Feature Engineering mit Python und MQL5 (Teil IV): Erkennung von Kerzenmustern mit der UMAP-Regression

Kerzenmuster werden von den meisten algorithmischen Händlern in unserer Community für viele verschiedene Handelsstrategien und -stile verwendet. Unser Verständnis dieser Muster ist jedoch auf die von uns aufgedeckten Kerzen beschränkt, während es in Wahrheit viele andere profitable Kerzenmuster geben könnte, die uns einfach noch nicht bekannt sind. Aufgrund der Fülle an Informationen, die die meisten modernen Märkte abdecken, ist es für Händler eine große Herausforderung, sicher zu sein, dass sie immer die zuverlässigsten Kerzenmuster verwenden, die ihnen in ihrem gewählten Markt zur Verfügung stehen.
Um dieses Problem zu entschärfen, werden wir eine Lösung vorschlagen, die es unserem Computer ermöglicht, neue Kerzenmuster zu erkennen, die uns nicht bekannt waren. Der von uns vorgeschlagene Rahmen ist teilweise mit einem Spiel aus der Kindheit vergleichbar, mit dem die meisten von uns vertraut sein dürften. Das Spiel hat verschiedene Namen. Die zugrunde liegende Prämisse ist jedoch dieselbe. Das Spiel fordert die Spieler auf, ein Substantiv mit Adjektiven zu beschreiben, die das Substantiv nicht enthalten. Wäre das gegebene Substantiv beispielsweise eine Banane, würde der Spieler, der das Spiel leitet, seinen Freunden Hinweise geben, die die Banane am besten beschreiben, wie z. B. „gelb und gekrümmt“, was für den Leser hoffentlich intuitiv zu verstehen ist.
Dieses Kinderspiel ist logischerweise identisch mit den Aufgaben, die wir unserem Computer stellen werden, damit wir neue Kerzenmuster aufdecken können, die sonst durch die große Anzahl von Dimensionen, die unsere Datensätze heutzutage in der Regel annehmen, verborgen geblieben wären. Analog zu dem soeben beschriebenen Spiel, bei dem der Spieler eine Banane mit 3 oder weniger Wörtern beschreiben soll, werden wir unserem Computer Marktdaten mit 10 Spalten zur Verfügung stellen, die die aktuelle Kerze beschreiben, und ihn dann bitten, die ursprünglichen Marktdaten in 8 Spalten (Einbettungen) oder weniger zu beschreiben. Dies wird als Dimensionenreduktion bezeichnet.
Es gibt viele bekannte Verfahren zur Dimensionenreduzierung, die dem Leser vielleicht schon bekannt sind, wie z. B. die Hauptkomponentenanalyse (PCA). Diese Techniken sind hilfreich, weil sie unseren Computer dazu bringen, sich auf den wichtigsten Aspekt der transformierten Daten zu konzentrieren. Heute werden wir eine Technik anwenden, die als Uniform Manifold Approximation And Projection (UMAP) bekannt ist. Dies ist ein neuer Algorithmus, der, wie der Leser bald sehen wird, uns helfen kann, nicht-lineare Beziehungen in unseren Marktdaten auf eine neuartige Weise aufzudecken.
Unser Ziel ist es, in unserem Originaldatensatz sorgfältig Spalten zu entwerfen und zu erstellen, die eine detaillierte Beschreibung des aktuellen Kerzen wiedergeben. Auf diese Weise kann der UMAP-Algorithmus unsere Daten transformieren, ähnliche Kerzen gruppieren und sie mit weniger „Wörtern“ (Einbettungen) beschreiben. Dies wiederum kann unserem Computer helfen, Kerzenmuster zu erkennen, die uns aufgrund der hohen Anzahl von Dimensionen, die wir zur genauen Beschreibung jedes Kerzen benötigen, verborgen blieben.
Um die Leistung des UMAP-Algorithmus zu testen, haben wir zwei identische statistische Modelle zur Vorhersage der Rendite des täglichen EURGBP-Wechselkurses trainiert. Das erste Modell wurde mit den ursprünglichen Marktdaten in ihrer ursprünglichen Form trainiert. In diesem speziellen Beispiel hatten die ursprünglichen Marktdaten 10 Dimensionen, die direkt vom Markt in unserem MetaTrader 5-Terminal erstellt wurden. Mit Hilfe des UMAP-Algorithmus konnten wir die ursprünglichen Marktdaten auf nur 3 Dimensionen heruntertransformieren, was ausreichte, um den Fehler der ursprünglichen Marktdaten, mit denen wir begonnen hatten, zu übertreffen.
Schließlich werden wir nicht darauf eingehen, wie der UMAP-Algorithmus von Grund auf in MQL5 implementiert werden kann. Der Grund dafür ist, dass der Algorithmus ziemlich anspruchsvoll ist und der Versuch, ihn mit numerischer Stabilität und Recheneffizienz zu implementieren, keine triviale Aufgabe darstellt. Wenn der Leser sicher ist, dass er über die erforderlichen Kenntnisse in analytischer Geometrie und algebraischer Topologie verfügt, kann er seinen Interessen nachgehen und den Algorithmus nativ in MQL5 implementieren. Ich habe einen Link zu der Original-Forschungsarbeit angegeben, in der die genauen mathematischen Spezifikationen des Algorithmus hier erläutert werden.
Andernfalls werden wir den Lesern, die nicht über alle erforderlichen numerischen Fähigkeiten verfügen, wie mir, zeigen, wie Sie den Algorithmus nicht von Grund auf neu implementieren müssen, sondern stattdessen unsere Fähigkeiten in der Funktionsannäherung nutzen können.
Warum UMAP?
Angesichts der Tatsache, dass es so viele nützliche und bekanntere Techniken zur Dimensionenreduktion gibt, werden sich einige Leser natürlich fragen: „Warum sollten wir daran interessiert sein, UMAP zu lernen? Muss ich wirklich noch eine weitere Bibliothek lernen?“. Einer der Hauptvorteile von UMAP besteht darin, dass mit zunehmender Größe unseres Datensatzes die Zeit, die die Bibliothek für die Transformation unserer Daten benötigt, nahezu konstant bleibt. Darüber hinaus ist der UMAP-Algorithmus so spezialisiert, dass er nichtlineare Effekte in den Daten aufdeckt, aber dennoch versucht, die ursprüngliche globale Struktur der Daten zu erhalten. Mit anderen Worten bedeutet dies, dass der Algorithmus ausdrücklich versucht, die Daten nicht zu verzerren und keine irreführenden Artefakte zu erzeugen, die zusätzliches Rauschen verursachen könnten. Dies ist bei den meisten Algorithmen zur Dimensionenreduktion nicht üblich.
Der UMAP-Algorithmus ist relativ neu und die Implementierung, die wir heute betrachten werden, wurde mit Python und Numba erstellt. Numba ist ein Compiler, der Python-Code in Maschinencode umwandelt. Diese Mischung aus Python und Maschinencode führt zu einer hohen Geschwindigkeit und numerisch stabilen Berechnungen, selbst bei großen Datensätzen. Diese spezielle Implementierung des UMAP-Algorithmus wurde von Leland McInnes et al. entwickelt. Die Bibliothek wurde erstmals im Jahr 2018 veröffentlicht.

Abb. 1: Leland McInnes ist einer der führenden Autoren des UMAP-Forschungspapiers und hilft bei der Pflege der Python-Bibliothek
Der Leser sollte sich jedoch darüber im Klaren sein, dass diese Qualitäten nicht garantiert werden können, wenn er eine Implementierung des UMAP-Algorithmus aus einer anderen Bibliothek als derjenigen verwendet, die wir in unserer heutigen Diskussion betrachten. Es ist zu erwarten, dass sich einzelne Implementierungen desselben Algorithmus in ihren numerischen Eigenschaften unterscheiden.
Erste Schritte in MQL5
Um den Ball ins Rollen zu bringen, werden wir quantitative Daten abrufen, die die aktuelle Kerze beschreiben. Wir wollen wissen, wie sich die Eröffnungs-, Höchst-, Tiefst- und Schlusskurse in einem bestimmten Zeitraum, in diesem Beispiel Horizont genannt, verändert haben. Darüber hinaus möchten wir das Wachstum vom Eröffnungskurs zum Hoch, Eröffnungskurs zum Tief und Eröffnungskurs zum Schlusskurs verfolgen. Wir wiederholen diese Wachstumsberechnung für jeden der 4 Preisströme, die uns in unserem MetaTrader 5 Terminal zur Verfügung stehen. Damit haben wir insgesamt 10 Spalten, ohne die ersten beiden Spalten, Zeit und True Close. Diese 10 Spalten können jedes Kerzenmuster beschreiben, z. B. Doji-Kerzen oder Hämmerchen. Unsere derzeitige Technik ist jedoch nicht geeignet, um Kerzenmuster zu erkennen, die von mehr als einer Kerze gebildet werden.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 24 //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " UMAP Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Close","Open","High","Low","Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Analysieren der Daten in Python
Unser Ziel ist ein zweifaches:
- Demonstrieren der Vorteile der Verwendung von UMAP-Transformationen anstelle der Verwendung von Preisdaten in ihrer ursprünglichen Form.
- Beschaffen einer Kopie des UMAP-Algorithmus mit Hilfe unserer Funktionsannäherungstechniken, damit wir die Wirksamkeit des Algorithmus überprüfen können.
Wir werden die Vorteile der Verwendung von UMAP gegenüber Preisdaten in ihrer ursprünglichen Form aufzeigen, um sicherzustellen, dass unsere Motivation klar ist und die Vorteile für den Leser offensichtlich sind. Nachdem wir die Vorteile des Einsatzes von UMAP aufgezeigt haben, werden wir die uns von der UMAP-Bibliothek zur Verfügung gestellten Transformationen verwenden, um unser erstes neuronales Netz zu trainieren, das die UMAP-Einbettungen von gegebenen Marktdaten schätzt.
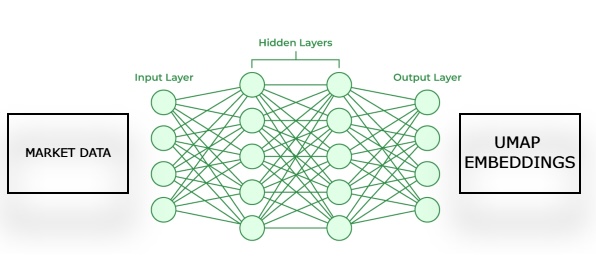
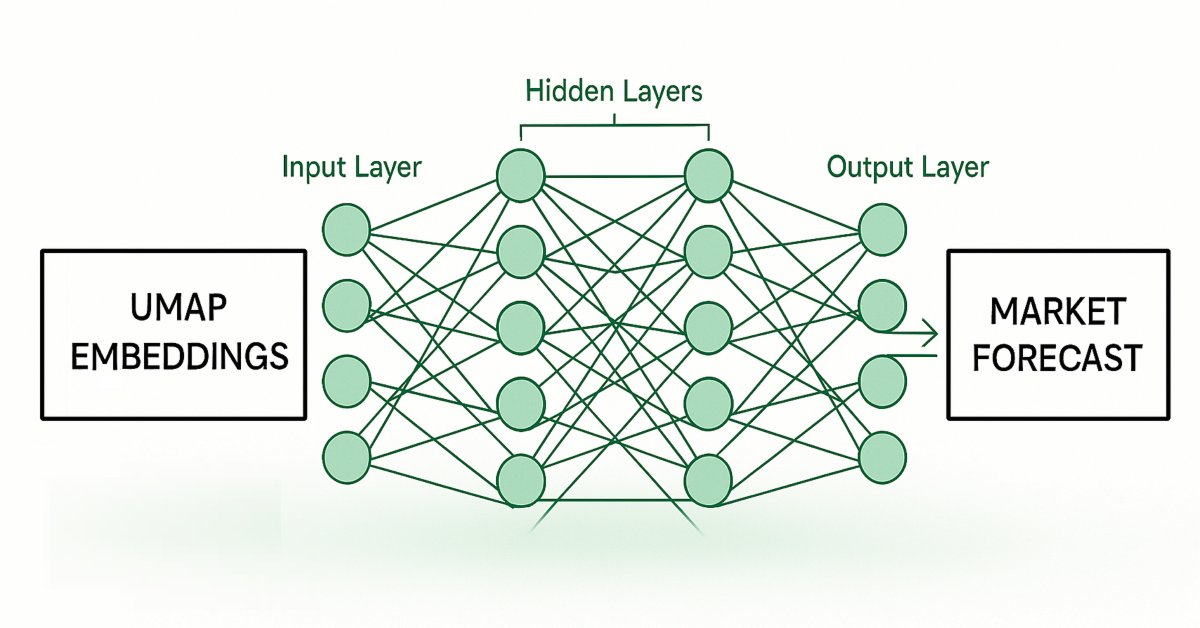
Abb. 2: Visualisierung unseres Rahmens für die Schätzung von UMAP-Einbettungen aus gegebenen Marktdaten.
Anschließend trainieren wir ein zweites Modell, das lernt, zukünftige Preisbewegungen auf dem Markt zu prognostizieren, und zwar auf der Grundlage einer Schätzung der UMAP-Einbettungen unseres ersten Modells. Unser Ziel ist es, dass diese beiden statistischen Modelle in einer Kette arbeiten. Das erste Modell schätzt UMAP-Einbettungen aus gegebenen Marktdaten, und das zweite Modell verwendet die Ergebnisse des ersten Modells, um die zukünftigen Renditen des von uns gehandelten Marktes zu prognostizieren. Dieser Rahmen wird sich als wesentlich schneller erweisen und möglicherweise genauso effektiv sein, wie wenn man den UMAP-Algorithmus von Grund auf neu implementiert.
Abb. 3: Visualisierung unseres Rahmens für die Erstellung einer Marktprognose aus unseren geschätzten UMAP-Einbettungen
Nachdem wir nun unsere Motivation und die Methodik, die wir verfolgen werden, erläutert haben, wollen wir mit Python beginnen. Wir beginnen mit dem Import der benötigten Bibliotheken. Die Leser müssen möglicherweise zuerst die UMAP-Bibliothek auf ihren Rechnern installieren, indem sie den Befehl „pip install umap-learn“ eingeben, wenn sie mitmachen wollen.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import umap import seaborn as sns
Danach, wenn der Leser bereit ist, uns zu folgen, werden wir im nächsten Schritt die Marktdaten einlesen, die wir mit unserem MQL5-Skript erzeugt haben.
HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1 data.dropna(inplace=True) data
Unsere Marktdaten wurden erfolgreich eingelesen, aber wenn Sie sich die Spalte Zeit ansehen, werden Sie feststellen, dass unsere CSV-Datei aktuelle Marktdaten enthält. Wir möchten die Marktdaten der letzten 5 Jahre aus unserer CSV-Datei entfernen, damit unser Backtest der Strategie nicht durch durchgesickerte Informationen verfälscht wird, die unserem Modell in der Vergangenheit nicht zur Verfügung standen.
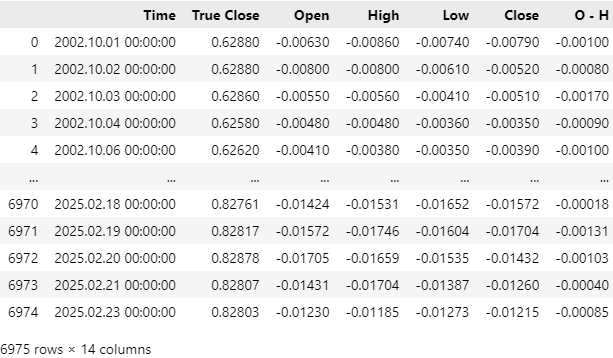
Abb. 4: Unsere historischen Marktdaten, die wir mit unserem MQL5-Skript abgerufen haben
Lassen Sie uns die Marktdaten der letzten 5 Jahre aus unserer CSV-Datei löschen. Beachten Sie, dass unser letztes Datum in der CSV-Datei jetzt der 16. Oktober 2019 ist. Unser Backtest wird ab dem 1. Januar 2020 laufen. Diese Lücke zwischen dem Ende unseres Trainingszeitraums und dem Beginn unseres Testzeitraums ist notwendig, um sicherzustellen, dass unsere Tests robust sind.
#Delete all the data that overlaps with our back test data = data.iloc[:(-(365 * 5) + (31 * 5)),:] data
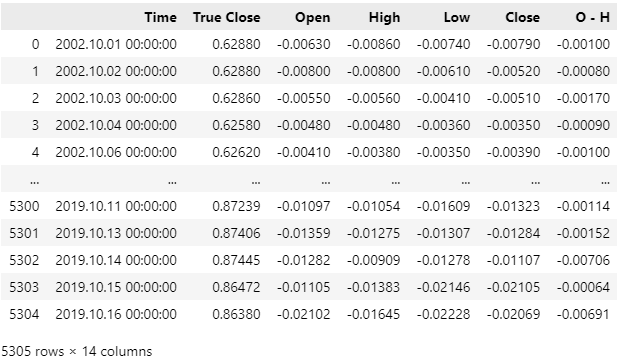
Abb. 5: Achten Sie darauf, alle Daten zu löschen, die sich mit dem Zeitraum überschneiden, den Sie zurücktesten möchten.
Veranschaulichen wir uns die Auswirkungen der Spalten, die wir für unsere Übung erstellt haben. Die Spalte „H - L“ stellt die Differenz zwischen dem Höchst- und dem Tiefstkurs des Tages dar. Dies ist die effektive Handelsspanne für jeden Tag. Die Spalte „O - C“ hingegen gibt die Nettopreisänderung für den Tag an. Indem wir ein Streudiagramm dieser beiden Spalten erstellen, wollen wir herausfinden, ob es eine Beziehung zwischen der Tagesspanne und der Nettoveränderung für den Tag gibt. Leider scheint die Beziehung kompliziert und nicht linear zu sein. Dies ist die Art von Daten, bei deren Analyse uns UMAP helfen kann.
sns.scatterplot(
data=data,
y='O - C',
x='H - L',
hue='Class'
)
plt.grid()
plt.title("Visualizing Our Custom Columns on EURUSD Market Data")
plt.axhline(0,color='black',linestyle='--')
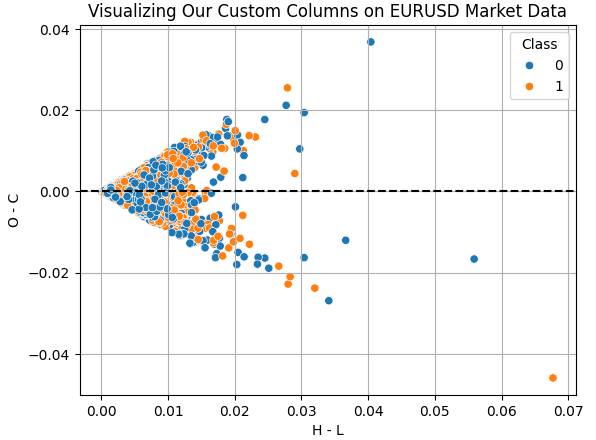
Abb. 6: Veranschaulichung des Verhältnisses zwischen der Handelsspanne und der Nettokursveränderung für denselben Tag
Die Anwendung der UMAP-Transformationen ist recht einfach. Zunächst müssen wir ein UMAP-Objekt erstellen. Anschließend passen wir das UMAP-Objekt an unsere Daten an und erhalten stattdessen transformierte Daten. Standardmäßig reduziert unser UMAP-Objekt die Daten auf 2 Spalten. Wir werden im weiteren Verlauf zeigen, wie Sie die gewünschte Anzahl von Spalten festlegen. Die 10 Spalten, die wir ursprünglich mit unserem MQL5-Skript abgerufen haben, wurden auf die 2 Dimensionen reduziert, die in Abbildung 7 zu sehen sind.
Im nachstehenden Codebeispiel werden bestimmte Abstimmungsparameter der UMAP-Bibliothek für den Leser sichtbar gemacht:
- n_neighbors: Dieser Abstimmungsparameter weist den Algorithmus an, wie viele Datenpunkte er versuchen soll, innerhalb derselben Nachbarschaft zu bleiben.
- metric: Es gibt verschiedene Messmethoden, um zu ermitteln, wie nah“ zwei Punkte beieinander liegen und ob sie als in derselben Gegend liegend gelten. Eine Änderung der Abstandsmetrik wird die Struktur der projizierten Daten erheblich verändern.
reducer = umap.UMAP(n_neighbors=100,metric="euclidean") embedding = reducer.fit_transform(data.iloc[:,2:-2]) embedding = pd.DataFrame(embedding,columns=['X1','X2']) embedding['Class'] = data['Class'] sns.scatterplot( data=embedding, x='X1', y='X2', hue='Class' ) plt.grid() plt.title("Visualizing the effects of UMAP on our EURUSD Market Data")
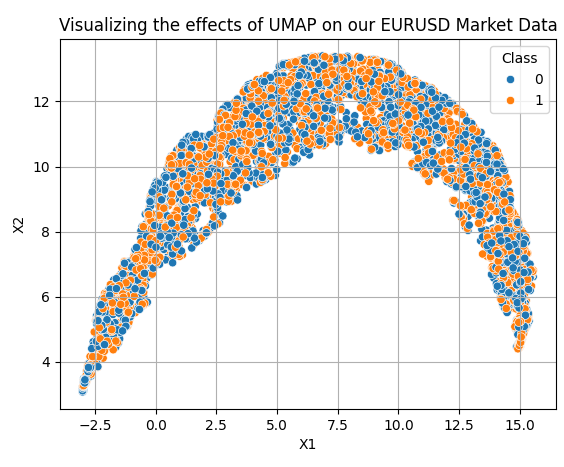
Abb. 7: Visualisierung unserer transformierten Daten nach Anwendung des UMAP-Algorithmus
Unsere neue Datendarstellung ist nicht perfekt. Es gibt jedoch Regionen, in denen orangefarbene Punkte dominieren, und andere, in denen blaue Punkte dominieren. Dies kann es unseren statistischen Modellen erleichtern, den Unterschied zwischen den beiden Klassen zu erkennen, die wir zu unterscheiden versuchen. Wir haben jedoch nur 2 Spalten willkürlich ausgewählt, um dem Leser einen Eindruck davon zu vermitteln, wie einfach der Einstieg ist. In Wahrheit wissen wir nicht, wie viele Dimensionen erforderlich sind, um die Daten effektiv zu transformieren. Daher werden wir eine Zeilensuche zwischen 1 und 9 durchführen. Die folgende Funktion nimmt einen Parameter entgegen, der die Anzahl der gewünschten Dimensionen angibt, und gibt die entsprechenden transformierten Daten an uns zurück.
def return_transformed_data(n_components): HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data.dropna(inplace=True) data = data.iloc[:(-(365 * 5) + (31 * 5)),:] reducer = umap.UMAP(n_neighbors=100,metric="euclidean",n_components=n_components,n_jobs=-1) embedding = reducer.fit_transform(data.iloc[:,2:-1]) cols = [] for i in np.arange(n_components): s = 'X' + ' ' + str(i) cols.append(s) embedding = pd.DataFrame(embedding,columns=cols) return embedding.copy()
Nun wollen wir unsere Modelle vorbereiten.
from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Wir definieren das geteilte Zeitreihenobjekt für eine geeignete Kreuzvalidierung der Zeitreihen.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Führen wir nun die Zeilensuche durch, um die optimale Anzahl der Dimensionen zu ermitteln, die für die Darstellung der Originaldaten erforderlich sind.
LEVELS = 8 res = pd.DataFrame(columns=['X'],index=np.arange(LEVELS)) for i in range(LEVELS): new_data = return_transformed_data(i+1) res.iloc[i,0] = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),new_data.iloc[:,0:],data['Target'],cv=tscv)))
Ermitteln wir noch den Mindestindex und den Mindestwert.
res['X'] = pd.to_numeric(res['X'], errors='coerce') min_value = min(res.iloc[:,0]) min_index = res['X'].idxmin()
Die besten Ergebnisse erzielten wir, wenn wir 3 Spalten zur Darstellung der ursprünglichen 10 verwendeten. Der Leser sollte verstehen, dass diese nicht als die 3 besten Säulen der 10, mit denen wir begonnen haben, angesehen werden sollen. Vielmehr wurden die 10 Spalten auf 3 reduziert,
plt.plot(res,color='black') plt.grid() plt.title('Finding The Optimal Number of U-MAP Components') plt.ylabel('RMSE Validation Error') plt.xlabel('Training Iteration') plt.scatter(min_index,min_value,color='red')
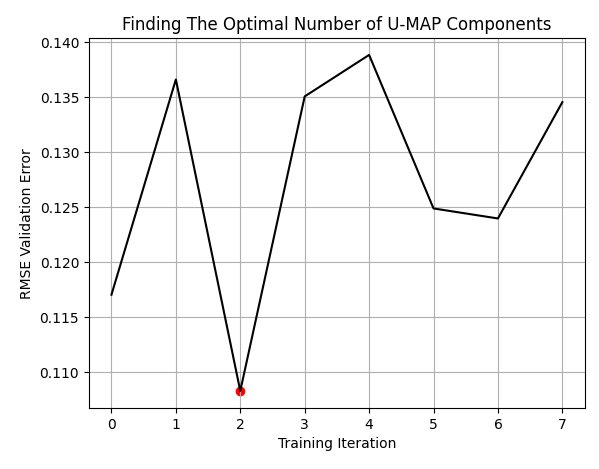
Abb. 8: Unsere optimale Anzahl von Spalten war 3, von den 10, mit denen wir begonnen hatten
Erfassen wir nun unsere Fehlerquote bei der Verwendung der Marktdaten in ihrer ursprünglichen Form.
classic_error = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),data.iloc[:,2:-2],data['Target'],cv=tscv)))
Wir werden nun den Fehler, der durch die Verwendung der transformierten UMAP-Daten entsteht, mit dem Fehler vergleichen, der durch die Verwendung der Marktdaten ohne jegliche Transformationen entsteht. Wie wir sehen können, hat die UMAP-Transformation unsere Fehlerquoten in optimale Bereiche gesenkt, die wir mit den Preisdaten in ihrer ursprünglichen Form nicht erreicht hätten.
results = [min(res.iloc[:,0]),classic_error] sns.barplot(results,color='black') plt.axhline(results[0],color='red',linestyle='--') plt.ylabel('RMSE Validation Error') plt.xlabel('0: UMAP Transformed Data | 1: Original OHLC Data') plt.title("UMAP Transformations Are Helping Us Reduce Our Error Rates")
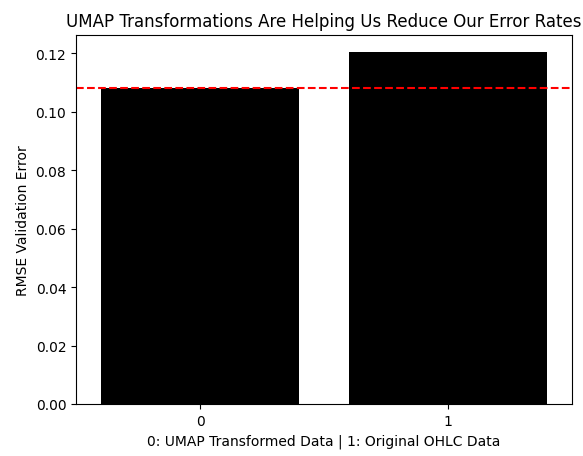
Abb. 9: Die UMAP-Transformation hat unsere Fehlerquote reduziert und übertrifft die Daten in ihrer ursprünglichen Form
Nachdem wir nun die Gründe für die Verwendung von UMAP-Transformationen dargelegt haben, können wir mit dem Aufbau der in Abb. 2 und 3 beschriebenen Architektur beginnen. Wir beginnen mit der Auswertung, wie viele Trainingsiterationen unser neuronales Netzwerk benötigt, um zu lernen, wie es unsere ursprünglichen Marktdaten effektiv in seine UMAP-Einbettungen umwandeln kann.
from sklearn.neural_network import MLPRegressor
Holen wir uns die gewünschten Daten.
new_data = return_transformed_data(3) Führen wir eine Zeilensuche durch, um die Beziehung zwischen dem Fehler des Modells und der Anzahl der erlaubten Trainingsepochen zu beobachten.
LEVELS = 18 NN_ERROR = pd.DataFrame(columns=['Error'],index=np.arange(LEVELS)) for i in range(LEVELS): model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=(2 ** i),solver='adam') NN_ERROR.iloc[i,0] = np.mean(np.abs(cross_val_score(model,new_data,data['Target'],cv=tscv)))
Stellen wir die Ergebnisse grafisch dar. Die besten Ergebnisse erzielten wir, wenn wir das Modell 65 536 Trainingsiterationen oder einfach 2 hoch 16 durchführen ließen.
NN_ERROR['Error'] = pd.to_numeric(NN_ERROR['Error'], errors='coerce') min_idx = NN_ERROR.idxmin() min_value = NN_ERROR.min() plt.plot(NN_ERROR,color='black') plt.grid() plt.ylabel('5 Fold CV RMSE') plt.xlabel('Max Iterations As Powers of 2') plt.scatter(min_idx,min_value,color='red') plt.title('Minimizing The Error of Our Neural Network')
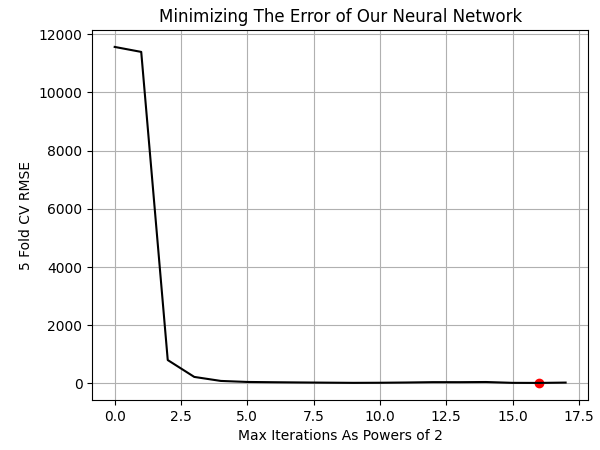
Abb. 10: Visualisierung der optimalen Anzahl von Trainingsiterationen unseres Modells, die zum Erlernen von UMAP-Einbettungen erforderlich sind
Jetzt können wir beide Modelle anpassen.
#The first model will transform the given market data into its UMAP embeddings umap_transform_model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') umap_transform_model.fit(data.iloc[:,2:-2],new_data) #The second model will forecast the future EURGBP returns, given UMAP embeddings forecast_model = MLPRegressor(hidden_layer_sizes=(new_data.shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') forecast_model.fit(new_data,data['Target'])
Bereiten wir den Export unserer Modelle in das ONNX-Format vor.
import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Das Modell, das für die Schätzung unserer UMAP-Einbettungen verantwortlich ist, hat eine einzigartige Eingabe- und Ausgabeform. Es nimmt 10 Parameter für seine Eingaben entgegen und gibt 3 Parameter für seine Ausgaben zurück. Wir werden dies mit Hilfe der initial_types und final_types aus der ONNX-API festlegen.
umap_transform_shape = [("float_input",FloatTensorType([1,data.iloc[:,2:-2].shape[1]]))] umap_transform_output_shape = [("float_output",FloatTensorType([new_data.shape[1],1]))]
Andererseits hat das Modell, das für die Vorhersage von Preisänderungen aus den gegebenen UMAP-Einbettungen verantwortlich ist, eine einfache Input- und Output-Form. Es nimmt die 3 Ausgaben des ersten Modells als Eingaben und gibt nur 1 Ausgabe aus.
forecast_shape = [("float_input",FloatTensorType([1,new_data.shape[1]]))]
Definieren wir die E/A-Formen der Modelle. Beachten Sie, dass wir einen zusätzlichen Schritt unternehmen müssen, um festzulegen, dass es sich bei dem ersten Modell um ein Multi-Output-Modell handelt, und dass wir dann die Form unseres Multi-Output-Modells angeben.
umap_model_proto = convert_sklearn(umap_transform_model,initial_types=umap_transform_shape,final_types=umap_transform_output_shape,target_opset=12) forecast_model_proto = convert_sklearn(forecast_model,initial_types=forecast_shape,target_opset=12)
Speichern wir die Modelle.
onnx.save(umap_model_proto,"EURGBP UMAP.onnx") onnx.save(forecast_model_proto,"EURGBP UMAP Forecast.onnx")
Erste Schritte in MQL5
Wir können nun mit dem Schreiben unseres MQL5-Codes beginnen, um die Rentabilität der UMAP-Regression zu testen. Wir erinnern daran, dass wir in Abb. 5 alle Daten von 2020 bis zur Gegenwart gelöscht haben. Daher gibt uns der Backtest, den wir heute durchführen werden, eine faire Vorstellung davon, wie unsere Strategie unter realen Bedingungen abschneiden wird, die sie noch nicht erlebt hat. Lassen Sie uns unsere ONNX-Modelle laden.
//+------------------------------------------------------------------+ //| UMAP Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP UMAP.onnx" as uchar umap_onnx_buffer[]; #resource "\\Files\\EURGBP UMAP Forecast.onnx" as uchar umap_forecast_onnx_buffer[];
Außerdem benötigen wir einige globale Variablen. Da unsere Strategie auf einem Algorithmus beruht, benötigen wir nicht so viele.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ long umap_onnx_model,umap_forecast_onnx_model; vectorf umap_onnx_output(3),umap_forecast_onnx_output(1); double trade_sl;
Definieren wir die Handles und Puffer für unsere technischen Indikatoren.
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
Wir laden die Handelsbibliothek.
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
Um den Code lesbar zu halten, haben wir uns dafür entschieden, jeder Ereignisbehandlung eine eigene Funktion zuzuweisen. Dies führt dazu, dass der Hauptteil unseres Programms von Anfang bis Ende leicht zu lesen ist. Wenn der Nutzer weitere Funktionen hinzufügen möchte, empfehle ich, dasselbe Designprinzip zu befolgen und das gewünschte Dienstprogramm in eine Methode zu verpacken und aus dem Hauptteil aufzurufen. Dadurch bleibt die Codebasis in einem Zustand, der viel einfacher zu pflegen ist als die Alternative, Hunderte von Codezeilen zu analysieren, die alle in einen Event-Handler verpackt sind.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- update(); } //+------------------------------------------------------------------+
Die Freigabefunktion räumt für unseren Expert Advisor auf, bevor er vollständig deaktiviert wird.
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Free up system memory | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handler); IndicatorRelease(ma_o_handler); OnnxRelease(umap_onnx_model); OnnxRelease(umap_forecast_onnx_model); }
Die Setup-Funktion ist für die Initialisierung unseres ONNX-Modells und anderer wichtiger Systemvariablen zuständig. Sie gibt einen booleschen Wert zurück, der false ist, wenn bei der Initialisierung ein Fehler aufgetreten ist. Andernfalls sollte die Funktion true zurückgeben. Die Formen der ONNX-Modelle sind als Ein- und Ausgänge gepaart, und ihre Aufrufe sind ebenfalls gepaart.
//+------------------------------------------------------------------+ //| Setup system variables | //+------------------------------------------------------------------+ bool setup(void) { umap_onnx_model = OnnxCreateFromBuffer(umap_onnx_buffer,ONNX_DATA_TYPE_FLOAT); umap_forecast_onnx_model = OnnxCreateFromBuffer(umap_forecast_onnx_buffer,ONNX_DATA_TYPE_FLOAT); ma_c_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_CLOSE); ma_o_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_OPEN); if(umap_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Transformer ONNX model"); return(false); } if(umap_forecast_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Forecast ONNX model"); return(false); } ulong umap_input_shape[] = { 1 , 10 }; ulong umap_forecast_input_shape[] = { 1 , 3 }; ulong umap_output_shape[] = { 3 , 1 }; ulong umap_forecast_output_shape[] = { 1 , 1 }; if(!OnnxSetInputShape(umap_onnx_model,0,umap_input_shape)) { Comment("Failed to specify ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetInputShape(umap_forecast_onnx_model,0,umap_forecast_input_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_onnx_model,0,umap_output_shape)) { Comment("Failed to specify ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_forecast_onnx_model,0,umap_forecast_output_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } trade_sl = 2e-2; return(true); }
Unsere Aktualisierungsfunktion wird uns dabei helfen, die Indikatorwerte in ihre Puffer zu kopieren und unsere Handelsroutinen regelmäßig, d.h. einmal am Tag, durchzuführen.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_CURRENT,0); if(current_time != time_stamp) { time_stamp = current_time; CopyBuffer(ma_c_handler,0,0,1,ma_c); CopyBuffer(ma_o_handler,0,0,1,ma_o); if(PositionsTotal() == 0) { GetModelForecast(); FindSetup(); } } }
Die Prognosefunktion wird benötigt, um unsere Prognosekette zu erhalten. Die erste Prognose ist eine Annäherung an die UMAP-Einbettung der ursprünglichen Marktdaten. Die zweite Prognose ist unser Handelssignal, die prognostizierte EURGBP-Marktrendite, die sich aus einer Annäherung an die UMAP-Einbettung ergibt.
//+------------------------------------------------------------------+ //| Get a forecast from our models | //+------------------------------------------------------------------+ void GetModelForecast(void) { vectorf model_inputs = GetUmapModelInputs(); OnnxRun(umap_onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,umap_onnx_output); OnnxRun(umap_forecast_onnx_model,ONNX_DATA_TYPE_FLOAT,umap_onnx_output,umap_forecast_onnx_output); Print("Model Inputs: \n",model_inputs); Print("Umap Transformer Forecast: \n",umap_onnx_output); Print("EURUSD Return UMAP Forecast: \n",umap_forecast_onnx_output); }
Bevor wir mit unserem Modell eine Prognose erstellen können, müssen wir seine Eingaben vorbereiten. Erinnern Sie sich daran, dass wir die Eingaben des ersten Modells vorbereiten müssen, und seine Ausgaben werden das zweite Modell speisen.
//+------------------------------------------------------------------+ //| Get our model's input data | //+------------------------------------------------------------------+ vectorf GetUmapModelInputs(void) { vectorf umap_model_inputs(10); umap_model_inputs[0] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iOpen(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[1] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[2] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[3] = (float)(iClose(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[4] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[5] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[6] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[7] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[8] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[9] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); return(umap_model_inputs); } //+------------------------------------------------------------------+
Wir erinnern daran, dass wir in den Abbildungen 4 und 5 alle historischen Daten gelöscht haben, die sich mit den in Abbildung 11 verwendeten Daten überschnitten. So können wir sehen, wie sich unser Modell wahrscheinlich verhält, wenn es mit Daten außerhalb der Stichprobe arbeitet, und es dient uns als echte Schätzung, wie profitabel die Strategie sein könnte.

Abb. 11: Unser Backtestzeitraum für die Bewertung unseres UMAP-Modellensembles
Wir werden nun die Bedingungen festlegen, unter denen die Strategie getestet werden soll. Um möglichst zuverlässige Ergebnisse zu erzielen, werden wir den Expert Advisor unter schwierigen Bedingungen einem Stresstest unterziehen, indem wir ihm eine zufällige Verzögerung zwischen seiner Auftragsausführung und der Ausführung des Auftrags im Backtest geben.

Abb. 12: Die Bedingungen, die wir oben simulieren, entsprechen realen Handelsszenarien
Im Journal unseres Strategietesters können wir sehen, dass die Eingaben für unsere ONNX-Modelle und die Kette der UMAP-Modelle gültige Ausgaben erzeugen. Das erste Modell reduzierte die 10 Inputs, die wir aus den Marktdaten ermittelt hatten, korrekt auf 3 Inputs, die anschließend zur Erstellung einer Marktprognose verwendet wurden.

Abb. 13: Unter der Haube scheint alles gut zu funktionieren
Unsere Kapitalkurve scheint uns ein positives Feedback über die Leistung unseres Systems zu geben. Dies ist ermutigend, denn wie der Leser wissen sollte, haben wir den UMAP-Algorithmus und seine Einbettungen nur angenähert.

Abb. 14: Unsere Strategie scheint bisher profitabel zu sein
Schauen wir uns die Leistung unserer Strategie genauer an. Unser System hat eine Sharpe Ratio von 0,42 mit einer erwarteten Auszahlung von 7,05, das sind positive Statistiken. Unser Anteil an gewinnbringenden Geschäften liegt bei 64 %, während wir insgesamt 25 Geschäfte platziert haben.

Abb. 15: Eine detaillierte Analyse unserer historischen Leistung mit Hilfe der UMAP-Regression
Im Durchschnitt wurde jeder unserer Handelsgeschäfte 1274 Stunden lang gehalten, was etwa 54 Tagen entspricht. Dies deutet darauf hin, dass unser Expert Advisor Markttrends aufspüren muss, denn unsere durchschnittliche Positionsdauer liegt bei 54 Tagen.

Abb. 16: Visualisierung der Verteilung unserer Handelsdauern
Bei der Überprüfung des Backtests stellten wir fest, dass der Expert Advisor tatsächlich anhaltende Markttrends auffing. Im folgenden Screenshot stellen die vertikalen weißen Linien Zeiträume von 1 Tag dar, und die beobachteten Trades wurden von unserem UMAP Regression EA während seines Backtests platziert. Wir können feststellen, dass die erste im April 2020 eröffnet und im darauffolgenden Monat, im Mai, geschlossen wurde. Der anschließende Handel dauerte von Ende Mai bis Anfang September.
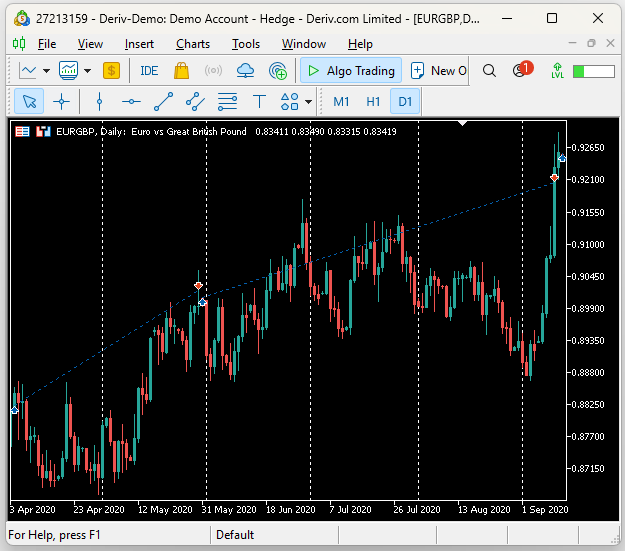
Abb. 17: Visualisierung der von unserem Expert Advisor platzierten Handelsgeschäfte
Schlussfolgerung
In diesem Artikel haben wir gezeigt, wie der Leser Techniken zur Dimensionenreduzierung einsetzen kann, um seinem statistischen Modell zu helfen, die vorherrschenden Marktmerkmale in den ihm vorliegenden Daten zu lernen. Wir haben gezeigt, dass der UMAP-Algorithmus unsere Fehlerquoten bei der Verwendung von statistischen Modellen um bis zu 40 % senken kann, verglichen mit einem identischen Modell, das auf den ursprünglichen Marktdaten ohne UMAP-Transformationen trainiert wurde. Schließlich hat der Leser einen neuen Rahmen kennen gelernt, der es ihm ermöglicht, Algorithmen, die er nicht selbst implementieren kann, sicher zu approximieren. Dies sollte Ihnen einen Wettbewerbsvorteil auf jedem Markt verschaffen, auf dem Sie handeln möchten. | Dateiname | Beschreibung |
|---|---|
| EURGBP UMAP Forecast.onnx | ONNX-Datei, die unsere approximierten UMAP-Embeddings als Input verwendet, um die zukünftige EURGBP-Rendite zu prognostizieren. |
| EURGBP UMAP.onnx | Die ONNX-Datei ist für die Eingabe unserer Marktdaten und die Approximation der korrekten UMAP-Einbettungen zuständig. |
| UMAP Candlestick Recognition.ipynb | Das Jupyter-Notebook, das wir für die Analyse unserer MetaTraer 5-Marktdaten und die Erstellung unserer ONNX-Dateien verwendet haben. |
| UMAP Candlestick Recognition.mq5 | Die MQL5-Skriptdatei, die wir zum Abrufen unserer detaillierten Marktdaten erstellt haben. |
| UMAP Regression.mq5 | Der Expert Advisor, den wir für den Handel mit dem EURGBP unter Verwendung unserer Zwei-Modell-Architektur entwickelt haben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/17631
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Vielen Dank, dies ist eine wirklich interessante Anwendung. Ein paar Dinge, die helfen können Fehlermodul 'umap' hat kein Attribut 'UMAP' Sie brauchen umap-learninstalled , können Sie dies mit einer Zeile !pip install umap-learn. wenn Sie NameError: name 'FloatTensorType' ist nicht definiert müssen Sie installieren oder aktualisieren onnixxmltools über !pip install onnxmltools. Meine Daten haben sich sehr von den hier gezeigten Daten unterschieden. Ich wäre daran interessiert, wie alle anderen mit dem Code zurechtkommen.
I want EA for MT5 and use Exness broker