
神经网络变得轻松(第十六部分):聚类运用实践

内容
概述
前两篇文章专门讨论数据聚类。 但我们的主要目标是学习如何利用所有研究过的方法来解决具体的实际问题。 特别是与交易有关的案例。 当我们开始研究无监督学习方法时,我们讨论了将独立获得的结果用作其它模型的输入数据的可能性。 在本文中,我们将探讨聚类结果的可能用例。
1. 聚类结果利用的理论层面
在我们继续讨论与实际运用聚类结果相关的案例之前,我们先谈谈这些方法的理论层面。
运用数据聚类结果的第一个选项是,在不需要任何额外资金的情况下,尽量充分利用数据聚类结果进行实际运用。 即,聚类结果可以独立运用,来制定交易决策。 我想提请大家的是,无监督学习方法不能用于解决回归任务。 而预测最近的价格走势恰恰是一项回归任务。 乍一看,我们看到了某种冲突。
但要从其它方面来看。 考虑到聚类的理论层面,我们已经将聚类与图形形态的定义进行了比较。 就像图表形态,我们可以在特定聚类的元素出现在图表上以后,去收集价格行为的统计数据。 好吧,这不会带给我们一个因果关系。 但这种关系在运用神经网络建立的任何数学模型中都不存在。 我们仅建立概率模型,没有深入研究因果关系。
为了收集统计数据,我们需要一个已经训练过的聚类模型和标记数据。 鉴于我们的聚类模型已经训练过了,标记数据集合可能比训练样本小得多。 然而,它应该是充分和具有代表性的。
乍一看,这种方式可能类似于监督学习。 但它有两个主要区别:
- 标记的样本规模可以更小,因为这样没有过度拟合的风险。
- 在监督学习中,我们使用迭代过程来选择最优权重系数。 这需要若干个训练世代,且资源和时间成本较高。 第一次通过就足以收集统计数据。 在这种情况下也无需执行模型调整。
我希望这个思路足够简单。 稍后我们将研究这种模型的实现。
此选项的缺点是忽略了至聚类中心的距离。 换言之,对于靠近聚类中心(“理想形态”)的元素,和聚类边界上的元素,我们会得到相同的结果。 您可尝试增加聚类的数量,从而降低图元与中心的最大距离。 但如果我们根据损失函数图正确选择了聚类数量,这种方式的有效性将是最小的。
您可以尝试采用聚类结果的第二种应用来解决这个问题:作为另一个模型的源数据。 但请注意,以数字或向量的形式将聚类数量输入到第二个模型,我们最多会收到与上述统计方法结果相当的数据。 花费额外的成本来获得同样的结果是没有意义的。
我们可以在模型中输入至聚类中心的距离,来取代聚类数量。 我们不应该忘记,神经网络更喜欢归一化数据。 我们利用 Softmax 函数对距离向量的数据进行归一化。
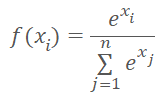
但 Softmax 是基于指数的,其图表如下图所示。

现在我们要研究一下,我们所得到的向量,是至聚类中心的距离,经 Softmax 函数归一化的结果。 显然,所有距离都是正值。 距离越大,指数越大,函数值伴随自身参量的变化也同样越大。 因此,最大距离将获得更大的权重。 随着距离的减小,值之间的差异减小。 因此,通过使用这种简单的归一化,我们将得到一个向量,该向量描述元素不属于哪些聚类,因此更难判定元素所属的聚类。 我们需要反其道而行之。
似乎可以通过简单地改变距离值的符号来校正这种情况。 但在负参量区域,指数函数的值接近 0。 随着参量的减小,函数值的偏差也趋于 0。
作为上述问题的解决方案,我们可以首先对 0 到 1 范围内的距离进行归一化。 然后将 Softmax 函数应用于 "1—X"。
模型的选择所输入的归一化数值,取决于问题,但这超出了本文的范畴。
现在,我们已经讨论了使用聚类结果的主要理论方法,我们可以进入本文的实践部分。
2. 使用聚类作为独立的解决方案
我们将开始实现统计方法,具体是在 OpenCL 程序中编写另一个内核 KmeansStatistic 的代码(文件 unsupervised.cl),其将计算与每个聚类信号处理相关的统计数据。 这个过程的组织方式类似于监督学习。 事实上,我们在运作时需要标记数据。 但是,该过程与先前的反向传播方法之间存在本质区别。 之前,我们优化了模型函数,从而获得非常接近参考值的结果。 现在,我们不会以任何方式更改模型。 取而代之的是,我们将收集系统针对特定形态所做反应的统计数据。
我们将在参数里传递给内核三个指针,指向三个数据缓冲区,以及训练集合中的元素总数。 但我们不会在该内核参数中传递训练样本。 执行此功能,我们不需要知道系统状态描述向量的内容。 在这个阶段,我们只需要知道分析的系统状态属于哪个类就足够了。 因此,我们将传递一个指向聚类向量的指针,替代内核参数中传递训练样本,该向量包含训练集合中每个系统状态的聚类标识符。
第二个输入数据缓冲区 target 将包含一个描述特定形态出现后系统反应的张量。 这个张量将拥有三个逻辑标志来描述形态出现后的信号:买入、卖出、和未定义。 通过使用标志,信号统计的计算变得更简单和直观。 不过,与此同时,它限制了可能信号的可变性。 因此,运用该方法必须符合任务的技术要求。 在本系列文章中,我们评估了所有已研究算法在最后一根烛条形成之前识别分形是否成形的能力。 如您所知,我们需要三根烛条来判定图表上的分形。 因此,事实上,我们只能在第三根烛条形成后才能判定它的形态。 然而,我们希望找到一种方式,当未来形态只有两根烛条形成时,就能判定形态的形成。 当然,要配合一定的概率等级。 为了解决这个问题,对于每个形态使用三个标志的目标信号就足够了。
此外,各种训练样本可用于在形态出现后收集信号统计数据,并训练模型。 例如,可以在足够长的历史区间上训练模型,以便模型可以尽可能多地学习所分析系统状态的特征。 而较短的历史区间可用于标记数据,和收集统计数据。 当然,在收集统计数据之前,我们已经进行了相应的聚类。 因为确保正确的统计数据收集,数据必须具有可比性。
我们回到我们的算法。 内核执行将在一维任务空间中运行。 并行线程的数量将等于所创建聚类的数量。
在内核的开始,我们定义了当前线程的 ID,由该 ID 可推断所分析聚类的序号。 此外,我们立即判定在概率结果张量里的偏移。 准备私密变量来计算每个信号的出现次数:买入、卖出、跳过。 每个变量的初始值赋值 0。
接下来,实现迭代,其循环次数等于训练样本中元素数量。 在循环主体中,首先检查系统状态是否属于所分析的聚类。 如果属于,则将目标标志张量的内容添加到相关的私密变量当中。
对于目标值,我们可用的标志只能为 0 或 1。 我们将使用互斥信号。 这意味着,在某一时刻,对于系统的每个单独状态,可能只有一个标志为 1。 感谢该属性,我们不必使用单独的计数器来计算形态出现的次数。 取而代之,在退出循环后,我们将所有 3 个私密变量相加,从而获得形态出现的总数。
现在我们需要将信号合计的自然数转换到概率领域。 为此,我们将每个私密变量的值除以形态出现的总数。 然而,有一些时刻需要注意。 首先,必须剔除严重除零错误的可能性。 第二,我们需要可以信赖的真实概率。 我来解释一下。 例如,如果某个参数出现一次,则此类信号的概率将为 100%。 但这样的信号能被信赖吗? 当然不能。 很有可能,它只是偶然出现的。 因此,对于发生少于 10 次的所有形态,所有信号将被赋予零概率。
__kernel void KmeansStatistic(__global double *clusters, __global double *target, __global double *probability, int total_m ) { int c = get_global_id(0); int shift_c = c * 3; double buy = 0; double sell = 0; double skip = 0; for(int i = 0; i < total_m; i++) { if(clusters[i] != c) continue; int shift = i * 3; buy += target[shift]; sell += target[shift + 1]; skip += target[shift + 2]; } //--- int total = buy + sell + skip; if(total < 10) { probability[shift_c] = 0; probability[shift_c + 1] = 0; probability[shift_c + 2] = 0; } else { probability[shift_c] = buy / total; probability[shift_c + 1] = sell / total; probability[shift_c + 2] = skip / total; } }
在 OpenCL 程序中创建内核之后,我们继续在主程序一侧工作。 首先,我们添加了用于处理早期创建的内核的常量。 当然,常量的命名必须符合我们的命名策略。
#define def_k_kmeans_statistic 4 #define def_k_kms_clusters 0 #define def_k_kms_targers 1 #define def_k_kms_probability 2 #define def_k_kms_total_m 3
创建常量后,转到 OpenCLCreate 函数,在其中,我们更改用到的内核总数。 我们还将加入一个新创建的内核。
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(5)) { delete result; .return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_statistic, "KmeansStatistic")) { delete result; .return NULL; } //--- return result; }
现在我们需要在主程序一侧实现此内核的调用。
若要启用此调用,我们要在 CKmeans 类中创建统计方法。 新方法将在参数中接收指向两个数据缓冲区的指针:训练样本和参考值。 尽管数据集合类似于监督学习,但在方法上存在本质区别。 在监督学习过程中,我们已针对模型进行优化,来获得最优结果,这是一个迭代过程。 现在我们可简单地在一遍里收集统计数据。
在方法主体中,我们检查指针与目标值缓冲区的相关性,并调用训练样本聚类方法。 不要忘记,在这种情况下,训练样本可能与来自训练模型的样本不同,但必须与目标值相对应。
bool CKmeans::Statistic(CBufferDouble *data, CBufferDouble *targets) { if(CheckPointer(targets) == POINTER_INVALID || !Clustering(data)) return false;
接下来,我们初始化缓冲区,写入预测系统行为的概率值。 我故意不使用“针对形态的反应”这一表述,因为我们不是在分析因果关系。 它可以是直接的,或间接的。 根本不可能有任何关系。 我们仅依据历史数据收集统计数据。
if(CheckPointer(c_aProbability) == POINTER_INVALID) { c_aProbability = new CBufferDouble(); if(CheckPointer(c_aProbability) == POINTER_INVALID) return false; } if(!c_aProbability.BufferInit(3 * m_iClusters, 0)) return false; //--- int total = c_aClasters.Total(); if(!targets.BufferCreate(c_OpenCL) || !c_aProbability.BufferCreate(c_OpenCL)) return false;
创建缓冲区之后,我们将所需数据加载到 OpenCL 环境的内存,并实现内核调用过程。 我们首先传递内核参数,判定任务空间的维度和每个维度中的偏移量。 之后,我们将内核放在执行队列中,并读取操作结果。 在操作执行期间,确保在每个步骤控制流程。
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_probability, c_aProbability.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_targers, targets.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_clusters, c_aClasters.GetIndex())) return false; if(!c_OpenCL.SetArgument(def_k_kmeans_statistic, def_k_kms_total_m, total)) return false; uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = m_iClusters; if(!c_OpenCL.Execute(def_k_kmeans_statistic, 1, global_work_offset, global_work_size)) return false; if(!c_aProbability.BufferRead()) return false; //--- data.BufferFree(); targets.BufferFree(); //--- return true; }
如果内核成功执行,则我们将接收的每个形态的发生概率存储在 c_aProbability 缓冲区当中。 我们只需要清除内存,并完成该方法。
但所研究的过程可归因于模型训练。 对于实际应用,我们需要获得实时系统的行为概率。 为此目的,我们创建了另一个方法 GetProbability。 在方法参数中,我们将只传递一个用来聚类的样本。 有一点非常重要,在调用该方法之前,需已形成 c_aProbability 概率矩阵。 因此,这是我们在方法主体中检查的第一件事。 在此之后,开始对接收到的数据进行聚类。 再次检查操作执行结果。
CBufferDouble *CKmeans::GetProbability(CBufferDouble *data)
{
if(CheckPointer(c_aProbability) == POINTER_INVALID ||
!Clustering(data))
.return NULL;
该方法的具体特点是,作为其操作的结果,我们返回的不是布尔值,而是指向数据缓冲区的指针。 因此,在下一步中,我们将创建一个新的缓冲区来收集数据。
CBufferDouble *result = new CBufferDouble(); if(CheckPointer(result) == POINTER_INVALID) return result;
我们假设我们将实时接收少量记录的概率数据。 大多时只有一个记录 — 系统的当前状态。 因此,我们将不再进一步研究并行计算。 我们将实现一个循环,在所研究的数据聚类的标识符缓冲区上迭代。 在循环主体中,我们将相应聚类的概率转移到结果缓冲区。
int total = c_aClasters.Total(); if(!result.Reserve(total * 3)) { delete result; return result; } for(int i = 0; i < total; i++) { int k = (int)c_aClasters.At(i) * 3; if(!result.Add(c_aProbability.At(k)) || !result.Add(c_aProbability.At(k + 1)) || !result.Add(c_aProbability.At(k + 2)) ) { delete result; return result; } } //--- return result; }
请注意,在结果缓冲区中,概率将按照与分析样本中的系统状态相同的顺序排列。 如果样本包含的数据属于一个聚类,则系统行为概率将重复。
为了测试该方法,我们创建了 “kmeans_stat.mq5” 智能系统。 其代码见附件。 从文件名可以看出,它提供了每个形态的分形出现概率的统计信息。
我们使用上一篇文章中训练的 500 个聚类模型进行了实验。 结果显示在下面的屏幕截图中。

已提供的数据证明,使用该方法可以预测分形出现后的行情反应,概率为 30-45%。 这是一个十分优秀的结果。 特别是考虑到我们没有使用多层神经网络的事实。
3. 使用聚类结果作为输入
我们继续讨论使用聚类结果的第二种变体的实现。 在这种方式中,我们将把已聚类的结果输入到另一个模型当中。 实际上,这可能是您针对任意问题选择的任意模型,包括采用监督学习算法的神经网络。
我们之前已经判定,在实施该方法时,聚类结果将采用至聚类中心的距离的归一化向量表示。 若要实现此功能,我们需要在 OpenCL 程序 unsupervised.cl 中创建另一个内核 KmeansOffmax。
我们不会在新内核中重新计算至每个聚类中心的距离,因为这个函数已经在 KmeanscucDistance 内核中执行。 在 KmeansSoftMax 中,我们仅将归一化所提供的数据。
在内核参数中,我们将传递指向两个数据缓冲区的指针,以及所用聚类总数。 在数据缓冲区中,将有一个源数据缓冲区 distance,和一个结果缓冲区 softmax。 两个缓冲区均拥有相同的大小,并且是矩阵的向量表示,矩阵的行表示序列的各个元素,列则表示聚类。
内核将根据聚类样本中元素的数量,在一维任务空间中启动。 我故意不将其称为“训练样本”,因为在训练第二个模型和最终操作时都要用到内核。 显然,这两种变体中的数据输入将有所不同。
在我们继续实现内核代码之前,我们要记住,我们对归一化函数做了一些修改,现在如下所示。
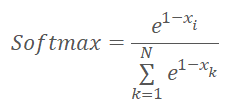
其中 x 是到聚类中心的距离,并在 0 和 1 之间的范围内归一化。
现在我们看看上述公式的实现。 在内核主体中,我们首先判定线程标识符,它标识在序列中所分析的元素。 我们还判定缓冲区中直至所分析向量开始的偏移量。 由于初始数据和结果张量大小相同,两个缓冲区中的偏移量也将相同。
接下来,为了在 0 到 1 范围内归一化距离,我们需要找到至聚类中心的最大偏差。 请记住,在计算距离时,我们用的是平方偏差。 这意味着距离向量中的所有数值都将为正值。 这会令事情变得容易一些。 我们声明私密变量 m,以便写入最大距离,并用向量的第一个元素值来初始化它。 接下来,我们创建一个循环,遍历向量的所有元素。 在向量主体中,我们将取元素值与保存值比较,并将最大值写入变量。
一旦确定了最高值,我们就可以继续计算每个元素的指数值。 此外,我们可以立即计算整个向量的指数值之和。 为了求和,我们用 0 值初始化私密变量 sum。 相关的算术运算将在下一个循环中执行。 循环迭代次数等于模型中的聚类数量。 在循环主体中,我们首先将至聚类中心的距离归一化,并将“反向”距离的指数值保存在私密变量之中。 将结果值添加到总和,然后存到结果缓冲区。 在将数值写入缓冲区之前,使用私密变量,可以最大限度地减少慢速全局内存访问的次数。
一旦循环迭代完成后,我们需要将获得的指数值除以总和来进行数据的归一化。 为了执行这些操作,我们创建另一个迭代循环,其次数等于聚类数量。 循环完成后退出内核。
__kernel void KmeansSoftMax(__global double *distance, __global double *softmax, inсt total_k ) { int i = get_global_id(0); int shift = i * total_k; double m=distance[shift]; for(int k = 1; k < total_k; k++) m = max(distance[shift + k],m); double sum = 0; for(int k = 0; k < total_k; k++) { double value = exp(1-distance[shift + k]/m); sum += value; softmax[shift + k] = value; } for(int k = 0; k < total_k; k++) softmax[shift + k] /= sum; }
我们已经扩展了 OpenCL 程序的功能。 现在我们只需要加入从 CKmeans 类中调用内核。 我们将坚持如先前的相同方案来添加调用内核代码。
首先,根据命名策略添加常量。
#define def_k_kmeans_softmax 5 #define def_k_kmsm_distance 0 #define def_k_kmsm_softmax 1 #define def_k_kmsm_total_k 2
然后,我们将内核声明添加到 OpenCL 环境初始化函数 OpenCLCreate 当中。
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(6)) { delete result; .return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_softmax, "KmeansSoftMax")) { delete result; .return NULL; } //--- return result; }
当然,我们需要类的一个新方法 CKmeans::SoftMax。 该方法在参数中接收指向初始数据缓冲区的指针。 操作的结果则是,该方法将返回相同大小的结果缓冲区。
在方法主体中,我们首先检查我们的聚类是否以前已训练过。 如有必要,初始化模型训练过程。 我要提醒大家,我们在模型训练方法中对学习样本的最大规模设置了限制。 因此,如果模型之前未经训练,则应在参数中向方法传递足够大的样本。 否则,该方法将返回指向结果缓冲区的无效指针。 如果数据聚类模型已训练过了,则解除对样本规模的限制。
CBufferDouble *CKmeans::SoftMax(CBufferDouble *data)
{
if(!m_bTrained && !Study(data, (c_aMeans.Maximum() == 0)))
.return NULL;
在下一步中,我们检查指向所用对象的指针的有效性。 这也许看起来很奇怪,我们首先要调用学习方法,然后再检查对象指针。 事实上,学习方法本身就拥有类似的控制模块。 如果我们在继续操作之前一直调用模型训练方法,这些控制则无必要,因为它们在训练方法内部会重复控制。 但是,如果我们采用预训练模型,我们就不会调用训练方法,那么我们就无法得到它的控制权。 而依据无效指针进一步执行操作将导致严重错误。 因此,我们必须重新检查指针。
if(CheckPointer(data) == POINTER_INVALID || CheckPointer(c_OpenCL) == POINTER_INVALID) .return NULL;
检查指针之后,我们要检查源数据缓冲区的大小。 它必须至少包含描述系统第一个状态的向量。 还有,缓冲区中的数据量必须是系统状态描述向量的倍数。
int total = data.Total(); if(total <= 0 || m_iClusters < 2 || (total % m_iVectorSize) != 0) .return NULL;
然后,我们将判定应该分布在聚类之间的系统状态数量。
int rows = total / m_iVectorSize; if(rows < 1) .return NULL;
接下来,我们需要初始化缓冲区,以便计算和归一化距离。 初始化算法非常简单。 我们首先检查缓冲区指针的有效性,如有必要,创建一个新对象。 然后我们用零值填充缓冲区。
if(CheckPointer(c_aDistance) == POINTER_INVALID) { c_aDistance = new CBufferDouble(); if(CheckPointer(c_aDistance) == POINTER_INVALID) .return NULL; } c_aDistance.BufferFree(); if(!c_aDistance.BufferInit(rows * m_iClusters, 0)) .return NULL; if(CheckPointer(c_aSoftMax) == POINTER_INVALID) { c_aSoftMax = new CBufferDouble(); if(CheckPointer(c_aSoftMax) == POINTER_INVALID) .return NULL; } c_aSoftMax.BufferFree(); if(!c_aSoftMax.BufferInit(rows * m_iClusters, 0)) .return NULL;
为了完成准备工作,我们在 OpenCL 环境中创建必要的数据缓冲区。
if(!data.BufferCreate(c_OpenCL) || !c_aMeans.BufferCreate(c_OpenCL) || !c_aDistance.BufferCreate(c_OpenCL) || !c_aSoftMax.BufferCreate(c_OpenCL)) .return NULL;
准备工作至此完成。 现在我们继续调用所需的内核。 为了实现该方法的全部功能,我们需要创建两个内核的顺序调用:
- 判定至聚类中心的距离 KmeanscultDistance;
- 距离归一化 KmeansSoftMax。
内核调用算法非常简单,类似于前面讲述的聚类结果的统计方法。 首先,我们需要将参数传递给内核。
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_data, data.GetIndex())) .return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_means, c_aMeans.GetIndex())) .return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_distance, c_aDistance.GetIndex())) .return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_distance, def_k_kmd_vector_size, m_iVectorSize)) .return NULL;
然后我们指定问题空间的维度,和每个维度中的偏移量。
uint global_work_offset[2] = {0, 0}; uint global_work_size[2]; global_work_size[0] = rows; global_work_size[1] = m_iClusters;
然后我们将内核放入执行队列,并读取操作执行结果。
if(!c_OpenCL.Execute(def_k_kmeans_distance, 2, global_work_offset, global_work_size)) .return NULL; if(!c_aDistance.BufferRead()) .return NULL;
针对第二个内核,重复这些操作。
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_distance, c_aDistance.GetIndex())) .return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_softmax, c_aSoftMax.GetIndex())) .return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_softmax, def_k_kmsm_total_k, m_iClusters)) .return NULL; uint global_work_offset1[1] = {0}; uint global_work_size1[1]; global_work_size1[0] = rows; if(!c_OpenCL.Execute(def_k_kmeans_softmax, 1, global_work_offset1, global_work_size1)) .return NULL; if(!c_aSoftMax.BufferRead()) .return NULL;
在最后,清除 OpenCL 环境的内存,并退出该方法,同时返回指向结果缓冲区的指针。
data.BufferFree(); c_aDistance.BufferFree(); //--- return c_aSoftMax; }
在 k-means 聚类里完成所有 CKmeans 修改相关的操作。 现在我们可以继续测试该方法。 为此目的,我们创建一个名为 kmeans_net.mq5 的智能系统,它是依据有关监督学习算法文章中的智能系统建模的。 为了测试实现,我将聚类结果输入到一个含有三个隐藏层的全连通感知器中。 附件中提供了完整的智能系统代码。 请注意 Train 学习函数。
在函数伊始,我们初始化一个对象实例,以便在聚类对象中使用 OpenCL 环境。 然后,我们将指向所创建对象的指针传递给聚类对象实例。 不要忘记检查操作执行结果。
void Train(datetime StartTrainBar = 0) { COpenCLMy *opencl = OpenCLCreate(cl_unsupervised); if(CheckPointer(opencl) == POINTER_INVALID) { ExpertRemove(); return; } if(!Kmeans.SetOpenCL(opencl)) { delete opencl; ExpertRemove(); return; }
初始化对象成功之后,我们判定训练周期的边界。
MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
正在加载历史数据。 请注意,加载到缓冲区的指标数据是以时间序列表达,而不是报价。 这很重要,因为我们可以对数组中的元素进行反向排序。 因此,为了实现数据的可比性,我们必须将报价数组转换为时间序列。
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
成功加载历史数据后,加载预训练的聚类模型。
int handl = FileOpen(StringFormat("kmeans_%d.net", Clusters), FILE_READ | FILE_BIN); if(handl == INVALID_HANDLE) { ExpertRemove(); return; } if(FileReadInteger(handl) != Kmeans.Type()) { ExpertRemove(); return; } bool result = Kmeans.Load(handl); FileClose(handl); if(!result) { ExpertRemove(); return; }
处理正在形成的训练样本和目标值。
int total = bars - (int)HistoryBars - 1; double data[], fractals[]; if(ArrayResize(data, total * 8 * HistoryBars) <= 0 || ArrayResize(fractals, total * 3) <= 0) { ExpertRemove(); return; } //--- for(int i = 0; (i < total && !IsStopped()); i++) { Comment(StringFormat("Create data: %d of %d", i, total)); for(int b = 0; b < (int)HistoryBars; b++) { int bar = i + b; int shift = (i * (int)HistoryBars + b) * 8; double open = Rates[bar].open; data[shift] = open - Rates[bar].low; data[shift + 1] = Rates[bar].high - open; data[shift + 2] = Rates[bar].close - open; data[shift + 3] = RSI.GetData(MAIN_LINE, bar); data[shift + 4] = CCI.GetData(MAIN_LINE, bar); data[shift + 5] = ATR.GetData(MAIN_LINE, bar); data[shift + 6] = MACD.GetData(MAIN_LINE, bar); data[shift + 7] = MACD.GetData(SIGNAL_LINE, bar); } int shift = i * 3; int bar = i + 1; fractals[shift] = (int)(Rates[bar - 1].high <= Rates[bar].high && Rates[bar + 1].high < Rates[bar].high); fractals[shift + 1] = (int)(Rates[bar - 1].low >= Rates[bar].low && Rates[bar + 1].low > Rates[bar].low); fractals[shift + 2] = (int)((fractals[shift] + fractals[shift]) == 0); } if(IsStopped()) { ExpertRemove(); return; } CBufferDouble *Data = new CBufferDouble(); if(CheckPointer(Data) == POINTER_INVALID || !Data.AssignArray(data)) return; CBufferDouble *Fractals = new CBufferDouble(); if(CheckPointer(Fractals) == POINTER_INVALID || !Fractals.AssignArray(fractals)) return;
由于我们的聚类方法可以处理初始数据数组,因此我们可以一次性对整个训练样本进行聚类。
ResetLastError(); CBufferDouble *softmax = Kmeans.SoftMax(Data); if(CheckPointer(softmax) == POINTER_INVALID) { printf("Runtime error %d", GetLastError()); ExpertRemove(); return; }
所有这些操作成功完成后,softmax 缓冲区将包含感知器的训练样本。 我们还提前准备了目标值。 如此,我们就可以进入第二个模型训练周期。
与监督学习算法测试类似,模型训练将用两个嵌套循环来实现。 外循环将计算训练世代。 我们在某个事件触发时退出循环。
首先,我们要做一些准备工作。 我们需要初始化所需的局部变量。
if(CheckPointer(TempData) == POINTER_INVALID) { TempData = new CArrayDouble(); if(CheckPointer(TempData) == POINTER_INVALID) { ExpertRemove(); return; } } delete opencl; double prev_un, prev_for, prev_er; dUndefine = 0; dForecast = 0; dError = -1; dPrevSignal = 0; bool stop = false; int count = 0; do { prev_un = dUndefine; prev_for = dForecast; prev_er = dError; ENUM_SIGNAL bar = Undefine; //--- stop = IsStopped();
只有这样,我们才能继续进行嵌套循环。 嵌套循环迭代的次数将等于训练样本的大小减去验证区域的小“尾巴”。
即使迭代次数等于样本大小,我们每次也都会为学习过程选择一个随机元素。 我们将在嵌套循环的开始处定义它。 使用来自训练样本的随机向量确保统一的模型训练。
for(int it = 0; (it < total - 300 && !IsStopped()); it++) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 300)) + 300;
依据随机所选元素的索引,判定初始数据缓冲区中的偏移量,并将必要的向量复制到临时缓冲区。
TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
在生成初始数据向量后,我们将其输入到神经网络的前向方法中。 在一次成功的前向通测后,我们得到了它的结果。
if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
调用 Softmax 函数对结果进行归一化。
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum);
为了直观地跟踪模型学习过程,我们在图表上显示当前状态。
switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; } string s = StringFormat("Study -> Era %d -> %.2f -> Undefine %.2f%% foracast %.2f%%\n %d of %d -> %.2f%% \nError %.2f\n%s -> %.2f ->> Buy %.5f - Sell %.5f - Undef %.5f", count, dError, dUndefine, dForecast, it + 1, total - 300, (double)(it + 1.0) / (total - 300) * 100, Net.getRecentAverageError(), EnumToString(DoubleToSignal(dPrevSignal)), dPrevSignal, TempData[1], TempData[2], TempData[0]); Comment(s); stop = IsStopped();
在循环迭代末尾,调用反向传播方法,并更新模型中的权重矩阵。
if(!stop) { shift = i * 3; TempData.Clear(); TempData.Add(Fractals.At(shift + 2)); TempData.Add(Fractals.At(shift)); TempData.Add(Fractals.At(shift + 1)); Net.backProp(TempData); ENUM_SIGNAL signal = DoubleToSignal(dPrevSignal); if(signal != Undefine) { if((signal == Sell && Fractals.At(shift + 1) == 1) || (signal == Buy && Fractals.At(shift) == 1)) dForecast += (100 - dForecast) / Net.recentAverageSmoothingFactor; else dForecast -= dForecast / Net.recentAverageSmoothingFactor; dUndefine -= dUndefine / Net.recentAverageSmoothingFactor; } else { if(Fractals.At(shift + 2) == 1) dUndefine += (100 - dUndefine) / Net.recentAverageSmoothingFactor; } } }
在每个训练世代之后,我们将在验证图上显示图形标签。 为了实现这个功能,我们来创建另一个嵌套循环。 循环主体中的操作主要重复前面所述的循环,只有两个主要区别:
- 我们将按元素的顺序提取元素,替代随机选择。
- 与此不会执行反向传播方法。
在验证样本中,检查模型如何能在参数不过度拟合的情况下处理新数据。 这就是为什么没有反向传播方法。 因此,模型操作结果不依赖于数据馈送序列(递归模型除外)。 如此,我们不需要花费资源来生成一个随机数,并按顺序获取系统的所有状态。
count++; for(int i = 0; i < 300; i++) { TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData); double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum); //--- switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; }
添加在图表上显示对象,并退出验证周期。
if(DoubleToSignal(dPrevSignal) == Undefine) DeleteObject(Rates[i + 2].time); else DrawObject(Rates[i + 2].time, dPrevSignal, Rates[i + 2].high, Rates[i + 2].low); }
在完成外循环的迭代之前,我们保存当前模型状态,并将误差值添加到训练动态文件中。
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, dUndefine, dForecast, Rates[0].time, false); printf("Era %d -> error %.2f %% forecast %.2f", count, dError, dForecast); ChartScreenShot(0, FileName + IntegerToString(count) + ".png", 750, 400); int h = FileOpen(FileName + ".csv", FILE_READ | FILE_WRITE | FILE_CSV); if(h != INVALID_HANDLE) { FileSeek(h, 0, SEEK_END); FileWrite(h, eta, count, dError, dUndefine, dForecast); FileFlush(h); FileClose(h); } } } while((!(DoubleToSignal(dPrevSignal) != Undefine || dForecast > 70) || !(dError < 0.1 && MathAbs(dError - prev_er) < 0.01 && MathAbs(dUndefine - prev_un) < 0.1 && MathAbs(dForecast - prev_for) < 0.1)) && !stop);
我们根据某些度量值退出学习周期。 这些度量值与我们在监督学习智能系统中所用的相同。
在退出训练方法之前,我们应该删除在模型训练方法主体中所创建的对象。
if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(TempData) == POINTER_DYNAMIC) delete TempData; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); }
完整的智能系统代码可在文后附件中找到。
为了评估该智能系统的性能,我们取用我们在前一篇文章中训练过,并在前一次测试中用到的 500 个聚类模型对其进行了测试。 训练图形如下所示。

如您所见,训练图非常平滑。 为了训练模型,我采用了 Adam 参数优化方法。 前 20 个世代展示出损失函数逐渐减少,而这伴随着动量累积。 然后,损失函数值显著地急剧下降到某一最小值。 先前获得的监督模型的训练图的损失函数具有明显的转折。 例如,下面是更复杂的关注度 模型的训练图。

比较两幅图形,您可以看到初步数据聚类在多大程度上提高了简单模型的效率。
结束语
在本文中,我们研究并实现了在解决实际案例中运用聚类结果的两个可能选项。 测试结果展示出两种方法的有效性。 在第一种情况下,我们有一个简单的模型,具有非常清晰和可理解的结果,非常透明和可理解。 第二种方法则令模型训练更加平滑和快速。 它还提高了模型的性能。
参考文献列表
- 神经网络变得轻松
- 神经网络变得轻松(第二部分):网络训练和测试
- 神经网络变得轻松(第三部分):卷积网络
- 神经网络变得轻松(第四部分):循环网络
- 神经网络变得轻松(第五部分):OpenCL 中的多线程计算
- 神经网络变得轻松(第六部分):神经网络学习率实验
- 神经网络变得轻松(第七部分):自适应优化方法
- 神经网络变得轻松(第八部分):关注机制
- 神经网络变得轻松(第九部分):操作归档
- 神经网络变得轻松(第十部分):多目击者关注
- 神经网络变得轻松(第十一部分):自 GPT 获取
- 神经网络变得轻松(第十二部分):舍弃
- 神经网络变得轻松(第十三部分):批次常规化
- 神经网络变得轻松(第十四部分):数据聚类
- 神经网络变得轻松(第十五部分):利用 MQL5 进行数据聚类
本文中用到的程序
| # | 发行 | 类型 | 说明 |
|---|---|---|---|
| 1 | kmeans.mq5 | 智能交易系统 | 训练模型的智能系统 |
| 2 | kmeans_net.mq5 | EA | 该智能系统测试给第二个模型传递数据 |
| 3 | kmeans_stat.mq5 | EA | 测试智能系统的统计方法 |
| 4 | kmeans.mqh | 类库 | 实现 k-均值方法的函数库 |
| 5 | unsupervised.cl | 代码库 | OpenCL 程序代码库,实现 k-均值方法 |
| 6 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 7 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/10943
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。


 数据科学与机器学习(第 03 部分):矩阵回归
数据科学与机器学习(第 03 部分):矩阵回归
 学习如何基于建仓/派发(AD)设计交易系统
学习如何基于建仓/派发(AD)设计交易系统
2022.05.30 21:57:27.477 kmeans (WDO$,H1) 800 Model error inf
2022.05.30 22:00:23.937 kmeans (WDO$,H1) 850 Model error inf
2022.05.30 22:04:22.069 kmeans (WDO$,H1) 900 模型错误 inf
2022.05.30 22:08:04.179 kmeans (WDO$,H1) 950 模型错误 inf
2022.05.30 22:10:56.190 kmeans (WDO$,H1) 1000 模型错误 inf
2022.05.30 22:10:56.211 kmeans (WDO$,H1) 调用 ExpertRemove() 函数
如何解决此错误?
如何解决此错误?
这不是程序执行错误。这一行显示的是模型误差(到聚类中心的平均距离)。但我们看到的 inf 值超出了计算精度。尝试缩放原始值。例如,除以 10,000
Este não é um erro de execução do programa.该行显示了模型错误(与群集中心的距离)。我们还看到了数值的精确性问题。我们需要对原始值进行标注。例如,除以 10.000
我还是找不到解决方案。
我还是找不到解决办法。