
Redes neurais de maneira fácil (Parte 16): Uso prático do agrupamento

Conteúdo
- Introdução
- 1. Aspectos teóricos do uso de resultados de agrupamento
- 2. Usando o agrupamento como uma solução autônoma
- 3. Usando os resultados de agrupamento como dados de entrada
- Fim do artigo
- Referências
- Programas utilizados no artigo
Introdução
Nós dedicamos os dois últimos artigos ao agrupamento de dados. Mas nossa principal tarefa é aprender a usar todos os métodos analisados para resolver problemas práticos específicos, especialmente para aplicar em nosso trading. Ao começar a analisar os métodos de aprendizado não supervisionado, falamos sobre a possibilidade de utilizar os resultados tanto como dados de entrada para outros modelos como de forma independente. Neste artigo, proponho analisar os possíveis usos dos resultados de agrupamento.
1. Aspectos teóricos do uso de resultados de agrupamento
E antes de passarmos a exemplos práticos do uso de resultados de agrupamento, vamos falar um pouco sobre os aspectos teóricos destas abordagens.
A primeira forma de utilizar os resultados de agrupamento de dados é tentar obter o máximo deles e usá-los na prática sem nenhuma ferramenta adicional. Em outras palavras, é utilizar os resultados de agrupamento como tal para tomar decisões de negociação. Porém, é necessário lembrar que os métodos de aprendizado não supervisionado não são usados para resolver problemas de regressão. Cabe dizer que o objetivo da regressão é prever o movimento de preços mais próximo. E à primeira vista, vemos uma espécie de conflito.
Mas vamos olhar para o lado positivo. Quando analisamos os aspectos teóricos, comparamos o agrupamento com a identificação de padrões gráficos. E, assim como com os padrões gráficos, podemos coletar estatísticas sobre o comportamento dos preços após um elemento de um agrupamento aparecer no gráfico. Sim, isso não nos dá um nexo causal. Porém, também não existe até o momento uma relação causa/efeito em nenhum modelo matemático construído usando redes neurais. A única coisa que fazemos é construir modelos probabilísticos sem nos aprofundarmos em causas e efeitos.
Para a coleta de estatísticas, precisaremos de um modelo de agrupamento já treinado e de dados rotulados. Como já temos um modelo de agrupamento treinado para os dados, a amostra com os dados rotulados pode ser muito menor do que a amostra de treinamento. Sendo que ela deve ser suficiente para permanecer representativa.
À primeira vista, esta abordagem irá se assemelhar ao aprendizado supervisionado, mas existem duas diferenças cruciais:
- O tamanho da amostra rotulada pode ser menor, com o qual não há risco de sobretreinamento.
- O aprendizado supervisionado emprega um processo iterativo com seleção de fatores de ponderação ótimos. O que requer várias épocas de aprendizado com um grande investimento de recursos e tempo. Precisamos apenas de 1 passagem para coletar estatísticas, sem ajustes no modelo.
Bem, espero que a ideia seja clara. Também veremos a implementação de tal modelo um pouco mais tarde.
Entre as desvantagens desta solução está o fato de ignorar a distância até o centro do agrupamento. Em outras palavras, elementos próximos ao centro do agrupamento (o padrão ideal, por assim dizer) e elementos nas bordas do agrupamento darão o mesmo resultado. Você pode tentar aumentar o número de agrupamentos para reduzir a distância máxima de elementos em relação ao centro. Mas a eficácia desta abordagem será mínima, é claro, se tivermos escolhido o número certo de agrupamentos a partir do gráfico de função de perda.
Podemos tentar resolver este problema, para isso utilizamos uma segunda forma, que consiste em utilizar os resultados do agrupamento como dados de entrada para outro modelo. No entanto, ao passar o número do agrupamento como um número ou vetor para a entrada do segundo modelo, no máximo obteremos dados comparáveis com os resultados do método estatístico discutido acima. Mas não queremos suportar custos extras para obter o mesmo resultado.
E não vamos apenas passar o número do agrupamento para a entrada do modelo, mas também um vetor de distâncias até os centros de agrupamento. Ao fazer isso, lembraremos que as redes neurais adoram dados normalizados. E normalizamos os dados vetoriais de distância com a função Softmax.
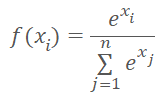
Mas lembremos que Softmax é baseado em um expoente, cujo gráfico é mostrado na figura abaixo.

Agora vamos pensar em que vetor obteremos após normalizarmos as distâncias até os centros de agrupamento com a função Softmax. É bastante óbvio que todas as distâncias que temos são positivas. Quanto maior a distância, maior o expoente e mais o valor da função muda para a mesma mudança em seu argumento. Logo, as distâncias máximas receberão mais peso. E à medida que a distância diminui, as diferenças entre os valores diminuem. Assim, ao normalizarmos as distâncias "de frente" obtemos um vetor que descreverá a que agrupamentos o elemento não se aplica, complicando assim a identificação do conjunto ao qual o elemento pertence. E gostaríamos que a situação fosse a oposta.
Parece que, para solucionar isso, poderíamos simplesmente mudar o sinal do valor da distância. Mas na área dos argumentos negativos, o valor da função expoente se aproxima de "0". E à medida que o argumento diminui, o desvio dos valores das funções também tende para "0".
Como solução para os problemas acima, podemos primeiro normalizar as distâncias entre 0 e 1. Em seguida, aplicar a função Softmax a "1-X".
A escolha do modelo que deve ser alimentado com os valores normalizados depende da tarefa em mãos e não será abrangida por este artigo.
E agora que discutimos as principais abordagens teóricas para os usos dos resultados de agrupamento, podemos iniciar a parte prática de nosso trabalho.
2. Usando o agrupamento como uma solução autônoma
Começamos a implementar o método estatístico escrevendo um código de outro kernel KmeansStatistic no programa OpenCL (arquivo "unsupervised.cl"), que calculará as estatísticas do processamento de sinais de cada agrupamento. A realização deste processo se assemelhará ao aprendizado supervisionado. E realmente precisaremos de dados rotulados. Mas há uma diferença dramática neste processo e o método de propagação de erro inverso usado em artigos anteriores, considerando que anteriormente otimizamos a função do modelo para obter resultados o mais próximo possível do padrão de referência. Não vamos mudar o modelo de forma alguma agora. Em vez disso, vamos coletar estatísticas sobre como o sistema reage ao surgimento deste ou daquele padrão.
Nos parâmetros para o núcleo, passaremos ponteiros para os 3 buffers de dados e o número total de elementos na amostra de treinamento. Mas nos parâmetros deste núcleo não vamos passar a amostra de treinamento. Não precisamos conhecer o conteúdo do vetor de descrição do estado do sistema para realizar esta função. Neste ponto basta sabermos a que agrupamento pertence o estado do sistema que está sendo analisado. Por esse motivo, em vez da amostra de treinamento nos parâmetros do núcleo, passaremos um ponteiro para o vetor clusters, que contém identificadores de agrupamento para cada estado do sistema a partir da amostra de treinamento.
O segundo buffer de dados de entrada target dará um tensor que descreve a resposta do sistema após o surgimento de um determinado padrão. Haverá 3 sinalizadores lógicos neste tensor para descrever o sinal depois que um padrão aparecer: comprar, vender, indefinido. O uso de sinalizadores torna simples e intuitivo o cálculo das estatísticas de sinais. Mas, ao mesmo tempo, limita a variabilidade de possíveis sinais. Portanto, o uso de tal método deve atender às exigências técnicas da tarefa em questão. Dentro desta série, foi avaliado se todos os algoritmos discutidos anteriormente eram capazes de detectar a formação de um fractal antes que a última vela começasse a se formar. Como você sabe, são necessárias 3 velas para identificar um fractal em um gráfico. Portanto, ele só pode ser realmente identificado após a formação da terceira vela do padrão. O que queremos encontrar é uma maneira para determinar a formação de um padrão quando apenas 2 velas de um padrão futuro tiverem sido formadas, com algum grau de probabilidade. Para resolver tal problema, o uso de sinais alvo a partir de 3 sinalizadores para cada padrão já é suficiente para nós.
Também deve ser dito que diferentes amostras de treinamento podem ser usadas quer seja para reunir estatísticas de sinais após o surgimento de padrões ou para treinar o modelo. Por exemplo, podemos treinar o modelo durante um intervalo histórico considerável para que possa entender o máximo possível os sinais e características do estado do sistema que está sendo analisado. Ao fazer isso, devemos rotular os dados e recolher estatísticas sobre o comportamento do sistema depois que os padrões aparecem em um intervalo histórico mais curto. Naturalmente, teremos que agrupar os padrões relevantes antes de coletar estatísticas. Afinal de contas, os dados devem ser comparáveis a fim de coletar estatísticas corretas.
Mas voltando ao nosso algoritmo. Iniciaremos a execução do kernel em um espaço de tarefa unidimensional. O número de fluxos paralelos será igual ao número de agrupamentos criados.
No início do núcleo, definiremos um identificador de fluxo atual, que nos dirá o número do agrupamento que está sendo analisado. E determinaremos imediatamente o deslocamento no tensor de resultados probabilísticos. Preparamos variáveis privadas para calcular o número de ocorrências de cada sinal: buy, sell, skip. Cada variável terá um valor inicial de "0".
Em seguida, geramos um loop com o número de iterações igual ao número de elementos da amostra de treinamento. No corpo do laço de repetição, verificaremos primeiro se o estado do sistema pertence ao conjunto em análise. E somente se coincidirem, adicionaremos o conteúdo do tensor de sinalizadores alvo às variáveis privadas correspondentes.
Assim, para valores-alvo, usamos sinalizadores que só podem adotar o valor "0" ou "1". Ao fazer isso, utilizamos sinais mutuamente exclusivos. Isto significa que só é possível ter "1" em uma sinalizador para cada estado individual do sistema de cada vez. Graças a esta propriedade, pudemos evitar usar um contador separado para o número de ocorrências de padrões. Em vez disso, depois de sair do loop para obter o número total de ocorrências de padrões, somamos todas as 3 variáveis parciais.
Resta-nos agora expressar as somas naturais dos sinais no idioma da matemática probabilística. Para fazer isso, dividimos o valor de cada variável privada pelo número total de ocorrências de padrões. Mas há nuances. Primeiramente, devemos descartar a possibilidade de erro crítico de divisão por zero. Em segundo lugar, precisamos de probabilidades reais que possam ser confiáveis. Se, por exemplo, um parâmetro for encontrado apenas uma vez, a probabilidade de tal sinal será de 100%. Mas é possível confiar em tal sinal? É claro que não. Sua ocorrência é muito provavelmente acidental. Portanto, para todos os padrões encontrados menos de 10 vezes, colocaremos probabilidades nulas para todos os sinais.
__kernel void KmeansStatistic(__global double *clusters, __global double *target, __global double *probability, int total_m ) { int c = get_global_id(0); int shift_c = c * 3; double buy = 0; double sell = 0; double skip = 0; for(int i = 0; i < total_m; i++) { if(clusters[i] != c) continue; int shift = i * 3; buy += target[shift]; sell += target[shift + 1]; skip += target[shift + 2]; } //--- int total = buy + sell + skip; if(total < 10) { probability[shift_c] = 0; probability[shift_c + 1] = 0; probability[shift_c + 2] = 0; } else { probability[shift_c] = buy / total; probability[shift_c + 1] = sell / total; probability[shift_c + 2] = skip / total; } }
Depois de criar o núcleo do programa OpenCL, passamos a trabalhar no lado do programa principal. E aqui adicionamos primeiro as constantes para trabalhar com o núcleo criado acima. E, é claro, os nomes das constantes deve ser consistente com nossa «política de nomeação».
#define def_k_kmeans_statistic 4 #define def_k_kms_clusters 0 #define def_k_kms_targers 1 #define def_k_kms_probability 2 #define def_k_kms_total_m 3
Após criar as constantes, passamos para a função OpenCLCreate, onde alteramos o número total de kernels utilizados. E acrescentamos a criação de um novo núcleo.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(5)) { delete result; return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_statistic, "KmeansStatistic")) { delete result; return NULL; } //--- return result; }
Agora temos que fazer uma chamada a este núcleo no lado do programa principal.
Para realizar esta função, criamos um método estatístico em nossa classe CKmeans. O novo método receberá ponteiros para 2 buffers de dados nos parâmetros: a amostra de treinamento e os valores de referência. Embora o conjunto de dados se pareça com o aprendizado supervisionado, há uma diferença dramática na abordagem. Se, no aprendizado supervisionado, otimizamos o modelo para produzir resultados ótimos é porque se trata de um processo iterativo. Agora só coletamos estatísticas de uma só vez.
No corpo do método, verificamos se o ponteiro para o buffer do valor-alvo está atualizado e chamamos o método de agrupamento da amostra de treinamento. Gostaria de lembrar que, neste caso, a amostra de treinamento pode ser diferente do modelo utilizado no treinamento, mas deve corresponder aos valores-alvo.
bool CKmeans::Statistic(CBufferDouble *data, CBufferDouble *targets) { if(CheckPointer(targets) == POINTER_INVALID || !Clustering(data)) return false;
Em seguida, inicializamos um buffer de registro de valores de probabilidade do comportamento previsto do sistema. Não utilizo deliberadamente a frase "reações ao padrão", pois não estamos analisando a causa/efeito. Ela pode ser direta, pode ser indireta. Ou talvez pode não existir. Nós apenas coletamos estatísticas baseadas em dados históricos.
if(CheckPointer(c_aProbability) == POINTER_INVALID) { c_aProbability = new CBufferDouble(); if(CheckPointer(c_aProbability) == POINTER_INVALID) return false; } if(!c_aProbability.BufferInit(3 * m_iClusters, 0)) return false; //--- int total = c_aClasters.Total(); if(!targets.BufferCreate(c_OpenCL) || !c_aProbability.BufferCreate(c_OpenCL)) return false;
Depois de criar o buffer, carregamos os dados necessários na memória do OpenCL context e geramos a chamada do kernel. Aqui passamos primeiro os parâmetros do núcleo, definimos o tamanho do espaço da tarefa e os deslocamentos em cada dimensão. Em seguida, colocamos o núcleo na fila de execução e lemos o resultado das operações. Durante a operação, não deixamos de monitorar o processo em cada etapa.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_probability, c_aProbability.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_targers, targets.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_clusters, c_aClasters.GetIndex())) return false; if(!c_OpenCL.SetArgument(def_k_kmeans_statistic, def_k_kms_total_m, total)) return false; uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = m_iClusters; if(!c_OpenCL.Execute(def_k_kmeans_statistic, 1, global_work_offset, global_work_size)) return false; if(!c_aProbability.BufferRead()) return false; //--- data.BufferFree(); targets.BufferFree(); //--- return true; }
Se o núcleo for executado com sucesso no buffer c_aProbability, teremos as probabilidades de ocorrência de um ou outro evento após cada padrão aparecer. Tudo o que temos que fazer é limpar a memória e encerrar o método.
Mas o procedimento que analisamos pode ser atribuído ao treinamento do modelo. E para dar um uso prático, precisaremos obter probabilidades de comportamento do sistema em tempo real. Para isso, criaremos outro método GetProbability. Nos parâmetros deste método, só passaremos a amostra para agrupamento. Mas é muito importante que a matriz de probabilidade c_aProbabilidade já tenha sido gerada antes que o método seja chamado. Isso é, portanto, a primeira coisa que verificamos no corpo do método. E iniciamos o agrupamento dos dados recebidos. E, como sempre, verificamos o resultado.
CBufferDouble *CKmeans::GetProbability(CBufferDouble *data)
{
if(CheckPointer(c_aProbability) == POINTER_INVALID ||
!Clustering(data))
return NULL;
A característica deste método é que ele devolve um ponteiro para um buffer de dados, não um valor lógico. Por isso, o próximo passo é criar um novo buffer para coleta de dados.
CBufferDouble *result = new CBufferDouble(); if(CheckPointer(result) == POINTER_INVALID) return result;
Partimos do princípio que, em tempo real, obteremos dados probabilísticos para um pequeno número de registros, e na maioria das vezes apenas uma coisa, o estado atual do sistema. Portanto, não vamos avançar mais na conversão deste trabalho na área de computação paralela. Criamos um loop para enumerar o buffer de identificadores de agrupamento dos dados em estudo. E no corpo do loop, transferimos as probabilidades dos agrupamentos correspondentes para o buffer de resultados.
int total = c_aClasters.Total(); if(!result.Reserve(total * 3)) { delete result; return result; } for(int i = 0; i < total; i++) { int k = (int)c_aClasters.At(i) * 3; if(!result.Add(c_aProbability.At(k)) || !result.Add(c_aProbability.At(k + 1)) || !result.Add(c_aProbability.At(k + 2)) ) { delete result; return result; } } //--- return result; }
Deve-se dizer que no buffer de resultados, as probabilidades serão organizadas seguindo a mesma sequência que o sistema indica na amostra analisada. E se a amostra contivesse dados pertencentes ao mesmo agrupamento, as probabilidades de comportamento do sistema se repetiriam.
Para testar o método, criamos o EA "kmeans_stat.mq5". Seu código é mostrado no anexo. E como você pode ver pelo nome do arquivo, nele coletamos estatísticas sobre as probabilidades dos fractais aparecerem após cada padrão.
Realizamos a experiência utilizando o modelo de 500 agrupamentos treinado no artigo anterior. Os resultados são mostrados na captura de tela abaixo.

Como mostram os dados apresentados, a utilização desta abordagem permite prever a reação do mercado após o aparecimento dos fractais com uma probabilidade de 30-45%. Você até concordaria que este não é um resultado ruim. Mais uma razão para não termos usado redes neurais multicamadas.
3. Usando os resultados de agrupamento como dados de entrada
Passemos à implementação da segunda forma de utilizar os resultados do agrupamento. Lembramos que nesta abordagem planejamos passar os resultados do agrupamento para a entrada de outro modelo como dados de entrada. Em essência, pode ser qualquer modelo que você escolher para solucionar a tarefa em questão, inclusive uma rede neural utilizando algoritmos de aprendizado supervisionado.
Já acima combinamos que, ao implementar esta abordagem, os resultados do agrupamento seriam representados como um vetor normalizado de distâncias até os centros de agrupamento. E para implementar esta funcionalidade, precisamos criar outro kernel KmeansSoftMax no programa OpenCL "unsupervised.cl".
Deve-se dizer que no novo núcleo não recalcularemos as distâncias até o centro de cada núcleo, pois esta função já é realizada no núcleo KmeansCulcDistance. No novo KmeansSoftMax, no entanto, somente normalizaremos os dados existentes.
Nos parâmetros do núcleo, passaremos ponteiros para os 2 buffers de dados e para o número total de agrupamentos em uso. Entre os buffers de dados, haverá um buffer de dados de entrada distance e um buffer de resultados softmax. Ambos os buffers têm o mesmo tamanho e são uma representação vetorial de uma matriz, com as filas representando os elementos individuais da sequência e as colunas representando os agrupamentos.
O núcleo será executado em espaço de tarefa unidimensional de acordo com o número de itens na amostra agrupada. Eu deliberadamente não escrevo "amostra de treinamento", pois o uso do kernel é possível tanto no treinamento do segundo modelo quanto no uso real. Obviamente, os dados fornecidos para a entrada serão diferentes em ambas as variantes.
Antes de começarmos a realizar o código do kernel, vamos lembrar que mudamos ligeiramente a função de normalização e que ela tomou a seguinte forma.
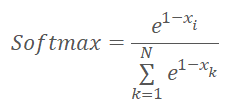
onde x é a distância até o centro do agrupamento, normalizada entre 0 e 1.
Agora vamos olhar para a implementação da fórmula acima. No corpo do núcleo, definimos primeiro um identificador de fluxo, que nos indicará o elemento de sequência a ser analisado. E determinamos o deslocamento nos buffers antes do início do vetor a ser analisado. Lembre que nossos tensores de dados de entrada e de resultados têm o mesmo tamanho. Portanto, o deslocamento em ambos os buffers também será a mesma.
Em seguida, para normalizar as distâncias entre 0 e 1, precisamos encontrar o desvio máximo em relação ao centro do agrupamento. Aqui deve ser lembrado que utilizamos o quadrado dos desvios ao calcular as distâncias. Isto significa que todos os valores em nosso vetor de distância serão positivos. E isso facilita um pouco as coisas para nós. Declaramos uma variável privada m para registrar a distância máxima e iniciamos essa variável com o valor do primeiro elemento do nosso vetor. Em seguida, criamos um loop percorrendo todos os elementos de nosso vetor. No corpo do vetor, vamos comparar o valor dos elementos com o valor armazenado e escrever o valor máximo para a variável.
Uma vez determinado o valor máximo, podemos avançar para o cálculo dos valores exponenciais para cada elemento. E aqui calculamos a soma dos valores exponenciais de todo o vetor. Para determinar a soma, inicializamos sum da variável privada com o valor "0". As operações aritméticas propriamente ditas serão realizadas no próximo loop. O número de iterações deste loop é igual ao número de agrupamentos em nosso modelo. No corpo do loop, armazenamos primeiro o valor exponencial da distância normalizada e "invertida" ao centro do agrupamento em uma variável privada. Primeiro acrescentamos o valor resultante à soma e depois o transferimos para o buffer de resultados. Para minimizar o número de acessos à memória global lenta, é necessário utilizar uma variável privada antes de escrever os valores no buffer.
Uma vez concluídas as iterações do loop, resta-nos normalizar os dados dividindo os valores exponenciais resultantes pela soma total. Para realizar estas operações, criamos outro laço de repetição com o número de iterações igual ao número de agrupamentos. E depois de completar o laço de repetição, saímos do núcleo.
__kernel void KmeansSoftMax(__global double *distance, __global double *softmax, inсt total_k ) { int i = get_global_id(0); int shift = i * total_k; double m=distance[shift]; for(int k = 1; k < total_k; k++) m = max(distance[shift + k],m); double sum = 0; for(int k = 0; k < total_k; k++) { double value = exp(1-distance[shift + k]/m); sum += value; softmax[shift + k] = value; } for(int k = 0; k < total_k; k++) softmax[shift + k] /= sum; }
Complementamos a funcionalidade do programa OpenCL e agora precisamos adicionar o código de chamada do kernel a partir de nossa classe CKmeans. Procederemos da mesma forma que acima para adicionar o código de chamada do kernel anterior.
Primeiro, adicionamos constantes, respeitando as regras de nomenclatura.
#define def_k_kmeans_softmax 5 #define def_k_kmsm_distance 0 #define def_k_kmsm_softmax 1 #define def_k_kmsm_total_k 2
Depois disso, adicionamos a declaração do kernel à função de inicialização do OpenCL context OpenCLCreate.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(6)) { delete result; return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_softmax, "KmeansSoftMax")) { delete result; return NULL; } //--- return result; }
E, é claro, precisaremos de um novo método de nossa classe CKmeans::SoftMax. O método recebe um ponteiro para o buffer de dados de entrada nos parâmetros. E o método retornará como resultado um buffer de resultados de tamanho semelhante.
No corpo do método, verificamos primeiro se nossa classe de agrupamento já foi treinada antes. E, se necessário, inicializamos o processo de treinamento do modelo. Aqui lembre que no método de treinamento de modelo fizemos uma restrição quanto ao tamanho mínimo da amostra de treinamento. Portanto, os parâmetros do método devem receber uma amostra de treinamento suficiente se o modelo ainda não tiver sido treinado. Caso contrário, o método retornará um ponteiro inválido para o buffer de resultados. Se o modelo de agrupamento de dados já tiver sido treinado, então a restrição do tamanho da amostra é removida.
CBufferDouble *CKmeans::SoftMax(CBufferDouble *data)
{
if(!m_bTrained && !Study(data, (c_aMeans.Maximum() == 0)))
return NULL;
Na etapa seguinte, verificamos se os ponteiros para os objetos utilizados são válidos. Pode parecer estranho aqui que chamemos primeiro o método de aprendizado e depois verifiquemos os indicadores de objetos. Na verdade, o próprio método de aprendizado tem um bloco similar de controles. E se chamássemos sempre o método de aprendizado do modelo antes de continuar com as operações, estes controles seriam redundantes, pois repetem os controles dentro do método de aprendizado. Mas no caso de usarmos um modelo pré-treinado, não chamaremos o método de aprendizado com seus controles. Porque outras operações sobre ponteiros inválidos resultarão em erros críticos. Somos, portanto, obrigados a repetir a verificação de ponteiros.
if(CheckPointer(data) == POINTER_INVALID || CheckPointer(c_OpenCL) == POINTER_INVALID) return NULL;
Após verificar os indicadores, checamos o tamanho do buffer de dados de entrada. Ele deve conter pelo menos um vetor para descrever o primeiro estado do sistema. A quantidade de dados no buffer deve ser um múltiplo do tamanho do vetor de descrição do estado do sistema.
int total = data.Total(); if(total <= 0 || m_iClusters < 2 || (total % m_iVectorSize) != 0) return NULL;
E depois determinamos o número de estados do sistema que temos que alocar para os agrupamentos.
int rows = total / m_iVectorSize; if(rows < 1) return NULL;
Em seguida, vamos iniciar os buffers para calcular as distâncias e normalizá-las. O algoritmo de inicialização é bastante simples. Primeiro verificamos se o ponteiro para o buffer é válido, e, se necessário, criamos um novo objeto. E depois preenchemos o buffer com valores zero.
if(CheckPointer(c_aDistance) == POINTER_INVALID) { c_aDistance = new CBufferDouble(); if(CheckPointer(c_aDistance) == POINTER_INVALID) return NULL; } c_aDistance.BufferFree(); if(!c_aDistance.BufferInit(rows * m_iClusters, 0)) return NULL; if(CheckPointer(c_aSoftMax) == POINTER_INVALID) { c_aSoftMax = new CBufferDouble(); if(CheckPointer(c_aSoftMax) == POINTER_INVALID) return NULL; } c_aSoftMax.BufferFree(); if(!c_aSoftMax.BufferInit(rows * m_iClusters, 0)) return NULL;
Para completar o trabalho preparatório, criamos os buffers de dados necessários no OpenCL context.
if(!data.BufferCreate(c_OpenCL) || !c_aMeans.BufferCreate(c_OpenCL) || !c_aDistance.BufferCreate(c_OpenCL) || !c_aSoftMax.BufferCreate(c_OpenCL)) return NULL;
Assim concluímos o trabalho preparatório e passamos a chamar os núcleos necessários. Para desenvolver toda a funcionalidade do método, teremos de gerar uma chamada sequencial para os dois núcleos:
- determinação das distâncias até os centros de agrupamento KmeansCulcDistance;
- KmeansSoftMax normalização da distância.
O algoritmo de chamada de kernels é bastante simples e semelhante ao utilizado no método de uso estatístico de resultados de agrupamento, mostrado acima. Primeiro temos que passar os parâmetros para o núcleo.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_data, data.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_means, c_aMeans.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_distance, c_aDistance.GetIndex())) return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_distance, def_k_kmd_vector_size, m_iVectorSize)) return NULL;
Em seguida, especificamos o tamanho do espaço de tarefa e o deslocamento em cada dimensão.
uint global_work_offset[2] = {0, 0}; uint global_work_size[2]; global_work_size[0] = rows; global_work_size[1] = m_iClusters;
Depois, colocamos o núcleo na fila de execução e lemos os resultados das operações.
if(!c_OpenCL.Execute(def_k_kmeans_distance, 2, global_work_offset, global_work_size)) return NULL; if(!c_aDistance.BufferRead()) return NULL;
Repetimos as operações para o segundo núcleo.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_distance, c_aDistance.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_softmax, c_aSoftMax.GetIndex())) return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_softmax, def_k_kmsm_total_k, m_iClusters)) return NULL; uint global_work_offset1[1] = {0}; uint global_work_size1[1]; global_work_size1[0] = rows; if(!c_OpenCL.Execute(def_k_kmeans_softmax, 1, global_work_offset1, global_work_size1)) return NULL; if(!c_aSoftMax.BufferRead()) return NULL;
Finalmente, limpamos a memória do OpenCL context e saímos do método retornando um ponteiro para o buffer de resultados.
data.BufferFree(); c_aDistance.BufferFree(); //--- return c_aSoftMax; }
Assim concluímos as mudanças em nossa classe de agrupamento mediante o método k-médias CKmeans. E podemos passar a testar esta abordagem. Para isso, criaremos o EA "kmeans_net.mq5", que é modelado nos EAs a partir dos artigos sobre algoritmos de aprendizado supervisionado. A questão é que, para testar a implementação, eu alimentei os resultados do agrupamento com a entrada de um perceptron interligado com 3 camadas ocultas. O código completo do EA pode ser encontrado no anexo. Agora eu gostaria de me concentrar na função de aprendizado Train.
No início da função, inicializamos uma instância do objeto para lidar com o OpenCL context dentro da classe de agrupamento. E passamos um ponteiro para o objeto criado à nossa classe de agrupamento. E não se esqueça, como sempre, de verificar o resultado da operação.
void Train(datetime StartTrainBar = 0) { COpenCLMy *opencl = OpenCLCreate(cl_unsupervised); if(CheckPointer(opencl) == POINTER_INVALID) { ExpertRemove(); return; } if(!Kmeans.SetOpenCL(opencl)) { delete opencl; ExpertRemove(); return; }
Uma vez que os objetos tenham sido inicializados com sucesso, determinamos os limites do período de aprendizado.
MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
E fazemos o carregamento dos dados históricos. Observe que os dados dos indicadores carregados nos buffers são representados por séries temporais, e as cotações carregadas não. Isto é importante para nós porque obtemos uma sequência inversa de numeração de elementos em arrays. Portanto, devemos "inverter" a matriz de cotações em uma série temporal a fim de tornar os dados comparáveis.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Uma vez que os dados históricos tenham sido carregados com sucesso, carregamos um modelo de agrupamento pré-treinado.
int handl = FileOpen(StringFormat("kmeans_%d.net", Clusters), FILE_READ | FILE_BIN); if(handl == INVALID_HANDLE) { ExpertRemove(); return; } if(FileReadInteger(handl) != Kmeans.Type()) { ExpertRemove(); return; } bool result = Kmeans.Load(handl); FileClose(handl); if(!result) { ExpertRemove(); return; }
E avançamos para a formação da amostra de treinamento e valores-alvo.
int total = bars - (int)HistoryBars - 1; double data[], fractals[]; if(ArrayResize(data, total * 8 * HistoryBars) <= 0 || ArrayResize(fractals, total * 3) <= 0) { ExpertRemove(); return; } //--- for(int i = 0; (i < total && !IsStopped()); i++) { Comment(StringFormat("Create data: %d of %d", i, total)); for(int b = 0; b < (int)HistoryBars; b++) { int bar = i + b; int shift = (i * (int)HistoryBars + b) * 8; double open = Rates[bar].open; data[shift] = open - Rates[bar].low; data[shift + 1] = Rates[bar].high - open; data[shift + 2] = Rates[bar].close - open; data[shift + 3] = RSI.GetData(MAIN_LINE, bar); data[shift + 4] = CCI.GetData(MAIN_LINE, bar); data[shift + 5] = ATR.GetData(MAIN_LINE, bar); data[shift + 6] = MACD.GetData(MAIN_LINE, bar); data[shift + 7] = MACD.GetData(SIGNAL_LINE, bar); } int shift = i * 3; int bar = i + 1; fractals[shift] = (int)(Rates[bar - 1].high <= Rates[bar].high && Rates[bar + 1].high < Rates[bar].high); fractals[shift + 1] = (int)(Rates[bar - 1].low >= Rates[bar].low && Rates[bar + 1].low > Rates[bar].low); fractals[shift + 2] = (int)((fractals[shift] + fractals[shift]) == 0); } if(IsStopped()) { ExpertRemove(); return; } CBufferDouble *Data = new CBufferDouble(); if(CheckPointer(Data) == POINTER_INVALID || !Data.AssignArray(data)) return; CBufferDouble *Fractals = new CBufferDouble(); if(CheckPointer(Fractals) == POINTER_INVALID || !Fractals.AssignArray(fractals)) return;
Uma vez que nossos métodos de agrupamento podem lidar com conjuntos de dados de entrada, podemos agrupar toda a amostra de treinamento de uma só vez.
ResetLastError(); CBufferDouble *softmax = Kmeans.SoftMax(Data); if(CheckPointer(softmax) == POINTER_INVALID) { printf("Ошибка выполнения %d", GetLastError()); ExpertRemove(); return; }
Uma vez que todas as operações acima tenham sido concluídas com sucesso, o buffer softmax conterá a amostra de treinamento para nosso perceptron. Também preparamos valores-alvo com antecedência. Assim, podemos avançar para o loop de aprendizado do segundo modelo.
Como antes, ao testar algoritmos de aprendizado supervisionado, o processo de treinamento do modelo será elaborado a partir de dois loops aninhados. O loop externo contará para baixo as épocas de aprendizado e sairá do loop na ocorrência de um determinado evento.
Em primeiro lugar, faremos um pequeno trabalho preparatório, no qual inicializamos as variáveis locais necessárias.
if(CheckPointer(TempData) == POINTER_INVALID) { TempData = new CArrayDouble(); if(CheckPointer(TempData) == POINTER_INVALID) { ExpertRemove(); return; } } delete opencl; double prev_un, prev_for, prev_er; dUndefine = 0; dForecast = 0; dError = -1; dPrevSignal = 0; bool stop = false; int count = 0; do { prev_un = dUndefine; prev_for = dForecast; prev_er = dError; ENUM_SIGNAL bar = Undefine; //--- stop = IsStopped();
Só então passamos a gerar o loop aninhado. O número de iterações do loop aninhado será igual ao tamanho da amostra de treinamento menos uma pequena "cauda" da área de validação.
Mesmo que o número de iterações seja igual ao tamanho da amostra, escolheremos um item aleatório cada vez para o processo de aprendizado. Isto é o que vamos fazer no início do loop aninhado. Vetores aleatórios a partir da amostra de treinamento tornam o treinamento de modelos mais uniforme.
for(int it = 0; (it < total - 300 && !IsStopped()); it++) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 300)) + 300;
Com o índice de um elemento selecionado aleatoriamente, determinamos o deslocamento no buffer de dados de entrada e copiamos o vetor necessário para o buffer temporário.
TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
Gerado o vetor de dados de entrada, nós o introduzimos na entrada do método de propagação de nossa rede neural. E após um passo para frente bem sucedido, obtemos o resultado.
if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
Normalizamos os resultados obtidos usando a função Softmax.
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum);
Para acompanhar visualmente o processo de treinamento do modelo, mostraremos o estado atual em um gráfico.
switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; } string s = StringFormat("Study -> Era %d -> %.2f -> Undefine %.2f%% foracast %.2f%%\n %d of %d -> %.2f%% \nError %.2f\n%s -> %.2f ->> Buy %.5f - Sell %.5f - Undef %.5f", count, dError, dUndefine, dForecast, it + 1, total - 300, (double)(it + 1.0) / (total - 300) * 100, Net.getRecentAverageError(), EnumToString(DoubleToSignal(dPrevSignal)), dPrevSignal, TempData[1], TempData[2], TempData[0]); Comment(s); stop = IsStopped();
E no final da iteração do loop, chamamos o método de retropropagação com uma atualização das matrizes de pesos de nosso modelo.
if(!stop) { shift = i * 3; TempData.Clear(); TempData.Add(Fractals.At(shift + 2)); TempData.Add(Fractals.At(shift)); TempData.Add(Fractals.At(shift + 1)); Net.backProp(TempData); ENUM_SIGNAL signal = DoubleToSignal(dPrevSignal); if(signal != Undefine) { if((signal == Sell && Fractals.At(shift + 1) == 1) || (signal == Buy && Fractals.At(shift) == 1)) dForecast += (100 - dForecast) / Net.recentAverageSmoothingFactor; else dForecast -= dForecast / Net.recentAverageSmoothingFactor; dUndefine -= dUndefine / Net.recentAverageSmoothingFactor; } else { if(Fractals.At(shift + 2) == 1) dUndefine += (100 - dUndefine) / Net.recentAverageSmoothingFactor; } } }
Após cada época de aprendizado, exibiremos etiquetas na seção de validação. Para por em prática isto, vamos criar outro loop aninhado. As operações no corpo do loop irão, em grande parte, repetir o laço descrito acima, exceto por duas grandes diferenças:
- Tomaremos os elementos em ordem, não de forma aleatória como acima.
- Não faremos uma retropropagação.
Na amostra de validação, testamos como nosso modelo funciona com os novos dados sem parâmetro de ajuste. Por isso, não realizamos a chamada de retropropagação. É por esse motivo que o resultado do modelo não depende da ordem na qual os dados são alimentados (excetuando modelos recorrentes). Isto significa que não desperdiçamos recursos na geração de um número aleatório e tomamos todos os estados do sistema sequencialmente.
count++; for(int i = 0; i < 300; i++) { TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData); double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum); //--- switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; }
Adicionamos a exibição dos objetos no gráfico e saímos do loop de validação.
if(DoubleToSignal(dPrevSignal) == Undefine) DeleteObject(Rates[i + 2].time); else DrawObject(Rates[i + 2].time, dPrevSignal, Rates[i + 2].high, Rates[i + 2].low); }
Antes de completar a iteração do loop externo, salvamos o estado atual do modelo e acrescentamos o valor do erro ao arquivo que contém a dinâmica do processo de aprendizado.
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, dUndefine, dForecast, Rates[0].time, false); printf("Era %d -> error %.2f %% forecast %.2f", count, dError, dForecast); ChartScreenShot(0, FileName + IntegerToString(count) + ".png", 750, 400); int h = FileOpen(FileName + ".csv", FILE_READ | FILE_WRITE | FILE_CSV); if(h != INVALID_HANDLE) { FileSeek(h, 0, SEEK_END); FileWrite(h, eta, count, dError, dUndefine, dForecast); FileFlush(h); FileClose(h); } } } while((!(DoubleToSignal(dPrevSignal) != Undefine || dForecast > 70) || !(dError < 0.1 && MathAbs(dError - prev_er) < 0.01 && MathAbs(dUndefine - prev_un) < 0.1 && MathAbs(dForecast - prev_for) < 0.1)) && !stop);
Saímos do loop de aprendizado de acordo com os valores que definimos. Eles são emprestados inteiramente dos EA de aprendizado supervisionado.
E antes de sair do método de aprendizado, removeremos os objetos criados no corpo de nosso método de treinamento do modelo.
if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(TempData) == POINTER_DYNAMIC) delete TempData; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); }
Você pode encontrar o código do EA completo no anexo.
Como queremos avaliar o desempenho do EA, vamos testá-lo usando o modelo de 500 agrupamentos treinados no artigo anterior e usados no teste anterior. O gráfico do treinamento é mostrado abaixo.

Como se pode ver, o gráfico de aprendizado é bastante uniforme. Usei o método de otimização de parâmetros Adam para treinar o modelo. Durante as primeiras 20 épocas, vemos um declínio suave na função de perda associado à acumulação de impulso. E, em seguida, há uma queda notável no valor da função de perda a um certo mínimo. Se você se lembrar dos gráficos dos modelos de aprendizado supervisionado, estes mostram quebras na função de perda com mais frequência. Por exemplo, abaixo segue um gráfico de aprendizado de um modelo de atenção mais complexo.

Comparando os 2 gráficos apresentados, pode-se ver como o agrupamento prévio de dados melhora a eficiência mesmo de modelos simples.
Considerações finais
Neste artigo, analisamos e implementamos duas maneiras de utilizar os resultados de agrupamento na resolução de casos práticos. E os resultados dos testes demonstram a aplicabilidade de ambos os métodos. No primeiro caso, temos um modelo simples com resultados muito claros e compreensíveis, que são bastante transparentes e simples. A utilização do segundo método torna o treinamento do modelo mais suave e rápido. Isto aumenta a eficiência dos modelos.
Referências
- Redes neurais de maneira fácil
- Redes neurais de maneira fácil (Parte 2): treinamento e teste da rede
- Redes neurais de maneira fácil (Parte 3): redes convolucionais
- Redes neurais de maneira fácil (Parte 4): redes recorrentes
- Redes neurais de maneira fácil (Parte 5): cálculos em paralelo com OpenCL
- Redes neurais de maneira fácil (Parte 6): experimentos com a taxa de aprendizado da rede neural
- Redes neurais de maneira fácil (Parte 7): métodos de otimização adaptativos
- Redes neurais de maneira fácil (Parte 8): mecanismos de atenção
- Redes neurais de maneira fácil (Parte 9): documentação do trabalho
- Redes neurais de maneira fácil (Parte 10): atenção multi-cabeça
- Redes neurais de maneira fácil (Parte 11): uma visão sobre GPT
- Redes neurais de maneira fácil (Parte 12): dropout
- Redes neurais de maneira fácil (Parte 13): normalização em lote
- Redes neurais de maneira fácil (Parte 14): agrupamento de dados
- Redes neurais de maneira fácil (Parte 15): agrupamento de dados via MQL5
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | kmeans.mq5 | EA | EA para treinamento de modelos |
| 2 | kmeans_net.mq5 | EA | EA de teste de transferência de dados de segundo modelo |
| 3 | kmeans_stat.mq5 | EA | EA de teste de métodos estatísticos |
| 4 | kmeans.mqh | Biblioteca da classe | Biblioteca para preparar o método k-médias |
| 5 | unsupervised.cl | Biblioteca | Biblioteca de códigos OpenCL para preparar o método k-médias |
| 6 | NeuroNet.mqh | Biblioteca da classe | Biblioteca de classes para a criação de uma rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de códigos do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/10943
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Vídeo: Negociação automatizada simples, como criar um EA simples mediante MQL5
Vídeo: Negociação automatizada simples, como criar um EA simples mediante MQL5
 Como desenvolver um sistema de negociação baseado no indicador OBV
Como desenvolver um sistema de negociação baseado no indicador OBV
 Vídeo: Configurando MetaTrader 5 e MQL5 para negociação automatizada simples
Vídeo: Configurando MetaTrader 5 e MQL5 para negociação automatizada simples
 Redes neurais de maneira fácil (Parte 15): Agrupamento de dados via MQL5
Redes neurais de maneira fácil (Parte 15): Agrupamento de dados via MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
2022.05.30 21:57:27.477 kmeans (WDO$,H1) 800 Model error inf
2022.05.30 22:00:23.937 kmeans (WDO$,H1) 850 Model error inf
2022.05.30 22:04:22.069 kmeans (WDO$,H1) 900 Model error inf
2022.05.30 22:08:04.179 kmeans (WDO$,H1) 950 Model error inf
2022.05.30 22:10:56.190 kmeans (WDO$,H1) 1000 Model error inf
2022.05.30 22:10:56.211 kmeans (WDO$,H1) Função ExpertRemove() chamada
Como resolver este erro?
Como resolver esse erro?
Esse não é um erro de execução do programa. Essa linha exibe o erro do modelo (distância média dos centros dos clusters). Mas vemos inf - valor além da precisão dos cálculos. Tente dimensionar os valores originais. Por exemplo, divida por 10.000
Este não é um erro de execução do programa. Esta linha exibe o erro do modelo (distância média aos centros dos clusters). Mas vemos além da precisão dos valores - valor. Tente dimensionar os valores originais. Por exemplo, divida por 10.000
Ainda não consegui encontrar uma solução.
Ainda não consegui encontrar uma solução.