
Wirtschaftsprognosen: Erkunden des Potenzials von Python

Einführung
Wirtschaftsprognosen sind eine recht komplexe und arbeitsintensive Aufgabe. Sie ermöglicht es uns, mögliche zukünftige Bewegungen anhand von Daten aus der Vergangenheit zu analysieren. Durch die Analyse historischer Daten und aktueller Wirtschaftsindikatoren können wir darüber spekulieren, wohin sich die Wirtschaft entwickeln könnte. Dies ist eine sehr nützliche Fähigkeit. Mit ihrer Hilfe können wir fundiertere Entscheidungen in der Wirtschaft, bei Investitionen und in der Wirtschaftspolitik treffen.
Wir werden dieses Tool mit Hilfe von Python und Wirtschaftsdaten von der Sammlung von Informationen bis zur Erstellung von Vorhersagemodellen entwickeln. Es wird analysieren und auch Vorhersagen für die Zukunft treffen.
Die Finanzmärkte sind ein gutes Barometer für die Wirtschaft. Sie reagieren auf die kleinsten Veränderungen. Das Ergebnis kann entweder vorhersehbar oder unerwartet sein. Schauen wir uns Beispiele an, bei denen die Messwerte dieses Barometers schwanken.
Wenn das BIP wächst, reagieren die Märkte in der Regel positiv. Wenn die Inflation ansteigt, ist in der Regel mit Unruhen zu rechnen. Wenn die Arbeitslosigkeit sinkt, wird dies in der Regel als gute Nachricht gewertet. Es kann jedoch auch Ausnahmen geben. Handelsbilanz, Zinssätze - jeder Indikator beeinflusst die Marktstimmung.
Wie die Praxis zeigt, reagieren die Märkte oft nicht auf das tatsächliche Ergebnis, sondern auf die Erwartungen der Mehrheit der Akteure. „Kaufe Gerüchte, verkaufe Fakten“ - diese alte Börsenweisheit trifft den Kern des Geschehens am besten. Außerdem kann das Ausbleiben signifikanter Veränderungen mehr Volatilität auf dem Markt verursachen als unerwartete Nachrichten.
Die Wirtschaft ist ein komplexes System. Hier ist alles miteinander verknüpft, und ein Faktor beeinflusst den anderen. Die Veränderung eines Parameters kann eine Kettenreaktion auslösen. Unsere Aufgabe ist es, diese Zusammenhänge zu verstehen und zu lernen, sie zu analysieren. Wir werden mit Hilfe des Python-Tools nach Lösungen suchen.
Einrichten der Umgebung: Importieren der erforderlichen Bibliotheken
Was brauchen wir also? Zuerst das Wichtigste: Python. Wenn Sie es noch nicht installiert haben, gehen Sie zu python.org. Vergessen Sie auch nicht, während der Installation das Kästchen „Add Python to PATH“ ( Python zu PATH) zu markieren.
Der nächste Schritt sind Bibliotheken. Die Bibliotheken erweitern die grundlegenden Möglichkeiten unseres Tools erheblich. Wir brauchen:
- pandas - für die Verarbeitung von Daten.
- wbdata - für die Interaktion mit der Weltbank. Mit Hilfe dieser Bibliothek werden wir die neuesten Wirtschaftsdaten erhalten.
- MetaTrader 5 - wir brauchen ihn, um direkt mit dem Markt selbst zu interagieren.
- CatBoostRegressor von catboost - eine kleine handgefertigte KI.
- train_test_split und mean_squared_error von sklearn - diese Bibliotheken helfen uns zu bewerten, wie effektiv unser Modell ist.
Um alles zu installieren, was Sie brauchen, öffnen Sie eine Eingabeaufforderung und geben Sie ein:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
Ist alles vorbereitet? Ausgezeichnet! Lassen Sie uns nun unsere ersten Code-Zeilen schreiben:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
Wir haben alle notwendigen Werkzeuge vorbereitet. Weiter geht's.
Arbeiten mit der API für die Weltbank: Laden von Wirtschaftsindikatoren
Lassen Sie uns nun herausfinden, wie wir Wirtschaftsdaten von der Weltbank erhalten werden.
Zunächst erstellen wir ein Wörterbuch mit Indikatorcodes:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
Jeder dieser Codes ermöglicht den Zugriff auf eine bestimmte Art von Daten.
Weiter geht's. Wir starten eine Schleife, die den gesamten Code durchlaufen wird:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
Hier versuchen wir, Daten für jeden Indikator zu erhalten. Wenn es funktioniert, setzen wir es auf die Liste. Wenn dies nicht möglich ist, wird eine Fehlermeldung gedruckt und die Suche fortgesetzt.
Danach sammeln wir alle unsere Daten in einem großen DataFrame:
data = pd.concat(data_frames, axis=1) In diesem Stadium müssen wir alle Wirtschaftsdaten erhalten.
Der nächste Schritt besteht darin, alles, was wir erhalten haben, in einer Datei zu speichern, damit wir es später für die von uns benötigten Zwecke verwenden können:
data.to_csv('economic_data.csv', index=True) Wir haben gerade eine Reihe von Daten von der Weltbank heruntergeladen. So einfach ist das.
Überblick über die wichtigsten Wirtschaftsindikatoren für die Analyse
Wenn Sie ein Neuling sind, kann es etwas schwierig sein, eine Menge Daten und Zahlen zu verstehen. Schauen wir uns die wichtigsten Indikatoren an, um den Prozess zu erleichtern:
- Das Wachstum des BIP ist eine Art Einkommen für ein Land. Steigende Indikatoren sind positiv, während sinkende Indikatoren negative Auswirkungen auf das Land haben.
- Inflation ist der Anstieg der Preise für Waren und Dienstleistungen.
- Realzins: Steigt er, verteuert dies die Kredite.
- Export und Import zeigen, was ein Land verkauft und kauft. Höhere Umsätze werden als positive Entwicklung gesehen.
- Leistungsbilanz - wie viel Geld andere Länder einem bestimmten Land schulden. Höhere Zahlen weisen auf eine gute Finanzlage eines Landes hin.
- Staatsschulden sind die Kredite eines Landes. Je kleiner die Zahlen sind, desto besser.
- Arbeitslosigkeit - wie viele Menschen sind arbeitslos. Weniger ist mehr.
- Das Wachstum des Pro-Kopf-BIP zeigt, ob eine durchschnittliche Person reicher wird oder nicht.
Im Code sieht das wie folgt aus:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
Jeder Indikator hat seine eigene Bedeutung. Einzeln sind sie wenig aussagekräftig, aber zusammen ergeben sie ein vollständigeres Bild. Es ist auch zu beachten, dass sich die Indikatoren gegenseitig beeinflussen. So ist eine niedrige Arbeitslosigkeit in der Regel eine gute Nachricht, kann aber zu einer höheren Inflation führen. Oder ein hohes BIP-Wachstum ist vielleicht nicht so positiv, wenn es auf Kosten riesiger Schulden erzielt wird.
Deshalb setzen wir das maschinelle Lernen ein, denn es hilft uns, all diese komplexen Zusammenhänge zu berücksichtigen. Sie beschleunigt den Prozess der Informationsverarbeitung erheblich und sortiert die Daten. Allerdings müssen Sie auch einige Anstrengungen unternehmen, um den Prozess zu verstehen.
Handhabung und Strukturierung von Weltbankdaten
Natürlich kann die Fülle der Daten der Weltbank auf den ersten Blick wie eine gewaltige Aufgabe erscheinen, die es zu verstehen gilt. Um die Arbeit und die Analyse zu erleichtern, werden wir die Daten in einer Tabelle sammeln.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
Als Nächstes nehmen wir jeden Indikator und versuchen, Daten für ihn zu erhalten. Es mag Probleme mit einzelnen Indikatoren geben, wir schreiben darüber und machen weiter. Dann sammeln wir die einzelnen Daten in einem großen DataFrame.
Aber das ist noch nicht alles. Jetzt beginnt der interessanteste Teil.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
Wir schauen auf das, was wir erreicht haben. Welche Indikatoren gibt es? Wie sehen die ersten Zeilen der Daten aus? Es ist wie der erste Blick auf ein fertiges Puzzle: Ist alles an seinem Platz? Und dann speichern wir all diese Daten in einer CSV-Datei.
Und zum Schluss noch ein paar Statistiken. Durchschnittswerte, Höchstwerte, Tiefstwerte. Es ist wie ein schneller Check - ist alles in Ordnung mit unseren Daten? Auf diese Weise verwandeln wir einen Haufen unzusammenhängender Zahlen in ein kohärentes Datensystem. Wir haben jetzt alle Instrumente für eine seriöse Wirtschaftsanalyse.
Einführung in MetaTrader 5: Aufbau einer Verbindung und Empfang von Daten
Lassen Sie uns nun über MetaTrader 5 sprechen. Zunächst müssen wir eine Verbindung herstellen. So sieht es aus:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
Der nächste wichtige Schritt ist die Beschaffung der Daten. Zunächst müssen wir prüfen, welche Währungspaare verfügbar sind:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
Sobald der obige Code ausgeführt wird, erhalten wir eine Liste aller verfügbaren Währungspaare. Als Nächstes müssen wir historische Kursdaten für jedes verfügbare Paar herunterladen:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
Was passiert in diesem Code, den wir eingegeben haben? Wir haben MetaTrader angewiesen, die Daten der letzten 1000 Tage für jedes Handelsinstrument herunterzuladen. Danach werden die Daten in die Tabelle geladen.
Die heruntergeladenen Daten enthalten alles, was in den letzten drei Jahren auf dem Devisenmarkt passiert ist, in allen Einzelheiten. Nun können die eingegangenen Zitate analysiert und Muster gefunden werden. Die Möglichkeiten sind hier praktisch unbegrenzt.
Aufbereitung der Daten: Kombination von Wirtschaftsindikatoren und Marktdaten
In dieser Phase werden wir uns direkt mit der Datenverarbeitung befassen. Wir haben zwei getrennte Bereiche: die Welt der Wirtschaftsindikatoren und die Welt der Wechselkurse. Unsere Aufgabe ist es, diese Sektoren zusammenzubringen.
Beginnen wir mit unserer Datenaufbereitungsfunktion. Dieser Code wird in unserer allgemeinen Aufgabe wie folgt aussehen:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Lassen Sie uns nun Schritt für Schritt vorgehen. Zunächst erstellen wir eine Kopie der Daten des Währungspaares. Warum? Es ist immer besser, mit einer Kopie der Daten zu arbeiten als mit dem Original. Im Falle eines Fehlers müssen wir die Originaldatei nicht erneut erstellen.
Jetzt kommt der interessanteste Teil. Wir fügen zwei neue Spalten hinzu: „close_diff“ und „close_corr“. Die erste zeigt, wie stark sich der Schlusskurs im Vergleich zum Vortag verändert hat. Auf diese Weise können wir feststellen, ob es eine positive oder negative Preisveränderung gibt. Die zweite ist die Korrelation des Schlusskurses mit sich selbst, jedoch mit einer Verschiebung um einen Tag. Wozu ist das gut? Es ist einfach der bequemste Weg, um zu verstehen, wie ähnlich der heutige Preis dem von gestern ist.
Jetzt kommt der schwierige Teil: Wir versuchen, unsere Währungsdaten um Wirtschaftsindikatoren zu ergänzen. Auf diese Weise beginnen wir, unsere Daten in ein einheitliches Konstrukt zu integrieren. Wir gehen alle unsere Wirtschaftsindikatoren durch und versuchen, sie in den Daten der Weltbank zu finden. Wenn wir sie finden, fügen wir sie zu unseren Währungsdaten hinzu. Wenn nicht, nun ja, das kommt vor. Wir schreiben einfach eine Warnung und machen weiter.
Nach all dem kann es vorkommen, dass Zeilen mit fehlenden Daten übrig bleiben. Wir löschen sie einfach.
Nun wollen wir sehen, wie wir diese Funktion anwenden:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
Wir nehmen jedes Währungspaar und wenden unsere geschriebene Funktion auf es an. Am Ausgang erhalten wir für jedes Paar einen fertigen Datensatz. Für jedes Paar gibt es ein eigenes Set, aber sie werden alle nach dem gleichen Prinzip zusammengesetzt.
Wissen Sie, was das Wichtigste an diesem Prozess ist? Wir sind dabei, etwas Neues zu schaffen. Wir nehmen verschiedene Wirtschaftsdaten und Live-Wechselkursdaten und machen daraus etwas Kohärentes. Einzeln betrachtet mögen sie chaotisch erscheinen, aber in ihrer Gesamtheit können wir Muster erkennen.
Und jetzt haben wir einen fertigen Datensatz für die Analyse. Wir können darin nach Sequenzen suchen, Vorhersagen treffen und Schlussfolgerungen ziehen. Wir müssen jedoch die Zeichen identifizieren, die wirklich Aufmerksamkeit verdienen. In der Welt der Daten gibt es keine unwichtigen Details. Jeder Schritt der Datenaufbereitung kann für das Endergebnis entscheidend sein.
Maschinelles Lernen in unserem Modell
Maschinelles Lernen ist ein ziemlich komplexer und arbeitsintensiver Prozess. CatBoostRegressor - diese Funktion wird später eine wichtige Rolle spielen. Wir verwenden es folgendermaßen:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Jeder Parameter ist hier wichtig. 1000 „iterations“ ist die Anzahl, die das Modell durch die Daten laufen lässt. learning_rate 0.1 - es ist nicht nötig, sofort eine hohe Geschwindigkeit einzustellen, wir sollten schrittweise lernen. depth 8 - Suche nach komplexen Zusammenhängen. RMSE - so bewerten wir Fehler. Das Training eines Modells nimmt eine gewisse Zeit in Anspruch. Wir zeigen Beispiele und bewerten richtige Antworten. CatBoost funktioniert besonders gut mit verschiedenen Arten von Daten. Sie ist nicht auf ein enges Spektrum von Funktionen beschränkt.
Um Währungen zu prognostizieren, gehen wir wie folgt vor:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
Ein Teil der Daten ist zum Trainieren, der andere zum Testen bestimmt. Es ist wie in der Schule: Erst lernt man, dann macht man eine Prüfung.
Wir unterteilen die Daten in zwei Teile. Warum? Ein Teil für das Training, der andere für die Prüfung. Schließlich müssen wir das Modell mit Daten testen, mit denen es noch nicht gearbeitet hat.
Nach dem Training versucht das Modell, Vorhersagen zu treffen. Der mittlere quadratische Fehler zeigt, wie gut es funktioniert hat. Je kleiner der Fehler, desto besser die Prognose. CatBoost zeichnet sich dadurch aus, dass es ständig verbessert wird. Es lernt aus Fehlern.
Natürlich ist CatBoost kein automatisches Programm. Sie braucht gute Daten. Andernfalls erhalten wir unwirksame Daten bei der Eingabe und unwirksame Daten bei der Ausgabe. Aber mit den richtigen Daten ist das Ergebnis positiv. Lassen Sie uns nun über die Datenaufteilung sprechen. Ich habe erwähnt, dass wir Angebote zur Überprüfung benötigen. So sieht es im Code aus:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) 50 % der Daten werden für Tests verwendet. Bringen Sie sie nicht durcheinander - es ist wichtig, dass die zeitliche Reihenfolge der Finanzdaten eingehalten wird.
Das Erstellen und Trainieren des Modells ist der interessanteste Teil. Hier zeigt CatBoost seine Fähigkeiten in vollem Umfang:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Das Modell saugt die Daten gierig auf und sucht nach Mustern. Jede Iteration ist ein Schritt zu einem besseren Verständnis des Marktes.
Und nun der Moment der Wahrheit. Bewertung der Genauigkeit:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
Der mittlere quadratische Fehler ist ebenfalls ein wichtiger Punkt in unserer Arbeit. Das zeigt, wie falsch das Modell ist. Weniger ist mehr. So können wir die Qualität des Programms bewerten. Denken Sie daran, dass es beim Handel keine endgültigen Garantien gibt. Aber mit CatBoost ist der Prozess effizienter. Sie sieht Dinge, die wir vielleicht übersehen. Und mit jeder Prognose wird das Ergebnis besser.
Vorhersage zukünftiger Werte von Währungspaaren
Die Vorhersage von Währungspaaren ist eine Arbeit mit Wahrscheinlichkeiten. Manchmal erzielen wir positive Ergebnisse, und manchmal erleiden wir Verluste. Die Hauptsache ist, dass das Endergebnis unseren Erwartungen entspricht.
In unserem Code arbeitet die Funktion „forecast“ mit Wahrscheinlichkeiten. So werden die Berechnungen durchgeführt:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
Zunächst trennen wir die bereits verfügbaren Daten von den vorhergesagten Daten. Dann teilen wir die Daten in zwei Teile auf: für das Training und für das Testen. Das Modell lernt aus einem Datensatz und wir testen es mit einem anderen. Nach dem Training macht das Modell Vorhersagen. Wir untersuchen, wie falsch sie lag, indem wir den mittleren quadratischen Fehler verwenden. Je niedriger die Zahl, desto besser die Prognose.
Am interessantesten ist jedoch die Analyse von Kursen im Hinblick auf mögliche künftige Kursbewegungen. Wir nehmen die Daten der letzten 30 Tage und bitten das Modell, vorherzusagen, was als Nächstes passieren wird. Es sieht nach einer Situation aus, in der wir auf die Prognosen erfahrener Analysten zurückgreifen. Was die Visualisierung betrifft... Leider bietet der Code noch keine explizite Visualisierung der Ergebnisse. Aber fügen wir sie hinzu und sehen wir uns an, wie sie aussehen könnte:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
Dieser Code würde ein Chart für jedes Währungspaar erstellen. Optisch ist sie linear aufgebaut. Jeder Punkt ist ein voraussichtlicher Preis für einen bestimmten Tag. Diese Charts sollen mögliche Trends aufzeigen. Es wurde mit einer riesigen Menge an Daten gearbeitet, die für den Durchschnittsbürger oft zu komplex sind. Wenn die Linie nach oben gerichtet ist, wird die Währung teurer. Gefallen? Bereiten Sie sich auf eine Zinssenkung vor.
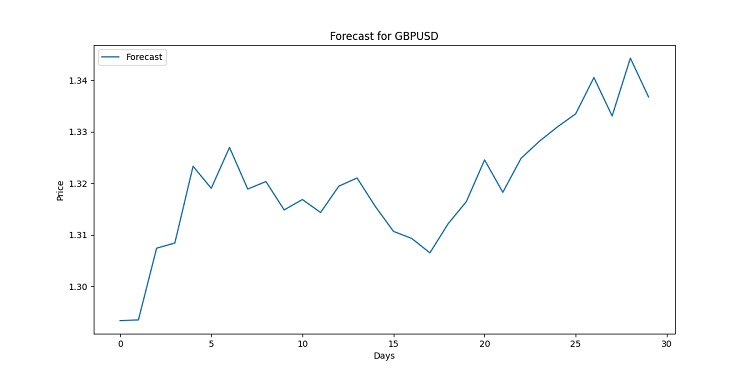
Denken Sie daran, dass Prognosen keine Garantien sind. Der Markt kann seine eigenen Änderungen vornehmen. Aber mit einer guten Visualisierung werden Sie zumindest wissen, was Sie erwartet. Schließlich haben wir in dieser Situation eine hochwertige Analyse zur Hand.
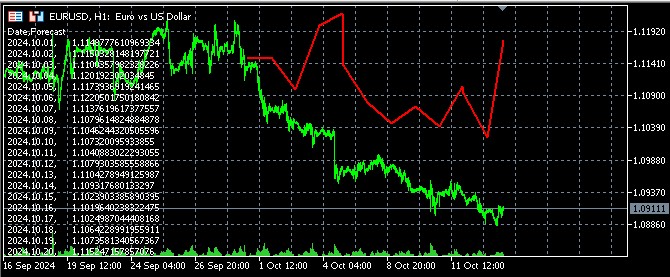
Ich habe auch einen Code erstellt, um die Vorhersageergebnisse in MQL5 zu visualisieren, indem ich eine Datei öffne und die Vorhersagen in Comment ausgibt:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
So sieht die Vorhersage im Terminal aus:
Interpretation der Ergebnisse: Analyse des Einflusses wirtschaftlicher Faktoren auf die Wechselkurse.
Schauen wir uns nun die Interpretation der Ergebnisse auf der Grundlage Ihres Codes genauer an. Wir haben Tausende von unzusammenhängenden Fakten in organisierten Daten gesammelt, die ebenfalls analysiert werden müssen.
Beginnen wir mit der Tatsache, dass wir eine Reihe von Wirtschaftsindikatoren haben - vom BIP-Wachstum bis zur Arbeitslosigkeit. Jeder Faktor hat seinen eigenen Einfluss auf den Markthintergrund. Einzelne Indikatoren haben ihre eigenen Auswirkungen, aber zusammen beeinflussen diese Daten die endgültigen Wechselkurse.
Nehmen Sie zum Beispiel das BIP. Im Code wird sie durch mehrere Indikatoren dargestellt:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
Das BIP-Wachstum stärkt in der Regel die Währung. Warum? Denn positive Nachrichten ziehen Akteure an, die nach einer Gelegenheit suchen, Kapital für weiteres Wachstum zu investieren. Investoren werden von wachsenden Volkswirtschaften angezogen, was die Nachfrage nach deren Währungen erhöht.
Im Gegenteil, die Inflation ('FP.CPI.TOTL.ZG': 'Inflation') ist ein alarmierendes Signal für Händler. Je höher die Inflation ist, desto schneller sinkt der Wert des Geldes. Eine hohe Inflation schwächt in der Regel eine Währung, einfach weil Dienstleistungen und Waren in dem betreffenden Land viel teurer werden.
Es ist interessant, die Handelsbilanz zu betrachten:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Diese Indikatoren sind wie Waagen. Wenn die Exporte die Importe überwiegen, erhält das Land mehr Devisen, was in der Regel die Landeswährung stärkt.
Nun wollen wir sehen, wie wir dies im Code analysieren. Der CatBoostRegressor ist unser Hauptinstrument. Wie ein erfahrener Dirigent hört er alle Instrumente auf einmal und weiß, wie sie sich gegenseitig beeinflussen.
Hier sehen Sie, was Sie der Prognosefunktion hinzufügen können, um die Auswirkungen der Faktoren besser zu verstehen:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
Dies wird uns zeigen, welche Faktoren für die Vorhersage der einzelnen Währungspaare am wichtigsten waren. Es könnte sich herausstellen, dass der Schlüsselfaktor für den EUR der EZB-Satz ist, während es für den JPY die japanische Handelsbilanz ist. Beispiel für die Datenausgabe:
Interpretation für EURUSD:
1. Preisentwicklung: Die Prognose zeigt einen Aufwärtstrend für die nächsten 30 Tage.
2. Volatilität: Die prognostizierte Kursentwicklung zeigt eine geringe Volatilität.
3. Der wichtigste Einflussfaktor: Das wichtigste Merkmal für diese Prognose ist niedrig ('low').
4. Wirtschaftliche Auswirkungen:
- Wenn das BIP-Wachstum ein wichtiger Faktor ist, deutet dies darauf hin, dass die starke Wirtschaftsleistung die Währung beeinflusst.
- Eine hohe Bedeutung der Inflationsrate könnte darauf hinweisen, dass sich geldpolitische Änderungen auf die Währung auswirken.
- Wenn Faktoren der Handelsbilanz ausschlaggebend sind, ist die Dynamik des internationalen Handels wahrscheinlich die treibende Kraft hinter den Währungsbewegungen.
5. Auswirkungen auf den Handel:
- Der Aufwärtstrend bietet Potenzial für Kaufpositionen.
- Eine geringere Volatilität könnte breitere Stop Loss ermöglichen.
6. Risikobewertung:
- Berücksichtigen Sie stets die Grenzen des Modells und das Potenzial für unerwartete Marktereignisse.
- Vergangene Leistungen sind keine Garantie für zukünftige Ergebnisse.
Aber denken Sie daran, dass es in der Wirtschaft keine einfachen Antworten gibt. Manchmal steigt eine Währung gegen alle Widerstände, und manchmal fällt sie ohne ersichtlichen Grund. Der Markt lebt oft eher von Erwartungen als von der aktuellen Realität.
Ein weiterer wichtiger Punkt ist die zeitliche Verzögerung. Veränderungen in der Wirtschaft spiegeln sich nicht unmittelbar im Wechselkurs wider. Es ist, als ob man ein großes Schiff steuert - man dreht das Steuerrad, aber das Schiff ändert nicht sofort seinen Kurs. Im Code werden tägliche Daten verwendet, aber einige Wirtschaftsindikatoren werden weniger häufig aktualisiert. Dies kann zu einem gewissen Fehler bei den Prognosen führen. Letztlich ist die Interpretation der Ergebnisse ebenso eine Kunst wie eine Wissenschaft. Das Modell ist ein leistungsfähiges Instrument, aber Entscheidungen werden immer von einem Menschen getroffen. Nutzen Sie diese Daten mit Bedacht, und mögen Ihre Vorhersagen richtig sein!
Suche nach nicht offensichtlichen Mustern in Wirtschaftsdaten
Der Devisenmarkt ist eine riesige Handelsplattform. Er ist nicht durch vorhersehbare Kursbewegungen gekennzeichnet, sondern es gibt darüber hinaus besondere Ereignisse, die die Volatilität und Liquidität im Moment erhöhen. Es handelt sich um globale Ereignisse.
In unserem Code stützen wir uns auf Wirtschaftsindikatoren:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
Aber was tun, wenn etwas Unerwartetes passiert? Zum Beispiel eine Pandemie oder eine politische Krise?
Eine Art „Überraschungsindex“ wäre hier nützlich. Stellen Sie sich vor, wir fügen unserem Code etwas wie das Folgende hinzu:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Dies würde es uns ermöglichen, plötzliche globale Ereignisse und deren allmähliche Abschwächung zu berücksichtigen.
Die interessanteste Frage ist jedoch, wie sich dies auf die Prognosen auswirkt. Manchmal können globale Ereignisse unsere Erwartungen völlig auf den Kopf stellen. In einer Krise können beispielsweise „sichere“ Währungen wie USD oder CHF entgegen der wirtschaftlichen Logik an Wert gewinnen.
In solchen Momenten sinkt die Produktivität unseres Modells. Und hier ist es wichtig, nicht in Panik zu verfallen, sondern sich anzupassen. Vielleicht lohnt es sich, den Prognosehorizont vorübergehend zu verkürzen oder den jüngsten Daten mehr Gewicht zu verleihen?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
Denken Sie daran: Wie beim Tanzen kommt es auch in der Welt der Währungen darauf an, sich dem Rhythmus anpassen zu können. Auch wenn sich dieser Rhythmus manchmal auf höchst unerwartete Weise ändert!
Auf der Jagd nach Anomalien: Wie man nicht offensichtliche Muster in Wirtschaftsdaten findet
Kommen wir nun zum interessantesten Teil - der Suche nach verborgenen Schätzen in unseren Daten. Es ist wie bei einem Detektiv, nur dass wir anstelle von Beweisen Zahlen und Charts haben.
Wir verwenden bereits eine ganze Reihe von Wirtschaftsindikatoren in unserem Code. Was aber, wenn es nicht offensichtliche Verbindungen zwischen ihnen gibt? Lasst uns versuchen, sie zu finden!
Zunächst können wir uns die Korrelationen zwischen verschiedenen Indikatoren ansehen:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Dies ist jedoch erst der Anfang. Der eigentliche Zauber beginnt, wenn wir nach nicht-linearen Beziehungen suchen. So kann sich beispielsweise herausstellen, dass eine Veränderung des BIP nicht sofort, sondern mit einer Verzögerung von mehreren Monaten auf den Wechselkurs wirkt.
Fügen wir unserer Datenaufbereitungsfunktion einige „verschobene“ Metriken hinzu:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Unser Modell wird nun in der Lage sein, Abhängigkeiten mit einer Verzögerung von 3 und 6 Monaten zu erfassen.
Aber das Interessanteste ist die Suche nach völlig unscheinbaren Mustern. Es könnte sich zum Beispiel herausstellen, dass der Kurs des EUR auf seltsame Weise mit den Eiscreme-Verkäufen in den USA korreliert (das ist ein Scherz, aber Sie verstehen schon).
Zu diesem Zweck können Methoden zur Merkmalsextraktion verwendet werden, z. B. die PCA (Principal Component Analysis):
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
Diese „verborgenen Muster“ können der Schlüssel zu genaueren Prognosen sein.
Vergessen Sie auch die Saisonalität nicht. Einige Währungen können sich je nach Jahreszeit unterschiedlich verhalten. Fügen Sie Ihren Daten Informationen über Monat und Wochentag hinzu - vielleicht finden Sie etwas Interessantes!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
Denken Sie daran, dass es in einer Welt der Daten immer Raum für Entdeckungen gibt. Seien Sie neugierig, experimentieren Sie, und wer weiß, vielleicht finden Sie genau das Muster, das die Welt des Handels verändern wird.
Schlussfolgerung: Aussichten für Wirtschaftsprognosen im algorithmischen Handel
Wir begannen mit einer einfachen Idee: Können wir die Entwicklung der Wechselkurse auf der Grundlage von Wirtschaftsdaten vorhersagen? Was haben wir herausgefunden? Es hat sich herausgestellt, dass diese Idee durchaus ihre Berechtigung hat. Aber es ist nicht so einfach, wie es auf den ersten Blick scheint.
Unser Code vereinfacht die Analyse von Wirtschaftsdaten erheblich. Wir haben gelernt, Informationen aus der ganzen Welt zu sammeln, sie zu verarbeiten und sogar den Computer dazu zu bringen, Vorhersagen zu treffen. Aber denken Sie daran, dass auch das fortschrittlichste Modell für maschinelles Lernen nur ein Werkzeug ist. Es ist ein sehr mächtiges Werkzeug, aber immer noch ein Werkzeug.
Wir haben gesehen, wie CatBoostRegressor komplexe Beziehungen zwischen Wirtschaftsindikatoren und Wechselkursen finden kann. Dadurch können wir über die menschlichen Fähigkeiten hinausgehen und den Zeitaufwand für die Bearbeitung und Analyse von Daten erheblich reduzieren. Aber selbst ein solch großartiges Instrument kann die Zukunft nicht mit 100-prozentiger Genauigkeit vorhersagen.
Warum? Denn die Wirtschaft ist ein Prozess, der von vielen Faktoren abhängt. Heute schaut jeder auf den Ölpreis, während morgen die ganze Welt durch ein unerwartetes Ereignis auf den Kopf gestellt werden könnte. Wir haben diesen Effekt erwähnt, als wir über den „Überraschungsindex“ sprachen. Genau deshalb ist sie so wichtig.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/15998
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hier geht es weiter. Ein alter Artikel zu diesem Thema.
Bislang kann ich der Fliege höchstens die aktuellen Daten für heute entlocken((((
Was ich nicht verstehe, ist: Was macht MQ?
Das ist das Signal des Autors oben.
Dieses Signal wurde nur gemacht, um ein Modell auf Sber zu testen. Aber ich habe es nie getestet, es ist nur Währung im Geldmarktfonds bereits. Grundsätzlich handele ich nicht selbst mit meinen Modellen, ich kann mich nicht von Ideen zur Verbesserung und Entwicklung lösen)))) Es gibt ständig neue Ideen zur Verbesserung) Und an der Börse investiere ich hauptsächlich in Aktien, langfristig kaufe ich Aktien an der MOEX als Nicht-Res, und an der KASE von Kazbirji-Index-Unternehmen.
Das Beste, was wir bisher aus der Fliege herausholen konnten, sind die aktuellen Daten für heute((((
Soweit ich weiß, sammeln sie Daten über die Konten, die mit der Überwachung verbunden sind? Selbst wenn alles ehrlich ist, ist das nur ein Tropfen auf den heißen Stein.
Imho sind die Daten der CFTC vertrauenswürdiger, auch wenn es sich nicht um Spot, sondern um Futures mit Optionen handelt. Dort gibt es eine Historie seit 2005, wenn auch nicht in einer sehr praktischen Form, aber es gibt wahrscheinlich einige APIs für Python.
Es liegt natürlich an Ihnen, ich teile nur meine Meinung.
Dieses Signal wurde nur gemacht, um ein Modell auf Sber zu testen. Aber ich habe es nie getestet, es ist nur Währung im Geldmarktfonds schon. Grundsätzlich handele ich nicht selbst auf meine Modelle, ich kann nicht weg von Ideen auf Verbesserungen und Entwicklung)))) Es gibt ständig neue Ideen zur Verbesserung) Und an der Börse investiere ich hauptsächlich in Aktien, auf lange Sicht, kaufe ich Aktien auf MOEX als nicht-rez, und auf KASE von Kazbirji Index-Unternehmen.
es gibt eine Diskrepanz der Informationen dort, keine Ansprüche an Sie