
Neuronale Netze im Handel: Kontrollierte Segmentierung

Einführung
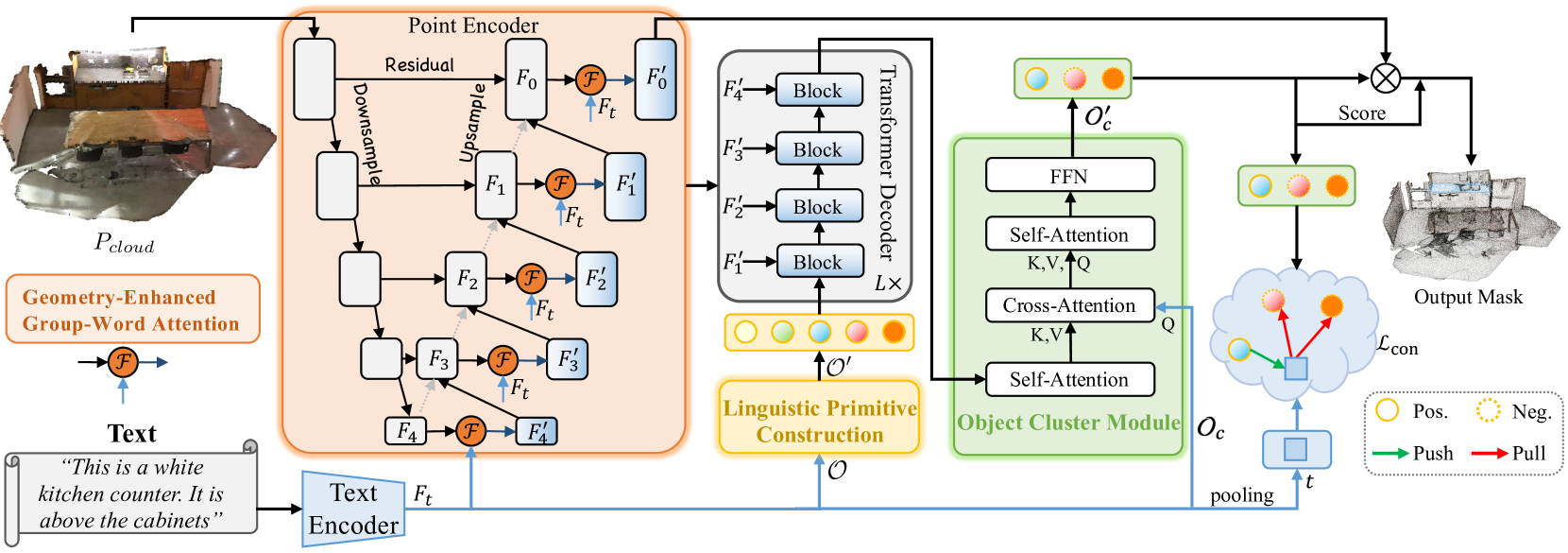
Die Aufgabe der geführten Segmentierung erfordert die Isolierung eines bestimmten Bereichs innerhalb einer Punktwolke auf der Grundlage einer natürlichsprachlichen Beschreibung des Zielobjekts. Um diese Aufgabe zu lösen, führt das Modell eine detaillierte Analyse komplexer, feinkörniger semantischer Abhängigkeiten durch und generiert eine punktweise Maske des Zielobjekts. Der Artikel „RefMask3D: Language-Guided Transformer for 3D Referring Segmentation“ stellt einen effizienten und umfassenden Rahmen vor, der sprachliche Informationen umfassend nutzt. Die vorgeschlagene Methode RefMask3D verbessert die multimodalen Interaktions- und Verständnismöglichkeiten.
Die Autoren schlagen die Verwendung einer frühen Phase der Merkmalskodierung vor, um einen reichhaltigen multimodalen Kontext zu extrahieren. Zu diesem Zweck führen sie das Modul „Geometry-Enhanced Group-Word Attention“ (Geometrie-erweiterte Wortgruppen-Aufmerksamkeit) ein, das in jeder Phase der Merkmalskodierung eine kreuz-modale Aufmerksamkeit zwischen der natürlichsprachlichen Objektbeschreibung und lokalen Punktgruppen (Subwolken) ermöglicht. Diese Integration reduziert nicht nur das Rauschen, das typischerweise mit direkten Punkt-Wort-Korrelationen verbunden ist und durch die spärliche und unregelmäßige Beschaffenheit von Punktwolken verursacht wird, sondern nutzt auch intrinsische geometrische Beziehungen und feine strukturelle Details innerhalb der Wolke. Dadurch wird die Fähigkeit des Modells, sowohl mit linguistischen als auch mit geometrischen Daten umzugehen, erheblich verbessert.
Zusätzlich bauen die Autoren ein lernbares „Hintergrund“-Token ein, das verhindert, dass irrelevante linguistische Merkmale mit lokalen Gruppenmerkmalen verwoben werden. Dieser Mechanismus stellt sicher, dass Darstellungen auf Punktebene mit relevanten semantischen linguistischen Informationen angereichert werden, wobei eine kontinuierliche und kontextbewusste Anpassung an den entsprechenden Sprachkontext für jede Gruppe oder jedes Objekt innerhalb der Punktwolke erfolgt.
Durch die Kombination von Computer Vision und der Verarbeitung natürlicher Sprache haben die Autoren eine effektive Strategie zur Identifizierung von Zielobjekten im Decoder entwickelt, die als Linguistic Primitives Construction (LPC) bezeichnet wird. Diese Strategie beinhaltet die Initialisierung einer Reihe verschiedener Primitive, die jeweils bestimmte semantische Attribute wie Form, Farbe, Größe, Beziehungen, Standort usw. darstellen sollen. Durch die Interaktion mit relevanten linguistischen Informationen erhalten diese Primitive entsprechende Attribute.
Durch die Verwendung semantisch angereicherter Primitive innerhalb des Decoders wird der Fokus des Modells auf die verschiedenen Semantiken der Punktwolke verstärkt, wodurch die Fähigkeit zur genauen Lokalisierung und Identifizierung des Zielobjekts erheblich verbessert wird.
Um ganzheitliche Informationen zu sammeln und Objekteinbettungen zu erzeugen, führt das RefMask3D Framework das Object Cluster Module (OCM) ein. Linguistische Primitive werden verwendet, um bestimmte Teile der Punktwolke hervorzuheben, die mit ihren semantischen Attributen korrelieren. Das eigentliche Ziel ist jedoch die Identifizierung des Zielobjekts auf der Grundlage der bereitgestellten Beschreibung. Dies erfordert ein umfassendes Verständnis der Sprache. Dies wird durch die Integration des Objektcluster-Moduls erreicht. Innerhalb dieses Moduls werden zunächst die Beziehungen zwischen den sprachlichen Primitiven analysiert, um gemeinsame Merkmale und Unterschiede in ihren Kernbereichen zu ermitteln. Anhand dieser Informationen werden Abfragen in natürlicher Sprache initiiert. Auf diese Weise können wir diese gemeinsamen Merkmale erfassen, die die endgültige Einbettung bilden, die für die Identifizierung des Zielobjekts unerlässlich ist.
Das vorgeschlagene Objektcluster-Modul spielt eine entscheidende Rolle dabei, dass das Modell ein tieferes, ganzheitlicheres Verständnis sowohl von sprachlichen als auch von visuellen Informationen erreicht.
1. Der Algorithmus RefMask3D
RefMask3D erzeugt eine punktweise Maske eines Zielobjekts, indem es die ursprüngliche Punktwolkenszene zusammen mit der textuellen Beschreibung der gewünschten Attribute analysiert. Die zu analysierende Szene besteht aus N Punkten, von denen jede 3D-Koordinate P und einen zusätzlichen Merkmalsvektor F enthält, der Attribute wie Farbe, Form und andere Eigenschaften beschreibt.
Zunächst wird ein Textkodierer eingesetzt, um aus der Textbeschreibung Einbettungen Ft zu erzeugen. Punktweise Merkmale werden dann mit Hilfe eines Punkt-Encoders extrahiert, der tiefe Wechselwirkungen zwischen der beobachteten geometrischen Form und der Texteingabe über das Modul Geometry-Enhanced Group-Word Attention herstellt. Der Punkt-Encoder fungiert als Backbone, ähnlich wie ein 3D-U-Netz.
Der Linguistic Primitives Constructor erzeugt eine Reihe von Primitiven 𝒪′ zur Darstellung verschiedener semantischer Attribute unter Verwendung informativer linguistischer Hinweise. Dadurch wird die Fähigkeit des Modells verbessert, das Zielobjekt genau zu lokalisieren und zu identifizieren, indem es auf spezifische semantische Signale achtet.
Die linguistischen Primitive 𝒪′, multiskalige Punktmerkmale {𝑭1′,𝑭2′,𝑭3′,𝑭4′} und Sprachmerkmale 𝑭t dienen als Eingabe für einen vierschichtigen kreuz-modalen Decoder, der auf der Architektur des Transformers basiert.
Angereicherte linguistische Primitive und Objektabfragen 𝒪c werden dann an das Object Cluster Module (OCM) weitergeleitet, um die Beziehungen zwischen den Primitiven zu analysieren, ihr semantisches Verständnis zu vereinheitlichen und gemeinsame Merkmale zu extrahieren.
Ein Modul zur Modalitätsfusion wird auf dem Grundgerüst des Bild- und Sprachmodells eingesetzt. Die Autoren integrieren die multimodale Fusion in den Punktcodierer. Eine frühzeitige Zusammenführung von modalübergreifenden Merkmalen verbessert die Effizienz des Zusammenführungsprozesses. Der Mechanismus Geometry-Enhanced Group-Word Attention verarbeitet auf innovative Weise lokale Punktgruppen (Teilwolken) mit geometrisch benachbarten Punkten. Dieser Ansatz reduziert das Rauschen von direkten Punkt-Wort-Korrelationen und nutzt inhärente geometrische Beziehungen innerhalb der Punktwolke, wodurch die Fähigkeit des Modells verbessert wird, linguistische Informationen mit der 3D-Struktur zu verschmelzen.
Die reinen kreuz-modale Aufmerksamkeitsmechanismen haben oft Probleme, wenn einem Punkt keine entsprechenden beschreibenden Wörter zugeordnet sind. Um dieses Problem zu lösen, führen die Autoren lernfähige Hintergrund-Token ein. Diese Strategie ermöglicht es Punkten ohne Bezug zu Textdaten, sich auf eine gemeinsame Hintergrund-Token-Einbettung zu konzentrieren, wodurch Verzerrungen durch nicht verwandte Textassoziationen minimiert werden.
Durch die Einbeziehung von Punkten, die sprachlich nicht übereinstimmen, in das Hintergrundobjekt-Cluster wird der Einfluss irrelevanter Elemente weiter verringert. Dies führt zu Punktmerkmalen, die mit linguistisch begründeten Attributen verfeinert sind, sich auf lokale Zentren konzentrieren und von nicht verwandten Wörtern unbeeinflusst sind. Die Hintergrundeinbettung ist ein trainierbarer Parameter, der die Gesamtverteilung des Datensatzes erfasst und die ursprünglichen Eingabedaten effektiv darstellt. Sie wird ausschließlich in der Phase der Aufmerksamkeitsberechnung verwendet. Durch diesen Mechanismus erreicht das Modell präzisere kreuz-modale Interaktionen, die nicht durch irrelevante Sprachhinweise beeinflusst werden.
Die meisten bestehenden Methoden stützen sich in der Regel auf Zentren, die direkt aus der Punktwolke abgetastet werden. Eine entscheidende Einschränkung dieses Ansatzes ist jedoch die Vernachlässigung des sprachlichen Kontexts, der für eine genaue Segmentierung unerlässlich ist. Wenn nur die am weitesten entfernten Punkte abgetastet werden, weichen die Vorhersagen oft von den tatsächlichen Zielen ab, insbesondere in unübersichtlichen Szenen, was die Konvergenz behindert und zu verpassten Erkennungen führt. Dies ist besonders problematisch, wenn die ausgewählten Punkte das Objekt ungenau darstellen oder an ein einziges beschreibendes Wort gebunden sind. Um dieses Problem zu lösen, schlagen die Autoren die Konstruktion von linguistischen Primitiven vor, die semantische Inhalte beinhalten und es dem Modell ermöglichen, verschiedene semantische Attribute zu lernen, die mit zielrelevanten Objekten verbunden sind.
Diese Primitive werden durch Stichproben aus verschiedenen Gaußschen Verteilungen initialisiert. Jede Verteilung steht für eine bestimmte semantische Eigenschaft. Die Primitive sind so konzipiert, dass sie Attribute wie Form, Farbe, Größe, Material, Beziehungen und Ort kodieren. Jedes Primitiv aggregiert bestimmte sprachliche Merkmale und extrahiert die entsprechenden Informationen. Die linguistischen Primitive dienen dazu, semantische Muster auszudrücken. Wenn sie den Transformer-Decoder durchlaufen, kann dieser ein breites Spektrum an sprachlichen Hinweisen extrahieren und so die Objektidentifizierung in späteren Phasen verbessern.
Jedes linguistische Primitiv konzentriert sich auf bestimmte semantische Muster innerhalb der gegebenen Punktwolke, die mit den jeweiligen linguistischen Attributen korrelieren. Das eigentliche Ziel bleibt jedoch die Identifizierung eines eindeutigen Zielobjekts auf der Grundlage der bereitgestellten Textbeschreibung. Dies erfordert ein umfassendes Verständnis und eine semantische Interpretation der Objektbeschreibung. Um dies zu erreichen, setzen die Autoren das Object Cluster Module ein, das die Beziehungen zwischen sprachlichen Primitiven analysiert und gemeinsame und abweichende Merkmale in ihren Schlüsselregionen identifiziert. Dies fördert ein tieferes Verständnis der beschriebenen Objekte. Ein Mechanismus der Selbstaufmerksamkeit (Self-Attention) wird verwendet, um gemeinsame Merkmale aus den sprachlichen Primitiven zu extrahieren. Bei der Dekodierung werden Objektabfragen als Queries eingeführt, während die durch linguistische Primitive angereicherten gemeinsamen Merkmale als Key-Value (Schlüssel-Werte) dienen. Diese Konfiguration ermöglicht es dem Decoder, sprachliche Erkenntnisse aus den Primitiven in Objektabfragen zusammenzuführen, wodurch Abfragen, die mit dem Zielobjekt verbunden sind, effektiv identifiziert und in 𝒪c′ und eine präzise Identifizierung zu erreichen.
Das vorgeschlagene Objektcluster-Modul ist zwar eine große Hilfe bei der Identifizierung von Zielobjekten, beseitigt aber nicht die Mehrdeutigkeiten, die bei der Inferenz in anderen Anwendungen auftreten können. Solche Zweideutigkeiten können zu falsch positiven Ergebnissen führen. Um dies abzumildern, setzen die Autoren von RefMask3D kontrastives Lernen ein, um das Ziel-Token von anderen zu unterscheiden. Dabei wird die Ähnlichkeit mit der richtigen Textreferenz maximiert und die Ähnlichkeit mit negativen (Nicht-Ziel-)Paaren minimiert.
Im Folgenden wird eine Visualisierung der Methode RefMask3D vorgestellt.
2. Die Implementation in MQL5
Nachdem wir uns mit den theoretischen Aspekten der Methode RefMask3D beschäftigt haben, kommen wir nun zum praktischen Teil unseres Artikels. In diesem Teil werden wir unsere Vision der vorgeschlagenen Ansätze mit MQL5 umsetzen.
In der obigen Beschreibung haben die Autoren der RefMask3D-Methode den komplexen Algorithmus in mehrere Funktionsblöcke unterteilt. Daher erscheint es logisch, unsere Implementierungen entsprechend in Form von entsprechenden Modulen aufzubauen.
2.1 Geometry-Enhanced Group-Word Attention
Wir beginnen mit der Konstruktion des Punkt-Encoders, der in der ursprünglichen Methode das Modul Geometry-Enhanced Group-Word Attention enthält. Wir werden dieses Modul in einer neuen Klasse namens CNeuronGEGWA implementieren. Wie im theoretischen Überblick über RefMask3D erwähnt, ist der Punktcodierer als U-Netz-ähnliches Backbone konzipiert. Dementsprechend haben wir ausgewählt CNeuronUShapeAttention als übergeordnete Klasse ausgewählt, die die für unser Objekt erforderliche Basisfunktionalität bereitstellt. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronGEGWA : public CNeuronUShapeAttention { protected: CNeuronBaseOCL cResidual; CNeuronMLCrossAttentionMLKV cCrossAttention; CBufferFloat cTemp; bool bAddNeckGradient; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGEGWA(void) : bAddNeckGradient(false) {}; ~CNeuronGEGWA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronGEGWA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CNeuronBaseOCL* GetInsideLayer(const int layer) const; virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; } };
Die meisten Variablen und Objekte, die es uns ermöglichen, das U-Net-Backbone zu organisieren, werden von der Elternklasse geerbt. Wir führen jedoch zusätzliche Komponenten für den Aufbau von Mechanismen der kreuz-modalen Aufmerksamkeit ein.
Alle Objekte werden als statisch deklariert, was es uns ermöglicht, den Konstruktor und den Destruktor der Klasse leer zu lassen. Die Initialisierung von geerbten und neu hinzugefügten Objekten wird in der Init-Methode durchgeführt. Wie Sie wissen, erhält diese Methode Parameter, die explizite Informationen über die erforderliche Architektur des zu erstellenden Objekts liefern.
bool CNeuronGEGWA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_kv, uint heads_kv, uint units_count_kv, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir zunächst die gleichnamige Methode aus der Basisklasse CNeuronBaseOCL auf, die als ultimativer Vorfahre aller unserer neuronalen Schichtobjekte dient.
Beachten Sie, dass wir in diesem Fall eine Methode aus der Basisklasse und nicht aus der unmittelbaren Elternklasse aufrufen. Dies ist auf bestimmte architektonische Merkmale zurückzuführen, die wir für den Aufbau des U-Net-Backbone verwenden. Insbesondere bei der Konstruktion des „neck“ (Hals) verwenden wir die rekursive Erstellung von Objekten. In diesem Stadium müssen wir Komponenten aus einer anderen Klasse verwenden.
Anschließend werden die Objekte der primären Aufmerksamkeit und der Skalierung initialisiert.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2*window, window, (units_count + 1) / 2, optimization, iBatch)) return false;
Darauf folgt der Algorithmus zur Erstellung des „neck“ (Hals). Die Art des „Hals“-Objekts hängt von seiner Größe ab. Im Allgemeinen erstellen wir ein Objekt, das dem aktuellen Objekt ähnelt. Wir verringern einfach die Größe des inneren „Halses“ um „1“.
if(inside_bloks > 0) { CNeuronGEGWA *temp = new CNeuronGEGWA(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, (units_count + 1) / 2, window_kv, heads_kv, units_count_kv, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Für die letzte Schicht verwenden wir einen Kreuzaufmerksamkeits-Block.
else { CNeuronMLCrossAttentionMLKV *temp = new CNeuronMLCrossAttentionMLKV(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, window_kv, heads_kv, (units_count + 1) / 2, units_count_kv, layers, 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Anschließend initialisieren wir das Modul für Re-Attention und inverse Skalierung.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, (units_count + 1) / 2, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, window, window, 2*window, (units_count + 1) / 2, optimization, iBatch)) return false;
Danach fügen wir eine Verbindungsschicht der Residuen und ein multimodales Kreuzaufmerksamkeits-Modul hinzu.
if(!cResidual.Init(0, 5, OpenCL, Neurons(), optimization, iBatch)) return false; if(!cCrossAttention.Init(0, 6, OpenCL, window, window_key, heads, window_kv, heads_kv, units_count, units_count_kv, layers, 1, optimization, iBatch)) return false;
Außerdem wird ein Hilfspuffer für die temporäre Datenspeicherung initialisiert.
if(!cTemp.BufferInit(MathMax(cCrossAttention.GetSecondBufferSize(), cAttention[0].Neurons()), 0) || !cTemp.BufferCreate(OpenCL)) return false;
Am Ende der Initialisierungsmethode ersetzen wir Zeiger auf Datenpuffer, um die Datenkopiervorgänge zu minimieren.
if(Gradient != cCrossAttention.getGradient()) { if(!SetGradient(cCrossAttention.getGradient(), true)) return false; } if(cResidual.getGradient() != cMergeSplit[1].getGradient()) { if(!cResidual.SetGradient(cMergeSplit[1].getGradient(), true)) return false; } if(Output != cCrossAttention.getOutput()) { if(!SetOutput(cCrossAttention.getOutput(), true)) return false; } //--- return true; }
Wir geben dann einen booleschen Wert an das aufrufende Programm zurück, der das Ergebnis der Ausführung der Methodenoperationen angibt.
Nachdem die Initialisierung des neuen Objekts abgeschlossen ist, wird der Vorwärtsdurchlauf-Algorithmus in der Methode feedForward implementiert. Anders als die übergeordnete Klasse benötigt unser neues Objekt zwei Datenquellen. Daher wurde die geerbte Methode, die für die Arbeit mit einer einzigen Datenquelle konzipiert ist, mit einem negativen Teil überschrieben. Die neue Methode wurde dagegen von Grund auf neu entwickelt.
In den Methodenparametern erhalten wir Zeiger auf zwei Eingabedatenobjekte. In diesem Stadium werden jedoch bei beiden keine Validierungsprüfungen durchgeführt.
bool CNeuronGEGWA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
Zunächst übergeben wir den Zeiger auf eine der Datenquellen an die gleichnamige Methode in der primären Aufmerksamkeitsunterschicht. Die Zeigervalidierung wird bereits intern von dieser Methode durchgeführt. Wir müssen also nur das logische Ergebnis der Ausführung überprüfen. Dann skalieren wir die Ausgabe des Aufmerksamkeitsblocks.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
Wir übergeben die skalierten Daten und einen Zeiger auf das zweite Datenquellenobjekt an den „Hals“.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject(), SecondInput)) return false;
Wir leiten das erhaltene Ergebnis durch den zweiten Aufmerksamkeitsblock und führen eine inverse Datenskalierung durch.
if(!cAttention[1].FeedForward(cNeck)) return false; if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
Danach fügen wir die restlichen Verbindungen hinzu und führen eine kreuz-modale Abhängigkeitsanalyse durch.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), cResidual.getOutput(), 1, false)) return false; if(!cCrossAttention.FeedForward(cResidual.AsObject(), SecondInput)) return false; //--- return true; }
Bevor wir mit der Arbeit an den Methoden des Rückwärtsdurchlaufs beginnen, muss noch ein Punkt diskutiert werden. Schauen Sie sich den Auszug aus der Visualisierung der Methode RefMask3D unten an.
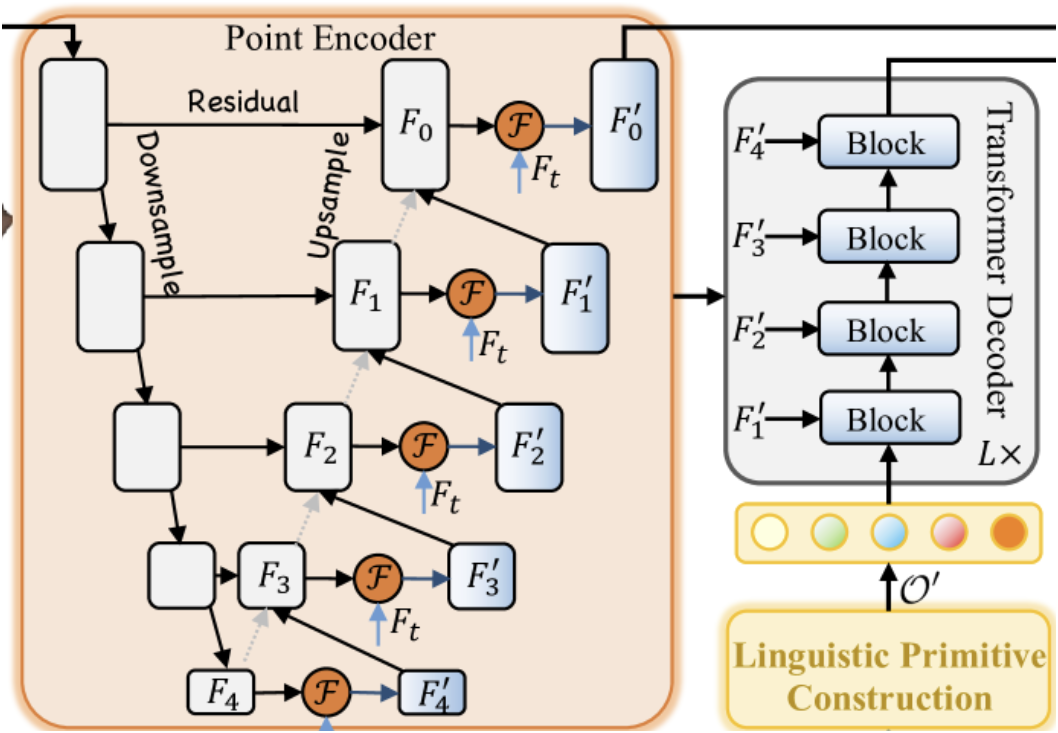
Der springende Punkt dabei ist, dass im Decoder eine kreuz-modale Aufmerksamkeit zwischen den trainierbaren Primitiven und den Zwischenergebnissen unseres Punkt-Encoders stattfindet. Dieser scheinbar einfache Vorgang erfordert in Wirklichkeit einen entsprechenden Fehlergradientenfluss. Natürlich müssen wir die entsprechenden Schnittstellen implementieren, um dies zu unterstützen. Bei der Implementierung der Gradientenverteilung in unserem vereinheitlichten Block RefMask3D berechnen wir zunächst die Decoder-Gradienten und anschließend die Gradienten der Punkt-Encoder. Bei einem klassischen Gradienten-Backpropagation-Modell würde diese Sequenzierung jedoch zum Verlust der vom Decoder übermittelten Gradientendaten führen. Wir erkennen jedoch an, dass diese spezielle Verwendung des Blocks einen Sonderfall darstellt. Daher gibt es in der Methode calcInputGradients zwei Betriebsmodi: einen, bei dem die zuvor gespeicherten Gradienten gelöscht werden (Standardverhalten), und einen, bei dem sie erhalten bleiben (für Sonderfälle wie diesen). Um diese Funktionalität zu ermöglichen, haben wir eine interne Flag-Variable bAddNeckGradient und eine entsprechende Setter-Methode AddNeckGradient eingeführt.
virtual void AddNeckGradient(const bool flag) { bAddNeckGradient = flag; }
Aber kommen wir zurück zum Algorithmus des Rückwärtsdurchlaufs. In den Parametern der Methode calcInputGradients erhalten wir Zeiger auf 3 Objekte und eine Konstante der Aktivierungsfunktion der zweiten Datenquelle.
bool CNeuronGEGWA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!prevLayer) return false;
Im Hauptteil der Methode wird nur die Relevanz des Zeigers auf die erste Datenquelle geprüft. Die übrigen Zeiger werden im Körper der Fehlergradientenverteilungsmethoden der internen Schichten überprüft.
Da wir die Substitution von Zeigern auf Datenpuffer implementiert haben, beginnt der Algorithmus zur Verteilung des Fehlergradienten in der inneren Schicht der kreuz-modalen Aufmerksamkeit.
if(!cResidual.calcHiddenGradients(cCrossAttention.AsObject(), SecondInput, SecondGradient, SecondActivation)) return false;
Danach führen wir eine Skalierung der Fehlergradienten durch.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
Dann organisieren wir die Verzweigung des Algorithmus in Abhängigkeit davon, ob wir den zuvor akkumulierten Fehlergradienten erhalten müssen. Wenn der Fehler erhalten bleiben soll, ersetzen wir den Fehler-Gradientenpuffer im „Hals“ durch einen ähnlichen Gradientenpuffer aus der ersten Datenskalierungsschicht. Dabei machen wir uns die folgende Eigenschaft zunutze: Die Größe der Ausgangstensoren der angegebenen Skalierungsschicht ist gleich der des „Halses“. Wir werden den Fehlergradienten später auf diese Ebene übertragen. Daher ist der Betrieb in diesem Fall sicher.
if(bAddNeckGradient) { CBufferFloat *temp = cNeck.getGradient(); if(!cNeck.SetGradient(cMergeSplit[0].getGradient(), false)) return false;
Anschließend wird der Fehlergradient auf der Ebene des „Halses“ mit der klassischen Methode ermittelt. Wir summieren die Ergebnisse aus den beiden Informationsdämpfen und geben Zeiger auf die Objekte zurück.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false; if(!SumAndNormilize(cNeck.getGradient(), temp, temp, 1, false, 0, 0, 0, 1)) return false; if(!cNeck.SetGradient(temp, false)) return false; }
Wenn der zuvor akkumulierte Fehlergradient nicht benötigt wird, erhalten wir den Fehlergradienten einfach mit Standardmethoden.
else if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
Als Nächstes müssen wir den Fehlergradienten durch das Objekt „neck“ propagieren. Dieses Mal verwenden wir die klassische Methode. Hier erhalten wir den Fehlergradienten der zweiten Datenquelle in den temporären Datenspeicher. Später müssen wir die vom Modul für kreuz-modale Aufmerksamkeit erhaltenen Werte des aktuellen Objekts und des Halses addieren.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject(), SecondInput, GetPointer(cTemp), SecondActivation)) return false; if(!SumAndNormilize(SecondGradient, GetPointer(cTemp), SecondGradient, 1, false, 0, 0, 0, 1)) return false;
Anschließend propagieren wir den Fehlergradienten bis zur Ebene der ersten Quelle von Eingabedaten.
if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Wir propagieren den Gradienten des Restverbindungsfehlers durch die Ableitung der Aktivierungsfunktion und summieren die Informationen aus den beiden Strömen.
if(!DeActivation(prevLayer.getOutput(), GetPointer(cTemp), cMergeSplit[1].getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getGradient(), 1, false)) return false; //--- return true; }
Die Methode updateInputWeights zum Aktualisieren der Modellparameter ist recht einfach. Wir rufen die entsprechenden Aktualisierungsmethoden der internen Schichten auf, die trainierbare Parameter enthalten. Daher möchte ich Sie ermutigen, deren Implementierungen unabhängig zu erkunden. Die vollständige Implementierung dieser Klasse und aller ihrer Methoden finden Sie im Anhang.
Ich möchte noch ein paar Worte über die Schaffung einer Schnittstelle für den Zugriff auf „Hals“-Objekte hinzufügen. Um diese Funktionalität zu implementieren, haben wir die Methode GetInsideLayer erstellt. In seinen Parametern übergeben wir den Index der gewünschten Ebene.
CNeuronBaseOCL* CNeuronGEGWA::GetInsideLayer(const int layer) const { if(layer < 0) return NULL;
Wird ein negativer Index ermittelt, bedeutet dies, dass ein Fehler aufgetreten ist. In diesem Fall gibt die Methode einen NULL-Zeiger zurück. Ein Wert von Null bedeutet, dass auf die aktuelle Ebene zugegriffen wird. Daher gibt die Methode einen Zeiger auf das Objekt „neck“ zurück.
if(layer == 0) return cNeck;
Andernfalls muss der Hals ein Objekt der entsprechenden Klasse sein, und wir rufen diese Methode rekursiv mit dem um 1 verringerten Index der gewünschten Ebene auf.
if(!cNeck || cNeck.Type() != Type()) return NULL; //--- CNeuronGEGWA* temp = cNeck; return temp.GetInsideLayer(layer - 1); }
2.2 Konstruktion linguistischer Primitive
Im nächsten Schritt erstellen wir ein Objekt für das Modul Linguistic Primitives Construction in der Klasse CNeuronLPC. Die Originalvisualisierung dieser Methode wird im Folgenden vorgestellt.
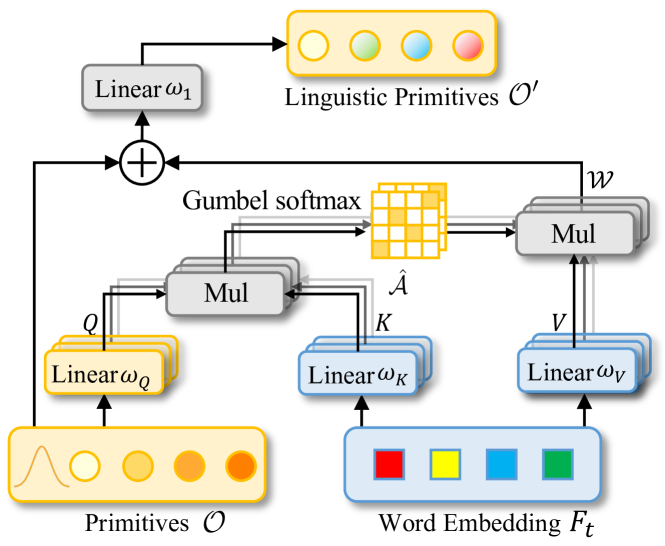
Hier sind Ähnlichkeiten mit dem klassischen Cross-Attention-Block zu erkennen, der die Auswahl der entsprechenden Elternklasse vorschlägt. In diesem Fall verwenden wir die Objektklasse der Kreuzaufmerksamkeit CNeuronMLCrossAttentionMLKV. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronLPC : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cPrimitives; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLPC(void) {}; ~CNeuronLPC(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLPC; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Im vorigen Fall haben wir Quellen von Eingabedaten für die Vorwärts- und Rückwärts-Durchläufe hinzugefügt. In diesem Fall ist es jedoch genau andersherum. Obwohl das Modul der Kreuzaufmerksamkeit zwei Datenquellen erfordert, wird in dieser Implementierung nur eine verwendet. Der Grund dafür ist, dass die zweite Datenquelle (die trainierbaren Primitive) intern in diesem Objekt generiert wird.
Um diese trainierbaren Primitive zu erzeugen, definieren wir zwei interne, vollständig verbundene Schichtobjekte. Diese beiden Objekte sind als statisch deklariert, sodass wir den Konstruktor und den Destruktor der Klasse leer lassen können. Die Initialisierung dieser deklarierten und geerbten Objekte wird in der Methode Init durchgeführt.
bool CNeuronLPC::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, window, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
In den Parametern dieser Methode erhalten wir Konstanten, mit denen wir die Architektur des zu erstellenden Objekts eindeutig bestimmen können. Im Methodenkörper rufen wir sofort die entsprechende Methode der Elternklasse auf, die die Kontrolle der empfangenen Parameter und die Initialisierung der geerbten Objekte implementiert.
Bitte beachten Sie, dass wir die Parameter der generierten Primitive als Informationen über die primäre Datenquelle verwenden.
Als Nächstes erzeugen wir eine einzelne, vollständig verbundene Schicht, die aus einem Element besteht.
if(!cOne.Init(window * units_count, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false;
Dann initialisieren wir die Erzeugungsschicht mit einem Primitiv.
if(!cPrimitives.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; //--- return true; }
Beachten Sie, dass wir in diesem Fall keine positionsbezogene Kodierungsschicht verwenden. Nach der ursprünglichen Logik sind einige Primitive für die Erfassung der Position des Objekts zuständig, während andere seine semantischen Attribute sammeln.
Die Methode FeedForward in dieser Implementierung ist ebenfalls recht einfach. Sie nimmt als Parameter einen Zeiger auf das Eingabedatenobjekt entgegen, und der erste Schritt besteht darin, die Gültigkeit dieses Zeigers zu überprüfen. Ich sollte darauf hinweisen, dass dies bei neueren Methoden für Vorwärtsdurchläufe nicht mehr üblich ist.
bool CNeuronLPC::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Solche Prüfungen werden normalerweise intern von verschachtelten Komponenten durchgeführt. In diesem Fall werden jedoch die vom externen Programm empfangenen Daten als Kontext verwendet. Das bedeutet, dass wir beim Aufruf von Methoden interner Objekte auf verschachtelte Mitglieder des bereitgestellten Eingabeobjekts zugreifen müssen. Aus diesem Grund sind wir verpflichtet, die Gültigkeit des eingehenden Zeigers ausdrücklich zu prüfen.
Als Nächstes erzeugen wir den Merkmalstensor.
if(bTrain && !cPrimitives.FeedForward(cOne.AsObject())) return false;
Um die Dauer des Entscheidungsprozesses zu verkürzen, wird dieser Vorgang nur während des Trainings durchgeführt. In der Errichtungsphase bleibt der primitive Tensor statisch und muss daher nicht bei jeder Iteration neu generiert werden.
Der Vorwärtsdurchlauf schließt mit einem Aufruf der Vorwärtsdurchlauf-Methode der übergeordneten Klasse ab. Dieser Methode übergeben wir den generierten Tensor von Primitiven als primäre Datenquelle und die Kontextinformationen aus dem externen Programm als sekundären Input.
if(!CNeuronMLCrossAttentionMLKV::feedForward(cPrimitives.AsObject(), NeuronOCL.getOutput())) return false; //--- return true; }
Bei der Gradientenfortpflanzungsmethode calcInputGradients werden die Operationen des Vorwärtsdurchlauf-Algorithmus in umgekehrter Reihenfolge durchgeführt.
bool CNeuronLPC::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Auch hier prüfen wir zunächst den empfangenen Zeiger auf das Quelldatenobjekt. Dann rufen wir die Methode der übergeordneten Klasse mit demselben Namen auf und verteilen den Fehlergradienten zwischen den Primitiven und dem ursprünglichen Kontext.
if(!CNeuronMLCrossAttentionMLKV::calcInputGradients(cPrimitives.AsObject(), NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
Danach fügen wir den Gradienten des primitiven Diversifikationsfehlers hinzu.
if(!DiversityLoss(cPrimitives.AsObject(), iUnits, iWindow, true)) return false; //--- return true; }
Die Fortpflanzung des Fehlergradienten bis hinunter auf die Ebene einer einzelnen Schicht ist von geringem praktischem Wert, sodass wir diesen Vorgang weglassen. Der Algorithmus zur Aktualisierung der Parameter wird ebenfalls einer unabhängigen Untersuchung unterzogen. Den vollständigen Code dieser Klasse und alle ihre Methoden finden Sie im Anhang.
Die nächste Komponente im Ablauf von RefMask3D ist der reine Transformer-Decoder-Block, der den multimodalen Cross-Attention-Mechanismus zwischen der Punktwolke und den erlernbaren Primitiven implementiert. Diese Funktionalität kann mit den von uns entwickelten Tools abgedeckt werden. Wir werden also keinen neuen Block speziell für diesen Zweck erstellen.
Ein weiteres Modul, das wir implementieren müssen, ist das Objekt-Clustering-Modul. Der Algorithmus für dieses Modul wird in der Klasse CNeuronOCM implementiert. Dies ist ein ziemlich komplexes Modul. Es kombiniert zwei Blöcke der Selbstaufmerksamkeit: einen für die Primitive und einen für die semantischen Merkmale. Sie werden durch einen Querbegrenzungsblock ergänzt. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); };
Ich glaube, es ist klar, dass die Methoden innerhalb dieser Klasse ziemlich komplexe Algorithmen beinhalten. Jede von ihnen bedarf einer ausführlichen Erläuterung. Allerdings ist das Format dieses Artikels etwas eingeschränkt. Daher schlage ich vor, die Diskussion in einem Folgeartikel fortzusetzen, um einen gründlichen und qualitativ hochwertigen Überblick über die implementierten Algorithmen zu geben. In diesem Artikel werden auch die Testergebnisse der Modelle vorgestellt, die die vorgeschlagenen Ansätze auf realen Daten anwenden.
Schlussfolgerung
In diesem Artikel haben wir die Methode RefMask3D untersucht, die für die Analyse komplexer multimodaler Interaktionen und das Verständnis von Merkmalen entwickelt wurde. Die Methode birgt erhebliches Potenzial für eine Innovation im Bereich des Handels. Durch die Nutzung multidimensionaler Daten kann es sowohl aktuelle als auch historische Muster im Marktverhalten berücksichtigen. RefMask3D setzt eine Reihe von Mechanismen ein, um sich auf die wichtigsten Merkmale zu konzentrieren und gleichzeitig die Auswirkungen von Rauschen und irrelevanten Eingaben zu minimieren.
Im praktischen Teil begannen wir mit der Umsetzung der vorgeschlagenen Konzepte mit MQL5 und entwickelten die Objekte für zwei der vorgeschlagenen Module. Der Umfang der abgeschlossenen Arbeiten geht jedoch über das hinaus, was in einem einzelnen Artikel sinnvollerweise behandelt werden kann. Deshalb werden wir die begonnene Arbeit fortsetzen.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16038
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Aufbau eines nutzerdefinierten Systems zur Erkennung von Marktregimen in MQL5 (Teil 2): Expert Advisor
Aufbau eines nutzerdefinierten Systems zur Erkennung von Marktregimen in MQL5 (Teil 2): Expert Advisor
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.