
Neuronale Netze im Handel: Kontrollierte Segmentierung (letzter Teil)

Einführung
Im vorigen Artikel haben wir die Methode RefMask3D vorgestellt, die für eine umfassende Analyse multimodaler Interaktionen und das Verständnis der Merkmale der betrachteten Punktwolke entwickelt wurde. RefMask3D ist ein umfassendes Framework, das mehrere Module umfasst:
- Ein Punktcodierer mit integriertem Geometrie-verstärktem Gruppen-Wort-Aufmerksamkeitsmodul. Dieses Modul führt in jeder Phase der Merkmalskodierung eine kreuz-modale Aufmerksamkeit zwischen der natürlichsprachlichen Beschreibung des Objekts und lokalen Punktgruppen (Teilwolken) durch. Die von den Autoren vorgeschlagene Blockarchitektur reduziert die Auswirkungen des Rauschens, das bei direkten Korrelationen zwischen Punkten und Wörtern auftritt, und wandelt gleichzeitig interne geometrische Beziehungen in eine verfeinerte Punktwolkenstruktur um. Dadurch wird die Fähigkeit des Modells, sowohl mit linguistischen als auch mit geometrischen Daten zu interagieren, erheblich verbessert.
- Ein Sprachmodell, das die textliche Beschreibung des Zielobjekts in eine Token-Struktur umwandelt, die vom Modell zur Identifizierung des Objekts verwendet wird.
- Eine Reihe trainierbarer linguistischer Primitive (Linguistic Primitives Construction - LPC), die verschiedene semantische Attribute wie Form, Farbe, Größe, Beziehungen, Ort usw. darstellen können. Bei der Interaktion mit einem bestimmten sprachlichen Input erhalten diese Primitive die entsprechenden Attribute.
- Ein Decoder auf Basis eines Transformers, der den Fokus des Modells auf verschiedene semantische Informationen innerhalb der Punktwolke verstärkt und damit die Fähigkeit zur genauen Lokalisierung und Identifizierung des Zielobjekts erheblich verbessert.
- Ein Object Cluster Module - OCM sammelt ganzheitliche Informationen und erzeugt Objekteinbettungen.
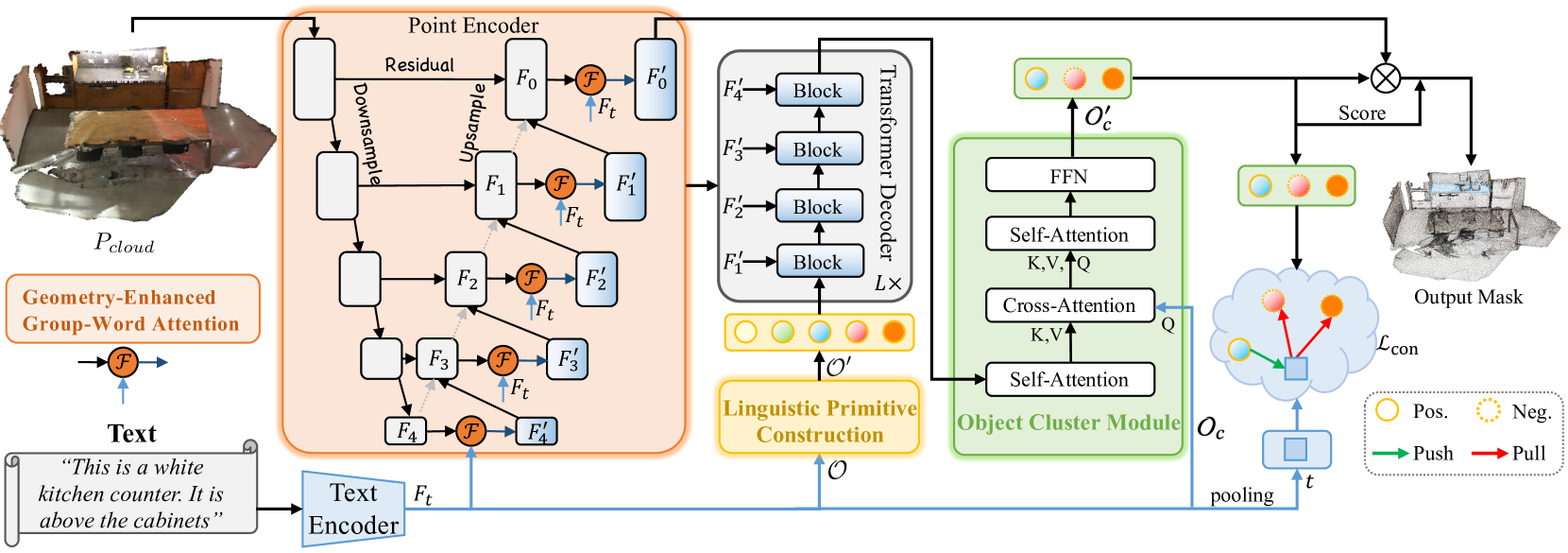
Im vorigen Artikel hatten wir bereits einen großen Teil der Implementierung des Frameworks abgeschlossen. Insbesondere haben wir die Module Geometry-Enhanced Group-Word Attention (erweiterte Geometrie von Wortgruppenaufmerksamkeit) und Linguistic Primitives Construction (Konstruktion sprachlicher Primitive) in ihren jeweiligen Klassen implementiert. Wir haben auch festgestellt, dass die Funktionsweise des Decoders durch bestehende Implementierungen verschiedener Kreuzaufmerksamkeits-Blöcke abgedeckt werden könnte. Wir sind bei der Entwicklung der Algorithmen für das Object Cluster Module stehen geblieben. Hier werden wir unsere Arbeit fortsetzen.
1. Implementierung des Objektcluster-Moduls
Wie bereits erwähnt, dient das Objektcluster-Modul dazu, ganzheitliche Informationen zu aggregieren und Objekteinbettungen zu erzeugen. Die Originalvisualisierung des Moduls finden Sie unten.
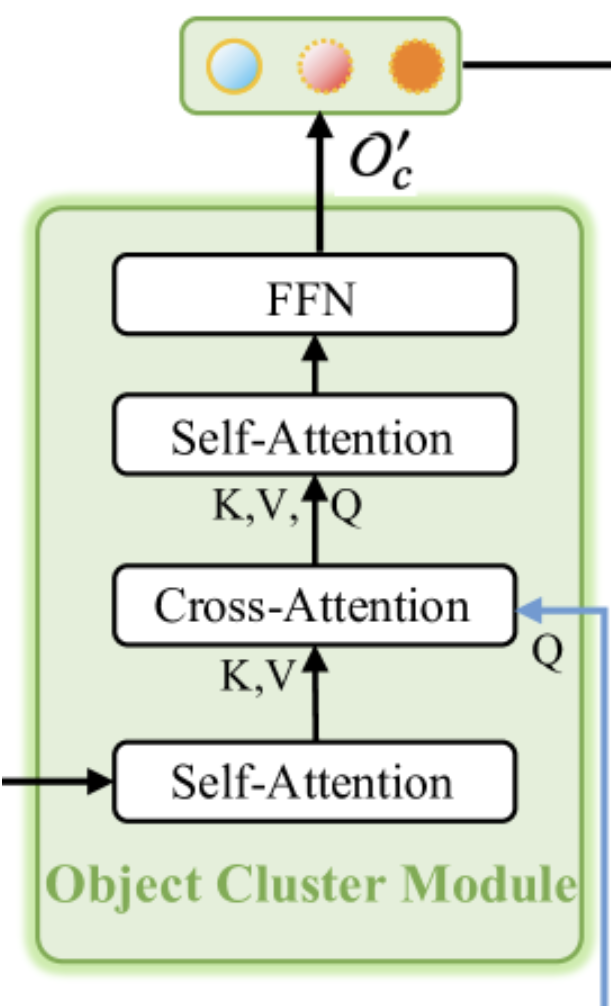
Wie aus der Visualisierung ersichtlich ist, besteht das Objektcluster-Modul aus zwei Blöcken der Selbstaufmerksamkeit, einem dazwischen liegenden Block der Kreuzaufmerksamkeit und einem FFN-Block am Ausgang, der als vollständig verbundenes MLP implementiert ist. Diese Architektur kann unterschiedliche Assoziationen hervorrufen. Einerseits ähnelt er einem normalen Transformer-Decoder mit einem zusätzlichen Selbstaufmerksamkeits-Block hinter dem Kreuzaufmerksamkeits-Block. Zu beachten ist jedoch die geänderte Funktionalität des Kreuzaufmerksamkeits-Blocks. In diesem Zusammenhang bietet sich die Methode SPFormer an. Bei einer solchen Interpretation dient der erste Selbstaufmerksamkeits-Block als Merkmalsextraktionsmodul für Punktdarstellungen.
Allerdings kann die vorgestellte architektonische Lösung auch als kompakte Version eines normalen Transformers betrachtet werden. Er verfügt über einen „beschnittenen“ Encoder, bei dem der FeedForward-Block wegfällt, und einen Decoder mit neu angeordneten Blöcken der Kreuzaufmerksamkeit und Selbstaufmerksamkeit. Diese Struktur macht das Modul zweifellos zu einem komplexen und integralen Bestandteil des gesamten RefMask3D-Rahmens, dessen Bedeutung durch die von den Autoren vorgelegten experimentellen Ergebnisse bestätigt wird. Durch die Einbeziehung des Objektcluster-Moduls wird die Modellleistung um 1,57 % verbessert.
Das Modul wird von zwei Quellen gespeist. Zunächst durchläuft die Ausgabe des Decoders, die mit Informationen über die analysierte Punktwolke angereicherte primitive Einbettungen enthält, den anfänglichen Selbstaufmerksamkeits-Block und dient als Kontext für den nachfolgenden Kreuzaufmerksamkeits-Block. Die primäre Informationsquelle für den Kreuzaufmerksamkeits-Block ist die Einbettung der textlichen Beschreibung des Zielobjekts. Diese Einbettungen werden verwendet, um die Abfragekomponenten des Kreuzaufmerksamkeits-Blocks zu bilden. Der Ausgang des Kreuzaufmerksamkeits-Blocks wird in den zweiten Block der Selbstaufmerksamkeit und dem FeedForward-Block eingegeben.
Der oben beschriebene Algorithmus ist in der Klasse CNeuronOCM implementiert, deren Struktur im Folgenden skizziert wird.
class CNeuronOCM : public CNeuronBaseOCL { protected: uint iPrimWindow; uint iPrimUnits; uint iPrimHeads; uint iContWindow; uint iContUnits; uint iContHeads; uint iWindowKey; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cMHAttentionOut; CLayer cAttentionOut; CArrayInt cScores; CLayer cResidual; CLayer cFeedForward; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } public: CNeuronOCM(void) {}; ~CNeuronOCM(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronOCM; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); virtual bool updateInputWeights(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context); //--- virtual uint GetPrimitiveWindow(void) const { return iPrimWindow; } virtual uint GetContextWindow(void) const { return iContWindow; } };
Die Kernfunktionalität der neuronalen Schicht wird von der vollständig verknüpften CNeuronBaseOCL abgeleitet, die wir als übergeordnete Klasse verwenden werden.
In der zuvor vorgestellten Struktur der neuen Klasse können wir eine vertraute Reihe von überschriebenen Methoden sowie eine Reihe von deklarierten internen Objekten und Variablen beobachten. Wir werden ihre Funktionsweise während der Implementierung der Methode im Detail untersuchen. Wichtig ist, dass alle internen Objekte als statisch deklariert wurden. Das bedeutet, dass wir den Konstruktor und den Destruktor der Klasse leer lassen können. Die Initialisierung dieser deklarierten und abgeleiteten, internen Objekte wird in der Methode Init durchgeführt. Wie Sie wissen, erhalten wir in den Parametern der angegebenen Methode eine Reihe von Konstanten, die uns eine eindeutige Interpretation der Architektur des erstellten Objekts ermöglichen.
bool CNeuronOCM::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint prim_window, uint window_key, uint prim_units, uint prim_heads, uint cont_window, uint cont_units, uint cont_heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cont_window * cont_units, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir zunächst die gleichnamige Methode der übergeordneten Klasse auf. Diese Methode implementiert bereits die Algorithmen für die minimal erforderliche Validierung der empfangenen Parameter und die Initialisierung der geerbten Objekte. Wir überwachen den Erfolg der Ausführung der übergeordneten Methode, indem wir den von ihr zurückgegebenen booleschen Wert überprüfen.
Nach erfolgreicher Ausführung der Methode der übergeordneten Klasse speichern wir die Werte der erhaltenen Konstanten in den internen Variablen unserer Klasse.
iPrimWindow = prim_window; iPrimUnits = prim_units; iPrimHeads = prim_heads; iContWindow = cont_window; iContUnits = cont_units; iContHeads = cont_heads; iWindowKey = window_key;
Als Nächstes werden die dynamischen Arrays, die mit internen Objekten verbunden sind, gelöscht.
cQuery.Clear(); cKey.Clear(); cValue.Clear(); cMHAttentionOut.Clear(); cAttentionOut.Clear(); cResidual.Clear(); cFeedForward.Clear();
Danach geht es an die Initialisierung der Komponenten der internen Blöcke. Nach dem zuvor beschriebenen Algorithmus ist der erste Block, der initialisiert wird, der Selbstaufmerksamkeits-Block, der für die Analyse der Abhängigkeiten zwischen den Primitiven zuständig ist.
An dieser Stelle sei daran erinnert, dass der Input für dieses Modul aus Primitiven besteht, die im Decoder mit Informationen über die analysierte Punktwolke angereichert wurden. Daher besteht die Aufgabe dieses Selbstaufmerksamkeits-Blocks darin, die Primitive zu identifizieren, die für die gegebene Punktwolke relevant sind.
Wir beginnen mit der Erstellung der Generatorobjekte Query, Key und Value. Für die Erzeugung aller drei Entitäten verwenden wir Faltungsschichten mit identischen Parametern. Die Zeiger auf diese initialisierten Objekte werden zu dynamischen Arrays hinzugefügt, die entsprechend den erzeugten Entitäten benannt werden.
CNeuronBaseOCL *neuron = NULL; CNeuronConvOCL *conv = NULL; //--- Primitives Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 0, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 2, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Als Nächstes fügen wir eine vollständig verknüpfte Schicht hinzu, um die Ausgabe der mehrköpfigen Aufmerksamkeit zu erfassen.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, iPrimHeads * iWindowKey * iPrimUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Wir verwenden eine Faltungsschicht, um die Ergebnisse der mehrköpfigen Aufmerksamkeit auf die Größe des ursprünglichen Datentensors zu skalieren.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 4, OpenCL, iPrimHeads * iWindowKey, iPrimHeads * iWindowKey, iPrimWindow, iPrimUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Der Block Selbstaufmerksamkeit wird durch eine vollständig vernetzte Schicht von Residual-Verbindungen ergänzt.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Sie sehen, dass die Struktur der oben vorgestellten Aufmerksamkeitsblock-Objekte universell ist. Es kann sowohl für Selbstaufmerksamkeits- als auch für Kreuzaufmerksamkeits-Blocks verwendet werden. Um den Algorithmus des nachfolgenden Kreuzaufmerksamkeits-Blocks zu implementieren, werden wir daher ähnliche Objekte erstellen und Zeiger auf sie in dieselben dynamischen Arrays einfügen. Der einzige Unterschied besteht in den Datenquellen für die Erstellung der Entitäten von Query, Key und Value. Bei der Erstellung der Entitäten Query werden Kontextinformationen als Input verwendet.
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 6, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false;
Um die Entitäten von Key und Value zu generieren, verwenden wir die Ergebnisse des vorangegangenen Blocks der Selbstaufmerksamkeit. Hier haben wir eine Tensorgröße, die identisch mit den lernbaren Primitiven ist.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 7, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 8, OpenCL, iPrimWindow, iPrimWindow, iPrimHeads * iWindowKey, iPrimUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Dann fügen wir eine Schicht von mehrköpfigen Aufmerksamkeitsergebnissen hinzu.
//--- Multi-Heads Cross-Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 9, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Fügen Sie eine Faltungsskalierungsschicht hinzu.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 10, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Der Kreuzaufmerksamkeits-Block wird durch eine Schicht der Residual-Verbindungensschicht ergänzt.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 11, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Im nächsten Schritt erstellen wir einen zusätzlichen Block der Selbstaufmerksamkeit. Dieser wird für die Analyse der kontextuellen Abhängigkeiten verwendet. Wir wiederholen den Prozess der Erstellung der entsprechenden aufmerksamkeitsbezogenen Objekte und fügen Zeiger auf diese neu erstellten Objekte in dieselben dynamischen Arrays ein, die wir zuvor verwendet haben. In diesem Fall werden jedoch alle Entitäten auf der Grundlage der Ausgabe des Kreuzaufmerksamkeits-Blocks erzeugt. Folglich hat der Eingabetensor nun die Dimensionalität des analysierten Kontexts.
//--- Context Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 12, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cQuery.Add(conv) ) return false; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 13, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cKey.Add(conv) ) return false; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 14, OpenCL, iContWindow, iContWindow, iContHeads * iWindowKey, iContUnits, 1, optimization, iBatch) || !cValue.Add(conv) ) return false;
Wir fügen eine Ebene mit mehrköpfigen Aufmerksamkeitsergebnissen hinzu.
//--- Multi-Heads Attention Out neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 15, OpenCL, iContHeads * iWindowKey * iContUnits, optimization, iBatch) || !cMHAttentionOut.Add(neuron) ) return false;
Daran schließt sich eine Faltungsskalierungsschicht an.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 16, OpenCL, iContHeads * iWindowKey, iContHeads * iWindowKey, iContWindow, iContUnits, 1, optimization, iBatch) || !cAttentionOut.Add(conv) ) return false;
Die letzte ist wiederum die Residual-Verbindungsschicht.
//--- Residual neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 17, OpenCL, conv.Neurons(), optimization, iBatch) || !cResidual.Add(neuron) ) return false;
Jetzt müssen wir die Blockobjekte von FeedForward hinzufügen. Ähnlich wie beim normalen Transformer verwenden wir in diesem Block 2 Faltungsschichten mit einer Aktivierungsfunktion LReLU dazwischen.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 18, OpenCL, iContWindow, iContWindow, 4 * iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false; conv.SetActivationFunction(LReLU); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 19, OpenCL, 4*iContWindow, 4*iContWindow, iContWindow, iContUnits, 1, optimization, iBatch) || !cFeedForward.Add(conv) ) return false;
In diesem Fall werden wir unsere von der übergeordneten Klasse geerbten Klassenpuffer als Residual-Verbindungsschicht verwenden. Wir organisieren jedoch die Ersetzung von Zeigern auf Fehlergradientenpuffer, um Datenkopiervorgänge zu reduzieren.
if(!SetGradient(conv.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Am Ende der Methode geben wir dem aufrufenden Programm einen booleschen Wert zurück, der den Erfolg der Operationen anzeigt.
Es ist wichtig zu beachten, dass wir keine Datenpufferobjekte für die Speicherung von Aufmerksamkeitskoeffizienten erstellt haben. Diese Puffer werden ausschließlich im OpenCL-Kontext instanziiert. Ihre Erstellung wurde in eine separate Methode CreateBuffers verlagert, die Sie sich bitte in der beigefügten Anlage selbst ansehen.
Nachdem wir die Initialisierungsmethode für das Objekt abgeschlossen haben, gehen wir zur Implementierung der Algorithmen der Vorwärtsdurchläufe über. Sie werden in der Methode feedForward definiert. Hier ist eine leichte Abweichung von der üblichen Struktur der Vorwärtsdurchlauf-Methoden, die in unseren früheren Implementierungen verwendet wurden, zu bemerken. Während wir normalerweise einen Zeiger auf ein Objekt der neuronalen Schicht als primäre Eingabe und einen Zeiger auf den Datenpuffer als sekundäre Eingabe übergeben, verwenden wir in diesem Fall Objekte der neuronalen Schicht für beide Eingaben. In diesem Stadium ist eine solche Implementierung jedoch nur für interne Komponenten anwendbar, die beim Aufbau der Algorithmen des übergeordneten Objekts der neuronalen Schicht verwendet werden. Für unsere derzeitigen Zwecke ist dies durchaus akzeptabel.
bool CNeuronOCM::feedForward(CNeuronBaseOCL *Primitives, CNeuronBaseOCL *Context) { CNeuronBaseOCL *neuron = NULL, *q = cQuery[0], *k = cKey[0], *v = cValue[0];
Im Hauptteil der Methode werden zunächst mehrere lokale Variablen deklariert, um Zeiger auf Objekte der neuronalen Schicht vorübergehend zu speichern. Diesen Variablen werden sofort Zeiger auf die Entity-Generierungskomponenten für den ersten Aufmerksamkeitsblock zugewiesen. Anschließend überprüfen wir die Gültigkeit der Zeiger und generieren die erforderlichen Entitäten aus dem Tensor der vom externen Programm erhaltenen Primitive.
if(!q || !k || !v) return false; if(!q.FeedForward(Primitives) || !k.FeedForward(Primitives) || !v.FeedForward(Primitives) ) return false;
Wir leiten die erhaltenen Entitäten an den mehrköpfigen Aufmerksamkeitsblock zur Abhängigkeitsanalyse weiter.
if(!AttentionOut(q, k, v, cScores[0], cMHAttentionOut[0], iPrimUnits, iPrimHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Wir skalieren die erhaltenen Ergebnisse und summieren sie mit den entsprechenden Eingabedaten. Danach normalisieren wir die Ergebnisse.
neuron = cAttentionOut[0]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[0]) ) return false; v = cResidual[0]; if(!v || !SumAndNormilize(Primitives.getOutput(), neuron.getOutput(), v.getOutput(), iPrimWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Als Eingabe für den ersten Selbstaufmerksamkeits-Block haben wir die Primitive mit Informationen über die analysierte Punktwolke angereichert. In diesem Block haben wir außerdem interne Abhängigkeiten eingeführt. Das Ziel dieses Schrittes ist es, die für die analysierte Szene wichtigsten Primitive hervorzuheben. Dieser Schritt ist im Wesentlichen mit der Durchführung einer Segmentierung der Punktwolke vergleichbar. In unserem Fall geht es jedoch darum, das Zielobjekt zu finden, das durch einen textuellen Ausdruck beschrieben wird. Deshalb gehen wir zur nächsten Stufe über - Kreuzaufmerksamkeit. Hier gleichen wir die Einbettungen der textlichen Beschreibung des Zielobjekts mit den Primitiven ab, die mit der analysierten Punktwolke verbunden sind. Um dies zu erreichen, rufen wir aus unseren Objekt-Arrays die neuronalen Schichten ab, die für die Erzeugung von Kreuzaufmerksamkeits-Entitäten verantwortlich sind. Wir überprüfen die Gültigkeit der erhaltenen Zeiger. Und wir erzeugen die erforderlichen Entitäten.
//--- Cross-Attention q = cQuery[1]; k = cKey[1]; v = cValue[1]; if(!q || !k || !v) return false; if(!q.FeedForward(Context) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Ich möchte Sie daran erinnern, dass die Entität Query aus den Einbettungen der Zielobjektbeschreibung generiert wird. Die Entitäten Schlüssel und Wert werden aus der Ausgabe des vorangegangenen Selbstaufmerksamkeits-Blocks erzeugt. Als Nächstes werden wir den Mechanismus der mehrköpfigen Aufmerksamkeit anwenden.
if(!AttentionOut(q, k, v, cScores[1], cMHAttentionOut[1], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Anschließend skalieren wir die erzielten Ergebnisse und ergänzen sie durch Residual-Verbindungen.
neuron = cAttentionOut[1]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[1]) ) return false; v = cResidual[1]; if(!v || !SumAndNormilize(Context.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Es ist wichtig zu beachten, dass wir den ursprünglichen Kontexttensor als Residual-Verbindung verwenden. Die Ergebnisse der Summierung der beiden Tensoren werden über die einzelnen Sequenzelemente normiert.
Am Ausgang des Kreuzaufmerksamkeits-Blocks erwarten wir Einbettungen der Beschreibung des Zielobjekts, angereichert mit Informationen aus der analysierten Punktwolke. Mit anderen Worten: Unser Ziel ist es, diejenigen Einbettungen der Zielobjektbeschreibung „hervorzuheben“, die für die zu analysierende Szene relevant sind.
Beachten Sie, dass wir in diesem Stadium keinen direkten Vergleich zwischen der analysierten Punktwolke und der Beschreibung des Zielobjekts durchführen. In früheren Phasen des Systems RefMask3D haben wir jedoch bereits Primitive aus der ursprünglichen Punktwolke extrahiert. Im Kreuzaufmerksamkeits-Block identifizieren wir anhand der Beschreibung des Zielobjekts die Primitive, die in der Punktwolke gefunden wurden. Dann fahren wir fort, ein „kohärentes Bild“ zu konstruieren, indem wir die ausgewählten Einbettungen durch gegenseitige Interaktionen im anschließenden Block Selbstaufmerksamkeit anreichern.
Wie zuvor rufen wir die nächsten Entity-Generationsebenen aus den internen dynamischen Arrays ab und validieren die erhaltenen Zeiger.
//--- Context Self-Attention q = cQuery[2]; k = cKey[2]; v = cValue[2]; if(!q || !k || !v) return false;
Danach erzeugen wir die Entitäten Query, Key und Value. In diesem Fall sind die Eingabedaten für die Generierung aller Entitäten die Ausgabe des vorherigen Kreuzaufmerksamkeits-Blocks.
if(!q.FeedForward(neuron) || !k.FeedForward(neuron) || !v.FeedForward(neuron) ) return false;
Wir verwenden auch den Algorithmus der mehrköpfigen Aufmerksamkeit, um Abhängigkeiten in der analysierten Datenfolge zu erkennen.
if(!AttentionOut(q, k, v, cScores[2], cMHAttentionOut[2], iContUnits, iContHeads, iPrimUnits, iPrimHeads, iWindowKey)) return false;
Wir skalieren die erzielten Ergebnisse und fügen Residual-Verbindungen mit anschließender Datennormalisierung hinzu.
q = cAttentionOut[1]; if(!q || !q.FeedForward(cMHAttentionOut[2]) ) return false; v = cResidual[2]; if(!v || !SumAndNormilize(q.getOutput(), neuron.getOutput(), v.getOutput(), iContWindow, true, 0, 0, 0, 1) ) return false; neuron = v;
Und dann müssen wir den angereicherten Kontext-Tensor durch den FeedForward-Block propagieren. Wir fügen den erhaltenen Ergebnissen Beziehungen der Residuen hinzu und normalisieren die Daten. Wir schreiben die erhaltenen Werte in den Ergebnispuffer unserer CNeuronOCM-Klasse. Dieses Objekt wurde von einer übergeordneten Klasse geerbt.
//--- Feed Forward q = cFeedForward[0]; k = cFeedForward[1]; if(!q || !k || !q.FeedForward(neuron) || !k.FeedForward(q) || !SumAndNormilize(neuron.getOutput(), k.getOutput(), Output, iContWindow, true, 0, 0, 0, 1) ) return false; //--- return true; }
Am Ende der Vorwärtsdurchlauf-Methode müssen wir lediglich das boolesche Ergebnis der Operationen an das aufrufende Programm zurückgeben.
Sobald die Implementierung der Vorwärtsdurchlauf-Methoden abgeschlossen ist, fahren wir mit der Organisation der Prozesse des Rückwärtsdurchläufe fort. Wie üblich ist die Funktion des Rückwärtsdurchlaufs in zwei Stufen unterteilt: Verteilung der Fehlergradienten auf alle Elemente entsprechend ihrem Einfluss auf die Gesamtleistung des Modells und Optimierung der lernbaren Parameter. Dementsprechend werden wir für jede Stufe eine eigene Methode entwickeln: calcInputGradients und updateInputWeights. Bei der ersten Methode werden die Vorgänge des Vorwärtsdurchlaufs vollständig umgekehrt. Im zweiten Fall rufen wir einfach nacheinander die gleichnamigen Methoden in den internen Objekten auf, die trainierbare Parameter enthalten. Ich möchte Sie ermutigen, die Algorithmen für diese Methoden selbst zu erforschen. Der vollständige Code dieser Klasse und alle ihre Methoden sind in den beigefügten Dateien enthalten.
2. Aufbau des Rahmens von RefMask3D
Wir haben die Arbeit an der Implementierung der einzelnen Module des Frameworks von RefMask3D abgeschlossen, und nun ist es an der Zeit, alles zu einem einheitlichen Objekt zusammenzufügen und die einzelnen Blöcke in eine gut strukturierte Architektur zu integrieren. Um diese Aufgabe zu erfüllen, wird eine neue Klasse CNeuronRefMask geschaffen, deren Struktur im Folgenden dargestellt wird.
class CNeuronRefMask : public CNeuronBaseOCL { protected: CNeuronGEGWA cGEGWA; CLayer cContentEncoder; CLayer cBackGround; CNeuronLPC cLPC; CLayer cDecoder; CNeuronOCM cOCM; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRefMask(void) {}; ~CNeuronRefMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRefMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
In der oben dargestellten Struktur sind die Module, die wir zuvor implementiert haben, leicht zu erkennen. Daneben gibt es jedoch auch dynamische Array-Objekte, deren Funktionsweise wir in der Phase der Methodenimplementierung der neuen Klasse erkunden werden.
Alle Objekte werden statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse „leer“ lassen können. Die Initialisierung dieser deklarierten und geerbten Objekte wird in der Methode Init durchgeführt.
Wie Sie wissen, liefern die Parameter dieser Methode Konstanten, die es uns ermöglichen, die Architektur des zu erstellenden Objekts eindeutig zu identifizieren. Die Komplexität und die Menge der internen Objekte führen jedoch zu einer hohen architektonischen Variabilität. Dies wiederum erhöht die Anzahl der erforderlichen beschreibenden Parameter. Unserer Ansicht nach würde eine übermäßige Anzahl von Parametern die Verwendung der Klasse nur erschweren. Daher haben wir uns dafür entschieden, die Parameter der internen Objekte zu vereinheitlichen und so die Anzahl der externen Eingaben deutlich zu reduzieren. Das bedeutet, dass die Initialisierungsmethode nur Konstanten beibehalten sollte, die die Parameter der Ein- und Ausgabedaten definieren. Soweit möglich, werden die internen Objekte die externen Datenparameter wiederverwenden. So wird beispielsweise die Fenstergröße für ein einzelnes Sequenzelement nur für die Eingabedaten angegeben. Der gleiche Parameter wird aber auch für die Erzeugung von Einbettungen der lernbaren Primitive und als Einbettungsgröße für den Kontext verwendet. Für die Tensorkonstruktion reicht es also aus, die Sequenzlängen für die Primitive und den Kontext festzulegen.
bool CNeuronRefMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint content_size, uint content_units, uint primitive_units, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * content_units, optimization_type, batch)) return false;
Die erste Operation innerhalb der Methode ist wie üblich der Aufruf der gleichnamigen Methode der Elternklasse, die bereits die minimale Validierungslogik für die empfangenen Parameter und die Initialisierung der geerbten Objekte enthält. Danach fahren wir mit der Initialisierung der deklarierten Objekte fort. Wir beginnen mit der Initialisierung des Punktwolken-Codierers unter Verwendung des zuvor implementierten Moduls: Geometry-Enhanced Group-Word Attention.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.Init(0, 0, OpenCL, window, window_key, heads, units_count, window, heads, (content_units + 3), 2, layers, optimization, iBatch)) return false; cGEGWA.AddNeckGradient(true);
Achten Sie bitte auf die folgenden beiden Momente. Zunächst fügen wir bei der Angabe der Sequenzlänge des Kontexts 3 Elemente zur Einbettungsgröße der Zielobjektbeschreibung hinzu. Wie bei der vorherigen Implementierung wird keine textuelle Beschreibung des Zielobjekts bereitgestellt. Stattdessen werden wir eine Reihe von Token aus dem Vektor generieren, der den aktuellen Kontostand und die offenen Positionen beschreibt. Der Grundgedanke ist derselbe: Die Erzeugung mehrerer unterschiedlicher Token aus einer einzigen Kontostandsbeschreibung ermöglicht eine umfassendere Analyse der aktuellen Marktsituation. Wir sind uns jedoch bewusst, dass die Eingabedaten Rauschen und Ausreißer enthalten können. Um ihren Einfluss abzuschwächen, führen wir drei zusätzliche lernbare Token ein, um irrelevante Werte zu akkumulieren. Im Wesentlichen handelt es sich dabei um eine Art „Hintergrund“-Token, wie von den Autoren des Rahmens RefMask3D vorgeschlagen.
Unser Punktcodierer verwendet auf jeder Stufe zweischichtige Aufmerksamkeitsblöcke. Der Parameter layers, den wir vom externen Programm erhalten, gibt die Anzahl der Einbettungen innerhalb des „Halses“ unseres U-förmigen Moduls an.
Außerdem aktivieren wir die Funktion der Gradientensummierung für die Halsmodule.
Anschließend gehen wir zum Kontext-Encoder über. Ф für dieses Modul wurde kein separater Block erstellt. Sie sind jedoch bereits mit seiner Architektur vertraut. Er bildet den Encoder zur Verfeinerung von Ausdrücken in der Methode 3D-GRES. Der Prozess beginnt mit der Erstellung einer vollständig verknüpften Schicht, die den Vektor speichert, der den aktuellen Kontostand darstellt.
//--- Content Encoder cContentEncoder.Clear(); cContentEncoder.SetOpenCL(OpenCL); CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * content_units, 1, OpenCL, content_size, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Dann fügen wir eine voll verknüpfte Schicht hinzu, um eine bestimmte Anzahl von Einbettungen in der erforderlichen Größe zu erzeugen.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 2, OpenCL, window * content_units, optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Hier fügen wir eine weitere Ebene hinzu, in die wir den verketteten Tensor aus Kontext- und „Hintergrund“-Token schreiben werden.
neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 3, OpenCL, window * (content_units + 3), optimization, iBatch) || !cContentEncoder.Add(neuron) ) return false;
Der nächste Schritt ist die Erstellung eines Modells zur Erzeugung eines Tensors von lernbaren Hintergrund-Token. Auch hier verwenden wir einen zweischichtigen MLP. Die erste Ebene ist statisch und enthält „1“. Die zweite Schicht erzeugt einen Tensor der gewünschten Größe auf der Grundlage der lernbaren Parameter.
//--- Background cBackGround.Clear(); cBackGround.SetOpenCL(OpenCL); neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(window * 3, 4, OpenCL, content_size, optimization, iBatch) || !cBackGround.Add(neuron) ) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, 5, OpenCL, window * 3, optimization, iBatch) || !cBackGround.Add(neuron) ) return false;
Dann fügen wir das Modul für linguistische Primitive hinzu.
//--- Linguistic Primitive Construction if(!cLPC.Init(0, 6, OpenCL, window, window_key, heads, heads, primitive_units, content_units, 2, 1, optimization, iBatch)) return false;
Darauf folgt ein Decoder. Hier haben wir eine leichte Abweichung von der von den Autoren der ursprünglichen Methode vorgeschlagenen Architektur vorgenommen: Wir haben die Decoder-Schichten des normalenTransformers durch das zuvor entwickelte Object-Cluster-Modul ersetzt. Wir haben die Gemeinsamkeiten und Unterschiede zwischen diesen Modulen bereits früher erörtert. Und wir hoffen, dass dieser Ansatz die Effizienz des resultierenden Modells weiter verbessern wird.
Es ist auch erwähnenswert, dass gemäß der von den Autoren vorgeschlagenen Struktur von RefMask3D jede Decoderschicht eine Abhängigkeitsanalyse mit einer entsprechenden Schicht des U-förmigen Punkt-Encoders durchführt. Um diesen Ansatz zu verwirklichen, organisieren wir eine Schleife, die nacheinander die entsprechenden Objekte extrahiert.
//--- Decoder cDecoder.Clear(); cDecoder.SetOpenCL(OpenCL); CNeuronOCM *ocm = new CNeuronOCM(); if(!ocm || !ocm.Init(0, 7, OpenCL, window, window_key, units_count, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; for(uint i = 0; i < layers; i++) { neuron = cGEGWA.GetInsideLayer(i); ocm = new CNeuronOCM(); if(!ocm || !neuron || !ocm.Init(0, i + 8, OpenCL, window, window_key, neuron.Neurons() / window, heads, window, primitive_units, heads, optimization, iBatch) || !cDecoder.Add(ocm) ) return false; }
Jetzt müssen wir nur noch das Objektcluster-Modul initialisieren.
//--- Object Cluster Module if(!cOCM.Init(0, layers + 8, OpenCL, window, window_key, primitive_units, heads, window, content_units, heads, optimization, iBatch)) return false;
Dann ersetzen wir Zeiger durch Datenpuffer, wodurch wir die Anzahl der Kopiervorgänge reduzieren können.
if(!SetOutput(cOCM.getOutput()) || !SetGradient(cOCM.getGradient()) ) return false; //--- return true; }
Am Ende der Methode geben wir dem aufrufenden Programm einen booleschen Wert zurück, der den Erfolg der Operationen anzeigt. Damit ist der Aufbau der Methode zur Initialisierung des Klassenobjekts abgeschlossen, und wir können mit der Organisation der Algorithmen der Vorwärtsdurchläufe fortfahren, die wir in der Methode feedForward implementieren. In den Parametern dieser Methode erhalten wir Zeiger auf zwei Objekte mit den ursprünglichen Daten. Der erste wird als Zeiger auf ein Objekt der neuronalen Schicht dargestellt, der zweite ist ein Datenpuffer. Nach diesem Schema haben wir die Schnittstellen in unserem Basismodell organisiert.
bool CNeuronRefMask::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
Im Hauptteil der Methode prüfen wir die Relevanz des empfangenen Zeigers auf die zweite Quelle der Ausgangsdaten und ersetzen den Zeiger gegebenenfalls durch den Ergebnispuffer in der ersten Schicht des Context Encoders.
//--- Context Encoder CNeuronBaseOCL *context = cContentEncoder[0]; if(context.getOutput() != SecondInput) { if(!context.SetOutput(SecondInput, true)) return false; }
Anschließend erzeugen wir auf der Grundlage der bereitgestellten Daten eine Kontexteinbettung.
int content_total = cContentEncoder.Total(); for(int i = 1; i < content_total - 1; i++) { context = cContentEncoder[i]; if(!context || !context.FeedForward(cContentEncoder[i - 1]) ) return false; }
Man beachte, dass die Vorwärtsdurchlauf-Operationen mit der Erzeugung der Kontexteinbettung beginnen. Der Punktcodierer verwendet diese Informationen als zweite Quelle von Ausgangsdaten.
Als Nächstes erzeugen wir einen Tensor von Hintergrund-Tokens.
//--- Background Encoder CNeuronBaseOCL *background = NULL; if(bTrain) { for(int i = 1; i < cBackGround.Total(); i++) { background = cBackGround[i]; if(!background || !background.FeedForward(cBackGround[i - 1]) ) return false; } } else { background = cBackGround[cBackGround.Total() - 1]; if(!background) return false; }
Und wir verketten ihn mit dem Kontext-Einbettungstensor.
CNeuronBaseOCL *neuron = cContentEncoder[content_total - 1]; if(!neuron || !Concat(context.getOutput(), background.getOutput(), neuron.getOutput(), context.Neurons(), background.Neurons(), 1)) return false;
Als Nächstes übertragen wir den verketteten Tensor zusammen mit dem Zeiger auf die erste Quelle von Ausgangsdaten, die wir von einem externen Programm erhalten haben, an unseren Punktcodierer.
//--- Geometry-Enhaced Group-Word Attention if(!cGEGWA.FeedForward(NeuronOCL, neuron.getOutput())) return false;
Darüber hinaus übergeben wir die Kontexteinbettung an das Modul zur Generierung linguistischer Primitive. Nur in diesem Fall verwenden wir einen Tensor ohne Hintergrund-Token.
//--- Linguistic Primitive Construction if(!cLPC.FeedForward(context)) return false;
Es sollte vielleicht angemerkt werden, dass Hintergrund-Token nur im Punkt-Encoder verwendet werden, um Rauschen und Ausreißer herauszufiltern.
In diesem Stadium haben wir bereits die Tensoren der Einbettungen der sprachlichen Primitive und der ursprünglichen Punktwolke gebildet. Der nächste Schritt besteht darin, sie in unserem Decoder abzugleichen, was dazu beiträgt, die in der analysierten Szene enthaltenen sprachlichen Primitive zu identifizieren. Hier bilden wir zunächst die Ergebnisse des Punktkodierers auf unsere Primitive ab.
//--- Decoder CNeuronOCM *decoder = cDecoder[0]; if(!decoder.feedForward(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Dann reichern wir die Einbettungen der linguistischen Primitive mit Zwischenergebnissen des Punktkodierers an. Zu diesem Zweck erstellen wir eine Schleife, in der wir nacheinander die nachfolgenden Schichten des Decoders und die entsprechenden Objekte des Punktcodierers mit anschließendem Datenvergleich extrahieren.
for(int i = 1; i < cDecoder.Total(); i++) { decoder = cDecoder[i]; if(!decoder.feedForward(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; }
Wir leiten die Decoderergebnisse durch das Objektcluster-Modul.
//--- Object Cluster Module if(!cOCM.feedForward(decoder, context)) return false; //--- return true; }
Danach schließen wir die Ausführung der Vorwärtsdurchlauf-Methode ab, indem wir das logische Ergebnis der Operationen an das aufrufende Programm zurückgeben.
Es ist erwähnenswert, dass der implementierte Algorithmus keine exakte Nachbildung des ursprünglichen Rahm3ns von RefMask3D ist. Im ursprünglichen Algorithmus werden die Ausgaben des Punktcodierers zusätzlich mit der Ausgabe des Objektclustermoduls multipliziert, und es gibt einen Kopf, der die Wahrscheinlichkeit der Zuordnung von Punkten zu bestimmten Objekten bestimmt. Der Grund für diese „Beschneidung“ des Algorithmus liegt in der Unterschiedlichkeit der zu lösenden Aufgaben. Wir benötigen keine visuelle Segmentierung einzelner Objekte innerhalb der analysierten Szene. Um eine Entscheidung über die Durchführung einer Handelsoperation zu treffen, reicht es aus, das Vorhandensein der gewünschten Muster und deren Parameter zu kennen. Daher haben wir beschlossen, den vorgeschlagenen Rahmen in dieser Form umzusetzen. Seine Betriebsergebnisse werden mit Hilfe des Akteursmodells analysiert.
Lassen Sie uns vorwärts gehen. Nach der Implementierung der Vorwärtsdurchlauf-Algorithmen entwickeln wir die Methoden für den Rückwärtsdurchlauf-Prozess. An dieser Stelle sollten ein paar Worte über die Methode calcInputGradients zur Verteilung von Fehlergradienten gesagt werden. Wie üblich werden bei dieser Methode die Operationen der Vorwärtsdurchläufe vollständig invertiert. Es ist jedoch wichtig zu beachten, dass wir während des Vorwärtsdurchlaufs eine Reihe von Entitäten erzeugen, die eine entscheidende Rolle für die Effektivität des Modells spielen. Dazu gehören trainierbare Primitive, Kontexteinbettungen und Hintergrund-Token. Natürlich wollen wir eine möglichst große Vielfalt dieser Einheiten generieren, um einen möglichst großen Bereich der beobachteten Marktszene abzudecken. Während wir diese Funktionalität bereits im Modul zur Erzeugung linguistischer Primitive implementiert haben, muss sie für die anderen Entitäten noch entwickelt werden. Daher schlage ich vor, dass Sie sich ein paar Minuten Zeit nehmen, um den Algorithmus zu studieren, mit dem die Methode der Fehlergradientenverteilung erstellt wurde.
bool CNeuronRefMask::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient) return false;
Die Methode erhält drei Parameter: den Zeiger auf ein Objekt der neuronalen Schicht und zwei Datenpuffer. Wie Sie wissen, enthält das Objekt der neuronalen Schicht Puffer für die Ergebnisse der ersten Quelle und Fehlergradienten. Für die zweite Datenquelle erhalten wir jedoch separate Puffer für die Eingangsdaten und die entsprechenden Fehlergradienten. Zusätzlich wird ein Zeiger auf die Aktivierungsfunktion für die zweite Datenquelle angegeben.
Innerhalb des Methodenkörpers überprüfen wir sofort die Gültigkeit der Zeiger für die erste Datenquelle und den Fehlergradienten der zweiten. Das Fehlen eines gültigen Zeigers auf den Eingangsdatenpuffer der zweiten Quelle ist nicht kritisch, da der überprüfte Zeiger während des Vorwärtsdurchlaufs erhalten blieb.
Falls erforderlich, ersetzen wir dann den Fehlergradientenpuffer innerhalb unseres internen Objekts für die zweite Datenquelle.
CNeuronBaseOCL *neuron = cContentEncoder[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) { if(!neuron.SetGradient(SecondGradient)) return false; neuron.SetActivationFunction(SecondActivation); }
Damit sind die vorbereitenden Arbeiten abgeschlossen, und wir gehen zu den eigentlichen Operationen der Fehlergradientenverteilung über.
Dank der bei der Objektinitialisierung durchgeführten Zeigersubstitution wird der von der nachfolgenden Schicht empfangene Fehlergradient direkt in den Puffer des Objektclustermoduls geschrieben. Um also unnötiges Kopieren von Daten zu vermeiden, beginnen wir die Operationen mit der Verteilung des Fehlergradienten durch das Objekt OCM.
//--- Object Cluster Module CNeuronBaseOCL *context = cContentEncoder[cContentEncoder.Total() - 2]; if(!cOCM.calcInputGradients(cDecoder[cDecoder.Total() - 1], context)) return false;
Beachten Sie, dass wir in diesem Fall den Gradienten an die letzte Decoderschicht und die vorletzte Kontext-Encoderschicht weitergeben. Der Grund dafür ist, dass die letzte Kontextencoder-Schicht einen verketteten Tensor der Kontexteinbettungen und Hintergrund-Token enthält, der nur vom Punkt-Encoder verwendet wird.
Als Nächstes propagieren wir den Fehlergradienten durch den Decoder. Um dies zu erreichen, organisieren wir eine umgekehrte Schleife, die über die Decoderschichten iteriert.
//--- Decoder CNeuronOCM *decoder = NULL; for(int i = cDecoder.Total() - 1; i > 0; i--) { decoder = cDecoder[i]; if(!decoder.calcInputGradients(cGEGWA.GetInsideLayer(i - 1), cDecoder[i - 1])) return false; } decoder = cDecoder[0]; if(!decoder.calcInputGradients(GetPointer(cGEGWA), GetPointer(cLPC))) return false;
Bitte beachten Sie, dass wir während des Prozesses der Verteilung des Fehlergradienten den Gradienten an die internen Schichten des Punktcodierers weitergeben. Genau um diese Werte zu erhalten, haben wir zuvor den Algorithmus zur Summierung der Fehlergradienten für die Halsobjekte eingeführt.
Die zweite Datenquelle für den Decoder ist das Modul zur Erzeugung von LPC-Primitiven. Der hier ermittelte Fehlergradient wird auf das interne Modul zur Erzeugung von Primitiven und die Kontexteinbettung ohne Hintergrund-Token verteilt. Der letztgenannte Puffer enthält jedoch bereits Daten aus früheren Vorgängen. Daher ersetzen wir vorübergehend den Zeiger auf den Gradientenpuffer für die Kontexteinbettung durch einen ungenutzten Puffer, der von der übergeordneten Klasse geerbt wurde. Erst dann rufen wir die Methode der Fehlergradientenverteilung des Moduls LPC auf. Anschließend addieren wir die Werte der beiden Datenpuffer.
//--- Linguistic Primitive Construction CBufferFloat *context_grad = context.getGradient(); if(!context.SetGradient(PrevOutput, false)) return false; if(!cLPC.FeedForward(context) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) ) return false;
Als Nächstes propagieren wir den Fehlergradienten durch den Punktencoder. Dieses Mal verteilen wir den Fehlergradienten zwischen der ersten Quelle von Originaldaten und der Kontext-Einbettung mit Hintergrund-Token.
//--- Geometry-Enhaced Group-Word Attention neuron = cContentEncoder[cContentEncoder.Total() - 1]; if(!neuron || !NeuronOCL.calcHiddenGradients((CObject*)GetPointer(cGEGWA), neuron.getOutput(), neuron.getGradient(), (ENUM_ACTIVATION)neuron.Activation())) return false;
Es ist wichtig zu beachten, dass wir sowohl die Kontext- als auch die Hintergrund-Token gemeinsam diversifizieren müssen. Wie Sie sehen können, gehören Hintergrund-Token und der Kontext zum selben Unterraum. Außerdem müssen wir nicht nur die Kontext- und Hintergrund-Token diversifizieren, sondern auch eine klare Unterscheidung zwischen diesen Entitäten treffen. Daher fügen wir zunächst einen Diversifikationsfehler zum verketteten Tensor von Kontext und Hintergrund hinzu.
if(!DiversityLoss(neuron, cOCM.GetContextWindow(), neuron.Neurons() / cOCM.GetContextWindow(), true)) return false; CNeuronBaseOCL *background = cBackGround[cBackGround.Total() - 1]; if(!background || !DeConcat(context.getGradient(), background.getGradient(), neuron.getGradient(), context.Neurons(), background.Neurons(), 1) || !DeActivation(context.getOutput(), context.getGradient(), context.getGradient(), context.Activation()) || !SumAndNormilize(context_grad, context.getGradient(), context_grad, 1, false, 0, 0, 0, 1) || !context.SetGradient(context_grad, false) ) return false;
Anschließend wird der resultierende Fehlergradient auf die entsprechenden Puffer dieser Einheiten verteilt. Wir passen den Kontextgradienten an, indem wir die Ableitung der Aktivierungsfunktion anwenden und die daraus resultierenden Werte zu den zuvor akkumulierten Werten addieren. Danach stellen wir den Zeiger auf den entsprechenden Datenpuffer wieder her. Von diesem Punkt aus können wir den Fehlergradienten bis zur zweiten Datenquelle fortschreiben.
//--- Context Encoder for(int i = cContentEncoder.Total() - 3; i >= 0; i--) { context = cContentEncoder[i]; if(!context || !context.calcHiddenGradients(cContentEncoder[i + 1]) ) return false; }
Erinnern Sie sich daran, dass der Zeiger auf den Fehlergradientenpuffer bereits im entsprechenden internen neuronalen Schichtobjekt gespeichert wurde. Dadurch wird das explizite Kopieren von Daten zwischen Puffern überflüssig.
In diesem Stadium haben wir den Fehlergradienten auf beide Datenquellen und fast alle internen Komponenten übertragen. „Beinahe“ - denn der letzte Schritt besteht darin, den Fehlergradienten durch das Modell zur Generierung von Hintergrund-Token zu verteilen. Wir passen den zuvor erhaltenen Gradienten mithilfe der Ableitung der Aktivierungsfunktion an und starten eine umgekehrte Iterationsschleife über die MLP-Schichten.
//--- Background if(!DeActivation(background.getOutput(), background.getGradient(), background.getGradient(), background.Activation())) return false; for(int i = cBackGround.Total() - 2; i > 0; i--) { background = cBackGround[i]; if(!background || !background.calcHiddenGradients(cBackGround[i + 1]) ) return false; } //--- return true; }
Und schließlich geben wir am Ende der Gradientenverteilungsmethode ein logisches Ergebnis an das aufrufende Programm zurück, das den Erfolg der Operation anzeigt.
Damit schließen wir unsere Diskussion über die Algorithmen der Rahmenimplementierung von RefMask3D ab. Den vollständigen Quellcode für alle vorgestellten Klassen und ihre Methoden finden Sie im Anhang. In diesem Anhang finden Sie auch die Architekturen der trainierten Modelle und alle Programme, die bei der Erstellung dieses Artikels verwendet wurden.
An den Modellarchitekturen wurden nur geringfügige Anpassungen vorgenommen, insbesondere die Änderung einer einzigen Schicht im Encoder, die für die Beschreibung des Umgebungszustands verantwortlich ist. Die Interaktions- und Schulungsprogramme wurden ohne Änderungen aus früheren Arbeiten übernommen. Daher werden wir sie hier nicht wieder aufgreifen und stattdessen zum letzten Teil unseres Artikels übergehen - dem Training der Modelle und der Bewertung ihrer Leistung.
3. Tests
Wie bereits erwähnt, hatten die Änderungen an der Modellarchitektur keine Auswirkungen auf die Struktur der Eingabedaten oder die Ausgabeergebnisse. Das bedeutet, dass wir den zuvor gesammelten Trainingsdatensatz für das anfängliche Modelltraining wiederverwenden können. Erinnern Sie sich, dass wir reale historische Daten des EURUSD-Instruments für das gesamte Jahr 2023 im H1-Zeitrahmen verwenden. Alle Indikatorparameter wurden auf ihre Standardwerte gesetzt.
Das Modelltraining wird offline durchgeführt. Um jedoch die Relevanz des Trainingsdatensatzes aufrechtzuerhalten, aktualisieren wir ihn regelmäßig, indem wir neue Episoden auf der Grundlage der aktuellen Politik des Akteurs hinzufügen. Das Modelltraining und die Aktualisierung der Datensätze werden wiederholt, bis die gewünschte Leistung erreicht ist.
Während der Vorbereitung dieses Artikels haben wir eine recht interessante Akteurspolitik entwickelt. Die Ergebnisse der Tests mit historischen Daten vom Januar 2024 werden im Folgenden dargestellt.
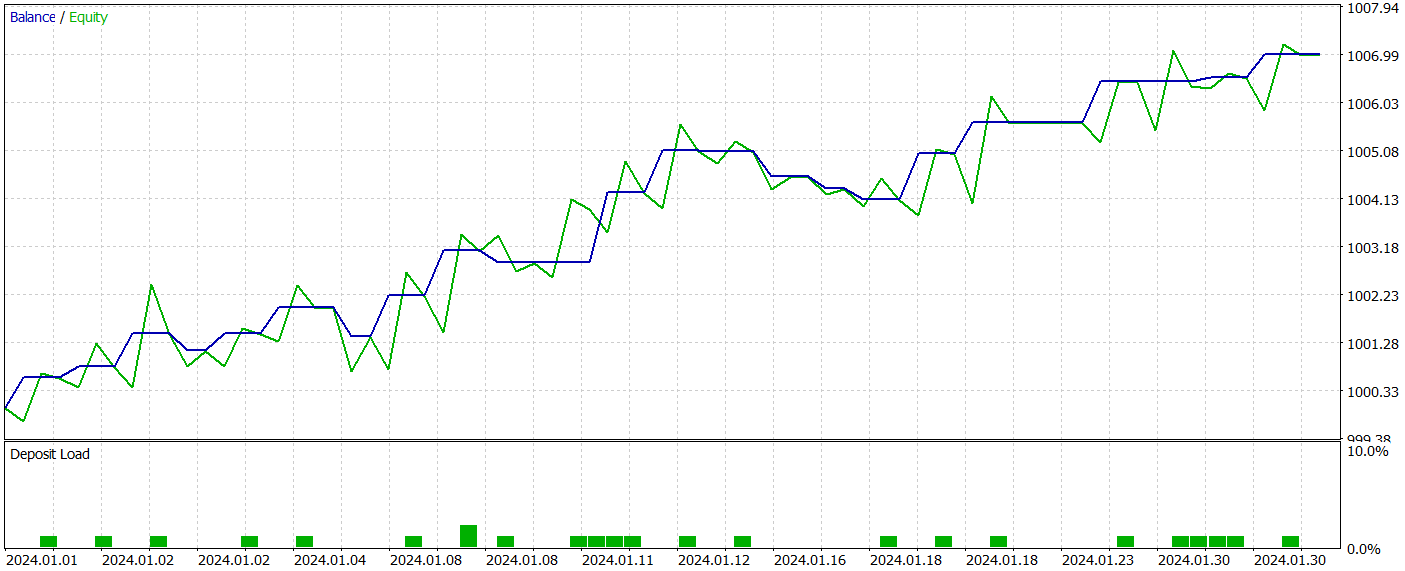
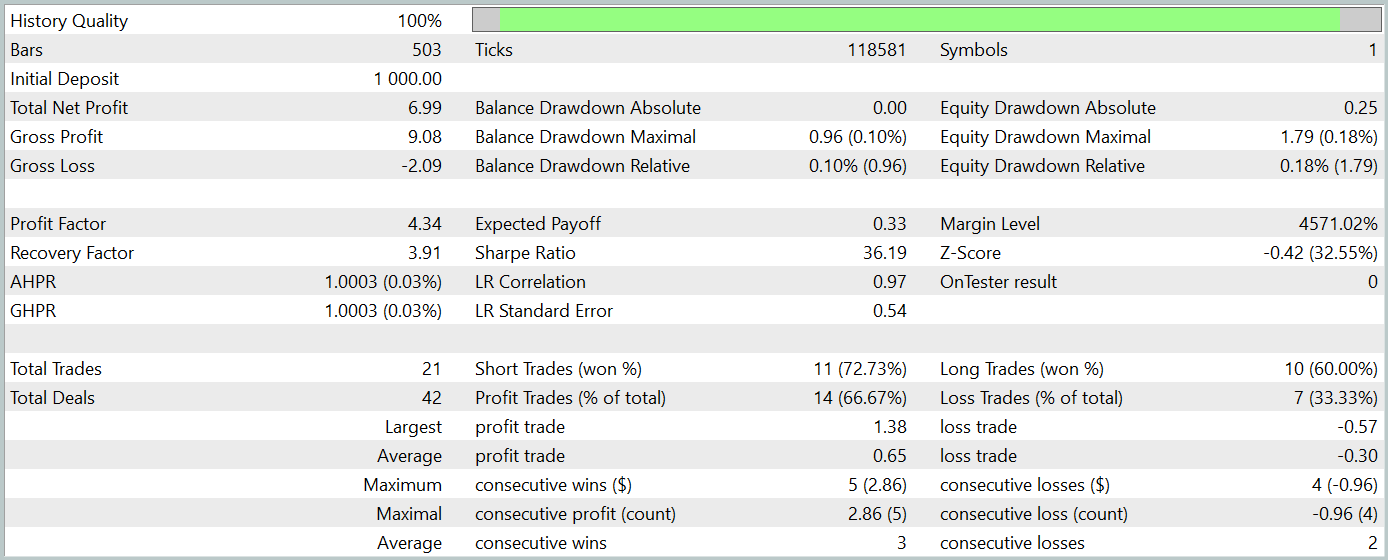
Der Testzeitraum wurde nicht in den Trainingsdatensatz aufgenommen. Dieser Testansatz simuliert die Verwendung des Modells in der Praxis so genau wie möglich.
Während des Testzeitraums führte das Modell 21 Handelsgeschäfte aus, von denen 14 gewinnbringend waren, was einem Anteil von über 66 % entspricht. Sowohl bei den Kauf- als auch bei den Verkaufs-Positionen war der Anteil der gewinnbringenden Geschäfte höher als der Anteil der mit einem Verlust. Außerdem war der durchschnittliche Gewinn pro Gewinngeschäft doppelt so hoch wie der durchschnittliche Verlust pro Verlustgeschäft. Der maximale Gewinn war fast dreimal so hoch wie der größte Verlust. Das Gleichgewichtsdiagramm zeigt einen klar definierten Aufwärtstrend.
Natürlich lässt die begrenzte Anzahl von Handelsgeschäften keine eindeutigen Rückschlüsse auf die langfristige Wirksamkeit des Modells zu. Der vorgeschlagene Ansatz ist jedoch sehr vielversprechend und sollte weiter erforscht werden.
Schlussfolgerung
In den letzten beiden Artikeln haben wir die im Rahmenwerk von RefMask3D vorgeschlagenen Methoden unter Verwendung von MQL5 umfassend umgesetzt. Natürlich weicht unsere Implementierung leicht vom ursprünglichen Rahmen ab. Dennoch zeigen die erzielten Ergebnisse das Potenzial dieses Ansatzes.
Ich muss jedoch betonen, dass alle in diesem Artikel vorgestellten Programme nur zu Demonstrationszwecken dienen und noch nicht für reale Handelsbedingungen geeignet sind.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16057
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo Dmitry. Ich habe diesen Fehler während des Trainings erhalten:
Was bedeutet das?
Übrigens, beim Kompilieren erscheinen diese 2 Warnungen:
Die Dateien aus dem Artikel sind unverändert.
Ausgezeichneter Artikel. Ich werde ihn herunterladen und am Wochenende ausprobieren. Es gibt zwei Dinge, die der Backtest-Bericht nicht anzeigt: das verwendete Währungspaar und den Zeitrahmen. Können Sie diese Informationen bitte zur Verfügung stellen oder auf einen früheren Artikel verweisen, in dem dies beschrieben wurde? Ich habe gerade die Antworten gefunden. Es ist EURUSD und H1
Viktor, ich hatte denselben Memo-Fehler bei veraltetem Verhalten. In meinem Fall entwickelte ich eine Klasse und rief versehentlich eine sichtbare Funktion auf, der ein Parameter fehlte, aber die Klasse enthielt die richtigen Parameter. Das Hinzufügen des Parameters löste mein Problem. Das Programm lief korrekt unter Verwendung des veralteten Verhaltens, weshalb es ein Memo-Fehler ist.