL デバイスによって異なります。 パフォーマンスを最大にするため、全体セクションが推奨されます。
したがって、Task[] バッファと扱うタスクバンクのインデックスは、時系列とは別にカーネルの引数に追加されます。 さらに、結果を保存するために Res [] バッファを追加します。
タスクバッファ内の実際のデータ量は、それぞれのバンクについて、2つの要素のサイズを持つ左 [] バッファを介して返されます。
テストは部品で実行されるため、ポジショントラッキングの開始足と終了小節の値は、カーネル引数の間で渡す必要があります。 時系列の現在の足の絶対インデックスを取得するために、ポジションの開始足のインデックスと合計される相対値です。 また、時系列の最大許容足インデックスは、バッファを超えないようにカーネルに渡す必要があります。
その結果、オープンポジションを追跡するための tester_step() カーネル引数のセットは次のようになります。
__kernel void tester_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1, //価格差は、ポイント単位ではありません __global ulong * TimeM1、 __global int *OrderM1, //オーダーバッファ、ここで、[0] は OHLC(M1) のインデックスであり、 [1] - (Buy/Sell) 操作 __global int *Tasks, //タスクバッファ (オープンポジション) OrderM1 バッファ内のオーダのインデックスを格納します。 __global int *Left, //残りのタスクの数、2つの要素: [0]-bank0、[1]-bank1 __global double *Res, //結果バッファ const uint bank, //現在のバンク const uint orders, //OrderM1 のオーダー数 const uint start_bar, //処理された足のシリアル番号 (OrderM1 の指定したインデックスからのシフトとして) const uint stop_bar, //処理される直近の足 const uint maxbar, //最大許容足インデックス (配列の直近の足) const doubleTP_dP, //価格差におけるTP const doubleSL_dP, //価格差のSL const ulong timeout) //強制的にトレードを閉じるとき (秒単位)
tester_step() カーネルは1次元で動作します。 ディメンションタスクのサイズは、各呼び出しで、各パスで減少するオーダーの数から 変わります。
カーネルコードの先頭にタスク ID を取得します。
size_t id=get_global_id(0);
次に、bank 引数を介して渡される現在のバンクのインデックスに基づいて、以下のインデックスを計算します。
uint bank_next=(bank)?0:1;
使用するオーダーのインデックスを計算します。 最初の起動 (start_bar がゼロに等しい場合) の間、タスクバッファはオーダーバッファに対応するため、order インデックスはタスクインデックスと等しくなります。 トレーリングの起動時に、現在のバンクとタスクインデックスを考慮して、タスクバッファから order インデックスが取得されます。
if(!start_bar) idx=id; else idx=Tasks[(orders*bank)+id];
オーダーのインデックスを知っている、時系列の足インデックスだけでなく、操作コードを取得します。
//---ポジションがバッファ M1 で開かれた足のインデックス uint iO=OrderM1[idx*2]; //---(OP_BUY/OP_SELL) 操作 uint op=OrderM1[(idx*2)+1];
timeout 引数の値に基づいて、強制ポジションクローズの時間を計算します。
ulong tclose=TimeM1[iO]+timeout;
その後、オープンポジションが処理されます。 例として BUY 操作を使用してを考えてみましょう (このケースはSELLに似ています)。
if(op==OP_BUY) { //---ポジション始値 double open=OpenM1[iO]+SpreadM1[iO]; doubleTP= open+tp_dP; double sl = open-sl_dP; double p=0; for(uint j=iO+start_bar; j<=(iO+stop_bar); j++) { for(uint k=0;k<4;k++) { if(k==0) { p=OpenM1[j]; if(j>=maxbar || TimeM1[j]>=tclose) { //---時間による強制決済 Res[idx]=p-open; return; } } else if(k==1) p=HighM1[j]; else if(k==2) p=LowM1[j]; else p=CloseM1[j]; //---TPまたは SL がトリガーされたかどうかを確認 if(p<=sl) { Res[idx]=sl-open; return; } else if(p>=tp) { Res[idx]=tp-open; return; } } } }
カーネルを終了するための条件がいずれもトリガーされない場合、タスクは次のパスまで延期されます。
uint i=atomic_inc(&Left[bank_next]);
Tasks[(orders*bank_next)+i]=idx;
すべてのパスを処理した後、Res [] バッファは、すべてのトレードの結果を格納します。 テスト結果を取得するには、合計する必要があります。
アルゴリズムが明確で、カーネルの準備ができたので、起動を開始する必要があります。
2.3 テストの起動
CTestPatterns クラスが役に立ちます。
class CTestPatterns : private COpenCLx { private: CBuffering *m_sbuf; //現在の期間の時系列 CBuffering *m_tbuf; //M1 期間の時系列 int m_prepare_passes; uint m_tester_passes; bool LoadTimeseries(datetime from,datetime to); bool LoadTimeseriesOCL(void); bool test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); bool optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); void buffers_free(void); public: CTestPatterns(); ~CTestPatterns(); //---単一のテストを起動する bool Test(STR_TEST_STAT &stat,datetime from,datetime to,STR_TEST_PARS &par); //---ローンチの最適化 bool Optimize(STR_TEST_STAT &stat,datetime from,datetime to,STR_OPT_PARS &par); //---プログラム実行統計へのポインタを取得する COCLStat *GetStat(void){return &m_stat;} //---直近のエラーのコードを取得します。 int GetLastError(void){return m_last_error.code;} //---直近のエラーの構造を取得する STR_ERROR GetLastErrorExt(void){return m_last_error;} //---直近のエラーをリセットする void ResetLastError(void); //---テストカーネルの起動が分割されるパスの数 void SetTesterPasses(uintTP){m_tester_passes=tp;} //---オーダー準備カーネルの起動が分割されるパスの数 void SetPrepPasses(int p){m_prepare_passes=p;} };
詳細については、Test() メソッドについて考えてみましょう。
bool CTestPatterns::Test(STR_TEST_RESULT &result,datetime from,datetime to,STR_TEST_PARS &par) { ResetLastError(); m_stat.Reset(); m_stat.time_total.Start(); //---時系列データのアップロード m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //---OpenCL の初期化 m_stat.time_ocl_init.Start(); if(Init(i_MODE_TESTER)==false) return false; m_stat.time_ocl_init.Stop(); //---テストを開始する bool result=test(stat,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return result; }
インプットでは、戦略をテストする必要がある日付範囲、およびパラメータとテスト結果の構造へのリンクがあります。
成功した場合、メソッドは "true " を返し、結果を ' result ' 引数に書き込みます。 実行中にエラーが発生した場合、メソッドは ' false ' を返します。 エラーの詳細を受信するには、 GetLastErrorExt()を呼び出します。
まず、時系列データをアップロードします。 次に OpenCL を初期化します。 オブジェクトとカーネルの作成が含まれます。 すべてが適切な場合は、テストアルゴリズム全体を含む test() メソッドを呼び出します。 事実、 Test()メソッドはtest()のラッパーです。 初期化解除が ' test ' メソッドからの任意の終了で実行され、時系列バッファがインプットされることを確認するために行われます。
test() メソッドでは、すべてが OpenCL バッファへの時系列バッファのアップロードから始まります。if(LoadTimeseriesOCL() ==false)returnfalse;
上記で説明した LoadTimeseriesOCL() メソッドを使用して行われます。
k_FIND_PATTERNS 列挙子が対応する find_patterns() カーネルが最初に起動されます。 起動する前に、オーダーと結果のバッファを作成する必要があります。
_BufferCreate(buf_ORDER,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
オーダーバッファのサイズは、現在の時間枠の足の数の2倍になります。 どれほど多くのパターンが見つかるかわからないので、各足にパターンがあると仮定します。 この予防措置は、現時点でタスクしているパターンを考えると、一見不合理に思えるかもしれません。 さらに、他のパターンを追加するときに、多くの問題を解決するかもしれません。
引数を設定します。
_SetArgumentBuffer(k_FIND_PATTERNS,0,buf_OPEN); _SetArgumentBuffer(k_FIND_PATTERNS,1,buf_HIGH); _SetArgumentBuffer(k_FIND_PATTERNS,2,buf_LOW); _SetArgumentBuffer(k_FIND_PATTERNS,3,buf_CLOSE); _SetArgumentBuffer(k_FIND_PATTERNS,4,buf_ORDER); _SetArgumentBuffer(k_FIND_PATTERNS,5,buf_COUNT); _SetArgument(k_FIND_PATTERNS,6,double(par.ref)*_Point); _SetArgument(k_FIND_PATTERNS,7,par.flags);
find_patterns() カーネルの場合は、最初のゼロオフセットを持つ1次元タスクスペースを設定します。
uint global_size[1]; global_size[0]=m_sbuf.Depth; uint work_offset[1]={0};
find_patterns() カーネルの実行を開始します。
_Execute(k_FIND_PATTERNS,1,work_offset,global_size);
Execute() メソッドを終了しても、プログラムが実行されるわけではないことに注意してください。 実行またはキューに入れられます。 現在のステータスを確認するには、 CLExecutionStatus()関数を使用します。 プログラムの完了を待つ必要がある場合は、その状態を定期的に調査するか、プログラムが結果を配置するバッファを読み取ることができます。 2番目のケースでは、BufferRead() バッファ読み取りメソッドで、プログラム完了の待機が発生します。
_BufferRead(buf_COUNT,count,0,0,2);
count [] バッファのインデックス0では、検出されたパターンの数、または対応するバッファにあるオーダーの数を見つけることができます。 次のステップは、M1 時間枠で対応するエントリポイントを見つけることです。 order_to_M1() カーネルは、検出された量をインデックス1の同じ count [] バッファに蓄積します。 (count[0]==count[1])条件のトリガは成功したと見なされます。
しかし、最初に M1 のオーダーのバッファを作成し、-1 の値で埋める必要があります。 既にオーダー数がわかっているので、マージンなしでバッファの正確なサイズを指定します。
int len=count[0]*2; _BufferCreate(buf_ORDER_M1,len*sizeof(int),CL_MEM_READ_WRITE);
array_fill() カーネルの引数を設定します。
_SetArgumentBuffer(k_ARRAY_FILL,0,buf_ORDER_M1); _SetArgument(k_ARRAY_FILL,1,int(-1));
初期シフトをゼロに、バッファサイズに等しいサイズの1次元タスクスペースを設定します。 実行の開始:
uint opt_init_work_size[1]; opt_init_work_size[0]=len; uint opt_init_work_offset[1]={0}; _Execute(k_ARRAY_FILL,1,opt_init_work_offset,opt_init_work_size);
次に、order_to_M1() カーネル実行の起動を準備する必要があります。
//---引数を設定する _SetArgumentBuffer(k_ORDER_TO_M1,0,buf_TIME); _SetArgumentBuffer(k_ORDER_TO_M1,1,buf_TIME_M1); _SetArgumentBuffer(k_ORDER_TO_M1,2,buf_ORDER); _SetArgumentBuffer(k_ORDER_TO_M1,3,buf_ORDER_M1); _SetArgumentBuffer(k_ORDER_TO_M1,4,buf_COUNT); //---k_ORDER_TO_M1 カーネルのタスク空間は2次元 uint global_work_size[2]; //---最初の次元は k_FIND_PATTERNS カーネルによって残されたオーダーで構成される global_work_size[0]=count[0]; //---2番目のディメンションは、すべての M1 チャート足で構成されます global_work_size[1]=m_tbuf.Depth; //---両方の次元のタスク空間における初期オフセットはゼロに等しい uint global_work_offset[2]={0,0};
インデックスが5の引数は、値が異なるため、カーネル実行の開始直前に設定されます。 上記の理由により、order_to_M1() カーネルの実行は、秒単位で異なるオフセット値で複数回実行されることがあります。 起動の最大数は、現在および M1 チャートの期間の比率によって制限されます。
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1);
ループ全体は次のようになります。
for(int s=0;s<maxshift;s++) { //---現在のパスのオフセットを設定する _SetArgument(k_ORDER_TO_M1,5,ulong(s*60)); //---カーネルを実行する _Execute(k_ORDER_TO_M1,2,global_work_offset,global_work_size); //---結果を読む _BufferRead(buf_COUNT,count,0,0,2); //---インデックス0では、現在のチャートのオーダー数を確認できます。 //--- at index 1, you can find the number of detected appropriate bars on М1 chart //---両方の値が一致すると、ループを終了します。 if(count[0]==count[1]) break; //---それ以外の場合は、次の反復に移動し、他のオフセットでカーネルを起動します。 } //---' break ' ではなくループを終了した場合に備えて、オーダーの数が再び有効であるかどうかを確認します。 if(count[0]!=count[1]) { SET_UERRt(UERR_ORDERS_PREPARE,"M1 orders preparation error"); return false; }
今では、検出されたエントリポイントによって開かれたトレードの結果を計算する tester_step() カーネルを起動する時間です。 まず、不足しているバッファを作成し、引数を設定してみましょう。
//---次のパスのタスク数が形成されるタスクバッファを作成する _BufferCreate(buf_TASKS,m_sbuf.Depth*2*sizeof(int),CL_MEM_READ_WRITE); //---トレード結果が格納される結果バッファを作成する _BufferCreate(buf_RESULT,m_sbuf.Depth*sizeof(double),CL_MEM_READ_WRITE); //---単一のテストカーネルの引数を設定する _SetArgumentBuffer(k_TESTER_STEP,0,buf_OPEN_M1); _SetArgumentBuffer(k_TESTER_STEP,1,buf_HIGH_M1); _SetArgumentBuffer(k_TESTER_STEP,2,buf_LOW_M1); _SetArgumentBuffer(k_TESTER_STEP,3,buf_CLOSE_M1); _SetArgumentBuffer(k_TESTER_STEP,4,buf_SPREAD_M1); _SetArgumentBuffer(k_TESTER_STEP,5,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_STEP,6,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_STEP,7,buf_TASKS); _SetArgumentBuffer(k_TESTER_STEP,8,buf_COUNT); _SetArgumentBuffer(k_TESTER_STEP,9,buf_RESULT); uint orders_count=count[0]; _SetArgument(k_TESTER_STEP,11,uint(orders_count)); _SetArgument(k_TESTER_STEP,14,uint(m_tbuf.Depth-1)); _SetArgument(k_TESTER_STEP,15, double(par.tp)*_Point); _SetArgument(k_TESTER_STEP,16, double(par.sl)*_Point); _SetArgument(k_TESTER_STEP,17,ulong(par.timeout));
次に、最大ポジション保持時間を M1 チャートの足の数に変換します。
uint maxdepth=(par.timeout/PeriodSeconds(PERIOD_M1))+1;
次に、指定された数のカーネル実行パスが有効かどうかを確認します。 デフォルトでは8に等しくなりますが、さまざまな OpenCL デバイスの最適パフォーマンスを定義するために、 SetTesterPasses()メソッドを使用して他の値を設定することができます。
if(m_tester_passes<1) m_tester_passes=1; if(m_tester_passes>maxdepth) m_tester_passes=maxdepth; uint step_size=maxdepth/m_tester_passes;
単一ディメンションのタスクスペースサイズを設定し、トレード結果計算ループを起動します。
global_size[0]=orders_count; m_stat.time_ocl_test.Start(); for(uint i=0;i<m_tester_passes;i++) { //---現在のバンクインデックスを設定する _SetArgument(k_TESTER_STEP,10,uint(i&0x01)); uint start_bar=i*step_size; //---現在のパスのテストを開始する足のインデックスを設定します。 _SetArgument(k_TESTER_STEP,12,start_bar); //---現在のパスでテストが実行される直近の足のインデックスを設定します。 uint stop_bar=(i==(m_tester_passes-1))?(m_tbuf.Depth-1):(start_bar+step_size-1); _SetArgument(k_TESTER_STEP,13,stop_bar); //---次のバンクのタスク数をリセットする //---次のパスの残りのオーダー数を格納する count[(~i)&0x01]=0; _BufferWrite(buf_COUNT,count,0,0,2); //---テストカーネルを起動する _Execute(k_TESTER_STEP,1,work_offset,global_size); //---次のパスの残りのオーダー数を読み取る _BufferRead(buf_COUNT,count,0,0,2); //---オーダー数に等しい新しいタスク数を設定する global_size[0]=count[(~i)&0x01]; //---タスクが残っていない場合は、ループを終了します。 if(!global_size[0]) break; } m_stat.time_ocl_test.Stop();
トレード結果を読み取るためのバッファを作成します。
double Result[]; ArrayResize(Result,orders_count); _BufferRead(buf_RESULT,Result,0,0,orders_count);
組み込みの teste と同等の結果を得るには、読み取り値を _Point に分割する必要があります。 結果と統計量の計算コードは、次のとおりです。
m_stat.time_proc.Start(); result.trades_total=0; result.gross_loss=0; result.gross_profit=0; result.net_profit=0; result.loss_trades=0; result.profit_trades=0; for(uint i=0;i<orders_count;i++) { double r=Result[i]/_Point; if(r>=0) { result.gross_profit+=r; result.profit_trades++; }else{ result.gross_loss+=r; result.loss_trades++; } } result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; m_stat.time_proc.Stop();
テスターを起動できる短いスクリプトを書いてみましょう。
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatternsTPat; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //---テストパラメータの設定 STR_TEST_PARS pars; pars.ref= 60; pars.SL= 350; pars.TP= 50; pars.flags=15; //すべてのパターン pars.timeout=12*3600; //---結果の構造 STR_TEST_RESULT res; //---テストを開始する tpat.Test(res,from,to,pars); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //---テスト結果 Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //---実行統計 COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
適用されたテスト時間範囲、シンボル、および期間は、MQL5 で実装されたEAをテストするためにすでに使用したものです。 適用されたレファレンスと ストップロス レベルの値は、最適化中に見つかったものです。 ここでは、スクリプトを実行し、取得した結果をビルトインテスターのものと比較するだけです。
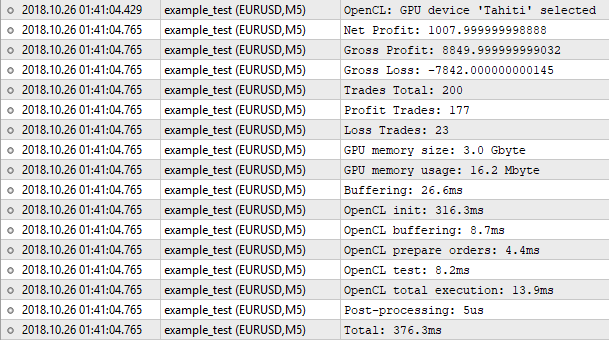
図8. OpenCL に実装されたテスターの結果
したがって、トレードの数は同じであり、純利益の値は同じではありません。 ビルトインテスターは1000.50 の数を示し、テスターは1007.99になります。 その理由は以下の通りです。 同じ結果を得るためには、他の間でスワップを考慮する必要があります。 しかし、テスターに実装することは正当化されません。 大まかなクオートでは、 "1 分 OHLC " モードが適用されるので、このようなささいなことは無視できます。 重要なことは、結果が近いということです, これはアルゴリズムが正しく動作することを意味します。
次に、プログラムの実行統計を見てみましょう。 16 MB のメモリのみが使用されました。 OpenCL の初期化にほとんど時間がかかりました。 全体のプロセスは、ビルトインテスターにほぼ似ている376ミリ秒を要しました。 ここでパフォーマンスの利得を期待することは無意味です。. 200のトレードでは、初期化、バッファのコピーなどの準備操作により多くの時間を費やすことになります。 差を感じるためには、テストに数百倍以上のオーダーが必要です。 さて、最適化に移る時間です。
2.4. 最適化
最適化アルゴリズムは、1つの基本的な差を持つ単一のテストアルゴリズムに似ています。 テスターではパターンを検索し、トレード結果をカウントしますが、ここではアクションのシーケンスが異なります。 まず、トレード結果を数え、その後のパターンの検索を開始します。 その理由は、2つの最適化されたパラメータがあることです。 最初は、パターンを見つけるためのレファレンス値です。 2つ目は、トレード結果の計算に参加する ストップロス レベルです。 したがって、そのうちの1つはエントリポイントの数に影響し、2つ目はトレード結果とオープンポジションの追跡期間に影響を与えます。 単一のテストアルゴリズムの場合と同じ一連のアクションを保持する場合、300ポイントの "tail" を持つピンバーは、この値以下の任意のレファレンス値で検出されるため、同じエントリポイントの再テストによって時間が大幅に失われるのを回避できません。
したがって、各足でのエントリポイント (買いと売りの両方を含む) でトレードの結果を計算し、パターン検索中にデータを操作する方がはるかに合理的です。 最適化中のアクションのオーダーは次のようになります。
- 時系列バッファのダウンロード
- OpenCL の初期化
- OpenCL バッファへの時系列バッファのコピー
- オーダー準備カーネルの起動 (2 つのオーダー-現在の時間枠の各足ごとに売買します)
- M1 チャートにオーダーを移動するカーネルの起動
- オーダー別のトレード結果をカウントするカーネルの起動
- パターンを発見し、既製のトレード結果から最適化されたパラメータの各組み合わせのテスト結果を形成するカーネルを起動します。
- 結果バッファの処理と最適な結果に一致する最適化されたパラメータの検索
- Deinitializing OpenCL
- 時系列バッファの削除
さらに、パターンを検索するためのタスクの数にレファレンス変数値の数を乗算し、トレード結果を計算するためのタスクの数に ストップロス レベル値の数を乗算します。
2.4.1 オーダーの準備
希望のパターンは、任意の足で見つけることができると仮定します。 つまり、各足に買いオーダーまたは売りオーダーを配置する必要があります。 バッファサイズは、次の式で定義できます。
N = Depth*4*SL_count;
Depthは時系列バッファのサイズであり、SL_count は ストップロス 値の数です。
また、足のインデックスは M1 の時系列からのものでなければなりません。 tester_opt_prepare()カーネルは、現在の期間の足の開始時間に対応するオープン時間で M1 足の時系列を検索し、上で指定された形式でオーダーバッファに配置します。 一般的に、その動作は order_to_M1() カーネルのものに似ています。
__kernel void tester_opt_prepare(__global ulong *Time,__global ulong *TimeM1, __global int *OrderM1,//オーダーバッファ __global int *Count, const int SL_count, //SL値の数 const ulong shift) //秒単位のタイムシフト { //---2次元でのタスク size_t x=get_global_id(0); //時間インデックス if(OrderM1[x*SL_count*4]>=0) return; size_t y=get_global_id(1); //TimeM1 のインデックス if((Time[x]+shift)==TimeM1[y]) { //--- find the maximum bar index for М1 period along the way atomic_max(&Count[1],y); uint offset=x*SL_count*4; for(int i=0;i<SL_count;i++) { uint idx=offset+i*4; //---各足に2つのオーダー (売買) を追加する OrderM1[idx++]=y; OrderM1[idx++]=OP_BUY |(i<<2); OrderM1[idx++]=y; OrderM1[idx] =OP_SELL|(i<<2); } atomic_inc(&Count[0]); } }
しかし、M1 時系列の最大インデックスを見つけるという重要な差が1つあります。 なぜこれが行われるのか説明しましょう。
1つのパスをテストする場合、比較的少数のオーダーを処理します。 M1 時系列のバッファのサイズを乗算したオーダー数に等しいタスクの数も比較的小さいです。 テストを実行したデータを考慮する場合、最終的に5580万タスクを提供する 279 039 м1足を乗じた200のオーダーです。
現在の状況では、タスクの数は大きくなります。 たとえば、279 039 M1 足には現在の期間 (M5) の 55 843 足が乗算され、156億 タスクです。 また、別のタイムシフト値でこのカーネルを再度実行する必要があることを考慮する価値があります。 列挙メソッドは、ここではリソースを大量に消費します。
この問題を解決するには、現在の期間足の処理範囲を部分に分割しますが、列挙はそのままにします。 また、適切な分足の範囲を制限する必要があります。 ただし、分足の上の境界線の計算されたインデックス値は、ほとんどの場合、実際のものを超えますので、この時点から次のパスを開始するためにCount[1] の後に分足の最大インデックスを返します。
2.4.2 トレード結果の取得
オーダーを準備した後、トレード結果の受け取りを開始する時間です。
tester_opt_step()カーネルはtester_step()によく似ています。 したがって、主に相違点に焦点を当てたコード全体を提供することはありません。 まず、インプットが変更されました。
__kernel void tester_opt_step(__global double *OpenM1,__global double *HighM1,__global double *LowM1,__global double *CloseM1, __global double *SpreadM1,//価格差では、ポイントではありません __global ulong * TimeM1、 __global int *OrderM1, //オーダーバッファ、ここで、[0] は OHLC のインデックスであり、[1] - (Buy/Sell) 操作 __global int *Tasks, //タスクのバッファ (オープンポジション) OrderM1 バッファ内のオーダのインデックスを格納する __global int *Left, //残りのタスクの数、2つの要素: [0]-bank0、[1]-bank1 __global double *Res, //受信されるとすぐに満たされた結果のバッファ、 const uint bank, //現在のバンク const uint orders, //OrderM1 のオーダー数 const uint start_bar, //処理された足のシリアル番号 (OrderM1 の指定したインデックスからのシフトとして)-実際には、カーネルを起動するループからの「i」 const uint stop_bar, //処理される直近の足。一般に、「bar」に等しい const uint maxbar, //最大許容足インデックス (配列の直近の足) const doubleTP_dP, //価格差におけるTP const uintSL_start, //ポイント内のSL - 初期値 const uintSL_step, //ポイントのSL - ステップ const ulong timeout, //トレードの有効期間 (秒)、その後、強制的に閉じられます const double point) //_Point
価格差で表される ストップロス レベル値を渡すために使用するSL_dP 引数の代わりに、sl_start とSL_step、および ' point ' 引数の2つの引数があります。 SLレベルの値を計算するには、次の式を適用する必要があります。
SL= (sl_start+sl_step*sli)*point;
ここで、sli は、オーダーに含まれる ストップロス インデックスの値です。
2つ目の差は、オーダーバッファからSLi インデックスを受信するコードです。
//---オペレーション (ビット 1:0) と ストップロス インデックス (ビット 9:2) uint opsl=OrderM1[(idx*2)+1]; //---SLインデックスを取得する uintSLi=opsl>>2;
残りのコードは tester_step() カーネルと同じです。
実行後、各足の売買結果と Res[] バッファ内の各 ストップロス 値を取得します。
2.4.3 パターンの検索とテスト結果の形成
テストとは異なり、ここでは、MQL コードではなく、カーネルで直接トレードの結果を要約します。 しかし、不愉快な欠点があります。結果を整数型に変換しなければならないので、必ず正確さが失われます。 したがって、point 引数では、 _Point値を100で割って渡す必要があります。
結果を ' int ' 型に強制的に変換することは、アトミック関数が ' double ' 型では動作しないという事実によるものです。 atomic_add()は、結果を合計するために使用します。
find_patterns_opt()カーネルは、3次元のタスク空間で動作します。
- ディメンション 0: 現在のタイムフレームの足インデックス
- 分析コード 1: パターンのレファレンス値インデックス
- 分析コード 2: ストップロス レベル値インデックス
タスクの過程で、結果のバッファが生成されます。 バッファには、SLレベルとレファレンス値の組み合わせごとの検定統計量があります。 テスト統計は、次の値を含む構造体です。
- 総利益
- 総損失
- 収益性の高いトレードの数
- 損失のトレードの数
すべて「int」型です。 これらに基づいて、また、純利益とトレードの合計数を計算することができます。 カーネルコードは以下に提供されています:
__kernel void find_patterns_opt(__global double *Open,__global double *High,__global double *Low,__global double *Close, __global double *Test, //各足のテスト結果のバッファ、サイズ 2 * x は、[0]-buy, [1]-sell ... __global int *Results, //結果バッファサイズ 4 * y * z const double ref_start, //パターンパラメータ const double ref_step, // const uint flags, //検索するパターン const double point) //_Point/100 { //---3次元で動作 //---足インデックス size_t x=get_global_id(0); //---ref 値インデックス size_t y=get_global_id(1); //---SL値インデックス size_t z=get_global_id(2); //---足の数 size_t x_sz=get_global_size(0); //---ref 値の数 size_t y_sz=get_global_size(1); //---SL値の数 size_t z_sz=get_global_size(2); //---パターン検索スペースのサイズ size_t depth=x_sz-PBARS; if(x>=depth)//バッファ端付近を開かない return; // uint res=Check(&Open[x],&High[x],&Low[x],&Close[x],ref_start+ref_step*y,flags); if(res==PAT_NONE) return; //---Test[] バッファ内のトレード結果インデックスを計算します。 int ri; if(res==PAT_PINBAR_BEARISH || res==PAT_ENGULFING_BEARISH) //売り ri = (x+PBARS)*z_sz*2+z*2+1; else //買い ri=(x+PBARS)*z_sz*2+z*2; //---計算されたインデックスによって結果を取得し、セントに変換します int r=Test[ri]/point; //---Result[] バッファ内のテスト結果のインデックスを計算する int idx=z*y_sz*4+y*4; //---現在のパターンにトレード結果を追加する if(r>=0) {//---利益 //---総利益をセントで合計する atomic_add(&Results[idx],r); //---収益性の高いトレードの数を増やす atomic_inc(&Results[idx+2]); } else {//---損失 //---総損失をセントで合計する atomic_add(&Results[idx+1],r); //---損失のトレードの数を増やす atomic_inc(&Results[idx+3]); } }
引数の Test [] バッファは、 tester_opt_step()カーネルを実行した後に得られる結果です。
2.5 ロンチング最適化
最適化中に MQL5 からカーネルを起動するコードは、テストプロセスと同様に構築されます。 Optimize() public メソッドは、カーネルの準備と起動のオーダーが実装されているオプティマイズ()メソッドのラッパーです。
bool CTestPatterns::Optimize(STR_TEST_RESULT &result,datetime from,datetime to,STR_OPT_PARS &par) { ResetLastError(); if(par.sl.step<=0 || par.sl.stop<par.sl.start || par.ref.step<=0 || par.ref.stop<par.ref.start) { SET_UERR (UERR_OPT_PARS、 "最適化パラメータが正しくありません ")。 return false; } m_stat.Reset(); m_stat.time_total.Start(); //---時系列データのアップロード m_stat.time_buffering.Start(); if(LoadTimeseries(from,to)==false) return false; m_stat.time_buffering.Stop(); //---OpenCL の初期化 m_stat.time_ocl_init.Start(); if(Init(i_MODE_OPTIMIZER)==false) return false; m_stat.time_ocl_init.Stop(); //---ローンチの最適化 bool res=optimize(result,from,to,par); Deinit(); buffers_free(); m_stat.time_total.Stop(); return res; }
各項目を詳細に検討するつもりはありません。 その代わりに、特にtester_opt_prepare()カーネルを起動するという差だけに注目してみましょう。
最初に、処理された足の数を管理し、M1 足の最大インデックスを返すためのバッファを作成します。
int count[2]={0,0}; _BufferFromArray(buf_COUNT,count,0,2,CL_MEM_READ_WRITE);
次に、タスクスペースの引数とサイズを設定します。
_SetArgumentBuffer(k_TESTER_OPT_PREPARE,0,buf_TIME); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,1,buf_TIME_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,2,buf_ORDER_M1); _SetArgumentBuffer(k_TESTER_OPT_PREPARE,3,buf_COUNT); _SetArgument(k_TESTER_OPT_PREPARE,4,int(slc)); //SL値の数 //---k_TESTER_OPT_PREPARE カーネルは2次元タスク空間を持つ uint global_work_size[2]; //---0分析コード-現在の期間オーダー global_work_size[0]=m_sbuf.Depth; //--- 1 st dimension - all М1 bars global_work_size[1]=m_tbuf.Depth; //---最初の起動では、タスクスペースのオフセットを両方のディメンションのゼロに等しくなるように設定します。 uint global_work_offset[2]={0,0};
タスクスペースの 1 st 次元のオフセットは、足の一部を処理した後に増加します。 その値は、カーネルを1増やして返すм 1 bar の最大値と等しくなります。
int maxshift=PeriodSeconds()/PeriodSeconds(PERIOD_M1); int prep_step=m_sbuf.Depth/m_prepare_passes; for(int p=0;p<m_prepare_passes;p++) { //現在の期間タスクスペースのオフセット global_work_offset[0]=p*prep_step; //M1 期間タスク・スペースのオフセット global_work_offset[1]=count[1]; //現在の期間のタスクのサイズ global_work_size[0]=(p<(m_prepare_passes-1))?prep_step:(m_sbuf.Depth-global_work_offset[0]); //M1 期間のタスクのサイズ uint sz=maxshift*global_work_size[0]; uint sz_max=m_tbuf.Depth-global_work_offset[1]; global_work_size[1]=(sz>sz_max)?sz_max:sz; // count[0]=0; _BufferWrite(buf_COUNT,count,0,0,2); for(int s=0;s<maxshift;s++) { _SetArgument(k_TESTER_OPT_PREPARE,5,ulong(s*60)); //---カーネルの実行 _Execute(k_TESTER_OPT_PREPARE,2,global_work_offset,global_work_size); //---結果を読む (数は m_sbuf.Depth と一致する必要があります。 _BufferRead(buf_COUNT,count,0,0,2); if(count[0]==global_work_size[0]) break; } count[1]++; } if(count[0]!=global_work_size[0]) { SET_UERRt(UERR_ORDERS_PREPARE,"Failed to prepare M1 orders"); return false; }
m_prepare_passesパラメータは、オーダー準備が分割されるパスの数を意味します。 デフォルトでは、その値は64ですが、 SetPrepPasses()メソッドを使用して変更することができます。
OptResults [] バッファ内のテスト結果を読み取った後、最適化されたパラメータの組み合わせに対して検索が行われるので、最大の純利益につながります。
int max_profit=-2147483648; uint idx_ref_best= 0; uint idx_sl_best = 0; for(uint i=0;i<refc;i++) for(uint j=0;j<slc;j++) { uint idx=j*refc*4+i*4; int profit=OptResults[idx]+OptResults[idx+1]; //sum+=profit; if(max_profit<profit) { max_profit=profit; idx_ref_best= i; idx_sl_best = j; } }
その後、結果を ' double ' で再計算し、最適化されたパラメータの望ましい値を適切な構造に設定します。
uint idx=idx_sl_best*refc*4+idx_ref_best*4; result.gross_profit=double(OptResults[idx])/100; result.gross_loss=double(OptResults[idx+1])/100; result.profit_trades=OptResults[idx+2]; result.loss_trades=OptResults[idx+3]; result.trades_total=result.loss_trades+result.profit_trades; result.net_profit=result.gross_profit+result.gross_loss; //--- par.ref.value= int(par.ref.start+idx_ref_best*par.ref.step); par.sl.value = int(par.sl.start+idx_sl_best*par.sl.step);
「int」を「double」に変換することと、その逆は、単一のテストで得られたものとは若干異なる結果になることに注意してください。
最適化を起動するための小さなスクリプトを記述します。
#include <OCL_Patterns\TestPatternsOCL.mqh> CTestPatternsTPat; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { datetime from=D'2018.01.01 00:00'; datetime to=D'2018.10.01 00:00'; //---最適化パラメータの設定 STR_OPT_PARS optpar; optpar.ref.start = 15; optpar.ref.step = 5; optpar.ref.stop = 510; optpar.sl.start = 15; optpar.sl.step = 5; optpar.sl.stop = 510; optpar.flags=15; optpar.tp=50; optpar.timeout=12*3600; //---結果の構造 STR_TEST_RESULT res; //---ローンチの最適化 tpat.Optimize(res,from,to,optpar); STR_ERROR oclerr=tpat.GetLastErrorExt(); if(oclerr.code) { Print(oclerr.comment); Print("code = ",oclerr.code,", function = ",oclerr.function,", line = ",oclerr.line); return; } //---最適化されたパラメータの値 Print("Ref: ",optpar.ref.value,",SL: ",optpar.sl.value); //---テスト結果 Print("Net Profit: ", res.net_profit); Print("Gross Profit: ", res.gross_profit); Print("Gross Loss: ", res.gross_loss); Print("Trades Total: ", res.trades_total); Print("Profit Trades: ",res.profit_trades); Print("Loss Trades: ", res.loss_trades); //---実行統計 COCLStat ocl_stat=tpat.GetStat(); Print("GPU memory size: ", ocl_stat.gpu_mem_size.ToStr()); Print("GPU memory usage: ", ocl_stat.gpu_mem_usage.ToStr()); Print("Buffering: ", ocl_stat.time_buffering.ToStr()); Print("OpenCL init: ", ocl_stat.time_ocl_init.ToStr()); Print("OpenCL buffering: ", ocl_stat.time_ocl_buf.ToStr()); Print("OpenCL prepare orders: ", ocl_stat.time_ocl_orders.ToStr()); Print("OpenCL test: ", ocl_stat.time_ocl_test.ToStr()); Print("OpenCL total execution: ",ocl_stat.time_ocl_exec.ToStr()); Print("Post-processing: ", ocl_stat.time_proc.ToStr()); Print("Total: ", ocl_stat.time_total.ToStr()); }
インプットは、ビルトインテスターで最適化するときに使用したものと同じです。 起動の実行:
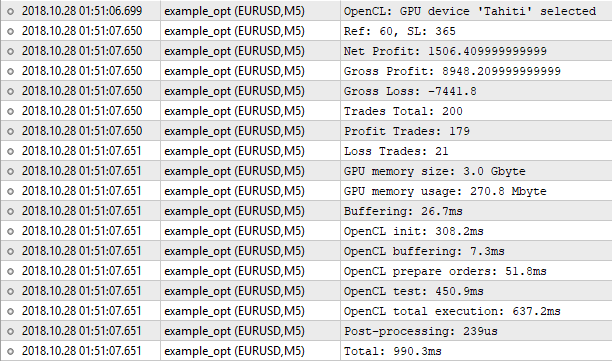
図9. OpenCL テスターでの最適化
ご覧の通り、結果は、ビルトインテスターのものと一致しません。 なぜでしょうか。 「double」を「int」に変換する際の精度の低下と、その逆は、ここで決定的な役割を果たす可能性があるでしょうか。 理論的には、結果が小数点の後の分数で異なっている場合に起こる可能性があります。 しかし、この差は重要です。
ビルトインテスターは1000.50 の純利益の Ref = 60 および ストップロス = 350 を示します。 OpenCL テスターは、1506.40 の純利益で Ref = 60 と ストップロス = 365 を表示します。 OpenCL テスターによって検出された値を使用して、通常のテスターを実行してみましょう。

図10. OpenCL テスターが見つけた最適化結果の確認
結果は我々のものとよく似ています。 よって、正確さの損失ではありません。 遺伝的アルゴリズムは、最適化されたパラメータのこの組み合わせをスキップしました。 パラメータの完全な列挙を使用して、低速の最適化モードでビルトインテスターを起動してみましょう。
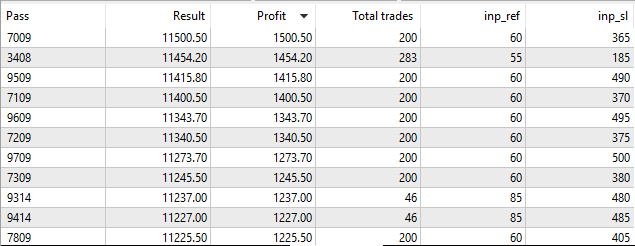
図11. 低速最適化モードでの組み込みストラテジーテスターの起動
ご覧の通り、パラメータの完全な列挙の場合、ビルトインテスターは、OpenCL テスターとして、Ref = 60 と ストップロス = 365 と同じ望ましい値を見つけます。 実装した最適化アルゴリズムが正しく動作することを意味します。
3. パフォーマンスの比較
さて、ビルトインと OpenCL テスターのパフォーマンスを比較しましょう。
上記のストラテジーのパラメータの最適化に費やされた時間を比較します。 ビルトインテスターは、高速 (遺伝的アルゴリズム) とスロー最適化 (パラメータの完全な列挙) の2つのモードで起動されます。 起動は、次の特性を持つ PC 上で実行されます。
| オペレーティング システム |
ウィンドウズ 10 (ビルド 17134) x64 |
| CPU |
AMD FX-8300 8-コアプロセッサ、3600MHz |
| RAM |
24 574 メガバイト |
| メタトレーダーがインストールされています |
HDD |
テストエージェントには、8つのうち6つのコアが割り当てられます。
OpenCL テスターはAMD Radeon HD 7950ビデオ 3gb RAM と 800Mhz GPU 周波数で起動されます。
最適化は、EURUSD、GBPUSD および USDJPY の3つのペアで実行されます。 各ペアでは、最適化モードごとに4つの時間範囲に対して最適化が実行されます。 次の略語を使用します。
| 最適化モード |
詳細 |
|---|---|
| テスター高速 |
組み込みストラテジーテスター、遺伝的アルゴリズム |
| テスタースロー |
組み込みストラテジーテスター、パラメータの完全な列挙 |
| テスト OpenCL |
OpenCL を使用して実装されるテスター |
テスト範囲の指定:
| 期間 |
時間範囲 |
|---|---|
| 1ヶ月 |
2018.09.01 ・2018.10.01 |
| 3ヶ月 |
2018.07.01 ・2018.10.01 |
| 6ヶ月 |
2018.04.01 ・2018.10.01 |
| 9ヶ月 |
2018.01.01 ・2018.10.01 |
最も重要な結果は、希望のパラメータ、純利益、トレード数と最適化時間の値です。
3.1. EURUSD の最適化
H1、1ヶ月:
| 結果 |
テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス |
15 |
15 |
15 |
| ストップロス |
330 |
510 |
500 |
| 純利益 |
942.5 |
954.8 |
909.59 |
| トレード数 |
48 |
48 |
47 |
| 最適化期間 |
10秒 |
6分2秒 |
405.8 ミリ秒 |
H1、3ヶ月:
| 結果 | テスター高速 |
テスタースロー | テスト OpenCL |
|---|---|---|---|
| レファレンス | 50 |
65 |
70 |
| ストップロス | 250 |
235 |
235 |
| 純利益 | 1233.8 |
1503.8 |
1428.35 |
| トレード数 | 110 |
89 |
76 |
| 最適化期間 | 9 sec |
8分8秒 |
457.9 ミリ秒 |
H1、6ヶ月:
| 結果 | テスター高速 | テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 15 |
20 |
20 |
| ストップロス | 455 |
435 |
435 |
| 純利益 | 1641.9 |
1981.9 |
1977.42 |
| トレード数 | 325 |
318 |
317 |
| 最適化期間 | 15秒 |
11分13秒 |
405.5 ミリ秒 |
H1、9ヶ月:
| 結果 | テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 15 |
15 |
15 |
| ストップロス | 440 |
435 |
435 |
| 純利益 | 1162.0 |
1313.7 |
1715.77 |
| トレード数 | 521 |
521 |
520 |
| 最適化期間 | 20秒 |
16分44秒 |
438.4 ミリ秒 |
M5、1ヶ月:
| 結果 |
テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス |
135 |
45 |
45 |
| ストップロス |
270 |
205 |
205 |
| 純利益 |
47 |
417 |
419.67 |
| トレード数 |
1 |
39 |
39 |
| 最適化期間 |
7 sec |
9分27秒 |
418ミリ秒 |
M5、3ヶ月:
| 結果 | テスター高速 |
テスタースロー | テスト OpenCL |
|---|---|---|---|
| レファレンス | 120 |
70 |
70 |
| ストップロス | 440 |
405 |
405 |
| 純利益 | 147 |
342 |
344.85 |
| トレード数 | 3 |
16 |
16 |
| 最適化期間 | 11秒 |
8分25秒 |
585.9 ミリ秒 |
M5、6ヶ月:
| 結果 | テスター高速 | テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 85 |
70 |
70 |
| ストップロス | 440 |
470 |
470 |
| 純利益 | 607 |
787 |
739.6 |
| トレード数 | 22 |
47 |
46 |
| 最適化期間 | 21秒 |
12分03秒 |
796.3 ミリ秒 |
M5、9ヶ月:
| 結果 | テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 60 |
60 |
60 |
| ストップロス | 495 |
365 |
365 |
| 純利益 | 1343.7 |
1500.5 |
1506.4 |
| トレード数 | 200 |
200 | 200 |
| 最適化期間 | 20秒 |
16分44秒 |
438.4 ミリ秒 |
3.2. GBPUSD の最適化
H1、1ヶ月:
| 結果 |
テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス |
175 |
90 |
90 |
| ストップロス |
435 |
185 |
185 |
| 純利益 |
143.40 |
173.4 |
179.91 |
| トレード数 |
3 |
13 |
13 |
| 最適化期間 |
10秒 |
4分33秒 |
385.1 ミリ秒 |
H1、3ヶ月:
| 結果 | テスター高速 |
テスタースロー | テスト OpenCL |
|---|---|---|---|
| レファレンス | 175 |
145 |
145 |
| ストップロス | 225 |
335 |
335 |
| 純利益 | 93.40 |
427 |
435.84 |
| トレード数 | 13 |
19 |
19 |
| 最適化期間 | 12秒 |
7分37秒 |
364.5 ミリ秒 |
H1、6ヶ月:
| 結果 | テスター高速 | テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 165 |
170 |
165 |
| ストップロス | 230 |
335 | 335 |
| 純利益 | 797.40 |
841.2 |
904.72 |
| トレード数 | 31 |
31 |
32 |
| 最適化期間 | 18秒 |
11分3秒 |
403.6 ミリ秒 |
H1、9ヶ月:
| 結果 | テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 165 |
165 | 165 |
| ストップロス | 380 |
245 |
245 |
| 純利益 | 1303.8 |
1441.6 |
1503.33 |
| トレード数 | 74 |
74 |
75 |
| 最適化期間 | 24秒 |
19分23秒 |
428.5 ミリ秒 |
M5、1ヶ月:
| 結果 |
テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス |
335 |
45 |
45 |
| ストップロス |
450 |
485 |
485 |
| 純利益 |
50 |
484.6 |
538.15 |
| トレード数 |
1 |
104 |
105 |
| 最適化期間 |
12秒 |
9分42秒 |
412.8 ミリ秒 |
M5、3ヶ月:
| 結果 | テスター高速 |
テスタースロー | テスト OpenCL |
|---|---|---|---|
| レファレンス | 450 | 105 |
105 |
| ストップロス | 440 | 240 |
240 |
| 純利益 | 0 |
220 |
219.88 |
| トレード数 | 0 |
16 |
16 |
| 最適化期間 | 15秒 |
8分17秒 |
552.6 ミリ秒 |
M5、6ヶ月:
| 結果 | テスター高速 | テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 510 |
105 |
105 |
| ストップロス | 420 |
260 |
260 |
| 純利益 | 0 |
220 |
219.82 |
| トレード数 | 0 |
23 |
23 |
| 最適化期間 | 24秒 |
14分58秒 |
796.5 ミリ秒 |
M5、9ヶ月:
| 結果 | テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 185 |
195 |
185 |
| ストップロス | 205 |
160 |
160 |
| 純利益 | 195 |
240 |
239.92 |
| トレード数 | 9 |
9 |
9 |
| 最適化期間 | 25秒 |
20分58秒 |
4.4 ミリ秒 |
3.3. USDJPY の最適化
H1、1ヶ月:
| 結果 |
テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス |
60 |
50 |
50 |
| ストップロス |
425 |
510 |
315 |
| 純利益 |
658.19 |
700.14 |
833.81 |
| トレード数 |
18 |
24 |
24 |
| 最適化期間 |
6 sec |
4分33秒 |
387.2 ミリ秒 |
H1、3ヶ月:
| 結果 | テスター高速 |
テスタースロー | テスト OpenCL |
|---|---|---|---|
| レファレンス | 75 |
55 |
55 |
| ストップロス | 510 |
510 |
460 |
| 純利益 | 970.99 |
1433.95 |
1642.38 |
| トレード数 | 50 |
82 |
82 |
| 最適化期間 | 10秒 |
6分32秒 |
369ミリ秒 |
H1、6ヶ月:
| 結果 | テスター高速 | テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 150 |
150 |
150 |
| ストップロス | 345 |
330 |
330 |
| 純利益 | 273.35 |
287.14 |
319.88 |
| トレード数 | 14 |
14 |
14 |
| 最適化期間 | 17秒 |
11分25秒 |
409.2 ミリ秒 |
H1、9ヶ月:
| 結果 | テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 190 |
190 |
190 |
| ストップロス | 425 |
510 |
485 |
| 純利益 | 244.51 |
693.86 |
755.84 |
| トレード数 | 16 |
16 |
16 |
| 最適化期間 | 24秒 |
17分47秒 |
445.3 ミリ秒 |
M5、1ヶ月:
| 結果 |
テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス |
30 |
35 |
35 |
| ストップロス |
225 |
100 |
100 |
| 純利益 |
373.60 |
623.73 |
699.79 |
| トレード数 |
53 |
35 |
35 |
| 最適化期間 |
7 sec |
4分34秒 |
415.4 ミリ秒 |
M5、3ヶ月:
| 結果 | テスター高速 |
テスタースロー | テスト OpenCL |
|---|---|---|---|
| レファレンス | 45 |
40 |
40 |
| ストップロス | 335 |
250 |
250 |
| 純利益 | 1199.34 |
1960.96 |
2181.21 |
| トレード数 | 71 |
99 |
99 |
| 最適化期間 | 12秒 |
8 min |
607.2 ミリ秒 |
M5、6ヶ月:
| 結果 | テスター高速 | テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 130 |
40 |
40 |
| ストップロス | 400 |
130 |
130 |
| 純利益 | 181.12 |
1733.9 |
1908.77 |
| トレード数 | 4 |
229 |
229 |
| 最適化期間 | 19秒 |
12分31秒 |
844ミリ秒 |
M5、9ヶ月:
| 結果 | テスター高速 |
テスタースロー |
テスト OpenCL |
|---|---|---|---|
| レファレンス | 35 |
30 |
30 |
| ストップロス | 460 |
500 |
500 |
| 純利益 | 3701.30 |
5612.16 |
6094.31 |
| トレード数 | 681 |
1091 |
1091 |
| 最適化期間 | 34秒 |
18分56秒 |
1 sec |
3.4. パフォーマンスサマリーテーブル
得られた結果は、ビルトインテスターが高速最適化モード (遺伝的アルゴリズム) で最良の結果をしばしばスキップすることを示します。 したがって、完全なパラメータ列挙モードで OpenCL に関連するパフォーマンスを比較する方が公平です。 可視性を高めるために、最適化に費やされた時間のサマリーテーブルを配置してみましょう。
| 最適化条件 |
テスタースロー |
テスト OpenCL |
比率 |
|---|---|---|---|
| EURUSD、H1、1ヶ月 |
6分2秒 |
405.8 ミリ秒 |
891 |
| EURUSD、H1、3ヶ月 |
8分8秒 |
457.9 ミリ秒 |
1065 |
| EURUSD、H1、6ヶ月 |
11分13秒 |
405.5 ミリ秒 |
1657 |
| EURUSD、H1、9ヶ月 |
16分44秒 |
438.4 ミリ秒 |
2292 |
| EURUSD、M5、1ヶ月 |
9分27秒 |
418ミリ秒 |
1356 |
| EURUSD、M5、3ヶ月 |
8分25秒 |
585.9 ミリ秒 |
861 |
| EURUSD、M5、6ヶ月 |
12分3秒 |
796.3 ミリ秒 |
908 |
| EURUSD、M5、9ヶ月 |
17分39秒 |
1 sec |
1059 |
| GBPUSD、H1、1ヶ月 | 4分33秒 |
385.1 ミリ秒 |
708 |
| GBPUSD、H1、3ヶ月 | 7分37秒 |
364.5 ミリ秒 |
1253 |
| GBPUSD、H1、6ヶ月 | 11分3秒 |
403.6 ミリ秒 |
1642 |
| GBPUSD、H1、9ヶ月 | 19分23秒 |
428.5 ミリ秒 |
2714 |
| GBPUSD、M5、1ヶ月 | 9分42秒 |
412.8 ミリ秒 |
1409 |
| GBPUSD、M5、3ヶ月 | 8分17秒 |
552.6 ミリ秒 |
899 |
| GBPUSD、M5、6ヶ月 | 14分58秒 |
796.4 ミリ秒 |
1127 |
| GBPUSD、M5、9ヶ月 | 20分58秒 |
970.4 ミリ秒 |
1296 |
| USDJPY、H1、1ヶ月 | 4分33秒 |
387.2 ミリ秒 |
705 |
| USDJPY、H1、3ヶ月 | 6分32秒 |
369ミリ秒 |
1062 |
| USDJPY、H1、6ヶ月 | 11分25秒 |
409.2 ミリ秒 |
1673 |
| USDJPY、H1、9ヶ月 | 17分47秒 |
455.3 ミリ秒 |
2396 |
| USDJPY、M5、1ヶ月 | 4分34秒 |
415.4 ミリ秒 |
659 |
| USDJPY、M5、3ヶ月 | 8 min |
607.2 ミリ秒 |
790 |
| USDJPY、M5、6ヶ月 | 12分31秒 |
844ミリ秒 |
889 |
| USDJPY、M5、9ヶ月 | 18分56秒 |
1 sec |
1136 |
結論
本稿では、OpenCL を用いた最もシンプルなトレーディングストラテジーのテスターを構築するためのアルゴリズムを実装しました。 もちろん、この実装は可能な解決策の1つにすぎないため、多くの欠点があります。 その中に含まれるもの:
- 大まかなクオートにのみ適した「1分 OHLC 」モードでのタスク
- スワップ・コミッションの計上なし
- クロスレートの不適切なタスク
- トレーリングストップなし
- 同時オープンポジション数の考慮
- 返されたパラメータの間の欠点無し
それにも関わらず、このアルゴリズムは、完全なパラメータの列挙モードと数十で実行されているビルトインテスターよりも速く 何千回も できるので、最もシンプルなパターンのパフォーマンスを迅速かつ大まかに評価する必要があるときに役立ちます。 遺伝的アルゴリズムを使用したテスターよりも数十倍も高速です。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/4236
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 DIY マルチスレッド非同期 MQL5 WebRequest
DIY マルチスレッド非同期 MQL5 WebRequest
 MQL5 と MQL4 でのシンボル選択とナビゲーションユーティリティの開発
MQL5 と MQL4 でのシンボル選択とナビゲーションユーティリティの開発
 リバーシング: エントリポイントを形式化し、裁量トレードアルゴリズムを開発する
リバーシング: エントリポイントを形式化し、裁量トレードアルゴリズムを開発する
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
まず、tester_step カーネルに、__global double *Res 結果バッファのように、インデックスを使用して取引を終了した時間(取引が終了したバー M1 のインデックス、または M1のバー数で 表されるポジションを保持している時間)を取得できるようにする引数を 1 つ追加する必要があります。
さらに、ご質問の内容が単一テストなのか最適化なのかによって異なります:
1. テスト。総利益が要約されるループでは、終値を使ってオープンポジションの重なりを除外する条件を追加する必要があります(これは最終的にtester_stepによって 返されます)。
2. 最適化。ここでは、利益を要約する find_patterns_opt カーネルの代わりに、単にエントリー・ポイントを返す find_patterns を使用する必要がある。一度に複数の取引を開始することが許されないという条件を考慮すると、mql5 コードで利益を要約する必要がある。ただし、この場合、並列実行されたものが順次実行される(最適化パスの数に最適化の深さが乗じられる)ので、時間がかかるかもしれません(試してみてください)。もう一つの妥協案として、(同時にオープンしたポジション数の条件を考慮して)1パス分の利益をカウントするカーネルを追加することもできますが、私自身の実践から言えるのは、「重い」カーネルを実行するのは良くないということです。理想的には、カーネルのコードをできるだけシンプルに保ち、できるだけ多くのカーネルを実行するように努めるべきである。
こんにちは。
早速のお返事ありがとうございます。最適化についての回答は、コードを実際に適用するためのアイデアとして、まず最初に興味を持ちました。このような記事は他にないので、ありがとうございました!また、tester_step (およびtester_step_opt)を少し修正して、p>open to buyという時間条件を追加してみます。if(j>=maxbar || (TimeM1[j]>=tclose && p>open))、売りの場合は if(j>=maxbar || (TimeM1[j]>=tclose && p<open)))を追加すれば、オプション取引用のストラテジーができあがります。
...オプション戦略に関する前回のコメントにも少し補足します。ここでは、Option Expiration Time変数を追加する必要があるので(同時に、StopLossとTakeProfitは最適化中のオプションには必要ありません)、tester_opt_stepのコードを以下のように修正します:
こんにちは。あなたの記事に従ってUSDRUBのOpenCL最適化を実行したところ、そのような問題に遭遇しました。最適化の結果は 常にプラスで、常に利益です。つまり、結果が生成されるint型の変数にオーバーフローがあるようです。一方、EURUSDの最適化は正しく機能します。おそらくUSDRUBの5桁の問題でもあるのでしょう。この問題を解決する方法を教えてください。
記事の中であなたはこう書いています:
В нашем случае функция atomic_inc() для начала запрещает доступ другим задачам к ячейке Count[0], затем увеличивает её значение на единицу, а предыдущее возвращает в виде результата.
私の理解では、この関数はint型の 配列に対してのみ機能しますが、異なる型の配列、例えばushort型の配列がある場合、どうすればよいのでしょうか?