
Нейросети — это просто (Часть 16): Практическое использование кластеризации

Содержание
- Введение
- 1. Теоретические аспекты использования результатов кластеризации
- 2. Использование кластеризации в качестве самостоятельного решения
- 3. Использование результатов кластеризации в качестве исходных данных
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
Последние 2 статьи мы посвятили кластеризации данных. Но наша главная задача — научиться использовать все рассмотренные методы для решения конкретных практических задач. В частности, для принятия в своей торговле. Начиная рассмотрение методов обучения без учителя, мы говорили о возможности использования полученных результатов как самостоятельно, так и в качестве исходных данных для других моделей. В этой статье я предлагаю рассмотреть возможные варианты использования результатов кластеризации.
1. Теоретические аспекты использования результатов кластеризации
И прежде чем перейти к практической реализации примеров использования результатов кластеризации, давайте немного проговорим теоретические аспекты этих подходов.
Первый вариант использования результатов кластеризации данных — это попытаться получить с них максимум для практического использования без каких-либо дополнительных средств. Т.е. использование результатов кластеризации как таковых для принятия своих торговых решений. И тут сразу следует вспомнить, что методы обучения без учителя не используются для решения задач регрессии. В то же время, прогнозирование ближайшего движения цены является именно задачей регрессии. На первый взгляд мы видим некий конфликт.
Но давайте посмотрим с другой стороны. Рассматривая теоретические аспекты кластеризации, мы уже сравнивали кластеризацию с определением графических паттернов. И мы также, как и в случае с графическими паттернами, можем собрать статистику поведения цены после появления на графике элемента того или иного кластера. Да, это не даст нам причинно-следственную связь. Но её нет и в любой математической модели, построенной с использованием нейронных сетей. Мы лишь строим вероятностные модели без углубления в причинно-следственные связи.
Для сбора статистики нам понадобятся уже обученная модель кластеризации и размеченные данные. Так как у нас модель кластеризации данных уже обучена, то выборка с размеченными данными может быть гораздо меньше обучающей выборки. При этом она должна быть достаточной, чтобы оставаться репрезентативной.
На первый взгляд такой подход напомнит обучение с учителем, но тут есть 2 кардинальных отличия:
- Размер размеченной выборки может быть меньше, так как отсутствует риск переобучения.
- При обучении с учителем мы используем итерационный процесс с подбором оптимальных весовых коэффициентов. Что требует нескольких эпох обучения с большими затратами ресурсов и времени. Для сбора статистики нам достаточно 1-го прохода. При этом не происходит каких-либо коррекций модели.
Надеюсь, идея понятна, а с реализацией такой модели познакомимся чуть позже.
К минусам такого варианта можно отнести игнорирование расстояния до центра кластера. Иными словами, у нас одинаковый результат дадут элементы близкие к центру кластера (так сказать идеальный паттерн) и элементы на границах кластера. Можно попробовать увеличить количество кластеров, чтобы уменьшить максимальное расстояние элементов от центра. Но результативность такого подхода будет минимальна, конечно, если мы правильно выбрали количество кластеров по графику функции потерь.
Можно попытаться решить этот вопрос с помощью второго варианта использования результатов кластеризации — в качестве исходных данных другой модели. Но тут надо понимать, что передавая номер кластера в виде числа или вектора на вход второй модели мы максимум получим данные сопоставимые с результатами рассмотренного выше статистического метода. Но мы же не хотим понести дополнительные затраты, чтобы получить тот же результат.
А давайте на вход модели передавать не просто номер кластера, а вектор расстояния до центров кластеров. При этом мы вспомним, что нейронные сети любят нормализованные данные. И мы нормализуем данные вектора расстояний функцией Softmax.
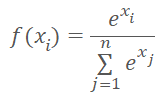
Но давайте вспомним, что в основе Softmax лежит экспонента, график которой представлен на рисунке ниже.

А теперь давайте подумаем, какой вектор мы получим в результате нормализации расстояний до центров кластеров функцией Softmax. Вполне очевидно, что все расстояния у нас положительные. Чем больше расстояние, тем больше экспонента и тем больше изменяется значение функции при одинаковом изменении её аргумента. Следовательно больший вес у нас получат максимальные расстояния. И со снижением расстояния различия между значениями снижаются. Таким образом, в результате нормализации расстояний "в лоб" мы получим вектор, который нам опишет к каким кластерам элемент не относится, тем самым осложняя выделение кластера, к которому относится элемент. А мы бы хотели получить обратную ситуацию.
Казалось бы, чтобы исправить ситуацию мы могли бы просто изменить знак значения расстояния. Но в зоне отрицательных аргументов значение функции экспоненты приближается к "0". И с уменьшением аргумента отклонение значений функции также стремится к "0".
Как вариант решения указанных выше проблем мы можем сначала нормализовать расстояния в диапазоне от 0 до 1. А затем применить функцию Softmax к "1—X".
Выбор модели, на вход которой подавать нормализованные значения зависит от решаемой задачи и выходит за рамки данной статьи.
А теперь, когда мы обсудили основные теоретические подходы к вариантам использования результатов кластеризации мы можем перейти к практической части нашей статьи.
2. Использование кластеризации в качестве самостоятельного решения
Работу над реализацией статистического метода мы начнем с написания кода ещё одного кернела KmeansStatistic в программе OpenCL (файл "unsupervised.cl"), который будет подсчитывать статистику отработки сигналов каждого кластера. Организация данного процесса напомнит обучение с учителем. Нам действительно понадобятся размеченные данные. Но в данном процессе и используемом в предыдущих статьях методе обратного распространении ошибки есть кардинальная разница. Если ранее мы оптимизировали функцию модели для получения результатов максимально приближенных к эталонным. То сейчас мы никоим образом не будем изменять модель. Мы, наоборот, собираем статистику реакции системы на появление того или иного паттерна.
В параметрах кернелу мы будем передавать указатели на 3 буфера данных и общее количество элементов в обучающей выборке. Но в параметрах данного кернела мы не будем передавать обучающую выборку. Для выполнения этого функционала нам абсолютно не нужно знать содержимое вектора описания состояния системы. На этом этапе нам достаточно знать к какому кластеру принадлежит анализируемое состояние системы. Поэтому, вместо обучающей выборки в параметрах кернела мы передадим указатель на вектор clusters, в котором содержатся идентификаторы кластера для каждого состояния системы из обучающей выборки.
Во втором буфере исходных данных target будет представлен тензор, описывающий реакцию системы после появление конкретного паттерна. В данном тензоре будет 3 логических флага для описания сигнала после появления паттерна: покупка, продажа, не определен. Использование флагов делает простым и интуитивно понятным подсчёт статистики сигналов. Но в то же время ограничивает вариативность возможных сигналов. Поэтому использование подобного метода должно соответствовать техническим требованиям поставленной задачи. В рамках этой серии статей все ранее рассмотренные алгоритмы оценивались на возможность определения формирования фрактала до начала формирования последней свечи. Как вы знаете для определения фрактала на графике необходимо 3 свечи. Поэтому, по факту его можно определить только после формирования третей свечи паттерна. Мы же хотим найти вариант определения формирования паттерна, когда сформированы только 2 свечи будущего паттерна. Конечно, с некой долей вероятности. Для решения такой задачи нас вполне удовлетворяет использование целевых сигналов из 3-х флагов для каждого паттерна.
Также надо сказать, что для сбора статистики сигналов после появления паттернов и обучения модели могут использоваться различные обучающие выборки. К примеру, мы можем обучить модель на достаточно длинном историческом интервале, чтобы модель могла максимально изучить признаки и особенности состояния анализируемой системы. При этом разметить данные и собрать статистику поведения системы после появления паттернов на более коротком историческом отрезке. Разумеется, перед сбором статистики мы должны будем провести кластеризацию соответствующих паттернов. Ведь для сбора корректной статистики данные должны быть сопоставимы.
Но вернемся к нашему алгоритму. Запускать выполнение кернела мы будем в одномерном пространстве задач. Число параллельных потоков будет равно количеству созданных кластеров.
В начале кернела мы определим идентификатор текущего потока, который укажет нам на порядковый номер анализируемого кластера. И сразу определим смещение в тензоре вероятностных результатов. Подготовим частные переменные для подсчета количества появления каждого сигнала: buy, sell, skip. Каждой переменной присвоим начальное значение "0".
Далее мы организуем цикл с числом итераций равным количеству элементов в обучающей выборке. В теле цикла, мы сначала проверим принадлежность состояния системы анализируемому кластеру. И только при соответствии мы добавим содержимое тензора целевых флагов в соответствующие частные переменные.
Так для целевых значений мы используем флаги, способные принимать только "0" или "1". При этом мы используем взаимоисключающие сигналы. А значит одномоментно возможно наличии "1" только в одном флаге для каждого отдельного состояния системы. Благодаря указанному свойству мы смогли отказаться от отдельного счетчика количества появления паттерна. Вместо этого, после выхода из цикла для получения общего числа появления паттерна мы суммируем все 3 частные переменные.
Теперь нам остается натуральные суммы сигналов перевести в область вероятностной математики. Для этого мы значение каждой частной переменной разделим на общее число появления паттерна. Но здесь есть нюансы. Во-первых, мы должны исключить возможность появления критической ошибки деления на ноль. Во-вторых, нам необходимы реальные вероятности, которым можно доверять. Ведь если, к примеру, какой-то параметр встретится только один раз, то вероятность такого сигнала будет 100%. Но можно ли доверять такому сигналу? Конечно, нет. Скорее всего, его появления является случайным. Поэтому, для всех паттернов, которые встретились менее 10 раз мы поставим нулевые вероятности для всех сигналов.
__kernel void KmeansStatistic(__global double *clusters, __global double *target, __global double *probability, int total_m ) { int c = get_global_id(0); int shift_c = c * 3; double buy = 0; double sell = 0; double skip = 0; for(int i = 0; i < total_m; i++) { if(clusters[i] != c) continue; int shift = i * 3; buy += target[shift]; sell += target[shift + 1]; skip += target[shift + 2]; } //--- int total = buy + sell + skip; if(total < 10) { probability[shift_c] = 0; probability[shift_c + 1] = 0; probability[shift_c + 2] = 0; } else { probability[shift_c] = buy / total; probability[shift_c + 1] = sell / total; probability[shift_c + 2] = skip / total; } }
После создания кернела в программе OpenCL мы переходим к работе на стороне основной программы. И здесь мы первым делом добавляем константы для работы с выше созданным кернелом. И, конечно, наименование констант должно соответствовать нашей политике формирования наименований.
#define def_k_kmeans_statistic 4 #define def_k_kms_clusters 0 #define def_k_kms_targers 1 #define def_k_kms_probability 2 #define def_k_kms_total_m 3
После создания констант мы переходим в функции OpenCLCreate, в которой изменим общее количество используемых кернелов. И добавим создание нового кернела.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(5)) { delete result; return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_statistic, "KmeansStatistic")) { delete result; return NULL; } //--- return result; }
Теперь нам предстоит организовать вызов этого кернела на стороне основной программы.
Для выполнения данного функционала создадим метод Statistic в нашем классе CKmeans. В параметрах новый метод получит указатели на 2 буфера данных: обучающая выборка и эталонные значения. Несмотря на то, что набор данных напоминает обучение с учителем, в подходах есть кардинальное отличие. Если при обучении с учителем мы оптимизировали модель для получения оптимальных результатом и это итерационный повторяющийся процесс. То сейчас мы просто собираем статистику за один проход.
В теле метода мы проверяем актуальность указателя на буфер целевых значений и вызываем метод кластеризации обучающей выборки. Хочу напомнить, что в данном случае обучающая выборка может отличаться от используемой при обучении модели, но должна соответствовать целевым значениям.
bool CKmeans::Statistic(CBufferDouble *data, CBufferDouble *targets) { if(CheckPointer(targets) == POINTER_INVALID || !Clustering(data)) return false;
Далее мы инициализируем буфер записи вероятностных значений прогнозируемого поведения системы. Я намеренно не использую выражение "реакции на паттерн", так как мы не анализируем причинно-следственную связь. Она может быть прямая, косвенная. А может и вообще не быть. Мы лишь собираем статистику на исторических данных.
if(CheckPointer(c_aProbability) == POINTER_INVALID) { c_aProbability = new CBufferDouble(); if(CheckPointer(c_aProbability) == POINTER_INVALID) return false; } if(!c_aProbability.BufferInit(3 * m_iClusters, 0)) return false; //--- int total = c_aClasters.Total(); if(!targets.BufferCreate(c_OpenCL) || !c_aProbability.BufferCreate(c_OpenCL)) return false;
После создания буфера мы загружаем необходимые данные в память контекста OpenCL и организовываем процедуру вызова кернела. Здесь мы сначала передаем параметры кернела, определяем размерность пространства задач и смещения в каждом измерении. После чего осуществляем постановку кернела в очередь выполнения и считываем результат операций. В ходе выполнения операций обязательно контролируем процесс на каждом шаге.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_probability, c_aProbability.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_targers, targets.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_clusters, c_aClasters.GetIndex())) return false; if(!c_OpenCL.SetArgument(def_k_kmeans_statistic, def_k_kms_total_m, total)) return false; uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = m_iClusters; if(!c_OpenCL.Execute(def_k_kmeans_statistic, 1, global_work_offset, global_work_size)) return false; if(!c_aProbability.BufferRead()) return false; //--- data.BufferFree(); targets.BufferFree(); //--- return true; }
При успешном выполнении кернела в буфере c_aProbability мы получим вероятности появления того или иного события после появления каждого паттерна. Нам остаётся лишь очистить память и завершить работу метода.
Но рассмотренную процедуру мы можем отнести к обучению модели. А для практического использования нам потребуется получение вероятностей поведения системы в режиме реального времени. Для этого мы создадим ещё один метод GetProbability. В параметрах этого метода мы будем передавать только выборку для кластеризации. Но очень важно, чтобы до вызова метода матрица вероятностей c_aProbability была уже сформирована. Поэтому, это первое что мы проверяем в теле метода. После чего запускаем кластеризацию полученных данных. И, как всегда, проверяем результат выполнения операций.
CBufferDouble *CKmeans::GetProbability(CBufferDouble *data)
{
if(CheckPointer(c_aProbability) == POINTER_INVALID ||
!Clustering(data))
return NULL;
Особенностью данного метода является то, что в результате его работы мы будем возвращать не логическое значение, а указатель на буфер данных. Поэтому следующим шагом создадим новый буфер для сбора данных.
CBufferDouble *result = new CBufferDouble(); if(CheckPointer(result) == POINTER_INVALID) return result;
Мы предполагаем, что в режиме реального времени мы будем получать вероятностные данные для небольшого количества записей. А чаще всего только для одного — текущего состояния системы. Поэтому дальнейшую работу мы не будем переводить в область параллельных вычислений. Мы организуем цикл для перебора буфера идентификаторов кластеров изучаемых данных. А в теле цикла перенесем вероятности соответствующих кластеров в буфер результатов.
int total = c_aClasters.Total(); if(!result.Reserve(total * 3)) { delete result; return result; } for(int i = 0; i < total; i++) { int k = (int)c_aClasters.At(i) * 3; if(!result.Add(c_aProbability.At(k)) || !result.Add(c_aProbability.At(k + 1)) || !result.Add(c_aProbability.At(k + 2)) ) { delete result; return result; } } //--- return result; }
Надо сказать, что в буфере результатов вероятности будут расположены в той же последовательности, в которой были состояния системы в анализируемой выборке. И если в выборке были данные, относящиеся к одному кластеру, то вероятности поведения системы будут повторены.
Для проверки работы метода мы создали советник "kmeans_stat.mq5". Его код приведен во вложении. И как можно понять из названия файла в нем мы собрали статистику вероятностей появления фракталов после каждого паттерна.
Эксперимент мы провели с использованием обученной в предыдущей статье модели на 500 кластеров. Результаты приведены на скриншоте ниже.

Как свидетельствуют представленные данные, использование такого подхода позволяет спрогнозировать реакцию рынка после появление фракталов с вероятностью 30-45%. Согласитесь, это неплохой результат. Тем более мы не использовали многослойных нейронных сетей.
3. Использование результатов кластеризации в качестве исходных данных
Переходим к реализации второго варианта использования результатов кластеризации. Напомню, в данном подходе мы планируем передать результаты кластеризации на вход другой модели в качестве исходных данных. По существу, это может быть любая модель, выбранная вами для решения поставленной задачи. В том числе и нейронная сеть с использованием алгоритмов обучения с учителем.
Выше мы определили, что при реализации данного подхода результаты кластеризации будут представлены в виде нормализованного вектора расстояний до центров кластеров. И для осуществления этого функционала нам необходимо создать ещё один кернел KmeansSoftMax в программе OpenCL "unsupervised.cl".
Надо сказать, что в новом кернеле мы не будем пересчитывать дистанции до центра каждого кластера, т.к. эта функция уже выполняется в кернеле KmeansCulcDistance. В новом же KmeansSoftMax мы лишь осуществим нормализацию уже имеющихся данных.
В параметрах кернела мы будем передавать указатели на 2 буфера данных и общее количество используемых кластеров. Среди буферов данных будет один буфер исходных данных distance и один буфер результатов softmax. Оба буфера имеют одинаковую размерность и являются векторным представлением матрицы, строки которой представляют отдельно взятые элементы последовательности, а столбцы — кластеры.
Запуск кернела будет осуществляться в одномерном пространстве задач по числу элементов в кластеризуемой выборке. Я намеренно не пишу "обучаемой выборки", т.к. использование кернела возможно как в процессе обучения второй модели, так и в процессе промышленной эксплуатации. Очевидно, что подаваемые на вход данные в обоих вариантах будут отличаться.
Прежде чем приступить к реализации кода кернела давайте вспомним, что мы немного изменили функции нормализации и она приняла нижеследующий вид.
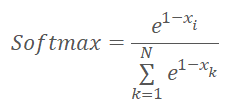
где x — расстояние до центра кластера, нормализованное в диапазоне от 0 до 1.
А теперь посмотрим на реализацию приведенной формулы. В теле кернела мы сначала определяем идентификатор потока, который нам укажет анализируемый элемент последовательности. И сразу мы определяем смещение в буферах до начала анализируемого вектора. Напомню, что тензоры исходных данных и результатов у нас имеют одинаковую размерность. Следовательно, и смещение в обоих буферах будет одинаковым.
Далее, чтобы нормализовать расстояния в диапазоне от 0 до 1 нам необходимо найти максимальное отклонение от центра кластера. Здесь надо вспомнить, что при расчете расстояний мы использовали квадрат отклонений. А значит все значения в нашем векторе расстояний будут положительными. И это нам немного упрощает задачу. Мы объявляем частную переменную m для записи максимального расстояния и инициализируем ее значением первого элемента нашего вектора. Далее мы организуем цикл с перебором всех элементов нашего вектора. В теле вектора мы будем сравнивать значение элементов с сохраненным значением и записывать в переменную максимальное значение.
После определения максимального значения мы можем переходить к вычислению экспоненциальных значений для каждого элемента. И тут же мы посчитаем сумму экспоненциальных значений всего вектора. Для определения суммы мы инициализируем частную переменную sum значением "0". Непосредственно же арифметические операции мы будем осуществлять в следующем цикле. Количество итераций этого цикла равно количеству кластеров в нашей модели. В теле цикла мы сначала сохраним в частную переменную экспоненциальное значение нормализованного и "перевернутого" расстояния до центра кластера. Полученное значение сначала добавим к сумме, а затем перенесем в буфер результатов. Использованием частной переменной перед записью значений в буфер сделано для минимизации количества обращений к медленной глобальной памяти.
После завершения итераций цикла нам остается нормализовать данные, разделим полученные экспоненциальные значения на общую сумму. Для выполнения этих операций создадим еще один цикл с количеством итераций равным количеству кластеров. И после завершения цикла выходим из кернела.
__kernel void KmeansSoftMax(__global double *distance, __global double *softmax, inсt total_k ) { int i = get_global_id(0); int shift = i * total_k; double m=distance[shift]; for(int k = 1; k < total_k; k++) m = max(distance[shift + k],m); double sum = 0; for(int k = 0; k < total_k; k++) { double value = exp(1-distance[shift + k]/m); sum += value; softmax[shift + k] = value; } for(int k = 0; k < total_k; k++) softmax[shift + k] /= sum; }
Функциональность программы OpenCL мы дополнили и остается добавить код вызова кернела из нашего класса CKmeans. Действовать мы будем по той же схеме, которую использовали выше для добавления кода вызова предыдущего кернела.
Сначала мы добавляем константы с соблюдением политики именования.
#define def_k_kmeans_softmax 5 #define def_k_kmsm_distance 0 #define def_k_kmsm_softmax 1 #define def_k_kmsm_total_k 2
После этого добавляем объявление кернела в функции инициализации контекста OpenCL OpenCLCreate.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(6)) { delete result; return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_softmax, "KmeansSoftMax")) { delete result; return NULL; } //--- return result; }
И конечно, нам потребуется новый метод нашего класса CKmeans::SoftMax. В параметрах метод получает указатель на буфер исходных данных. И в результате работы метод вернет буфер результатов аналогичного размера.
В теле метода мы сначала поверяем был ли ранее обучен наш класс кластеризации. И, при необходимости, инициализируем процесс обучения модели. Здесь надо напомнить, что в методе обучения модели мы сделали ограничение по минимальному размеру обучающей выборки. Поэтому, если модель еще не обучена, то в параметрах методу нужно подать достаточную обучающую выборку. В противном случае метод вернет недействительный указатель на буфер результатов. Если же модель кластеризации данных уже обучена, то и снимается ограничение по размеру выборки.
CBufferDouble *CKmeans::SoftMax(CBufferDouble *data)
{
if(!m_bTrained && !Study(data, (c_aMeans.Maximum() == 0)))
return NULL;
На следующем шаге мы проверяем действительность указателей на используемые объекты. Здесь может показаться странным, что мы сначала вызываем метод обучения, а потом проверяем указатели объектов. На самом деле, метод обучения сам имеет аналогичный блок контролей. И если бы мы всегда вызывали метод обучения модели перед продолжением операций, то эти контроли были бы излишними, т.к. повторяют контроли внутри метода обучения. Но ведь в случае использования предварительно обученной модели мы не будем вызывать метод обучения с его контролями. А дальнейшее выполнение операций с недействительными указатели приведет к критическим ошибкам. Поэтому мы вынуждены повторить проверку указателей.
if(CheckPointer(data) == POINTER_INVALID || CheckPointer(c_OpenCL) == POINTER_INVALID) return NULL;
После проверки указателей проверим размер буфера исходных данных. Он должен содержать как минимум вектор описания 1-го состояния системы. При этом количество данных в буфере должно быть кратно размеру вектора описания состояния системы.
int total = data.Total(); if(total <= 0 || m_iClusters < 2 || (total % m_iVectorSize) != 0) return NULL;
И затем определим количество состояний системы, которое нам предстоит распределить по кластерам.
int rows = total / m_iVectorSize; if(rows < 1) return NULL;
Далее нам предстоит инициализировать буферы для расчета дистанций и их нормализации. Алгоритм инициализации довольно прост. Мы сначала проверяем действительность указателя на буфер и, при необходимости, создаем новый объект. А затем заполняем буфер нулевыми значениями.
if(CheckPointer(c_aDistance) == POINTER_INVALID) { c_aDistance = new CBufferDouble(); if(CheckPointer(c_aDistance) == POINTER_INVALID) return NULL; } c_aDistance.BufferFree(); if(!c_aDistance.BufferInit(rows * m_iClusters, 0)) return NULL;
if(CheckPointer(c_aSoftMax) == POINTER_INVALID) { c_aSoftMax = new CBufferDouble(); if(CheckPointer(c_aSoftMax) == POINTER_INVALID) return NULL; } c_aSoftMax.BufferFree(); if(!c_aSoftMax.BufferInit(rows * m_iClusters, 0)) return NULL;
В завершение подготовительной работы мы создаем необходимые буфера данных в контексте OpenCL.
if(!data.BufferCreate(c_OpenCL) || !c_aMeans.BufferCreate(c_OpenCL) || !c_aDistance.BufferCreate(c_OpenCL) || !c_aSoftMax.BufferCreate(c_OpenCL)) return NULL;
На этом подготовительная работа закончена, и мы переходим к вызову необходимых кернелов. Для реализации полного функционала метода нам предстоит организовать последовательный вызов двух кернелов:
- определение расстояний до центров кластеров KmeansCulcDistance;
- нормализация расстояний KmeansSoftMax.
Алгоритм вызова кернелов довольно прост и аналогичен используемому в выше описанном методе статистического использования результатов кластеризации. Вначале нам предстоит передать параметры кернелу.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_data, data.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_means, c_aMeans.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_distance, c_aDistance.GetIndex())) return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_distance, def_k_kmd_vector_size, m_iVectorSize)) return NULL;
Затем указываем размерность пространства задач и смещение в каждом измерении.
uint global_work_offset[2] = {0, 0}; uint global_work_size[2]; global_work_size[0] = rows; global_work_size[1] = m_iClusters;
После чего ставим кернел в очередь выполнения и считываем результаты выполнения операций.
if(!c_OpenCL.Execute(def_k_kmeans_distance, 2, global_work_offset, global_work_size)) return NULL; if(!c_aDistance.BufferRead()) return NULL;
Повторим операции для второго кернела.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_distance, c_aDistance.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_softmax, c_aSoftMax.GetIndex())) return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_softmax, def_k_kmsm_total_k, m_iClusters)) return NULL; uint global_work_offset1[1] = {0}; uint global_work_size1[1]; global_work_size1[0] = rows; if(!c_OpenCL.Execute(def_k_kmeans_softmax, 1, global_work_offset1, global_work_size1)) return NULL; if(!c_aSoftMax.BufferRead()) return NULL;
В заключение очистим память контекста OpenCL и выходим из метода, вернув указатель на буфер результатов.
data.BufferFree(); c_aDistance.BufferFree(); //--- return c_aSoftMax; }
На этом завершается наша работа по внесению изменений в наш класс кластеризации методом k-средних CKmeans. И мы можем перейти к тестированию данного подхода. Для этого мы создадим советник "kmeans_net.mq5", который создан по образу советников из статей об алгоритмах обучения с учителем. Дело в том, что для тестирования реализации я подал результаты кластеризации на вход полносвязного перцептрона с 3-мя скрытыми слоями. С полным кодом советника можно познакомиться во вложении. А сейчас я бы хотел остановиться на функции обучения Train.
Вначале функции мы инициализируем экземпляр объекта для работы с контекстом OpenCL в рамках класса кластеризации. И передадим указатель на созданный объект в наш класс кластеризации. И обязательно, как всегда, не забываем проверить результат выполнения операций.
void Train(datetime StartTrainBar = 0) { COpenCLMy *opencl = OpenCLCreate(cl_unsupervised); if(CheckPointer(opencl) == POINTER_INVALID) { ExpertRemove(); return; } if(!Kmeans.SetOpenCL(opencl)) { delete opencl; ExpertRemove(); return; }
После успешной инициализации объектов определяем границы периода обучения.
MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
И загружаем исторические данные. Обратите внимание, что данные индикаторов, загруженные в буферы, представлены таймсериями. А загруженные котировки нет. Для нас это важно, так как мы получаем обратную последовательность нумерации элементов в массивах. Следовательно, для сопоставимости данных мы должны массив котировок "перевернуть" в таймсерию.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; }
RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
После успешной загрузки исторических данных мы загружаем предварительно обученную модель кластеризации.
int handl = FileOpen(StringFormat("kmeans_%d.net", Clusters), FILE_READ | FILE_BIN); if(handl == INVALID_HANDLE) { ExpertRemove(); return; } if(FileReadInteger(handl) != Kmeans.Type()) { ExpertRemove(); return; } bool result = Kmeans.Load(handl); FileClose(handl); if(!result) { ExpertRemove(); return; }
И переходим к формированию обучающей выборки и целевых значений.
int total = bars - (int)HistoryBars - 1; double data[], fractals[]; if(ArrayResize(data, total * 8 * HistoryBars) <= 0 || ArrayResize(fractals, total * 3) <= 0) { ExpertRemove(); return; } //--- for(int i = 0; (i < total && !IsStopped()); i++) { Comment(StringFormat("Create data: %d of %d", i, total)); for(int b = 0; b < (int)HistoryBars; b++) { int bar = i + b; int shift = (i * (int)HistoryBars + b) * 8; double open = Rates[bar].open; data[shift] = open - Rates[bar].low; data[shift + 1] = Rates[bar].high - open; data[shift + 2] = Rates[bar].close - open; data[shift + 3] = RSI.GetData(MAIN_LINE, bar); data[shift + 4] = CCI.GetData(MAIN_LINE, bar); data[shift + 5] = ATR.GetData(MAIN_LINE, bar); data[shift + 6] = MACD.GetData(MAIN_LINE, bar); data[shift + 7] = MACD.GetData(SIGNAL_LINE, bar); } int shift = i * 3; int bar = i + 1; fractals[shift] = (int)(Rates[bar - 1].high <= Rates[bar].high && Rates[bar + 1].high < Rates[bar].high); fractals[shift + 1] = (int)(Rates[bar - 1].low >= Rates[bar].low && Rates[bar + 1].low > Rates[bar].low); fractals[shift + 2] = (int)((fractals[shift] + fractals[shift]) == 0); } if(IsStopped()) { ExpertRemove(); return; } CBufferDouble *Data = new CBufferDouble(); if(CheckPointer(Data) == POINTER_INVALID || !Data.AssignArray(data)) return; CBufferDouble *Fractals = new CBufferDouble(); if(CheckPointer(Fractals) == POINTER_INVALID || !Fractals.AssignArray(fractals)) return;
Так как наши методы кластеризации могут работать с массивами исходных данных, то мы можем провести кластеризацию сразу всей обучающей выборки.
ResetLastError(); CBufferDouble *softmax = Kmeans.SoftMax(Data); if(CheckPointer(softmax) == POINTER_INVALID) { printf("Ошибка выполнения %d", GetLastError()); ExpertRemove(); return; }
После успешного выполнения всех вышеописанных операций в буфере softmax будет содержаться обучающая выборка для нашего перцептрона. Целевые значения мы также подготовили заранее. Значит мы можем перейти к циклу обучения второй модели.
Как и ранее, при тестировании алгоритмов обучения с учителем, процесс обучения модели будет организован из двух вложенных циклов. Внешний цикл будет отсчитывать эпохи обучения и выход из цикла будет по наступлению определенного события.
Вначале мы проведем небольшую подготовительную работу. В которой инициализируем необходимые локальные переменные.
if(CheckPointer(TempData) == POINTER_INVALID) { TempData = new CArrayDouble(); if(CheckPointer(TempData) == POINTER_INVALID) { ExpertRemove(); return; } } delete opencl; double prev_un, prev_for, prev_er; dUndefine = 0; dForecast = 0; dError = -1; dPrevSignal = 0; bool stop = false; int count = 0; do { prev_un = dUndefine; prev_for = dForecast; prev_er = dError; ENUM_SIGNAL bar = Undefine; //--- stop = IsStopped();
И только потом перейдем к организации вложенного цикла. Количество итераций вложенного цикла будет равно размеру обучающей выборки за вычетом небольшого "хвоста" зоны валидации.
Надо сказать, что несмотря на то, что количество итераций равно размеру выборки, мы все же будем каждый раз выбирать случайный элемент для процесса обучения. Его мы и определим в начале вложенного цикла. Использование случайных векторов из обучающей выборки делает обучение модели более равномерным.
for(int it = 0; (it < total - 300 && !IsStopped()); it++) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 300)) + 300;
По индексу случайно выбранного элемента определим смещение в буфере исходных данных и скопируем необходимый вектор во временный буфер.
TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
После формирования вектора исходных данных мы подаем его на вход метода прямого прохода нашей нейронной сети. И после успешного прямого прохода получим результат прямого прохода.
if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
Полученные результаты мы нормализуем с использованием функции Softmax.
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum);
Для визуального отслеживания процесса обучения модели мы выведем текущее состояние на график.
switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; } string s = StringFormat("Study -> Era %d -> %.2f -> Undefine %.2f%% foracast %.2f%%\n %d of %d -> %.2f%% \nError %.2f\n%s -> %.2f ->> Buy %.5f - Sell %.5f - Undef %.5f", count, dError, dUndefine, dForecast, it + 1, total - 300, (double)(it + 1.0) / (total - 300) * 100, Net.getRecentAverageError(), EnumToString(DoubleToSignal(dPrevSignal)), dPrevSignal, TempData[1], TempData[2], TempData[0]); Comment(s); stop = IsStopped();
И в завершении итерации цикла мы вызываем метод обратного прохода с обновлением матрицы весов нашей модели.
if(!stop) { shift = i * 3; TempData.Clear(); TempData.Add(Fractals.At(shift + 2)); TempData.Add(Fractals.At(shift)); TempData.Add(Fractals.At(shift + 1)); Net.backProp(TempData); ENUM_SIGNAL signal = DoubleToSignal(dPrevSignal); if(signal != Undefine) { if((signal == Sell && Fractals.At(shift + 1) == 1) || (signal == Buy && Fractals.At(shift) == 1)) dForecast += (100 - dForecast) / Net.recentAverageSmoothingFactor; else dForecast -= dForecast / Net.recentAverageSmoothingFactor; dUndefine -= dUndefine / Net.recentAverageSmoothingFactor; } else { if(Fractals.At(shift + 2) == 1) dUndefine += (100 - dUndefine) / Net.recentAverageSmoothingFactor; } } }
После каждой эпохи обучения мы выведем графические метки на участке валидации. Для реализации этого функционала мы создадим еще один вложенный цикл. Операции в теле цикла в большей своей степени будут повторять описанный выше цикл, за исключением двух основных отличий:
- Мы будем брать элементы по порядку, а не случайным образом как выше.
- Мы не будем осуществлять обратного прохода.
На валидационной выборке мы проверяем как отработает наша модель на новых данных без "подгона" параметром. Поэтому не осуществляем вызов обратного прохода. И вследствие этого, результат работы модели не зависит от последовательности подачи данных (исключение для рекуррентных моделей). А значит мы не тратим ресурсы на генерацию случайного числа и берем все состояния системы последовательно.
count++; for(int i = 0; i < 300; i++) { TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum); //--- switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; }
Добавим отображение объектов на графике и выйдем из цикла валидации.
if(DoubleToSignal(dPrevSignal) == Undefine) DeleteObject(Rates[i + 2].time); else DrawObject(Rates[i + 2].time, dPrevSignal, Rates[i + 2].high, Rates[i + 2].low); }
Перед завершением итерации внешнего цикла сохраним текущее состояние модели и добавим значение ошибки в файл динамики процесса обучения.
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, dUndefine, dForecast, Rates[0].time, false); printf("Era %d -> error %.2f %% forecast %.2f", count, dError, dForecast); ChartScreenShot(0, FileName + IntegerToString(count) + ".png", 750, 400); int h = FileOpen(FileName + ".csv", FILE_READ | FILE_WRITE | FILE_CSV); if(h != INVALID_HANDLE) { FileSeek(h, 0, SEEK_END); FileWrite(h, eta, count, dError, dUndefine, dForecast); FileFlush(h); FileClose(h); } } } while((!(DoubleToSignal(dPrevSignal) != Undefine || dForecast > 70) || !(dError < 0.1 && MathAbs(dError - prev_er) < 0.01 && MathAbs(dUndefine - prev_un) < 0.1 && MathAbs(dForecast - prev_for) < 0.1)) && !stop);
Выход из цикла обучения мы осуществляем по определенным нами метрикам. Они полностью заимствованы из советников обучения с учителем.
И перед выходом из метода обучения мы удалим объекты, созданные в теле нашего метода обучения модели.
if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(TempData) == POINTER_DYNAMIC) delete TempData; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); }
С полным кодом советника вы можете ознакомиться во вложении.
Чтобы оценить работу советника мы провели его тестирование с использованием модели кластеризации из 500 кластеров, обученную в предыдущей статье и используемой в предыдущем тесте. График обучения приведен ниже.

Как можно заметить график обучения довольно ровный. Для обучения модели я использовал метод оптимизации параметров Adam. В течение первых 20 эпох мы видим плавное снижение функции потерь, связанное с накоплением импульсов. А затем заметно резкое снижение значение функции потерь до некоего минимума. Если вспомните графики обучения моделей с учителем, то там чаще всего заметны ломанные линии функции потерь. К примеру, ниже приведен график обучения более сложной модели внимания.

Сравнивая 2 представленных графика можно заметить, насколько предварительная кластеризация данных повышает эффективность даже простых моделей.
Заключение
В данной статье мы рассмотрели и реализовали 2 варианта использования результатов кластеризации в решении практических кейсов. И результаты тестирования демонстрируют эффективность использования обоих методов. В первом случае мы имеем простую модель с весьма понятными и объяснимыми результатами, которые довольно прозрачны и понятны. Использование второго метода делает обучение моделей более ровным и быстрым. При этом повышается эффективность работы моделей.
Ссылки
- Нейросети — это просто
- Нейросети — это просто (Часть 2): обучение и тестирование сети
- Нейросети — это просто (Часть 3): сверточные сети
- Нейросети — это просто (Часть 4): рекуррентные сети
- Нейросети — это просто (Часть 5): многопоточные вычисления в OpenCL
- Нейросети — это просто (Часть 6): эксперименты с коэффициентом обучения нейронной сети
- Нейросети — это просто (Часть 7): Адаптивные методы оптимизации
- Нейросети — это просто (Часть 8): Механизмы внимания
- Нейросети — это просто (Часть 9): Документируем проделанную работу
- Нейросети — это просто (Часть 10): Multi-Head Attention (многоголовое внимание)
- Нейросети — это просто (Часть 11): Вариации на тему GPT
- Нейросети — это просто (Часть 12): Dropout
- Нейросети — это просто (Часть 13): Пакетная нормализация (Batch Normalization)
- Нейросети — это просто (Часть 14): Кластеризация данных
- Нейросети — это просто (Часть 15): Кластеризации данных средствами MQL5
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | kmeans.mq5 | Советник | Советник для обучения модели |
| 2 | kmeans_net.mq5 | Советник | Советник тестирования передачи данных второй можели |
| 3 | kmeans_stat.mq5 | Советник | Советник тестирования статистического метода |
| 4 | kmeans.mqh | Библиотека класса | Библиотека для организации метода k-средних |
| 5 | unsupervised.cl | Библиотека | Библиотека кода программы OpenCL для организации метода k-средних |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Разработка торгового советника с нуля (Часть 10): Доступ к пользовательским индикаторам
Разработка торгового советника с нуля (Часть 10): Доступ к пользовательским индикаторам
 Разработка торгового советника с нуля (Часть 9): Концептуальный скачок (II)
Разработка торгового советника с нуля (Часть 9): Концептуальный скачок (II)
 Разработка торгового советника с нуля (Часть 11): Система кросс-ордеров
Разработка торгового советника с нуля (Часть 11): Система кросс-ордеров
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
2022.05.30 21:57:27.477 kmeans (WDO$,H1) 800 Ошибка модели inf
2022.05.30 22:00:23.937 kmeans (WDO$,H1) 850 Ошибка модели inf
2022.05.30 22:04:22.069 kmeans (WDO$,H1) 900 Ошибка модели inf
2022.05.30 22:08:04.179 kmeans (WDO$,H1) 950 Ошибка модели inf
2022.05.30 22:10:56.190 kmeans (WDO$,H1) 1000 Ошибка модели inf
2022.05.30 22:10:56.211 kmeans (WDO$,H1) ExpertRemove() function called
Como resolver este erro?
How to resolve this error?
This is not a program execution error. This line displays the model error (average distance to the centers of the clusters). But we see inf - value beyond the accuracy of calculations. Try to scale the original values. For example, divide by 10,000
Este não é um erro de execução do programa. Esta linha exibe o erro do modelo (distância média aos centros dos clusters). Mas vemos inf alem da precisao dos valores - valor. Tente dimensionar os valores originais. Por exemplo, divida por 10.000
I still couldn't find a solution.
I still couldn't find a solution.