
Нейросети — это просто (Часть 9): Документируем проделанную работу

Содержание
- Введение
- 1.Основные принципы документирования разработок
- 2.Выбор инструментов
- 3.Способы документирования в коде
- 4.Подготовительная работа в файле исходного кода
- 5.Генерация документации
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
На протяжении 8 статей мы добавляли новые объекты и расширяли функционал существующих, тем самым постоянно увеличивая нашу библиотеку. Добавили файл OpenCL программы. Сейчас наш код превышает первоначальный в 10 раз, и уже становится трудно проследить взаимосвязи между объектами в коде. А читателю, наверное, код представляется сильно запутанным и сложным для понимания. В каждой статье, я стараюсь детально описать логическую цепочку действий. Но демонстрация отдельных цепочек не дает общего представления.
И поэтому, сегодня я решил продемонстрировать путь создания технической документации к коду, которая позволит нам посмотреть на код с другой стороны. Она позволит обобщить все объекты и методы в библиотеке, построит иерархию наследования объектов и методов. И даст нам общее представление о проделанной работе.
1. Основные принципы документирования разработок
Для чего же нужна техническая документация ИТ разработок? Прежде всего, рабочая документация дает общее представление об устройстве, архитектуре и функционировании программы. Такая документация позволяет правильно выстроить зоны ответственности в команде разработчиков, отслеживать все изменения в коде и их влияние на весь алгоритм и целостность архитектуры разработки. Облегчает процесс передачи знаний. Понимание целостности архитектуры программы дает возможность для анализа и выработки путей развития проекта.
Правильно составленная техническая документация должна учитывать квалификацию своего целевого пользователя. Подаваемая информация должна быть понятна и не содержать излишних пояснений. Документация должна содержать всю необходимую пользователю информацию. В тоже время, она должна быть одновременно максимально сжатой и легко читаемой. Излишнее содержание требует дополнительные затраты времени на ее прочтение и раздражает читателя. Но еще больше раздражает пользователя, когда после длительного перечитывания обширной документации он не находит требуемую информацию. Отсюда следует следующее правило - документация должна иметь удобный функционал для поиска информации. Дружелюбный интерфейс и наличие перекрестных ссылок облегчают поиск нужной информации.
Документация должна содержать полную архитектуру решения и описание реализованных технических решений. Полнота и детализация описания решений облегчает разработку решения и дальнейшую его поддержку. И очень важно всегда поддерживать актуальность документации. Искаженная информация может привести к противоречим управленческим решениям и, как следствие, разбалансированию всей разработки.
И обязательно в документации должны быть описаны интерфейсы между компонентами с детальным описанием.
2. Выбор инструментов
Непосредственно процесс документирования разработок могут облегчить специализированные программы. Наиболее распространенными, на мой взгляд, являются Doxygen, Sphinx, Latex, но существуют и другие. Все они созданы с целью снижения трудозатрат на создание документации и предлагают свой инструментарий. Конечно, каждая программа создавалась разработчиками для решения конкретных задач. К примеру, Doxygen позиционируется как программа для создания документации к разработкам на C++ и подобным языкам программирования. В свою очередь Sphinx была создана для документирования Python. Но это не означает, что они являются узко специализированными по языкам программирования. И обе эти программы хорошо работают с разработками довольно широкого круга языков программирования. На сайте каждой вышеуказанной программы приводится подробная помощь по использованию программ и каждый может выбрать подходящую для себя.
На MQL5 ранее также уже подымался вопрос документирования разработок в статье "Автоматическое создание документации к программам на MQL5". В этой статье было предложено использование Doxygen. В своей работе я тоже пользуюсь данной программой. Синтаксис MQL5 довольно близок к С++ и вполне логично использование Doxygen для его документирования. Лично мне импонирует, что для создания документации достаточно тщательно прокомментировать код программы, а все остальное возьмет на себя специализированное ПО. Кроме того, Doxygen позволяет вставлять гиперссылки и математические формулы, что немаловажно с учетом темы статей. Об особенностях использования функционала будет рассказано в статье на конкретных примерах.
3. Способы документирования в коде.
Как уже было сказано выше, для генерации документации нужно проставить комментарии по коду программы. На основании этих комментариев Doxygen и будет составлять документацию. Вполне естественно, что не все комментарии из кода должны попасть в документацию. Где-то могут быть заметки разработчика, где-то закомментирован не используемый код. Предусмотрительные разработчики Doxygen определили способы выделения комментариев для документирования. При этом существует несколько вариантов, среди которых каждый пользователь может выбрать любой удобный именно ему.
По аналогии с MQL5, комментарии для документирования могут быть однострочными и многострочными. И чтобы не мешать последующему использованию кода по прямому назначению, используются стандартные варианты вставки комментариев с добавлением дополнительного слеша для однострочных комментариев или звездочки для многострочных комментариев. Также возможна идентификация блоков для документирования с использованием восклицательного знака.
/// Однострочный комментарий для документирования /** Многострочный блок для документирования */ //! Альтернативный однострочный комментарий для документирования /*! Альтернативный многострочный блок для документирования */
Здесь следует обратить внимание, что многострочное написание комментария вовсе не означает многострочное представление в документации. Если требуется разделить краткое и детальное описание объекта программы, то можно сделать различные блоки комментариев или воспользоваться специальными командами, которые обозначаются символом "\" или "@". Для принудительного окончания строки можно воспользоваться командой "\n".
Вариант 1: Раздельные блоки /// Краткое описание /** Детальное описание */ Вариант 2: Использование специальных команд /** \brief Краткое описание \details Детальное описание */
В общем случае предполагается, что объект документирования находится в файле непосредственно за блоком комментариев. Но на практике может потребоваться прокомментировать и объект, находящийся перед блоком комментариев. В таком случае необходимо воспользоваться символом "<", благодаря которому Doxygen поймет, что объект комментирования находится перед блоком. Для создания перекрестных ссылок в комментарии перед объектом ссылки следует поставить знак "#". Ниже приведен пример кода и сгенерированный им блок в документации. При этом в сгенерированном шаблоне "CConnection" является ссылкой-указателем на страницу документирования соответствующего класса.
#define defConnect 0x7781 ///<Connection \details Identified class #CConnection
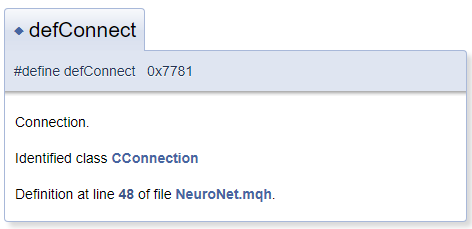
В целом возможности Doxygen довольно обширны и полный список команд с их описанием представлены на странице программы в разделе документации. Кроме того, Doxygen понимает HTML и XML разметку. И все это позволяет решать множество задач при документировании разработок.
4. Подготовительная работа в файле исходного кода.
После ознакомления с возможностями нашего инструмента можно приступить и к работе над документацией. Для начала опишем наши файлы.
/// \file /// \brief NeuroNet.mqh /// Library for creating Neural network for use in MQL5 experts /// \author [DNG](https://www.mql5.com/en/users/dng) /// \copyright Copyright 2019, DNG
и
/// \file /// \brief NeuroNet.cl /// Library consist OpenCL kernels /// \author <A HREF="https://www.mql5.com/en/users/dng"> DNG </A> /// \copyright Copyright 2019, DNG
Обратите внимание, что в первом случае после указателя \author идет разметка, предлагаемая Doxygen, а во втором используется HTML разметка. Это сделано для демонстрации различных вариантов создания гиперссылок. В обоих случаях результат идентичен - создана ссылка на мой профиль на этом сайте.
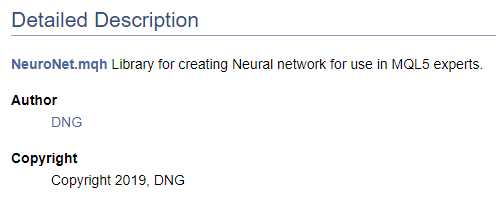
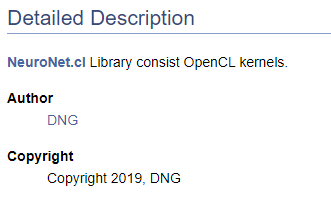
Конечно, начиная работу с документированием кода необходимо иметь как минимум верхнеуровневую структуру желаемого результата. Именно понимание конечной структуры дает нам возможность правильно сгруппировать объекты документирования. В отдельную группу выделим созданные перечисления. Для объявления группы воспользуемся командой "\defgroup", границы группы обозначим символами "@{" и "@}".
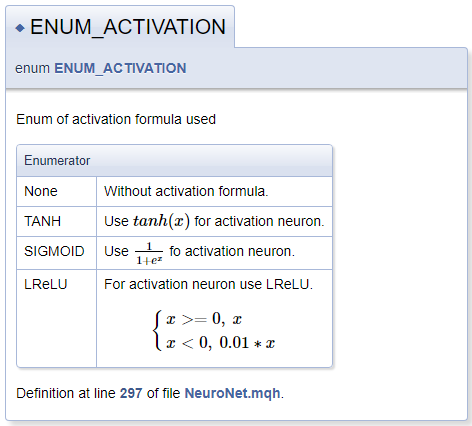
///\defgroup enums ENUM ///@{ //+------------------------------------------------------------------+ /// Enum of activation formula used //+------------------------------------------------------------------+ enum ENUM_ACTIVATION { None=-1, ///< Without activation formula TANH, ///< Use \f$tanh(x)\f$ for activation neuron SIGMOID, ///< Use \f$\frac{1}{1+e^x}\f$ fo activation neuron LReLU ///< For activation neuron use LReLU \f[\left\{ \begin{array} a x>=0, \ x \\x<0, \ 0.01*x \end{array} \right.\f] }; //+------------------------------------------------------------------+ /// Enum of optimization method used //+------------------------------------------------------------------+ enum ENUM_OPTIMIZATION { SGD, ///< Stochastic gradient descent ADAM ///< Adam }; ///@}
При описании функций активации продемонстрирован функционал по объявлению математических формул средствами MathJax. Описание таких формул следует поместить между парой команд "\f$" для отображения формулы в текстовой строке или между командами "\f[" и "\f]" для отображения формулы в отдельной строке. Команда "\frac" позволяет описать дробь. Следом за командой идут числитель и знаменатель дроби выделенные фигурными скобками.
При описании LReLU нам потребовалась объединяющая левая фигурная скобка, для создания которой мы воспользовались командами "\left\{" и "\right\.". За командой "\right" стоит "\.", т.к. в формуле нам не нужна правая фигурная скобка. В противном случае мы бы заменили току на закрывающую фигурную скобку. Внутри блока мы объявили массив строк с помощью команд "\begin{array} a" и "\end{array}", разделение элементов массива осуществляется командой "\\". Для принудительного добавления пробела воспользуемся набором символов "\ ".
Сгенерированный блок документации представлен ниже.
Следующим шагом выделим в отдельную группу идентификаторы классов в библиотеке. Внутри группы выделим подгруппы массивов, нейронов с вычислением операций в CPU и нейронов с вычислением операций в GPU. И конечно, как было описано выше, к каждой константе добавим ссылку на соответствующий класс.
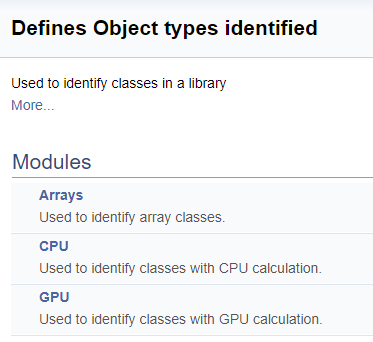
///\defgroup ObjectTypes Defines Object types identified ///Used to identify classes in a library ///@{ //+------------------------------------------------------------------+ ///\defgroup arr Arrays ///Used to identify array classes ///\{ #define defArrayConnects 0x7782 ///<Array of connections \details Identified class #CArrayCon #define defLayer 0x7787 ///<Layer of neurons \details Identified class #CLayer #define defArrayLayer 0x7788 ///<Array of layers \details Identified class #CArrayLayer #define defNet 0x7790 ///<Neuron Net \details Identified class #CNet ///\} ///\defgroup cpu CPU ///Used to identify classes with CPU calculation ///\{ #define defConnect 0x7781 ///<Connection \details Identified class #CConnection #define defNeuronBase 0x7783 ///<Neuron base type \details Identified class #CNeuronBase #define defNeuron 0x7784 ///<Full connected neuron \details Identified class #CNeuron #define defNeuronConv 0x7785 ///<Convolution neuron \details Identified class #CNeuronConv #define defNeuronProof 0x7786 ///<Proof neuron \details Identified class #CNeuronProof #define defNeuronLSTM 0x7791 ///<LSTM Neuron \details Identified class #CNeuronLSTM ///\} ///\defgroup gpu GPU ///Used to identify classes with GPU calculation ///\{ #define defBufferDouble 0x7882 ///<Data Buffer OpenCL \details Identified class #CBufferDouble #define defNeuronBaseOCL 0x7883 ///<Neuron Base OpenCL \details Identified class #CNeuronBaseOCL #define defNeuronConvOCL 0x7885 ///<Conolution neuron OpenCL \details Identified class #CNeuronConvOCL #define defNeuronProofOCL 0x7886 ///<Proof neuron OpenCL \details Identified class #CNeuronProofOCL #define defNeuronAttentionOCL 0x7887 ///<Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL ///\} ///@}
Разделение на группы в сгенерированной документации выглядит нижеследующим образом.
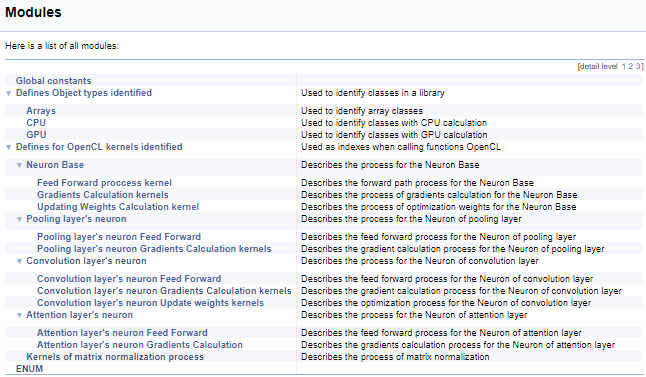
Далее проработаем большую группу дефайнов работы с кернелами OpenCL. В этом блоке присваиваются мнемонические названия индексам кернелов и их параметров, которые используются при вызове кернелов из основной программы. Используя вышеописанную технологию, мы разобьём эту группу по классу нейронов, из которых вызывается кернел, и далее по содержанию операций в кернеле (прямой проход, обратное распространение градиента, обновление весовых коэффициентов). Позвольте не приводить здесь полный код, но все желающие смогут найти его во вложении. Логика построения подгрупп аналогична приведенному выше примеру. На скриншоте ниже представлена полная структура групп.
Продолжая работу с кернелами, перейдем к комментированию программы OpenCL. С целью создания целостной структуры документации и получения общей картины нашей документации воспользуемся еще одной командой Doxygen "\ingroup", которая позволяет добавить новые объекты документирования в ранее созданные группы. С ее помощью мы добавим кернелы в выше созданные группы индексов работы с кернелами. В описании кернела добавим ссылку на вызывающий его класс и статью на данном сайте с описанием процесса. Далее по коду опишем параметры кернела. Использование указателей "[in]" и "[out]" подскажет направление потока информации. А перекрестные ссылки подскажут формат данных.
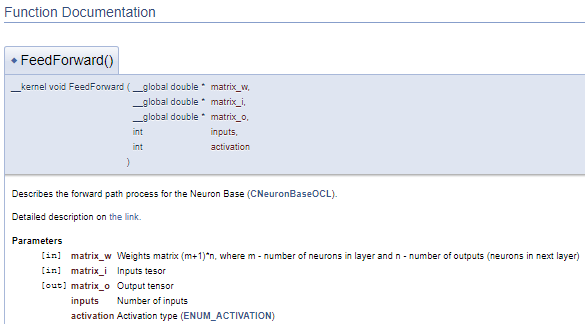
///\ingroup neuron_base_ff Feed forward process kernel /// Describes the forward path process for the Neuron Base (#CNeuronBaseOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8435#para41">the link.</A> //+------------------------------------------------------------------+ __kernel void FeedForward(__global double *matrix_w,///<[in] Weights matrix (m+1)*n, where m - number of neurons in layer and n - number of outputs (neurons in next layer) __global double *matrix_i,///<[in] Inputs tesor __global double *matrix_o,///<[out] Output tensor int inputs,///< Number of inputs int activation///< Activation type (#ENUM_ACTIVATION) )
Представленный выше код сгенерирует нижеследующий блок документации.
В выше представленном примере, описание параметров приведено непосредственно после их объявления. Но часто такой подход сильно загромождает код. В таких случаях предлагается воспользоваться командой "\param" для описания параметров. Ее использование позволяет описать параметры в любой части файла, но требует непосредственного указания имени параметра.
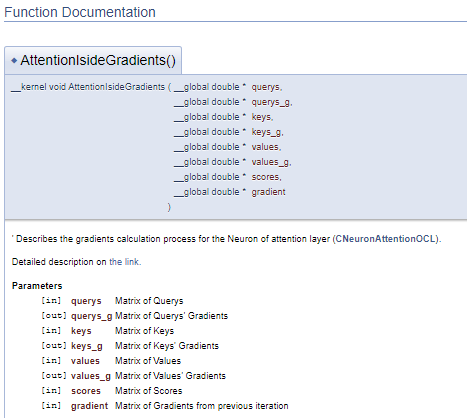
///\ingroup neuron_atten_gr Attention layer's neuron Gradients Calculation kernel /// Describes the gradients calculation process for the Neuron of attention layer (#CNeuronAttentionOCL). ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8765#para44">the link.</A> /// @param[in] querys Matrix of Querys /// @param[out] querys_g Matrix of Querys' Gradients /// @param[in] keys Matrix of Keys /// @param[out] keys_g Matrix of Keys' Gradients /// @param[in] values Matrix of Values /// @param[out] values_g Matrix of Values' Gradients /// @param[in] scores Matrix of Scores /// @param[in] gradient Matrix of Gradients from previous iteration //+------------------------------------------------------------------+ __kernel void AttentionIsideGradients(__global double *querys,__global double *querys_g, __global double *keys,__global double *keys_g, __global double *values,__global double *values_g, __global double *scores, __global double *gradient)
Такой подход генерирует аналогичный блок документации, но при этом позволяет отделить блок комментариев от кода программы. Что делает более читабельным код.
И конечно основная работа будет в документировании классов нашей библиотеки и их методов. Здесь нам предстоит описать все используемые классы и их методы. Это потребует использование всех выше указанных команд в различных вариациях и добавить немного новых. Вначале мы добавим класс к соответствующей группе, как это было показано с кернелами (команда \ingroup). Команда "\class" укажет Doxygen, что нижеследующее описание относится к классу. В параметрах команды нужно указать имя класса, чтобы привязать описание к правильному объекту.
С помощью команд "\brief" и "\details" дадим краткое и расширенное описание класса. В детальном описании сделаем гиперссылку на соответствующую статью. Здесь мы сделаем якорную ссылку на конкретный раздел статьи, что поможет быстрее найти необходимую информацию.
Непосредственно в строке объявления переменных добавим их описание. При необходимости добавим ссылки на поясняющие объекты. Нужно отметить, что нет необходимости в комментариях задавать указатели на классы объявляемых объектов, Doxygen добавит их автоматически.
Аналогичным образом описываем методы классов. Но в отличии от переменных, в комментарии нужно добавить описание параметров. Для этого воспользуемся уже описанной выше командой "\param" и указателями "[in]", "[out]", "[in,out]". Результат выполнения метода опишем с помощью команды "\return".
Также существует возможность присоединить отдельные методы к группам по принадлежности. К примеру, объединить по функционалу.
Всё вышеперечисленное продемонстрировано в приведенном ниже коде.
///\ingroup neuron_base ///\class CNeuronBaseOCL ///\brief The base class of neuron for GPU calculation. ///\details Detailed description on <A HREF="https://www.mql5.com/ru/articles/8435#para45">the link.</A> //+------------------------------------------------------------------+ class CNeuronBaseOCL : public CObject { protected: COpenCLMy *OpenCL; ///< Object for working with OpenCL CBufferDouble *Output; ///< Buffer of Output tenzor CBufferDouble *PrevOutput; ///< Buffer of previous iteration Output tenzor CBufferDouble *Weights; ///< Buffer of weights matrix CBufferDouble *DeltaWeights; ///< Buffer of last delta weights matrix (#SGD) CBufferDouble *Gradient; ///< Buffer of gradient tenzor CBufferDouble *FirstMomentum; ///< Buffer of first momentum matrix (#ADAM) CBufferDouble *SecondMomentum; ///< Buffer of second momentum matrix (#ADAM) //--- const double alpha; ///< Multiplier to momentum in #SGD optimization int t; ///< Count of iterations //--- int m_myIndex; ///< Index of neuron in layer ENUM_ACTIVATION activation; ///< Activation type (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Optimization method (#ENUM_OPTIMIZATION) //--- ///\ingroup neuron_base_ff virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///< \brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previos layer. ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); ///< Method for updating weights.\details Calling one of kernels ::UpdateWeightsMomentum() or ::UpdateWeightsAdam() in depends of optimization type (#ENUM_OPTIMIZATION).@param NeuronOCL Pointer to previos layer. public: /** Constructor */CNeuronBaseOCL(void); /** Destructor */~CNeuronBaseOCL(void); virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. virtual void SetActivationFunction(ENUM_ACTIVATION value) { activation=value; } ///< Set the type of activation function (#ENUM_ACTIVATION) //--- virtual int getOutputIndex(void) { return Output.GetIndex(); } ///< Get index of output buffer @return Index virtual int getPrevOutIndex(void) { return PrevOutput.GetIndex(); } ///< Get index of previous iteration output buffer @return Index virtual int getGradientIndex(void) { return Gradient.GetIndex(); } ///< Get index of gradient buffer @return Index virtual int getWeightsIndex(void) { return Weights.GetIndex(); } ///< Get index of weights matrix buffer @return Index virtual int getDeltaWeightsIndex(void) { return DeltaWeights.GetIndex(); } ///< Get index of delta weights matrix buffer (SGD)@return Index virtual int getFirstMomentumIndex(void) { return FirstMomentum.GetIndex(); } ///< Get index of first momentum matrix buffer (Adam)@return Index virtual int getSecondMomentumIndex(void) { return SecondMomentum.GetIndex();} ///< Get index of Second momentum matrix buffer (Adam)@return Index //--- virtual int getOutputVal(double &values[]) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return Output.GetData(values); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getPrevVal(double &values[]) { return PrevOutput.GetData(values); } ///< Get values of previous iteration output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return Gradient.GetData(values); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual int getWeights(double &values[]) { return Weights.GetData(values); } ///< Get values of weights matrix buffer @param[out] values Array of data @return number of items virtual int Neurons(void) { return Output.Total(); } ///< Get number of neurons in layer @return Number of neurons virtual int Activation(void) { return (int)activation; } ///< Get type of activation function @return Type (#ENUM_ACTIVATION) virtual int getConnections(void) { return (CheckPointer(Weights)!=POINTER_INVALID ? Weights.Total()/(Gradient.Total()) : 0); } ///< Get number of connections 1 neuron to next layer @return Number of connections //--- virtual bool FeedForward(CObject *SourceObject); ///< Dispatch method for defining the subroutine for feed forward process. @param SourceObject Pointer to the previous layer. virtual bool calcHiddenGradients(CObject *TargetObject); ///< Dispatch method for defining the subroutine for transferring the gradient to the previous layer. @param TargetObject Pointer to the next layer. virtual bool UpdateInputWeights(CObject *SourceObject); ///< Dispatch method for defining the subroutine for updating weights.@param SourceObject Pointer to previos layer. ///\ingroup neuron_base_gr ///@{ virtual bool calcHiddenGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. virtual bool calcOutputGradients(CArrayDouble *Target); ///< Method of output gradients calculation by calling kernel ::CalcOutputGradient().@param Target Traget value ///@} //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronBaseOCL; }///< Identificator of class.@return Type of class };
В завершении работы с кодом создадим титульную страницу. Для идентификации блока титульной страницы используется команда "\mainpage". Следом за командой следует указать название титульной страницы. Ниже сделаем описание нашего проекта и создадим список ссылок. Пункты списка выделим символом "-", а для создания ссылок на ранее созданные группы воспользуемся командой "\ref". При генерации документации Doxygen создается страницы иерархии классов (hierarchy.html) и используемых файлов (files.html). Добавим в наш список гиперссылки на указанные страницы. Финальный код титульной страницы представлен ниже.
///\mainpage NeuronNet /// Library for creating Neural network for use in MQL5 experts. /// - \ref const /// - \ref enums /// - \ref ObjectTypes /// - \ref group1 /// - [<b>Class Hierarchy</b>](hierarchy.html) /// - [<b>Files</b>](files.html)
На основании выше представленного кода будет сгенерирована нижеследующая страница.
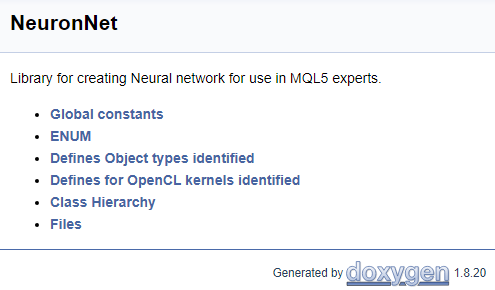
С полным кодом всех комментариев можно ознакомиться во вложении.
5. Генерация документации
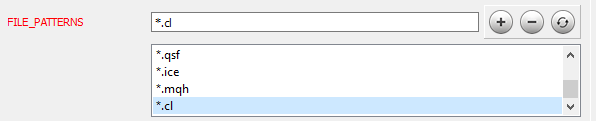
После окончания работы с кодом, можно перейти к следующему этапу. Об установке Doxygen и его настройке подробно рассказано в статье [9]. Остановимся лишь на настройке некоторых параметров программы. Вначале следует указать Doxygen с какими файлами он должен работать, на вкладке Expert в топике Input добавим нужные маски файлов в параметр FILE_PATTERNS. В данном случае я добавил "*.mqh" и "*.cl".
Теперь нужно указать Doxygen каким образом осуществлять парсинг добавленных файлов. Переходим в топик Project на той же вкладке Expert и редактируем параметр EXTENSION_MAPPING как показано на рисунке ниже.

Чтобы Doxygen мог генерировать математические формулы нужно активировать использование MathJax. Для этого в топике HTML вкладки Expert нужно активировать параметр USE_MATHJAX, как показано на рисунке ниже.

После проведения настроек программы, переходим на вкладку Wizard и указываем имя проекта, путь к исходным файлам и путь для вывода сгенерированной документации (данные шаги хорошо проиллюстрированы в статье [9]). Переходим на вкладку Run и запускаем программу генерации документации.
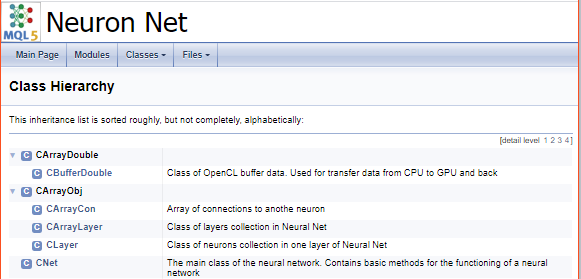
После отработки программы получаем готовую к использованию документацию. Некоторые скриншоты приведены ниже. С полной документацией можно ознакомиться во вложении.
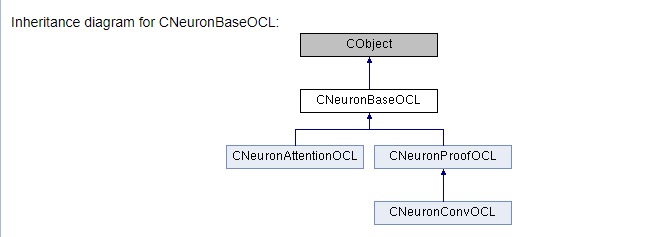
Заключение
Документированию разработок часто отводится далеко не первое место. Тем не менее, при разработке сложных проектов документация становится просто необходима. Ее наличие помогает в отслеживании выполнения поставленных задач, координации работы группы разработчиков и просто дает целостное представление о разработке. Документация просто не заменима при передаче знаний.
В статье предложен механизм документирования разработок на языке MQL5. Подробно описаны и проиллюстрированы все шаги предложенного механизма. Результаты проведенной работы находятся во вложении и каждый желающий может их оценить.
Надеюсь, мой опыт будет полезен.
Ссылки
- Нейросети — это просто
- Нейросети — это просто (Часть 2): обучение и тестирование сети
- Нейросети — это просто (Часть 3): сверточные сети
- Нейросети — это просто (Часть 4): рекуррентные сети
- Нейросети — это просто (Часть 5): многопоточные вычисления в OpenCL
- Нейросети — это просто (Часть 6): эксперименты с коэффициентом обучения нейронной сети
- Нейросети — это просто (Часть 7): Адаптивные методы оптимизации
- Нейросети — это просто (Часть 8): Механизмы внимания
- Автоматическое создание документации к программам на MQL5
- Doxygen
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 2 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
| 3 | html.zip | ZIP-архив | Архив документации сгенерированной Doxygen |
| 4 | NN.chm | HTML-справка | Сконвертированный файл HTML-справки. |
| 5 | Doxyfile | Файл параметров Doxygen |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Рынок и физика его глобальных закономерностей
Рынок и физика его глобальных закономерностей
 Самоадаптирующийся алгоритм (Часть III): Отказываемся от оптимизации
Самоадаптирующийся алгоритм (Часть III): Отказываемся от оптимизации
 Разработка самоадаптирующегося алгоритма (Часть II): Повышение эффективности
Разработка самоадаптирующегося алгоритма (Часть II): Повышение эффективности
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Не совсем так. Мы проверяем значения таргета, как и в скрытых слоях прибавляем к градиенту outpuVal для получения таргета и проверки его значения. Дело в том, что сигмоиды имеют ограниченный диапазон результатов: логистическая функция от 0 до 1, tanh - от -1 до 1. Если мы будем неограниченно наказывать нейрон за отклонение и увеличивать весовой коэффициент, то придем к переполнению веса. Ведь если мы в какой-то пришли к значению нейрона равному 1, а последующий слой передавая ошибку говорит что надо нарастить значение до 1,5. Нейрон будет послушно на каждой итерации увеличивать веса, а функция активации будет обрезать значения на уровне 1. Поэтому, я ограничиваю значения таргета диапазонам допустимых значений функции активации. А корректировку за пределами диапазона оставляю на веса последующего слоя.
Думаю я понял. Но всё же интересно насколько это верный подход, такой пример:
если сеть ошиблась выдав 0, когда реально 1. С последнего слоя тогда градиент взвешенный на предыдущий приходит (скорее всего, как я понимаю) положительный и может быть более 1, допустим 1,6.
Допустим в предыдущем слое есть нейрон, который выдавал +0,6, т.е. он же выдавал значение верное - его вес должен увеличиться в плюс. А этой нормировкой мы урезаем изменение его веса.
получится норм(1,6)=1. 1-0,6=0,4, а если нормировать как я предложил, то будет 1. В этом случае мы тормозим усиление правильного "нейрона".
Как считаете?
Насчёт бесконечного увеличения весов, что-то вроде слышал что это бывает в случае "плохой функции ошибок", когда много локальных минимумов и нет выраженного глобального, или функция невыпуклая, что-то такое, я не супер спец, просто полагаю что бороться с бесконечными весами можно и нужно и другими методами.
Проситься эксперимент протестить оба варианта. Если додумаюсь как сформулировать тест )
При сохранении-чтении сети из файла, на слое трансформеров ошибка.
в методе
bool CLayer::CreateElement(int index)
в строке
int type=FileReadInteger(iFileHandle);
читает 0 и switch уходит в дефолтный false.
(Видимо рассинхрон с записью)
Если уже пофиксено подскажите плиз для скорости, или скиньте файл.
Ну чтоб одно и тоже не фиксить дважды и просто не хочу сильно изменения вносить в библиотеку.
Для работы в тестере вносил изменения, и потом зараза забываешь когда новая статья выходит что надо перенести в новую версию свои правки)
При сохранении-чтении сети из файла, на слое трансформеров ошибка.
в методе
bool CLayer::CreateElement(int index)
в строке
int type=FileReadInteger(iFileHandle);
читает 0 и switch уходит в дефолтный false.
(Видимо рассинхрон с записью)
Если уже пофиксено подскажите плиз для скорости, или скиньте файл.
Ну чтоб одно и тоже не фиксить дважды и просто не хочу сильно изменения вносить в библиотеку.
Для работы в тестере вносил изменения, и потом зараза забываешь когда новая статья выходит что надо перенести в новую версию свои правки)
Добрый день,
Сейчас новая статья на проверке модератором. Там эта ошибка исправлена.
Добрый день,
Сейчас новая статья на проверке модератором. Там эта ошибка исправлена.
Супер! подождём.