
Datenwissenschaft und ML (Teil 36): Der Umgang mit verzerrten Finanzmärkten

Inhalt
- Einführung
- Unzulänglichkeiten von unausgewogenen Zielvariablen beim maschinellen Lernen
- Techniken zur Bewältigung des Problems unausgewogener Datensätze
- Die Wahl der richtigen Bewertungsmetrik
- Ein Expert Advisor (EA) zum Testen
- Oversampling-Techniken
- Undersampling-Techniken
- Hybride Methoden
- Schlussfolgerung
Einführung
Verschiedene Devisenmärkte und Finanzinstrumente verhalten sich zu verschiedenen Zeiten unterschiedlich. Während einige Finanzmärkte wie Aktien und Indizes auf lange Sicht oft nach oben tendieren, zeigen andere wie die Devisenmärkte oft ein fallendes Verhalten und vieles mehr. Diese Unsicherheit erhöht die Komplexität, wenn man versucht, den Markt mithilfe von Techniken der künstlichen Intelligenz (KI) und Modellen des maschinellen Lernens (ML) vorherzusagen.

Nehmen wir ein paar Finanzmärkte (Handelssymbole) und visualisieren wir die Marktrichtungen von 1000 Balken auf dem täglichen Zeitrahmen. Wenn der Schlusskurs eines Balkens über seinem Eröffnungskurs liegt, können wir ihn als Aufwärts-Balken (1) bezeichnen, andernfalls als Abwärts-Balken (0).
import pandas as pd import numpy as np symbols = [ "EURUSD", "USTEC", "XAUUSD", "USDJPY", "BTCUSD", "CA60", "UK100" ] for symbol in symbols: df = pd.read_csv(fr"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\1640F6577B1C4EC659BF41EA9F6C38ED\MQL5\Files\{symbol}.PERIOD_D1.data.csv") df["Candle type"] = (df["Close"] > df["Open"]).astype(int) print(f"{symbol}(unique):",np.unique(df["Candle type"], return_counts=True))
Das Ergebnis.
EURUSD(unique): (array([0, 1]), array([496, 504])) USTEC(unique): (array([0, 1]), array([472, 528])) XAUUSD(unique): (array([0, 1]), array([472, 528])) USDJPY(unique): (array([0, 1]), array([408, 592])) BTCUSD(unique): (array([0, 1]), array([478, 522])) CA60(unique): (array([0, 1]), array([470, 530])) UK100(unique): (array([0, 1]), array([463, 537]))
Wie aus dem obigen Ergebnis ersichtlich ist, ist keines der Handelssymbole perfekt ausbalanciert, da es eine unterschiedliche Anzahl von Auf-und Abwärtskerzen gibt, die in der Vergangenheit erschienen sind.
Es ist nicht schlimm, wenn der Markt in eine bestimmte Richtung tendiert, aber diese Verzerrung in den historischen Daten könnte beim Training von maschinellen Lernmodellen einige Probleme verursachen:
Nehmen wir an, wir wollen ein Modell für USDJPY trainieren, das auf dem aktuellen Datensatz mit 1000 Balken basiert. Wir haben 408 Abwärtskerzen (markiert als 0), was 40,8% aller Handelssignale entspricht, während wir 592 bullische Kerzen (markiert als 1) haben, was 59,2% aller Handelssignale entspricht.
Das Vorhandensein von Aufwärtssignalen, die das Vorhandensein von Abwärtssignalen überwiegen, wird von maschinellen Lernmodellen meistens übersehen, da die Modelle dazu neigen, die dominanteste Klasse zu bevorzugen und daher Vorhersagen zu Gunsten der dominantesten Klasse treffen.
Da alle Modelle darauf abzielen, den geringstmöglichen Verlustwert zu erreichen, der mit dem höchstmöglichen Genauigkeitswert einhergeht, bevorzugen die Modelle die bullische Klasse, die in 59,2 % von 100 % der Fälle auftritt, da dies ein einfacher Weg ist, den maximalen Genauigkeitswert zu erreichen.
Das ist keine Raketenwissenschaft, denn basierend auf dieser einfachen Information, wenn Sie alle Prädiktoren und alles, was auf dem Markt passiert, ignorieren und nur diese Information verwenden, wenn Sie den USDJPY vorhersagen, können Sie sagen, dass alle Balken die ganze Zeit bullisch sein werden, und Sie werden in etwa 59,2% der Zeit richtig liegen, nicht schlecht, oder? Falsch!
Denn damit gehen Sie davon aus, dass das, was in der Vergangenheit passiert ist, auch wieder passieren wird, was in dieser Handelswelt schrecklich unrichtig und verdammt falsch ist.
Wie Sie sehen, stellt eine unausgewogene Zielvariable in Klassifizierungsdaten für das maschinelle Lernen ein Problem dar, und im Folgenden werden einige der damit verbundenen Nachteile beschrieben.
Unzulänglichkeiten von unausgewogenen Zielvariablen beim maschinellen Lernen
- Schlechte Leistungen in der Minderheitenklasse
Wie ich bereits sagte, neigt das Modell zu Vorhersagen in Richtung der Mehrheitsklasse, weil es die Gesamtgenauigkeit optimiert. Ein Beispiel: Bei Betrugserkennungsdaten (99 % Nicht-Betrug und 1 % Betrug) kann ein Modell , da die meisten Personen keine Betrüger sind, immer Nicht-Betrug vorhersagen und trotzdem die 99 %ige Genauigkeit erreichen, aber keinen Betrug erkennen. - Irreführende Bewertungsmetriken
Der Genauigkeitswert wird unzuverlässig, man kann ein Modell mit einer gemeinsamen Genauigkeit von 72 % haben, ohne zu wissen, dass eine Klasse zu 95 % genau vorhergesagt wurde, während eine andere Klasse zu 50 % genau war. - Überanpassung der Modelle an die Mehrheitsklasse
Die Modelle könnten sich Geräusche aus der Mehrheitsklasse merken und voreingenommene Entscheidungen treffen, anstatt allgemeine Muster aus den Prädiktoren zu lernen. Bei medizinischen Diagnosedaten (95% gesund und 5% krank) kann das Modell zum Beispiel die kranken Fälle völlig ignorieren. - Schlechte Verallgemeinerung auf ungesehene Daten (aus der realen Welt)
In der realen Welt ändert sich die Verteilung häufig und schnell, und wenn ein Modell in einer voreingenommenen Umgebung trainiert wurde, wird es früher oder später versagen, da es auf einem unrealistischen Gleichgewicht trainiert wurde.
Techniken zur Behandlung des Problems unausgewogener Datensätze
Da wir nun wissen, welche Nachteile unausgewogene (voreingenommene) Zielvariablen in einem Klassifizierungsproblem mit sich bringen, wollen wir verschiedene Möglichkeiten zur Lösung dieses Problems erörtern.
01: Die Wahl der richtigen Bewertungsmetrik
Die erste Technik zum Umgang mit unausgewogenen Daten ist die Wahl einer geeigneten Bewertungsmetrik. Wie in den Unzulänglichkeiten erwähnt, kann die Genauigkeit eines Klassifikators, die die Gesamtzahl der richtigen Vorhersagen geteilt durch die Gesamtzahl der Vorhersagen ist, bei unausgewogenen Daten irreführend sein.
Bei einem Problem mit unausgewogenen Daten sind andere Metriken wie Präzision, die die Genauigkeit der Vorhersage einer bestimmten Klasse durch den Klassifikator misst, und Recall, der die Fähigkeit des Klassifikators misst, eine Klasse zu identifizieren, viel nützlicher als die Genauigkeitsmetrik.
Bei der Arbeit mit einem unausgewogenen Datensatz verwenden die meisten Experten für maschinelles Lernen die f1-Punktzahl, da dieser besser geeignet ist.
Er ist einfach das harmonische Mittel aus Precision und Recall, dargestellt durch die Formel.

Wenn also der Klassifikator die Minderheitenklasse vorhersagt, die Vorhersage aber fehlerhaft ist und die falsch-positiven Ergebnisse zunehmen, wird die Präzisionsmetrik niedrig sein und damit auch die F1-Punktzahl.
Wenn der Klassifikator die Minderheitenklasse schlecht identifiziert, steigt auch die Zahl der falsch-negativen Ergebnisse, sodass Recall und F1-Punktzahl niedrig sind.
Die F1-Punktzahl steigt nur, wenn sich die Anzahl und die Gesamtqualität der Vorhersagen verbessern.
Um dies im Detail zu verstehen, lassen Sie uns einen einfachen RandomForest-Klassifikator auf das verzerrte USDJPY-Instrument trainieren.
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report # Global variables symbol = "USDJPY" timeframe = "PERIOD_D1" lookahead = 1 common_path = r"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\Common\Files" df = pd.read_csv(f"{common_path}\{symbol}.{timeframe}.data.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) # future closing price based on lookahead value df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) print("Signals(unique): ",np.unique(df["Signal"], return_counts=True)) X = df.drop(columns=["Signal", "future_close"]) y = df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False) model = RandomForestClassifier(n_estimators=100, max_depth=5, min_samples_split=3, random_state=42) model.fit(X_train, y_train)
Nach dem Training können wir das Modell im ONNX-Format für die spätere Verwendung im MetaTrader 5 speichern.
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType import os def saveModel(model, n_features: int, technique_name: str): initial_type = [("input", FloatTensorType([None, n_features]))] onnx_model = convert_sklearn(model, initial_types=initial_type, target_opset=14) with open(os.path.join(common_path, f"{symbol}.{timeframe}.{technique_name}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
saveModel(model=model, n_features=X_train.shape[1], technique_name="no-sampling")
Ich musste die Methode des Klassifizierungsberichts verwenden, um verschiedene Metriken zu beobachten, die unter Scikit-Learn zu finden sind.
Train Classification report precision recall f1-score support 0 0.98 0.41 0.57 158 1 0.68 1.00 0.81 204 accuracy 0.74 362 macro avg 0.83 0.70 0.69 362 weighted avg 0.81 0.74 0.71 362
Analyse des Berichts über die Zugklassifizierung
Die Gesamtgenauigkeit des Trainings des Modells liegt bei 0,74, was auf den ersten Blick anständig erscheint. Ein genauerer Blick auf die klassenbezogenen Metriken zeigt jedoch ein erhebliches Ungleichgewicht in der Leistung des Modells in den beiden Klassen, wobei die Klasse 0 eine sehr hohe Genauigkeit von 0,98, aber einen niedrigen Recall von 0,41 aufweist, was zu einer bescheidenen F1-Punktzahl von 0,57 führt.
Das bedeutet, dass das Modell zwar sehr sicher die Klasse 0 vorhersagt, aber eine große Anzahl von Proben der Klasse 0 übersehen wird, was auf eine geringe Empfindlichkeit hinweist.
Die Klasse 1 hingegen weist einen Recall von 1,00 und eine F1-Punktzahl von 0,81 auf, aber eine relativ geringere Präzision von 0,68.
Dies deutet darauf hin, dass das Modell zu sehr auf die Vorhersage von Klasse 1 ausgerichtet ist, was möglicherweise zu einer hohen Anzahl von falsch positiven Ergebnissen führt.
Die perfekte Trefferquote (1,00) für Klasse 1 ist ein Warnsignal, da sie wahrscheinlich auf eine Überanpassung oder eine Voreingenommenheit gegenüber der Mehrheitsklasse hinweist.
Das Modell sagt für fast alles die Klasse 1 voraus und übersieht viele tatsächliche Proben der Klasse 0, was aus dem schlechten Erinnerungswert der Klasse 0 von 0,41 ersichtlich ist.
Insgesamt zeigen diese Metriken nicht nur ein Ungleichgewicht, sondern geben auch Anlass zu Bedenken hinsichtlich der Verallgemeinerungsfähigkeit des Modells und seiner Fairness zwischen den Klassen. Hier stimmt eindeutig etwas nicht.
Wir wollen die Oversampling-Techniken nutzen, um unser Modell zu verbessern und eine ausgewogene Vorhersage zu finden.
Ein Expert Advisor (EA) zum Testen
Es gibt immer einen Unterschied zwischen den Analyseergebnissen eines maschinellen Lernmodells wie dem obigen Klassifizierungsbericht und den tatsächlichen Handelsergebnissen von MetaTrader 5. Da wir das Modell im ONNX-Format für die spätere Verwendung speichern werden, können wir einen einfachen Handelsroboter erstellen, der ein Modell verwendet, das auf jeder in diesem Artikel besprochenen Resampling-Technik trainiert wurde, und es verwendet, um Handelsentscheidungen auf dem Strategietester auf dem Trainingsmuster zu treffen.
Die verwendeten Daten wurden in der Datei Collectdata.mq5 gesammelt, einem Skript, das die Trainingsdaten vom 01.01.2025 bis zurück zum 01.01.2023 sammelt. Sie finden sie in den Anhängen zu diesem Artikel.
Im Expert Advisor (EA) mit dem Namen Test Resampling Techniques.mq5 initialisieren wir das Modell im ONNX-Format und verwenden es dann zur Erstellung von Prognosen.
#include <Random Forest.mqh> CRandomForestClassifier random_forest; //A class for loading the RFC in ONNX format #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> CTrade m_trade; CPositionInfo m_position; input string symbol_ = "USDJPY"; input int magic_number= 14042025; input int slippage = 100; input ENUM_TIMEFRAMES timeframe_ = PERIOD_D1; input string technique_name = "randomoversampling"; int lookahead = 1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!random_forest.Init(StringFormat("%s.%s.%s.onnx", symbol_, EnumToString(timeframe_), technique_name), ONNX_COMMON_FOLDER)) //Initializing the RFC in ONNX format from a commmon folder return INIT_FAILED; //--- Setting up the CTrade module m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(symbol_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- vector x = { iOpen(symbol_, timeframe_, 1), iHigh(symbol_, timeframe_, 1), iLow(symbol_, timeframe_, 1), iClose(symbol_, timeframe_, 1) }; long signal = random_forest.predict_bin(x); //Predicted class double proba = random_forest.predict_proba(x).Max(); //Maximum predicted probability MqlTick ticks; if (!SymbolInfoTick(symbol_, ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(symbol_, SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, symbol_, ticks.ask,0,0); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, symbol_, ticks.bid,0,0); } //--- CloseTradeAfterTime((Timeframe2Minutes(timeframe_)*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool PosExists(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol()==symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) return (true); return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool ClosePos(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol() == symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) { if (m_trade.PositionClose(m_position.Ticket())) return true; } return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CloseTradeAfterTime(int period_seconds) { for (int i = PositionsTotal() - 1; i >= 0; i--) if (m_position.SelectByIndex(i)) if (m_position.Magic() == magic_number) if (TimeCurrent() - m_position.Time() >= period_seconds) m_trade.PositionClose(m_position.Ticket(), slippage); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int Timeframe2Minutes(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return 1; case PERIOD_M2: return 2; case PERIOD_M3: return 3; case PERIOD_M4: return 4; case PERIOD_M5: return 5; case PERIOD_M6: return 6; case PERIOD_M10: return 10; case PERIOD_M12: return 12; case PERIOD_M15: return 15; case PERIOD_M20: return 20; case PERIOD_M30: return 30; case PERIOD_H1: return 60; case PERIOD_H2: return 120; case PERIOD_H3: return 180; case PERIOD_H4: return 240; case PERIOD_H6: return 360; case PERIOD_H8: return 480; case PERIOD_H12: return 720; case PERIOD_D1: return 1440; // 1 day = 1440 minutes case PERIOD_W1: return 10080; // 1 week = 7 * 1440 minutes case PERIOD_MN1: return 43200; // Approx. 1 month = 30 * 1440 minutes default: PrintFormat("Unknown timeframe: %d", tf); return 0; } }
Da wir das Modell auf die Zielvariable basierend auf dem Lookahead-Wert von 1 trainiert haben, müssen wir den Handel schließen, nachdem die Lookahead-Anzahl von Balken im aktuellen Zeitrahmen verstrichen ist. Auf diese Weise stellen wir sicher, dass der Lookahead-Wert respektiert wird, da wir unsere Geschäfte entsprechend dem Vorhersagehorizont des Modells halten und schließen.
Bevor wir uns die Handelsergebnisse der Modelle ansehen, die mit den neu abgetasteten Daten trainiert wurden, wollen wir die Handelsergebnisse eines Modells betrachten, das mit den nicht neu abgetasteten Trainingsdaten (Rohdaten) trainiert wurde.
Tester-Konfigurationen.
Inputs: technique_name = no-sampling.
Testergebnisse.
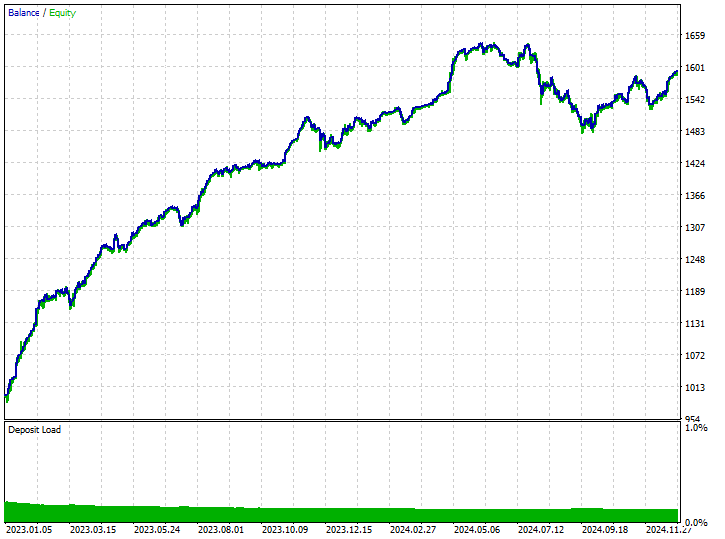
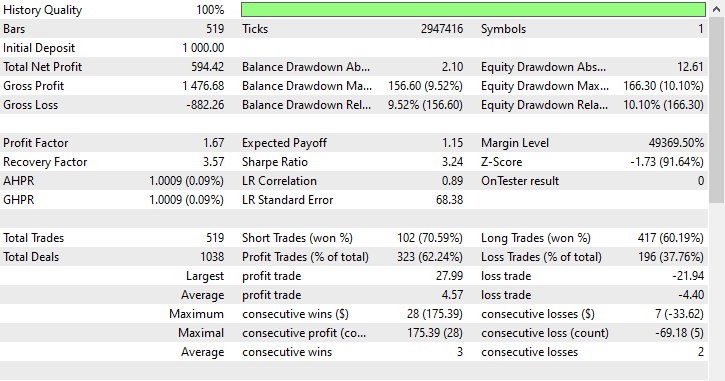
Obwohl das Modell in der Lage war, einige gute Signale zu erkennen und einige beeindruckende Handelsergebnisse zu erzielen, wobei die insgesamt profitablen Geschäfte 62,24 % aller getätigten Geschäfte ausmachten. Wenn Sie sich die gewonnenen Kauf- und Verkaufs-Geschäfte ansehen, können Sie feststellen, dass das Verhältnis zwischen Kauf- und Verkaufs-Geschäfte 1:4 ist.
102 der 519 getätigten Handelsgeschäfte waren Verkaufs-Geschäfte, was zu einer Gewinnquote von 70,59% führt, während 417 der 519 getätigten Handelsgeschäfte Kauf-Geschäfte waren, was zu einer Gewinngenauigkeit von 60,19% führt. Irgendetwas stimmt hier eindeutig nicht, denn wenn wir die Kerzenrichtung vom 1. Januar 2023 bis zum 1. Januar 2025 auf der Grundlage des Lookahead-Wertes von 1 analysieren.
print("classes in y: ",np.unique(y, return_counts=True))
Das Ergebnis.
classes in y: (array([0, 1]), array([225, 293]))
Wir können sehen, dass 225 fallende Kursbewegungen waren, während 293 Aufwärts-Bewegungen waren. Da die Mehrheit der Kerzen sich in dieser 2-Jahres-Periode (vom 1. Januar 2023 bis zum 1. Januar 2025) in die Aufwärts-Richtung des USDJPY bewegte, könnte jedes schreckliche Modell, das die Aufwärts-Bewegung begünstigt, einen Gewinn erzielen. Das ist gar nicht so schwer.
Jetzt können wir verstehen, dass der einzige Grund, warum das Modell einen gewissen Gewinn erwirtschaftet hat, der war, dass es die Kauf-Geschäfte viermal mehr begünstigt hat als die Verkaufs-Geschäfte.
Da sich der Markt in dieser Zeit überwiegend im Aufwärtstrend befand, konnte er einige Gewinne erzielen.
Lassen Sie uns mit Resampling-Techniken fortfahren und sehen, wie wir diese verzerrte Entscheidungsfindung in unseren Modellen angehen können.
Oversampling-Techniken
Zufälliges Oversampling
Diese Technik wird verwendet, um ein Klassenungleichgewicht in Datensätzen zu beheben, indem synthetische Stichproben der Minderheitenklasse erstellt werden.
Dabei werden nach dem Zufallsprinzip Beispiele für Minderheitsklassen ausgewählt und dupliziert, um ihre Repräsentanz in den Trainingsdaten zu erhöhen; Ziel ist es, die Klassenverteilung in unausgewogenen Datensätzen auszugleichen.
Das am häufigsten verwendete Tool für diese Aufgabe ist imbalanced-learn, nachstehend finden Sie eine einfache Anleitung für die Verwendung dieses Tools.
from imblearn.over_sampling import RandomOverSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomOverSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
Ausgabe:
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([395, 395]))
Wir können die neu abgetasteten Daten an dieselbe RandomForestClassifier anpassen, die wir zuvor verwendet haben, und den Unterschied im Ergebnis im Vergleich zu den Ergebnissen ohne Neuabtastung der Daten beobachten.
model.fit(X_resampled, y_resampled)
Die Bewertung des Modells.
y_train_pred = model.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred))
Das Ergebnis.
Train Classification report precision recall f1-score support 0 0.82 0.85 0.83 158 1 0.88 0.86 0.87 204 accuracy 0.85 362 macro avg 0.85 0.85 0.85 362 weighted avg 0.85 0.85 0.85 362
Erstaunlicherweise zeigen diese Ergebnisse eine signifikante Verbesserung bei allen Messgrößen. Die F1-Punktzahl von 0,87 für beide Klassen deuten darauf hin, dass das Modell unvoreingenommene und konsistente Vorhersagen macht, was auf ein Modell mit gesunder Generalisierung und gut verteiltem Lernen über die Zielklassen hinweist.
Trotz seiner Einfachheit und Effektivität kann das Oversampling das Risiko einer Überanpassung erhöhen, indem es doppelte Instanzen der Minderheitenklasse erzeugt, die dem Modell möglicherweise keine neuen Informationen hinzufügen.
Unter Verwendung der gleichen Testerkonfigurationen können wir das auf diesen Daten trainierte Modell auf dem Strategietester testen.
Inputs: technique_name = randomoversampling.
Testergebnisse.
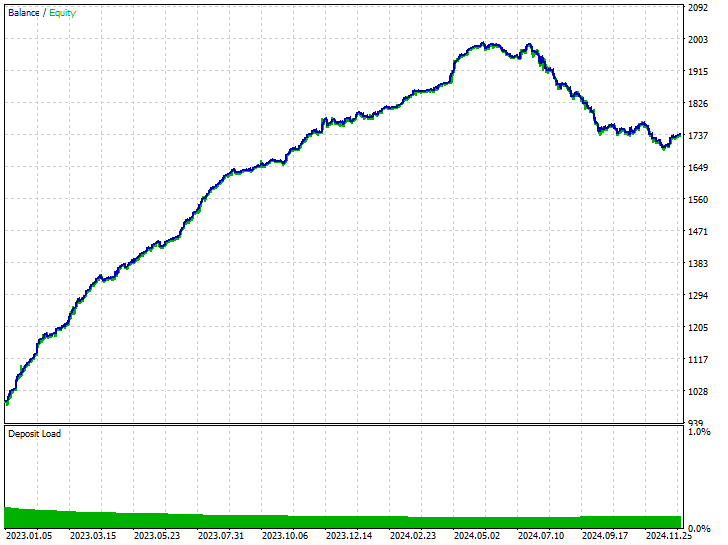
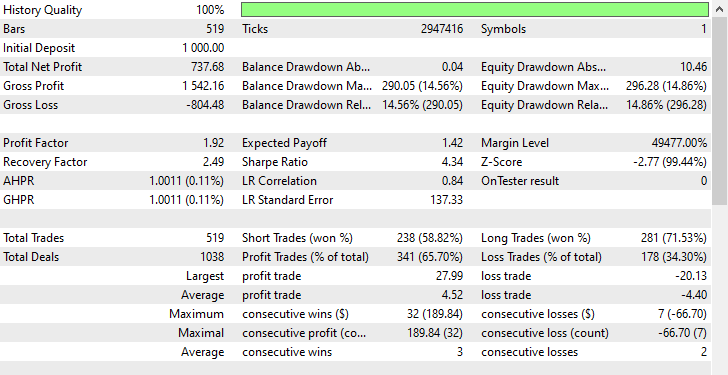
Wie Sie sehen können, haben wir Verbesserungen in allen Handelsaspekten, dieses Modell ist robuster als das, das mit Rohdaten trainiert wurde. Jetzt eröffnet der Roboter mehr Verkaufs-Geschäfte und das hat zu einer deutlichen Reduzierung der Kauf-Geschäfte geführt.
Auch in diesem Trainingszeitraum wies der Markt 293 bzw. 225 Aufwärts- und Abwärts-Bewegungen auf, je nachdem, wie wir die Zielvariable gestaltet haben. Dieses neue Modell, das auf übermäßig ausgewählten Daten trainiert wurde, scheint 281 bzw. 238 Kauf- und Verkaufs-Geschäfte zu eröffnen, was ein gutes Zeichen dafür ist, dass das Modell nicht voreingenommen ist, da es seine Entscheidungen eher auf der Grundlage der erlernten Muster trifft.
Undersampling-Techniken
Es gibt eine Reihe von Undersampling-Techniken, die wir in verschiedenen Python Modulen verwenden können. Einige davon sind:
Random Undersampling
Dabei handelt es sich um eine Technik zur Beseitigung eines Klassenungleichgewichts in Datensätzen, bei der die Anzahl der Stichproben aus der Mehrheitsklasse reduziert wird, um ein Gleichgewicht mit der Minderheitsklasse herzustellen.
Dabei werden zufällig oder strategisch Stichproben aus der Mehrheitsklasse entfernt.
Ähnlich wie bei der Anwendung des Oversamplings können wir die Hauptklasse wie folgt undersamplen.
from imblearn.under_sampling import RandomUnderSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomUnderSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
Das Ergebnis.
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([304, 304]))
Zufälliges Undersampling und andere unzureichende Stichproben können die Leistung des Modells beeinträchtigen, da informative Stichproben der Mehrheitsklasse entfernt werden, was zu einem weniger repräsentativen Trainingssatz führt. Dies könnte möglicherweise zu einer unzureichenden Anpassung des Modells führen.
Diese Technik verbesserte die Leistung des Modells bei den Trainingsdaten für beide Klassen.
Train Classification report precision recall f1-score support 0 0.76 0.90 0.82 158 1 0.91 0.78 0.84 204 accuracy 0.83 362 macro avg 0.83 0.84 0.83 362 weighted avg 0.84 0.83 0.83 362
Unter Verwendung der gleichen Testerkonfigurationen können wir das auf diesen Daten trainierte Modell auf dem Strategietester testen.
Inputs: technique_name = randomundersampling.
Testergebnisse.
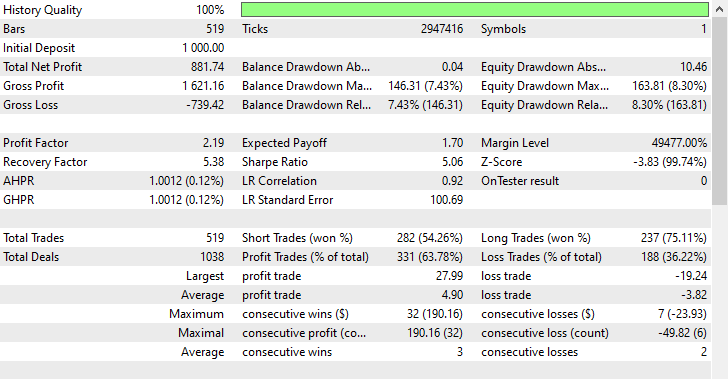
Diese Technik führte zu 282 bzw. 237 Kauf- und Verkaufs-Geschäfte. Obwohl dieses Modell Verkaufs-Geschäfte gegenüber Kauf-Geschäfte bevorzugte, was auf dem Markt nicht vorkam, war es dennoch in der Lage, mehr Gewinne zu erzielen als das voreingenommene Modell, das mit Rohdaten trainiert wurde, und das Oversampling-Modell, das Aufwärtsbewegungen bevorzugte.
Diese Ergebnisse des Modells zeigen uns, dass wir auf dem Markt in beide Richtungen Gewinne erzielen können, unabhängig davon, was in der Vergangenheit passiert ist.
Tomek Links
Tomek-Links beziehen sich auf ein Paar von Instanzen aus verschiedenen Klassen, die sehr nahe beieinander liegen und oft als Nächste Nachbarn betrachtet werden. Hier eine einfache Erklärung, wie die Technik der Tomek-Links für das Undersampling von maschinellen Lerndaten funktioniert.
Stellen Sie sich vor, wir haben zwei Punkte A und B aus verschiedenen Klassen, A gehört zur Mehrheitsklasse, während B zur Minderheitsklasse gehört (oder umgekehrt).
Wenn diese beiden Punkte (A und B) nahe beieinander liegen (Nachbarn), wird eine Beobachtung aus der Mehrheitsklasse (in diesem Fall A) gelöscht.
Diese Technik hilft dabei, die Entscheidungsgrenzen zu bereinigen und die Klassen deutlicher zu machen, während gleichzeitig einige Proben aus der Mehrheitsklasse entfernt werden.
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Ausgabe:
Before --> y (unique): (array([0, 1]), array([304, 395])) After --> y (unique): (array([0, 1]), array([304, 283]))
Diese Technik kann zu beeindruckend ausgewogenen Vorhersageergebnissen des Modells führen, ist jedoch auf die binäre Klassifizierung beschränkt, weniger effektiv bei stark überlappenden Daten und kann wie andere Stichprobentechniken zu Datenverlusten führen.
Diese Technik hatte auch eine bessere Leistung bei den Trainingsdaten.
Train Classification report precision recall f1-score support 0 0.69 0.94 0.80 158 1 0.93 0.68 0.78 204 accuracy 0.79 362 macro avg 0.81 0.81 0.79 362 weighted avg 0.83 0.79 0.79 362
Unter Verwendung der gleichen Testerkonfiguration können wir das auf diesen Daten trainierte Modell auf dem Strategietester testen.
Inputs: technique_name = tomek-links.
Testergebnisse.

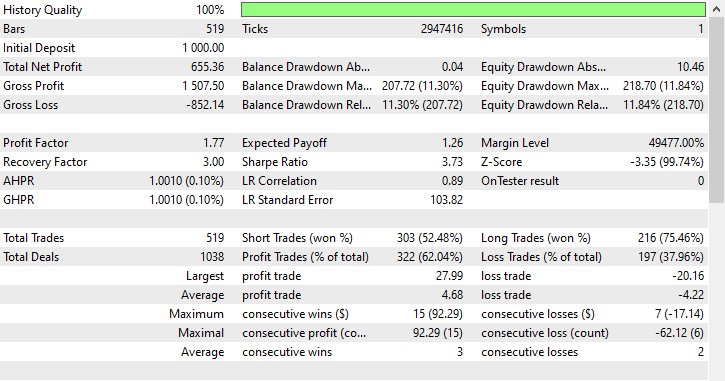
Ähnlich wie beim Random-Undersampling bevorzugte Tomek Links Verkaufs-Geschäfte. Obwohl er 303 Verkaufs-Geschäfte und nur 216 Kauf-Geschäfte eröffnet wurden, konnte er trotzdem Gewinne erzielen.
Cluster-Zentroide
Hierbei handelt es sich um eine Undersampling-Technik, bei der die Mehrheitsklasse reduziert wird, indem ihre Stichproben durch die Zentren von Clustern (in der Regel aus dem K-Means-Clustering) ersetzt werden.
Es funktioniert folgendermaßen.
- Das K-Means-Clustering wird auf die Mehrheitsklasse angewendet.
- Die K-Anzahl der gewünschten Proben wird ausgewählt.
- Die Mehrheit der Proben in der Klasse wird durch k Clusterzentren ersetzt.
- Dieses Ergebnis wird mit der Minderheitenklasse kombiniert, um einen ausgewogenen Datensatz zu erhalten.
from imblearn.under_sampling import ClusterCentroids cc = ClusterCentroids(random_state=42) X_resampled, y_resampled = cc.fit_resample(X, y) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Ausgabe:
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([225, 225]))
Nachfolgend ist das Ergebnis des Modells für die mit Hilfe von Clusterschwerpunkten unterabgetasteten Trainingsdaten dargestellt.
Train Classification report precision recall f1-score support 0 0.64 0.86 0.73 158 1 0.85 0.62 0.72 204 accuracy 0.73 362 macro avg 0.75 0.74 0.73 362 weighted avg 0.76 0.73 0.73 362
Bisher ist diese Technik diejenige mit dem geringsten Genauigkeitswert. Ein Wert von 0,73 könnte darauf hindeuten, dass das Modell weniger überangepasst ist als die vorhergehenden, sodass es auch das bestmögliche Modell sein könnte, das es bisher gab.
Inputs: technique_name = cluster-centroids.
Testergebnisse.
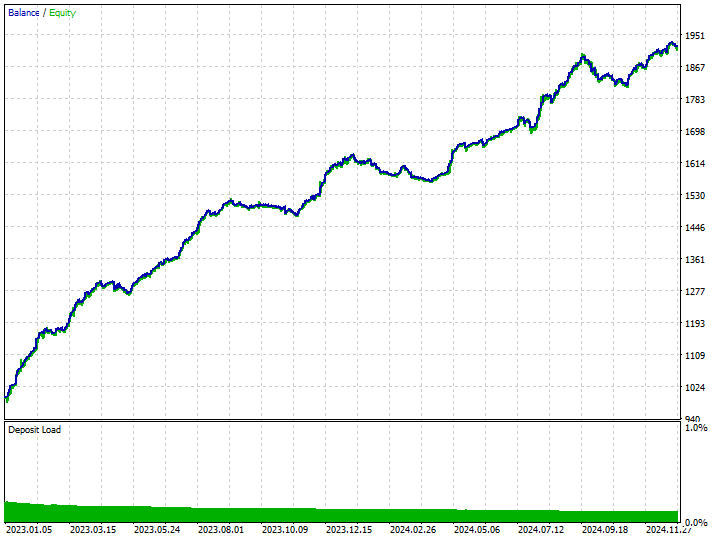
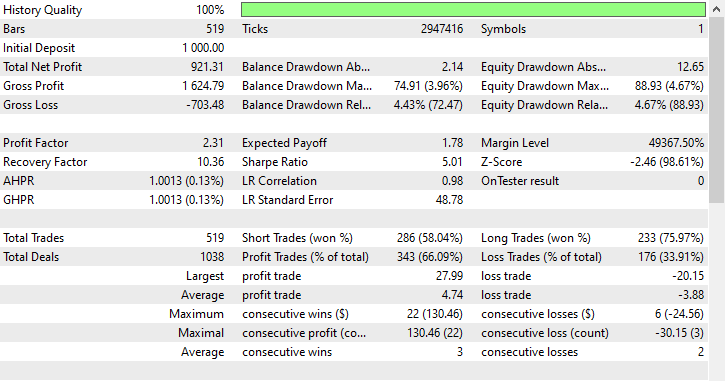
Diese Technik lieferte mit 343 von 519 Handelsgeschäfte die meisten Gewinne, was einer Genauigkeit von 66,09 % entspricht, da die Gewinne fast die ursprüngliche Einlage erreichten. Obwohl das Modell Verkaufs-Geschäfte bevorzugt, war es sehr genau bei der Vorhersage der Aufwärts-Signale, was zu satten 75,97 % von 100 % erfolgreichen Kaufpositionen führte.
Hybride Methoden
SMOTE + Tomek Links
Wendet zuerst SMOTE an und bereinigt dann den Lärm mit Tomek Links.
from imblearn.combine import SMOTETomek smt = SMOTETomek(random_state=42) X_resampled, y_resampled = smt.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Ausgabe:
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([159, 159]))
Nachfolgend sehen Sie das Ergebnis des Modells, das mit Hilfe dieser Technik auf neu abgetasteten Trainingsdaten trainiert wurde.
Train Classification report precision recall f1-score support 0 0.74 0.73 0.73 158 1 0.79 0.80 0.80 204 accuracy 0.77 362 macro avg 0.77 0.77 0.77 362 weighted avg 0.77 0.77 0.77 362
Nachstehend sind die Ergebnisse des Handels aufgeführt.
Inputs: technique_name = smote-tomeklinks.
Testergebnisse.
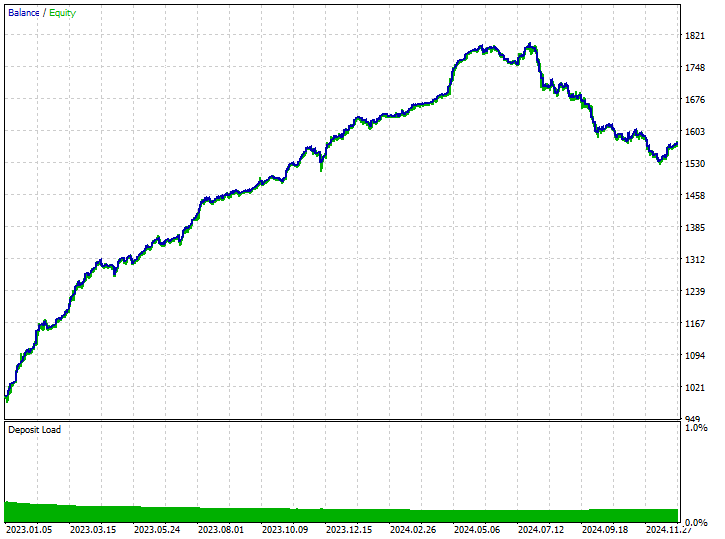
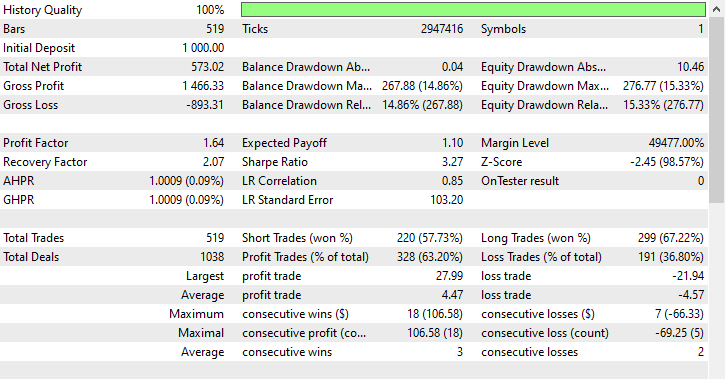
299 bzw. 220 Kauf- und Verkaufs-Geschäfte, nicht schlecht.
SMOTE + ENN (Edited Nearest Neighbors)
SMOTE erzeugt synthetische Proben, ENN entfernt dann falsch klassifizierte Proben.
from imblearn.combine import SMOTEENN sme = SMOTEENN(random_state=42) X_resampled, y_resampled = sme.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Mit dieser Technik wurde ein großer Teil der Daten entfernt, die Trainingsdaten wurden auf insgesamt 61 Stichproben reduziert.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([37, 24]))
Nachfolgend finden Sie den Klassifizierungsbericht für ein Übungsbeispiel.
Train Classification report precision recall f1-score support 0 0.46 0.76 0.58 158 1 0.63 0.32 0.42 204 accuracy 0.51 362 macro avg 0.55 0.54 0.50 362 weighted avg 0.56 0.51 0.49 362
Das resultierende Modell ist erwartungsgemäß schlecht, da es mit insgesamt 61 Stichproben trainiert wurde, was nicht ausreicht, um sinnvolle Muster zu lernen. Beobachten wir die Ergebnisse des Handels.
Inputs: technique_name = smote-enn.
Testergebnisse.
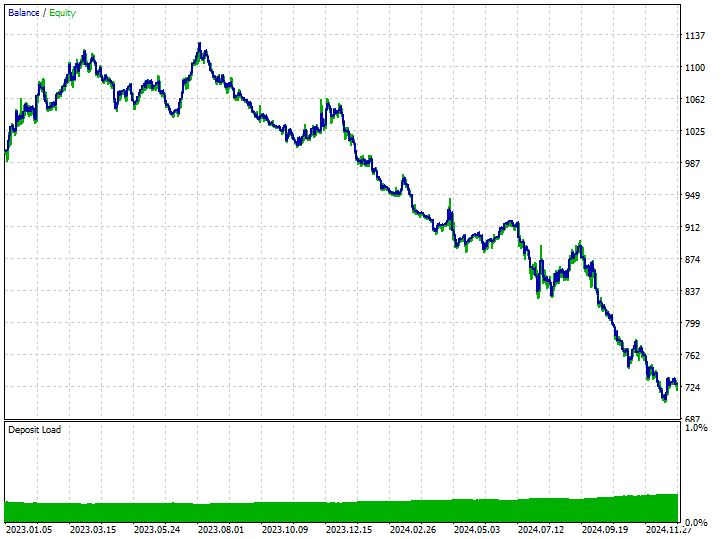
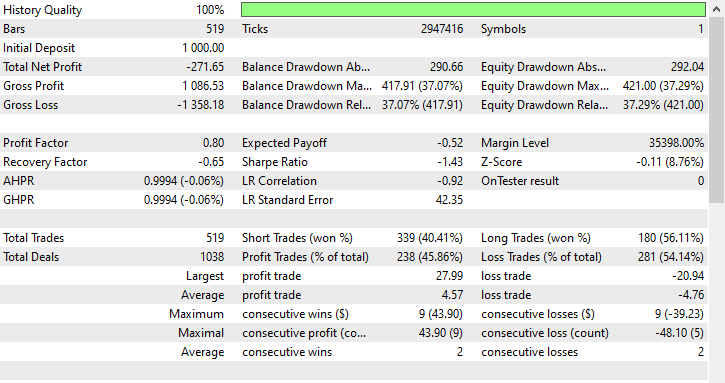
Diese Technik hat überhaupt nicht geholfen, sie hat die Situation sogar noch verschlimmert. Es führte zu verzerrten Handelsergebnissen, da der Roboter 180 von 519 Kauf- und 339 Verkaufstransaktionen eröffnete.
Das bedeutet nicht, dass die Technik schlecht ist, sie ist nur in dieser Situation nicht optimal.
Schlussfolgerung
Wir leben in einer nicht perfekten Welt, in der es nicht für alle Phänomene geeignete Erklärungen oder einen klaren Weg gibt. Dies gilt auch für den Handel, wo sich die Märkte schnell und häufig ändern, sodass die meisten unserer Strategien sofort überholt sind.
Wir können zwar nicht kontrollieren, was auf dem Markt passiert, aber das Beste, was wir tun können, ist sicherzustellen, dass wir zumindest über robuste Handelssysteme und Strategien verfügen, die für den Einsatz unter extremen Bedingungen ausgelegt sind.
Da sich die Geschichte nicht immer wiederholt, ist es gut, dafür zu sorgen, dass wir unvoreingenommene Handelssysteme haben, die für jeden Markt geeignet sind, indem wir die Muster erkennen, die in der Vergangenheit auf dem Markt aufgetaucht sind, uns aber nicht zu sehr auf sie verlassen, um Handelsentscheidungen zu treffen. So hilfreich diese Techniken auch sein können, müssen Sie sich ihrer Nachteile und Kompromisse bewusst sein, die mit der Verwendung von Resampling-Techniken für Ihre maschinellen Lerndaten einhergehen. Zu diesen Nachteilen gehören das Risiko einer Überanpassung durch Oversampling, der potenzielle Verlust wertvoller Informationen bei Undersampling und die Einführung von Rauschen oder Verzerrungen, wenn das Resampling nicht sorgfältig durchgeführt wird.
Das richtige Gleichgewicht zu finden, ist der Schlüssel zum Aufbau robuster Modelle, die sich gut auf unbekannte Marktbedingungen verallgemeinern lassen.
Mit freundlichen Grüßen.
Tabelle der Anhänge
| Dateiname | Beschreibung/Verwendung |
|---|---|
| Experts\Test Resampling Techniques.mq5 | Ein Expert Advisor (EA) für den Einsatz von .ONNX-Dateien in MQL5 |
| Include\pandas.mqh | Python-ähnliche Pandas-Bibliothek für Datenmanipulation und -speicherung |
| Scripts\Collectdata.mq5 | Ein Skript zur Erfassung der Trainingsdaten |
| Common\*.onnx | Modelle für maschinelles Lernen im ONNX-Format |
| Common\*.csv | Trainingsdaten von verschiedenen Instrumenten für das maschinelle Lernen |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/17736
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Aufbau eines nutzerdefinierten Systems zur Erkennung von Marktregimen in MQL5 (Teil 1): Der Indikator
Aufbau eines nutzerdefinierten Systems zur Erkennung von Marktregimen in MQL5 (Teil 1): Der Indikator
 Websockets für MetaTrader 5: Asynchrone Client-Verbindungen mit dem Windows-API
Websockets für MetaTrader 5: Asynchrone Client-Verbindungen mit dem Windows-API
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Die benötigten Komponenten sind die neuesten Versionen von allem, was in das Notebook importiert wurde. Sie können pip install ohne sich um die Versionskonflikte zu kümmern durchführen. Alternativ können Sie auch dem Link in der Tabelle mit den Anhängen folgen, der Sie zu Kaggle.com führt, wo Sie den Code bearbeiten und ändern können.
Undeclared identifier, könnte bedeuten, dass eine Variable oder ein Objekt nicht definiert ist. Überprüfen Sie Ihren Code oder senden Sie mir einen Screenshot des Codes.