Нейросети — это просто (Часть 10): Multi-Head Attention (многоголовое внимание)

Содержание
- Введение
- 1. Multi-Head Attention
- 2. Немного математики
- 3. Positional Encoding
- 4. Реализация
- 4.1. Отказ от использования тензора Ключей
- 4.2. Класс Multi-Head Attention
- 4.3. Прямой проход
- 4.4. Обратный проход
- 4.5. Точечные изменения в базовых классах нейронной сети
- 5. Тестирование
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
В статье "Нейросети — это просто (Часть 8): Механизмы внимания" мы рассмотрели механизм само-внимания и вариант его реализации. В практике современных архитектур нейронных сетей используется так называемый Multi-Head Attention. Это запуск нескольких параллельных потоков self-attention с различными весовыми коэффициентами. Подобное решение должно лучше выявлять связи между различными элементами последовательности. Предлагаю реализовать подобную архитектуру и на практике сравнить результаты работы двух вариантов.
1. Multi-Head Attention
Немного напомню, в алгоритме Self-Attention используется 3 обучаемых матрицы весовых коэффициентов (Wq, Wk и Wv). Данные матрицы используются для получения 3-х сущностей Query (Запрос), Key (Ключ) и Value (Значение). Первые две определяют попарную взаимосвязь между элементами последовательности, а последняя — контекст анализируемого элемента.
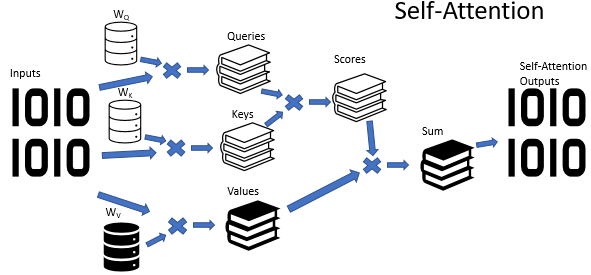
Не секрет, что далеко не всегда ситуации бывают однозначны. Наверное, даже чаще одну и ту же ситуацию можно трактовать с различных точек зрения. И от выбранной точки зрения выводы могут быть абсолютно противоположными. В таких ситуациях важно рассмотреть все возможные варианты, и только после тщательного анализа сделать вывод. Именно для решения таких задач и было предложено многоголовое внимание. Здесь каждая "голова" имеет свое мнение, а решение принимается взвешенным голосованием.
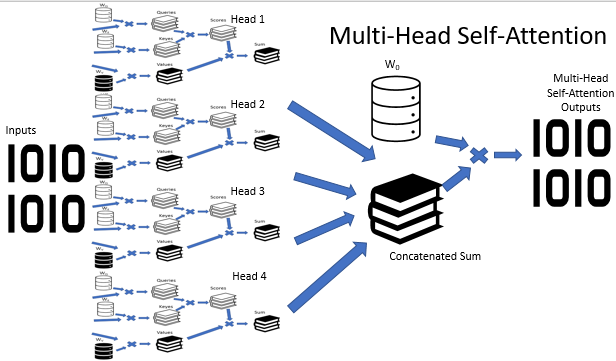
В архитектуре Multi-Head Attention параллельно используется несколько потоков само-внимания с различными весовыми коэффициентами, что имитирует разносторонний разбор ситуации. Результаты работы потоков само-внимания конкатенируются в единый тензор. А итоговый результат алгоритма определяется умножением тензора на матрицу W0, параметры которой подбираются в процессе обучения нейронной сети. Вся эта архитектура подменяет блок Self-Attention в энкодере и декодере архитектуры трансформер.
2. Немного математики
Описывая алгоритм Self-Attention математическим языком, получаем формулу:
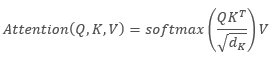 ,
,
где Q - тензор Запросов, K — тензор Ключей, V — тензор Значений, d — размерность вектора одного ключа.
В свою очередь
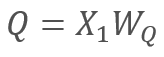 и
и 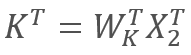 ,
,
где X1 и X2 — элементы последовательности, Wq и Wk — матрицы весовых коэффициентов запросов и ключей, соответственно. Таким образом получаем:
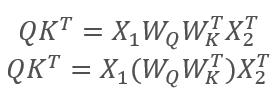
По свойству ассоциативности матриц мы можем сначала умножить матрицы весовых коэффициентов Wq и Wk. Легко заметить, что произведение матриц весовых коэффициентов не зависит от входной последовательности и едино для всех итераций конкретного блока Self-Attention (разумеется, до следующего обновления параметров матриц). Отсюда, с целью сокращения операций вычислений, мы можем для конкретного прохода сначала один раз вычислить промежуточную матрицу и потом воспользоваться ею для последующих вычислений.
Или же мы можем пойти еще дальше и обучать одну матрицу вместо двух. Здесь следует обратить внимание, как бы ни казалось странным, но не всегда обучение одной матрицы позволит сократить количество операций. К примеру, для больших размерностей вектора входной последовательности можно матрицами Wq и Wk понизить размерность. В таком случае, при длине входных векторов X1 и X2 в 100 элементов единая матрица будет содержать 10k элементов (100*100). В тоже время при понижении размерности матрицами Wq и Wk в 10 раз получим 2 матрицы по 1k элементов (100*10). Поэтому следует подходить внимательно к выбору пути решения с учетом производительности сети и качества результатов ее работы.
3. Positional Encoding
Еще один момент, на который следует обратить внимание при работе с тайм-сериями, это расстояние между элементами в последовательности. Алгоритм внимания осуществляет попарную проверку зависимостей между элементами последовательности, используя одни и те же матрицы для всех элементов последовательности. В тоже время, взаимовлияние элементов таймсерий сильно зависит от временного промежутка между ними. Поэтому становится острым вопрос добавления алгоритма позиционного кодирования.
Идеальный алгоритм кодирования позиции должен удовлетворять нескольким критериям:
- каждый элемент последовательности должен получить уникальный код;
- шаг между любыми двумя последовательными элементами должен быть постоянным;
- модель должна без труда подстраиваться и обобщаться для последовательностей любой длины;
- модель должна быть детерминирована.
Авторы архитектуры Трансформер предложили использовать для кодирования последовательности не отдельный элемент, а целый вектор размерностью равным размерности элемента входной последовательности. При этом для описания четных элементов вектора используется синус, а для нечетных элементов — косинус. Наверно следует уточнить, что здесь под элементом последовательности считается не конкретный элемент массива, а вектор, описывающий состояние отдельной позиции. В нашем случае это будет вектор, описывающий одну свечу.
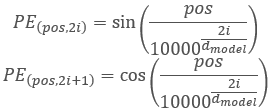 ,
,
где pos — позиция элемента последовательности, i — позиция элемента в векторе одного элемента последовательности, d — размерность вектора одного элемента последовательности.
Такое решение позволяет не только задать позиции каждого элемента последовательности, но и определить расстояние между ними.
Непосредственно в архитектуре Трансформера позиционное кодирование вынесено за ее рамки и осуществляется путем сложения тензора позиционного кодирования с тензором входной последовательности до передачи данных на вход первого энкодера. Вполне ожидаемы 2 вопроса:
- Почему сложение, а не конкатенация векторов?
- Насколько сложение тензоров исказит исходные данные?
Конкатенация бы увеличила размерность данных, а, следовательно, и количество итераций. Все это снижает общую производительность системы. Второй аспект такого решение — сложение векторов позволяет позиционировать не только вектор отдельного элемента последовательности, но и каждый элемент вектора. Гипотетически это позволяет анализировать зависимости не только между элементами последовательности, но и между их отдельными составляющими.
По поводу искажения данных, нейросеть ничего не знает о значении каждого элемента и обучается уже на данных с добавленным кодированием, т.е. она не анализирует отдельно элемент и его позицию. К примеру, если мы увидим одинаковые дожи на 2-й и 20-й позиции, то, наверное, отдадим предпочтение ближайшей. Для нейронной сети с позиционным кодированием это будут абсолютно разные сигналы и будут отработаны согласно накопленным при обучении данным.
4. Реализация
Рассмотрим реализацию изложенных выше решений. В предыдущей реализации алгоритма Self-Attention для векторов Запросов и Ключей мы использовали размерность аналогичную входной последовательности. Поэтому, первое, что я изменил, это перестроил алгоритм на обучение одной матрицы.
4.1. Отказ от использования тензора Ключей
Практическое решение данного вопроса оказалось довольно простым. В методе прямого прохода CNeuronAttentionOCL::feedForward закомментировал вызов аналогичного метода сверточного слоя Key и при вызове кернела расчета Score подменил сверточный слой Key на предыдущий нейронный слой. Изменения по коду метода выделены заливкой.
bool CNeuronAttentionOCL::feedForward(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=1; OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,prevLayer.getOutputIndex()); OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,prevLayer.Neurons()); if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Normalize: %d",GetLastError()); return false; } if(!prevLayer.Output.BufferRead()) return false; } //--- if(CheckPointer(Querys)==POINTER_INVALID || !Querys.FeedForward(prevLayer)) return false; //if(CheckPointer(Keys)==POINTER_INVALID || !Keys.FeedForward(prevLayer)) // return false; if(CheckPointer(Values)==POINTER_INVALID || !Values.FeedForward(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_score,Scores.GetIndex()); OpenCL.SetArgument(def_k_AttentionScore,def_k_as_dimension,iWindow); if(!OpenCL.Execute(def_k_AttentionScore,1,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionScore: %d",GetLastError()); return false; } if(!Scores.BufferRead()) return false; } //--- Далее код без изменений
Подобным образом были внесены изменения и в метод обратного распространения ошибки CNeuronAttentionOCL::calcInputGradients. Следует обратить внимание, поскольку запись первой порции градиентов ошибки в буфер предыдущего слоя осуществляется раньше, то и процесс аккумулирование градиентов начинается раньше. Изменения по тексту кода выделены заливкой.
bool CNeuronAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- if(!FF2.calcInputGradients(FF1)) return false; if(!FF1.calcInputGradients(AttentionOut)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,Gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } //--- { uint global_work_offset[2]={0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iWindow; OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_gradient,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys_g,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys_g,Querys.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values,Values.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values_g,Values.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_scores,Scores.GetIndex()); if(!OpenCL.Execute(def_k_AttentionGradients,2,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionGradients: %d",GetLastError()); return false; } double temp[]; if(Querys.getGradient(temp)<=0) return false; } //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } //--- if(!Querys.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } ////--- // if(!Keys.calcInputGradients(prevLayer)) // return false; ////--- // { // uint global_work_offset[1]={0}; // uint global_work_size[1]; // global_work_size[0]=iUnits; // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); // OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); // OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); // if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) // { // printf("Error of execution kernel MatrixSum: %d",GetLastError()); // return false; // } // double temp[]; // if(AttentionOut.getGradient(temp)<=0) // return false; // } //--- Далее код без изменений
Аналогично закомментировано обновление весовых коэффициентов сверточного слоя Key в методе CNeuronAttentionOCL::updateInputWeights, как и в целом объявление данного объекта.
С полным кодом всех методов и функций можно ознакомиться во вложении.
4.2. Класс Multi-Head Attention
Построение Multi-Head Attention вынесено в отдельный класс CNeuronMHAttentionOCL на базе родительского класса CNeuronAttentionOCL. В блоке protected объявим дополнительные экземпляры сверточных слоев Querys и Values по количеству голов внимания. В примере используется 4 головы. Также добавим буфер Scores и полносвязный слой AttentionOut для каждой головы внимания. Кроме того, нам потребуется полносвязный слой для конкатенации данных с голов внимания AttentionConcatenate и сверточный слой Weights0, который позволит имитировать взвешенное голосование и понизить размерность тензора результатов.
class CNeuronMHAttentionOCL : public CNeuronAttentionOCL { protected: CNeuronConvOCL *Querys2; ///< Convolution layer for Querys Head 2 CNeuronConvOCL *Querys3; ///< Convolution layer for Querys Head 3 CNeuronConvOCL *Querys4; ///< Convolution layer for Querys Head 4 CNeuronConvOCL *Values2; ///< Convolution layer for Values Head 2 CNeuronConvOCL *Values3; ///< Convolution layer for Values Head 3 CNeuronConvOCL *Values4; ///< Convolution layer for Values Head 4 CBufferDouble *Scores2; ///< Buffer for Scores matrix Head 2 CBufferDouble *Scores3; ///< Buffer for Scores matrix Head 3 CBufferDouble *Scores4; ///< Buffer for Scores matrix Head 4 CNeuronBaseOCL *AttentionOut2; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionOut3; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionOut4; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionConcatenate;///< Layer of Concatenate Self-Attention Out CNeuronConvOCL *Weights0; ///< Convolution layer for Weights0 //--- virtual bool feedForward(CNeuronBaseOCL *prevLayer); ///< Feed Forward method.@param prevLayer Pointer to previos layer. virtual bool updateInputWeights(CNeuronBaseOCL *prevLayer); ///< Method for updating weights.@param prevLayer Pointer to previos layer. /// Method to transfer gradients inside Head Self-Attention virtual bool calcHeadGradient(CNeuronConvOCL *query, CNeuronConvOCL *value, CBufferDouble *score, CNeuronBaseOCL *attention, CNeuronBaseOCL *prevLayer); public: /** Constructor */CNeuronMHAttentionOCL(void){}; /** Destructor */~CNeuronMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
Набор методов класса переписывает виртуальные методы родительского класса и, наверно, можно уже назвать стандартным. Единственным исключением является метод calcHeadGradient, который описывает итерации распространения градиента ошибки, повторяющиеся для каждой головы внимания.
Конструктор класса оставим пустой, инициализацию новых объектов перенесем в метод инициализации Init. В деструкторе класса организуем удаление экземпляров объектов, созданных данным классом и объявленных в блоке protected.
CNeuronMHAttentionOCL::~CNeuronMHAttentionOCL(void) { if(CheckPointer(Querys2)!=POINTER_INVALID) delete Querys2; if(CheckPointer(Querys3)!=POINTER_INVALID) delete Querys3; if(CheckPointer(Querys4)!=POINTER_INVALID) delete Querys4; if(CheckPointer(Values2)!=POINTER_INVALID) delete Values2; if(CheckPointer(Values3)!=POINTER_INVALID) delete Values3; if(CheckPointer(Values4)!=POINTER_INVALID) delete Values4; if(CheckPointer(Scores2)!=POINTER_INVALID) delete Scores2; if(CheckPointer(Scores3)!=POINTER_INVALID) delete Scores3; if(CheckPointer(Scores4)!=POINTER_INVALID) delete Scores4; if(CheckPointer(Weights0)!=POINTER_INVALID) delete Weights0; if(CheckPointer(AttentionOut2)!=POINTER_INVALID) delete AttentionOut2; if(CheckPointer(AttentionOut3)!=POINTER_INVALID) delete AttentionOut3; if(CheckPointer(AttentionOut4)!=POINTER_INVALID) delete AttentionOut4; if(CheckPointer(AttentionConcatenate)!=POINTER_INVALID) delete AttentionConcatenate; }
Метод Init построен по аналогии с методом родительского класса. В начале метода вызовем одноименный метод родительского класса.
bool CNeuronMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint units_count,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronAttentionOCL::Init(numOutputs,myIndex,open_cl,window,units_count,optimization_type)) return false;
Затем проинициализируем экземпляры сверточных слоев Querys. Обратите внимание, что инициализируем объекты, начиная со второй головы, т.к. экземпляры всех объектов для первой головы инициализированы в родительском классе.
if(CheckPointer(Querys2)==POINTER_INVALID) { Querys2=new CNeuronConvOCL(); if(CheckPointer(Querys2)==POINTER_INVALID) return false; if(!Querys2.Init(0,6,open_cl,window,window,window,units_count,optimization_type)) return false; Querys2.SetActivationFunction(None); } //--- if(CheckPointer(Querys3)==POINTER_INVALID) { Querys3=new CNeuronConvOCL(); if(CheckPointer(Querys3)==POINTER_INVALID) return false; if(!Querys3.Init(0,7,open_cl,window,window,window,units_count,optimization_type)) return false; Querys3.SetActivationFunction(None); } //--- if(CheckPointer(Querys4)==POINTER_INVALID) { Querys4=new CNeuronConvOCL(); if(CheckPointer(Querys4)==POINTER_INVALID) return false; if(!Querys4.Init(0,8,open_cl,window,window,window,units_count,optimization_type)) return false; Querys4.SetActivationFunction(None); }
Аналогично инициализируем экземпляры классов для Values, Scores для AttentionOut.
if(CheckPointer(Values2)==POINTER_INVALID) { Values2=new CNeuronConvOCL(); if(CheckPointer(Values2)==POINTER_INVALID) return false; if(!Values2.Init(0,9,open_cl,window,window,window,units_count,optimization_type)) return false; Values2.SetActivationFunction(None); } //--- if(CheckPointer(Values3)==POINTER_INVALID) { Values3=new CNeuronConvOCL(); if(CheckPointer(Values3)==POINTER_INVALID) return false; if(!Values3.Init(0,10,open_cl,window,window,window,units_count,optimization_type)) return false; Values3.SetActivationFunction(None); } //--- if(CheckPointer(Values4)==POINTER_INVALID) { Values4=new CNeuronConvOCL(); if(CheckPointer(Values4)==POINTER_INVALID) return false; if(!Values4.Init(0,11,open_cl,window,window,window,units_count,optimization_type)) return false; Values4.SetActivationFunction(None); } //--- if(CheckPointer(Scores2)==POINTER_INVALID) { Scores2=new CBufferDouble(); if(CheckPointer(Scores2)==POINTER_INVALID) return false; } if(!Scores2.BufferInit(units_count*units_count,0.0)) return false; if(!Scores2.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(Scores3)==POINTER_INVALID) { Scores3=new CBufferDouble(); if(CheckPointer(Scores3)==POINTER_INVALID) return false; } if(!Scores3.BufferInit(units_count*units_count,0.0)) return false; if(!Scores3.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(Scores4)==POINTER_INVALID) { Scores4=new CBufferDouble(); if(CheckPointer(Scores4)==POINTER_INVALID) return false; } if(!Scores4.BufferInit(units_count*units_count,0.0)) return false; if(!Scores4.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(AttentionOut2)==POINTER_INVALID) { AttentionOut2=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut2)==POINTER_INVALID) return false; if(!AttentionOut2.Init(0,12,open_cl,window*units_count,optimization_type)) return false; AttentionOut2.SetActivationFunction(None); } //--- if(CheckPointer(AttentionOut3)==POINTER_INVALID) { AttentionOut3=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut3)==POINTER_INVALID) return false; if(!AttentionOut3.Init(0,13,open_cl,window*units_count,optimization_type)) return false; AttentionOut3.SetActivationFunction(None); } //--- if(CheckPointer(AttentionOut4)==POINTER_INVALID) { AttentionOut4=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut4)==POINTER_INVALID) return false; if(!AttentionOut4.Init(0,14,open_cl,window*units_count,optimization_type)) return false; AttentionOut4.SetActivationFunction(None); }
Инициализируем слой для конкатенации данных AttentionConcatenate. Это полносвязный слой, который будет использоваться только для передачи данных, следовательно количество исходящих соединений равно "0". При этом размер слоя должен быть достаточным, что бы хранить выходные данные всех 4-х голов внимания. Укажем количество нейронов в слое равным произведению 4-х окон выходного слоя одной головы на количество элементов в последовательности.
if(CheckPointer(AttentionConcatenate)==POINTER_INVALID) { AttentionConcatenate=new CNeuronBaseOCL(); if(CheckPointer(AttentionConcatenate)==POINTER_INVALID) return false; if(!AttentionConcatenate.Init(0,15,open_cl,4*window*units_count,optimization_type)) return false; AttentionConcatenate.SetActivationFunction(None); }
И в заключении метода инициализируем сверточный слой Weights0. Его задача выбрать оптимальную стратегию на основании данных, полученных от всех голов внимания. При этом будет понижена размерность выходных данных до размерности исходных данных, подаваемых на вход блока Multi-Head Attention. При инициализации слоя укажем размер входного окна и шага равным 4-м окнам данных предыдущего слоя, а размер выходного окна равным окну данных предыдущего слоя.
if(CheckPointer(Weights0)==POINTER_INVALID) { Weights0=new CNeuronConvOCL(); if(CheckPointer(Weights0)==POINTER_INVALID) return false; if(!Weights0.Init(0,16,open_cl,4*window,4*window,window,units_count,optimization_type)) return false; Weights0.SetActivationFunction(None); } //--- return true; }
С полным кодом всех методов и функций можно ознакомиться во вложении.
4.3. Прямой проход
Построение алгоритма прямого прохода осуществлялось большей частью с использованием ранее созданной программы OpenCL. Единственным исключением стало создание кернела конкатенации данных 4-х тензоров от каждой головы внимания в единый тензор. В параметрах кернел получает указатели на буферы исходных данных и размеры окон каждого буфера, а также указатель на буфер тензора результатов. Детализация размеров окон по буферам входящих данных добавлена для возможности конкатенации тензоров разных размеров с различными размерами окон.
__kernel void ConcatenateBuffers(__global double *input1, int window1, __global double *input2, int window2, __global double *input3, int window3, __global double *input4, int window4, __global double *output)
В теле кернела осуществляется поэлементное копирование данных из входящих массивов в исходящий. Алгоритм довольно простой, и я думаю, читателю не составит труда самостоятельно разобрать код во вложении.
В классе CNeuronMHAttentionOCL прямой проход организован в методе feedForward. В начале метода проверим действительность полученной ссылки на предыдущий слой и нормализуем входящие данные.
bool CNeuronMHAttentionOCL::feedForward(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=1; OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,prevLayer.getOutputIndex()); OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,prevLayer.Neurons()); if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Normalize: %d",GetLastError()); return false; } if(!prevLayer.Output.BufferRead()) return false; }
Затем вызовем одноименные методы сверточных слоев и пересчитаем значение тензоров Querys и Values для всех голов внимания.
if(CheckPointer(Querys)==POINTER_INVALID || !Querys.FeedForward(prevLayer)) return false; if(CheckPointer(Querys2)==POINTER_INVALID || !Querys2.FeedForward(prevLayer)) return false; if(CheckPointer(Querys3)==POINTER_INVALID || !Querys3.FeedForward(prevLayer)) return false; if(CheckPointer(Querys4)==POINTER_INVALID || !Querys4.FeedForward(prevLayer)) return false; if(CheckPointer(Values)==POINTER_INVALID || !Values.FeedForward(prevLayer)) return false; if(CheckPointer(Values2)==POINTER_INVALID || !Values2.FeedForward(prevLayer)) return false; if(CheckPointer(Values3)==POINTER_INVALID || !Values3.FeedForward(prevLayer)) return false; if(CheckPointer(Values4)==POINTER_INVALID || !Values4.FeedForward(prevLayer)) return false;
Далее пересчитаем внимание по каждой голове. Алгоритм аналогичен родительскому классу описанном в статье [8]. Ниже приведен код для одной головы-внимания. По остальным идентичный код, изменяются только указатели на объекты соответствующей головы внимания.
//--- Scores Head 1 { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_score,Scores.GetIndex()); OpenCL.SetArgument(def_k_AttentionScore,def_k_as_dimension,iWindow); if(!OpenCL.Execute(def_k_AttentionScore,1,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionScore: %d",GetLastError()); return false; } if(!Scores.BufferRead()) return false; } //--- { uint global_work_offset[2]={0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iWindow; OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_scores,Scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_inputs,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_values,Values.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_out,AttentionOut.getOutputIndex()); if(!OpenCL.Execute(def_k_AttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel Attention Out: %d",GetLastError()); return false; } double temp[]; if(!AttentionOut.getOutputVal(temp)) return false; }
После пересчета внимания по каждой голове конкатенируем результаты в единый тензор с помощью написанного ранее кернела.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input1,AttentionOut.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window1,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input2,AttentionOut2.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window2,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input3,AttentionOut3.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window3,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input4,AttentionOut4.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window4,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_out,AttentionConcatenate.getOutputIndex());
if(!OpenCL.Execute(def_k_ConcatenateMatrix,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Concatenate Matrix: %d",GetLastError());
return false;
}
double temp[];
if(!AttentionConcatenate.getOutputVal(temp))
return false;
}
Результат конкатенации тензоров пропускаем через сверточный слой Weights0 для понижения размерности результата работы Multi-Head Attention.
if(CheckPointer(Weights0)==POINTER_INVALID || !Weights0.FeedForward(AttentionConcatenate)) return false;
После чего усредняем полученный результат с данными предыдущего слоя и нормализуем результата.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Weights0.getOutputIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
if(!Output.BufferRead())
return false;
}
//---
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=1;
OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,Weights0.getOutputIndex());
OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,Weights0.Neurons());
if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Normalize: %d",GetLastError());
return false;
}
double temp[];
if(!Weights0.getOutputVal(temp))
return false;
}
Далее, по аналогии с родительским классом, пропускаем полученный результат через блок FeedForward.
if(!FF1.FeedForward(Weights0)) return false; if(!FF2.FeedForward(FF1)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,FF2.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Output.GetIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } if(!Output.BufferRead()) return false; } //--- return true; }
С полным кодом всех методов и функций можно ознакомиться во вложении.
4.4. Обратный проход
Обратный проход содержит два подпроцесса: передача градиента ошибки на уровень ниже и обновление матриц весовых коэффициентов. И если для обновления весовых коэффициентов мы будем использовать ранее созданные кернелы OpenCL, то для подпроцесса распределения градиента ошибки потребуются небольшие доработки.
Прежде всего нам потребуется распределить градиент ошибки по головам внимания. Для выполнения этой функции создадим кернел DeconcatenateBuffers. В параметрах кернелу передадим указатели на буферы для распределения градиента, размеры окон для каждого буфера и указатель на буфер градиентов, полученных от предыдущей итерации.
__kernel void DeconcatenateBuffers(__global double *output1, int window1, __global double *output2, int window2, __global double *output3, int window3, __global double *output4, int window4, __global double *inputs)
В начале кернела определим порядковый номер обрабатываемого элемента последовательности и смещение первой позиции для исходного тензора и тензора первой головы внимания.
{
int n=get_global_id(0);
int shift=n*(window1+window2+window3+window4);
int shift_out=n*window1;
Далее в цикле перенесем вектор градиентов ошибки для первой головы внимания.
for(int i=0;i<window1;i++) output1[shift_out+i]=inputs[shift+i];
По завершении цикла скорректируем позицию указателя в исходном тензоре и определим смещение первой позиции в буфере второй головы внимания. После чего запустим цикл копирования данных уже для второй головы внимания. Операции повторяются для каждой головы внимания.
//--- Head 2 shift+=window1; shift_out=n*window2; for(int i=0;i<window2;i++) output2[shift_out+i]=inputs[shift+i]; //--- Head 3 shift+=window2; shift_out=n*window3; for(int i=0;i<window3;i++) output3[shift_out+i]=inputs[shift+i]; //--- Head 4 shift+=window3; shift_out=n*window4; for(int i=0;i<window4;i++) output4[shift_out+i]=inputs[shift+i]; }
Позже, после пересчета градиентов ошибок по каждой голове внимания, нам потребуется объединить градиенты в единый буфер данных на предыдущий слой нейронной сети. Технически, мы могли бы воспользоваться кернелом SumMatrix, попарно складывая градиенты всех голов внимания. Но такое решение будет не оптимальным с точки зрения производительности. Поэтому, создадим еще один кернел Sum5Matrix. В параметрах кернела передадим указатели на буферы данных (5 входящих и 1 исходящий), размер окна данных и мультипликатор (коэффициент корректировки суммы). Наверно, следует уточнить, почему 5 входящих буферов при 4-х головах внимания. Пятый буфер предназначен для сквозной передачи градиента ошибки, позволяющий минимизировать риск затухания градиента.
__kernel void Sum5Matrix(__global double *matrix1, ///<[in] First matrix __global double *matrix2, ///<[in] Second matrix __global double *matrix3, ///<[in] Third matrix __global double *matrix4, ///<[in] Fourth matrix __global double *matrix5, ///<[in] Fifth matrix __global double *matrix_out, ///<[out] Output matrix int dimension, ///< Dimension of matrix double multiplyer ///< Multiplyer for output )
В теле кернела определим сдвиг первого элемента обрабатываемых векторов в последовательностях и запустим цикл по суммированию градиентов. Умножение суммы градиентов ошибки на мультипликатор, равный 0.2, позволяет усреднить значения передаваемой ошибки на предыдущий слой нейронной сети. В свою очередь, вывод мультипликатора в параметры сделан намеренно, для обеспечения возможности его подбора в процессе настройки работы алгоритма.
{
const int i=get_global_id(0)*dimension;
for(int k=0;k<dimension;k++)
matrix_out[i+k]=(matrix1[i+k]+matrix2[i+k]+matrix3[i+k]+matrix4[i+k]+matrix5[i+k])*multiplyer;
}
В классе CNeuronMHAttentionOCL каждый подпроцесс получит свой метод. За распространение градиента ошибки отвечает метод calcInputGradients. В параметрах метод получает указатель на объект предыдущего слоя нейронной сети, и в начале метода проверим действительность полученного указателя.
bool CNeuronMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
Затем посчитаем градиенты ошибки через блок FeedForward, воспользовавшись одноименными методами сверточных слоев FF1 и FF2.
if(!FF2.calcInputGradients(FF1)) return false; if(!FF1.calcInputGradients(Weights0)) return false;
И пронесем градиент ошибки в обход блока FeedForward. Среднее значение ошибки сохраним в буфере градиента слоя Weights0.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,Gradient.GetIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Weights0.getGradientIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
double temp[];
if(Weights0.getGradient(temp)<=0)
return false;
}
Мы подошли к моменту распределения градиента ошибки по головам внимания. Нам нужно увеличить размерность тензора градиента до размера конкатенированного буфера внимания. Для этого проведем градиент ошибки через сверточный слой Weights0, вызвав соответствующий метод сверточного слоя.
if(!Weights0.calcInputGradients(AttentionConcatenate)) return false;
Получив тензор градиентов ошибок достаточной длины, мы можем распределить ошибку по буферам голов внимания. Воспользуемся созданным выше кернелом деконкатенации.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output1,AttentionOut.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window1,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output2,AttentionOut2.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window2,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output3,AttentionOut3.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window3,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output4,AttentionOut4.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window4,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_inputs,AttentionConcatenate.getGradientIndex());
if(!OpenCL.Execute(def_k_DeconcatenateMatrix,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Deconcatenate Matrix: %d",GetLastError());
return false;
}
double temp[];
if(AttentionConcatenate.getGradient(temp)<=0)
return false;
}
Расчет градиента ошибки внутри головы внимания вынесен в отдельный метод calcHeadGradient, здесь же мы только вызовем данный метод для каждого потока внимания.
if(!calcHeadGradient(Querys,Values,Scores,AttentionOut,prevLayer)) return false; if(!calcHeadGradient(Querys2,Values2,Scores2,AttentionOut2,prevLayer)) return false; if(!calcHeadGradient(Querys3,Values3,Scores3,AttentionOut3,prevLayer)) return false; if(!calcHeadGradient(Querys4,Values4,Scores4,AttentionOut4,prevLayer)) return false;
В заключение метода суммируем градиент ошибки от всех голов внимания и передадим результат на предыдущий слой нейронной сети.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix1,AttentionOut.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix2,AttentionOut2.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix3,AttentionOut3.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix4,AttentionOut4.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix5,Weights0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix_out,prevLayer.getGradientIndex());
OpenCL.SetArgument(def_k_Matrix5Sum,def_k_sum5_dimension,iWindow);
OpenCL.SetArgument(def_k_Matrix5Sum,def_k_sum5_multiplyer,0.2);
if(!OpenCL.Execute(def_k_Matrix5Sum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Matrix5Sum: %d",GetLastError());
return false;
}
double temp[];
if(prevLayer.getGradient(temp)<=0)
return false;
}
//---
return true;
}
Посмотрим на метод calcHeadGradient. В параметрах методу передаются указатели на внутренние нейронные слои query, value, score, attention, относящиеся к рассматриваемой голове внимания и указатель на предыдущий нейронный слой.
bool CNeuronMHAttentionOCL::calcHeadGradient(CNeuronConvOCL *query,CNeuronConvOCL *value,CBufferDouble *score,CNeuronBaseOCL *attention,CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
Тело метода начинается с проверки действительности указателя на предыдущий нейронный слой. Для распределения градиента ошибки по внутренним слоям вызовем кернел AttentionInsideGradients, который был ранее рассмотрен в статье [8].
{
uint global_work_offset[2]={0,0};
uint global_work_size[2];
global_work_size[0]=iUnits;
global_work_size[1]=iWindow;
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_gradient,attention.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys,prevLayer.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys_g,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys,query.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys_g,query.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values,value.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values_g,value.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_scores,score.GetIndex());
if(!OpenCL.Execute(def_k_AttentionGradients,2,global_work_offset,global_work_size))
{
printf("Error of execution kernel AttentionGradients: %d",GetLastError());
return false;
}
double temp[];
if(query.getGradient(temp)<=0)
return false;
}
В этом примере используется обучение одной матрицы, без разделения на query и key. Поэтому, вместо буферов слоя ключей указаны буфера предыдущего слоя. Чтобы не перезатереть полученный на предыдущий слой градиент ошибки при пересчете на других внутренних слоях, перенесем данные на уже отработанный на данном шаге тензор AttentionOut текущей головы внимания. Я не стал делать отдельный тензор для копирования данных между буферами. Данная операция была выполнена с помощью кернела сложения 2-х матриц SumMatrix. Но так как у нас только одна матрица, то в указателях обоих тензоров укажем предыдущий слой. А с целью исключения задвоения значений применим мультипликатор 0.5.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
double temp[];
if(attention.getGradient(temp)<=0)
return false;
}
Далее, пересчитаем градиент ошибки, проходящий через слой запросов, вызвав соответствующий метод слоя query. Полученный результат суммируем с градиентом, полученным на предыдущей итерации. На данном шаге используем мультипликатор равный 1, увеличенный градиент усредним на следующем шаге.
if(!query.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,attention.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(attention.getGradient(temp)<=0) return false; }
В заключении метода аналогично пересчитаем градиент через слой value и суммируем с ранее полученными градиентами. Использование мультипликатора 0.33 позволяет усреднить градиент в целом по голове внимания.
if(!value.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,attention.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow+1); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.33); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(prevLayer.getGradient(temp)<=0) return false; } //--- return true; }
После пересчета градиентов ошибки обновим весовые коэффициенты всех внутренних слоев. Пропишем в методе updateInputWeights последовательный вызов одноименных методов всех внутренних нейронных слоев.
bool CNeuronMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *prevLayer) { if(!Querys.UpdateInputWeights(prevLayer) || !Querys2.UpdateInputWeights(prevLayer) || !Querys3.UpdateInputWeights(prevLayer) || !Querys4.UpdateInputWeights(prevLayer)) return false; //--- if(!Values.UpdateInputWeights(prevLayer) || !Values2.UpdateInputWeights(prevLayer) || !Values3.UpdateInputWeights(prevLayer) || !Values4.UpdateInputWeights(prevLayer)) return false; if(!Weights0.UpdateInputWeights(AttentionConcatenate)) return false; if(!FF1.UpdateInputWeights(Weights0)) return false; if(!FF2.UpdateInputWeights(FF1)) return false; //--- return true; }
С полным кодом всех методов и функций можно ознакомиться во вложении.
4.5. Точечные изменения в базовых классах нейронной сети
После реализации алгоритма Multi-Head Attention у нас остается открытым вопрос реализации Positional Encoder. Данный процесс был включен в метод CNet::feedForward класса нейронной сети. Для его реализации в метод было добавлено 2 параметра window и tem. В первом указывается размер окна данных, а второй отвечает за необходимость включения/выключения функции.
bool CNet::feedForward(CArrayDouble *inputVals,int window=1,bool tem=true)
Сам же процесс реализован в блоке передачи в сеть исходных данных. Вначале объявляем 2 внутренних переменных pos (позиция в последовательности) и dim (порядковый номер элемента внутри окна данных). Первым определяем порядковый номер элемента внутри окна данных. Для этого возьмем остаток от деления порядкового номера элемента в тензоре исходных данных на размер окна. Позиция в последовательности определяется по целому числу результата деления порядкового номера элемента в тензоре исходных данных на размер окна. Далее при сохранении исходных данных в тензор входящих данных нейронной сети добавляем результат вычисления по формулам, указанным в 3-м разделе данной статьи.
CNeuronBaseOCL *neuron_ocl=current.At(0); double array[]; int total_data=inputVals.Total(); if(ArrayResize(array,total_data)<0) return false; for(int d=0;d<total_data;d++) { int pos=d; int dim=0; if(window>1) { dim=d%window; pos=(d-dim)/window; } array[d]=inputVals.At(d)+(tem ? (dim%2==0 ? sin(pos/pow(10000,(2*dim+1)/(window+1))) : cos(pos/pow(10000,(2*dim+1)/(window+1)))) : 0); } if(!opencl.BufferWrite(neuron_ocl.getOutputIndex(),array,0,0,total_data)) return false;
Остается внести точечные изменения для нормального функционирования нейронной сети. В блок дефайнов добавим константы для работы с новыми кернелами.
#define def_k_ConcatenateMatrix 17 ///< Index of the Multi Head Attention Neuron Concatenate Output kernel (#ConcatenateBuffers) #define def_k_conc_input1 0 ///< Matrix of Buffer 1 #define def_k_conc_window1 1 ///< Window of Buffer 1 #define def_k_conc_input2 2 ///< Matrix of Buffer 2 #define def_k_conc_window2 3 ///< Window of Buffer 2 #define def_k_conc_input3 4 ///< Matrix of Buffer 3 #define def_k_conc_window3 5 ///< Window of Buffer 3 #define def_k_conc_input4 6 ///< Matrix of Buffer 4 #define def_k_conc_window4 7 ///< Window of Buffer 4 #define def_k_conc_out 8 ///< Output tesor //--- #define def_k_DeconcatenateMatrix 18 ///< Index of the Multi Head Attention Neuron Deconcatenate Output kernel (#DeconcatenateBuffers) #define def_k_dconc_output1 0 ///< Matrix of Buffer 1 #define def_k_dconc_window1 1 ///< Window of Buffer 1 #define def_k_dconc_output2 2 ///< Matrix of Buffer 2 #define def_k_dconc_window2 3 ///< Window of Buffer 2 #define def_k_dconc_output3 4 ///< Matrix of Buffer 3 #define def_k_dconc_window3 5 ///< Window of Buffer 3 #define def_k_dconc_output4 6 ///< Matrix of Buffer 4 #define def_k_dconc_window4 7 ///< Window of Buffer 4 #define def_k_dconc_inputs 8 ///< Input tesor //--- #define def_k_Matrix5Sum 19 ///< Index of the kernel for calculation Sum of 2 matrix with multiplyer (#SumMatrix) #define def_k_sum5_matrix1 0 ///< First matrix #define def_k_sum5_matrix2 1 ///< Second matrix #define def_k_sum5_matrix3 2 ///< Third matrix #define def_k_sum5_matrix4 3 ///< Fourth matrix #define def_k_sum5_matrix5 4 ///< Fifth matrix #define def_k_sum5_matrix_out 5 ///< Output matrix #define def_k_sum5_dimension 6 ///< Dimension of matrix #define def_k_sum5_multiplyer 7 ///< Multiplyer for output
Добавим константу для идентификации нового класса.
#define defNeuronMHAttentionOCL 0x7888 ///<Multi-Head Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL
В конструкторе класса нашей нейронной сети добавим новый класс в блок инициализации класса OpenCL.
next=Description.At(1); if(next.type==defNeuron || next.type==defNeuronBaseOCL || next.type==defNeuronConvOCL || next.type==defNeuronAttentionOCL || next.type==defNeuronMHAttentionOCL) { opencl=new COpenCLMy(); if(CheckPointer(opencl)!=POINTER_INVALID && !opencl.Initialize(cl_program,true)) delete opencl; }
Добавим новый вид нейронов в блоке инициализации нейронов в сети.
case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break;
Добавим объявление новых кернелов.
if(CheckPointer(opencl)==POINTER_INVALID) return; //--- create kernels opencl.SetKernelsCount(20); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers");
Добавим новый класс в диспетчерские методы класса CNeuronBaseOCL, изменения выделены заливкой.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; } //--- return false; }
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
С полным кодом всех методов и функций можно ознакомиться во вложении.
5. Тестирование
Для тестирования новой архитектуры нейронной сети был создан советник Fractal_OCL_AttentionMHTE. Данный советник был создан на базе советника Fractal_OCL_Attention из статьи [8] и отличается от родительского советника только типом класса нейронов внимания и использованием механизма кодирования позиции элементов входных данных.
CArrayObj *Topology=new CArrayObj(); if(CheckPointer(Topology)==POINTER_INVALID) return INIT_FAILED; //--- CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=36; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- bool result=true; for(int i=0; (i<2 && result); i++) { desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMHAttentionOCL; desc.window=36; desc.optimization=ADAM; desc.activation=None; result=Topology.Add(desc); } if(!result) { delete Topology; return INIT_FAILED; } //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; delete Net; Net=new CNet(Topology); delete Topology;
Для чистоты эксперимента проводилось параллельное тестирование 2-х советников (Self-Attention и Multi-Head Attention). Тестирование осуществлялось при тех же условиях, что и в предыдущих статьях этого цикла: инструмент EURUSD, таймфрейм H1, на вход подаются данные за 20 последовательных свечей, обучение проводится на истории за 2 последних года с обновлением параметров методом Adam.
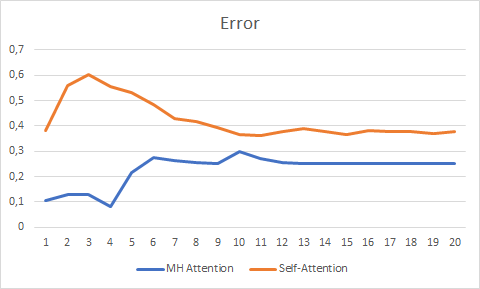
Тестирование на протяжении 20 эпох показало преимущество Multi-Head Attention, который показал более гладкий график изменения ошибки и стабилизировался с ошибкой 0,25 против 0,37 у Self-Attention.
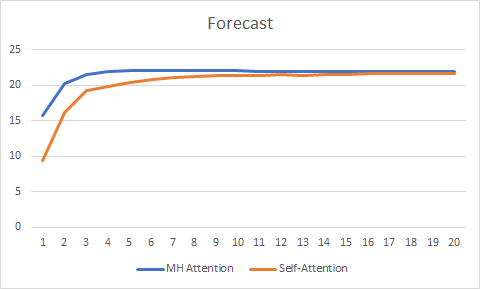
График правильных предсказаний также показал преимущества многоголового внимания, хотя и не столь значительные.
С полным кодом всех классов и советников можно ознакомиться во вложении.
Заключение
В данной статье мы рассмотрели вариант реализации архитектуры Multi-Head Attention и провели сравнительное тестирование с архитектурой одноголового Self-Attention. При равных исходных условиях многоголовое внимание показала лучшие результаты. Но при этом следует отметить, что за повышение качества работы сети требуется платить дополнительными вычислительными затратами.
Ссылки
- Нейросети — это просто
- Нейросети — это просто (Часть 2): обучение и тестирование сети
- Нейросети — это просто (Часть 3): сверточные сети
- Нейросети — это просто (Часть 4): рекуррентные сети
- Нейросети — это просто (Часть 5): многопоточные вычисления в OpenCL
- Нейросети — это просто (Часть 6): эксперименты с коэффициентом обучения нейронной сети
- Нейросети — это просто (Часть 7): Адаптивные методы оптимизации
- Нейросети — это просто (Часть 8): Механизмы внимания
- Нейросети — это просто (Часть 9): Документируем проделанную работу
- Attention Is All You Need
- Multi-Head Attention: Collaborate Instead of Concatenate
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Fractal_OCL_Attention.mq5 | Советник | Советник с нейронной сетью классификации (3 нейрона в выходном слое) с использованием механизма Self-Attention |
| 2 | Fractal_OCL_AttentionMHTE.mq5 | Советник | Советник с нейронной сетью классификации (3 нейрона в выходном слое) с использованием механизма Multi-Head Attention |
| 3 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 4 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 5 | NN.chm | HTML-справка | Сконвертированный файл HTML-справки. |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Брутфорс-подход к поиску закономерностей (Часть III): Новые горизонты
Брутфорс-подход к поиску закономерностей (Часть III): Новые горизонты
 Поиск сезонных закономерностей на валютном рынке с помощью алгоритма CatBoost
Поиск сезонных закономерностей на валютном рынке с помощью алгоритма CatBoost
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Комитет самых продвинутых архитектур НС на GPU, в Питоне это вообще есть? )
жаль пока с обычными трансформерами из статьи 8 ещё не до конца разобрался ))