
Datenwissenschaft und ML (Teil 33): Pandas Dataframe in MQL5, Vereinfachung der Datensammlung für ML-Nutzung

Inhalt
- Einführung
- Grundlegende Datenstrukturen in Pandas
- Ein Pandas-Datenrahmen
- Hinzufügen von Daten in die Dataframe-Klasse
- Zuweisen einer CSV-Datei zum Dataframe
- Visualisierung der Daten im Dataframe
- Exportieren des Dataframe in eine CSV-Datei
- Auswahl und Indizierung des Dataframe
- Untersuchung und Inspektion von Pandas Dataframe
- Zeitreihen und Datenumwandlungsmethoden
- Sammeln von Daten für maschinelles Lernen
- Training eines maschinellen Lernmodells
- Bereitstellen eines Modells für maschinelles Lernen in MQL5
- Schlussfolgerung
Einführung
Bei der Arbeit mit maschinellen Lernmodellen ist es wichtig, dass wir für alle Umgebungen die gleiche Datenstruktur, wenn nicht sogar die gleichen Werte haben: Training, Validierung und Test. Mit der Unterstützung der Modelle von Open Neural Network Exchange (ONNX) in MQL5 und MetaTrader 5 haben wir heute die Möglichkeit, außerhalb trainierte Modelle in die MQL5-Sprache zu importieren und für Handelszwecke zu verwenden.
Da die meisten Nutzer Python für das Training dieser Modelle der künstlichen Intelligenz (KI) verwenden, die dann in MetaTrader 5 durch MQL5-Code eingesetzt werden, kann es einen großen Unterschied in der Art und Weise geben, wie die Daten organisiert sind, und oft können sogar die Werte innerhalb der gleichen Datenstruktur leicht unterschiedlich sein, was auf den Unterschied in den beiden Technologien zurückzuführen ist.

In diesem Artikel werden wir die in der Sprache Python verfügbare Bibliothek Pandas nachbilden. Es ist eine der beliebtesten Bibliotheken, die vor allem bei der Arbeit mit großen Datenmengen nützlich ist.
Da diese Bibliothek von Datenwissenschaftlern verwendet wird, um Daten für das Training von ML-Modellen vorzubereiten und zu bearbeiten, wollen wir durch die Nutzung ihrer Fähigkeiten den gleichen Datenspielplatz in MQL5 wie in Python haben.
Grundlegende Datenstrukturen in Pandas
Die Pandas-Bibliothek bietet zwei Arten von Klassen für die Verarbeitung von Daten.
- Series: ein eindimensionales, gekennzeichnetes Array zur Aufnahme von Daten beliebigen Typs, z. B. Ganzzahlen, Zeichenketten, Objekte usw.
s = pd.Series([1, 3, 5, np.nan, 6, 8])
- Dataframe: eine zweidimensionale Datenstruktur, die Daten wie ein zweidimensionales Feld oder eine Tabelle mit Zeilen und Spalten enthält.
Da die Datenklasse der Pandas-Serie eindimensional ist, ist eher wie ein Array oder Vektor in MQL5, daher werden wir nicht damit arbeiten. Unser Schwerpunkt liegt auf dem zweidimensionalen „Dataframe“.
Ein Pandas DataFrame
Auch diese Datenstruktur enthält Daten wie ein zweidimensionales Array oder eine Tabelle mit Zeilen und Spalten. In MQL5 können wir mit zweidimensionalen Arrays arbeiten, aber das praktischste zweidimensionale Objekt, das wir für diese Aufgabe verwenden können, ist eine Matrix.
Da wir nun wissen, dass der Kern des Pandas Dataframe ein zweidimensionales Array ist, können wir diese ähnliche Grundlage in unserer Pandas-Klasse in MQL5 implementieren.
Datei: pandas.mqh
class CDataFrame { public: string m_columns[]; //An array of string values for keeping track of the column names matrix m_values; // A 2D matrix CDataFrame(); ~CDataFrame(void); }
Wir brauchen ein Array mit dem Namen „m_columns“ um die Spaltennamen für jede Spalte im Dataframe zu speichern. Im Gegensatz zu anderen Bibliotheken für die Arbeit mit Daten wie Numpy stellt Pandas sicher, dass die gespeicherten Daten nutzerfreundlich sind, indem es die Spaltennamen festhält.
Pandas Datafrme in Python unterstützt verschiedene Datentypen wie Integers, Strings, Objekte, etc.
import pandas as pd df = pd.DataFrame({ "Integers": [1,2,3,4,5], "Doubles": [0.1,0.2,0.3,0.4,0.5], "Strings": ["one","two","three","four","five"] })
Wir werden diese Flexibilität nicht in unserer MQL5-Bibliothek implementieren, da das Ziel dieser Bibliothek darin besteht, uns bei der Arbeit mit maschinellen Lernmodellen zu unterstützen, bei denen Variablen vom Datentyp float und double am nützlichsten sind.
Vergewissern Sie sich also, dass Sie Werte (Integer, Long, Ulong usw.) in Werte des Datentyps Double umwandeln und alle (String-)Variablen kodieren, bevor Sie sie in die Dataframe-Klasse einfügen, da alle Variablen gezwungen werden, den Datentyp Double anzunehmen.
Hinzufügen von Daten in die Dataframe-Klasse
Da wir nun wissen, dass eine Matrix im Kern eines Dataframe-Objekts für die Speicherung aller Daten verantwortlich ist, sollten wir Möglichkeiten implementieren, um ihr Informationen hinzuzufügen.
In Python können Sie einfach einen neuen Datenrahmen erstellen und ihm Objekte hinzufügen, indem Sie die Methode aufrufen;
df = pd.DataFrame({
"first column": [1,2,3,4,5],
"second column": [10,20,30,40,50]
})
Aufgrund der Syntax der MQL5-Sprache können wir nicht zulassen, dass sich eine Klasse oder Methode so verhält. Implementieren wir eine Methode namens Insert.
Datei: pandas.mqh
void CDataFrame::Insert(string name, const vector &values) { //--- Check if the column exists in the m_columns array if it does exists, instead of creating a new column we modify an existing one int col_index = -1; for (int i=0; i<(int)m_columns.Size(); i++) if (name == m_columns[i]) { col_index = i; break; } //--- We check if the dimensiona are Ok if (m_values.Rows()==0) m_values.Resize(values.Size(), m_values.Cols()); if (values.Size() > m_values.Rows() && m_values.Rows()>0) //Check if the new column has a bigger size than the number of rows present in the matrix { printf("%s new column '%s' size is bigger than the dataframe",__FUNCTION__,name); return; } //--- if (col_index != -1) { m_values.Col(values, col_index); if (MQLInfoInteger(MQL_DEBUG)) printf("%s column '%s' exists, It will be modified",__FUNCTION__,name); return; } //--- If a given vector to be added to the dataframe is smaller than the number of rows present in the matrix, we fill the remaining values with Not a Number (NaN) vector temp_vals = vector::Zeros(m_values.Rows()); temp_vals.Fill(NaN); //to create NaN values when there was a dimensional mismatch for (ulong i=0; i<values.Size(); i++) temp_vals[i] = values[i]; //--- m_values.Resize(m_values.Rows(), m_values.Cols()+1); //We resize the m_values matrix to accomodate the new column m_values.Col(temp_vals, m_values.Cols()-1); //We insert the new column after the last column ArrayResize(m_columns, m_columns.Size()+1); //We increase the sice of the column names to accomodate the new column name m_columns[m_columns.Size()-1] = name; //we assign the new column to the last place in the array }
Wir können neue Informationen wie folgt in den Dataframe einfügen;
#include <MALE5\pandas.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDataFrame df; vector v1= {1,2,3,4,5}; vector v2= {10,20,30,40,50}; df.Insert("first column", v1); df.Insert("second column", v2); }
Alternativ können wir der Klasse constructur die Fähigkeit geben, eine Matrix und ihre Spaltennamen zu empfangen.
CDataFrame::CDataFrame(const string &columns, const matrix &values) { string columns_names[]; //A temporary array for obtaining column names from a string ushort sep = StringGetCharacter(",", 0); if (StringSplit(columns, sep, columns_names)<0) { printf("%s failed to obtain column names",__FUNCTION__); return; } if (columns_names.Size() != values.Cols()) //Check if the given number of column names is equal to the number of columns present in a given matrix { printf("%s dataframe's columns != columns present in the values matrix",__FUNCTION__); return; } ArrayCopy(m_columns, columns_names); //We assign the columns to the m_columns array m_values = values; //We assing the given matrix to the m_values matrix }
Wir können der Klasse Dataframe auch wie folgt neue Informationen hinzufügen;
void OnStart() { //--- matrix data = { {1,10}, {2,20}, {3,30}, {4,40}, {5,50}, }; CDataFrame df("first column,second column",data); }
Ich schlage vor, Sie verwenden die Methode Insert für das Hinzufügen von Daten zur Dataframe-Klasse, dass jede andere Methode für die Aufgabe.
Die beiden zuvor besprochenen Methoden sind nützlich, wenn Sie Datensätze vorbereiten, aber wir brauchen auch eine Funktion zum Laden der in einem Datensatz vorhandenen Daten.
Zuweisen einer CSV-Datei zum Dataframe
Die Methode zum Lesen einer CSV-Datei und zum Zuweisen der Werte zu einem Dataframe gehört zu den nützlichsten Funktionen in Pandas, wenn Sie mit der Bibliothek in Python arbeiten.
df = pd.read_csv("EURUSD.PERIOD_D1.csv")
Lassen Sie uns diese Methode in unserer MQL5-Klasse implementieren;
bool CDataFrame::ReadCSV(string file_name,string delimiter=",",bool is_common=false, bool verbosity=false) { matrix mat_ = {}; int rows_total=0; int handle = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI|(is_common?FILE_IS_COMMON:FILE_ANSI),delimiter); //Open a csv file ResetLastError(); if(handle == INVALID_HANDLE) //Check if the file handle is ok if not return false { printf("Invalid %s handle Error %d ",file_name,GetLastError()); Print(GetLastError()==0?" TIP | File Might be in use Somewhere else or in another Directory":""); return false; } else { int column = 0, rows=0; while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(m_columns,column+1); m_columns[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); //add a value to the matrix column++; //--- if(FileIsLineEnding(handle)) //At the end of the each line { rows++; mat_.Resize(rows,column); //Resize the matrix to accomodate new values column = 0; } } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Reading a CSV file... record [%d]",rows); rows_total = rows; FileClose(handle); //Close the file after reading it } mat_.Resize(rows_total-1,mat_.Cols()); m_values = mat_; return true; }
Nachfolgend wird beschrieben, wie Sie eine CSV-Datei lesen und sie direkt dem Dataframe zuweisen können.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Visualisierung der Daten im Dataframe
Wir haben gesehen, wie Sie Informationen in einen Datenrahmen einfügen können, aber es ist sehr wichtig, einen kurzen Blick in den Datenrahmen zu werfen, um zu sehen, worum es sich handelt. In den meisten Fällen werden Sie mit großen Dataframes arbeiten, die oft einen Blick zurück in den Dataframe zu Explorations- und Abrufzwecken erfordern.
Pandas hat eine Methode, die als „head“, die ersten n Zeilen für das Dataframe-Objekt auf der Grundlage der Position zurückgibt. Diese Methode ist nützlich, um schnell zu testen, ob Ihr Objekt die richtige Art von Daten enthält.
Wenn die Methode „head“ in einer Zelle des Jupyter-Notebook mit dem/den Standardwert(en) aufgerufen wird, werden die ersten fünf Zeilen des Dataframe in der Zellenausgabe angezeigt.
Datei: main.ipynb
df = pd.read_csv("EURUSD.PERIOD_D1.csv") df.head()
Output
| Open | High | Low | Close | |
|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 |
Wir können eine ähnliche Funktion für die Aufgabe in MQL5 erstellen.
void CDataFrame::Head(const uint count=5) { // Calculate maximum width needed for each column uint num_cols = m_columns.Size(); uint col_widths[]; ArrayResize(col_widths, num_cols); for (uint col = 0; col < num_cols; col++) //Determining column width for visualizing a simple table { uint max_width = StringLen(m_columns[col]); for (uint row = 0; row < count && row < m_values.Rows(); row++) { string num_str = StringFormat("%.8f", m_values[row][col]); max_width = MathMax(max_width, StringLen(num_str)); } col_widths[col] = max_width + 4; // Extra padding for readability } // Print column headers with calculated padding string header = ""; for (uint col = 0; col < num_cols; col++) { header += StringFormat("| %-*s ", col_widths[col], m_columns[col]); } header += "|"; Print(header); // Print rows with padding for each column for (uint row = 0; row < count && row < m_values.Rows(); row++) { string row_str = ""; for (uint col = 0; col < num_cols; col++) { row_str += StringFormat("| %-*.*f ", col_widths[col], 8, m_values[row][col]); } row_str += "|"; Print(row_str); } // Print dimensions printf("(%dx%d)", m_values.Rows(), m_values.Cols()); }
Standardmäßig zeigt diese Funktion die ersten fünf Zeilen in unserem Datenrahmen an.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Ausgabe:
GI 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | Open | High | Low | Close | RH 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | DI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | EI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | CI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | FE 0 12:37:02.984 pandas test (Volatility 75 Index,H1) (1000x4)
Exportieren des Dataframe in eine CSV-Datei
Nachdem wir alle verschiedenen Arten von Daten im Dataframe gesammelt haben, müssen wir sie aus dem MetaTrader 5 exportieren, wo alle maschinellen Lernverfahren stattfinden.
Eine CSV-Datei ist praktisch, wenn es darum geht, Daten zu exportieren, zumal wir anschließend die Pandas-Bibliothek verwenden werden, um die CSV-Datei in die Sprache Python zu importieren.
Lassen Sie uns den Datenrahmen, den wir aus einer CSV-Datei extrahiert haben, wieder in der CSV-Datei speichern.
In Python.
df.to_csv("EURUSDcopy.csv", index=False) Das Ergebnis ist eine csv-Datei namens EURUSDcopy.csv.
Nachstehend finden Sie eine Implementierung dieser Methode in MQL5.
bool CDataFrame::ToCSV(string csv_name, bool common=false, int digits=5, bool verbosity=false) { FileDelete(csv_name); int handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI|(common?FILE_COMMON:FILE_ANSI),",",CP_UTF8); //open a csv file if(handle == INVALID_HANDLE) //Check if the handle is OK { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return (false); } //--- string concstring; vector row = {}; vector colsinrows = m_values.Row(0); if (ArraySize(m_columns) != (int)colsinrows.Size()) { printf("headers=%d and columns=%d from the matrix vary is size ",ArraySize(m_columns),colsinrows.Size()); DebugBreak(); return false; } //--- string header_str = ""; for (int i=0; i<ArraySize(m_columns); i++) //We concatenate the header only separating it with a comma delimeter header_str += m_columns[i] + (i+1 == colsinrows.Size() ? "" : ","); FileWrite(handle,header_str); FileSeek(handle,0, SEEK_SET); for(ulong i=0; i<m_values.Rows() && !IsStopped(); i++) { ZeroMemory(concstring); row = m_values.Row(i); for(ulong j=0, cols =1; j<row.Size() && !IsStopped(); j++, cols++) { concstring += (string)NormalizeDouble(row[j],digits) + (cols == m_values.Cols() ? "" : ","); } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Writing a CSV file... record [%d/%d]",i+1,m_values.Rows()); FileSeek(handle,0,SEEK_END); FileWrite(handle,concstring); } FileClose(handle); return (true); }
Im Folgenden wird beschrieben, wie Sie diese Methode anwenden.
void OnStart() { CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Assign a csv file into the dataframe df.ToCSV("EURUSDcopy.csv"); //Save the dataframe back into a CSV file as a copy }
Das Ergebnis ist die Erstellung einer CSV-Datei mit dem Namen EURUSDcopy.csv.
Nachdem wir nun über die Erstellung eines Datenrahmens, das Einfügen von Werten, den Import und den Export von Daten gesprochen haben, wollen wir uns nun die Techniken der Datenauswahl und Indizierung ansehen.
Auswahl und Indizierung des Dataframe
Es ist sehr wichtig, die Möglichkeit zu haben, bestimmte Teile des Datenrahmens zu schneiden, auszuwählen oder darauf zuzugreifen. Wenn Sie beispielsweise ein Modell für Vorhersagen verwenden, möchten Sie vielleicht nur auf die neuesten Werte (die letzte Zeile) im Datenrahmen zugreifen, während Sie beim Training auf einige Zeilen am Anfang des Datenrahmens zugreifen möchten.
Zugriff auf eine Spalte
Um auf eine Spalte zuzugreifen, können wir in unserer Klasse einen Indexoperator implementieren, der eine Zeichenkette übernimmt.
vector operator[] (const string index) {return GetColumn(index); } //Access a column by its name
Die Funktion „GetColumn“ gibt bei Angabe eines Spaltennamens einen Vektor der Werte zurück, wenn er gefunden wird.
Verwendung
Print("Close column: ",df["Close"]);
Ausgabe:
2025.01.27 16:16:19.726 pandas test (EURUSD,H1) Close column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.09321,1.09156,1.09188,1.09236,1.09315,1.09511,1.09107,1.07913,1.08258,1.08142,1.08211,1.08551,1.0845,1.08392,1.08529,1.08905,1.08818,1.08959,1.09396,1.08986,
Die Indizierung mit „loc“
Diese Indizierung hilft beim Zugriff auf eine Gruppe oder auf Zeilen und Spalten durch Kennzeichnung(en) oder ein boolesches Array.
In Pandas Python.
df.loc[0] Ausgabe.
Open 1.09381 High 1.09548 Low 1.09003 Close 1.09373 Name: 0, dtype: float64
In MQL5 können wir dies als reguläre Funktion implementieren.
vector CDataFrame::Loc(int index, uint axis=0) { if(axis == 0) { vector row = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Rows() + index; if(index < 0 || index >= (int)m_values.Rows()) { printf("%s Error: Row index out of bounds. Given index: %d", __FUNCTION__, index); return row; } return m_values.Row(index); } else if(axis == 1) { vector column = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Cols() + index; //--- Check bounds if(index < 0 || index >= (int)m_values.Cols()) { printf("%s Error: Column index out of bounds. Given index: %d", __FUNCTION__, index); return column; } return m_values.Col(index); } else printf("%s Failed, Unknown axis ",__FUNCTION__); return vector::Zeros(0); }
Ich habe das Argument axis hinzugefügt, um die Möglichkeit zu haben, zwischen dem Erhalt einer Zeile (entlang der Achse 0) und einer Spalte (entlang der Achse 1) zu wählen.
Wenn diese Funktion einen negativen Wert empfängt, greift sie auf die Elemente in umgekehrter Reihenfolge zu. Ein Indexwert von -1 ist das letzte Element im Datenrahmen (letzte Zeile bei Achse=0, letzte Spalte bei Achse=1).
Verwendung
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); Print("First row",df.Loc(0)); //--- Print("Last 5 items in df\n",df.Tail()); Print("Last row: ",df.Loc(-1)); Print("Last Column: ",df.Loc(-1, 1)); }
Ausgabe:
RM 0 09:04:21.355 pandas test (EURUSD,H1) | Open | High | Low | Close | IN 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GP 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | NS 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | IE 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | IG 0 09:04:21.355 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | NJ 0 09:04:21.355 pandas test (EURUSD,H1) (1000x4) EO 0 09:04:21.355 pandas test (EURUSD,H1) First row[1.09381,1.09548,1.09003,1.09373] JF 0 09:04:21.355 pandas test (EURUSD,H1) Last 5 items in df DN 0 09:04:21.355 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] JK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] PR 0 09:04:21.355 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] OO 0 09:04:21.355 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] FK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]] EM 0 09:04:21.355 pandas test (EURUSD,H1) Last row: [1.21444,1.21774,1.21101,1.21203] QM 0 09:04:21.355 pandas test (EURUSD,H1) Last Column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.00063,…]
Die Methode „iloc“
Die in unserer Klasse eingeführte Funktion Iloc wählt Zeilen und Spalten eines Datenrahmens nach ganzzahligen Positionen aus, ähnlich wie die von Pandas in Python angebotene Methode iloc.
Diese Methode gibt einen neuen Datenrahmen zurück, der das Ergebnis der scheibchenweisen Operation ist.
MQL-Implementierung:
CDataFrame Iloc(ulong start_row, ulong end_row, ulong start_col, ulong end_col);
Verwendung:
df = df.Iloc(0,100,0,3); //Slice from the first row to the 99th from the first column to the 2nd df.Head();
Ausgabe:
DJ 0 16:40:19.699 pandas test (EURUSD,H1) | Open | High | Low | LQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | PM 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | EI 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | DE 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | FQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | GS 0 16:40:19.699 pandas test (EURUSD,H1) (100x3)
Die Methode „at“
Diese Methode gibt einen einzelnen Wert aus dem Dataframe zurück.
MQL-Implementierung:
double CDataFrame::At(ulong row, string col_name) { ulong col_number = (ulong)ColNameToIndex(col_name, m_columns); return m_values[row][col_number]; }
Verwendung:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.At(0,"Close")); //Returns the first value within the Close column }
Ausgabe:
2025.01.27 16:47:16.701 pandas test (EURUSD,H1) 1.09373
Die Methode „iat“
Dies ermöglicht uns den Zugriff auf einen einzelnen Wert im Datenrahmen nach Position.
MQL-Implementierung:
double CDataFrame::Iat(ulong row,ulong col) { return m_values[row][col]; }
Verwendung:
Print(df.Iat(0,0)); //Returns the value at first row and first colum
Ausgabe:
2025.01.27 16:53:32.627 pandas test (EURUSD,H1) 1.09381
Entfernen von Spalten aus dem Datenrahmen mit der Methode „Drop“.
Manchmal kommt es vor, dass wir unerwünschte Spalten in unserem Datenrahmen haben oder einige Variablen zu Trainingszwecken entfernen wollen. Die Drop-Funktion kann bei dieser Aufgabe helfen.
MQL-Implementierung:
CDataFrame CDataFrame::Drop(const string cols) { CDataFrame df; string column_names[]; ushort sep = StringGetCharacter(",",0); if(StringSplit(cols, sep, column_names) < 0) { printf("%s Failed to get the columns, ensure they are separated by a comma. Error = %d", __FUNCTION__, GetLastError()); return df; } int columns_index[]; uint size = column_names.Size(); ArrayResize(columns_index, size); if(size > m_values.Cols()) { printf("%s failed, The number of columns > columns present in the dataframe", __FUNCTION__); return df; } // Fill columns_index with column indices to drop for(uint i = 0; i < size; i++) { columns_index[i] = ColNameToIndex(column_names[i], m_columns); if(columns_index[i] == -1) { printf("%s Column '%s' not found in this DataFrame", __FUNCTION__, column_names[i]); //ArrayRemove(column_names, i, 1); continue; } } matrix new_data(m_values.Rows(), m_values.Cols() - size); string new_columns[]; ArrayResize(new_columns, (int)m_values.Cols() - size); // Populate new_data with columns not in columns_index for(uint i = 0, count = 0; i < m_values.Cols(); i++) { bool to_drop = false; for(uint j = 0; j < size; j++) { if(i == columns_index[j]) { to_drop = true; break; } } if(!to_drop) { new_data.Col(m_values.Col(i), count); new_columns[count] = m_columns[i]; count++; } } // Replace original data with the updated matrix and columns df.m_values = new_data; ArrayResize(df.m_columns, new_columns.Size()); ArrayCopy(df.m_columns, new_columns); return df; }
Verwendung:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); CDataFrame new_df = df.Drop("Open,Close"); //drop the columns and assign the dataframe to a new object new_df.Head(); }
Ausgabe:
II 0 19:18:22.997 pandas test (EURUSD,H1) | High | Low | GJ 0 19:18:22.997 pandas test (EURUSD,H1) | 1.09548000 | 1.09003000 | EP 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09810000 | 1.09361000 | CF 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09973000 | 1.09606000 | RL 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09869000 | 1.09542000 | MR 0 19:18:22.998 pandas test (EURUSD,H1) | 1.10396000 | 1.09513000 | DH 0 19:18:22.998 pandas test (EURUSD,H1) (1000x2)
Nachdem wir nun Funktionen zur Indizierung und Auswahl einiger Teile des Datenrahmens haben, wollen wir mehrere Pandas-Funktionen implementieren, die uns bei der Datenexploration und -inspektion helfen.
Untersuchung und Inspektion von Pandas Dataframe
Die Funktion „tail“
Diese Methode zeigt die letzten Zeilen des Datenrahmens an.
MQL5-Implementierung:
matrix CDataFrame::Tail(uint count=5) { ulong rows = m_values.Rows(); if(count>=rows) { printf("%s count[%d] >= number of rows in the df[%d]",__FUNCTION__,count,rows); return matrix::Zeros(0,0); } ulong start = rows-count; matrix res = matrix::Zeros(count, m_values.Cols()); for(ulong i=start, row_count=0; i<rows; i++, row_count++) res.Row(m_values.Row(i), row_count); return res; }
Verwendung:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.Tail()); }Standardmäßig gibt die Funktion die letzten 5 Zeilen des Datenrahmens zurück.
GR 0 17:06:42.044 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] MG 0 17:06:42.044 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] KQ 0 17:06:42.044 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] DK 0 17:06:42.044 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] MO 0 17:06:42.044 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]]
Die Funktion „info“
Diese Funktion ist sehr nützlich, um die Struktur des Datenrahmens, die Datentypen, die Speichernutzung und das Vorhandensein von Nicht-Null-Werten zu verstehen.
Im Folgenden wird die MQL5-Implementierung dargestellt.
void CDataFrame::Info(void)
Ausgabe:
ES 0 17:34:04.968 pandas test (EURUSD,H1) <class 'CDataFrame'> IH 0 17:34:04.968 pandas test (EURUSD,H1) RangeIndex: 1000 entries, 0 to 999 LR 0 17:34:04.968 pandas test (EURUSD,H1) Data columns (total 4 columns): PD 0 17:34:04.968 pandas test (EURUSD,H1) # Column Non-Null Count Dtype OQ 0 17:34:04.968 pandas test (EURUSD,H1) --- ------ -------------- ----- FS 0 17:34:04.968 pandas test (EURUSD,H1) 0 Open 1000 non-null double GH 0 17:34:04.968 pandas test (EURUSD,H1) 1 High 1000 non-null double LS 0 17:34:04.968 pandas test (EURUSD,H1) 2 Low 1000 non-null double IH 0 17:34:04.968 pandas test (EURUSD,H1) 3 Close 1000 non-null double FJ 0 17:34:04.968 pandas test (EURUSD,H1) memory usage: 31.2 KB
Die Funktion „describe“
Diese Funktion liefert deskriptive Statistiken für alle numerischen Spalten in einem Dataframe. Die Informationen umfassen den Mittelwert, die Standardabweichung, die Anzahl, den Minimalwert und den Maximalwert der Spalten sowie die 25%-, 50%- und 75%-Perzentilwerte jeder Spalte.
Nachfolgend finden Sie eine Übersicht, wie die Funktion in MQL5 implementiert wurde.
void CDataFrame::Describe(void)
Verwendung:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Print(df.Tail()); df.Describe(); }
Ausgabe:
MM 0 18:10:42.459 pandas test (EURUSD,H1) Open High Low Close JD 0 18:10:42.460 pandas test (EURUSD,H1) count 1000 1000 1000 1000 HD 0 18:10:42.460 pandas test (EURUSD,H1) mean 1.104156 1.108184 1.100572 1.104306 HM 0 18:10:42.460 pandas test (EURUSD,H1) std 0.060646 0.059900 0.061097 0.060507 NQ 0 18:10:42.460 pandas test (EURUSD,H1) min 0.959290 0.967090 0.953580 0.959320 DI 0 18:10:42.460 pandas test (EURUSD,H1) 25% 1.069692 1.073520 1.066225 1.069950 DE 0 18:10:42.460 pandas test (EURUSD,H1) 50% 1.090090 1.093640 1.087100 1.090385 FN 0 18:10:42.460 pandas test (EURUSD,H1) 75% 1.142937 1.145505 1.139295 1.142365 CG 0 18:10:42.460 pandas test (EURUSD,H1) max 1.232510 1.234950 1.226560 1.232620
Abrufen der Datenrahmenform und der vorhandenen Spalten im Datenrahmen
Pandas in Python haben Methoden wie pandas.DataFrame.shape, die die Form des Datenrahmens zurückgeben, und pandas.DataFrame.columns, die die im Datenrahmen vorhandenen Spalten zurückgeben.
In unserer Klasse können wir auf diese Werte über eine global definierte Matrix namens m_values wie folgt zugreifen.
printf("df shape = (%dx%d)",df.m_values.Rows(),df.m_values.Cols());
Ausgabe:
2025.01.27 18:24:14.436 pandas test (EURUSD,H1) df shape = (1000x4)
Zeitreihen und Datenumwandlungsmethoden
In diesem Abschnitt werden wir einige der Methoden implementieren, die häufig verwendet werden, um die Daten zu transformieren und Änderungen über einen bestimmten Zeitraum zwischen den Zeilen des Datenrahmens zu analysieren.
Die in diesem Abschnitt behandelten Methoden werden am häufigsten bei der Entwicklung von Merkmalen eingesetzt.
Die Methode shift()
Sie verschiebt den Index um eine bestimmte Anzahl von Perioden und wird häufig in Zeitreihendaten verwendet, um einen Wert mit seinem vorherigen oder zukünftigen Wert zu vergleichen.
MQL5-Implementierung:
vector CDataFrame::Shift(const vector &v, const int shift) { // Initialize a result vector filled with NaN vector result(v.Size()); result.Fill(NaN); if(shift > 0) { // Positive shift: Move elements forward for(ulong i = 0; i < v.Size() - shift; i++) result[i + shift] = v[i]; } else if(shift < 0) { // Negative shift: Move elements backward for(ulong i = -shift; i < v.Size(); i++) result[i + shift] = v[i]; } else { // Zero shift: Return the vector unchanged result = v; } return result; }
vector CDataFrame::Shift(const string index, const int shift) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Shift(v, shift); }
Wenn dieser Funktion ein positiver Indexwert gegeben wird, verschiebt sie Elemente vorwärts und erzeugt so eine verzögerte Version eines bestimmten Vektors oder einer Spalte.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_lag_1 = df.Shift("Close", 1); //Create a previous 1 lag on the close price df.Insert("Close lag 1",close_lag_1); //Insert this new column into a dataframe df.Head(); }
Ausgabe:
EP 0 19:40:14.257 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | NO 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | PR 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | ES 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | PS 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | PP 0 19:40:14.257 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | QO 0 19:40:14.257 pandas test (EURUSD,H1) (1000x5)
Wenn jedoch eine negative Funktion empfangen wird, erstellt die Funktion eine zukünftige Variable für eine bestimmte Spalte. Dies ist sehr nützlich für die Erstellung der Zielvariablen.
vector future_close_1 = df.Shift("Close", -1); //Create a future 1 variable df.Insert("Future 1 close",future_close_1); //Insert this new column into a dataframe df.Head();
Ausgabe:
CI 0 19:43:08.482 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | Future 1 close | GJ 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | 1.09399000 | MR 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | 1.09805000 | FM 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | 1.09742000 | IH 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | 1.09757000 | OK 0 19:43:08.483 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | 1.10297000 | GG 0 19:43:08.483 pandas test (EURUSD,H1) (1000x6)
Die Methode pct_change()
Diese Funktion berechnet die prozentuale Veränderung zwischen dem aktuellen und dem vorherigen Element. Sie wird häufig in Finanzdaten zur Berechnung von Renditen verwendet.
Im Folgenden wird gezeigt, wie dies in der Klasse DataFrame umgesetzt wird.
vector CDataFrame::Pct_change(const string index) { vector col = GetColumn(index); return Pct_change(col); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Pct_change(const vector &v) { vector col = v; ulong size = col.Size(); vector results(size); results.Fill(NaN); for(ulong i=1; i<size; i++) { double prev_value = col[i - 1]; double curr_value = col[i]; // Calculate percentage change and handle division by zero if(prev_value != 0.0) { results[i] = ((curr_value - prev_value) / prev_value) * 100.0; } else { results[i] = 0.0; // Handle division by zero case } } return results; }
Verwendung:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_pct_change = df.Pct_change("Close"); df.Insert("Close pct_change", close_pct_change); df.Head(); }
Ausgabe:
IM 0 19:49:59.858 pandas test (EURUSD,H1) | Open | High | Low | Close | Close pct_change | CO 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | DS 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.02377186 | DD 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.37111857 | QE 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.05737444 | NF 0 19:49:59.858 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.01366842 | NJ 0 19:49:59.858 pandas test (EURUSD,H1) (1000x5)
Die Methode diff()
Diese Funktion berechnet die Differenz zwischen dem aktuellen und dem vorhergehenden Element in einer Sequenz und wird häufig verwendet, um Veränderungen im Zeitverlauf festzustellen.
vector CDataFrame::Diff(const vector &v, int period=1) { vector res(v.Size()); res.Fill(NaN); for(ulong i=period; i<v.Size(); i++) res[i] = v[i] - v[i-period]; //Calculate the difference between the current value and the previous one return res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Diff(const string index, int period=1) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Diff(v, period); }
Verwendung:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector diff_open = df.Diff("Open"); df.Insert("Open diff", diff_open); df.Head(); }
Ausgabe:
GS 0 19:54:10.283 pandas test (EURUSD,H1) | Open | High | Low | Close | Open diff | HM 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | OQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.00297000 | QQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.00023000 | FF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.00062000 | LF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.00663000 | OI 0 19:54:10.283 pandas test (EURUSD,H1) (1000x5)
Die Methode rolling()
Diese Methode bietet eine bequeme Möglichkeit für gleitende Fensterberechnungen. Sie ist praktisch für diejenigen, die die Werte innerhalb eines bestimmten Zeitraums (Periode) berechnen wollen, z. B. die Berechnung der gleitenden Durchschnitte von Variablen in einem Datenrahmen.
Datei: main.ipynb Sprache: Python
df["Close sma_5"] = df["Close"].rolling(window=5).mean() df
Im Gegensatz zu anderen Methoden erfordert die Rolling-Methode die Erstellung einer zweidimensionalen Matrix mit geteilten Fenstern entlang der Zeilen. Da wir die resultierende 2D-Matrix dann auf einige mathematische Funktionen unserer Wahl anwenden müssen, müssen wir möglicherweise eine separate Struktur nur für diese Aufgabe erstellen.
struct rolling_struct { public: matrix matrix__; vector Mean() { vector res(matrix__.Rows()); res.Fill(NaN); for(ulong i=0; i<res.Size(); i++) res[i] = matrix__.Row(i).Mean(); return res; } };
Wir können die Funktionen zum Auffüllen der Matrixvariablen namens matrix__ erstellen.
rolling_struct CDataFrame::Rolling(const vector &v, const uint window) { rolling_struct roll_res; roll_res.matrix__.Resize(v.Size(), window); roll_res.matrix__.Fill(NaN); for(ulong i = 0; i < v.Size(); i++) { for(ulong j = 0; j < window; j++) { // Calculate the index in the vector for the Rolling window ulong index = i - (window - 1) + j; if(index >= 0 && index < v.Size()) roll_res.matrix__[i][j] = v[index]; } } return roll_res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ rolling_struct CDataFrame::Rolling(const string index, const uint window) { vector v = GetColumn(index); return Rolling(v, window); }
Wir können diese Funktion nun verwenden, um den Mittelwert eines Fensters und viele weitere mathematische Funktionen zu berechnen, wie es uns gefällt.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_sma_5 = df.Rolling("Close", 5).Mean(); df.Insert("Close sma_5", close_sma_5); df.Head(10); }
Ausgabe:
RP 0 20:15:23.126 pandas test (EURUSD,H1) | Open | High | Low | Close | Close sma_5 | KP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | QP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | nan | HP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | nan | GO 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | nan | RR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09615200 | CR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10431000 | 1.10495000 | 1.10084000 | 1.10297000 | 1.09800000 | NS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10616000 | 1.10828000 | 1.10326000 | 1.10453000 | 1.10010800 | JS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11262000 | 1.11442000 | 1.10459000 | 1.10678000 | 1.10185400 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11529000 | 1.12088000 | 1.11139000 | 1.11350000 | 1.10507000 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11765000 | 1.12029000 | 1.11249000 | 1.11594000 | 1.10874400 | RO 0 20:15:23.126 pandas test (EURUSD,H1) (1000x5)
Sie können noch viel mehr mit der Rolling-Struktur machen und weitere Formeln für die gesamte Mathematik, die Sie auf das Rolling-Fenster anwenden wollen, hinzufügen. Weitere mathematische Funktionen für Matrizen und Vektoren finden Sie hier.
Im Moment habe ich mehrere Funktionen implementiert, die Sie auf die Rolling Matrix anwenden können;
- Std() zur Berechnung der Standardabweichung der Daten in einem bestimmten Fenster.
- Var() berechnet die Varianz des Fensters.
- Skew() berechnet die Schiefe aller Daten in einem bestimmten Fenster.
- Kurtosis() berechnet die Kurtosis aller Daten in einem bestimmten Fenster.
- Median() berechnet den Median aller Daten in einem bestimmten Fenster.
Dies sind nur einige nützliche Funktionen, die von der Pandas-Bibliothek in Python übernommen wurden. Nun wollen wir sehen, wie wir diese Bibliothek verwenden können, um Daten für das maschinelle Lernen vorzubereiten.
Wir werden die Daten in MQL5 sammeln, sie in eine CSV-Datei exportieren, die in ein Python-Skript importiert wird, ein trainiertes Modell wird im ONNX-Format gespeichert, das ONNX-Modell wird importiert und in MQL5 mit demselben Ansatz der Datensammlung und -speicherung eingesetzt.
Sammeln von Daten für maschinelles Lernen
Wir sammeln etwa 20 Variablen und fügen sie zu einer Dataframe-Klasse hinzu.
- Die Werte von Open, High, Low, and Close (OHLC).
CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close);
Diese Merkmale sind von wesentlicher Bedeutung, da sie dazu beitragen, weitere Merkmale abzuleiten, sie sind einfach die Grundlage für alle Muster, die wir auf dem Markt sehen.
- Da der Devisenmarkt 5 Tage lang geöffnet ist, addieren wir die Schlusskurse der letzten 5 Tage (verzögerte Schlusskurse). Diese Daten können KI-Modellen helfen, Muster im Laufe der Zeit zu verstehen.
int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); }
Damit gibt es jetzt insgesamt 9 Variablen im Datenrahmen.
- Tägliche prozentuale Veränderung des Schlusskurses (zur Ermittlung der täglichen Schlusskursänderungen).
vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change);
- Da wir mit einem täglichen Zeitrahmen arbeiten, addieren wir die Varianz der 5 Tage, um die Variabilitätsmuster innerhalb eines rollierenden 5-Tage-Zeitraums zu erfassen.
vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5);
- Wir können die differenzierten Merkmale hinzufügen, um die Volatilität und die Preisbewegungen zwischen den OHLC-Werten zu erfassen.
df.Insert("open_close",open-close); df.Insert("high_low",high-low);
- Wir können den Durchschnittspreis hinzufügen, in der Hoffnung, dass er den Modellen hilft, die Muster innerhalb der OHLC-Werte selbst zu erfassen.
df.Insert("Avg price",(open+high+low+close)/4);
- Schließlich können wir noch einige Indikatoren in den Mix einbringen. Ich werde den in diesem Artikel besprochenen Ansatz zur Erhebung von Indikatorendaten verwenden. Bitte zögern Sie nicht, einen anderen Ansatz für die Erhebung von Indikatordaten zu wählen, wenn dieser Ihnen nicht zusagt.
BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values
Wir haben insgesamt 21 Variablen.
df.Head();
Ausgabe:
PG 0 11:32:21.371 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | DD 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15620000 | 1.15660000 | 1.15030000 | 1.15080000 | nan | nan | nan | nan | nan | nan | nan | 0.00540000 | 0.00630000 | 1.15347500 | nan | nan | nan | nan | nan | nan | nan | JN 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15100000 | 1.15130000 | 1.14220000 | 1.14280000 | 1.15080000 | nan | nan | nan | nan | -0.69516858 | nan | 0.00820000 | 0.00910000 | 1.14682500 | nan | nan | nan | nan | nan | nan | nan | ID 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14300000 | 1.15360000 | 1.14230000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | nan | 0.72628631 | nan | -0.00810000 | 0.01130000 | 1.14750000 | nan | nan | nan | nan | nan | nan | nan | ES 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15070000 | 1.15490000 | 1.14890000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | -0.05212406 | nan | 0.00020000 | 0.00600000 | 1.15125000 | nan | nan | nan | nan | nan | nan | nan | LJ 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14820000 | 1.14900000 | 1.13560000 | 1.13870000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | -1.02564103 | 0.00002596 | 0.00950000 | 0.01340000 | 1.14287500 | nan | nan | nan | nan | nan | nan | nan | HG 0 11:32:21.371 pandas test (EURUSD,H1) (10000x22)
Werfen wir einen kurzen Blick auf den Datensatz.
df.Info();
Ausgabe:
FN 0 12:18:01.745 pandas test (EURUSD,H1) <class 'CDataFrame'> QE 0 12:18:01.745 pandas test (EURUSD,H1) RangeIndex: 10000 entries, 0 to 9999 NL 0 12:18:01.745 pandas test (EURUSD,H1) Data columns (total 21 columns): MR 0 12:18:01.745 pandas test (EURUSD,H1) # Column Non-Null Count Dtype DI 0 12:18:01.745 pandas test (EURUSD,H1) --- ------ -------------- ----- CO 0 12:18:01.745 pandas test (EURUSD,H1) 0 open 10000 non-null double GR 0 12:18:01.746 pandas test (EURUSD,H1) 1 high 10000 non-null double LK 0 12:18:01.746 pandas test (EURUSD,H1) 2 low 10000 non-null double JF 0 12:18:01.747 pandas test (EURUSD,H1) 3 close 10000 non-null double QS 0 12:18:01.748 pandas test (EURUSD,H1) 4 close lag_1 9999 non-null double JO 0 12:18:01.748 pandas test (EURUSD,H1) 5 close lag_2 9998 non-null double GH 0 12:18:01.748 pandas test (EURUSD,H1) 6 close lag_3 9997 non-null double KD 0 12:18:01.749 pandas test (EURUSD,H1) 7 close lag_4 9996 non-null double FP 0 12:18:01.749 pandas test (EURUSD,H1) 8 close lag_5 9995 non-null double EL 0 12:18:01.750 pandas test (EURUSD,H1) 9 close pct_change 9999 non-null double ME 0 12:18:01.750 pandas test (EURUSD,H1) 10 var close 5 days 9996 non-null double GI 0 12:18:01.751 pandas test (EURUSD,H1) 11 open_close 10000 non-null double ES 0 12:18:01.752 pandas test (EURUSD,H1) 12 high_low 10000 non-null double LF 0 12:18:01.752 pandas test (EURUSD,H1) 13 Avg price 10000 non-null double DI 0 12:18:01.752 pandas test (EURUSD,H1) 14 bb_lower 9981 non-null double FQ 0 12:18:01.753 pandas test (EURUSD,H1) 15 bb_middle 9981 non-null double NQ 0 12:18:01.753 pandas test (EURUSD,H1) 16 bb_upper 9981 non-null double QI 0 12:18:01.753 pandas test (EURUSD,H1) 17 ATR 14 9986 non-null double CF 0 12:18:01.753 pandas test (EURUSD,H1) 18 macd histogram 9975 non-null double DO 0 12:18:01.754 pandas test (EURUSD,H1) 19 macd main 9975 non-null double FR 0 12:18:01.754 pandas test (EURUSD,H1) 20 macd signal 9992 non-null double FF 0 12:18:01.754 pandas test (EURUSD,H1) memory usage: 1640.6 KB
Unsere Daten verbrauchen etwa 1,6 MB im Speicher, es gibt viele Nullwerte (nan), die wir löschen müssen.
CDataFrame new_df = df.Dropnan(); new_df.Head();
Ausgabe:
JO 0 12:18:01.762 pandas test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/10000 JR 0 12:18:01.766 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | FQ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.23060000 | 1.23900000 | 1.20370000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | 1.22350000 | -1.32412673 | 0.00005234 | 0.01590000 | 0.03530000 | 1.22200000 | 1.16702297 | 1.20237000 | 1.23771703 | 0.01279286 | -1.19628486 | 0.02253736 | 1.21882222 | OJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21540000 | 1.22120000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | -0.27990450 | 0.00008191 | 0.00410000 | 0.01190000 | 1.21430000 | 1.17236514 | 1.20446500 | 1.23656486 | 0.01265000 | -1.19925638 | 0.02076585 | 1.22002222 | IO 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21040000 | 1.21390000 | 1.20730000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | -0.16511186 | 0.00010988 | 0.00110000 | 0.00660000 | 1.21022500 | 1.17774730 | 1.20631000 | 1.23487270 | 0.01253571 | -1.20115162 | 0.01898171 | 1.22013333 | QP 0 12:18:01.766 pandas test (EURUSD,H1) | 1.20840000 | 1.20840000 | 1.19490000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | -0.48788555 | 0.00008624 | 0.00500000 | 0.01350000 | 1.20377500 | 1.17941845 | 1.20699500 | 1.23457155 | 0.01292857 | -1.20208086 | 0.01689692 | 1.21897778 | DJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21000000 | 1.21930000 | 1.20900000 | 1.21330000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 0.82266910 | 0.00001558 | -0.00330000 | 0.01030000 | 1.21290000 | 1.18119695 | 1.20804500 | 1.23489305 | 0.01360714 | -1.20198373 | 0.01586072 | 1.21784444 | MS 0 12:18:01.766 pandas test (EURUSD,H1) (9975x21)
Wir können diesen Datenrahmen in einer CSV-Datei speichern.
string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8);
Training eines maschinellen Lernmodells
Wir beginnen mit dem Importieren der Bibliotheken, die wir in einem Python Jupyter Notebook benötigen.
Datei: main.ipynb
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler from sklearn.model_selection import train_test_split import skl2onnx from sklearn.metrics import r2_score sns.set_style("darkgrid")
Wir importieren die Daten und ordnen sie einem Pandas Dataframe zu.
df = pd.read_csv("EURUSD.dailytf.data.csv")
Lassen Sie uns die Zielvariable erstellen.
df["future_close"] = df["close"].shift(-1) # Shift the close price by one to get df = df.dropna() # drop nan values caused by the shift operation
Da wir nun die Zielvariable für ein Regressionsproblem haben, können wir die Daten in Trainings- und Teststichproben aufteilen.
X = df.drop(columns=[ "future_close" # drop the target veriable from the independent variables matrix ]) y = df["future_close"] # Train test split X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=False)
Wir setzen den Shuffle-Wert auf false, damit wir das Problem als Zeitreihenproblem behandeln können.
Wir verpacken dann ein Modell der Linearen Regression in eine Pipeline und trainieren es.
pipe_model = Pipeline([ ("scaler", RobustScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train) # Training a Linear regression model
Ausgabe:
Um das Modell zu evaluieren, das wir haben, entschied ich mich, das Ziel auf der Grundlage der Trainings- und Testdaten vorherzusagen, fügte diese Informationen in einen Pandas Dataframe ein und zeichnete dann das Ergebnis mit Seaborn und Matplotlib auf.
# Preparing the data for plotting train_pred = pipe_model.predict(X_train) test_pred = pipe_model.predict(X_test) train_data = pd.DataFrame({ 'Index': range(len(y_train)), 'True Values': y_train, 'Predicted Values': train_pred, 'Set': 'Train' }) test_data = pd.DataFrame({ 'Index': range(len(y_test)), 'True Values': y_test, 'Predicted Values': test_pred, 'Set': 'Test' }) # figure size 750x1000 pixels fig, axes = plt.subplots(2, 1, figsize=(7.5, 10), sharex=False) # Plot Train Data sns.lineplot(ax=axes[0], data=train_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[0], data=train_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[0].set_title(f'Train Set: True vs Predicted Values | Acc = {r2_score(y_train, train_pred)}', fontsize=14) axes[0].set_ylabel('Values', fontsize=12) axes[0].legend() # Plot Test Data sns.lineplot(ax=axes[1], data=test_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[1], data=test_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[1].set_title(f'Test Set: True vs Predicted Values | Acc = {r2_score(y_test, test_pred)}', fontsize=14) axes[1].set_xlabel('Index', fontsize=12) axes[1].set_ylabel('Values', fontsize=12) axes[1].legend() # Final adjustments plt.tight_layout() plt.show()
Ausgabe:
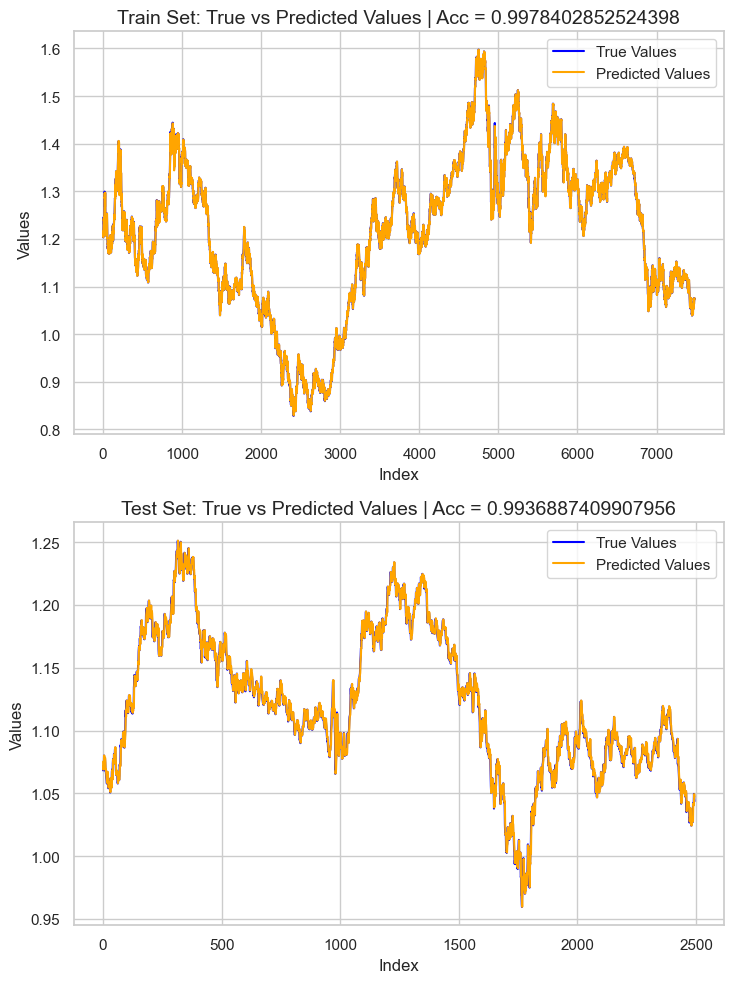
Das Ergebnis ist ein überangepasstes Modell mit einem r2-Wert von etwa 0,99. Dies ist kein gutes Zeichen für das Wohl des Modells. Überprüfen wir die Merkmalsbedeutung, um zu sehen, welche Merkmale sich positiv auf das Modell auswirken, werden diejenigen mit einem schlechten Einfluss auf das Modell entfernt, wenn sie entdeckt werden.
# Extract the linear regression model from the pipeline lr_model = pipe_model.named_steps['LR'] # Get feature importance (coefficients) feature_importance = pd.Series(lr_model.coef_, index=X_train.columns) # Sort feature importance feature_importance = feature_importance.sort_values(ascending=False) print(feature_importance)
Ausgabe:
macd main 266.706747 close 0.093652 open 0.093435 Avg price 0.042505 close lag_1 0.006972 close lag_3 0.003645 bb_upper 0.001423 close lag_5 0.001415 bb_middle 0.000766 high_low 0.000201 bb_lower 0.000087 var close 5 days -0.000179 ATR 14 -0.000185 close pct_change -0.001046 close lag_4 -0.002636 close lag_2 -0.003881 open_close -0.004705 high -0.008575 low -0.008663 macd histogram -5504.010453 macd signal -5518.035201 dtype: float64
Das informativste Merkmal war macd main, während das macd-Histogramm und das macd-Signal die am wenigsten informativen Variablen für das Modell waren. Lassen wir alle Werte mit negativer Merkmalsbedeutung weg, trainieren wir das Modell erneut und beobachten wir die Genauigkeit erneut.
X = df.drop(columns=[ "future_close", # drop the target veriable from the independent variables matrix "var close 5 days", "ATR 14", "close pct_change", "close lag_4", "close lag_2", "open_close", "high", "low", "macd histogram", "macd signal" ])
pipe_model = Pipeline([ ("scaler", MinMaxScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train)
Die Genauigkeit des neu trainierten Modells war dem vorherigen Modell sehr ähnlich, das Modell war immer noch überangepasst. Das reicht für den Moment, exportieren wir das Modell ins ONNX-Format.
Bereitstellen eines Modells für maschinelles Lernen in MQL5
In unserem Expert Advisor (EA) fügen wir zunächst das Modell als Ressource hinzu, damit es mit dem Programm kompiliert werden kann.
Datei: LR-Modell Test.mq5
#resource "\\Files\\EURUSD.dailytf.model.onnx" as uchar lr_onnx[]
Wir importieren alle notwendigen Bibliotheken, die Pandas-Bibliothek, ta-lib (für Indikatoren) und Linear Regression (zum Laden des Modells).
#include <Linear Regression.mqh> #include <MALE5\pandas.mqh> #include <ta-lib.mqh> CLinearRegression lr;
Wir initialisieren das lineare Regressionsmodell in der Funktion OnInit.
int OnInit() { //--- if (!lr.Init(lr_onnx)) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
Das Gute an der Verwendung dieser nutzerdefinierten Pandas-Bibliothek ist, dass man nicht von Grund auf neu mit dem Schreiben von Code beginnen muss, um die Daten erneut zu sammeln. Wir müssen nur den Code kopieren, den wir verwendet haben, und ihn in den Hauptexpertenberater einfügen und kleine Änderungen daran vornehmen.
void OnTick() { //--- CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close); int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); } vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change); vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5); df.Insert("open_close",open-close); df.Insert("high_low",high-low); df.Insert("Avg price",(open+high+low+close)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values df.Info(); CDataFrame new_df = df.Dropnan(); new_df.Head(); string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8); }
Die Änderungen umfassen;
Ändern der Größe der gewünschten Daten. Wir brauchen nicht mehr 10000 Balken, sondern nur noch etwa 30 Balken, weil der MACD-Indikator eine Periodenlänge von 26, die Bollinger-Bänder eine Periodenlänge von 20 und die ATR eine Periodenlänge von 14 haben. Mit einem Wert von 30 lassen wir tatsächlich etwas Spielraum für Berechnungen.
Die Funktion OnTick kann sehr fließend und explosiv sein, sodass wir nicht jedes Mal, wenn ein neuer Tick empfangen wird, die Variablen neu definieren müssen.
Wir brauchen die Daten nicht in einer CSV-Datei zu speichern, sondern nur die letzte Zeile des Datenrahmens in einen Vektor umzuwandeln, der in das Modell eingefügt werden kann.
Wir können diese Codezeilen in eine eigenständige Funktion verpacken, um die Arbeit damit zu erleichtern.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values CDataFrame new_df = df_.Dropnan(); //Drop NaN values return new_df.Loc(-1); //return the latest row }
Auf diese Weise haben wir anfangs Daten für das Training gesammelt. Einige der in dieser Funktion enthaltenen Merkmale wurden aus verschiedenen Gründen nicht in das endgültige Modell übernommen, und wir mussten sie fallen lassen, ähnlich wie wir sie im Python-Skript fallen ließen.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values df_ = df_.Drop( //"future_close", "var close 5 days,"+ "ATR 14,"+ "close pct_change,"+ "close lag_4,"+ "close lag_2,"+ "open_close,"+ "high,"+ "low,"+ "macd histogram,"+ "macd signal" ); CDataFrame new_df = df_.Dropnan(); return new_df.Loc(-1); //return the latest row }
Anstatt die Spalten wie in der obigen Funktion zu löschen, ist es ratsam, den Code zu entfernen, der verwendet wird, um sie überhaupt erst zu erzeugen. Dadurch können unnötige Berechnungen vermieden werden, die das Programm verlangsamen können, wenn viele Merkmale zu berechnen sind, nur damit sie kurz gelöscht werden können.
Wir werden vorerst bei der Methode Drop bleiben.
Nach dem Aufruf der Methode Head(), um zu sehen, was sich auf dem Datenrahmen befindet, war das folgende Ergebnis zu sehen:
PM 0 15:45:36.543 LR model Test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/30 HI 0 15:45:36.543 LR model Test (EURUSD,H1) | open | close | close lag_1 | close lag_3 | close lag_5 | high_low | Avg price | bb_lower | bb_middle | bb_upper | macd main | GK 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04057000 | 1.04079000 | 1.04057000 | 1.02806000 | 1.03015000 | 0.00575000 | 1.04176750 | 1.02125891 | 1.03177350 | 1.04228809 | 0.00028705 | QI 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04079000 | 1.04159000 | 1.04079000 | 1.04211000 | 1.02696000 | 0.00661000 | 1.04084750 | 1.02081967 | 1.03210400 | 1.04338833 | 0.00085370 | PL 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04158000 | 1.04956000 | 1.04159000 | 1.04057000 | 1.02806000 | 0.01099000 | 1.04611250 | 1.01924805 | 1.03282750 | 1.04640695 | 0.00192371 | JR 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04795000 | 1.04675000 | 1.04956000 | 1.04079000 | 1.04211000 | 0.00204000 | 1.04743000 | 1.01927184 | 1.03382650 | 1.04838116 | 0.00251595 | CP 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04675000 | 1.04370000 | 1.04675000 | 1.04159000 | 1.04057000 | 0.01049000 | 1.04664500 | 1.01938012 | 1.03447300 | 1.04956588 | 0.00270798 | CH 0 15:45:36.543 LR model Test (EURUSD,H1) (5x11)
Wir haben 11 Merkmale. Die gleiche Anzahl von Merkmalen ist auch auf dem Modell zu sehen.
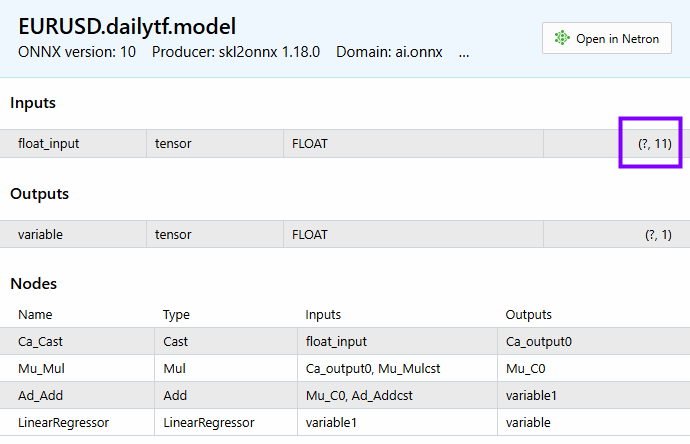
Im Folgenden wird erläutert, wie wir die endgültigen Vorhersagen des Modells erhalten können.
void OnTick() { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); }
Es ist nicht klug, alle Datenerfassungen und Modellberechnungen bei jedem Tick durchzuführen, wir müssen sie beim Öffnen eines neuen Balkens im Chart berechnen.
void OnTick() { if (isNewBar()) { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); } }
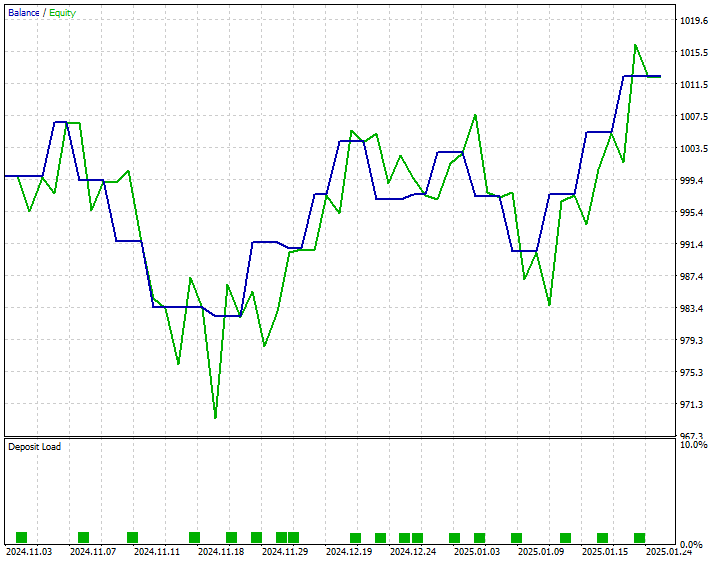
Ich habe eine einfache Strategie entwickelt, um einen Kauf zu tätigen, wenn der vorhergesagte Schlusskurs über dem aktuellen Geldkurs (Bid) liegt, und einen Verkauf zu tätigen, wenn der vorhergesagte Schlusskurs unter dem aktuellen Briefkurs (Ask) liegt.
Nachstehend finden Sie die Ergebnisse des Strategietesters vom 01. November 2024 bis zum 25. Januar 2025.
Schlussfolgerung
Es ist jetzt einfach, hochentwickelte KI-Modelle in MQL5 zu importieren und sie in MetaTrader 5 zu verwenden. Es ist immer noch nicht einfach, Ihr Modell mit der Datenstruktur, die der für das Training verwendeten ähnelt, synchron zu halten. In diesem Artikel habe ich eine nutzerdefinierte Klasse namens CDataframe eingeführt, die uns beim Umgang mit zweidimensionalen Daten in einer Umgebung helfen soll, die der Pandas-Bibliothek ähnelt, die der Gemeinschaft des maschinellen Lernens und Datenwissenschaftlern mit Python-Hintergrund sehr vertraut ist.
Ich hoffe, dass die Pandas-Bibliothek in MQL5 von großem Nutzen sein wird und uns das Leben beim Umgang mit komplexen KI-Daten in MQL5 sehr erleichtert.
Mit freundlichen Grüßen.
Bleiben Sie dran und tragen Sie zur Entwicklung von Algorithmen für maschinelles Lernen für die Sprache MQL5 in diesem GitHub Repository bei.
Tabelle der Anhänge
| Dateiname | Beschreibung/Verwendung |
|---|---|
| Experts\LR model Test.mq5 | Ein Expert Advisor für die Anwendung des endgültigen linearen Regressionsmodells. |
| Include\Linear Regression.mqh | Eine Bibliothek, die den gesamten Code zum Laden eines linearen Regressionsmodells im ONNX-Format enthält. |
| Include\pandas.mqh | Enthält alle nutzerdefinierten Pandas-Methoden für die Arbeit mit Daten in einer Dataframe-Klasse. |
| Scripts\pandas test.mq5 | Ein Skript, das für die Erfassung der Daten für ML-Trainingszwecke zuständig ist. |
| Python\main.ipynb | Eine Jupyter-Notebook-Datei mit dem gesamten Code für das Training eines in diesem Artikel verwendeten linearen Regressionsmodells. |
| Files\ | Dieser Ordner enthält ein lineares Regressionsmodell in ONNX-Modellen und CSV-Dateien für das Training von KI-Modellen. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/17030
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Meistern der Log-Einträge (Teil 5): Optimierungen mit Cache und Rotation
Meistern der Log-Einträge (Teil 5): Optimierungen mit Cache und Rotation
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.