
Нейросети в трейдинге: Модель темпоральных запросов (Окончание)

Введение
Фреймворк TQNet представляет собой один из наиболее элегантных и гибких подходов к построению нейросетевых моделей, способных эффективно работать с временными рядами и структурированными данными. Его ключевое преимущество заключается в умении сочетать локальные и глобальные зависимости, создавая своеобразный баланс между глубиной анализа и вычислительной эффективностью. В отличие от традиционных архитектур, TQNet органично объединяет механизмы последовательной обработки данных и методы захвата долгосрочных зависимостей. Это особенно ценно при работе с финансовыми временными рядами, где важны мгновенные колебания и тенденции, растянутые во времени.
В основе алгоритма лежит оригинальная организация вычислений. Центральную роль в них играет тензор глобальных корреляций. Он формирует своего рода карту взаимосвязей между элементами последовательности, позволяя модели фиксировать локальные закономерности и выстраивать целостное представление о структуре данных.
Процесс вычислений внутри TQNet можно описать как последовательность согласованных шагов. На первом этапе исходные данные проходят через слой формирования локальных признаков, где извлекаются ключевые характеристики текущего состояния. Затем активируется механизм глобальной корреляции, который накладывает на эти признаки структурные зависимости, аккумулированные за все предыдущие шаги. Эта итеративная схема позволяет модели гибко подстраиваться к изменяющимся условиям и учитывать скрытые паттерны. Особенность подхода в том, что модель не ограничивается жёстким порядком прохождения данных — взаимосвязи могут формироваться в любом направлении внутри последовательности, что расширяет её возможности в задачах прогнозирования и анализа.
Практическая ценность TQNet проявляется в условиях, когда данные подвержены шуму или имеют сложную внутреннюю структуру. Финансовые рынки, прогнозы погодны, анализ промышленных процессов — во всех этих случаях важен не только уровень точности прогноза, но и устойчивость модели к неожиданным выбросам и изменениям динамики. Благодаря продуманному алгоритму обновления параметров и эффективному использованию вычислительных ресурсов, TQNet демонстрирует стабильную работу даже на больших выборках, не требуя чрезмерных затрат на обучение.
Авторская визуализация фреймворка представлена ниже.
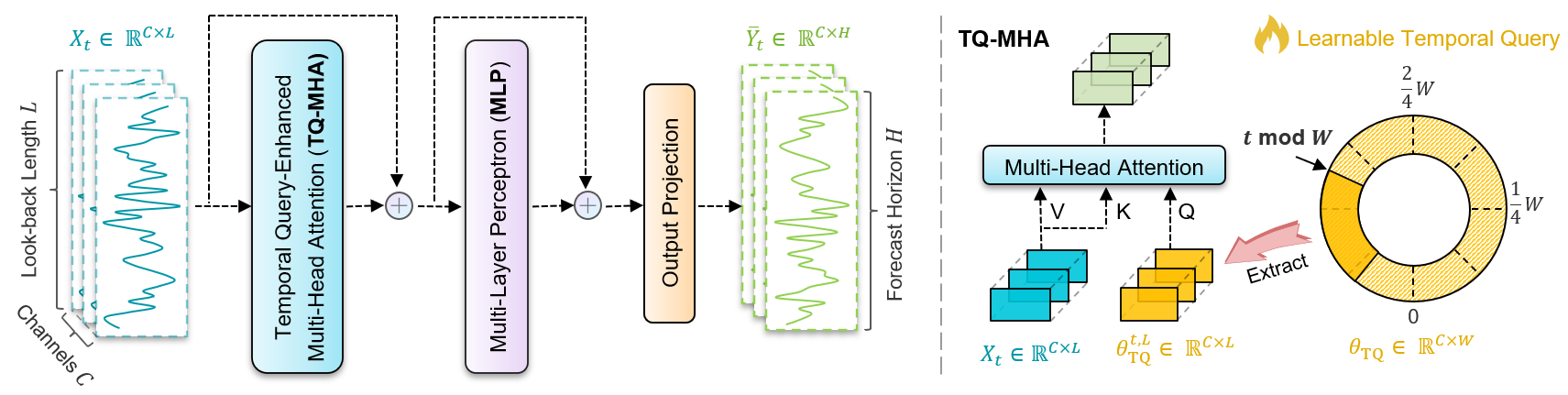
В прошлой статье мы познакомились с теоретическими аспектами фреймворка TQNet — его модульной архитектурой, способностью гибко адаптироваться под рыночные реалии и экономичным управление ресурсами. Однако теория — это лишь каркас. И мы разобрали объект CCircleParams, который позволяет хранить глобальные корреляции в виде динамически переключаемых на каждом временном шаге объектов. Сегодня мы продолжаем работу по построению подходов, предложенных авторами фреймворка TQNet, средствами MQL5.
Модуль TQ-MHA
Следующим логичным этапом, к которому мы подошли после успешной реализации алгоритма организации карусели тензоров параметров корреляции, становится создание модуля TQ-MHA. В авторской концепции этот модуль играет особую роль: он выполняет функцию интеллектуального фильтра, способного анализировать накопленные параметры корреляции не в отрыве, а в тесной увязке с анализируемыми исходными данными. Иными словами, он обрабатывает статистику и пытается уловить живую ткань взаимосвязей, дополняя её текущим рыночным контекстом. Такой подход можно сравнить с работой опытного аналитика, который не ограничивается сухими таблицами и графиками, а всегда проверяет цифры на прочность, сопоставляя их с реальными событиями и динамикой рынка.
Если проводить параллели со знакомыми нам архитектурными решениями, то TQ-MHA во многом близок к модулю кросс-внимания. Однако здесь есть своя особенность: вместо прямого сопоставления двух потоков информации — ключей и запросов — мы имеем более тонкий процесс. Модуль TQ-MHA накладывает исходные данные на матрицы корреляционных зависимостей, выделяя наиболее значимые пересечения. Это не просто техническая оптимизация, а качественно новый уровень анализа, позволяющий фреймворку воспринимать рыночные сигналы в более широком контексте.
Здесь стоит отметить ещё один любопытный момент. В реализованных нами ранее модулях кросс-внимания по канонам архитектур трансформеров всегда присутствовал блок FeedForward — компактный, но важный элемент, выполняющий роль нелинейного преобразователя данных между слоями внимания, авторы же фреймворка TQNet этот блок формально опускают, как будто оставляя за кадром целый шаг привычной цепочки. На первый взгляд, это может показаться упрощением, но при более внимательном изучении внутренней логики фреймворка мы обнаружили, что за TQ-MHA следует MLP-модуль, который, по сути, воспроизводит весь функционал классического FeedForward-блока.
Разница лишь в одном нюансе: функции активации. Однако для нас это не становится препятствием — напротив, открывает пространство для эксперимента. Мы можем без особых усилий заменить функцию активации на ту, которая лучше согласуется с нашими задачами и спецификой финансовых временных рядов.
Таким образом, мы подошли к проектированию специализированного объекта CNeuronTQMHA, который объединяет логику кросс-внимания с учётом накопленных параметров корреляции и обеспечивает плавное взаимодействие с остальными модулями фреймворка. Структура нового класса представлена ниже.
class CNeuronTQMHA : public CNeuronCrossAttention { protected: uint iTimeframe; CCircleParams cParams; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); public: CNeuronTQMHA(void) {}; ~CNeuronTQMHA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_in, uint period, uint timeframe, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTQMHA; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj); };
Класс CNeuronTQMHA наследует базовый основной функционал и большую часть внутренних объектов от объекта кросс-внимания CNeuronCrossAttention. Но в отличие от базового варианта кросс-внимания, он ориентирован на работу с параметрами корреляции, полученными от карусели тензоров.
В теле класса мы объявляем лишь два ключевых элемента. Первый — iTimeframe, фиксирующий размер временного шага для смены матрицы корреляций в нашей карусели. Второй — cParams, экземпляр класса CCircleParams, отвечающий за накопленные параметры корреляции. Именно эти параметры и становятся сырьём, которое многоголовое внимание будет анализировать в контексте исходных данных.
Внутренние объекты в нашем классе объявлены статично, поэтому конструктор и деструктор могут оставаться пустыми — ничего лишнего при создании или удалении не происходит. Все тяжёлые операции вынесены в метод инициализации. Это даёт чистую и предсказуемую семантику жизни объекта: создание — дешёвое, подготовка к работе — контролируемая и явная.
Метод Init выполняет несколько важных шагов и аккуратно проверяет результат каждого из них.
bool CNeuronTQMHA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint period, uint timeframe, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, heads, units_count, window, units_count, optimization_type, batch)) return false;
Сначала управление передается одноименному методу родительского класса, тем самым наследуя и настраивая базовую логику кросс-внимания. Если базовая инициализация по какой-то причине не удалась, метод немедленно возвращает false — такой ранний выход защищает от проброса некорректного состояния дальше по стеку и упрощает отладку.
Далее осуществляем установку функции активации между слоями блока FeedForward.
FF[0].SetActivationFunction(GELU);
Как уже обсуждалось выше, MLP, используемый авторами фреймворка после TQ-MHA, по своей сути выполняет роль классического FeedForward-блока. И смена функции активации позволяет гибко подбирать нелинейность под специфику финансовых рядов. GeLU даёт более плавную аппроксимацию и часто ведёт себя стабильнее на шумных данных по сравнению с жёсткими ReLU-порциями. Мгновенные импульсы рынка не разбивают такую функцию так жёстко, а значит, обучение получается ровнее.
Параметр iTimeframe защищён нижней границей значений — это простая, но важная защита: значение параметра не может упасть до нуля. Практически это означает, что даже при ошибочной конфигурации модуль будет работать в минимально разумном режиме.
iTimeframe = MathMax(1, timeframe); if(!cParams.Init(0, 0, OpenCL, window * units_count, period, optimization, iBatch)) return false; if(!cParams.Zeros()) return false; //--- return true; }
Ключевой кусок инициализации — подготовка объекта cParams. Здесь мы явно создаём внутренний каркас глобальных корреляций. Для каждого временного окна (window) и для каждой анализируемой унитарной последовательности (units_count) создается соответствующий элемент в тензоре корреляций. Инициализация привязывает эти буферы к OpenCL-контексту, что обеспечивает дальнейшую эффективность при больших объёмах данных.
Наконец, вызов cParams.Zeros задаёт рекомендованную авторами стратегию стартовой инициализации — все параметры глобальной памяти обнуляются. Это важное дизайн-решение: нулевая инициализация убирает начальные предубеждения в корреляциях и даёт модели честный чистый лист, на котором она сама выстраивает взаимосвязи, опираясь только на данные обучающей выборки. Такой старт часто оказывается предпочтительнее случайной инициализации в задачах, где мы не хотим вносить посторонние шумы на уровне параметров памяти.
Если все шаги успешны, метод возвращает true — объект полностью подготовлен к работе: буферы созданы, функция активации установлена, периодическая память готова и очищена. В сумме этот метод задаёт устойчивую, предсказуемую и эффективную платформу для последующих операций, где CNeuronTQMHA начнёт реально связывать накопленные θ-векторы с анализируемыми данными и обучаться на исторических котировках.
После описания структуры класса естественно перейти к разбору его ключевой рабочей процедуры — алгоритма прямого прохода. Метод начинается с самого простого, но принципиального шага — проверки актуальности полученного указателя на буфер SecondInput.
bool CNeuronTQMHA::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
В данном буфере мы ожидаем получить ориентир для позиционирования карусели параметров корреляции. Если он отсутствует, выполнение немедленно прерывается, и возвращается false. Эта проверка защищает модуль от некорректных вызовов и предотвращает дальнейшие бессмысленные вычисления.
Далее мы определяем текущую позицию в карусели. Для этого считаем нулевой элемент из буфера SecondInput. Практически мы ожидаем получить здесь время открытия последнего бара.
int pos = int(SecondInput[0]); pos = (pos / int(iTimeframe)) % cParams.GetPeriod(); if(!cParams.SetPosition(pos) || !cParams.FeedForward()) return false;
Полученное целое значение затем преобразуется в индекс позиции карусели параметров. Сначала делением на iTimeframe мы группируем последовательные шаги в коробки по заданному шагу — это даёт нам номер блока. Затем, остаток от деления на размер периода данных — индекс конкретного элемента в карусели параметров корреляции. В сумме эти две операции реализуют идею периодической памяти: для моментов времени, лежащих в одном и том же блоке и отстоящих на длину периода, будет использован один и тот же набор TQ-векторов.
Следующий блок строго переключает активную реплику параметров и прогоняет через неё прямой проход, в рамках которого подготавливаются к использованию параметры корреляции. Если хоть на одном из этих шагов возникает ошибка — метод завершает работу с результатом false. Такое поведение гарантирует, что дальше мы всегда работаем с корректно подготовленным набором глобальных параметров.
Последующие шаги повторяют работу модуля кросс-внимания. И мы бы могли передать управление одноименному методу родительского класса, но семантически это порождает проблему. В базовой реализации остаточные связи проходят по магистрали запросов (Query). В нашем случае Query — это не локальное представление текущего окна, а аккумулированные TQ-векторы, то есть глобальная память. Если прокинуть эту же память по пути остаточных связей, мы рискуем затереть текущий локальный сигнал Key/Value и подавить важные признаки, приходящие с исходными данными. На финансовых рынках это быстро проявится: модель начнёт сильнее опираться на исторический каркас и хуже реагировать на свежие импульсы — точность упадёт.
Поэтому мы сознательно переиспользуем низкоуровневую логику вычисления внимания, но реализуем собственную логику остаточных связей и нормализации результатов. Это сохраняет влияние текущих данных и одновременно использует глобальные TQ-знания при расчёте весов внимания.
После того, как глобальные корреляционные векторы активированы и подготовлены, мы проецируем их в пространство Запросов.
if(!Q_Embedding.FeedForward(cParams.AsObject())) return false; //--- if(!KV_Embedding.FeedForward(NeuronOCL)) return false;
Здесь Q_Embedding выполняет линейную проекцию глобальных корреляций и развёртывание их по головам внимания.
Параллельно формируются ключи и значения на основании исходных данных, полученных от внешней программы. В результате у нас появляются два потока: глобальные запросы, несущие «память» о долгосрочных зависимостях, и локальные Key/Value, отражающие текущее поведение рынка.
Следующий вызов унаследованного метода attentionOut отвечает за вычисление многоголового внимания. На этом этапе происходит стандартная MHA-операция. Результатом является матрица внимания по головам, агрегированная в общий буфер MHAttentionOut.
Важно, что здесь реализована именно логика сочетания глобального (Query из θTQ) и локального (Key/Value из исходных данных) — это сердце TQ-подхода.
if(!attentionOut()) return false; //--- if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false; //--- if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
После получения результатов внимания, они проходят выходную проекцию. Это та самая матрица WO, которая объединяет выходы всех голов внимания обратно в размерность пространства исходных данных.
Затем выполняется суммирование данных двух информационных потоков и нормализация полученных результатов. Это стандартный шаг остаточных связей. К проекции внимания добавляется тензор исходных данных, после чего результат нормализуется по окну iWindow. Такая конструкция стабилизирует обучение, сохраняет информацию из входа и предотвращает затухание сигналов. Нормализация здесь также играет роль защиты от дрейфа распределения, что критично для финансовых рядов с переменной волатильностью.
Далее запускается последовательность MLP-блока.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false; //--- if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
Это две ступени многослойного перцептрона с промежуточной нелинейностью (в нашей реализации использовали GeLU). По смыслу эти слои выполняют ту же роль, что и традиционный FeedForward в трансформерах: они расширяют представление, вводят нелинейность, усиливают полезные признаки и корректируют спектр частот, на которых модель слушает сигнал.
Наконец, второй вызов SumAndNormilize объединяет выход MLP с предыдущим представлением, нормализует и формирует окончательный результат. Этот шаг завершает полный цикл обработки: от извлечения глобальных TQ-векторов до получения адаптированного и нормализованного представления для следующего уровня модели.
Если все шаги прошли успешно, метод возвращает true, сигнализируя о корректном выполнении прямого прохода и готовности к использованию результатов.
Важной архитектурной деталью является последовательность ранних проверок и аварийных возвратов: они экономят ресурсы и не допускают неконсистентной работы с буферами OpenCL, что критично в продакшн-средах.
Плавно перетекая от обсуждения прямого прохода, перейдём к зеркальному этапу — распределению градиентов ошибки внутри CNeuronTQMHA. Здесь мы идём в обратном порядке вычислений: от выходов блока назад к исходным данным, аккуратно аккумулируя сигналы ошибки и распределяя их по всем составляющим — MLP, Attention, проекциям, и глобальной памяти cParams.
bool CNeuronTQMHA::calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!prevLayer) return false;
В теле метода сразу проверяем корректность полученного указателя на объект исходных данных. Этот шаг служит простой, но критически важной защитой. Если нет предыдущего слоя, продолжать бессмысленную расчётную цепочку нельзя.
Далее мы начинаем сдирать градиенты с конца MLP-цепочки. Внутренние параметры MLP получают корректный вклад ошибки, а градиенты аккуратно готовятся к передаче дальше по цепочке.
if(!FF[0].CalcHiddenGradients(FF[1].AsObject())) return false; if(!AttentionOut.CalcHiddenGradients(FF[0].AsObject())) return false;
Следующая строка кода переносит сигнал из MLP обратно в точку, где MLP получал данные — в AttentionOut. Иначе говоря, мы сообщаем блоку внимания: вот часть ошибки, объясняющаяся работой MLP; распределите её по своим входам. Это обеспечивает согласованность между нелинейной доработкой представления и самим представлением, сформированным Attention.
Но прежде чем двигаться дальше, нам необходимо вычислить градиенты ошибки второго информационного потока остаточных связей, формируя градиент для проекции W0 и дальнейшей передачи вниз.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false; if(!MHAttentionOut.CalcHiddenGradients(W0.AsObject())) return false; if(!AttentionInsideGradients()) return false;
Следующий шаг перемещает градиент внутрь выхода многоголового внимания, который образовался до проекции W0. Иначе говоря, мы «раскручиваем» проекцию W0: её градиент уже посчитан, теперь нужно знать, какие ошибки приходят к самим голам внимания.
Вызов AttentionInsideGradients — это ключевая операция разбора внутренних частностей Attention. Здесь вычисляются градиенты по всем внутренним составляющим механизма внимания и, в итоге, по тензорам Query, Key и Value. Этот шаг отвечает за преобразование агрегированного сигнала ошибки из пространства агрегированных голов внимания в отдельные вклады для глобальных Запросов и локальных Ключей/Значений.
Далее передаём накопленные градиенты в сторону исходных данных (prevLayer — локального входа). Мы вызываем соответствующий метод, чтобы корректно распределить ошибку по весам и подготовить градиенты для самого prevLayer.
if(!prevLayer.CalcHiddenGradients(KV_Embedding.AsObject())) return false; if(!cParams.CalcHiddenGradients(Q_Embedding.AsObject())) return false;
Параллельно осуществляем зеркальное обслуживание глобальной памяти: градиенты, полученные для Запросов (Query), передаются в cParams. Таким образом, обучение затрагивает не только локальные проекции, но и сами параметры глобальной корреляционной памяти — θTQ аккуратно получает свой вклад ошибки, который затем будет использован в обновлении весов.
После разделения вкладов нам предстоит дополнить градиент ошибки исходных данных значениями по магистрали исходных данных. Но прежде мы скорректируем их на производную функции активации предшествующего слоя. И лишь после этого можно суммировать результаты двух информационных потоков.
if(!DeActivation(prevLayer.getOutput(), W0.getPrevOutput(), W0.getGradient(), prevLayer.Activation())) return false; if(!SumAndNormilize(prevLayer.getGradient(), W0.getPrevOutput(), prevLayer.getGradient(), iWindow_K, false)) return false; //--- return true; }
Это важный шаг: он гарантирует, что финальный градиент, передаваемый в prevLayer, учитывает и влияние локального входа, и вклад проекции W0, корректно распределённый с учётом нормализации, применённой в прямом проходе.
После успешного выполнения всех этих стадий, метод сигнализирует о корректном распределении градиентов по всем внутренним компонентам модуля и готовности к шагу обновления весов.
За аккуратным распределением градиентов ошибки по всем внутренним структурам нейрона следует естественный и логичный шаг их прикладного применения — обновление параметров. Метод updateInputWeights замыкает цикл обучения. Он берет рассчитанные градиенты и последовательно применяет их к проекциям, MLP и, что особенно важно, к самой глобальной памяти корреляций.
Используемый нами модульный подход позволяет создать довольно лаконичный метод обновления параметров. Мы лишь последовательно передаем управление одноименным методам внутренних объектов с передачей корректных указателей на соответствующие буферы исходных данных.
bool CNeuronTQMHA::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!cParams.UpdateInputWeights()) return false; if(!Q_Embedding.UpdateInputWeights(cParams.AsObject())) return false; if(!KV_Embedding.UpdateInputWeights(NeuronOCL)) return false; if(!W0.UpdateInputWeights(GetPointer(MHAttentionOut))) return false; if(!FF[0].UpdateInputWeights(GetPointer(AttentionOut))) return false; if(!FF[1].UpdateInputWeights(GetPointer(FF[0]))) return false; //--- return true; }
Метод updateInputWeights — это аккуратный и преднамеренный финал цикла обучения. Он гарантирует, что глобальная память корреляций и все её отображения с последующими преобразованиями получат корректные и согласованные обновления, что особенно важно для устойчивого и надежного применения TQNet в задачах прогнозирования финансовых временных рядов.
Полный код класса CNeuronTQMHA и всех его методов представлен во вложении.
Архитектура модели
После сборки всех ключевых компонентов фреймворка TQNet, мы переходим к следующему этапу — описанию архитектуры обучаемых моделей. Как и раньше, наша цель — обучить торговую систему, способную самостоятельно анализировать рыночную ситуацию и принимать торговые решения. Обучение ведётся в парадигме Актёр–Критик, где TQNet выступает в роли Энкодера состояния окружающей среды. Он формирует компактное, информативное представление текущей рыночной ситуации, на которое опирается Актёр при выборе действий, а Критик — при оценке их качества.
В отличие от первоначального варианта TQNet, мы расширили модель в части подготовки данных и генерации признаков: добавлены блоки предобработки и агрегирования контекстной информации, что повышает устойчивость и обобщающую способность системы. Создание описания архитектуры моделей реализовано в методе CreateDescriptions. В нем формируется та самая скелетная последовательность слоёв, на которую опирается вся дальнейшая логика обучения и инференса.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Метод начинается с элементарной, но важной работы: если указатели на контейнеры слоёв пусты, он создаёт новые объекты. Это не просто формальность — мы гарантируем, что каждый из трёх блоков архитектуры получит собственную, независимую коллекцию описаний слоёв, готовую к последовательному заполнению. Такая явная аллокация даёт прозрачность. Дальнейший код может предполагать наличие контейнера и не проверять его на актуальность в нескольких местах.
Далее дело доходит до построения Энкодера — центрального элемента нашей модели. Мы очищаем контейнер и последовательно добавляем описание слоёв, причём каждый этап сопровождается строгой проверкой успешности: если создание объекта или добавление в массив по какой-то причине не удастся, метод аккуратно освобождает ресурсы и возвращает ошибку. Такая дисциплина по управлению памятью и состояниями полезна при отладке и в продакшене — она не даёт проблемам расползтись по стеку.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Первый слой Энкодера — это слой базового нейрона CNeuronBaseOCL, число нейронов задаётся как произведение HistoryBars * BarDescr. Идея здесь понятна: мы подаём на сеть историческое окно, разбитое по описательным признакам. Этот слой не содержит активации — он служит вратами, буфером, куда мы просто передаем исходные данные.
Следующий блок — CNeuronBatchNormWithNoise — сохраняет размерность предыдущего слоя, но добавляет нормализацию и шумовую регуляризацию. Это не декоративная деталь: финансовые ряды подвержены дрейфу распределения и выбросам. BatchNorm с шумом повышает устойчивость к таким аномалиям, нормализует входы для последующих слоёв и одновременно стимулирует модель не переобучаться на мелких, случайных вариациях.
После нормализации, мы переходим к трансформации временной структуры через CNeuronConcatDiff. Этот слой собирает историю по барам, но делает это с акцентом на разности c шагом (step = 1), обеспечивая явное представление динамики — не только уровней, но и их изменений. Такой приём часто даёт модели лучшее представление о тиках тренда, инерции и локальных разворотах.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Дальше следует слой CMamba4CastEmbeding, который реализует многооконную логику встраивания синусоидальных временных меток. Это даёт модели способность смотреть одновременно на краткосрочные и долгосрочные паттерны, формируя насыщенное представление состояния рынка.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = 2 * BarDescr; uint prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_D1), PeriodSeconds(PERIOD_MN1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь стоит обратить внимание, что предшествующие операции выполнялись в представлении мультимодального временного ряда. А для корректной работы фреймворка TQNet нам необходима последовательность унитарных временных рядов. Поэтому следующим шагом мы транспонируем тензор, перестраивая размерности для последующего применения внимания.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
И вот мы приближаемся к сердцу — к слою CNeuronTQMHA. Здесь мы указываем размер периода как произведение 24*7, что соответствует календарной неделе на таймфрейме H1. И размер шага соответствует количеству секунд в одном баре указанного таймфрейма. Мы хотим, чтобы TQ-карусель хранила недельные шаблоны и подтягивала их с шагом часового таймфрейма.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTQMHA; { uint temp[] = {prev_out, 64, 24*7, PeriodSeconds(PERIOD_H1)}; // window, window_key, period, timeframe if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.step=NHeads; descr.count=prev_count; descr.batch = BatchSize; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } uint count = prev_count; uint window = prev_out;
Обратите внимание, что мы используем календарную неделю (7 дней), даже если анализируемый инструмент не торгуется в выходные дни. Это вынужденная мера, так как элемент карусели мы рассчитываем от времени открытия бара.
Далее идёт свёрточный слой с TANH-активацией, который служит для сжатия и проекции полученных представлений на заданный горизонт планирования. Это — этап, где богатое представление переводится в конкретные прогнозные сигналы.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.count;
Потом снова транспонирование, чтобы вернуть данные в представление мультимодальной последовательности, аналогичной исходным данным.
Ещё одна свёртка призвана сжать размерность признаков до уровня исходных данных.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = BarDescr; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Такие свёрточные проходы выступают в роли локальных агрегаторов — они аккумулируют информацию по компонентам прогноза и выдают готовое для денормализации представление.
Завершает энкодер слой CNeuronRevInDenormOCL. Этот модуль возвращает прогнозы в исходный масштаб, восстанавливая среднее и дисперсию анализируемых данных, которые были удалены на этапе предобработки.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
Для финансовых приложений это принципиально: прогнозы должны иметь интерпретируемый масштаб, пригодный для торговли и расчёта рисков.
Во всём конструкте прослеживается единая идея: сначала аккуратно подготовить и нормализовать вход, затем выделить динамические признаки и встраивания на разных масштабах, после чего, применить TQ-усиленное внимание, и наконец — агрегировать и проецировать прогнозные значения в пространство исходных данных с восстановлением масштаба.
Архитектуры моделей Актера и Критика перенесены из прошлых работ без изменений, и мы не будем сейчас останавливаться на детальном их рассмотрении. Полное архитектурное решение всех обучаемых моделей представлено во вложении.
Тестирование
Процесс обучения выстроен в два последовательных и дополняющих друг друга этапа — это даёт и надёжный фундамент и гибкость для работы в реальных рыночных условиях.
На первом, офлайн-этапе мы провели основательное обучение на исторических данных по паре EURUSD с таймфреймом H1 за весь 2024 год. Этот год включал полный набор рыночных режимов — спокойные флэты, устойчивые тренды, внезапные скачки волатильности и периоды возрастания шумности, поэтому прекрасно подходит в роли школы для модели.
Второй этап — тонкая онлайн-настройка. Обучение реализовано в среде, максимально приближённой к рабочему трейдингу: в тестере стратегий MetaTrader 5 модель обрабатывала поток свечей последовательно, как это происходило бы в реальном времени. Онлайн-режим выявляет совершенно другие свойства, нежели батч-обучение: способность выдерживать шумы, реагировать на смену ликвидности, корректно учитывать задержки и эффект сквозного проскальзывания. Во время настройки мы имитировали реальные условия исполнения, чтобы поведение модели было предсказуемо при переносе в реальные торговые условия.
Финальным и, пожалуй, самым строгим этапом стала проверка на полностью внешней выборке — котировках с Января по Март2025 года. Все параметры модели и гиперпараметры при этом оставались замороженными; не было дополнительной подстройки под эти данные. Такая проверка показывает объективную картину практической эффективности: она отражает способность алгоритма сохранять предсказуемость и устойчивость в новых условиях.
Результаты тестирования приведены ниже.


Результаты тестирования показали довольно тонкий положительный край. При стартовом депозите 100 долларов чистая прибыль составила 21.07. Доля прибыльных операций оказалась близкой к 49%. Причём короткие позиции завершались в плюс чуть чаще, чем длинные. Средняя прибыльная сделка приносила 1.13 доллара, тогда как средний убыток составлял 0.92. Профит-фактор на уровне 1.18 при ожидаемом доходе 0,09 доллара на сделку указывает, что запас прочности минимален.
Линейная регрессия по кривой доходности показывает корреляцию 0.86, но ошибка остаётся заметной. Это подтверждает шумность результатов.
Риск-профиль пока далёк от оптимального. Глубокие просадки при небольшом ожидаемом доходе на сделку не дают возможности безопасно наращивать капитал. Нагрузка на маржу при этом невысокая, значит, проблема не в размере позиций, а в качестве точек входа и дисциплине закрытия.
Заключение
В данной работе мы детально рассмотрели теоретические основы фреймворка TQNet, а также особенности его интеграции в архитектуру обучаемых торговых моделей. Были проанализированы ключевые принципы построения модулей, включая модифицированные механизмы кросс-внимания, что позволило добиться более гибкой и устойчивой работы алгоритма в условиях финансовых рынков.
В практической части проекта мы реализовали предложенные в TQNet подходы средствами MQL5, дополнив их собственными улучшениями в части генерации признаков и предварительной обработки данных. Модель была обучена в два этапа: на исторических данных (офлайн-обучение) и в условиях, приближённых к реальному рынку (онлайн-настройка в тестере стратегий MetaTrader 5).
Итоговое тестирование на новых, ранее неиспользованных, котировках показало положительную динамику. Баланс модели продемонстрировал устойчивый рост после периода начальной просадки, что указывает на способность алгоритма адаптироваться к изменяющимся рыночным условиям.
Полученные результаты подтверждают, что TQNet, в комбинации с доработанными архитектурными решениями и двухэтапным процессом обучения, способен обеспечивать положительное математическое ожидание.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Искусство ведения логов (Часть 2): Форматирование логов
Искусство ведения логов (Часть 2): Форматирование логов
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования