
Нейросети — это просто (Часть 12): Dropout

Содержание
- Введение
- 1. Dropout, как метод повышения сходимости нейронных сетей
- 2. Реализация
- 2.1. Создаем новый класс для нашей модели
- 2.2. Прямой проход
- 2.3. Обратный проход
- 2.4. Методы сохранения и загрузки данных
- 2.5. Точечные изменения в базовых классах нейронной сети
- 3. Тестирование
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
От начала данного цикла статей мы уже хорошо продвинулись в изучении различных моделей нейронных сетей. Но процесс обучения всегда проходил без нашего участия. В то же время постоянно возникает желание как-то помочь нейронной сети повысить результаты ее обучения, так называемую, сходимость нейронной сети. В данной статье предлагаю рассмотреть один из таких методов — Dropout.
1. Dropout, как метод повышения сходимости нейронных сетей
При обучении нейронной сети на вход каждого нейрона подается большое количество признаков и сложно оценить влияние каждого из них. В результате, ошибки одних нейронов сглаживаются правильными значениями других, а на выходе нейронной сети ошибки накапливаются. И как результат, обучение останавливается в некоем локальном минимуме с достаточно большой ошибкой. Данный эффект был назван совместной адаптацией признаков, когда влияние каждого признака как-бы подстраивается под окружающую среду. Для нас было бы лучше получить обратный эффект, когда среда будет разложена по отдельным признакам и оценивать отдельно влияние каждого.
Для борьбы со сложной совместной адаптацией признаков в июле 2012 года группа ученных из университета Торонто предложила случайным образом исключать часть нейронов в процессе обучения [12]. Снижение количества признаков при обучении повышает значимость каждого, а постоянное изменение количественного и качественного состава признаков снижает риск их совместной адаптации. Такой метод и получил название Dropout. Некоторые сравнивают применение данного метода с деревьями решений, ведь согласитесь, исключая часть нейронов, мы на каждой итерации обучения получаем новую нейронную сеть со своими весовыми коэффициентами. А по правилам комбинаторики вариативность таких сетей довольно высока.
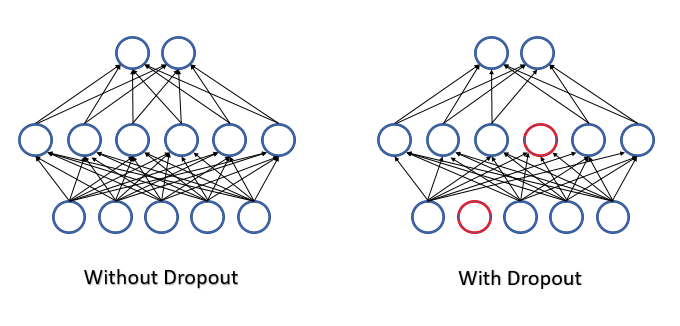
В процессе эксплуатации нейронной сети оцениваются все признаки и нейроны, тем самым получаем максимально точную и независимую оценку текущего состояния изучаемой среды.
Авторы решения в своей статье [12] указывают на возможность использования метода и для повышения качества предварительно обученных моделей.
Описывая, предложенное решение, с точки зрения математики можно сказать, что каждый отдельный нейрон выкидывается из процесса с некой заданной вероятностью p. Или нейрон будет участвовать в процессе обучения нейронной сети с вероятностью q=1-p.
Для определения списка исключаемых нейронов используется генератор псевдослучайных чисел с нормальным распределением. Такой подход позволяет достичь максимально-возможного равномерного исключения нейронов. На практике сгенерируем вектор размером равным входной последовательности. Для используемых признаков в векторе пропишем "1", а для исключаемых элементов поставим "0".
Однако, исключение анализируемых признаков несомненно ведет к снижению суммы на входе функции активация нейрона. Для компенсации этого эффекта умножим значение каждого признака на коэффициент 1/q. Легко заметить, что данный коэффициент будет увеличивать значения, так как вероятность q всегда будет в диапазоне от 0 до 1.
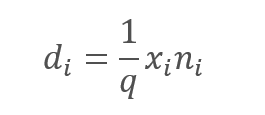 ,
,
гд:
d — элементы вектора результатов Dropout,
q — вероятность использования нейрона в процессе обучения,
x - элементы вектора маскирования,
n - элементы входной последовательности.
При обратном проходе в процессе обучения градиент ошибки умножается на производную вышеприведенной функции. Как легко заметить, в случае Dropout обратный проход будет аналогичен прямому с использованием вектора маскирования из прямого прохода.
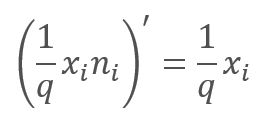
В процессе эксплуатации нейронной сети вектор маскирования заполняется "1", что позволяет значениям беспрепятственно передаваться в обоих направлениях.
На практике коэффициент 1/q постоянен на протяжении всего обучения, поэтому мы легко можем посчитать данный коэффициент один раз и записывать его вместо "1" в тензор маскирования. Тем самым исключим операции пересчета коэффициента и умножения его на "1" маски в каждой итерации обучения.
2. Реализация
После рассмотрения теоретических аспектов предлагаю перейти к рассмотрению вариантов реализации данного метода в нашей библиотеке. И первое, с чем мы сталкиваемся — это реализация двух различных алгоритмов. Один для процесса обучения, второй для тестирования и промышленной эксплуатации. Соответственно, нам нужно явно указать нейрону, по какому алгоритму нужно работать в каждом отдельно взятом случае. Для этого на уровне базового нейрона введем флаг bTrain, которому будем присваивать значение true в процессе обучения и false в процессе тестирования.
class CNeuronBaseOCL : public CObject { protected: bool bTrain; ///< Training Mode Flag
Для управления значениями флага создадим вспомогательные методы.
virtual void TrainMode(bool flag) { bTrain=flag; }///< Set Training Mode Flag virtual bool TrainMode(void) { return bTrain; }///< Get Training Mode Flag
Введение флага и методов на уровне базового нейрона сделано намерено. Это позволит нам использовать наработки dropout в последующих разработках.
2.1. Создаем новый класс для нашей модели
Для реализации алгоритма Dropout создадим новый класс CNeuronDropoutOCL, который мы будем включать в нашу модель отдельным слоем. Новый класс будет наследоваться на прямую от класса базового нейрона CNeuronBaseOCL. В блоке protected объявим переменные:
- OutProbability — заданная вероятность исключения нейронов.
- OutNumber — количество исключаемых нейронов.
- dInitValue — значение для инициализации вектора маскирования, в теоретической части этой статьи мы обозначали данный коэффициент как 1/q.
Также объявим два указателя на классы:
- DropOutMultiplier — вектор маскирования.
- PrevLayer — указатель на объект предыдущего слоя, будем использовать в процессе тестирования и промышленной эксплуатации.
class CNeuronDropoutOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL *PrevLayer; double OutProbability; double OutNumber; CBufferDouble *DropOutMultiplier; double dInitValue; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///<\brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.@param NeuronOCL Pointer to previos layer. //--- int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); } ///< Generates a random neuron position to turn off public: CNeuronDropoutOCL(void); ~CNeuronDropoutOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons,double out_prob, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. //#param[in] numNeurons Number of neurons in layer #param[in] out_prob Probability of neurons shutdown @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. //--- virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); } ///< Get index of output buffer @return Index virtual int getGradientIndex(void) { return (bTrain ? Gradient.GetIndex() : PrevLayer.getGradientIndex()); } ///< Get index of gradient buffer @return Index //--- virtual int getOutputVal(double &values[]) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return (bTrain ? Gradient.GetData(values) : PrevLayer.getGradient(values)); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual CBufferDouble *getOutput(void) { return (bTrain ? Output : PrevLayer.getOutput()); } ///< Get pointer of output buffer @return Pointer to object virtual CBufferDouble *getGradient(void) { return (bTrain ? Gradient : PrevLayer.getGradient()); } ///< Get pointer of gradient buffer @return Pointer to object //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronDropoutOCL; }///< Identificator of class.@return Type of class };
Список методов класса довольно узнаваем и все они переопределяют методы родительского класса. Исключением из этого правила является метод RND, который предназначен для генерации псевдослучайных чисел равномерного распределения. Алгоритм этого метода позаимствован из статьи [13]. С целью получения максимально случайных значений во всех объектах нашей нейронной сети, генератор псевдослучайной последовательности реализован в виде макроподстановки с использованием глобальных переменных.
#define xor128 rnd_t=(rnd_x^(rnd_x<<11)); \ rnd_x=rnd_y; \ rnd_y=rnd_z; \ rnd_z=rnd_w; \ rnd_w=(rnd_w^(rnd_w>>19))^(rnd_t^(rnd_t>>8)) uint rnd_x=MathRand(), rnd_y=MathRand(), rnd_z=MathRand(), rnd_w=MathRand(), rnd_t=0;
Предложенный алгоритм генерирует последовательность целых чисел в диапазоне [0,UINT_MAX=4294967295]. Поэтому в методе генератора псевдослучайной последовательности после выполнения макроса полученное значение нормализуется до размера последовательности.
int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); }
Читатель, знакомый с предыдущими публикациями данной серии статей, может обратить внимание, что раньше мы не переопределяли методы работы с буферами данных класса из других объектов. Напомню, что указанные методы используются для обмена данными между слоями нейронной сети, когда нейроны обращаются к данными предшествующего или последующего слоя.
Такое решение было принято в попытке оптимизировать работу нейронной сети в процессе промышленной эксплуатации. Повторюсь, слой Dropout используется только в процессе обучения нейронной сети. При тестировании и промышленной эксплуатации алгоритм исключения нейронов отключается. Переопределив методы обращения к буферам данных, мы организовали пропуск слоя Dropout. Все переопределенные методы построены по одному принципу. Вместо копирования данных организовываем подмену буферов слоя Dropout буферами предыдущего слоя. Таким образом, в режиме промышленной эксплуатации скорость работы нейронной сети со слоем Dropout сопоставима со скоростью работы аналогичной сети без Dropout, при этом получаем все преимущества исключений нейронов при обучении сети.
virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); }
С полным кодом всех методов и классов можно ознакомиться во вложении.
2.2. Прямой проход
Не нарушая традиции, прямой проход организуем в методе feedForward. В начале метода проверим действительность полученного в параметрах указателя на предыдущий слой нейронной сети и указателя на объект OpenCL. После чего сохраним функцию активации, используемую на предыдущем слое и сам указатель на объект предыдущего слоя. Для режима промышленной эксплуатации нейронной сети на этом заканчивается прямой проход слоя Dropout. Далее, при обращении от последующего слоя включится механизм подмены буферов данных, описанный выше.
bool CNeuronDropoutOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- activation=(ENUM_ACTIVATION)NeuronOCL.Activation(); PrevLayer=NeuronOCL; if(!bTrain) return true;
Последующие итерации релевантные только для режима обучения нейронной сети. В начале сформируем вектор маскирования, в котором определим нейроны к отключению на данном шаге. Маску прописываем в буфер DropOutMultiplier, проверим наличие ранее созданного объекта и при необходимости создадим новый. Проинициализируем буфер начальными значениями. Для сокращения вычислений мы будем инициализировать буфер сразу повышающим коэффициентом 1/q.
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(NeuronOCL.Neurons(),dInitValue)) return false; for(int i=0;i<OutNumber;i++) { uint p=RND(); double val=DropOutMultiplier.At(p); if(val==0 || val==DBL_MAX) { i--; continue; } if(!DropOutMultiplier.Update(RND(),0)) return false; }
После инициализации буфера организуем цикл с числом повторений равным числу нейронов к исключению и будем заменять случайно выбранные элементы буфера нулевыми значениями. Для исключения риска дважды записать "0" в одну ячейку организуем дополнительную проверку внутри нашего цикла.
После генерации маски создадим буфер непосредственно в памяти GPU и перенесем данные.
if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
Теперь нам осталось произвести поэлементное умножение двух векторов. Результат этой операции и будет выходом слоя Dropout. Операцию умножения векторов выполним средствами OpenCL в GPU. Для умножения элементов наиболее эффективным будет использование векторных операций. Я в кернеле OpenCL использовал переменные типа double4, т. е. вектор из 4-х элементов. Поэтому число запускаемых потоков будет в 4 раза меньше количества элементов в векторах.
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0);
Далее укажем буферs и переменные исходных данных и запустим на выполнение кернел.
if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; }
В заключение метода получим результат выполнения операций в кернеле и удалим из памяти GPU буфер маскирования.
if(!Output.BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
После выполнения операций выходим из метода с результатом true.
Описание метода прямого прохода без рассмотрения операций на стороне GPU будет неполным. Посмотрим на код кернела.
__kernel void Dropout (__global double *inputs, ///<[in] Input matrix __global double *map, ///<[in] Dropout map matrix __global double *out, ///<[out] Output matrix int dimension ///< Dimension of matrix )
В параметрах кернел получает указатели на 2 входящих тензора c исходными данными и тензор результатов, а также размерность векторов.
Непосредственно в коде кернела по номеру потока определяем элементы для умножения и далее код разделяется на 2 ветки. Первая, основная: с использованием векторных операций осуществляем умножение 4-х последовательных элементов и записываем полученные данные в соответствующие элементы буфера результатов.
{
const int i=get_global_id(0)*4;
if(i+3<dimension)
{
double4 k=(double4)(inputs[i],inputs[i+1],inputs[i+2],inputs[i+3])*(double4)(map[i],map[i+1],map[i+2],map[i+3]);
out[i]=k.s0;
out[i+1]=k.s1;
out[i+2]=k.s2;
out[i+3]=k.s3;
}
else
for(int k=i;k<min(dimension,i+4);k++)
out[i+k]=(inputs[i+k]*map[i+k]);
}
Вторая ветка включается только в случаях, когда количество элементов в тензорах не кратно 4 и в цикле перемножаются оставшиеся элементы. Легко заметить, что в данном цикле будет не более 3-х итераций и не будет критичным по времени вычислений.
С полным кодом всех классов и их методов можно ознакомиться во вложении.
2.3. Обратный проход
Обратный проход во всех ранее рассмотренных нейронах делился на 2 метода:
- calcInputGradients — передача градиента ошибки на предыдущий слой.
- updateInputWeights — обновление весовых коэффициентов нейронного слоя.
В случае Dropout у нас отсутствует тензор весовых коэффициентов, но для поддержания общей структуры объектов мы все же переопределим метод updateInputWeights, но в данном случае он всегда будет возвращать значение true.
virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.
Рассмотрим реализацию метода calcInputGradients. В параметрах он получает указатель на предшествующий слой, и в начале метода проверим действительность полученного указателя и указателя на объект OpenCL. И далее, как и при прямом проходе, делаем разделение алгоритма на процесс обучения и процесс промышленной эксплуатации. В режиме тестирования или промышленной эксплуатации на этом месте мы выходим из метода, т. к. благодаря нашей подмене буферов данных последующий нейронный слой записал градиент напрямую в буфер предшествующего слоя, миную излишние итерации в слое Dropout.
bool CNeuronDropoutOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- if(!bTrain) return true;
В режиме обучения передача градиента будет осуществляться по другому пути. И приведенный ниже алгоритм будет релевантный только в процессе обучения нейронной сети. Как и в методе прямого прохода проверим действительность указателя на буфер маскирования DropOutMultiplier. Только в отличие от прямого прохода, ошибка проверки не повлечет создание нового буфера, а приведет к выходу из метода с результатом false. Это связано с тем, что при обратном проходе используется маска, сгенерированная при прямом проходе. Такой подход обеспечивает сопоставимость данных и правильное распределение градиента ошибки между нейронами.
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) return false; //--- if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
После успешной проверки объекта DropOutMultiplier создадим буфер в памяти GPU и заполним его данными.
Теперь нам осталось произвести поэлементное умножение двух векторов. Ничего не напоминает? Точно такое предложение приведено выше при описании прямого прохода. Да, действительно. В теоретической части показано, что производная математической функции Dropout равна повышающему коэффициенту. Поэтому при обратном проходе мы также будем умножать градиент от последующего слоя на повышающий коэффициент, записанный в буфере маскирования DropOutMultiplier. Таким образом, класс CNeuronDropoutOCL является тем уникальным случаем, когда и для прямого и для обратного проходов мы будем использовать один кернел, только на вход будем подавать разные данные: при прямом проходе — выходные данные нейронов, при обратном проходе — градиент ошибки.
И так далее осуществим указание буферов данных и вызов исполнения кернела. Приведенный код аналогичен коду прямого прохода и, думаю, не требует дополнительных пояснений.
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0); if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,Gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; } if(!NeuronOCL.getGradient().BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
С полным кодом всех классов и их методов можно ознакомиться во вложении.
2.4. Методы сохранения и загрузки данных
Немного остановимся на методах сохранения и загрузки объекта нейронного слоя Dropout. Нам нет необходимости сохранять объект буфера маски, т. к. новая маска генерируется на каждом цикле обучения. В методе инициализации класса CNeuronDropoutOCL была добавлена только одна переменная — вероятность исключения нейрона, ее мы и сохраним.
Таким образом, в методе сохранения Save вызовем одноименный метод родительского класса и после успешного завершения сохраним заданную вероятность исключения нейронов.
bool CNeuronDropoutOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteDouble(file_handle,OutProbability)<=0) return false; //--- return true; }
В методе загрузка класса Load нам предстоит считать данные с диска и восстановить все элементы класса, поэтому алгоритм метода будет немного сложнее метода сохранения.
Повторяя код метода сохранения класса, вызовем одноименный метод родительского класса. После его завершения считаем вероятность исключения нейронов. На этом метод сохранения завершился, но нам нужно восстановить недостающие элементы. Исходя из вероятности исключения нейронов посчитаем количество нейронов к исключению и значение повышающего коэффициента, который также служит значением для инициализации вектора маскирования.
bool CNeuronDropoutOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; //--- OutProbability=FileReadDouble(file_handle); OutNumber=(int)(Neurons()*OutProbability); dInitValue=1/(1-OutProbability); if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(Neurons()+1,dInitValue)) return false; //--- return true; }
После проведенного расчета восстановим вектор маскирования. Проверим действительность указателя на объект буфера данных в DropOutMultiplier и, при необходимости, создадим новый объект. После чего проинициализируем вектор маскирования начальными значениями.
2.5. Точечные изменения в базовых классах нейронной сети
И как всегда, после создания нового класса нам нужно корректно вписать его в работу нашей библиотеки. Первое, что мы сделаем, это объявим макроподстановки для работы с новым кернелом, а также зададим константу идентификации нового класса.
#define def_k_Dropout 23 ///< Index of the kernel for Dropout process (#Dropout) #define def_k_dout_input 0 ///< Inputs Tensor #define def_k_dout_map 1 ///< Map Tensor #define def_k_dout_out 2 ///< Out Tensor #define def_k_dout_dimension 3 ///< Dimension of Inputs
#define defNeuronDropoutOCL 0x7890 ///<Dropout neuron OpenCL \details Identified class #CNeuronDropoutOCL
Затем, в метод описания нейронного слоя добавим новую переменную для записи вероятности исключения нейронов.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) double probability; ///< Probability of neurons shutdown, only Dropout used };
В методе создания нейронной сети CNet::CNet в блоке создания и инициализации слоев добавим код инициализации нового слоя (ниже по коду выделено заливкой).
for(int i=0; i<total; i++) { prev=desc; desc=Description.At(i); if((i+1)<total) { next=Description.At(i+1); if(CheckPointer(next)==POINTER_INVALID) return; } else next=NULL; int outputs=(next==NULL || (next.type!=defNeuron && next.type!=defNeuronBaseOCL) ? 0 : next.count); temp=new CLayer(outputs); int neurons=(desc.count+(desc.type==defNeuron || desc.type==defNeuronBaseOCL ? 1 : 0)); if(CheckPointer(opencl)!=POINTER_INVALID) { CNeuronBaseOCL *neuron_ocl=NULL; CNeuronConvOCL *neuron_conv_ocl=NULL; CNeuronAttentionOCL *neuron_attention_ocl=NULL; CNeuronMLMHAttentionOCL *neuron_mlattention_ocl=NULL; CNeuronDropoutOCL *dropout=NULL; switch(desc.type) { case defNeuron: case defNeuronBaseOCL: neuron_ocl=new CNeuronBaseOCL(); if(CheckPointer(neuron_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_ocl.Init(outputs,0,opencl,desc.count,desc.optimization)) { delete neuron_ocl; delete temp; return; } neuron_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_ocl)) { delete neuron_ocl; delete temp; return; } neuron_ocl=NULL; break; //--- case defNeuronConvOCL: neuron_conv_ocl=new CNeuronConvOCL(); if(CheckPointer(neuron_conv_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_conv_ocl.Init(outputs,0,opencl,desc.window,desc.step,desc.window_out,desc.count,desc.optimization)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_conv_ocl)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl=NULL; break; //--- case defNeuronAttentionOCL: neuron_attention_ocl=new CNeuronAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break; //--- case defNeuronDropoutOCL: dropout=new CNeuronDropoutOCL(); if(CheckPointer(dropout)==POINTER_INVALID) { delete temp; return; } if(!dropout.Init(outputs,0,opencl,desc.count,desc.probability,desc.optimization)) { delete dropout; delete temp; return; } if(!temp.Add(dropout)) { delete dropout; delete temp; return; } dropout=NULL; break; //--- default: return; break; } }
И не забудем в этом же методе объявить новый кернел.
opencl.SetKernelsCount(24); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut"); opencl.KernelCreate(def_k_Dropout,"Dropout");
Аналогичное объявление нового кернела необходимо добавить в метод считывания предварительно обученной нейронной сети с диска CNet::Load.
Продолжая разговор о процессе загрузке предварительно обученной нейронной сети, следует скорректировать и метод создания элемента слоя нейронной сети CLayer::CreateElement, добавив туда код по созданию элемента Dropout. Изменения выделены заливкой.
bool CLayer::CreateElement(int index) { if(index>=m_data_max) return false; //--- bool result=false; CNeuronBase *temp=NULL; CNeuronProof *temp_p=NULL; CNeuronBaseOCL *temp_ocl=NULL; CNeuronConvOCL *temp_con_ocl=NULL; CNeuronAttentionOCL *temp_at_ocl=NULL; CNeuronMLMHAttentionOCL *temp_mlat_ocl=NULL; CNeuronDropoutOCL *temp_drop_ocl=NULL; if(iFileHandle<=0) { temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID || !temp.Init(iOutputs,index,SGD)) return false; result=true; } else { int type=FileReadInteger(iFileHandle); switch(type) { case defNeuron: temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID) result=false; result=temp.Init(iOutputs,index,ADAM); break; case defNeuronProof: temp_p=new CNeuronProof(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronConv: temp_p=new CNeuronConv(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronLSTM: temp_p=new CNeuronLSTM(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronBaseOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_ocl=new CNeuronBaseOCL(); if(CheckPointer(temp_ocl)==POINTER_INVALID) result=false; if(temp_ocl.Init(iOutputs,index,OpenCL,1,ADAM)) { m_data[index]=temp_ocl; return true; } break; case defNeuronConvOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_con_ocl=new CNeuronConvOCL(); if(CheckPointer(temp_con_ocl)==POINTER_INVALID) result=false; if(temp_con_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,ADAM)) { m_data[index]=temp_con_ocl; return true; } break; case defNeuronAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMLMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_mlat_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(temp_mlat_ocl)==POINTER_INVALID) result=false; if(temp_mlat_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,0,ADAM)) { m_data[index]=temp_mlat_ocl; return true; } break; case defNeuronDropoutOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_drop_ocl=new CNeuronDropoutOCL(); if(CheckPointer(temp_drop_ocl)==POINTER_INVALID) result=false; if(temp_drop_ocl.Init(iOutputs,index,OpenCL,1,0.1,ADAM)) { m_data[index]=temp_drop_ocl; return true; } break; default: result=false; break; } } if(result) m_data[index]=temp; //--- return (result); }
И конечно, добавим новый класс в диспетчерские методы базового класса CNeuronBaseOCL.
Прямой проход CNeuronBaseOCL::FeedForward.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
Метод распространения градиента ошибки CNeuronBaseOCL::calcHiddenGradients.
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; CNeuronDropoutOCL *dropout=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; case defNeuronDropoutOCL: dropout=TargetObject; temp=GetPointer(this); return dropout.calcInputGradients(temp); break; } //--- return false; }
И, как бы это не звучало странным, метод обновления весовых коэффициентов CNeuronBaseOCL::UpdateInputWeights.
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
Помните, как бы не казались указанные выше изменения точечными и незначительными, отсутствие хотя бы одного из них ведет к неправильной работе всей нейронной сети.
С полным кодом всех классов и их методов можно ознакомиться во вложении.
3.Тестирование
Соблюдая принципы преемственности и наследования, базой для тестирования метода послужил советник из статьи [11] в который было добавлено 4 слоя Dropout:
- после исходных данных,
- после слоя эмбединга,
- после блока внимания,
- после первого полносвязного слоя.
Структура нейронной сети описана в коде ниже.
//--- 0 CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 1 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 2 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=24; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMLMHAttentionOCL; desc.window=24; desc.window_out=4; desc.step=8; //heads desc.layers=5; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 6 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 9 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM;
Тестирование советника проводилось на инструмент EURUSD, таймфрейм H1, на вход нейронной сети подаются исторические данные за 20 последних свечей. Тестирование всех архитектур на схожих датасетах позволяет минимизировать влияние внешних факторов и оценить работу различных архитектур в схожих условиях.
Сравнивая графики обучения нейронной сети с использованием Dropout и без, можно заметить, что первые 30 эпох линии ошибки нейронной сети были практически параллельны, при этом нейронная сеть без Dropout показывала немногим лучший результат. Но после 33 эпохи наблюдается снижение показателя у советника с использованием Dropout. И после 35 эпохи Dropout показывает лучший результат, намечается тенденция к снижению показателя. При этом советник без Dropout продолжает удерживать ошибку на прежнем уровне.
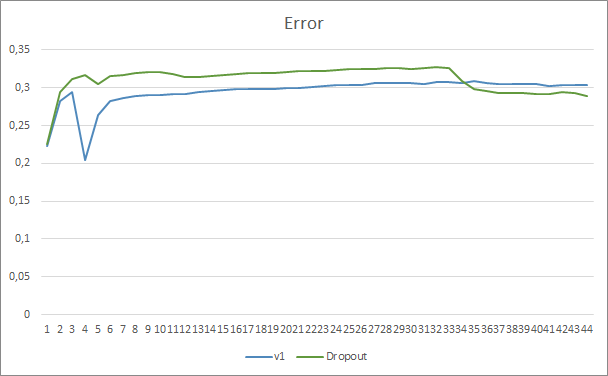
График пропуска паттернов также показывает преимущества советника с использованием технологии Dropout. И данный график более красноречив. При худшем старте советник с использованием Dropout сразу показывает тенденцию к снижению пропусков. В то время, как советник без Dropout постепенно наращивает пропуски.
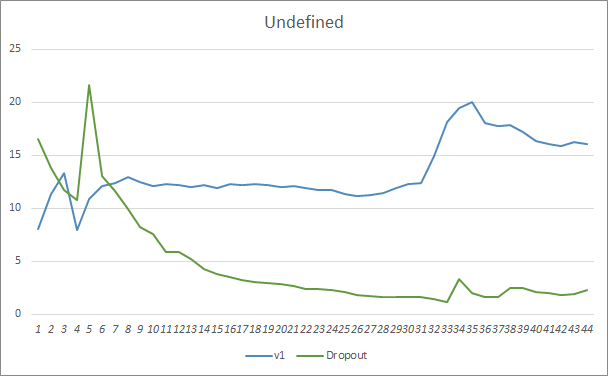
Графики уровня попадания предсказанных паттернов обоих советников лежат довольно близко и, практически, переплетаются. После 44 эпох обучения преимущества советника с Dropout составляет только 0.5%.
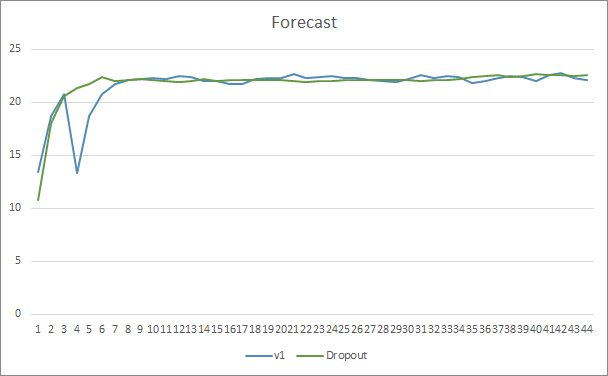
Заключение
В данной статье мы начали рассматривать методы повышения сходимости нейронных сетей и познакомились с одним из таких методов Dropout. Добавив его в один из ранее созданных советников, мы на тестах увидели его эффективность. Конечно, использование данного метода может увеличить затраты на обучение нейронной сети, но они будут оплачены повышением эффективности конечного результата.
Предлагаю всем попробовать данный метод в своих разработках и оценить его эффективность.
Ссылки
- Нейросети — это просто
- Нейросети — это просто (Часть 2): обучение и тестирование сети
- Нейросети — это просто (Часть 3): сверточные сети
- Нейросети — это просто (Часть 4): рекуррентные сети
- Нейросети — это просто (Часть 5): многопоточные вычисления в OpenCL
- Нейросети — это просто (Часть 6): эксперименты с коэффициентом обучения нейронной сети
- Нейросети — это просто (Часть 7): Адаптивные методы оптимизации
- Нейросети — это просто (Часть 8): Механизмы внимания
- Нейросети — это просто (Часть 9): Документируем проделанную работу
- Нейросети — это просто (Часть 10): Multi-Head Attention (многоголовое внимание)
- Нейросети — это просто (Часть 11): Вариации на тему GPT
- Improving neural networks by preventing co-adaptation of feature detectors
- Статистические оценки
…
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | Советник | Советник с нейронной сетью классификации (3 нейрона в выходном слое) с использованием архитектуры GPT, 5 слоев внимания |
| 2 | Fractal_OCL_AttentionMLMH_d.mq5 | Советник | Советник с нейронной сетью классификации (3 нейрона в выходном слое) с использованием архитектуры GPT, 5 слоев внимания + Dropout |
| 3 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 4 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 5 | NN.chm | HTML-справка | Скомпилированный CHM-файл помощи по библиотеке. |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Многослойный перцептрон и алгоритм обратного распространения ошибки
Многослойный перцептрон и алгоритм обратного распространения ошибки
 Машинное обучение в торговых системах на сетке и мартингейле. Есть ли рыба?
Машинное обучение в торговых системах на сетке и мартингейле. Есть ли рыба?
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Я так понимаю, что без OCL ничего не работает? Жаль, я не игрун и карта старая...