
Нейросети в трейдинге: Декомпозиция вместо масштабирования (Окончание)

Введение
Финансовые рынки сегодня — это не просто поле для встреч продавца и покупателя, а сложная динамическая экосистема, где каждый тик цены — результат мгновенного взаимодействия сотен факторов. Здесь нет места случайности в привычном смысле этого слова: за кажущимся хаосом скрываются закономерности, пусть и облечённые в сложные, многослойные формы. Именно умение распознать эти скрытые структуры и предугадать их развитие определяет успех трейдера или алгоритмической системы. В предыдущих статьях мы познакомились с фреймворком SSCNN (Spatial-Sequential Convolutional Neural Network). За этим, на первый взгляд, громоздким названием скрывается весьма стройная и изящная концепция, объединяющая пространственные и временные зависимости в единый вычислительный алгоритм.
В основе SSCNN лежит идея, что временной ряд — это развёрнутый во времени отпечаток многомерных процессов. Каждый момент времени связан не только с прошлым и будущим, но и с параллельными структурами — внутренними пространствами признаков, которые изменяются синхронно или с задержкой.
Чтобы уловить эти связи, модель использует каскад блоков, способных извлекать локальные паттерны, и модулей последовательной обработки, которые удерживают и аккумулируют контекст. Ключевым звеном здесь является модуль Attention-based Normalization — комбинация внимания и нормализации, которая позволяет системе акцентироваться на действительно значимых участках данных, одновременно стабилизируя процесс обучения. Благодаря такой архитектуре, SSCNN способна не только анализировать сигналы с разной степенью детализации, но и адаптироваться к изменяющейся структуре данных, что особенно важно для финансовых инструментов с их непостоянной волатильностью и сменой рыночных режимов.

Ещё одним важным преимуществом является модульность. Архитектура SSCNN легко масштабируется и настраивается под конкретную задачу — будь то краткосрочное прогнозирование ценового импульса или поиск долгосрочных циклов. Концепция слоистого восприятия данных, где каждый уровень модели выделяет свою порцию признаков и передаёт её следующему, даёт гибкость и устойчивость.
В предыдущих публикациях мы подробно разобрали, как эти идеи были воплощены в коде и интегрировали их в среду MQL5, создав основу для полноценной торговой системы.
Теперь же мы подходим к завершающему этапу, где теория должна встретиться с практикой в её самом требовательном проявлении. Нам предстоит собрать отдельные блоки в целостную архитектуру фреймворка и оценить, как SSCNN обрабатывает и интерпретирует рыночные данные. Мы проверим эффективность реализованных решений в условиях, максимально приближенных к реальной торговле. Этот шаг важен не только для того, чтобы измерить точность прогнозов или устойчивость модели, но и для того, чтобы понять, насколько глубоко её алгоритмы чувствуют рынок, различают скрытые структуры и способны распознавать смену контекста. Ведь в конечном счёте успех любой торговой системы определяется не блеском архитектуры, а тем, как она справляется с шумом, неожиданными всплесками и коварными поворотами графиков.
Энкодер
В предыдущих работах мы построили отдельные блоки архитектуры SSCNN, и сегодня начинаем их соединять в едином Энкодере — том самом узле, где множество потоков информации (долгосрочные тренды, сезонные паттерны, краткосрочные флуктуации и пространственные взаимосвязи) аккуратно раскладываются, упорядочиваются, генерируются их проекции на заданный горизонт планирования и затем сливаются в единое прогнозное представление.
Класс CNeuronSSCNNEncoder воплощает эту идею в коде. Его задача — не просто последовательно вызвать набор модулей, а синхронизировать их работу: выделить каждую компоненту по своей логике, экстраполировать её на требуемый горизонт, спрогнозировать соответствующие статистики и только затем собрать всё это в богатое, структурированное представление для финальной полиномиальной регрессии. Энкодер управляет потоками данных, организует транспонирования там, где это необходимо для корректной работы по фазам, и гарантирует, что каждый результат работы отдельной подсистемы попадёт в своё место конкатенации в нужном формате. Структура класса представлена ниже.
class CNeuronSSCNNEncoder : public CNeuronTransposeOCL { protected: CNeuronPeriodNorm cLongNorm; CNeuronConvOCL cLongExtrapolate; CNeuronTransposeOCL cLongMeanSTDevTransp; CNeuronBaseOCL cLongMeanExtrapolate; CNeuronTransposeVRCOCL cSeasonTransp; CNeuronAttentNorm cSeasonNorm; CNeuronTransposeVRCOCL cUnSeasonTransp; CNeuronConvOCL cSeasonExtrapolate; CNeuronConvOCL cSeasonMeanExtrapolate; CNeuronAttentNorm cShortNorm; CNeuronConvOCL cShortExtrapolate; CNeuronConvOCL cShortMeanExtrapolate; CNeuronSAttentNorm cSpatialNorm; CNeuronConvOCL cSpatialExtrapolate; CNeuronConvOCL cSpatialMeanExtrapolate; CNeuronBaseOCL cConcatenated; CNeuronTransposeOCL cTranspose; CNeuronPolynomialRegression cFusion; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSSCNNEncoder(void) {}; ~CNeuronSSCNNEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint variables, uint forecast, uint season_period, uint short_period, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronSSCNNEncoder; } virtual void TrainMode(bool flag) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { } };
Рабочая цепочка внутри Энкодера аккуратно выстроена. Все внутренние объекты объявлены статично, поэтому конструктор и деструктор класса остаются пустыми, а фактическая сборка вычислительного графа выполняется централизовано в методе Init.
bool CNeuronSSCNNEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint variables, uint forecast, uint season_period, uint short_period, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, units_count + forecast, variables, optimization_type, batch)) return false; activation = None;
Алгоритм метода начинает с инициализации родительского класса CNeuronTransposeOCL, в который передаются базовые параметры создаваемой архитектуры. Этот вызов подготавливает общую инфраструктуру — выделение глобальных буферов, установку размеров тензоров и привязку OpenCL-контекста.
Обратите внимание, что размерность тензора результатов указывается в виде суммы длины анализируемой последовательности и горизонта планирования. Здесь становится очевидно, что на выходе модуля мы планируем получить очищенные исходные данные и необходимый прогноз в едином сопоставимом представлении.
Сразу после базовой инициализации мы явно отключаем функцию активацию у текущего слоя (activation = None), поскольку Энкодер работает с числовыми представлениями и статистиками.
Далее переходим к инициализации внутренних объектов. Первой идет долгосрочная ветвь — cLongNorm. Здесь создаётся модуль нормализации по периодам, который готовит устойчивую компоненту ряда (тренд).
int index = 0; if(!cLongNorm.Init(0, index, OpenCL, 1, units_count, iWindow, optimization, iBatch)) return false;
Затем инициализируем cLongExtrapolate — блок экстраполяции тренда, который будет расширять долгосрочную компоненту на горизонт прогноза.
index++; if(!cLongExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cLongExtrapolate.SetActivationFunction(None);
Здесь следует обратить внимание, что в авторской реализации для экстраполяции данных используется матрица обучаемых параметров E.
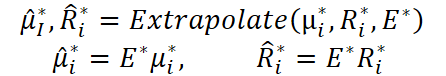
Мы же в своей реализации для выполнения указанной функции решили использовать сверточный слой без функции активации. Сверточный слой при нулевой активации — это тоже линейный оператор, но с дополнительными преимуществами инженерного характера. Свертки дают параметрическое разрежение (shared weights), аппаратно оптимизированы, а так же естественным образом описывают локальные и квазилокальные преобразования, которые часто встречаются во временных рядах.
После того как мы экстраполировали остатки долгосрочной компоненты, наступает очередь экстраполяции самих средних значений. Практический нюанс в том, что CNeuronPeriodNorm возвращает тензор, в котором значения записаны парами — среднее и дисперсия. Вместо того чтобы выполнять явную деконкатенацию и копирование данных, мы воспользовались аккуратным приёмом: простым транспонированием тензора.
Транспонирование перестраивает данные так, что конвейер последовательно выстраивает отдельные последовательности всех средних и всех дисперсий, причём последовательность средних оказывается первой. Это даёт возможность передать транспонированный тензор напрямую в модуль экстраполяции средних. По существу мы используем свойство порядка элементов в памяти, чтобы получить логически разделённые потоки данных минимальными усилиями.
index++; if(!cLongMeanSTDevTransp.Init(0, index, OpenCL, iWindow, 2, optimization, iBatch)) return false; if(!cLongMeanSTDevTransp.getGradient().Fill(0)) return false; index++; if(!cLongMeanExtrapolate.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cLongExtrapolate.SetActivationFunction(None); if(!cLongMeanExtrapolate.getPrevOutput().Fill(1)) return false;
Но здесь есть ещё два узких, но важных момента, о которых стоит заранее позаботиться. Первый — защита от загрязнения градиентов дисперсий. Поскольку наш модуль экстраполяции работает только со средними, нам нужно гарантировать, что в память градиентов для дисперсий не попадут случайные значения, способные исказить дальнейший обратный проход. В реализации это просто и надёжно решается на этапе инициализации: буфер градиентов транспонирующего объекта обнуляется. Так мы явно снимаем любую историческую наэлектризованность памяти и исключаем влияние мусорных значений на σ².
Второй момент — сама экстраполяция средних. В оригинальной формулировке авторы используют простое заполнение тензора полученными значениями. Мы же пошли по инженерно-экономичному пути: для получения нужного заполненного тензора мы используем внешнее произведение (outer product) в простом виде. Берём вектор-столбец средних µ размера N•1 и умножаем его на вектор-строку единиц размера 1•M. Результат — матрица N•M, где каждая строка является копией соответствующего µi. Это делает копирование значений в тензор нужного размера без явных циклов. Практические преимущества такого решения очевидны: это линейная операция, легко распараллеливаемая на GPU, она экономна по памяти и ясно транслируется в OpenCL.
В итоге, при минимальном коде и с малыми накладными расходами мы получаем чистый, понятный и эффективно реализуемый механизм экстраполяции средних значений. Он сохраняет семантику авторского замысла (линейная проекция по времени), но делает её более экономной и хорошо приспособленной к параллельным вычислениям на OpenCL.
Следующей идёт ветвь сезонности. Сначала объект cSeasonTransp настраивает транспонирование по циклам: мы группируем данные по фазам одного цикла, используя параметр season_period. Это облегчает последующую операцию отбора одинаковых фаз и позволяет использовать универсальный модуль нормализации с коэффициентами внимания CNeuronAttentNorm.
index++; if(!cSeasonTransp.Init(0, index, OpenCL, iWindow, units_count / season_period, season_period, optimization, iBatch)) return false; index++; if(!cSeasonNorm.Init(0, index, OpenCL, season_period, cSeasonTransp.GetCount(), iWindow, optimization, iBatch)) return false; index++; if(!cUnSeasonTransp.Init(0, index, OpenCL, iWindow, season_period, cSeasonTransp.GetCount(), optimization, iBatch)) return false;
Объект cSeasonNorm извлекает сезонную компоненту и нормализует остаточные значения, а cUnSeasonTransp вернёт данные к исходной ориентации перед экстраполяцией. Непосредственно экстраполяция сезонных компонент осуществляется объектами cSeasonExtrapolate и cSeasonMeanExtrapolate.
index++; if(!cSeasonExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cSeasonExtrapolate.SetActivationFunction(None); index++; if(!cSeasonMeanExtrapolate.Init(0, index, OpenCL, season_period, season_period, iCount, iWindow, 1, optimization, iBatch)) return false; cSeasonMeanExtrapolate.SetActivationFunction(None);
Краткосрочная ветвь задаётся похожим набором модулей, но без транспонирования данных. Объект cShortNorm выделяет локальные, быстрые эффекты по окну short_period, cShortExtrapolate строит их прогноз, а cShortMeanExtrapolate — прогноз статистик краткосрочного слоя. Обратите внимание, что в параметрах инициализации объекта экстраполяции средних значений мы используем cShortNorm.GetUnits() для согласования форматов — это гарантирует, что последующие блоки корректно принимают выходы нормализатора как входы.
index++; if(!cShortNorm.Init(0, index, OpenCL, units_count / short_period, short_period, iWindow, optimization, iBatch)) return false; index++; if(!cShortExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cShortExtrapolate.SetActivationFunction(None); index++; if(!cShortMeanExtrapolate.Init(0, index, OpenCL, cShortNorm.GetUnits(), cShortNorm.GetUnits(), iCount, iWindow, 1, optimization, iBatch)) return false; cShortMeanExtrapolate.SetActivationFunction(None); index++;
Далее инициализируется пространственная ветвь: cSpatialNorm — это модуль S-AttnNorm, который выделяет пространственно согласованные паттерны между унитарными последовательностями отдельных признаков.
if(!cSpatialNorm.Init(0, index, OpenCL, units_count, variables, optimization, iBatch)) return false; index++; if(!cSpatialExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, iWindow, 1, optimization, iBatch)) return false; cSpatialExtrapolate.SetActivationFunction(None); index++; if(!cSpatialMeanExtrapolate.Init(0, index, OpenCL, units_count, units_count, iCount, 1, iWindow, optimization, iBatch)) return false; cSpatialMeanExtrapolate.SetActivationFunction(None); index++;
За ним следуют cSpatialExtrapolate и cSpatialMeanExtrapolate, которые прогнозируют пространственную компоненту и её статистики на заданный горизонт.
Все прогнозные компоненты и их статистики затем собираются в единый тензор cConcatenated. Здесь мы явно умножаем размерность тензора на восемь, потому что на выходе каждой ветви формируется пара структура + остаток (Rlt, μlt, Rse, μse, Rst, μst, Rsi, μsi), то есть восемь потоков информации на единицу.
if(!cConcatenated.Init(0, index, OpenCL, 8 * Neurons(), optimization, iBatch)) return false; index++; if(!cTranspose.Init(0, index, OpenCL, 8 * iWindow, iCount, optimization, iBatch)) return false;
Получившийся широкий тензор затем транспонируется модулем cTranspose, чтобы привести данные в формат, ожидаемый финальным слоем фьюжна.
Последним шагом инициализации является cFusion — это наш модуль полиномиальный регрессор (фьюжн), который принимает на вход объединённый набор признаков размером 8*iWindow и выдаёт сжатое, но информативное представление длиной iWindow для каждого временного шага. Именно здесь реализуется схема сочетание мультипликативных и аддитивных эффектов между компонентами.
index++; if(!cFusion.Init(0, index, OpenCL, iCount, 8 * iWindow, iWindow, optimization, iBatch)) return false; //--- return true; }
На каждом этапе мы контролируем процесс инициализации объектов и в случае возникновения ошибки метод возвращает false. Такое защищённое программирование позволяет немедленно остановить сборку Энкодера при любой проблеме. Если все модули успешно созданы и сконфигурированы, метод завершает работу с результатом true, сигнализируя о готовности Энкодера к работе.
После инициализации структуры объекта мы переходим к организации прямого прохода Энкодера в методе feedForward, где каждый модуль появляется в нужный момент и передаёт эстафету дальше. Метод организован пошагово и отражает логику обработки четырёх компонент: долгосрочной, сезонной, краткосрочной и пространственной, затем собирает всё в единый вектор признаков и передаёт его на полиномиальный фьюжн. В коде это видно ясно: на каждом шаге мы вызываем FeedForward для соответствующего блока, проверяем успешность и переходим далее — если где-то что-то пошло не так, функция возвращает false и цепочка останавливается.
bool CNeuronSSCNNEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Long if(!cLongNorm.FeedForward(NeuronOCL)) return false; if(!cLongExtrapolate.FeedForward(cLongNorm.AsObject())) return false; if(!cLongMeanSTDevTransp.FeedForward(cLongNorm.GetMeanSTDevs())) return false; if(!MatMul(cLongMeanSTDevTransp.getOutput(), cLongMeanExtrapolate.getPrevOutput(), cLongMeanExtrapolate.getOutput(), 1, 1, iCount, iWindow, true)) return false;
Сначала запускается долгосрочная ветвь. Вызов cLongNorm.FeedForward вычисляет нормализованную долгосрочную компоненту анализируемых данных — это подготовительный шаг, который отделяет тренд от локальных эффектов. Далее cLongExtrapolate.FeedForward берёт результат нормализации и строит прогноз остатков долгосрочной компоненты на требуемый горизонт. Здесь важно отметить, что модуль получает уже структурированные данные от cLongNorm.
Затем необходимо экстраполировать статистики — средние и стандартные отклонения. Для этого сначала транспонируется тензор статистик cLongMeanSTDevTransp, чтобы собрать последовательности средних отдельно от дисперсий (о приёме с транспонированием мы говорили ранее). После этого выполняется матричное умножение. Здесь мы фактически проецируем транспонированные статистики в необходимы нам формат, используя вектор-строку. Реализация даёт желаемое поведение репликации средних по горизонту без лишних копирований.
Далее стартует сезонная ветвь. Сначала cSeasonTransp проводит транспонирование анализируемых данных по фазам цикла — это подготовка к фазово-ориентированной нормализации
//--- Season if(!cSeasonTransp.FeedForward(cLongNorm.AsObject())) return false; if(!cSeasonNorm.FeedForward(cSeasonTransp.AsObject())) return false; if(!cUnSeasonTransp.FeedForward(cSeasonNorm.AsObject())) return false; if(!cSeasonExtrapolate.FeedForward(cUnSeasonTransp.AsObject())) return false; if(!cSeasonMeanExtrapolate.FeedForward(cSeasonNorm.GetMeans())) return false;
Затем cSeasonNorm выполняет Attention-based Normalization по циклам, выделяя релевантные фазовые позиции. Обратное транспонирование cUnSeasonTransp возвращает данные в исходную форму, готовую для экстраполяции. После этого cSeasonExtrapolate получает восстановленные сезонные остатки и прогнозирует их, а cSeasonMeanExtrapolate экстраполирует средние сезонных компонент, полученные из нормализатора.
Краткосрочная ветвь следует похожему сценарию:
- cShortNorm берёт уже очищенные от сезонности данные и выделяет локальные, быстрые эффекты;
- cShortExtrapolate прогнозирует эти краткосрочные остатки;
- cShortMeanExtrapolate формирует прогнозы их статистик.
//--- Short if(!cShortNorm.FeedForward(cUnSeasonTransp.AsObject())) return false; if(!cShortExtrapolate.FeedForward(cShortNorm.AsObject())) return false; if(!cShortMeanExtrapolate.FeedForward(cShortNorm.GetMeans())) return false;
Обратите внимание, что передача данных из сезонной ветви в краткосрочную — сознательное решение: сначала убрать крупные циклы, затем ловить локальные всплески.
Следом идёт пространственная ветвь. Модуль cSpatialNorm анализирует наборы рядов во временном срезе и выделяет пространственно согласованные структуры. Затем cSpatialExtrapolate и cSpatialMeanExtrapolate выполняют прогноз пространственных остатков и их статистик, соответственно.
//--- Spatial if(!cSpatialNorm.FeedForward(cShortNorm.AsObject())) return false; if(!cSpatialExtrapolate.FeedForward(cSpatialNorm.AsObject())) return false; if(!cSpatialMeanExtrapolate.FeedForward(cSpatialNorm.GetMeans())) return false;
Такая последовательность гарантирует, что пространственная нормализация видит локальные эффекты, уже очищенные от тренда и сезонности.
Когда все ветви дали свои прогнозы, идёт аккуратная сборка признаков. Первый вызов метода конкатенации Concat объединяет экстраполированные остатки и средние для долгосрочной и сезонной ветвей в широкий буфер.
//--- Concat if(!Concat(cLongExtrapolate.getOutput(), cLongMeanExtrapolate.getOutput(), cSeasonExtrapolate.getOutput(), cSeasonMeanExtrapolate.getOutput(), cConcatenated.getOutput(), iCount, iCount, iCount, iCount, iWindow)) return false; if(!Concat(cConcatenated.getOutput(), cShortExtrapolate.getOutput(), cShortMeanExtrapolate.getOutput(), cConcatenated.getPrevOutput(), 4 * iCount, iCount, iCount, iWindow)) return false; if(!Concat(cConcatenated.getPrevOutput(), cSpatialExtrapolate.getOutput(), cSpatialMeanExtrapolate.getOutput(), cConcatenated.getOutput(), 6 * iCount, iCount, iCount, iWindow)) return false;
Далее второй вызов Concat добавляет краткосрочные данные, расширяя накопленный тензор. Третий вызов метода конкатенации дополняет результат пространственными компонентами.
Наконец следует этап фьюжна. Предварительно cTranspose приводит широкий тензор анализируемых данных к форме, пригодной для полиномиального регрессора — это перестановка размерностей признаков и временных шагов, которое делает структуру данных удобной для последующей агрегации. А модуль cFusion запускает сам полиномиальный фьюжн: комбинацию аддитивных и мультипликативных путей, которая даёт сжатое, но информативное представление прогноза.
//--- Fusion if(!cTranspose.FeedForward(cConcatenated.AsObject())) return false; if(!cFusion.FeedForward(cTranspose.AsObject())) return false; //--- return CNeuronTransposeOCL::feedForward(cFusion.AsObject()); }
Заканчивается алгоритм прямого прохода вызовом одноименного метода родительского класса CNeuronTransposeOCL, который приводит тензор результатов в набор унитарных последовательностей отдельных признаков, пригодную для анализа последующими нейронными слоями модели.
На каждом шаге код строго проверяет результат выполнения операций. И это не формализм, а осознанная защита: любое исключение, ошибка выделения буфера или неверный формат тут же прекращают выполнение, что облегчает отладку и делает поведение модели безопасным в продакшене.
С архитектурной точки зрения порядок вызовов отражает принцип снизу вверх: сначала извлекаем и экстраполируем грубые, устойчивые компоненты, затем последовательность компонентов более высокого разрешения, затем исследуем пространственные связи и, наконец, аккуратно сливаем всё в фьюжн. Такой стиль упрощает трассировку ошибок, даёт явную семантику каждому блоку и делает возможной поэтапную валидацию качества — от тренда до локальных всплесков.
Если рассматривать метод прямого прохода в качестве сценария, где мы последовательно выводим актёров на сцену. То в этом контексте calcInputGradients — это мгновение после спектакля, когда нужно аккуратно разобрать реквизит, собрать замечания режиссёра и вернуть энергию ошибки назад к каждому модулю, позволяя ему скорректировать своё поведение.
bool CNeuronSSCNNEncoder::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода сразу проверяем валидность указателя на объект исходных данных NeuronOCL. Простая и необходимая защита: без корректного указателя никто не знает, куда возвращать градиенты, поэтому мы аккуратно выходим при ошибке.
Далее начинается фаза фьюжна. Поскольку на прямом проходе финальным шагом был полиномиальный фьюжн и транспонирование, в обратном порядке сначала снимаем градиенты с этих модулей.
//--- Fusion if(!CNeuronTransposeOCL::calcInputGradients(cFusion.AsObject())) return false; if(!cTranspose.CalcHiddenGradients(cFusion.AsObject())) return false; if(!cConcatenated.CalcHiddenGradients(cTranspose.AsObject())) return false;
Вызываем одноименный метод родительского класса CNeuronTransposeOCL, который передаёт ошибку от внешнего контекста в модуль полиномиальной регрессии. Затем спускаем градиенты до уровня объекта транспонирования cTranspose. И наконец, передаем полученные значения в объект широкого тензора конкатенации результатов всех компонент cConcatenated.
Далее нам предстоит последовательно распаковывают вклад каждой компоненты, выполнив последовательную деконкатенацию (DeConcat), чтобы распилить общий градиент на составляющие.
//--- DeConcat if(!DeConcat(cConcatenated.getPrevOutput(), cSpatialExtrapolate.getGradient(), cSpatialMeanExtrapolate.getGradient(), cConcatenated.getGradient(), 6 * iCount, iCount, iCount, iWindow)) return false; if(!DeConcat(cConcatenated.getGradient(), cShortExtrapolate.getGradient(), cShortMeanExtrapolate.getGradient(), cConcatenated.getPrevOutput(), 4 * iCount, iCount, iCount, iWindow)) return false; if(!DeConcat(cLongExtrapolate.getGradient(), cLongMeanExtrapolate.getGradient(), cSeasonExtrapolate.getGradient(), cSeasonMeanExtrapolate.getGradient(), cConcatenated.getGradient(), iCount, iCount, iCount, iCount, iWindow)) return false;
Первыми извлекаем градиенты для пространственной ветви (cSpatialExtrapolate и cSpatialMeanExtrapolate) из cConcatenated. Следующие два вызова метода DeConcat разбирают градиенты для краткосрочной, сезонной и для долгосрочной компонент. По сути, единый широкий буфер рассылается по адресатам: каждый модуль получает ровно ту долю градиента, которую он породил на прямом проходе.
Теперь начинается последовательное снятие градиентов по ветвям в логическом порядке, обратном их построению. Для пространственной ветви сначала передаём градиенты статистик — это перенос ошибки от блока прогнозирования средних пространственной компоненты в модуль нормализации, который отвечал за эти средние.
//--- Spatial if(!cSpatialNorm.GetMeans().CalcHiddenGradients(cSpatialMeanExtrapolate.AsObject())) return false; if(!cSpatialNorm.CalcHiddenGradients(cSpatialExtrapolate.AsObject())) return false;
Затем метод cSpatialNorm.CalcHiddenGradients снимает градиент с основной Spatial-ветви и подготавливает его к передаче вниз.
Краткосрочная ветвь требует аккуратности: сначала cShortNorm.CalcHiddenGradients передаёт градиент пространственной нормализации в нормализатор краткосрочных эффектов.
//--- Short if(!cShortNorm.CalcHiddenGradients(cSpatialNorm.AsObject())) return false; CBufferFloat* temp = cShortNorm.getGradient(); if(!cShortNorm.SetGradient(cShortNorm.getPrevOutput(), false) || !cShortNorm.CalcHiddenGradients(cShortExtrapolate.AsObject()) || !SumAndNormilize(temp, cShortNorm.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cShortNorm.SetGradient(temp, false)) return false; if(!cShortNorm.GetMeans().CalcHiddenGradients(cShortMeanExtrapolate.AsObject())) return false;
Затем нам необходимо получить градиент ошибки от объекта экстраполяции данных. И чтобы не потерять ранее полученные значения, мы сохраняем текущий указатель буфер градиентов ошибки в локальную переменную temp. Дальше идёт хитрый приём: мы временно меняем текущий указатель буфера градиентов нормализатора на свободный объект того же размера. А затем вычисляем градиенты относительно модуля экстраполяции. После этого мы суммируем значения двух информационных потоков и возвращаем указатели на буферы данных в исходное состояние. В завершении работы блока распределения градиентов ошибки краткосрочной компоненты возвращаем погрешность от блока прогнозирования средних краткосрочной ветви обратно в путь, который их породил.
Сезонная ветвь обрабатывается по аналогичной схеме, но с дополнительным транспонированием.
//--- Season if(!cUnSeasonTransp.CalcHiddenGradients(cShortNorm.AsObject())) return false; temp = cUnSeasonTransp.getGradient(); if(!cUnSeasonTransp.SetGradient(cUnSeasonTransp.getPrevOutput(), false) || !cUnSeasonTransp.CalcHiddenGradients(cSeasonExtrapolate.AsObject()) || !SumAndNormilize(temp, cUnSeasonTransp.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cUnSeasonTransp.SetGradient(temp, false)) return false; if(!cSeasonNorm.GetMeans().CalcHiddenGradients(cSeasonMeanExtrapolate.AsObject())) return false; if(!cSeasonNorm.CalcHiddenGradients(cUnSeasonTransp.AsObject())) return false; if(!cSeasonTransp.CalcHiddenGradients(cSeasonNorm.AsObject())) return false;
Сначала cUnSeasonTransp.CalcHiddenGradients возвращает градиенты из краткосрочной нормализации к блоку обратного транспонирования. Снова применён приём с временным буфером: сохраняем в temp, переключаем градиент на свободный буфер, вычисляем CalcHiddenGradients, аккумулируем и возвращаем результат в cUnSeasonTransp. Это гарантирует корректное суммирование вкладов и согласование масштабов.
После этого переносим ошибки вниз в Seasonal-Normalizer и распаковывает транспонирование — то есть возвращаемся к формату, в котором данные приходили из долгосрочного нормализатора.
Долгосрочная ветвь содержит самый деликатный фрагмент — обратное матричное умножение для статистик. В методе MatMulGrad мы выполняем обратную операцию по отношению к умножению векторов из прямого прохода: это вычисляет вклад ошибки в транспонированный буфер cLongMeanSTDevTransp из cLongMeanExtrapolate. Фактически мы распределяем градиенты по средним, учитывая структуру репликации, которую мы использовали при экстраполяции средних. Затем направляет полученные градиенты в модуль нормализации.
//--- Long if(!MatMulGrad(cLongMeanSTDevTransp.getOutput(), cLongMeanSTDevTransp.getGradient(), cLongMeanExtrapolate.getPrevOutput(), cLongMeanExtrapolate.getGradient(), cLongMeanExtrapolate.getGradient(), 1, 1, iCount, iWindow, true)) return false; if(!cLongNorm.GetMeanSTDevs().CalcHiddenGradients(cLongMeanSTDevTransp.AsObject())) return false; if(!cLongNorm.CalcHiddenGradients(cSeasonTransp.AsObject())) return false; temp = cLongNorm.getGradient(); if(!cLongNorm.SetGradient(cLongNorm.getPrevOutput(), false) || !cLongNorm.CalcHiddenGradients(cLongExtrapolate.AsObject()) || !SumAndNormilize(temp, cLongNorm.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cLongNorm.SetGradient(temp, false)) return false;
После этого cLongNorm.CalcHiddenGradients передаёт накопленные градиенты из сезонной транспозиции назад в долгосрочный нормализатор, и мы снова применяем приём с временным буфером. Это обеспечивает аккумулирование вкладов от экстраполяции остатка долгосрочной компоненты и от других зависимых модулей, не теряя промежуточных результатов.
Наконец, законченная цепочка обратной передачи передаёт градиенты дальше, в предыдущий слой (NeuronOCL). Это естественная точка выхода для ошибки: после всех внутренних перерасчётов Энкодер отдал корректно сформированный вклад предыдущему звену вычислительной графа.
//--- if(!NeuronOCL.CalcHiddenGradients(cLongNorm.AsObject())) return false; //--- return true; }
По ходу метода все вызовы обёрнуты проверкой результатов. Это не просто надёжность — это политика fail-fast: на раннем этапе улавливаем проблему, чтобы избежать тонких несогласованностей в буферах, которые потом было бы трудно отследить. Важные приёмы, которые повторяются во всём методе и заслуживают отдельного внимания:
- использование временных буферов данных для аккумулирования частичных градиентов,
- переключение активного градиентного буфера, чтобы не потерять данные,
- вызов SumAndNormilize для корректного объединения вкладов по размерности окна.
В сухом остатке: метод аккуратно идёт по обратному порядку прямого прохода, распаковывает конкатенированные буферы, распределяет градиенты по ветвям, аккумулирует многократные источники вклада через временные буферы и нормализацию, и в конце возвращает ошибку назад на уровень ниже. Такой порядок гарантирует, что каждый модуль получает именно тот градиент, который он породил, и что суммарная корректировка будет состоятельной и стабильно сходимой при обучении.
После того как градиенты собраны и аккуратно распределены по всем ветвям Энкодера, наступает финальная фаза — собственно обновление обучаемых параметров. В нашем коде это сведено к последовательным вызовам одноимённых методов внутренних компонентов: каждый модуль сам отвечает за то, как применить накопленный градиент к своим весам.
bool CNeuronSSCNNEncoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { //--- Long if(!cLongNorm.UpdateInputWeights(NeuronOCL)) return false; if(!cLongExtrapolate.UpdateInputWeights(cLongNorm.AsObject())) return false; //--- Season if(!cSeasonNorm.UpdateInputWeights(cSeasonTransp.AsObject())) return false; if(!cSeasonExtrapolate.UpdateInputWeights(cUnSeasonTransp.AsObject())) return false; if(!cSeasonMeanExtrapolate.UpdateInputWeights(cSeasonNorm.GetMeans())) return false; //--- Short if(!cShortNorm.UpdateInputWeights(cUnSeasonTransp.AsObject())) return false; if(!cShortExtrapolate.UpdateInputWeights(cShortNorm.AsObject())) return false; if(!cShortMeanExtrapolate.UpdateInputWeights(cShortNorm.GetMeans())) return false; //--- Spatial if(!cSpatialNorm.UpdateInputWeights(cShortNorm.AsObject())) return false; if(!cSpatialExtrapolate.UpdateInputWeights(cSpatialNorm.AsObject())) return false; if(!cSpatialMeanExtrapolate.UpdateInputWeights(cSpatialNorm.GetMeans())) return false; //--- Fusion if(!cFusion.UpdateInputWeights(cTranspose.AsObject())) return false; //--- return true; }
В итоге метод updateInputWeights — это лаконичный, но мощный диспетчер: он просто идёт по списку компонентов, делегирует им ответственность за свои веса и аккуратно собирает статусы выполнения. Такой подход сохраняет модульность, облегчает тестирование и упрощает расширение архитектуры: при добавлении новых обучаемых компонентов достаточно вставить их обновление в нужное место в этой цепочке.
На этом мы завершаем подробное рассмотрение логики построения Энкодера. Полный исходный код класса CNeuronSSCNNEncoder и всех его методов представлен во вложении и может служить опорой при внедрении или модификации.
Объект верхнего уровня
Фреймворк SSCNN изначально задумывался как композиция из цепочки Энкодеров, каждый из которых углубляет анализ и повышает степень абстракции признаков. На практике это даёт возможность сначала выровнять и извлечь очевидные компоненты (тренд, сезонность, локальные всплески), а затем последовательно работать со всё более богатым и сжатым представлением, выделяя тонкие взаимосвязи. Именно для управления такой последовательностью мы и вводим объект верхнего уровня CNeuronSSCNN, унаследованный от CNeuronSCNN.
Класс служит диспетчером: он инкапсулирует последовательность Энкодеров, организует поток тензоров между ними, решает вопросы согласования размеров и форматов, обеспечивая корректный прямой и обратный проход по всей цепочке.
class CNeuronSSCNN : public CNeuronSCNN { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSSCNN(void) {}; ~CNeuronSSCNN(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint variables, uint forecast, uint season_period, uint short_period, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronSSCNN; } };
Стоит отметить, что поведение CNeuronSSCNN полностью соответствует логике, унаследованной от родительского класса — мы не изобретаем новый алгоритм, а лишь явно указываем, какие именно Энкодеры используются в новой конфигурации. Причина переопределения класса сугубо прагматическая: нужно закрепить конкретный тип Энкодера и его параметры для последовательного построения нескольких уровней. В новых методах мы выполняем лишь точечные изменения — подменяем типы и форматы используемых Энкодеров, не трогая саму вычислительную логику. Поэтому сейчас нет смысла детально рассматривать алгоритмы, уже разобранные ранее — их реализация остаётся прежней. Полный исходный код класса и всех его методов доступен во вложении.
Обучение модели
Несколько слов о процессе обучения модели. Мы сохраняем двухэтапную стратегию: сначала мощное офлайн-обучение, затем тонкая онлайн-донастройка в рабочем режиме. Чтобы ускорить офлайн-этап, мы сознательно упростили представление состояния среды в Энкодере состояния окружающей среды и исключили обучение вспомогательных прогнозных модулей — это даёт заметный выигрыш по скорости подготовки, но снижает репрезентативность начального представления. Процесс обучения реализован в методе Train.
void Train(void) { int start = iBarShift(Symb.Name(), TimeFrame, Start); int end = iBarShift(Symb.Name(), TimeFrame, End); int bars = CopyRates(Symb.Name(), TimeFrame, 0, start, Rates);
Сначала метод вычисляет индексы начала и конца обучающего окна, а затем загружает исторические данные из терминала. Это стандартная подготовка данных: нам нужны сырые цены и метки времени, на которых будут строиться все последующие признаки и выборки.
if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Следующий блок проверяет, удалось ли изменить размер буферов для индикаторов. Если хотя бы один буфер не удалось выделить, мы выводим отладочное сообщение и корректно завершаем работу эксперта (ExpertRemove), чтобы не продолжать в неконсистентном состоянии.
Далее идёт цикл ожидания расчёта индикаторов. Мы проверяем, посчитаны ли индикаторы в течение ограниченного числа итераций. Это защищает от ситуаций, когда данные ещё не готовы: вместо того, чтобы стартовать с неполными данными, мы даём системе время, но не вечно. При превышении лимита — выводим сообщение и завершаем работу.
//--- int count = -1; bool calculated = false; do { count++; calculated = (RSI.BarsCalculated() >= bars && CCI.BarsCalculated() >= bars && ATR.BarsCalculated() >= bars && MACD.BarsCalculated() >= bars ); Sleep(100); count++; } while(!calculated && count < 100); if(!calculated) { PrintFormat("%s -> %d The training data has not been loaded", __FUNCTION__, __LINE__); ExpertRemove(); return; } RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } bars -= end + HistoryBars + NForecast; if(bars < 0) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
После этого обновляем индикаторы методом Refres и выставляем массив Rates в режим Series, чтобы обращения по индексам работали в привычном порядке для исторических данных. Затем корректируем число доступных баров. Это учитывает, что для каждого обучающего примера нам нужны HistoryBars предыдущих значений и запас на прогноз NForecast. Если результата получается меньше нуля — это сигнал, что данных мало, и мы прекращаем работу.
Подготавливаем рабочие векторы и флаг досрочной остановки. Также отмечаем текущее время — это понадобится для периодического обновления UI и контроля времени.
vector<float> result, target, neg_target; bool Stop = false; //--- uint ticks = GetTickCount();
Главный цикл обучения — по эрам (epoch). Он идёт до тех пор, пока не достигнут предел Epochs, не вызван IsStopped (внешний стоп) или не поднят флаг Stop из-за внутренней ошибки. В начале каждой эпохи очищаем внутреннее состояние Энкодера.
for(int epoch = 0; (epoch < Epochs && !IsStopped() && !Stop); epoch ++) { if(!cEncoder.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Внутри эпохи идёт цикл по позициям posit, который идёт от старта к концу исторического окна. Для каждой позиции сначала готовим исходные данные вызовом CreateBuffers — это формирует State и Time буферы, которые затем подаются в сеть. Затем формируем вектор состояния счёта и генерируем эталонное действие.
for(int posit = start - HistoryBars - NForecast - 1; posit >= end; posit--) { if(!CreateBuffers(posit, GetPointer(bState), GetPointer(bTime), Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } const vector<float> account = SampleAccount(GetPointer(bState), datetime(bTime[0])); const vector<float> target_action = OraculAction(account, Result); if(!bAccount.AssignArray(account)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
Мы используем гибридное обучение — по сигналам вознаграждения и эталонной траектории с заглядыванием в будущее.
Далее начинается прямой проход. Сначала Энкодер состояния окружающей среды формирует представление текущего состояния рынка.
//--- Feed Forward if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Затем Actor выдаёт действие агента. А Critic оценивает качество действия в текущем состоянии.
if(!cActor.feedForward(GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.feedForward(GetPointer(cActor), -1, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Все вызовы защищены проверками — при ошибке немедленно прерываем и ставим флаг Stop.
Блок Study — это основной шаг обновления на основе вознаграждения. Мы получаем действие Агента и формируем вознаграждение. Интересная деталь — если reward отрицателен, мы умножаем его на 2, то есть усиливаем штрафы за плохие решения. Такое усиление ускоряет обучение на примерах ошибок, но требует осторожности: слишком агрессивный штраф может дестабилизировать обучение.
//--- Study cActor.getResults(Action); double equity = bAccount[2] * bAccount[0] * EtalonBalance / (1 + bAccount[1]); double reward = CheckAction(Action, equity, posit - NForecast + 1) / EtalonBalance; if(reward < 0) reward *= 2; Result.Clear(); if(!Result.Add(float(reward))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.backProp(Result, GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, NULL, LatentLayer, true) || !cActor.backPropGradient(GetPointer(cEncoder), LatentLayer, -1, true) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Затем выполняем последовательный обратный проход: сначала Critic, затем Encoder и Actor. Это классическая схема Actor-Critic: Критик обновляется по ошибке оценки ценности, а затем сигнал идёт в Актор и Энкодер. Здесь важно учитывать порядок: Critic -> Encoder -> Actor, чтобы градиенты корректно прокатились по общей графовой структуре.
Далее идёт Oracul этап — обучение эталонной траектории. Снова выполняем прямой проход через Энкодер и Актор, ведь немногим ранее мы обновили их параметры и результат анализа того же состояния окружающей среды ожидаемо будет иной.
//--- Oracul if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cActor.feedForward(GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Action.AssignArray(target_action)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } reward = CheckAction(Action, equity, posit - NForecast + 1) / EtalonBalance;
Затем вместо действия агента ставим эталонное и считаем вознаграждение для него. После этого делаем обратный проход Актера — то есть обучаем его имитировать эталон.
if(!cActor.backProp(Action, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.feedForward(Action, 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Result.Update(0, float(reward))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!cCritic.backProp(Result, GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, NULL, LatentLayer, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- if(GetTickCount() - ticks > 500) { double percent = (epoch + 1.0 - double(posit - end) / (start - end - HistoryBars - NForecast)) / Epochs * 100.0; string str = ""; str += StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Actor", percent, cActor.getRecentAverageError()); str += StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Critic", percent, cCritic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Затем запускаем Critic на эталонном действии, выполняя прямой и обратный проходы. После этого снова вызываем оптимизацию параметров Энкодера. Таким образом, на каждом шаге мы сначала учимся на собственном опыте (Reinforcement), а затем подправляем политику в сторону эталона (Supervised). Это часто даёт более стабильную и быструю сходимость.
Во время цикла раз в ~500 мс формируем строку статуса с процентом прогресса и текущими ошибками Актёра и Критика. Это важный механизм информирования пользователя о ходе обучения.
По завершении всех эпох очищаем комментарий и печатаем финальные метрики в журнал терминала, после чего безопасно завершаем работу программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", cActor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", cCritic.getRecentAverageError()); ExpertRemove(); //--- }
Полный код программы офлайн обучения представлен во вложении. Там же вы найдете код всех программ, используемых при подготовке статьи, и архитектуру обучаемых моделей, которые перенесены из предыдущей работы практически без изменений. В Архитектуру Энкодера мы лишь изменили тип основного слоя Энкодера.
Тестирование
Как уже упоминалось ранее, процесс обучения состоит из двух последовательных этапов. На первом, офлайн-этапе, модель обучалась на исторических данных по паре EURUSD с таймфреймом H1 за весь 2024 год. Этот период включал широкий спектр рыночных сценариев — от спокойных фаз до резких всплесков — и позволил модели ознакомиться как с типичными, так и с редкими ситуациями.
На втором этапе мы провели тонкую онлайн-настройку в условиях, максимально приближённых к реальному рынку. Обучение велось в тестере стратегий MetaTrader 5, где модель поступательно обрабатывала живой поток свечей. Такой режим выявляет устойчивость к шумам и искажениям и даёт возможность адаптировать поведение при смене рыночного контекста.
В конце мы проверили модель на полностью новых данных — котировках за период с Января по Март 2025 года. Все параметры и настройки оставались неизменными. Полученные результаты дают объективную картину точности и практической надёжности предложенного подхода. Результаты тестирования приведены ниже.


Результаты тестирования показывает умеренную положительную динамику. Начав с депозита $100, советник сумел заработать $62.25, продемонстрировав небольшую положительную разницу между общими прибылью и убытком. При этом фактор прибыли едва превышает 1, что говорит о слабой эффективности стратегии.
За период тестирования было совершено 898 сделок, почти поровну распределённых между покупками и продажами. В обоих случаях прибыльность осталась около 50%, с незначительным перевесом в сторону коротких позиций. Средняя прибыльная сделка приносила $1.97, тогда как убыточная — $1.82. Максимальная прибыль достигала $13.56, а максимальный убыток — $12.42.
В целом, советник демонстрирует стабильную работу с точной реализацией сделок, но прибыльность и устойчивость стратегии остаются под вопросом.
Заключение
Статья завершает работу по построению подходов, предложенных авторами фреймворка SSCNN, средствами MQL5. Читатель познакомился с идеей пространственно-временной интеграции признаков, где каждый момент времени отражает сложные взаимосвязи между внутренними структурами данных и внешними рыночными импульсами.
Такая модель не только расширяет границы понимания рыночного поведения, но и предлагает инструмент адаптации к смене режимов — от спокойных фаз до бурных изменений волатильности. Внедрение Attention-based Normalization усиливает фокусировку на значимых участках и стабилизирует обучение, превращая SSCNN в гибкий аналитический механизм, способный распутывать структурную сложность финансовых рядов.
Ссылки
- Parsimony or Capability? Decomposition Delivers Both in Long-term Time Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования