Artikel über maschinelles Lernen im Handel.
Erstellen von KI-basierten Handelsrobotern: native Integration der Bibliotheken für Python, Matrizen und Vektoren, Mathematik und Statistik und vieles mehr.
Finden Sie heraus, wie Sie maschinelles Lernen im Handel einsetzen können. Neuronen, Perzeptronen, Faltungs- und rekurrente Netze, Vorhersagemodelle – beginnen Sie mit den Grundlagen und arbeiten Sie sich bis zur Entwicklung Ihrer eigenen KI vor. Sie lernen, wie man neuronale Netze für den algorithmischen Handel auf Finanzmärkten trainiert und anwendet.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Neuroboids Optimierungsalgorithmus (NOA)
Eine neue bioinspirierte Metaheuristik zur Optimierung, NOA (Neuroboids Optimization Algorithm), kombiniert die Prinzipien der kollektiven Intelligenz und der neuronalen Netze. Im Gegensatz zu herkömmlichen Methoden verwendet der Algorithmus eine Population von selbstlernenden „Neuroboiden“, von denen jeder sein eigenes neuronales Netz hat, das seine Suchstrategie in Echtzeit anpasst. Der Artikel zeigt die Architektur des Algorithmus, die Mechanismen des Selbstlernens der Agenten und die Aussichten für die Anwendung dieses hybriden Ansatzes auf komplexe Optimierungsprobleme.

Forex Arbitrage-Handel: Analyse der Bewegungen synthetischer Währungen und ihrer mittleren Umkehrung
In diesem Artikel werden wir die Bewegungen synthetischer Währungen mit Hilfe von Python und MQL5 untersuchen und herausfinden, wie praktikabel Forex-Arbitrage heute ist. Wir werden uns auch mit fertigem Python-Code für die Analyse synthetischer Währungen befassen und mehr Details darüber mitteilen, was synthetische Währungen im Devisenhandel sind.

Entwicklung von Trendhandelsstrategien mit maschinellem Lernen
In dieser Studie wird eine neuartige Methodik für die Entwicklung von Trendfolgestrategien vorgestellt. In diesem Abschnitt wird der Prozess der Annotation von Trainingsdaten und deren Verwendung zum Training von Klassifikatoren beschrieben. Dieser Prozess führt zu voll funktionsfähigen Handelssystemen, die für den MetaTrader 5 entwickelt wurden.

Aufbau eines Remote-Forex-Risikomanagementsystems in Python
Wir entwickeln einen professionellen Remote-Risikomanager für Forex in Python, der Schritt für Schritt auf dem Server installiert wird. Im Laufe des Artikels werden wir verstehen, wie man die Forex-Risiken programmatisch verwalten kann und wie man eine Forex-Einlage nicht mehr verschwenden kann.

Der Algorithmus Central Force Optimization (CFO)
Der Artikel stellt den von den Gesetzen der Schwerkraft inspirierten Algorithmus Central Force Optimization (CFO) vor. Es wird untersucht, wie die Prinzipien der physikalischen Schwerkraft Optimierungsprobleme lösen können, bei denen „schwerere“ Lösungen weniger erfolgreiche Gegenstücke anziehen.

Neuronale Netze im Handel: Zweidimensionale Verbindungsraummodelle (letzter Teil)
Wir erforschen weiterhin den innovativen Chimera-Rahmen – ein zweidimensionales Zustandsraummodell, das neuronale Netzwerktechnologien zur Analyse mehrdimensionaler Zeitreihen nutzt. Diese Methode bietet eine hohe Vorhersagegenauigkeit bei geringen Rechenkosten.

Algorithmus der erfolgreichen Gastronomen (SRA)
Der Successful Restaurateur Algorithm (SRA) ist eine innovative Optimierungsmethode, die sich an den Prinzipien des Restaurantbetriebs orientiert. Im Gegensatz zu traditionellen Ansätzen werden bei der SRA schwache Lösungen nicht verworfen, sondern durch die Kombination mit Elementen erfolgreicher Lösungen verbessert. Der Algorithmus zeigt konkurrenzfähige Ergebnisse und bietet eine neue Perspektive für das Gleichgewicht zwischen Erkunden und Nutzen bei Optimierungsproblemen.

Billard-Optimierungsalgorithmus (BOA)
Die BOA-Methode ist vom klassischen Billardspiel inspiriert und simuliert die Suche nach optimalen Lösungen als ein Spiel, bei dem die Kugeln versuchen, in die Taschen zu fallen, die die besten Ergebnisse darstellen. In diesem Artikel werden wir die Grundlagen von BOA, sein mathematisches Modell und seine Effizienz bei der Lösung verschiedener Optimierungsprobleme betrachten.

Neuronale Netze im Handel: Zweidimensionale Verbindungsraummodelle (Chimera)
In diesem Artikel wird das innovative Chimera-System vorgestellt: ein zweidimensionales Zustandsraummodell, das neuronale Netze zur Analyse multivariater Zeitreihen verwendet. Diese Methode bietet eine hohe Genauigkeit bei geringen Rechenkosten und übertrifft damit traditionelle Ansätze und Transformer-Architekturen.

Analyse aller Preisbewegungsoptionen auf dem IBM-Quantencomputer
Wir werden einen Quantencomputer von IBM einsetzen, um alle Möglichkeiten der Preisentwicklung zu ermitteln. Klingt nach Science Fiction? Willkommen in der Welt des Quantencomputers für den Handel!

Fibonacci am Devisenmarkt (Teil I): Prüfung des Verhältnisses zwischen Preis und Zeit
Wie beobachtet der Markt Fibonacci-basierte Beziehungen? Diese Folge, bei der jede nachfolgende Zahl gleich der Summe der beiden vorhergehenden ist (1, 1, 2, 3, 5, 8, 13, 21...), beschreibt nicht nur das Wachstum der Kaninchenpopulation. Wir werden die pythagoreische Hypothese betrachten, dass alles in der Welt bestimmten Zahlenbeziehungen unterliegt...

Neuronale Netze im Handel: Multi-Task-Lernen auf der Grundlage des ResNeXt-Modells (letzter Teil)
Wir erforschen weiterhin ein auf ResNeXt basierendes Multitasking-Lernsystem, das sich durch Modularität, hohe Recheneffizienz und die Fähigkeit, stabile Muster in Daten zu erkennen, auszeichnet. Die Verwendung eines einzigen Encoders und spezieller „Köpfe“ verringert das Risiko einer Überanpassung des Modells und verbessert die Qualität der Prognosen.

Blood inheritance optimization (BIO)
Ich stelle Ihnen meinen neuen Algorithmus zur Populationsoptimierung vor – Blood Inheritance Optimization (BIO), inspiriert durch das menschliche Blutgruppenvererbungssystem. Bei diesem Algorithmus hat jede Lösung ihre eigene „Blutgruppe“, die bestimmt, wie sie sich weiterentwickelt. Wie in der Natur, wo die Blutgruppe eines Kindes nach bestimmten Regeln vererbt wird, erhalten neue Lösungen in BIO ihre Eigenschaften durch ein System von Vererbung und Mutationen.

Kreis-Such-Algorithmus (CSA)
Der Artikel stellt einen neuen metaheuristischen Optimierungs-Kreis-Such-Algorithmus (CSA) vor, der auf den geometrischen Eigenschaften eines Kreises basiert. Der Algorithmus nutzt das Prinzip der Bewegung von Punkten entlang von Tangenten, um die optimale Lösung zu finden, und kombiniert die Phasen der globalen Erkundung und der lokalen Ausbeutung.

Chaos Game Optimization (CGO)
Der Artikel stellt einen neuen metaheuristischen Algorithmus, Chaos Game Optimization (CGO), vor, der eine einzigartige Fähigkeit zur Aufrechterhaltung einer hohen Effizienz bei hochdimensionalen Problemen aufweist. Im Gegensatz zu den meisten Optimierungsalgorithmen verliert CGO nicht nur nicht an Leistung, sondern steigert sie manchmal sogar, wenn ein Problem skaliert wird, was sein Hauptmerkmal ist.

Biologisches Neuron zur Vorhersage von Finanzzeitreihen
Wir werden ein biologisch korrektes System von Neuronen für die Vorhersage von Zeitreihen aufbauen. Die Einführung einer plasmaähnlichen Umgebung in die Architektur des neuronalen Netzes schafft eine Art „kollektive Intelligenz“, bei der jedes Neuron den Betrieb des Systems nicht nur durch direkte Verbindungen, sondern auch durch weitreichende elektromagnetische Wechselwirkungen beeinflusst. Mal sehen, wie sich das neuronale Gehirnmodellierungssystem auf dem Markt schlagen wird.

Royal-Flush-Optimierung (RFO)
Der ursprüngliche Royal Flush Optimierung-Algorithmus bietet einen neuen Ansatz zur Lösung von Optimierungsproblemen, indem er die klassische binäre Kodierung genetischer Algorithmen durch einen sektorbasierten Ansatz ersetzt, der von den Prinzipien des Pokerspiels inspiriert ist. RFO zeigt, wie die Vereinfachung von Grundprinzipien zu einer effizienten und praktischen Optimierungsmethode führen kann. Der Artikel enthält eine detaillierte Analyse des Algorithmus und der Testergebnisse.

Neuronale Netze im Handel: Hierarchical Dual-Tower Transforme (letzter Teil)
Wir setzen die Entwicklung des Modells von „Hidformer Hierarchical Dual-Tower Transformer“ fort, das für die Analyse und Vorhersage komplexer multivariater Zeitreihen entwickelt wurde. In diesem Artikel werden wir die Arbeit, die wir zuvor begonnen haben, zu einem logischen Abschluss bringen - wir werden das Modell an realen historischen Daten testen.

Neuronale Netze im Handel: Hierarchischer Dual-Tower-Transformer (Hidformer)
Wir laden Sie ein, sich mit dem Hierarchical Double-Tower Transformer (Hidformer) vertraut zu machen, der für Zeitreihenprognosen und Datenanalysen entwickelt wurde. Die Autoren des Rahmenwerks schlugen mehrere Verbesserungen an der Transformer-Architektur vor, die zu einer höheren Vorhersagegenauigkeit und einem geringeren Verbrauch an Rechenressourcen führten.

Neuronale Netze im Handel: Speichererweitertes kontextbezogenes Lernen für Kryptowährungsmärkte (letzter Teil)
Das MacroHFT-Framework für den Hochfrequenzhandel mit Kryptowährungen nutzt kontextbezogenes Verstärkungslernen und Speicher, um sich an dynamische Marktbedingungen anzupassen. Am Ende dieses Artikels werden wir die implementierten Ansätze an realen historischen Daten testen, um ihre Wirksamkeit zu bewerten.

Neuronale Netze im Handel: Multi-Task-Lernen auf der Grundlage des ResNeXt-Modells
Ein auf ResNeXt basierendes Multi-Task-Learning-System optimiert die Analyse von Finanzdaten unter Berücksichtigung ihrer hohen Dimensionalität, Nichtlinearität und Zeitabhängigkeit. Die Verwendung von Gruppenfaltung und spezialisierten Köpfen ermöglicht es dem Modell, effektiv Schlüsselmerkmale aus den Eingabedaten zu extrahieren.

Neuronale Netze im Handel: Speichererweitertes kontextbezogenes Lernen (MacroHFT) für Kryptowährungsmärkte
Ich lade Sie ein, das MacroHFT-Framework zu erkunden, das kontextbewusstes Verstärkungslernen und eine Speicherverwendung anwendet, um Hochfrequenzhandelsentscheidungen für Kryptowährungen mithilfe von makroökonomischen Daten und adaptiven Agenten zu verbessern.

Dialektische Suche (DA)
Der Artikel stellt den dialektischen Algorithmus (DA) vor, eine neue globale Optimierungsmethode, die vom philosophischen Konzept der Dialektik inspiriert ist. Der Algorithmus macht sich eine einzigartige Aufteilung der Bevölkerung in spekulative und praktische Denker (thinker) zunutze. Tests zeigen eine beeindruckende Leistung von bis zu 98 % bei niedrigdimensionalen Problemen und eine Gesamteffizienz von 57,95 %. Der Artikel erläutert diese Metriken und präsentiert eine detaillierte Beschreibung des Algorithmus sowie die Ergebnisse von Experimenten mit verschiedenen Arten von Funktionen.

Neuronale Netze im Handel: Ein Multi-Agenten-System mit konzeptioneller Verstärkung (letzter Teil)
Wir setzen weiterhin die von den Autoren des FinCon-Rahmens vorgeschlagenen Ansätze um. FinCon ist ein Multi-Agenten-System, das auf Large Language Models (LLMs) basiert. Heute werden wir die erforderlichen Module implementieren und umfassende Tests des Modells mit realen historischen Daten durchführen.

Marktsimulation (Teil 06): Übertragen von Informationen von MetaTrader 5 nach Excel
Viele Menschen, insbesondere Nicht-Programmierer, finden es sehr schwierig, Informationen zwischen MetaTrader 5 und anderen Programmen zu übertragen. Ein solches Programm ist Excel. Viele verwenden Excel, um ihre Risikokontrolle zu verwalten und aufrechtzuerhalten. Es ist ein ausgezeichnetes Programm und leicht zu erlernen, auch für diejenigen, die keine VBA-Programmierer sind. Im Folgenden werden wir uns ansehen, wie man eine Verbindung zwischen MetaTrader 5 und Excel herstellt (eine sehr einfache Methode).

Neuronale Netze im Handel: Ein Multi-Agenten-System mit konzeptioneller Verstärkung (FinCon)
Wir laden Sie ein, den FinCon-Rahmen zu erkunden, der ein auf einem Large Language Model (LLM) basierendes Multi-Agenten-System ist. Der Rahmen nutzt konzeptionelle verbale Verstärkung, um die Entscheidungsfindung und das Risikomanagement zu verbessern und eine effektive Leistung bei einer Vielzahl von Finanzaufgaben zu ermöglichen.

Neuronale Netze im Handel: Ein multimodaler, werkzeuggestützter Agent für Finanzmärkte (letzter Teil)
Wir entwickeln weiterhin die Algorithmen für FinAgent, einen multimodalen Finanzhandelsagenten, der multimodale Marktdynamikdaten und historische Handelsmuster analysiert.

Neuronale Netze im Handel: Ein multimodaler, werkzeuggestützter Agent für Finanzmärkte (FinAgent)
Wir laden Sie ein, FinAgent kennenzulernen, ein multimodales Finanzhandelsagenten-Framework zur Analyse verschiedener Datentypen, die die Marktdynamik und historische Handelsmuster widerspiegeln.

Erstellung eines Indikators für die Volatilitätsprognose mit Python
In diesem Artikel prognostizieren wir die zukünftige extreme Volatilität anhand einer binären Klassifizierung. Außerdem werden wir mit Hilfe von maschinellem Lernen einen Indikator für extreme Volatilität entwickeln.

Neuronale Netze im Handel: Ein Agent mit geschichtetem Gedächtnis (letzter Teil)
Wir setzen unsere Arbeit an der Entwicklung des Systems von FinMem fort, das mehrschichtige Speicheransätze verwendet, die menschliche kognitive Prozesse nachahmen. Dadurch kann das Modell nicht nur komplexe Finanzdaten effektiv verarbeiten, sondern sich auch an neue Signale anpassen, was die Genauigkeit und Effektivität von Anlageentscheidungen auf sich dynamisch verändernden Märkten erheblich verbessert.
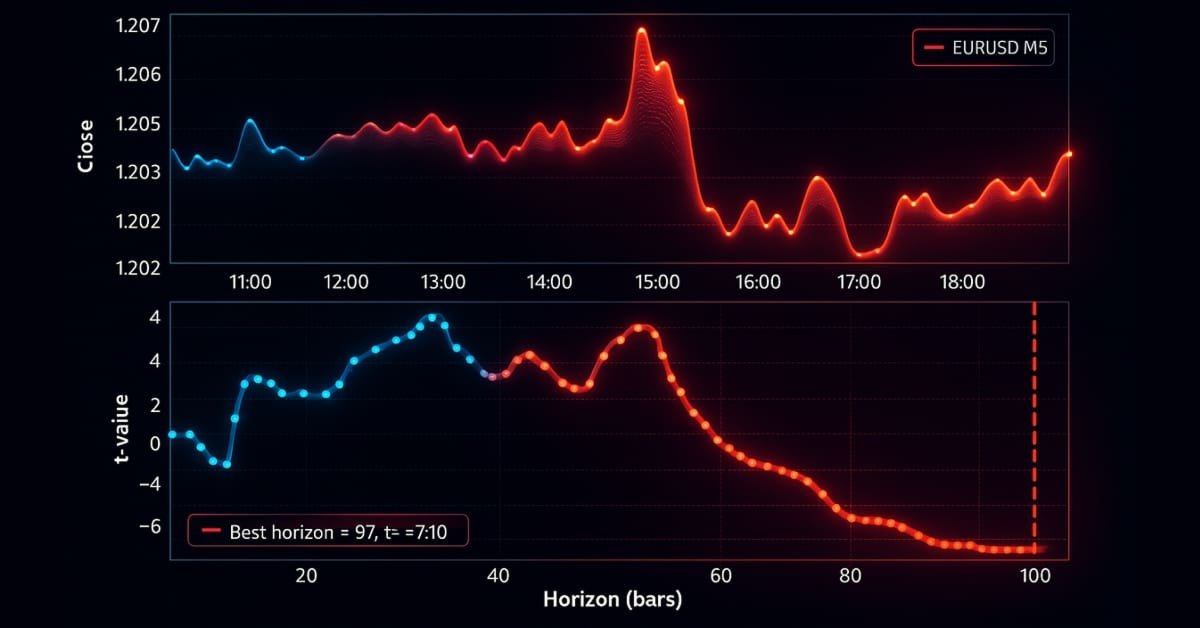
MetaTrader 5 Machine Learning Blueprint (Teil 3): Methoden der Kennzeichnung von Trend-Scanning
Wir haben eine Pipline für eine robuste Eigenschaftsentwicklung entwickelt, die geeignete tick-basierte Balken verwendet, um Datenverluste zu vermeiden, und das kritische Problem der Kennzeichnung der meta-gekennzeichneten Signale des Triple-Barrier gelöst. Dieser Teil behandelt die fortgeschrittene Technik der Kennzeichnung, dem Trend-Scanning, für adaptive Horizonte. Nach der Erläuterung der Theorie wird anhand eines Beispiels gezeigt, wie Kennzeichnungen des Trend-Scanning mit Meta-Kennzeichen verwendet werden können, um die klassische Kreuzungsstrategie mit gleitendem Durchschnitt zu verbessern.

Selbstoptimierende Expert Advisors in MQL5 (Teil 16): Überwachte lineare Systemidentifikation
Die lineare Systemidentifikation kann mit dem Lernen gekoppelt werden, um den Fehler in einem überwachten Lernalgorithmus zu korrigieren. So können wir Anwendungen entwickeln, die von statistischen Modellierungstechniken abhängen, ohne zwangsläufig die Anfälligkeit der restriktiven Annahmen des Modells zu übernehmen. Klassische überwachte Lernalgorithmen haben viele Bedürfnisse, die durch die Kombination dieser Modelle mit einem Feedback-Controller ergänzt werden können, der das Modell korrigieren kann, um mit den aktuellen Marktbedingungen Schritt zu halten.

Die Grenzen des maschinellen Lernens überwinden (Teil 6): Effektive Speichervalidierung
In dieser Diskussion stellen wir den klassischen Ansatz der Zeitreihen-Kreuzvalidierung modernen Alternativen gegenüber, die seine Grundannahmen in Frage stellen. Wir zeigen die wichtigsten blinden Flecken der traditionellen Methode auf – insbesondere ihr Versagen, die sich verändernden Marktbedingungen zu berücksichtigen. Um diese Lücken zu schließen, führen wir die Effective Memory Cross-Validation (EMCV) ein, einen domänenspezifischen Ansatz, der die lange gehegte Annahme in Frage stellt, dass mehr historische Daten immer die Leistung verbessern.

Klassische Strategien neu interpretiert (Teil 16): Doppelte Ausbrüche aus den Bollinger Bänder
Dieser Artikel führt den Leser durch eine neu gestaltete Version der klassischen Bollinger Band Ausbruchsstrategie. Sie zeigt wesentliche Schwachstellen des ursprünglichen Ansatzes auf, wie z. B. seine bekannte Anfälligkeit für falsche Ausbrüche. In diesem Artikel soll eine mögliche Lösung vorgestellt werden: die Handelsstrategie der doppelten Bollinger Bänder. Dieser relativ weniger bekannte Ansatz ergänzt die Schwächen der klassischen Version und bietet eine dynamischere Perspektive auf die Finanzmärkte. Sie hilft uns, die alten Beschränkungen zu überwinden, die durch die ursprünglichen Regeln festgelegt wurden, und bietet den Händlern einen stärkeren und anpassungsfähigeren Rahmen.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 85): Verwendung von Mustern des Stochastik-Oszillators und der FrAMA mit Beta-VAE-Inferenzlernen
Dieser Beitrag schließt an Teil 84 an, in dem wir die Kombination von Stochastik und Fractal Adaptive Moving Average vorgestellt haben. Wir verlagern nun den Schwerpunkt auf das Inferenzlernen, um zu sehen, ob die im letzten Artikel unterlegenen Muster eine Trendwende erfahren könnten. Der Stochastik und der FrAMA sind eine sich ergänzende Paarung von Momentum und Trend. Für unser Inferenzlernen greifen wir auf den Beta-Algorithmus eines Variational Auto Encoders zurück. Außerdem implementieren wir, wie immer, eine nutzerdefinierte Signalklasse, die für die Integration mit dem MQL5-Assistenten entwickelt wurde.

Bivariate Copulae in MQL5 (Teil 1): Implementierung von Gauß- und Studentische t-Copulae für die Modellierung von Abhängigkeiten
Dies ist der erste Teil einer Artikelserie, in der die Implementierung von bivariaten Copulae in MQL5 vorgestellt wird. Dieser Artikel enthält Code zur Implementierung der Gauß‘schen und Studentischen t-Copulae. Außerdem werden die Grundlagen der statistischen Copulae und verwandte Themen behandelt. Der Code basiert auf dem Python-Paket Arbitragelab von Hudson und Thames.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 82): Verwendung von TRIX- und WPR-Mustern mit DQN-Verstärkungslernen
Im letzten Artikel haben wir die Paarung von Ichimoku und ADX im Rahmen des Inferenzlernens untersucht. In diesem Beitrag greifen wir das Verstärkungslernen in Verbindung mit einem Indikatorpaar auf, das wir zuletzt in „Teil 68“ betrachtet haben. Der TRIX und Williams Percent Range. Unser Algorithmus für diese Überprüfung wird die Quantilregression DQN sein. Wie üblich stellen wir dies als nutzerdefinierte Signalklasse vor, die für die Implementierung mit dem MQL5-Assistenten entwickelt wurde.
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 81): Verwendung von Ichimoku-Mustern und des ADX-Wilder mit Beta-VAE-Inferenzlernen
Dieser Beitrag schließt an Teil 80 an, in dem wir die Paarung von Ichimoku und ADX im Rahmen eines Reinforcement Learning untersucht haben. Wir wenden uns nun dem Inferenzlernen zu. Ichimoku und ADX ergänzen sich, wie bereits erwähnt, jedoch werden wir die Schlussfolgerungen des letzten Artikels in Bezug auf die Verwendung von Pipelines wieder aufgreifen. Für unser Inferenzlernen verwenden wir den Beta-Algorithmus eines Variational Auto Encoders. Wir bleiben auch bei der Implementierung einer nutzerdefinierten Signalklasse für die Integration mit dem MQL5-Assistenten.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 80): Verwendung von Ichimoku-Muster und des ADX-Wilder mit TD3 Reinforcement Learning
Dieser Artikel schließt an Teil 74 an, in dem wir die Paarung von Ichimoku und ADX im Rahmen des überwachten Lernens untersuchten, und verlagert den Schwerpunkt auf das Bestärkende Lernen. Ichimoku und ADX bilden eine komplementäre Kombination von Unterstützungs-/Widerstandskartierung und Trendstärkemessung. In dieser Folge wird gezeigt, wie der Twin Delayed Deep Deterministic Policy Gradient (TD3) Algorithmus mit diesem Indikatorensatz verwendet werden kann. Wie bei früheren Teilen der Serie erfolgt die Implementierung in einer nutzerdefinierten Signalklasse, die für die Integration mit dem MQL5-Assistenten entwickelt wurde, was eine problemlose Zusammenstellung von Expert Advisors ermöglicht.

Pipelines in MQL5
In diesem Beitrag befassen wir uns mit einem wichtigen Schritt der Datenaufbereitung für das maschinelle Lernen, der zunehmend an Bedeutung gewinnt. Pipelines für die Datenvorverarbeitung. Dabei handelt es sich im Wesentlichen um eine rationalisierte Abfolge von Datenumwandlungsschritten, mit denen Rohdaten aufbereitet werden, bevor sie in ein Modell eingespeist werden. So uninteressant dies für den Laien auch erscheinen mag, diese „Datenstandardisierung“ spart nicht nur Trainingszeit und Ausführungskosten, sondern trägt auch zu einer besseren Generalisierung bei. In diesem Artikel konzentrieren wir uns auf einige SCIKIT-LEARN Vorverarbeitungsfunktionen, und während wir den MQL5-Assistenten nicht ausnutzen, werden wir in späteren Artikeln darauf zurückkommen.