取引における機械学習に関する記事
AIベースの取引ロボットの作成: ネイティブPythonとの統合、行列とベクトル、数学と統計のライブラリなど
取引に機械学習を使用する方法をご覧ください。ニューロン、パーセプトロン、畳み込みネットワークと再帰型ネットワーク、予測モデルなどの基本から始めて、独自のAIの開発に取り組みます。金融市場でのアルゴリズム取引のためにニューラル ネットワークを訓練して適用する方法を学びます。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
知っておくべきMQL5ウィザードのテクニック(第72回):教師あり学習でMACDとOBVのパターンを活用する
前回の記事で紹介したMACDとOBVのインジケーターペアをフォローアップし、今回はこのペアを機械学習でどのように強化できるかを見ていきます。MACDとOBVは、それぞれトレンド系と出来高系という補完的なペアです。私たちの機械学習アプローチでは、畳み込みニューラルネットワーク(CNN)を使い、カーネルとチャンネルのサイズを調整する際に指数カーネルを利用して、このインジケーターペアの予測をファインチューニングします。今回もこれまでと同様に、MQL5ウィザードでエキスパートアドバイザー(EA)を組み立てられるようにしたカスタムシグナルクラスファイル内で実装しています。

ニューラルネットワークが簡単に(第70回):閉形式方策改善演算子(CFPI)
この記事では、閉形式の方策改善演算子を使用して、オフラインモードでエージェントの行動を最適化するアルゴリズムを紹介します。

MQL5とデータ処理パッケージの統合(第3回):データ可視化の強化
この記事では、基本的なチャートの枠を超え、インタラクティブ性、データの層化、ダイナミックな要素といった機能を組み込むことで、トレーダーがトレンド、パターン、相関関係をより効果的に探求できるようにする、データ可視化の高度化について解説します。

市場イベント予測のための因果ネットワーク分析(CNA)とベクトル自己回帰モデルの例
この記事では、MQL5で因果ネットワーク分析(CNA: Causal Network Analysis)とベクトル自己回帰(VAR: Vector Autoregression)デルを使用した高度な取引システムを実装するための包括的なガイドを紹介します。これらの手法の理論的背景をカバーし、取引アルゴリズムにおける主要な機能を詳細に説明し、実装のためのサンプルコードも含んでいます。

プライスアクション分析ツールキットの開発(第34回):高度なデータ取得パイプラインを用いた生の市場データからの予測モデル構築
突然のマーケットスパイクを見逃したり、それが発生したときに対応が間に合わなかったことはありませんか。ライブイベントを予測する最良の方法は、過去のパターンから学ぶことです。本記事では、MetaTrader 5で履歴データを取得し、それをPythonに送信して保存するスクリプトの作成方法を紹介します。これにより、スパイク検知システムの基礎を構築できます。以下で各ステップを詳しく見ていきましょう。

人工生態系ベースの最適化(AEO)アルゴリズム
この記事では、初期の解候補集団を生成し、適応的な更新戦略を適用することで、生態系構成要素間の相互作用を模倣するメタヒューリスティック手法、人工エコシステムベース最適化(AEO: Artificial Ecosystem-based Optimization)アルゴリズムについて検討します。AEOの動作過程として、消費フェーズや分解フェーズ、さらに多様なエージェント行動戦略など、各段階を詳細に説明します。あわせて、本アルゴリズムの特徴と利点についても紹介します。

取引におけるニューラルネットワーク:階層型ベクトルTransformer (HiVT)
マルチモーダル時系列の高速かつ正確な予測のために開発された階層的ベクトルTransformer (HiVT: Hierarchical Vector Transformer)メソッドについて詳しく説明します。

雲モデル最適化(ACMO):実践編
この記事では、ACMO(Atmospheric Cloud Model Optimization:雲モデル最適化)アルゴリズムの実装について、さらに詳しく掘り下げていきます。特に、低気圧領域への雲の移動および水滴の初期化と雲間での分布を含む降雨シミュレーションという2つの重要な側面に焦点を当てます。また、雲の状態を管理し、環境との相互作用を適切に保つために重要な役割を果たす他の手法についても紹介します。

アフリカ水牛最適化(ABO)
この記事では、アフリカ水牛の特異な行動に着想を得て2015年に開発されたメタヒューリスティック手法、アフリカ水牛最適化(ABO)アルゴリズムを紹介します。アルゴリズムの実装プロセスと、複雑な問題の解決におけるその高い効率性について詳しく解説しており、最適化分野における有用なツールであることが示されています。

取引におけるニューラルネットワーク:状態空間モデル
これまでにレビューしたモデルの多くは、Transformerアーキテクチャに基づいています。ただし、長いシーケンスを処理する場合には非効率的になる可能性があります。この記事では、状態空間モデルに基づく時系列予測の別の方向性について説明します。
プライスアクション分析ツールキットの開発(第35回):予測モデルの学習とデプロイ
履歴データは決して「ゴミ」ではありません。それは、堅牢な市場分析の基盤です。本記事では、履歴データの収集から、それを用いた予測モデルの学習、そして学習済みモデルを用いたリアルタイムの価格予測のデプロイまでを、ステップごとに解説します。ぜひ最後までお読みください。
行列分解:基本
ここでの目的は教訓を得ることなので、できるだけシンプルに話を進めたいと思います。具体的には、必要な行列の乗算だけを実装します。行列とスカラーの乗算をシミュレートするにはこれで十分であることが今日わかるでしょう。行列分解を実装する際に多くの人が直面する最大の課題は、スカラーの分解と異なり、因子の順序が結果に影響を与えるため、行列の場合はその点に注意が必要だということです。

主成分を用いた特徴量選択と次元削減
この記事では、Luca Puggini氏とSean McLoone氏による論文「Forward Selection Component Analysis: Algorithms and Applications」に基づき、修正版のForward Selection Component Analysis (FSCA)アルゴリズムの実装について詳しく解説します。

知っておくべきMQL5ウィザードのテクニック(第16回):固有ベクトルによる主成分分析
データ分析における次元削減技術である主成分分析について、固有値とベクトルを用いてどのように実装できるかを考察します。いつものように、MQL5ウィザードで使用可能なExpertSignalクラスのプロトタイプの開発を目指します。

母集団最適化アルゴリズム:ボイドアルゴリズム
この記事では、動物の群れ行動のユニークな例に基づいたボイドアルゴリズムについて考察しています。その結果、ボイドアルゴリズムは、「群知能(Swarm Intelligence)」の名の下に統合されたアルゴリズム群全体の基礎となった。

ディープラーニングを用いたCNA(因果ネットワーク分析)、SMOC(確率モデル最適制御)、ナッシュゲーム理論の例
以前の記事で発表されたこれら3つの例にディープラーニング(DL)を加え、以前の結果と比較します。目的は、他のEAにディープラーニングを追加する方法を学ぶことです。

MQL5とPythonで自己最適化エキスパートアドバイザーを構築する(第4回):スタッキングモデル
本日は、自らの失敗から学習するAI搭載の取引アプリケーションの構築方法について解説します。特に、「スタッキング」と呼ばれる手法を紹介します。この手法では、2つのモデルを組み合わせて1つの予測をおこないます。1つ目のモデルは通常、性能が比較的低い学習者であり、2つ目のモデルはその学習者の残差を学習する、より高性能なモデルです。目標は、これらのモデルをアンサンブルとして統合することで、より高精度な予測を実現することです。

取引におけるニューラルネットワーク:価格変動予測におけるマスクアテンションフリーアプローチ
この記事では、Mask-Attention-Free Transformer (MAFT)法と、それを取引分野に応用する可能性について説明します。従来のTransformerはシーケンスを処理する際にマスキングを必要としますが、MAFTはこのマスキングを不要にすることでアテンション処理を最適化し、計算効率を大幅に向上させています。

ニューラルネットワークが簡単に(第78回):Transformerを用いたデコーダなしの物体検出器(DFFT)
この記事では、取引戦略の構築という問題を別の角度から見てみようと思います。将来の値動きを予測するのではなく、過去のデータの分析に基づいた取引システムの構築を試みます。

ALGLIBライブラリの最適化手法(第2回):
この記事では、ALGLIBライブラリにおける残りの最適化手法の検討を続けていきます。特に、複雑な多次元関数でのテストに重点を置きます。これにより、各アルゴリズムの効率性を評価できるだけでなく、さまざまな条件下における強みと弱みを明らかにすることができます。

純粋なMQL5におけるエネルギーベースの学習を用いた特徴量選択アルゴリズム
この記事では、「FREL:A stable feature selection algorithm」と題された学術論文に記載された、Feature Weighting as Regularized Energy-Based Learningと呼ばれる特徴量選択アルゴリズムの実装を紹介します。

取引におけるニューラルネットワーク:一般化3次元指示表現セグメンテーション
市場の状況を分析する際には、それを個別のセグメントに分割し、主要なトレンドを特定します。しかし、従来の分析手法は一つの側面に偏りがちで、全体像の適切な把握を妨げます。この記事では、複数のオブジェクトを選択できる手法を通じて、状況をより包括的かつ多層的に理解する方法を紹介します。

不一致問題(Disagreement Problem):AIにおける複雑性の説明可能性を深く掘り下げる
説明可能性という波乱の海を航海しながら、人工知能(AI)の謎の核心に飛び込みましょう。モデルがその内部構造を隠す領域において、私たちの探求は、機械学習の回廊にこだまする「不一致問題」を明らかにします。

知っておくべきMQL5ウィザードのテクニック(第15回):ニュートンの多項式を用いたサポートベクトルマシン
サポートベクトルマシンは、データの次元を増やす効果を調べることで、あらかじめ定義されたクラスに基づいてデータを分類します。これは教師あり学習法で、多次元のデータを扱う可能性を考えるとかなり複雑です。この記事では、2次元データの非常に基本的な実装であるニュートンの多項式が、価格とアクションを分類する際にどのように効率的に実行できるかを検討します。

取引におけるニューラルネットワーク:独立したチャネルへのグローバル情報の注入(InjectTST)
最新のマルチモーダル時系列予測方法のほとんどは、独立チャネルアプローチを使用しています。これにより、同じ時系列の異なるチャネルの自然な依存関係が無視されます。2つのアプローチ(独立チャネルと混合チャネル)を賢く使用することが、モデルのパフォーマンスを向上させる鍵となります。

ニューラルネットワークが簡単に(第81回):Context-Guided Motion Analysis (CCMR)
これまでの作業では、常に環境の現状を評価しました。同時に、指標の変化のダイナミクスは常に「舞台裏」にとどまっていました。この記事では、連続する2つの環境状態間のデータの直接的な変化を評価できるアルゴリズムを紹介したいと思います。

ALGLIBライブラリの最適化手法(第1回):
この記事では、MQL5におけるALGLIBライブラリの最適化手法について紹介します。記事には、最適化問題を解決するためにALGLIBを使用するシンプルで分かりやすい例が含まれており、これらの手法をできるだけ身近に感じられるように構成されています。BLEIC、L-BFGS、NSといったアルゴリズムのつながりを詳しく見ていき、それらを使って簡単なテスト問題を解いてみます。

FX裁定取引:合成通貨の動きとその平均回帰の分析
本記事では、PythonおよびMQL5を用いて合成通貨の動きを分析し、現在のFX裁定取引の実現可能性について検討します。また、合成通貨を分析するための既製Pythonコードを紹介するとともに、FXにおける合成通貨の概念についても詳しく解説します。

どんな市場でも優位性を得る方法(第3回):VISA消費指数
ビッグデータの世界では、取引戦略を向上させる可能性を秘めた数百万もの代替データセットが存在します。この連載では、最も有益な公共データセットを特定するお手伝いをします。

アーチェリーアルゴリズム(AA)
この記事では、アーチェリーに着想を得た最適化アルゴリズムについて詳しく検討し、有望な「矢」の着地点を選定するメカニズムとしてルーレット法の活用に焦点を当てます。この手法により、解の質を評価し、さらなる探索に最も有望な位置を選び出すことが可能になります。

知っておくべきMQL5ウィザードのテクニック(第41回):DQN (Deep-Q-Network)
DQN (Deep-Q-Network)は強化学習アルゴリズムであり、機械学習モジュールの学習プロセスにおいて、次のQ値と理想的な行動を予測する際にニューラルネットワークを関与させます。別の強化学習アルゴリズムであるQ学習についてはすでに検討しました。そこでこの記事では、強化学習で訓練されたMLPが、カスタムシグナルクラス内でどのように使用できるかを示すもう1つの例を紹介します。

従来の機械学習手法を使用した為替レートの予測:ロジットモデルとプロビットモデル
この記事では、為替レートの予測を目的とした取引用EAの構築を試みます。アルゴリズムは、ロジスティック回帰およびプロビット回帰といった古典的な分類モデルに基づいています。取引シグナルのフィルターとして、尤度比検定が用いられます。

知っておくべきMQL5ウィザードのテクニック(第80回):TD3強化学習で一目均衡表とADX-Wilderのパターンを使用する
本記事は第74回の続編です。第74回では、教師あり学習の枠組みにおける一目均衡表とADXの組み合わせを検討しました。本記事では焦点を強化学習に移します。一目均衡表とADXは、サポート/レジスタンスの把握とトレンドの強さの検出という点で、互いに補完し合う組み合わせを形成します。今回は、TD3 (Twin Delayed Deep Deterministic Policy Gradient)アルゴリズムをこのインジケーターセットでどのように活用できるかを詳しく解説します。前回までと同様に、実装はMQL5ウィザードに統合できるカスタムシグナルクラスとしておこないます。MQL5ウィザードを使用すると、エキスパートアドバイザー(EA)の構築をスムーズに進めることが可能です。

ニューラルネットワークの実践:割線
理論的な部分ですでに説明したように、ニューラルネットワークを扱う場合、線形回帰と導関数を使用する必要があります。なぜでしょうか。その理由は、線形回帰は現存する最も単純な公式の1つだからです。本質的に、線形回帰は単なるアフィン関数です。しかし、ニューラルネットワークについて語るとき、私たちは直接線形回帰の効果には興味がありません。この直線を生み出す方程式に興味があるのです。作られた線にはそれほど興味がありません。私たちが理解すべき主要な方程式をご存じですか。ご存じでなければ、この記事を読んで理解することをお勧めします。
化学反応最適化(CRO)アルゴリズム(第1回):最適化におけるプロセス化学
この記事の最初の部分では、化学反応の世界に飛び込み、最適化への新しいアプローチを発見します。化学反応最適化(CRO)は、熱力学の法則から導き出された原理を使用して効率的な結果をもたらします。この革新的な方法の基礎となった分解、合成、その他の化学プロセスの秘密を明らかにします。

知っておくべきMQL5ウィザードのテクニック(第74回): 教師あり学習で一目均衡表とADX Wilderのパターンを利用する
前回の記事では、一目均衡表とADXのインジケーターペアを紹介しました。今回は、このペアを教師あり学習でどのように改善できるかを見ていきます。一目均衡表とADXは、サポート/レジスタンスとトレンドを補完する組み合わせとして機能します。今回の教師あり学習アプローチでは、ディープスペクトル混合カーネルを用いたニューラルネットワークを活用し、このインジケーターペアの予測精度を微調整します。通常どおり、この処理はMQL5ウィザードでエキスパートアドバイザー(EA)を組み立てる際に利用できるカスタムシグナルクラスファイル内でおこないます。

ニューラルネットワークが簡単に(第76回):Multi-future Transformerで多様な相互作用パターンを探る
この記事では、今後の値動きを予測するというトピックを続けます。Multi-future Transformerのアーキテクチャーをお見せします。その主なアイデアは、未来のマルチモーダル分布をいくつかのユニモーダル分布に分解することで、シーンのエージェント間の相互作用のさまざまなモデルを効果的にシミュレートすることができるというものです。

知っておくべきMQL5ウィザードのテクニック(第62回):強化学習TRPOでADXとCCIのパターンを活用する
ADXオシレーターとCCIオシレーターはそれぞれトレンドフォローインジケーターおよびモメンタムインジケーターであり、エキスパートアドバイザー(EA)を開発する際に組み合わせることができます。前回の記事に続き、今回は開発済みモデルの運用中の学習や更新を、強化学習を用いてどのように実現できるかを検討します。この記事で使用するアルゴリズムは、本連載ではまだ扱っていない「TRPO(Trust Region Policy Optimization、信頼領域方策最適化)」として知られる手法です。また、MQL5ウィザードによるEAの組み立ては、モデルのテストをより迅速におこなえるだけでなく、異なるシグナルタイプで配布し検証できる形でセットアップできる点も利点です。
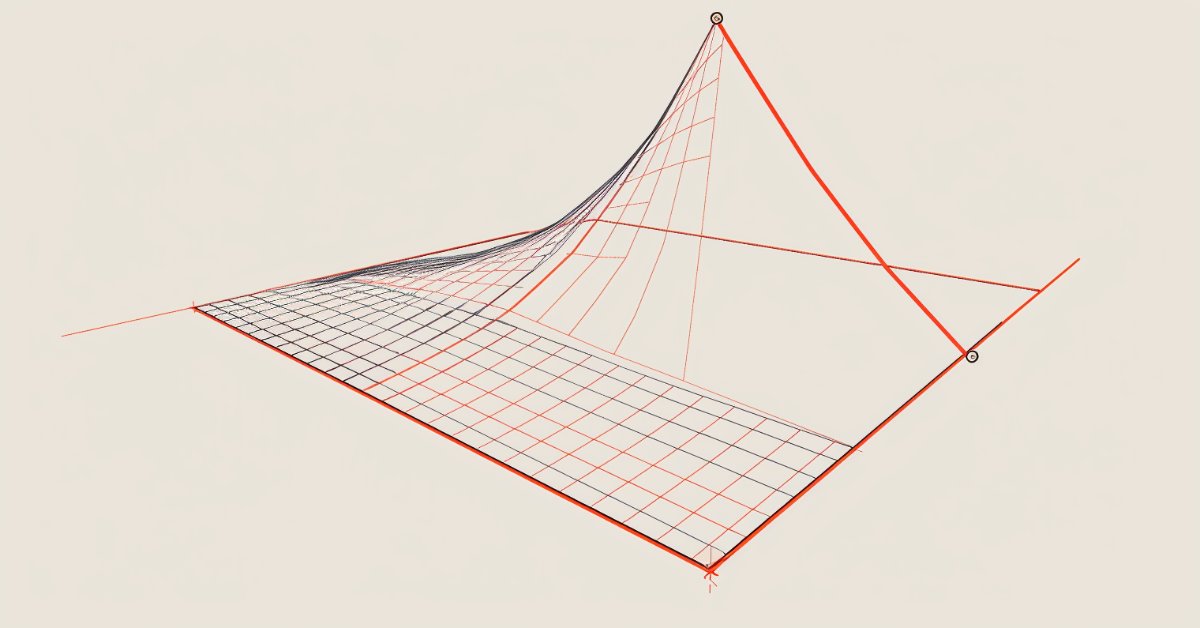
ニューラルネットワークの実践:最小二乗法
この記事では、数式がコードで実装されたときよりも見た目が複雑になる理由など、いくつかのアイデアについて説明します。さらに、チャートの象限を設定する方法と、MQL5コードで発生する可能性のある1つの興味深い問題についても検討します。正直に言うと、まだどう説明すればいいのかよくわかりません。とにかく、コードで修正する方法を紹介します。

母集団最適化アルゴリズム:人工多社会的検索オブジェクト(MSO)
前回に引き続き、社会的集団について考えてみたいと思います。この記事では、移動と記憶のアルゴリズムを用いて社会集団の進化を探求しています。その結果は、社会システムの進化を理解し、最適化や解の探索に応用するのに役立つでしょう。