
Neuronale Netze leicht gemacht (Teil 16): Praktische Anwendung des Clustering

Inhalt
- Einführung
- 1. Theoretische Aspekte der Nutzung von Clustering-Ergebnissen
- 2. Einsatz von Clustering als unabhängige Lösung
- 3. Verwendung der Clustering-Ergebnisse als Eingabe
- Schlussfolgerung
- Liste der Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Die beiden vorangegangenen Artikel waren dem Clustering von Daten gewidmet. Unser Hauptziel ist es jedoch, zu lernen, wie man alle betrachteten Methoden zur Lösung konkreter praktischer Probleme einsetzt. Insbesondere Fälle, die den Handel betreffen. Als wir anfingen, Methoden des unüberwachten Lernens zu erwägen, sprachen wir über die Möglichkeit, die erzielten Ergebnisse sowohl unabhängig als auch als Eingabedaten für andere Modelle zu verwenden. In diesem Artikel werden wir mögliche Anwendungsfälle für Clustering-Ergebnisse betrachten.
1. Theoretische Aspekte der Nutzung von Clustering-Ergebnissen
Bevor wir zur praktischen Umsetzung von Beispielen im Zusammenhang mit der Verwendung von Clustering-Ergebnissen übergehen, wollen wir ein wenig über die theoretischen Aspekte dieser Ansätze sprechen.
Die erste Möglichkeit, die Ergebnisse der Datenclustering zu nutzen, besteht darin, zu versuchen, das Beste aus ihnen herauszuholen, um sie ohne zusätzliche Mittel praktisch zu nutzen. D.h. die Clustering-Ergebnisse können unabhängig voneinander verwendet werden, um Handelsentscheidungen zu treffen. Ich möchte daran erinnern, dass unüberwachte Lernmethoden nicht zur Lösung von Regressionsaufgaben verwendet werden. Die Vorhersage der nächsten Kursbewegung ist eine Regressionsaufgabe. Auf den ersten Blick sehen wir eine Art von Konflikt.
Aber schauen wir mal von der anderen Seite. Was die theoretischen Aspekte des Clustering angeht, so haben wir das Clustering bereits mit der Definition von grafischen Mustern verglichen. Wie bei den Chartmustern können wir Statistiken über das Kursverhalten nach dem Erscheinen eines Elements eines bestimmten Clusters im Chart erstellen. Nun, daraus lässt sich kein kausaler Zusammenhang ableiten. Eine solche Beziehung besteht jedoch in keinem mathematischen Modell, das mit neuronalen Netzen erstellt wurde. Wir erstellen nur probabilistische Modelle, ohne tief in kausale Zusammenhänge einzutauchen.
Um Statistiken zu erstellen, benötigen wir ein bereits trainiertes Clustermodell und markierte Daten. Da unser Clustering-Modell bereits trainiert wurde, kann der markierte Datensatz viel kleiner sein als die Trainingsstichprobe. Sie sollte jedoch ausreichend und repräsentativ sein.
Auf den ersten Blick mag dieser Ansatz dem überwachten Lernen ähneln. Es gibt jedoch zwei wesentliche Unterschiede:
- Der Umfang der beschrifteten Stichprobe kann kleiner sein, da keine Gefahr der Überanpassung besteht.
- Beim überwachten Lernen verwenden wir einen iterativen Prozess, bei dem die optimalen Gewichtskoeffizienten ausgewählt werden. Dies erfordert mehrere Trainingsepochen mit hohen Ressourcen- und Zeitkosten. Der erste Durchgang reicht aus, um Statistiken zu sammeln. In diesem Fall wird keine Modellanpassung vorgenommen.
Ich hoffe, die Idee ist einfach. Auf die Umsetzung eines solchen Modells werden wir etwas später eingehen.
Der Nachteil dieser Option ist, dass der Abstand zum Zentrum des Clusters ignoriert wird. Mit anderen Worten, wir erhalten das gleiche Ergebnis für Elemente in der Nähe des Clustermittels („ein ideales Muster“) und für Elemente am Rande des Clusters. Sie können versuchen, die Anzahl der Cluster zu erhöhen, um den maximalen Abstand der Elemente vom Zentrum zu verringern. Die Effektivität dieses Ansatzes ist jedoch minimal, vorausgesetzt, wir haben die Anzahl der Cluster entsprechend dem Graphen der Verlustfunktion richtig gewählt.
Sie können versuchen, dieses Problem zu lösen, indem Sie die zweite Anwendung der Clustering-Ergebnisse nutzen: als Quelldaten eines anderen Modells. Es ist jedoch zu beachten, dass wir durch die Eingabe der Clusternummer in Form einer Zahl oder eines Vektors in das zweite Modell höchstens Daten erhalten, die mit den Ergebnissen der oben betrachteten statistischen Methode vergleichbar sind. Es macht keinen Sinn, zusätzlichen Aufwand zu treiben, um das gleiche Ergebnis zu erzielen.
Anstelle der Clusternummer können wir den Abstand zu den Clusterzentren in das Modell eingeben. Wir sollten nicht vergessen, dass neuronale Netze normalisierte Daten bevorzugen. Wir normalisieren die Daten des Entfernungsvektors mit Hilfe der Softmax-Funktion.
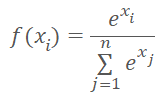
Softmax basiert jedoch auf dem Exponenten, dessen Graphik in der folgenden Abbildung dargestellt ist.

Überlegen wir uns nun, welchen Vektor wir als Ergebnis der Normalisierung der Abstände zu den Zentren der Cluster mit der Softmax-Funktion erhalten werden. Es ist offensichtlich, dass alle Abstände positiv sind. Je größer der Abstand, desto größer der Exponent und desto mehr ändert sich der Funktionswert bei gleicher Änderung des Arguments. Daher wird dem maximalen Abstand mehr Gewicht beigemessen. Mit abnehmendem Abstand nehmen die Unterschiede zwischen den Werten ab. Durch diese einfache Normalisierung erhalten wir also einen Vektor, der beschreibt, zu welchen Clustern das Element nicht gehört. Das erschwert die Bestimmung jenes Clusters, zu dem das Element gehört. Wir brauchen das Gegenteil.
Es scheint, dass die Situation durch einen einfachen Wechsel des Vorzeichens des Abstands korrigiert werden könnte. Im Bereich der negativen Argumente nähert sich der Wert der Exponentialfunktion jedoch 0. Wenn das Argument abnimmt, tendiert auch die Abweichung der Funktionswerte gegen 0.
Als Lösung für die oben genannten Probleme können wir zunächst die Abstände im Bereich von 0 bis 1 normalisieren. Wenden wir dann die Softmax-Funktion auf „1—X“ an.
Die Wahl des Modells, in das die normierten Werte eingegeben werden, hängt von der Problemstellung ab und geht über den Rahmen dieses Artikels hinaus.
Nachdem wir nun die wichtigsten theoretischen Ansätze für die Nutzung von Clustering-Ergebnissen erörtert haben, können wir zum praktischen Teil unseres Artikels übergehen.
2. Einsatz von Clustering als unabhängige Lösung
Wir beginnen mit der Implementierung der statistischen Methode, indem wir den Code eines weiteren Kernels KmeansStatistic in das OpenCL-Programm (Datei unsupervised.cl) schreiben, der die Statistiken für die Signalverarbeitung jedes Clusters berechnet. Die Art und Weise, wie dieser Prozess organisiert ist, ähnelt dem überwachten Lernen. In der Tat brauchen wir gekennzeichnete Daten. Es gibt jedoch einen grundlegenden Unterschied zwischen diesem Verfahren und der früheren Backpropagation-Methode. Zuvor hatten wir die Modellfunktion optimiert, um Ergebnisse zu erzielen, die den Referenzwerten sehr nahe kommen. Jetzt werden wir das Modell in keiner Weise ändern. Stattdessen werden wir Statistiken über die Reaktion des Systems auf das Auftreten eines bestimmten Musters sammeln.
Als Parameter werden dem Kernel Zeiger auf drei Datenpuffer und die Gesamtzahl der Elemente im Trainingssatz übergeben. Aber wir werden die Trainingsstichprobe nicht in diese Kernel-Parameter einfügen. Um diese Funktion auszuführen, brauchen wir den Inhalt des Systemzustandsbeschreibungsvektors nicht zu kennen. In diesem Stadium reicht es aus, wenn wir wissen, zu welcher Klasse der analysierte Systemzustand gehört. Daher wird in den Kernel-Parametern nicht die Trainingsstichprobe, sondern ein Zeiger auf den Cluster-Vektor übergeben, der Cluster-Kennungen für jeden Systemzustand aus der Trainingsmenge enthält.
Der zweite Eingangsdatenpuffer target enthält einen Tensor, der die Reaktion des Systems nach dem Auftreten eines bestimmten Puffers beschreibt. Dieser Tensor enthält drei logische Flags, die das Signal nach dem Auftreten des Musters beschreiben: Kauf, Verkauf, undefiniert. Durch die Verwendung von Flags wird die Berechnung von Signalstatistiken einfacher und intuitiver. Gleichzeitig wird jedoch die Variabilität der möglichen Signale eingeschränkt. Daher muss die Anwendung dieser Methode mit den technischen Anforderungen der Aufgabe übereinstimmen. In dieser Artikelserie haben wir alle in Frage kommenden Algorithmen auf ihre Fähigkeit hin untersucht, Fraktalbildung zu erkennen, bevor die Bildung der letzten Kerze beginnt. Wie Sie wissen, benötigen wir drei Kerzen, um ein Fraktal auf einem Chart zu bestimmen. Daher können wir sie eigentlich erst nach der Bildung der dritten Kerze des Musters bestimmen. Wir wollen jedoch einen Weg finden, um die Bildung eines Musters zu bestimmen, wenn nur zwei Kerzen des zukünftigen Musters gebildet werden. Natürlich mit einem gewissen Grad an Wahrscheinlichkeit. Um dieses Problem zu lösen, genügt es, für jedes Muster Zielsignale mit drei Flags zu verwenden.
Außerdem können verschiedene Trainingsmuster verwendet werden, um nach dem Auftreten von Mustern Signalstatistiken zu sammeln und das Modell zu trainieren. So kann das Modell beispielsweise über einen ausreichend langen Zeitraum trainiert werden, damit es die Merkmale des Zustands des analysierten Systems so gut wie möglich erlernen kann. Ein kürzerer historischer Zeitraum kann zur Kennzeichnung der Daten und zur Erhebung von Statistiken verwendet werden. Bevor wir Statistiken erstellen, müssen wir natürlich die entsprechenden Cluster zusammenstellen. Denn um eine korrekte statistische Erfassung zu gewährleisten, müssen die Daten vergleichbar sein.
Kehren wir zu unserem Algorithmus zurück. Der Kernel wird in einem eindimensionalen Aufgabenraum ausgeführt. Die Anzahl der parallelen Threads ist gleich der Anzahl der erstellten Cluster.
Zu Beginn des Kernels wird die ID des aktuellen Threads festgelegt, die die Sequenznummer des analysierten Clusters bestimmt. Außerdem können wir sofort die Verschiebung im Tensor der probabilistischen Ergebnisse bestimmen. Bereiten wir private Variablen vor, um die Anzahl des Auftretens der einzelnen Signale zu zählen: buy, sell, skip. Wir weisen jeder Variablen den Anfangswert 0 zu.
Als Nächstes implementieren wir eine Schleife mit einer Anzahl von Iterationen, die der Anzahl der Elemente in der Trainingsstichprobe entspricht. Im Schleifenkörper wird zunächst geprüft, ob der Systemzustand zu dem analysierten Cluster gehört. Wenn es dazugehört, fügen wir den Inhalt des Zielflag-Tensors zu den entsprechenden privaten Variablen hinzu.
Für Zielwerte verwenden wir die Flags, die nur 0 oder 1 sein können. Wir werden Signale verwenden, die sich gegenseitig ausschließen. Das bedeutet, dass es zu einem bestimmten Zeitpunkt nur eine Flags für jeden einzelnen Zustand des Systems geben kann. Dank dieser Eigenschaft ist es nicht erforderlich, einen separaten Zähler für die Anzahl der Mustervorkommen zu verwenden. Stattdessen werden nach dem Verlassen der Schleife alle drei privaten Variablen addiert, um die Gesamtzahl der auftretenden Muster zu ermitteln.
Nun müssen wir die natürlichen Signalsummen in den Bereich der Wahrscheinlichkeitsmathematik übertragen. Dazu teilen wir den Wert jeder privaten Variable durch die Gesamtzahl der auftretenden Muster. Es gibt jedoch einige Momente, auf die Sie achten sollten. Erstens muss die Möglichkeit des kritischen Fehlers Teilen-durch-Null ausgeschlossen werden. Zweitens brauchen wir echte Wahrscheinlichkeiten, denen wir vertrauen können. Lassen Sie mich das erklären. Wenn zum Beispiel ein bestimmter Parameter einmal auftritt, beträgt die Wahrscheinlichkeit eines solchen Signals 100 %. Aber kann man einem solchen Signal trauen? Nein, natürlich nicht. Höchstwahrscheinlich ist sein Auftreten zufällig. Daher werden für alle Muster, die weniger als 10 Mal vorkommen, allen Signalen Nullwahrscheinlichkeiten zugeordnet.
__kernel void KmeansStatistic(__global double *clusters, __global double *target, __global double *probability, int total_m ) { int c = get_global_id(0); int shift_c = c * 3; double buy = 0; double sell = 0; double skip = 0; for(int i = 0; i < total_m; i++) { if(clusters[i] != c) continue; int shift = i * 3; buy += target[shift]; sell += target[shift + 1]; skip += target[shift + 2]; } //--- int total = buy + sell + skip; if(total < 10) { probability[shift_c] = 0; probability[shift_c + 1] = 0; probability[shift_c + 2] = 0; } else { probability[shift_c] = buy / total; probability[shift_c + 1] = sell / total; probability[shift_c + 2] = skip / total; } }
Nachdem wir einen Kernel im OpenCL-Programm erstellt haben, fahren wir mit der Arbeit an der Seite des Hauptprogramms fort. Zunächst fügen wir Konstanten für die Arbeit mit dem zuvor erstellten Kernel hinzu. Natürlich muss die Benennung der Konstanten mit unserer Benennungspolitik übereinstimmen.
#define def_k_kmeans_statistic 4 #define def_k_kms_clusters 0 #define def_k_kms_targers 1 #define def_k_kms_probability 2 #define def_k_kms_total_m 3
Nachdem wir die Konstanten erstellt haben, gehen wir zur Funktion OpenCLCreate über, in der wir die Gesamtzahl der verwendeten Kerne ändern. Wir werden auch die Erstellung eines neuen Kernels hinzufügen.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(5)) { delete result; .return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_statistic, "KmeansStatistic")) { delete result; .return NULL; } //--- return result; }
Nun müssen wir den Aufruf dieses Kernels auf der Seite des Hauptprogramms implementieren.
Um diesen Aufruf zu ermöglichen, müssen wir die Methode Statistic in unserer Klasse CKmeans erstellen. Die neue Methode erhält als Parameter Zeiger auf zwei Datenpuffer: ein Trainingsmuster und Referenzwerte. Obwohl der Datensatz dem überwachten Lernen ähnelt, gibt es einen grundlegenden Unterschied in den Ansätzen. Während des überwachten Lernens haben wir das Modell optimiert, um optimale Ergebnisse zu erzielen, was ein iterativer Prozess ist. Jetzt sammeln wir die Statistiken einfach in einem Durchgang.
Im Methodenrumpf wird die Relevanz des Zeigers auf den Zielwertepuffer geprüft und die Clustermethode für die Trainingsbeispiele aufgerufen. Vergessen wir nicht, dass die Trainingsstichprobe in diesem Fall von derjenigen abweichen kann, die zum Trainieren des Modells verwendet wurde, aber sie muss den Zielwerten entsprechen.
bool CKmeans::Statistic(CBufferDouble *data, CBufferDouble *targets) { if(CheckPointer(targets) == POINTER_INVALID || !Clustering(data)) return false;
Als Nächstes initialisieren wir den Puffer, um die probabilistischen Werte des vorhergesagten Systemverhaltens zu schreiben. Ich verwende absichtlich nicht den Ausdruck „Reaktion auf Muster“, da wir keine Kausalität analysieren. Sie kann direkt oder indirekt sein. Es kann überhaupt keinen Zusammenhang geben. Wir erheben nur Statistiken auf der Grundlage historischer Daten.
if(CheckPointer(c_aProbability) == POINTER_INVALID) { c_aProbability = new CBufferDouble(); if(CheckPointer(c_aProbability) == POINTER_INVALID) return false; } if(!c_aProbability.BufferInit(3 * m_iClusters, 0)) return false; //--- int total = c_aClasters.Total(); if(!targets.BufferCreate(c_OpenCL) || !c_aProbability.BufferCreate(c_OpenCL)) return false;
Nach der Erstellung eines Puffers laden wir die erforderlichen Daten in den OpenCL-Kontextspeicher und implementieren die Kernel-Aufrufprozedur. Zunächst werden die Kernel-Parameter übergeben und die Dimension des Aufgabenraums sowie die Offsets in jeder Dimension bestimmt. Danach stellen wir den Kernel in die Ausführungswarteschlange und lesen das Ergebnis der Operationen ab. Achten Sie bei der Durchführung von Vorgängen darauf, dass Sie den Prozess bei jedem Schritt kontrollieren.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_probability, c_aProbability.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_targers, targets.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_clusters, c_aClasters.GetIndex())) return false; if(!c_OpenCL.SetArgument(def_k_kmeans_statistic, def_k_kms_total_m, total)) return false; uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = m_iClusters; if(!c_OpenCL.Execute(def_k_kmeans_statistic, 1, global_work_offset, global_work_size)) return false; if(!c_aProbability.BufferRead()) return false; //--- data.BufferFree(); targets.BufferFree(); //--- return true; }
Wenn der Kernel erfolgreich ausgeführt wird, erhalten wir im Puffer c_aProbability die Wahrscheinlichkeiten für das Auftreten der einzelnen Muster. Wir müssen nur den Speicher löschen und die Methode abschließen.
Das betrachtete Verfahren kann jedoch auf das Modelltraining zurückgeführt werden. Für die praktische Anwendung müssen wir die Wahrscheinlichkeiten für das Verhalten des Echtzeitsystems ermitteln. Zu diesem Zweck erstellen wir eine weitere Methode GetProbability. In den Methodenparametern wird nur eine Probe für das Clustering übergeben. Es ist sehr wichtig, dass die Wahrscheinlichkeitsmatrix c_aProbability vor dem Aufruf der Methode gebildet wird. Daher ist dies das erste, was wir im Methodenrumpf überprüfen. Danach beginnt das Clustering der empfangenen Daten. Wir überprüfen auch hier das Ergebnis der Vorgangsausführung.
CBufferDouble *CKmeans::GetProbability(CBufferDouble *data)
{
if(CheckPointer(c_aProbability) == POINTER_INVALID ||
!Clustering(data))
.return NULL;
Die Besonderheit dieser Methode besteht darin, dass wir als Ergebnis ihrer Operation keinen booleschen Wert, sondern einen Zeiger auf den Datenpuffer zurückgeben. Daher legen wir im nächsten Schritt einen neuen Puffer an, um Daten zu sammeln.
CBufferDouble *result = new CBufferDouble(); if(CheckPointer(result) == POINTER_INVALID) return result;
Wir gehen davon aus, dass wir in Echtzeit probabilistische Daten für eine kleine Anzahl von Datensätzen erhalten werden. Meistens gibt es nur einen Datensatz — den aktuellen Zustand des Systems. Daher werden wir keine weiteren Arbeiten zur parallelen Datenverarbeitung durchführen. Wir werden eine Schleife implementieren, um über den Puffer mit den Identifikatoren der untersuchten Datencluster zu iterieren. Im Schleifenkörper übertragen wir die Wahrscheinlichkeiten der entsprechenden Cluster in den Ergebnispuffer.
int total = c_aClasters.Total(); if(!result.Reserve(total * 3)) { delete result; return result; } for(int i = 0; i < total; i++) { int k = (int)c_aClasters.At(i) * 3; if(!result.Add(c_aProbability.At(k)) || !result.Add(c_aProbability.At(k + 1)) || !result.Add(c_aProbability.At(k + 2)) ) { delete result; return result; } } //--- return result; }
Beachten Sie, dass die Wahrscheinlichkeiten im Ergebnispuffer in der gleichen Reihenfolge angeordnet werden wie die Systemzustände in der analysierten Probe. Wenn die Stichprobe Daten enthält, die zu einem Cluster gehören, werden die Wahrscheinlichkeiten für das Systemverhalten wiederholt.
Um die Methode zu testen, haben wir den Expert Advisor „kmeans_stat.mq5“ erstellt. Der vollständige Code befindet sich im Anhang. Wie aus dem Dateinamen hervorgeht, liefert sie Statistiken über die Wahrscheinlichkeiten des Auftretens von Fraktalen nach jedem Muster.
Wir haben das Experiment mit dem 500-Cluster-Modell durchgeführt, das im vorherigen Artikel trainiert wurde. Die Ergebnisse sind in der nachstehenden Abbildung zu sehen.

Die vorgelegten Daten beweisen, dass die Anwendung dieses Ansatzes es ermöglicht, die Marktreaktion nach dem Auftreten von Fraktalen mit einer Wahrscheinlichkeit von 30-45% vorherzusagen. Dies ist ein recht gutes Ergebnis. Vor allem, wenn man bedenkt, dass wir keine mehrschichtigen neuronalen Netze verwendet haben.
3. Verwendung der Clustering-Ergebnisse als Eingabe
Kommen wir nun zur Umsetzung der zweiten Variante der Nutzung von Clustering-Ergebnissen. Bei diesem Ansatz werden wir die Ergebnisse des Clustering in ein anderes Modell eingeben. Eigentlich kann dies jedes beliebige Modell sein, das für Ihr Problem geeignet ist, einschließlich eines neuronalen Netzes, das überwachte Lernalgorithmen verwendet.
Wir haben zuvor festgelegt, dass bei der Implementierung dieses Ansatzes die Clustering-Ergebnisse als normalisierter Vektor der Abstände zu den Zentren der Cluster dargestellt werden sollen. Um diese Funktionalität zu implementieren, müssen wir einen weiteren Kernel KmeansSoftMax im OpenCL-Programm unsupervised.cl erstellen.
Wir werden die Abstände zum Zentrum jedes Clusters im neuen Kernel nicht neu berechnen, da diese Funktion bereits im KmeansCulcDistance-Kernel ausgeführt wird. In KmeansSoftMax werden nur die verfügbaren Daten normalisiert.
In den Kernelparametern übergeben wir Zeiger auf zwei Datenpuffer und die Gesamtzahl der verwendeten Cluster. Unter den Datenpuffern wird es einen Quelldatenpuffer distance und einen Ergebnispuffer softmax geben. Beide Puffer haben die gleiche Größe und sind Vektordarstellungen einer Matrix, deren Zeilen die einzelnen Elemente der Sequenz und die Spalten die Cluster darstellen.
Der Kernel wird in einem eindimensionalen Aufgabenraum entsprechend der Anzahl der Elemente in der geclusterten Stichprobe gestartet. Ich spreche bewusst nicht von einer „Trainingsstichprobe“, denn der Kernel kann sowohl beim Training des zweiten Modells als auch bei der daraus resultierenden Operation verwendet werden. Es liegt auf der Hand, dass die Dateneingabe in diesen beiden Varianten unterschiedlich sein wird.
Bevor wir mit der Implementierung des Kernel-Codes fortfahren, sollten wir uns daran erinnern, dass wir die Normalisierungsfunktionen leicht verändert haben und sie nun wie folgt aussehen.
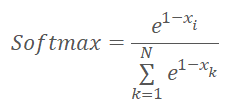
wobei x der Abstand zum Clusterzentrum ist, normiert im Bereich zwischen 0 und 1.
Schauen wir uns nun die Umsetzung der obigen Formel an. Im Kernelkörper wird zunächst der Thread-Identifikator ermittelt, der das analysierte Element der Sequenz angibt. Wir bestimmen auch die Verschiebung in Puffern bis zum Beginn des analysierten Vektors. Da die Ausgangsdaten und die Ergebnistensoren die gleiche Größe haben, ist auch der Versatz in den beiden Puffern gleich groß.
Um die Abstände im Bereich zwischen 0 und 1 zu normalisieren, müssen wir als Nächstes die maximale Abweichung vom Zentrum des Clusters ermitteln. Vergessen wir nicht, dass wir bei der Berechnung der Abstände die quadrierten Abweichungen verwendet haben. Das bedeutet, dass alle Werte im Abstandsvektor positiv sind. Das macht die Sache ein wenig einfacher. Wir deklarieren die private Variable m, um den maximalen Abstand zu schreiben und initialisieren sie mit dem Wert des ersten Elements unseres Vektors. Anschließend erstellen wir eine Schleife, die alle Elemente des Vektors durchläuft. Im Vektorkörper werden wir die Werte der Elemente mit dem gespeicherten Wert vergleichen und den Höchstwert in die Variable schreiben.
Sobald der höchste Wert ermittelt ist, können wir mit der Berechnung von Exponentialwerten für jedes Element fortfahren. Außerdem können wir sofort die Summe der Exponentialwerte des gesamten Vektors berechnen. Um die Summe zu ermitteln, initialisieren wir die private Variable sum mit dem Wert 0. Die entsprechenden arithmetischen Operationen werden in der nächsten Schleife durchgeführt. Die Anzahl der Schleifeniterationen ist gleich der Anzahl der Cluster im Modell. Im Schleifenkörper speichern wir zunächst in einer privaten Variablen den Exponentialwert des normalisierten und „invertierten“ Abstands zum Clusterzentrum. Der resultierende Wert wird zur Summe addiert und dann in den Ergebnispuffer übertragen. Durch die Verwendung einer privaten Variablen vor dem Schreiben von Werten in den Puffer wird die Anzahl der langsamen globalen Speicherzugriffe minimiert.
Sobald die Schleifeniterationen abgeschlossen sind, müssen wir die Daten normalisieren, indem wir die erhaltenen Exponentialwerte durch die Gesamtsumme dividieren. Um diese Operationen durchzuführen, erstellen wir eine weitere Schleife, deren Anzahl der Iterationen der Anzahl der Cluster entspricht. Beendet den Kernel, nachdem die Schleife beendet ist.
__kernel void KmeansSoftMax(__global double *distance, __global double *softmax, inсt total_k ) { int i = get_global_id(0); int shift = i * total_k; double m=distance[shift]; for(int k = 1; k < total_k; k++) m = max(distance[shift + k],m); double sum = 0; for(int k = 0; k < total_k; k++) { double value = exp(1-distance[shift + k]/m); sum += value; softmax[shift + k] = value; } for(int k = 0; k < total_k; k++) softmax[shift + k] /= sum; }
Wir haben die Funktionalität des OpenCL-Programms erweitert. Jetzt müssen wir nur noch den Kernel-Aufruf aus unserer Klasse CKmeans hinzufügen. Wir halten uns an das gleiche Schema, das wir oben verwendet haben, um den vorherigen Kernel-Aufrufcode hinzuzufügen.
Wir fügen zunächst Konstanten entsprechend der Benennungsrichtlinie hinzu.
#define def_k_kmeans_softmax 5 #define def_k_kmsm_distance 0 #define def_k_kmsm_softmax 1 #define def_k_kmsm_total_k 2
Dann fügen wir die Kernel-Deklaration in die OpenCL-Kontextinitialisierungsfunktion OpenCLCreate ein.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(6)) { delete result; .return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_softmax, "KmeansSoftMax")) { delete result; .return NULL; } //--- return result; }
Und natürlich brauchen wir eine neue Methode in unserer Klasse CKmeans::SoftMax. Die Methode erhält als Parameter einen Zeiger auf den Anfangsdatenpuffer. Als Ergebnis der Operation gibt die Methode einen Ergebnispuffer der gleichen Größe zurück.
Im Hauptteil der Methode wird zunächst geprüft, ob unsere Clusterklasse zuvor trainiert wurde. Initialisieren Sie bei Bedarf den Modellbildungsprozess. Ich möchte an dieser Stelle daran erinnern, dass wir die maximale Größe der Lernstichprobe bei der Modellbildungsmethode begrenzt haben. Wenn das Modell also nicht vorher trainiert wurde, sollte eine ausreichend große Stichprobe in den Parametern der Methode übergeben werden. Andernfalls gibt die Methode einen ungültigen Zeiger auf den Ergebnispuffer zurück. Wenn das Daten-Clustering-Modell bereits trainiert wurde, wird die Beschränkung des Stichprobenumfangs aufgehoben.
CBufferDouble *CKmeans::SoftMax(CBufferDouble *data)
{
if(!m_bTrained && !Study(data, (c_aMeans.Maximum() == 0)))
.return NULL;
Im nächsten Schritt überprüfen wir die Gültigkeit der Zeiger auf die verwendeten Objekte. Es mag seltsam erscheinen, dass wir zuerst die Lernmethode aufrufen und dann die Objektzeiger überprüfen. Auch die Lernmethode selbst verfügt über einen ähnlichen Kontrollblock. Wenn wir immer die Modelltrainingsmethode aufrufen würden, bevor wir weitere Operationen durchführen, wären diese Steuerelemente unnötig, da sie die Steuerelemente innerhalb der Trainingsmethode wiederholen. Wenn wir jedoch ein vortrainiertes Modell verwenden, rufen wir die Trainingsmethode nicht auf und haben daher auch keine Kontrollen. Die weitere Ausführung von Operationen mit ungültigen Zeigern führt hingegen zu kritischen Fehlern. Daher müssen wir die Zeiger erneut überprüfen.
if(CheckPointer(data) == POINTER_INVALID || CheckPointer(c_OpenCL) == POINTER_INVALID) .return NULL;
Nachdem wir die Zeiger überprüft haben, wollen wir die Größe des Quelldatenpuffers überprüfen. Sie muss mindestens den Vektor mit der Beschreibung des ersten Zustands des Systems enthalten. Außerdem muss die Datenmenge im Puffer ein Vielfaches des Systemzustandsbeschreibungsvektors sein.
int total = data.Total(); if(total <= 0 || m_iClusters < 2 || (total % m_iVectorSize) != 0) .return NULL;
Dann bestimmen wir die Anzahl der Systemzustände, die auf die Cluster verteilt werden sollen.
int rows = total / m_iVectorSize; if(rows < 1) .return NULL;
Als Nächstes müssen wir Puffer für die Berechnung und Normalisierung von Entfernungen initialisieren. Der Initialisierungsalgorithmus ist recht einfach. Zunächst wird die Gültigkeit des Pufferzeigers überprüft und gegebenenfalls ein neues Objekt erstellt. Dann füllen wir den Puffer mit Null.
if(CheckPointer(c_aDistance) == POINTER_INVALID) { c_aDistance = new CBufferDouble(); if(CheckPointer(c_aDistance) == POINTER_INVALID) .return NULL; } c_aDistance.BufferFree(); if(!c_aDistance.BufferInit(rows * m_iClusters, 0)) .return NULL; if(CheckPointer(c_aSoftMax) == POINTER_INVALID) { c_aSoftMax = new CBufferDouble(); if(CheckPointer(c_aSoftMax) == POINTER_INVALID) .return NULL; } c_aSoftMax.BufferFree(); if(!c_aSoftMax.BufferInit(rows * m_iClusters, 0)) .return NULL;
Um die Vorarbeiten abzuschließen, erstellen wir die erforderlichen Datenpuffer im OpenCL-Kontext.
if(!data.BufferCreate(c_OpenCL) || !c_aMeans.BufferCreate(c_OpenCL) || !c_aDistance.BufferCreate(c_OpenCL) || !c_aSoftMax.BufferCreate(c_OpenCL)) .return NULL;
Damit ist die Vorbereitungsphase abgeschlossen. Nun geht es an den Aufruf der erforderlichen Kernel. Um die volle Funktionalität der Methode zu implementieren, müssen wir einen sequentiellen Aufruf von zwei Kernels erstellen:
- Bestimmung der Abstände zu den Clusterzentren KmeansCulcDistance;
- Normalisierung der Abstände KmeansSoftMax.
Der Algorithmus des Kernelaufrufs ist recht einfach und ähnelt dem, der bei der zuvor beschriebenen Methode zur statistischen Nutzung von Clustering-Ergebnissen verwendet wird. Zunächst müssen wir dem Kernel Parameter übergeben.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_data, data.GetIndex())) .return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_means, c_aMeans.GetIndex())) .return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_distance, c_aDistance.GetIndex())) .return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_distance, def_k_kmd_vector_size, m_iVectorSize)) .return NULL;
Dann geben wir die Dimension des Problemraums und den Offset in jeder Dimension an.
uint global_work_offset[2] = {0, 0}; uint global_work_size[2]; global_work_size[0] = rows; global_work_size[1] = m_iClusters;
Dann stellen wir den Kernel in die Ausführungswarteschlange und lesen die Ergebnisse der Operationsausführung.
if(!c_OpenCL.Execute(def_k_kmeans_distance, 2, global_work_offset, global_work_size)) .return NULL; if(!c_aDistance.BufferRead()) .return NULL;
Wir wiederholen die Vorgänge für den zweiten Kernel.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_distance, c_aDistance.GetIndex())) .return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_softmax, c_aSoftMax.GetIndex())) .return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_softmax, def_k_kmsm_total_k, m_iClusters)) .return NULL; uint global_work_offset1[1] = {0}; uint global_work_size1[1]; global_work_size1[0] = rows; if(!c_OpenCL.Execute(def_k_kmeans_softmax, 1, global_work_offset1, global_work_size1)) .return NULL; if(!c_aSoftMax.BufferRead()) .return NULL;
Am Ende wird der Speicher des OpenCL-Kontexts gelöscht und die Methode beendet, wobei ein Zeiger auf den Ergebnispuffer zurückgegeben wird.
data.BufferFree(); c_aDistance.BufferFree(); //--- return c_aSoftMax; }
Damit sind die Operationen im Zusammenhang mit der Modifikation in unserer k-means-Clusterklasse CKmeans abgeschlossen. Jetzt können wir mit dem Testen des Ansatzes fortfahren. Zu diesem Zweck erstellen wir einen Expert Advisor mit dem Namen kmeans_net.mq5, der sich an Expert Advisors aus Artikeln über Algorithmen des überwachten Lernens orientiert. Um die Implementierung zu testen, habe ich die Clustering-Ergebnisse in ein vollverknüpftes Perzeptron mit drei versteckten Schichten eingegeben. Den vollständigen Code des Expert Advisors finden Sie im Anhang. Achten Sie auf die Lernfunktion Train.
Zu Beginn der Funktion initialisieren wir eine Objektinstanz, um mit dem OpenCL-Kontext innerhalb der Clustering-Klasse zu arbeiten. Dann übergeben wir den Zeiger auf das erstellte Objekt an unsere Clusterklasse. Vergessen Sie nicht, die Ergebnisse der Ausführung der Operation zu überprüfen.
void Train(datetime StartTrainBar = 0) { COpenCLMy *opencl = OpenCLCreate(cl_unsupervised); if(CheckPointer(opencl) == POINTER_INVALID) { ExpertRemove(); return; } if(!Kmeans.SetOpenCL(opencl)) { delete opencl; ExpertRemove(); return; }
Nach erfolgreicher Initialisierung der Objekte legen wir die Grenzen des Trainingszeitraums fest.
MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
Laden historischer Daten. Bitte beachten Sie, dass die in die Puffer geladenen Indikatordaten im Gegensatz zu den Kursen durch Zeitreihen dargestellt werden. Dies ist wichtig, da wir die umgekehrte Sortierung von Elementen in Arrays erhalten. Um die Vergleichbarkeit der Daten zu ermöglichen, müssen wir daher die Reihe von Kursen in eine Zeitreihe umwandeln.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Nachdem wir die historischen Daten erfolgreich geladen haben, laden wir das vorab trainierte Clustering-Modell.
int handl = FileOpen(StringFormat("kmeans_%d.net", Clusters), FILE_READ | FILE_BIN); if(handl == INVALID_HANDLE) { ExpertRemove(); return; } if(FileReadInteger(handl) != Kmeans.Type()) { ExpertRemove(); return; } bool result = Kmeans.Load(handl); FileClose(handl); if(!result) { ExpertRemove(); return; }
Fahren wir mit der Bildung einer Trainingsstichprobe und von Zielwerten fort.
int total = bars - (int)HistoryBars - 1; double data[], fractals[]; if(ArrayResize(data, total * 8 * HistoryBars) <= 0 || ArrayResize(fractals, total * 3) <= 0) { ExpertRemove(); return; } //--- for(int i = 0; (i < total && !IsStopped()); i++) { Comment(StringFormat("Create data: %d of %d", i, total)); for(int b = 0; b < (int)HistoryBars; b++) { int bar = i + b; int shift = (i * (int)HistoryBars + b) * 8; double open = Rates[bar].open; data[shift] = open - Rates[bar].low; data[shift + 1] = Rates[bar].high - open; data[shift + 2] = Rates[bar].close - open; data[shift + 3] = RSI.GetData(MAIN_LINE, bar); data[shift + 4] = CCI.GetData(MAIN_LINE, bar); data[shift + 5] = ATR.GetData(MAIN_LINE, bar); data[shift + 6] = MACD.GetData(MAIN_LINE, bar); data[shift + 7] = MACD.GetData(SIGNAL_LINE, bar); } int shift = i * 3; int bar = i + 1; fractals[shift] = (int)(Rates[bar - 1].high <= Rates[bar].high && Rates[bar + 1].high < Rates[bar].high); fractals[shift + 1] = (int)(Rates[bar - 1].low >= Rates[bar].low && Rates[bar + 1].low > Rates[bar].low); fractals[shift + 2] = (int)((fractals[shift] + fractals[shift]) == 0); } if(IsStopped()) { ExpertRemove(); return; } CBufferDouble *Data = new CBufferDouble(); if(CheckPointer(Data) == POINTER_INVALID || !Data.AssignArray(data)) return; CBufferDouble *Fractals = new CBufferDouble(); if(CheckPointer(Fractals) == POINTER_INVALID || !Fractals.AssignArray(fractals)) return;
Da unsere Clustering-Methoden mit anfänglichen Datenarrays arbeiten können, können wir die gesamte Trainingsstichprobe auf einmal clustern.
ResetLastError(); CBufferDouble *softmax = Kmeans.SoftMax(Data); if(CheckPointer(softmax) == POINTER_INVALID) { printf("Runtime error %d", GetLastError()); ExpertRemove(); return; }
Nach erfolgreichem Abschluss all dieser Operationen enthält der Softmax-Puffer ein Trainingsmuster für unser Perzeptron. Wir haben auch Zielwerte im Voraus vorbereitet. Wir können also mit dem zweiten Modellschulungszyklus fortfahren.
Ähnlich wie beim Testen von Algorithmen des überwachten Lernens wird das Modelltraining in zwei verschachtelten Schleifen durchgeführt. In der äußeren Schleife wird die Trainingsepoche gezählt. Wir verlassen die Schleife bei einem bestimmten Ereignis.
Zunächst werden wir ein wenig Vorbereitungsarbeit leisten. Wir müssen die notwendigen lokalen Variablen initialisieren.
if(CheckPointer(TempData) == POINTER_INVALID) { TempData = new CArrayDouble(); if(CheckPointer(TempData) == POINTER_INVALID) { ExpertRemove(); return; } } delete opencl; double prev_un, prev_for, prev_er; dUndefine = 0; dForecast = 0; dError = -1; dPrevSignal = 0; bool stop = false; int count = 0; do { prev_un = dUndefine; prev_for = dForecast; prev_er = dError; ENUM_SIGNAL bar = Undefine; //--- stop = IsStopped();
Und erst dann gehen wir zur verschachtelten Schleife über. Die Anzahl der Iterationen der verschachtelten Schleife entspricht der Größe der Trainingsstichprobe abzüglich eines kleinen „Schwänzchens“ der Validierungszone.
Auch wenn die Anzahl der Iterationen gleich der Stichprobengröße ist, wird jedes Mal ein Zufallselement für den Lernprozess ausgewählt. Wir werden sie am Anfang der verschachtelten Schleife definieren. Die Verwendung von Zufallsvektoren aus einer Trainingsstichprobe gewährleistet ein einheitliches Modelltraining.
for(int it = 0; (it < total - 300 && !IsStopped()); it++) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 300)) + 300;
Ermitteln Sie anhand des Index eines zufällig ausgewählten Elements den Offset im Ausgangsdatenpuffer und kopieren Sie den erforderlichen Vektor in den temporären Puffer.
TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
Nachdem wir den anfänglichen Datenvektor erzeugt haben, geben wir ihn in die Vorwärtsmethode unseres neuronalen Netzes ein. Nach einem erfolgreichen Vorwärtspass erhalten wir das Ergebnis.
if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
Normalisieren wir die Ergebnisse mit der Funktion Softmax.
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum);
Um den Lernprozess des Modells visuell zu verfolgen, zeigen wir den aktuellen Zustand im Diagramm an.
switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; } string s = StringFormat("Study -> Era %d -> %.2f -> Undefine %.2f%% foracast %.2f%%\n %d of %d -> %.2f%% \nError %.2f\n%s -> %.2f ->> Buy %.5f - Sell %.5f - Undef %.5f", count, dError, dUndefine, dForecast, it + 1, total - 300, (double)(it + 1.0) / (total - 300) * 100, Net.getRecentAverageError(), EnumToString(DoubleToSignal(dPrevSignal)), dPrevSignal, TempData[1], TempData[2], TempData[0]); Comment(s); stop = IsStopped();
Am Ende der Iteration der Schleife rufen wir die Backpropagation-Methode auf und aktualisieren die Gewichtsmatrix in unserem Modell.
if(!stop) { shift = i * 3; TempData.Clear(); TempData.Add(Fractals.At(shift + 2)); TempData.Add(Fractals.At(shift)); TempData.Add(Fractals.At(shift + 1)); Net.backProp(TempData); ENUM_SIGNAL signal = DoubleToSignal(dPrevSignal); if(signal != Undefine) { if((signal == Sell && Fractals.At(shift + 1) == 1) || (signal == Buy && Fractals.At(shift) == 1)) dForecast += (100 - dForecast) / Net.recentAverageSmoothingFactor; else dForecast -= dForecast / Net.recentAverageSmoothingFactor; dUndefine -= dUndefine / Net.recentAverageSmoothingFactor; } else { if(Fractals.At(shift + 2) == 1) dUndefine += (100 - dUndefine) / Net.recentAverageSmoothingFactor; } } }
Nach jeder Trainingsepoche werden grafische Beschriftungen auf dem Validierungsdiagramm angezeigt. Um diese Funktionalität zu implementieren, erstellen wir eine weitere verschachtelte Schleife. Die Operationen im Schleifenkörper wiederholen größtenteils die zuvor beschriebene Schleife, mit nur zwei wesentlichen Unterschieden:
- Wir nehmen die Elemente in der Reihenfolge, in der sie vorhanden sind, anstatt eine zufällige Auswahl zu treffen.
- Hier wird keine Rückverfolgungsmethode durchgeführt.
Wir prüfen in der Validierungsstichprobe, wie das Modell bei neuen Daten funktioniert, ohne dass die Parameter überangepasst werden. Aus diesem Grund gibt es keine Rückverfolgungsmethode. Daher hängt das Ergebnis der Modelloperation nicht von der Reihenfolge der Dateneinspeisung ab (eine Ausnahme für rekurrente Modelle). Wir brauchen also keine Ressourcen für die Generierung einer Zufallszahl aufzuwenden und alle Zustände des Systems nacheinander zu erfassen.
count++; for(int i = 0; i < 300; i++) { TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData); double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum); //--- switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; }
Fügen wir noch die Darstellung Anzeige der Objekte im Diagramm hinzu und beenden Sie den Validierungszyklus.
if(DoubleToSignal(dPrevSignal) == Undefine) DeleteObject(Rates[i + 2].time); else DrawObject(Rates[i + 2].time, dPrevSignal, Rates[i + 2].high, Rates[i + 2].low); }
Bevor wir die Iteration der äußeren Schleife abschließen, speichern wir den aktuellen Modellzustand und fügen den Fehlerwert zur Trainingsdynamikdatei hinzu.
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, dUndefine, dForecast, Rates[0].time, false); printf("Era %d -> error %.2f %% forecast %.2f", count, dError, dForecast); ChartScreenShot(0, FileName + IntegerToString(count) + ".png", 750, 400); int h = FileOpen(FileName + ".csv", FILE_READ | FILE_WRITE | FILE_CSV); if(h != INVALID_HANDLE) { FileSeek(h, 0, SEEK_END); FileWrite(h, eta, count, dError, dUndefine, dForecast); FileFlush(h); FileClose(h); } } } while((!(DoubleToSignal(dPrevSignal) != Undefine || dForecast > 70) || !(dError < 0.1 && MathAbs(dError - prev_er) < 0.01 && MathAbs(dUndefine - prev_un) < 0.1 && MathAbs(dForecast - prev_for) < 0.1)) && !stop);
Wir beenden den Lernzyklus nach bestimmten Maßstäben. Dies sind die gleichen Metriken, die wir in den Expert Advisors mit überwachtem Lernen verwenden.
Und bevor wir die Trainingsmethode beenden, sollten wir die Objekte löschen, die im Körper unserer Methode zum Trainieren des Modells erstellt wurden.
if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(TempData) == POINTER_DYNAMIC) delete TempData; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); }
Den vollständigen Code des Expert Advisors finden Sie im Anhang.
Um die Leistung des Expert Advisors zu bewerten, haben wir ihn mit dem 500-Cluster-Clustermodell getestet, das wir im vorherigen Artikel trainiert und im vorherigen Test verwendet haben. Das Trainingsdiagramm ist unten abgebildet.

Wie Sie sehen können, ist die Trainingskurve recht gleichmäßig. Um das Modell zu trainieren, habe ich die Adam-Parameter-Optimierungsmethode verwendet. Die ersten 20 Epochen zeigen eine allmähliche Abnahme der Verlustfunktion, die mit der Akkumulation von Momenten zusammenhängt. Und dann ist ein deutlicher Abfall des Verlustfunktionswertes bis zu einem bestimmten Minimum zu beobachten. Zuvor erhaltene Trainingsgraphen von überwachten Modellen hatten auffällige gestrichelte Linien der Verlustfunktion. Nachfolgend sehen wir zum Beispiel ein Trainingsdiagramm für ein komplexeres Aufmerksamkeitsmodell.

Vergleicht man die beiden Diagramme, so wird deutlich, wie sehr das vorläufige Clustering der Daten die Effizienz selbst einfacher Modelle erhöht.
Schlussfolgerung
In diesem Artikel haben wir zwei mögliche Optionen für die Verwendung von Clustering-Ergebnissen bei der Lösung praktischer Fälle geprüft und umgesetzt. Die Testergebnisse belegen die Effizienz beider Methoden. Im ersten Fall haben wir ein einfaches Modell mit sehr klaren und verständlichen Ergebnissen, die sehr transparent und nachvollziehbar sind. Die Anwendung der zweiten Methode macht die Modellbildung reibungsloser und schneller. Außerdem wird dadurch die Leistung der Modelle verbessert.
Liste der Referenzen
- Neuronale Netze leicht gemacht
- Neuronale Netze leicht gemacht (Teil 2): Netztraining und -prüfung
- Neuronale Netze leicht gemacht (Teil 3): Convolutional Neurale Netzwerke
- Neuronale Netze leicht gemacht (Teil 4): Rekurrente Netzwerke
- Neuronale Netze leicht gemacht (Teil 5): Multithreading-Berechnungen in OpenCL
- Neuronale Netze leicht gemacht (Teil 6): Experimentieren mit der Lernrate des neuronalen Netzes
- Neuronale Netze leicht gemacht (Teil 7): Adaptive Optimierungsverfahren
- Neuronale Netze leicht gemacht (Teil 8): Attention-Mechanismen
- Neuronale Netze leicht gemacht (Teil 9): Dokumentieren der Arbeit
- Neuronale Netze leicht gemacht (Teil 10): Multi-Head Aufmerksamkeit
- Neuronale Netze leicht gemacht (Teil 11): Ein Blick auf GPT
- Neuronale Netze leicht gemacht (Teil 12): Dropout
- Neuronale Netze leicht gemacht (Teil 13): Batch-Normalisierung
- Neuronale Netze leicht gemacht (Teil 14): Datenclustering
- Neuronale Netze leicht gemacht (Teil 15): Datenclustering mit MQL5
Programme, die im diesem Artikel verwendet werden
| # | Ausgeben für | Typ | Beschreibung |
|---|---|---|---|
| 1 | kmeans.mq5 | Expert Advisor | Expert Advisor zum Trainieren des Modells |
| 2 | kmeans_net.mq5 | EA | Expert Advisor, um die Übergabe der Daten an das zweite Modell zu testen |
| 3 | kmeans_stat.mq5 | EA | Statistische Methodenprüfung Expert Advisor |
| 4 | kmeans.mqh | Klassenbibliothek | Bibliothek zur Implementierung der k-means-Methode |
| 5 | unsupervised.cl | Code Base | OpenCL-Programmcode-Bibliothek zur Implementierung der k-means-Methode |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/10943
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Das Preisbewegungsmodell und seine wichtigsten Bestimmungen (Teil 1): Die einfachste Modellversion und ihre Anwendungen
Das Preisbewegungsmodell und seine wichtigsten Bestimmungen (Teil 1): Die einfachste Modellversion und ihre Anwendungen
 Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 16): Zugang zu Daten im Internet (II)
Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 16): Zugang zu Daten im Internet (II)
 Automatisierter Grid-Handel mit Limit-Orders an der Moskauer Börse (MOEX)
Automatisierter Grid-Handel mit Limit-Orders an der Moskauer Börse (MOEX)
 Lernen Sie, wie man ein Handelssystem mit der Standardabweichung entwirft
Lernen Sie, wie man ein Handelssystem mit der Standardabweichung entwirft
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
2022.05.30 21:57:27.477 kmeans (WDO$,H1) 800 Modellfehler inf
2022.05.30 22:00:23.937 kmeans (WDO$,H1) 850 Modellfehler inf
2022.05.30 22:04:22.069 kmeans (WDO$,H1) 900 Modellfehler inf
2022.05.30 22:08:04.179 kmeans (WDO$,H1) 950 Modellfehler inf
2022.05.30 22:10:56.190 kmeans (WDO$,H1) 1000 Modellfehler inf
2022.05.30 22:10:56.211 kmeans (WDO$,H1) Funktion ExpertRemove() aufgerufen
Como resolver este erro?
Wie kann dieser Fehler behoben werden?
Es handelt sich nicht um einen Fehler bei der Programmausführung. In dieser Zeile wird der Modellfehler (durchschnittlicher Abstand zu den Zentren der Cluster) angezeigt. Aber wir sehen inf - Werte, die über die Genauigkeit der Berechnungen hinausgehen. Versuchen Sie, die ursprünglichen Werte zu skalieren. Zum Beispiel, teilen Sie durch 10.000
Este não é um erroro de execução do programa. Esta linha exibe o erro do modelo (distância média aos centros dos clusters). Wir sehen aber, dass die Genauigkeit der Werte - valor - nicht gegeben ist. Tente dimensionar os valores originais. Por exemplo, divida por 10.000
Ich konnte immer noch keine Lösung finden.
Ich konnte immer noch keine Lösung finden.