
Нейросети в трейдинге: Обучение метапараметров на основе гетерогенности (Окончание)

Введение
Алгоритмическая торговля редко прощает избыточную сложность и неоправданную лёгкость решений. Любая модель, будь то сложнейший нейросетевой ансамбль или минималистичный авторегрессионный фильтр, в конечном счёте должна пройти проверку временем и рынком. Именно с этой позиции был задуман HimNet — фреймворк, который не стремится впечатлить количеством обучаемых параметров или экзотичностью вычислений. Напротив, он сосредоточен на том, чтобы давать устойчивый, воспроизводимый и экономически оправданный результат.
С первых шагов HimNet проявляет три качества, которые выгодно отличают его от многих других подходов. Во-первых, это рациональность архитектуры: в нём нет перегруженных слоёв, которые лишь создают иллюзию глубины анализа. Каждый модуль здесь функционален и оправдан. Во-вторых, это сдержанная адаптивность: вместо того, чтобы бездумно подстраиваться под шум каждого рыночного колебания, фреймворк выстраивает баланс между гибкостью и устойчивостью. И в-третьих, — минимализм в управлении параметрами. HimNet построен таким образом, что число обучаемых коэффициентов сведено к необходимому минимуму. Это позволяет избежать чрезмерной подгонки под исторические данные и сохранять предсказательную силу даже на отдалённых отрезках временных рядов.
В предыдущих работах мы последовательно раскрывали внутреннюю механику этого фреймворка. Начав с теоретических основ, мы подробно изучили способы формирования эмбеддингов и проанализировали, каким образом рекуррентные и сверточные элементы взаимодополняют друг друга. Архитектура HimNet подобна слаженному механизму, где каждая шестерёнка — будь то блок полиномов Чебышева или механизм GCRU — имеет свою точную роль. Это не нагромождение технологий, а тщательно рассчитанная конструкция, позволяющая получать информативное представление рынка без потерь скорости обработки и чрезмерного усложнения вычислительной цепочки.

Фреймворк HimNet построен по классической и во многом проверенной временем архитектуре Энкодер–Декодер. Эта схема хорошо зарекомендовала себя в задачах обработки сложных последовательностей, где важно не просто зафиксировать текущее состояние рынка, но и извлечь из него устойчивые закономерности для дальнейшего прогнозирования. Энкодер и Декодер опираются на одинаковую основу: они оба используют обучаемые эмбеддинги и графовые рекуррентные блоки (GCRU). Однако между ними есть тонкое, но важное различие — в самом способе формирования эмбеддингов.
В Энкодере временные и пространственные эмбеддинги напрямую извлекаются из заранее подготовленных словарей, причём они применяются как своего рода Запросы к пулам метапараметров. Это позволяет Энкодеру адаптироваться к контексту.
Декодер, напротив, формирует эмбеддинги косвенно — на основе латентного представления, объединённого из результатов работы Энкодера. Он проецирует скрытое представление в пространственно-временнойэмбеддинг, который становится запросом к ST-модели мета-параметров, позволяя Декодеру генерировать веса.
Мы уже проделали внушительную подготовительную работу: реализовали фундаментальные компоненты модели, включая графовые рекуррентные блоки, способные эффективно учитывать пространственно-временные зависимости данных. Теперь пришло время подняться на следующий уровень иерархии — построение полноценной структуры Энкодера и Декодера. Этот этап станет связующим звеном между отдельными элементами фреймворка и его практическим применением. Именно здесь абстрактные блоки обретают взаимосвязь, а поток данных начинает формировать осмысленное представление будущих состояний рынка.
Энкодер
Авторы фреймворка HimNet предусмотрели двухпоточный механизм обработки данных, где за каждый тип зависимости (пространственную и временную) отвечает отдельный Энкодер. Такой подход позволяет не смешивать воедино разные структуры сигналов, а рассматривать их в параллельных ветках, обеспечивая более точное и чистое выделение ключевых закономерностей. Следуя предложенным идеям, сегодня мы начнем работу с построения Энкодера временных зависимостей. Ведь именно время является той нитью, на которой выстраивается любая рыночная динамика.
Временной Энкодер
Объект CNeuronHimNetTempEncoder — это своеобразный временной фильтр фреймворка, предназначенный для извлечения закономерностей, скрытых в последовательности котировок и рыночных паттернов. Причём делает он это на нескольких масштабах одновременно.
class CNeuronHimNetTempEncoder : public CNeuronBaseOCL { protected: uint aTimeframes[2]; CCircleParams caEmbeddings[2]; CNeuronBaseOCL cConcatEmbeddings; CLayer cGRCUs; CBufferFloat bSupportAccum; public: CNeuronHimNetTempEncoder(void) {}; ~CNeuronHimNetTempEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support, int label); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); //--- virtual int Type(void) const { return defNeuronHimNetTempEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; //--- virtual uint GetCount(void) const; virtual uint GetWindowIn(void) const; virtual uint GetWindowOut(void) const; virtual uint GetChebK(void) const; //--- virtual bool SetGradient(CBufferFloat *buffer, bool delete_prev = true); };
Ключевыми элементами являются два словаря эмбеддингов, представленных массивом caEmbeddings. Каждый из этих словарей хранит не полные данные, а лишь компактные представления отдельных временных шагов — эмбеддинги, выступающие в роли запросов к пулам параметров модели. Это значит, что каждый временной шаг фактически обращается к своему собственному подпространству параметров, извлекая нужное значение и тем самым настраивая дальнейший поток данных.
Важно подчеркнуть, что оба словаря эмбеддингов работают согласованно, но независимо — благодаря этому модель одновременно смотрит на два временных масштаба и не смешивает быстротечный шум с долгосрочной инерцией. Подробно, как эти Запросы взаимодействуют с потоком данных, и какие задачи берут на себя остальные компоненты временного Энкодера, мы разберём по ходу реализации методов.
Все внутренние объекты объявлены статически, поэтому конструктор и деструктор остаются минималистичными. Реальная инициализация всего набора объявленных компонентов и унаследованных объектов выполняется централизованно в методе Init.
bool CNeuronHimNetTempEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch) { if(layers <= 0) return false;
Алгоритм метода начинается с небольшого контрольного блока — проверяем количество внутренних слоев энкодера. И если значение параметра layers меньше или равно "0", метод сразу отказывает. Это защищает от бессмысленных конфигураций: нет слоёв — нечему учиться.
Затем вызывается одноименный метод родительского класса, в который передаются базовые параметры объекта. На этом шаге мы задаём форму тензора результатов работы Энкодера и резервируем базовые ресурсы. Если базовая инициализация не проходит, то выполнять операции дальше смысла нет — метод возвращает false.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units, optimization_type, batch)) return false;
Следом идёт подготовка словарей эмбеддингов и сразу фиксируется временной размер временного шага в соответствующих элементах массива aTimeframes.
int index = 0; if(!caEmbeddings[0].Init(0, index, OpenCL, embed_dim, period1, optimization, iBatch)) return false; aTimeframes[0] = MathMax(1, timeframe1); index ++; if(!caEmbeddings[1].Init(0, index, OpenCL, embed_dim, period2, optimization, iBatch)) return false; aTimeframes[1] = MathMax(1, timeframe2); if(!cConcatEmbeddings.Init(numOutputs, myIndex, open_cl, 2 * embed_dim, optimization_type, batch)) return false;
Каждый словарь эмбеддингов настраивается под свою временную гранулярность: размер встраивания и период задают, какие именно временные Запросы будут использоваться к пулу параметров. Если любая из этих инициализаций проваливается, метод прерывается — мы не допускаем частично собранного Энкодера.
После определения словарей, создаётся cConcatEmbeddings — объект, который будет объединять два эмбеддинга в один вектор.
Далее начинается построение слоёв GRCU. Сначала очищаем контейнер cGRCUs и явно привязываем OpenCL-контекст.
cGRCUs.Clear(); cGRCUs.SetOpenCL(OpenCL); index++; CNeuronHimNetGCRU *temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window, window_out, cheb_k, 2 * embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) return false;
Затем создаётся первый объект CNeuronHimNetGCRU и инициализируется с параметрами первого слоя: для него размер признаков на входе задаётся равным соответствующему измерению анализируемого временного ряда, а на выходе — латентному представлению. Этот первый слой — нижняя точка стека.
Если инициализация прошла успешно, слой добавляется в контейнер cGRCUs. А в случае, если добавление или инициализация не удались — возвращаем false.
Для всех последующих слоёв логика чуть упрощается. В цикле создаются дополнительные объекты CNeuronHimNetGCRU, но теперь тензоры на входе и выходе имеют одинаковые размерности. Это стандартный приём: первый слой расширяет и собирает контекст, а последующие уже перетирают этот контекст в глубину. При любой неудаче — создание, инициализация или добавление — мы аккуратно завершаем методом с результатом false, чтобы не оставить систему в неконсистентном состоянии.
for(uint i = 1; i < layers; i++) { index++; temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window_out, window_out, cheb_k, 2 * embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) return false; }
После того как стек GRCU сформирован, мы инициализируем вспомогательный буфер bSupportAccum, который будет использован для аккумулирования градиентов ошибки полиномов Чебышева, получаемых от различных слоев Энкодера.
bSupportAccum.BufferFree(); bSupportAccum.Clear(); if(!bSupportAccum.BufferInit(units * units * cheb_k, 0) || !bSupportAccum.BufferCreate(OpenCL)) return false;
Далее — важный практический шаг: результатом работы Энкодера является выход последнего объекта в контейнере cGRCUs. Чтобы исключить излишние копирования больших тензоров, мы синхронизируем функции активации, а так же указатели на буферы результатов и градиентов. То есть Энкодер перенимает активационную семантику последнего слоя и направляет свои внешние интерфейсы прямо на внутренние буферы последнего GRCU. Это даёт существенную экономию памяти и времени.
SetActivationFunction((ENUM_ACTIVATION)temp.Activation()); if(!SetOutput(temp.getOutput(), true) || !SetGradient(temp.getGradient(), true)) return false; //--- return true; }
От инициализации объекта переходим к основному функционалу временного Энкодера — создадим метод прямого прохода feedForward.
bool CNeuronHimNetTempEncoder::feedForward(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support, int label) { for(uint i = 0; i < caEmbeddings.Size(); i++) { int position = (label / int(aTimeframes[i])) % caEmbeddings[i].GetPeriod(); if(!caEmbeddings[i].SetPosition(position) || !caEmbeddings[i].FeedForward()) return false; } if(!Concat(caEmbeddings[0].getOutput(), caEmbeddings[1].getOutput(), cConcatEmbeddings.getOutput(), 1, 1, caEmbeddings[0].Neurons())) return false;
Его алгоритм начинается с получения эмбеддингов из наших словарей. Работа организована в цикле, который последовательно перебирает словари в массиве. Для каждого словаря вычисляем текущую позицию на основании временной отметки, полученной от внешней программы. А затем генерируем конкретный временной эмбеддинг, путем вызова метода FeedForward соответствующего словаря.
По сути это то место, где время превращается в адрес для получения специализированных весов. В торговой аналогии: при наступлении определённого временного окна мы выбираем соответствующую настройку модели, не переобучая её заново — просто используем другой Запрос.
После того как оба эмбеддинга получены, их результаты объединяются в единый тензор.
Затем начинается ключевая часть: прохождение через контейнер GRCU. Локальная переменная inputs инициализируется указателем на объект исходных данных. В цикле по элементам контейнера cGRCUs мы последовательно берём каждый слой и вызываем его метод прямого прохода.
CNeuronBaseOCL *inputs = NeuronOCL; CNeuronHimNetGCRU *current = NULL; for(int i = 0; i < cGRCUs.Total(); i++) { current = cGRCUs[i]; if(!current || !current. Feedforward(inputs, Support, cConcatEmbeddings.AsObject())) return false; inputs = current; } //--- return true; }
Важно понять контракт: первый GRCU получает сырые данные анализируемой последовательности и общий эмбеддинг-запрос. Он формирует своё скрытое представление. После этого указатель в inputs заменяется на текущий объект — выход первого слоя становится входом для следующего. Таким образом строится стек последовательных преобразований: первый слой расширяет контекст, а последующие уточняют и сжимают представление. В торговой практике это похоже на первый аналитический проход, где собираются все детали, а последующие слои — как более опытные менеджеры — фильтруют, агрегируют и готовят сигнал к выдаче.
Буфер полиномов Чебышева (Support) — служит ядром графовой агрегации (K-hop). Передача одного и того же объекта в каждый слой гарантирует единый взгляд на структуру связей между унитарными последовательностями во всём стеке, при этом каждый GRCU использует свои мета-параметры (сгенерированные по эмбеддингу) для интерпретации этой поддержки.
После того как мы разобрали прямой проход, логично перейти к обратному — к тому моменту, когда модель сдаёт экзамен, и аккуратно распределяем ответственность за ошибку по всем её частям. Метод calcInputGradients — это именно та процедура, где ошибки, накопленные на выходе энкодера, возвращаются назад через стек GRCU и словари эмбеддингов, корректируя поведение каждого компонента.
bool CNeuronHimNetTempEncoder::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support) { if(!NeuronOCL || !Support) return false;
Сначала метод защищённой проверкой убеждается, что ему дали на вход корректные указатели. Затем определяется источник входа для последнего слоя. Если слоёв в стеке больше одного — мы возьмём предпоследний GRCU, иначе — объект исходных данных. А распределение градиентов ошибки начнем с последнего GRCU — того самого объекта, результат которого при инициализации мы назначили в качестве внешнего выхода энкодера. Это логично: градиент сначала поступает на вершину стека и оттуда начинает распространяться вниз.
CNeuronBaseOCL *inputs = (cGRCUs.Total() > 1 ? cGRCUs[-2] : NeuronOCL); CNeuronHimNetGCRU* current = cGRCUs[-1]; if(!current || !current.calcInputGradients(inputs, Support, cConcatEmbeddings.AsObject())) return false; if(!DeConcat(caEmbeddings[0].getGradient(), caEmbeddings[1].getGradient(), cConcatEmbeddings.getGradient(), 1, 1, caEmbeddings[0].Neurons())) return false;
Здесь происходит основная локальная работа: последний GRCU распределяет полученный градиент между своим входом, внутренними мета-параметрами и буфером градиентов полиномов Чебышева (Support). Важно понимать, что Support в этой точке выступает как общая карта связей, и каждый слой в стеке может вносить в неё свой вклад. Поэтому нам необходим аккумулирующий механизм.
Следующим шагом раскладываем градиент объединённого эмбеддинга обратно на две части — градиенты двух словарей эмбеддингов. Мы возвращаем каждой ветке её собственный вклад в ошибку, чтобы словари могли позже скорректировать свои Запросы к пулам параметров.
Если в стеке более одного слоя, начинается аккуратный процесс накопления градиентов по Support. Сначала мы сохраняем указатель на текущий буфер градиентов в локальной переменной temp, чтобы не потерять прежний буфер с ранее накопленными значениями. Затем мы временно перенаправляем градиенты ошибки на буфер bSupportAccum, который заранее выделили.
if(cGRCUs.Total() > 1) { CBufferFloat *temp = Support.getGradient(); if(!Support.SetGradient(GetPointer(bSupportAccum), false)) return false; for(int i = cGRCUs.Total() - 2; i >= 0; i--) { current = cGRCUs[i]; inputs = (i > 0 ? cGRCUs[i - 1] : NeuronOCL); if(!current || !current.calcInputGradients(inputs, Support, cConcatEmbeddings.AsObject())) return false; if(!SumAndNormilize(temp, Support.getGradient(), temp, 1, false, 0, 0, 0, 1)) return false; if(!DeConcat(caEmbeddings[0].getPrevOutput(), caEmbeddings[1].getPrevOutput(), cConcatEmbeddings.getGradient(), 1, 1, caEmbeddings[0].Neurons())) return false; for(uint i = 0; i < caEmbeddings.Size(); i++) if(!SumAndNormilize(caEmbeddings[i].getGradient(), caEmbeddings[i].getPrevOutput(), caEmbeddings[i].getGradient(), 1, false, 0, 0, 0, 1)) return false; } if(!Support.SetGradient(temp, false)) return false; } //--- return true; }
В цикле, перебирающем объекты стека в обратном порядке, мы для каждого слоя вызываем метод распределения градиентов ошибки. Затем агрегируем новый вклад с уже накопленным в буфере temp. После этого, снова раскладываем градиент объединённого эмбеддинга на два информационных потока. И наконец, для каждого словаря суммируем полученные значения с ранее накопленными.
После прохождения всех слоёв, возвращаем указатели на буферы данных в начальное состояние. Это важно: только таким образом внешние оптимизаторы увидят корректный сигнал для обновления параметров, лежащих в основе графовой агрегации.
И после успешного выполнения всех итераций, метод возвращает true, что означает успешное распределение градиента по всем компонентам Энкодера до уровня исходных данных.
После аккуратного сбора градиентов наступает этап обновления параметров. Метод updateInputWeights здесь прост по форме, но важен по смыслу — он последовательно передает управление тем внутренним компонентам, которые содержат обучаемые веса. И делает это в том порядке, в котором реализована вычислительная последовательность.
bool CNeuronHimNetTempEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support) { for(uint i = 0; i < caEmbeddings.Size(); i++) if(!caEmbeddings[i].UpdateInputWeights()) return false;
Сначала в цикле обновляются оба словаря эмбеддингов. Каждый вызов UpdateInputWeights применяет накопленные в предыдущем шаге градиенты к параметрам соответствующего словаря.
Далее метод проходит по стеку GRCU в прямом порядке: каждый слой отвечает за локальное обновление параметров своих эмбеддингов и мета-пулов.
CNeuronBaseOCL* inputs = NeuronOCL; CNeuronHimNetGCRU* current = NULL; for(int i = 0; i < cGRCUs.Total(); i++) { current = cGRCUs[i]; if(!current.updateInputWeights(inputs, Support, cConcatEmbeddings.AsObject())) return false; inputs = current; } //--- return true; }
Полный исходный код этого класса с реализацией всех методов приложен во вложении — в нём можно увидеть все детали, о которых шла речь. На этом разбор временного Энкодера можно считать завершённым, и мы готовы идти дальше.
Пространственный Энкодер
Прежде чем двигаться дальше, давайте проговорим, что собой представляет пространственный Энкодер и чем он отличается от временного, — ведь понимание этой разницы важно для корректной интеграции в общую архитектуру HimNet.
Временной Энкодер оперировал набором словарей эмбеддингов, которые выступали в качестве Запросов к пулам параметров для разных временных гранулярностей. Пространственный Энкодер, напротив, не нуждается в множестве периодических ключей — структура пространственных данных в рассматриваемой задаче стабильна. Поэтому вместо словарей мы используем единый набор обучаемых параметров, инкапсулированный в объекте cEmbedding. Это позволяет модели иметь одно централизованное представление пространства рынка, которое корректируется в процессе обучения и затем используется как постоянный источник контекстных запросов для GRCU.
class CNeuronHimNetSpatEncoder : public CNeuronBaseOCL { protected: CParams cEmbedding; CLayer cGRCUs; CBufferFloat bSupportAccum; CBufferFloat bEmbeddingAccum; public: CNeuronHimNetSpatEncoder(void) {}; ~CNeuronHimNetSpatEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CChebPolinom *Support); //--- virtual int Type(void) const { return defNeuronHimNetSpatEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; //--- virtual uint GetCount(void) const; virtual uint GetWindowIn(void) const; virtual uint GetWindowOut(void) const; virtual uint GetChebK(void) const; //--- virtual bool SetGradient(CBufferFloat *buffer, bool delete_prev = true); };
Архитектурно объект CNeuronHimNetSpatEncoder очень похож на временной Энкодер. Тот же стек графовых рекуррентных блоков cGRCUs, аналогичный аккумулятор градиентов полиномов Чебышева и набор методов для прямого и обратного проходов. Главное отличие — вместо двух словарей эмбеддингов, у нас один параметризованный модуль cEmbedding и дополнительный буфер bEmbeddingAccum. Этот буфер необходим для аккумулирования вкладов градиента по эмбеддингу от всех слоёв стека.
Поскольку пространственный Энкодер отличается от временного лишь отдельными нюансами, сосредоточение внимания на архитектурной логике и потоке данных позволяет не загромождать текст лишними повторениями. Полный код класса и всех его методов, представленный во вложении, даёт возможность читателю самостоятельно проследить тонкие различия и понять, как именно обновляются embedding-параметры и градиенты внутри GRCU-слоёв.
Сводный Энкодер
На этом этапе мы переходим к ключевому модулю, который связывает работу двух параллельных Энкодеров в единое, согласованное представление. Класс CNeuronHimNetEncoder выполняет роль координатора, обеспечивая интеграцию пространственных и временных представлений. Временной Энкодер фиксирует динамику изменений во времени, выявляя краткосрочные и долгосрочные тренды, тогда как пространственный анализирует взаимосвязи между различными объектами. Результаты работы обоих потоков аккуратно консолидируются внутри класса, формируя полноценное латентное представление состояния системы.
class CNeuronHimNetEncoder : public CNeuronBaseOCL { protected: CParams cEmbedding; CNeuronTransposeOCL cEmbeddingT; CNeuronBaseOCL cSupport; CNeuronSoftMaxOCL cNormSupport; CChebPolinom cPolinomSupport; CNeuronHimNetTempEncoder cTempEncoder; CNeuronHimNetSpatEncoder cSpatEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHimNetEncoder(void) {}; ~CNeuronHimNetEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronHimNetEncoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; virtual bool SetGradient(CBufferFloat *buffer, bool delete_prev = true); };
Архитектурно объект содержит собственный набор обучаемых параметров (cEmbedding), которые являются основой для формирования полином Чебышева.
Как и в предыдущих модулях фреймворка, структура класса построена так, чтобы минимизировать накладные расходы и исключить ненужные динамические операции. Все внутренние объекты здесь объявлены статически, поэтому конструктор и деструктор остаются пустыми. Их задача — лишь формально обозначить жизненный цикл объекта, не вмешиваясь в логику распределения ресурсов. Вся реальная работа по подготовке компонентов сосредоточена в методе Init, который выступает в роли своеобразного дирижера — он последовательно настраивает каждый внутренний элемент, распределяет роли между Энкодерами и связывает их в единую вычислительную цепь.
bool CNeuronHimNetEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, uint period1, uint timeframe1, uint period2, uint timeframe2, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units, optimization_type, batch)) return false;
Инициализация начинается с передачи управления родительскому классу, в котором уже выстроен алгоритм создания базовых интерфейсов. Затем формируется последовательность связанных компонентов: обучаемые параметры эмбеддинга, слой их транспонирования, объекты создания диагональной матрицы корреляции и нормализации полученных зависимостей. А так же объект формирования полином Чебышева для графовых преобразований.
int index = 0; if(!cEmbedding.Init(0, index, OpenCL, units * embed_dim, optimization, iBatch)) return false; SetActivationFunction(TANH); index++; if(!cEmbeddingT.Init(0, index, OpenCL, units, embed_dim, optimization, iBatch)) return false; index++; if(!cSupport.Init(0, index, OpenCL, units * units, optimization, iBatch)) return false; cSupport.SetActivationFunction(None); index++; if(!cNormSupport.Init(0, index, OpenCL, cSupport.Neurons(), optimization, iBatch)) return false; cNormSupport.SetHeads(units); cNormSupport.SetActivationFunction(None); index++; if(!cPolinomSupport.Init(0, index, OpenCL, units, cheb_k, optimization, iBatch)) return false;
Каждый элемент получает собственный индекс в конвейере вычислений, а активационные функции устанавливаются строго по месту. Для объекта формирования эмбеддингов мы используем гиперболический тангенс, позволяющий нормализовано задать прямые и обратные зависимости.
Особое внимание уделяется синхронизации двух потоков: временного (cTempEncoder) и пространственного (cSpatEncoder). Первый отвечает за извлечение временных закономерностей с учётом многомасштабных периодов и окон прогнозирования, второй — за картографию взаимосвязей между единицами анализа. В завершении буферы их градиентов синхронизируются, что позволяет избежать избыточного копирования данных и обеспечивает плавное распространение ошибки в обратном проходе.
index++; if(!cTempEncoder.Init(0, index, OpenCL, units, window, window_out, cheb_k, layers, (embed_dim + 1) / 2, period1, timeframe1, period2, timeframe2, optimization, iBatch)) return false; index++; if(!cSpatEncoder.Init(0, index, OpenCL, units, window, window_out, cheb_k, layers, embed_dim, optimization, iBatch)) return false; //--- if(!SetGradient(cTempEncoder.getGradient(), true)) return false; //--- return true; }
Таким образом, метод Init выступает точкой сборки всего модуля, превращая разрозненные компоненты в единую согласованную архитектуру, готовую к обучению и эксплуатации на реальных финансовых данных.
После завершения работы по инициализации объекта мы переходим к построению алгоритма прямого прохода.
bool CNeuronHimNetEncoder::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
Начинаем с самых приземлённых вещей: проверяем, что пришёл корректный указатель на объект исходных данных второго информационного потока. В нем мы ожидаем получить временную метку анализируемой последовательности. Если указателя нет, сразу выходим, не рискуя испортить состояние графа и буферов.
Дальше срабатывает важная развилка. В режиме обучения мы перестраиваем адаптивный граф с нуля. Сначала генерируем эмбеддинг. И следом готовим транспонированное его представление.
if(bTrain) { if(!cEmbedding.FeedForward()) return false; if(!cEmbeddingT.FeedForward(cEmbedding.AsObject())) return false; if(!MatMul(cEmbedding.getOutput(), cEmbeddingT.getOutput(), cSupport.getOutput(), cEmbeddingT.GetCount(), cEmbeddingT.GetWindow(), cEmbeddingT.GetCount(), 1, false)) return false; if(!cNormSupport.FeedForward(cSupport.AsObject())) return false; if(!cPolinomSupport.FeedForward(cNormSupport.AsObject())) return false; }
Операция MatMul осуществляет матричное умножение полученного эмбеддинга на его транспонированную копию, формируя сырую диагональную матрицу корреляции между узлами. В трейдинговом контексте это значит, что пары инструментов с похожими поведенческими отпечатками окажутся плотнее связаны.
Сырой граф нормализуем функцией SoftMax, применяя стабильную постобработку. В результате операции получаем стохастическую матрицу смежности, пригодную для графовой свёртки.
Затем строим полиномы Чебышева. Это наш K-hop телескоп, который позволяет аккумулировать влияние соседей на расстоянии до K рёбер без диагонализации лапласиана — быстро, численно устойчиво и полностью на GPU.
В режиме инференса эта секция пропускается. Мы используем уже полученные на обучении эмбеддинги и полиномы, чтобы не тратить наносекунды понапрасну и сохранить детерминизм.
Далее очередь двух Энкодеров. Сначала в темпоральный поток передаем мультимодальную последовательность анализируемых данных, набор полиномов Чебышева и метку времени.
if(!cTempEncoder.feedForward(NeuronOCL, cPolinomSupport.AsObject(), int(SecondInput[0]))) return false;
Энкодер смешивает что происходит сейчас и когда именно это происходит, накладывая временной режим на графовую динамику.
Параллельно запускаем пространственный Энкодер.
if(!cSpatEncoder.feedForward(NeuronOCL, cPolinomSupport.AsObject())) return false;
Ему не нужен временной ярлык — здесь работают стационарные узловые эмбеддинги. Пространственная магистраль отвечает за устойчивую карту рынка. Оба потока видят один и тот же K-hop базис, но смотрят на него под разными углами — через время и через пространство.
Финальный штрих — аккуратная сборка результатов. Мы суммируем выходы Энкодеров.
if(!SumAndNormilize(cTempEncoder.getOutput(), cSpatEncoder.getOutput(), Output, cTempEncoder.GetWindowOut(), false, 0, 0, 0, 1)) return false; //--- return true; }
На практике это работает как простой, но надёжный ансамбль: темпоральный канал ловит режимы сессии и календарные эффекты, пространственный — устойчивые кластеры. На выходе получаем латентное представление, которое одинаково уверенно ведёт себя и на спокойном рынке, и во время новостных всплесков — модель не переобучается на одном типе сигналов, потому что сигнал приходит из двух согласованных источников.
Если каждое звено отрабатывает без ошибок, метод возвращает true. В противном случае, мы мгновенно выходим, не оставляя грязных состояний в буферах. Такой консервативный контроль потока особенно важен в реальном трейдинге: когда вы крутите модель на тиках или 1-минутках, у вас нет роскоши восстанавливаться из полубитых данных — либо прогноз корректен и своевременен, либо его не должно быть вовсе.
После завершения прямого прохода, модель переходит к одной из самых ответственных стадий — распределению градиентов ошибки. Именно здесь решается, насколько корректно каждый элемент архитектуры воспримет сигнал обратной связи и сможет скорректировать свои веса. Метод calcInputGradients в данном классе организован так, чтобы этот процесс протекал последовательно, без лишних вычислительных издержек и с минимальными затратами на копирование данных.
bool CNeuronHimNetEncoder::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!cTempEncoder.calcInputGradients(prevLayer, cPolinomSupport.AsObject())) return false;
В первую очередь градиенты извлекаются из временного Энкодера и аккуратно передаются в буферы полиномиальной поддержки и предыдущего слоя.
Здесь процедура повторяется для пространственного Энкодера, но предварительно нам предстоит позаботиться о сохранности уже полученных данных. И здесь речь не только о внутренних компонентах, но и об объекте исходных данных. Ведь оба Энкодера при прямом проходе анализируют один пул исходных данных
CBufferFloat* temp = cPolinomSupport.getGradient(); CBufferFloat* prev = prevLayer.getGradient(); if(!cPolinomSupport.SetGradient(cPolinomSupport.getPrevOutput(), false) || !prevLayer.SetGradient(prevLayer.getPrevOutput(), false) || !cSpatEncoder.calcInputGradients(prevLayer, cPolinomSupport.AsObject()) || !SumAndNormilize(temp, cPolinomSupport.getGradient(), temp, cSpatEncoder.GetCount(), false, 0, 0, 0, 1) || !SumAndNormilize(prev, prevLayer.getGradient(), prev, cSpatEncoder.GetCount(), false, 0, 0, 0, 1) || !cPolinomSupport.SetGradient(temp, false) || !prevLayer.SetGradient(prev, false)) return false; if(prevLayer.Activation() != None) if(!DeActivation(prevLayer.getOutput(), prev, prev, prevLayer.Activation())) return false;
Данные двух информационных потоков аккуратно суммируем.
Затем обратное распространение продвигается по цепочке ниже — нам предстоит распределить градиенты ошибки от полиномов Чебышева до уровня эмбеддингов, сохраняя непрерывность информационного потока.
//--- if(!cNormSupport.CalcHiddenGradients(cPolinomSupport.AsObject())) return false; if(!cSupport.CalcHiddenGradients(cNormSupport.AsObject())) return false; if(!MatMulGrad(cEmbedding.getOutput(), cEmbedding.getPrevOutput(), cEmbeddingT.getOutput(), cEmbeddingT.getGradient(), cSupport.getGradient(), cEmbeddingT.GetCount(), cEmbeddingT.GetWindow(), cEmbeddingT.GetCount(), 1, false)) return false; if(!cEmbedding.CalcHiddenGradients(cEmbeddingT.AsObject())) return false; if(!SumAndNormilize(cEmbedding.getGradient(), cEmbedding.getPrevOutput(), cEmbedding.getGradient(), cEmbeddingT.GetWindow(), false, 0, 0, 0, 1)) return false; if(cEmbedding.Activation() != None) if(!DeActivation(cEmbedding.getOutput(), cEmbedding.getGradient(), cEmbedding.getGradient(), cEmbedding.Activation())) return false; //--- return true; }
В итоге метод выполняет тщательно выстроенный маршрут обратной связи, где каждый слой получает ровно ту порцию корректирующего сигнала, которая ему положена. Это снижает риск расхождения градиентов, повышает устойчивость обучения и делает процесс оптимизации более контролируемым.
Метод обновления параметров реализован предельно лаконично, но в этом и кроется его сила. Он не пытается вмешаться в вычисления каждого блока, а лишь делегирует ответственность соответствующим компонентам.
bool CNeuronHimNetEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cEmbedding.UpdateInputWeights()) return false; if(!cTempEncoder.updateInputWeights(NeuronOCL, cPolinomSupport.AsObject())) return false; if(!cSpatEncoder.updateInputWeights(NeuronOCL, cPolinomSupport.AsObject())) return false; //--- return true; }
Для тех, кто хочет глубже разобраться в деталях, полный код класса и всех его методов приложен во вложении — можно изучить его в удобном темпе.
Декодер
Завершая нашу работу по реализации подходов фреймворка HimNet, мы переходим к финальному и не менее значимому компоненту — Декодеру. Если Энкодер выполнял роль сборщика информации, уплотняя и структурируя данные для компактного представления, то Декодер действует, как искусный реставратор: слой за слоем он восстанавливает исходное содержание из скрытого латентного пространства, возвращая данным их привычную форму, но уже обогащённую и очищенную от избыточного шума.
class CNeuronHimNetDecoder : public CNeuronBaseOCL { protected: CNeuronConvOCL cProjection; CNeuronTransposeOCL cProjectionT; CNeuronConvOCL cEmbedding; CNeuronBaseOCL cSupport; CNeuronSoftMaxOCL cNormSupport; CChebPolinom cPolinomSupport; CLayer cGRCUs; CBufferFloat bSupportAccum; CBufferFloat bEmbeddingAccum; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHimNetDecoder(void) {}; ~CNeuronHimNetDecoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronHimNetDecoder; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual bool Clear(void) override; };
В архитектурном плане Декодер сохраняет преемственность и симметрию с Энкодером, что делает общую структуру сети сбалансированной и легко интерпретируемой. Однако, в отличие от Энкодера, где пространственные и временные эмбеддинги могли формироваться раздельно и дополнять друг друга, в Декодере применяется единый пространственно-временной эмбеддинг, который формируется на основе латентного представления, полученного на выходе Энкодера. Это же латентное представление служит основой для формирования полиномов Чебышева, используемых для аппроксимации сложной динамики при восстановлении временных рядов.
После того как мы познакомились с архитектурой Декодера, следующим шагом становится последовательная инициализация всех его внутренних компонентов. Метод Init начинает работу с передачи управления родительскому классу, который реализует инициализацию базовых интерфейсов.
bool CNeuronHimNetDecoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint window_out, uint cheb_k, uint layers, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * units, optimization_type, batch)) return false;
Далее создается слой проекции исходных данных cProjection и объект транспонирования полученной проекции cProjectionT.
int index = 0; if(!cProjection.Init(0, index, OpenCL, window, window, embed_dim, units, 1, optimization, iBatch)) return false; SetActivationFunction(TANH); index++; if(!cProjectionT.Init(0, index, OpenCL, units, embed_dim, optimization, iBatch)) return false;
Первому назначается функция активации TANH, что позволяет корректно формировать пространственно-временные представления на основе латентного представления, полученного от Энкодера.
После этого формируется слой генерации эмбеддингов cEmbedding, размеры которого соответствуют количеству нейронов и признаковой размерности. Эти эмбеддинги используются для последующих вычислений в рекуррентных блоках.
index++; if(!cEmbedding.Init(0, index, OpenCL, units, units, 1, 1, embed_dim, optimization, iBatch)) return false; SetActivationFunction(SIGMOID); index++; if(!cSupport.Init(0, index, OpenCL, units * units, optimization, iBatch)) return false; cSupport.SetActivationFunction(None); index++; if(!cNormSupport.Init(0, index, OpenCL, cSupport.Neurons(), optimization, iBatch)) return false; cNormSupport.SetHeads(units); cNormSupport.SetActivationFunction(None); index++; if(!cPolinomSupport.Init(0, index, OpenCL, units, cheb_k, optimization, iBatch)) return false;
Объекты cSupport и cNormSupport играют ключевую роль в подготовке данных для полиномов Чебышева. Сначала cSupport формирует диагональную матрицу корреляции, отражающую взаимосвязи между различными признаками или временными потоками. Затем cNormSupport приводит значения этой матрицы к единому масштабу, обеспечивая стабильность вычислений и корректность последующих операций. Именно эта нормированная матрица служит основой для блока cPolinomSupport, где на её базе строятся полиномы Чебышева, которые далее участвуют в вычислениях рекуррентных блоков GCRU. Такой подход позволяет моделировать сложные зависимости между признаками, сохраняя точность и согласованность в вычислительном процессе.
Следующий этап — создание контейнера cGRCUs для рекуррентных блоков GCRU. В него последовательно добавляются блоки: первый получает размер пространства признаков, соответствующий исходным данным, а все последующие используют фиксированный размер тензоров.
//--- cGRCUs.Clear(); cGRCUs.SetOpenCL(OpenCL); index++; CNeuronHimNetGCRU *temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window, window_out, cheb_k, embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) { DeleteObj(temp); return false; } for(uint i = 1; i < layers; i++) { index++; temp = new CNeuronHimNetGCRU(); if(!temp || !temp.Init(0, index, OpenCL, units, window_out, window_out, cheb_k, 2 * embed_dim, optimization, iBatch) || !cGRCUs.Add(temp)) { DeleteObj(temp); return false; } }
Все блоки связываются с OpenCL-контекстом, что обеспечивает ускорение вычислений.
Для хранения промежуточных результатов градиентов ошибки выделяются буферы bSupportAccum и bEmbeddingAccum.
bSupportAccum.BufferFree(); bSupportAccum.Clear(); if(!bSupportAccum.BufferInit(cPolinomSupport.Neurons(), 0) || !bSupportAccum.BufferCreate(OpenCL)) return false; bEmbeddingAccum.BufferFree(); bEmbeddingAccum.Clear(); if(!bEmbeddingAccum.BufferInit(cEmbedding.Neurons(), 0) || !bEmbeddingAccum.BufferCreate(OpenCL)) return false; //--- SetActivationFunction((ENUM_ACTIVATION)temp.Activation()); if(!SetOutput(temp.getOutput(), true) || !SetGradient(temp.getGradient(), true)) return false; //--- return true; }
Завершается процесс инициализации синхронизацией функций активации последнего блока для всего декодера, а также указателей на выходные буферы и градиенты ошибки. Это исключает излишние копирования данных и гарантирует готовность модели к обучению и прямому проходу. Каждый этап тщательно проверяется: в случае любой ошибки метод возвращает false, предотвращая некорректное состояние модели и обеспечивая устойчивость дальнейших вычислений.
После успешной инициализации всех компонентов Декодера, мы переходим к построению метода прямого прохода, который является сердцем процесса обработки сигнала. На этом этапе анализируемая информация последовательно проходит через несколько взаимосвязанных блоков, каждый из которых выполняет свою специфическую функцию, обеспечивая точную и скоординированную работу модели.
bool CNeuronHimNetDecoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cProjection.FeedForward(NeuronOCL)) return false; if(!cProjectionT.FeedForward(cProjection.AsObject())) return false; if(!MatMul(cProjection.getOutput(), cProjectionT.getOutput(), cSupport.getOutput(), cProjectionT.GetCount(), cProjectionT.GetWindow(), cProjectionT.GetCount(), 1, false)) return false; if(!cNormSupport.FeedForward(cSupport.AsObject())) return false;
На начальном этапе сигнал проходит обработку в модулях cProjection и cProjectionT, преобразующих исходные данные в латентное представление заданной размерности. Результирующие тензоры подвергаются матричному умножению, в результате которого формируется диагональная матрица корреляции. Далее эта матрица нормализуется с использованием функции SoftMax. Такая нормализация критически важна для формирования полиномов Чебышева в блоке cPolinomSupport, так как она гарантирует стабильность вычислений и правильное масштабирование влияния каждого элемента на последующие слои.
if(!cPolinomSupport.FeedForward(cNormSupport.AsObject())) return false; //--- if(!cEmbedding.FeedForward(cProjectionT.AsObject())) return false;
Далее формируются эмбеддинги в блоке cEmbedding, которые создают компактное и информативное представление скрытых характеристик данных.
После подготовки данных сигнал поступает в первый блок GCRU из контейнера cGRCUs, где реализуется графово-рекуррентная обработка информации. Каждый последующий блок GCRU получает на вход выход предыдущего, что позволяет декодеру аккумулировать временные и пространственные зависимости и выявлять сложные паттерны на исторических данных.
CNeuronHimNetGCRU* current = NULL; CNeuronBaseOCL* inputs = NeuronOCL; for(int i = 0; i < cGRCUs.Total(); i++) { current = cGRCUs[i]; if(!current || !current. Feedforward(NeuronOCL, cPolinomSupport.AsObject(), cEmbedding.AsObject())) return false; inputs = current; } //--- return true; }
В результате этих последовательных преобразований формируется окончательный выход декодера. Такой подход обеспечивает согласованную работу модели и оптимизацию вычислительных ресурсов, что особенно важно при обработке больших массивов финансовых данных и обучении на исторических временных рядах.
Вы, вероятно, уже заметили, насколько алгоритмы работы Декодера органично наследуют логику, продемонстрированную в рассмотренных выше Энкодерах. Поэтому детальное изучение методов обратного прохода я предлагаю оставить на самостоятельное ознакомление. Полный код класса вместе со всеми его методами представлен во вложении.
Тестирование
После того как мы собрали все ключевые компоненты фреймворка HimNet, наступает время перейти к самому интересному этапу — обучению и тестированию модели. Наша цель остаётся прежней: создать торговую систему, способную самостоятельно анализировать рынок и принимать решения. В этой схеме HimNet выступает в роли Энкодера состояния окружающей среды, формирующего компактное, но информативное представление текущей рыночной ситуации. Актёр опирается на это представление при выборе действий, а Критик оценивает их качество, обеспечивая обратную связь и корректировку стратегии.
Обучение организовано в два взаимодополняющих этапа, что одновременно даёт надёжный фундамент и гибкость для работы в реальных рыночных условиях. На первом, офлайн-этапе, мы провели основательное обучение на исторических данных по паре EURUSD с таймфреймом H1 за весь 2024 год. Этот период включал полный спектр рыночных режимов — спокойные флэты, устойчивые тренды, резкие скачки волатильности и периоды усиленного шума, поэтому он стал отличной школой для модели.
Второй этап — тонкая онлайн-настройка. Модель обрабатывала поток свечей последовательно в тестере стратегий MetaTrader 5, максимально приближенном к реальному трейдингу. Этот этап выявляет совершенно другие свойства, нежели офлайн-обучение: способность выдерживать шум, адекватно реагировать на изменения ликвидности, учитывать задержки и эффект проскальзывания. Мы тщательно имитировали реальные условия исполнения, чтобы поведение модели оставалось предсказуемым при переносе в реальные рыночные условия.
Финальный и наиболее строгий этап проверки проводился на полностью внешней выборке — котировках с Января по Март 2025 года. Все параметры модели при этом оставались замороженными. Такая проверка демонстрирует объективную картину практической эффективности: способность алгоритма сохранять устойчивость и предсказуемость в новых условиях.
Результаты тестирования приведены ниже.
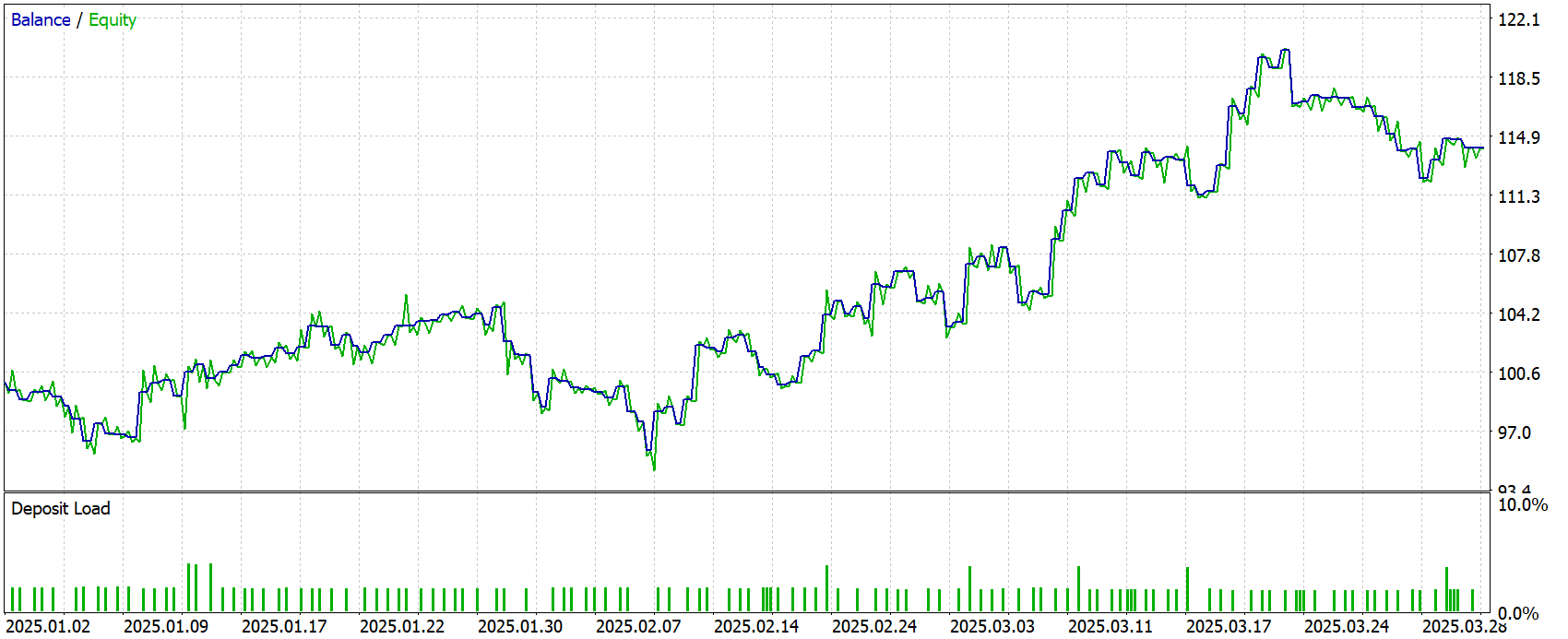
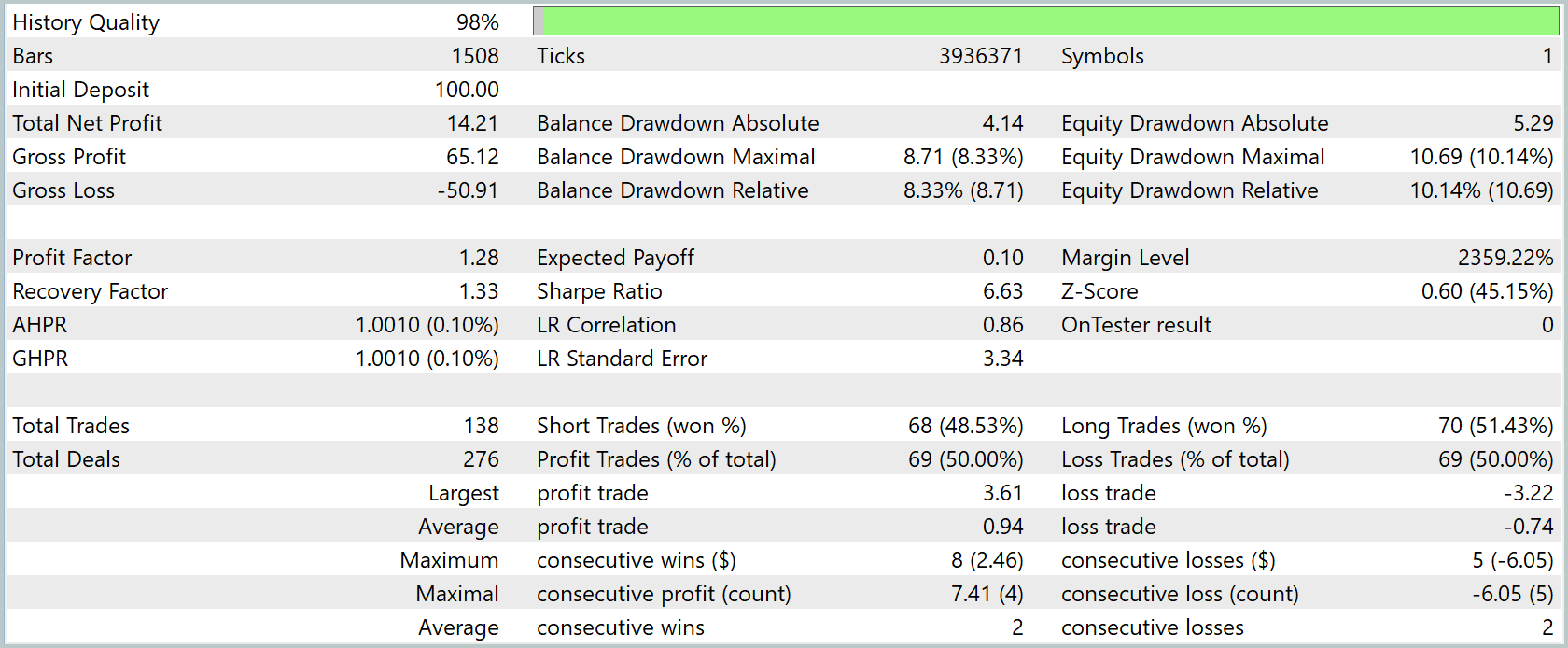
За три месяца периода тестирования чистая прибыль достигла 14.21% к первоначальному капиталу. Прибыль на каждый доллар убытка составляла $1.28, а среднее математическое ожидание сделки — всего $0.10. Коэффициент восстановления 1.33 говорит о том, что итоговая прибыль превысила максимальную просадку по балансу.
Просадки выглядели умеренными: абсолютная составляла $4.14 по балансу и $5.29 по эквити, максимальная относительная — 8.33 % и 10.14 % соответственно. При этом линия прибыли демонстрировала устойчивый рост, что подтверждает корреляция тренда по времени на уровне 0.86.
За весь тест советник совершил 138 сделок, распределённых почти поровну между покупками и продажами, а доля прибыльных была близка к 50 % в обе стороны. Средний профит в успешной сделке составил $0.94, средний убыток — $0.74, крупнейший выигрыш достиг $3.61, а наибольший проигрыш — $3.22. В среднем позиции держались чуть больше часа, а колебания времени удержания колебались от 57 минут до двух часов, что указывает на ярко выраженный краткосрочный, внутридневной стиль работы.
В совокупности результаты говорят о достаточно стабильной, но умеренно прибыльной стратегии. Её сильные стороны — контролируемые просадки, равномерная работа в обе стороны рынка и положительное математическое ожидание. Слабые — невысокий запас по фактору прибыли и малая средняя прибыль на сделку, что может сделать её чувствительной к спредам и комиссиям на реальном счёте.
Заключение
В данной статье завершена работа над реализацией подходов фреймворка HimNet средствами MQL5. Ключевыми преимуществами фреймворка являются его архитектурная гибкость и способность адаптироваться к разнообразным задачам, связанным с прогнозированием и анализом временных рядов.
Результаты итогового тестирования на новых котировках, не входивших в обучающую выборку, показали положительную динамику. Баланс модели демонстрировал стабильный рост, что свидетельствует о её способности эффективно адаптироваться к изменяющимся рыночным условиям.
Ссылки
- Heterogeneity-Informed Meta-Parameter Learning for Spatiotemporal Time Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования