
Нейросети — это просто (Часть 11): Вариации на тему GPT

Содержание
- Введение
- 1. Общее представление о моделях GPT
- 2. Отличительные особенности моделей GPT от рассмотренного ранее Трансформера
- 3. Реализация
- 3.1. Создаем новый класс для нашей модели
- 3.2. Прямой проход
- 3.3. Обратный проход
- 3.4. Точечные изменения в базовых классах нейронной сети
- 4. Тестирование
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
В июне 2018 года OpenAI представила миру модель нейронной сети GPT, которая сразу показала лучшие результаты по целому ряду языковых тестов. В феврале 2019 года появилась GPT-2 и в мае 2020 года все узнали о GPT-3. Данные модели продемонстрировали возможность генерации нейронной сетью связанного текста. Также проводились эксперименты по генерации музыки и изображений. Основным же недостатком моделей можно назвать требования к вычислительным ресурсам. Для обучения первой GPT потребовался месяц на машине с 8 GPU. Этот недостаток отчасти компенсируется возможностью использования предобученных моделей для решения новых задач. Но размеры модели требуют ресурсов для ее функционирования.
1. Общее представление о моделях GPT
Концептуально, модели GPT построены на базе уже рассмотренного нами трансформера. Основная идея заключается в предварительном обучении модели "без учителя" на большом объеме данных и последующей тонкой настройкой на относительно не большом количестве размеченных данных.
Причиной двухэтапного обучения является размер модели. Современные модели глубокого машинного обучения, подобные GPT, насчитывают большое количество параметров, число которых уже исчисляется сотнями миллионов. Следовательно, обучение подобных нейронных сетей требует огромной обучающей выборки. При использовании обучения с учителем создание размеченной обучающей выборки потребует значительных трудозатрат. В тоже время, в сети сейчас есть много оцифрованных и неразмеченных различных текстов, которые отлично подходят для обучения модели без учителя. Однако, результаты обучения без учителя по статистике уступают обучению с учителем. Поэтому, после обучения без учителя осуществляется тонкая настройка модели на сравнительно небольшой выборке размеченных данных.
Обучение без учителя позволяет GPT изучить языковую модель, а тонкая настройка на размеченных данных настраивает модель для выполнения конкретных задач. Таким образом, одна предобученная модель может быть тиражирована и настроена на выполнения различных языковых задач. Ограничением выступает язык исходной выборки для обучения без учителя.
Как показала практика, подобный подход дает неплохие результаты в широком спектре языковых задач. К примеру, модель GPT-3 способна генерировать связанные тексты на заданную тему. Но тут следует отметить, что указанная модель содержит 175 млрд. параметров и предобучена на датасете в 570 ГБ.
Несмотря на то, что модели GPT были разработаны для обработки естественного языка, они также показали достойные результаты и в задачах генерации музыки и изображений.
Теоретически, возможно использование моделей GPT с любыми последовательностями оцифрованных данных. Вопрос в достаточности данных и ресурсов для предобучения без учителя.
2. Отличительные особенности моделей GPT от рассмотренного ранее Трансформера
Рассмотрим отличительные особенности моделей GPT от ранее рассмотренного Трансформера. Прежде всего, в моделях GPT отказались от использования енкодера, оставив только декодер. При этом, отказ от енкодера повлек и отказ от внутреннего слоя Encoder-Decoder Self-Attention. На рисунке ниже представлен блок трансформера в GPT.
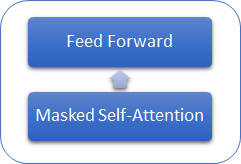
Так же как и в классическом Трансформере, в моделях GPT данные блоки выстраиваются друг над другом. И каждый блок имеет свои матрицы весовых коэффициентов для механизма внимания и полносвязных слоев Feed Forward. Количество таких блоков определяет размер модели. Как оказалось, стек блоков может быть довольно большим. В GPT-1 и самой маленькой из GPT-2 (GPT-2 Small) их 12, в GPT-2 Extra Large - 48, а в GPT-3 их уже 96.
Как и традиционные языковые модели, GPT позволяет находить взаимосвязи только с предшествующими элементами последовательности, не позволяя заглядывать в будущее. Но в отличии от трансформера, использует не маскирование элементов, а вносит изменения в вычислительный процесса. В GPT обнуляются коэффициенты внимания в матрице Score для последующих элементов.
В тоже время GPT можно отнести к авторегрессионным моделям. Генерируя по одному токену последовательности на каждой итерации, полученный токен добавляется к входной последовательности и подается на вход модели для следующей итерации.
Как и в классическом трансформере, внутри механизма самовнимания для каждого токена генерируются три вектора: запроса (query), ключа (key) и значения (value). В авторегрессионной модели, когда на каждой новой итерации входная последовательность изменяется только на 1 токен, нет необходимости пересчитывать вектоы для каждого токена. Поэтому, в GPT каждый слой осуществляет расчет векторов только для новых элементов последовательности и сохраняет их для каждого элемента последовательности. Каждый блок трансоформера сохраняет свои векторы для последующего использования.
Такой подход позволяет модели генерировать тексты слово за словом до получения конечного токена.
И конечно, в моделях GPT используется механизм многоголового самовнимания.
3. Реализация
Приступая к реализации давайте вкратце повторим алгоритм:
- На вход блока трансформера подается входная последовательность токенов.
- Для каждого токена рассчитываются 3 вектора (query, key, value) путем умножения вектора токена на соответствующую обучаемую матрицу весовых коэффициентов W.
- Перемножая векторы query и key определяем зависимости между элементами последовательности. На данном этапе вектор query каждого элемента последовательности умножается на векторы key текущего и всех предшествующих элементов последовательности.
- Матрица полученных коэффициентов внимания нормализуется с использованием функции Softmax в разрезе каждого запроса (query). При этом для последующих элементов последовательности устанавливается нулевой коэффициент внимания.
- Путем перемножения нормализованных коэффициентов внимания на векторы value соответствующих элементов последовательности и последующего сложения полученных векторов получаем скорректированное на внимание значение для каждого элемента последовательности (Z).
- Далее определяем взвешенный вектор Z по результатам отработки всех голов внимания. Для этого скорректированные векторы value от всех голов внимания конкатенируются в единый вектор и умножаются на обучаемую матрицу W0.
- Полученный тензор складывается с входной последовательностью и нормализуется.
- За механизмом Multi-Heads Self-Attention следует 2 полносвязных слоя блока Feed Forward. Первый (скрытый) слой содержит нейронов в 4 раза больше входной последовательности с функцией активации ReLU. Размерность второго слоя равна размерности входной последовательности и нейроны не используют функцию активации.
- Результат отработки полносвязных слоев суммируем с тензором, подаваемым на вход блока Feed Forward, и нормализуем полученный тензор.
Одна последовательность для всех голов (потоков) самовнимания. Далее действия в пунктах 2-5 идентичны для каждой головы внимания.
В результате выполнения пунктов 3 и 4 получаем квадратную матрицу Score размерностью равной количеству элементов в последовательности, где сумма всех элементов в разрезе каждого query равна "1".
3.1. Создаем новый класс для нашей модели.
Для реализации нашей модели создадим новый класс CNeuronMLMHAttentionOCL на основе базового класса CNeuronBaseOCL. Здесь я намеренно отступил на шаг назад и не использовал созданные ранее классы внимания. Это связано с изменением принципов создания многоголового самовнимания. Напомню, в статье [10] мы создали класс CNeuronMHAttentionOCL, в котором был организован последовательный пересчет 4 потоков внимания, при этом количество потоков зашито в коде методов и изменение количества потоков потребует значительных трудозатрат по внесению изменений в код класса и его методов.
И еще один момент. Как было сказано выше, в модели GPT использует стек идентичных блоков трансформера с теми же (неизменяемыми) гиперпараметрами, отличие только в обучаемых матрицах. Поэтому было принято решение о создании многослойного блока, который бы позволял создавать модели с гиперпараметрами, передаваемыми при создании класса. В том числе и количества повторений блоков трансформера в стеке.
В результате мы получили класс, способный создавать практически всю модель на основании нескольких задаваемых параметров. Итак, в блоке protected нового класса объявляются 5 переменных для хранения параметров блока:
| iLayers | Количество блоков трансформера в модели |
| iHeads | Количество голов самовнимания |
| iWindow | Размер входного окна (1 токена входной последовательности) |
| iWindowKey | Размерность внутренних векторов Query, Key, Value |
| iUnits | Количество элементов (токенов) в входной последовательности |
Также в блоке protected объявим 6 массивов для хранения коллекции буферов для наших тензоров и обучающих матриц весов:
| QKV_Tensors | Массив для хранения тензоров Query, Key, Value и их градиентов |
| QKV_Weights | Массив для хранения коллекции матриц весов Wq, Wk, Wv и матриц их моментов |
| S_Tensors | Массив для хранения коллекции матриц Score и их градиентов |
| AO_Tensors | Массив для хранения выходных тензоров механизма самовнимания и их градиентов |
| FF_Tensors | Массив для хранения входных, скрытых и выходных тензоров блока Feed Forward и их градиентов |
| FF_Weights | Массив для хранения матриц весов блока Feed Forward и их моментов. |
С методами класса предлагаю познакомиться позже по мере их реализации.
class CNeuronMLMHAttentionOCL : public CNeuronBaseOCL { protected: uint iLayers; ///< Number of inner layers uint iHeads; ///< Number of heads uint iWindow; ///< Input window size uint iUnits; ///< Number of units uint iWindowKey; ///< Size of Key/Query window //--- CCollection *QKV_Tensors; ///< The collection of tensors of Queries, Keys and Values CCollection *QKV_Weights; ///< The collection of Matrix of weights to previous layer CCollection *S_Tensors; ///< The collection of Scores tensors CCollection *AO_Tensors; ///< The collection of Attention Out tensors CCollection *FF_Tensors; ///< The collection of tensors of Feed Forward output CCollection *FF_Weights; ///< The collection of Matrix of Feed Forward weights ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. virtual bool ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ); ///< \brief Convolution Feed Forward method of calling kernel ::FeedForwardConv(). virtual bool AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true); ///< \brief Multi-heads attention scores method of calling kernel ::MHAttentionScore(). virtual bool AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out); ///< \brief Multi-heads attention out method of calling kernel ::MHAttentionOut(). virtual bool SumAndNormilize(CBufferDouble *tensor1, CBufferDouble *tensor2, CBufferDouble *out); ///< \brief Method sum and normilize 2 tensors by calling 2 kernels ::SumMatrix() and ::Normalize(). ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends of optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. virtual bool ConvolutuionUpdateWeights(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *momentum1, CBufferDouble *momentum2, uint window, uint window_out); ///< Method for updating weights in convolution layer.\details Calling one of kernels ::UpdateWeightsConvMomentum() or ::UpdateWeightsConvAdam() in depends of optimization type (#ENUM_OPTIMIZATION). virtual bool ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ); ///< Method of passing gradients through a convolutional layer. virtual bool AttentionInsideGradients(CBufferDouble *qkv,CBufferDouble *qkv_g,CBufferDouble *scores,CBufferDouble *scores_g,CBufferDouble *gradient); ///< Method of passing gradients through attention layer. public: /** Constructor */CNeuronMLMHAttentionOCL(void); /** Destructor */~CNeuronMLMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMLMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
В конструкторе класса зададим начальные значения гипер параметров класса и инициализируем массивы наших коллекций.
CNeuronMLMHAttentionOCL::CNeuronMLMHAttentionOCL(void) : iLayers(0), iHeads(0), iWindow(0), iWindowKey(0), iUnits(0) { QKV_Tensors=new CCollection(); QKV_Weights=new CCollection(); S_Tensors=new CCollection(); AO_Tensors=new CCollection(); FF_Tensors=new CCollection(); FF_Weights=new CCollection(); }
Соответственно, в деструкторе класса удалим массивы коллекций.
CNeuronMLMHAttentionOCL::~CNeuronMLMHAttentionOCL(void) { if(CheckPointer(QKV_Tensors)!=POINTER_INVALID) delete QKV_Tensors; if(CheckPointer(QKV_Weights)!=POINTER_INVALID) delete QKV_Weights; if(CheckPointer(S_Tensors)!=POINTER_INVALID) delete S_Tensors; if(CheckPointer(AO_Tensors)!=POINTER_INVALID) delete AO_Tensors; if(CheckPointer(FF_Tensors)!=POINTER_INVALID) delete FF_Tensors; if(CheckPointer(FF_Weights)!=POINTER_INVALID) delete FF_Weights; }
Непосредственно инициализация класса и построение модели осуществляется в методе Init. В параметрах метод получает:
| numOutputs | Количество элементов в последующем слое для создания связей |
| myIndex | Индекс нейрона в слое |
| open_cl | Указатель на объект OpenCL |
| window | Размер входного окна (токена входной последовательности) |
| window_key | Размерность внутренних векторов Query, Key, Value |
| heads | Количество голов (потоков) самовнимания |
| units_count | Количество элементов входной последовательности |
| layers | Количество блоков (слоев) в стеке модели |
| optimization_type | Метод оптимизации параметров при обучении |
bool CNeuronMLMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint window_key,uint heads,uint units_count,uint layers,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronBaseOCL::Init(numOutputs,myIndex,open_cl,window*units_count,optimization_type)) return false; //--- iWindow=fmax(window,1); iWindowKey=fmax(window_key,1); iUnits=fmax(units_count,1); iHeads=fmax(heads,1); iLayers=fmax(layers,1);
В начале метода инициализируем родительский класс, вызвав соответствующий метод. Обратите внимание, что мы не делаем базовые проверки на действительность полученного указателя объекта OpenCL и размера входной последовательности, т.к. эти проверки уже реализованы в методе родительского класса.
После успешной инициализации родительского класса сохраним гиперпараметры в соответствующие переменные.
Далее рассчитаем размеры создаваемых тензоров. Здесь следует обратить внимание на упомянутый ранее измененный подход к организации многоголового внимания. Мы не будем создавать отдельные массивы для векторов query, key и value, а объединим их в одном массиве. Более того, мы не будем создавать отдельные массивы для каждой головы внимания, а создадим общие массивы QKV (query + key + value), Scores и выходов механизма самовнимания. Разделять элементы по последовательностям будем на уровне индексов в тензоре. Такой подход, конечно, сложнее в понимании и поиске нужного элемента в тензоре, но позволяет сделать модель гибкой к количеству голов внимания и организовать одновременный пересчет всех голов внимания, распараллелив потоки на уровне кернелов.
Итак, размер тензора QKV_Tensor (num) определим как произведение 3-х размеров внутреннего вектора (query + key + value) на количество голов. Размерность конкатенированной матрицы весов QKV_Weight определим как произведение 3-х размеров токена входной последовательности увеличенного на элемент смещения на размер внутреннего вектора и количество голов внимания. Аналогично посчитаем размерности остальных тензоров.
uint num=3*iWindowKey*iHeads*iUnits; //Size of QKV tensor uint qkv_weights=3*(iWindow+1)*iWindowKey*iHeads; //Size of weights' matrix of QKV tenzor uint scores=iUnits*iUnits*iHeads; //Size of Score tensor uint mh_out=iWindowKey*iHeads*iUnits; //Size of multi-heads self-attention uint out=iWindow*iUnits; //Size of our tensore uint w0=(iWindowKey+1)*iHeads*iWindow; //Size W0 tensor uint ff_1=4*(iWindow+1)*iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2=(4*iWindow+1)*iWindow; //Size of weights' matrix 2-nd feed forward layer
После определения размерности всех тензоров запустим цикл по количеству слоев внимания в нашем блоке для создания необходимых тензоров. Обратите внимание, что внутри тела цикла организовано два вложенных цикла. В первом создаются массивы для тензоров значений и их градиентов. Во втором создаются массивы для матриц весов и их моментов. Обратите внимание, что для последнего слоя не создаются новые массивы для тензора выхода из блока Feed Forward и его градиента, вместо этого в коллекцию добавляются указатели на массивы выходных значений и градиентов родительского класса. Такой нехитрый шаг позволит нам исключить лишнюю итерацию переноса значений между массивами и исключит излишнее потребление памяти.
for(uint i=0; i<iLayers; i++) { CBufferDouble *temp=NULL; for(int d=0; d<2; d++) { //--- Initilize QKV tensor temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(num,0)) return false; if(!QKV_Tensors.Add(temp)) return false; //--- Initialize scores temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(scores,0)) return false; if(!S_Tensors.Add(temp)) return false; //--- Initialize multi-heads attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(mh_out,0)) return false; if(!AO_Tensors.Add(temp)) return false; //--- Initialize attention out temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(4*out,0)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i==iLayers-1) { if(!FF_Tensors.Add(d==0 ? Output : Gradient)) return false; continue; } temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(out,0)) return false; if(!FF_Tensors.Add(temp)) return false; } //--- Initilize QKV weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; for(uint w=0; w<qkv_weights; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!QKV_Weights.Add(temp)) return false; //--- Initilize Weights0 temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w=0; w<w0; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; for(uint w=0; w<ff_1; w++) { if(!temp.Add(GenerateWeight())) return false; } if(!FF_Weights.Add(temp)) return false; //--- for(int d=0; d<(optimization==SGD ? 1 : 2); d++) { temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights,0)) return false; if(!QKV_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(w0,0)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_1,0)) return false; if(!FF_Weights.Add(temp)) return false; temp=new CBufferDouble(); if(CheckPointer(temp)==POINTER_INVALID) return false; if(!temp.BufferInit(ff_2,0)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
В результате для каждого слоя получим нижеследующую матрицу тензоров.
| QKV_Tensor |
|
| S_Tensors |
|
| AO_Tensors |
|
| FF_Tensors |
|
| QKV_Weights |
|
| FF_Weights |
|
После создания коллекций массивов выходим из метода с результатом true. С полным кодом всех классов и их методов можно ознакомиться во вложении.
3.2. Прямой проход.
Прямой проход по традиции организован в методе feedForward, которому в параметрах передается указатель на предыдущий слой нейронной сети. В начале метода проверим действительность полученного указателя.
bool CNeuronMLMHAttentionOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false;
Дале организуем цикл по пересчету всех слоев нашего блока. В отличии от описанных ранее одноименных методов других классов, данный метод является верхнеуровневым. Операции, организованные в нем, сводятся к подготовке данных и вызове вспомогательных методов, логика которых будет описана ниже.
В начале цикла получим из коллекции соответствующие текущему слою буферы входных данных тензоров QKV и QKV_Weights. И вызовем метод ConvolutionForward для расчета векторов Query, Key и Value.
for(uint i=0; (i<iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferDouble *inputs=(i==0? NeuronOCL.getOutput() : FF_Tensors.At(6*i-4)); CBufferDouble *qkv=QKV_Tensors.At(i*2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),inputs,qkv,iWindow,3*iWindowKey*iHeads,None)) return false;
Еще один момент, с которым я столкнулся при увеличении слоев внимания. В какой-то момент я получил ошибку 5113 ERR_OPENCL_TOO_MANY_OBJECTS, что заставило меня задуматься о постоянном хранении всех тензоров в памяти GPU. Поэтому после выполнения операций я освобождаю буферы, которые уже не будут использоваться на данном шаге. В своих разработках не забудьте считать из памяти GPU последние данные освобождаемых буферов. В представленном в статье классе считывание данных буферов осуществляется в методах инициализации кернелов, о которых мы поговорим чуть позже.
CBufferDouble *temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree();
Аналогично, вызовом соответствующих методов осуществляется расчет коэффициентов внимания и взвешенных векторов значений механизма Self-Attention.
//--- Score calculation temp=S_Tensors.At(i*2); if(IsStopped() || !AttentionScore(qkv,temp,true)) return false; //--- Multi-heads attention calculation CBufferDouble *out=AO_Tensors.At(i*2); if(IsStopped() || !AttentionOut(qkv,temp,out)) return false; qkv.BufferFree(); temp.BufferFree();
После расчета Multi-Heads Self-Attention свернем конкатенированный выход внимания до размера входной последовательности, сложим два вектора и нормализуем полученный результат.
//--- Attention out calculation temp=FF_Tensors.At(i*6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out,temp,iWindowKey*iHeads,iWindow,None)) return false; out.BufferFree(); //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp,inputs,temp)) return false; if(i>0) inputs.BufferFree();
За механизмом самовнимания в алгоритме трансформера следует блок Feed Forward, состоящий из двух полносвязных слоев и последующим сложением результата с входной последовательностью. Суммарный тензор нормализуется и подается на последующий слой. В нашем случае мы закрываем цикл.
//--- Feed Forward inputs=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),inputs,temp,iWindow,4*iWindow,LReLU)) return false; out=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); out.BufferFree(); out=FF_Tensors.At(i*6+2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),temp,out,4*iWindow,iWindow,activation)) return false; temp.BufferFree(); temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out,inputs,out)) return false; inputs.BufferFree(); } //--- return true; }
С полным кодом метода можно ознакомиться во вложении, а сейчас давайте рассмотрим вспомогательные методы, вызываемые из метода feedForward. И первым мы вызывали метод ConvolutionForward, который вызывается 4 раза за один цикл метода прямого прохода. В теле этого метода осуществляется вызов кернела прямого прохода сверточного слоя, который в данном случае выполняет роль полносвязного слоя для каждого отдельного токена входной последовательности. Подробнее это решение рассматривалось в статье [8]. В отличии от описанного ранее решения, новый метод получает в параметрах указатели на буферы для передачи данных в кернел OpenCL. Поэтому в начале метода проверим действительность полученных указателей.
bool CNeuronMLMHAttentionOCL::ConvolutionForward(CBufferDouble *weights, CBufferDouble *inputs,CBufferDouble *outputs, uint window, uint window_out, ENUM_ACTIVATION activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(outputs)==POINTER_INVALID) return false;
Следующим шагом создадим буферы в памяти GPU и передадим в них необходимую информацию.
if(!weights.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!outputs.BufferCreate(OpenCL)) return false;
Далее следует код описанный в статье [8] без изменений. Вызываемый кернел используется без изменений.
uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=outputs.Total()/window_out; OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_i,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_FeedForwardConv,def_k_ffc_matrix_o,outputs.GetIndex()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_inputs,inputs.Total()); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_step,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_window_in,window); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffс_window_out,window_out); OpenCL.SetArgument(def_k_FeedForwardConv,def_k_ffc_activation,(int)activ); if(!OpenCL.Execute(def_k_FeedForwardConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel FeedForwardConv: %d",GetLastError()); return false; } //--- return outputs.BufferRead(); }
Далее по коду метода feedForward вызывается метод AttentionScore, в котором осуществляется вызов кернела для расчета и нормализации коэффициентов внимания с последующей записью полученных значений в матрицу Score. Кернел для этого метода был написан новый и будет рассмотрен после рассмотрения метода.
Как и предыдущий метод, метод AttentionScore получает в параметрах указатели на буферы исходных данных и записи полученных значений. Соответственно, в начале метода проверяем действительность полученных указателей.
bool CNeuronMLMHAttentionOCL::AttentionScore(CBufferDouble *qkv, CBufferDouble *scores, bool mask=true) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID) return false;
Следуя описанной выше логике, создадим буферы обмена данными с GPU.
if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false;
После проведения подготовительной работы прейдем к указанию параметров кернела. Потоки данного кернела создадим в двух измерениях: в разрезе элементов входной последовательности и в разрезе голов внимания. Тем самым мы организуем параллельное вычисление для всех элементов последовательности и всех голов внимания.
uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionScore,def_k_mhas_score,scores.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_dimension,iWindowKey); OpenCL.SetArgument(def_k_MHAttentionScore,def_k_mhas_mask,(int)mask);
Затем перейдем непосредственно к вызову кернела. И считаем результаты вычислений в буфер score.
if(!OpenCL.Execute(def_k_MHAttentionScore,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionScore: %d",GetLastError()); return false; } //--- return scores.BufferRead(); }
Рассмотрим логику вызываемого кернела MHAttentionScore. Как было показано выше, в параметрах кернел получает указатель на массив исходных данных qkv и массив для записи результатов score. Также в параметрах кернелу передается размерность внутренних векторов (Query, Key) и флаг включения алгоритма маскирования последующих элементов.
Вначале получим порядковые номера обрабатываемого запроса q и головы внимания h. А также размерности количества запросов и голов внимания.
__kernel void MHAttentionScore(__global double *qkv, ///<[in] Matrix of Querys, Keys, Values __global double *score, ///<[out] Matrix of Scores int dimension, ///< Dimension of Key int mask ///< 1 - calc only previous units, 0 - calc all ) { int q=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1);
По полученным данным определим смещение в массивах для query и score.
int shift_q=dimension*(h+3*q*heads); int shift_s=units*(h+q*heads);
И посчитаем коэффициент для коррекции Score.
double koef=sqrt((double)dimension); if(koef<1) koef=1;
Непосредственно расчет коэффициентов внимания осуществляется в цикле, в котором будем перебирать ключи всей последовательности элементов в соответствующей голове внимания.
Вначале цикла проверим условие использования механизма внимания. В случае включения данного функционала проверяем порядковый номер ключа. Если текущий ключ соответствует последующему элементу последовательности, то записываем в массив score нулевой коэффициент и переходим к следующему элементу.
double sum=0; for(int k=0;k<units;k++) { if(mask>0 && k>q) { score[shift_s+k]=0; continue; }
Если же для анализируемого ключа рассчитывается коэффициент внимания, то организуем вложенный цикл для подсчета произведения двух векторов. Следует обратить внимание, что в теле цикла организовано две ветви вычислений: с использование векторных вычислений и без них. Первая ветвь используется в случаях, когда есть 4 и более элементов от текущей позиции в векторе ключа до его последнего элемента, вторая ветвь используется для последних некратных 4-м элементов вектора ключа.
double result=0; int shift_k=dimension*(h+heads*(3*k+1)); for(int i=0;i<dimension;i++) { if((dimension-i)>4) { result+=dot((double4)(qkv[shift_q+i],qkv[shift_q+i+1],qkv[shift_q+i+2],qkv[shift_q+i+3]), (double4)(qkv[shift_k+i],qkv[shift_k+i+1],qkv[shift_k+i+2],qkv[shift_k+i+3])); i+=3; } else result+=(qkv[shift_q+i]*qkv[shift_k+i]); }
Напомню, что по алгоритму трансформера коэффициенты внимания нормализуются функцией softmax. Для реализации этого момента разделим результат произведения векторов на наш коэффициент коррекции и определим экспоненту для полученного значения. Результат вычисления запишем в соответствующий элемент тензора score и добавим к сумме экспонент.
result=exp(clamp(result/koef,-30.0,30.0)); if(isnan(result)) result=0; score[shift_s+k]=result; sum+=result; }
Таким образом посчитаем экспоненты для всех элементов. Для завершения нормализации коэффициентов внимания по Softmax организуем еще один цикл, в котором все элементы тензора Score разделим на ранее посчитанную сумму экспонент.
for(int k=0;(k<units && sum>1);k++) score[shift_s+k]/=sum; }
По завершении цикла выходим из кернела.
Продолжим наше движение по методу feedForward и рассмотрим следующий вспомогательный метод AttentionOut. В параметрах данный метод получает указатели на 3 тензора: QKV, Scores и Out. Внутри метод построен аналогично рассмотренным выше и запускает кернел MHAttentionOut в двух измерениях: элементов последовательности и голов внимания.
bool CNeuronMLMHAttentionOCL::AttentionOut(CBufferDouble *qkv, CBufferDouble *scores, CBufferDouble *out) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(qkv)==POINTER_INVALID || CheckPointer(scores)==POINTER_INVALID || CheckPointer(out)==POINTER_INVALID) return false; uint global_work_offset[2]= {0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iHeads; if(!qkv.BufferCreate(OpenCL)) return false; if(!scores.BufferCreate(OpenCL)) return false; if(!out.BufferCreate(OpenCL)) return false; //--- OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_qkv,qkv.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_score,scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MHAttentionOut,def_k_mhao_out,out.GetIndex()); OpenCL.SetArgument(def_k_MHAttentionOut,def_k_mhao_dimension,iWindowKey); if(!OpenCL.Execute(def_k_MHAttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel MHAttentionOut: %d",GetLastError()); return false; } //--- return out.BufferRead(); }
Кернел MHAttentionOut, так же как и предыдущий, был написан новый с учетом многоголового внимания и использованием единого буфера для тензоров запросов, ключей и значений. В параметрах кернел получает указатели на тензоры Scores, QKV, Out и размерность вектора значений. Первый и второй буферы несут исходные данные, а последний предназначен для записи результата.
Также вначале кернела определим порядковые номера обрабатываемого запроса q, головы внимания h и размерности количества запросов и голов внимания.
__kernel void MHAttentionOut(__global double *scores, ///<[in] Matrix of Scores __global double *qkv, ///<[in] Matrix of Values __global double *out, ///<[out] Output tesor int dimension ///< Dimension of Value ) { int u=get_global_id(0); int units=get_global_size(0); int h=get_global_id(1); int heads=get_global_size(1);
Следующим шагом определим позицию нужного коэффициента внимания и первого элемента анализируемого вектора выходных значений. Дополнительно посчитаем длину вектора одного элемента в тензоре QKV, данное значение будем использовать для определения смещения по тензору QKV.
int shift_s=units*(h+heads*u); int shift_out=dimension*(h+heads*u); int layer=3*dimension*heads;
Для осуществления основного объема вычислений организуем вложенные циклы — внешний по размерности вектора значений, внутренний по количеству элементов в исходной последовательности. В начале внешнего цикла объявим и инициализируем нулевым значением переменную для подсчета результирующего значения. Внутренний цикл начинается с определения смещения для вектора значений. Обратите внимание, что шаг внутреннего цикла равен 4, т. к. далее планируется использование векторных вычислений.
for(int d=0;d<dimension;d++) { double result=0; for(int v=0;v<units;v+=4) { int shift_v=dimension*(h+heads*(3*v+2))+d;
Как и в кернеле MHAttentionScore, разделим вычисления на 2 потока: с использованием векторных вычислений и без них. Второй поток будет использоваться только для последних элементов в случаях, когда длина последовательности некратна 4.
if((units-v)>4) { result+=dot((double4)(scores[shift_s+v],scores[shift_s+v+1],scores[shift_s+v+1],scores[shift_s+v+3]), (double4)(qkv[shift_v],qkv[shift_v+layer],qkv[shift_v+2*layer],qkv[shift_v+3*layer])); } else for(int l=0;l<(int)fmin((double)(units-v),4.0);l++) result+=scores[shift_s+v+l]*qkv[shift_v+l*layer]; } out[shift_out+d]=result; } }
После выхода из вложенного цикла, запишем полученное значение в соответствующий элемент выходного тензора.
Далее в методе feedForward используется рассмотренный выше метод ConvolutionForward. С полным кодом всех методов и функций можно ознакомиться во вложении.
3.3. Обратный проход.
Обратный проход, как и во всех рассмотренных ранее классах, делится на 2 подпроцесса: распределение градиента ошибки и непосредственно корректировка весовых коэффициентов. Первая часть реализована в методе calcInputGradients, а вторая в методе updateInputWeights.
Построение метода calcInputGradients аналогично методу feedForward. В параметрах метод получает указатель на предшествующий слой нейронов, которому должен передать градиент ошибки, и вначале метода проверяем действительность полученного указателя.
bool CNeuronMLMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
Затем фиксируем тензор полученного градиента от последующего слоя нейронов и организовываем цикл по перебору всех внутренних слоев для последовательного пересчета градиента ошибки. Т. к. у нас процесс обратного прохода, то и цикл будет перебирать внутренние слоя в обратном порядке.
for(int i=(int)iLayers-1; (i>=0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2),out_grad,FF_Tensors.At(i*6+1),FF_Tensors.At(i*6+4),4*iWindow,iWindow,None)) return false; CBufferDouble *temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(i*6+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+3); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(i*6+4),FF_Tensors.At(i*6),temp,iWindow,4*iWindow,LReLU)) return false;
В начале цикла посчитаем прохождение градиента ошибки через полносвязные слои нейронов блока Feed Forward трансформера. Для выполнения данной итерации воспользуемся методом ConvolutionInputGradients. После выполнения метода освобождаем отработанные буферы.
Так как в нашем алгоритме организован сквозной поток передачи данных, то и для градиента ошибки необходим аналогичный процесс. Поэтому, полученный градиент ошибки из блока Feed Forward суммируем с градиентом ошибки, полученным с предыдущего слоя нейронов. Для исключения риска "взрыва градиента" нормализуем сумму двух векторов. Описанные операции выполняются в методе SumAndNormilize. После выполнения метода освобождаем отработанные буферы данных.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; if(i!=(int)iLayers-1) out_grad.BufferFree(); out_grad=temp; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(i*6+4); temp.BufferFree(); temp=FF_Tensors.At(i*6); temp.BufferFree();
Спускаясь ниже по нашему алгоритму, разделим градиент ошибки по головам внимания. Для этого вызовем метод ConvolutionInputGradients для матрицы W0.
//--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 6 : 9)),out_grad,AO_Tensors.At(i*2),AO_Tensors.At(i*2+1),iWindowKey*iHeads,iWindow,None)) return false; temp=FF_Weights.At(i*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=AO_Tensors.At(i*2); temp.BufferFree();
Дальнейшее прохождение градиента внутри голов внимания организовано в методе AttentionInsideGradients.
if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i*2),QKV_Tensors.At(i*2+1),S_Tensors.At(i*2),S_Tensors.At(i*2+1),AO_Tensors.At(i*2+1))) return false; temp=QKV_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2); temp.BufferFree(); temp=S_Tensors.At(i*2+1); temp.BufferFree(); temp=AO_Tensors.At(i*2+1); temp.BufferFree();
И в заключении цикла посчитаем градиент ошибки, передаваемый на предыдущий слой. Для этого градиент ошибки, полученный на предыдущей итерации, пропустим через конкатенированный тензор QKV_Weights, а затем полученный вектор сложим с градиентом ошибки от блока Feed Forward механизма самовнимания и нормализуем результат, для исключения риска взрыва градиентов.
CBufferDouble *inp=NULL; if(i==0) { inp=prevLayer.getOutput(); temp=prevLayer.getGradient(); } else { temp=FF_Tensors.At(i*6-1); inp=FF_Tensors.At(i*6-4); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(i*2+1),inp,temp,iWindow,3*iWindowKey*iHeads,None)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad,temp,temp)) return false; out_grad.BufferFree(); if(i>0) out_grad=temp; temp=QKV_Weights.At(i*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(i*2+1); temp.BufferFree(); } //--- return true; }
Не забываем освобождать отработанные буферы данных. При этом следует учесть момент, что буферы данных предшествующего слоя оставляем в памяти GPU.
Рассмотрим вызываемые методы. Как можно заметить, наиболее часто вызывается метод ConvolutionInputGradients, который создан на базе аналогичного метода сверточного слоя и оптимизирован для текущей задачи. В параметрах метод получает указатели на тензоры весовых коэффициентов, градиента от последующего слоя, выходных данных предшествующего слоя и тензора для сохранения результата итерации. Также в параметрах методу передаются размеры входного и выходного окна данных и используемая функция активации.
bool CNeuronMLMHAttentionOCL::ConvolutionInputGradients(CBufferDouble *weights, CBufferDouble *gradient, CBufferDouble *inputs, CBufferDouble *inp_gradient, uint window, uint window_out, uint activ) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(weights)==POINTER_INVALID || CheckPointer(gradient)==POINTER_INVALID || CheckPointer(inputs)==POINTER_INVALID || CheckPointer(inp_gradient)==POINTER_INVALID) return false;
Вначале метода проверяем действительность полученных указателей и создаем буферы данных в памяти GPU.
if(!weights.BufferCreate(OpenCL)) return false; if(!gradient.BufferCreate(OpenCL)) return false; if(!inputs.BufferCreate(OpenCL)) return false; if(!inp_gradient.BufferCreate(OpenCL)) return false;
После создания буферов данных организуем процесс вызова соответствующего кернела программы OpenCL. Здесь используется кернел сверточной сети без изменений.
//--- uint global_work_offset[1]= {0}; uint global_work_size[1]; global_work_size[0]=inputs.Total(); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_w,weights.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_g,gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_o,inputs.GetIndex()); OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv,def_k_chgc_matrix_ig,inp_gradient.GetIndex()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_outputs,gradient.Total()); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_step,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_in,window); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_window_out,window_out); OpenCL.SetArgument(def_k_CalcHiddenGradientConv,def_k_chgc_activation,activ); //Comment(com+"\n "+(string)__LINE__+"-"__FUNCTION__); if(!OpenCL.Execute(def_k_CalcHiddenGradientConv,1,global_work_offset,global_work_size)) { printf("Error of execution kernel CalcHiddenGradientConv: %d",GetLastError()); return false; } //--- return inp_gradient.BufferRead(); }
Метод AttentionInsideGradients, также вызываемый из метода ConvolutionInputGradients, построен по аналогичному алгоритму и с его кодом можно познакомиться во вложении. Сейчас же я предлагаю посмотреть на вызываемый из указанного метода кернел программы OpenCL, т. к. все вычисления осуществляются именно в кернеле.
Кернел MHAttentionInsideGradients запускается потоками в двух измерениях: элементов последовательности и голов внимания. В параметрах кернел получает указатели на конкатенированный тензор QKV и тензор его градиентов, тензор матрицы Scores и его градиентов, тензор градиентов ошибки с предыдущей итерации и размерность вектора ключей.
__kernel void MHAttentionInsideGradients(__global double *qkv,__global double *qkv_g, __global double *scores,__global double *scores_g, __global double *gradient, int dimension) { int u=get_global_id(0); int h=get_global_id(1); int units=get_global_size(0); int heads=get_global_size(1); double koef=sqrt((double)dimension); if(koef<1) koef=1;
Вначале метода получим порядковые номера обрабатываемого элемента последовательности и головы внимания, а также их размерность. Сразу посчитаем коэффициент коррекции матрицы Scores.
Затем организуем цикл для расчёта градиента ошибки для матрицы Scores. Установка барьера после цикла позволит нам синхронизировать процесс вычислений по всем потокам и переход к следующему блоку операций будет осуществлен только после полного пересчета градиентов матрицы Scores.
//--- Calculating score's gradients uint shift_s=units*(h+u*heads); for(int v=0;v<units;v++) { double s=scores[shift_s+v]; if(s>0) { double sg=0; int shift_v=dimension*(h+heads*(3*v+2)); int shift_g=dimension*(h+heads*v); for(int d=0;d<dimension;d++) sg+=qkv[shift_v+d]*gradient[shift_g+d]; scores_g[shift_s+v]=sg*(s<1 ? s*(1-s) : 1)/koef; } else scores_g[shift_s+v]=0; } barrier(CLK_GLOBAL_MEM_FENCE);
И организуем еще один цикл для пересчета градиентов ошибок на векторах запроса, ключей и значений.
//--- Calculating gradients for Query, Key and Value uint shift_qg=dimension*(h+3*u*heads); uint shift_kg=dimension*(h+(3*u+1)*heads); uint shift_vg=dimension*(h+(3*u+2)*heads); for(int d=0;d<dimension;d++) { double vg=0; double qg=0; double kg=0; for(int l=0;l<units;l++) { uint shift_q=dimension*(h+3*l*heads)+d; uint shift_k=dimension*(h+(3*l+1)*heads)+d; uint shift_g=dimension*(h+heads*l)+d; double sg=scores_g[shift_s+l]; kg+=sg*qkv[shift_q]; qg+=sg*qkv[shift_k]; vg+=gradient[shift_g]*scores[shift_s+l]; } qkv_g[shift_qg+d]=qg; qkv_g[shift_kg+d]=kg; qkv_g[shift_vg+d]=vg; } }
С полным кодом всех методов и функций можно ознакомиться во вложении.
Обновление весовых коэффициентов осуществляется в методе updateInputWeights, который построен по принципам рассмотренных выше методов feedForward и calcInputGradients. Внутри метода последовательно вызывается только один вспомогательный метод обновления весов сверточной сети ConvolutuionUpdateWeights.
bool CNeuronMLMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL)==POINTER_INVALID) return false; CBufferDouble *inputs=NeuronOCL.getOutput(); for(uint l=0; l<iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l*(optimization==SGD ? 2 : 3)),QKV_Tensors.At(l*2+1),inputs,(optimization==SGD ? QKV_Weights.At(l*2+1) : QKV_Weights.At(l*3+1)),(optimization==SGD ? NULL : QKV_Weights.At(l*3+2)),iWindow,3*iWindowKey*iHeads)) return false; if(l>0) inputs.BufferFree(); CBufferDouble *temp=QKV_Weights.At(l*(optimization==SGD ? 2 : 3)); temp.BufferFree(); temp=QKV_Tensors.At(l*2+1); temp.BufferFree(); if(optimization==SGD) { temp=QKV_Weights.At(l*2+1); } else { temp=QKV_Weights.At(l*3+1); temp.BufferFree(); temp=QKV_Weights.At(l*3+2); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)),FF_Tensors.At(l*6+3),AO_Tensors.At(l*2),(optimization==SGD ? FF_Weights.At(l*6+3) : FF_Weights.At(l*9+3)),(optimization==SGD ? NULL : FF_Weights.At(l*9+6)),iWindowKey*iHeads,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)); temp.BufferFree(); temp=FF_Tensors.At(l*6+3); temp.BufferFree(); temp=AO_Tensors.At(l*2); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+3); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+3); temp.BufferFree(); temp=FF_Weights.At(l*9+6); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1),FF_Tensors.At(l*6+4),FF_Tensors.At(l*6),(optimization==SGD ? FF_Weights.At(l*6+4) : FF_Weights.At(l*9+4)),(optimization==SGD ? NULL : FF_Weights.At(l*9+7)),iWindow,4*iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+1); temp.BufferFree(); temp=FF_Tensors.At(l*6+4); temp.BufferFree(); temp=FF_Tensors.At(l*6); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+4); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+4); temp.BufferFree(); temp=FF_Weights.At(l*9+7); temp.BufferFree(); } //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2),FF_Tensors.At(l*6+5),FF_Tensors.At(l*6+1),(optimization==SGD ? FF_Weights.At(l*6+5) : FF_Weights.At(l*9+5)),(optimization==SGD ? NULL : FF_Weights.At(l*9+8)),4*iWindow,iWindow)) return false; temp=FF_Weights.At(l*(optimization==SGD ? 6 : 9)+2); temp.BufferFree(); temp=FF_Tensors.At(l*6+5); if(temp!=Gradient) temp.BufferFree(); temp=FF_Tensors.At(l*6+1); temp.BufferFree(); if(optimization==SGD) { temp=FF_Weights.At(l*6+5); temp.BufferFree(); } else { temp=FF_Weights.At(l*9+5); temp.BufferFree(); temp=FF_Weights.At(l*9+8); temp.BufferFree(); } inputs=FF_Tensors.At(l*6+2); } //--- return true; }
С полным кодом всех классов и их методов можно ознакомиться во вложении.
3.4. Точечные изменения в базовых классах нейронной сети
И как всегда, после создания нового класса внесем точечные изменения в базовые классы нашей нейронной сети для ее корректного функционирования.
Добавим идентификатор нового класса.
#define defNeuronMLMHAttentionOCL 0x7889 ///<Multilayer multi-headed attention neuron OpenCL \details Identified class #CNeuronMLMHAttentionOCL
Также в блоке дефайнов добавим константы для работы с новыми кернелами программы OpenCL.
#define def_k_MHAttentionScore 20 ///< Index of the kernel of the multi-heads attention neuron to calculate score matrix (#MHAttentionScore) #define def_k_mhas_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhas_score 1 ///< Matrix of Scores #define def_k_mhas_dimension 2 ///< Dimension of Key #define def_k_mhas_mask 3 ///< 1 - calc only previous units, 0 - calc all //--- #define def_k_MHAttentionOut 21 ///< Index of the kernel of the multi-heads attention neuron to calculate multi-heads out matrix (#MHAttentionOut) #define def_k_mhao_score 0 ///< Matrix of Scores #define def_k_mhao_qkv 1 ///< Matrix of Queries, Keys, Values #define def_k_mhao_out 2 ///< Matrix of Outputs #define def_k_mhao_dimension 3 ///< Dimension of Key //--- #define def_k_MHAttentionGradients 22 ///< Index of the kernel for gradients calculation process (#AttentionInsideGradients) #define def_k_mhag_qkv 0 ///< Matrix of Queries, Keys, Values #define def_k_mhag_qkv_g 1 ///< Matrix of Gradients to Queries, Keys, Values #define def_k_mhag_score 2 ///< Matrix of Scores #define def_k_mhag_score_g 3 ///< Matrix of Scores Gradients #define def_k_mhag_gradient 4 ///< Matrix of Gradients from previous iteration #define def_k_mhag_dimension 5 ///< Dimension of Key
Добавим объявление новых кернелов в конструкторе класса нейронной сети.
//--- create kernels opencl.SetKernelsCount(23); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut");
И создание нового типа нейронов в конструкторе нейронной сети.
case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break;
Также добавим обработку нового класса нейронов в диспетчерские методы базового класса нейронов CNeuronBaseOCL.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; } //--- return false; }
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
С полным кодом всех классов и их методов можно ознакомиться во вложении.
4. Тестирование
Для тестирования новой архитектуры было создано 2 советника Fractal_OCL_AttentionMLMH и Fractal_OCL_AttentionMLMH_v2. Советники были созданы на базе советника из предыдущей статьи, заменен только блок внимания. В советнике Fractal_OCL_AttentionMLMH используется 5-ти слойный блок с 8 головами самовнимания. Во втором советнике используется блок из 12 слоев с 12 головами самовнимания.
Тестирование нового класса нейронной сети проводилось на том же датасете, что и предыдущие тестирования: инструмент EURUSD, таймфрейм H1, на вход нейронной сети подаются исторические данные за 20 последних свечей.
Результаты тестов подтвердили предположение, что большее количество параметров требует большего периода обучения. На первых эпохах обучения советник с меньшим количеством параметров показывает более стабильные результаты. Но с ростом периода обучения у советника с большим количеством параметров улучшаются показатели. В целом, ошибка у советника Fractal_OCL_AttentionMLMH_v2 после 33 эпох обучения снизилась ниже уровня ошибки советника Fractal_OCL_AttentionMLMH и дальше оставалась только ниже.
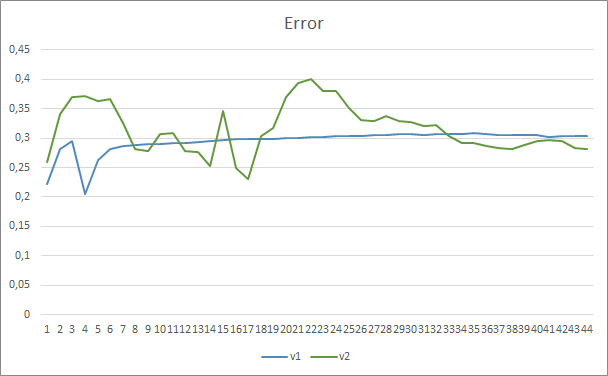
Подобные результаты показал и параметр пропуска паттернов. Вначале обучения разбалансированные параметры советника Fractal_OCL_AttentionMLMH_v2 пропускали более 50% паттернов, но по мере обучения данный показатель снизился и после 27 эпох стабилизировался на уровне 3-5%, в то время как советник с меньшим количеством параметров показал более ровные результаты, но при этом пропускал 10-16% паттернов.
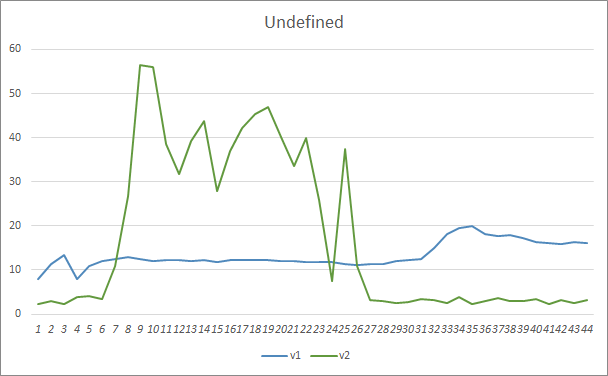
По уровню точности предсказания паттернов оба советника показали ровные результаты на уровне 22-23%.
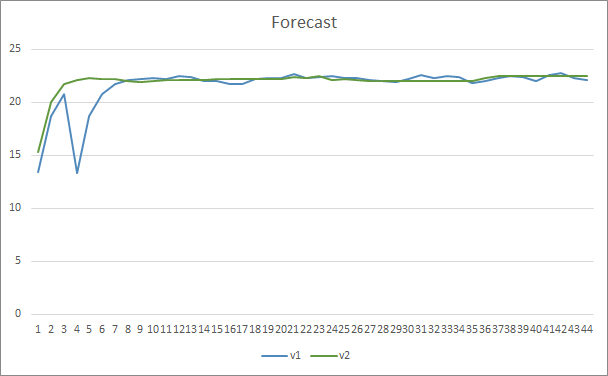
Заключение
В данной статье мы создали новый класс нейронов внимания, по аналогии с представленными компанией OpenAI архитектур GPT. Разумеется, что в домашних условиях мы не можем повторить и обучить данные архитектуры в полном их виде, т. к. их обучение и функционирование довольно затратное, как по времени, так и в вычислительных ресурсах. Но и созданный нами объект вполне может быть использован в нейронных сетях для создания торговых роботов.
Ссылки
- Нейросети — это просто
- Нейросети — это просто (Часть 2): обучение и тестирование сети
- Нейросети — это просто (Часть 3): сверточные сети
- Нейросети — это просто (Часть 4): рекуррентные сети
- Нейросети — это просто (Часть 5): многопоточные вычисления в OpenCL
- Нейросети — это просто (Часть 6): эксперименты с коэффициентом обучения нейронной сети
- Нейросети — это просто (Часть 7): Адаптивные методы оптимизации
- Нейросети — это просто (Часть 8): Механизмы внимания
- Нейросети — это просто (Часть 9): Документируем проделанную работу
- Нейросети — это просто (Часть 10): Multi-Head Attention (многоголовое внимание)
- Improving Language Understanding with Unsupervised Learning
- Better Language Models and Their Implications
- How GPT3 Works - Visualizations and Animations
…
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | Советник | Советник с нейронной сетью классификации (3 нейрона в выходном слое) с использованием архитектуры GPT, 5 слоев внимания |
| 2 | Fractal_OCL_AttentionMLMH_v2.mq5 | Советник | Советник с нейронной сетью классификации (3 нейрона в выходном слое) с использованием архитектуры GPT, 12 слоев внимания |
| 3 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 4 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 5 | NN.chm | HTML-справка | Скомпилированный CHM-файл. |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Самоадаптирующийся алгоритм (Часть IV): Дополнительный функционал и тесты
Самоадаптирующийся алгоритм (Часть IV): Дополнительный функционал и тесты
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте,
Проверьте NN.chm. Возможно, это поможет вам.
Привет,
Да, спасибо.
Теперь код не так плох, и я могу ясно видеть, как изменить архитектуру сети, если это необходимо.
У меня есть все в отдельных файлах классов, плюс гораздо меньше спагетти, которые все еще необходимы, потому что mt5 имеет и определение и реализацию в тех же файлах.
Я попытался провести некоторое обучение на GBPUSD, используя код как есть, но результаты не кажутся хорошими, ошибка поднимается от естественных 50% до 70% и остается там, не улучшаясь в последующие эпохи.
Есть предложения, с чего начать настройку?
BTW эта строка:
Необходимо исправить на:
Сначала я не очень понимал статью, потому что не до конца улавливал основную мысль.
Когда я спросил самого ChatGPT об этом тексте, он многое прояснил, и я понял большую часть прочитанного:
"Алгоритм Transformer - это модель, используемая для обработки естественного языка, то есть текста. Эта модель разбивает текст на последовательность слов (или "лексем"), а затем выполняет ряд операций над каждым из этих слов, чтобы лучше понять их значение.
Одной из операций, выполняемых моделью, является самовнимание, которое заключается в вычислении важности, которую имеет каждое слово по отношению к другим словам в последовательности. Для этого модель использует три вектора: вектор запроса, вектор ключа и вектор значения, которые вычисляются для каждого слова.
Затем модель рассчитывает внимание, которое представляет собой важность, которую имеет каждое слово по отношению к другим словам в последовательности. Для нормализации коэффициентов внимания используется математическая функция softmax.
Наконец, модель объединяет все операции с самовниманием, чтобы получить окончательный результат, который используется для предсказания смысла текста.
Одним словом, алгоритм Transformer использует сложные математические операции, чтобы понять смысл текста".
Привет еще раз :) Я нашел проблему. В папке include конфиг Opencl был неудачным, потому что я протестировал свою систему, и GPU не поддерживает код, только процессор, немного изменений и работает отлично, но медленно :S